w3cschool-Storm 入门教程
Storm 基础知识
基础知识
Storm 是一个分布式的,可靠的,容错的数据流处理系统。它会把工作任务委托给不同类型的组件,每个组件负责处理一项简单特定的任务。Storm 集群的输入流由一个被称作 spout 的组件管理,spout 把数据传递给 bolt, bolt 要么把数据保存到某种存储器,要么把数据传递给其它的 bolt。你可以想象一下,一个 Storm 集群就是在一连串的 bolt 之间转换 spout 传过来的数据。
这里用一个简单的例子来说明这个概念。昨晚我在新闻节目里看到主持人在谈论政治人物和他们对于各种政治话题的立场。他们一直重复着不同的名字,而我开始考虑这些名字是否被提到了相同的次数,以及不同次数之间的偏差。
想像播音员读的字幕作为你的数据输入流。你可以用一个 spout 读取一个文件(或者 socket,通过 HTTP,或者别的方法)。文本行被 spout 传给一个 bolt,再被 bolt 按单词切割。单词流又被传给另一个 bolt,在这里每个单词与一张政治人名列表比较。每遇到一个匹配的名字,第二个 bolt 为这个名字在数据库的计数加1。你可以随时查询数据库查看结果, 而且这些计数是随着数据到达实时更新的。所有组件(spouts和bolts)及它们之间的关系请参考拓扑图1-1
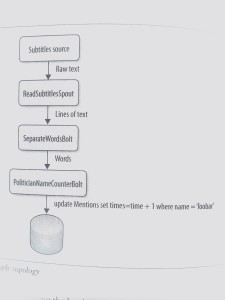
现在想象一下,很容易在整个 Storm 集群定义每个 bolt 和 spout 的并行性级别,因此你可以无限的扩展你的拓扑结构。很神奇,是吗?尽管这是个简单例子,你也可以看到 Storm 的强大。
有哪些典型的 Storm 应用案例?
数据处理流
正如上例所展示的,不像其它的流处理系统,Storm 不需要中间队列。
连续计算
连续发送数据到客户端,使它们能够实时更新并显示结果,如网站指标。
分布式远程过程调用
频繁的 CPU 密集型操作并行化。
Storm 组件
对于一个Storm集群,一个连续运行的主节点组织若干节点工作。
在 Storm 集群中,有两类节点:主节点 master node 和工作节点 worker nodes。主节点运行着一个叫做 Nimbus 的守护进程。这个守护进程负责在集群中分发代码,为工作节点分配任务,并监控故障。Supervisor守护进程作为拓扑的一部分运行在工作节点上。一个 Storm 拓扑结构在不同的机器上运行着众多的工作节点。
因为 Storm 在 Zookeeper 或本地磁盘上维持所有的集群状态,守护进程可以是无状态的而且失效或重启时不会影响整个系统的健康(见图1-2)

在系统底层,Storm 使用了 zeromq(0mq, zeromq(http://www.zeromq.org))。这是一种先进的,可嵌入的网络通讯库,它提供的绝妙功能使 Storm 成为可能。下面列出一些 zeromq 的特性。
- 一个并发架构的 Socket 库
- 对于集群产品和超级计算,比 TCP 要快
- 可通过 inproc(进程内), IPC(进程间), TCP 和 multicast(多播协议)通信
- 异步 I / O 的可扩展的多核消息传递应用程序
- 利用扇出(fanout), 发布订阅(PUB-SUB),管道(pipeline), 请求应答(REQ-REP),等方式实现 N-N 连接
NOTE: Storm 只用了 push/pull sockets
Storm 的特性
在所有这些设计思想与决策中,有一些非常棒的特性成就了独一无二的 Storm。
- 简化编程:如果你曾试着从零开始实现实时处理,你应该明白这是一件多么痛苦的事情。使用 Storm,复杂性被大大降低了。
- 使用一门基于 JVM 的语言开发会更容易,但是你可以借助一个小的中间件,在 Storm 上使用任何语言开发。有现成的中间件可供选择,当然也可以自己开发中间件。
- 容错:Storm 集群会关注工作节点状态,如果宕机了必要的时候会重新分配任务。
- 可扩展:所有你需要为扩展集群所做的工作就是增加机器。Storm 会在新机器就绪时向它们分配任务。
- 可靠的:所有消息都可保证至少处理一次。如果出错了,消息可能处理不只一次,不过你永远不会丢失消息。
- 快速:速度是驱动 Storm 设计的一个关键因素
- 事务性:You can get exactly once messaging semantics for pretty much any computation. 你可以为几乎任何计算得到恰好一次消息语义。
Storm 拓扑
拓扑
在这一章,你将学到如何在同一个 Storm 拓扑结构内的不同组件之间传递元组,以及如何向一个运行中的 Storm 集群发布一个拓扑。
数据流组
设计一个拓扑时,你要做的最重要的事情之一就是定义如何在各组件之间交换数据(数据流是如何被 bolts 消费的)。一个据数流组指定了每个 bolt 会消费哪些数据流,以及如何消费它们。
NOTE:一个节点能够发布一个以上的数据流,一个数据流组允许我们选择接收哪个。
数据流组在定义拓扑时设置,就像我们在第二章看到的:
···
builder.setBolt("word-normalizer", new WordNormalizer())
.shuffleGrouping("word-reader");
··· 在前面的代码块里,一个 bolt 由 TopologyBuilder 对象设定, 然后使用随机数据流组指定数据源。数据流组通常将数据源组件的 ID 作为参数,取决于数据流组的类型不同还有其它可选参数。
NOTE:每个 InputDeclarer 可以有一个以上的数据源,而且每个数据源可以分到不同的组。
随机数据流组
随机流组是最常用的数据流组。它只有一个参数(数据源组件),并且数据源会向随机选择的 bolt 发送元组,保证每个消费者收到近似数量的元组。
随机数据流组用于数学计算这样的原子操作。然而,如果操作不能被随机分配,就像第二章为单词计数的例子,你就要考虑其它分组方式了。
域数据流组
域数据流组允许你基于元组的一个或多个域控制如何把元组发送给 bolts。 它保证拥有相同域组合的值集发送给同一个 bolt。 回到单词计数器的例子,如果你用 word 域为数据流分组,word-normalizer bolt 将只会把相同单词的元组发送给同一个 word-counterbolt 实例。
···
builder.setBolt("word-counter", new WordCounter(),2)
.fieldsGrouping("word-normalizer", new Fields("word"));
··· NOTE: 在域数据流组中的所有域集合必须存在于数据源的域声明中。
全部数据流组
全部数据流组,为每个接收数据的实例复制一份元组副本。这种分组方式用于向 bolts 发送信号。比如,你要刷新缓存,你可以向所有的 bolts 发送一个刷新缓存信号。在单词计数器的例子里,你可以使用一个全部数据流组,添加清除计数器缓存的功能(见拓扑示例)
public void execute(Tuple input) {
String str = null;
try{
if(input.getSourceStreamId().equals("signals")){
str = input.getStringByField("action");
if("refreshCache".equals(str))
counters.clear();
}
}catch (IllegalArgumentException e){
//什么也不做
}
···
} 我们添加了一个 if 分支,用来检查源数据流。 Storm 允许我们声明具名数据流(如果你不把元组发送到一个具名数据流,默认发送到名为 ”default“ 的数据流)。这是一个识别元组的极好的方式,就像这个例子中,我们想识别 signals 一样。 在拓扑定义中,你要向 word-counter bolt 添加第二个数据流,用来接收从 signals-spout 数据流发送到所有 bolt 实例的每一个元组。
builder.setBolt("word-counter", new WordCounter(),2)
.fieldsGroupint("word-normalizer",new Fields("word"))
.allGrouping("signals-spout","signals"); signals-spout的实现请参考git仓库。
自定义数据流组
你可以通过实现 backtype.storm.grouping.CustormStreamGrouping 接口创建自定义数据流组,让你自己决定哪些 bolt 接收哪些元组。
让我们修改单词计数器示例,使首字母相同的单词由同一个 bolt 接收。
public class ModuleGrouping mplents CustormStreamGrouping, Serializable{
int numTasks = 0;
@Override
public List<Integer> chooseTasks(List<Object> values) {
List<Integer> boltIds = new ArrayList<Integer>();
if(values.size()>0){
String str = values.get(0).toString();
if(str.isEmpty()){
boltIds.add(0);
}else{
boltIds.add(str.charAt(0) % numTasks);
}
}
return boltIds;
}
@Override
public void prepare(TopologyContext context, Fields outFields, List<Integer> targetTasks) {
numTasks = targetTasks.size();
}
} 这是一个 CustomStreamGrouping 的简单实现,在这里我们采用单词首字母字符的整数值与任务数的余数,决定接收元组的 bolt。
按下述方式 word-normalizer 修改即可使用这个自定义数据流组。
builder.setBolt("word-normalizer", new WordNormalizer())
.customGrouping("word-reader", new ModuleGrouping()); 直接数据流组
这是一个特殊的数据流组,数据源可以用它决定哪个组件接收元组。与前面的例子类似,数据源将根据单词首字母决定由哪个 bolt 接收元组。要使用直接数据流组,在 WordNormalizer bolt 中,使用 emitDirect 方法代替 emit。
public void execute(Tuple input) {
...
for(String word : words){
if(!word.isEmpty()){
...
collector.emitDirect(getWordCountIndex(word),new Values(word));
}
}
//对元组做出应答
collector.ack(input);
}
public Integer getWordCountIndex(String word) {
word = word.trim().toUpperCase();
if(word.isEmpty()){
return 0;
}else{
return word.charAt(0) % numCounterTasks;
}
} 在 prepare 方法中计算任务数
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
this.numCounterTasks = context.getComponentTasks("word-counter");
} 在拓扑定义中指定数据流将被直接分组:
builder.setBolt("word-counter", new WordCounter(),2)
.directGrouping("word-normalizer"); 全局数据流组
全局数据流组把所有数据源创建的元组发送给单一目标实例(即拥有最低 ID 的任务)。
不分组
写作本书时(Stom0.7.1 版),这个数据流组相当于随机数据流组。也就是说,使用这个数据流组时,并不关心数据流是如何分组的。
LocalCluster VS StormSubmitter
到目前为止,你已经用一个叫做 LocalCluster 的工具在你的本地机器上运行了一个拓扑。Storm 的基础工具,使你能够在自己的计算机上方便的运行和调试不同的拓扑。但是你怎么把自己的拓扑提交给运行中的 Storm 集群呢?Storm 有一个有趣的功能,在一个真实的集群上运行自己的拓扑是很容易的事情。要实现这一点,你需要把 LocalCluster 换成 StormSubmitter 并实现 submitTopology 方法, 它负责把拓扑发送给集群。
下面是修改后的代码:
//LocalCluster cluster = new LocalCluster();
//cluster.submitTopology("Count-Word-Topology-With-Refresh-Cache", conf,
//builder.createTopology());
StormSubmitter.submitTopology("Count-Word-Topology-With_Refresh-Cache", conf,
builder.createTopology());
//Thread.sleep(1000);
//cluster.shutdown(); NOTE: 当你使用 StormSubmitter 时,你就不能像使用 LocalCluster 时一样通过代码控制集群了。
接下来,把源码压缩成一个 jar 包,运行 Storm 客户端命令,把拓扑提交给集群。如果你已经使用了 Maven, 你只需要在命令行进入源码目录运行:mvn package。
现在你生成了一个 jar 包,使用 storm jar 命令提交拓扑(关于如何安装 Storm 客户端请参考附录 A )。命令格式:storm jar allmycode.jar org.me.MyTopology arg1 arg2 arg3。
对于这个例子,在拓扑工程目录下面运行:
storm jar target/Topologies-0.0.1-SNAPSHOT.jar countword.TopologyMain src/main/resources/words.txt 通过这些命令,你就把拓扑发布集群上了。
如果想停止或杀死它,运行:
storm kill Count-Word-Topology-With-Refresh-Cache NOTE:拓扑名称必须保证惟一性。
NOTE:如何安装Storm客户端,参考附录A
DRPC 拓扑
有一种特殊的拓扑类型叫做分布式远程过程调用(DRPC),它利用 Storm 的分布式特性执行远程过程调用(RPC)(见下图)。Storm 提供了一些用来实现 DRPC 的工具。第一个是 DRPC 服务器,它就像是客户端和 Storm 拓扑之间的连接器,作为拓扑的 spout 的数据源。它接收一个待执行的函数和函数参数,然后对于函数操作的每一个数据块,这个服务器都会通过拓扑分配一个请求 ID 用来识别 RPC 请求。拓扑执行最后的 bolt 时,它必须分配 RPC 请求 ID 和结果,使 DRPC 服务器把结果返回正确的客户端。
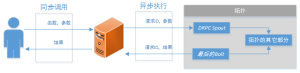
NOTE:单实例 DRPC 服务器能够执行许多函数。每个函数由一个惟一的名称标识。
Storm 提供的第二个工具(已在例子中用过)是 LineDRPCTopologyBuilder**,一个辅助构建DRPC 拓扑的抽象概念。生成的拓扑创建 DRPCSpouts ——它连接到 DRPC 服务器并向拓扑的其它部分分发数据——并包装 bolts,使结果从最后一个 bolt 返回。依次执行所有添加到LinearDRPCTopologyBuilder* 对象的 bolts*。
作为这种类型的拓扑的一个例子,我们创建了一个执行加法运算的进程。虽然这是一个简单的例子,但是这个概念可以扩展到复杂的分布式计算。
bolt 按下面的方式声明输出:
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id","result"));
} 因为这是拓扑中惟一的 bolt,它必须发布 RPC ID 和结果。execute 方法负责执行加法运算。
public void execute(Tuple input) {
String[] numbers = input.getString(1).split("\\+");
Integer added = 0;
if(numbers.length<2){
throw new InvalidParameterException("Should be at least 2 numbers");
}
for(String num : numbers){
added += Integer.parseInt(num);
}
collector.emit(new Values(input.getValue(0),added));
} 包含加法 bolt 的拓扑定义如下:
public static void main(String[] args) {
LocalDRPC drpc = new LocalDRPC();
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("add");
builder.addBolt(AdderBolt(),2);
Config conf = new Config();
conf.setDebug(true);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("drpcder-topology", conf,
builder.createLocalTopology(drpc));
String result = drpc.execute("add", "1+-1");
checkResult(result,0);
result = drpc.execute("add", "1+1+5+10");
checkResult(result,17);
cluster.shutdown();
drpc.shutdown();
} 创建一个 LocalDRPC 对象在本地运行 DRPC 服务器。接下来,创建一个拓扑构建器(译者注:LineDRpctopologyBuilder 对象),把 bolt 添加到拓扑。运行 DRPC 对象(LocalDRPC 对象)的 execute 方法测试拓扑。
NOTE:使用 DRPCClient 类连接远程 DRPC 服务器。DRPC 服务器暴露了 Thrift API,因此可以跨语言编程;并且不论是在本地还是在远程运行DRPC服务器,它们的 API 都是相同的。 对于采用 Storm 配置的 DRPC 配置参数的 Storm 集群,调用构建器对象的createRemoteTopology 向 Storm 集群提交一个拓扑,而不是调用 createLocalTopology。
Storm Spouts
Spouts
你将在本章了解到 spout 作为拓扑入口和它的容错机制相关的最常见的设计策略。
可靠的消息 VS 不可靠的消息
在设计拓扑结构时,始终在头脑中记着的一件重要事情就是消息的可靠性。当有无法处理的消息时,你就要决定该怎么办,以及作为一个整体的拓扑结构该做些什么。举个例子,在处理银行存款时,不要丢失任何事务报文就是很重要的事情。但是如果你要统计分析数以百万的 tweeter 消息,即使有一条丢失了,仍然可以认为你的结果是准确的。
对于 Storm 来说,根据每个拓扑的需要担保消息的可靠性是开发者的责任。这就涉及到消息可靠性和资源消耗之间的权衡。高可靠性的拓扑必须管理丢失的消息,必然消耗更多资源;可靠性较低的拓扑可能会丢失一些消息,占用的资源也相应更少。不论选择什么样的可靠性策略,Storm 都提供了不同的工具来实现它。
要在 spout 中管理可靠性,你可以在分发时包含一个元组的消息 ID(collector.emit(new Values(…),tupleId))。在一个元组被正确的处理时调用 ack** 方法,而在失败时调用 fail** 方法。当一个元组被所有的靶 bolt 和锚 bolt 处理过,即可判定元组处理成功(你将在第5章学到更多锚 bolt 知识)。
发生下列情况之一时为元组处理失败:
- 提供数据的 spout 调用 collector.fail(tuple)
- 处理时间超过配置的超时时间
让我们来看一个例子。想象你正在处理银行事务,需求如下:
- 如果事务失败了,重新发送消息
- 如果失败了太多次,终结拓扑运行
创建一个 spout 和一个 bolt,spout 随机发送100个事务 ID,有80%的元组不会被 bolt 收到(你可以在例子 ch04-spout 查看完整代码)。实现 spout 时利用 Map 分发事务消息元组,这样就比较容易实现重发消息。
public void nextTuple() {
if(!toSend.isEmpty()){
for(Map.Entry<Integer, String> transactionEntry : toSend.entrySet()){
Integer transactionId = transactionEntry.getKey();
String transactionMessage = transactionEntry.getValue();
collector.emit(new Values(transactionMessage),transactionId);
}
toSend.clear();
}
} 如果有未发送的消息,得到每条事务消息和它的关联 ID,把它们作为一个元组发送出去,最后清空消息队列。值得一提的是,调用 map 的 clear 是安全的,因为 nextTuple 失败时,只有 ack 方法会修改 map,而它们都运行在一个线程内。
维护两个 map 用来跟踪待发送的事务消息和每个事务的失败次数。ack 方法只是简单的把事务从每个列表中删除。
public void ack(Object msgId) {
messages.remove(msgId);
failCounterMessages.remove(msgId);
} fail 方法决定应该重新发送一条消息,还是已经失败太多次而放弃它。
NOTE:如果你使用全部数据流组,而拓扑里的所有 bolt 都失败了,spout 的 fail 方法才会被调用。
public void fail(Object msgId) {
Integer transactionId = (Integer) msgId;
//检查事务失败次数
Integer failures = transactionFailureCount.get(transactionId) + 1;
if(failes >= MAX_FAILS){
//失败数太高了,终止拓扑
throw new RuntimeException("错误, transaction id 【"+
transactionId+"】 已失败太多次了 【"+failures+"】");
}
//失败次数没有达到最大数,保存这个数字并重发此消息
transactionFailureCount.put(transactionId, failures);
toSend.put(transactionId, messages.get(transactionId));
LOG.info("重发消息【"+msgId+"】");
} 首先,检查事务失败次数。如果一个事务失败次数太多,通过抛出 RuntimeException 终止发送此条消息的工人。否则,保存失败次数,并把消息放入待发送队列(toSend),它就会再次调用 nextTuple 时得以重新发送。
NOTE:Storm 节点不维护状态,因此如果你在内存保存信息(就像本例做的那样),而节点又不幸挂了,你就会丢失所有缓存的消息。Storm 是一个快速失败的系统。拓扑会在抛出异常时挂掉,然后再由 Storm 重启,恢复到抛出异常前的状态。
获取数据
接下来你会了解到一些设计 spout 的技巧,帮助你从多数据源获取数据。
直接连接
在一个直接连接的架构中,spout 直接与一个消息分发器连接。
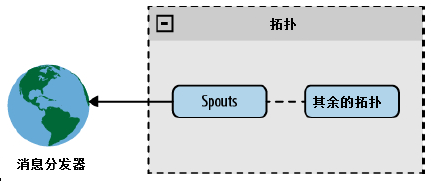
图 直接连接的 spout
这个架构很容易实现,尤其是在消息分发器是已知设备或已知设备组时。已知设备满足:拓扑从启动时就已知道该设备,并贯穿拓扑的整个生命周期保持不变。未知设备就是在拓扑运行期添加进来的。已知设备组就是从拓扑启动时组内所有设备都是已知的。
下面举个例子说明这一点。创建一个 spout 使用 Twitter 流 API 读取 twitter 数据流。spout 把 API 当作消息分发器直接连接。从数据流中得到符合 track 参数的公共 tweets(参考 twitter 开发页面)。完整的例子可以在链接 https://github.com/storm-book/examples-ch04-spouts/找到。
spout 从配置对象得到连接参数(track,user,password),并连接到 API(在这个例子中使用 Apache 的 DefaultHttpClient)。它一次读一行数据,并把数据从 JSON 转化成 Java 对象,然后发布它。
public void nextTuple() {
//创建http客户端
client = new DefaultHttpClient();
client.setCredentialsProvider(credentialProvider);
HttpGet get = new HttpGet(STREAMING_API_URL+track);
HttpResponse response;
try {
//执行http访问
response = client.execute(get);
StatusLine status = response.getStatusLine();
if(status.getStatusCode() == 200){
InputStream inputStream = response.getEntity().getContent();
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String in;
//逐行读取数据
while((in = reader.readLine())!=null){
try{
//转化并发布消息
Object json = jsonParser.parse(in);
collector.emit(new Values(track,json));
}catch (ParseException e) {
LOG.error("Error parsing message from twitter",e);
}
}
}
} catch (IOException e) {
LOG.error("Error in communication with twitter api ["+get.getURI().toString()+"],
sleeping 10s");
try {
Thread.sleep(10000);
} catch (InterruptedException e1) {}
}
} NOTE:在这里你锁定了 nextTuple 方法,所以你永远也不会执行 ack** 和 fail** 方法。在真实的应用中,我们推荐你在一个单独的线程中执行锁定,并维持一个内部队列用来交换数据(你会在下一个例子中学到如何实现这一点:消息队列)。
棒极了!现在你用一个 spout 读取 Twitter 数据。一个明智的做法是,采用拓扑并行化,多个 spout 从同一个流读取数据的不同部分。那么如果你有多个流要读取,你该怎么做呢?Storm 的第二个有趣的特性(译者注:第一个有趣的特性已经出现过,这句话原文都是一样的,不过按照中文的行文习惯还是不重复使用措词了)是,你可以在任意组件内(spouts/bolts)访问TopologyContext。利用这一特性,你能够把流划分到多个 spouts 读取。
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
//从context对象获取spout大小
int spoutsSize =
context.getComponentTasks(context.getThisComponentId()).size();
//从这个spout得到任务id
int myIdx = context.getThisTaskIndex();
String[] tracks = ((String) conf.get("track")).split(",");
StringBuffer tracksBuffer = new StringBuffer();
for(int i=0; i< tracks.length;i++){
//Check if this spout must read the track word
if( i % spoutsSize == myIdx){
tracksBuffer.append(",");
tracksBuffer.append(tracks[i]);
}
}
if(tracksBuffer.length() == 0) {
throw new RuntimeException("没有为spout得到track配置" +
" [spouts大小:"+spoutsSize+", tracks:"+tracks.length+"] tracks的数量必须高于spout的数量");
this.track =tracksBuffer.substring(1).toString();
}
...
} 利用这一技巧,你可以把 collector 对象均匀的分配给多个数据源,当然也可以应用到其它的情形。比如说,从web服务器收集日志文件
图 直连 hash
通过上一个例子,你学会了从一个 spout 连接到已知设备。你也可以使用相同的方法连接未知设备,不过这时你需要借助于一个协同系统维护的设备列表。协同系统负责探察列表的变化,并根据变化创建或销毁连接。比如,从 web 服务器收集日志文件时,web 服务器列表可能随着时间变化。当添加一台 web 服务器时,协同系统探查到变化并为它创建一个新的 spout。
图 直连协同
消息队列
第二种方法是,通过一个队列系统接收来自消息分发器的消息,并把消息转发给 spout。更进一步的做法是,把队列系统作为 spout 和数据源之间的中间件,在许多情况下,你可以利用多队列系统的重播能力增强队列可靠性。这意味着你不需要知道有关消息分发器的任何事情,而且添加或移除分发器的操作比直接连接简单的多。这个架构的问题在于队列是一个故障点,另外你还要为处理流程引入新的环节。
下图展示了这一架构模型
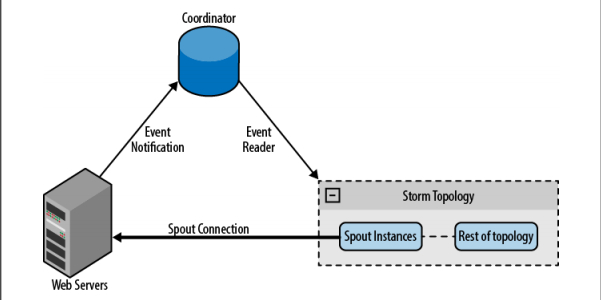
图 使用队列系统
NOTE:你可以通过轮询队列或哈希队列(把队列消息通过哈希发送给 spouts 或创建多个队列使队列 spouts 一一对应)在多个 spouts 之间实现并行性。
接下来我们利用 Redishttp://redis.io/ 和它的 java 库 Jedis 创建一个队列系统。在这个例子中,我们创建一个日志处理器从一个未知的来源收集日志,利用 lpush 命令把消息插入队列,利用 blpop 命令等待消息。如果你有很多处理过程,blpop 命令采用了轮询方式获取消息。
我们在 spout 的 open** 方法创建一个线程,用来获取消息(使用线程是为了避免锁定nextTuple** 在主循环的调用):
new Thread(new Runnable() {
@Override
public void run() {
try{
Jedis client= new Jedis(redisHost, redisPort);
List res = client.blpop(Integer.MAX_VALUE, queues);
messages.offer(res.get(1));
}catch(Exception e){
LOG.error("从redis读取队列出错",e);
try {
Thread.sleep(100);
}catch(InterruptedException e1){}
}
}
}).start(); 这个线程的惟一目的就是,创建 redis 连接,然后执行 blpop 命令。每当收到了一个消息,它就被添加到一个内部消息队列,然后会被 nextTuple**** 消费。对于 spout 来说数据源就是 redis 队列,它不知道消息分发者在哪里也不知道消息的数量。
NOTE:我们不推荐你在 spout 创建太多线程,因为每个 spout 都运行在不同的线程。一个更好的替代方案是增加拓扑并行性,也就是通过 Storm 集群在分布式环境创建更多线程。
在 nextTuple 方法中,要做的惟一的事情就是从内部消息队列获取消息并再次分发它们。
public void nextTuple(){
while(!messages.isEmpty()){
collector.emit(new Values(messages.poll()));
}
} NOTE:你还可以借助 redis 在 spout 实现消息重发,从而实现可靠的拓扑。(译者注:这里是相对于开头的可靠的消息VS不可靠的消息讲的)
DRPC
DRPCSpout从DRPC 服务器接收一个函数调用,并执行它(见第三章的例子)。对于最常见的情况,使用 backtype.storm.drpc.DRPCSpout 就足够了,不过仍然有可能利用 Storm 包内的DRPC类创建自己的实现。
Storm Bolts
Bolts
正如你已经看到的,bolts 是一个 Storm 集群中的关键组件。你将在这一章学到 bolt 生命周期,一些 bolt 设计策略,以及几个有关这些内容的例子。
Bolt 生命周期
Bolt 是这样一种组件,它把元组作为输入,然后产生新的元组作为输出。实现一个 bolt 时,通常需要实现 IRichBolt 接口。Bolts 对象由客户端机器创建,序列化为拓扑,并提交给集群中的主机。然后集群启动工人进程反序列化 bolt,调用 prepare****,最后开始处理元组。
NOTE:要创建一个 bolt 对象,它通过构造器参数初始化成员属性,bolt 被提交到集群时,这些属性值会随着一起序列化。
Bolt 结构
Bolts拥有如下方法:
declareOutputFields(OutputFieldsDeclarer declarer)
为bolt声明输出模式
prepare(java.util.Map stormConf, TopologyContext context, OutputCollector collector)
仅在bolt开始处理元组之前调用
execute(Tuple input)
处理输入的单个元组
cleanup()
在bolt即将关闭时调用 下面看一个例子,在这个例子中 bolt 把一句话分割成单词列表:
class SplitSentence implements IRichBolt {
private OutputCollector collector;
publlic void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word : sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void cleanup(){}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
} 正如你所看到的,这是一个很简单的 bolt。值得一提的是在这个例子里,没有消息担保。这就意味着,如果 bolt 因为某些原因丢弃了一些消息——不论是因为 bolt 挂了,还是因为程序故意丢弃的——生成这条消息的 spout 不会收到任何通知,任何其它的 spouts 和 bolts 也不会收到。
然而在许多情况下,你想确保消息在整个拓扑范围内都被处理过了。
可靠的 bolts 和不可靠的 bolts
正如前面所说的,Storm 保证通过 spout 发送的每条消息会得到所有 bolt 的全面处理。基于设计上的考虑,这意味着你要自己决定你的 bolts 是否保证这一点。
拓扑是一个树型结构,消息(元组)穿过其中一条或多条分支。树上的每个节点都会调用 ack(tuple) 或 fail(tuple),Storm 因此知道一条消息是否失败了,并通知那个/那些制造了这些消息的 spout(s)。既然一个 Storm 拓扑运行在高度并行化的环境里,跟踪始发 spout 实例的最好方法就是在消息元组内包含一个始发 spout 引用。这一技巧称做锚定(译者注:原文为Anchoring)。修改一下刚刚讲过的 SplitSentence,使它能够确保消息都被处理了。
class SplitSentence implenents IRichBolt {
private OutputCollector collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word : sentence.split(" ")) {
collector.emit(tuple, new Values(word));
}
collector.ack(tuple);
}
public void cleanup(){}
public void declareOutputFields(OutputFieldsDeclarer declarer){
declar.declare(new Fields("word"));
}
} 锚定发生在调用 collector.emit() 时。正如前面提到的,Storm 可以沿着元组追踪到始发spout。collector.ack(tuple) 和 collector.fail(tuple)会告知 spout 每条消息都发生了什么。当树上的每条消息都已被处理了,Storm 就认为来自 spout 的元组被全面的处理了。如果一个元组没有在设置的超时时间内完成对消息树的处理,就认为这个元组处理失败。默认超时时间为30秒。
NOTE:你可以通过修改Config.TOPOLOGY_MESSAGE_TIMEOUT修改拓扑的超时时间。
当然了spout需要考虑消息的失败情况,并相应的重试或丢弃消息。
NOTE:你处理的每条消息要么是确认的(译者注:collector.ack())要么是失败的(译者注:collector.fail())。Storm 使用内存跟踪每个元组,所以如果你不调用这两个方法,该任务最终将耗尽内存。
多数据流
一个 bolt 可以使用 emit(streamId, tuple) 把元组分发到多个流,其中参数 streamId 是一个用来标识流的字符串。然后,你可以在 TopologyBuilder 决定由哪个流订阅它。
多锚定
为了用 bolt 连接或聚合数据流,你需要借助内存缓冲元组。为了在这一场景下确保消息完成,你不得不把流锚定到多个元组上。可以向 emit 方法传入一个元组列表来达成目的。
...
List anchors = new ArrayList();
anchors.add(tuple1);
anchors.add(tuple2);
collector.emit(anchors, values);
... 通过这种方式,bolt 在任意时刻调用 ack 或 fail 方法,都会通知消息树,而且由于流锚定了多个元组,所有相关的 spout 都会收到通知。
使用 IBasicBolt 自动确认
你可能已经注意到了,在许多情况下都需要消息确认。简单起见,Storm 提供了另一个用来实现bolt 的接口,IBasicBolt。对于该接口的实现类的对象,会在执行 execute 方法之后自动调用 ack 方法。
class SplitSentence extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word : sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
} NOTE:分发消息的 BasicOutputCollector 自动锚定到作为参数传入的元组。
Storm 使用非 JVM 语言开发
有时候你可能想使用不是基于 JVM 的语言开发一个 Storm 工程,你可能更喜欢使用别的语言或者想使用用某种语言编写的库。
Storm 是用 Java 实现的,你看到的所有这本书中的 spout 和 bolt 都是用 java 编写的。那么有可能使用像 Python、Ruby、 或者 JavaScript 这样的语言编写 spout 和 bolt 吗?答案是当然
可以!可以使用多语言协议达到这一目的。
多语言协议是 Storm 实现的一种特殊的协议,它使用标准输入输出作为 spout 和 bolt 进程间的通讯通道。消息以 JSON 格式或纯文本格式在通道中传递。
我们看一个用非 JVM 语言开发 spout 和 bolt 的简单例子。在这个例子中有一个 spout 产生从1到10,000的数字,一个 bolt 过滤素数,二者都用 PHP 实现。
NOTE: 在这个例子中,我们使用一个很笨的办法验证素数。有更好当然也更复杂的方法,它们已经超出了这个例子的范围。
有一个专门为 Storm 实现的 PHP DSL (译者注:领域特定语言),我们将会在例子中展示我们的实现。首先定义拓扑。
1
...
2
TopologyBuilder builder = new TopologyBuilder();
3
builder.setSpout("numbers-generator", new NumberGeneratorSpout(1, 10000));
4
builder.setBolt("prime-numbers-filter", new
5
PrimeNumbersFilterBolt()).shuffleGrouping("numbers-generator");
6
StormTopology topology = builder.createTopology();
7
... NOTE:有一种使用非 JVM 语言定义拓扑的方式。既然 Storm 拓扑是 Thrift 架构,而且Nimbus 是一个 Thrift 守护进程,你就可以使用任何你想用的语言创建并提交拓扑。但是这已经超出了本书的范畴了。
这里没什么新鲜了。我们看一下 NumbersGeneratorSpout 的实现。
01
public class NumberGeneratorSpout extends ShellSpout implements IRichSpout {
02
public NumberGeneratorSpout(Integer from, Integer to) {
03
super("php", "-f", "NumberGeneratorSpout.php", from.toString(), to.toString());
04
}
05
public void declareOutputFields(OutputFieldsDeclarer declarer) {
06
declarer.declare(new Fields("number"));
07
}
08
public Map<String, Object> getComponentConfiguration() {
09
return null;
10
}
11
} 你可能已经注意到了,这个 spout 继承了 ShellSpout。 这是个由 Storm 提供的特殊的类,用来帮助你运行并控制用其它语言编写的 spout。 在这种情况下它告诉 Storm 如何执行你的PHP 脚本。
NumberGeneratorSpout 的 PHP 脚本向标准输出分发元组,并从标准输入读取确认或失败信号。
在开始实现 NumberGeneratorSpout.php 脚本之前,多观察一下多语言协议是如何工作的。
spout 按照传递给构造器的参数从 from 到 to 顺序生成数字。
接下来看看 PrimeNumbersFilterBolt。 这个类实现了之前提到的壳。它告诉 Storm 如何执行你的PHP脚本。 Storm 为这一目的提供了一个特殊的叫做 ShellBolt 的类,你惟一要做的事就是指出如何运行脚本以及声明要分发的属性。
1
public class PrimeNumbersFilterBolt extends ShellBolt implements IRichBolt {
2
public PrimeNumbersFilterBolt() {
3
super("php", "-f", "PrimeNumbersFilterBolt.php");
4
}
5
public void declareOutputFields(OutputFieldsDeclarer declarer) {
6
declarer.declare(new Fields("number"));
7
}
8
} 在这个构造器中只是告诉 Storm 如何运行PHP脚本。它与下列命令等价。
1
php -f PrimeNumbersFilterBolt.php PrimeNumbersFilterBolt.php 脚本从标准输入读取元组,处理它们,然后向标准输出分发、确认或失败。在开始这个脚本之前,我们先多了解一些多语言协议的工作方式。
Storm 事务性拓扑
事务性拓扑
正如书中之前所提到的,使用 Storm 编程,可以通过调用 ack 和 fail 方法来确保一条消息的处理成功或失败。不过当元组被重发时,会发生什么呢?你又该如何砍不会重复计算?
Storm0.7.0 实现了一个新特性——事务性拓扑,这一特性使消息在语义上确保你可以安全的方式重发消息,并保证它们只会被处理一次。在不支持事务性拓扑的情况下,你无法在准确性,可扩展性,以空错性上得到保证的前提下完成计算。
NOTE:事务性拓扑是一个构建于标准 Storm spout 和 bolt 之上的抽象概念。
设计
在事务性拓扑中,Storm 以并行和顺序处理混合的方式处理元组。spout 并行分批创建供 bolt 处理的元组(译者注:下文将这种分批创建、分批处理的元组称做批次)。其中一些 bolt 作为提交者以严格有序的方式提交处理过的批次。这意味着如果你有每批五个元组的两个批次,将有两个元组被 bolt 并行处理,但是直到提交者成功提交了第一个元组之后,才会提交第二个元组。
NOTE: 使用事务性拓扑时,数据源要能够重发批次,有时候甚至要重复多次。因此确认你的数据源——你连接到的那个 spout ——具备这个能力。 这个过程可以被描述为两个阶段: 处理阶段 纯并行阶段,许多批次同时处理。 提交阶段 严格有序阶段,直到批次一成功提交之后,才会提交批次二。 这两个阶段合起来称为一个 Storm 事务。 NOTE: Storm 使用 zookeeper 储存事务元数据,默认情况下就是拓扑使用的那个 zookeeper。你可以修改以下两个配置参数键指定其它的 zookeeper——transactional.zookeeper.servers 和transactional.zookeeper.port。
事务实践
下面我们要创建一个 Twitter 分析工具来了解事务的工作方式。我们从一个 Redis 数据库读取tweets,通过几个 bolt 处理它们,最后把结果保存在另一个 Redis 数据库的列表中。处理结果就是所有话题和它们的在 tweets 中出现的次数列表,所有用户和他们在 tweets 中出现的次数列表,还有一个包含发起话题和频率的用户列表。 这个工具的拓扑图。

图 拓扑概览
正如你看到的,TweetsTransactionalSpout 会连接你的 tweet 数据库并向拓扑分发批次。UserSplitterBolt 和 HashTagSplitterBolt 两个 bolt,从 spout 接收元组。UserSplitterBolt 解析 tweets 并查找用户——以 @ 开头的单词——然后把这些单词分发到名为 users 的自定义数据流组。HashtagSplitterBolt 从 tweet 查找 # 开头的单词,并把它们分发到名为 hashtags 的自定义数据流组。第三个 bolt,UserHashtagJoinBolt,接收前面提到的两个数据流组,并计算具名用户的一条 tweet 内的话题数量。为了计数并分发计算结果,这是个 BaseBatchBolt(稍后有更多介绍)。
最后一个 bolt——RedisCommitterBolt—— 接收以上三个 bolt 的数据流组。它为每样东西计数,并在对一个批次完成处理时,把所有结果保存到 redis。这是一种特殊的 bolt,叫做提交者,在本章后面做更多讲解。
用 TransactionalTopologyBuilder 构建拓扑,代码如下:
01
TransactionalTopologyBuilder builder=
02
new TransactionalTopologyBuilder("test", "spout", new TweetsTransactionalSpout());
03
04
builder.setBolt("users-splitter", new UserSplitterBolt(), 4).shuffleGrouping("spout");
05
buildeer.setBolt("hashtag-splitter", new HashtagSplitterBolt(), 4).shuffleGrouping("spout");
06
07
builder.setBolt("users-hashtag-manager", new UserHashtagJoinBolt(), r)
08
.fieldsGrouping("users-splitter", "users", new Fields("tweet_id"))
09
.fieldsGrouping("hashtag-splitter", "hashtags", new Fields("tweet_id"));
10
11
builder.setBolt("redis-commiter", new RedisCommiterBolt())
12
.globalGrouping("users-splitter", "users")
13
.globalGrouping("hashtag-splitter", "hashtags")
14
.globalGrouping("user-hashtag-merger"); 接下来就看看如何在一个事务性拓扑中实现 spout。
Spout
一个事务性拓扑的 spout 与标准 spout 完全不同。
1
public class TweetsTransactionalSpout extends BaseTransactionalSpout<TransactionMetadata>{ 正如你在这个类定义中看到的,TweetsTransactionalSpout 继承了带范型的BaseTransactionalSpout。指定的范型类型的对象是事务元数据集合。它将在后面的代码中用于从数据源分发批次。
在这个例子中,TransactionMetadata 定义如下:
01
public class TransactionMetadata implements Serializable {
02
private static final long serialVersionUID = 1L;
03
long from;
04
int quantity;
05
06
public TransactionMetadata(long from, int quantity) {
07
this.from = from;
08
this.quantity = quantity;
09
}
10
} 该类的对象维护着两个属性 from 和 quantity,它们用来生成批次。
spout 的最后需要实现下面的三个方法:
01
@Override
02
public ITransactionalSpout.Coordinator<TransactionMetadata> getCoordinator(
03
Map conf, TopologyContext context) {
04
return new TweetsTransactionalSpoutCoordinator();
05
}
06
07
@Override
08
public backtype.storm.transactional.ITransactionalSpout.Emitter<TransactionMetadata> getEmitter(Map conf, TopologyContext contest) {
09
return new TweetsTransactionalSpoutEmitter();
10
}
11
12
@Override
13
public void declareOutputFields(OuputFieldsDeclarer declarer) {
14
declarer.declare(new Fields("txid", "tweet_id", "tweet"));
15
} getCoordinator 方法,告诉 Storm 用来协调生成批次的类。getEmitter,负责读取批次并把它们分发到拓扑中的数据流组。最后,就像之前做过的,需要声明要分发的域。
RQ 类
为了让例子简单点,我们决定用一个类封装所有对 Redis 的操作。
01
public class RQ {
02
public static final String NEXT_READ = "NEXT_READ";
03
public static final String NEXT_WRITE = "NEXT_WRITE";
04
05
Jedis jedis;
06
07
public RQ() {
08
jedis = new Jedis("localhost");
09
}
10
11
public long getavailableToRead(long current) {
12
return getNextWrite() - current;
13
}
14
15
public long getNextRead() {
16
String sNextRead = jedis.get(NEXT_READ);
17
if(sNextRead == null) {
18
return 1;
19
}
20
return Long.valueOf(sNextRead);
21
}
22
23
public long getNextWrite() {
24
return Long.valueOf(jedis.get(NEXT_WRITE));
25
}
26
27
public void close() {
28
jedis.disconnect();
29
}
30
31
public void setNextRead(long nextRead) {
32
jedis.set(NEXT_READ, ""+nextRead);
33
}
34
35
public List<String> getMessages(long from, int quantity) {
36
String[] keys = new String[quantity];
37
for (int i = 0; i < quantity; i++) {
38
keys[i] = ""+(i+from);
39
}
40
return jedis.mget(keys);
41
}
42
} 仔细阅读每个方法,确保自己理解了它们的用处。
协调者 Coordinator
下面是本例的协调者实现。
01
public static class TweetsTransactionalSpoutCoordinator implements ITransactionalSpout.Coordinator<TransactionMetadata> {
02
TransactionMetadata lastTransactionMetadata;
03
RQ rq = new RQ();
04
long nextRead = 0;
05
06
public TweetsTransactionalSpoutCoordinator() {
07
nextRead = rq.getNextRead();
08
}
09
10
@Override
11
public TransactionMetadata initializeTransaction(BigInteger txid, TransactionMetadata prevMetadata) {
12
long quantity = rq.getAvailableToRead(nextRead);
13
quantity = quantity > MAX_TRANSACTION_SIZE ? MAX_TRANSACTION_SIZE : quantity;
14
TransactionMetadata ret = new TransactionMetadata(nextRead, (int)quantity);
15
nextRead += quantity;
16
return ret;
17
}
18
19
@Override
20
public boolean isReady() {
21
return rq.getAvailableToRead(nextRead) > 0;
22
}
23
24
@Override
25
public void close() {
26
rq.close();
27
}
28
} 值得一提的是,在整个拓扑中只会有一个提交者实例。创建提交者实例时,它会从 redis 读取一个从1开始的序列号,这个序列号标识要读取的 tweet 下一条。
第一个方法是 isReady。在 initializeTransaction 之前调用它确认数据源已就绪并可读取。此方法应当相应的返回 true 或 false。在此例中,读取 tweets 数量并与已读数量比较。它们之间的不同就在于可读 tweets 数。如果它大于0,就意味着还有 tweets 未读。
最后,执行 initializeTransaction。正如你看到的,它接收 txid 和 prevMetadata作为参数。第一个参数是 Storm 生成的事务 ID,作为批次的惟一性标识。prevMetadata 是协调器生成的前一个事务元数据对象。
在这个例子中,首先确认有多少 tweets 可读。只要确认了这一点,就创建一个TransactionMetadata 对象,标识读取的第一个 tweet(译者注:对象属性 from ),以及读取的 tweets 数量(译者注:对象属性 quantity )。
元数据对象一经返回,Storm 把它跟 txid 一起保存在 zookeeper。这样就确保了一旦发生故障,Storm 可以利用分发器(译者注:Emitter,见下文)重新发送批次。
Emitter
创建事务性 spout 的最后一步是实现分发器(Emitter)。实现如下:
01
public static class TweetsTransactionalSpoutEmitter implements ITransactionalSpout.Emitter<TransactionMetadata> {
02
03
</pre>
04
<pre> RQ rq = new RQ();</pre>
05
<pre> public TweetsTransactionalSpoutEmitter() {}</pre>
06
<pre> @Override
07
public void emitBatch(TransactionAttempt tx, TransactionMetadata coordinatorMeta, BatchOutputCollector collector) {
08
rq.setNextRead(coordinatorMeta.from+coordinatorMeta.quantity);
09
List<String> messages = rq.getMessages(coordinatorMeta.from, <span style="font-family: Georgia, 'Times New Roman', 'Bitstream Charter', Times, serif; font-size: 13px; line-height: 19px;">coordinatorMeta.quantity);
10
</span> long tweetId = coordinatorMeta.from;
11
for (String message : messages) {
12
collector.emit(new Values(tx, ""+tweetId, message));
13
tweetId++;
14
}
15
}
16
17
@Override
18
public void cleanupBefore(BigInteger txid) {}
19
20
@Override
21
public void close() {
22
rq.close();
23
}</pre>
24
<pre>
25
} 分发器从数据源读取数据并从数据流组发送数据。分发器应当问题能够为相同的事务 id 和事务元数据发送相同的批次。这样,如果在处理批次的过程中发生了故障,Storm 就能够利用分发器重复相同的事务 id 和事务元数据,并确保批次已经重复过了。Storm 会在TransactionAttempt 对象里为尝试次数增加计数(译者注:attempt id )。这样就能知道批次已经重复过了。
在这里 emitBatch 是个重要方法。在这个方法中,使用传入的元数据对象从 redis 得到tweets,同时增加 redis 维持的已读 tweets 数。当然它还会把读到的 tweets 分发到拓扑。
Bolts
首先看一下这个拓扑中的标准 bolt:
01
public class UserSplitterBolt implements IBasicBolt{
02
private static final long serialVersionUID = 1L;
03
04
@Override
05
public void declareOutputFields(OutputFieldsDeclarer declarer) {
06
declarer.declareStream("users", new Fields("txid","tweet_id","user"));
07
}
08
09
@Override
10
public Map<String, Object> getComponentConfiguration() {
11
return null;
12
}
13
14
@Override
15
public void prepare(Map stormConf, TopologyContext context) {}
16
17
@Override
18
public void execute(Tuple input, BasicOutputCollector collector) {
19
String tweet = input.getStringByField("tweet");
20
String tweetId = input.getStringByField("tweet_id");
21
StringTokenizer strTok = new StringTokenizer(tweet, " ");
22
HashSet<String> users = new HashSet<String>();
23
24
while(strTok.hasMoreTokens()) {
25
String user = strTok.nextToken();
26
27
//确保这是个真实的用户,并且在这个tweet中没有重复
28
if(user.startsWith("@") && !users.contains(user)) {
29
collector.emit("users", new Values(tx, tweetId, user));
30
users.add(user);
31
}
32
}
33
}
34
35
@Override
36
public void cleanup(){}
37
} 正如本章前面提到的,UserSplitterBolt 接收元组,解析 tweet 文本,分发 @ 开头的单词————tweeter 用户。HashtagSplitterBolt 的实现也非常相似。
01
public class HashtagSplitterBolt implements IBasicBolt{
02
private static final long serialVersionUID = 1L;
03
04
@Override
05
public void declareOutputFields(OutputFieldsDeclarer declarer) {
06
declarer.declareStream("hashtags", new Fields("txid","tweet_id","hashtag"));
07
}
08
09
@Override
10
public Map<String, Object> getComponentConfiguration() {
11
return null;
12
}
13
14
@Override
15
public void prepare(Map stormConf, TopologyContext context) {}
16
17
@Oerride
18
public void execute(Tuple input, BasicOutputCollector collector) {
19
String tweet = input.getStringByField("tweet");
20
String tweetId = input.getStringByField("tweet_id");
21
StringTokenizer strTok = new StringTokenizer(tweet, " ");
22
TransactionAttempt tx = (TransactionAttempt)input.getValueByField("txid");
23
HashSet<String> words = new HashSet<String>();
24
25
while(strTok.hasMoreTokens()) {
26
String word = strTok.nextToken();
27
28
if(word.startsWith("#") && !words.contains(word)){
29
collector.emit("hashtags", new Values(tx, tweetId, word));
30
words.add(word);
31
}
32
}
33
}
34
35
@Override
36
public void cleanup(){}
37
} 现在看看 UserHashTagJoinBolt 的实现。首先要注意的是它是一个 BaseBatchBolt。这意味着,execute 方法会操作接收到的元组,但是不会分发新的元组。批次完成时,Storm 会调用 finishBatch 方法。
01
public void execute(Tuple tuple) {
02
String source = tuple.getSourceStreamId();
03
String tweetId = tuple.getStringByField("tweet_id");
04
05
if("hashtags".equals(source)) {
06
String hashtag = tuple.getStringByField("hashtag");
07
add(tweetHashtags, tweetId, hashtag);
08
} else if("users".equals(source)) {
09
String user = tuple.getStringByField("user");
10
add(userTweets, user, tweetId);
11
}
12
} 既然要结合 tweet 中提到的用户为出现的所有话题计数,就需要加入前面的 bolts 创建的两个数据流组。这件事要以批次为单位进程,在批次处理完成时,调用 finishBatch 方法。
01
@Override
02
public void finishBatch() {
03
for(String user:userTweets.keySet()){
04
Set<String> tweets = getUserTweets(user);
05
HashMap<String, Integer> hashtagsCounter = new HashMap<String, Integer>();
06
for(String tweet:tweets){
07
Set<String> hashtags=getTweetHashtags(tweet);
08
if(hashtags!=null){
09
for(String hashtag:hashtags){
10
Integer count=hashtagsCounter.get(hashtag);
11
if(count==null){count=0;}
12
count++;
13
hashtagsCounter.put(hashtag,count);
14
}
15
}
16
}
17
for(String hashtag:hashtagsCounter.keySet()){
18
int count=hashtagsCounter.get(hashtag);
19
collector.emit(new Values(id,user,hashtag,count));
20
}
21
}
22
} 这个方法计算每对用户-话题出现的次数,并为之生成和分发元组。
你可以在 GitHub 上找到并下载完整代码。(译者注:https://github.com/storm-book/examples-ch08-transactional-topologies 这个仓库里没有代码,谁知道哪里有代码麻烦说一声。)
提交者 bolts
我们已经学习了,批次通过协调器和分发器怎样在拓扑中传递。在拓扑中,这些批次中的元组以并行的,没有特定次序的方式处理。
协调者 bolts 是一类特殊的批处理 bolts,它们实现了 IComh mitter 或者通过TransactionalTopologyBuilder 调用 setCommiterBolt 设置了提交者 bolt。它们与其它的批处理 bolts 最大的不同在于,提交者 bolts的finishBatch 方法在提交就绪时执行。这一点发生在之前所有事务都已成功提交之后。另外,finishBatch 方法是顺序执行的。因此如果同时有事务 ID1 和事务 ID2 两个事务同时执行,只有在 ID1 没有任何差错的执行了 finishBatch 方法之后,ID2 才会执行该方法。
下面是这个类的实现
01
public class RedisCommiterCommiterBolt extends BaseTransactionalBolt implements ICommitter {
02
public static final String LAST_COMMITED_TRANSACTION_FIELD = "LAST_COMMIT";
03
TransactionAttempt id;
04
BatchOutputCollector collector;
05
Jedis jedis;
06
07
@Override
08
public void prepare(Map conf, TopologyContext context,
09
BatchOutputCollector collector, TransactionAttempt id) {
10
this.id = id;
11
this.collector = collector;
12
this.jedis = new Jedis("localhost");
13
}
14
15
HashMap<String, Long> hashtags = new HashMap<String,Long>();
16
HashMap<String, Long> users = new HashMap<String, Long>();
17
HashMap<String, Long> usersHashtags = new HashMap<String, Long>();
18
19
private void count(HashMap<String, Long> map, String key, int count) {
20
Long value = map.get(key);
21
if(value == null){value = (long)0;}
22
value += count;
23
map.put(key,value);
24
}
25
26
@Override
27
public void execute(Tuple tuple) {
28
String origin = tuple. getSourceComponent();
29
if("sers-splitter".equals(origin)) {
30
String user = tuple.getStringByField("user");
31
count(users, user, 1);
32
} else if("hashtag-splitter".equals(origin)) {
33
String hashtag = tuple.getStringByField("hashtag");
34
count(hashtags, hashtag, 1);
35
} else if("user-hashtag-merger".quals(origin)) {
36
String hashtag = tuple.getStringByField("hashtag");
37
String user = tuple.getStringByField("user");
38
String key = user + ":" + hashtag;
39
Integer count = tuple.getIntegerByField("count");
40
count(usersHashtags, key, count);
41
}
42
}
43
44
@Override
45
public void finishBatch() {
46
String lastCommitedTransaction = jedis.get(LAST_COMMITED_TRANSACTION_FIELD);
47
String currentTransaction = ""+id.getTransactionId();
48
49
if(currentTransaction.equals(lastCommitedTransaction)) {return;}
50
51
Transaction multi = jedis.multi();
52
53
multi.set(LAST_COMMITED_TRANSACTION_FIELD, currentTransaction);
54
55
Set<String> keys = hashtags.keySet();
56
for (String hashtag : keys) {
57
Long count = hashtags.get(hashtag);
58
multi.hincrBy("hashtags", hashtag, count);
59
}
60
61
keys = users.keySet();
62
for (String user : keys) {
63
Long count =users.get(user);
64
multi.hincrBy("users",user,count);
65
}
66
67
keys = usersHashtags.keySet();
68
for (String key : keys) {
69
Long count = usersHashtags.get(key);
70
multi.hincrBy("users_hashtags", key, count);
71
}
72
73
multi.exec();
74
}
75
76
@Override
77
public void declareOutputFields(OutputFieldsDeclarer declarer) {}
78
} 这个实现很简单,但是在 finishBatch 有一个细节。
1
...
2
multi.set(LAST_COMMITED_TRANSACTION_FIELD, currentTransaction);
3
... 在这里向数据库保存提交的最后一个事务 ID。为什么要这样做?记住,如果事务失败了,Storm将会尽可能多的重复必要的次数。如果你不确定已经处理了这个事务,你就会多算,事务拓扑也就没有用了。所以请记住:保存最后提交的事务 ID,并在提交前检查。
分区的事务 Spouts
对一个 spout 来说,从一个分区集合中读取批次是很普通的。接着这个例子,你可能有很多redis 数据库,而 tweets 可能会分别保存在这些 redis 数据库里。通过实现IPartitionedTransactionalSpout,Storm 提供了一些工具用来管理每个分区的状态并保证重播的能力。
下面我们修改 TweetsTransactionalSpout,使它可以处理数据分区。
首先,继承 BasePartitionedTransactionalSpout,它实现了IPartitionedTransactionalSpout。
1
public class TweetsPartitionedTransactionalSpout extends
2
BasePartitionedTransactionalSpout<TransactionMetadata> {
3
...
4
} 然后告诉 Storm 谁是你的协调器。
01
public static class TweetsPartitionedTransactionalCoordinator implements Coordinator {
02
@Override
03
public int numPartitions() {
04
return 4;
05
}
06
07
@Override
08
public boolean isReady() {
09
return true;
10
}
11
12
@Override
13
public void close() {}
14
} 在这个例子里,协调器很简单。numPartitions 方法,告诉 Storm 一共有多少分区。而且你要注意,不要返回任何元数据。对于 IPartitionedTransactionalSpout,元数据由分发器直接管理。
下面是分发器的实现:
01
public static class TweetsPartitionedTransactionalEmitter
02
implements Emitter<TransactionMetadata> {
03
PartitionedRQ rq = new ParttionedRQ();
04
05
@Override
06
public TransactionMetadata emitPartitionBatchNew(TransactionAttempt tx,
07
BatchOutputCollector collector, int partition,
08
TransactionMetadata lastPartitioonMeta) {
09
long nextRead;
10
11
if(lastPartitionMeta == null) {
12
nextRead = rq.getNextRead(partition);
13
}else{
14
nextRead = lastPartitionMeta.from + lastPartitionMeta.quantity;
15
rq.setNextRead(partition, nextRead); //移动游标
16
}
17
18
long quantity = rq.getAvailableToRead(partition, nextRead);
19
quantity = quantity > MAX_TRANSACTION_SIZE ? MAX_TRANSACTION_SIZE : quantity;
20
TransactionMetadata metadata = new TransactionMetadata(nextRead, (int)quantity);
21
22
emitPartitionBatch(tx, collector, partition, metadata);
23
return metadata;
24
}
25
26
@Override
27
public void emitPartitionBatch(TransactionAttempt tx, BatchOutputCollector collector,
28
int partition, TransactionMetadata partitionMeta) {
29
if(partitionMeta.quantity <= 0){
30
return;
31
}
32
33
List<String> messages = rq.getMessages(partition, partitionMeta.from,
34
partitionMeta.quantity);
35
36
long tweetId = partitionMeta.from;
37
for (String msg : messages) {
38
collector.emit(new Values(tx, ""+tweetId, msg));
39
tweetId++;
40
}
41
}
42
43
@Override
44
public void close() {}
45
} 这里有两个重要的方法,emitPartitionBatchNew,和 emitPartitionBatch。对于 emitPartitionBatchNew,从 Storm 接收分区参数,该参数决定应该从哪个分区读取批次。在这个方法中,决定获取哪些 tweets,生成相应的元数据对象,调用 emitPartitionBatch,返回元数据对象,并且元数据对象会在方法返回时立即保存到 zookeeper。
Storm 会为每一个分区发送相同的事务 ID,表示一个事务贯穿了所有数据分区。通过emitPartitionBatch 读取分区中的 tweets,并向拓扑分发批次。如果批次处理失败了,Storm 将会调用 emitPartitionBatch 利用保存下来的元数据重复这个批次。
NOTE: 完整的源码请见:https://github.com/storm-book/examples-ch08-transactional-topologies(译者注:原文如此,实际上这个仓库里什么也没有)
模糊的事务性拓扑
到目前为止,你可能已经学会了如何让拥有相同事务 ID 的批次在出错时重播。但是在有些场景下这样做可能就不太合适了。然后会发生什么呢?
事实证明,你仍然可以实现在语义上精确的事务,不过这需要更多的开发工作,你要记录由 Storm 重复的事务之前的状态。既然能在不同时刻为相同的事务 ID 得到不同的元组,你就需要把事务重置到之前的状态,并从那里继续。
比如说,如果你为收到的所有 tweets 计数,你已数到5,而最后的事务 ID 是321,这时你多数了8个。你要维护以下三个值 ——previousCount=5,currentCount=13,以及lastTransactionId=321。假设事物 ID321 又发分了一次,而你又得到了4个元组,而不是之前的8个,提交器会探测到这是相同的事务 ID,它将会把结果重置到 previousCount 的值5,并在此基础上加4,然后更新 currentCount 为9。
另外,在之前的一个事务被取消时,每个并行处理的事务都要被取消。这是为了确保你没有丢失任何数据。
你的 spout 可以实现 IOpaquePartitionedTransactionalSpout,而且正如你看到的,协调器和分发器也很简单。
01
public static class TweetsOpaquePartitionedTransactionalSpoutCoordinator implements IOpaquePartitionedTransactionalSpout.Coordinator {
02
@Override
03
public boolean isReady() {
04
return true;
05
}
06
}
07
08
public static class TweetsOpaquePartitionedTransactionalSpoutEmitter
09
implements IOpaquePartitionedTransactionalSpout.Emitter<TransactionMetadata> {
10
PartitionedRQ rq = new PartitionedRQ();
11
12
@Override
13
public TransactionMetadata emitPartitionBatch(TransactionAttempt tx,
14
BatchOutputCollector collector, int partion,
15
TransactionMetadata lastPartitonMeta) {
16
long nextRead;
17
18
if(lastPartitionMeta == null) {
19
nextRead = rq.getNextRead(partition);
20
}else{
21
nextRead = lastPartitionMeta.from + lastPartitionMeta.quantity;
22
rq.setNextRead(partition, nextRead);//移动游标
23
}
24
25
long quantity = rq.getAvailabletoRead(partition, nextRead);
26
quantity = quantity > MAX_TRANSACTION_SIZE ? MAX_TRANSACTION_SIZE : quantity;
27
TransactionMetadata metadata = new TransactionMetadata(nextRead, (int)quantity);
28
emitMessages(tx, collector, partition, metadata);
29
return metadata;
30
}
31
32
private void emitMessage(TransactionAttempt tx, BatchOutputCollector collector,
33
int partition, TransactionMetadata partitionMeta) {
34
if(partitionMeta.quantity <= 0){return;}
35
36
List<String> messages = rq.getMessages(partition, partitionMeta.from, partitionMeta.quantity);
37
long tweetId = partitionMeta.from;
38
for(String msg : messages) {
39
collector.emit(new Values(tx, ""+tweetId, msg));
40
tweetId++;
41
}
42
}
43
44
@Override
45
public int numPartitions() {
46
return 4;
47
}
48
49
@Override
50
public void close() {}
51
} 最有趣的方法是 emitPartitionBatch,它获取之前提交的元数据。你要用它生成批次。这个批次不需要与之前的那个一致,你可能根本无法创建完全一样的批次。剩余的工作由提交器 bolts借助之前的状态完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号