biancheng-HBase
目录http://c.biancheng.net/view/6509.html
1HBase是什么?
2HBase的优势有哪些?
3Hadoop与HBase的关系
4HDFS
5HDFS的特点与使用场景
6HBase的组件和功能
7Zookeeper是什么?
8HMaster是什么?
9RegionServer是什么?
10HBase的使用场景及案例
11HBase的安装与配置
12HBase数据模型
13HBase Shell及其常用命令
14HBase创建表
15HBase修改表
16HBase删除表
17HBase插入数据
18HBase删除数据
19HBase获取数据
20HBase查询全表数据
21HBase过滤器
22HBase Java编程
23HBase Thrift协议编程
24MapReduce处理分布式数据
25Region分区及定位
26HBase数据的读写流程
27HBase WAL机制
28HBase Region管理
29HBase集群管理
HBase 是一个开源的、分布式的、版本化的非关系型数据库,它利用 Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)提供分布式数据存储。
HBase 是一个可以进行随机访问的存取和检索数据的存储平台,存储结构化和半结构化的数据,因此一般的网站可以将网页内容和日志信息都存在 HBase 里。
如果数据量不是非常庞大,HBase 甚至可以存储非结构化的数据。它不要求数据有预定义的模式,允许动态和灵活的数据模型,也不限制存储数据的类型。
HBase 是非关系型数据库,它不具备关系型数据库的一些特点,例如,它不支持 SQL 的跨行事务,也不要求数据之间有严格的关系,同时它允许在同一列的不同行中存储不同类型的数据。
HBase 作为 Hadoop 框架下的数据库,是被设计成在一个服务器集群上运行的。
HBase 是典型的 NoSQL 数据库,通常被描述成稀疏的、分布式的、持久化的,由行键、列键和时间戳进行索引的多维有序映射数据库,主要用来存储非结构化和半结构化的数据。因为 HBase 基于 Hadoop 的 HDFS 完成分布式存储,以及 MapReduce 完成分布式并行计算,所以它的一些特点与 Hadoop 相同,依靠横向扩展,通过不断增加性价比高的商业服务器来增加计算和存储能力。
HBase 虽然基于 Bigtable 的开源实现,但它们之间还是有很多差别的,Bigtable 经常被描述成键值数据库,而 HBase 则是面向列存储的分布式数据库。
下面介绍 HBase 具备的显著特性,这些特性让 HBase 成为当前和未来最实用的数据库之一。
容量巨大
HBase 的单表可以有百亿行、百万列,可以在横向和纵向两个维度插入数据,具有很大的弹性。
当关系型数据库的单个表的记录在亿级时,查询和写入的性能都会呈现指数级下降,这种庞大的数据量对传统数据库来说是一种灾难,而 HBase 在限定某个列的情况下对于单表存储百亿甚至更多的数据都没有性能问题。
HBase 采用 LSM 树作为内部数据存储结构,这种结构会周期性地将较小文件合并成大文件,以减少对磁盘的访问。
列存储
与很多面向行存储的关系型数据库不同,HBase 是面向列的存储和权限控制的,它里面的每个列是单独存储的,且支持基于列的独立检索。通过下图的例子来看行存储与列存储的区别。
从上图可以看到,行存储里的一张表的数据都放在一起,但在列存储里是按照列分开保存的。在这种情况下,进行数据的插入和更新,行存储会相对容易。而进行行存储时,查询操作需要读取所有的数据,列存储则只需要读取相关列,可以大幅降低系统 I/O 吞吐量。
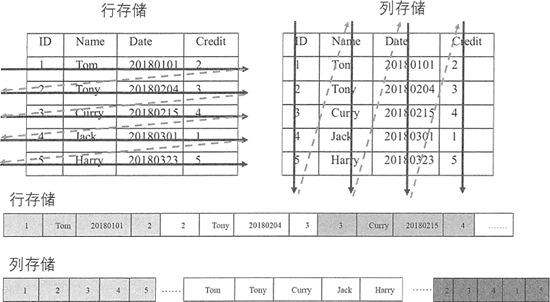
从上图可以看到,行存储里的一张表的数据都放在一起,但在列存储里是按照列分开保存的。在这种情况下,进行数据的插入和更新,行存储会相对容易。而进行行存储时,查询操作需要读取所有的数据,列存储则只需要读取相关列,可以大幅降低系统 I/O 吞吐量。
稀疏性
通常在传统的关系性数据库中,每一列的数据类型是事先定义好的,会占用固定的内存空间,在此情况下,属性值为空(NULL)的列也需要占用存储空间。
而在 HBase 中的数据都是以字符串形式存储的,为空的列并不占用存储空间,因此 HBase 的列存储解决了数据稀疏性的问题,在很大程度上节省了存储开销。所以 HBase 通常可以设计成稀疏矩阵,同时这种方式比较接近实际的应用场景。
扩展性强
HBase 工作在 HDFS 之上,理所当然地支持分布式表,也继承了 HDFS 的可扩展性。HBase 的扩展是横向的,横向扩展是指在扩展时不需要提升服务器本身的性能,只需添加服务器到现有集群即可。
HBase 表根据 Region 大小进行分区,分别存在集群中不同的节点上,当添加新的节点时,集群就重新调整,在新的节点启动 HBase 服务器,动态地实现扩展。这里需要指出,HBase 的扩展是热扩展,即在不停止现有服务的前提下,可以随时添加或者减少节点。
高可靠性
HBase 运行在 HDFS 上,HDFS 的多副本存储可以让它在岀现故障时自动恢复,同时 HBase 内部也提供 WAL 和 Replication 机制。
WAL(Write-Ahead-Log)预写日志是在 HBase 服务器处理数据插入和删除的过程中用来记录操作内容的日志,保证了数据写入时不会因集群异常而导致写入数据的丢失;而 Replication 机制是基于日志操作来做数据同步的。
当集群中单个节点出现故障时,协调服务组件 ZooKeeper 通知集群的主节点,将故障节点的 HLog 中的日志信息分发到各从节点进行数据恢复。
Hadoop与HBase的关系
Google 公司的 Bigtable 建模,而 Bigtable 是基于 GFS 来完成数据的分布式存储的,因此,HBase 与 HDFS 有非常紧密的关系,它使用 HDFS 作为底层存储系统。虽然 HBase 可以单独运行在本地文件系统上,但这不是 HBase 设计的初衷。
HBase 是在 Hadoop 这种分布式框架中提供持久化的数据存储与管理的工具。在使用 HBase 的分布式集群模式时,前提是必须有 Hadoop 系统。
Hadoop 系统为 HBase 提供给了分布式文件存储系统,同时也使得 MapReduce 组件能够直接访问 HBase 进行分布式计算。
HBase 最重要的访问方式是 Java API(Application Programming Interface,应用程序编程接口),MapReduce 的批量操作方式并不常用。
下图展示了 HBase 在 Hadoop 生态系统中的位置。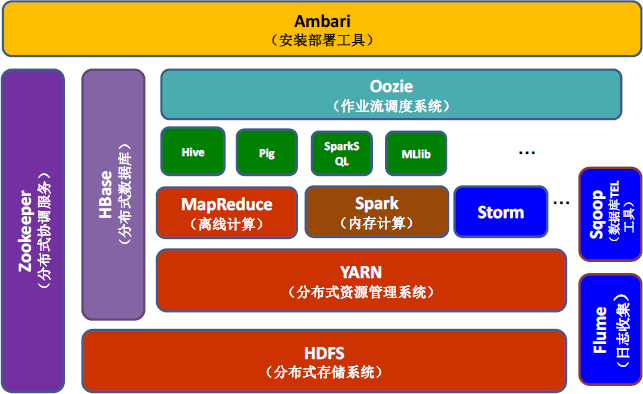
本节的知识点都基于 HBase 1.2.6 稳定版本,因为 HBase 底层依赖 Hadoop,所以对 Hadoop 的版本也有要求。
一、spark与storm的比较
|
比较点 |
Storm |
Spark Streaming |
|
实时计算模型 |
纯实时,来一条数据,处理一条数据 |
准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 |
|
实时计算延迟度 |
毫秒级 |
秒级 |
|
低 |
高 |
|
|
事务机制 |
支持完善 |
支持,但不够完善 |
|
健壮性 / 容错性 |
ZooKeeper,Acker,非常强 |
Checkpoint,WAL,一般 |
|
动态调整并行度 |
支持 |
不支持 |
对于Storm来说:
1、建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
2、此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
3、如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
4、如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择
对于Spark Streaming来说:
1、如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
2、考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性
Spark Streaming与Storm的优劣分析
事实上,Spark Streaming绝对谈不上比Storm优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
Spark Streaming仅仅在吞吐量上比Storm要优秀,而吞吐量这一点,也是历来挺Spark Streaming,贬Storm的人着重强调的。但是问题是,是不是在所有的实时计算场景下,都那么注重吞吐量?不尽然。因此,通过吞吐量说Spark Streaming强于Storm,不靠谱。
事实上,Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性 / 容错性、动态调整并行度等特性,都要比Spark Streaming更加优秀。
Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark生态技术栈中,因此Spark Streaming可以和Spark Core、Spark SQL无缝整合,也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark Streaming的优势和功能。
HDFS 的基本架构
HDFS ( Hadoop Distributed File System)即 Hadoop 分布式文件系统,它的设计目标是把超大数据集存储到集群中的多台普通商用计算机上,并提供高可靠性和高吞吐量的服务。
HDFS 是参考 Google 公司的 GFS 实现的,不管是 Google 公司的计算平台还是 Hadoop 计算平台,都是运行在大量普通商用计算机上的,这些计算机节点很容易出现硬件故障,而这两种计算平台都将硬件故障作为常态,通过软件设计来保证系统的可靠性。
例如,HDFS 的数据是分块地存储在每个节点上,当某个节点出现 故障时,HDFS 相关组件能快速检测节点故障并提供容错机制完成数据的自动恢复。
HDFS 主要由 3 个组件构成,分别是 NameNode、SecondaryNameNode 和 DataNode。
HDFS 是以 Master/Slave 模式运行的,其中,NameNode 和 SecondaryNameNode 运行在 Master 节点 上,而 DataNode 运行在 Slave 节点上,所以 HDFS 集群一般由一个 NameNode、一个 SecondaryNameNode 和许多 DataNode 组成,其架构如下图所示。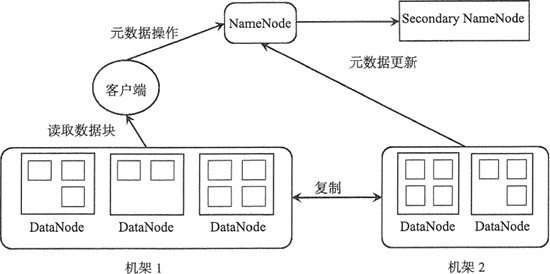
在 HDFS 中,文件是被分成块来进行存储的,一个文件可以包含许多个块,每个块存储在不同的 DataNode 中。从上图中可知,当一个客户端请求读取一个文件时,它需要先从 NameNode 中获取文件的元数据信息,然后从对应的数据节点上并行地读取数据块。
下面介绍 HDFS 架构中 NameNode、SecondaryNameNode 和 DataNode 的功能。
NameNode
NameNode 是主服务器,负责管理文件系统的命名空间以及客户端对文件的访问。当客户端请求数据时,仅仅从 NameNode 中获取文件的元数据信息,具体的数据传输不经过 NameNode,而是直接与具体的 DataNode 进行交互。
这里文件的元数据信息记录了文件系统中的文件名和目录名,以及它们之间的层级关系,同时也记录了每个文件目录的所有者及其权限,甚至还记录每个文件由哪些块组成,这些元数据信息记录在文件 fsimage 中,当系统初次启动时,NameNode 将读取 fsimage 中的信息并保存到内存中。
这些块的位置信息是由 NameNode 启动后从每个 DataNode 获取并保存在内存当中的,这样既减少了 NameNode 的启动时间,又减少了读取数据的查询时间,提高了整个系统的效率。
SecondaryNameNode
从字面上来看,SecondaryNameNode 很容易被当作是 NameNode 的备份节点,其实不然。可以通过下图看 HDFS 中 SecondaryNameNode 的作用。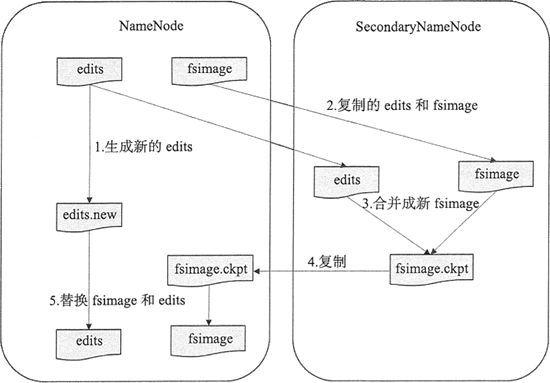
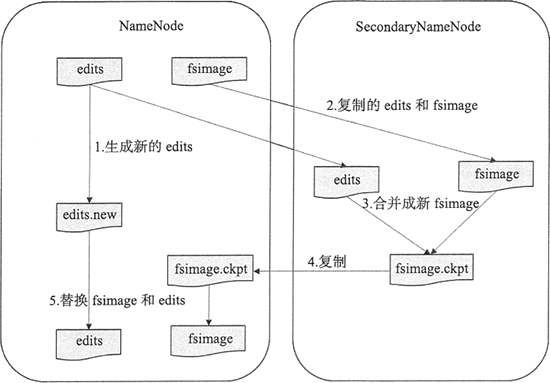
NameNode 管理着元数据信息,元数据信息会定期保存到 edits 和 fsimage 文件中。其中的 edits 保存操作日志信息,在 HDFS 运行期间,新的操作日志不会立即与 fsimage 进行合并,也不会存到 NameNode 的内存中,而是会先写到 edits 中。
当 edits 文件达到一定域值或间隔一段时间后触发 SecondaryNameNode 进行工作,这个时间点称为 checkpoint。
SecondaryNameNode 的角色就是定期地合并 edits 和 fsimage 文件,其合并步骤如下。
- 在进行合并之前,SecondaryNameNode 会通知 NameNode 停用当前的 editlog 文件, NameNode 会将新记录写入新的 editlog.new 文件中。
- SecondaryNameNode 从 NameNode 请求并复制 fsimage 和 edits 文件。
- SecondaryNameNode 把 fsimage 和 edits 文件合并成新的 fsimage 文件,并命名为 fsimage.ckpto
- NameNode 从 SecondaryNameNode 获取 fsimage.ckpt,并替换掉 fsimage,同时用 edits.new 文件替换旧的 edits 文件。
- 更新 checkpoint 的时间。
最终 fsimage 保存的是上一个 checkpoint 的元数据信息,而 edits 保存的是从上个 checkpoint 开始发生的 HDFS 元数据改变的信息。
DataNode
DataNode 是 HDFS 中的工作节点,也是从服务器,它负责存储数据块,也负责为客户端提供数据块的读写服务,同时也响应 NameNode 的相关指令,如完成数据块的复制、删除等。
另外, DataNode 会定期发送心跳信息给 NameNode,告知 NameNode 当前节点存储的文件块信息。当客户端给 NameNode 发送读写请求时,NameNode 告知客户端每个数据块所在的 DataNode 信息,然后客户端直接与 DataNode 进行通信,减少 NameNode 的系统开销。
当 DataNode 在执行块存储操作时,DataNode 还会与其他 DataNode 通信,复制这些块到其他 DataNode 上实现冗余。
HDFS 的分块机制和副本机制
在 HDFS 中,文件最终是以数据块的形式存储的,而副本机制极大程度上避免了宕机所造成的数据丢失,可以在数据读取时进行数据校验。
分块机制
HDFS 中数据块大小默认为 64MB,而一般磁盘块的大小为 512B,HDFS 块之所以这么大,是为了最小化寻址开销。
如果块足够大,从磁盘传输数据的时间会明显大于寻找块的地址的时间,因此,传输一个由多个块组成的大文件的时间取决于磁盘传输速率。
随着新一代磁盘驱动器传输速率的提升,寻址开销会更少,在更多情况下 HDFS 使用更大的块。当然块的大小不是越大越好,因为 Hadoop 中一个 map 任务一次通常只处理一个块中的数据,如果块过大,会导致整体任务数量过小,降低作业处理的速度。
HDFS 按块存储还有如下好处。
1) 文件可以任意大,不会受到单个节点的磁盘容量的限制。理论上讲,HDFS 的存储容量是无限的。
2) 简化文件子系统的设计。将系统的处理对象设置为块,可以简化存储管理,因为块大小固定,所以每个文件分成多少个块,每个 DataNode 能存多少个块,都很容易计算。同时系统中 NameNode 只负责管理文件的元数据,DataNode 只负责数据存储,分工明确,提高了系统的效率。
3) 有利于提高系统的可用性。HDFS 通过数据备份来提供数据的容错能力和高可用性,而按照块的存储方式非常适合数据备份。同时块以副本方式存在多个 DataNode 中,有利于负载均衡,当某个节点处于繁忙状态时,客户端还可以从其他节点获取这个块的副本。
副本机制
HDFS 中数据块的副本数默认为 3,当然可以设置更多的副本数,这些副本分散存储在集群中,副本的分布位置直接影响 HDFS 的可靠性和性能。
一个大型的分布式文件系统都是需要跨多个机架的,如下图中,HDFS 涉及两个机架。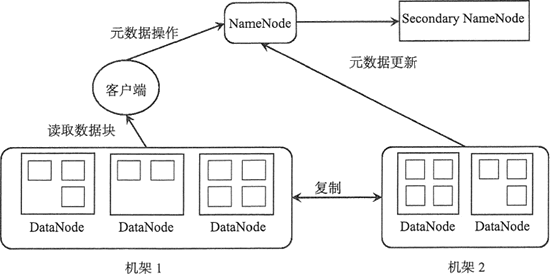
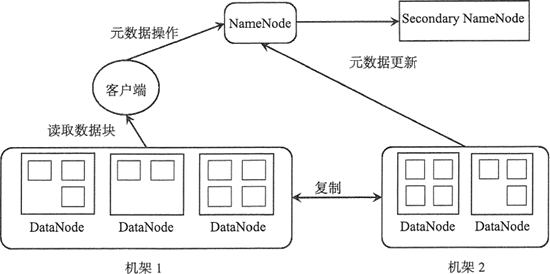
如果把所有副本都存放在不同的机架上,可以防止机架故障从而导致数据块不可用,同时在多个客户端访问文件系统时很容易实现负载均衡。如果是写数据,各个数据块需要同步到不同机架上,会影响写数据的效率。
在 HDFS 默认 3 个副本情况下,会把第一个副本放到机架的一个节点上,第二副本放在同一 个机架的另一个节点上,第三个副本放在不同的机架上。
这种策略减少了跨机架副本的个数,提高了数据块的写性能,也可以保证在一个机架出现故障时,仍然能正常运转。
HDFS 的读写机制
前面讲到,客户端读、写文件是与 NameNode 和 DataNode 通信的,下面详细介绍 HDFS 中读写文件的过程。
读文件
HDFS 通过 RPC 调用 NameNode 获取文件块的位置信息,并且对每个块返回所在的 DataNode 的地址信息,然后再从 DataNode 获取数据块的副本。
HDFS 读文件的过程如图所示。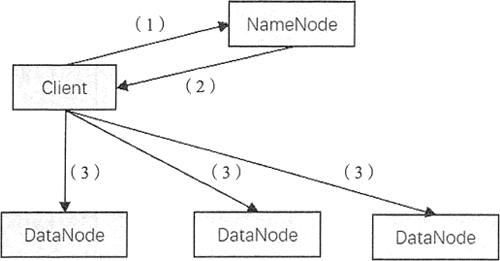
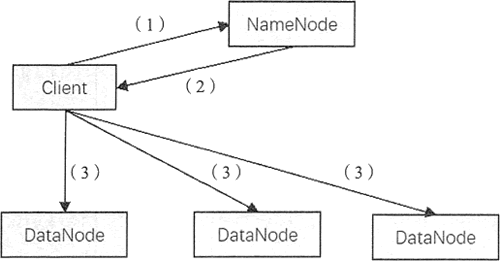
操作步骤如下:
- 客户端发起文件读取的请求。
- NameNode 将文件对应的数据块信息及每个块的位置信息,包括每个块的所有副本的位置信息(即每个副本所在的 DataNode 的地址信息)都传送给客户端。
- 客户端收到数据块信息后,直接和数据块所在的 DataNode 通信,并行地读取数据块。
在客户端获得 NameNode 关于每个数据块的信息后,客户端会根据网络拓扑选择与它最近的 DataNode 来读取每个数据块。当与 DataNode 通信失败时,它会选取另一个较近的 DataNode,同时会对出故障的 DataNode 做标记,避免与它重复通信,并发送 NameNode 故障节点的信息。
写文件
当客户端发送写文件请求时,NameNode 负责通知 DataNode 创建文件,在创建之前会检查客户端是否有允许写入数据的权限。通过检测后,NameNode 会向 edits 文件写入一条创建文件的操作记录。
HDFS 中写文件的过程如图所示。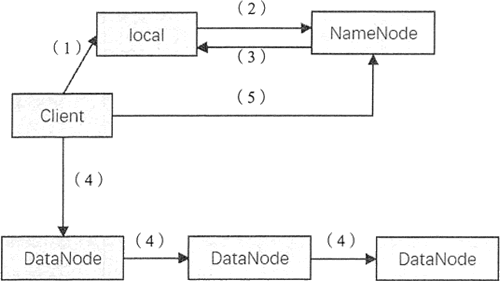
操作步骤如下:
1) 客户端在向 NameNode 发送写请求之前,先将数据写入本地的临时文件中。
2) 待临时文件块达到系统设置的块大小时,开始向 NameNode 请求写文件。
3) NameNode 在此步骤中会检查集群中每个 DataNode 状态信息,获取空闲的节点,并在检查客户端权限后创建文件,返回客户端一个数据块及其对应 DataNode 的地址列表。列表中包含副本存放的地址。
4) 客户端在获取 DataNode 相关信息后,将临时文件中的数据块写入列表中的第一个 DataNode,同时第一个 DataNode 会将数据以副本的形式传送至第二个 DataNode,第二个节点也会将数据传送至第三个 DataNode。
DataNode 以数据包的形式从客户端接收数据,并以流水线的形式写入和备份到所有的 DataNode 中,每个 DataNode 收到数据后会向前一个节点发送确认信息。 最终数据传输完毕,第一个 DataNode 会向客户端发送确认信息。
5) 当客户端收到每个 DataNode 的确认信息时,表示数据块已经持久化地存储在所有 DataNode 当中,接着客户端会向 NameNode 发送确认信息。如果在第(4 )步中任何一个 DataNode 失败,客户端会告知 NameNode,将数据备份到新的 DataNode 中。
适合存储超大文件
HDFS 支持 GB 级别甚至 TB 级别的文件,每个文件大小可以大于集群中任意一个节点的磁盘容量,文件的所有数据块存在不同节点中,在进行大文件读写时采用并行的方式提高数据的吞吐量。
HDFS 不适合存储大量的小文件,这里的小文件指小于块大小的文件。因为 NameNode 将文件系统的元数据信息存在内存当中,所以 HDFS 所能存储的文件总数受到 NameNode 内存容量的限制。
下面通过举例来计算同等容量的单个大文件和多个小文件所占的文件块的个数。
假设 HDFS 中块的大小为 64MB,备份数量为 3,—般情况下,一条元数据记录占用 200B 的内存。那么,对于 1GB 的大文件,将占用 1GB/64MB x 3 个文件块;对于 1024 个 1MB 的小文件,则占用 1024 x3 个文件块。可以看到,存储同等大小的文件,单个文件越小,所需的元数据信息越大,占用的内存越大,因此 HDFS 适合存储超大文件。
适用于流式的数据访问
HDFS 适用于批量数据的处理,不适用于交互式处理。它设计的目标是通过流式的数据访问保证高吞吐量,不适合对低延迟用户响应的应用。可以选择 HBase 满足低延迟用户的访问需求。
支持简单的一致性模型
HDFS 中的文件支持一次写入、多次读取,写入操作是以追加的方式添加在文件末尾,不支持多个写入者的操作,也不支持对文件的任意位置进行修改。
计算向数据靠拢
在 Hadoop 系统中,对数据进行计算时,采用将计算向数据靠拢的方式,即选择最近的数据进行计算,减少数据在网络中的传输延迟。
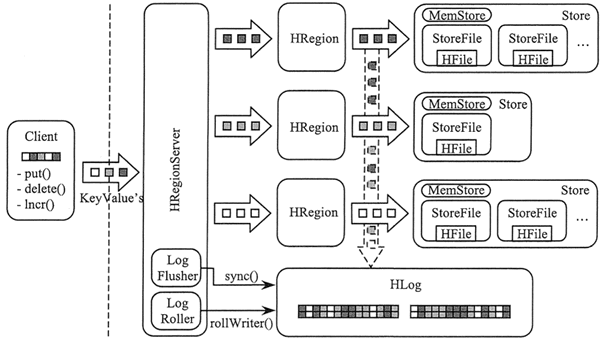
HBase的组件和功能
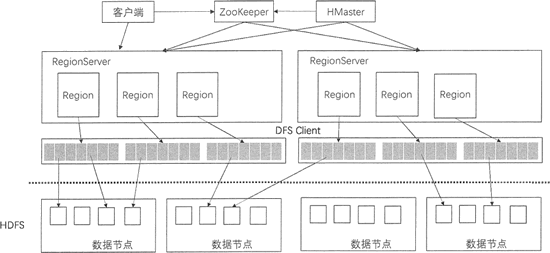
HBase 是一个高可靠、高性能、面向列、可伸缩的分布式数据库,底层基于 Hadoop 的 HDFS 来存储数据。本节将介绍 HBase 的系统架构以及每个组件的功能。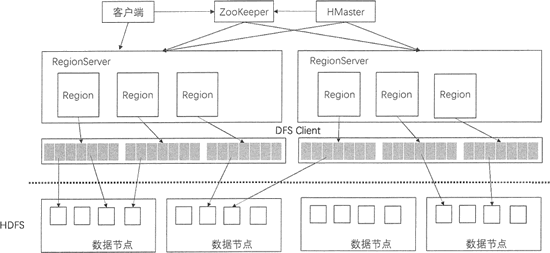
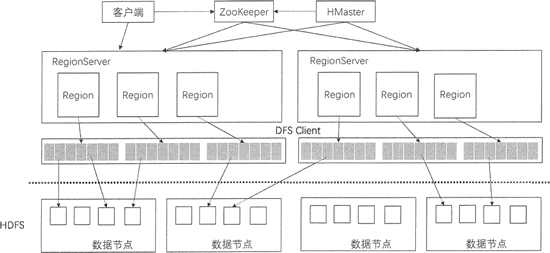
上图展示了 HBase 的系统架构,包括客户端、ZooKeeper 服务器、HMaster 主服务器和 RegionServer。Region 是 HBase 中数据的物理切片,每个 Region 中记录了全局数据的一小部分,并且不同的 Region 之间的数据是互不重复的。
客户端
客户端包含访问 HBase 的接口,是整个 HBase 系统的入口,使用者直接通过客户端操作 HBase。客户端使用 HBase 的 RPC 机制与 HMaster 和 RegionServer 进行通信。在一般情况下,客户端与 HMaster 进行管理类操作的通信,在获取 RegionServer 的信息后,直接与 RegionServer 进行数据读写类操作。而且客户端获取 Region 的位置信息后会缓存下来,用来加速后续数据的访问过程。
客户端可以用 Java 语言来实现,也可以使用 Thtift、Rest 等客户端模式,甚至 MapReduce 也可以算作一种客户端。
由于篇幅限制,本节只介绍 HBase 系统架构的客户端,ZooKeeper 服务器、HMaster 主服务器和 RegionServer 会在下面章节中讲解。
Zookeeper是什么?
ZooKeeper 是一个高性能、集中化、分布式应用程序协调服务,主要是用来解决分布式应用中用户经常遇到的一些数据管理问题,例如,数据发布/订阅、命名服务、分布式协调通知、集群管理、Master 选举、分布式锁和分布式队列等功能。其中,Master 选举是 ZooKeeper 最典型的应用场景。
在 Hadoop 中,ZooKeeper 主要用于实现高可靠性(High Availability, HA),包括 HDFS 的 NameNode 和 YARN 的 ResourceManager 的 HA。 以 HDFS 为例,NameNode 作为 HDFS 的主节点,负责管理文件系统的命名空间以及客户端对文件的访问,同时需要监控整个 HDFS 中每个 DataNode 的状态,实现负载均衡和容错。
为了实现 HA,必须有多个 NameNode 并存,并且只有一个 NameNode 处于活跃状态,其他的则处于备用状态。当活跃的 NameNode 无法正常工作时, 处于备用状态的 NameNode 会通过竞争选举产生新的活跃节点来保证 HDFS 集群的高可靠性。
从上图中可以看到,在 HBase 的系统架构中,ZooKeeper 是串联 HBase 集群和 Client 的关键。
ZooKeeper 在 HBase 中的负责协调的任务如下。
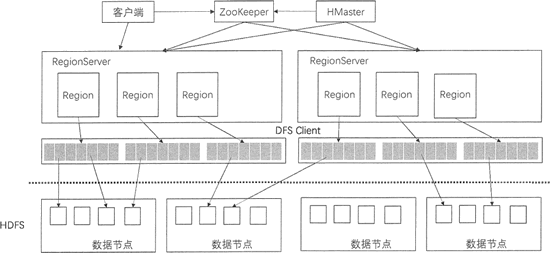
Master 选举
同 HDFS 的 HA 机制一样,HBase 集群中有多个 HMaster 并存,通过竞争选举机制保证同一时刻只有一个 HMaster 处于活跃状态,一旦这个 HMaster 无法使用,则从备用节点中选出一个顶上,保证集群的高可靠性。
系统容错
在 HBase 启动时,每个 RegionServer 在加入集群时都需要到 ZooKeeper 中进行注册,创建一个状态节点,ZooKeeper 会实时监控每个 RegionServer 的状态,同时 HMaster 会监听这些注册的 RegionServer。
当某个 RegionServer 挂断的时候,ZooKeeper 会因为一段时间内接收不到它的心跳信息而删除该 RegionServer 对应的状态节点,并且给 HMaster 发送节点删除的通知。这时,HMaster 获知集群中某节点断开,会立即调度其他节点开启容错机制。
Region 元数据管理
在 HBase 集群中,Region 元数据被存储在 Meta 表中。每次客户端发起新的请求时,需要查询 Meta 表来获取 Region 的位置,而 Meta 表是存在 ZooKeeper 中的。
当 Region 发生变化时,例如,Region 的手工移动、进行负载均衡的移动或 Region 所在的 RegionServer 出现故障等,就能够通过 ZooKeeper 来感知到这一变化,保证客户端能够获得正确的 Region 元数据信息。
Region 状态管理
HBase 集群中 Region 会经常发生变更,其原因可能是系统故障,配置修改,或者是 Region 的分裂和合并。只要 Region 发生变化,就需要让集群的所有节点知晓,否则就会出现某些事务性的异常。
而对于 HBase 集群,Region 的数量会达到 10 万,甚至更多。如此规模的 Region 状态管理如果直接由 HMaster 来实现,则 HMaster 的负担会很重,因此只有依靠 ZooKeeper 系统来完成。
提供 Meta 表存储位置
在 HBase 集群中,数据库表信息、列族信息及列族存储位置信息都属于元数据。这些元数据存储在 Meta 表中,而 Meta 表的位置入口由 ZooKeeper 来提供。
在分布式集群中,HMaster 服务器通常运行在 HDFS 的 NameNode上,HMaster 通过 ZooKeeper 来避免单点故障,在集群中可以启动多个 HMaster,但 ZooKeeper 的选举机制能够保证同时只有一个 HMaster 处于 Active 状态,其他的 HMaster 处于热备份状态。
HMaster是什么?
HMaster 主要负责表和 Region 的管理工作。HMaster 是 HBase 集群中的主服务器,负责监控集群中的所有 RegionServer,并且是所有元数据更改的接口。
在分布式集群中,HMaster 服务器通常运行在 HDFS 的 NameNode上,HMaster 通过 ZooKeeper 来避免单点故障,在集群中可以启动多个 HMaster,但 ZooKeeper 的选举机制能够保证同时只有一个 HMaster 处于 Active 状态,其他的 HMaster 处于热备份状态。
1) 管理用户对表的增、删、改、查操作。
HMaster 提供了下表中的一些基于元数据方法的接口,便于用户与 HBase 进行交互。
| 相关接口 | 功能 |
|---|---|
| HBase 表 | 创建表、删除表、启用/失效表、修改表 |
| HBase 列表 | 添加列、修改列、移除列 |
| HBase 表 Region | 移动 Region、分配和合并 Region |
2) 管理 RegionServer 的负载均衡,调整 Region 的分布。
3) Region 的分配和移除。
4) 处理 RegionServer 的故障转移。
当某台 RegionServer 出现故障时,总有一部分新写入的数据还没有持久化地存储到磁盘中,因此在迁移该 RegionServer 的服务时,需要从修改记录中恢复这部分还在内存中的数据,HMaster 需要遍历该 RegionServer 的修改记录,并按 Region 拆分成小块移动到新的地址下。
另外,当 HMaster 节点发生故障时,由于客户端是直接与 RegionServer 交互的,且 Meta 表也是存在于 ZooKeeper 当中,整个集群的工作会继续正常运行,所以当 HMaster 发生故障时,集群仍然可以稳定运行。
但是 HMaster 还会执行一些重要的工作,例如,Region 的切片、RegionServer 的故障转移等,如果 HMaster 发生故障而没有及时处理,这些功能都会受到影响,因此 HMaster 还是要尽快恢复工作。 ZooKeeper 组件提供了这种多 HMaster 的机制,提高了 HBase 的可用性和稳健性。
在 HDFS 中,DataNode 负责存储实际数据。RegionServer 主要负责响应用户的请求,向 HDFS 读写数据。一般在分布式集群中,RegionServer 运行在 DataNode 服务器上,实现数据的本地性。
RegionServer是什么?
在 HDFS 中,DataNode 负责存储实际数据。RegionServer 主要负责响应用户的请求,向 HDFS 读写数据。一般在分布式集群中,RegionServer 运行在 DataNode 服务器上,实现数据的本地性。
每个 RegionServer 包含多个 Region,它负责的功能如下:
- 处理分批给它的 Region。
- 处理客户端读写请求。
- 刷新缓存到 HDFS 中。
- 处理 Region 分片。
- 执行压缩。
RegionServer 是 HBase 中最核心的模块,其内部管理了一系列 Region 对象,每个 Region 由多个 HStore 组成,每个 HStore 对应表中一个列族的存储。
HBase 是按列进行存储的,将列族作为一个集中的存储单元,并且 HBase 将具备相同 I/O 特性的列存储到一个列族中,这样可以保证读写的高效性。

在上图中,RegionServer 最终将 Region 数据存储在 HDFS 中,采用 HDFS 作为底层存储。
HBase 自身并不具备数据复制和维护数据副本的功能,而依赖 HDFS 为 HBase 提供可靠和稳定的存储。
当然,HBase 也可以不采用 HDFS,如它可以使用本地文件系统或云计算环境中的 Amazon S3。本专题中 HBase 的内容都是以 HDFS 为底层存储来描述的。
在实际应用中,有很多公司使用 HBase,如 Facebook 公司的 Social Inbox 系统,使用 HBase 作为消息服务的基础存储设施,每月可处理几千亿条的消息;Yahoo 公司使用 HBase 存储检查近似重复的指纹信息的文档,它的集群当中分别运行着 Hadoop 和 HBase,表中存了上百万行数据;Adobe 公司使用 Hadoop+HBase 的生产集群,将数据直接持续地存储在 HBase 中,并将 HBase 作为数据源进行 MapReduce 的作业处理;Apache 公司使用 HBase 来维护 Wiki 的相关信息。
HBase的使用场景及案例
HBase 解决不了所有的问题,但是针对某些特点的数据可以使用 HBase 高效地解决,如以下的应用场景。
- 数据模式是动态的或者可变的,且支持半结构化和非结构化的数据。
- 数据库中的很多列都包含了很多空字段,在 HBase 中的空字段不会像在关系型数据库中占用空间。
- 需要很高的吞吐量,瞬间写入量很大。
- 数据有很多版本需要维护,HBase 利用时间戳来区分不同版本的数据。
- 具有高可扩展性,能动态地扩展整个存储系统。
搜索引擎应用
前面讲到 HBase 是 Google Bigtable 的开源实现,而 Google 公司开发 Bigtable 是为了它的搜索引擎应用。Google 和其他搜索引擎是基于建立索引来完成快速搜索服务的。该索引提供了特定词语,包含该词语的所有文档的映射。
搜索引擎的文档库是整个互联网,搜索的特定词语就是用户搜索框里输入的任何信息,Bigtable 和开源的 HBase 为这种文档库提供存储及行级的访问。下面简单地分析 HBase 应用于网络搜索的逻辑过程。
首先,网络爬虫持续不断地从网络上抓取新页面,并将页面内容存储到 HBase 中,爬虫可以插入和更新 HBase 里的内容;然后,用户可以利用 MapReduce 在整张表上计算并生成索引,为网络搜索做准备;接着,用户发起搜索请求;最后,搜索引擎查询建立好的索引列表, 获取文档索引后,再从 HBase 中获取所需的文档内容,最后将搜索结果提交给用户。
捕获增量数据
数据通常是动态增加的,随着时间的推移,数据量会越来越大,例如,网站的日志信息、邮箱的邮件信息等。通常通过采集工具捕获来自各种数据源的增量数据,再使用 HBase 进行存储。
例如,这种采集工具可能是网页爬虫,采集的数据源可能是记录用户点击的广告信息、驻留的时间长度以及对应的广告效果数据,也可能是记录服务器运行的各种参数数据。
下面介绍一些有关该使用场景的成功案例。
存储监控参数
大型的、基于 Web 的产品后台一般都拥有成百上千台服务器,这些服务器不仅为前端的大量用户提供服务,同时还需要提供日志采集、数据存储、数据处理等各种功能。
为了保证产品的正常运行,监控服务器和服务器上运行的软件的健康状态是至关重要的。大规模监控整个环境需要能够采集和存储来自不同数据源的各种参数的监控系统。OpenTSDB 正是这种监控系统,它可以从大规模集群中获取相应的参数并进行存储、索引和服务。
OpenTSDB(Open Time Series Database)是一个开源框架,其含义是开放时间序列数据库。这个框架使用 HBase 作为核心平台来存储和检索所收集的参数,可以灵活地支持增加参数,也可以支持采集上万台机器和上亿个数据点,具有高可扩展性。
OpenTSDB 作为数据收集和监控系统,一方面能够存储和检索参数数据并保存很长时间,另一方面如果需要增加功能也可以添加各种新参数。最终 OpenSTDB 对 HBase 中存储的数据进行分析,并以图形化方式展示集群中的网络设备、操作系统及应用程序的状态。
存储用户交互数据
对基于 Web 的应用,还有一种很重要的数据,即用户交互数据。这一类数据包含了用户的访问网站的行为习惯。通过分析用户交互数据,就可以获取用户在网站上的活动信息。例如,用户看了什么?某个按钮被用户点击了多少次?用户最近搜索了什么?从这些信息就可以了解用户的需求,从而针对不同的用户提供不同的应用。
例如,Facebook 里的 Like 按钮,每次用户 Like —个特定主题,计数器增加一次。FaceBook 使用 HBase 的计数器来计量人们 Like 特定网页的次数。内容原创人或网页主人可以得到近乎实时的、用户 Like 他们网页的数据信息。他们可以据此更敏捷地判断应该提供什么内容。
Facebook 为此创建了一个名为 Facebook Insight 的系统,该系统需要一个可扩展的存储系统。公司考虑了很多种可能,包括关系型数据库、内存数据库和 Cassandra 数据库,最后决定使用 HBase。基于 HBase,Facebook 可以很方便地横向扩展服务规模,提供给数百万用户,也可以继续使用他们已有的运行大规模 HBase 机群的经验。该系统每天处理数百亿条事件,记录数百个参数。
存储遥测数据
软件在运行时经常会岀现异常的情况,这时大部分软件都会生成一个软件崩溃报告,这类软件运行报告会返回软件开发者,用来评测软件质量和规划软件开发路线图。
例如,FireFox 网络浏览器是 Mozilla 基金会旗下的产品,支持各种操作系统,全世界数百万台计算机上都有它的身影。 当 FireFox 浏览器崩溃时,会以 Bug 报告的形式返回一个软件崩溃报告给 Mozilla。
Mozilla 使用一个叫作 Socorro 的系统收集这些报告,用来指导研发部门研制更稳定的产品。Socorro 系统的数据存储和分析建构在 HBase 上,采用 HBase 使得基本分析可以用到比以前多得多的数据。用这些分析数据指导 Mozilla 的开发人员,使其更有针对性地研制出 Bug 更少的版本。
趋势科技(TrendMicro)为企业客户提供互联网安全解决方案,来应对网络上千变万化的安全威胁。安全的重要环节是感知,日志收集和分析对于提供这种感知能力是至关重要的。
趋势科技使用 HBase 来收集和分析日志活动,每天可收集数十亿条记录。HBase 中灵活的模式支持可变的数据结构,当分析流程重新调整时,可以增加新属性。
广告效果和点击流
在线广告是互联网产品的一项主要收入来源。互联网企业提供免费服务给用户,在用户使用服务时投放广告给目标用户。这种精准投放需要针对用户交互数据做详细的捕获和分析,以理解用户的特征;再基于这种特征,选择并投放广告。企业可使用精细的用户交互数据建立更优的模型,进而获得更好的广告投放效果和更多的收入。
但这类数据有两个特点:它以连续流的形式出现,它很容易按用户划分。在理想情况下,这种数据一旦产生就能够马上使用。
HBase 非常适合收集这种用户交互数据,并已经成功地应用在相关领域。它可以增量捕获第 一手点击流和用户交互数据,然后用不同处理方式来处理数据,电商和广告监控行业都已经非常熟练地使用了类似的技术。
例如,淘宝的实时个性化推荐服务,中间推荐结果存储在 HBase 中,广告相关的用户建模数据也存储在 HBase 中,用户模型多种多样,可以用于多种不同场景,例如,针对特定用户投放什么广告,用户在电商门户网站上购物时是否实时报价等。
HBase 已成熟地应用于国内外的很多大公司,总之,HBase 适合用来存储各种类型的大规模的数据,可为用户提供实时的在线查询,同时也支持离线的应用。但对于需要 JOIN 和其他一些关系型数据特性要求时,HBase 就不适用了,因此,还是要根据应用场景合理地使用 HBase,发挥 HBase 的优势。
HBase的安装与配置(非常详细)
本节讲述如何安装、部署 HBase 集群,以及如何通过命令行方式来完成 HBase 集群的启动和停止。
首先介绍部署 HBase 之前需要做的准备工作,如 Java、SSH 和 Hadoop 这些先决条件的配置;然后介绍如何安装 HBase,以及如何配置集群中相关文件。
同时需要注意的是,本节介绍的是分布式 HBase 集群的部署,在对一台机器修改配置文件后需要同步到集群中的所有节点。
准备工作
Hadoop 和 HBase 可以工作在 Linux 和 Windows 操作系统上,但是在 Windows 上安装 Hadoop 和 HBase 只适用于评估和测试,一个成熟稳定的 Hadoop+HBase 集群还是需要运行在 Linux 上, 因此本节中的安装配置及操作命令都是在 Linux 中完成的。Linux 操作系统的选择也有多个,本节使用的是 CentOS 7,可以从其官网上获取。
除了操作系统的选择外,还涉及分布式 Hadoop 的部署、JDK、SSH 等,在运行 HBase 之前要确保这些条件已经具备。JDK 和 SSH 的配置同时也是 Hadoop 安装的前提条件,因此,如何配置 JDK 和 SSH 本节也不做介绍,只介绍这些软件在运行 HBase 时的作用。
JDK
JDK 是 Hadoop 和 HBase 运行的环境。Hadoop 和 HBase 都采用 Java 语言实现,它们的守护进程都运行在 JVM 下,所以安装 JDK 是基本要求,而且使用 JDK 1.6 以上的版本才能更好地支持 HBase,同时为了能够管理超过 4GB 的内存空间,需要安装 64 位的 JDK。
JDK 版本一般选择 Oracle 公司推荐的版本,用户最好使用一个稍旧(稳定)的版本,因为使用最新 Java 版本时可能会出现意想不到的问题,本实验使用的是 jdk-8u161-linux-x64.rpm 包。
SSH
配置 SSH 可以实现简单的服务器到主机的通信,在集群中,只有启动 sshd 后,才可以通过脚本远程操控其他的 Hadoop 和 HBase 进程。但是进程间通信时每次都需要输入密码,因此,为了实现自动化操作,需要配置 SSH 免密码的登录方式。
本节中使用的 CentOS 操作系统内置了 SSH 服务,只需做简单配置即可。
Hadoop
HBase 是以 HDFS 作为底层存储文件系统的,因此 Hadoop 是先行条件。Hadoop 安装文件可从 Hadoop 官网上获取,本节使用的是 Hadoop 2.7.6 版本。
HBase 的安装与配置
安装 Java、SSH 和 Hadoop 以后,接下来要安装配置 HBase。HBase 的运行模式包括单机、伪分布式和分布式三种。
单机模式使用本地文件系统,所有进程运行在一个 JVM 上,单机模式一 般只用于测试,HBase 需要结合 Hadoop 才能展现出其分布式存储的能力。
伪分布式和分布式模式是一种主从模式,基本由一个 Master 节点和多个 Slave 节点组成,均使用 HDFS 作为底层文件系统。但伪分布式模式下,所有进程运行在一个 JVM 上,可以进行小集群的配置,用于测试。在生产环境下,需要在不同机器上的 JVM 中运行守护进程。
下面着重介绍伪分布式和分布式两种模式的安装与配置。
下载安装
本节使用 HBase 1.2.6 版本,安装文件可以从 HBase 官网下载。下载完成后,解压 TAR 包到指定的目录,如/usr/local 目录,并切换到该目录下,查看已解压的文件,然后用 mv 命令重命名 hbase-1.2.6 文件夹为 hbase。
[root@localhost ~]# tar xzvf hbase-1.2.6-bin.tar.gz /usr/local
[root@localhost ~]# cd /usr/local/ //切换到 hbase 所在目录
[root@localhost local] # mv hbase-1.2.6 hbase //重命名为 hbase
[root@localhost local] # Is //查看此目录下文件
bin etc games hadoop hbase hbase-1.2.6-bin.tar.gz include lib
修改配置文件
在配置伪分布式和分布式集群时,需要修改安装目录下 conf 文件夹中相关的配置文件,主要涉及以下两个文件,同时需要将这些配置文件分发到集群中的各个 Regionserver 节点。
- hbase-env.sh:配置 HBase 运行时的变量,如 Java路径、RegionServer 相关参数等。
- hbase-site.xml:在这个文件中可以添加 HBase 的相关配置,如分布式的模式、ZooKeeper 的配置等。
首先修改 hbase-env.sh 文件,配置 Java 的运行环境,将其中的 JAVA_HOME 指向 Java 的安装目录,编辑 hbase-env.sh 文件,添加下面这一行代码:
export JAVA_HOME=/usr/j ava/j dkl.8.0_161
另外,ZooKeeper 可以作为 HBase 的一部分来管理启动,即 ZooKeeper 随着 HBase 的启动而启动,随其关闭而关闭,这时需要在 hbase-env.sh 中设置 HBASE_MANAGES_ZK 变量,即添加下面这一行代码:
export HBASE_MANAGES_ZKrue
当然 ZooKeeper 也可以作为独立的集群来运行,即完全与 HBase 脱离关系,这时需要设置 HBASE_MANAGES_ZK 变量为 false。
下面通过一个分布式集群示例来介绍如何配置 hbase-site.xml 文件,如下示例中的 <description></description> 标记对之间的内容是对每个属性的中文解释,在具体使用时可以不用修改,使用默认设置即可,代码如下:
- <configuration>
- <property>
- <name> hbase.rootdir </name>
- <value>hdfs://example0:9000/hbase</value>
- <description> hbase.rootdir是RegionServer的共享目录,用于持久化存储HBase数据,默认写入/tmp中。如果不修改此配置,在HBase重启时,数据会丢失。此处一般设置的是hdfs的文件目录,如NameNode运行在namenode.Example.org主机的9090端口,则需要设置为hdfs://namenode.example.org:9000/hbase
- </description>
- </property>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- <description>此项用于配置HBase的部署模式,false表示单机或者伪分布式模式,true表不完全分布式模式。
- </description>
- </property>
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>examplelz example2,example3</value>
- <description>此项用于配置ZooKeeper集群所在的主机地址。examplel、 example2、example3是运行数据节点的主机地址。
- </description>
- </property>
- <property>
- <name>hbase.zookeeper.property.dataDir</name>
- <value>/var/zookeeper</value>
- <description>此项用于设置存储ZooKeeper的元数据,如果不设置默认存在/tmp下,重启时数据会丢失。
- </description>
- </property>
- </configuration>
当然还有很多其他参数可以根据需求进行设置,具体可查看官网上的配置项。
另外,在完全分布式模式下,还需要修改 conf/regionservers 文件,此文件罗列了所有 Region 服务器的主机名。HBase 的运维脚本会依次迭代访问每一行来启动所有的 Region 服务器进程。配置完上述文件后,需要同步这些文件到集群上的其他节点。
HBase 的启动和关闭
在 Master 服务器上已经配置了对集群中所有 Slave 机器的无密码登录,使用 start-hbase.sh 脚本即可启动整个集群。
首先,确认 HDFS 处于运行状态,使用 jps 命令查看 NameNode 和 DataNode 的服务是否正常启动。以下示例为伪分布式模式,因此 NameNode 和 DataNode 都在同一台机器上运行。
[root@localhost local]# jps
24371 NameNode
24680 SecondaryNameNode
24506 DataNode
然后,用如下命令启动 HBase,下例启动的是伪分布式集群,使用完全分布式模式的启动命令也是如此。
[rootglocalhost hbase]# bin/start-hbase.sh
localhost: starting zookeeper, logging to /usr/local/hbase/bin/../logs/hbase-root-zookeeper-localhost.localdomain.out
starting mas ter, logging to /usr/local/hbase/bin/../logs/hbase-root-master-localhost. localdomain.out
starting regionserver, logging to /usr/local/hbase/bin/../logs/hbase-root-1-regionserver-localhost.localdomain.out
接着,使用 jps 命令查看进程,如果是完全分布式模式,则在 Master 节点运行有 Hmaster 和 HQuorumPeer 进程,在 Slave 节点上运行 HRegionServer 和 HQuorumPeer 进程。
[rootQlocalhost local]# jps
24371 NameNode
24680 SecondaryNameNode
26328 HRegionServer
24506 DataNode
26508 Jps
25455 HQuorumPeer
25519 HMaster
以上显示 HBase 集群正常启动,可以输入 hbase shell 命令进入 HBase 执行数据库的操作。
最后,使用 stop-hbase.sh 脚本关闭 HBase 集群,如下所示:
[root@localhost hbase]# bin/stop-hbase.sh
stopping hbase................................
localhost: stopping zookeeper.
HBase 的基本概念
HBase 是一种列存储模式与键值对存储模式结合的 NoSQL 数据库,它具有灵活的数据模型,不仅可以基于键进行快速查询,还可以实现基于值、列名等的全文遍历和检索。
HBase 可以实现自动的数据分片,用户不需要知道数据存储在哪个节点上,只要说明检索的要求,系统会自动进行数据的查询和反馈。
HBase 不支持关系模型,它可以根据用户的需求提供更灵活和可扩展的表设计。与传统的关系型数据库类似,HBase 也是以表的方式组织数据,应用程序将数据存于 HBase 的表中,HBase 的表也由行和列组成。
但有一点不同的是,HBase 有列族的概念,它将一列或多列组织在一起,HBase 的每个列必须属于某一个列族。
下面具体介绍 HBase 数据模型中一些名词的概念。
1) 表(Table)
HBase 中的数据以表的形式存储。同一个表中的数据通常是相关的,使用表主要是可以把某些列组织起来一起访问。表名作为 HDFS 存储路径的一部分来使用,在 HDFS 中可以看到每个表名都作为独立的目录结构。
2) 行(Row)
在 HBase 表里,每一行代表一个数据对象,每一行都以行键(Row Key)来进行唯一标识,行键可以是任意字符串。在 HBase 内部,行键是不可分割的字节数组,并且行键是按照字典排序由低到高存储在表中的。在 HBase 中可以针对行键建立索引,提高检索数据的速度。
3) 列族(Colunm Family)
HBase 中的列族是一些列的集合,列族中所有列成员有着相同的前缀,列族的名字必须是可显示的字符串。列族支持动态扩展,用户可以很轻松地添加一个列族或列,无须预定义列的数量以及类型。所有列均以字符串形式存储,用户在使用时需要自行进行数据类型转换。
4) 列标识(Column Qualifier)
列族中的数据通过列标识来进行定位,列标识也没有特定的数据类型,以二进制字节来存储。通常以 Column Family:Colunm Qualifier 来确定列族中的某列。
5) 单元格(Cell)
每一个行键、列族、列标识共同确定一个单元格,单元格的内容没有特定的数据类型,以二进制字节来存储。每个单元格保存着同一份数据的多个版本,不同时间版本的数据按照时间先后顺序排序,最新的数据排在最前面。单元格可以用 <RowKey,Column Family: Column Qualifier,Timestamp> 元组来进行访问。
6) 时间戳(Timestamp)
在默认情况下,每一个单元格插入数据时都会用时间戳来进行版本标识。读取单元格数据时,如果时间戳没有被指定,则默认返回最新的数据;写入新的单元格数据时,如果没有设置时间戳,默认使用当前时间。每一个列族的单元数据的版本数量都被 HBase 单独维护,默认情况下 HBase 保留 3 个版本数据。
数据模型
表是 HBase 中数据的逻辑组织方式,从用户视角来看,HBase 表的逻辑模型如表 1 所示。HBase 中的一个表有若干行,每行有多个列族,每个列族中包含多个列,而列中的值有多个版本。
| 行键 | 列族 StuInfo | 列族 Grades | 时间戳 | |||||
|---|---|---|---|---|---|---|---|---|
| Name | Age | Sex | Class | BigData | Computer | Math | ||
| 0001 | Tom Green | 18 | Male | 80 | 90 | 85 | T2 | |
| 0002 | Amy | 19 | 01 | 95 | 89 | T1 | ||
| 0003 | Allen | 19 | Male | 02 | 90 | 88 | T1 | |
表 1 展示的是 HBase 中的学生信息表 Student,有三行记录和两个列族,行键分别为 0001、0002 和 0003,两个列族分别为 Stulnfo 和 Grades,每个列族中含有若干列,如列族 Stulnfo 包括 Name、Age、Sex 和 Class 四列,列族 Grades 包括 BigData、Computer 和 Math 三列。
在 HBase 中,列不是固定的表结构,在创建表时,不需要预先定义列名,可以在插入数据时临时创建。
从表 1 的逻辑模型来看,HBase 表与关系型数据库中的表结构之间似乎没有太大差异,只不过多了列族的概念。但实际上是有很大差别的,关系型数据库中表的结构需要预先定义,如列名及其数据类型和值域等内容。
如果需要添加新列,则需要修改表结构,这会对已有的数据产生很大影响。同时,关系型数据库中的表为每个列预留了存储空间,即表 1 中的空白 Cell 数据在关系型数据库中以“NULL”值占用存储空间。因此,对稀疏数据来说,关系型数据库表中就会产生很多“NULL”值,消耗大量的存储空间。
在 HBase 中,如表 1 中的空白 Cell 在物理上是不占用存储空间的,即不会存储空白的键值对。因此,若一个请求为获取 RowKey 为 0001 在 T2 时间的 Stulnfo:class 值时,其结果为空。类似地,若一个请求为获取 RowKey 为 0002 在 T1 时间的 Grades Computer 值时,其结果也为空。
与面向行存储的关系型数据库不同,HBase 是面向列存储的,且在实际的物理存储中,列族是分开存储的,即表 1 中的学生信息表将被存储为 Stulnfo 和 Grades 两个部分。
表 2 展示了 Stulnfo 这个列族的实际物理存储方式,列族 Grades 的存储与之类似。在表 2 中可以看到空白 Cell 是没有被存储下来的。
| 行键 | 列标识 | 值 | 时间戳 |
|---|---|---|---|
| 0001 | Name | TomGreen | T2 |
| 0001 | Age | 18 | T2 |
| 0001 | Sex | Male | T2 |
| 0002 | Name | Amy | T1 |
| 0002 | Age | 19 | T1 |
| 0002 | Class | 01 | T1 |
| 0003 | Name | Allen | T1 |
| 0003 | Age | 19 | T1 |
| 0003 | Sex | Male | T1 |
| 0003 | Class | 02 | T1 |
HBase Shell及其常用命令
HBase 数据库默认的客户端程序是 HBase Shell,它是一个命令行工具。用户可以使用 HBase Shell,通过命令行的方式与 HBase 进行交互。
在 Shell 中输入help可以获取可用命令列表,输入help commandname可获取特定命令的帮助,还可以输入各种命令查看集群、数据库和数据的各项详情。
例如,使用status命令查看当前集群各节点的状态,使用version命令查看当前 HBase 的版本号,输入命令exit或quit即可退出 HBase Shell。
下面对常用命令做一下汇总。
| 命令 | 描述 |
|---|---|
| create | 创建指定模式的新表 |
| alter | 修改表的结构,如添加新的列族 |
| describe | 展示表结构的信息,包括列族的数量与属性 |
| list | 列出 HBase 中已有的表 |
| disable/enable | 为了删除或更改表而禁用一个表,更改完后需要解禁表 |
| disable_all | 禁用所有的表,可以用正则表达式匹配表 |
| is_disable | 判断一个表是否被禁用 |
| drop | 删除表 |
| truncate | 如果只是想删除数据而不是表结构,则可用 truncate 来禁用表、删除表并自动重建表结构 |
| 命令 | 描述 |
|---|---|
| put | 添加一个值到指定单元格中 |
| get | 通过表名、行键等参数获取行或单元格数据 |
| scan | 遍历表并输出满足指定条件的行记录 |
| count | 计算表中的逻辑行数 |
| delete | 删除表中列族或列的数据 |
HBase创建表(create命令)
与关系型数据库不同,在 HBase 中,基本组成为表,不存在多个数据库。因此,在 HBase 中存储数据先要创建表,创建表的同时需要设置列族的数量和属性。
| 行键 | 列族 StuInfo | 列族 Grades | 时间戳 | |||||
|---|---|---|---|---|---|---|---|---|
| Name | Age | Sex | Class | BigData | Computer | Math | ||
| 0001 | Tom Green | 18 | Male | 80 | 90 | 85 | T2 | |
| 0002 | Amy | 19 | 01 | 95 | 89 | T1 | ||
| 0003 | Allen | 19 | Male | 02 | 90 | 88 | T1 |
|
HBase 使用 creat 命令来创建表,创建表时需要指明表名和列族名,如创建上表中的学生信息表 Student 的命令如下:
create 'Student','StuInfo','Grades'
这条命令仓建了名为 Student 的表,表中包含两个列族,分别为 Stulnfo 和 Grades。
注意在 HBase Shell 语法中,所有字符串参数都必须包含在单引号中,且区分大小写,如 Student 和 student 代表两个不同的表。
另外,在上条命令中没有对列族参数进行定义,因此使用的都是默认参数,如果建表时要设置列族的参数,参考以下方式:
create 'Student', {NAME => 'Stulnfo', VERSIONS => 3}, {NAME =>'Grades', BLOCKCACHE => true}
大括号内是对列族的定义,NAME、VERSION 和 BLOCKCACHE 是参数名,无须使用单引号,符号=>表示将后面的值赋给指定参数。例如,VERSIONS => 3是指此单元格内的数据可以保留最近的 3 个版本,BLOCKCACHE => true指允许读取数据时进行缓存
describe 命令描述了表的详细结构,包括有多少个列族、每个列族的参数信息,这些显示的参数都可以使用 alter 命令进行修改。
修改列族
首先修改列族的参数信息,如修改列族的版本。例如上面的 Student 表,假设它的列族 Grades 的 VERSIONS 为 1,但是实际可能需要保存最近的 3 个版本,可使用以下命令完成:
alter 'Student', {NAME => 'Grades', VERSIONS => 3}
修改多个列族的参数,形式与 create 命令类似。
这里要注意,修改已存有数据的列族属性时,HBase 需要对列族里所有的数据进行修改,如果数据量很大,则修改可能要占很长时间。
增加列族
如果需要在 Student 表中新增一个列族 hobby,使用以下命令:
alter 'Student', 'hobby'
删除列族
如果要移除或者删除已有的列族,以下两条命令均可完成:
alter 'Student', { NAME => 'hobby', METHOD => 'delete' }
alter 'Student', 'delete' => 'hobby'
另外,HBase 表至少要包含一个列族,因此当表中只有一个列族时,无法将其删除。
HBase删除表(disable和drop命令)
使用 drop 命令删除表,但是在删除表之前需要先使用 disable 命令禁用表。
例如有一个 Student 表,删除该表的完整流程如下:
disable 'Student'
drop 'Student'
使用 disable 禁用表以后,可以使用 is_disable 查看表是否禁用成功。
另外,如果只是想清空表中的所有数据,使用 truncate 命令即可,此命令相当于完成禁用表、删除表,并按原结构重新建立表操作:
truncate 'Student'
插入数据
HBase 使用 put 命令向数据表中插入数据,put 向表中增加一个新行数据,或覆盖指定行的数据。
例如有以上结构的数据表,向其中插入一条数据的写法为:
put 'Student', '0001', 'Stulnfo:Name', 'Tom Green', 1
在上述命令中:
- 第一个参数
Student为表名; - 第二个参数
0001为行键的名称,为字符串类型; - 第三个参数
StuInfo:Name为列族和列的名称,中间用冒号隔开。列族名必须是已经创建的,否则 HBase 会报错;列名是临时定义的,因此列族里的列是可以随意扩展的; - 第四个参数
Tom Green为单元格的值。在 HBase 里,所有数据都是字符串的形式; - 最后一个参数
1为时间戳,如果不设置时间戳,则系统会自动插入当前时间为时间戳。
注意,put 命令只能插入一个单元格的数据,上表中的一行数据需要通过以下几条命令一起完成:
put 'Student', '0001', 'StuInfo:Name', 'Tom Green', 1
put 'Student', '0001', 'StuInfo:Age', '18'
put 'Student', '0001', 'StuInfo:Sex', 'Male'
put 'Student', '0001', 'Grades:BigData', '80'
put 'Student', '0001', 'Grades:Computer', '90'
put 'Student', '0001', 'Grades:Math', '85'
如以下命令可将行键为 0001 的学生姓名改为 Jim Green:
put 'Student', '0001', 'Stulnfo:Name', 'Jim Green'
如果在初始创建表时,已经设定了列族 VERSIONS 参数值为 n,则 put 操作可以保存 n 个版本数据,即可查询到行键为 0001 的学生的 n 个版本的姓名数据。删除数据(delete命令)
HBase delete 命令可以从表中删除一个单元格或一个行集,语法与 put 类似,必须指明表名和列族名称,而列名和时间戳是可选的。
将删除 Student 表中行键为 0002 的 Grades 列族的所有数据:
delete 'Student', '0002', 'Grades'
需要注意的是,delete 操作并不会马上删除数据,只会将对应的数据打上删除标记(tombstone),只有在合并数据时,数据才会被删除。
另外,delete 命令的最小粒度是单元格(Cell)。例如,执行以下命令将删除 Student 表中行键为 0001,Grades 列族成员为 Math,时间戳小于等于 2 的数据:
delete 'Student', '0001', 'Grades:Math', 2
delete 命令不能跨列族操作,如需删除表中所有列族在某一行上的数据,即删除上表中一个逻辑行,则需要使用 deleteall 命令,如下所示,不需要指定列族和列的名称:
deleteall 'Student', '0001'
从表中获取数据
HBase get 命令可以从数据表中获取某一行记录,类似于关系型数据库中的 select 操作。get 命令必须设置表名和行键名,同时可以选择指明列族名称、时间戳范围、数据版本等参数。
对于上面的数据表,执行以下命令可以获取 Student 表中行键为 0001 的所有列族数据:
get 'student', '0001'
下图展示了在 get 语句中使用限定词 VERSIONS 后获取的数据内容。

上图中首先 put 三条数据,因为初始创建 Student 表和 Stulnfo 列族时,已经设定 VERSIONS 为 3,即使用 get 获取数据时最多得到 3 个版本的数据。
HBase scan命令:查询全表数据
HBase scan 命令用来查询全表数据,使用时只需指定表名即可。
例如对于上面的 Student 表,使用下面的写法即可查询数据:
scan 'Student'
同样地,还可以指定列族和列的名称,或指定输出行数,甚至指定输出行键范围,如下图所示。

scan 指定条件输出时,需要使用大括号将参数包含起来。
注意指定列族和列名称使用 COLUMN 限定符;指定输出行键范围使用 STARTROW 和 ENDROW 限定符,此时输出行不包括 ENDROW 行。例如,上图中 ENDROW=>0003,只会输出行键为 0002 的记录,不会输出 0003 记录。
上述限定条件也可以联合使用,中间用逗号隔开即可。
在 HBase 中,具有相同行键的单元格,无论其属于哪个列族,都可以将整体看作一个逻辑行, 使用 count 命令可以计算表的逻辑行数。
在关系型数据库中,有多少条记录就有多少行,表中的行数很容易统计。而在 HBase 里,计算逻辑行需要扫描全表的内容,重复的行键是不纳入计数的,且标记为 tombstone 的删除数据也不纳入计数。
执行 count 命令其实是一个开销较大的进程,特别是应用在大数据场景时,可能需要持续很长时间,因此,用户一般会结合 Hadoop 的 MapReduce 架构来进行分布式的扫描计数。
HBase过滤器
在 HBase 中,get 和 scan 操作都可以使用过滤器来设置输出的范围,类似 SQL 里的 Where 查询条件。
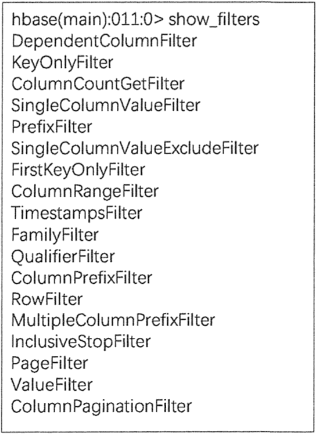
使用 show_filter 命令可以查看当前 HBase 支持的过滤器类型,如下图所示。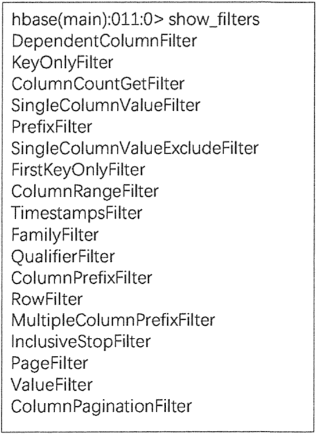
使用上述过滤器时,一般需要配合比较运算符或比较器使用,如下面两个表所示。
| 比较运算符 | 描述 |
|---|---|
| = | 等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| != | 不等于 |
| 比较器 | 描述 |
|---|---|
| BinaryComparator | 匹配完整字节数组 |
| BinaryPrefixComparator | 匹配字节数组前缀 |
| BitComparator | 匹配比特位 |
| NullComparator | 匹配空值 |
| RegexStringComparator | 匹配正则表达式 |
| SubstringComparator | 匹配子字符串 |
使用过滤器的语法格式如下所示:
scan '表名', { Filter => "过滤器(比较运算符, '比较器') }
在上述语法中,Filter=> 指明过滤的方法,整体可用大括号引用,也可以不用大括号。过滤的方法用双引号引用,而比较方式用小括号引用。
下面介绍常见的过滤器使用方法。
行键过滤器
RowFilter 可以配合比较器和运算符,实现行键字符串的比较和过滤。例如,匹配行键中大于 0001 的数据,可使用 binary 比较器;匹配以 0001 开头的行键,可使用 substring 比较器,注意 substring 不支持大于或小于运算符。

针对行键进行匹配的过滤器还有 PrefixFilter、KeyOnlyFilter、FirstKeyOnlyFilter 和 InclusiveStopFilter,其具体含义和使用示例如下表所示。
其中,FirstKeyOnlyFilter 过滤器可以用来实现对逻辑行进行计数的功能,并且比其他计数方式效率高。
| 行键过滤器 | 描述 | 示例 |
|---|---|---|
| PrefixFilter | 行键前缀比较器,比较行键前缀 | scan 'Student', FILTER => "PrefixFilter('0001')" 同 scan 'Student', FILTER => "RowFilter(=,'substring:0001')" |
| KeyOnlyFilter | 只对单元格的键进行过滤和显示,不显示值 | scan 'Student', FILTER => "KeyOnlyFilter()" |
| FirstKeyOnlyFilter | 只扫描显示相同键的第一个单元格,其键值对会显示出来 | scan 'Student', FILTER => "FirstKeyOnlyFilter()" |
| InclusiveStopFilter | 替代 ENDROW 返回终止条件行 | scan 'Student', { STARTROW => '0001', FIILTER => "InclusiveStopFilter('binary:0002')" } 同 scan 'Student', { STARTROW => '0001', ENDROW => '0003' } |
上表中的命令示例操作结果如下图所示。

列族与列过滤器
针对列族进行过滤的过滤器为 FamilyFilter,其语法结构与 RowFilter 类似,不同之处在于 FamilyFilter 是对列族名称进行过滤的。
例如,以下命令扫描Student表显示列族为 Grades 的行。
scan 'Student', FILTER=>" FamilyFilter(= , 'substring:Grades')"
针对列的过滤器如下表所示,这些过滤器也需要结合比较运算符和比较器进行列族或列的扫描过滤。
| 列过滤器 | 描述 | 示例 |
|---|---|---|
| QualifierFilter | 列标识过滤器,只显示对应列名的数据 | scan 'Student', FILTER => "QualifierFilter(=,'substring:Math')" |
| ColumnPrefixFilter | 对列名称的前缀进行过滤 | scan 'Student', FILTER => "ColumnPrefixFilter('Ma')" |
| MultipleColumnPrefixFilter | 可以指定多个前缀对列名称过滤 | scan 'Student', FILTER => "MultipleColumnPrefixFilter('Ma','Ag')" |
| ColumnRangeFilter | 过滤列名称的范围 | scan 'Student', FILTER => "ColumnRangeFilter('Big',true,'Math',false')" |
上表中 QualifierFilter 和 ColumnPrefixFilter 过滤效果类似,只是 ColumnPrefixFilter 无须结合运算符和比较器即可完成字符串前缀的过滤。
MultipleColumnPrefixFilter 过滤器是对 ColumnPrefixFilter 的延伸,可以一次过滤多个列前缀。
ColumnRangeFilter过滤器则可以扫描出符合过滤条件的列范围,起始和终止列名用单引号引用,true 和 false 参数可指明结果中包含的起始或终止列。
上表中的过滤器示例在 HBase Shell 中扫描结果如下图所示。

值过滤器
在 HBase 的过滤器中也有针对单元格进行扫描的过滤器,即值过滤器,如下表所示。
| 值过滤器 | 描述 | 示例 |
|---|---|---|
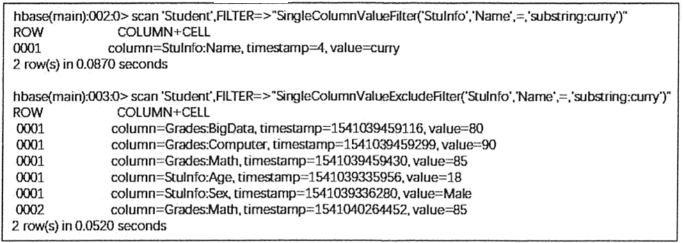
| ValueFilter | 值过滤器,找到符合值条件的键值对 | scan 'Student', FILTER => "ValueFilter(=,'substring:curry')" 同 get 'Student', '0001', FILTER => "ValueFilter(=,'substring:curry')" |
| SingleColumnValueFilter | 在指定的列族和列中进行比较的值过滤器 | scan 'Student', Filter => "SingleColumnValueFilter('StuInfo', 'Name', =, 'binary:curry')" |
| SingleColumnValueExcludeFilter | 排除匹配成功的值 | scan 'Student', Filter => "SingleColumnValueExcludeFilter('StuInfo', 'Name', =, 'binary:curry')" |
ValueFilter 过滤器可以利用 get 和 scan 方法对单元格进行过滤,但是使用 get 方法时,需要指定行键。
SingleColumnValueFilter 和 SingleColumnValueExcludeFilter 过滤器扫描的结果是相反的, 都需要在过滤条件中指定列族和列的名称。
上表中的值过滤器示例在 HBase Shell 中扫描结果如下图所示。
其他过滤器
还有一些其他的过滤器,其过滤方式和示例如下表所示。
| 值过滤器 | 描述 | 示例 |
|---|---|---|
| ColumnCountGetFilter | 限制每个逻辑行返回键值对的个数,在 get 方法中使用 | get 'Student', '0001', FILTER => "ColumnCountGetFilter(3)" |
| TimestampsFilter | 时间戳过滤,支持等值,可以设置多个时间戳 | scan 'Student', Filter => "TimestampsFilter(1,4)" |
| InclusiveStopFilter | 设置停止行 | scan 'Student', { STARTROW => '0001', ENDROW => '0005', FILTER => "InclusiveStopFilter('0003')" } |
| PageFilter | 对显示结果按行进行分页显示 | scan 'Student', { STARTROW => '0001', ENDROW => '0005', FILTER => "PageFilter(3)" } |
| ColumnPaginationFilter | 对一行的所有列分页,只返回 [offset,offset+limit] 范围内的列 | scan 'Student', { STARTROW => '0001', ENDROW => '0005', FILTER => "ColumnPaginationFilter(2,1)" } |
ColumnCountGetFilter 过滤器限制每个逻辑行返回多少列,一般不用在 scan 方法中,Timestamps Filter 匹配相同时间戳的数据。
InclusiveStopFilter过滤器设置停止行,且包含停止的行,上表中示例最终展示数据为行键 0001〜0003 范围内的数据。PageFilter 设置每页最多显示多少逻辑行, 示例中显示三个逻辑行。
ColumnPaginationFilter过滤器对一个逻辑行的所有列进行分页显示。
HBase MapReduce处理分布式数据
MapReduce 是 Hadoop 框架的重要组成部分,是在可扩展的方式下处理超过 TB 级数据的分布式处理的组件。它遵循分而治之的原则,通过将数据拆分到分布式文件系统中的不同机器上, 让服务器能够尽快直接访问和处理数据,最终合并全局结果。
以下图所示网站点击率排行为例,简单介绍 MapReduce 处理数据的过程。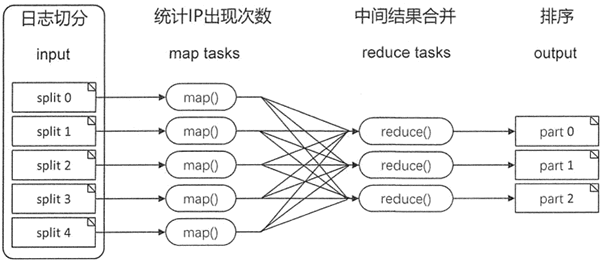
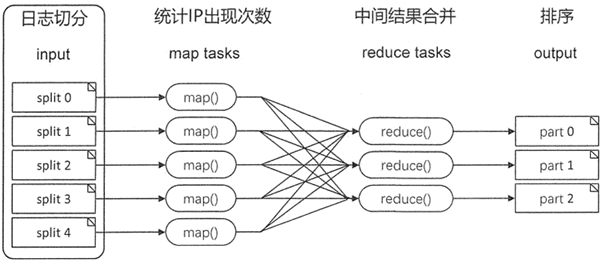
首先将网站的日志文件拆分成大小合理的块,每个服务器使用 map 任务处理一个块。一般来说,拆分过程要尽可能地利用可用的服务器和基础设施。
网站的日志文件是非常大的,处理时划分为大小相等的分片,每台服务器完成一个分片的处理后通过 shuffle,最终通过 reduce 任务将所有结果进行汇总。
HBase 中 MapRecude 包
MapReduce 可用于完成批量数据的分布式处理,而 HBase 中表格的数据是非常庞大的,通常是 GB 或 TB 级,将 MapReduce 和 HBase 结合,能快速完成批量数据的处理。
在应用过程中,HBase 可以作为数据源,即将表中的数据作为 MapReduce 的输入;同时,HBase 可以在 MapReduce 作业结束时接收数据,甚至在 MapReduce 任务过程中使用 HBase 来共享资源。
HBase 支持使用 org.apache.hadoop.hbase.mapieduce 包中的方法来实现 MapReduce 作业,完成 HBase 表中数据的功能如下表所示。
| 类名 | 描述 |
|---|---|
| CellCounter | 利用 MapReduce 计算表中单元格的个数 |
| Export | 将 HBase 中的表导出序列化文件,存储在 HDFS 中 |
| GroupingTableMapper | 从输入记录中抽取列进行组合 |
| HFileOutputFormat2 | 写入 HFile 文件 |
| HRegionPartitioner<KEY,VALUE> | 将输出的 key 分到指定的 key 分组中。key 是根据已存在的 Region 进行分组的,所以每个 Reducer 拥有一个单独的 Region |
| Import | 导入 HDFS 中的序列化文件这些文件是由 Export 导出的 |
| ImportTsv | 导入 TSV 文件的数据 |
| KeyValueSortReducer | 产生排序的键值 |
| LoadIncrementalHFiles | 将 HFileOutputFormat2 的输出导入 HBase 表 |
| MultiTableInputFormat | 将表格数据转换为 MapReduce 格式 |
| MultiTableOutputFormat | 将 Hadoop 的输出写到一个或多个 HBase 表中 |
| TableInputFormat | 将 HBase 表的数据转化为 MapReduce 格式 |
| TableOutputFormat<KEY> | 转化 MapReduce 的输出,写入 HBase 中 |
| TableSplit | 对表进行拆分 |
| WALInputFormat | 作为输入格式用于 WAL |
HBase 还提供了 HBase MapReduce 作业中用到的输入/输出格式化等其他辅助工具,这些都是利用 MapReduce 框架完成的。
读者若要了解更多功能请参考 HBase MapReduce API 官网。
执行 HBase MapReduce 任务
HBase 可以通过执行 hbase/lib 中的 hbase-server-1.2.6.jar 来完成一些简单的 MapReduce 操作。
下面通过 hbase/bin/hbase mapredcp 命令来查看执行 MapReduce 会用到的 jar 文件。
[root@localhost bin]# ./hbase mapredcp/usr/local/hbase/lib/zookeeper-3.4.6.jar:/usr/local/hbase/lib/hbase-client-1.2.6.j ar:/usr/local/hbase/lib/netty-all-4.0.23.Final.jar:/usr/local/hbase/lib/metrics-core-2 .2.0.jar:/usr/local/hbase/lib/protobuf-java—2.5.0.jar:/usr/local/hbase/lib/guava-12.0. 1.jar:/usr/local/hbase/lib/hbase-protocol-1.2.6.jar:/usr/local/hbase/lib/hbase-prefix-tree-1.2.6.jar:/usr/local/hbase/lib/htrace-core-3.1.0-incubating.jar:/usr/local/hbase/ lib/hbase-common-1.2.6.jar:/usr/local/hbase/lib/hbase-hadoop-compat-1.2.6.jar:/usr/loc al/hbase/lib/hbase-server-1.2.6.jar
在执行这些任务之前,需要将这些库绑定到 Hadoop 框架中,确保这些库在任务执行之前已 经可用,通过修改 hadoop/etc/hadoop-env.sh 文件来配置库文件。
在 hadoop-env.sh 中加入以下两行代码:
#hbase的安装路径
export HBASE_HOME=/usr/local/hbase
#加载hbase/lib下的所有库
export HADOOP_CLASSPATH= $HBASE_HOME/lib/*:classpath
完成以上配置后,重新启动 Hadoop 服务,然后在 hadoop 的 bin 目录中执行以下命令:
hbase-server-1.2.6.jar 包提供 CellCounter、export、 import、rowcounter 等类,用户可以直接使用,下图所示为使用 rowcounter 类来统计表中的行数。
HBase Region分区及定位
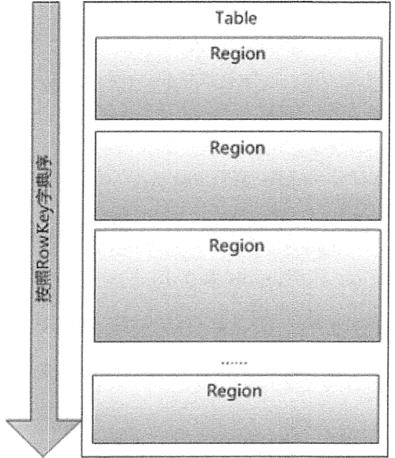
每张表一开始只有一个 Region,但是随着数据的插入,HBase 会根据一定的规则将表进行水平拆分,形成两个 Region。当表中的行越来越多时,就会产生越来越多的 Region,而这些 Region 无法存储到一台机器上时,则可将其分布存储到多台机器上。
Master 主服务器把不同的 Region 分配到不同的 Region 服务器上,同一个行键的 Region 不会被拆分到多个 Region 服务器上。每个 Region 服务器负责管理一个 Region,通常在每个 Region 服务器上会放置 10 ~ 1000 个 Region,HBase中Region 的物理存储如下图所示。
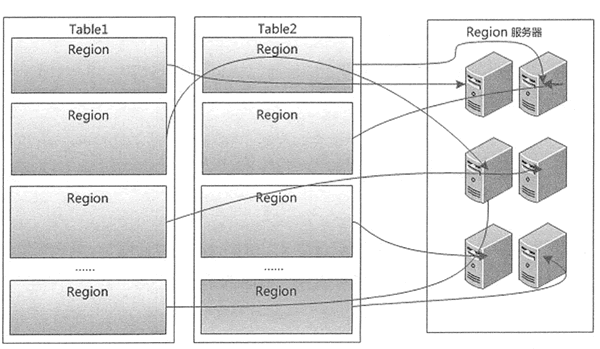
客户端在插入、删除、查询数据时需要知道哪个 Region 服务器上存储所需的数据,这个查找 Region 的过程称为 Region 定位。
HBase 中的每个 Region 由三个要素组成,包括 Region 所属的表、第一行和最后一行。其中,第一个 Region 没有首行,最后一个 Region 没有末行。每个 Region 都有一个 RegionlD 来标识它的唯一性,Region 标识符就可以表示成“表名+开始行键+RegionID”。
Meta 表
有了 Region 标识符,就可以唯一标识每个 Region。为了定位每个 Region 所在的位置,可以构建一张映射表。
映射表的每个条目包含两项内容,一项是 Region 标识符,另一项是 Region 服务器标识。这个条目就表示 Region 和 Region 服务器之间的对应关系,从而就可以使用户知道某个 Region 存储在哪个 Region 服务器中。这个映射表包含了关于 Region 的元数据,因此也被称为“元数据表”,又名“Meta表”。
使用 scan 命令可查看 Meta 表的结构,如图所示。

Meta 表中的每一行记录了一个 Region 的信息。RowKey 包含表名、起始行键和时间戳信息,中间用逗号隔开,第一个 Region 的起始行键为空。时间戳之后用.隔开的为分区名称的编码字符串,该信息是由前面的表名、起始行键和时间戳进行字符串编码后形成的。
Meta 表里有一个列族 info。info 包含了三个列,分别为 RegioninfoServer 和 Serverstartcode。Regionlnfo中记录了 Region 的详细信息,包括行键范围 StartKey 和 EndKey、列族列表和属性。
Server 记录了管理该 Region 的 Region 服务器的地址,如 localhost:16201。Serverstartcode 记录了 Region 服务器开始托管该 Region 的时间。
当用户表特别大时,用户表的 Region 也会非常多。Meta 表存储了这些 Region 信息,也变得非常大。Meta 表也需要划分成多个 Region,每个 Meta 分区记录一部分用户表和分区管理的情况。
Region 定位
在 HBase 的早期设计中,Region 的查找是通过三层架构来进行查询的,即在集群中有一个总入口 ROOT 表,记录了 Meta 表分区信息及各个入口的地址。这个 ROOT 表存储在某个 Region 服务器上,但是它的地址保存在 ZooKeeper 中。
这种早期的三层架构通过先找到 ROOT 表,从中获取分区 Meta 表位置;然后再获取分区 Meta 表信息,找出 Region 所在的 Region 服务器。
从 0.96 版本以后,三层架构被改为二层架构,去掉了 ROOT 表,同时 ZooKeeper 中的 /hbase/root-region-server 也被去掉。Meta 表所在的 Region 服务器信息直接存储在 ZooKeeper 中的 /hbase/meta-region-server 中。
下图为表和分区的分级管理机制。当客户端进行数据操作时, 根据操作的表名和行键,再按照一定的顺序即可寻找到对应的分区数据。
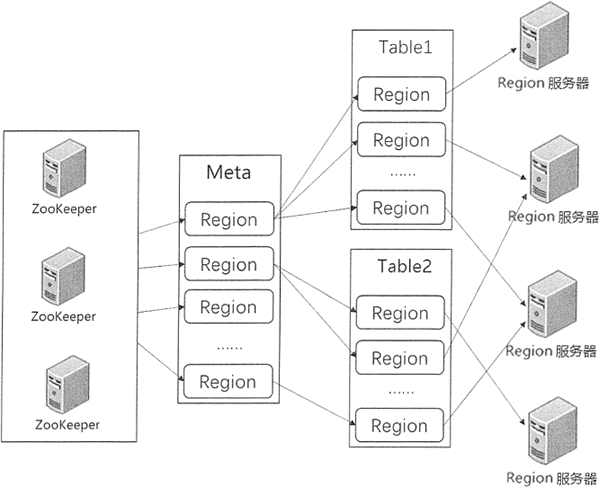
客户端通过 ZooKeeper 获取 Meta 表分区存储的地址,首先在对应的 Region 服务器上获取 Meta 表的信息,得到所需的表和行键所在的 Region 信息,然后从 Region 服务器上找到所需的数据。
一般客户端获取 Region 信息后会进行缓存,用户下次再查询不必从 ZooKeeper 开始寻址。
HBase数据的读写流程

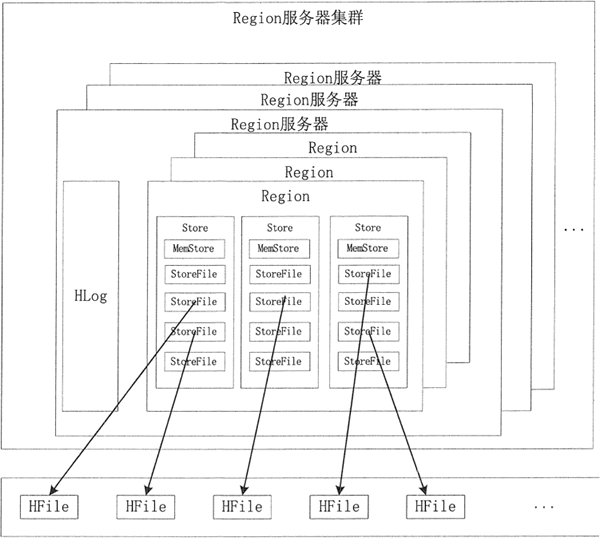
核心模块是 Region 服务器。Region 服务器由多个 Region 块构成,Region 块中存储一系列连续的数据集。Region 服务器主要构成部分是 HLog 和 Region 块。HLog 记录该 Region 的操作日志。
Region 对象由多个 Store 组成,每个 Store 对应当前分区中的一个列族,每个 Store 管理一块内存,即 MemStoreo 当 MemStore 中的数据达到一定条件时会写入 StoreFile 文件中,因此每个 Store 包含若干个 StoreFile 文件。StoreFile 文件对应 HDFS 中的 HFile 文件。
HBase 群集数据的构成如图所示。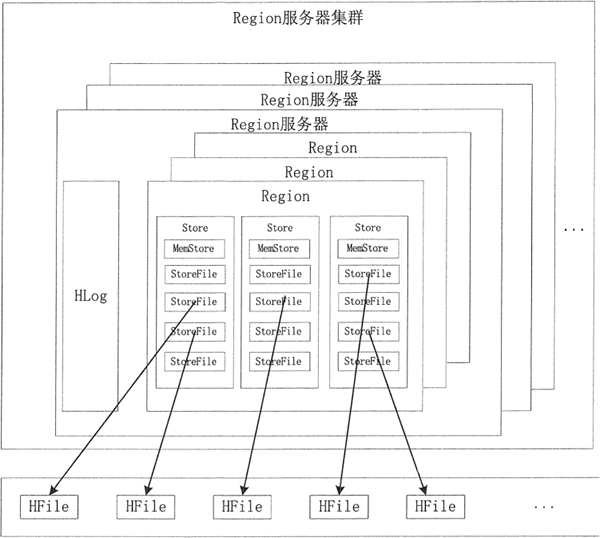
MemStore
当 Region 服务器收到写请求的时候,Region 服务器会将请求转至相应的 Region。数据先被写入 MemStore,当到达一定的阈值时,MemStore 中的数据会被刷新到 HFile 中进行持久化存储。
HBase 将最近接收到的数据缓存在 MemStore 中,在持久化到 HDFS 之前完成排序,再顺序写入 HDFS,为后续数据的检索进行优化。因为 MemStore 缓存的是最近增加的数据,所以也提高了对近期数据的操作速度。
在持久化写入之前,在内存中对行键或单元格进行优化。例如,当数据的 version 被设为 1 时,对某些列族中的一些数据,MemStore 缓存单元格的最新数据,在写入 HFile 时,仅需要保存一个最新的版本。
Store
Store 是 Region 服务器的核心,存储的是同一个列族下的数据,每个 Store 包含一块 MemStore 和 StoreFile( 0 个或多个)。StoreFile 是 HBase 中最小的数据存储单元。
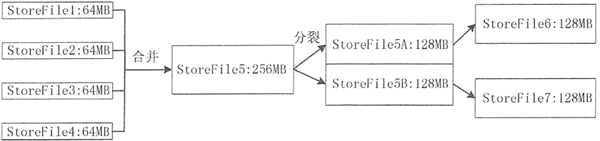
数据写入 MemStore 缓存,当 MemStore 缓存满时,内存中的数据会持久化到磁盘中一个 StoreFile 文件中,随着 StoreFile 文件数量的不断增加,数量达到一个阈值后,就会促使文件合并成一个大的 StoreFile 文件。
由于 StoreFile 文件的不断合并,造成 StoreFile 文件的大小超过一定的阈值,因此,会促使文件进行分裂操作。同时,当前的一个父 Region 会被分成两个子 Region, 父 Region 会下线,新分裂出的两个子 Region 会被 Master 分配到相应的 Regio n服务器上。
Store 的合并和分裂过程如下图所示。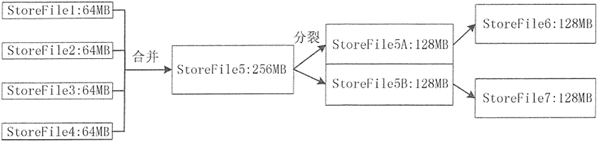
HFile
将 MemStore 内存中的数据写入 StoreFile 文件中,StoreFile 底层是以 HFile 格式保存的。
HFile 的存储格式如下图所示。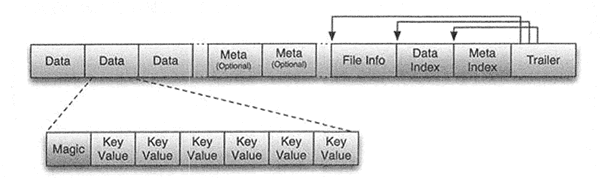

HFile 文件是不定长的,长度固定的只有其中的两块:Trailer 和 File Info。Trailer 中有指针指向其他数据块的起始点,File Info 记录了文件的一些 Meta 信息。每个 Data 块的大小可以在创建一个 Table 的时候通过参数指定(默认块大小为 64KB)。每个 Data 块除了开头的 Magic 以外就是由一个键值对拼接而成的,Magic 内容是一些随机数字,用于防止数据损坏。
HFile 里面的每个键值对就是一个简单的 Byte 数组。但是这个 Byte 数组里面包含了很多项, 并且有固定的结构,其具体结构如图所示。


键值对结构以两个固定长度的数值开始,分别表示 Key 的长度和 Value 的长度。紧接着是 Key,Key 以 RowLength 开始,是固定长度的数值,表示 RowKey 的长度;接着是 Row,然后是固定长度的数值 ColumnFamilyLength,表示 Family 的长度;之后是 Family 列族,接着是 Qualifier 列标识符,Key 最后以两个固定长度的数值 Time Stamp 和 Key Type(Put/Delete) 结束。Value部分没有这么复杂的结构,就是纯粹的二进制数据。
HBase 数据写入流程
1) 客户端访问 ZooKeeper,从 Meta 表得到写入数据对应的 Region 信息和相应 的Region 服务器。
2) 客户端访问相应的 Region 服务器,把数据分别写入 HLog 和 MemStore。MemStore 数据容量有限,当达到一个阈值后,则把数据写入磁盘文件 StoreFile 中,在 HLog 文件中写入一个标记,表示 MemStore 缓存中的数据已被写入 StoreFile 中。如果 MemStore 中的数据丢失,则可以从 HLog 上恢复。
3) 当多个 StoreFile 文件达到阈值后,会触发 Store.compact() 将多个 StoreFile 文件合并为一个 大文件。
HBase 数据读取流程
1) 客户端先访问 ZooKeeper,从 Meta 表读取 Region 信息对应的服务器。
2) 客户端向对应 Region 服务器发送读取数据的请求,Region 接收请求后,先从 MemStore 查找数据;如果没有,再到 StoreFile 上读取,然后将数据返回给客户端。
HBase WAL机制
在分布式环境下,用户必须要考虑系统出错的情形,例如,Region服务器发生故障时, MemStore 缓存中还没有被写入文件的数据会全部丢失。因此,HBase 采用 HLog 来保证系统发生故障时能够恢复到正常的状态。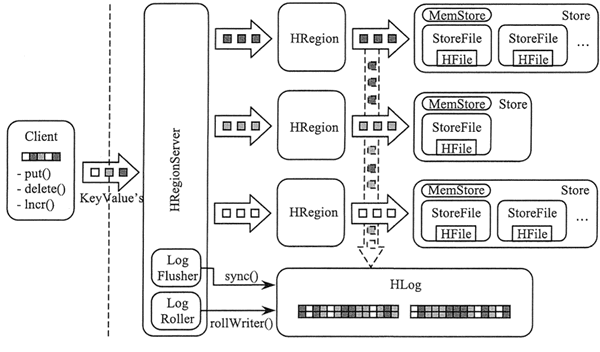
如上图所示,每个 Region 服务器都有一个 HLog 文件,同一个 Region 服务器的 Region 对象共用一个 HLog,HLog 是一种预写日志(Write Ahead Log)文件。
也就是说,用户更新数据必须先被记入日志后才能写入 MemStore 缓存,当缓存内容对应的日志已经被写入磁盘后,即日志写成功后,缓存的内容才会被写入磁盘。
ZooKeeper 会实时监测每个 Region 服务器的状态,当某个 Region 服务器发生故障时,ZooKeeper 会通知 Master,Master 首先会处理该故障 Region 服务器上遗留的 HLog 文件。
由于一个 Region 服务器上可能会维护着多个 Region 对象,这些 Region 对象共用一个 HLog 文件,因此这个遗留的 HLog 文件中包含了来自多个 Region 对象的日志记录。
系统会根据每条日志记录所属的 Region 对象对 HLog 数据进行拆分,并分别存放到相应 Region 对象的目录下。再将失效的 Region 重新分配到可用的 Region 服务器中,并在可用的 Region 服务器中重新进行日志记录中的各种操作, 把日志记录中的数据写入 MemStore 然后刷新到磁盘的 StoreFile 文件中,完成数据恢复。
在 HBase 系统中每个 Region 服务器只需要一个 HLog 文件,所有 Region 对象共用一个 HLog,而不是每个 Region 使用一个 HLog。在这种 Region 对象共用一个 HLog 的方式中,多个 Region 对象在进行更新操作需要修改日志时,只需要不断地把日志记录追加到单个日志文件中,而不需要同时打开、写入多个日志文件中,因此可以减少磁盘寻址次数,提高对表的写操作性能。
HBase Region管理(拆分+合并+负载均衡)
HFile 合并
前面章节讲到 Region 的概念,它是 HBase 集群的负载均衡和数据分发的基本单元。当 HBase中 表的容量非常庞大时,用户就需要将表中的内容分布到多台机器上。那么,需要根据行键的值对表中的行进行划分,每个行区间构成一个 Region,一个 Region 包含了位于某个阈值区间的所有数据。
下面将介绍 Region 在集群运行过程中进行合并、拆分及分配的过程。
每个 RegionServer 包含多个 Region,而每个 Region 又对应多个 Store,每一个 Store 对应表中一个列族的存储,且每个 Store 由一个 MemStore 和多个 StoreFile 文件组成。
StoreFile 在底层文件系统中由 HFile 实现,也可以把 Store 看作由一个 MemStore 和多个 HFile 文件组成。MemStore 充当内存写缓存,默认大小 64MB,当 MemStore 超过阈值时,MemStore 中的数据会刷新到一个新的 HFile 文件中来持久化存储。
久而久之,每个 Store 中的 HFile 文件会越来越多,I/O 操作的速度也随之变慢,读写也会延时,导致慢操作。因此,需要对 HFile 文件进行合并,让文件更紧凑,让系统更有效率。
HFile 的合并分为两种类型,分别是 Minor 合并和 Major 合并。这两种合并都发生在 Stow 内部,不是 Region 的合并,如下图所示。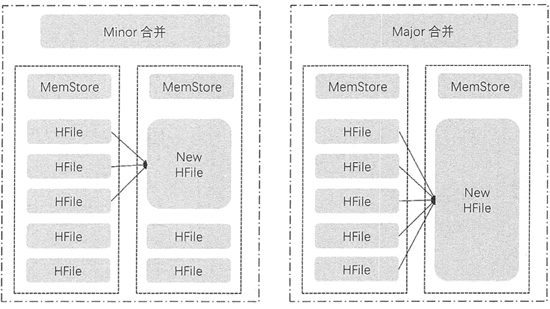
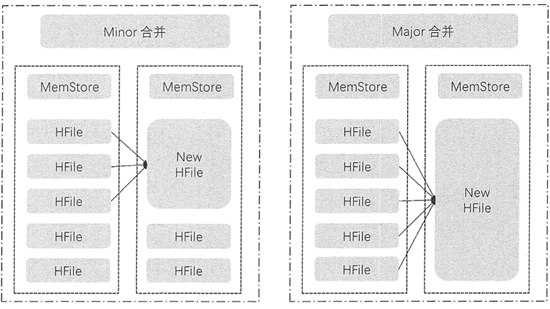
图 1:Minor 合并与 Major 合并
Minor 合并
Minor 合并是把多个小 HFile 合并生成一个大的 HFile。
执行合并时,HBase 读出已有的多个 HFile 的内容,把记录写入一个新文件中。然后把新文件设置为激活状态,并标记旧文件为删除。
在 Minor 合并中,这些标记为删除的旧文件是没有被移除的,仍然会出现在 HFile 中,只有在进行 Major 合并时才会移除这些旧文件。对需要进行 Minor 合并的文件的选择是触发式的,当达到触发条件才会进行 Minor 合并,而触发条件有很多,例如, 在将 MemStore 的数据刷新到 HFile 时会申请对 Store下符合条件的 HFile 进行合并,或者定期对 Store 内的 HFile 进行合并。
另外对选择合并的 HFile 也是有条件的,如下表所示。
| 参数名 | 配置项 | 默认值 | 备注 |
|---|---|---|---|
| minFileToCompact | hbase.hstore.compaction.min | 3 | 至少需要三个满足条件的 HFile 才启动合并 |
| minFileToCompact | hbase.hstore.compaction.max | 10 | 一次合并最多选择 10 个 |
| maxCompactSize | hbase.hstore.compaction.max.size | Long.MAX_VALUE | HFile 大于此值时被排除合并,避免对大文件的合并 |
| minCompactSize | hbase.hstore.compaction.min.size | MemStoreFlushSize | HFile 小于 MemStore 的默认值时被加入合并队列 |
在执行 Minor 合并时,系统会根据上述配置参数选择合适的 HFile 进行合并。Minor 合并对 HBase 的性能是有轻微影响的,因此,合并的 HFile 数量是有限的,默认最多为 10 个。
Major 合并
Major 合并针对的是给定 Region 的一个列族的所有 HFile,如图 1 所示。它将 Store 中的所有 HFile 合并成一个大文件,有时也会对整个表的同一列族的 HFile 进行合并,这是一个耗时和耗费资源的操作,会影响集群性能。
一般情况下都是做 Minor 合并,不少集群是禁止 Major 合并的,只有在集群负载较小时进行手动 Major 合并操作,或者配置 Major 合并周期,默认为 7 天。另外,Major 合并时会清理 Minor 合并中被标记为删除的 HFile。
Region 拆分
Region 拆分是 HBase 能够拥有良好扩展性的最重要因素。一旦 Region 的负载过大或者超过阈值时,它就会被分裂成两个新的 Region,如图 2 所示。
这个过程是由 RegionServer 完成的,其拆分流程如下。
- 将需要拆分的 Region下线,阻止所有对该 Region 的客户端请求,Master 会检测到 Region 的状态为 SPLITTING。
- 将一个 Region 拆分成两个子 Region,先在父 Region下建立两个引用文件,分别指向 Region 的首行和末行,这时两个引用文件并不会从父 Region 中复制数据。
- 之后在 HDFS 上建立两个子 Region 的目录,分别复制上一步建立的引用文件,每个子 Region 分别占父 Region 的一半数据。复制登录完成后删除两个引用文件。
- 完成子 Region 创建后,向 Meta 表发送新产生的 Region 的元数据信息。
- 将 Region 的拆分信息更新到 HMaster,并且每个 Region 进入可用状态。
以上是 Region 的拆分过程,那么,Region 在什么时候才会触发拆分呢?常用的拆分策略如下表所示
| 策略 | 原理 | 描述 |
|---|---|---|
| ConstantSizeRegionSplitPolicy | Region 中最大 Store 的大小大于设置阈值(hbase.hregion.max.filesize)之后才会触发拆分。 拆分策略原理相同,只是阈值的设置不同 |
拆分策略对于大表和小表没有明显的区分。阈值设置较大时小表可能不会触发分裂。如果阈值设置较小,大表就会在整个集群产生大量的 Region,影响整个集群的性能 |
| IncreasingToUpper BoundRegionSplitPolicy |
阈值在一定条件下不断调整,调整规则与 Region 所属表在当前 Region 服务器上的 Region 个数有关系 | 很多小表会在大集群中产生大量小 Region,分散在整个集群中 |
| SteppingSplitPolicy | 阈值可变。如果 Region 个数等于 1,则拆分阈值为 flushsize × 2;否则为 MaxRegionFileSize | 小表不会再产生大量的小 Region,而是适可而止 |
| DisabledRegionSplitPolicy | 关闭策略,手动拆分 | 可控制拆分时间,选择集群空闲时间 |
上表中列举的拆分策略中,拆分点的定义是一致的,即当 Region 中最大 Store 的大小大于设置阈值之后才会触发拆分。而在不同策略中,阈值的定义是不同的,且对集群中 Region 的分布有很大的影响。
Region 合并
从 Region 的拆分过程中可以看到,随着表的增大,Region 的数量也越来越大。如果有很多 Region,它们中 MemStore 也过多,会频繁出现数据从内存被刷新到 HFile 的操作,从而会对用户请求产生较大的影响,可能阻塞该 Region 服务器上的更新操作。过多的 Region 会增加 ZooKeeper 的负担。
因此,当 Region 服务器中的 Region 数量到达阈值时,Region 服务器就会发起 Region 合并,其合并过程如下。
- 客户端发起 Region 合并处理,并发送 Region 合并请求给 Master。
- Master 在 Region 服务器上把 Region 移到一起,并发起一个 Region 合并操作的请求。
- Region 服务器将准备合并的 Region下线,然后进行合并。
- 从 Meta 表删除被合并的 Region 元数据,新的合并了的 Region 的元数据被更新写入 Meta 表中。
- 合并的 Region 被设置为上线状态并接受访问,同时更新 Region 信息到 Master。
Region 负载均衡
当 Region 分裂之后,Region 服务器之间的 Region 数量差距变大时,Master 便会执行负载均衡来调整部分 Region 的位置,使每个 Region 服务器的 Region 数量保持在合理范围之内,负载均衡会引起 Region 的重新定位,使涉及的 Region 不具备数据本地性。
Region 的负载均衡由 Master 来完成,Master 有一个内置的负载均衡器,在默认情况下,均衡器每 5 分钟运行一次,用户可以配置。负载均衡操作分为两步进行:首先生成负载均衡计划表, 然后按照计划表执行 Region 的分配。
执行负载均衡前要明确,在以下几种情况时,Master 是不会执行负载均衡的。
- 均衡负载开关关闭。
- Master 没有初始化。
- 当前有 Region 处于拆分状态。
- 当前集群中有 Region 服务器出现故障。
Master 内部使用一套集群负载评分的算法,来评估 HBase 某一个表的 Region 是否需要进行重新分配。这套算法分别从 Region 服务器中 Region 的数目、表的 Region 数、MenStore 大小、 StoreFile 大小、数据本地性等几个维度来对集群进行评分,评分越低代表集群的负载越合理。
确定需要负载均衡后,再根据不同策略选择 Region 进行分配,负载均衡策略有三种,如下表所示。
| 策略 | 原理 |
|---|---|
| RandomRegionPicker | 随机选出两个 Region 服务器下的 Region 进行交换 |
| LoadPicker | 获取 Region 数目最多或最少的两个 Region 服务器,使两个 Region 服务器最终的 Region 数目更加平均 |
| LocalityBasedPicker | 选择本地性最强的 Region |
根据上述策略选择分配 Region 后再继续对整个表的所有 Region 进行评分,如果依然未达到标准,循环执行上述操作直至整个集群达到负载均衡的状态。
HBase集群的管理(非常全面)
本节介绍 HBase 集群的管理,包括在系统的运行期间对集群进行维护和管理等内容。一旦集群开始运转,用户可能需要改变集群的大小或添加一些额外的机器应对出现的故障,有时用户还需要将数据备份或迁移到不同的集群,这些操作都需要在不影响集群正常工作的情况下完成。
运维管理
在集群运行时,有些操作任务是必需的,包括移除和增加节点。
移除 Region 服务器节点
当集群由于升级或更换硬件等原因需要在单台机器上停止守护进程时,需要确保集群的其他 部分正常工作,并且确保从客户端应用来看停用时间最短。满足此条件必须把这台 Region 服务器服务的 Region 主动转移到其他 Region 服务器上,而不是让 HBase 被动地对此 Region 服务器的下线进行反应。
用户可以在指定节点的 HBase 目录下使用hbase-damon.sh stop命令来停止集群中的一个 Region 服务器。执行此命令后,Region 服务器先将所有 Region 关闭,然后再把自己的进程停止,Region 服务器在 ZooKeeper 中对应的临时节点将会过期。
Master 检测到 Region 服务器停止服务后,将此 Region 服务器上的 Region 重新分配到其他机器上。这种停止服务器方法的坏处是,Region 会下线一段时间,时间长度由 ZooKeeper 超时时间来决定,而且会影响集群性能,同时整个集群系统会经历一次可用性的轻微降级。
HBase 也提供了脚本来主动转移 Region 到其他 Region 服务器,然后卸掉下线的 Region 服务器,这样会让整个过程更加安全。在 HBase 的 bin 目录下提供了 gracefiil_stop.sh 脚本,可以实现这种主动移除节点的功能。
此脚本停止一个 Region 服务器的过程如下。
- 关闭 Region 均衡器。
- 从需要停止的 Region 服务器上移出 Region,并随机把它们分配给集群中其他服务器。
- 停止 Region 服务器进程。
graceful_stop.sh 脚本会把 Region 从对应服务器上一个个移出以减少抖动,并且会在移动下一 个 Region 前先检测新服务器上的 Region 是否已经部署好。
此脚本关闭了需要停止的 Region 服务器,Master 会检测到停止服务的 Region 服务器,但此时 Master 无须再来转移 Region。同时,由于 Region 服务器关闭时已经没有 Region 了,所以不会执行 WAL 拆分的相关操作。
增加 Region 服务器节点
随着应用系统需求的增长,整个 HBase 集群需要进行扩展,这时就需要向 HBase 集群中增加 一个节点。添加一个新的 Region 服务器是运行集群的常用操作,首先需要修改 conf 目录下的 Region 服务器文件,然后将此文件复制到集群中的所有机器上,这样使用启动脚本就能够添加新的服务器。
HBase 底层是以 HDFS 来存储数据的,一般部署 HBase 集群时,HDFS 的 DataNode 和 HBase 的 Region 服务器位于同一台物理机上。因此,向 HBase 集群增加一个 Region 服务器之前,需要向 HDFS 里增加 DataNode。
等待 DataNode 进程启动并加入 HDFS 集群后,再启动 HBase 的 Region 服务器进程。启动新增节点上的 Region 服务器可以使用命令 hbase-damon.sh start,启动成功后,用户可以在 Master 用户界面看到此节点。如果需要重新均衡分配每个节点上的 Region,则可使用 HBase 的负载均衡功能。
增加 Master 备份节点
为了增加 HBase 集群的可用性,可以为 HBase 增加多个备份 Master。当 Master 出现故障后, 备份 Master 可以自动接管整个 HBase 的集群。
配置备份 Master 的方式是在 HBase 的 conf 下增加文件 backup-masters,然后通过 hbase-damon.sh start 命令启动。
Master 进程使用 ZooKeeper 来决定哪一个是当前活动的进程。当集群启动时,所有进程都会去竞争作为主 Master 来提供服务,其他 Master 会轮询检测当前主 Master 是否失效;如果失效,则会触发新的 Master 选举。
数据管理
在使用 HBase 集群时,需要处理一张或多张表中的大量数据,例如,备份数据时移动全部数据或部分数据到归档文件中。使用 HBase 内置的一些有用的工具,用户可以完成数据的迁移以及数据的查看操作。
下面将介绍几种数据管理的方法。
数据的导出
在 HBase 集群中,有时候需要将表进行导出备份,HBase 提供了自带的工具 Export,可以将表的内容输出为 HDFS 的序列化文件,在 HBase 安装目录的 bin 目录下执行 hbase org.apache.hadoop.hbase.mapreduce.Export 命令,具体参数如下:
[root@localhost bin]# ./hbase org.apache.hadoop.hbase.mapreduce.Export
ERROR: Wrong number of arguments: 0
Usage: Export [-D <property=va1ue>] * <tab丄ename> <outputdir> [<versions> [<starttime> [<endtime>] ] [^[regex pattern] or [Prefix] to filter]]
Note: -D properties will be applied to the conf used.
For example:
-D mapreduce.output.fileoutputformat.compress=true
-D mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec
-D mapreduce.output.fileoutputformat.compress.type=BLOCK Additionally, the following SCAN properties can be specified to control/limit what is exported..
-D hbase.mapreduce.scan.column.fami1y=<fami1yName>
-D hbase.mapreduce.include.deleted.rows=true
-D hbase.mapreduce.scan.row.start=<ROWSTART>
-D hbase.mapreduce.scan.row.stop=<ROWSTOP>
For performance consider the following properties:
-Dhbase.client.scanner.caching=100
-Dmapreduce.map.speculative=false
-Dmapreduce.reduce.speculative=false
For tables with very wide rows consider setting the batch size as below:
-Dhbase.export.scanner.batch=10
从上述代码中可以看到,该命令提供了多种选 tablename 和 outputdir 是必需的,其他参数可选,参数 -D 可以设定键值类型配置属性,还可以使用正则表达式或者过滤器过滤掉部分数据。
下表列出了所有可用选项及其含义。
| 名字 | 描述 |
|---|---|
| tablename | 准备导出的表名 |
| outputdir | 导出数据存放在 HDFS 中的路径 |
| version | 每列备份的版本数量,默认值为 1 |
| starttime | 开始时间 |
| endtime | 扫描所使用的时间范围的结束时间 |
| regexp/prefix | 以 ^ 开始表示该选项被当做表达式类匹配行键,否则被当做行键的前缀 |
数据的导入
同样地,HBase 也提供了自带的工具 Import,可以将数据加载到 HBase 当中。在 bin 目录下执行 hbase org.apache.hadoop.hbase.mapreduce.Import 命令, 具体参数如下:
[root@localhost bin]# ./hbase org.apache.hadoop.hbase.mapreduce.Import
ERROR: Wrong number of arguments: 0
Usage: Import [options] <tablename> <inputdir>
By default Import will load data direct丄y into HBase. To instead generate
HFiles of data to prepare for a bulk data load, pass the option:
-Dimport.bulk.output=/path/for/output
To apply a generic org.apache.hadoop.hbase.filter.Filter to the input, use
-Dimpor t.fi It er. class=<name of fiJLt er class>
-Dimport.fi]_ter.a3?gs=<comma separated list of args for filter
NOTE: The filter will be applied BEFORE doing key renames via the HBASE_IMPORTER_RENAME_CFS property. Futher, filters will only use the Filter#filterRowKey(byte[] buffer, int offset, int length) method to identify whether the current row needs to be ignored completely for processing and Filter#filterKeyValue(KeyVa丄ue) method to determine if the KeyValue should be added; Filter.ReturnCode#TNCLUDE and #INCLUDE_AND_NEXT_COL will be considered as including the KeyValue.
To import data exported from HBase 0.94, use
-Dhbase.import.version=0.94
For performance consider the following options:
-Dmapreduce.map.speculative=false
-Dmapreduce.reduce.speculative=false
-Dimport.wal.durability=<Used while writing data to hbase. Allowed values are the supported durability values like SKIP_WAL/ASYNC_WAL/SYNC_WAL/...>
从上述代码中可以看到,参数很简单,只有一个表名和一个输入的目录,这里输入目录的文件格式必须与 Export 导出的文件格式一致。Export 也可以带 -D 参数。
数据迁移
在 HBase 系统中,有时候需要在同集群内部或集群之间复制表的部分或全部数据,可使用 HBase 自带 CopyTable 工具来完成此功能。
同样地,在 bin 目录下执行以下命令:
[root@localhost]#./hbase org.apache.hadoop.hbase.mapreduce.CopyTable
Usage: CopyTable [general options] [--starttime=X] [一一endtime=Y] [--new.name=NEW] [--peer.adr=ADR] <tablename〉
Options:
rs.class hbase.regionserver.class of the peer cluster specify if different from current cluster
rs.impl hbase.regionserver.impl of the peer cluster
startrow the start row
stoprow the stop row
starttime beginning of the time range (unixtime in millis) without endtime means from starttime to forever
endtime end of the time range. Ignored if no starttime specified.
versions number of cell versions to copy
new.name new table's name
peer.adr Address of the peer cluster given in the format hbase.zookeeer.quorum:hbase.zookeeper.client.port:zookeeper.znode.parent
families conuna-separated list of families to copy To copy from cf1 to cf2f give sourceCfName:destCfName. To keep the same name, just give "cfName"
all.cells also copy delete markers and deleted cells
bulkload Write input into HFiles and bulk load to the destination table
Args :
tab1ename Name of the table to copy
Examples:
To copy 'TestTable' to a cluster that uses replication for a 1 hour window:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1265875194289 —endtime=126587879428 9 ―peer .:adr=serverl, server2, server3:2181: /hbase --families=my01dCf:myNewCf,cf2,cf3 TestTable
For performance consider the following general option:
It is recommended that you set the following: to >=100. A higher value uses more memory but
decreases the round trip time to the server and may increase performance.
-Dhbase.client.scanner.caching=100
The following should always be set to [false, to prevent writing data twiceA which may produce
inaccurate results.
-Dmapreduce.map.speculative=false
其中,根据 -peer.adr 参数可以区分集群内部还是集群间的复制,当设置为与当前运行命令的集群相同时为集群内复制,否则为集群间复制。另外,复制时还可以只复制部分数据,如用 -families 来表示要复制的列族。
故障处理
HBase自带的工具除了数据移动外,还有很多调试、分析等工具,在HBase的bin目录下执 行HBase命令,会列出它所包含的工具:
[root@localhost bin]# ./hbase
Usage: hbase [<options>]\<command> [<args>]
Options:
-config DIR Configuration direction to:use. DefauIt: ./conf
-hosts HOSTS Override the list in 'regionservers' file
--auth-as-server Authenticate to ZooKeeper using servers configuration
Commands:
Some commands take arguments. Pass no args or -h for usage.
shell Run the HBase shell
hbck Run the hbase 'fsck' tool
snapshot Create a new snapshot of a table
snapshotinfo Tool for dumping snapshot information
wal Write-ahead-log analyzer
hfile Store file analyzer
zkcli Run the ZooKeeper shell.
upgrade Upgrade hbase
master Run an HBase HMaster node
regionserver Run an HBase HRegionServer node
zookeeper Run a Zookeeper server
rest Run an HBase REST server
thrift Run the HBase Thrift server
thrift2 Run the HBase Thrifserver
clean Run the HBase clean up script
classpath Dump hbase CLASSPATH
mapredcp Dump CLASSPATH entries required by mapreduce
pe Run PerformanceEvaluation
ltt Run LoadTestTool
version Print the version
CLASSNAME Run the class named CLASSNAME
本节简单介绍几个工具,其他请参考 HBase 官网提供的资料。
文件检测修复工具 hbck
hbck 工具用于 HBase 底层文件系统的检测和修复,它可以检测 Master,Region 服务器内存中的状态以及 HDFS 中数据的状态之间的一致性、完整性等。
下面执行 hbck 命令,使用 -h 参数查看 hbck 能提供哪些功能,代码如下:
[root@localhost bin]# ./hbase hbck -h
Usage: fsck [opts] {only tables}
where [opts] are:
-help Display help options (this)
-details Display full report of all regions.
-timelag <timeInSeconds> Process only regions. that have not experienced any metadata updates in the last <timeInSeconds> seconds.
-sleepBeforeRerun <timeInSeconds> Sleep this many seconds before checking if the fix worked if run with -fix
-summary Print only summary of the tables and status.
-metaonly Only check the state of the hbase:meta table.
-sidelineDir <hdfs://> HDFS path to backup existing meta.
-boundaries Verify t hat regions boundaries are the same betw een META and store files.
-exclusive Abort if another hbck is exclusive or fixing.
-disableBalancer Disable the load balancer.
Metadata Repair options: (expert features, use with caution!)
-fix Try to fix region assignments. This is for backwards compatiblity
-fixAssignments Try to fix region assignments. Replaces the old -fix
-fixMeta Try to fix meta problems. This assumes HDFS region info is good.
-noHdfsChecking Don't load/check region info from HDFS. Assumes hbase:meta region info is good. Won't check/fix any HDFS issue, e.g.hole, orphan, or overlap
-fixHdfsHoles Try to fix region holes in hdfs.
-fixHdfsOrphans Try to fix region dirs with no .regioninfo file in hdfs
-fixTableOrphans Try to fix table dirs with no .tableinfo file in hdfs (online mode only)
-fixHdfsOverlaps Try to fix region overlaps in hdfs.
-fixVersionFile Try to fix missing hbase.version file in hdfs.
-maxMerge <n> When fixing region overlaps, allow at most <n> regions to merge.(n=5 by default)
-sidelineBigOverlaps When fixing region overlaps, allow to sideline big overlaps
-maxOverlapsToSideline <n> When fixing region overlaps, allow at most <n> regions to sideline per group. (n=2 by default)
-fixSplitParents Try to force offline split parents to be online.
-removeParents Try to offline and sideline lingering parents and keep daughter regions.
-ignorePreCheckPermission ignore filesystem permission pre-check
-fixReferenceFiles Try to offline lingering reference store files
-fixEmptyMetaCells Try to fix hbase:meta entries not referencing any region (empty REGIONINFO_QUALIFIER rows)
Datafile Repair options: (expert features, use with caution!)
-checkCorruptHFiles Check all Hf iles by opening them to make sure they are valid
-sidelineCorruptHFiles Quarantine corrupted HFiles. implies -checkCorruptHFiles
Metadata Repair shortcuts
-repair Shortcut for -fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps -fixReferenceFiles -fixTableLocks -fixOrphanedTableZnodes -repairHoles Shortcut for -fixAssignments -fixMeta -fixHdfsHoles
Table lock options
-fixTableLocks Deletes table locks held for a long time (hbase.table.lock.expire.ms, lOmin by default)
Table Znode options
-fixOrphanedTableZnodes Set table state in ZNode to disabled if table does not exists
从上述参数来看,hbck 命令的参数分为几类,首先是基本的参数,如 details,表示执行 hbck 时会显示所有 Region 的完整报告;然后还有一些修复的参数,包括 Metadata. Datafile 的修复选项。
hbck 命令开始执行时,会扫描 Meta 表收集所有的相关信息,同时也会扫描 HDFS 中的 root 目录,然后比较收集的信息,报告相关的一致性和完整性问题。
一致性检查主要检测 Region 是否同时存在于 Meta 表和 HDFS 中,并检查是否只被指派给唯一的 Region 服务器;而完整性检查则以表为单位,将 Region 与表的细节信息进行比较以找到缺失的 Region,同时也会检查 Region 的起止键范围中的空洞或重叠情况。如果存在一致性或完整性问题,则可以使用 fix 选项来修复。
文件查看工具 hfile
HBase 提供了查看文件格式 HFile 的内容,它所使用的命令是 hfile,具体参数如下:
[root@localhost bin]# ./hbase hfile
usage: HFile [-a] [-b] [-e] [-f <arg> | -r <arg>] [-h] [-k] [-m] [-p] [-s] [-v] [-w <arg>]
-a,--checkfamily Enable family check
-b,--printblocks Print b丄ock index meta data
-e,--printkey Print keys
-fr--file <arg> File to scan. Pass full-path; e.g.hdfs://a:9000/hbase/hbase:meta/12/34
-h,--printblockheaders Print block headers for each block.
-kz--checkrow Enable row order check; :looks for out-of-order keys
-m,-printmeta Print meta data of file
-p,-printkv Print key/value pairs
-rr―region <arg> Region to scan. Pass region name; e.g.'hbase:meta,,1'
-sf--stats Print statistics
-v,--verbose Verbose output; emits file and meta datadelimiters
-w,--seekToRow <arg> Seek to this row and print all the kvs for this row only
例如,查看文件的内容,可以使用以下命令查看文件 /hbase/users/f0bad95c7999b57010dfb4707a29c747/info/2584769dd8334bcda4632b57f50bbe76。
[root@localhost bin]# ./hbase hfile -s -f /hbase/users/f0bad95c7999b57010dfb4707a29c747/info/2584769dd8334bcda4632b57f50bbe76 Stats: Key length: count: 3 min: 31 max: 31 mean: 31.0 Vai length: count: 3 min: 10242 max: 10242 mean: 10242.0 Row size (bytes) : count: 1 min: 30843 max: 30843 mean: 30843.0 Row size (columns) : coun t: 1 min: 3 max: 3 mean: 3.0 Key of biggest row: -2016043148
若用户在测试或应用中,发现数据有误,可以使用该工具,查看 HFile 中的真实数据。
HBase Java编程入门教程
一款优秀的数据库除了会提供客户端,还会提供编程语言接口,HBase 也不例外。HBase 除了支持使用 Shell 客户端来操作(请看《HBase Shell及其常用命令》),还提供了多种编程语言的接口,其中 Java API 是原生支持的,其它编程语言接口需要通过 Thrift 协议支持。
本节只讲解 Java 接口编程,其它编程语言接口请转到《HBase Thrift协议编程入门教程》。
HBase 官方代码包里含有原生访问客户端,由 Java 语言实现,相关的类在 org.apache.hadoop.hbase.client 包中,都是与 HBase 数据存储管理相关的 API。
例如,若要管理 HBase,则用 Admin 接口来创建、删除、更改表;若要向表格添加数据或查询数据,则使用 Table 接口等。
下面主要介绍 Admin 和 Table 接 口以及 HBaseConfiguration、HTableDescriptor、HClounmDescriptor、Put、Get、Result、Scan 这些类的功能和常用方法。
开发环境配置
使用 Java 开发 Hbase,只需要将用到的 HBase 库包加入引用路径即可。本节使用 Eclipse 集成开发环境进行编程,如果系统已经安装 Maven,可以创建 Maven 项目,在 pom.xml 配置 HBase 的依赖即可自动下载 jar 包。
下面讲解如何在 Eclipse 中手动导入 HBase 库包。
首先创建 Java 工程,然后鼠标右键单击工程名,选择属性,在“Java构建路径”→“库”→ “添加外部JAR”中找到 HBase 安装目录下的 lib 子目录,将需要的库包导入工程,即可进行基本的 HBase 操作,如下图所示。
然后在工程目录 src下新建类文件,在 Java 文件中导入需要的 HBase 包,如 HBase 的环境配置包、HBase 客户端接口、工具包等:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
在使用过程中可以根据需要加入更多的包,如 HBase 的过滤器等。
构建 Java 客户端
在分布式环境下,客户端访问 HBase 需要通过 ZooKeeper 的地址和端口来获取当前活跃的 Master 和所需的 RegionServer 地址。因此需要先用 HBaseCongifiguration 类配置 ZooKeeper 的地址和端口,然后再使用 Connection 类建立连接。
示例代码如下:
- public static Configuration conf;
- public static Connection connection;
- public void getconnect() throws IOException {
- conf=HBaseConfiguration.create();
- conf.set("hbase.zookeeper.quorum", "cm-cdh01");
- conf.set("hbase.zookeeper.property.clientPort","2181");
- try{
- connection=ConnectionFactory.createConnection(conf);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
cm-cdh01 为 ZooKeeper 的地址,2181 为端口号。HBaseConfiguration.create() 方法用来创建相关配置,然后使用此配置信息进行数据库的连接。
表操作
连接数据库后,完成表的创建和删除。示例代码如下:
- public void createtable() throws IOException{
- TableName tableName = TableName.valueOf("Student");
- Admin admin = connection.getAdmin();
- if{admin.tableExists(tableName)) {
- admin.disableTable(tableName);
- admin.deleteTable(tableName);
- System.out.printin(tableName.toString() + "is exist,delete it");
- }
- HTableDescriptor tdesc = new HTableDescriptor(tableName);
- HColumnDescriptor colDesc = new HColumnDescriptor("Stulnfo");
- tdesc.addFamily(colDesc);
- tdesc.addFamily(new HColumnDescriptor("Grades"));
- admin.createTable(tdesc);
- admin.close();
- }
其中,Admin 是 Java 的接口类型,在使用 Admin 时,必须调用 Connection.getAdmin() 方法返回一个子对象,然后用这个 Admin 接口来操作返回的子对象方法。
这个接口用于管理 HBase 数据库的表信息,包括创建、删除表和列出所有表项等,主要的方法参见下表。
| 方法返回类型 | 方法描述 |
|---|---|
| void | abort(String why, Throwable e) 终止服务器或客户端 |
| void | closeRegion(byte[] regionname, String serverName) 关闭 Region |
| void | createTableb(TableDescriptor, desc) 创建表 |
| void | deleteTable(TableName tableName) 删除表 |
| void | disableTable(TableName tableName) 使表无效 |
| void | enableTable(TableName tableName) 使表有效 |
| HTableDescriptor[] | listTables() 列出所有表项 |
| HTableDescriptor[] | getTableDescriptor(TableName tableName) 获取表的详细信息 |
使用 get 方法获取某一行数据,代码示例如下:
- public void getData() throws IOException{
- Table table = connection.getTable(TableName.valueOf("Student"));
- Get get = new Get(Bytes.toBytes("row1"));
- Result result= table.get(get);
- for (Cell cell:resuIt.rawCells()){
- System.out.println(new String(CellUtil.getCellKeyAsString(cell)));
- System.out.printin(new String(CellUtil.cloneFamily(cell)));
- System.out.printin(new String(CellUtil.cloneQualifier(cell)));
- System.out.printin(new String(CellUtil.cloneValue(cell)));
- System.out.printin(cell.getTimestamp());
- }
- table.close();
- }
通过 table.get() 方法进行查询后,将结果存入 result 中,其中包含多个键值对,本例中使用循环的方法将键值对逐个打印出来。CellUtil 接口提供每个单元格的定位值,如行键、列族、列和时间戳。
对 HBase 表的增、删、改、查,org.apache.hadoop.hbase.client 包提供了相应的类,除了已经举例说明的插入数据使用的 put 类、根据行键获取数据的 get 类外,还有进行全表扫描的 scan 类、 删除某行信息的 delete 类,甚至提供了扫描数据时进行过滤的 FilterList 类,读者可以在 HBase 官网获取详细信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号