biancheng-Python教程
目录http://c.biancheng.net/python/
1Python编程基础
2Python编程环境搭建
3变量类型和运算符
4列表、元组、字典和集合
5Python字符串常用方法
6Python流程控制
7函数和lambda表达式
8Python类和对象
9类特殊成员(属性和方法)
10Python异常处理机制
11Python模块和包
12Python文件操作(I/O)
编译型语言和解释型语言的区别
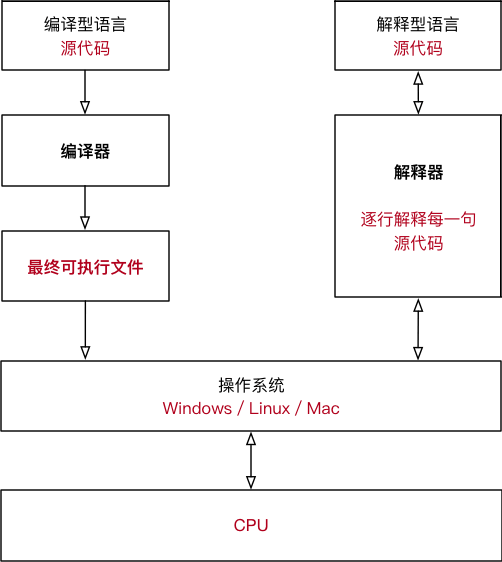
总结
我们将编译型语言和解释型语言的差异总结为下表:
| 类型 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 编译型语言 | 通过专门的编译器,将所有源代码一次性转换成特定平台(Windows、Linux 等)执行的机器码(以可执行文件的形式存在)。 | 编译一次后,脱离了编译器也可以运行,并且运行效率高。 | 可移植性差,不够灵活。 |
| 解释型语言 | 由专门的解释器,根据需要将部分源代码临时转换成特定平台的机器码。 | 跨平台性好,通过不同的解释器,将相同的源代码解释成不同平台下的机器码。 | 一边执行一边转换,效率很低。 |
Python的特点(优点和缺点)
Python 是一种面向对象的、解释型的、通用的、开源的脚本编程语言,它之所以非常流行,我认为主要有三点原因:
- Python 简单易用,学习成本低,看起来非常优雅干净;
- Python 标准库和第三库众多,功能强大,既可以开发小工具,也可以开发企业级应用;
- Python 站在了人工智能和大数据的风口上,站在风口上,猪都能飞起来。
Python 的优点
1) 语法简单
和传统的 C/C++、Java、C# 等语言相比,Python 对代码格式的要求没有那么严格,这种宽松使得用户在编写代码时比较舒服,不用在细枝末节上花费太多精力。我来举两个典型的例子:
- Python 不要求在每个语句的最后写分号,当然写上也没错;
- 定义变量时不需要指明类型,甚至可以给同一个变量赋值不同类型的数据。
这两点也是 PHP、JavaScript、MATLAB 等常见脚本语言都具备的特性。
Python 是一种代表极简主义的编程语言,阅读一段排版优美的 Python 代码,就像在阅读一个英文段落,非常贴近人类语言,所以人们常说,Python 是一种具有伪代码特质的编程语言。
伪代码(Pseudo Code)是一种算法描述语言,它介于自然语言和编程语言之间,使用伪代码的目的是为了使被描述的算法可以容易地以任何一种编程语言(Pascal,C,Java,etc)实现。因此,伪代码必须结构清晰、代码简单、可读性好,并且类似自然语言。
如果你学过数据结构,阅读过严蔚敏的书籍,那你一定知道什么是伪代码。
为什么说简单就是杀手锏?一旦简单了,一件事情就会变得很纯粹;我们在开发 Python 程序时,可以专注于解决问题本身,而不用顾虑语法的细枝末节。在简单的环境中做一件纯粹的事情,那简直是一种享受。
2) Python 是开源的
开源,也即开放源代码,意思是所有用户都可以看到源代码。
Python 的开源体现在两方面:
① 程序员使用 Python 编写的代码是开源的。
比如我们开发了一个 BBS 系统,放在互联网上让用户下载,那么用户下载到的就是该系统的所有源代码,并且可以随意修改。这也是解释型语言本身的特性,想要运行程序就必须有源代码。
② Python 解释器和模块是开源的。
官方将 Python 解释器和模块的代码开源,是希望所有 Python 用户都参与进来,一起改进 Python 的性能,弥补 Python 的漏洞,代码被研究的越多就越健壮。
这个世界上总有那么一小撮人,他们或者不慕名利,或者为了达到某种目的,会不断地加强和改善 Python。千万不要认为所有人都是只图眼前利益的,总有一些精英会放长线钓大鱼,总有一些极客会做一些炫酷的事情。
3) Python 是免费的
开源并不等于免费,开源软件和免费软件是两个概念,只不过大多数的开源软件也是免费软件;Python 就是这样一种语言,它既开源又免费。
如果你想区分开源和免费的概念,请猛击:开源就等于免费吗?用事实来说话
用户使用 Python 进行开发或者发布自己的程序,不需要支付任何费用,也不用担心版权问题,即使作为商业用途,Python 也是免费的。
4) Python 是高级语言
这里所说的高级,是指 Python 封装较深,屏蔽了很多底层细节,比如 Python 会自动管理内存(需要时自动分配,不需要时自动释放)。
高级语言的优点是使用方便,不用顾虑细枝末节;缺点是容易让人浅尝辄止,知其然不知其所以然。
5) Python 是解释型语言,能跨平台
解释型语言一般都是跨平台的(可移植性好),Python 也不例外,我们已经在《编译型语言和解释型语言的区别》中进行了讲解,这里不再赘述。
5) Python 是面向对象的编程语言
面向对象是现代编程语言一般都具备的特性,否则在开发中大型程序时会捉襟见肘。
Python 支持面向对象,但它不强制使用面向对象。Java 是典型的面向对象的编程语言,但是它强制必须以类和对象的形式来组织代码。
6) Python 功能强大(模块众多)
Python 的模块众多,基本实现了所有的常见的功能,从简单的字符串处理,到复杂的 3D 图形绘制,借助 Python 模块都可以轻松完成。
Python 社区发展良好,除了 Python 官方提供的核心模块,很多第三方机构也会参与进来开发模块,这其中就有 Google、Facebook、Microsoft 等软件巨头。即使是一些小众的功能,Python 往往也有对应的开源模块,甚至有可能不止一个模块。
7) Python 可扩展性强
Python 的可扩展性体现在它的模块,Python 具有脚本语言中最丰富和强大的类库,这些类库覆盖了文件 I/O、GUI、网络编程、数据库访问、文本操作等绝大部分应用场景。
这些类库的底层代码不一定都是 Python,还有很多 C/C++ 的身影。当需要一段关键代码运行速度更快时,就可以使用 C/C++ 语言实现,然后在 Python 中调用它们。Python 能把其它语言“粘”在一起,所以被称为“胶水语言”。
Python 依靠其良好的扩展性,在一定程度上弥补了运行效率慢的缺点。
Python 的缺点
除了上面提到的各种优点,Python 也是有缺点的。
1) 运行速度慢
运行速度慢是解释型语言的通病,Python 也不例外。
Python 速度慢不仅仅是因为一边运行一边“翻译”源代码,还因为 Python 是高级语言,屏蔽了很多底层细节。这个代价也是很大的,Python 要多做很多工作,有些工作是很消耗资源的,比如管理内存。
Python 的运行速度几乎是最慢的,不但远远慢于 C/C++,还慢于 Java。
但是速度慢的缺点往往也不会带来什么大问题。首先是计算机的硬件速度运来越快,多花钱就可以堆出高性能的硬件,硬件性能的提升可以弥补软件性能的不足。
其次是有些应用场景可以容忍速度慢,比如网站,用户打开一个网页的大部分时间是在等待网络请求,而不是等待服务器执行网页程序。服务器花 1ms 执行程序,和花 20ms 执行程序,对用户来说是毫无感觉的,因为网络连接时间往往需要 500ms 甚至 2000ms。
2) 代码加密困难
不像编译型语言的源代码会被编译成可执行程序,Python 是直接运行源代码,因此对源代码加密比较困难。
Python能干什么,Python的应用领域
Web应用开发
自动化运维
人工智能领域
网路爬虫
科学计算
游戏开发
Python编程环境搭建
Mac OS X 安装 Python 3.x
Python 官方下载地址:https://www.python.org/downloads/
macOS 64-bit installer即为 Mac OS X 系统的 Python 安装包。点击该链接,下载完成后得到一个 python-3.8.1-macosx10.9.pkg 安装包。
双击 python-3.8.1-macosx10.9.pkg 就进入了 Python 安装向导,然后按照向导一步一步向下安装,一切保持默认即可。
安装完成以后,你的 Mac OS X 上将同时存在 Python 3.x 和 Python 2.x 的运行环境,在终端(Terminal)输入python命令将进入 Python 2.x 开发环境,在终端(Terminal)输入python3命令将进入 Python 3.x 开发环境。
c.biancheng.net:~ mozhiyan$ python3
Python变量类型和运算符
3.1 Python变量的定义和使用
3.2 Python整数类型(int)
3.3 Python小数/浮点数(float)
3.4 Python复数类型(complex)
3.5 为什么Python浮点类型存在误差?
3.6 Python字符串
3.7 Python字符串使用哪种编码格式?
3.8 Python bytes
3.9 Python bool布尔类型
3.10 Python初始化变量,并不一定开辟新的内存!
3.11 Python input()函数:获取用户输入的字符串
3.12 Python print()函数高级用法
3.13 Python格式化字符串
3.14 Python转义字符
3.15 Python数据类型转换
3.16 Python算术运算符
3.17 Python赋值运算符
3.18 Python位运算符
3.19 Python比较运算符
3.20 Python逻辑运算符
3.21 Python三目运算符
Python列表(list)、元组(tuple)、字典(dict)和集合(set)详解
4.1 什么是序列,Python序列详解
4.2 Python列表(list)
4.3 Python list列表添加元素
4.4 Python list列表删除元素
4.5 Python list列表修改元素
4.6 Python list列表查找元素
4.7 结合实例,再深入剖析Python list列表!
4.8 Python range()快速初始化数字列表
4.9 Python list列表实现栈和队列
4.10 Python tuple元组详解
4.11 Python元组和列表的区别
4.12 Python列表和元组的底层实现是怎样的?
4.13 Python dict字典
4.14 Python dict字典基本操作
4.15 Python dict字典方法完全攻略
4.16 Python使用字典格式化字符串
4.17 Python set集合
4.18 Python set集合基本操作
4.19 Python set集合方法
4.20 Python frozenset集合
4.21 深入底层了解Python字典和集合,一眼看穿他们的本质!
4.22 Python深拷贝和浅拷贝详解
Python创建列表
在 Python 中,创建列表的方法可分为两种,下面分别进行介绍。
1) 使用 [ ] 直接创建列表
使用[ ]创建列表后,一般使用=将它赋值给某个变量,具体格式如下:
listname = [element1 , element2 , element3 , ... , elementn]
其中,listname 表示变量名,element1 ~ elementn 表示列表元素。
例如,下面定义的列表都是合法的:
- num = [1, 2, 3, 4, 5, 6, 7]
- name = ["C语言中文网", "http://c.biancheng.net"]
- program = ["C语言", "Python", "Java"]
Python创建元组
Python 提供了两种创建元组的方法,下面一一进行介绍。
1) 使用 ( ) 直接创建
通过( )创建元组后,一般使用=将它赋值给某个变量,具体格式为:
tuplename = (element1, element2, ..., elementn)
其中,tuplename 表示变量名,element1 ~ elementn 表示元组的元素。
例如,下面的元组都是合法的:
- num = (7, 14, 21, 28, 35)
- course = ("Python教程", "http://c.biancheng.net/python/")
- abc = ( "Python", 19, [1,2], ('c',2.0) )
Python创建字典
创建字典的方式有很多,下面一一做介绍。
1) 使用 { } 创建字典
由于字典中每个元素都包含两部分,分别是键(key)和值(value),因此在创建字典时,键和值之间使用冒号:分隔,相邻元素之间使用逗号,分隔,所有元素放在大括号{ }中。
使用{ }创建字典的语法格式如下:
dictname = {'key':'value1', 'key2':'value2', ..., 'keyn':valuen}
其中 dictname 表示字典变量名,keyn : valuen 表示各个元素的键值对。需要注意的是,同一字典中的各个键必须唯一,不能重复。
如下代码示范了使用花括号语法创建字典:
- #使用字符串作为key
- scores = {'数学': 95, '英语': 92, '语文': 84}
- print(scores)
- #使用元组和数字作为key
- dict1 = {(20, 30): 'great', 30: [1,2,3]}
- print(dict1)
- #创建空元组
- dict2 = {}
- print(dict2)
Python创建set集合
Python 提供了 2 种创建 set 集合的方法,分别是使用 {} 创建和使用 set() 函数将列表、元组等类型数据转换为集合。
1) 使用 {} 创建
在 Python 中,创建 set 集合可以像列表、元素和字典一样,直接将集合赋值给变量,从而实现创建集合的目的,其语法格式如下:
setname = {element1,element2,...,elementn}
其中,setname 表示集合的名称,起名时既要符合 Python 命名规范,也要避免与 Python 内置函数重名。
举个例子:
- a = {1,'c',1,(1,2,3),'c'}
- print(a)
运行结果为:
{1, 'c', (1, 2, 3)}
2) set()函数创建集合
set() 函数为 Python 的内置函数,其功能是将字符串、列表、元组、range 对象等可迭代对象转换成集合。该函数的语法格式如下:
setname = set(iteration)
其中,iteration 就表示字符串、列表、元组、range 对象等数据。
例如:
- set1 = set("c.biancheng.net")
- set2 = set([1,2,3,4,5])
- set3 = set((1,2,3,4,5))
- print("set1:",set1)
- print("set2:",set2)
- print("set3:",set3)
Python字符串常用方法详解
5.1 Python字符串拼接(包含字符串拼接数字)
5.2 Python截取字符串
5.3 Python len()函数:获取字符串长度或字节数
5.4 Python split()分割字符串方法
5.5 Python join()合并字符串方法
5.6 Python count()统计字符串出现的次数
5.7 Python find()检测字符串中是否包含某子串
5.8 Python index()检测字符串中是否包含某子串
5.9 Python ljust()、rjust()和center()方法
5.10 Python startswith()和endswith()
5.11 Python字符串大小写转换
5.12 Python去除字符串中空格
5.13 Python format()格式化输出方法
5.14 Python encode()和decode()方法
5.15 Python dir()和help()
str() 和 repr() 的区别
str() 和 repr() 函数虽然都可以将数字转换成字符串,但它们之间是有区别的:
- str() 用于将数据转换成适合人类阅读的字符串形式。
- repr() 用于将数据转换成适合解释器阅读的字符串形式(Python 表达式的形式),适合在开发和调试阶段使用;如果没有等价的语法,则会发生 SyntaxError 异常。
请看下面的例子:
- s = "http://c.biancheng.net/shell/"
- s_str = str(s)
- s_repr = repr(s)
- print( type(s_str) )
- print (s_str)
- print( type(s_repr) )
- print (s_repr)
获取多个字符(字符串截去/字符串切片)
使用[ ]除了可以获取单个字符外,还可以指定一个范围来获取多个字符,也就是一个子串或者片段,具体格式为:
strname[start : end : step]
对各个部分的说明:
- strname:要截取的字符串;
- start:表示要截取的第一个字符所在的索引(截取时包含该字符)。如果不指定,默认为 0,也就是从字符串的开头截取;
- end:表示要截取的最后一个字符所在的索引(截取时不包含该字符)。如果不指定,默认为字符串的长度;
- step:指的是从 start 索引处的字符开始,每 step 个距离获取一个字符,直至 end 索引出的字符。step 默认值为 1,当省略该值时,最后一个冒号也可以省略。
【实例1】基本用法:
- url = 'http://c.biancheng.net/java/'
- #获取索引从7处到22(不包含22)的子串
- print(url[7: 22]) # 输出 zy
- #获取索引从7处到-6的子串
- print(url[7: -6]) # 输出 zyit.org is very
- #获取索引从-21到6的子串
- print(url[-21: -6])
- #从索引3开始,每隔4个字符取出一个字符,直到索引22为止
- print(url[3: 22: 4])
Python流程控制
6.1 Python if else条件语句
6.2 Python if else对缩进的要求
6.3 Python if语句嵌套
6.4 Python pass
6.5 Python assert断言
6.6 如何合理使用assert,千万不要和if混用!
6.7 Python while循环语句
6.8 Python for循环
6.9 Python循环结构中else用法
6.10 Python循环嵌套
6.11 Python嵌套循环实现冒泡排序
6.12 Python break:跳出当前循环体
6.13 Python continue:直接执行下次循环
6.14 教你一招,彻底告别死(无限)循环!
6.15 Python推导式,快速初始化各种序列!
6.16 Python zip函数
6.17 Python reversed函数
6.18 Python sorted函数
【实例2】改进上面的代码,年龄不符合时退出程序:
- import sys
- age = int( input("请输入你的年龄:") )
- if age < 18 :
- print("警告:你还未成年,不能使用该软件!")
- print("未成年人应该好好学习,读个好大学,报效祖国。")
- sys.exit()
- else:
- print("你已经成年,可以使用该软件。")
- print("时间宝贵,请不要在该软件上浪费太多时间。")
- print("软件正在使用中...")
Python函数和lambda表达式
7.1 Python函数
7.2 Python函数值传递和引用传递(包括形式参数和实际参数)
7.3 深度剖析Python函数参数传递的内部机制
7.4 Python位置参数
7.5 Python关键字参数
7.6 Python默认参数
7.7 Python函数如何传入任意个参数?
7.8 Python如何用序列中元素给函数传递参数?
7.9 Python None(空值)
7.10 Python return函数返回值
7.11 Python函数怎样返回多个值?
7.12 Python partial偏函数
7.13 从实例出发,攻克Python函数递归
7.14 Python变量作用域(全局变量和局部变量)
7.15 Python如何在函数中使用同名的全局变量?
7.16 Python局部函数
7.17 更高级的Python函数用法,玩转Python函数!
7.18 Python闭包函数
7.19 Python lambda表达式(匿名函数)
7.20 Python eval()和exec()函数
7.21 使用exec()和eval(),不要犯这样的低级错误!
7.22 Python函数式编程(map()、filter()和reduce())详解
7.23 函数注解,号称Python3新增的最独特的功能!
7.24 如何才能提高代码颜值,让代码变得有逼格?
Python类和对象
8.1 Python面向对象
8.2 Python class:定义类
8.3 Python __init__()类构造方法
8.4 Python类对象的创建和使用
8.5 Python self
8.6 Python类属性和实例属性
8.7 Python实例方法、静态方法和类方法
8.8 Python类调用实例方法
8.9 为什么说Python类是独立的命名空间?
8.10 什么是描述符,Python描述符详解
8.11 Python property()
8.12 Python @property装饰器
8.13 Python封装
8.14 探究Python封装的底层实现原理
8.15 Python继承机制
8.16 在子类中,Python到底是如何找到父类的属性和方法的?(深度揭秘)
8.17 Python父类方法重写
8.18 如何使用Python继承机制提高开发效率?
8.19 Python super()
8.20 切记,super()只能在新式类中使用!
8.21 使用super(),这些“坑”千万别踩!
8.22 Python __slots__
8.23 Python type()动态创建类
8.24 Python MetaClass元类
8.25 Python底层是如何实现MetaClass元类的?
8.26 什么是多态,Python多态及用法详解
8.27 Python枚举类
Python类特殊成员(属性和方法)
9.1 Python __new__
9.2 Python __repr__
9.3 Python __del__()
9.4 Python __dir__()
9.5 Python __dict__
9.6 Python setattr、getattr、hasattr
9.7 Python issubclass和isinstance
9.8 Python __call__()
9.9 什么是运算符重载,Python可重载运算符有哪些?
9.10 Python重载运算符实现自定义序列
9.11 Python迭代器
9.12 【Python项目实战】迭代器实现字符串的逆序输出
9.13 Python生成器
9.14 Python更高级的生成器用法!
9.15 Python @函数装饰器
9.16 结合实例,深入了解装饰器!
Python异常处理机制
10.1 什么是异常处理
10.2 为什么一定要学Python异常处理机制?
10.3 Python try except
10.4 深度剖析Python异常处理机制的底层实现
10.5 Python try except else
10.6 Python try except finally
10.7 一篇文章,带你重温整个Python异常处理机制
10.8 Python raise
10.9 Python sys.exc_info()获取异常信息
10.10 Python traceback模块:获取异常信息
10.11 Python如何自定义一个异常类?
10.12 正确使用Python异常处理机制
10.13 Python使用logging模块调试程序
10.14 Python IDLE调试程序
10.15 Python assert调试程序
举个例子:
- try:
- result = 20 / int(input('请输入除数:'))
- print(result)
- except ValueError:
- print('必须输入整数')
- except ArithmeticError:
- print('算术错误,除数不能为 0')
- else:
- print('没有出现异常')
- print("继续执行")
举个例子:
- try:
- a = int(input("请输入 a 的值:"))
- print(20/a)
- except:
- print("发生异常!")
- else:
- print("执行 else 块中的代码")
- finally :
- print("执行 finally 块中的代码")
Python模块和包
11.1 什么是模块
11.2 Python import导入模块
11.3 Python自定义模块
11.4 含有空格或以数字开头的模块名,应该如何引入?
11.5 Python __name__=='__main__'的作用是什么?
11.6 Python导入模块的3种方式
11.7 Python导入模块的本质
11.8 Python __all__变量
11.9 Python包:存放多个模块的文件夹
11.10 Python创建包,导入包
11.11 Python __init__.py的作用
11.12 Python查看模块方法
11.13 Python __doc__
11.14 Python __file__
11.15 Python第三方库(模块)下载和安装
Python文件操作(I/O)
12.1 什么是文件路径,Python中如何书写文件路径?
12.2 Python绝对路径和相对路径
12.3 Python文件基本操作
12.4 Python open
12.5 以文本格式和二进制格式打开文件,到底有什么区别?
12.6 Python read
12.7 Python readline()和readlines()
12.8 Python write和writelines
12.9 Python close
12.10 Python seek和tell
12.11 Python with as
12.12 什么是上下文管理器,深入底层了解Python with as语句
12.13 Python pickle模块
12.14 Python fileinput模块:逐行读取多个文件
12.15 Python linecache模块用法:随机读取文件指定行
12.16 Python pathlib模块
12.17 Python os.path模块
12.18 Python fnmatch模块
12.19 Python使用os模块操作文件和目录
12.20 Python tempfile模块:生成临时文件和临时目录
open() 函数用于创建或打开指定文件,该函数的常用语法格式如下:
file = open(file_name [, mode='r' [ , buffering=-1 [ , encoding = None ]]])
此格式中,用 [] 括起来的部分为可选参数,即可以使用也可以省略。其中,各个参数所代表的含义如下:
- file:表示要创建的文件对象。
- file_name:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
- mode:可选参数,用于指定文件的打开模式。可选的打开模式如表 1 所示。如果不写,则默认以只读(r)模式打开文件。
- buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区(本节后续会详细介绍)。
- encoding:手动设定打开文件时所使用的编码格式,不同平台的 ecoding 参数值也不同,以 Windows 为例,其默认为 cp936(实际上就是 GBK 编码)。
open() 函数支持的文件打开模式如表 1 所示。
| 模式 | 意义 | 注意事项 |
|---|---|---|
| r | 只读模式打开文件,读文件内容的指针会放在文件的开头。 | 操作的文件必须存在。 |
| rb | 以二进制格式、采用只读模式打开文件,读文件内容的指针位于文件的开头,一般用于非文本文件,如图片文件、音频文件等。 | |
| r+ | 打开文件后,既可以从头读取文件内容,也可以从开头向文件中写入新的内容,写入的新内容会覆盖文件中等长度的原有内容。 | |
| rb+ | 以二进制格式、采用读写模式打开文件,读写文件的指针会放在文件的开头,通常针对非文本文件(如音频文件)。 | |
| w | 以只写模式打开文件,若该文件存在,打开时会清空文件中原有的内容。 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
| wb | 以二进制格式、只写模式打开文件,一般用于非文本文件(如音频文件) | |
| w+ | 打开文件后,会对原有内容进行清空,并对该文件有读写权限。 | |
| wb+ | 以二进制格式、读写模式打开文件,一般用于非文本文件 | |
| a | 以追加模式打开一个文件,对文件只有写入权限,如果文件已经存在,文件指针将放在文件的末尾(即新写入内容会位于已有内容之后);反之,则会创建新文件。 | |
| ab | 以二进制格式打开文件,并采用追加模式,对文件只有写权限。如果该文件已存在,文件指针位于文件末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| a+ | 以读写模式打开文件;如果文件存在,文件指针放在文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| ab+ | 以二进制模式打开文件,并采用追加模式,对文件具有读写权限,如果文件存在,则文件指针位于文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |
文件打开模式,直接决定了后续可以对文件做哪些操作。例如,使用 r 模式打开的文件,后续编写的代码只能读取文件,而无法修改文件内容。
图 2 中,将以上几个容易混淆的文件打开模式的功能做了很好的对比:
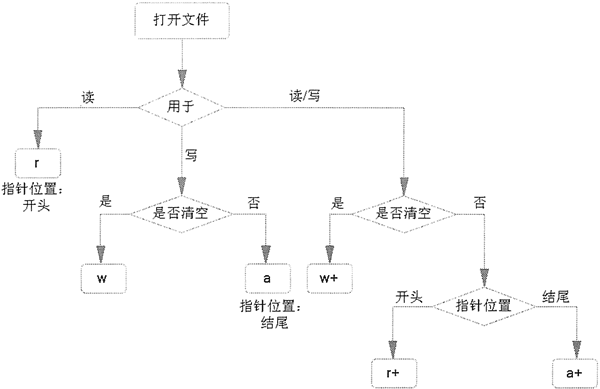
图 2 不同文件打开模式的功能
【例 1】默认打开 "a.txt" 文件。
- #当前程序文件同目录下没有 a.txt 文件
- file = open("a.txt")
- print(file)
当以默认模式打开文件时,默认使用 r 权限,由于该权限要求打开的文件必须存在,因此运行此代码会报如下错误:
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\demo.py", line 1, in <module>
file = open("a.txt")
FileNotFoundError: [Errno 2] No such file or directory: 'a.txt'
现在,在程序文件同目录下,手动创建一个 a.txt 文件,并再次运行该程序,其运行结果为:
<_io.TextIOWrapper name='a.txt' mode='r' encoding='cp936'>
可以看到,当前输出结果中,输出了 file 文件对象的相关信息,包括打开文件的名称、打开模式、打开文件时所使用的编码格式。
使用 open() 打开文件时,默认采用 GBK 编码。但当要打开的文件不是 GBK 编码格式时,可以在使用 open() 函数时,手动指定打开文件的编码格式,例如:
file = open("a.txt",encoding="utf-8")
注意,手动修改 encoding 参数的值,仅限于文件以文本的形式打开,也就是说,以二进制格式打开时,不能对 encoding 参数的值做任何修改,否则程序会抛出 ValueError 异常,如下所示:
ValueError: binary mode doesn't take an encoding argument
open()是否需要缓冲区
通常情况下、建议大家在使用 open() 函数时打开缓冲区,即不需要修改 buffing 参数的值。
如果 buffing 参数的值为 0(或者 False),则表示在打开指定文件时不使用缓冲区;如果 buffing 参数值为大于 1 的整数,该整数用于指定缓冲区的大小(单位是字节);如果 buffing 参数的值为负数,则代表使用默认的缓冲区大小。
为什么呢?原因很简单,目前为止计算机内存的 I/O 速度仍远远高于计算机外设(例如键盘、鼠标、硬盘等)的 I/O 速度,如果不使用缓冲区,则程序在执行 I/O 操作时,内存和外设就必须进行同步读写操作,也就是说,内存必须等待外设输入(输出)一个字节之后,才能再次输出(输入)一个字节。这意味着,内存中的程序大部分时间都处于等待状态。
而如果使用缓冲区,则程序在执行输出操作时,会先将所有数据都输出到缓冲区中,然后继续执行其它操作,缓冲区中的数据会有外设自行读取处理;同样,当程序执行输入操作时,会先等外设将数据读入缓冲区中,无需同外设做同步读写操作。
open()文件对象常用的属性
成功打开文件之后,可以调用文件对象本身拥有的属性获取当前文件的部分信息,其常见的属性为:
- file.name:返回文件的名称;
- file.mode:返回打开文件时,采用的文件打开模式;
- file.encoding:返回打开文件时使用的编码格式;
- file.closed:判断文件是否己经关闭。
举个例子:
- # 以默认方式打开文件
- f = open('my_file.txt')
- # 输出文件是否已经关闭
- print(f.closed)
- # 输出访问模式
- print(f.mode)
- #输出编码格式
- print(f.encoding)
- # 输出文件名
- print(f.name)
程序执行结果为:
False
r
cp936
my_file.txt
然后在和 my_file.txt 同目录下,创建一个 file.py 文件,并编写如下语句:
- #以 utf-8 的编码格式打开指定文件
- f = open("my_file.txt",encoding = "utf-8")
- #输出读取到的数据
- print(f.read())
- #关闭文件
- f.close()
程序执行结果为:
Python教程
http://c.biancheng.net/python/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号