nginx平台初探-4
模块开发高级篇(30%)
变量(80%)
综述
在Nginx中同一个请求需要在模块之间数据的传递或者说在配置文件里面使用模块动态的数据一般来说都是使用变量,比如在HTTP模块中导出了host/remote_addr等变量,这样我们就可以在配置文件中以及在其他的模块使用这个变量。在Nginx中,有两种定义变量的方式,一种是在配置文件中,使用set指令,一种就是上面我们提到的在模块中定义变量,然后导出.
在Nginx中所有的变量都是与HTTP相关的(也就是说赋值都是在请求阶段),并且基本上是同时保存在两个数据结构中,一个就是hash表(可选),另一个是数组. 比如一些特殊的变量,比如arg_xxx/cookie_xxx等,这些变量的名字是不确定的(因此不能内置),而且他们还是只读的(不能交由用户修改),如果每个都要放到hash表中的话(不知道用户会取多少个),会很占空间的,因此这些变量就没有hash,只有索引.这里要注意,用户不能定义这样的变量,这样的变量只存在于Nginx内部.
对应的变量结构体是这样子(每一个变量都是一个ngx_http_variable_s结构体)的:
struct ngx_http_variable_s {
ngx_str_t name; /* must be first to build the hash */
ngx_http_set_variable_pt set_handler;
ngx_http_get_variable_pt get_handler;
uintptr_t data;
ngx_uint_t flags;
ngx_uint_t index;
};
其中name表示对应的变量名字,set/get_handler表示对应的设置以及读取回调,而data是传递给回调的参数,flags表示变量的属性,index提供了一个索引(数组的脚标),从而可以迅速定位到对应的变量。set/get_handler只有在真正读取设置变量的时候才会被调用.
这里要注意flag属性,flag属性就是由下面的几个属性组合而成:
#define NGX_HTTP_VAR_CHANGEABLE 1
#define NGX_HTTP_VAR_NOCACHEABLE 2
#define NGX_HTTP_VAR_INDEXED 4
#define NGX_HTTP_VAR_NOHASH 8
- NGX_HTTP_VAR_CHANGEABLE表示这个变量是可变的.Nginx有很多内置变量是不可变的,比如arg_xxx这类变量,如果你使用set指令来修改,那么Nginx就会报错.
- NGX_HTTP_VAR_NOCACHEABLE表示这个变量每次都要去取值,而不是直接返回上次cache的值(配合对应的接口).
- NGX_HTTP_VAR_INDEXED表示这个变量是用索引读取的.
- NGX_HTTP_VAR_NOHASH表示这个变量不需要被hash.
而变量在Nginx中的初始化流程是这样的:
- 首先当解析HTTP之前会调用ngx_http_variables_add_core_vars(pre_config)来将HTTP core模块导出的变量(http_host/remote_addr...)添加进全局的hash key链中.
- 解析完HTTP模块之后,会调用ngx_http_variables_init_vars来初始化所有的变量(不仅包括HTTP core模块的变量,也包括其他的HTTP模块导出的变量,以及配置文件中使用set命令设置的变量),这里的初始化包括初始化hash表,以及初始化数组索引.
- 当每次请求到来时会给每个请求创建一个变量数组(数组的个数就是上面第二步所保存的变量个数)。然后只有取变量值的时候,才会将变量保存在对应的变量数组位置。
创建变量
在Nginx中,创建变量有两种方式,分别是在配置文件中使用set指令,和在模块中调用对应的接口,在配置文件中创建变量比较简单,因此我们主要来看如何在模块中创建自己的变量。
在Nginx中提供了下面的接口,可以供模块调用来创建变量。
ngx_http_variable_t *ngx_http_add_variable(ngx_conf_t *cf, ngx_str_t *name, ngx_uint_t flags);
这个函数所做的工作就是将变量 “name”添加进全局的hash key表中,然后初始化一些域,不过这里要注意,对应的变量的get/set回调,需要当这个函数返回之后,显式的设置,比如在split_clients模块中的例子:
var = ngx_http_add_variable(cf, &name, NGX_HTTP_VAR_CHANGEABLE);
if (var == NULL) {
return NGX_CONF_ERROR;
}
//设置回调
var->get_handler = ngx_http_split_clients_variable;
var->data = (uintptr_t) ctx;
而对应的回调函数原型是这样的:
typedef void (*ngx_http_set_variable_pt) (ngx_http_request_t *r,
ngx_http_variable_value_t *v, uintptr_t data);
typedef ngx_int_t (*ngx_http_get_variable_pt) (ngx_http_request_t *r,
ngx_http_variable_value_t *v, uintptr_t data);
回调函数比较简单,第一个参数是当前请求,第二个是需要设置或者获取的变量值,第三个是初始化时的回调指针,这里我们着重来看一下ngx_http_variable_value_t,下面就是这个结构体的原型:
typedef struct {
unsigned len:28;
unsigned valid:1;
unsigned no_cacheable:1;
unsigned not_found:1;
unsigned escape:1;
u_char *data;
} ngx_variable_value_t;
这里主要是data域,当我们在get_handle中设置变量值的时候,只需要将对应的值放入到data中就可以了,这里data需要在get_handle中分配内存,比如下面的例子(ngx_http_fastcgi_script_name_variable),就是fastcgi_script_name变量的get_handler代码片段:
v->len = f->script_name.len + flcf->index.len;
v->data = ngx_pnalloc(r->pool, v->len);
if (v->data == NULL) {
return NGX_ERROR;
}
p = ngx_copy(v->data, f->script_name.data, f->script_name.len);
ngx_memcpy(p, flcf->index.data, flcf->index.len);
使用变量
Nginx的内部变量指的就是Nginx的官方模块中所导出的变量,在Nginx中,大部分常用的变量都是CORE HTTP模块导出的。而在Nginx中,不仅可以在模块代码中使用变量,而且还可以在配置文件中使用。
假设我们需要在配置文件中使用http模块的host变量,那么只需要这样在变量名前加一个$符号就可以了($host).而如果需要在模块中使用host变量,那么就比较麻烦,Nginx提供了下面几个接口来取得变量:
ngx_http_variable_value_t *ngx_http_get_indexed_variable(ngx_http_request_t *r,
ngx_uint_t index);
ngx_http_variable_value_t *ngx_http_get_flushed_variable(ngx_http_request_t *r,
ngx_uint_t index);
ngx_http_variable_value_t *ngx_http_get_variable(ngx_http_request_t *r,
ngx_str_t *name, ngx_uint_t key);
他们的区别是这样子的,ngx_http_get_indexed_variable和ngx_http_get_flushed_variable都是用来取得有索引的变量,不过他们的区别是后一个会处理 NGX_HTTP_VAR_NOCACHEABLE这个标记,也就是说如果你想要cache你的变量值,那么你的变量属性就不能设置NGX_HTTP_VAR_NOCACHEABLE,并且通过ngx_http_get_flushed_variable来获取变量值.而ngx_http_get_variable和上面的区别就是它能够得到没有索引的变量值.
通过上面我们知道可以通过索引来得到变量值,可是这个索引该如何取得呢,Nginx也提供了对应的接口:
ngx_int_t ngx_http_get_variable_index(ngx_conf_t *cf, ngx_str_t *name);
通过这个接口,就可以取得对应变量名的索引值。
接下来来看对应的例子,比如在http_log模块中,如果在log_format中配置了对应的变量,那么它会调用ngx_http_get_variable_index来保存索引:
static ngx_int_t
ngx_http_log_variable_compile(ngx_conf_t *cf, ngx_http_log_op_t *op,
ngx_str_t *value)
{
ngx_int_t index;
//得到变量的索引
index = ngx_http_get_variable_index(cf, value);
if (index == NGX_ERROR) {
return NGX_ERROR;
}
op->len = 0;
op->getlen = ngx_http_log_variable_getlen;
op->run = ngx_http_log_variable;
//保存索引值
op->data = index;
return NGX_OK;
}
然后http_log模块会使用ngx_http_get_indexed_variable来得到对应的变量值,这里要注意,就是使用这个接口的时候,判断返回值,不仅要判断是否为空,也需要判断value->not_found,这是因为只有第一次调用才会返回空,后续返回就不是空,因此需要判断value->not_found:
static u_char *
ngx_http_log_variable(ngx_http_request_t *r, u_char *buf, ngx_http_log_op_t *op)
{
ngx_http_variable_value_t *value;
//获取变量值
value = ngx_http_get_indexed_variable(r, op->data);
if (value == NULL || value->not_found) {
*buf = '-';
return buf + 1;
}
if (value->escape == 0) {
return ngx_cpymem(buf, value->data, value->len);
} else {
return (u_char *) ngx_http_log_escape(buf, value->data, value->len);
}
}
upstream
使用subrequest访问upstream
超越upstream
event机制
例讲(主动健康检查模块)
使用lua模块
nginx架构详解(50%)
nginx的下篇将会更加深入的介绍nginx的实现原理。上一章,我们了解到了如何设计一个高性能服务器,那这一章将会开始讲解,nginx是如何一步一步实现高性能服务器的。
nginx的源码目录结构(100%)
nginx的优秀除了体现在程序结构以及代码风格上,nginx的源码组织也同样简洁明了,目录结构层次结构清晰,值得我们去学习。nginx的源码目录与nginx的模块化以及功能的划分是紧密结合,这也使得我们可以很方便地找到相关功能的代码。这节先介绍nginx源码的目录结构,先对nginx的源码有一个大致的认识,下节会讲解nginx如何编译。
下面是nginx源码的目录结构:
.
├── auto 自动检测系统环境以及编译相关的脚本
│ ├── cc 关于编译器相关的编译选项的检测脚本
│ ├── lib nginx编译所需要的一些库的检测脚本
│ ├── os 与平台相关的一些系统参数与系统调用相关的检测
│ └── types 与数据类型相关的一些辅助脚本
├── conf 存放默认配置文件,在make install后,会拷贝到安装目录中去
├── contrib 存放一些实用工具,如geo配置生成工具(geo2nginx.pl)
├── html 存放默认的网页文件,在make install后,会拷贝到安装目录中去
├── man nginx的man手册
└── src 存放nginx的源代码
├── core nginx的核心源代码,包括常用数据结构的定义,以及nginx初始化运行的核心代码如main函数
├── event 对系统事件处理机制的封装,以及定时器的实现相关代码
│ └── modules 不同事件处理方式的模块化,如select、poll、epoll、kqueue等
├── http nginx作为http服务器相关的代码
│ └── modules 包含http的各种功能模块
├── mail nginx作为邮件代理服务器相关的代码
├── misc 一些辅助代码,测试c++头的兼容性,以及对google_perftools的支持
└── os 主要是对各种不同体系统结构所提供的系统函数的封装,对外提供统一的系统调用接口
nginx的configure原理(100%)
nginx的编译旅程将从configure开始,configure脚本将根据我们输入的选项、系统环境参与来生成所需的文件(包含源文件与Makefile文件)。configure会调用一系列auto脚本来实现编译环境的初始化。
auto脚本
auto脚本由一系列脚本组成,他们有一些是实现一些通用功能由其它脚本来调用(如have),有一些则是完成一些特定的功能(如option)。脚本之间的主要执行顺序及调用关系如下图所示(由上到下,表示主流程的执行):

接下来,我们结合代码来分析下configure的原理:
- 初始化
. auto/options
. auto/init
. auto/sources
这是configure源码开始执行的前三行,依次交由auto目录下面的option、init、sources来处理。
- auto/options主是处理用户输入的configure选项,以及输出帮助信息等。读者可以结合nginx的源码来阅读本章内容。由于篇幅关系,这里大致列出此文件的结构:
##1. 设置选项对应的shell变量以及他们的初始值
help=no
NGX_PREFIX=
NGX_SBIN_PATH=
NGX_CONF_PREFIX=
NGX_CONF_PATH=
NGX_ERROR_LOG_PATH=
NGX_PID_PATH=
NGX_LOCK_PATH=
NGX_USER=
NGX_GROUP=
...
## 2, 处理每一个选项值,并设置到对应的全局变量中
for option
do
opt="$opt `echo $option | sed -e \"s/\(--[^=]*=\)\(.* .*\)/\1'\2'/\"`"
# 得到此选项的value部分
case "$option" in
-*=*) value=`echo "$option" | sed -e 's/[-_a-zA-Z0-9]*=//'` ;;
*) value="" ;;
esac
# 根据option内容进行匹配,并设置相应的选项
case "$option" in
--help) help=yes ;;
--prefix=) NGX_PREFIX="!" ;;
--prefix=*) NGX_PREFIX="$value" ;;
--sbin-path=*) NGX_SBIN_PATH="$value" ;;
--conf-path=*) NGX_CONF_PATH="$value" ;;
--error-log-path=*) NGX_ERROR_LOG_PATH="$value";;
--pid-path=*) NGX_PID_PATH="$value" ;;
--lock-path=*) NGX_LOCK_PATH="$value" ;;
--user=*) NGX_USER="$value" ;;
--group=*) NGX_GROUP="$value" ;;
...
*)
# 没有找到的对应选项
echo "$0: error: invalid option \"$option\""
exit 1
;;
esac
done
## 3. 对选项进行处理
# 如果有--help,则输出帮助信息
if [ $help = yes ]; then
cat << END
--help print this message
--prefix=PATH set installation prefix
--sbin-path=PATH set nginx binary pathname
--conf-path=PATH set nginx.conf pathname
--error-log-path=PATH set error log pathname
--pid-path=PATH set nginx.pid pathname
--lock-path=PATH set nginx.lock pathname
--user=USER set non-privileged user for
worker processes
--group=GROUP set non-privileged group for
worker processes
END
exit 1
fi
# 默认文件路径
NGX_CONF_PATH=${NGX_CONF_PATH:-conf/nginx.conf}
NGX_CONF_PREFIX=`dirname $NGX_CONF_PATH`
NGX_PID_PATH=${NGX_PID_PATH:-logs/nginx.pid}
NGX_LOCK_PATH=${NGX_LOCK_PATH:-logs/nginx.lock}
...
上面的代码中,我们选用了文件中的部分代码进行了说明。大家可结合源码再进行分析。auto/options的目的主要是处理用户选项,并由选项生成一些全局变量的值,这些值在其它文件中会用到。该文件也会输出configure的帮助信息。
- auto/init
该文件的目录在于初始化一些临时文件的路径,检查echo的兼容性,并创建Makefile。
# 生成最终执行编译的makefile文件路径
NGX_MAKEFILE=$NGX_OBJS/Makefile
# 动态生成nginx模块列表的路径,由于nginx的的一些模块是可以选择编译的,而且可以添加自己的模块,所以模块列表是动态生成的
NGX_MODULES_C=$NGX_OBJS/ngx_modules.c
NGX_AUTO_HEADERS_H=$NGX_OBJS/ngx_auto_headers.h
NGX_AUTO_CONFIG_H=$NGX_OBJS/ngx_auto_config.h
# 自动测试目录与日志输出文件
NGX_AUTOTEST=$NGX_OBJS/autotest
# 如果configure出错,可用来查找出错的原因
NGX_AUTOCONF_ERR=$NGX_OBJS/autoconf.err
NGX_ERR=$NGX_OBJS/autoconf.err
MAKEFILE=$NGX_OBJS/Makefile
NGX_PCH=
NGX_USE_PCH=
# 检查echo是否支持-n或\c
# check the echo's "-n" option and "\c" capability
if echo "test\c" | grep c >/dev/null; then
# 不支持-c的方式,检查是否支持-n的方式
if echo -n test | grep n >/dev/null; then
ngx_n=
ngx_c=
else
ngx_n=-n
ngx_c=
fi
else
ngx_n=
ngx_c='\c'
fi
# 创建最初始的makefile文件
# default表示目前编译对象
# clean表示执行clean工作时,需要删除makefile文件以及objs目录
# 整个过程中只会生成makefile文件以及objs目录,其它所有临时文件都在objs目录之下,所以执行clean后,整个目录还原到初始状态
# 要再次执行编译,需要重新执行configure命令
# create Makefile
cat << END > Makefile
default: build
clean:
rm -rf Makefile $NGX_OBJS
END
- auto/sources
该文件从文件名中就可以看出,它的主要功能是跟源文件相关的。它的主要作用是定义不同功能或系统所需要的文件的变量。根据功能,分为CORE/REGEX/EVENT/UNIX/FREEBSD/HTTP等。每一个功能将会由四个变量组成,”_MODULES”表示此功能相关的模块,最终会输出到ngx_modules.c文件中,即动态生成需要编译到nginx中的模块;”INCS”表示此功能依赖的源码目录,查找头文件的时候会用到,在编译选项中,会出现在”-I”中;”DEPS”显示指明在Makefile中需要依赖的文件名,即编译时,需要检查这些文件的更新时间;”SRCS”表示需要此功能编译需要的源文件。
拿core来说:
CORE_MODULES="ngx_core_module ngx_errlog_module ngx_conf_module ngx_emp_server_module ngx_emp_server_core_module"
CORE_INCS="src/core"
CORE_DEPS="src/core/nginx.h \
src/core/ngx_config.h \
src/core/ngx_core.h \
src/core/ngx_log.h \
src/core/ngx_palloc.h \
src/core/ngx_array.h \
src/core/ngx_list.h \
src/core/ngx_hash.h \
src/core/ngx_buf.h \
src/core/ngx_queue.h \
src/core/ngx_string.h \
src/core/ngx_parse.h \
src/core/ngx_inet.h \
src/core/ngx_file.h \
src/core/ngx_crc.h \
src/core/ngx_crc32.h \
src/core/ngx_murmurhash.h \
src/core/ngx_md5.h \
src/core/ngx_sha1.h \
src/core/ngx_rbtree.h \
src/core/ngx_radix_tree.h \
src/core/ngx_slab.h \
src/core/ngx_times.h \
src/core/ngx_shmtx.h \
src/core/ngx_connection.h \
src/core/ngx_cycle.h \
src/core/ngx_conf_file.h \
src/core/ngx_resolver.h \
src/core/ngx_open_file_cache.h \
src/core/nginx_emp_server.h \
src/core/emp_server.h \
src/core/task_thread.h \
src/core/standard.h \
src/core/dprint.h \
src/core/ngx_crypt.h"
CORE_SRCS="src/core/nginx.c \
src/core/ngx_log.c \
src/core/ngx_palloc.c \
src/core/ngx_array.c \
src/core/ngx_list.c \
src/core/ngx_hash.c \
src/core/ngx_buf.c \
src/core/ngx_queue.c \
src/core/ngx_output_chain.c \
src/core/ngx_string.c \
src/core/ngx_parse.c \
src/core/ngx_inet.c \
src/core/ngx_file.c \
src/core/ngx_crc32.c \
src/core/ngx_murmurhash.c \
src/core/ngx_md5.c \
src/core/ngx_rbtree.c \
src/core/ngx_radix_tree.c \
src/core/ngx_slab.c \
src/core/ngx_times.c \
src/core/ngx_shmtx.c \
src/core/ngx_connection.c \
src/core/ngx_cycle.c \
src/core/ngx_spinlock.c \
src/core/ngx_cpuinfo.c \
src/core/ngx_conf_file.c \
src/core/ngx_resolver.c \
src/core/ngx_open_file_cache.c \
src/core/nginx_emp_server.c \
src/core/emp_server.c \
src/core/standard.c \
src/core/task_thread.c \
src/core/dprint.c \
src/core/ngx_crypt.c"
如果我们自己写一个第三方模块,我们可能会引用到这些变量的值,或对这些变量进行修改,比如添加我们自己的模块,或添加自己的一个头文件查找目录(在第三方模块的config中),在后面,我们会看到它是如何加框第三方模块的。 在继续分析执行流程之前,我们先介绍一些工具脚本。
- auto/have
cat << END >> $NGX_AUTO_CONFIG_H
#ifndef $have
#define $have 1
#endif
END
从代码中,我们可以看到,这个工具的作用是,将$have变量的值,宏定义为1,并输出到auto_config文件中。通常我们通过这个工具来控制是否打开某个特性。这个工具在使用前,需要先定义宏的名称 ,即$have变量。
- 再回到configure文件中来:
# NGX_DEBUG是在auto/options文件中处理的,如果有--with-debug选项,则其值是YES
if [ $NGX_DEBUG = YES ]; then
# 当有debug选项时,会定义NGX_DEBUG宏
have=NGX_DEBUG . auto/have
fi
这段代码中,可以看出,configure是如何定义一个特性的:通过宏定义,输出到config头文件中,然后在程序中可以判断这个宏是否有定义,来实现不同的特性。
configure文件中继续向下:
# 编译器选项
. auto/cc/conf
# 头文件支持宏定义
if [ "$NGX_PLATFORM" != win32 ]; then
. auto/headers
fi
# 操作系统相关的配置的检测
. auto/os/conf
# unix体系下的通用配置检测
if [ "$NGX_PLATFORM" != win32 ]; then
. auto/unix
fi
configure会依次调用其它几个文件,来进行环境的检测,包括编译器、操作系统相关。
- auto/feature
nginx的configure会自动检测不同平台的特性,神奇之处就是auto/feature的实现,在继续向下分析之前,我们先来看看这个工具的实现原理。此工具的核心思想是,输出一小段代表性c程序,然后设置好编译选项,再进行编译连接运行,再对结果进行分析。例如,如果想检测某个库是否存在,就在小段c程序里面调用库里面的某个函数,再进行编译链接,如果出错,则表示库的环境不正常,如果编译成功,且运行正常,则库的环境检测正常。我们在写nginx第三方模块时,也常使用此工具来进行环境的检测,所以,此工具的作用贯穿整个configure过程。
先看一小段使用例子:
ngx_feature="poll()"
ngx_feature_name=
ngx_feature_run=no
ngx_feature_incs="#include <poll.h>"
ngx_feature_path=
ngx_feature_libs=
ngx_feature_test="int n; struct pollfd pl;
pl.fd = 0;
pl.events = 0;
pl.revents = 0;
n = poll(&pl, 1, 0);
if (n == -1) return 1"
. auto/feature
if [ $ngx_found = no ]; then
# 如果没有找到poll,就设置变量的值
EVENT_POLL=NONE
fi
这段代码在auto/unix里面实现,用来检测当前操作系统是否支持poll函数调用。在调用auto/feature之前,需要先设置几个输入参数变量的值,然后结果会存在$ngx_found变量里面, 并输出宏定义以表示支持此特性:
$ngx_feature 特性名称
$ngx_feature_name 特性的宏定义名称,如果特性测试成功,则会定义该宏定义
$ngx_feature_path 编译时要查找头文件目录
$ngx_feature_test 要执行的测试代码
$ngx_feature_incs 在代码中要include的头文件
$ngx_feature_libs 编译时需要link的库文件选项
$ngx_feature_run 编译成功后,对二进制文件需要做的动作,可以是yes value bug 其它
#ngx_found 如果找到,并测试成功,其值为yes,否则其值为no
看看ngx_feature的关键代码:
# 初始化输出结果为no
ngx_found=no
#将特性名称小写转换成大写
if test -n "$ngx_feature_name"; then
# 小写转大写
ngx_have_feature=`echo $ngx_feature_name \
| tr abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ`
fi
# 将所有include目录转换成编译选项
if test -n "$ngx_feature_path"; then
for ngx_temp in $ngx_feature_path; do
ngx_feature_inc_path="$ngx_feature_inc_path -I $ngx_temp"
done
fi
# 生成临时的小段c程序代码。
# $ngx_feature_incs变量是程序需要include的头文件
# $ngx_feature_test是测试代码
cat << END > $NGX_AUTOTEST.c
#include <sys/types.h>
$NGX_INCLUDE_UNISTD_H
$ngx_feature_incs
int main() {
$ngx_feature_test;
return 0;
}
END
# 编译命令
# 编译之后的目标文件是 $NGX_AUTOTEST,后面会判断这个文件是否存在来判断是否编译成功
ngx_test="$CC $CC_TEST_FLAGS $CC_AUX_FLAGS $ngx_feature_inc_path \
-o $NGX_AUTOTEST $NGX_AUTOTEST.c $NGX_TEST_LD_OPT $ngx_feature_libs"
# 执行编译过程
# 编译成功后,会生成$NGX_AUTOTEST命名的文件
eval "/bin/sh -c \"$ngx_test\" >> $NGX_AUTOCONF_ERR 2>&1"
# 如果文件存在,则编译成功
if [ -x $NGX_AUTOTEST ]; then
case "$ngx_feature_run" in
# 需要运行来判断是否支持特性
# 测试程序能否正常执行(即程序退出后的状态码是否是0),如果正常退出,则特性测试成功,设置ngx_found为yes,并添加名为ngx_feature_name的宏定义,宏的值为1
yes)
# 如果程序正常退出,退出码为0,则程序执行成功,我们可以在测试代码里面手动返回非0来表示程序出错
# /bin/sh is used to intercept "Killed" or "Abort trap" messages
if /bin/sh -c $NGX_AUTOTEST >> $NGX_AUTOCONF_ERR 2>&1; then
echo " found"
ngx_found=yes
# 添加宏定义,宏的值为1
if test -n "$ngx_feature_name"; then
have=$ngx_have_feature . auto/have
fi
else
echo " found but is not working"
fi
;;
# 需要运行程序来判断是否支持特性,如果支持,将程序标准输出的结果作为宏的值
value)
# /bin/sh is used to intercept "Killed" or "Abort trap" messages
if /bin/sh -c $NGX_AUTOTEST >> $NGX_AUTOCONF_ERR 2>&1; then
echo " found"
ngx_found=yes
# 与yes不一样的是,value会将程序从标准输出里面打印出来的值,设置为ngx_feature_name宏变量的值
# 在此种情况下,程序需要设置ngx_feature_name变量名
cat << END >> $NGX_AUTO_CONFIG_H
#ifndef $ngx_feature_name
#define $ngx_feature_name `$NGX_AUTOTEST`
#endif
END
else
echo " found but is not working"
fi
;;
# 与yes正好相反
bug)
# /bin/sh is used to intercept "Killed" or "Abort trap" messages
if /bin/sh -c $NGX_AUTOTEST >> $NGX_AUTOCONF_ERR 2>&1; then
echo " not found"
else
echo " found"
ngx_found=yes
if test -n "$ngx_feature_name"; then
have=$ngx_have_feature . auto/have
fi
fi
;;
# 不需要运行程序,最后定义宏变量
*)
echo " found"
ngx_found=yes
if test -n "$ngx_feature_name"; then
have=$ngx_have_feature . auto/have
fi
;;
esac
else
# 编译失败
echo " not found"
# 编译失败,会保存信息到日志文件中
echo "----------" >> $NGX_AUTOCONF_ERR
# 保留编译文件的内容
cat $NGX_AUTOTEST.c >> $NGX_AUTOCONF_ERR
echo "----------" >> $NGX_AUTOCONF_ERR
# 保留编译文件的选项
echo $ngx_test >> $NGX_AUTOCONF_ERR
echo "----------" >> $NGX_AUTOCONF_ERR
fi
# 最后删除生成的临时文件
rm $NGX_AUTOTEST*
- auto/cc/conf
在了解了工具auto/feature后,继续我们的主流程,auto/cc/conf的代码就很好理解了,这一步主要是检测编译器,并设置编译器相关的选项。它先调用auto/cc/name来得到编译器的名称,然后根据编译器选择执行不同的编译器相关的文件如gcc执行auto/cc/gcc来设置编译器相关的一些选项。
- auto/include
这个工具用来检测是头文件是否支持。需要检测的头文件放在$ngx_include里面,如果支持,则$ngx_found变量的值为yes,并且会产生NGX_HAVE_{ngx_include}的宏定义。
- auto/headers
生成头文件的宏定义。生成的定义放在objs/ngx_auto_headers.h里面:
#ifndef NGX_HAVE_UNISTD_H
#define NGX_HAVE_UNISTD_H 1
#endif
#ifndef NGX_HAVE_INTTYPES_H
#define NGX_HAVE_INTTYPES_H 1
#endif
#ifndef NGX_HAVE_LIMITS_H
#define NGX_HAVE_LIMITS_H 1
#endif
#ifndef NGX_HAVE_SYS_FILIO_H
#define NGX_HAVE_SYS_FILIO_H 1
#endif
#ifndef NGX_HAVE_SYS_PARAM_H
#define NGX_HAVE_SYS_PARAM_H 1
#endif
- auto/os/conf
针对不同的操作系统平台特性的检测,并针对不同的操作系统,设置不同的CORE_INCS、CORE_DEPS、CORE_SRCS变量。nginx跨平台的支持就是在这个地方体现出来的。
- auto/unix
针对unix体系的通用配置或系统调用的检测,如poll等事件处理系统调用的检测等。
- 回到configure里面
# 生成模块列表
. auto/modules
# 配置库的依赖
. auto/lib/conf
- auto/modules
该脚本根据不同的条件,输出不同的模块列表,最后输出的模块列表的文件在objs/ngx_modules.c:
#include <ngx_config.h>
#include <ngx_core.h>
extern ngx_module_t ngx_core_module;
extern ngx_module_t ngx_errlog_module;
extern ngx_module_t ngx_conf_module;
extern ngx_module_t ngx_emp_server_module;
...
ngx_module_t *ngx_modules[] = {
&ngx_core_module,
&ngx_errlog_module,
&ngx_conf_module,
&ngx_emp_server_module,
...
NULL
};
这个文件会决定所有模块的顺序,这会直接影响到最后的功能,下一小节我们将讨论模块间的顺序。这个文件会加载我们的第三方模块,这也是我们值得关注的地方:
if test -n "$NGX_ADDONS"; then
echo configuring additional modules
for ngx_addon_dir in $NGX_ADDONS
do
echo "adding module in $ngx_addon_dir"
if test -f $ngx_addon_dir/config; then
# 执行第三方模块的配置
. $ngx_addon_dir/config
echo " + $ngx_addon_name was configured"
else
echo "$0: error: no $ngx_addon_dir/config was found"
exit 1
fi
done
fi
这段代码比较简单,确实现了nginx很强大的扩展性,加载第三方模块。$ngx_addon_dir变量是在configure执行时,命令行参数–add-module加入的,它是一个目录列表,每一个目录,表示一个第三方模块。从代码中,我们可以看到,它就是针对每一个第三方模块执行其目录下的config文件。于是我们可以在config文件里面执行我们自己的检测逻辑,比如检测库依赖,添加编译选项等。
- auto/lib/conf
该文件会针对nginx编译所需要的基础库的检测,比如rewrite模块需要的PCRE库的检测支持。
- configure接下来定义一些宏常量,主要是是文件路径方面的:
case ".$NGX_PREFIX" in
.)
NGX_PREFIX=${NGX_PREFIX:-/usr/local/nginx}
have=NGX_PREFIX value="\"$NGX_PREFIX/\"" . auto/define
;;
.!)
NGX_PREFIX=
;;
*)
have=NGX_PREFIX value="\"$NGX_PREFIX/\"" . auto/define
;;
esac
if [ ".$NGX_CONF_PREFIX" != "." ]; then
have=NGX_CONF_PREFIX value="\"$NGX_CONF_PREFIX/\"" . auto/define
fi
have=NGX_SBIN_PATH value="\"$NGX_SBIN_PATH\"" . auto/define
have=NGX_CONF_PATH value="\"$NGX_CONF_PATH\"" . auto/define
have=NGX_PID_PATH value="\"$NGX_PID_PATH\"" . auto/define
have=NGX_LOCK_PATH value="\"$NGX_LOCK_PATH\"" . auto/define
have=NGX_ERROR_LOG_PATH value="\"$NGX_ERROR_LOG_PATH\"" . auto/define
have=NGX_HTTP_LOG_PATH value="\"$NGX_HTTP_LOG_PATH\"" . auto/define
have=NGX_HTTP_CLIENT_TEMP_PATH value="\"$NGX_HTTP_CLIENT_TEMP_PATH\""
. auto/define
have=NGX_HTTP_PROXY_TEMP_PATH value="\"$NGX_HTTP_PROXY_TEMP_PATH\""
. auto/define
have=NGX_HTTP_FASTCGI_TEMP_PATH value="\"$NGX_HTTP_FASTCGI_TEMP_PATH\""
. auto/define
have=NGX_HTTP_UWSGI_TEMP_PATH value="\"$NGX_HTTP_UWSGI_TEMP_PATH\""
. auto/define
have=NGX_HTTP_SCGI_TEMP_PATH value="\"$NGX_HTTP_SCGI_TEMP_PATH\""
. auto/define
- configure最后的工作,生成编译安装的makefile
# 生成objs/makefile文件
. auto/make
# 生成关于库的编译选项到makefile文件
. auto/lib/make
# 生成与安装相关的makefile文件内容,并生成最外层的makefile文件
. auto/install
# STUB
. auto/stubs
have=NGX_USER value="\"$NGX_USER\"" . auto/define
have=NGX_GROUP value="\"$NGX_GROUP\"" . auto/define
# 编译的最后阶段,汇总信息
. auto/summary
模块编译顺序
上一节中,提到过,nginx模块的顺序很重要,会直接影响到程序的功能。而且,nginx和部分模块,也有着自己特定的顺序要求,比如ngx_http_write_filter_module模块一定要在filter模块的最后一步执行。想查看模块的执行顺序,可以在objs/ngx_modules.c这个文件中找到,这个文件在configure之后生成,上一节中,我们看过这个文件里面的内容。
下面是一个ngx_modules.c文件的示例:
ngx_module_t *ngx_modules[] = {
// 全局core模块
&ngx_core_module,
&ngx_errlog_module,
&ngx_conf_module,
&ngx_emp_server_module,
&ngx_emp_server_core_module,
// event模块
&ngx_events_module,
&ngx_event_core_module,
&ngx_kqueue_module,
// 正则模块
&ngx_regex_module,
// http模块
&ngx_http_module,
&ngx_http_core_module,
&ngx_http_log_module,
&ngx_http_upstream_module,
// http handler模块
&ngx_http_static_module,
&ngx_http_autoindex_module,
&ngx_http_index_module,
&ngx_http_auth_basic_module,
&ngx_http_access_module,
&ngx_http_limit_conn_module,
&ngx_http_limit_req_module,
&ngx_http_geo_module,
&ngx_http_map_module,
&ngx_http_split_clients_module,
&ngx_http_referer_module,
&ngx_http_rewrite_module,
&ngx_http_proxy_module,
&ngx_http_fastcgi_module,
&ngx_http_uwsgi_module,
&ngx_http_scgi_module,
&ngx_http_memcached_module,
&ngx_http_empty_gif_module,
&ngx_http_browser_module,
&ngx_http_upstream_ip_hash_module,
&ngx_http_upstream_keepalive_module,
//此处是第三方handler模块
// http filter模块
&ngx_http_write_filter_module,
&ngx_http_header_filter_module,
&ngx_http_chunked_filter_module,
&ngx_http_range_header_filter_module,
&ngx_http_gzip_filter_module,
&ngx_http_postpone_filter_module,
&ngx_http_ssi_filter_module,
&ngx_http_charset_filter_module,
&ngx_http_userid_filter_module,
&ngx_http_headers_filter_module,
// 第三方filter模块
&ngx_http_copy_filter_module,
&ngx_http_range_body_filter_module,
&ngx_http_not_modified_filter_module,
NULL
};
http handler模块与http filter模块的顺序很重要,这里我们主要关注一下这两类模块。
http handler模块,在后面的章节里面会讲到多阶段请求的处理链。对于content phase之前的handler,同一个阶段的handler,模块是顺序执行的。比如上面的示例代码中,ngx_http_auth_basic_module与ngx_http_access_module这两个模块都是在access phase阶段,由于ngx_http_auth_basic_module在前面,所以会先执行。由于content phase只会有一个执行,所以不存在顺序问题。另外,我们加载的第三方handler模块永远是在最后执行。
http filter模块,filter模块会将所有的filter handler排成一个倒序链,所以在最前面的最后执行。上面的例子中,&ngx_http_write_filter_module最后执行,ngx_http_not_modified_filter_module最先执行。注意,我们加载的第三方filter模块是在copy_filter模块之后,headers_filter模块之前执行。
nginx的进程机制
master进程
worker进程
进程间通讯
nginx基础设施
内存池
简介:
Nginx里内存的使用大都十分有特色:申请了永久保存,抑或伴随着请求的结束而全部释放,还有写满了缓冲再从头接着写.这么做的原因也主要取决于Web Server的特殊的场景,内存的分配和请求相关,一条请求处理完毕,即可释放其相关的内存池,降低了开发中对内存资源管理的复杂度,也减少了内存碎片的存在.
所以在Nginx使用内存池时总是只申请,不释放,使用完毕后直接destroy整个内存池.我们来看下内存池相关的实现。
结构:
struct ngx_pool_s {
ngx_pool_data_t d;
size_t max;
ngx_pool_t *current;
ngx_chain_t *chain;
ngx_pool_large_t *large;
ngx_pool_cleanup_t *cleanup;
ngx_log_t *log;
};
struct ngx_pool_large_s {
ngx_pool_large_t *next;
void *alloc;
};
typedef struct {
u_char *last;
u_char *end;
ngx_pool_t *next;
ngx_uint_t failed;
} ngx_pool_data_t;
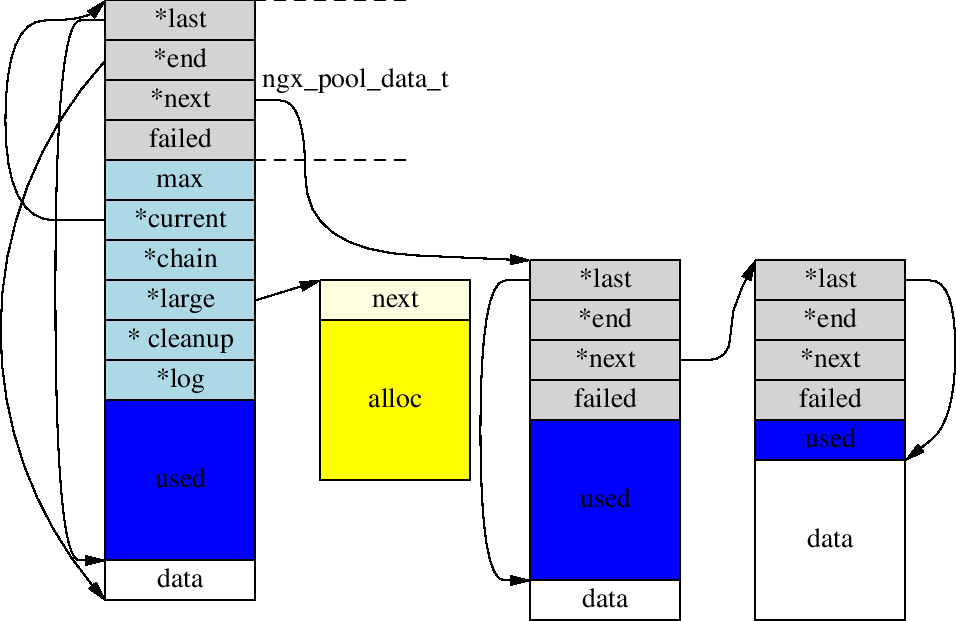
实现:
这三个数据结构构成了基本的内存池的主体.通过ngx_create_pool可以创建一个内存池,通过ngx_palloc可以从内存池中分配指定大小的内存。
ngx_pool_t *
ngx_create_pool(size_t size, ngx_log_t *log)
{
ngx_pool_t *p;
p = ngx_memalign(NGX_POOL_ALIGNMENT, size, log);
if (p == NULL) {
return NULL;
}
p->d.last = (u_char *) p + sizeof(ngx_pool_t);
p->d.end = (u_char *) p + size;
p->d.next = NULL;
p->d.failed = 0;
size = size - sizeof(ngx_pool_t);
p->max = (size < NGX_MAX_ALLOC_FROM_POOL) ? size : NGX_MAX_ALLOC_FROM_POOL;
p->current = p;
p->chain = NULL;
p->large = NULL;
p->cleanup = NULL;
p->log = log;
return p;
}
这里首申请了一块大小为size的内存区域,其前sizeof(ngx_pool_t)字节用来存储ngx_pool_t这个结构体自身自身.所以若size小于sizeof(ngx_pool_t)将会有coredump的可能性。
我们常用来分配内存的有三个接口:ngx_palloc,ngx_pnalloc,ngx_pcalloc。
分别来看下它们的实现:
void *
ngx_palloc(ngx_pool_t *pool, size_t size)
{
u_char *m;
ngx_pool_t *p;
if (size <= pool->max) {
p = pool->current;
do {
m = ngx_align_ptr(p->d.last, NGX_ALIGNMENT);
if ((size_t) (p->d.end - m) >= size) {
p->d.last = m + size;
return m;
}
p = p->d.next;
} while (p);
return ngx_palloc_block(pool, size);
}
return ngx_palloc_large(pool, size);
}
void *
ngx_pnalloc(ngx_pool_t *pool, size_t size)
{
u_char *m;
ngx_pool_t *p;
if (size <= pool->max) {
p = pool->current;
do {
m = p->d.last;
if ((size_t) (p->d.end - m) >= size) {
p->d.last = m + size;
return m;
}
p = p->d.next;
} while (p);
return ngx_palloc_block(pool, size);
}
return ngx_palloc_large(pool, size);
}
void *
ngx_pcalloc(ngx_pool_t *pool, size_t size)
{
void *p;
p = ngx_palloc(pool, size);
if (p) {
ngx_memzero(p, size);
}
return p;
}
ngx_pcalloc其只是ngx_palloc的一个封装,将申请到的内存全部初始化为0。
ngx_palloc相对ngx_pnalloc,其会将申请的内存大小向上扩增到NGX_ALIGNMENT的倍数,以方便内存对齐,减少内存访问次数。
Nginx的内存池不仅用于内存方面的管理,还可以通过`ngx_pool_cleanup_add`来添加内存池释放时的回调函数,以便用来释放自己申请的其他相关资源。
从代码中可以看出,这些由自己添加的释放回调是以链表形式保存的,也就是说你可以添加多个回调函数来管理不同的资源。
共享内存
slab算法
buffer管理
buffer重用机制
buffer防拷贝机制
chain管理
chain重用机制
aio原理
锁实现
基本数据结构
时间缓存
文件缓存
log机制
nginx的启动阶段 (30%)
概述 (100%)
nginx启动阶段指从nginx初始化直至准备好按最新配置提供服务的过程。
在不考虑nginx单进程工作的情况下,这个过程包含三种方式:
- 启动新的nginx
- reload配置
- 热替换nginx代码
三种方式有共同的流程,下面这幅图向我们展现了这个流程:
图11-1
流程的开端是解析nginx配置、初始化模块,接着是初始化文件句柄,初始化共享内存,然后是监听端口,再后来创建worker子进程和其他辅助子进程,最后是worker初始化事件机制。以上步骤结束以后,nginx各个子进程开始各司其职,比如worker进程开始accept请求并按最新配置处理请求,cache-manager进程开始管理cache文件目录等等。
除了这些共同流程,这三种方式的差异也非常明显。第一种方式包含命令行解析的过程,同时输出有一段时间是输出到控制台。reload配置有两种形式,一种是使用nginx命令行,一种是向master进程发送HUP信号,前者表面上与第一种方式无异,但实际上差别很大,后者则完全不支持控制台输出,无法直接查看nginx的启动情况。而且reload配置时,nginx需要自动停止以往生成的子进程,所以还包含复杂的进程管理操作,这一点在启动新的nginx的方式中是不存在的。热替换nginx代码虽然使用上与reload配置的后一种形式相似,但在解析nginx配置方面,与reload配置的方式差距非常大。另外,热替换nginx代码时,对以往创建的子进程管理也不像reload配置那样,需要手工触发进行。所以,我们想弄懂nginx的启动阶段,就必须理解所有这三种方式下nginx都是如何工作的。
共有流程 (100%)
从概述中我们了解到,nginx启动分为三种方式,虽然各有不同,但也有一段相同的流程。在这一节中,我们对nginx启动阶段的共用流程进行讨论。
共有流程的代码主要集中在ngx_cycle.c、ngx_process.c、ngx_process_cycle.c和ngx_event.c这四个文件中。我们这一节只讨论nginx的框架代码,而与http相关的模块代码,我们会在后面进行分析。
共有流程开始于解析nginx配置,这个过程集中在ngx_init_cycle函数中。ngx_init_cycle是nginx的一个核心函数,共有流程中与配置相关的几个过程都在这个函数中实现,其中包括解析nginx配置、初始化CORE模块,接着是初始化文件句柄,初始化错误日志,初始化共享内存,然后是监听端口。可以说共有流程80%都是现在ngx_init_cycle函数中。
在具体介绍以前,我们先解决一个概念问题——什么叫cycle?
cycle就是周期的意思,对应着一次启动过程。也就是说,不论发生了上节介绍的三种启动方式的哪一种,nginx都会创建一个新的cycle与这次启动对应。
配置解析接口 (100%)
ngx_init_cycle提供的是配置解析接口。接口是一个切入点,通过少量代码提供一个完整功能的调用。配置解析接口分为两个阶段,一个是准备阶段,另一个就是真正开始调用配置解析。准备阶段指什么呢?主要是准备三点:
- 准备内存
nginx根据以往的经验(old_cycle)预测这一次的配置需要分配多少内存。比如,我们可以看这段:
if (old_cycle->shared_memory.part.nelts) {
n = old_cycle->shared_memory.part.nelts;
for (part = old_cycle->shared_memory.part.next; part; part = part->next)
{
n += part->nelts;
}
} else {
n = 1;
}
if (ngx_list_init(&cycle->shared_memory, pool, n, sizeof(ngx_shm_zone_t))
!= NGX_OK)
{
ngx_destroy_pool(pool);
return NULL;
}
这段代码的意思是遍历old_cycle,统计上一次系统中分配了多少块共享内存,接着就按这个数据初始化当前cycle中共享内存的规模。
- 准备错误日志
nginx启动可能出错,出错就要记录到错误日志中。而错误日志本身也是配置的一部分,所以不解析完配置,nginx就不能了解错误日志的信息。nginx通过使用上一个周期的错误日志来记录解析配置时发生的错误,而在配置解析完成以后,nginx就用新的错误日志替换旧的错误日志。具体代码摘抄如下,以说明nginx解析配置时使用old_cycle的错误日志:
log = old_cycle->log;
pool->log = log;
cycle->log = log;
- 准备数据结构
主要是两个数据结果,一个是ngx_cycle_t结构,一个是ngx_conf_t结构。前者用于存放所有CORE模块的配置,后者则是用于存放解析配置的上下文信息。具体代码如下:
for (i = 0; ngx_modules[i]; i++) {
if (ngx_modules[i]->type != NGX_CORE_MODULE) {
continue;
}
module = ngx_modules[i]->ctx;
if (module->create_conf) {
rv = module->create_conf(cycle);
if (rv == NULL) {
ngx_destroy_pool(pool);
return NULL;
}
cycle->conf_ctx[ngx_modules[i]->index] = rv;
}
}
conf.ctx = cycle->conf_ctx;
conf.cycle = cycle;
conf.pool = pool;
conf.log = log;
conf.module_type = NGX_CORE_MODULE;
conf.cmd_type = NGX_MAIN_CONF;
准备好了这些内容,nginx开始调用配置解析模块,其代码如下:
if (ngx_conf_param(&conf) != NGX_CONF_OK) {
environ = senv;
ngx_destroy_cycle_pools(&conf);
return NULL;
}
if (ngx_conf_parse(&conf, &cycle->conf_file) != NGX_CONF_OK) {
environ = senv;
ngx_destroy_cycle_pools(&conf);
return NULL;
}
第一个if解析nginx命令行参数’-g’加入的配置。第二个if解析nginx配置文件。好的设计就体现在接口极度简化,模块之间的耦合非常低。这里只使用区区10行完成了配置的解析。在这里,我们先浅尝辄止,具体nginx如何解析配置,我们将在后面的小节做细致的介绍。
配置解析
通用过程 (100%)
配置解析模块在ngx_conf_file.c中实现。模块提供的接口函数主要是ngx_conf_parse,另外,模块提供一个单独的接口ngx_conf_param,用来解析命令行传递的配置,当然,这个接口也是对ngx_conf_parse的包装。
ngx_conf_parse函数支持三种不同的解析环境:
- parse_file:解析配置文件;
- parse_block:解析块配置。块配置一定是由“{”和“}”包裹起来的;
- parse_param:解析命令行配置。命令行配置中不支持块指令。
我们先来鸟瞰nginx解析配置的流程,整个过程可参见下面示意图:
图11-2
这是一个递归的过程。nginx首先解析core模块的配置。core模块提供一些块指令,这些指令引入其他类型的模块,nginx遇到这些指令,就重新迭代解析过程,解析其他模块的配置。这些模块配置中又有一些块指令引入新的模块类型或者指令类型,nginx就会再次迭代,解析这些新的配置类型。比如上图,nginx遇到“events”指令,就重新调用ngx_conf_parse()解析event模块配置,解析完以后ngx_conf_parse()返回,nginx继续解析core模块指令,直到遇到“http”指令。nginx再次调用ngx_conf_parse()解析http模块配置的http级指令,当遇到“server”指令时,nginx又一次调用ngx_conf_parse()解析http模块配置的server级指令。
了解了nginx解析配置的流程,我们来看其中的关键函数ngx_conf_parse()。
ngx_conf_parse()解析配置分成两个主要阶段,一个是词法分析,一个是指令解析。
词法分析通过ngx_conf_read_token()函数完成。指令解析有两种方式,其一是使用nginx内建的指令解析机制,其二是使用第三方自定义指令解析机制。自定义指令解析可以参见下面的代码:
if (cf->handler) {
rv = (*cf->handler)(cf, NULL, cf->handler_conf);
if (rv == NGX_CONF_OK) {
continue;
}
if (rv == NGX_CONF_ERROR) {
goto failed;
}
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0, rv);
goto failed;
}
这里注意cf->handler和cf->handler_conf两个属性,其中handler是自定义解析函数指针,handler_conf是conf指针。
下面着重介绍nginx内建的指令解析机制。本机制分为4个步骤:
- 只有处理的模块的类型是NGX_CONF_MODULE或者是当前正在处理的模块类型,才可能被执行。nginx中有一种模块类型是NGX_CONF_MODULE,当前只有ngx_conf_module一种,只支持一条指令“include”。“include”指令的实现我们后面再进行介绍。
ngx_modules[i]->type != NGX_CONF_MODULE && ngx_modules[i]->type != cf->module_type
- 匹配指令名,判断指令用法是否正确。
- 指令的Context必须当前解析Context相符;
!(cmd->type & cf->cmd_type)
- 非块指令必须以“;”结尾;
!(cmd->type & NGX_CONF_BLOCK) && last != NGX_OK
- 块指令必须后接“{”;
(cmd->type & NGX_CONF_BLOCK) && last != NGX_CONF_BLOCK_START
- 指令参数个数必须正确。注意指令参数有最大值NGX_CONF_MAX_ARGS,目前值为8。
if (!(cmd->type & NGX_CONF_ANY)) {
if (cmd->type & NGX_CONF_FLAG) {
if (cf->args->nelts != 2) {
goto invalid;
}
} else if (cmd->type & NGX_CONF_1MORE) {
if (cf->args->nelts < 2) {
goto invalid;
}
} else if (cmd->type & NGX_CONF_2MORE) {
if (cf->args->nelts < 3) {
goto invalid;
}
} else if (cf->args->nelts > NGX_CONF_MAX_ARGS) {
goto invalid;
} else if (!(cmd->type & argument_number[cf->args->nelts - 1])) {
goto invalid;
}
}
- 取得指令工作的conf指针。
if (cmd->type & NGX_DIRECT_CONF) {
conf = ((void **) cf->ctx)[ngx_modules[i]->index];
} else if (cmd->type & NGX_MAIN_CONF) {
conf = &(((void **) cf->ctx)[ngx_modules[i]->index]);
} else if (cf->ctx) {
confp = *(void **) ((char *) cf->ctx + cmd->conf);
if (confp) {
conf = confp[ngx_modules[i]->ctx_index];
}
}
- NGX_DIRECT_CONF常量单纯用来指定配置存储区的寻址方法,只用于core模块。
- NGX_MAIN_CONF常量有两重含义,其一是指定指令的使用上下文是main(其实还是指core模块),其二是指定配置存储区的寻址方法。所以,在代码中常常可以见到使用上下文是main的指令的cmd->type属性定义如下:
NGX_MAIN_CONF|NGX_DIRECT_CONF|...
表示指令使用上下文是main,conf寻址方式是直接寻址。
使用NGX_MAIN_CONF还表示指定配置存储区的寻址方法的指令有4个:“events”、“http”、“mail”、“imap”。这四个指令也有共同之处——都是使用上下文是main的块指令,并且块中的指令都使用其他类型的模块(分别是event模块、http模块、mail模块和mail模块)来处理。
NGX_MAIN_CONF|NGX_CONF_BLOCK|...
后面分析ngx_http_block()函数时,再具体分析为什么需要NGX_MAIN_CONF这种配置寻址方式。
- 除开core模块,其他类型的模块都会使用第三种配置寻址方式,也就是根据cmd->conf的值从cf->ctx中取出对应的配置。举http模块为例,cf->conf的可选值是NGX_HTTP_MAIN_CONF_OFFSET、NGX_HTTP_SRV_CONF_OFFSET、NGX_HTTP_LOC_CONF_OFFSET,分别对应“http{}”、“server{}”、“location{}”这三个http配置级别。
- 执行指令解析回调函数
rv = cmd->set(cf, cmd, conf);
cmd是词法分析得到的结果,conf是上一步得到的配置存贮区地址。
http的解析
http是作为一个core模块被nginx通用解析过程解析的,其核心就是“http”块指令回调,它完成了http解析的整个功能,从初始化到计算配置结果。
因为这是本书第一次提到块指令,所以在这里对其做基本介绍。
块指令的流程是:
- 创建并初始化上下文环境;
- 调用通用解析流程解析;
- 根据解析结果进行后续合并处理;
- 善后工作。
下面我们以“http”指令为例来介绍这个流程:
创建并初始化上下文环境
ctx = ngx_pcalloc(cf->pool, sizeof(ngx_http_conf_ctx_t));
*(ngx_http_conf_ctx_t **) conf = ctx;
...
ctx->main_conf = ngx_pcalloc(cf->pool,
sizeof(void *) * ngx_http_max_module);
ctx->srv_conf = ngx_pcalloc(cf->pool, sizeof(void *) * ngx_http_max_module);
ctx->loc_conf = ngx_pcalloc(cf->pool, sizeof(void *) * ngx_http_max_module);
for (m = 0; ngx_modules[m]; m++) {
if (ngx_modules[m]->type != NGX_HTTP_MODULE) {
continue;
}
module = ngx_modules[m]->ctx;
mi = ngx_modules[m]->ctx_index;
if (module->create_main_conf) {
ctx->main_conf[mi] = module->create_main_conf(cf);
}
if (module->create_srv_conf) {
ctx->srv_conf[mi] = module->create_srv_conf(cf);
}
if (module->create_loc_conf) {
ctx->loc_conf[mi] = module->create_loc_conf(cf);
}
}
pcf = *cf;
cf->ctx = ctx;
for (m = 0; ngx_modules[m]; m++) {
if (ngx_modules[m]->type != NGX_HTTP_MODULE) {
continue;
}
module = ngx_modules[m]->ctx;
if (module->preconfiguration) {
if (module->preconfiguration(cf) != NGX_OK) {
return NGX_CONF_ERROR;
}
}
}
http模块的上下文环境ctx(注意我们在通用解析流程中提到的ctx是同一个东西)非常复杂,它是由三个指针数组组成的:main_conf、srv_conf、loc_conf。根据上面的代码可以看到,这三个数组的元素个数等于系统中http模块的个数。想想我们平时三四十个http模块的规模,大家也应该可以理解这一块结构的庞大。nginx还为每个模块分别执行对应的create函数分配空间。我们需要注意后面的这一句“cf->ctx = ctx;”,正是这一句将解析配置的上下文切换成刚刚建立的ctx。最后一段代码通过调用各个http模块的preconfiguration回调函数完成了对应模块的预处理操作,其主要工作是创建模块用到的变量。
调用通用解析流程解析
cf->module_type = NGX_HTTP_MODULE;
cf->cmd_type = NGX_HTTP_MAIN_CONF;
rv = ngx_conf_parse(cf, NULL);
基本上所有的块指令都类似上面的三行语句(例外是map,它用的是cf->handler),改变通用解析流程的工作状态,然后调用通用解析流程。
根据解析结果进行后续合并处理
for (m = 0; ngx_modules[m]; m++) {
if (module->init_main_conf) {
rv = module->init_main_conf(cf, ctx->main_conf[mi]);
}
rv = ngx_http_merge_servers(cf, cmcf, module, mi);
}
for (s = 0; s < cmcf->servers.nelts; s++) {
if (ngx_http_init_locations(cf, cscfp[s], clcf) != NGX_OK) {
return NGX_CONF_ERROR;
}
if (ngx_http_init_static_location_trees(cf, clcf) != NGX_OK) {
return NGX_CONF_ERROR;
}
}
if (ngx_http_init_phases(cf, cmcf) != NGX_OK) {
return NGX_CONF_ERROR;
}
if (ngx_http_init_headers_in_hash(cf, cmcf) != NGX_OK) {
return NGX_CONF_ERROR;
}
for (m = 0; ngx_modules[m]; m++) {
if (module->postconfiguration) {
if (module->postconfiguration(cf) != NGX_OK) {
return NGX_CONF_ERROR;
}
}
}
if (ngx_http_variables_init_vars(cf) != NGX_OK) {
return NGX_CONF_ERROR;
}
if (ngx_http_init_phase_handlers(cf, cmcf) != NGX_OK) {
return NGX_CONF_ERROR;
}
if (ngx_http_optimize_servers(cf, cmcf, cmcf->ports) != NGX_OK) {
return NGX_CONF_ERROR;
}
以上是http配置处理最重要的步骤。首先,在这里调用了各个模块的postconfiguration回调函数完成了模块配置过程。更重要的是,它为nginx建立了一棵完整的配置树(叶子节点为location,包含location的完整配置)、完整的location搜索树、一张变量表、一张完成的阶段处理回调表(phase handler)、一张server对照表和一张端口监听表。下面我们将分别介绍这些配置表的生成过程。
location配置树
介绍这部分以前,先说明一个nginx的公理
公理11-1:所有存放参数为NGX_HTTP_SRV_CONF_OFFSET的配置,配置仅在请求匹配的虚拟主机(server)上下文中生效,而所有存放参数为NGX_HTTP_LOC_CONF_OFFSET的配置,配置仅在请求匹配的路径(location)上下文中生效。
正因为有公理11-1,所以nginx需要调用merge_XXX回调函数合并配置。具体的原因是很多配置指令可以放在不同配置层级,比如access_log既可以在http块中配置,又可以在server块中配置,还可以在location块中配置。 但是因为公理11-1,access_log指令配置只有在路径(location)上下文中生效,所以需要将在http块中配置的access_log指令的配置向路径上下文做两次传递,第一次从HTTP(http)上下文到虚拟主机(server)上下文,第二次从虚拟主机上下文到路径上下文。
可能有人会疑惑,为什么需要传递和合并呢?难道它们不在一张表里么?对,在创建并初始化上下文环境的过程中,大家已经看到,nginx为HTTP上下文创建了main_conf,为虚拟主机上下文创建了srv_conf,为路径上下文创建了loc_conf。但是,这张表只是用于解析在http块但不包含server块中定义的指令。而后面我们会看到,在server块指令中,同样建立了srv_conf和loc_conf,用于解析在server块但不含location块中定义的指令。所以nginx其实维护了很多张配置表,因此nginx必须将配置在这些表中从顶至下不断传递。
前面列出的
for (m = 0; ngx_modules[m]; m++) {
if (module->init_main_conf) {
rv = module->init_main_conf(cf, ctx->main_conf[mi]);
}
rv = ngx_http_merge_servers(cf, cmcf, module, mi);
}
就是初始化HTTP上下文,并且完成两步配置合并操作:从HTTP上下文合并到虚拟主机上下文,以及从虚拟主机上下文合并到路径上下文。其中,合并到路径上下问的操作是在ngx_http_merge_servers函数中进行的,见
if (module->merge_loc_conf) {
/* merge the server{}'s loc_conf */
/* merge the locations{}' loc_conf's */
}
大家注意观察ngx_http_merge_servers函数中的这段,先将HTTP上下文中的location配置合并到虚拟主机上下文,再将虚拟主机上下文中的location配置合并到路径上下文。
location搜索树
公理11-2:nginx搜索路径时,正则匹配路径和其他的路径分开搜。
公理11-3:nginx路径可以嵌套。
所以,nginx存放location的有两个指针,分别是
struct ngx_http_core_loc_conf_s {
...
ngx_http_location_tree_node_t *static_locations;
#if (NGX_PCRE)
ngx_http_core_loc_conf_t **regex_locations;
#endif
...
}
通过这段代码,大家还可以发现一点——nginx的正则表达式需要PCRE支持。
正则表达式的路径是个指针数组,指针类型就是ngx_http_core_loc_conf_t,所以数据结构决定算法,正则表达式路径的添加非常简单,就是在表中插入一项,这里不做介绍。
而其他路径,保存在ngx_http_location_tree_node_t指针指向的搜索树static_locations,则是变态复杂,可以看得各位大汗淋漓。
为了说明这棵树的构建,我们先了解其他路径包含哪些:
- 普通前端匹配的路径,例如location / {}
- 抢占式前缀匹配的路径,例如location ^~ / {}
- 精确匹配的路径,例如location = / {}
- 命名路径,比如location @a {}
- 无名路径,比如if {}或者limit_except {}生成的路径
我们再来看ngx_http_core_loc_conf_t中如何体现这些路径:
| 普通前端匹配的路径 | 无 |
| 抢占式前缀匹配的路径 | noregex = 1 |
| 精确匹配的路径 | exact_match = 1 |
| 命名路径 | named = 1 |
| 无名路径 | noname = 1 |
| 正则路径 | regex != NULL |
有了这些基础知识,可以看代码了。首先是ngx_http_init_locations函数
ngx_queue_sort(locations, ngx_http_cmp_locations);
for (q = ngx_queue_head(locations);
q != ngx_queue_sentinel(locations);
q = ngx_queue_next(q))
{
clcf = lq->exact ? lq->exact : lq->inclusive;
if (ngx_http_init_locations(cf, NULL, clcf) != NGX_OK) {
return NGX_ERROR;
}
if (clcf->regex) {
r++;
if (regex == NULL) {
regex = q;
}
continue;
}
if (clcf->named) {
n++;
if (named == NULL) {
named = q;
}
continue;
}
if (clcf->noname) {
break;
}
}
if (q != ngx_queue_sentinel(locations)) {
ngx_queue_split(locations, q, &tail);
}
if (named) {
...
cscf->named_locations = clcfp;
...
}
if (regex) {
...
pclcf->regex_locations = clcfp;
...
}
大家可以看到,这个函数正是根据不同的路径类型将locations分成多段,并以不同的指针引用。首先注意开始的排序,根据ngx_http_cmp_locations比较各个location,排序以后的顺序依次是
- 精确匹配的路径和两类前缀匹配的路径(字母序,如果某个精确匹配的路径的名字和前缀匹配的路径相同,精确匹配的路径排在前面)
- 正则路径(出现序)
- 命名路径(字母序)
- 无名路径(出现序)
这样nginx可以简单的截断列表得到不同类型的路径,nginx也正是这样处理的。
另外还要注意一点,就是ngx_http_init_locations的迭代调用,这里的clcf引用了两个我们没有介绍过的字段exact和inclusive。这两个字段最初是在ngx_http_add_location函数(添加location配置时必然调用)中设置的:
if (clcf->exact_match
#if (NGX_PCRE)
|| clcf->regex
#endif
|| clcf->named || clcf->noname)
{
lq->exact = clcf;
lq->inclusive = NULL;
} else {
lq->exact = NULL;
lq->inclusive = clcf;
}
当然这部分的具体逻辑我们在介绍location解析是再具体说明。
接着我们看ngx_http_init_static_location_trees函数。通过刚才的ngx_http_init_locations函数,留在locations数组里面的还有哪些类型的路径呢?
还有普通前端匹配的路径、抢占式前缀匹配的路径和精确匹配的路径这三类。
if (ngx_http_join_exact_locations(cf, locations) != NGX_OK) {
return NGX_ERROR;
}
ngx_http_create_locations_list(locations, ngx_queue_head(locations));
pclcf->static_locations = ngx_http_create_locations_tree(cf, locations, 0);
if (pclcf->static_locations == NULL) {
return NGX_ERROR;
}
请注意除开这段核心代码,这个函数也有一个自迭代过程。
ngx_http_join_exact_locations函数是将名字相同的精确匹配的路径和两类前缀匹配的路径合并,合并方法
lq->inclusive = lx->inclusive;
ngx_queue_remove(x);
简言之,就是将前缀匹配的路径放入精确匹配的路径的inclusive指针中,然后从列表删除前缀匹配的路径。
ngx_http_create_locations_list函数将和某个路径名拥有相同名称前缀的路径添加到此路径节点的list指针域下,并将这些路径从locations中摘除。其核心代码是
ngx_queue_split(&lq->list, x, &tail);
ngx_queue_add(locations, &tail);
ngx_http_create_locations_list(&lq->list, ngx_queue_head(&lq->list));
ngx_http_create_locations_list(locations, x);
ngx_http_create_locations_tree函数则将刚才划分的各个list继续细分,形成一个二分搜索树,每个中间节点代表一个location,每个location有如下字段:
- exact:两类前缀匹配路径的inclusive指针域指向这两类路径的配置上下文;
- inclusive:精确匹配路径的exact指针域指向这些路径的配置上下文;
- auto_redirect:为各种upstream模块,比如proxy、fastcgi等等开启自动URI填充的功能;
- len:路径前缀的长度。任何相同前缀的路径的len等于该路径名长度减去公共前缀的长度。比如路径/a和/ab,前者的len为2,后者的len也为1;
- name:路径前缀,任何相同前缀的路径的name是其已于公共前缀的部分。仍举路径/a和/ab为例,前者的name为/a,后者的name为b;
- left:左子树,当然是长度短或者字母序小的不同前缀的路径;
- right:右子树,当然是长度长或者字母序大的不同前缀的路径。
通过上面三个步骤,nginx就将locations列表中各种类型的路径分类处理并由不同的指针引用。对于前缀路径和精确匹配的路径,形成一棵独特的二分前缀树。
变量表
变量表的处理相对简单,即对照变量名表,为变量表中的每一个元素设置对应的get_handler和data字段。在前面的章节大家已经知道,变量表variables用以处理索引变量,而变量名表variables_keys用于处理可按变量名查找的变量。对于通过ngx_http_get_variable_index函数创建的索引变量,在变量表variables中的get_handler初始为空,如果没有认为设置的话,将会在这里进行初始化。
特殊变量的get_handler初始化也在这里进行:
| 变量前缀 | get_handler | 标志 |
| http | ngx_http_variable_unknown_header_in | |
| sent_http | ngx_http_variable_unknown_header_out | |
| upstream_http | ngx_http_upstream_header_variable | NGX_HTTP_VAR_NOCACHEABLE |
| cookie | ngx_http_variable_cookie | |
| arg | ngx_http_variable_argument | NGX_HTTP_VAR_NOCACHEABLE |
阶段处理回调表
按照下表顺序将各个模块设置的phase handler依次加入cmcf->phase_engine.handlers列表,各个phase的phase handler的checker不同。checker主要用于限定某个phase的框架逻辑,包括处理返回值。
| 处理阶段PHASE | checker | 可自定义handler |
| NGX_HTTP_POST_READ_PHASE | ngx_http_core_generic_phase | 是 |
| NGX_HTTP_SERVER_REWRITE_PHASE | ngx_http_core_rewrite_phase | 是 |
| NGX_HTTP_FIND_CONFIG_PHASE | ngx_http_core_find_config_phase | 否 |
| NGX_HTTP_REWRITE_PHASE | ngx_http_core_rewrite_phase | 是 |
| NGX_HTTP_POST_REWRITE_PHASE | ngx_http_core_post_rewrite_phase | 否 |
| NGX_HTTP_PREACCESS_PHASE | ngx_http_core_generic_phase | 是 |
| NGX_HTTP_ACCESS_PHASE | ngx_http_core_access_phase | 是 |
| NGX_HTTP_POST_ACCESS_PHASE | ngx_http_core_post_access_phase | 否 |
| NGX_HTTP_TRY_FILES_PHASE | ngx_http_core_try_files_phase | 否 |
| NGX_HTTP_CONTENT_PHASE | ngx_http_core_content_phase | 是 |
注意相同PHASE的phase handler是按模块顺序的反序加入回调表的。另外在NGX_HTTP_POST_REWRITE_PHASE中,ph->next指向NGX_HTTP_FIND_CONFIG_PHASE第一个phase handler,以实现rewrite last逻辑。
server对照表
大家如果读过nginx的“Server names”这篇官方文档,会了解nginx对于server name的处理分为4中情况:精确匹配、前缀通配符匹配、后缀通配符匹配和正则匹配。那么,下面是又一个公理,
公理11-4:nginx对于不同类型的server name分别处理。
所以,所谓server对照表,其实是四张表,分别对应四种类型的server。数据结构决定算法,四张表决定了nginx必须建立这四张表的行为。鉴于前三种类型和正则匹配可以分成两大类,nginx使用两套策略生成server对照表——对正则匹配的虚拟主机名,nginx为其建立一个数组,按照主机名在配置文件的出现顺序依次写入数组;而对于其他虚拟主机名,nginx根据它们的类型为它们分别存放在三张hash表中。三张hash表的结构完全相同,但对于前缀通配或者后缀通配这两种类型的主机名,nginx对通配符进行的预处理不同。其中“.taobao.com”这种特殊的前缀通配与普通的前缀通配处理又有不同。我们现在来介绍这些不同。
处理前缀通配是将字符串按节翻转,然后去掉通配符。举个例子,“*.example.com”会被转换成“com.example.\0”,而特殊的前缀通配“.example.com”会被转换成“com.example\0”。
处理后缀通配更简单,直接去掉通配符。也举个例子,“www.example.*”会被转换成“www.example\0”。
端口监听表
对于所有写在server配置中的listen指令,nginx开始会建立一张server和端口的对照索引表。虽然这不是本节的要点,但要说明索引表到监听表的转换过程,还是需要描述其结构。如图11-3所示,这张索引表是二级索引,第一级索引以listen指定的端口为键,第二级索引以listen指定的地址为键,索引的对象就是server上下文数据结构。而端口监视表是两张表,其结构如图11-4所示。 索引表和监听表在结构上非常类似,但是却有一个非常明显的不同。索引表中第一张表的各表项的端口是唯一的,而监听表的第一张表中的不同表项的端口却可能是相同的。之所以出现这样的差别,是因为nginx会为监听表第一张表中的每一项分别建立监听套接字,而在索引表中,如果配置显式定义了需要监听不同IP地址的相同端口,它在索引表中会放在同一个端口的二级索引中,而在监听表中必须存放为两个端口相同的不同监听表项。
说明了两张表的结构,现在可以介绍转换过程:
第一步,在ngx_http_optimize_servers()函数中,对索引表一级索引中的所有port下辖的二级索引分别进行排序。排序的规则是
- 含wildcard属性的二级索引最终会尽可能排到尾部。这些二级索引类似于
listen *:80;
listen 80;
- 含bind属性的二级索引最终会尽可能排到首部。这些二级索引是由那些设置了”bind”、”backlog”、”rcvbuf”、”sndbuf”、”accept_filter”、”deferred”、”ipv6only”和”so_keepalive”参数的listen指令生成的。
- 其他二级索引,其相对顺序不变,排在含bind属性的二级索引之后,而在含wildcard属性的二级索引之前。
第二步,将索引表转换为监听表,这是在ngx_http_init_listening()函数中实现的。其步骤是
- 得到是否有二级索引含有wildcard属性,只需要看看排序后的二级索引的最后一项就可以了。
- 顺次将所有含有bind属性的二级索引以一对一的方式生成监听表的表项(第一级和第二级都只有一项)。
- 如果第一步检测到不含wildcard属性,则顺次将后续所有二级索引以一对一的方式生成监听表的表项。
- 如果第一步检测到含wildcard属性,则以含wildcard属性的二级索引创建监听表的一级表项,并将二级索引中从第一不含bind属性的表项开始的所有表项一同转换成为刚刚创建的监听表一级表项的下级表项。
善后工作
善后工作基本的就是一件事,还原解析上下文。“http”指令是这个进行的
*cf = pcf;
server的管理
前面介绍的http处理逻辑在处理“server {}”时仍然适用。server相对较为特殊的是两个指令,一个是”server_name”,一个是”listen”。
就在上一节,我们已经介绍了”server_name”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号