【Docker】---部署集群(2)
=前言=
1、因为自己只买了一台阿里云服务器,所以RocketMQ集群都部署在单台服务器上只是端口不同,如果实际开发,可以分别部署在多台服务器上。
2、这里有关 Broker 和 NameServer 分别都做了了集群部署(各部署两个),且BroKer是按两主进行部署。
之所以选用Docker部署主要还是考虑 :通过Docker部署RocketMQ集群更快速,而且对系统的资源利用更好!
之前有写过Liunx如何部署Docker的博客:【Docker】(3)---linux部署Docker、Docker常用命令
之前有关RocketMQ概念做了介绍的博客:RocketMQ(1)-架构原理
下面先写好所需配置文件,在运行配置文件,最终看运行结果!
一、写配置文件
1、创建所需文件夹
mkdir -p /opt/rocketmq/logs/nameserver-a
mkdir -p /opt/rocketmq/logs/nameserver-b
mkdir -p /opt/rocketmq/store/nameserver-a
mkdir -p /opt/rocketmq/store/nameserver-b
mkdir -p /opt/rocketmq/logs/broker-a
mkdir -p /opt/rocketmq/logs/broker-b
mkdir -p /opt/rocketmq/store/broker-a
mkdir -p /opt/rocketmq/store/broker-b
mkdir -p /home/rocketmq/broker-a/
mkdir -p /home/rocketmq/broker-b/
2、创建broker.conf
broker.conf是Broker的配置文件,因为此时RocketMQ镜像还没有拉取,所以还没有默认的broker.conf。所以这里直接写好,到时候通过命令替换默认的broker.conf。
因为是双主模式部署,所以会有两个broker.conf,这里暂且命名 broker-a.conf 和 broker-b.conf
1) broker-a.conf
brokerClusterName = rocketmq-cluster
brokerName = broker-a
brokerId = 0
#这个很有讲究 如果是正式环境 这里一定要填写内网地址(安全)
#如果是用于测试或者本地这里建议要填外网地址,因为你的本地代码是无法连接到阿里云内网,只能连接外网。
brokerIP1 = xxxxx
deleteWhen = 04
fileReservedTime = 48
brokerRole = ASYNC_MASTER
flushDiskType = ASYNC_FLUSH
# 内网的(阿里云有内网IP和外网IP)
namesrvAddr=172.18.0.5:9876;172.18.0.5:9877
autoCreateTopicEnable=true
#Broker 对外服务的监听端口,
listenPort = 10911
#Broker角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=ASYNC_MASTER
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=ASYNC_FLUSH
这里配置的主要信息有:
1、当前Broker对外暴露的端口号
2、注册到NameServer的地址,看到这里有两个地址,说明NameServer也是集群部署。
3、当前Broker的角色,是主还是从,这里表示是主。
2)broker-b.conf
brokerClusterName = rocketmq-cluster
brokerName = broker-b
brokerId = 0
brokerIP1 = xxxxx
deleteWhen = 04
fileReservedTime = 48
brokerRole = ASYNC_MASTER
flushDiskType = ASYNC_FLUSH
# 内网的(阿里云有内网IP和外网IP)
namesrvAddr=172.18.0.5:9876;172.18.0.5:9877
autoCreateTopicEnable=true
#Broker 对外服务的监听端口,
listenPort = 10909
#Broker角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=ASYNC_MASTER
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=ASYNC_FLUSH
这个上面并无差别,只是当前Brocker对外暴露的端口不一样。
3、编写 docker-compose.yml
我们可以简单把docker-compose.yml理解成一个类似Shell的脚本,这个脚本定义了运行多容器应用程序的信息。
version: '3.5'
services:
rmqnamesrv-a:
image: rocketmqinc/rocketmq:4.3.0
container_name: rmqnamesrv-a
ports:
- 9876:9876
volumes:
- /opt/rocketmq/logs/nameserver-a:/opt/logs
- /opt/rocketmq/store/nameserver-a:/opt/store
command: sh mqnamesrv
networks:
rmq:
aliases:
- rmqnamesrv-a
rmqnamesrv-b:
image: rocketmqinc/rocketmq:4.3.0
container_name: rmqnamesrv-b
ports:
- 9877:9877
volumes:
- /opt/rocketmq/logs/nameserver-b:/opt/logs
- /opt/rocketmq/store/nameserver-b:/opt/store
command: sh mqnamesrv
networks:
rmq:
aliases:
- rmqnamesrv-b
rmqbroker-a:
image: rocketmqinc/rocketmq:4.3.0
container_name: rmqbroker-a
ports:
- 10911:10911
volumes:
- /opt/rocketmq/logs/broker-a:/opt/logs
- /opt/rocketmq/store/broker-a:/opt/store
- /home/rocketmq/broker-a/broker-a.conf:/opt/rocketmq-4.3.0/conf/broker.conf
environment:
TZ: Asia/Shanghai
NAMESRV_ADDR: "rmqnamesrv-a:9876"
JAVA_OPTS: " -Duser.home=/opt"
JAVA_OPT_EXT: "-server -Xms256m -Xmx256m -Xmn256m"
command: sh mqbroker -c /opt/rocketmq-4.3.0/conf/broker.conf autoCreateTopicEnable=true &
links:
- rmqnamesrv-a:rmqnamesrv-a
- rmqnamesrv-b:rmqnamesrv-b
networks:
rmq:
aliases:
- rmqbroker-a
rmqbroker-b:
image: rocketmqinc/rocketmq:4.3.0
container_name: rmqbroker-b
ports:
- 10909:10909
volumes:
- /opt/rocketmq/logs/broker-b:/opt/logs
- /opt/rocketmq/store/broker-b:/opt/store
- /home/rocketmq/broker-b/broker-b.conf:/opt/rocketmq-4.3.0/conf/broker.conf
environment:
TZ: Asia/Shanghai
NAMESRV_ADDR: "rmqnamesrv-b:9876"
JAVA_OPTS: " -Duser.home=/opt"
JAVA_OPT_EXT: "-server -Xms256m -Xmx256m -Xmn256m"
command: sh mqbroker -c /opt/rocketmq-4.3.0/conf/broker.conf autoCreateTopicEnable=true &
links:
- rmqnamesrv-a:rmqnamesrv-a
- rmqnamesrv-b:rmqnamesrv-b
networks:
rmq:
aliases:
- rmqbroker-b
rmqconsole:
image: styletang/rocketmq-console-ng
container_name: rmqconsole
ports:
- 9001:9001
environment:
JAVA_OPTS: -Drocketmq.namesrv.addr=rmqnamesrv-a:9876;rmqnamesrv-b:9877 -Dcom.rocketmq.sendMessageWithVIPChannel=false
networks:
rmq:
aliases:
- rmqconsole
networks:
rmq:
name: rmq
driver: bridge
从配置文件可以大致看出几点:
1、通过Docker总共拉取了5条镜像记录。rmqnamesrv-a、rmqnamesrv-b、rmqbroker-a、rmqbroker-b、rmqconsole。
2、rmqconsole是一个可视化的工具,可以通过页面来查看RocketMQ相关信息。
3、可以看出对于broker的配置文件broker.conf已经被broker-a/b.conf替换。
二、环境部署
上面仅仅是把配置文件写好,但启动RocketMQ还有很多前提条件
1、所需环境
1. 建议使用64位操作系统,Linux / Unix / Mac;
2. 64位JDK 1.8+;
3. Maven 3.2.x;
4. Git的;
5. 4g +免费磁盘用于Broker服务器
同时需要运行docker-compose.yml还需要安装docker-compose
2、安装docker-compose
有关的介绍可以看官方GitHub : https://github.com/docker/compose
安装docker-compose
curl -L https://github.com/docker/compose/releases/download/1.24.1/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
查看是否安装成功
[root@izbp13196wp34obmnd4avdz ~]# docker-compose --version
docker-compose version 1.24.1, build 4667896b
3、关键一步
前面所有的操作,都是为这一步的铺垫,通过docker-compose执行docker-compose.yml配置文件
docker-compose -f docker-compose.yml up -d
如果你看到,那说明你大功告成!

查看可视化界面

完美!
想加强ES有关的知识,看了阮一鸣老师讲的《Elasticsearch核心技术与实战》收获很大,所以接下来会跟着他来更加深入的学习ES。
这篇博客的目的就是部署好ES和跟ES相关的辅助工具,同时通过Logstash将测试数据导入ES,这些工作完成之后,之后我们就可以在此基础上深入的去学习它。
一、Docker容器中运行ES,Kibana,Cerebro
1、所需环境
Docker + docker-compose
首先环境要部署好 Docker 和 docker-compose
检验是否成功
命令 docker —version
xubdeMacBook-Pro:~ xub$ docker --version
Docker version 17.03.1-ce-rc1, build 3476dbf
命令 docker-compose —version
xubdeMacBook-Pro:~ xub$ docker-compose --version
docker-compose version 1.11.2, build dfed245
2、docker-compose.yml
我们可以简单把docker-compose.yml理解成一个类似Shell的脚本,这个脚本定义了运行多个容器应用程序的信息。
version: '2.2'
services:
cerebro:
image: lmenezes/cerebro:0.8.3
container_name: cerebro
ports:
- "9000:9000"
command:
- -Dhosts.0.host=http://elasticsearch:9200
networks:
- es7net
kibana:
image: docker.elastic.co/kibana/kibana:7.1.0
container_name: kibana7
environment:
- I18N_LOCALE=zh-CN
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
ports:
- "5601:5601"
networks:
- es7net
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_01
environment:
- cluster.name=xiaoxiao
- node.name=es7_01
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01,es7_02
- cluster.initial_master_nodes=es7_01,es7_02
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data1:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- es7net
elasticsearch2:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_02
environment:
- cluster.name=xiaoxiao
- node.name=es7_02
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01,es7_02
- cluster.initial_master_nodes=es7_01,es7_02
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data2:/usr/share/elasticsearch/data
networks:
- es7net
volumes:
es7data1:
driver: local
es7data2:
driver: local
networks:
es7net:
driver: bridge
启动命令
docker-compose up #启动
docker-compose down #停止容器
docker-compose down -v #停止容器并且移除数据
3、查看是否成功
es访问地址
localhost:9200 #ES默认端口为9200

kibana访问地址
localhost:5601 #kibana默认端口5601

cerebro访问地址
localhost:9000 #cerebro默认端口9000

整体这样就安装成功了。
说明 项目是在Mac系统部署成功的,尝试在自己的阿里云服务进行部署但是因为内存太小始终无法成功。
二、 Logstash安装与数据导入ES
注意 Logstash和kibana下载的版本要和你的elasticsearch的版本号一一致。
1、配置movices.yml
这个名称是完全任意的
# input代表读取数据 这里读取数据的位置在data文件夹下,文件名称为movies.csv
input {
file {
path => "/Users/xub/opt/logstash-7.1.0/data/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
# 输入位置 这里输入数据到本地es ,并且索引名称为movies
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}
启动命令 : 启动命令会和配置文件movices.yml的摆放位置有关,进入bin目录
./logstash ../movices.yml
movices.yml存放的位置

启动成功

这个时候你去cerebro可视化界面可以看到,已经有名称为movies的索引存在的,上面的图片其实已经存在movies索引了,因为我是Logstash数据导入ES成功才截的图。
总结总的来说这里还是简单的,之前通过Logstash将Mysql数据数据迁移到es会相对复杂点,毕竟它还需要一个数据库驱动包。
这样环境就已经搭建成功了,接下来的学习都在这个的基础上进行演示。
【Docker】(9)---每天5分钟玩转 Docker 容器技术之镜像
镜像是 Docker 容器的基石,容器是镜像的运行实例,有了镜像才能启动容器。为什么我们要讨论镜像的内部结构?
如果只是使用镜像,当然不需要了解,直接通过 docker 命令下载和运行就可以了。
但如果我们想创建自己的镜像,或者想理解 Docker 为什么是轻量级的,就非常有必要学习这部分知识了。
一、最小的镜像
1、运行hello-world镜像
hello-world 是 Docker 官方提供的一个镜像,通常用来验证 Docker 是否安装成功。
我们先通过 docker pull 从 Docker Hub 下载它。

用 docker images 命令查看镜像的信息。

hello-world 镜像竟然还不到 14KB! 通过 docker run 运行。

其实我们更关心 hello-world 镜像包含哪些内容。
2. hello-world镜像内容
Dockerfile 是镜像的描述文件,定义了如何构建Docker镜像。Dockerfile的语法简洁且可读性强,后面我们会专门讨论如何编写Dockerfile。
hello-world 的 Dockerfile 内容如下:

只有短短三条指令。
#1、此镜像是从白手起家,从 0 开始构建。
FROM scratch
#2、将文件“hello”复制到镜像的根目录。
COPY hello /
#3、容器启动时,执行 /hello
CMD ["/hello"]
镜像 hello-world 中就只有一个可执行文件 “hello”,其功能就是打印出 “Hello from Docker ......” 等信息。
/hello 就是文件系统的全部内容,连最基本的 /bin,/usr, /lib, /dev 都没有。
hello-world 虽然是一个完整的镜像,但它并没有什么实际用途。通常来说,我们希望镜像能提供一个基本的操作系统环境,用户可以根据
需要安装和配置软件。这样的镜像我们称作 base 镜像。我们下一节讨论 base 镜像。
二、base 镜像
1.base镜像含义
base 镜像有两层含义:
1、不依赖其他镜像,从 scratch 构建。
2、其他镜像可以之为基础进行扩展。
所以,能称作 base 镜像的通常都是各种 Linux 发行版的 Docker 镜像,比如 Ubuntu, Debian, CentOS 等。
2.base镜像内容
我们以 CentOS 为例考察 base 镜像包含哪些内容。
下载镜像:docker pull centos
查看镜像信息

镜像大小 231MB。等一下!一个 CentOS 才 200MB ?平时我们安装一个 CentOS 至少都有几个 GB,怎么可能才 200MB !
相信这是几乎所有 Docker 初学者都会有的疑问,包括我自己。下面我们来解释这个问题。
Linux 操作系统由内核空间和用户空间组成。如下图所示:

内核空间是kernel,Linux 刚启动时会加载 bootfs 文件系统,之后 bootfs 会被卸载掉。用户空间的文件系统是 rootfs,包含我们熟悉的
/dev, /proc, /bin 等目录。对于 base 镜像来说,底层直接用 Host 的 kernel,自己只需要提供 rootfs 就行了。
而对于一个精简的 OS,rootfs 可以很小,只需要包括最基本的命令、工具和程序库就可以了。相比其他 Linux 发行版,CentOS 的 rootfs
已经算臃肿的了,alpine 还不到 10MB。我们平时安装的 CentOS 除了 rootfs 还会选装很多软件、服务、图形桌面等,需要好几个 GB 就
不足为奇了。下面是 CentOS 镜像的 Dockerfile 的内容:

第二行 ADD 指令添加到镜像的 tar 包就是 CentOS 7 的 rootfs。在制作镜像时,tar包会自动解压到 / 目录下,生成 /dev, /porc, /bin 等目录。
不同 Linux 发行版的区别主要就是 rootfs。
比如 Ubuntu 14.04 使用 upstart 管理服务,apt 管理软件包;而 CentOS 7 使用 systemd 和 yum。这些都是用户空间上的区别,
Linux kernel 差别不大。所以 Docker 可以同时支持多种 Linux 镜像,模拟出多种操作系统环境。

上图 Debian 和 BusyBox(一种嵌入式 Linux)上层提供各自的 rootfs,底层共用 Docker Host 的 kernel。
这里需要说明的是:
容器只能使用 Host 的 kernel,并且不能修改。
所有容器都共用 host 的 kernel,在容器中没办法对 kernel 升级。如果容器对 kernel 版本有要求(比如应用只能在某个 kernel 版本下运行),则不建议用容器,这种场景虚拟机可能更合适。
下一节我们讨论镜像的分层结构。
三、镜像的分层结构
Docker 支持通过扩展现有镜像,创建新的镜像。
1、镜像分层示例
实际上,Docker Hub 中 99% 的镜像都是通过在 base 镜像中安装和配置需要的软件构建出来的。比如我们现在构建一个新的镜像,Dockerfile 如下:

① 新镜像不再是从 scratch 开始,而是直接在 Debian base 镜像上构建。
② 安装 emacs 编辑器。
③ 安装 apache2。
④ 容器启动时运行 bash。
构建过程如下图所示:

可以看到,新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层。
2、镜像分层好处
问什么 Docker 镜像要采用这种分层结构呢?
最大的一个好处就是 - 共享资源。
比如:有多个镜像都从相同的 base 镜像构建而来,那么 Docker Host 只需在磁盘上保存一份 base 镜像;同时内存中也只需加载一份 base
镜像,就可以为所有容器服务了。而且镜像的每一层都可以被共享,我们将在后面更深入地讨论这个特性。
这时可能就有人会问了:如果多个容器共享一份基础镜像,当某个容器修改了基础镜像的内容,比如 /etc 下的文件,这时其他容器的 /etc
是否也会被修改?
答案是不会!
修改会被限制在单个容器内。
这就是我们接下来要学习的容器 Copy-on-Write 特性。
3、Copy-on-Write 特性
可写的容器层
当容器启动时,一个新的可写层被加载到镜像的顶部。这一层通常被称作“容器层”,“容器层”之下的都叫“镜像层”。

所有对容器的改动 - 无论添加、删除、还是修改文件都只会发生在容器层中。
只有容器层是可写的,容器层下面的所有镜像层都是只读的。
下面我们深入讨论容器层的细节。
镜像层数量可能会很多,所有镜像层会联合在一起组成一个统一的文件系统。如果不同层中有一个相同路径的文件,比如 /a,上层的 /a 会
覆盖下层的 /a,也就是说用户只能访问到上层中的文件 /a。在容器层中,用户看到的是一个叠加之后的文件系统。
添加文件
在容器中创建文件时,新文件被添加到容器层中。
读取文件
在容器中读取某个文件时,Docker 会从上往下依次在各镜像层中查找此文件。一旦找到,打开并读入内存。
修改文件
在容器中修改已存在的文件时,Docker 会从上往下依次在各镜像层中查找此文件。一旦找到,立即将其复制到容器层,然后修改之。
删除文件
在容器中删除文件时,Docker 也是从上往下依次在镜像层中查找此文件。找到后,会在容器层中记录下此删除操作。
只有当需要修改时才复制一份数据,这种特性被称作 Copy-on-Write。可见容器层保存的是镜像变化的部分,不会对镜像本身进行任何修改。
这样就解释了我们前面提出的问题:*容器层记录对镜像的修改,所有镜像层都是只读的,不会被容器修改,所以镜像可以被多个容器共享。
理解了镜像的原理和结构,下一节我们学习如何构建镜像。
四、构建镜像
1、为何要构建镜像
对于 Docker 用户来说,最好的情况是不需要自己创建镜像。几乎所有常用的数据库、中间件、应用软件等都有现成的 Docker 官方镜像或
其他人和组织创建的镜像,我们只需要稍作配置就可以直接使用。
使用现成镜像的好处除了省去自己做镜像的工作量外,更重要的是可以利用前人的经验。特别是使用那些官方镜像,因为 Docker 的工程师
知道如何更好的在容器中运行软件。
当然,某些情况下我们也不得不自己构建镜像,比如:
1. 找不到现成的镜像,比如自己开发的应用程序。
2. 需要在镜像中加入特定的功能,比如官方镜像几乎都不提供 ssh。
所以本节我们将介绍构建镜像的方法。同时分析构建的过程也能够加深我们对前面镜像分层结构的理解。
2、构建镜像方法
Docker 提供了两种构建镜像的方法:
1. docker commit 命令
2. Dockerfile 构建文件
3、docker commit构建镜像
docker commit 命令是创建新镜像最直观的方法,其过程包含三个步骤:
1. 运行容器
2. 修改容器
3. 将容器保存为新的镜像
举个例子:在 ubuntu base 镜像中安装 vi 并保存为新镜像。
1)、第一步:运行容器

-it 参数的作用是以交互模式进入容器,并打开终端。6e2d389d4576 是容器的内部 ID。
2)、第二步:安装 vi

确认 vi 没有安装。开始安装 apt-get install -y vim

3)、第三步:保存新镜像
在新窗口中查看当前运行的容器。
gifted_stallman 是 Docker 为我们的容器随机分配的名字。
执行 docker commit 命令将容器保存为镜像。
新镜像命名为 ubuntu-with-vi。
查看新镜像的属性。

从 size 上看到镜像因为安装了软件而变大了。从新镜像启动容器,验证 vi 已经可以使用。

以上演示了如何用 docker commit 创建新镜像。然而,Docker 并不建议用户通过这种方式构建镜像。原因如下:
1. 这是一种手工创建镜像的方式,容易出错,效率低且可重复性弱。比如要在 debian base 镜像中也加入 vi,还得重复前面的所有步骤。
2. 更重要的:使用者并不知道镜像是如何创建出来的,里面是否有恶意程序。也就是说无法对镜像进行审计,存在安全隐患。
既然 docker commit 不是推荐的方法,我们干嘛还要花时间学习呢?
原因是:即便是用 Dockerfile(推荐方法)构建镜像,底层也 docker commit 一层一层构建新镜像的。学习 docker commit 能够帮助我们
更加深入地理解构建过程和镜像的分层结构。
下一节我们学习如何通过 Dockerfile 构建镜像。
五、Dockerfile 构建镜像
Dockerfile 是一个文本文件,记录了镜像构建的所有步骤。
1、Dockerfile 构建镜像
1)创建Dockerfile文件
touch Dockerfile
2)用 Dockerfile 创建上节的 ubuntu-with-vi,其内容则为:

3)构建镜像
docker build -t ubuntu-with-vi-dockerfile .
ubuntu-with-vi-dockerfile是构建镜像所取的名字
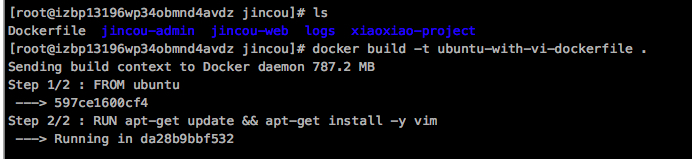
运行 docker build 命令,-t 将新镜像命名为 ubuntu-with-vi-dockerfile,命令末尾的 . 指明 build context 为当前目录。
Docker 默认会从 build context 中查找 Dockerfile 文件,我们也可以通过 -f 参数指定 Dockerfile 的位置。
4)镜像构建成功
通过 docker images 查看镜像信息。

可以看到新镜像已经构建成功,而且大小跟之前docker commit 构建的大小是一样大的。
【Docker】(10)---详细说说 Dockerfile文件
一、基础概念
1、基本概念
Dockerfile 是一个文本文件,其内包含了一条条的指令,每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。有了 Dockerfile,当我们需要定制额外的
需求时,只需在 Dockerfile上添加或者修改指令,重新生成image即可,省去了敲命令的麻烦。
2、文件格式
Dockerfile由一行行命令语句组成,并且支持用“#”开头作为注释,一般的Dockerfile分为四部分:基础镜像信息,维护者信息,镜像操作指令和容器启动时执行的指令。
二、基础命令
1、FROM
指定base镜像。
# 制作基准镜像
FROM 镜像
# 比如我们要发布一个应用到tomcat里,那么的第一步就是FROM tomcat
FROM tomcat<:tags>
第一条指令必须为FROM指令,并且,如果在同一个Dockerfile中创建多个镜像时,可以使用多个FROM指令(每个镜像一次)
2、LABEL&MAINTAINER
指定维护者的信息。
# MAINTAINER,一般写个人id或组织id
# LABEL 就是注释,方便阅读的,纯注释说明。不会对Dockerfile造成任何影响
# 比如:
MAINTAINER zhangsan
LABEL version = "1.0.0"
LABEL description = "我们是大百度!"
# ...等等描述性信息,纯注释。
3、WORKDIR
类似于Linux中的cd命令,但是他比cd高级的地方在于,我先cd,发现没有这个目录,我就自动创建出来,然后在cd进去,为后续的RUN 、 CMD 、 ENTRYPOINT
指令配置工作目录。
WORKDIR /usr/local/testdir
4、COPY
将文件从 本地 复制到镜像。
# 示例
# 将1.txt拷贝到根目录下。它不仅仅能拷贝单个文件,还支持Go语言风格的通配符,比如如下:
COPY 1.txt /
# 拷贝所有 abc 开头的文件到testdir目录下
COPY abc* /testdir/
# ? 是单个字符的占位符,比如匹配文件 abc1.log
COPY abc?.log /testdir/
5、ADD
将文件从 本地 复制到镜像。可以是Dockerfile所在的目录的一个相对路径;可以是URL,也可以是tar.gz(自动解压)
# 示例
# 将1.txt拷贝到根目录的abc目录下。若/abc不存在,则会自动创建
ADD 1.txt /abc
# 将test.tar.gz解压缩然后将解压缩的内容拷贝到/home/work/test
ADD test.tar.gz /home/work/test
docker官方建议当要从远程复制文件时,尽量用curl/wget命令来代替ADD。因为用ADD的时候会创建更多的镜像层。镜像层的size也大。
6、COPY与ADD比较
1)COPY能干的事ADD都能干,甚至还有附加功能。
2) ADD可以支持拷贝的时候顺带解压缩文件,以及添加远程文件(不在本宿主机上的文件)类似wget。
3) 只是文件拷贝的话可以用COPY,有额外操作只能用ADD代替。
7、ENV
设置环境变量,环境变量可被后面的指令使用。例如:
# 设置环境常量,方便下文引用,比如:
ENV JAVA_HOME /usr/local/jdk1.8
# 引用上面的常量,下面的RUN指令可以先不管啥意思,目的是想说明下文可以通过${xxx}的方式引用
RUN ${JAVA_HOME}/bin/java -jar xxx.jar
8、VOLUME
创建一个可以从本地主机或其他容器挂载的挂载点,一般用来存放数据库和需要保持的数据等。后面单独文章讲解。
VOLUME ["/data"]
三、运行指令
一共有三个:RUN、CMD、ENTRYPOINT
1、RUN
构建镜像时执行的命令。
1.1 执行时机
RUN指令是在构建镜像时运行,在构建时能修改镜像内部的文件。每条指令将在当前镜像基础上执行,并提交为新的镜像。
1.2 命令格式
注: 命令格式不光是RUN独有,而是下面的CMD和ENTRYPOINT都通用。
SHELL命令格式
RUN yum -y install vim
EXEC命令格式
RUN ["yum","-y","install","vim"]
二者对比
SHELL:当前shell是父进程,生成一个子shell进程去执行脚本,脚本执行完后退出子shell进程,回到当前父shell进程。
EXEC:用EXEC进程替换当前进程,并且保持PID不变,执行完毕后直接退出,不会退回原来的进程。
总结:也就是说shell会创建子进程执行,EXEC不会创建子进程。
1.3 举例
举个最简单的例子,构建镜像时输出一句话,那么在Dockerfile里写如下即可:
RUN ["echo", "image is building!!!"]
再比如我们要下载vim,那么在Dockerfile里写如下即可:
RUN ["yum","-y","install","vim"]
下面会有实战来完完整整的演示。
2、CMD
2.1 执行时机
容器启动时执行,而不是镜像构建时执行。
2.2 解释说明
容器启动时运行指定的命令。
Dockerfile 中可以有多个 CMD 指令,但只有最后一个生效。重点在于如果容器启动的时候有其他额外的附加指令,则CMD指令不生效。
2.3 举例
CMD ["echo", "container starting..."]
3、ENTRYPOINT
3.1 执行时机
容器创建时执行,而不是镜像构建时执行。
3.2 解释说明
在容器启动的时候执行此命令,且Dockerfile中只有最后一个ENTRYPOINT会被执行,推荐用EXEC格式。
3.3 举例
ENTRYPOINT ["ps","-ef"]
4、RUN vs CMD vs ENTRYPOINT
简单的说:
1、RUN 执行命令并创建新的镜像层,RUN 经常用于安装软件包。
2、CMD 设置容器启动后默认执行的命令及其参数,但 CMD 能够被 docker run 后面跟的命令行参数替换。
3、ENTRYPOINT 配置容器启动时运行的命令。
RUN
RUN是在构建层面的,就是每执行一个RUN,就代表多一层。所以我们经常会用于安装软件包,好比 RUN yum -y install vim。执行这个命令就是让当前镜像可以支持vim指令。
CMD
CMD 指令允许用户指定容器的默认执行的命令。此命令会在容器启动且 docker run 没有指定其他命令时运行。如果 docker run 指定了其他命令,CMD 命令将被忽略。
如果 Dockerfile 中有多个 CMD 指令,只有最后一个 CMD 有效。
ENTRYPOINT
ENTRYPOINT 指令可让容器以应用程序或者服务的形式运行。ENTRYPOINT 看上去与 CMD 很像,它们都可以指定要执行的命令及其参数。不同的地方在于 ENTRYPOINT
不会被忽略,一定会被执行,即使运行 docker run 时指定了其他命令。
5、RUN VS CMD案例
上面虽然用文字阐述了它们之间的区别,但是估计还是会有点不太明白,所以这里通过一个小小案例来理解。
创建Dockerfile,并添加如下内容
FROM centos
RUN ["echo", "image building!!!"]
CMD ["echo", "container starting..."]
构建镜像
docker build -t runvscmd-test .

可以看出构建镜像的过程中发现RUN的image building!!! 输出了,所以RUN命令是在镜像构建时执行。而并没有container starting…的输出。
启动容器
docker run runvscmd-test

启动容器的时候 container starting...,足以发现CMD命令是在容器启动的时候执行。
总结: 这就是上面所说的 run是 构建镜像 时候的指令,CMD和ENTRYPOINT是启动容器时的指令。
接下来在举个例子来理解区分CMD和ENTRYPOINT。
6、CMD VS ENTRYPOINT案例
ENTRYPOINT和CMD可以共用,若共用则他会一起合并执行。如下Demo:
FROM centos
RUN ["echo", "image building!!!"]
ENTRYPOINT ["ps"]
CMD ["-ef"]
构建启动容器
# 构建镜像
docker build -t docker-test .
# 启动容器
docker run docker-test
输出结果
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 13:02 ? 00:00:00 ps -ef
他给我们合并执行了:ps -ef,这么做的好处在于如果容器启动的时候添加额外指令,CMD会失效,可以理解成我们可以动态的改变CMD内容而不需要重新构建镜像等操作。比如
docker run docker-test -aux
输出结果:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 2.0 0.0 46340 1692 ? Rs 13:02 0:00 ps -aux
结果直接变成了 ps -aux,CMD命令不执行了。
总结:从这个示例中就可以看出区别,ENTRYPOINT无论容器启动是否带参数,都会执行。而CMD就不一样。上面没带参数那么它就会被执行。而下面带了 -aux,
CMD指令就不会执行了。
四、项目实战
这里就是以当前自己的vue项目来演示,正常不用docker,那么就是先打包项目,npm run bulid,再启动项目 npm run start。
但是因为vue项目依赖Node,就好像我们java项目依赖JDk一样。所以不同环境版本一直很重要,所以这里通过镜像来启动项目。
1、DockerFile文件
在vue项目当前目录创建DockerFile文件,并写入以下脚本。
#获取基础镜像
FROM node:12.17
#指定作者
MAINTAINER xiaoxiao
#指定工作目录
WORKDIR /app
#将当前根目录的vue项目所有文件,都移动到/app目录下
#COPY package*.json ./
COPY . .
##安装项目相关依赖
RUN npm install
#将当前根目录的vue项目所有文件,都移动到/app目录下
#打包项目
RUN npm run build
#暴露端口
EXPOSE 8000
#启动项目
ENTRYPOINT ["npm","run","start"]
2、构建镜像
命令
# docker build代表构建镜像 -t后面指定生成镜像名称 .代表在当前目录构建
docker build -t xiaoxiao-web .

构建镜像命令执行完后,我们可以看下该镜像有没有创建成功

可以看出镜像已经构建成功,不过镜像有点大。
3、启动容器
# docker run表示启动容器 -d 在后台运行 --name 容器的名称 -p端口映射 xiaoxiao-web就是指定哪个镜像
docker run -d --name=xiaoxiao-run-web -p 7000:8000 xiaoxiao-web

说明容器已经启动成功。
4、进入容器
#09ff5738660e 为容器ID
docker exec -it 09ff5738660e /bin/bash

从这里可以看出2点 1:我一进来就是根目录就是/app 这就是上面我们自己设置的工作目录。2:前端项目文件已经都拷贝到当前根目录下。
5、访问项目

成功
【Docker】(11)---Docker的网络概念
一、实现原理
1、实现原理
Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,
同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
Docker网桥是宿主机虚拟出来的,并不是真实存在的网络设备,外部网络是无法寻址到的,这也意味着外部网络无法通过直接Container-IP访问到容器。如果容器希望外部访问能够
访问到,可以通过映射容器端口到宿主主机(端口映射),即docker run创建容器时候通过 -p 或 -P 参数来启用,访问容器的时候就通过[宿主机IP]:[容器端口]访问容器。
二、四种网络模式
安装Docker时,它会自动创建三个网络,bridge(创建容器默认连接到此网络)、 none 、host

安装好docker,我们可以通过命令来查看当前的网络模式
[root@izbp13196 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
a6fb564d8107 bridge bridge local
8f63ceca4d5a host host local
de62f8161011 none null local
我们在使用docker run创建Docker容器时,可以用 --net 选项指定容器的网络模式,Docker可以有以下4种网络模式:
host模式:使用 --net=host 指定。
none模式:使用 --net=none 指定。
bridge模式:使用 --net=bridge 指定,默认设置。
container模式:使用 --net=container:NAME_or_ID 指定。
下面分别介绍一下Docker的各个网络模式。
1、Host模式
如果启动容器时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个NetworkNamespace。容器将不会虚拟出自己的网卡,
配置自己的IP等,而是使用宿主机的IP和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
使用host模式的容器可以直接使用宿主机的IP地址与外界通信,容器内部的服务端口也可以使用宿主机的端口,host最大的优势就是网络性能比较好,但是docker host上已经
使用的端口就不能再用了,网络的隔离性不好。

2、Container模式
这个模式指定新创建的容器和已经存在的一个容器共享一个Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的
容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。

3、none模式
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们
自己为Docker容器添加网卡、配置IP等。
这种网络模式下容器只有lo回环网络,没有其他网卡。none模式可以在容器创建时通过--network=none来指定。这种类型的网络没有办法联网,封闭的网络能很好的保证容器
的安全性。
4、bridge模式
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。容器启动时,Docker会创建一对veth pair
(虚拟网络接口)设备,veth设备的特点是成对存在,从一端进入的数据会同时出现在另一端。Docker会将一端挂载到docker0网桥上,另一端放入容器的Network Namespace
内,从而实现容器与主机通信的目的。
bridge模式是docker的默认网络模式,不写--net参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。

三、 学容器必须懂bridge网络
前面有说过 Docker启动的时候会在主机上自动创建一个docker0网桥,实际上是一个Linux网桥,所有容器的启动如果在docker run的时候如果不指定--network,都会挂载
到docker0网桥上。这样容器就可以和主机甚至是其他容器之间通讯了。
具体看下图片

1、新创建容器
如果只是安装了docker,但并没有启动任何docker项目,我们可以看到当前 docker0 上没有任何其他网络设备
[root@izbp1319 ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242b79eef68 no
这时我们创建一个容器看看有什么变化。
#启动容器
[root@izbp13196 ~]# docker run -d httpd
#查看容器
[root@izbp13196 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ae4959077e70 httpd "httpd-foreground" 17 minutes ago Up 17 minutes 80/tcp loving_ptolemy
再来查看下网络设备
[root@izbp13196wp34obmnd4avdz ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242b79eef68 no vethb37e106
一个新的网络接口 vethb37e106 被挂到了 docker0 上,vethb37e106就是新创建容器的虚拟网卡。
2、查看新建容器网络配置
我们进入刚创建的容器内部,查看网络配置。
# ae4959077e70为该容器id
[root@izbp13196 ~]# docker exec -it ae4959077e70 bash
root@ae4959077e70:/usr/local/apache2#
先安装ip命令,因为默认是没有ip命令的,所以我们要先安装这个命令,才能查看当前容器网络地址
#先更新
root@ae4959077e70:/usr/local/apache2# apt-get update
#在安装iproute,如果安装失败那就安装iproute2
root@ae4959077e70:/usr/local/apache2# apt-get install iproute
查看网络

容器有一个网卡 eth0@if1004。大家可能会问了,为什么不是vethb37e106 呢?
实际上 eth0@if1004 和 vethb37e106 是一对 veth pair。veth pair 是一种成对出现的特殊网络设备,可以把它们想象成由一根虚拟网线连接起来的一对网卡,网卡的一头
(eth0@if1004)在容器中,另一头(vethb37e106)挂在网桥 docker0 上,其效果就是将 eth0@if1004 也挂在了 docker0 上。
3、查看宿主机
[root@izbp13196wp34obmnd4avdz ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:16:3e:14:50:2d brd ff:ff:ff:ff:ff:ff
inet 172.16.255.238/20 brd 172.16.255.255 scope global eth0
valid_lft forever preferred_lft forever
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:b7:9e:ef:68 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
1004: vethb37e106@if1003: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP
link/ether d6:b4:d1:b6:ee:f0 brd ff:ff:ff:ff:ff:ff link-netnsid 11
把上面整理成一份图大致就是下面这样的

四、容器之间的通信
1、容器内部能否ping通外部?
# 测试 运行一个tomcat
$ docker run -d --name tomcat01 tomcat
# 查看主机网络地址
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
551: vethbfc37e3@if550: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 1a:81:06:13:ec:a1 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::1881:6ff:fe13:eca1/64 scope link
valid_lft forever preferred_lft forever
# 进入容器内部,查看网络地址
$ docker exec -it 容器id
$ ip addr
# 查看容器内部网络地址 发现容器启动的时候会得到一个 eth0@if551 ip地址,docker分配!
550: eth0@if551: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
# 思考? linux能不能ping通容器内部! 可以 容器内部可以ping通外界吗? 可以!
$ ping 172.17.0.2
PING 172.17.0.2 (172.17.0.2) 56(84) bytes of data.
64 bytes from 172.17.0.2: icmp_seq=1 ttl=64 time=0.069 ms
64 bytes from 172.17.0.2: icmp_seq=2 ttl=64 time=0.074 ms
原因:我们每启动一个docker容器,docker就会给docker容器分配一个ip,我们只要按照了docker,就会有一个docker0桥接模式,使用的技术是veth-pair技术!
2、容器之间能否ping通

# 启动tomcat01 查看ip地址为172.17.0.2
$ docker-tomcat docker exec -it tomcat01 ip addr #获取tomcat01的ip 172.17.0.2
550: eth0@if551: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
#启动tomcat02 看能否ping通172.17.0.2
$ docker-tomcat docker exec -it tomcat02 ping 172.17.0.2
PING 172.17.0.2 (172.17.0.2) 56(84) bytes of data.
64 bytes from 172.17.0.2: icmp_seq=1 ttl=64 time=0.098 ms
64 bytes from 172.17.0.2: icmp_seq=2 ttl=64 time=0.071 ms
# 可以ping通
思考
虽然所我们通过tomcat02,能够ping通tomcat1,但这里不是直接ping通过的,而是通过路由器,也就是docker0,来进行桥接的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号