Redis的分布式锁详解
Redis实现的分布式锁
-
# 对资源key加锁,key不存在时创建,并且设置,10秒自动过期
-
SET key value EX 10 NX
-
# 删除key
-
DEL key
NX的作用
NX参数是为了保证当分布式锁不存在时,只有一个client能写入次key成功,获取到锁。
分布式锁的第一核心要素就是互斥性、安全性,在同一时间内,不允许多个client同时获得锁
未设置key的自动过期时间
分布式锁的第二个核心要素,活性。在实现分布式锁的过程中要考虑到client可能会出现crash或者网络分区,需要原子申请分布式锁以及设置锁的自动过期时间,
通过过期、超时等机智自动释放锁,避免死锁,导致业务中断。
设置过期时间,仍然出现超卖
Redis分布式锁的是实现是阻塞的请求执行完成后,不能保证原子性操作,可以通过lua脚本来实现redis比较库存、扣件库存操作的原子性。
为什么喜欢用redis做分布式锁
Redis的核心优点是快、简单、部署方便。
Redis分布式锁的问题
Redis分布式锁存在的问题:
1.存在单点故障问题,官方给出了 解决的方法,就是RedLock算法。
2.获取锁失败后,只能抛出异常,不能阻塞线程。Redisson 开源框架解决了这些问题。
分布式锁创建的方案
Zookeeper是一个典型的分布式元数据存储服务,它的分布式锁实现基于Zookeeper的临时节点和顺序特性。
临时节点具备数据自动删除的功能,当client和Zookeeper连接和session断掉时,相应的临时节点就会被删除。
Zookeeper也提供了Watch特性可监听key的数据变化。
etcd分布式锁实现
事务与锁的安全性
etcd的事务特性有IF语句、ELSE语句、THEN语句组成,IF语句支持比较key的是修改版本号mod_version和创建版本号create_version.
可以通过key的创建版本号create_version来检查key是否存在,如果不存在,create_revision的版本号是0。
Lease与锁的活性
Lease是一种活性检测机制,提供了检测各个客户端存活的能力。
通过Lease机制就可以优雅地解决了client出现crash故障、client与etcd集群网络出现隔离等各类故障场景下的死锁问题,超过Lease TTL,就会自动释放。
Watch与锁的可用性
watch提供高效的数据监听能力,当client收到watch delete事件后,就可以快速判断自己是否有资格获取锁,极大减少了锁的不可用时间。
Jedis与Redisson选型对比
1 概述
1.1. 主要内容
本文的主要内容为对比Redis的两个框架:Jedis与Redisson,分析各自的优势与缺点,为项目中Java缓存方案中的Redis编程模型的选择提供参考。
2. Jedis与Redisson对比
2.1. 概况对比
Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持;Redisson实现了分布式和可扩展的Java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
2.2. 编程模型
Jedis中的方法调用是比较底层的暴露的Redis的API,也即Jedis中的Java方法基本和Redis的API保持着一致,了解Redis的API,也就能熟练的使用Jedis。而Redisson中的方法则是进行比较高的抽象,每个方法调用可能进行了一个或多个Redis方法调用。
如下分别为Jedis和Redisson操作的简单示例:
Jedis设置key-value与set操作:
Jedis jedis = …;
jedis.set("key", "value");
List<String> values = jedis.mget("key", "key2", "key3");
Redisson操作map:
Redisson redisson = …
RMap map = redisson.getMap("my-map"); // implement java.util.Map
map.put("key", "value");
map.containsKey("key");
map.get("key");
2.3. 可伸缩性
Jedis使用阻塞的I/O,且其方法调用都是同步的,程序流需要等到sockets处理完I/O才能执行,不支持异步。Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis。
Redisson使用非阻塞的I/O和基于Netty框架的事件驱动的通信层,其方法调用是异步的。Redisson的API是线程安全的,所以可以操作单个Redisson连接来完成各种操作。
2.4. 数据结构
Jedis仅支持基本的数据类型如:String、Hash、List、Set、Sorted Set。
Redisson不仅提供了一系列的分布式Java常用对象,基本可以与Java的基本数据结构通用,还提供了许多分布式服务,其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service)。
在分布式开发中,Redisson可提供更便捷的方法。
2.5. 第三方框架整合
1 Redisson提供了和Spring框架的各项特性类似的,以Spring XML的命名空间的方式配置RedissonClient实例和它所支持的所有对象和服务;
2 Redisson完整的实现了Spring框架里的缓存机制;
3 Redisson在Redis的基础上实现了Java缓存标准规范;
4 Redisson为Apache Tomcat集群提供了基于Redis的非黏性会话管理功能。该功能支持Apache Tomcat的6、7和8版。
5 Redisson还提供了Spring Session会话管理器的实现。
Redisson几种锁说明
1. 可重入锁(Reentrant Lock)
Redisson的分布式可重入锁RLock Java对象实现了java.util.concurrent.locks.Lock接口,同时还支持自动过期解锁。
- public void testReentrantLock(RedissonClient redisson){ RLock lock = redisson.getLock("anyLock"); try{ // 1. 最常见的使用方法 //lock.lock(); // 2. 支持过期解锁功能,10秒钟以后自动解锁, 无需调用unlock方法手动解锁 //lock.lock(10, TimeUnit.SECONDS); // 3. 尝试加锁,最多等待3秒,上锁以后10秒自动解锁 boolean res = lock.tryLock(3, 10, TimeUnit.SECONDS); if(res){ //成功 // do your business } } catch (InterruptedException e) { e.printStackTrace(); } finally { lock.unlock(); } }
Redisson同时还为分布式锁提供了异步执行的相关方法:
- public void testAsyncReentrantLock(RedissonClient redisson){ RLock lock = redisson.getLock("anyLock"); try{ lock.lockAsync(); lock.lockAsync(10, TimeUnit.SECONDS); Future res = lock.tryLockAsync(3, 10, TimeUnit.SECONDS); if(res.get()){ // do your business } } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } finally { lock.unlock(); } }
2. 公平锁(Fair Lock)
Redisson分布式可重入公平锁也是实现了java.util.concurrent.locks.Lock接口的一种RLock对象。在提供了自动过期解锁功能的同时,保证了当多个Redisson客户端线程同时请求加锁时,优先分配给先发出请求的线程。
- public void testFairLock(RedissonClient redisson){ RLock fairLock = redisson.getFairLock("anyLock"); try{ // 最常见的使用方法 fairLock.lock(); // 支持过期解锁功能, 10秒钟以后自动解锁,无需调用unlock方法手动解锁 fairLock.lock(10, TimeUnit.SECONDS); // 尝试加锁,最多等待100秒,上锁以后10秒自动解锁 boolean res = fairLock.tryLock(100, 10, TimeUnit.SECONDS); } catch (InterruptedException e) { e.printStackTrace(); } finally { fairLock.unlock(); } }
Redisson同时还为分布式可重入公平锁提供了异步执行的相关方法:
- RLock fairLock = redisson.getFairLock("anyLock"); fairLock.lockAsync(); fairLock.lockAsync(10, TimeUnit.SECONDS); Future res = fairLock.tryLockAsync(100, 10, TimeUnit.SECONDS);
3. 联锁(MultiLock)
Redisson的RedissonMultiLock对象可以将多个RLock对象关联为一个联锁,每个RLock对象实例可以来自于不同的Redisson实例。
- public void testMultiLock(RedissonClient redisson1, RedissonClient redisson2, RedissonClient redisson3){ RLock lock1 = redisson1.getLock("lock1"); RLock lock2 = redisson2.getLock("lock2"); RLock lock3 = redisson3.getLock("lock3"); RedissonMultiLock lock = new RedissonMultiLock(lock1, lock2, lock3); try { // 同时加锁:lock1 lock2 lock3, 所有的锁都上锁成功才算成功。 lock.lock(); // 尝试加锁,最多等待100秒,上锁以后10秒自动解锁 boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS); } catch (InterruptedException e) { e.printStackTrace(); } finally { lock.unlock(); } }
4. 红锁(RedLock)
Redisson的RedissonRedLock对象实现了Redlock介绍的加锁算法。该对象也可以用来将多个RLock
对象关联为一个红锁,每个RLock对象实例可以来自于不同的Redisson实例。
- public void testRedLock(RedissonClient redisson1, RedissonClient redisson2, RedissonClient redisson3){ RLock lock1 = redisson1.getLock("lock1"); RLock lock2 = redisson2.getLock("lock2"); RLock lock3 = redisson3.getLock("lock3"); RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3); try { // 同时加锁:lock1 lock2 lock3, 红锁在大部分节点上加锁成功就算成功。 lock.lock(); // 尝试加锁,最多等待100秒,上锁以后10秒自动解锁 boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS); } catch (InterruptedException e) { e.printStackTrace(); } finally { lock.unlock(); } }
5. 读写锁(ReadWriteLock)
Redisson的分布式可重入读写锁RReadWriteLock Java对象实现了java.util.concurrent.locks.ReadWriteLock接口。同时还支持自动过期解锁。该对象允许同时有多个读取锁,但是最多只能有一个写入锁。
- RReadWriteLock rwlock = redisson.getLock("anyRWLock"); // 最常见的使用方法 rwlock.readLock().lock(); // 或 rwlock.writeLock().lock(); // 支持过期解锁功能 // 10秒钟以后自动解锁 // 无需调用unlock方法手动解锁 rwlock.readLock().lock(10, TimeUnit.SECONDS); // 或 rwlock.writeLock().lock(10, TimeUnit.SECONDS); // 尝试加锁,最多等待100秒,上锁以后10秒自动解锁 boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS); // 或 boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS); ... lock.unlock();
6. 信号量(Semaphore)
Redisson的分布式信号量(Semaphore)Java对象RSemaphore采用了与java.util.concurrent.Semaphore相似的接口和用法。
- RSemaphore semaphore = redisson.getSemaphore("semaphore"); semaphore.acquire(); //或 semaphore.acquireAsync(); semaphore.acquire(23); semaphore.tryAcquire(); //或 semaphore.tryAcquireAsync(); semaphore.tryAcquire(23, TimeUnit.SECONDS); //或 semaphore.tryAcquireAsync(23, TimeUnit.SECONDS); semaphore.release(10); semaphore.release(); //或 semaphore.releaseAsync();
7. 可过期性信号量(PermitExpirableSemaphore)
Redisson的可过期性信号量(PermitExpirableSemaphore)实在RSemaphore对象的基础上,为每个信号增加了一个过期时间。每个信号可以通过独立的ID来辨识,释放时只能通过提交这个ID才能释放。
- RPermitExpirableSemaphore semaphore = redisson.getPermitExpirableSemaphore("mySemaphore"); String permitId = semaphore.acquire(); // 获取一个信号,有效期只有2秒钟。 String permitId = semaphore.acquire(2, TimeUnit.SECONDS); // ... semaphore.release(permitId);
8. 闭锁(CountDownLatch)
Redisson的分布式闭锁(CountDownLatch)Java对象RCountDownLatch采用了与java.util.concurrent.CountDownLatch相似的接口和用法。
分布式锁的实现方式也有很多种,基于zookeeper的,基于分布式数据库的以及本文我们要介绍的基于Redis的。为了系统而全面的介绍基于Redis的实现方案,本文主要涉及如下内容:
- Redis单节点锁的实现
- Redis集群锁的实现(RedLock)
- Redis锁的使用场景分析
- 一个RedLock的python实现及需要的改进方案
单节点Redis的锁实现
单节点Redis的锁实现主要有三大点: SETNX的使用、超时时间设置以及释放锁前先检查锁,下面一一介绍。
SETNX
前面我们说过,锁的实现一定是要基于各个工作流都能看到的公共区域实现。而Redis本身作为一个内存数据库就天然的适合锁的实现。就跟击鼓传花似的,只要有一个进程拿到了这个花,别的进程就必须得有办法知道这个花被占用了,这样他就可以原地等待直到这个花被释放出来,各个进程再去抢这朵花。Redis的SETNX命令非常适合排他性的锁实现。该命令只会在键不存在的情况下才会为键设置值,一个进程申明独占某个资源的方式就是对一个键使用SETNX,这样当别的进程再去使用这个命令设置这个键的时候就会失败进而无法获得锁,这样满足了我们的前言中锁的互斥性原则。这时我们的程序和我们的锁获得与释放可以这么写。
def Job():
identifier = str(uuid.uuid4())
lock_name = "mylock"
try:
#一直循环等待获得锁
while True:
#如果获得锁c成功就完成工作并退出循环
if lock(lock_name):
do_something()
break
finally:
#释放锁
unlock(lock_name)
def lock(lock_name):
return redis.setnx(lock_name, identifier)
def unlock(lock_name):
redis.delete(lock_name)
超时时间设置
但是只用上述方法,避免死锁的性质能否被满足呢?假设当前获得锁的进程挂掉了,那么由于当前进程没有释放锁,那么其他的进程就会永远都没法获得锁(因为setnx命令会一直返回False)。所以我们不能只依赖工作进程自己主动去释放锁。还需要给锁加一个生存期间,如果锁过了生存期间还没有被释放,则Redis强制释放该锁。这样,即使获得锁的进程挂掉了,其他的进程还是可以在一段时间后获得锁而不会现如死锁的困境。Redis的超时限制特性可以解决这个问题。此时,我们的锁获得和释放可以这么写:
def lock(lock_name, lock_timeout):
if redis.setnx(lock_name, identifier):
redis.expire(lock_name,lock_timeout)
return True
return False
def unlock(lock_name):
redis.delete(lock_name)释放锁时先检查
带有超时特性的锁满足了避免死锁的性质,但是这种auto release的机制的却很有可能破坏锁的互斥性质。举个例子,比如当进程A获得了锁,并设置锁的超期时间为10s,进程A由于处理任务花费的时间较长,10s后任务还没处理完,但是此时锁已经过期被释放了,进程B重新获得了锁(不要忘了,锁实际上是对资源独占的一种申明)。这个时候由于进程A没有主动释放锁,进程B又获得了锁,对A、B来讲,他们都认为自己独占了资源,当他们按照独占资源的想法去操作资源的时候就可能会导致冲突。同时还存在的另一个问题,A的锁由于超时被释放了且B重新获得了锁,但是A并不知道自己的锁已经被释放了,A做完处理工作之后开始释放锁,然而这时释放的其实是B的锁(因为都删除的是mylock键)。B吃着火锅唱着歌,回头一看,锁没了==,很糟糕。对于第一个问题的解决方案我们后续介绍,但是对于第二个误释放别人的锁,我们可以在unlock中使用如下步骤释放锁:
- 从redis中使用GET命令得到mylock的值,并检查锁对应的值是不是自己当时存的identifier
- 如果是,那就使用DELETE释放,如果不是,说明自己的锁已经被自动释放了,则不做任何处理。
为保证上述整个操作的原子性,防止在GET之后,DELETE之前的期间Redis恰巧把锁给自动释放了,一般把上述的过程写到一个Lua的脚本中提交给Redis执行,因为Redis执行Lua脚本中的命令是原子性质的。
代码如下:
def unlock(lock_name, identifier):
unlock_script = """
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end"""
redis.eval(unlock_script, 1, lock_name, identifier)
到这里Redis单节点的锁实现已经基本介绍完了,主要有三点
- 使用SETNX实现排他性锁
- 使用超时限制特性来避免死锁
- 释放锁的时候需要进行检查来避免误释放别的进程的锁
那么我们接下来要讨论的一个问题是:如果在使用的过程中Redis突然挂了会怎样?Redis介绍1中介绍过Redis是有持久化机制的。当Redis挂了之后,再次恢复的时候可以从磁盘上把数据恢复出来。
但是问题在于如果A进程获得了锁(即在Redis中使用SETNX设置了键),在Redis把这个操作持久化到磁盘之前Redis就挂了的话,那么Redis再次启动的时候,通过磁盘持久化文件恢复出来的数据中是没有这个锁的信息的。当B去尝试获得锁时发现自己可以获得锁,但是此时A认为自己还没有释放锁,于是又导致了A、B两个进程同时认为自己持有锁的情况发生,破坏了性质1。
上述的问题主要发生本质原因还是在于单点问题,当我们只依赖单个Redis节点时,我们就只能承受单点不可靠带来的风险。而我们都知道,在分布式系统中,常用的应对单点风险的解决方案就是冗余节点。那我们能不能多启动几个Redis,保留键的多副本,这样即使一个Redis因为意外挂掉了,我们也可以使用别的Redis服务器继续正常服务?答案是YES! 这就是我们接下来要介绍的RedLock。
RedLock
RedLock是Redis之父Salvatore Sanfilippo提出来的基于多个Redis实例的分布式锁的实现方案。其核心思想就在于使用多个Redis冗余实例来避免单Redis实例的不可靠性。比如我们采用5个Redis实例,我们可以把5个Redis全部部署到同一台机器上,也可以把5个Redis部署在5个不同的机器上。一般为了实现更好的读写性能以及抗风险能力,我们选择部署5个Redis在5个机器上。
基于Redis的锁的实现本质都是针对数据库的读写操作。那么采用5个Redis节点我们就需要考虑副本读写的一致性问题。基于不同的准则,我们有不同的权衡,比如写入的副本一致性,可以要求到只要一个节点写入成功则成功,或者依据法团准则,写入(N/2 +1)个节点后才成功,或者写入所有的节点后才成功等等。RedLock采用的就是依据法团准则的方案:
 多副本情况下的一致性准则
多副本情况下的一致性准则
假如我们现在有5台机器上跑着5个Redis服务器,RedLock的获取步骤如下:
- 依次向每个Redis服务器获取锁(即使用SETNX设置键值), 如果获得至少(N/2 +1)个服务器的锁(在本例中就是3),则认为获得锁成功
- 如果第一步中获得的锁的个数少于3个,则认为获得锁失败。为保证其他节点获得锁正常,在所有Redis节点上释放锁(因为有可能有的节点设置成功了锁)
释放锁的过程也很简单,就和上述的单节点的锁释放步骤一致,只不过改成了在所有的节点上都执行一遍锁释放。
那我们先来看看这样是否能够解决如果一个Redis节点挂了出现锁被同时两个客户端获得的情况。假设我们总共有5台机器,客户端A从R1,R2,R3上获得了锁,但是在R1未来得及把这个操作持久化到磁盘上时,R1挂掉了。此时R1重启之后,其从磁盘上恢复的数据并没有A的锁的信息,所以进程B可以从R1,R4,R5再次获得锁(满足法团协议),这样就又造成了冲突。为解决这个问题,Redis作者提出了延迟重启的解决方案。
延迟重启
假设R1挂掉了之后,我们不再让R1提供服务会怎么样呢?首先可以保证的时,上述的A、B同时获得锁的情况不会发生,因为B最多从R4,R5获得两个锁,不满足法团协议。但是显然我们不能让R1永远的不提供服务。但我们可以让他等一会再重新对外提供服务,那得等待多久呢?我们可以发现的是,受R1挂了然后接着重启这件事影响的锁只是在R1挂的那个时刻R1上存的所有锁,之后创建的新锁或者没在R1上存储的锁都不受R1挂了这件事的影响。而我们前面又知道,在设置锁的时候,为避免陷入死锁的困境,我们给每个锁设置了一个过期时间。那R1只需要等到R1挂掉的那个时刻其上面所有的键都过期之后再对外提供服务即可,即可以等待一个所有键的MAX TTL即可。但是这个MAX TTL我们是没法只通过统计R1上的键准确的知道的,因为R1有一部分键的信息由于没有持久化到磁盘上已经丢失了。但是为了保险,我们可以通过统计当前时刻所有机器上的MAX TTL,然后取所有机器的MAX TTL即可。这样我们就可以保证R1加入服务后,其上所有的锁都肯定已经失效了。有了延迟重启和多Redis实例的解决方案,我们对Redis节点可能会挂这个风险有了更强的的抵抗能力。
但是软件行业里显然没有任何银弹方案。引入了副本在提升鲁棒性的同时也对整个系统引入了复杂性和不确定性。我们来看这样一个例子:我们有5个Redis服务器,客户端A试图获得一个超时期限为10s的锁。按照上述的流程,我们是从R1到R5依次尝试获得锁mylock,当前时间戳假设是12300
- 我们先从R1获得了锁,此时R1机器上记录的mylock的到期时间戳为12310
- 我们再尝试从R2获得锁,由于网络的问题,等R2获得请求时,时间已经到了12302了,那么R2机器上记录的mylock的到期时间戳即为12312
- 同理,当我们再次尝试从R3获得锁时,网络畅通,当前时间戳仍然是12302,R3上记录的mylock的到期时间戳为12312
发现了么,R1, R2,R3的到期时间戳是不一样的。如果我们按照三个机器的最大时间戳来当作mylock的过期时间戳会导致如果客户端B在时间戳为12311时尝试获得mylock锁,由于R1中mylock已经过期,则B从R1,R4,R5获得锁,满足法团协议,获得获得锁成功,此时出现A、B同时得到锁。所以显然不能使用最大时间戳来当作过期时间戳,使用理论时间戳(即开始设置时,本地机器的时间戳+TTL)是最保险的方案,因为他肯定是最小的。为了避免在获取锁的过程中因为网络的问题占用了过多的锁可使用时间,每次从一个机器获取锁的时候都在网络上只等一个非常小的时间,超时还未获得锁就立马尝试下一个节点。
到这似乎问题都被解决了,那是不是RedLock就真的完美了么?显然不是
RedLock的问题
RedLock可能的最大问题在于对各个机器时间流速的一致性假设。什么叫时间流速一致性假设呢?就是机器A上过了一分钟,机器B上也过了几乎一分钟。读者看到这会想,这不是废话么,难道还有流速不一致的情况。其问题在于,一个机器的时间是有可能跳变的。比如管理员重新校正机器时间,或者机器的时钟模块收到外部更新信号,重新校对时间等。这就有可能导致如下的情况出现:客户端A从R1,R2,R3获得了锁,并设置了过期时间为10s,但是在其中的某个时刻,可能R1的时间被重新校正,“快进了10s”,调整完时间之后,R1上的锁就已经过期了。此时B再次申请同样的锁,则可以从R1,R4,R5获得锁,满足法团协议。获得锁成功。当然,这种问题发生的概率可能是足够低的,能不能承受这样的情况带来的损失决定着是否采用Redis来实现分布式锁。
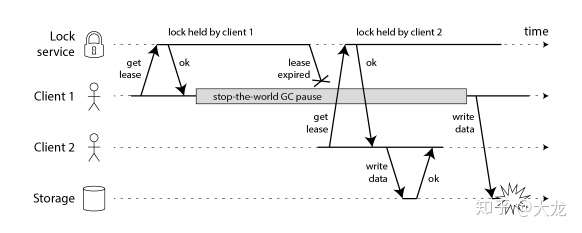
第二个问题出现在auto release的机制上。auto release的使用解决了持有锁的进程不能正常释放锁导致的死锁问题,但是同时带来的问题可能就是如下这种情况,即客户端1还没使用完锁但是锁已经过期了,这时客户端2获得了锁,结果客户端1、客户端2都对资源进行了使用。当然,设置过期时间实际上是租约机制的一种,但是RedLock的算法中没有提到续租的相关机制。后来开源的实现中,Java的redisson实现了基于watchdog的续租机制,就比较好的缓解了该问题。
那RedLock有这样的问题的话,我们是否该用RedLock呢?我觉得回答这个问题我们首先需要明确我们为什么需要使用锁。这个问题我觉得Martin的博客中总结的非常好,所以直接拿来用。即用锁主要有两个目的,第一便是为了效率着想,比如我们不想让一个耗时的任务被重复的执行,第二个目的便是为了程序的正确性考虑。比如12306的订票问题,如果不使用锁,很容易出现剩余一张票,但是10个人都在网站上抢到了这张票的情况。
- Efficiency: Taking a lock saves you from unnecessarily doing the same work twice (e.g. some expensive computation). If the lock fails and two nodes end up doing the same piece of work, the result is a minor increase in cost (you end up paying 5 cents more to AWS than you otherwise would have) or a minor inconvenience (e.g. a user ends up getting the same email notification twice).
- Correctness: Taking a lock prevents concurrent processes from stepping on each others’ toes and messing up the state of your system. If the lock fails and two nodes concurrently work on the same piece of data, the result is a corrupted file, data loss, permanent inconsistency, the wrong dose of a drug administered to a patient, or some other serious problem.
当我们基于Efficiency的目标的时候,基于Redis的的分布式锁是很好的实现方式,但是实际上如果只是为了Efficiency考虑的话,RedLock的使用就没有必要了,基于单节点的Redis分布式锁就完全能够满足需要。如果程序的正确性严格的依赖于锁的使用的话,那么就看用户是否能够承受可能的时间不一致性带来的风险,如果能,那么就可以使用RedLock,如果不能那么就不要使用RedLock。那么使用什么呢?虽然我没用过,但是貌似听说常用的解决方案就是基于zookeeper的分布式锁。
RedLock的分布式实现
俗话说得好,Talk is cheap, show me the code。RedLock的思想本身不复杂,所以实现也非常的简单。这里给出的RedLock的python实现是Redis官网列出来的实现,应该是比较靠谱的。源代码很简单,就放个git链接给大家自己去研究吧。对着上面的RedLock和单机版的锁实现,这段代码大家就秒懂了。
但我个人认为这个python的实现有个需要完善的地方在于没有watchdog的机制来实现续租,包括这个开源代码中的issue中也提到了这个问题。java的redisson实现了watchdog的feature,但是这个里面没有。我觉得基于watchdog的续租需要满足如下的特性:
- 如果程序正常运行,但是锁的到期时间快到了,那么就应该续租
- 如果程序终止,则停止续租
- 如果程序使用锁期间,陷入死循环,则停止续租。
就目前而言,我觉得在python里面实现锁的续租机制的话,基于多线程应该是个比较好的解决方案之一。具体的研究和实现可以在下一次的博客进行分享~
总结
本篇介绍了基于单节点Redis服务器的分布式锁实现以及为了应对单点风险而基于多节点的分布式锁RedLock实现。无论是单节点锁还是多节点锁,整体的思想还是比较简单的。如果要用基于Redis的锁,我们一定要先衡量我们的场景对锁的要求是否足够严格,如果有非常严格的正确性要求,那么就可能要三思一下是否使用基于Redis的分布式锁了。
redis分布式锁就几个方法
1、setnx(key,value) 返回boolean 1为获取锁 0为没获取锁
2、expire() 设置锁的有效时间
3、getSet(key,value) 获取锁当前key对应的锁的有效时间
4、deleteKey() 删除锁
setnx(lockkey, 当前时间+过期超时时间),如果返回 1,则获取锁成功;如果返回 0 则没有获取到锁,转向 2。
get(lockkey) 获取值 oldExpireTime ,并将这个 value 值与当前的系统时间进行比较,如果小于当前系统时间,则认为这个锁已经超时,可以允许别的请求重新获取,转向 3。
计算 newExpireTime = 当前时间+过期超时时间,然后 getset(lockkey, newExpireTime) 会返回当前 lockkey 的值currentExpireTime。
判断 currentExpireTime 与 oldExpireTime 是否相等,如果相等,说明当前 getset 设置成功,获取到了锁。如果不相等,说明这个锁又被别的请求获取走了,那么当前请求可以直接返回失败,或者继续重试。
在获取到锁之后,当前线程可以开始自己的业务处理,当处理完毕后,比较自己的处理时间和对于锁设置的超时时间,如果小于锁设置的超时时间,则直接执行 delete 释放锁;如果大于锁设置的超时时间,则不需要再锁进行处理。
过程分析:
当A通过setnx(lockkey,currenttime+timeout)命令能成功设置lockkey时,即返回值为1,过程与原理1一致;
当A通过setnx(lockkey,currenttime+timeout)命令不能成功设置lockkey时,这是不能直接断定获取锁失败;因为我们在设置锁时,设置了锁的超时时间timeout,当当前时间大于redis中存储键值为lockkey的value值时,可以认为上一任的拥有者对锁的使用权已经失效了,A就可以强行拥有该锁;具体判定过程如下;
A通过get(lockkey),获取redis中的存储键值为lockkey的value值,即获取锁的相对时间lockvalueA
lockvalueA!=null && currenttime>lockvalue,A通过当前的时间与锁设置的时间做比较,如果当前时间已经大于锁设置的时间临界,即可以进一步判断是否可以获取锁,否则说明该锁还在被占用,A就还不能获取该锁,结束,获取锁失败;
步骤4返回结果为true后,通过getSet设置新的超时时间,并返回旧值lockvalueB,以作判断,因为在分布式环境,在进入这里时可能另外的进程获取到锁并对值进行了修改,只有旧值与返回的值一致才能说明中间未被其他进程获取到这个锁
lockvalueB == null || lockvalueA==lockvalueB,判断:若果lockvalueB为null,说明该锁已经被释放了,此时该进程可以获取锁;旧值与返回的lockvalueB一致说明中间未被其他进程获取该锁,可以获取锁;否则不能获取锁,结束,获取锁失败。
举个例子:
现在有两台redis服务器,两个进程同时访问redis代理,并且代理按顺序指向redis服务器,当访问A服务器时候,在setnx()执行后并且expiro()执行前A宕机了,这时候B在执行的时候就先去判断 系统当前时间是否大于oldtime+expiro()设置的时间设置的时间,如果大于oldtime+expiro()设置的时间,可以证明A事物的锁使用权已经失效了,我们就可以删除事物A的锁,然后在事物B上重新生成个锁。
1、什么是分布式锁
分布式锁就是 多个服务器都有redis,但是共用同一套资源。
2、分布式锁实现原理
主要就两个方法
1、getlock() 获取锁方法
2、releaselock()释放锁方法
然后我们看一下 getlock()方法是怎么写的
当生成锁的时候会有一个key也就是上面的taskId,existskey()意思是在分布式的key中是否有和taskId一致的(这个taskId可以认识取随机数),如果没有一致的就获取锁
然后是releaselock()这个方法里就执行了 deletekey()删除key方法
上述做法有几个问题
1、当获取锁之后同时还没有删除key,这时候断网了,那么就会导致我这个锁永远都无法delete
2、同一时间被不同服务器的调用获取到锁
先说第一个问题:我们可以通过设置一个释放锁的时间来解决这个问题比如2秒,如果断网了或者其他问题2秒之后自动释放
在说第二个问题:获取锁进行原子性,也就是说在获取锁的时候多一步操作,就是当前key不存在时候才可以获取锁
SET my_key my_value NX PX milliseconds
其中,NX表示只有当键key不存在的时候才会设置key的值,PX表示设置键key的过期时间,单位是毫秒。
就算是这样还会有问题:
3、当时间设置2秒,但是我的逻辑代码执行了3秒,这时候这个锁会被别的请求获取到
其实解决也很简单,我们在释放锁的时候设置一个随机数,在进行deletekey的时候进行随机数的判断如果相同才delete当然这个随机数是在逻辑方法执行完之后生成的
本文主要给大家介绍了关于redis实现加锁的几种方法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。
1. redis加锁分类
redis能用的的加锁命令分表是INCR、SETNX、SET
2. 第一种锁命令INCR
这种加锁的思路是, key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作进行加一。
然后其它用户在执行 INCR 操作进行加一时,如果返回的数大于 1 ,说明这个锁正在被使用当中。
1、 客户端A请求服务器获取key的值为1表示获取了锁
2、 客户端B也去请求服务器获取key的值为2表示获取锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求的时候获取key的值为1表示获取锁成功
5、 客户端B执行代码完成,删除锁
|
1
2
|
$redis->incr($key);$redis->expire($key, $ttl); //设置生成时间为1秒 |
3. 第二种锁SETNX
这种加锁的思路是,如果 key 不存在,将 key 设置为 value
如果 key 已存在,则 SETNX 不做任何动作
1、 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
2、 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求设置key的值,设置成功
5、 客户端B执行代码完成,删除锁
|
1
2
|
$redis->setNX($key, $value);$redis->expire($key, $ttl); |
4. 第三种锁SET
上面两种方法都有一个问题,会发现,都需要设置 key 过期。那么为什么要设置key过期呢?如果请求执行因为某些原因意外退出了,导致创建了锁但是没有删除锁,那么这个锁将一直存在,以至于以后缓存再也得不到更新。于是乎我们需要给锁加一个过期时间以防不测。
但是借助 Expire 来设置就不是原子性操作了。所以还可以通过事务来确保原子性,但是还是有些问题,所以官方就引用了另外一个,使用 SET 命令本身已经从版本 2.6.12 开始包含了设置过期时间的功能。
1、 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
2、 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求设置key的值,设置成功
5、 客户端B执行代码完成,删除锁
|
1
|
$redis->set($key, $value, array('nx', 'ex' => $ttl)); //ex表示秒 |
5. 其它问题
虽然上面一步已经满足了我们的需求,但是还是要考虑其它问题?
1、 redis发现锁失败了要怎么办?中断请求还是循环请求?
2、 循环请求的话,如果有一个获取了锁,其它的在去获取锁的时候,是不是容易发生抢锁的可能?
3、 锁提前过期后,客户端A还没执行完,然后客户端B获取到了锁,这时候客户端A执行完了,会不会在删锁的时候把B的锁给删掉?
6. 解决办法
针对问题1:使用循环请求,循环请求去获取锁
针对问题2:针对第二个问题,在循环请求获取锁的时候,加入睡眠功能,等待几毫秒在执行循环
针对问题3:在加锁的时候存入的key是随机的。这样的话,每次在删除key的时候判断下存入的key里的value和自己存的是否一样
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
do { //针对问题1,使用循环 $timeout = 10; $roomid = 10001; $key = 'room_lock'; $value = 'room_'.$roomid; //分配一个随机的值针对问题3 $isLock = Redis::set($key, $value, 'ex', $timeout, 'nx');//ex 秒 if ($isLock) { if (Redis::get($key) == $value) { //防止提前过期,误删其它请求创建的锁 //执行内部代码 Redis::del($key); continue;//执行成功删除key并跳出循环 } } else { usleep(5000); //睡眠,降低抢锁频率,缓解redis压力,针对问题2 }} while(!$isLock); |
7. 另外一个锁
以上的锁完全满足了需求,但是官方另外还提供了一套加锁的算法,这里以PHP为例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
$servers = [ ['127.0.0.1', 6379, 0.01], ['127.0.0.1', 6389, 0.01], ['127.0.0.1', 6399, 0.01],];$redLock = new RedLock($servers);//加锁$lock = $redLock->lock('my_resource_name', 1000);//删除锁$redLock->unlock($lock) |
上面是官方提供的一个加锁方法,就是和第6的大体方法一样,只不过官方写的更健壮。所以可以直接使用官方提供写好的类方法进行调用。官方提供了各种语言如何实现锁。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
redis和redission分布式锁原理及区别
我最近做租车项目,在处理分布式时用到分布式锁,我发现很多同事都在网上找分布式锁的资料,但是看的资料都不是很全,所以在这里我谈谈自己的分布式锁理解。
结合我的其中某一业务需求:多个用户在同一个区域内发现只有一辆可租的车,最终结果肯定只有一位用户租车成功,这就产生了多线程(多个用户)抢同一资源的问题。
1、有的同伴想到了synchronized关键字锁,暂且抛开性能问题,项目为了高可用,都会做集群部署,那么synchronized就失去了加锁的意义,这里多嘴解释一下:
2、有的小伙伴可能想到了乐观锁,没错!!乐观锁可以解决的我的问题,但是在高并发的场景,频繁的操作数据库,数据库的资源是很珍贵的,并且还存在性能的问题。
但是我这里简单说下乐观锁的使用:
我们在车的表中添加一个字段:version(int类型)(建议使用这个名称,这样别人看到就会直觉这是乐观锁字段,也可以使用别的名称)
查询出该车的数据,数据中就有version字段,假如version=1
select * from u_car where car_id = 10;
修改该车的状态为锁定,
update u_car set status = 2,version = version +1 where car_id = 10 and version = 1
在修改的时候将version作为参数,如果其他用户锁车,那么version已经发生变化(version = version +1),所以version = 1不成立,修改失败
乐观锁不是本次的终点,但还是简单说下;
3、使用redis的分布式锁:
public boolean lock(String key, V v, int expireTime){
//获取锁
//在redis早期版本中,设置key和key的存活时间是分开的,设置key成功,但是设置存活时间时服务宕机,那么你的key就永远不会过期,有BUG
//后来redis将加锁和设置时间用同一个命令
//这里是重点,redis.setNx(key,value,time)方法是原子性的,设置key成功说明锁车成功,如果失败说明该车被别人租了
boolean b = false;
try {
b = redis.setNx(key, v, expireTime);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return b;
}
public boolean unlock(String key){
return redis.delete(key);
}
}
但是这样写还是存在BUG的,我的key设置了加锁时间为5秒,但是我的业务逻辑5秒还没有执行完成,key过期了,那么其他用户执行redis.setNx(key, v, expireTime)时就成功了,将该车锁定,又产生了抢资源;
我们想一下,如果我能够在业务逻辑没有执行完的时候,让锁过期后能够延长锁的时间,是不是就解决了上面的BUG;
实现这个锁的延长,非要自己动手的话就得另启一个线程来监听我们的业务线程,每隔1秒监测当前业务线程是否执行完成,如果没有就获取key的存活时间,时间小于一个阈值时,就自动给key设置N秒;
当然,我们可以不用自己动手,redission已经帮我们实现key的时间时间过期问题;
4、使用redission的分布式锁:
//引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.10.6</version>
</dependency>
redisson支持单点、集群等模式,这里选择单点的。application.yml配置好redis的连接:
spring:
redis:
host: 127.0.0.1
port: 6379
password:
配置redisson的客户端bean
@Configuration
public class RedisConfig {
@Value("${spring.redis.host}")
private String host;
@Bean(name = {"redisTemplate", "stringRedisTemplate"})
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory factory) {
StringRedisTemplate redisTemplate = new StringRedisTemplate();
redisTemplate.setConnectionFactory(factory);
return redisTemplate;
}
@Bean
public Redisson redisson() {
Config config = new Config();
config.useSingleServer().setAddress("redis://" + host + ":6379");
return (Redisson) Redisson.create(config);
}
}
加锁使用
private Logger log = LoggerFactory.getLogger(getClass());
@Resource
private Redisson redisson;
//加锁
public Boolean lock(String key,long waitTime,long leaseTime){
Boolean b = false;
try {
RLock rLock = redisson.getLock(key);
//说下参数 waitTime:锁的存活时间 leaseTime:锁的延长时间 后面的参数是单位
b = rLock.tryLock(waitTime,leaseTime,TimeUnit.SECONDS);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
return b;
}
//释放锁
public void unlock(String key){
try {
RLock rLock = redisson.getLock(key);
if(null!=lock){
lock.unlock();
lock.forceUnlock();
fileLog.info("unlock succesed");
}
} catch (Exception e) {
fileLog.error(e.getMessage(), e);
}
}
————————————————
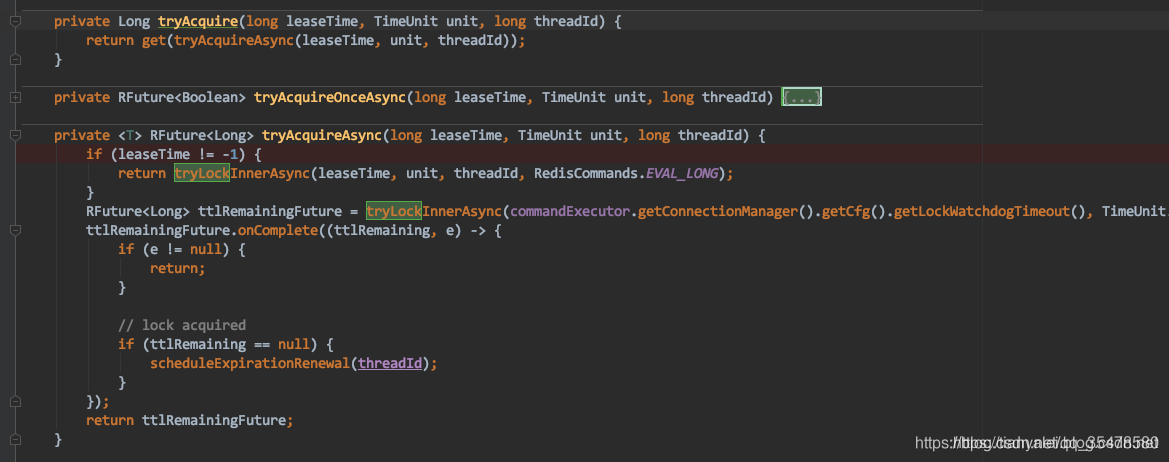
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long time = unit.toMillis(waitTime);
long current = System.currentTimeMillis();
long threadId = Thread.currentThread().getId();
//尝试获取锁,如果没取到锁,则获取锁的剩余超时时间
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return true;
}
//如果waitTime已经超时了,就返回false
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
current = System.currentTimeMillis();
RFuture<RedissonLockEntry> subscribeFuture = subscribe(threadId);
if (!await(subscribeFuture, time, TimeUnit.MILLISECONDS)) {
if (!subscribeFuture.cancel(false)) {
subscribeFuture.onComplete((res, e) -> {
if (e == null) {
unsubscribe(subscribeFuture, threadId);
}
});
}
acquireFailed(threadId);
return false;
}
try {
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
//进入死循环,反复去调用tryAcquire尝试获取锁,ttl为null时就是别的线程已经unlock了
while (true) {
long currentTime = System.currentTimeMillis();
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return true;
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
// waiting for message
currentTime = System.currentTimeMillis();
if (ttl >= 0 && ttl < time) {
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
getEntry(threadId).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
acquireFailed(threadId);
return false;
}
}
} finally {
unsubscribe(subscribeFuture, threadId);
}
// return get(tryLockAsync(waitTime, leaseTime, unit));
}
————————————————
可以看到,其中主要的逻辑就是尝试加锁,成功了就返回true,失败了就进入死循环反复去尝试加锁。中途还有一些超时的判断。逻辑还是比较简单的。
再看看tryAcquire方法
这个方法的调用栈也是比较多,之后会进入下面这个方法
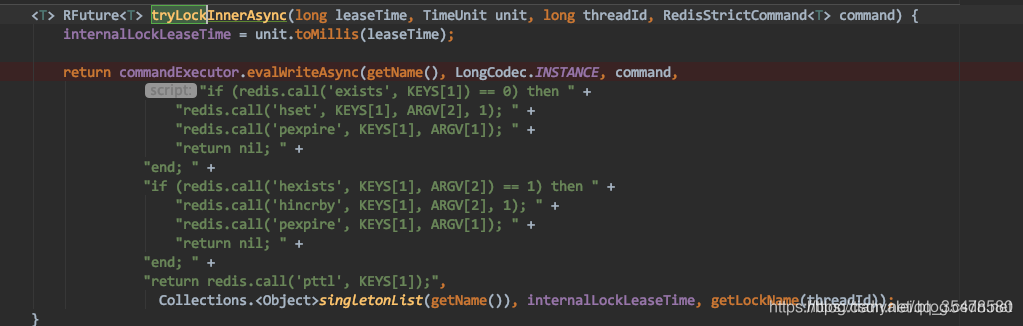
上面的lua(俗称胶水语言)脚本比较重要,主要是为了执行命令的原子性解释一下:
KEYS[1]代表你的key
ARGV[1]代表你的key的存活时间,默认存活30秒
ARGV[2]代表的是请求加锁的客户端ID,后面的1则理解为加锁的次数,简单理解就是 如果该客户端多次对key加锁时,就会执行hincrby原子加1命令
第一段if就是判断你的key是否存在,如果不存在,就执行redis call(hset key ARGV[2],1)加锁和设置redis call(pexpire key ARGV[1])存活时间;
当第二个客户来加锁时,第一个if判断已存在key,就执行第二个if判断key的hash是否存在客户端2的ID,很明显不是;
则进入到最后的return返回该key的剩余存活时间
当加锁成功后会在后台启动一个watch dog(看门狗)线程,key的默认存活时间为30秒,则watch dog每隔10秒钟就会检查一下客户端1是否还持有该锁,如果持有,就会不断的延长锁key的存活时间
所以这里建议大家在设置key的存活时间时,最好大于10秒,延续时间也大于等于10秒
所以,总体流程应该是这样的。
————————————————
一、Jedis,Redisson,Lettuce 三者的区别
共同点:都提供了基于 Redis 操作的 Java API,只是封装程度,具体实现稍有不同。
不同点:
-
1.1、Jedis
是 Redis 的 Java 实现的客户端。支持基本的数据类型如:String、Hash、List、Set、Sorted Set。
特点:使用阻塞的 I/O,方法调用同步,程序流需要等到 socket 处理完 I/O 才能执行,不支持异步操作。Jedis 客户端实例不是线程安全的,需要通过连接池来使用 Jedis。
-
1.1、Redisson
优点点:分布式锁,分布式集合,可通过 Redis 支持延迟队列。
-
1.3、 Lettuce
用于线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器。
基于 Netty 框架的事件驱动的通信层,其方法调用是异步的。Lettuce 的 API 是线程安全的,所以可以操作单个 Lettuce 连接来完成各种操作。
二、Jedis
三、RedisTemplate
3.1、使用配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
application-dev.yml
spring:
redis:
host: 192.168.1.140
port: 6379
password:
database: 15 # 指定redis的分库(共16个0到15)
3.2、使用示例
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public CustomersEntity findById(Integer id) {
// 需要缓存
// 所有涉及的缓存都需要删除,或者更新
try {
String toString = stringRedisTemplate.opsForHash().get(REDIS_CUSTOMERS_ONE, id + "").toString();
if (toString != null) {
return JSONUtil.toBean(toString, CustomersEntity.class);
}
} catch (Exception e) {
e.printStackTrace();
}
// 缓存为空的时候,先查,然后缓存redis
Optional<CustomersEntity> byId = customerRepo.findById(id);
if (byId.isPresent()) {
CustomersEntity customersEntity = byId.get();
try {
stringRedisTemplate.opsForHash().put(REDIS_CUSTOMERS_ONE, id + "", JSONUtil.toJsonStr(customersEntity));
} catch (Exception e) {
e.printStackTrace();
}
return customersEntity;
}
return null;
}
3.3、扩展
3.3.1、spring-boot-starter-data-redis 的依赖包
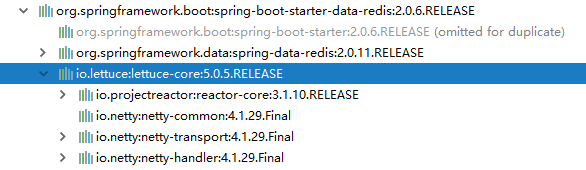
3.3.2、stringRedisTemplate API(部分展示)
opsForHash --> hash 操作
opsForList --> list 操作
opsForSet --> set 操作
opsForValue --> string 操作
opsForZSet --> Zset 操作
3.3.3 StringRedisTemplate 默认序列化机制
public class StringRedisTemplate extends RedisTemplate<String, String> {
/**
* Constructs a new <code>StringRedisTemplate</code> instance. {@link #setConnectionFactory(RedisConnectionFactory)}
* and {@link #afterPropertiesSet()} still need to be called.
*/
public StringRedisTemplate() {
RedisSerializer<String> stringSerializer = new StringRedisSerializer();
setKeySerializer(stringSerializer);
setValueSerializer(stringSerializer);
setHashKeySerializer(stringSerializer);
setHashValueSerializer(stringSerializer);
}
}
四、RedissonClient 操作示例
4.1 基本配置
4.1.1、Maven pom 引入
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.8.2</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>LATEST</version>
</dependency>
4.1.2、添加配置文件 Yaml 或者 json 格式
redisson-config.yml 或者,配置 redisson-config.json
# Redisson 配置
singleServerConfig:
address: "redis://192.168.1.140:6379"
password: null
clientName: null
database: 15 #选择使用哪个数据库0~15
idleConnectionTimeout: 10000
pingTimeout: 1000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
reconnectionTimeout: 3000
failedAttempts: 3
subscriptionsPerConnection: 5
subscriptionConnectionMinimumIdleSize: 1
subscriptionConnectionPoolSize: 50
connectionMinimumIdleSize: 32
connectionPoolSize: 64
dnsMonitoringInterval: 5000
#dnsMonitoring: false
threads: 0
nettyThreads: 0
codec:
class: "org.redisson.codec.JsonJacksonCodec"
transportMode: "NIO"
-----------------------
{
"singleServerConfig": {
"idleConnectionTimeout": 10000,
"pingTimeout": 1000,
"connectTimeout": 10000,
"timeout": 3000,
"retryAttempts": 3,
"retryInterval": 1500,
"reconnectionTimeout": 3000,
"failedAttempts": 3,
"password": null,
"subscriptionsPerConnection": 5,
"clientName": null,
"address": "redis://192.168.1.140:6379",
"subscriptionConnectionMinimumIdleSize": 1,
"subscriptionConnectionPoolSize": 50,
"connectionMinimumIdleSize": 10,
"connectionPoolSize": 64,
"database": 0,
"dnsMonitoring": false,
"dnsMonitoringInterval": 5000
},
"threads": 0,
"nettyThreads": 0,
"codec": null,
"useLinuxNativeEpoll": false
}
4.1.3、读取配置
新建读取配置类
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redisson() throws IOException {
// 两种读取方式,Config.fromYAML 和 Config.fromJSON
// Config config = Config.fromJSON(RedissonConfig.class.getClassLoader().getResource("redisson-config.json"));
Config config = Config.fromYAML(RedissonConfig.class.getClassLoader().getResource("redisson-config.yml"));
return Redisson.create(config);
}
}
或者,在 application.yml 中配置如下
spring:
redis:
redisson:
config: classpath:redisson-config.yaml
4.2 使用示例
@RestController
@RequestMapping("/")
public class TeController {
@Autowired
private RedissonClient redissonClient;
static long i = 20;
static long sum = 300;
// ========================== String =======================
@GetMapping("/set/{key}")
public String s1(@PathVariable String key) {
// 设置字符串
RBucket<String> keyObj = redissonClient.getBucket(key);
keyObj.set(key + "1-v1");
return key;
}
@GetMapping("/get/{key}")
public String g1(@PathVariable String key) {
// 设置字符串
RBucket<String> keyObj = redissonClient.getBucket(key);
String s = keyObj.get();
return s;
}
// ========================== hash =======================-=
@GetMapping("/hset/{key}")
public String h1(@PathVariable String key) {
Ur ur = new Ur();
ur.setId(MathUtil.randomLong(1,20));
ur.setName(key);
// 存放 Hash
RMap<String, Ur> ss = redissonClient.getMap("UR");
ss.put(ur.getId().toString(), ur);
return ur.toString();
}
@GetMapping("/hget/{id}")
public String h2(@PathVariable String id) {
// hash 查询
RMap<String, Ur> ss = redissonClient.getMap("UR");
Ur ur = ss.get(id);
return ur.toString();
}
// 查询所有的 keys
@GetMapping("/all")
public String all(){
RKeys keys = redissonClient.getKeys();
Iterable<String> keys1 = keys.getKeys();
keys1.forEach(System.out::println);
return keys.toString();
}
// ================== ==============读写锁测试 =============================
@GetMapping("/rw/set/{key}")
public void rw_set(){
// RedissonLock.
RBucket<String> ls_count = redissonClient.getBucket("LS_COUNT");
ls_count.set("300",360000000l, TimeUnit.SECONDS);
}
// 减法运算
@GetMapping("/jf")
public void jf(){
String key = "S_COUNT";
// RAtomicLong atomicLong = redissonClient.getAtomicLong(key);
// atomicLong.set(sum);
// long l = atomicLong.decrementAndGet();
// System.out.println(l);
RAtomicLong atomicLong = redissonClient.getAtomicLong(key);
if (!atomicLong.isExists()) {
atomicLong.set(300l);
}
while (i == 0) {
if (atomicLong.get() > 0) {
long l = atomicLong.getAndDecrement();
try {
Thread.sleep(1000l);
} catch (InterruptedException e) {
e.printStackTrace();
}
i --;
System.out.println(Thread.currentThread().getName() + "->" + i + "->" + l);
}
}
}
@GetMapping("/rw/get")
public String rw_get(){
String key = "S_COUNT";
Runnable r = new Runnable() {
@Override
public void run() {
RAtomicLong atomicLong = redissonClient.getAtomicLong(key);
if (!atomicLong.isExists()) {
atomicLong.set(300l);
}
if (atomicLong.get() > 0) {
long l = atomicLong.getAndDecrement();
i --;
System.out.println(Thread.currentThread().getName() + "->" + i + "->" + l);
}
}
};
while (i != 0) {
new Thread(r).start();
// new Thread(r).run();
// new Thread(r).run();
// new Thread(r).run();
// new Thread(r).run();
}
RBucket<String> bucket = redissonClient.getBucket(key);
String s = bucket.get();
System.out.println("================线程已结束================================" + s);
return s;
}
}
4.3 扩展
4.3.1 丰富的 jar 支持,尤其是对 Netty NIO 框架
4.3.2 丰富的配置机制选择,这里是详细的配置说明
关于序列化机制中,就有很多

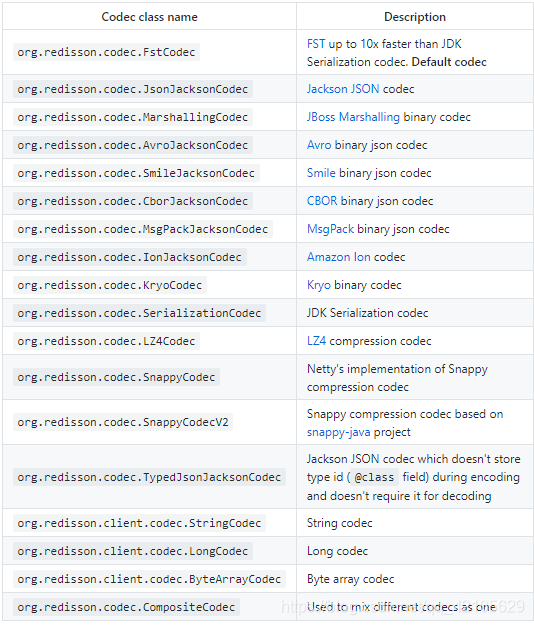
4.3.3 API 支持(部分展示),具体的 Redis --> RedissonClient , 可查看这里
4.3.4 轻便的丰富的锁机制的实现
4.3.4.1 Lock
4.3.4.2 Fair Lock
4.3.4.3 MultiLock
4.3.4.4 RedLock
4.3.4.5 ReadWriteLock
4.3.4.6 Semaphore
4.3.4.7 PermitExpirableSemaphore
4.3.4.8 CountDownLatch
五、基于注解实现的 Redis 缓存
5.1 Maven 和 YML 配置
参考 RedisTemplate 配置
另外,还需要额外的配置类
// todo 定义序列化,解决乱码问题
@EnableCaching
@Configuration
@ConfigurationProperties(prefix = "spring.cache.redis")
public class RedisCacheConfig {
private Duration timeToLive = Duration.ZERO;
public void setTimeToLive(Duration timeToLive) {
this.timeToLive = timeToLive;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
// 解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题)
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(timeToLive)
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
5.2 使用示例
@Transactional
@Service
public class ReImpl implements RedisService {
@Resource
private CustomerRepo customerRepo;
@Resource
private StringRedisTemplate stringRedisTemplate;
public static final String REDIS_CUSTOMERS_ONE = "Customers";
public static final String REDIS_CUSTOMERS_ALL = "allList";
// =====================================================================使用Spring cahce 注解方式实现缓存
// ==================================单个操作
@Override
@Cacheable(value = "cache:customer", unless = "null == #result",key = "#id")
public CustomersEntity cacheOne(Integer id) {
final Optional<CustomersEntity> byId = customerRepo.findById(id);
return byId.isPresent() ? byId.get() : null;
}
@Override
@Cacheable(value = "cache:customer", unless = "null == #result", key = "#id")
public CustomersEntity cacheOne2(Integer id) {
final Optional<CustomersEntity> byId = customerRepo.findById(id);
return byId.isPresent() ? byId.get() : null;
}
// todo 自定义redis缓存的key,
@Override
@Cacheable(value = "cache:customer", unless = "null == #result", key = "#root.methodName + '.' + #id")
public CustomersEntity cacheOne3(Integer id) {
final Optional<CustomersEntity> byId = customerRepo.findById(id);
return byId.isPresent() ? byId.get() : null;
}
// todo 这里缓存到redis,还有响应页面是String(加了很多转义符\,),不是Json格式
@Override
@Cacheable(value = "cache:customer", unless = "null == #result", key = "#root.methodName + '.' + #id")
public String cacheOne4(Integer id) {
final Optional<CustomersEntity> byId = customerRepo.findById(id);
return byId.map(JSONUtil::toJsonStr).orElse(null);
}
// todo 缓存json,不乱码已处理好,调整序列化和反序列化
@Override
@Cacheable(value = "cache:customer", unless = "null == #result", key = "#root.methodName + '.' + #id")
public CustomersEntity cacheOne5(Integer id) {
Optional<CustomersEntity> byId = customerRepo.findById(id);
return byId.filter(obj -> !StrUtil.isBlankIfStr(obj)).orElse(null);
}
// ==================================删除缓存
@Override
@CacheEvict(value = "cache:customer", key = "'cacheOne5' + '.' + #id")
public Object del(Integer id) {
// 删除缓存后的逻辑
return null;
}
@Override
@CacheEvict(value = "cache:customer",allEntries = true)
public void del() {
}
@CacheEvict(value = "cache:all",allEntries = true)
public void delall() {
}
// ==================List操作
@Override
@Cacheable(value = "cache:all")
public List<CustomersEntity> cacheList() {
List<CustomersEntity> all = customerRepo.findAll();
return all;
}
// todo 先查询缓存,再校验是否一致,然后更新操作,比较实用,要清楚缓存的数据格式(明确业务和缓存模型数据)
@Override
@CachePut(value = "cache:all",unless = "null == #result",key = "#root.methodName")
public List<CustomersEntity> cacheList2() {
List<CustomersEntity> all = customerRepo.findAll();
return all;
}
}
5.3 扩展
基于 spring 缓存实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号