Java基础知识面试题
面向对象
什么是面向对象?什么是面向过程?
面向过程就是分析出实现需求所需要的步骤,通过函数一步一步实现这些步骤,接着依次调用即可。
面向对象是把整个需求按照特点、功能划分,将这些存在共性的部分封装成对象,创建对象不是为了完成某一个步骤,而是描述某个事物在解决问题的步骤中的行为
面向对象是将每一个步骤抽象为行为,便于复用和扩展
面向对象的三大基本特征是什么?
封装就是隐藏对象的属性和实现细节,封装的目的是增强安全性和简化编程,使用者不必了解具体的实现细节
继承机制允许创建分等级层次的类。继承就是子类继承父类的特征和行为。
多态是指一个对象的相同方法在不同情形有不同表现形式。
多态存在的三个必要条件:
继承
重写(子类继承父类后对父类方法进行重新定义)
父类引用指向子类对象
面向对象的五大基本原则是什么?
单一职责原则(SRP):一个类应该有且只有一个去改变它的理由,是指一个类的功能要单一
开放封闭原则(OCP):对象或实体应该对扩展开放,对修改封闭。软件实体(类,模块,函数等等)应该是可扩展的,但是不可修改。因为修改程序有可能会对原来的程序造成错误。不能修改,但是可以添加功能,尽可能的在外边添加新的类。
里氏替换原则(LSP):子类应当可以替换父类并出现在父类能够出现的任何地方。
依赖倒置原则(DIP):高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。简单来说,解决耦合。一般情况下抽象的变化概率很小,让用户程序依赖于抽象,实现的细节也依赖于抽象。即使实现细节不断变动,只要抽象不变,客户程序就不需要变化。这大大降低了客户程序与实现细节的耦合度。
接口隔离原则(ISP):接口端不应该依赖它不需要的接口,接口要尽量的小,实现类不必实现不需要的方法。
什么是JVM、JDK、JRE
JDK:Java Development Kit,是JAVA程序开发时用的开发工具包,其内部也有JRE运行环境。
JRE:Java Runtime Environment,是JAVA程序运行时需要的运行环境,就是只为了运行JAVA程序而不是去搞开发的话,只安装JRE就能运行已经存在的JAVA程序了。
JVM:Java Virtual Machine,JDK、JRE内部都包含JVM,JAVA虚拟机内部包含许多应用程序的类的解释器和类加载器等等。
为什么Java是跨平台的?
Java程序编译之后的代码不是能被硬件系统直接运行的代码,而是一种中间码——字节码。然后不同的硬件平台上安装有不同的Java虚拟机,由JVM来把字节码再翻译成所对应的硬件平台能够执行的代码。
因此对于Java编程者来说,不需要考虑硬件平台是什么。所以Java可以跨平台。
Java的平台无关性是建立在Java虚拟机的平台有关性基础之上的,是因为Java虚拟机屏蔽了底层操作系统和硬件的差异。
值传递、引用传递的区别
java中方法参数传递方式是按值传递。
如果参数是基本类型,传递的是基本类型的字面量值的拷贝。
如果参数是引用类型,传递的是该参量所引用的对象在堆中地址值的拷贝。
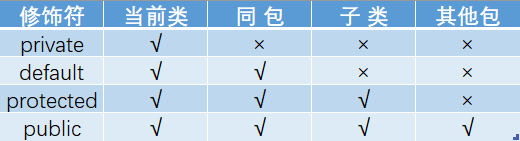
访问修饰符public、private、protected,以及不写(默认)时的区别?
抽象类与抽象接口
抽象类和普通类的区别:
在Java语言中使用abstract class来定义抽象类,抽象类中并不是只能有抽象方法,和普通类一样,同样可以拥有成员变量和普通的成员方法
抽象方法的访问修饰符必须为public和protected;
抽象类不能被实例化;
如果一个类继承于抽象类,则子类必须实现父类的抽象方法,如果子类没有实现父类的抽象方法,则子类必须也一个抽象类。
抽象类和接口区别:
抽象类内部可以有方法的实现细节,而接口中只能存在public abstract方法;
抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
接口中不能含有静态代码块以及静态方法,而抽象类中可以有静态代码旷和静态方法;
一个类只能继承一个抽象类,而一个类可以实现多个接口。
重写与重载的区别
重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写!
重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
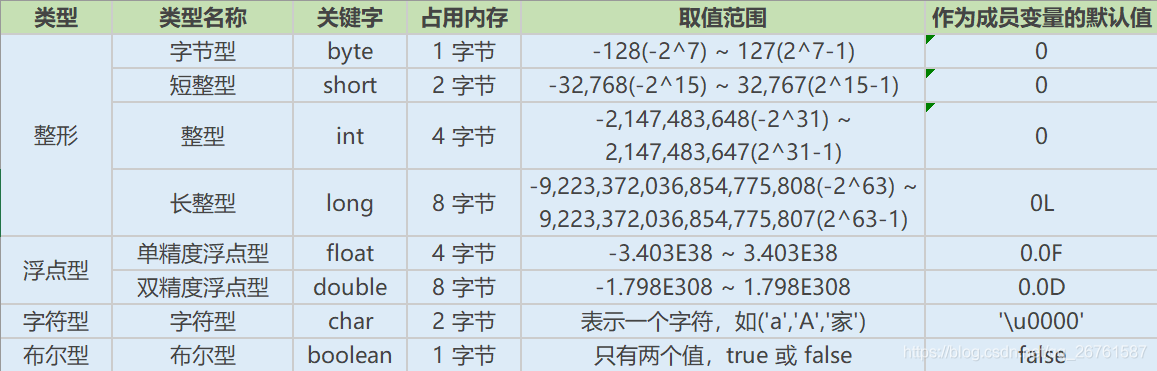
基本数据类型
Java的基本数据类型有哪些
整型:byte, short, int, long
字符型:char
浮点型:float, double
布尔型:boolean
Java中最小的计算单元为字节,1字节=8位(bit)
各个基本数据类型的取值范围
关键字
transient 声明不用序列化的成员域
native 用来声明一个方法是由与计算机相关的语言(如C/C++语言)实现的
throw 抛出一个异常
throws 声明在当前定义的成员方法中所有需要抛出的异常
String
为什么字符串是不可变的?
String是引用类型,String变量储存一个地址,地址指向内存堆中的String对象。当我们说变量不可变,有两种不可变性:
变量储存的地址不可变
地址指向的对象内容不可变
String变量指向的地址是可变的,他的不可变性是指第2种——地址指向的对象内容不可变。
纵览String的方法,String类确实没有提供能从String外部修改对象的方法。我们熟悉的replace,substring等等方法都要返回一个String,其实都是在返回一个新的对象,而没有修改原有的对象。
为什么要设计成对象内容不可变?
String常量池:便于实现String常量池。String存在于常量池中,当新创建一个字符串变量,如果字符串在内存中已经存在,那么就会把这个已经存在于常量池对象的地址赋给变量。这样可节省内存开销。但是通过构造函数new String()的并不是。
线程安全:对象内容不可变,就不会有线程安全问题。
代码安全:如果String可变,一旦代码某处改动了字符串,会对系统有安全和稳定性威胁。一个字符串对象被多个变量引用,直接修改对象内容,引起所有引用该对象的变量都发生变化,容易引起bug。
String.valueOf和Integer.toString的区别
java.lang.Object类里已有public方法.toString(),所以对任何严格意义上的java对象都可以调用此方法。但在使用时要注意,必须保证object不是null值,否则将抛出NullPointerException异常。
valueOf(Object obj)对null值进行了处理,不会报任何异常。但当object为null 时,String.valueOf(object)的值是字符串”null”,而不是null。
swtich对string的支持
Java1.7之前switch只能局限于int 、short 、byte 、char四类做判断条件。在JVM内部实际大部分字节码指令只有int类型的版本。在使用switch的时候,如果是非int型,会先转为int型,再进行条件判断。
Java1.7的switch增加了对String的支持,可String并不能直接转为int型,switch比较的是字符串常量的哈希值(int类型),但是hash值可能会有冲突,所以还需要再调用equals方法进行二次比较。
intern
对于任意两个字符串 s 和 t,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true。
在调用”ab”.intern()方法的时候会返回”ab”,但是这个方法会首先检查字符串池中是否有”ab”这个字符串,如果存在则返回这个字符串的引用,否则就将这个字符串添加到字符串池中,然会返回这个字符串的引用。
可以利用String.intern方法来提高程序效率或者减少内存占用的情况
== 和 equals 的区别是什么
它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型 == 比较的是值,引用数据类型 == 比较的是内存地址)
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来两个对象的内容相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
自动拆装箱
什么是包装类型?什么是基本类型
为什么存在这两种类型呢?
主要是效率,基本数据类型基于值,对象类型基于对象的引用。对象类似存储在堆中,通过栈中的引用来使用这些对象,但是对于一些局部变量,这个变量直接存储“值”,并置于栈中,更加高效些。
有了基本类型为什么还要有包装类型呢?
我们知道Java是一个面相对象的编程语言,基本类型并不具有对象的性质,为了让基本类型也具有对象的特征,就出现了包装类型(如我们在使用集合类型Collection时就一定要使用包装类型而非基本类型),它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
另外,当需要往ArrayList,HashMap中放东西时,像int,double这种基本类型是放不进去的,因为容器都是装object的,这是就需要这些基本类型的包装器类了。
二者的区别:
声明方式不同:
基本类型不使用new关键字,而包装类型需要使用new关键字来在堆中分配存储空间;
存储方式及位置不同:
基本类型是直接将变量值存储在栈中,而包装类型是将对象放在堆中,然后通过引用来使用;
初始值不同:
基本类型的初始值如int为0,boolean为false,而包装类型的初始值为null;
使用方式不同:
基本类型直接赋值直接使用就好,而包装类型在集合如Collection、Map时会使用到。
什么是自动拆装箱
有了基本数据类型和包装类,肯定有些时候要在他们之间进行转换。比如把一个基本数据类型的int转换成一个包装类型的Integer对象。
我们认为包装类是对基本类型的包装,所以,把基本数据类型转换成包装类的过程就是打包装,英文对应于boxing,中文翻译为装箱。反之,把包装类转换成基本数据类型的过程就是拆包装,英文对应于unboxing,中文翻译为拆箱。
在Java SE5中,为了减少开发人员的工作,Java提供了自动拆箱与自动装箱功能。
Integer i =10; //自动装箱
int b= i; //自动拆箱
Integer的缓存机制是什么
Integer里面默认的缓存数字是-128-127,
1、Integer与Integer相互比较,数据在-128-127范围内,就会从缓存中拿去数据,使用== 比较就相等;如果不在这个范围,就会直接新创建一个Integer对象,使用 == 判断的是两个内存的应用地址,所以不相等。
2、Integer和int类型相比,在jdk1.5会自动拆箱,然后==比较栈内存中的数据,所以都是相等的
异常
异常类型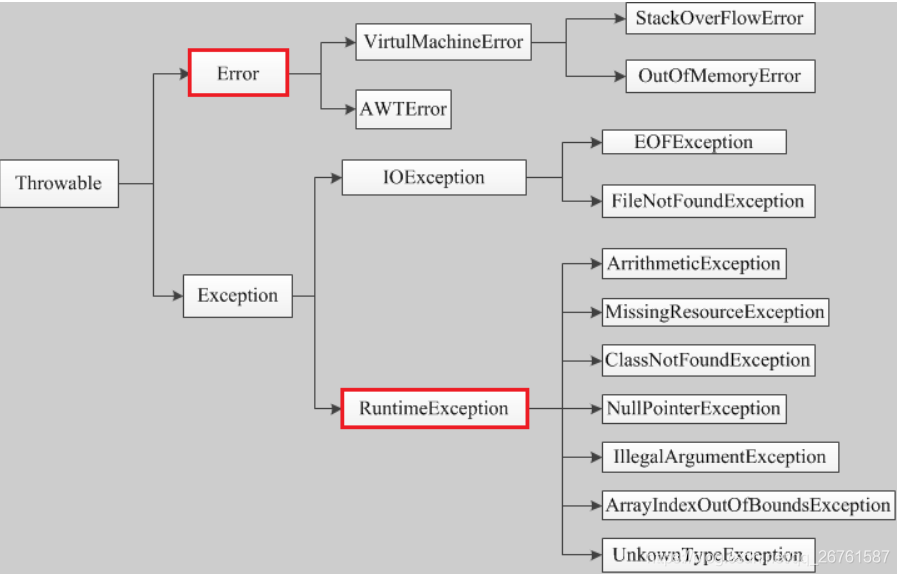
自定义异常
是否需要定义成 Checked Exception(检查性异常必须在编写代码时,使用 try catch 捕获),因为这种类型设计的初衷更是为了从异常情况恢复,作为异常设计者,我们往往有充足信息进行分类。
在保证诊断信息足够的同时,也要考虑避免包含敏感信息,因为那样可能导致潜在的安全问题。如果我们看 Java 的标准类库,你可能注意到类似 java.net.ConnectException,出错信息是类似“ Connection refused (Connection refused)”,而不包含具体的机器名、IP、端口等,一个重要考量就是信息安全。类似的情况在日志中也有,比如,用户数据一般是不可以输出到日志里面的。
Error 和 Exception
首先 Exception 和 Error 都是继承于 Throwable 类,在 Java 中只有 Throwable 类型的实例才可以被抛出(throw)或者捕获(catch),Exception 和 Error 体现了JAVA 这门语言对于异常处理的两种方式。
Exception 是 Java 程序运行中可预料的异常情况,我们可以获取到这种异常,并且对这种异常进行业务外的处理。
分为检查性异常和非检查性(RuntimeException)异常。两个根本的区别在于,检查性异常必须在编写代码时,使用 try catch 捕获,比如:IOException异常。非检查性异常在代码编写时,可以忽略捕获操作,比如:ArrayIndexOutOfBoundsException,这种异常是在代码编写或者使用过程中通过规范可以避免发生的。
Error 是 Java 程序运行中不可预料的异常情况,这种异常发生以后,会直接导致 JVM 不可处理或者不可恢复的情况。所以这种异常不可能抓取到,比如 OutOfMemoryError、NoClassDefFoundError等。
finally和return的执行顺序
不管有没有出现异常,finally块中代码都会执行;
当try和catch中有return时,finally仍然会执行;
finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,仍然是之前保存的值),所以函数返回值是在finally执行前确定的;
finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
泛型
泛型与继承
泛型:参数化类型,将类型由原来的具体类型参数化,把类型也定义为行参。方法中均使用同一类型。属于编译期信息,无法提供动态绑定,当类型与方法无关时,使用泛型。使用泛型的类应该有共同的方法,为水平方法,而继承是垂直方向。
类型擦除是什么
List和List等类型,在编译后都会变成List
泛型中 K T V R ? object等的含义
K:key(键值);
T:Type(Java类);
V:Value(值);
N:Number(数值类型);
E:Element(元素,集合元素);
?:无限定
Object:所有类的根类
限定通配符和非限定通配符
表示类型的上界:<? Extends T>,类型必须为T或者其子类
表示类型的下界:<? Super T>,类型必须为T或者T的父类
List<?>和List之间的区别
List:可以添加任意类型的元素,不安全(编译通过),不便利(需要自己强制转换类型),不表述(可以直接看到实参就是其类型)。
List<?>:通配符类型,接受List任意参数化类型,包括List,不能添加元素,保证安全和便利,但不保证表述。
List< Object> 参数为对象,可以添加List,可以添加元素,但不能接受除了本身外的任何参数化类型。
序列化
什么是序列化和反序列化
序列化:对象存储转换为二进制,对象和元数据(属性)都存储为二进制。
反序列化:把对象和元数据从二进制恢复。
场景:持久化,存入数据库;远程传输,进程之间传输。
为什么要序列化
有些时候我们需要把应用程序中的数据以另一种形式进行表达,以便于将数据存储起来,并在未来某个时间点再次使用,或者便于通过网络传输给接收方。这一过程我们把它叫做序列化。
序列化的底层原理
实现的API:ObjectOutputStream中的writeObject(Object obj),ObjectInputStream中的readObject()
只有实现了Serializable或者Externalizable接口的类的对象才可以被实例化。父类实现上述接口,子类就不需要显示的实现,静态类不可以实现序列化。
序列化与单例模式
正常的序列化会破坏单例模式,产生新的对象,保证单例时,需要添加private Object readResolve(){}方法
为什么说序列化并不安全
可以实现远程代码执行;序列化明文存储,可以根据对象序列化生产很多私有属性。通过反序列化产生非预期对象,根源在于ObjectInputSteam对生成的对象类型没有限制。
不安全的反序列化
单元测试
junit
单元测试各个注解执行的先后顺序:
@BeforeClass -> @Before -> @Test -> @After -> @AfterClass;
时间处理
Java时间API
Util.Date:能够精确到毫秒级
Sql.Date:数据库日期API,操作日期,不能读取和修改时间
Sql.Time:数据库时间类,获取操作时间
Sql.Timestamp:纳秒级Util.Date
System.currentTimeMillis():当前系统时间,毫秒
System.nanoTime(); 当前系统时间,纳秒
SimpleDateFormat线程安全问题
主要因为SimpleDateFormat继承于DateFormat,而DateFormat使用成员变量传值,其Calendar在多个方法中调用,Format和subFormat都使用了DateFormat的成员变量Calendar
Java 8 对时间的处理
引入新类java.time:线程安全,不可变。主要类:
Instant:时间戳
LocalDate:不包含具体时间的日期,2014-01-01
LocalTime:不包含日期的时间
LocalDateTime:包含时间于日期,但无时区偏移
ZonedDateTime:完整时间,偏移量以GMT和UTC为准。
注解
什么是元注解
注解的注解:@Retention、@Target、@Document、@Inherited
@Retentiond:定义注解的保留策略,RetentionPolicy.SOURCE:在源码 .CLASS在字节码,运行时无效,.RUNTIME在字节码。反射可以获取
@Target:定义注解的目标
@Document:说明注解被包含在Javadoc中
@Inherited:说明子类可以继承父类的该注解
怎么自定义注解
Public @interface xx{} java.lang.annotation
Java中有哪些常用注解
@Override:重写标志,标示覆盖父类的方法
@Deprecated: 已过期,表示方法时不建议使用的。
@SuppressWarnings: 压制告警,抑制告警
什么是SPI?
SPI ,全称为 Service Provider Interface,是一种服务发现机制。它通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类。
这一机制为很多框架扩展提供了可能,比如在Dubbo、JDBC中都使用到了SPI机制。
反射有什么用
反射(Reflection)是其Java非常突出的一个动态相关机制。它可以于运行时加载、使用编译期间完全未知的classes(但是要知道类的名字)。也就是说,在运行时,我们还可以获取一个类中所有的方法和属性,可以实例化任何类的对象,还能判断一个对象所属的类。可以用于热部署。
反射最重要的用途就是开发各种通用框架。
很多框架(比如 Spring)都是配置化的(比如通过 XML 文件配置 Bean),为了保证框架的通用性,它们可能需要根据配置文件加载不同的对象或类,调用不同的方法,这个时候就必须用到反射,运行时动态加载需要加载的对象。
Class类
Java中,无论生成某个类的多少个对象,这些对象都会对应于同一个Class对象,这个Class对象是由JVM生成的,通过它能够获悉整个类的结构。要想使用反射,首先需要获得待操作的类所对应的Class对象。
获取class对象方法:
1.使用Class类的静态方法
eg:Class.forName(“java.lang.String”);
2.使用类的.class语法
eg:Class c = Employee.class;
3.使用对象的getClass()方法
eg:Employee e = new Employee();
Class c3 = e.getClass();
原理
所有的java类都是继承了object这个类,在object这个类中有一个方法:getclass().这个方法是用来取得该类已经被实例化了的对象的该类的引用,这个引用指向的是Class类的对象。我们自己无法生成一个Class对象(构造函数为private),而 这个Class类的对象是在当各类被调入时,由 Java 虚拟机自动创建 Class 对象,或通过类装载器中的 defineClass 方法生成。我们生成的对象都会有个字段记录该对象所属类在CLass类的对象的所在位置。如下图所示: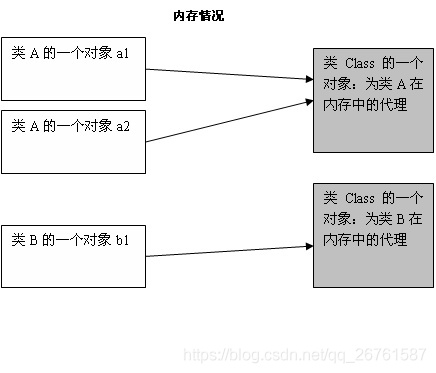
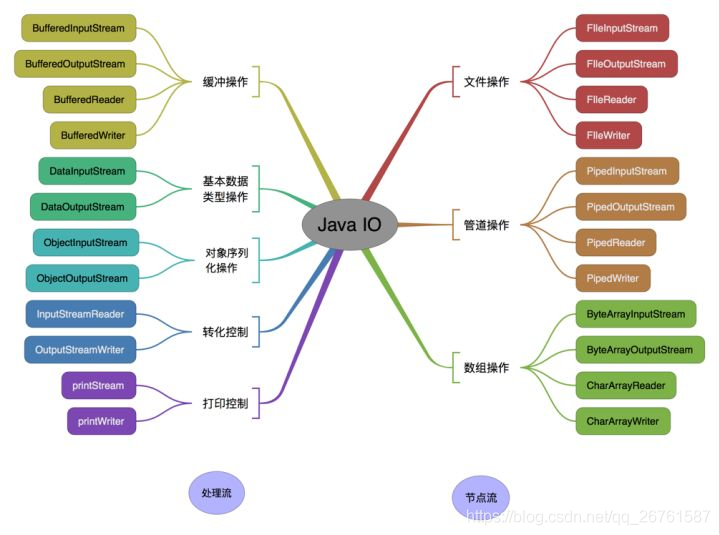
IO
字符流、字节流、输入流、输出流的区别
字节流:
1.字节流在操作的时候不会用到缓冲区(也就是内存)
2.字节流可用于任何类型的对象,包括二进制对象
3.字节流处理单元为1个字节,操作字节和字节数组。
InputStream是所有字节输入流的祖先,而OutputStream是所有字节输出流的祖先。
字符流:
1.而字符流在操作的时候会用到缓冲区
2.而字符流只能处理字符或者字符串
3.字符流处理的单元为2个字节的Unicode字符,操作字符、字符数组或字符串,
Reader是所有读取字符串输入流的祖先,而writer是所有输出字符串的祖先。
同步与异步的区别
同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。 换句话说,就是由调用者主动等待这个调用的结果。
而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。典型的异步编程模型比如Node.js
举个通俗的例子:
你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下”,然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。
而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
实质:访问数据的方式,同步需要当前线程读写数据,在读写数据的过程中还是会阻塞;异步只需要I/O操作完成的通知,当前进程并不主动读写数据,由操作系统内核完成数据的读写。
阻塞与非阻塞的区别
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
还是上面的例子,
你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。
在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
Linux5种IO模型
阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动IO模型以及异步IO模型。
https://www.jianshu.com/p/486b0965c296
BIO、NIO和AIO的区别
同步阻塞IO(JAVA BIO):
同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
同步非阻塞IO(Java NIO):
同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。用户进程也需要时不时的询问IO操作是否就绪,这就要求用户进程不停的去询问。
异步阻塞IO(Java NIO):
此种方式下是指应用发起一个IO操作以后,不等待内核IO操作的完成,等内核完成IO操作以后会通知应用程序,这其实就是同步和异步最关键的区别,同步必须等待或者主动的去询问IO是否完成,那么为什么说是阻塞的呢?因为此时是通过select系统调用来完成的,而select函数本身的实现方式是阻塞的,而采用select函数有个好处就是它可以同时监听多个文件句柄(如果从UNP的角度看,select属于同步操作。因为select之后,进程还需要读写数据),从而提高系统的并发性!
异步非阻塞IO(Java AIO(NIO.2)):
在此种模式下,用户进程只需要发起一个IO操作然后立即返回,等IO操作真正的完成以后,应用程序会得到IO操作完成的通知,此时用户进程只需要对数据进行处理就好了,不需要进行实际的IO读写操作,因为真正的IO读取或者写入操作已经由内核完成了。
三种IO的用法和原理
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。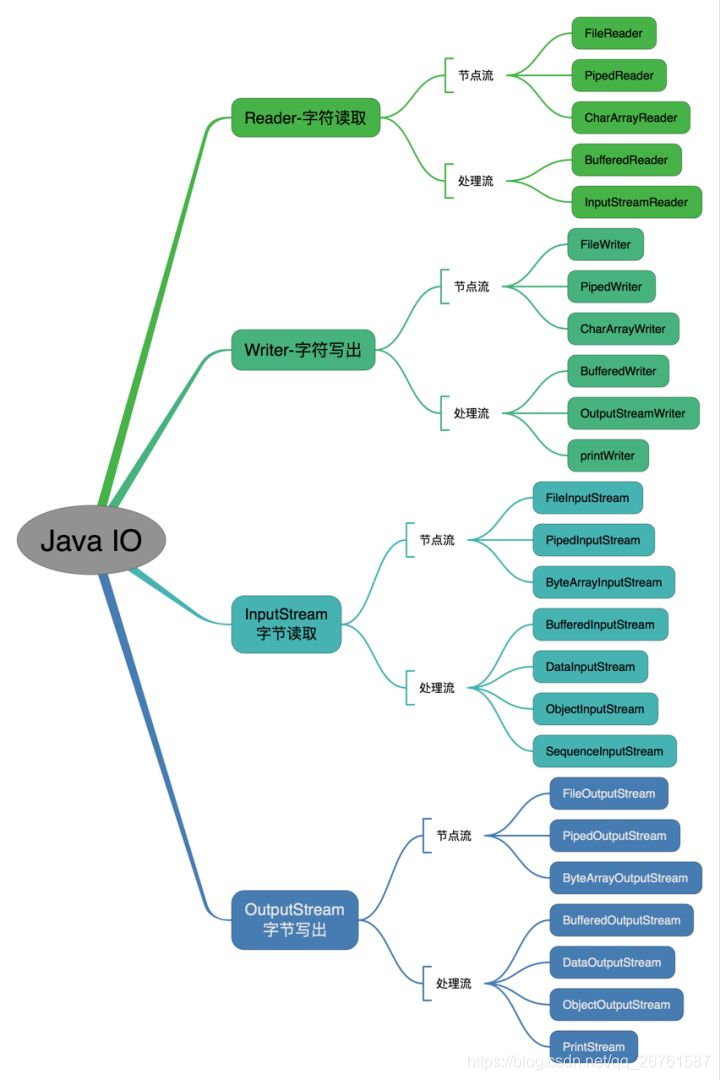
正则表达式
用\d可以匹配一个数字,\w可以匹配一个字母或数字
在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符:
要做更精确地匹配,可以用[]表示范围,比如:
[0-9a-zA-Z_]可以匹配一个数字、字母或者下划线;
[0-9a-zA-Z_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如’a100’,‘0_Z’,'Py3000’等等;
[a-zA-Z_][0-9a-zA-Z_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量;
[a-zA-Z_][0-9a-zA-Z_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号