w3cschool-R语言 教程
https://www.w3cschool.cn/r/
R语言教程
R语言是用于统计分析,图形表示和报告的编程语言和软件环境。 R语言由Ross Ihaka和Robert Gentleman在新西兰奥克兰大学创建,目前由R语言开发核心团队开发。
R语言在GNU通用公共许可证下免费提供,并为各种操作系统(如Linux,Windows和Mac)提供预编译的二进制版本。
这种编程语言被命名为R语言,基于两个R语言作者的名字的第一个字母(Robert Gentleman和Ross Ihaka),并且部分是贝尔实验室语言S的名称。
适用人群
本教程是为期待使用R编程开发统计软件的软件程序员,统计学家和数据挖掘者设计的。 如果你试图理解R编程语言作为一个初学者,本教程将给你足够的了解语言的几乎所有的概念,从那里你可以把自己的更高水平的专业知识。
R的特点
如前所述,R语言是用于统计分析,图形表示和报告的编程语言和软件环境。 以下是R语言的重要特点:
-
R语言是一种开发良好,简单有效的编程语言,包括条件,循环,用户定义的递归函数以及输入和输出设施。
-
R语言具有有效的数据处理和存储设施,
-
R语言提供了一套用于数组,列表,向量和矩阵计算的运算符。
-
R语言为数据分析提供了大型,一致和集成的工具集合。
-
R语言提供直接在计算机上或在纸张上打印的图形设施用于数据分析和显示。
R语言 环境设置
安装R语言环境
1. 安装包下载地址:https://cran.r-project.org
2. 点击macOS对应的安装包,下图中由红框标出。(我的操作系统版本是macOS 10.14.5)
3. 点击R-verson.pkg,下图红框标出。可以看到我下载的版本是R-3.6.2
4. 下载完成,在“Finder->下载”中点击pkg文件,一直按下一步就可安装完成。
R语言 基本语法
命令提示符
如果你已经配置好R语言环境,那么你只需要按一下的命令便可轻易开启命令提示符
$ R
这将启动R语言解释器,你会得到一个提示 > 在那里你可以开始输入你的程序,具体如下。
> myString <- "Hello, World!" > print ( myString) [1] "Hello, World!"
在这里,第一个语句先定义一个字符串变量myString,并将“Hello,World!”赋值其中,第二句则使用print()语句将变量myString的内容进行打印。
脚本文件
通常,您将通过在脚本文件中编写程序来执行编程,然后在命令提示符下使用R解释器(称为Rscript)来执行这些脚本。 所以让我们开始在一个命名为test.R的文本文件中编写下面的代码
# My first program in R Programming myString <- "Hello, World!" print ( myString)
将上述代码保存在test.R文件中,并在Linux命令提示符下执行,如下所示。 即使您使用的是Windows或其他系统,语法也将保持不变。
$ Rscript test.R
当我们运行上面的程序,它产生以下结果。
[1] "Hello, World!"
注释
注释能帮助您解释R语言程序中的脚本,它们在实际执行程序时会被解释器忽略。 单个注释使用#在语句的开头写入,如下所示
# My first program in R Programming
R语言不支持多行注释,但你可以使用一个小技巧,如下
if(FALSE) {
"This is a demo for multi-line comments and it should be put inside either a single
OR double quote"
}
myString <- "Hello, World!"
print ( myString)
虽然上面的注释将由R解释器执行,但它们不会干扰您的实际程序。 但是你必须为内容加上单引号或双引号。
R语言 数据类型
您可能想存储各种数据类型的信息,如字符,宽字符,整数,浮点,双浮点,布尔等。基于变量的数据类型,操作系统分配内存并决定什么可以存储在保留内存中。
与其他编程语言(如 C 中的 C 和 java)相反,变量不会声明为某种数据类型。 变量分配有 R 对象,R 对象的数据类型变为变量的数据类型。尽管有很多类型的 R 对象,但经常使用的是:
- 矢量
- 列表
- 矩阵
- 数组
- 因子
- 数据帧
这些对象中最简单的是向量对象,并且这些原子向量有六种数据类型,也称为六类向量。 其他 R 对象建立在原子向量之上。
| 数据类型 | 例 | 校验 |
|---|---|---|
| Logical(逻辑型) | TRUE, FALSE |
v <- TRUE print(class(v)) 它产生以下结果 - [1] "logical" |
| Numeric(数字) | 12.3,5,999 |
v <- 23.5 print(class(v)) 它产生以下结果 - [1] "numeric" |
| Integer(整型) | 2L,34L,0L |
v <- 2L print(class(v)) 它产生以下结果 - [1] "integer" |
| Complex(复合型) | 3 + 2i |
v <- 2+5i print(class(v)) 它产生以下结果 - [1] "complex" |
| Character(字符) | 'a' , "good", "TRUE", '23.4' |
v <- "TRUE" print(class(v)) 它产生以下结果 - [1] "character" |
| Raw(原型) | "Hello" 被存储为 48 65 6c 6c 6f |
v <- charToRaw("Hello")
print(class(v))
它产生以下结果 - [1] "raw" |
在 R 编程中,非常基本的数据类型是称为向量的 R 对象,其保存如上所示的不同类的元素。 请注意,在 R 中,类的数量不仅限于上述六种类型。 例如,我们可以使用许多原子向量并创建一个数组,其类将成为数组。
Vectors 向量
当你想用多个元素创建向量时,你应该使用 c() 函数,这意味着将元素组合成一个向量。
# Create a vector.
apple <- c('red','green',"yellow")
print(apple)
# Get the class of the vector.
print(class(apple))
当我们执行上面的代码,它产生以下结果
[1] "red" "green" "yellow" [1] "character"
Lists 列表
列表是一个R对象,它可以在其中包含许多不同类型的元素,如向量,函数甚至其中的另一个列表。
# Create a list. list1 <- list(c(2,5,3),21.3,sin) # Print the list. print(list1)
当我们执行上面的代码,它产生以下结果
[[1]]
[1] 2 5 3
[[2]]
[1] 21.3
[[3]]
function (x) .Primitive("sin")
Matrices 矩阵
矩阵是二维矩形数据集。 它可以使用矩阵函数的向量输入创建。
# Create a matrix.
M = matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE)
print(M)
当我们执行上面的代码,它产生以下结果
[,1] [,2] [,3] [1,] "a" "a" "b" [2,] "c" "b" "a"
Arrays 数组
虽然矩阵被限制为二维,但阵列可以具有任何数量的维度。 数组函数使用一个 dim 属性创建所需的维数。 在下面的例子中,我们创建了一个包含两个元素的数组,每个元素为 3x3 个矩阵。
# Create an array.
a <- array(c('green','yellow'),dim = c(3,3,2))
print(a)
当我们执行上面的代码,它产生以下结果
, , 1
[,1] [,2] [,3]
[1,] "green" "yellow" "green"
[2,] "yellow" "green" "yellow"
[3,] "green" "yellow" "green"
, , 2
[,1] [,2] [,3]
[1,] "yellow" "green" "yellow"
[2,] "green" "yellow" "green"
[3,] "yellow" "green" "yellow"
Factors 因子
因子是使用向量创建的 r 对象。 它将向量与向量中元素的不同值一起存储为标签。 标签总是字符,不管它在输入向量中是数字还是字符或布尔等。 它们在统计建模中非常有用。
使用 factor() 函数创建因子。nlevels 函数给出级别计数。
# Create a vector.
apple_colors <- c('green','green','yellow','red','red','red','green')
# Create a factor object.
factor_apple <- factor(apple_colors)
# Print the factor.
print(factor_apple)
print(nlevels(factor_apple))
当我们执行上面的代码,它产生以下结果
[1] green green yellow red red red green Levels: green red yellow # applying the nlevels function we can know the number of distinct values [1] 3
Data Frames 数据帧
数据帧是表格数据对象。 与数据帧中的矩阵不同,每列可以包含不同的数据模式。 第一列可以是数字,而第二列可以是字符,第三列可以是逻辑的。 它是等长度的向量的列表。
使用 data.frame() 函数创建数据帧。
# Create the data frame.
BMI <- data.frame(
gender = c("Male", "Male","Female"),
height = c(152, 171.5, 165),
weight = c(81,93, 78),
Age = c(42,38,26)
)
print(BMI)
当我们执行上面的代码,它产生以下结果
gender height weight Age 1 Male 152.0 81 42 2 Male 171.5 93 38 3 Female 165.0 78 26
R语言 变量
变量为我们提供了我们的程序可以操作的命名存储。 R语言中的变量可以存储原子向量,原子向量组或许多Robject的组合。 有效的变量名称由字母,数字和点或下划线字符组成。 变量名以字母或不以数字后跟的点开头。
| 变量名 | 合法性 | 原因 |
|---|---|---|
| var_name2. | 有效 | 有字母,数字,点和下划线 |
| VAR_NAME% | 无效 | 有字符'%'。只有点(.)和下划线允许的。 |
| 2var_name | 无效 | 以数字开头 |
| .var_name, var.name |
有效 | 可以用一个点(.),但启动点(.),不应该后跟一个数字。 |
| .2var_name | 无效 | 起始点后面是数字使其无效。 |
| _var_name | 无效 | 开头_这是无效的 |
变量赋值
可以使用向左,向右和等于运算符来为变量分配值。 可以使用print()或cat()函数打印变量的值。 cat()函数将多个项目组合成连续打印输出。
# Assignment using equal operator.
var.1 = c(0,1,2,3)
# Assignment using leftward operator.
var.2 <- c("learn","R")
# Assignment using rightward operator.
c(TRUE,1) -> var.3
print(var.1)
cat ("var.1 is ", var.1 ,"
")
cat ("var.2 is ", var.2 ,"
")
cat ("var.3 is ", var.3 ,"
")
当我们执行上面的代码,它产生以下结果 -
[1] 0 1 2 3 var.1 is 0 1 2 3 var.2 is learn R var.3 is 1 1
注 - 向量c(TRUE,1)具有逻辑和数值类的混合。 因此,逻辑类强制转换为数字类,使TRUE为1。
变量的数据类型
在R语言中,变量本身没有声明任何数据类型,而是获取分配给它的R - 对象的数据类型。 所以R称为动态类型语言,这意味着我们可以在程序中使用同一个变量时,一次又一次地更改变量的数据类型。
var_x <- "Hello"
cat("The class of var_x is ",class(var_x),"
")
var_x <- 34.5
cat(" Now the class of var_x is ",class(var_x),"
")
var_x <- 27L
cat(" Next the class of var_x becomes ",class(var_x),"
")
当我们执行上面的代码,它产生以下结果 -
The class of var_x is character
Now the class of var_x is numeric
Next the class of var_x becomes integer
查找变量
要知道工作空间中当前可用的所有变量,我们使用ls()函数。 ls()函数也可以使用模式来匹配变量名。
print(ls())
当我们执行上面的代码,它产生以下结果 -
[1] "my var" "my_new_var" "my_var" "var.1" [5] "var.2" "var.3" "var.name" "var_name2." [9] "var_x" "varname"
注意 - 它是一个示例输出,取决于在您的环境中声明的变量。
ls()函数可以使用模式来匹配变量名。
# List the variables starting with the pattern "var". print(ls(pattern = "var"))
当我们执行上面的代码,它产生以下结果 -
[1] "my var" "my_new_var" "my_var" "var.1" [5] "var.2" "var.3" "var.name" "var_name2." [9] "var_x" "varname"
以点(.)开头的变量被隐藏,它们可以使用ls()函数的“all.names = TRUE”参数列出。
print(ls(all.name = TRUE))
当我们执行上面的代码,它产生以下结果 -
[1] ".cars" ".Random.seed" ".var_name" ".varname" ".varname2" [6] "my var" "my_new_var" "my_var" "var.1" "var.2" [11]"var.3" "var.name" "var_name2." "var_x"
删除变量
可以使用rm()函数删除变量。 下面我们删除变量var.3。 打印时,抛出变量错误的值。
rm(var.3) print(var.3)
当我们执行上面的代码,它产生以下结果 -
[1] "var.3" Error in print(var.3) : object 'var.3' not found
所有的变量可以通过使用rm()和ls()函数一起删除。
rm(list = ls()) print(ls())
当我们执行上面的代码,它产生以下结果 -
character(0)
R语言 条形图
条形图表示矩形条中的数据,条的长度与变量的值成比例。 R语言使用函数 barplot() 创建条形图。 R 语言可以在条形图中绘制垂直和水平条。 在条形图中,每个条可以给予不同的颜色。
语法
在 R 语言中创建条形图的基本语法是 -
barplot(H, xlab, ylab, main, names.arg, col)
以下是所使用的参数的描述 -
-
H 是包含在条形图中使用的数值的向量或矩阵。
-
xlab 是 x 轴的标签。
-
ylab 是 y 轴的标签。
-
main 是条形图的标题。
-
names.arg 是在每个条下出现的名称的向量。
-
col 用于向图中的条形提供颜色。
例
使用输入向量和每个条的名称创建一个简单的条形图。
以下脚本将创建并保存当前 R 语言工作目录中的条形图。
# Create the data for the chart. H <- c(7,12,28,3,41) # Give the chart file a name. png(file = "barchart.png") # Plot the bar chart. barplot(H) # Save the file. dev.off()
当我们执行上面的代码,它产生以下结果 -
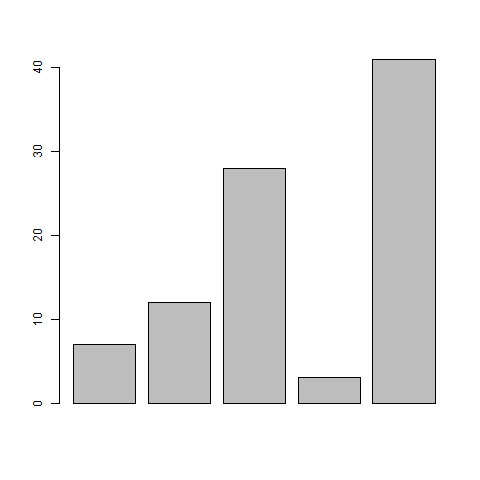
R语言 箱线图
箱线图是数据集中的数据分布良好的度量。 它将数据集分成三个四分位数。 此图表表示数据集中的最小值,最大值,中值,第一四分位数和第三四分位数。 它还可用于通过绘制每个数据集的箱线图来比较数据集之间的数据分布。
R语言中使用boxplot()函数来创建箱线图。
语法
在R语言中创建箱线图的基本语法是 -
boxplot(x, data, notch, varwidth, names, main)
以下是所使用的参数的描述 -
-
x是向量或公式。
-
数据是数据帧。
-
notch是逻辑值。 设置为TRUE以绘制凹口。
-
varwidth是一个逻辑值。 设置为true以绘制与样本大小成比例的框的宽度。
-
names是将打印在每个箱线图下的组标签。
-
main用于给图表标题。
例
我们使用R语言环境中可用的数据集“mtcars”来创建基本箱线图。 让我们看看mtcars中的列“mpg”和“cyl”。
input <- mtcars[,c('mpg','cyl')]
print(head(input))
当我们执行上面的代码,它会产生以下结果 -
mpg cyl Mazda RX4 21.0 6 Mazda RX4 Wag 21.0 6 Datsun 710 22.8 4 Hornet 4 Drive 21.4 6 Hornet Sportabout 18.7 8 Valiant 18.1 6
创建箱线图
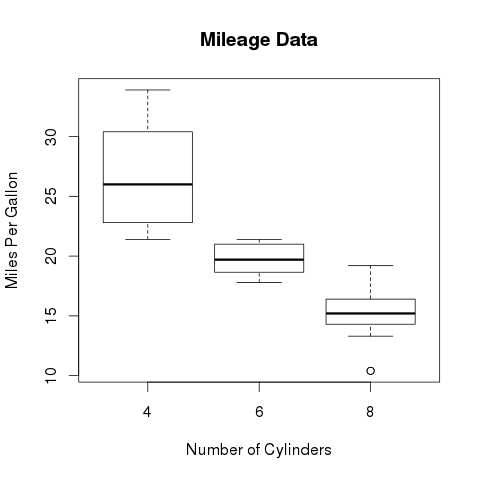
以下脚本将为mpg(英里/加仑)和cyl(气缸数)之间的关系创建箱线图。
# Give the chart file a name. png(file = "boxplot.png") # Plot the chart. boxplot(mpg ~ cyl, data = mtcars, xlab = "Number of Cylinders", ylab = "Miles Per Gallon", main = "Mileage Data") # Save the file. dev.off()
当我们执行上面的代码,它产生以下结果 -
带槽的箱线图
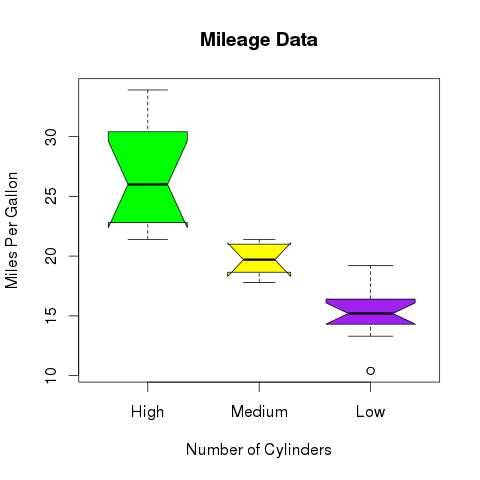
我们可以绘制带槽的箱线图,以了解不同数据组的中值如何相互匹配。
以下脚本将为每个数据组创建一个带缺口的箱线图。
# Give the chart file a name.
png(file = "boxplot_with_notch.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars,
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon",
main = "Mileage Data",
notch = TRUE,
varwidth = TRUE,
col = c("green","yellow","purple"),
names = c("High","Medium","Low")
)
# Save the file.
dev.off()
当我们执行上面的代码,它产生以下结果 -
R语言 CSV文件
在 R 语言中,我们可以从存储在 R 语言环境外的文件中读取数据。 我们还可以将数据写入将被操作系统存储和访问的文件。 R 语言可以读取和写入各种文件格式,如csv,excel,xml等。
在本章中,我们将学习从csv文件读取数据,然后将数据写入csv文件。 该文件应该存在于当前工作目录中,以便 R 语言可以读取它。 当然我们也可以设置我们自己的目录并从那里读取文件。
获取和设置工作目录
您可以使用getwd()函数检查R语言工作区指向的目录。 您还可以使用setwd()函数设置新的工作目录。
# Get and print current working directory.
print(getwd())
# Set current working directory.
setwd("/web/com")
# Get and print current working directory.
print(getwd())
当我们执行上面的代码,它产生以下结果 -
[1] "/web/com/1441086124_2016" [1] "/web/com"
此结果取决于您的操作系统和您当前工作的目录。
输入为CSV文件
csv 文件是一个文本文件,其中列中的值由逗号分隔。 让我们考虑名为input.csv的文件中出现的以下数据。
您可以通过复制和粘贴此数据使用 Windows 记事本创建此文件。 使用记事本中的保存为所有文件(*.*)选项将文件保存为input.csv。
id,name,salary,start_date,dept 1,Rick,623.3,2012-01-01,IT 2,Dan,515.2,2013-09-23,Operations 3,Michelle,611,2014-11-15,IT 4,Ryan,729,2014-05-11,HR ,Gary,843.25,2015-03-27,Finance 6,Nina,578,2013-05-21,IT 7,Simon,632.8,2013-07-30,Operations 8,Guru,722.5,2014-06-17,Finance
读取CSV文件
以下是read.csv()函数的一个简单示例,用于读取当前工作目录中可用的 CSV 文件 -
data <- read.csv("input.csv")
print(data)
当我们执行上面的代码,它产生以下结果 -
id, name, salary, start_date, dept 1 1 Rick 623.30 2012-01-01 IT 2 2 Dan 515.20 2013-09-23 Operations 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 NA Gary 843.25 2015-03-27 Finance 6 6 Nina 578.00 2013-05-21 IT 7 7 Simon 632.80 2013-07-30 Operations 8 8 Guru 722.50 2014-06-17 Finance
分析CSV文件
默认情况下,read.csv()函数将输出作为数据帧。 这可以容易地如下检查。 此外,我们可以检查列和行的数量。
data <- read.csv("input.csv")
print(is.data.frame(data))
print(ncol(data))
print(nrow(data))
当我们执行上面的代码,它产生以下结果 -
[1] TRUE [1] 5 [1] 8
一旦我们读取数据帧中的数据,我们可以应用所有适用于数据帧的函数,如下一节所述。
获得最高工资
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
print(sal)
当我们执行上面的代码,它产生以下结果 -
[1] 843.25
获取具有最高工资的人的详细信息
我们可以获取满足特定过滤条件的行,类似于SQL where子句。
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
# Get the person detail having max salary.
retval <- subset(data, salary == max(salary))
print(retval)
当我们执行上面的代码,它产生以下结果 -
id name salary start_date dept 5 NA Gary 843.25 2015-03-27 Finance
获取所有的 IT 部门员工的信息
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset( data, dept == "IT")
print(retval)
当我们执行上面的代码,它产生以下结果 -
id name salary start_date dept 1 1 Rick 623.3 2012-01-01 IT 3 3 Michelle 611.0 2014-11-15 IT 6 6 Nina 578.0 2013-05-21 IT
获得工资大于600的 IT 部门的人员
# Create a data frame.
data <- read.csv("input.csv")
info <- subset(data, salary > 600 & dept == "IT")
print(info)
当我们执行上面的代码,它产生以下结果 -
id name salary start_date dept 1 1 Rick 623.3 2012-01-01 IT 3 3 Michelle 611.0 2014-11-15 IT
获得2014年或之后加入的人
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
print(retval)
当我们执行上面的代码,它产生以下结果 -
id name salary start_date dept 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 NA Gary 843.25 2015-03-27 Finance 8 8 Guru 722.50 2014-06-17 Finance
写入CSV文件
R 语言可以创建csv文件形式的现有数据帧。 write.csv()函数用于创建csv文件。 此文件在工作目录中创建。
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv")
newdata <- read.csv("output.csv")
print(newdata)
当我们执行上面的代码,它产生以下结果 -
X id name salary start_date dept 1 3 3 Michelle 611.00 2014-11-15 IT 2 4 4 Ryan 729.00 2014-05-11 HR 3 5 NA Gary 843.25 2015-03-27 Finance 4 8 8 Guru 722.50 2014-06-17 Finance
这里列 X 来自数据集newper。 这可以在写入文件时使用附加参数删除。
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv", row.names = FALSE)
newdata <- read.csv("output.csv")
print(newdata)
当我们执行上面的代码,它产生以下结果 -
id name salary start_date dept 1 3 Michelle 611.00 2014-11-15 IT 2 4 Ryan 729.00 2014-05-11 HR 3 NA Gary 843.25 2015-03-27 Finance 4 8 Guru 722.50 2014-06-17 Finance
R语言 Excel文件
Microsoft Excel是最广泛使用的电子表格程序,以.xls或.xlsx格式存储数据。 R语言可以直接从这些文件使用一些excel特定的包。 很少这样的包是 - XLConnect,xlsx,gdata等。我们将使用xlsx包。 R语言也可以使用这个包写入excel文件。
安装xlsx软件包
您可以在R控制台中使用以下命令来安装“xlsx”软件包。 它可能会要求安装一些额外的软件包这个软件包依赖。 按照具有所需软件包名称的同一命令安装其他软件包。
install.packages("xlsx")
验证并加载“xlsx”软件包
使用以下命令验证并加载“xlsx”软件包。
# Verify the package is installed.
any(grepl("xlsx",installed.packages()))
# Load the library into R workspace.
library("xlsx")
当脚本运行,我们得到以下输出。
[1] TRUE Loading required package: rJava Loading required package: methods Loading required package: xlsxjars
输入为xlsx文件
打开Microsoft Excel。 将以下数据复制并粘贴到名为sheet1的工作表中。
id name salary start_date dept 1 Rick 623.3 1/1/2012 IT 2 Dan 515.2 9/23/2013 Operations 3 Michelle 611 11/15/2014 IT 4 Ryan 729 5/11/2014 HR 5 Gary 843.25 3/27/2015 Finance 6 Nina 578 5/21/2013 IT 7 Simon 632.8 7/30/2013 Operations 8 Guru 722.5 6/17/2014 Finance
还要将以下数据复制并粘贴到另一个工作表,并将此工作表重命名为“city”。
name city Rick Seattle Dan Tampa Michelle Chicago Ryan Seattle Gary Houston Nina Boston Simon Mumbai Guru Dallas
将Excel文件另存为“input.xlsx”。 应将其保存在R工作区的当前工作目录中。
读取Excel文件
通过使用read.xlsx()函数读取input.xlsx,如下所示。 结果作为数据帧存储在R语言环境中。
# Read the first worksheet in the file input.xlsx.
data <- read.xlsx("input.xlsx", sheetIndex = 1)
print(data)
当我们执行上面的代码,它产生以下结果 -
id, name, salary, start_date, dept 1 1 Rick 623.30 2012-01-01 IT 2 2 Dan 515.20 2013-09-23 Operations 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 NA Gary 843.25 2015-03-27 Finance 6 6 Nina 578.00 2013-05-21 IT 7 7 Simon 632.80 2013-07-30 Operations 8 8 Guru 722.50 2014-06-17 Finance
R语言 XML文件
XML是一种文件格式,它使用标准ASCII文本共享万维网,内部网和其他地方的文件格式和数据。 它代表可扩展标记语言(XML)。 类似于HTML它包含标记标签。 但是与HTML中的标记标记描述页面的结构不同,在xml中,标记标记描述了包含在文件中的数据的含义。
您可以使用“XML”包读取R语言中的xml文件。 此软件包可以使用以下命令安装。
install.packages("XML")
输入数据
通过将以下数据复制到文本编辑器(如记事本)中来创建XMl文件。 使用.xml扩展名保存文件,并将文件类型选择为所有文件(*.*)。
<RECORDS>
<EMPLOYEE>
<ID>1</ID>
<NAME>Rick</NAME>
<SALARY>623.3</SALARY>
<STARTDATE>1/1/2012</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>2</ID>
<NAME>Dan</NAME>
<SALARY>515.2</SALARY>
<STARTDATE>9/23/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>3</ID>
<NAME>Michelle</NAME>
<SALARY>611</SALARY>
<STARTDATE>11/15/2014</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>4</ID>
<NAME>Ryan</NAME>
<SALARY>729</SALARY>
<STARTDATE>5/11/2014</STARTDATE>
<DEPT>HR</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>5</ID>
<NAME>Gary</NAME>
<SALARY>843.25</SALARY>
<STARTDATE>3/27/2015</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>6</ID>
<NAME>Nina</NAME>
<SALARY>578</SALARY>
<STARTDATE>5/21/2013</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>7</ID>
<NAME>Simon</NAME>
<SALARY>632.8</SALARY>
<STARTDATE>7/30/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>8</ID>
<NAME>Guru</NAME>
<SALARY>722.5</SALARY>
<STARTDATE>6/17/2014</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
</RECORDS>
读取XML文件
xml文件由R语言使用函数xmlParse()读取。 它作为列表存储在R语言中。
# Load the package required to read XML files.
library("XML")
# Also load the other required package.
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Print the result.
print(result)
当我们执行上面的代码,它产生以下结果 -
R语言 JSON文件
JSON文件以人类可读格式将数据存储为文本。 Json代表JavaScript Object Notation。 R可以使用rjson包读取JSON文件。
安装rjson包
在R语言控制台中,您可以发出以下命令来安装rjson包。
install.packages("rjson")
输入数据
通过将以下数据复制到文本编辑器(如记事本)中来创建JSON文件。 使用.json扩展名保存文件,并将文件类型选择为所有文件(*.*)。
{
"ID":["1","2","3","4","5","6","7","8" ],
"Name":["Rick","Dan","Michelle","Ryan","Gary","Nina","Simon","Guru" ],
"Salary":["623.3","515.2","611","729","843.25","578","632.8","722.5" ],
"StartDate":[ "1/1/2012","9/23/2013","11/15/2014","5/11/2014","3/27/2015","5/21/2013",
"7/30/2013","6/17/2014"],
"Dept":[ "IT","Operations","IT","HR","Finance","IT","Operations","Finance"]
}
读取JSON文件
JSON文件由R使用来自JSON()的函数读取。 它作为列表存储在R中。
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Print the result.
print(result)
当我们执行上面的代码,它产生以下结果 -
R语言 数据库
数据是关系数据库系统以规范化格式存储。 因此,要进行统计计算,我们将需要非常先进和复杂的Sql查询。 但R语言可以轻松地连接到许多关系数据库,如MySql,Oracle,Sql服务器等,并从它们获取记录作为数据框。 一旦数据在R语言环境中可用,它就变成正常的R语言数据集,并且可以使用所有强大的包和函数来操作或分析。
在本教程中,我们将使用MySql作为连接到R语言的参考数据库。
RMySQL包
R语言有一个名为“RMySQL”的内置包,它提供与MySql数据库之间的本地连接。 您可以使用以下命令在R语言环境中安装此软件包。
install.packages("RMySQL")
将R连接到MySql
一旦安装了包,我们在R中创建一个连接对象以连接到数据库。 它使用用户名,密码,数据库名称和主机名作为输入。
# Create a connection Object to MySQL database. # We will connect to the sampel database named "sakila" that comes with MySql installation. mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila', host = 'localhost') # List the tables available in this database. dbListTables(mysqlconnection)
当我们执行上面的代码,它产生以下结果 -
[1] "actor" "actor_info" [3] "address" "category" [5] "city" "country" [7] "customer" "customer_list" [9] "film" "film_actor" [11] "film_category" "film_list" [13] "film_text" "inventory" [15] "language" "nicer_but_slower_film_list" [17] "payment" "rental" [19] "sales_by_film_category" "sales_by_store" [21] "staff" "staff_list" [23] "store"
查询表
我们可以使用函数dbSendQuery()查询MySql中的数据库表。 查询在MySql中执行,并使用R语言fetch()函数返回结果集。 最后,它被存储为R语言中的数据帧。
# Query the "actor" tables to get all the rows. result = dbSendQuery(mysqlconnection, "select * from actor") # Store the result in a R data frame object. n = 5 is used to fetch first 5 rows. data.frame = fetch(result, n = 5) print(data.frame)
当我们执行上面的代码,它产生以下结果 -
actor_id first_name last_name last_update 1 1 PENELOPE GUINESS 2006-02-15 04:34:33 2 2 NICK WAHLBERG 2006-02-15 04:34:33 3 3 ED CHASE 2006-02-15 04:34:33 4 4 JENNIFER DAVIS 2006-02-15 04:34:33 5 5 JOHNNY LOLLOBRIGIDA 2006-02-15 04:34:33
带过滤条件的查询
我们可以传递任何有效的select查询来获取结果。
result = dbSendQuery(mysqlconnection, "select * from actor where last_name = 'TORN'") # Fetch all the records(with n = -1) and store it as a data frame. data.frame = fetch(result, n = -1) print(data)
当我们执行上面的代码,它产生以下结果 -
actor_id first_name last_name last_update 1 18 DAN TORN 2006-02-15 04:34:33 2 94 KENNETH TORN 2006-02-15 04:34:33 3 102 WALTER TORN 2006-02-15 04:34:33
更新表中的行
我们可以通过将更新查询传递给dbSendQuery()函数来更新Mysql表中的行。
dbSendQuery(mysqlconnection, "update mtcars set disp = 168.5 where hp = 110")
在执行上面的代码后,我们可以看到在MySql环境中更新的表。
将数据插入表中
dbSendQuery(mysqlconnection,
"insert into mtcars(row_names, mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb)
values('New Mazda RX4 Wag', 21, 6, 168.5, 110, 3.9, 2.875, 17.02, 0, 1, 4, 4)"
)
在执行上面的代码后,我们可以看到插入到MySql环境中的表中的行。
在MySql中创建表
我们可以在MySql中使用函数dbWriteTable()创建表。 如果表已经存在,它将覆盖该表,并将数据帧用作输入。
# Create the connection object to the database where we want to create the table. mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila', host = 'localhost') # Use the R data frame "mtcars" to create the table in MySql. # All the rows of mtcars are taken inot MySql. dbWriteTable(mysqlconnection, "mtcars", mtcars[, ], overwrite = TRUE)
执行上面的代码后,我们可以看到在MySql环境中创建的表。
删除MySql中的表
我们可以删除MySql数据库中的表,将drop table语句传递到dbSendQuery()中,就像我们使用它查询表中的数据一样。
dbSendQuery(mysqlconnection, 'drop table if exists mtcars')
执行上面的代码后,我们可以看到表在MySql环境中被删除。
R语言 平均值,中位数和模式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号