Java注意事项
一、Comparable简介
Comparable是排序接口。若一个类实现了Comparable接口,就意味着该类支持排序。实现了Comparable接口的类的对象的列表或数组可以通过Collections.sort或Arrays.sort进行自动排序。
此外,实现此接口的对象可以用作有序映射中的键或有序集合中的集合,无需指定比较器。该接口定义如下:
package java.lang; import java.util.*; public interface Comparable<T>
{ public int compareTo(T o); }
T表示可以与此对象进行比较的那些对象的类型。
此接口只有一个方法compare,比较此对象与指定对象的顺序,如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
现在我们假设一个Person类,代码如下:
public class Person
{
String name;
int age;
public Person(String name, int age)
{
super();
this.name = name;
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
}
现在有两个Person类的对象,我们如何来比较二者的大小呢?我们可以通过让Person实现Comparable接口:
public class Person implements Comparable<Person>
{
String name;
int age;
public Person(String name, int age)
{
super();
this.name = name;
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
@Override
public int compareTo(Person p)
{
return this.age-p.getAge();
}
public static void main(String[] args)
{
Person[] people=new Person[]{new Person("xujian", 20),new Person("xiewei", 10)};
System.out.println("排序前");
for (Person person : people)
{
System.out.print(person.getName()+":"+person.getAge());
}
Arrays.sort(people);
System.out.println("\n排序后");
for (Person person : people)
{
System.out.print(person.getName()+":"+person.getAge());
}
}
}
程序执行结果为:

二、Comparator简介
Comparator是比较接口,我们如果需要控制某个类的次序,而该类本身不支持排序(即没有实现Comparable接口),那么我们就可以建立一个“该类的比较器”来进行排序,这个“比较器”只需要实现Comparator接口即可。也就是说,我们可以通过实现Comparator来新建一个比较器,然后通过这个比较器对类进行排序。该接口定义如下:
package java.util;
public interface Comparator<T>
{
int compare(T o1, T o2);
boolean equals(Object obj);
}
注意:1、若一个类要实现Comparator接口:它一定要实现compare(T o1, T o2) 函数,但可以不实现 equals(Object obj) 函数。
2、int compare(T o1, T o2) 是“比较o1和o2的大小”。返回“负数”,意味着“o1比o2小”;返回“零”,意味着“o1等于o2”;返回“正数”,意味着“o1大于o2”。
现在假如上面的Person类没有实现Comparable接口,该如何比较大小呢?我们可以新建一个类,让其实现Comparator接口,从而构造一个“比较器"。
public class PersonCompartor implements Comparator<Person>
{
@Override
public int compare(Person o1, Person o2)
{
return o1.getAge()-o2.getAge();
}
}
现在我们就可以利用这个比较器来对其进行排序:
public class Person
{
String name;
int age;
public Person(String name, int age)
{
super();
this.name = name;
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public static void main(String[] args)
{
Person[] people=new Person[]{new Person("xujian", 20),new Person("xiewei", 10)};
System.out.println("排序前");
for (Person person : people)
{
System.out.print(person.getName()+":"+person.getAge());
}
Arrays.sort(people,new PersonCompartor());
System.out.println("\n排序后");
for (Person person : people)
{
System.out.print(person.getName()+":"+person.getAge());
}
}
}
程序运行结果为:

三、Comparable和Comparator区别比较
Comparable是排序接口,若一个类实现了Comparable接口,就意味着“该类支持排序”。而Comparator是比较器,我们若需要控制某个类的次序,可以建立一个“该类的比较器”来进行排序。
Comparable相当于“内部比较器”,而Comparator相当于“外部比较器”。
两种方法各有优劣, 用Comparable 简单, 只要实现Comparable 接口的对象直接就成为一个可以比较的对象,但是需要修改源代码。 用Comparator 的好处是不需要修改源代码, 而是另外实现一个比较器, 当某个自定义的对象需要作比较的时候,把比较器和对象一起传递过去就可以比大小了, 并且在Comparator 里面用户可以自己实现复杂的可以通用的逻辑,使其可以匹配一些比较简单的对象,那样就可以节省很多重复劳动了。
JAVA中try、catch、finally带return的执行顺序总结
异常处理中,try、catch、finally的执行顺序,大家都知道是按顺序执行的。即,如果try中没有异常,则顺序为try→finally,如果try中有异常,则顺序为try→catch→finally。但是当try、catch、finally中加入return之后,就会有几种不同的情况出现,下面分别来说明一下。也可以跳到最后直接看总结。
一、try中带有return
1 private int testReturn1() {
2 int i = 1;
3 try {
4 i++;
5 System.out.println("try:" + i);
6 return i;
7 } catch (Exception e) {
8 i++;
9 System.out.println("catch:" + i);
10 } finally {
11 i++;
12 System.out.println("finally:" + i);
13 }
14 return i;
15 }
输出:
try:2
finally:3
2
因为当try中带有return时,会先执行return前的代码,然后暂时保存需要return的信息,再执行finally中的代码,最后再通过return返回之前保存的信息。所以,这里方法返回的值是try中计算后的2,而非finally中计算后的3。但有一点需要注意,再看另外一个例子:
1 private List<Integer> testReturn2() {
2 List<Integer> list = new ArrayList<>();
3 try {
4 list.add(1);
5 System.out.println("try:" + list);
6 return list;
7 } catch (Exception e) {
8 list.add(2);
9 System.out.println("catch:" + list);
10 } finally {
11 list.add(3);
12 System.out.println("finally:" + list);
13 }
14 return list;
15 }
输出:
try:[1]
finally:[1, 3]
[1, 3]
看完这个例子,可能会发现问题,刚提到return时会临时保存需要返回的信息,不受finally中的影响,为什么这里会有变化?其实问题出在参数类型上,上一个例子用的是基本类型,这里用的引用类型。list里存的不是变量本身,而是变量的地址,所以当finally通过地址改变了变量,还是会影响方法返回值的。
二、catch中带有return
1 private int testReturn3() {
2 int i = 1;
3 try {
4 i++;
5 System.out.println("try:" + i);
6 int x = i / 0 ;
7 } catch (Exception e) {
8 i++;
9 System.out.println("catch:" + i);
10 return i;
11 } finally {
12 i++;
13 System.out.println("finally:" + i);
14 }
15 return i;
16 }
输出:
try:2
catch:3
finally:4
3
catch中return与try中一样,会先执行return前的代码,然后暂时保存需要return的信息,再执行finally中的代码,最后再通过return返回之前保存的信息。所以,这里方法返回的值是try、catch中累积计算后的3,而非finally中计算后的4。
三、finally中带有return
1 private int testReturn4() {
2 int i = 1;
3 try {
4 i++;
5 System.out.println("try:" + i);
6 return i;
7 } catch (Exception e) {
8 i++;
9 System.out.println("catch:" + i);
10 return i;
11 } finally {
12 i++;
13 System.out.println("finally:" + i);
14 return i;
15 }
16 }
输出:
try:2
finally:3
3
当finally中有return的时候,try中的return会失效,在执行完finally的return之后,就不会再执行try中的return。这种写法,编译是可以编译通过的,但是编译器会给予警告,所以不推荐在finally中写return,这会破坏程序的完整性,而且一旦finally里出现异常,会导致catch中的异常被覆盖。
总结:
1、finally中的代码总会被执行。
2、当try、catch中有return时,也会执行finally。return的时候,要注意返回值的类型,是否受到finally中代码的影响。
3、finally中有return时,会直接在finally中退出,导致try、catch中的return失效
Java中throws和throw的区别讲解
当然,你需要明白异常在Java中式以一个对象来看待。
并且所有系统定义的编译和运行异常都可以由系统自动抛出,称为标准异常,但是一般情况下Java 强烈地要求应用程序进行完整的异常处理,给用户友好的提示,或者修正后使程序继续执行。
直接进入正题哈:
1.用户程序自定义的异常和应用程序特定的异常,必须借助于 throws 和 throw 语句来定义抛出异常。
1.1 throw是语句抛出一个异常。
语法:throw (异常对象);
throw e;
1.2 throws是方法可能抛出异常的声明。(用在声明方法时,表示该方法可能要抛出异常)
语法:[(修饰符)](返回值类型)(方法名)([参数列表])[throws(异常类)]{......}
public void doA(int a) throws Exception1,Exception3{......}
举例:
throws E1,E2,E3只是告诉程序这个方法可能会抛出这些异常,方法的调用者可能要处理这些异常,而这些异常E1,E2,E3可能是该函数体产生的。
throw则是明确了这个地方要抛出这个异常。
如: void doA(int a) throws IOException,{
try{
......
}catch(Exception1 e){
throw e;
}catch(Exception2 e){
System.out.println("出错了!");
}
if(a!=b)
throw new Exception3("自定义异常");
}
代码块中可能会产生3个异常,(Exception1,Exception2,Exception3)。
如果产生Exception1异常,则捕获之后再抛出,由该方法的调用者去处理。
如果产生Exception2异常,则该方法自己处理了(即System.out.println("出错了!");)。所以该方法就不会再向外抛出Exception2异常了,void doA() throws Exception1,Exception3 里面的Exception2也就不用写了。
而Exception3异常是该方法的某段逻辑出错,程序员自己做了处理,在该段逻辑错误的情况下抛出异常Exception3,则该方法的调用者也要处理此异常。
throw语句用在方法体内,表示抛出异常,由方法体内的语句处理。
throws语句用在方法声明后面,表示再抛出异常,由该方法的调用者来处理。
throws主要是声明这个方法会抛出这种类型的异常,使它的调用者知道要捕获这个异常。
throw是具体向外抛异常的动作,所以它是抛出一个异常实例。
throws说明你有那个可能,倾向。
throw的话,那就是你把那个倾向变成真实的了。
同时:
1、throws出现在方法函数头;而throw出现在函数体。
2、throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常。
3、两者都是消极处理异常的方式(这里的消极并不是说这种方式不好),只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
一共分为五个级别:DEBUG、INFO、WARN、ERROR和FATAL。这五个级别是有顺序的,DEBUG < INFO < WARN < ERROR < FATAL,明白这一点很重要,这里Log4j有一个规则:假设设置了级别为P,如果发生了一个级别Q比P高,则可以启动,否则屏蔽掉。
DEBUG: 这个级别最低的东东,一般的来说,在系统实际运行过程中,一般都是不输出的。因此这个级别的信息,可以随意的使用,任何觉得有利于在调试时更详细的了解系统运行状态的东东,比如变量的值等等,都输出来看看也无妨。
INFO:这个应该用来反馈系统的当前状态给最终用户的,所以,在这里输出的信息,应该对最终用户具有实际意义,也就是最终用户要能够看得明白是什么意思才行。从某种角度上说,Info 输出的信息可以看作是软件产品的一部分(就像那些交互界面上的文字一样),所以需要谨慎对待,不可随便。
WARN、ERROR和FATAL:警告、错误、严重错误,这三者应该都在系统运行时检测到了一个不正常的状态,他们之间的区别,要区分还真不是那么简单的事情。我大致是这样区分的:
所谓警告,应该是这个时候进行一些修复性的工作,应该还可以把系统恢复到正常状态中来,系统应该可以继续运行下去。
所谓错误,就是说可以进行一些修复性的工作,但无法确定系统会正常的工作下去,系统在以后的某个阶段,很可能会因为当前的这个问题,导致一个无法修复的错误(例如宕机),但也可能一直工作到停止也不出现严重问题。
所谓Fatal,那就是相当严重的了,可以肯定这种错误已经无法修复,并且如果系统继续运行下去的话,可以肯定必然会越来越乱。这时候采取的最好的措施不是试图将系统状态恢复到正常,而是尽可能地保留系统有效数据并停止运行。
也就是说,选择 Warn、Error、Fatal 中的具体哪一个,是根据当前的这个问题对以后可能产生的影响而定的,如果对以后基本没什么影响,则警告之,如果肯定是以后要出严重问题的了,则Fatal之,拿不准会怎么样,则 Error 之。
代理模式
定义:给某个对象提供一个代理对象,并由代理对象控制对于原对象的访问,即客户不直接操控原对象,而是通过代理对象间接地操控原对象。
在上图中:
RealSubject 是原对象(也称为”委托对象”),Proxy 是代理对象
Subject 是委托对象和代理对象都共同实现的接口。
Request() 是委托对象和代理对象共同拥有的方法。
生活中的代理模式:
远程代理:我们在国内因为GFW,所以不能访问 facebook,我们可以用FQ(设置代理)的方法访问。访问过程是:
(1)用户把HTTP请求发给代理
(2)代理把HTTP请求发给web服务器
(3)web服务器把HTTP响应发给代理
(4)代理把HTTP响应发回给用户
Java 实现上面的UML图的代码(即实现静态代理)为:
public class ProxyDemo {
public static void main(String args[]){
RealSubject subject = new RealSubject();
Proxy p = new Proxy(subject);
p.request();
}
}
interface Subject{
void request();
}
class RealSubject implements Subject{
public void request(){
System.out.println("request");
}
}
class Proxy implements Subject{
private Subject subject;
public Proxy(Subject subject){
this.subject = subject;
}
public void request(){
System.out.println("PreProcess");
subject.request();
System.out.println("PostProcess");
}
}
代理的实现分为:
静态代理:代理类是在编译时就实现好的。也就是说 Java 编译完成后代理类是一个实际的 class 文件。
动态代理:代理类是在运行时生成的。也就是说 Java 编译完之后并没有实际的 class文件,而是在运行时动态生成的类字节码,并加载到JVM中。
JDK动态代理
为了提高代理的灵活性和可扩展性,减少重复代码,我们可以使用JDK提供的动态代理。
实现JDK动态代理的步骤:
通过实现 InvocationHandler 接口创建自己的调用处理器;
通过为 Proxy 类指定 ClassLoader 对象和一组 interface 来创建动态代理类;
通过反射机制获得动态代理类的构造函数,其唯一参数类型是调用处理器接口类型;
通过构造函数创建动态代理类实例,构造时调用处理器对象作为参数被传入。
// InvocationHandlerImpl 实现了 InvocationHandler 接口,并能实现方法调用从代理类到委托类的分派转发
// 其内部通常包含指向委托类实例的引用,用于真正执行分派转发过来的方法调用
InvocationHandler handler = new InvocationHandlerImpl(..);
// 通过 Proxy 为包括 Interface 接口在内的一组接口动态创建代理类的类对象
Class clazz = Proxy.getProxyClass(classLoader, new Class[] { Interface.class, ... });
// 通过反射从生成的类对象获得构造函数对象
Constructor constructor = clazz.getConstructor(new Class[] { InvocationHandler.class });
// 通过构造函数对象创建动态代理类实例
Interface Proxy = (Interface)constructor.newInstance(new Object[] { handler });
实际使用过程更加简单,因为 Proxy 的静态方法 newProxyInstance 已经为我们封装了步骤 2 到步骤 4 的过程:
public class DynamicProxyDemo01 {
public static void main(String[] args) {
RealSubject realSubject = new RealSubject(); //1.创建委托对象
ProxyHandler handler = new ProxyHandler(realSubject); //2.创建调用处理器对象
Subject proxySubject =(Subject)Proxy.newProxyInstance(RealSubject.class.getClassLoader(),
RealSubject.class.getInterfaces(),handler); //3.动态生成代理对象
proxySubject.request(); //4.通过代理对象调用方法
}
}
/**
* 接口
*/
interface Subject{
void request();
}
/**
* 委托类
*/
class RealSubject implements Subject{
public void request(){
System.out.println("====RealSubject Request====");
}
}
/**
* 代理类的调用处理器
*/
class ProxyHandler implements InvocationHandler{
private Subject subject;
public ProxyHandler(Subject subject){
this.subject = subject;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
System.out.println("====before====");//定义预处理的工作,当然你也可以根据 method 的不同进行不同的预处理工作
Object result = method.invoke(subject, args);
System.out.println("====after====");
return result;
}
}
Proxy 静态方法生成动态代理类同样需要通过类装载器来进行装载才能使用,它与普通类的唯一区别就是其字节码是由 JVM 在运行时动态生成的而非预存在于任何一个 .class 文件中。每次生成动态代理类对象时都需要指定一个类装载器对象。
基于CGLIB的动态代理
由于JDK的动态代理依靠接口实现,如果有些类并没有实现接口,则不能使用JDK代理,这就要使用cglib动态代理了。
CGlib概述:
cglib(Code Generation Library)是一个强大的,高性能,高质量的Code生成类库。它可以在运行期扩展Java类与实现Java接口。
cglib封装了asm,可以在运行期动态生成新的class。
cglib用于AOP,jdk中的proxy必须基于接口,cglib却没有这个限制。
JDK的动态代理机制只能代理实现了接口的类,而不能实现接口的类就不能实现JDK的动态代理,cglib是针对类来实现代理的,他的原理是对指定的目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对final修饰的类进行代理。
有一个Manager类:
public class Manager {
public void query() {
System.out.println("query...");
}
public void insert() {
System.out.println("insert...");
}
public String update() {
System.out.println("update....");
return "I'm update";
}
public void delete() {
System.out.println("delete....");
}
}
我们想要在这个类中的每个方法前面和后面都打印一句话。
public class AuthProxy implements MethodInterceptor{
@Override
public Object intercept(Object arg0, Method method, Object[] args,
MethodProxy proxy) throws Throwable {
System.out.println("Before...");
Object result = proxy.invokeSuper(arg0, args);
System.out.println("After....");
return result;
}
}
如上,CGLIB实现的代理类必须实现MethodInterceptor接口,该接口中只有一个方法需要实现,即intercept方法。通过MethodProxy中的invokeSuper即可执行被代理类的方法。
什么是RESTful
一、名称解释
REST,即Representational State Transfer的缩写,有人翻译为“表现层状态转化”。如果一个架构符合REST原则,就称它为RESTful架构。简答来说:URL定位资源,用HTTP动词(GET,POST,DELETE,PUT)描述操作。
二、资源(Resources)
所谓”资源”,就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
所谓”上网”,就是与互联网上一系列的”资源”互动,调用它的URI。
三、表现层(Representation)
“资源”是一种信息实体,它可以有多种外在表现形式。我们把”资源”具体呈现出来的形式,叫做它的”表现层”(Representation)。
比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
URI只代表资源的实体,不代表它的形式。严格地说,有些网址最后的”.html”后缀名是不必要的,因为这个后缀名表示格式,属于”表现层”范畴,而URI应该只代表”资源”的位置。它的具体表现形式,应该在HTTP请求的头信息中用Accept和Content-Type字段指定,这两个字段才是对”表现层”的描述。
四、状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生”状态转化”(State Transfer)。而这种转化是建立在表现层之上的,所以就是”表现层状态转化”。
客户端用到的手段,只能是HTTP协议。具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
五、总结
1、API 的版本信息推荐放到HTTP的header中。
2、3. URI使用名词而不是动词,且推荐用复数。
BAD:
- /getProducts
- /listOrders
- /retrieveClientByOrder?orderId=1
GOOD:
- GET /products : will return the list of all products
- POST /products: will add a product to the collection
- GET /products/4 : will retrieve product #4
- PUT /products/4 : will update product #4
3、保证 HEAD 和 GET 方法是安全的,不会对资源状态有所改变(污染)。
4、使用正确的HTTP Status Code表示访问状态。
更详细的补充:
GET(SELECT):从服务器取出资源(一项或多项)。
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新资源(客户端提供完整资源数据)。
PATCH(UPDATE):在服务器更新资源(客户端提供需要修改的资源数据)。
DELETE(DELETE):从服务器删除资源。
JAVA中的SPI机制
SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的API,它可以用来启用框架扩展和替换组件。
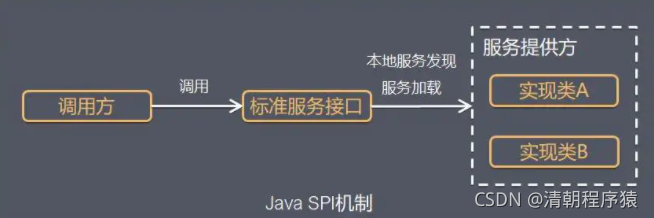
java SPI 实际上是 “基于接口的编程+策略模式+配置文件” 组合实现的动态加载机制。
系统设计的各个抽象,往往有很多不同的实现方案,在面向的对象的设计里,一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。
Java SPI就是提供这样的一个机制:为某个接口寻找服务实现的机制。有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。所以SPI的核心思想就是解耦,增加可扩展性。
二、使用场景
概括地说,适用于:调用者根据实际使用需要,启用、扩展、或者替换框架的实现策略
比较常见的例子:
数据库驱动加载接口实现类的加载
JDBC加载不同类型数据库的驱动
日志门面接口实现类加载
SLF4J加载不同提供商的日志实现类
Spring
Spring中大量使用了SPI,比如:对servlet3.0规范对ServletContainerInitializer的实现、自动类型转换Type Conversion SPI(Converter SPI、Formatter SPI)等
Dubbo
Dubbo中也大量使用SPI的方式实现框架的扩展, 不过它对Java提供的原生SPI做了封装,允许用户扩展实现Filter接口
三、总结
优点:
使用Java SPI机制的优势是实现解耦,使得第三方服务模块的装配控制的逻辑与调用者的业务代码分离,而不是耦合在一起。应用程序可以根据实际业务情况启用框架扩展或替换框架组件。
相比使用提供接口jar包,供第三方服务模块实现接口的方式,SPI的方式使得源框架,不必关心接口的实现类的路径,可以不用通过下面的方式获取接口实现类:
代码硬编码import 导入实现类
指定类全路径反射获取:例如在JDBC4.0之前,JDBC中获取数据库驱动类需要通过Class.forName("com.mysql.jdbc.Driver"),类似语句先动态加载数据库相关的驱动,然后再进行获取连接等的操作
第三方服务模块把接口实现类实例注册到指定地方,源框架从该处访问实例
通过SPI的方式,第三方服务模块实现接口后,在第三方的项目代码的META-INF/services目录下的配置文件指定实现类的全路径名,源码框架即可找到实现类
缺点:
虽然ServiceLoader也算是使用的延迟加载,但是基本只能通过遍历全部获取,也就是接口的实现类全部加载并实例化一遍。如果你并不想用某些实现类,它也被加载并实例化了,这就造成了浪费。获取某个实现类的方式不够灵活,只能通过Iterator形式获取,不能根据某个参数来获取对应的实现类。
多个并发多线程使用ServiceLoader类的实例是不安全的。
List remove的三种正确方法
1、倒序循环,因为list删除只会导致当前元素之后的元素位置发生改变,所以采用倒序可以保证前面的元素没有变化;
for(int i=list.size()-1;i>=0;i--){
list.remove(i);
}
2、顺序循环时,删除当前位置的值,下一个值就会补到当前位置,所以需要执行i–操作;
for (int i=0; i<list.size(); i++) {
if (list.get(i) == 3) {
list.remove(i);
i--;
}
}
3、注意必须用迭代器的remove()方法,不要用list的remove,不然会发生java.util.ConcurrentModificationException 异常;
if (null != list && list.size() > 0) {
Iterator it = list.iterator();
while(it.hasNext()){
Student stu = (Student)it.next();
if (stu.getStudentId() == studentId) {
it.remove(); //移除该对象
}
}
}
————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号