w3cschool-Hibernate 教程
什么是 ORM?
ORM 表示 Object-Relational Mapping (ORM),是一个方便在关系数据库和类似于 Java, C# 等面向对象的编程语言中转换数据的技术。一个 ORM 系统相比于普通的 JDBC 有以下的优点。
Java ORM 框架
在 Java 中有几个持久化的框架和 ORM 选项。一个持久化的框架是 ORM 存储和索引对象到关系型数据库的服务。
- Enterprise JavaBeans Entity Beans
- Java Data Objects
- Castor
- TopLink
- Spring DAO
- Hibernate
- And many more
JDBC 的优点和缺点
| JDBC 的优点 | JDBC 的缺点 |
|---|---|
| 干净整洁的 SQL 处理 | 大项目中使用很复杂 |
| 大数据下有良好的性能 | 很大的编程成本 |
| 对于小应用非常好 | 没有封装 |
| 易学的简易语法 | 难以实现 MVC 的概念 |
| 查询需要指定 DBMS |
简介
Hibernate 是由 Gavin King 于 2001 年创建的开放源代码的对象关系框架。它强大且高效的构建具有关系对象持久性和查询服务的 Java 应用程序。
Hibernate 将 Java 类映射到数据库表中,从 Java 数据类型中映射到 SQL 数据类型中,并把开发人员从 95% 的公共数据持续性编程工作中解放出来。
Hibernate 是传统 Java 对象和数据库服务器之间的桥梁,用来处理基于 O/R 映射机制和模式的那些对象。

Hibernate 优势
- Hibernate 使用 XML 文件来处理映射 Java 类别到数据库表格中,并且不用编写任何代码。
- 为在数据库中直接储存和检索 Java 对象提供简单的 APIs。
- 如果在数据库中或任何其它表格中出现变化,那么仅需要改变 XML 文件属性。
- 抽象不熟悉的 SQL 类型,并为我们提供工作中所熟悉的 Java 对象。
- Hibernate 不需要应用程序服务器来操作。
- 操控你数据库中对象复杂的关联。
- 最小化与访问数据库的智能提取策略。
- 提供简单的数据询问。
支持的数据库
Hibernate 支持几乎所有的主要 RDBMS。以下是一些由 Hibernate 所支持的数据库引擎。
- HSQL Database Engine
- DB2/NT
- MySQL
- PostgreSQL
- FrontBase
- Oracle
- Microsoft SQL Server Database
- Sybase SQL Server
- Informix Dynamic Server
支持的技术
Hibernate 支持多种多样的其它技术,包括以下:
- XDoclet Spring
- J2EE
- Eclipse plug-ins
- Maven
架构
Hibernate 架构是分层的,作为数据访问层,你不必知道底层 API 。Hibernate 利用数据库以及配置数据来为应用程序提供持续性服务(以及持续性对象)。
下面是一个非常高水平的 Hibernate 应用程序架构视图。
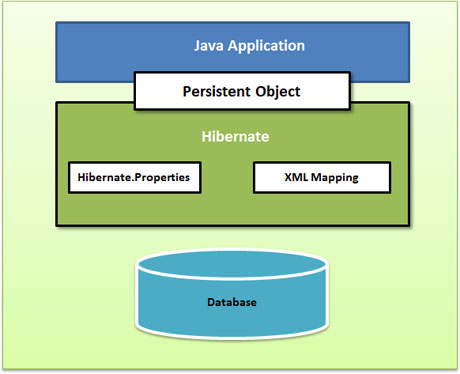
下面是一个详细的 Hibernate 应用程序体系结构视图以及一些重要的类。
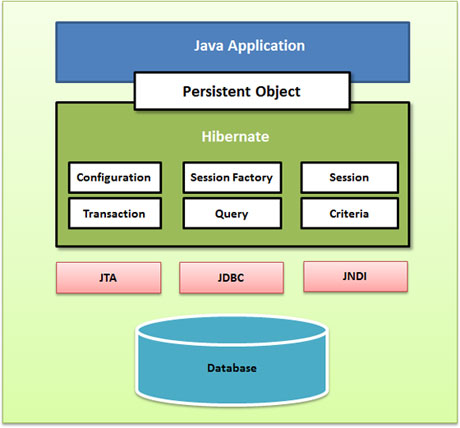
Hibernate 使用不同的现存 Java API,比如 JDBC,Java 事务 API(JTA),以及 Java 命名和目录界面(JNDI)。JDBC 提供了一个基本的抽象级别的通用关系数据库的功能, Hibernate 支持几乎所有带有 JDBC 驱动的数据库。JNDI 和 JTA 允许 Hibernate 与 J2EE 应用程序服务器相集成。
下面的部分简要地描述了在 Hibernate 应用程序架构所涉及的每一个类对象。
配置对象
配置对象是你在任何 Hibernate 应用程序中创造的第一个 Hibernate 对象,并且经常只在应用程序初始化期间创造。它代表了 Hibernate 所需一个配置或属性文件。配置对象提供了两种基础组件。
- 数据库连接:由 Hibernate 支持的一个或多个配置文件处理。这些文件是 hibernate.properties 和 hibernate.cfg.xml。
- 类映射设置:这个组件创造了 Java 类和数据库表格之间的联系。
SessionFactory 对象
配置对象被用于创造一个 SessionFactory 对象,使用提供的配置文件为应用程序依次配置 Hibernate,并允许实例化一个会话对象。SessionFactory 是一个线程安全对象并由应用程序所有的线程所使用。
SessionFactory 是一个重量级对象所以通常它都是在应用程序启动时创造然后留存为以后使用。每个数据库需要一个 SessionFactory 对象使用一个单独的配置文件。所以如果你使用多种数据库那么你要创造多种 SessionFactory 对象。
Session 对象
一个会话被用于与数据库的物理连接。Session 对象是轻量级的,并被设计为每次实例化都需要与数据库的交互。持久对象通过 Session 对象保存和检索。
Session 对象不应该长时间保持开启状态因为它们通常情况下并非线程安全,并且它们应该按照所需创造和销毁。
Transaction 对象
一个事务代表了与数据库工作的一个单元并且大部分 RDBMS 支持事务功能。在 Hibernate 中事务由底层事务管理器和事务(来自 JDBC 或者 JTA)处理。
这是一个选择性对象,Hibernate 应用程序可能不选择使用这个接口,而是在自己应用程序代码中管理事务。
Query 对象
Query 对象使用 SQL 或者 Hibernate 查询语言(HQL)字符串在数据库中来检索数据并创造对象。一个查询的实例被用于连结查询参数,限制由查询返回的结果数量,并最终执行查询。
Criteria 对象
Criteria 对象被用于创造和执行面向规则查询的对象来检索对象。
配置
Hibernate 需要事先知道在哪里找到映射信息,这些映射信息定义了 Java 类怎样关联到数据库表。Hibernate 也需要一套相关数据库和其它相关参数的配置设置。所有这些信息通常是作为一个标准的 Java 属性文件提供的,名叫 hibernate.properties。又或者是作为 XML 文件提供的,名叫 hibernate.cfg.xml。
我们将考虑 hibernate.cfg.xml 这个 XML 格式文件,来决定在我的例子里指定需要的 Hibernate 应用属性。这个 XML 文件中大多数的属性是不需要修改的。这个文件保存在应用程序的类路径的根目录里。
Hibernate 属性
下面是一个重要的属性列表,你可能需要表中的属性来在单独的情况下配置数据库。
| S.N. | 属性和描述 |
|---|---|
| 1 | hibernate.dialect 这个属性使 Hibernate 应用为被选择的数据库生成适当的 SQL。 |
| 2 | hibernate.connection.driver_class JDBC 驱动程序类。 |
| 3 | hibernate.connection.url 数据库实例的 JDBC URL。 |
| 4 | hibernate.connection.username 数据库用户名。 |
| 5 | hibernate.connection.password 数据库密码。 |
| 6 | hibernate.connection.pool_size 限制在 Hibernate 应用数据库连接池中连接的数量。 |
| 7 | hibernate.connection.autocommit 允许在 JDBC 连接中使用自动提交模式。 |
如果您正在使用 JNDI 和数据库应用程序服务器然后您必须配置以下属性:
| S.N. | 属性和描述 |
|---|---|
| 1 | hibernate.connection.datasource 在应用程序服务器环境中您正在使用的应用程序 JNDI 名。 |
| 2 | hibernate.jndi.class JNDI 的 InitialContext 类。 |
| 3 | hibernate.jndi.<JNDIpropertyname> 在 JNDI的 InitialContext 类中通过任何你想要的 Java 命名和目录接口属性。 |
| 4 | hibernate.jndi.url 为 JNDI 提供 URL。 |
| 5 | hibernate.connection.username 数据库用户名。 |
| 6 | hibernate.connection.password 数据库密码。 |
Hibernate 和 MySQL 数据库
MySQL 数据库是目前可用的开源数据库系统中最受欢迎的数据库之一。我们要创建 hibernate.cfg.xml 配置文件并将其放置在应用程序的 CLASSPATH 的根目录里。你要确保在你的 MySQL 数据库中 testdb 数据库是可用的,而且你要有一个用户 test 可用来访问数据库。
XML 配置文件一定要遵守 Hibernate 3 Configuration DTD,在 http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd. 这个网址中是可以找到的。
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-configuration SYSTEM
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="hibernate.dialect">
org.hibernate.dialect.MySQLDialect
</property>
<property name="hibernate.connection.driver_class">
com.mysql.jdbc.Driver
</property>
<!-- Assume test is the database name -->
<property name="hibernate.connection.url">
jdbc:mysql://localhost/test
</property>
<property name="hibernate.connection.username">
root
</property>
<property name="hibernate.connection.password">
root123
</property>
<!-- List of XML mapping files -->
<mapping resource="Employee.hbm.xml"/>
</session-factory>
</hibernate-configuration> 上面的配置文件包含与 hibernate-mapping 文件相关的 <mapping> 标签,我们将在下章看看 hibernate mapping 文件到底是什么并且要知道为什么用它,怎样用它。以下是各种重要数据库同源语属性类型的列表:
| DB2 | org.hibernate.dialect.DB2Dialect |
| HSQLDB | org.hibernate.dialect.HSQLDialect |
| HypersonicSQL | org.hibernate.dialect.HSQLDialect |
| Informix | org.hibernate.dialect.InformixDialect |
| Ingres | org.hibernate.dialect.IngresDialect |
| Interbase | org.hibernate.dialect.InterbaseDialect |
| Microsoft SQL Server 2000 | org.hibernate.dialect.SQLServerDialect |
| Microsoft SQL Server 2005 | org.hibernate.dialect.SQLServer2005Dialect |
| Microsoft SQL Server 2008 | org.hibernate.dialect.SQLServer2008Dialect |
| MySQL | org.hibernate.dialect.MySQLDialect |
| Oracle (any version) | org.hibernate.dialect.OracleDialect |
| Oracle 11g | org.hibernate.dialect.Oracle10gDialect |
| Oracle 10g | org.hibernate.dialect.Oracle10gDialect |
| Oracle 9i | org.hibernate.dialect.Oracle9iDialect |
| PostgreSQL | org.hibernate.dialect.PostgreSQLDialect |
| Progress | org.hibernate.dialect.ProgressDialect |
| SAP DB | org.hibernate.dialect.SAPDBDialect |
| Sybase | org.hibernate.dialect.SybaseDialect |
| Sybase Anywhere | org.hibernate.dialect.SybaseAnywhereDialec |
会话
Session 用于获取与数据库的物理连接。 Session 对象是轻量级的,并且设计为在每次需要与数据库进行交互时被实例化。持久态对象被保存,并通过 Session 对象检索找回。
该 Session 对象不应该长时间保持开放状态,因为它们通常不能保证线程安全,而应该根据需求被创建和销毁。Session 的主要功能是为映射实体类的实例提供创建,读取和删除操作。这些实例可能在给定时间点时存在于以下三种状态之一:
- 瞬时状态: 一种新的持久性实例,被 Hibernate 认为是瞬时的,它不与 Session 相关联,在数据库中没有与之关联的记录且无标识符值。
- 持久状态:可以将一个瞬时状态实例通过与一个 Session 关联的方式将其转化为持久状态实例。持久状态实例在数据库中没有与之关联的记录,有标识符值,并与一个 Session 关联。
- 脱管状态:一旦关闭 Hibernate Session,持久状态实例将会成为脱管状态实例。
若 Session 实例的持久态类别是序列化的,则该 Session 实例是序列化的。一个典型的事务应该使用以下语法:
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
// do some work
...
tx.commit();
}
catch (Exception e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
}finally {
session.close();
}如果 Session 引发异常,则事务必须被回滚,该 session 必须被丢弃。
Session 接口方法
Session 接口提供了很多方法,但在以下讲解中我将仅列出几个我们会在本教程中应用的重要方法。您可以查看 Hibernate 文件,查询与 Session 及 SessionFactory 相关的完整方法目录。
| 序号 | Session 方法及说明 |
|---|---|
| 1 | Transaction beginTransaction() 开始工作单位,并返回关联事务对象。 |
| 2 | void cancelQuery() 取消当前的查询执行。 |
| 3 | void clear() 完全清除该会话。 |
| 4 | Connection close() 通过释放和清理 JDBC 连接以结束该会话。 |
| 5 | Criteria createCriteria(Class persistentClass) 为给定的实体类或实体类的超类创建一个新的 Criteria 实例。 |
| 6 | Criteria createCriteria(String entityName) 为给定的实体名称创建一个新的 Criteria 实例。 |
| 7 | Serializable getIdentifier(Object object) 返回与给定实体相关联的会话的标识符值。 |
| 8 | Query createFilter(Object collection, String queryString) 为给定的集合和过滤字符创建查询的新实例。 |
| 9 | Query createQuery(String queryString) 为给定的 HQL 查询字符创建查询的新实例。 |
| 10 | SQLQuery createSQLQuery(String queryString) 为给定的 SQL 查询字符串创建 SQLQuery 的新实例。 |
| 11 | void delete(Object object) 从数据存储中删除持久化实例。 |
| 12 | void delete(String entityName, Object object) 从数据存储中删除持久化实例。 |
| 13 | Session get(String entityName, Serializable id) 返回给定命名的且带有给定标识符或 null 的持久化实例(若无该种持久化实例)。 |
| 14 | SessionFactory getSessionFactory() 获取创建该会话的 session 工厂。 |
| 15 | void refresh(Object object) 从基本数据库中重新读取给定实例的状态。 |
| 16 | Transaction getTransaction() 获取与该 session 关联的事务实例。 |
| 17 | boolean isConnected() 检查当前 session 是否连接。 |
| 18 | boolean isDirty() 该 session 中是否包含必须与数据库同步的变化? |
| 19 | boolean isOpen() 检查该 session 是否仍处于开启状态。 |
| 20 | Serializable save(Object object) 先分配一个生成的标识,以保持给定的瞬时状态实例。 |
| 21 | void saveOrUpdate(Object object) 保存(对象)或更新(对象)给定的实例。 |
| 22 | void update(Object object) 更新带有标识符且是给定的处于脱管状态的实例的持久化实例。 |
| 23 | void update(String entityName, Object object) 更新带有标识符且是给定的处于脱管状态的实例的持久化实例。 |
持久化类
Hibernate 的完整概念是提取 Java 类属性中的值,并且将它们保存到数据库表单中。映射文件能够帮助 Hibernate 确定如何从该类中提取值,并将它们映射在表格和相关域中。
映射文件
一个对象/关系型映射一般定义在 XML 文件中。映射文件指示 Hibernate 如何将已经定义的类或类组与数据库中的表对应起来。
<hibernate-mapping>
<class name="Employee" table="EMPLOYEE">
<meta attribute="class-description">
This class contains the employee detail.
</meta>
<id name="id" type="int" column="id">
<generator class="native"/>
</id>
<property name="firstName" column="first_name" type="string"/>
<property name="lastName" column="last_name" type="string"/>
<property name="salary" column="salary" type="int"/>
</class>
</hibernate-mapping>
Hibernate 映射类型
映射类型
当你准备一个 Hibernate 映射文件时,我们已经看到你把 Java 数据类型映射到了 RDBMS 数据格式。在映射文件中已经声明被使用的 types 不是 Java 数据类型;它们也不是 SQL 数据库类型。这种类型被称为 Hibernate 映射类型,可以从 Java 翻译成 SQL,反之亦然。
在这一章中列举出所有的基础,日期和时间,大型数据对象,和其它内嵌的映射数据类型。
原始类型
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| integer | int 或 java.lang.Integer | INTEGER |
| long | long 或 java.lang.Long | BIGINT |
| short | short 或 java.lang.Short | SMALLINT |
| float | float 或 java.lang.Float | FLOAT |
| double | double 或 java.lang.Double | DOUBLE |
| big_decimal | java.math.BigDecimal | NUMERIC |
| character | java.lang.String | CHAR(1) |
| string | java.lang.String | VARCHAR |
| byte | byte 或 java.lang.Byte | TINYINT |
| boolean | boolean 或 java.lang.Boolean | BIT |
| yes/no | boolean 或 java.lang.Boolean | CHAR(1) ('Y' or 'N') |
| true/false | boolean 或 java.lang.Boolean | CHAR(1) ('T' or 'F') |
日期和时间类型
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| date | java.util.Date 或 java.sql.Date | DATE |
| time | java.util.Date 或 java.sql.Time | TIME |
| timestamp | java.util.Date 或 java.sql.Timestamp | TIMESTAMP |
| calendar | java.util.Calendar | TIMESTAMP |
| calendar_date | java.util.Calendar | DATE |
二进制和大型数据对象
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| binary | byte[] | VARBINARY (or BLOB) |
| text | java.lang.String | CLOB |
| serializable | any Java class that implements java.io.Serializable | VARBINARY (or BLOB) |
| clob | java.sql.Clob | CLOB |
| blob | java.sql.Blob | BLOB |
JDK 相关类型
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| class | java.lang.Class | VARCHAR |
| locale | java.util.Locale | VARCHAR |
| timezone | java.util.TimeZone | VARCHAR |
| currency | java.util.Currency | VARCHAR |
Hibernate O/R 映射
O/R 映射
目前为止我们已经通过应用 Hibernate 见识过十分基础的 O/R 映射了,但是还有三个更加重要的有关映射的话题需要我们更详细的探讨。这三个话题是集合的映射,实体类之间的关联映射以及组件映射。
集合映射
如果一个实例或者类中有特定变量的值的集合,那么我们可以应用 Java 中的任何的可用的接口来映射这些值。Hibernate 可以保存 java.util.Map, java.util.Set, java.util.SortedMap, java.util.SortedSet, java.util.List 和其它持续的实例或者值的任何数组的实例。
| 集合类型 | 映射和描述 |
|---|---|
| java.util.Set | 它和 \<set> 元素匹配并且用 java.util.HashSet 初始化。 |
| java.util.SortedSet | 它和 \<set> 元素匹配并且用 java.util.TreeSet 初始化。sort 属性可以设置成比较器或者自然排序。 |
| java.util.List | 它和 \<list> 元素匹配并且用 java.util.ArrayList 初始化。 |
| java.util.Collection | 它和 \<bag> 或者 \<ibag> 元素匹配以及用 java.util.ArrayList 初始化。 |
| java.util.Map | 它和 \<map> 元素匹配并且用 java.util.HashMap 初始化。 |
| java.util.SortedMap") | 它和 \<map> 元素匹配并且用 java.util.TreeMap 初始化。sort 属性可以设置成比较器或者 自然排序。 |
对于 Java 的原始数值 Hibernate 采用<primitive-array>支持数组,对于 Java 的其它数值 Hibernate 采用<array>支持数组。然而它们很少被应用,因此我也就不在本指导中讨论它们。
如果你想要映射一个用户定义的集合接口而这个接口不是 Hibernate 直接支持的话,那么你需要告诉 Hibernate 你定义的这个集合的语法,这个很难操作而且不推荐使用。
关联映射
实体类之间的关联映射以及表之间的关系是 ORM 的灵魂之处。对象间的关系的子集可以用下列四种方式解释。关联映射可以是单向的也可以是双向的。
| 映射类型 | 描述 |
|---|---|
| Many-to-One | 使用 Hibernate 映射多对一关系 |
| One-to-One | 使用 Hibernate 映射一对一关系 |
| One-to-Many | 使用 Hibernate 映射一对多关系 |
| Many-to-Many | 使用 Hibernate 映射多对多关系 |
组件映射
作为变量的一员实体类很可能和其它类具有相关关系。如果引用的类没有自己的生命周期并且完全依靠于拥有它的那个实体类的生命周期的话,那么这个引用类因此就可以叫做组件类。
组件集合的映射很可能和正常集合的映射相似,只会有很少的设置上的不同。我们可以在例子中看看这两种映射。
| 映射类型 | 描述 |
|---|---|
| Component Mappings | 类的映射对于作为变量的一员的另外的类具有参考作用。 |
Hibernate 注释的环境设置
首先你必须确定你使用的是 JDK 5.0,否则你需要升级你的 JDK 至 JDK 5.0,来使你的主机能够支持注释。
其次,你需要安装 Hibernate 3.x 注释包,可以从 sourceforge 行下载:(下载 Hibernate 注释) 并且从 Hibernate 注释发布中拷贝 hibernate-annotations.jar, lib/hibernate-comons-annotations.jar 和 lib/ejb3-persistence.jar 到你的 CLASSPATH。
注释类示例
正如我上面所提到的,所有的元数据被添加到 POJO java 文件代码中,这有利于用户在开发时更好的理解表的结构和 POJO。
下面我们将使用 EMPLOYEE 表来存储对象:
create table EMPLOYEE (
id INT NOT NULL auto_increment,
first_name VARCHAR(20) default NULL,
last_name VARCHAR(20) default NULL,
salary INT default NULL,
PRIMARY KEY (id)
);以下是用带有注释的 Employee 类来映射使用定义好的 Employee 表的对象:
import javax.persistence.*;
@Entity
@Table(name = "EMPLOYEE")
public class Employee {
@Id @GeneratedValue
@Column(name = "id")
private int id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@Column(name = "salary")
private int salary;
public Employee() {}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
}Hibernate 检测到 @Id 注释字段并且认定它应该在运行时通过字段直接访问一个对象上的属性。如果你将 @Id 注释放在 getId() 方法中,你可以通过默认的 getter 和 setter 方法来访问属性。因此,所有其它注释也放在字段或是 getter 方法中,决定于选择的策略。下一节将解释上面的类中使用的注释。
@Entity 注释
EJB 3 标准的注释包含在 javax.persistence 包,所以我们第一步需要导入这个包。第二步我们对 Employee 类使用 @Entity 注释,标志着这个类为一个实体 bean,所以它必须含有一个没有参数的构造函数并且在可保护范围是可见的。
@Table 注释
@table 注释允许您明确表的详细信息保证实体在数据库中持续存在。
@table 注释提供了四个属性,允许您覆盖的表的名称,目录及其模式,在表中可以对列制定独特的约束。现在我们使用的是表名为 EMPLOYEE。
@Id 和 @GeneratedValue 注释
每一个实体 bean 都有一个主键,你在类中可以用 @Id 来进行注释。主键可以是一个字段或者是多个字段的组合,这取决于你的表的结构。
默认情况下,@Id 注释将自动确定最合适的主键生成策略,但是你可以通过使用 @GeneratedValue 注释来覆盖掉它。strategy 和 generator 这两个参数我不打算在这里讨论,所以我们只使用默认键生成策略。让 Hibernate 确定使用哪些生成器类型来使代码移植于不同的数据库之间。
@Column Annotation
@Column 注释用于指定某一列与某一个字段或是属性映射的细节信息。您可以使用下列注释的最常用的属性:
- name 属性允许显式地指定列的名称。
- length 属性为用于映射一个值,特别为一个字符串值的列的大小。
- nullable 属性允许当生成模式时,一个列可以被标记为非空。
- unique 属性允许列中只能含有唯一的内容
Hibernate 查询语言
查询语言
Hibernate 查询语言(HQL)是一种面向对象的查询语言,类似于 SQL,但不是去对表和列进行操作,而是面向对象和它们的属性。 HQL 查询被 Hibernate 翻译为传统的 SQL 查询从而对数据库进行操作。
尽管你能直接使用本地 SQL 语句,但我还是建议你尽可能的使用 HQL 语句,以避免数据库关于可移植性的麻烦,并且体现了 Hibernate 的 SQL 生成和缓存策略。
在 HQL 中一些关键字比如 SELECT ,FROM 和 WHERE 等,是不区分大小写的,但是一些属性比如表名和列名是区分大小写的。
FROM 语句
如果你想要在存储中加载一个完整并持久的对象,你将使用 FROM 语句。以下是 FROM 语句的一些简单的语法:
String hql = "FROM Employee";
Query query = session.createQuery(hql);
List results = query.list();如果你需要在 HQL 中完全限定类名,只需要指定包和类名,如下:
String hql = "FROM com.hibernatebook.criteria.Employee";
Query query = session.createQuery(hql);
List results = query.list();AS 语句
在 HQL 中 AS 语句能够用来给你的类分配别名,尤其是在长查询的情况下。例如,我们之前的例子,可以用如下方式展示:
String hql = "FROM Employee AS E";
Query query = session.createQuery(hql);
List results = query.list();关键字 AS 是可选择的并且你也可以在类名后直接指定一个别名,如下:
String hql = "FROM Employee E";
Query query = session.createQuery(hql);
List results = query.list();SELECT 语句
SELECT 语句比 from 语句提供了更多的对结果集的控制。如果你只想得到对象的几个属性而不是整个对象你需要使用 SELECT 语句。下面是一个 SELECT 语句的简单语法示例,这个例子是为了得到 Employee 对象的 first_name 字段:
String hql = "SELECT E.firstName FROM Employee E";
Query query = session.createQuery(hql);
List results = query.list();值得注意的是 Employee.firstName 是 Employee 对象的属性,而不是一个 EMPLOYEE 表的字段。
WHERE 语句
如果你想要精确地从数据库存储中返回特定对象,你需要使用 WHERE 语句。下面是 WHERE 语句的简单语法例子:
String hql = "FROM Employee E WHERE E.id = 10";
Query query = session.createQuery(hql);
List results = query.list();ORDER BY 语句
为了给 HSQ 查询结果进行排序,你将需要使用 ORDER BY 语句。你能利用任意一个属性给你的结果进行排序,包括升序或降序排序。下面是一个使用 ORDER BY 语句的简单示例:
String hql = "FROM Employee E WHERE E.id > 10 ORDER BY E.salary DESC";
Query query = session.createQuery(hql);
List results = query.list();如果你想要给多个属性进行排序,你只需要在 ORDER BY 语句后面添加你要进行排序的属性即可,并且用逗号进行分割:
String hql = "FROM Employee E WHERE E.id > 10 " +
"ORDER BY E.firstName DESC, E.salary DESC ";
Query query = session.createQuery(hql);
List results = query.list();GROUP BY 语句
这一语句允许 Hibernate 将信息从数据库中提取出来,并且基于某种属性的值将信息进行编组,通常而言,该语句会使用得到的结果来包含一个聚合值。下面是一个简单的使用 GROUP BY 语句的语法:
String hql = "SELECT SUM(E.salary), E.firtName FROM Employee E " +
"GROUP BY E.firstName";
Query query = session.createQuery(hql);
List results = query.list();使用命名参数
Hibernate 的 HQL 查询功能支持命名参数。这使得 HQL 查询功能既能接受来自用户的简单输入,又无需防御 SQL 注入攻击。下面是使用命名参数的简单的语法:
String hql = "FROM Employee E WHERE E.id = :employee_id";
Query query = session.createQuery(hql);
query.setParameter("employee_id",10);
List results = query.list();Hibernate 标准查询
标准查询
Hibernate 提供了操纵对象和相应的 RDBMS 表中可用的数据的替代方法。一种方法是标准的 API,它允许你建立一个标准的可编程查询对象来应用过滤规则和逻辑条件。
Hibernate Session 接口提供了 createCriteria() 方法,可用于创建一个 Criteria 对象,使当您的应用程序执行一个标准查询时返回一个持久化对象的类的实例。
以下是一个最简单的标准查询的例子,它只是简单地返回对应于员工类的每个对象:
Criteria cr = session.createCriteria(Employee.class);
List results = cr.list(); 对标准的限制
你可以使用 Criteria 对象可用的 add() 方法去添加一个标准查询的限制。
以下是一个示例,它实现了添加一个限制,令返回工资等于 2000 的记录:
Criteria cr = session.createCriteria(Employee.class);
cr.add(Restrictions.eq("salary", 2000));
List results = cr.list(); 原生 SQL
如果你想使用数据库特定的功能如查询提示或 Oracle 中的 CONNECT 关键字的话,你可以使用原生 SQL 数据库来表达查询。Hibernate 3.x 允许您为所有的创建,更新,删除,和加载操作指定手写 SQL ,包括存储过程。
您的应用程序会在会话界面用 createSQLQuery() 方法创建一个原生 SQL 查询:
public SQLQuery createSQLQuery(String sqlString) throws HibernateException当你通过一个包含 SQL 查询的 createsqlquery() 方法的字符串时,你可以将 SQL 的结果与现有的 Hibernate 实体,一个连接,或一个标量结果分别使用 addEntity(), addJoin(), 和 addScalar() 方法进行关联。
标量查询
最基本的 SQL 查询是从一个或多个列表中获取一个标量(值)列表。以下是使用原生 SQL 进行获取标量的值的语法:
String sql = "SELECT first_name, salary FROM EMPLOYEE";
SQLQuery query = session.createSQLQuery(sql);
query.setResultTransformer(Criteria.ALIAS_TO_ENTITY_MAP);
List results = query.list();实体查询
以上的查询都是关于返回标量值的查询,只是基础性地返回结果集中的“原始”值。以下是从原生 SQL 查询中通过 addEntity() 方法获取实体对象整体的语法:
String sql = "SELECT * FROM EMPLOYEE";
SQLQuery query = session.createSQLQuery(sql);
query.addEntity(Employee.class);
List results = query.list();
Hibernate 缓存
缓存
缓存是关于应用程序性能的优化,降低了应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。
缓存对 Hibernate 来说也是重要的,它使用了如下解释的多级缓存方案:
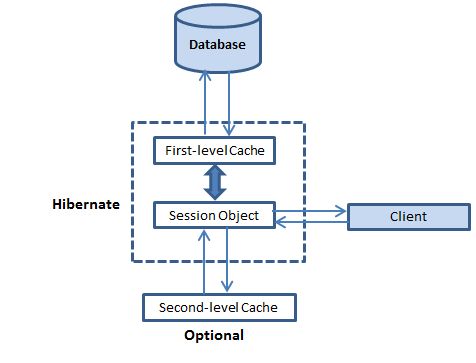
一级缓存
第一级缓存是 Session 缓存并且是一种强制性的缓存,所有的要求都必须通过它。Session 对象在它自己的权利之下,在将它提交给数据库之前保存一个对象。
如果你对一个对象发出多个更新,Hibernate 会尝试尽可能长地延迟更新来减少发出的 SQL 更新语句的数目。如果你关闭 session,所有缓存的对象丢失,或是存留,或是在数据库中被更新。
二级缓存
第二级缓存是一种可选择的缓存并且第一级缓存在任何想要在第二级缓存中找到一个对象前将总是被询问。第二级缓存可以在每一个类和每一个集合的基础上被安装,并且它主要负责跨会话缓存对象。
任何第三方缓存可以和 Hibernate 一起使用。org.hibernate.cache.CacheProvider 接口被提供,它必须实现来给 Hibernate 提供一个缓存实现的解决方法。
查询层次缓存
Hibernate 也实现了一个和第二级缓存密切集成的查询结果集缓存。
这是一个可选择的特点并且需要两个额外的物理缓存区域,它们保存着缓存的查询结果和表单上一次更新时的时间戳。这仅对以同一个参数频繁运行的查询来说是有用的。
第二级缓存
Hibernate 使用默认的一级缓存并且你不用使用一级缓存。让我们直接看向可选的二级缓存。不是所有的类从缓存中获益,所以能关闭二级缓存是重要的。
Hibernate 的二级缓存通过两步设置。第一,你必须决定好使用哪个并发策略。之后,你使用缓存提供程序来配置缓存到期时间和物理缓存属性。
并发策略
一个并发策略是一个中介,它负责保存缓存中的数据项和从缓存中检索它们。如果你将使用一个二级缓存,你必须决定,对于每一个持久类和集合,使用哪一个并发策略。
- Transactional:为主读数据使用这个策略,在一次更新的罕见状况下并发事务阻止过期数据是关键的。
- Read-write:为主读数据再一次使用这个策略,在一次更新的罕见状况下并发事务阻止过期数据是关键的。
- Nonstrict-read-write:这个策略不保证缓存和数据库之间的一致性。如果数据几乎不改变并且过期数据不是很重要,使用这个策略。
- Read-only:一个适合永不改变数据的并发策略。只为参考数据使用它。
如果我们将为我们的 Employee 类使用二级缓存,让我们使用 read-write 策略来添加需要告诉 Hibernate 来缓存 Employee 实例的映射元素。
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="Employee" table="EMPLOYEE">
<meta attribute="class-description">
This class contains the employee detail.
</meta>
<cache usage="read-write"/>
<id name="id" type="int" column="id">
<generator class="native"/>
</id>
<property name="firstName" column="first_name" type="string"/>
<property name="lastName" column="last_name" type="string"/>
<property name="salary" column="salary" type="int"/>
</class>
</hibernate-mapping>usage="read-write" 参数告诉 Hibernate 为定义的缓存使用 read-write 并发策略。
缓存提供者
在考虑你将为你的缓存候选类所使用的并发策略后你的下一步是挑选一个缓存提供者。Hibernate 让你为整个应用程序选择一个单独的缓存提供者。
| S.N. | 缓存名 | 描述 |
|---|---|---|
| 1 | EHCache | 它能在内存或硬盘上缓存并且集群缓存,而且它支持可选的 Hibernate 查询结果缓存。 |
| 2 | OSCache | 支持在一个单独的 JVM 中缓存到内存和硬盘,同时有丰富的过期策略和查询缓存支持。 |
| 3 | warmCache | 一个基于 JGroups 的聚集缓存。它使用集群失效但是不支持 Hibernate 查询缓存。 |
| 4 | JBoss Cache | 一个也基于 JGroups 多播库的完全事务性的复制集群缓存。它支持复制或者失效,同步或异步通信,乐观和悲观锁定。Hibernate 查询缓存被支持。 |
每一个缓存提供者都不和每个并发策略兼容。以下的兼容性矩阵将帮助你选择一个合适的组合。
| 策略/提供者 | Read-only | Nonstrictread-write | Read-write | Transactional |
|---|---|---|---|---|
| EHCache | X | X | X | |
| OSCache | X | X | X | |
| SwarmCache | X | X | ||
| JBoss Cache | X | X |
你将在 hibernate.cfg.xml 配置文件中指定一个缓存提供者。我们选择 EHCache 作为我们的二级缓存提供者:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-configuration SYSTEM
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="hibernate.dialect">
org.hibernate.dialect.MySQLDialect
</property>
<property name="hibernate.connection.driver_class">
com.mysql.jdbc.Driver
</property>
<!-- Assume students is the database name -->
<property name="hibernate.connection.url">
jdbc:mysql://localhost/test
</property>
<property name="hibernate.connection.username">
root
</property>
<property name="hibernate.connection.password">
root123
</property>
<property name="hibernate.cache.provider_class">
org.hibernate.cache.EhCacheProvider
</property>
<!-- List of XML mapping files -->
<mapping resource="Employee.hbm.xml"/>
</session-factory>
</hibernate-configuration>现在,你需要指定缓存区域的属性。EHCache 有它自己的配置文件,ehcache.xml,它应该在应用程序的 CLASSPATH 中。Employee 类的 ehcache.xml 缓存配置像如下这样:
<diskStore path="java.io.tmpdir"/>
<defaultCache
maxElementsInMemory="1000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
/>
<cache name="Employee"
maxElementsInMemory="500"
eternal="true"
timeToIdleSeconds="0"
timeToLiveSeconds="0"
overflowToDisk="false"
/>就是这样,现在我们有 Employee 类的二级缓存并且 Hibernate 现在能命中缓存无论是你导航到 Employee 时或是当你通过标识符上传 Employee 时。
你应该为每个类分析你所有的类并选择合适的缓存策略。有时候,二级缓存可能使应用程序的表现下降。所以首先不允许缓存用基准程序测试你的应用程序,然后开启合适的缓存,之后检测表现是推荐的。如果缓存不提升系统表现那么支持任何类型的缓存都是没有意义的。
查询层次缓存
为了使用查询缓存,你必须首先使用配置文件中的 hibernate.cache.use_query_cache="true" 属性激活它。通过设置这个属性为真,你使得 Hibernate 创建内存中必要的缓存来保存查询和标识符集。
然后,为了使用查询缓存,你使用 Query 类的 setCacheable(Boolean) 方法。例如:
Session session = SessionFactory.openSession();
Query query = session.createQuery("FROM EMPLOYEE");
query.setCacheable(true);
List users = query.list();
SessionFactory.closeSession();Hibernate 通过缓存区域的概念也支持非常细粒度的缓存支持。一个缓存区域是被给予名字的缓存部分。
Session session = SessionFactory.openSession();
Query query = session.createQuery("FROM EMPLOYEE");
query.setCacheable(true);
query.setCacheRegion("employee");
List users = query.list();
SessionFactory.closeSession();这段代码使用方法来告诉 Hibernate 存储和寻找缓存 employee 区域的查询。
Hibernate 批处理
批处理
因为默认下,Hibernate 将缓存所有的在会话层缓存中的持久的对象并且最终你的应用程序将和 OutOfMemoryException 在第 50000 行的某处相遇。你可以解决这个问题,如果你在 Hibernate 使用批处理。
为了使用批处理这个特性,首先设置 hibernate.jdbc.batch_size 作为批处理的尺寸,取一个依赖于对象尺寸的值 20 或 50。这将告诉 hibernate 容器每 X 行为一批插入。为了在你的代码中实现这个我们将需要像以下这样做一些修改:
Session session = SessionFactory.openSession();
Transaction tx = session.beginTransaction();
for ( int i=0; i<100000; i++ ) {
Employee employee = new Employee(.....);
session.save(employee);
if( i % 50 == 0 ) { // Same as the JDBC batch size
//flush a batch of inserts and release memory:
session.flush();
session.clear();
}
}
tx.commit();
session.close();Hibernate 拦截器
拦截器
你已经学到,在 Hibernate 中,一个对象将被创建和保持。一旦对象已经被修改,它必须被保存到数据库里。这个过程持续直到下一次对象被需要,它将被从持久的存储中加载。
因此一个对象通过它生命周期中的不同阶段,并且 Interceptor 接口提供了在不同阶段能被调用来进行一些所需要的任务的方法。这些方法是从会话到应用程序的回调函数,允许应用程序检查或操作一个持续对象的属性,在它被保存,更新,删除或上传之前。以下是在 Interceptor 接口中可用的所有方法的列表。
| S.N. | 方法和描述 |
|---|---|
| 1 | findDirty() 这个方法在当 flush() 方法在一个 Session 对象上被调用时被调用。 |
| 2 | instantiate() 这个方法在一个持续的类被实例化时被调用。 |
| 3 | isUnsaved() 这个方法在当一个对象被传到 saveOrUpdate() 方法时被调用。 |
| 4 | onDelete() 这个方法在一个对象被删除前被调用。 |
| 5 | onFlushDirty() 这个方法在当 Hibernate 探测到一个对象在一次 flush(例如,更新操作)中是脏的(例如,被修改)时被调用。 |
| 6 | onLoad() 这个方法在一个对象被初始化之前被调用。 |
| 7 | onSave() 这个方法在一个对象被保存前被调用。 |
| 8 | postFlush() 这个方法在一次 flush 已经发生并且一个对象已经在内存中被更新后被调用。 |
| 9 | preFlush() 这个方法在一次 flush 前被调用。 |
Hibernate 拦截器给予了我们一个对象如何应用到应用程序和数据库的总控制。
如何使用拦截器?
为了创建一个拦截器你可以直接实现 Interceptor 类或者继承 EmptyInterceptor 类。以下是简单的使用 Hibernate 拦截器功能的步骤。
创建拦截器
我们将在例子中继承 EmptyInterceptor,当 Employee 对象被创建和更新时拦截器的方法将自动被调用。你可以根据你的需求实现更多的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号