biancheng-Hibernate框架
目录http://c.biancheng.net/hibernate/
1ORM是什么
2Hibernate是什么
3Hibernate项目创建流程
4Hibernate增删改查操作
5Hibernate工作原理
6Hibernate核心配置文件
7Hibernate映射文件
8Hibernate核心接口
9Hibernate持久化类
10Hibernate一级缓存
11Hibernate关联映射
有了 ORM 技术以后,只要提前配置好对象和数据库之间的映射关系,ORM 就可以自动生成 SQL 语句,并将对象中的数据自动存储到数据库中,整个过程不需要人工干预。在 Java 中,ORM 一般使用 XML 或者注解来配置对象和数据库之间的映射关系。

和自动生成 SQL 语句相比,手动编写 SQL 语句的缺点是非常明显的,主要体现在以下两个方面:
- 对象的属性名和数据表的字段名往往不一致,我们在编写 SQL 语句时需要非常小心,要逐一核对属性名和字段名,确保它们不会出错,而且彼此之间要一一对应。
- 此外,当 SQL 语句出错时,数据库的提示信息往往也不精准,这给排错带来了不小的困难。
ORM 的出现,恰好解决了这些难题。
面向对象编程和关系型数据库都是广泛使用的两种技术,ORM 使得两者之间的数据交互变得自动化,解放了程序员的双手,同时也让源代码中不再出现 SQL 语句。
需要说明的是,ORM 是一种双向数据交互技术,它不仅可以将对象中的数据存储到数据库中,也可以反过来将数据库中的数据提取到对象中。
下表说明了关系型数据库和对象之间的对应关系:
| 数据库 | 类/对象 |
|---|---|
| 表(table) | 类(class) |
| 表中的记录(record,也称行) | 对象(object) |
| 表中的字段(field,也称列) | 对象中的属性(attribute) |
例如,现在有一张 user 表,它包含 id、user_id 和 user_name 三个字段,另外还有一个 Java User 类,它包含 id、userId 和 userName 三个属性,下图演示了它们之间的对应关系: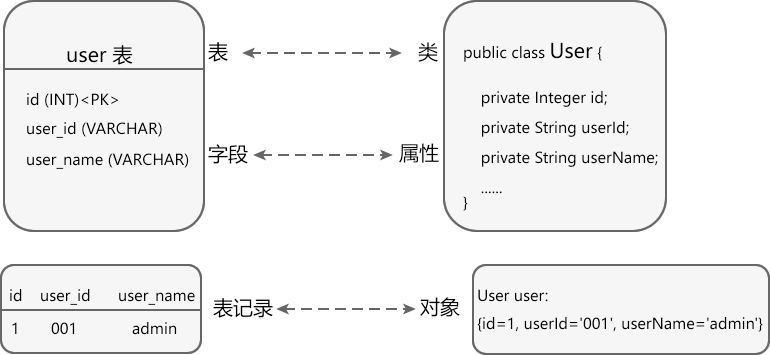
你看,数据表和类用来描述数据的表现形式,它们之间是相互对应的;记录和对象用来真正地存储数据,它们之间也是相互对应的。
ORM 的缺点
ORM 在提高开发效率的同时,也带来了以下几个缺点:
- ORM 增加了大家的学习成本,为了使用 ORM 技术,您至少需要掌握一种 ORM 框架。
- 自送生成 SQL 语句会消耗计算资源,这势必会对程序性能造成一定的影响。
- 对于复杂的数据库操作,ORM 通常难以处理,即使能处理,自动生成的 SQL 语句在性能方面也不如手写的原生 SQL。
- 生成 SQL 语句的过程是自动进行的,不能人工干预,这使得开发人员无法定制一些特殊的 SQL 语句。
ORM 框架
ORM 技术通常使用单独的框架,或者框架的某个模块来实现,下面列出了常用的 ORM 框架:
- 常用的 Java ORM 框架有 Hibernate 和 Mybatis。
- 常用的 Python ORM 实现有 SQLAlchemy 框架、Peewee 框架、Django 框架的 ORM 模块等。
- 常用的 PHP ORM 实现有 Laravel 框架、Yii 框架的 ORM 模块、ThinkPHP 框架的 ORM 模块等。
Hibernate 支持的数据库
Hibernate 支持几乎所有主流的关系型数据库,只要在配置文件中设置好当前正在使用的数据库,程序员就不需要操心不同数据库之间的差异。
以下常见数据库都被 Hibernate 支持:
- MySQL
- Oracle
- Microsoft SQL Server
- DB2
- PostgreSQL
- FrontBase
- Sybase
Hibernate 是一种全自动的 ORM 框架
Hibernate 是一款全自动的 ORM 框架。之所以将 Hibernate 称为全自动的 ORM 框架,这其实是相对于 MyBatis 来说的。
我们知道,ORM 思想的核心是将 Java 对象与数据表之间建立映射关系。所谓的映射关系,简单点说就是一种对应关系,这种对应关系是双向的:
- 将数据表对应到 Java 对象上,这样数据表中的数据就能自动提取到 Java 对象中;
- 将 Java 对象对应到数据表上,这样 Java 对象中的数据就能自动存储到数据表中。
MyBatis 虽然是一种 ORM 框架,但它建立的映射关系是不完整的。Mybatis 只能将数据表映射到 Java 对象上,却不能将 Java 对象映射到数据表上,所以数据只能从数据表自动提取到 Java 对象中,反之则不行。要想将 Java 对象中的数据存储数据表中,开发人员需要手动编写 SQL 语句,依然非常麻烦,这就是 MyBatis 被称为半自动 ORM 框架的原因。
与 MyBatis 相比,Hibernate 建立了完整的映射关系,它不仅能将数据表中的数据自动提取到 Java 对象中,还能自动生成并执行 SQL 语句,将 Java 对象中的数据存储到数据表中,整个过程不需要人工干预,因此 Hibernate 被称为全自动的 ORM 框架。
Hibernate 和 MyBatis 都是业界主流的 ORM 框架和持久层解决方案,但两者存在一些区别,详情请参考 MyBatis 和 Hibernate 的区别。
Hibernate 提供了缓存机制
Hibernate 提供了缓存机制(一级缓存、二级缓存、查询缓存),我们可以将那些经常使用的数据存放到 Hibernate 缓存中。当 Hibernate 在查询数据时,会优先到缓存中查找,如果找到则直接使用,只有在缓存中找不到指定的数据时,Hibernate 才会到数据库中检索,因此 Hibernate 的缓存机制能够有效地降低应用程序对数据库访问的频次,提高应用程序的运行性能。
JDBC vs Hibernate
我们知道,JDBC 是 Java 领域中出现最早一种数据库访问技术,而 Hibernate 则是对 JDBC 的轻量级封装,它们都可以完成对数据库的增删改查(CRUD)操作,但两者存在以下差异,如下表。
| 区别 | JDBC | Hibernate |
|---|---|---|
| 代码量 | 代码繁琐,开发成本较高。 | 代码精简,开发成本较低。 |
| 语言 | JDBC 使用的是基于关系型数据库的标准 SQL 语句。 | Hibernate 使用的是 HQL(Hibernate query language)语句。 |
| 操作的对象 | JDBC 操作的是数据,将数据通过 SQL 语句直接传送到数据库中执行。 | Hibernate 操作的是 Java 对象。Hibernate 使用了 ORM 思想,在 Java 对象与数据库表之间建立映射关系,通过操作 Java 对象来实现对数据库的操作。 |
| 缓存 | JDBC 没有提供缓存机制。 | Hibernate 提供了缓存机制(例如一级缓存、二级缓存、查询缓存),对于那些经常使用的数据,可以将它们放到缓存中,不必在每次使用时都去数据库查询,缓存机制对提升性能大有裨益。 |
| 可移植性 | JDBC 可移植性差,JDBC 中使用的 SQL 语句是以字符串的形式嵌入到代码中的,但不同数据库所使用的的 SQL 语法不尽相同,如果切换数据库(例如从 MySQL 数据库切换到 Oracle 数据库),需要修改大量代码。 | Hibernate 可移植性好,能够屏蔽不同数据库之间的差异。当需要更换数据库时,通常只需要修改其配置文件(hibernate.cfg.xml)中的 hibernate.dialect(方言) 属性,指定数据库类型即可,Hibernate 会根据指定的方言自动生成适合的 SQL 语句。 |
| 读写性能 | JDBC 是 Java 领域内性能最好的数据库访问技术。 | Hibernate 性能较差。 |
| 可扩展性 | JDBC 不具有可扩展性 | Hibernate 框架开源免费,用户可以根据自身需要进行功能定制,具有良好的可扩展性。 |
Hibernate 和 JDBC 都是十分优秀的数据库访问技术,它们都各有优缺点,但两者不存在孰优孰劣的问题,我们只需要根据自身需求和应用场景选择即可。
查询数据
我们知道,Hibernate 通过 Session 接口提供的 get() 方法能够查询出一条指定的数据,但该方法无法查询多条或所有数库数据。
Hibernate 为用户提供了以下 3 种查询方式,它们都可以用来查询多条数据。
- HQL 查询
- QBC 查询
- SQL 查询
HQL 查询
HQL 全称:Hibernate Query Language,它是一种面向对象的查询语言,它和 SQL 的语法相似,但 HQL 操作的是实体类对象及其中的属性,而不是数据库表中的字段。在 Hibernate 提供的各种检索方式中,HQL 是使用最广的一种检索方式。
@Test
public void testHqlQuery() {
//加载 Hibernate 核心配置文件
Configuration configuration = new Configuration().configure();
//创建一个 SessionFactory 用来获取 Session 连接对象
SessionFactory sessionFactory = configuration.buildSessionFactory();
//获取session 连接对象
Session session = sessionFactory.openSession();
//开始事务
Transaction transaction = session.beginTransaction();
//创建 HQL 语句,语法与 SQL 类似,但操作的是实体类及其属性
Query query = session.createQuery("from User where email like ?1");
//查询所有使用 163 邮箱的用户
query.setParameter(1, "%@163.com%");
//获取结果集
List<User> resultList = query.getResultList();
//遍历结果集
for (User user : resultList) {
System.out.println(user);
}
//提交事务
transaction.commit();
//释放资源
session.close();
sessionFactory.close();
}
QBC 查询
QBC 全称 Query By Criteria,是一种完全面向对象(比 HQL 更加面向对象)的对数据库查询技术。通过它对数据库进行查询时,应用程序不需要提供查询语句,而是通过 QBC API 中的相关的接口和类来设定需要查询的数据、查询条件等。
在 Hibernate 的早期版本中,通常通过以下方式使用 Criteria 查询数据库中的数据。
- Criteria criteria = session.createCriteria(User.class);
- criteria.add(Restrictions.eq("userName", "admin"));
- List<Customer> list = criteria.list();
但 Hibernate5.2 之后,出于安全性考虑,这种方式已经基本废弃,现在 QBC 查询基本上都是使用 JPA(javax.persistence-api-xxx.jar)包中的 CriteriaBuilder(一个工厂类),来创建 CriteriaQuery 对象,以实现对数据库的操作。
QBC API 位于 javax.persistence.criteria 包中,主要包括以下接口:
| 接口 | 功能描述 |
|---|---|
| CriteriaBuilder | 用来生成 CriteriaQuery 实例对象的工厂。 |
| CriteriaQuery | QBC 主要的查询接口,通过它可以设定需要查询的数据。 |
| Root | 指定需要检索的对象图的根节点对象。 |
| Selection | 用来指定查询语句。 |
| Expression | Selection 接口的子接口,用来指定查询表达式。 |
| Predicate | Expression 接口的子接口,用来指定查询条件。 |
使用 QBC 查询时,需要以下步骤:
- 通过 Session 对象创建一个 CriteriaBuilder 实例;
- 通过 CriteriaBuilder 的实例对象创建一个 CriteriaQuery 的实例对象;
- 通过 CriteriaBuilder 对象创建一个 Root 的实例对象,并指定需要查询的对象图的根节点对象,Hibernate 会根据它来决定查询语句中的主表。
- 通过 CriteriaBuilder 提供的方法指定查询条件,并返回 Predicate 对象,Hibernate 根据它来决定查询语句中 where 子句的内容。
- 通过 Query 接口查询数据。
SQL 查询
Hibernate 同样支持使用原生的 SQL 语句对数据库进行查询。
@Test
public void testSqlQuery() {
//加载 Hibernate 核心配置文件
Configuration configuration = new Configuration().configure();
//创建一个 SessionFactory 用来获取 Session 连接对象
SessionFactory sessionFactory = configuration.buildSessionFactory();
//获取session 连接对象
Session session = sessionFactory.openSession();
//开始事务
Transaction transaction = session.beginTransaction();
//构建 sql 查询
NativeQuery sqlQuery = session.createSQLQuery("select * from user where email like '%163.com%'");
sqlQuery.addEntity(User.class);
//获得结果集
List<User> resultList = sqlQuery.getResultList();
//遍历结果集
for (User user : resultList) {
System.out.println(user);
}
//提交事务
transaction.commit();
//释放资源
session.close();
sessionFactory.close();
}
Hibernate工作原理(图解)
主要涉及到了 Configuration、SessionFactory、Session、Transaction 和 Query 等多个接口,这些接口在 Hibernate 运行时都扮演着十分重要的角色,本节我们就来介绍以一下 Hibernate 运行时的工作原理。
关于 Configuration、SessionFactory、Session、Transaction 和 Query 等接口的使用,我们会在 Hibernate 的核心接口一节中进行详细的讲解,
Hibernate 运行时的执行流程如下图。
由上图可知,Hibernate 工作流程一般分为如下 7 步:
- Hibernate 启动,Configruation 会读取并加载 Hibernate 核心配置文件和映射文件钟的信息到它实例对象中。
- 通过 Configuration 对象读取到的配置文件信息,创建一个 SessionFactory 对象,该对象中保存了当前数据库的配置信息、映射关系等信息。
- 通过 SessionFactory 对象创建一个 Session 实例,建立数据库连接。Session 主要负责执行持久化对象的增、删、改、查操作,创建一个 Session 就相当于创建一个新的数据库连接。
- 通过 Session 对象创建 Transaction(事务)实例对象,并开启事务。Transaction 用于事务管理,一个 Transaction 对象对应的事务可以包含多个操作。需要注意的是,Hibernate 的事务默认是关闭的,需要手动开启和关闭。
- Session 接口提供了各种方法,可以对实体类对象进行持久化操作(即对数据库进行操作),例如 get()、load()、save()、update()、saveOrUpdate() 等等,除此之外,Session 对象还可以创建Query 对象 或 NativeQuery 对象,分别使用 HQL 语句或原生 SQL 语句对数据库进行操作。
- 对实体对象持久化操作完成后,必须提交事务,若程序运行过程中遇到异常,则回滚事务。
- 关闭 Session 与 SessionFactory,断开与数据库的连接,释放资源。
hibernate.cfg.xml(Hibernate核心配置文件)
hibernate.cfg.xml 被称为 Hibernate 的核心配置文件,它包含了数据库连接的相关信息以及映射文件的基本信息。通常情况下,该配置文件默认放在项目的 src 目录下,当项目发布后,该文件会在项目的 WEB-INF/classes 路径下。
hibernate.cfg.xml 中通常可以进行以下配置,这些配置中有些是必需配置,有些则是可选配置。
- <?xml version='1.0' encoding='utf-8'?>
- <!DOCTYPE hibernate-configuration PUBLIC
- "-//Hibernate/Hibernate Configuration DTD//EN"
- "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
- <hibernate-configuration>
- <session-factory>
- <!--使用 Hibernate 自带的连接池配置-->
- <property name="connection.url">jdbc:mysql://localhost:3306/bianchengbang_jdbc</property>
- <property name="hibernate.connection.username">root</property>
- <property name="hibernate.connection.password">root</property>
- <property name="connection.driver_class">com.mysql.jdbc.Driver</property>
- <!--hibernate 方言-->
- <property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</property>
- <!--打印sql语句-->
- <property name="hibernate.show_sql">true</property>
- <!--格式化sql-->
- <property name="hibernate.format_sql">true</property>
- <!-- 加载映射文件 -->
- <mapping resource="net/biancheng/www/mapping/User.hbm.xml"/>
- </session-factory>
- </hibernate-configuration>
我们知道,在 XML 配置文件中 dtd 信息十分重要,它规定了 XML 中的语法和格式。Hibernate 核心配置的 dtd 信息,可以在 Hibernate 核心 Jar 包(hibernate-core-xxx.jar)下的 org.hibernate.hibernate-configuration-3.0.dtd 中找到,初学者只需要复制并使用该 dtd 信息即可。
Hibernate 核心配置文件的根元素是 <hibernate-configuration>,该元素中包含一个 <session-factory> 子元素。
<property> 元素
在 <session-factory> 元素中,包含了多个 <property> 子元素,这些元素用于配置 Hibernate 连接数据库的各种信息,例如,数据库的方言、驱动、URL、用户名、密码等。这些 property 属性中,有些是 Hibernate 的必需配置,有些则是可选配置,如下表。
| property 属性名 | 描述 | 是否为必需属性 |
|---|---|---|
| connection.url | 指定连接数据库 URL | 是 |
| hibernate.connection.username | 指定数据库用户名 | 是 |
| hibernate.connection.password | 指定数据库密码 | 是 |
| connection.driver_class | 指定数据库驱动程序 | 是 |
| hibernate.dialect | 指定数据库使用的 SQL 方言,用于确定 Hibernate 自动生成的 SQL 语句的类型 | 是 |
| hibernate.show_sql | 用于设置是否在控制台输出 SQL 语句 | 否 |
| hibernate.format_sql | 用于设置是否格式化控制台输出的 SQL 语句 | 否 |
| hibernate.hbm2ddl.auto | 当创建 SessionFactory 时,是否根据映射文件自动验证表结构或自动创建、自动更新数据库表结构。 该参数的取值为 validate 、update、create 和 create-drop |
否 |
| hibernate.connection.autocommit | 事务是否自动提交 | 否 |
Hibernate 能够访问多种关系型数据库,例如 MySQL、Oracle 等等,尽管多数关系型数据库都支持标准的 SQL 语言,但它们往往都还存在一些它们各自的独特的 SQL 方言,就像在不同地区的人既会说普通话,还能说他们各自的方言一样。hibernate.dialect 用于指定被访问的数据库的 SQL 方言,当 Hibernate 自动生成 SQL 语句或者使用 native 策略成主键时,都会参看该属性设置的方言。
<mapping> 元素
在 <session-factory> 元素中,除了 property 元素外,还可以包含一个或多个 <mapping> 元素,它们用来指定 Hibernate 映射文件的信息,加载映射文件。
Hibernate映射文件(Xxx.hbm.xml)
配置文件主要分为 2 种:核心配置文件(hibernate.cfg.xml)和映射文件(Xxx.hbm.xml),它们主要用于配置数据库连接、事务管理、Hibernate 本身的配置信息以及 Hibernate 映射文件信息。
Hibernate 映射文件用于在实体类对象与数据表之间建立映射关系,每个映射文件的结构基本相同,示例代码如下所示。
- <?xml version='1.0' encoding='utf-8'?>
- <!DOCTYPE hibernate-mapping PUBLIC
- "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
- <hibernate-mapping schema="bianchengbang_jdbc">
- <!-- name:类的全路径:-->
- <!-- table:表的名称:(可以省略的.使用类的名称作为表名.)-->
- <class name="net.biancheng.www.po.User" table="user">
- <!--主键-->
- <id name="id" column="id">
- <!--主键生成策略-->
- <generator class="native"></generator>
- </id>
- <property name="userId" column="user_id" type="java.lang.String"/>
- <property name="userName" column="user_name"/>
- <property name="password" column="password"/>
- <property name="email" column="email"/>
- </class>
- </hibernate-mapping>
Hibernate 映射文件的 dtd 信息可以在 Hibernate 的核心 Jar 包(hibernate-core-xxx.jar)下的 org.hibernate.hibernate-mapping-3.0.dtd 文件中找到,初学者只需要复制并使用即可。
<hibernate-mapping> 元素
<hibernate-mapping> 是 Hibernate 映射文件的根元素,在该元素中定义的配置在整个映射文件中都有效。
<hibernate-mapping> 元素中常用的属性配置及其功能描述如下表。
| 属性名 | 描述 | 是否必需 |
|---|---|---|
| schema | 指定映射文件所对应的数据库名字空间 | 否 |
| package | 为映射文件对应的实体类指定包名 | 否 |
| catalog | 指定映射文件所对应的数据库目录 | 否 |
| default-access | 指定 Hibernate 用于访问属性时所使用的策略,默认为 property。当 default-access="property" 时,使用 getter 和 setter 方法访问成员变量;当 default-access = "field"时,使用反射访问成员变量。 | 否 |
| default-cascade | 指定默认的级联风格 | 否 |
| default-lazy | 指定 Hibernate 默认使用的延迟加载策略 | 否 |
<class> 元素
<class> 元素是 Hibernate 映射文件的根元素 <hibernate-mapping> 的子元素,它主要用来定义一个实体类与数据库表之间的映射关系,该元素中包含的常用属性如下表。
| 属性名 | 描述 | 是否必需 |
|---|---|---|
| name | 实体类的完全限定名(包名+类名),若根元素 <hibernate-mapping> 中已经指定了 package 属性,则该属性可以省略包名 | 否 |
| table | 对应的数据库表名。 | 否 |
| catalog | 指定映射文件所对应的数据库 catalog 名称,若根元素 <hibernate-mapping> 中已经指定 catalog 属性,则该属性会覆盖根元素中的配置。 | 否 |
| schema | 指定映射文件所对应的数据库 schema 名称,若根元素 <hibernate-mapping> 中已经指定 schema 属性,则该属性会覆盖根元素中的配置。 | 否 |
| lazy | 指定是否使用延迟加载。 | 否 |
<id> 元素
通常情况下,Hibernate 推荐我们在持久化类(实体类)中定义一个标识属性,用于唯一地标识一个持久化实例(实体类对象),且标识属性需要映射到底层数据库的主键上。
在 Hibernate 映射文件中,标识属性通过 <id> 元素来指定,它是 <class> 元素的子元素,该元素中包含的常用属性如下表。
| 属性名 | 描述 | 是否必需 |
|---|---|---|
| name | 与数据库表主键向对应的实体类的属性 | 否 |
| column | 数据库表主键的字段名 | 否 |
| type | 用于指定数据表中的字段需要转化的类型,这个类型既可以是 Hibernate 类型,也可以是 Java 类型 | 否 |
<id> 元素中通常还包含一个 <generator> 元素,该元素通过 class 属性来指定 Hibernate 的主键生成策略。
- <id name="id" column="id" type="integer">
- <!--主键生成策略-->
- <generator class="native" ></generator>
- </id>
Hibernate 提供了以下 7 主键生成策略,如下表。
| 主键生成策略 | 说明 |
|---|---|
| increment | 自动增长策略之一,适合 short、int、long 等类型的字段。该策略不是使用数据库的自动增长机制,而是使用 Hibernate 框架提供的自动增长方式,即先从表中查询主键的最大值, 然后在最大值的基础上+1。该策略存在多线程问题,一般不建议使用。 |
| identity | 自动增长策略之一,适合 short、int、long 等类型的字段。该策略采用数据库的自动增长机制,但该策略不适用于 Oracle 数据库。 |
| sequence | 序列,适合 short、int、long 等类型的字段。该策略应用在支持序列的数据库,例如 Oracle 数据库,但不是适用于 MySQL 数据库。 |
| uuid | 适用于字符串类型的主键,采用随机的字符串作为主键。 |
| native | 本地策略,Hibernate 会根据底层数据库不同,自动选择适用 identity 还是 sequence 策略,该策略也是最常用的主键生成策略。 |
| assigned | Hibernate 框架放弃对主键的维护,主键由程序自动生成。 |
| foreign | 主键来自于其他数据库表(应用在多表一对一的关系)。 |
<property> 元素
<class> 元素中可以包含一个或多个 <property> 子元素,它用于表示实体类的普通属性(除与数据表主键字段对应的属性之外的其他属性)和数据表中非主键字段的映射关系。该元素中包含的常用属性如下表。
| 属性名 | 描述 |
|---|---|
| name | 实体类属性的名称 |
| column | 数据表字段名 |
| type | 用于指定数据表中的字段需要转化的类型,这个类型既可以是 Hibernate 类型,也可以是 Java 类型 |
| length | 数据表字段的长度 |
| lazy | 该属性使用延迟加载,默认值是 false |
| unique | 是否对该字段使用唯一性约束。 |
| not-null | 是否允许该字段为空 |
此外,在 Hibernate 映射文件中,父元素中子元素必须遵循一定的配置顺序,例如在 <class> 元素中必须先定义 <id>元素,再定义 <property> 元素,否则 Hibernate 的 XML 解析器在运行时会报错。
Hibernate核心接口(5个)
1. Configuration
正如其名,Configuration 主要用于管理 Hibernate 配置信息,并在启动 Hibernate 应用时,创建 SessionFactory 实例。
在 Hibernate 应用启动时,需要获取一些基本信息,例如,数据库 URL、数据库用户名、数据库用户密码、数据库驱动程序和数据库方言等等。这些属性都可以在 Hibernate 的核心配置文件(hiberntae.cfg.xml)中进行设置。
创建 Configuration 实例
Hibernate 通常使用以下方式创建 Configuration 实例,此时 Hibernate 会自动在当前项目的类路径(CLASSPATH)中,搜索核心配置文件 hibernate.cfg.xml 并将其加载到内存中,作为后续操作的基础配置 。
- Configuration configuration = new Configuration().configure();
若 Hibernate 核心配置文件没有在项目的类路径( src 目录)下,则需要在 configure() 方法中传入一个参数指定配置文件位置,示例代码如下:
- Configuration configuration = new Configuration().configure("/net/biancheng/www/mapping/hibernate.cfg.xml");
加载映射文件
我们知道,在 Hibernate 的核心配置文件中,<mapping> 元素用来指定 Hibernate 映射文件的位置信息,加载映射文件,但该元素并非核心配置文件中的必须元素,即我们可以不在 hibernate.cfg.xml 中指定映射文件的位置。此时,我们可以通过 2 种方式加载映射文件。
1. 调用 Configuration 提供的 addResource() 方法,并在该方法中传入一个参数指定映射文件的位置,示例代码如下。
- configuration.addResource("net/biancheng/www/mapping/User.hbm.xml");
2. 调用 Configuration 提供的 addClass() 方法,并将与映射文件对应的实体类以参数的形式传入该方法中,示例代码如下。
- configuration.addClass(User.class);
使用 addClass() 方法加载映射文件时,需要同时满足以下 2 个条件,否则将无法加载映射文件。
- 映射文件的命名要规范,即映射文件要完全按照“实体类.hbm.xml ”的形式命名;
- 映射文件要与实体类在同一个包下。
需要注意的是,Configuration 对象只存在于系统的初始化阶段,将 SessionFactory 创建完成后,它的使命就完成了。
2. SessionFactory
SessionFactory 对象用来读取和解析映射文件,并负责创建和管理 Session 对象。
SessionFactory 对象中保存了当前的数据库配置信息、所有映射关系以及 Hibernate 自动生成的预定义 SQL 语句,同时它还维护了 Hibernate 的二级缓存。
一个 SessionFactory 实例对应一个数据库存储源,Hibernate 应用可以从 SessionFactory 实例中获取 Session 实例。
SessionFactory 具有以下特点:
- SessionFactory 是线程安全的,它的同一个实例可以被应用多个不同的线程共享。
- SessionFactory 是重量级的,不能随意创建和销毁它的实例。如果应用只访问一个数据库,那么在应用初始化时就只需创建一个 SessionFactory 实例;如果应用需要同时访问多个数据库,那么则需要为每一个数据库创建一个单独的 SesssionFactory 实例。
SessionFactory 之所以是重量级的,是因为它需要一个很大的缓存,用来存放预定义 SQL 语句以及映射关系数据等内容。我们可以为 SessionFactory 配置一个缓存插件,它被称为 Hiernate 的二级缓存,此处了解即可,我们会在后面详细介绍。
创建 SessionFactory 对象
通常情况下,我们通过 Configuration 的 buildSessionFactory() 方法来创建 SessionFactory 的实例对象,示例代码如下。
- SessionFactory sessionFactory = configuration.buildSessionFactory();
抽取工具类
由于 SessionFactory 是重量级的,它的实例不能随意创建和销毁,因此在实际开发时,我们通常会抽取出一个工具类,将 SessionFactory 对象的创建过程放在静态代码快中,以避免 SessionFactory 对象被多次创建。
例如,在 hibernate-demo 项目的 net.biancheng.www.utils 包下,创建一个工具类 HibernateUtils,代码如下。
- package net.biancheng.www.utils;
- import org.hibernate.Session;
- import org.hibernate.SessionFactory;
- import org.hibernate.cfg.Configuration;
- /**
- * 工具类
- */
- public class HibernateUtils {
- private static final Configuration configuration;
- private static final SessionFactory sessionFactory;
- //在静态代码块中创建 SessionFactory 对象
- static {
- configuration = new Configuration().configure();
- sessionFactory = configuration.buildSessionFactory();
- }
- //通过 SessionFactory 对象创建 Session 对象
- public static Session openSession() {
- return sessionFactory.openSession();
- }
- public static void main(String[] args) {
- // openSession();
- HibernateUtils hibernateUtils = new HibernateUtils();
- }
- }
由以上代码可知,我们直接调用 HibernateUtils 的 getSession() 的方式,便可以获取 Session 对象。
3. Session
Session 是 Hibernate 应用程序与数据库进行交互时,使用最广泛的接口,它也被称为 Hibernate 的持久化管理器,所有持久化对象必须在 Session 的管理下才可以进行持久化操作。持久化类只有与 Session 关联起来后,才具有了持久化的能力。
Session 具有以下特点:
- 不是线程安全的,因此应该避免多个线程共享同一个 Session 实例;
- Session 实例是轻量级的,它的创建和销毁不需要消耗太多的资源。通常我们会将每一个Session 实例和一个数据库事务绑定,每执行一个数据库事务,不论执行成功与否,最后都因该调用 Session 的 Close() 方法,关闭 Session 释放占用的资源。
Session 对象维护了 Hibernate 的一级缓存,在显式执行 flush 之前,所有的持久化操作的数据都缓存在 Session 对象中。
这里的持久化指的是对数据库数据的保存、更新、删除和查询。持久化类指与数据库表建立了映射关系的实体类,持久化对象指的是持久化类的对象。
关于持久化以及一级缓存的概念,这里了解即可,我们会在 Hibernate 持久化类和 Hibernate 一级缓存中详细讲解。
创建 Session 对象
我们可以通过以下 2 个方法创建 Session 对象:
1.调用 SessionFactrory 提供的 openSession() 方法,来获取 Session 对象,示例代码如下。
- //采用 openSession() 方法获取 Session 对象
- Session session = sessionFactory.openSession();
2. 调用SessionFactrory 提供的 getCurrentSession() 方法,获取 Session 对象,示例代码如下。
- //采用 getCurrentSession() 方法获取 Session 对象
- Session session = sessionFactory.getCurrentSession();
以上 2 种方式都能获取 Session 对象,但两者的区别在于:
- 采用 openSession() 方法获取 Session 对象时,SessionFactory 直接创建一个新的 Session 实例,且在使用完成后需要调用 close() 方法进行手动关闭。
- 采用 getCurrentSession() 方法创建的 Session 实例会被绑定到当前线程中,它在事务提交或回滚后会自动关闭。
Session 中的持久化方法
在 Session 中,提供了多个持久化的操作方法,其常用方法如下表。
| 方法 | 描述 |
|---|---|
| save() | 执行插入操作 |
| update() | 执行修改操作 |
| saveOrUpdate() | 根据参数,执行插入或修改操作 |
| delete() | 执行删除操作 |
| get() | 根据主键查询数据(立即加载) |
| load() | 根据主键查询数据(延迟加载) |
| createQuery() | 获取 Hibernate 查询对象 |
| createSQLQuery() | 获取 SQL 查询对象 |
注意:Hibernate 中的 Session 与 Java Web 中的 HttpSession 没有任何关系,如无特别说明,本教程中的 Session 都指的是 Hibernate 中的 Session。
4. Transaction
Transaction 是 Hibernate 提供的数据库事务管理接口,它对底层的事务接口进行了封装。所有的持久化操作(即使是只读操作)都应该在事务管理下进行,因此在进行 CRUD 持久化操作之前,必须获得 Trasaction 对象并开启事务。
获取 Transaction 对象
我们可以通过 Session 提供的以下两个方法来获取 Transaction 对象:
1. 调用 Session 提供的 beginTransaction() 方法获取 Transaction 对象,示例代码如下。
- Transaction transaction = session.beginTransaction();
2. 调用 Session 提供的 getTransaction() 方法获取 Transaction 对象,示例代码如下。
- Transaction transaction1 = session.getTransaction();
以上两个方法均可以获取 Transaction 对象,但两者存在以下不同:
- getTransaction() 方法:根据 Session 获得一个 Transaction 对象,但是并没有开启事务。
- beginTransaction() 方法:是在根据 Session 获得一个 Transaction 对象后,又继续调用 Transaction 的 begin() 方法,开启了事务。
Transation 接口中提供了管理事务的方法,常用方法如下表。
| 方法 | 描述 |
|---|---|
| begin() | 该方法用于开启事务 |
| commit() | 该方法用于提交事务 |
| rollback() | 该方法用于回滚事务 |
提交或回滚事务
持久化操作执行完成后,需要调用了 Transaction 接口的 commit() 方法进行事务提交,只有在事务提交后,才能真正地将数据同步到数据库中。当发生异常时,则需要调用 rollback() 方法进行事务回滚,以避免数据发生错误,示例代码如下。
- @Test
- public void test() {
- User user = new User();
- Session session = HibernateUtils.openSession();
- //获取事务对象
- Transaction transaction = session.getTransaction();
- //开启事务
- transaction.begin();
- try {
- //执行持久化操作
- Serializable save = session.save(user);
- //提交事务
- transaction.commit();
- } catch (Exception e) {
- //发生异常回滚事务
- transaction.rollback();
- } finally {
- //释放资源
- session.close();
- }
- }
5. Query
Query 是 Hibernate 提供的查询接口,主要用执行 Hinernate 的查询操作。Query 对象中通常包装了一个 HQL(Hibernate Query Language)语句,HQL 语句与 SQL 语句存在相似之处,但 HQL 语句是面向对象的,它使用的是类名和类的属性名,而不是表名和表中的字段名。HQL 能够提供更加丰富灵活、更为强大的查询能力,因此 Hibernate 官方推荐使用 HQL 进行查询。
在 Hibernate 应用中使用 Query 对象进行查询,通常需要以下步骤:
- 获得 Hibernate 的 Sesssin 对象;
- 定义 HQL 语句;
- 调用 Session 接口提供的 createQuery() 方法创建 Query 对象,并将 HQL 语句以参数的形式传入到该方法中;
- 若 HQL 语句中包含参数,则调用 Query 接口提供的 setXxx() 方法设置参数;
- 调用 Query 的 getResultList() 方法,进行查询,并获取查询结果集。
HQL 查询的实例,请参考 Hibernate 增删改查操作中的 HQL 查询,这里就不再赘述。
除了 getResultList() 方法外,Query 接口中还包含一些其他的常用方法,如下表。
| 方法 | 描述 |
|---|---|
| setXxx() | Query 接口中提供了一系列 setXxx() 方法,用于设置查询语句中的参数。这些方法都需要两个参数,分别是:参数名或占位符位置、参数值。我们需要根据参数类型的不同,分别调用不同的 setXxx() 方法,例如 setString()、setInteger()、setLong()、setBoolean() 和 setDate() 等等。 |
| Iterator<R> iterate(); | 该方法用于执行查询语句,并返回一个 Iterator 对象。我们可以通过返回的 Iterator 对象,遍历得到结果集。 |
| Object uniqueResult(); | 该方法用户执行查询,并返回一个唯一的结果。使用该方法时,需要确保查询结果只有一条数据,否则就会报错。 |
| int executeUpdate(); | 该方法用于执行 HQL 的更新和删除操作。 |
| Query<R> setFirstResult(int var1); | 该方法用户设置结果集第一条记录的位置,即设置从第几条记录开始查询,默认从 0 开始。 |
| Query<R> setMaxResults(int var1); | 该方法用于设置结果集的最大记录数,通常与 setFirstResult() 方法结合使用,用于限制结果集的范围,以实现分页功能。 |
除了数据库查询外,HQL 语句还可以进行更新和删除操操作,需要注意的是 HQL 并不支持 insert 操作,想要保存数据请使用 Session 接口提供的 save() 或 saveOrUpate() 方法。
Hibernate持久化类详解
持久化类(Persistent Object )简称 PO,在 Hibernate 中, PO 是由 POJO(即 java 类或实体类)和 hbm 映射配置组成。
简单点说,持久化类本质上就是一个与数据库表建立了映射关系的普通 Java 类(实体类),例如 User 类与数据库中 user 表通过映射文件 User.hbm.xml 建立了映射关系,此时 User 就是一个持久化类。
持久化类的规范
持久化类需要遵守一定的规范,具体如下:
- 持久化类中需要提供一个使用 public 修饰的无参构造器;
- 持久化类中需要提供一个标识属性 OID,与数据表主键字段向对应,例如实体类 User 中的 id 属性。为了保证 OID 的唯一性,OID 应该由 Hibernate 进行赋值,尽量避免人工手动赋值;
- 持久化类中所有属性(包括 OID)都要与数据库表中的字段相对应,且都应该符合 JavaBean 规范,即属性使用 private 修饰,且提供相应的 setter 和 getter 方法;
- 标识属性应尽量使用基本数据类型的包装类型,例如 Interger,目的是为了与数据库表的字段默认值 null 保持一致;
- 不能用 final 修饰持久化类。
持久化对象
“持久化对象”就是持久化类的实例对象,它与数据库表中一条记录相对应,Hibernate 通过操作持久化对象即可实现对数据库表的 CRUD 操作。
在 Hibernate 中,持久化对象是存储在一级缓存中的,一级缓存指 Session 级别的缓存,它可以根据缓存中的持久化对象的状态改变同步更新数据库,这里了解即可,我们会在后面的 Hibernate 一级缓存中详细介绍。
持久化对象的状态
Hibernate 是一款持久层的 ORM 框架,专注于数据的持久化工作。在进行数据持久化操作时,持久化对象可能处于不同的状态当中,这些状态可分为三种,分别为瞬时态、持久态和脱管态,如下表。
| 状态 | 别名 | 产生时机 | 特点 |
|---|---|---|---|
| 瞬时态(transient) | 临时态或自由态 | 由 new 关键字开辟内存空间的对象(即使用 new 关键字创建的对象) |
|
| 持久态(persistent) | - | 当对象加入到 Session 的一级缓存中时,与 Session 实例建立关联关系时 |
|
| 脱管态(detached) | 离线态或游离态 | 持久态对象与 Session 断开联系时 |
|
在 Hibernate 运行时,持久化对象的三种状态可以通过 Session 接口提供的 一系列方法进行转换。这三种状态之间的转换关系具体如下图。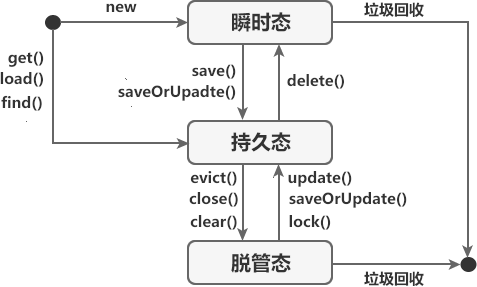
通过上图可知,持久化对象的状态转换遵循以下规则:
- 当一个实体类对象通过 new 关键字创建时,此时该对象就处于瞬时态。
- 当执行 Session 接口提供的 save() 或 saveOrUpate() 方法,将瞬时态对象保存到 Session 的一级缓存中时,该对象就从瞬时态转换为了持久态。
- 当执行 Session 接口提供的 evict()、close() 或 clear() 方法,将持久态对象与 Session 断开关联关系时,该对象就从持久态转换为了脱管态。
- 当执行 Session 接口提供的 update()、saveOrUpdate() 方法,将脱管态对象重新与 Session 建立关联关系时,该对象会从脱管态转换为持久态。
- 直接执行 Session 接口提供的 get()、load() 或 find() 方法从数据库中查询出的对象,是处于持久态的。
- 当执行 Session 接口提供的 delete() 方法时,持久态对象就会从持久态转换为瞬时态。
- 由于瞬时态和脱管态对象都不在 Session 的管理范围内,因此一段时间后,它们就会被 JVM 回收。
Hibernate一级缓存详解
缓存
缓存是位于应用程序和永久性数据存储源(例如硬盘上的文件或者数据库)之间,用于临时存放备份数据的内存区域,通过它可以降低应用程序读写永久性数据存储源的次数,提高应用程序的运行性能。

注:永久性数据存储源一般包括两种,数据库和硬盘上的文件,它们都可以永久的保存数据,但本教程中的永久性数据库存储源则是特指数据库,因此在后面的教程中,我们将使用数据库来代替永久性数据存储源的书法,特此说明。
缓存具有以下特点:
- 缓存中的数据通常是数据库中数据的备份,两者中存放的数据完全一致,因此应用程序运行时,可以直接读写缓存中的数据,而不再对数据库进行访问,可以有效地降低应用程序对数据库的访问频率。
- 缓存的物理介质通常是内存,永久性数据存储源的物理介质为硬盘或磁盘,而应用程序读取内存的速度要明显高于硬盘,因此使用缓存能够有效的提高数据读写的速度,提高应用程序的性能。
- 由于应用程序可以修改(即“写”)缓存中的数据,为了保证缓存和数据库中的数据保持一致,应用程序通常会在在某些特定时刻,将缓存中的数据同步更新到数据库中。
Hibernate 也提供了缓存机制,当查询数据时,首先 Hibernate 会到缓存中查找,如果找到就直接使用,找不到时才从永久性数据存储源(通常指的是数据库)中检索,因此,把频繁使用的数据加载到缓存中,可以减少应用程序对数据库的访问频次,使应用程序的运行性能得以提升。
Hibernate 提供了两种缓存机制:一级缓存和二级缓存。下面,我们就对一级缓存进行介绍。
Hibernate 一级缓存
Hibernate 一级缓存是 Session 级别的缓存,它是由 Hibernate 管理的,不可卸载。
Hibernate 一级缓存是由 Session 接口实现中的一系列 Java 集合构成的,其生命周期与 Session 保持一致。
Hibernate 一级缓存中存放的数据是数据库中数据的备份,在数据库中数据以数据库记录的形式保存,而在 Hibernate 一级缓存中数据是以对象的形式存放的。
当使用 Hibernate 查询对象时,会首先从一级缓存中查找,若在一级缓存中找到了匹配的对象,则直接取出并使用;若没有在一级缓存中找到匹配的对象,则去数据库中查询对应的数据,并将查询到的数据添加到一级缓存中。由此可见,Hibernate 的一级缓存机制能够在 Session 范围内,有效的减少对数据库的访问次数,优化 Hibernate 的性能。
一旦对象被存入一级缓存中,除非用户手动清除,不然只要 Session 实例的生命周期没有结束,存放在其中的对象就会一直存在。当 Session 关闭时,Session 的生命周期结束,该 Session 所管理的一级缓存也会立即被清除;
一级缓存的特点
Hibernate 一级缓存具有以下特点:
- 一级缓存是 Hibernate 自带的,默认是开启状态,无法卸载。
- Hibernate 一级缓存中只能保存持久态对象。
- Hibernate 一级缓存的生命周期与 Session 保持一致,且一级缓存是 Session 独享的,每个 Session 不能访问其他的 Session 的缓存区,Session 一旦关闭或销毁,一级缓存中的所有对象将全部丢失。
- 当通过 Session 接口提供的 save()、update()、saveOrUpdate() 和 lock() 等方法,对对象进行持久化操作时,该对象会被添加到一级缓存中。
- 当通过 Session 接口提供的 get()、load() 方法,以及 Query 接口提供的 getResultList、list() 和 iterator() 方法,查询某个对象时,会首先判断缓存中是否存在该对象,如果存在,则直接取出来使用,而不再查询数据库;反之,则去数据库查询数据,并将查询结果添加到缓存中。
- 当调用 Session 的 close() 方法时,Session 缓存会被清空。
- 一级缓存中的持久化对象具有自动更新数据库能力。
- 一级缓存是由 Hibernate 维护的,用户不能随意操作缓存内容,但用户可以通过 Hibernate 提供的方法,来管理一级缓存中的内容,如下表。
| 返回值类型 | 方法 | 描述 |
|---|---|---|
| void | clear() | 该方法用于清空一级缓存中的所有对象。 |
| void | evict(Object var1) | 该方法用于清除一级缓存中某一个对象。 |
| void | flush() throws HibernateException | 该方法用于刷出缓存,使数据库与一级缓存中的数据保持一致。 |
示例 1
下面,我们通过一个实例,来验证 Hibernate 一级缓存是否真的存在。
1. 在 hibernate-demo 的单元测试类 MyTest 中,添加一个名为 testCacheExist 的方法,代码如下。
- @Test
- public void testCacheExist() {
- Session session = HibernateUtils.openSession();
- Transaction transaction = session.getTransaction();
- transaction.begin();
- //第一次查询
- User user = session.get(User.class, 1);
- System.out.println("第一次查询:" + user);
- //第二次查询
- User user2 = session.get(User.class, 1);
- System.out.println("第二次查询:" + user2);
- transaction.commit();
- session.close();
- }
2. 执行该测试方法,控制台输出如下。
Hibernate:
select
user0_.id as id1_0_0_,
user0_.user_id as user_id2_0_0_,
user0_.user_name as user_nam3_0_0_,
user0_.password as password4_0_0_,
user0_.email as email5_0_0_
from
user user0_
where
user0_.id=?
第一次查询:net.biancheng.www.po.User{id=1, userId='001', userName='admin', password='admin', email='12345678@qq.com'}
第二次查询:net.biancheng.www.po.User{id=1, userId='001', userName='admin', password='admin', email='12345678@qq.com'}
从控制台输出可以看出,只有第一次查询时,去数据库查询并执行了 SQL,第二次查询时,虽然没有执行任何 SQL,但也依然得到了查询结果。
这是因为第一次到数据库查询数据时,就将查询结果添加到了一级缓存中,当第二次查询时,就会直接从一级缓存中获取结果,而并没有到数据库中查询,因此没有任何 SQL 输出。
快照区
Hibernate 的缓存机制,可以有效的减少应用程序对数据库的访问次数,但该机制有一个非常重要的前提,那就是必须确保一级缓存中的数据域与数据库的数据保持一致,为此 Hibernate 中还提供了快照技术。
Hibernate 的 Session 中,除了一级缓存外,还存在一个与一级缓存相对应的快照区。当 Hibernate 向一级缓存中存入数据(持久态对象)时,还会复制一份数据存入快照区中,使一级缓存和快照区的数据完全相同。
当事务提交时,Hibernate 会检测一级缓存中的数据和快照区的数据是否相同。若不同,则 Hibernate 会自动执行 update() 方法,将一级缓存的数据同步更新到数据库中,并更新快照区,这一过程被称为刷出缓存(flush);反之,则不会刷出缓存。
默认情况下,Session 会在以下时间点刷出缓存:
- 当应用程序调用 Transaction 的 commit() 方法时, 该方法先刷出缓存(session.flush()),然后再向数据库提交事务(tx.commit());
- 当应用程序执行一些查询操作时,如果缓存中持久化对象的属性已经发生了变化,会先刷出缓存,以保证查询结果能够反映持久化对象的最新状态;
- 手动调用 Session 的 flush() 方法。
示例 2
下面,我们通过一个实例验证缓存刷出。
在单元测试类 MyTest 中,添加一个名为 testCacheFlush 的测试方法,代码如下。
- @Test
- public void testCacheFlush() {
- Session session = HibernateUtils.openSession();
- Transaction transaction = session.getTransaction();
- transaction.begin();
- //查询,并将结果对象添加到一级缓存和快照区中
- User user = session.get(User.class, 1);
- System.out.println("查询结果为:" + user);
- //修改结果对象
- user.setUserName("缓存刷出 name");
- //提交事务
- transaction.commit();
- //释放资源
- session.close();
- }
Hibernate关联映射(非常详细)
Hibernate 是一款基于 ORM 设计思想的框架,它将关系型数据库中的表与我们 Java 实体类进行映射,表中的记录对应实体类的对象,而表中的字段对应着实体类中的属性。Hibernate 进行增删改查等操作时,不再直接操作数据库表,而是对与之对应的实体类对象进行处理。那么,Hibernate 是如何处理多表关联问题的呢?本节我们针对此问题进行介绍。
关联映射
在关系型数据库中,多表之间存在着三种关联关系,分别为一对一、一对多和多对多,如图 1 所示。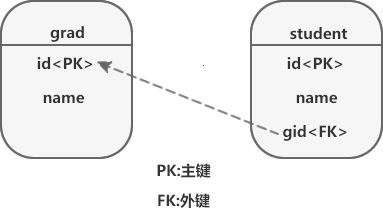
关联关系描述的是数据库表之间的引用关系,而 Hibernate 关联映射指的就是与数据库表对应的实体类之间的引用关系。
在数据库中,如果两张表想要建立关联关系,就需要外键来连接它们,数据库表之间的关系是没有方向性的,且彼此是透明的。而在 Java 中,如两个类想要建立关系的话,那就需要这两个类都通过属性(变量)来管理对方的引用,以达到建立关联关系的目的,Hibernate 关联映射也是通过这种方式实现的。
一对多
在三种关联关系中,一对多(或者多对一)是最常见的一种关联关系。
在关系型数据库中,一对多映射关系通常是由“多”的一方指向“一”的一方。在表示“多”的一方的数据表中增加一个外键,指向“一”的一方的数据表的主键,“一”的一方称为主表,而“多”的一方称为从表。
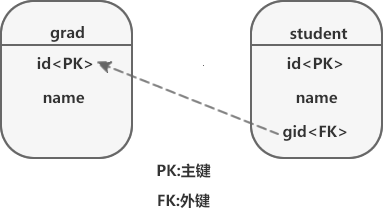
图 1 说明如下:
- student 表为学生表,id 为学生表的主键,name 表示学生名称;
- grade 表为班级表,id 为班级表的主键,name 表示班级名称;
- gid 为学生表的外键,指向班级表的主键 id;
使用 Hibernate 映射“一对多”关联关系时,需要如下步骤:
- 在“多”的一方的实体类中,引入“一”的一方实体类对象作为其属性,并在映射文件中通过 <many-to-one> 标签进行映射;
- 在“一”的一方的实体类中,以 Set 集合的形式引入“多”的一方实体类对象作为其属性,并在映射文件中通过 <set> 标签进行映射。
学生和班级之间的关系,是典型的一对多关联关系,一个学生只能属于一个班级,而一个班级可以有多个学生,下面我们以学生(Student)和班级(grade)为例,演示如何使用 Hibernate 建立一对多关联映射。
多对多
在实际的应用中,“多对多”也是一种常见的关联关系,例如学生和课程的关系,一个学生可以选修多门课程,一个课程可以被多名学生选修。
在关系型数据库中,是无法直接表达“多对多”关联关系的,我们一般会采用新建一张中间表,将一个“多对多”关联拆分为两个“一对多”关联解决此问题,如下图。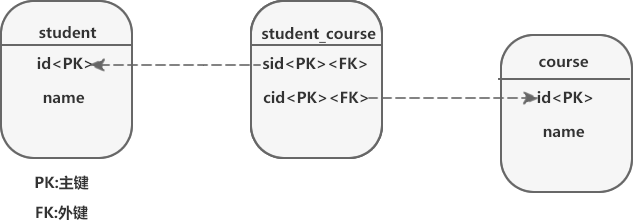
图 1 说明如下:
- student 表为学生表,id 为学生表的主键,name 表示学生名称;
- course 表为课程表,id 为课程表的主键,name 表示课程名称;
- student_course 表为中间表,其中字段 cid 和 sid 是中间表的两个外键,分别指向 student 表和 course 表的主键 id;
- 在 student_course 表中,sid 和 cid 是该表的联合主键。
Hibernate 在映射“多对多”关联关系时,需要在两个实体类中,分别以 Set 集合的方式引入对方的对象,并在映射文件中通过 <set> 标签进行映射。
下面我们以学生(Student)和课程(Course)为例,演示如何使用 Hibernate 建立多对多关联映射。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号