w3cschool-Python3 高级教程
https://www.w3cschool.cn/python3/python3-reg-expressions.html
Python3 正则表达式
re.match 函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
我们可以使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例 1:
#!/usr/bin/python
import re
print(re.match('www', 'www.w3cschool.cn').span()) # 在起始位置匹配
print(re.match('cn', 'www.w3cschool.cn')) # 不在起始位置匹配re.search 方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功 re.search 方法返回一个匹配的对象,否则返回 None。
我们可以使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例 1:
#!/usr/bin/python3
import re
print(re.search('www', 'www.w3cschool.cn').span()) # 在起始位置匹配
print(re.search('cn', 'www.w3cschool.cn').span()) # 不在起始位置匹配re.match 与 re.search 的区别
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None;而 re.search 匹配整个字符串,直到找到一个匹配。
正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'/t',等价于'//t')匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字 |
| \W | 匹配非字母数字 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的子表达式。 |
| \10 | 匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。 |
正则表达式实例
字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
特殊字符类
| 实例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
Python3 CGI 编程
网页浏览
为了更好的了解 CGI 是如何工作的,我们可以从在网页上点击一个链接或 URL 的流程:
- 1、使用你的浏览器访问 URL 并连接到 HTTP web 服务器。
- 2、Web 服务器接收到请求信息后会解析 URL,并查找访问的文件在服务器上是否存在,如果存在返回文件的内容,否则返回错误信息。
- 3、浏览器从服务器上接收信息,并显示接收的文件或者错误信息。
CGI 程序可以是 Python 脚本,PERL 脚本,SHELL 脚本,C 或者 C++ 程序等。
CGI 架构图
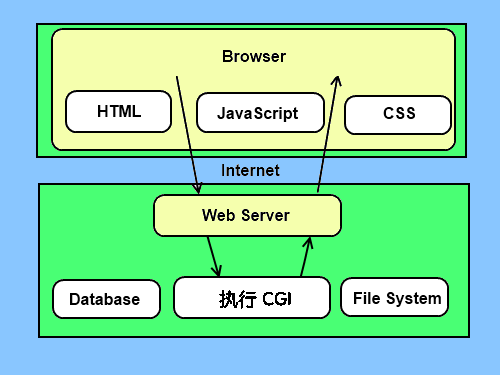
Web 服务器支持及配置
在你进行 CGI 编程前,确保您的 Web 服务器支持 CGI 及已经配置了 CGI 的处理程序。
Apache 支持 CGI 配置(这里使用PHPstudy集成的Apache):
打开Apache的配置文件httpd-conf,在文件中找到如下内容:
首先找到ScriptAlias(图片内容为已经修改过的值,默认值应该有所不同而且是被注释掉的)
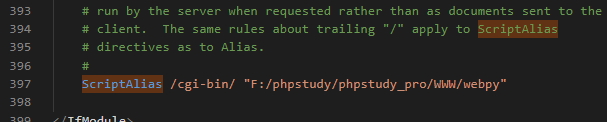
修改为项目地址 ScriptAlias /cgi-bin/ "F:/phpstudy/phpstudy_pro/WWW/webpy" (之前的项目都放在F:/phpstudy/phpstudy_pro/WWW/下,这个文件夹是PHPstudy的apache默认项目文件夹,将路径改为这样可以方便localhost访问)。
然后找到Directory,将其修改为
<Directory "F:/phpstudy/phpstudy_pro/WWW/webpy">
AllowOverride None
Options +ExecCGI
Order allow,deny
Allow from all
</Directory>
第一个CGI程序
我们使用 Python 创建第一个 CGI 程序,文件名为 hello.py,文件位于 /var/www/cgi-bin目录中,内容如下:
#!/usr/bin/python3# 请注意第一行代码,在linux中需要在py文件中正确指定python解释器的路径才能运行 # 在Windows中使用Python CGI文件也需要正确指定python解释器的路径才能运行
#coding=utf-8
print("Content-type:text/html") # 指定返回的类型,没有这行代码会报错
print() # 空行,告诉服务器结束头部
# 以下是要返回的HTML正文 print ('<html>')
print ('<head>')
print ('<title>Hello Word - 我的第一个 CGI 程序!</title>')
print ('</head>')
print ('<body>')
print ('<h2>Hello Word! 我的第一CGI程序</h2>')
print ('</body>')
print ('</html>')
文件保存后修改 hello.py,修改文件权限为 755(linux和macos需要在webpy文件夹下使用下面的命令来修改文件读写权限,在Windows环境下需要修改文件的读写权限):
chmod 755 hello.py 以上程序在浏览器访问显示结果如下:
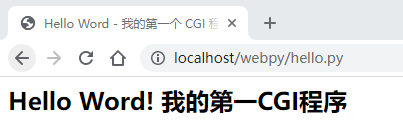
这个的 hello.py 脚本是一个简单的 Python 脚本,脚本第一行的输出内容"Content-type:text/html"发送到浏览器并告知浏览器显示的内容类型为"text/html"。
用 print 输出一个空行用于告诉服务器结束头部信息。
HTTP头部
hello.py 文件内容中的" Content-type:text/html"即为 HTTP 头部的一部分,它会发送给浏览器告诉浏览器文件的内容类型。
HTTP 头部的格式如下:
HTTP 字段名: 字段内容
例如:
Content-type: text/html以下表格介绍了 CGI 程序中 HTTP 头部经常使用的信息:
| 头 | 描述 |
|---|---|
| Content-type: | 请求的与实体对应的 MIME 信息。例如: Content-type:text/html |
| Expires: Date | 响应过期的日期和时间 |
| Location: URL | 用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 |
| Last-modified: Date | 请求资源的最后修改时间 |
| Content-length: N | 请求的内容长度 |
| Set-Cookie: String | 设置 Http Cookie |
CGI 环境变量
所有的 CGI 程序都接收以下的环境变量,这些变量在 CGI 程序中发挥了重要的作用:
| 变量名 | 描述 |
|---|---|
| CONTENT_TYPE | 这个环境变量的值指示所传递来的信息的 MIME 类型。目前,环境变量 CONTENT_TYPE 一般都是:application/x-www-form-urlencoded,他表示数据来自于 HTML 表单。 |
| CONTENT_LENGTH | 如果服务器与 CGI 程序信息的传递方式是 POST,这个环境变量即使从标准输入 STDIN 中可以读到的有效数据的字节数。这个环境变量在读取所输入的数据时必须使用。 |
| HTTP_COOKIE | 客户机内的 COOKIE 内容。 |
| HTTP_USER_AGENT | 提供包含了版本数或其他专有数据的客户浏览器信息。 |
| PATH_INFO | 这个环境变量的值表示紧接在 CGI 程序名之后的其他路径信息。它常常作为 CGI 程序的参数出现。 |
| QUERY_STRING | 如果服务器与 CGI 程序信息的传递方式是 GET,这个环境变量的值即使所传递的信息。这个信息经跟在 CGI 程序名的后面,两者中间用一个问号'?'分隔。 |
| REMOTE_ADDR | 这个环境变量的值是发送请求的客户机的IP地址,例如上面的192.168.1.67。这个值总是存在的。而且它是 Web 客户机需要提供给Web服务器的唯一标识,可以在 CGI 程序中用它来区分不同的 Web 客户机。 |
| REMOTE_HOST | 这个环境变量的值包含发送 CGI 请求的客户机的主机名。如果不支持你想查询,则无需定义此环境变量。 |
| REQUEST_METHOD | 提供脚本被调用的方法。对于使用 HTTP/1.0 协议的脚本,仅 GET 和 POST 有意义。 |
| SCRIPT_FILENAME | CGI 脚本的完整路径 |
| SCRIPT_NAME | CGI 脚本的的名称 |
| SERVER_NAME | 这是你的 WEB 服务器的主机名、别名或IP地址。 |
| SERVER_SOFTWARE | 这个环境变量的值包含了调用 CGI 程序的 HTTP 服务器的名称和版本号。例如,上面的值为 Apache/2.2.14(Unix) |
以下是一个简单的 CGI 脚本输出 CGI 的环境变量:
#!/usr/bin/python3
#coding=utf-8
import os
print ("Content-type: text/html")
print ()
print ("<b>环境变量</b><br>")
print ("<ul>")
for key in os.environ.keys():
print ("<li><span style='color:green'>%30s </span> : %s </li>" % (key,os.environ[key]))
print ("</ul>")
将以上点保存为 test.py ,并修改文件权限为 755,执行结果如下:

GET 和 POST 方法
浏览器客户端通过两种方法向服务器传递信息,这两种方法就是 GET 方法和 POST 方法。
使用 GET 方法传输数据
GET 方法发送编码后的用户信息到服务端,数据信息包含在请求页面的 URL 上,以"?"号分割, 如下所示:
http://localhost/webpy/test.py?key1=value1&key2=value2
有关 GET 请求的其他一些注释:
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
简单的 url 实例:GET 方法
以下是一个简单的 URL,使用 GET 方法向 test_get.py 程序发送两个参数:
http://localhost/webpy/test_get.py?name=W3Cschool教程&url=http://www.w3cschool.cn
以下为 test_get.py 文件的代码:
#!/usr/bin/python3
#coding=utf-8
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<title>W3Cschool教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2>%s官网:%s</h2>" % (site_name, site_url))
print ("</body>")
print ("</html>")
文件保存后修改 hello_get.py,修改文件权限为 755:
CGI 中使用 Cookie
在 http 协议一个很大的缺点就是不对用户身份的进行判断,这样给编程人员带来很大的不便,而 cookie 功能的出现弥补了这个不足。
cookie 就是在客户访问脚本的同时,通过客户的浏览器,在客户硬盘上写入纪录数据 ,当下次客户访问脚本时取回数据信息,从而达到身份判别的功能,cookie 常用在身份校验中。
cookie 的语法
http cookie 的发送是通过 http 头部来实现的,他早于文件的传递,头部set-cookie 的语法如下:
Set-cookie:name=name;expires=date;path=path;domain=domain;secure
- name=name: 需要设置cookie的值(name不能使用";"和","号),有多个name值时用 ";" 分隔,例如:name1=name1;name2=name2;name3=name3。
- expires=date: cookie的有效期限,格式: expires="Wdy,DD-Mon-YYYY HH:MM:SS"
- path=path: 设置 cookie 支持的路径,如果path是一个路径,则 cookie 对这个目录下的所有文件及子目录生效,例如: path="/webpy/",如果path是一个文件,则cookie指对这个文件生效,例如:path="/webpy/cookie.py"。
- domain=domain: 对 cookie 生效的域名,例如:domain="www.w3cschool.cn"
- secure: 如果给出此标志,表示cookie只能通过SSL协议的https服务器来传递。
- cookie的接收是通过设置环境变量 HTTP_COOKIE 来实现的,CGI 程序可以通过检索该变量获取 cookie 信息。
Cookie 设置
Cookie 的设置非常简单,cookie 会在 http 头部单独发送。以下实例在 cookie 中设置了name 和 expires:
#!/usr/bin/python3#coding=utf-8
print ('Content-Type: text/html')
print ('Set-Cookie: name="W3Cschool";expires=Thu 02 Dec 2021 18:30:00 GMT')//注意,这个cookie在这个时间前有效,之后使用cookie会过期
print ()
print ("""
<html>
<head>
<meta charset="gbk">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<h1>Cookie set OK!</h1>
</body>
</html>
""")
将以上代码保存到 cookie_set.py,并修改 cookie_set.py 权限:
chmod 755 cookie_set.py
以上实例使用了 Set-Cookie 头信息来设置 Cookie 信息,可选项中设置了 Cookie 的其他属性,如过期时间 Expires,域名 Domain,路径 Path。这些信息设置在 "Content-type:text/html"之前。
注意:cookie不能存放中文,本文采用英文例子,如果要使用中文可以使用后端编码(可以采用utf-8等编码,python和JavaScript都有提供响应的编解码的功能),传到前端后再将其解码即可。
检索Cookie信息
Cookie 信息检索页非常简单,Cookie 信息存储在 CGI 的环境变量 HTTP_COOKIE 中,存储格式如下:
key1=value1;key2=value2;key3=value3....
以下是一个简单的 CGI 检索 cookie 信息的程序:
#!/usr/bin/python3#coding=utf-8
# 导入模块
import os
import http.cookies
print ("Content-type: text/html")
print ()
print ("""
<html>
<head>
<meta charset="gbk">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<h1>读取cookie信息</h1>
""")
if 'HTTP_COOKIE' in os.environ:
cookie_string=os.environ.get('HTTP_COOKIE')
c=http.cookies.SimpleCookie()
c.load(cookie_string)
try:
data=c['name'].value
print ("cookie data: "+data+"<br>")
except KeyError:
print ("cookie 没有设置或者已过去<br>")
print ("""
</body>
</html>
""")
将以上代码保存到 cookie_get.py,并修改 cookie_get.py 权限:
文件上传实例
HTML 设置上传文件的表单需要设置 enctype 属性为 multipart/form-data,代码如下所示:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<form enctype="multipart/form-data"
action="/webpy/save_file.py" method="post">
<p>选中文件: <input type="file" name="filename" /></p>
<p><input type="submit" value="上传" /></p>
</form>
</body>
</html>save_file.py 脚本文件代码如下:
#!/usr/bin/python3#coding=utf-8
import cgi, os
import cgitb
cgitb.enable()
form = cgi.FieldStorage()
# 获取文件名
fileitem = form['filename']
# 检测文件是否上传
if fileitem.filename:
# 设置文件路径
fn = os.path.basename(fileitem.filename)
open(os.getcwd()+'/tmp/' + fn, 'wb').write(fileitem.file.read())
message = '文件 "' + fn + '" 上传成功'
else:
message = '文件没有上传'
print ("Content-type: text/html")
print ()
print ("""
<html>
<head>
<meta charset="gbk">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<p>%s</p>
</body>
</html>
""" % (message,))
将以上代码保存到 save_file.py,并修改 save_file.py 权限:
文件下载对话框
我们先在当前目录下创建 foo.txt 文件,用于程序的下载。
文件下载通过设置 HTTP 头信息来实现,功能代码如下:
#!/usr/bin/python3
# HTTP 头部
print ("Content-Disposition: attachment; filename=\"foo.txt\"")
print ()
# 打开文件
fo = open("foo.txt", "rb")
str = fo.read();
print (str)
# 关闭文件
fo.close()Python3 MySQL 数据库连接
什么是 PyMySQL?
PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2 中则使用mysqldb。
PyMySQL 遵循 Python 数据库 API v2.0 规范,并包含了 pure-Python MySQL 客户端库。
PyMySQL 安装
在使用 PyMySQL 之前,我们需要确保 PyMySQL 已安装。
PyMySQL 下载地址:https://github.com/PyMySQL/PyMySQL。
如果还未安装,我们可以使用以下命令安装最新版的 PyMySQL:
$ pip install PyMySQL
如果你的系统不支持 pip 命令,可以使用以下方式安装:
1、使用 git 命令下载安装包安装(你也可以手动下载):
$ git clone https://github.com/PyMySQL/PyMySQL
$ cd PyMySQL/
$ python3 setup.py install
2、如果需要制定版本号,可以使用 curl 命令来安装:
$ # X.X 为 PyMySQL 的版本号
$ curl -L https://github.com/PyMySQL/PyMySQL/tarball/pymysql-X.X | tar xz
$ cd PyMySQL*
$ python3 setup.py install
$ # 现在你可以删除 PyMySQL* 目录
注意:请确保您有 root 权限来安装上述模块。
删除操作
删除操作用于删除数据表中的数据,以下实例演示了删除数据表 EMPLOYEE 中 AGE 大于 20 的所有数据:
#!/usr/bin/python3
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost","testuser","test123","TESTDB" )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 删除语句
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20)
try:
# 执行SQL语句
cursor.execute(sql)
# 提交修改
db.commit()
except:
# 发生错误时回滚
db.rollback()
# 关闭连接
db.close()
Python3 网络编程
Python 提供了两个级别访问的网络服务。:
- 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统 Socket 接口的全部方法。
- 高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
什么是 Socket?
Socket 又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
什么是 Socket?
Socket 又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
socket()函数
Python 中,我们用 socket()函数来创建套接字,语法格式如下:
socket.socket([family[, type[, proto]]])
参数
- family: 套接字家族可以使 AF_UNIX 或者 AF_INET
- type: 套接字类型可以根据是面向连接的还是非连接分为
SOCK_STREAM或SOCK_DGRAM - protocol: 一般不填默认为0.
Socket 对象(内建)方法
| 函数 | 描述 |
|---|---|
| 服务器端套接字 | |
| s.bind() | 绑定地址(host,port)到套接字, 在 AF_INET 下,以元组(host,port)的形式表示地址。 |
| s.listen() | 开始 TCP 监听。backlog 指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为 1,大部分应用程序设为 5 就可以了。 |
| s.accept() | 被动接受 TCP 客户端连接,(阻塞式)等待连接的到来 |
| 客户端套接字 | |
| s.connect() | 主动初始化 TCP 服务器连接,。一般 address 的格式为元组(hostname,port),如果连接出错,返回 socket.error 错误。 |
| s.connect_ex() | connect() 函数的扩展版本,出错时返回出错码,而不是抛出异常 |
| 公共用途的套接字函数 | |
| s.recv() | 接收 TCP 数据,数据以字符串形式返回,bufsize指定要接收的最大数据量。flag 提供有关消息的其他信息,通常可以忽略。 |
| s.send() | 发送 TCP 数据,将 string 中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于 string 的字节大小。 |
| s.sendall() | 完整发送 TCP 数据,完整发送 TCP 数据。将 string 中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回 None,失败则抛出异常。 |
| s.recvfrom() | 接收 UDP 数据,与 recv() 类似,但返回值是(data,address)。其中 data 是包含接收数据的字符串,address 是发送数据的套接字地址。 |
| s.sendto() | 发送 UDP 数据,将数据发送到套接字,address 是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。 |
| s.close() | 关闭套接字 |
| s.getpeername() | 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 |
| s.getsockname() | 返回套接字自己的地址。通常是一个元组(ipaddr,port) |
| s.setsockopt(level,optname,value) | 设置给定套接字选项的值。 |
| s.getsockopt(level,optname[.buflen]) | 返回套接字选项的值。 |
| s.settimeout(timeout) | 设置套接字操作的超时期,timeout 是一个浮点数,单位是秒。值为 None 表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如 connect()) |
| s.gettimeout() | 返回当前超时期的值,单位是秒,如果没有设置超时期,则返回 None。 |
| s.fileno() | 返回套接字的文件描述符。 |
| s.setblocking(flag) | 如果 flag 为 0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用 recv() 没有发现任何数据,或 send() 调用无法立即发送数据,那么将引起 socket.error 异常。 |
| s.makefile() | 创建一个与该套接字相关连的文件 |
简单实例
服务端
我们使用 socket 模块的 socket 函数来创建一个 socket 对象。socket 对象可以通过调用其他函数来设置一个 socket 服务。
现在我们可以通过调用 bind(hostname, port) 函数来指定服务的 port(端口)。
接着,我们调用 socket 对象的 accept 方法。该方法等待客户端的连接,并返回 connection 对象,表示已连接到客户端。
完整代码如下:
#!/usr/bin/python3
# 文件名:server.py
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
serversocket = socket.socket(
socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
port = 9999
# 绑定端口
serversocket.bind((host, port))
# 设置最大连接数,超过后排队
serversocket.listen(5)
while True:
# 建立客户端连接
clientsocket,addr = serversocket.accept()
print("连接地址: %s" % str(addr))
msg='欢迎访问W3Cschool教程!'+ "\r\n"
clientsocket.send(msg.encode('utf-8'))
clientsocket.close()
客户端
接下来我们写一个简单的客户端实例连接到以上创建的服务。端口号为 12345。
socket.connect(hosname, port ) 方法打开一个 TCP 连接到主机为 hostname 端口为 port 的服务商。连接后我们就可以从服务端后期数据,记住,操作完成后需要关闭连接。
完整代码如下:
#!/usr/bin/python3
# 文件名:client.py
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
# 设置端口好
port = 9999
# 连接服务,指定主机和端口
s.connect((host, port))
# 接收小于 1024 字节的数据
msg = s.recv(1024)
s.close()
print (msg.decode('utf-8'))
现在我们打开连个终端,第一个终端执行 server.py 文件:
$ python3 server.py第二个终端执行 client.py 文件:
$ python3 client.py
欢迎访问W3Cschool教程!
这是我们再打开第一个终端,就会看到有以下信息输出:
连接地址: ('192.168.0.118', 33397)
Python Internet 模块
以下列出了 Python 网络编程的一些重要模块:
| 协议 | 功能用处 | 端口号 | Python 模块 |
|---|---|---|---|
| HTTP | 网页访问 | 80 | httplib, urllib, xmlrpclib |
| NNTP | 阅读和张贴新闻文章,俗称为"帖子" | 119 | nntplib |
| FTP | 文件传输 | 20 | ftplib, urllib |
| SMTP | 发送邮件 | 25 | smtplib |
| POP3 | 接收邮件 | 110 | poplib |
| IMAP4 | 获取邮件 | 143 | imaplib |
| Telnet | 命令行 | 23 | telnetlib |
| Gopher | 信息查找 | 70 | gopherlib, urllib |
Python3 SMTP发送邮件
在Python3 中应用的SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。
python的 smtplib 提供了一种很方便的途径发送电子邮件。它对 smtp 协议进行了简单的封装。
Python创建 SMTP 对象语法如下:
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )
参数说明:
- host: SMTP 服务器主机。 你可以指定主机的 ip 地址或者域名如:w3cschool.cn,这个是可选参数。
- port: 如果你提供了 host 参数, 你需要指定 SMTP 服务使用的端口号,一般情况下 SMTP 端口号为 25。
- local_hostname: 如果 SMTP 在你的本机上,你只需要指定服务器地址为 localhost 即可。
Python SMTP 对象使用 sendmail 方法发送邮件,语法如下:
SMTP.sendmail(from_addr, to_addrs, msg[, mail_options, rcpt_options]
参数说明:
- from_addr: 邮件发送者地址。
- to_addrs: 字符串列表,邮件发送地址。
- msg: 发送消息
这里要注意一下第三个参数,msg 是字符串,表示邮件。我们知道邮件一般由标题,发信人,收件人,邮件内容,附件等构成,发送邮件的时候,要注意 msg 的格式。这个格式就是 smtp 协议中定义的格式。
实例
以下是一个使用 Python 发送邮件简单的实例:
#!/usr/bin/python3
import smtplib
from email.mime.text import MIMEText
from email.header import Header
sender = 'from@w3cschool.cn'
receivers = ['429240967@qq.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 三个参数:第一个为文本内容,第二个 plain 设置文本格式,第三个 utf-8 设置编码
message = MIMEText('Python 邮件发送测试...', 'plain', 'utf-8')
message['From'] = Header("W3Cschool教程", 'utf-8')
message['To'] = Header("测试", 'utf-8')
subject = 'Python SMTP 邮件测试'
message['Subject'] = Header(subject, 'utf-8')
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message.as_string())
print ("邮件发送成功")
except smtplib.SMTPException:
print ("Error: 无法发送邮件")
我们使用三个引号来设置邮件信息,标准邮件需要三个头部信息: From, To, 和 Subject ,每个信息直接使用空行分割。
我们通过实例化 smtplib 模块的 SMTP 对象 smtpObj 来连接到 SMTP 访问,并使用 sendmail 方法来发送信息。
Python3 多线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
- 程序的运行速度可能加快
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组 CPU 寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的 CPU 寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断)。
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) -- 这就是线程的退让。
线程可以分为:
- 内核线程:由操作系统内核创建和撤销。
- 用户线程:不需要内核支持而在用户程序中实现的线程。
Python3 线程中常用的两个模块为:
- _thread
- threading(推荐使用)
线程模块
Python3 通过两个标准库 _thread 和 threading 提供对线程的支持。
_thread 提供了低级别的、原始的线程以及一个简单的锁,它相比于 threading 模块的功能还是比较有限的。
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与 len(threading.enumerate()) 有相同的结果。
除了使用方法外,线程模块同样提供了 Thread 类来处理线程,Thread 类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的 join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
使用 threading 模块创建线程
我们可以通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,即它调用了线程的 run() 方法:
#!/usr/bin/python3
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.counter, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")
以上程序执行结果如下;
线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是 0,线程"set"从后向前把所有元素改成 1,而线程"print"负责从前往后读取列表并打印。
那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半 0 一半 1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
经过这样的处理,打印列表时要么全部输出 0,要么全部输出 1,不会再出现一半 0 一半 1 的尴尬场面。
线程优先级队列( Queue)
Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括 FIFO(先入先出)队列 Queue,LIFO(后入先出)队列 LifoQueue,和优先级队列 PriorityQueue。
这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
Queue 模块中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回 True,反之 False
- Queue.full() 如果队列满了,返回 True,反之 False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]]) 获取队列,timeout 等待时间
- Queue.get_nowait() 相当 Queue.get(False)
- Queue.put(item) 写入队列,timeout 等待时间
- Queue.put_nowait(item) 相当 Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done() 函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
Python3 XML解析
什么是XML?
XML 指可扩展标记语言(eXtensible Markup Language),标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言。 你可以通过本站学习 XML教程
XML 被设计用来传输和存储数据。
XML 是一套定义语义标记的规则,这些标记将文档分成许多部件并对这些部件加以标识。
它也是元标记语言,即定义了用于定义其他与特定领域有关的、语义的、结构化的标记语言的句法语言。
python对XML的解析
常见的 XML 编程接口有 DOM 和 SAX,这两种接口处理 XML 文件的方式不同,当然使用场合也不同。
Python 有三种方法解析 XML,SAX,DOM,以及 ElementTree:
1.SAX (simple API for XML )
Python 标准库包含 SAX 解析器,SAX 用事件驱动模型,通过在解析 XML 的过程中触发一个个的事件并调用用户定义的回调函数来处理 XML 文件。
2.DOM(Document Object Model)
将 XML 数据在内存中解析成一个树,通过对树的操作来操作 XML。
ContentHandler 类方法介绍
characters(content) 方法
调用时机:
从行开始,遇到标签之前,存在字符,content 的值为这些字符串。
从一个标签,遇到下一个标签之前, 存在字符,content 的值为这些字符串。
从一个标签,遇到行结束符之前,存在字符,content 的值为这些字符串。
标签可以是开始标签,也可以是结束标签。
startDocument() 方法
文档启动的时候调用。
endDocument() 方法
解析器到达文档结尾时调用。
startElement(name, attrs) 方法
遇到XML开始标签时调用,name 是标签的名字,attrs 是标签的属性值字典。
endElement(name) 方法
遇到XML结束标签时调用。
make_parser 方法
以下方法创建一个新的解析器对象并返回。
xml.sax.make_parser( [parser_list] )参数说明:
- parser_list - 可选参数,解析器列表
parser 方法
以下方法创建一个 SAX 解析器并解析xml文档:
xml.sax.parse( xmlfile, contenthandler[, errorhandler])参数说明:
- xmlfile - xml文件名
- contenthandler - 必须是一个 ContentHandler 的对象
- errorhandler - 如果指定该参数,errorhandler 必须是一个 SAX ErrorHandler 对象
parseString 方法
parseString 方法创建一个 XML 解析器并解析 xml 字符串:
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])参数说明:
- xmlstring - xml字符串
- contenthandler - 必须是一个 ContentHandler 的对象
- errorhandler - 如果指定该参数,errorhandler 必须是一个 SAX ErrorHandler对象
Python3 JSON 数据解析
Python3 JSON 数据解析
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。
Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数:
- json.dumps(): 对数据进行编码。
- json.loads(): 对数据进行解码。
在json的编解码过程中,Python 的原始类型与 json 类型会相互转换,具体的转化对照如下:
Python 编码为 JSON 类型转换对应表:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True | true |
| False | false |
| None | null |
JSON 解码为 Python 类型转换对应表:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
| null | None |
json.dumps 与 json.loads 实例
以下实例演示了 Python 数据结构转换为 JSON:
#!/usr/bin/python3
import json
# Python 字典类型转换为 JSON 对象
data = {
'no' : 1,
'name' : 'W3CSchool',
'url' : 'http://www.w3cschool.cn'
}
json_str = json.dumps(data)
print ("Python 原始数据:", repr(data))
print ("JSON 对象:", json_str)
执行以上代码输出结果为:
Python 原始数据: {'url': 'http://www.w3cschool.cn', 'no': 1, 'name': 'W3CSchool'}
JSON 对象: {"url": "http://www.w3cschool.cn", "no": 1, "name": "W3CSchool"}
通过输出的结果可以看出,简单类型通过编码后跟其原始的repr()输出结果非常相似。
接着以上实例,我们可以将一个JSON编码的字符串转换回一个Python数据结构:
#!/usr/bin/python3
import json
# Python 字典类型转换为 JSON 对象
data1 = {
'no' : 1,
'name' : 'W3CSchool',
'url' : 'http://www.w3cschool.cn'
}
json_str = json.dumps(data1)
print ("Python 原始数据:", repr(data1))
print ("JSON 对象:", json_str)
# 将 JSON 对象转换为 Python 字典
data2 = json.loads(json_str)
print ("data2['name']: ", data2['name'])
print ("data2['url']: ", data2['url'])
执行以上代码输出结果为:
ython 原始数据: {'name': 'W3CSchool', 'no': 1, 'url': 'http://www.w3cschool.cn'}
JSON 对象: {"name": "W3CSchool", "no": 1, "url": "http://www.w3cschool.cn"}
data2['name']: W3CSchool
data2['url']: http://www.w3cschool.cn
如果你要处理的是文件而不是字符串,你可以使用 json.dump() 和 json.load() 来编码和解码 JSON 数据。例如:
# 写入 JSON 数据
with open('data.json', 'w') as f:
json.dump(data, f)
# 读取数据
with open('data.json', 'r') as f:
data = json.load(f)
Python3 日期和时间
Python3 日期和时间
Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能。
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从 1970 年 1 月 1 日午夜(历元)经过了多长时间来表示。
Python 的 time 模块下有很多函数可以转换常见日期格式。
获取当前时间
从返回浮点数的时间辍方式向时间元组转换,只要将浮点数传递给如 localtime 之类的函数。
#!/usr/bin/python3
import time
localtime = time.localtime(time.time())
print ("本地时间为 :", localtime)以上实例输出结果:
本地时间为 : time.struct_time(tm_year=2016, tm_mon=4, tm_mday=7, tm_hour=10, tm_min=28, tm_sec=49, tm_wday=3, tm_yday=98, tm_isdst=0)日历(Calendar)模块
此模块的函数都是日历相关的,例如打印某月的字符月历。
星期一是默认的每周第一天,星期天是默认的最后一天。更改设置需调用calendar.setfirstweekday() 函数。模块包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) 返回一个多行字符串格式的 year 年年历,3 个月一行,间隔距离为 c。 每日宽度间隔为 w 字符。每行长度为 21* W+18+2* C。l 是每星期行数。 |
| 2 | calendar.firstweekday( ) 返回当前每周起始日期的设置。默认情况下,首次载入 calendar 模块时返回 0,即星期一。 |
| 3 | calendar.isleap(year) 是闰年返回 True,否则为 False。 |
| 4 | calendar.leapdays(y1,y2) 返回在 Y1,Y2 两年之间的闰年总数。 |
| 5 | calendar.month(year,month,w=2,l=1) 返回一个多行字符串格式的 year 年 month 月日历,两行标题,一周一行。每日宽度间隔为 w 字符。每行的长度为 7* w+6。l 是每星期的行数。 |
| 6 | calendar.monthcalendar(year,month) 返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的整数。Year 年 month 月外的日期都设为 0;范围内的日子都由该月第几日表示,从 1 开始。 |
| 7 | calendar.monthrange(year,month) 返回两个整数。第一个是该月的星期几的日期码,第二个是该月的日期码。日从 0(星期一)到 6 (星期日);月从 1 到 12。 |
| 8 | calendar.prcal(year,w=2,l=1,c=6) 相当于 print calendar.calendar(year,w,l,c). |
| 9 | calendar.prmonth(year,month,w=2,l=1) 相当于 print calendar.calendar(year,w,l,c)。 |
| 10 | calendar.setfirstweekday(weekday) 设置每周的起始日期码。0(星期一)到 6(星期日)。 |
| 11 | calendar.timegm(tupletime) 和 time.gmtime 相反:接受一个时间元组形式,返回该时刻的时间辍(1970 纪元后经过的浮点秒数)。 |
| 12 | calendar.weekday(year,month,day) 返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1(一月) 到 12(12月)。 |
Python3 内置函数
本节介绍了 Python3 中的内置函数以及调试的两种方法。
Python 调试方法
1、print
print('here')
# 可以发现某段逻辑是否执行
# 打印出变量的内容2、assert
assert false, 'blabla'
# 如果条件不成立,则打印出 'blabla' 并抛出AssertionError异常3、debugger
可以通过 pdb、IDE 等工具进行调试。
调试的具体方法这里不展开。
Python 中有两个内置方法在这里也很有帮助:
- locals: 执行 locals() 之后, 返回一个字典, 包含(current scope)当前范围下的局部变量。
- globals: 执行 globals() 之后, 返回一个字典, 包含(current scope)当前范围下的全局变量。
Python3 爬虫实战教程
(1) requests安装
在cmd中,使用如下指令安装requests:
pip install requests(2) 简单实例
requests库的基础方法如下:

requests中文文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
requests库的开发者为我们提供了详细的中文教程,查询起来很方便。本文不会对其所有内容进行讲解,摘取其部分使用到的内容,进行实战说明。
首先,让我们看下requests.get()方法,它用于向服务器发起GET请求,不了解GET请求没有关系。我们可以这样理解:get的中文意思是得到、抓住,那这个requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。让我们看一个例子(以 www.gitbook.cn为例)来加深理解:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://gitbook.cn/'
req = requests.get(url=target)
print(req.text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号