网站架构核心技disruptor
一 序:
本章业务场景:队列在数据结构中是一种线性表,从一端插入数据,然后从另一端删除数据。作者举例的场景有:进行异步处理、系统解耦、数据同步、流量削峰、缓冲、限流等。
前面的比较浅,总结起来,核心知识点有两块:
1. disruptor+redis队列
2. 基于canal实现数据异构。
下面说的就是整理其中的系统内部的内存式队列,非kafka那种分布式队列。
*************************************************
二 blockingqueue
jdk常用的队列有
队列 有界性 锁 数据结构
ArrayBlockingQueue bounded 加锁 arraylist
LinkedBlockingQueue optionally-bounded 加锁 linkedlist
ConcurrentLinkedQueue unbounded 无锁 linkedlist
LinkedTransferQueue unbounded 无锁 linkedlist
PriorityBlockingQueue unbounded 加锁 heap
DelayQueue unbounded 加锁 heap
考虑到内存回收,防止无姐队列内存溢出,通常使用 ArrayBlockingQueue
常用于生产者-消费者模式:
demo:
package com.daojia.web.bm.disruptor;
import java.util.concurrent.BlockingQueue;
public class ThreadForConsumer extends Thread {
private BlockingQueue<String> blockingQueue;
public ThreadForConsumer(BlockingQueue<String> blockingQueue) {
this.blockingQueue = blockingQueue;
}
@Override
public void run() {
String msg;
try {
while (true) {
msg = blockingQueue.take();
if(msg==null)
{
System.out.println("nodata");
Thread.sleep(1);
}else{
// 消费
System.out.println(msg+"over");
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
public class QueueMain {
public static void main(String[] args) throws InterruptedException {
// TODO Auto-generated method stub
// 初始化阻塞队列
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(1024);
// 创建消费者线程
Thread consumer = new Thread(new ThreadForConsumer(blockingQueue));
consumer.start();
long t1 =System.currentTimeMillis();
System.out.println("begin="+t1);
// 创建数据
for(int i=0;i<=1000000;i++)
{
blockingQueue.put(i+"");
}
System.out.println("over ,user="+(System.currentTimeMillis()-t1));
}
}
简化了生产者,没有单独放到线程去写,常见的是这种:
public class ThreadForProducer extends Thread {
private BlockingQueue<String> blockingQueue;
public ThreadForProducer(BlockingQueue<String> blockingQueue) {
this.blockingQueue = blockingQueue;
}
@Override
public void run() {
try {
for(int i=0;i<=1000000;i++)
{
blockingQueue.put(i+"");
}
System.out.println("put orver");
} catch (Exception e) {
e.printStackTrace();
}
}
}
这里有相关知识点:整理一下:
2.1. 底层实现:加锁与CAS
看下底层的关键方法:put放入数据
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
获取数据:take
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
可见阻塞队列使用锁,当然为提高效率用通知模式。 就是当生产者往满的队列里添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。notempty,notfull就是condition。
CAS是CPU的一个指令,由CPU保证原子性。
常见的例子是juc下面的atmoic的类。
通常情况(竞争不那么高)cas的性能是比锁好的,当然高并发情况下,锁比cas要好。
2.2 CPU伪共享
下图(来自《深入理解计算机系统》),在此层次中,从上至下,容量越来越大,访问速度越来越慢,但是造价也更便宜
下图是个简化的计算机CPU与缓存的示意图
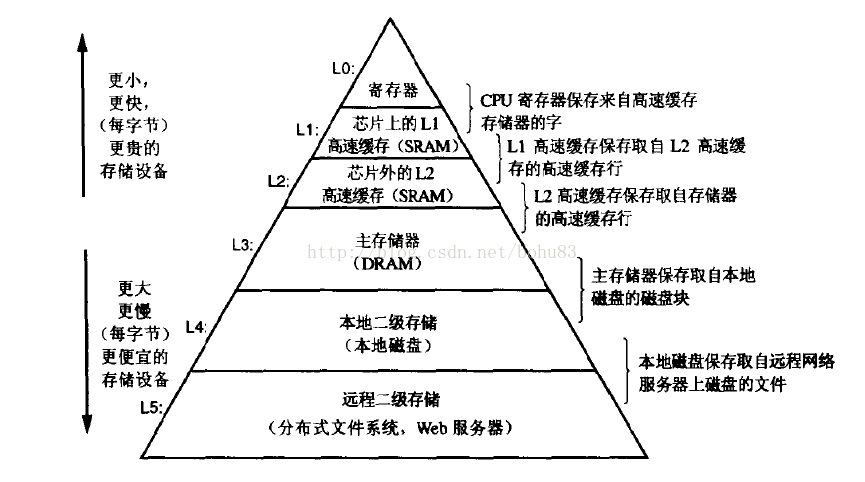
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。
另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。
下面是从CPU访问不同层级数据的时间概念:
从CPU到 大约需要的CPU周期 大约需要的时间
主存 约60-80ns
QPI 总线传输(between sockets, not drawn) 约20ns
L3 cache 约40-45 cycles 约15ns
L2 cache 约10 cycles 约3ns
L1 cache 约3-4 cycles 约1ns
寄存器 1 cycle
可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级。
今天的CPU不再是按字节访问内存,而是以64字节(64位系统)为单位的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址,整个缓存行将从主存换入缓存,并且访问同一个缓存行内的其它值的开销是很小的。
比如,Java中的long类型是8个字节,因此在一个缓冲行中可以存8个long类型的变量,也就是说如果访问一个long类型的数组,访问第一个元素的时候,会把另外7个也加载到缓存中,可以非常快速的遍历数组,这也是数组比链表快的原因。
美团的测试代码如下:
public class CacheLineEffect {
//考虑一般缓存行大小是64字节,一个 long 类型占8字节
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
arr[i] = new long[8];
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i+=1) {
for(int j =0; j< 8;j++){
sum = arr[i][j];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
marked = System.currentTimeMillis();
for (int i = 0; i < 8; i+=1) {
for(int j =0; j< 1024 * 1024;j++){
sum = arr[j][i];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
}
}
运行结果:
Loop times:13ms
Loop times:54ms
缓存行利用局部性的确能提高效率,但是有一个弊端,当我们的数据不相关,只是一个单独的变量,这两个数据在一个缓存行中,而且他们的访问频率都很高,这时候反而会影响效率。如下图:
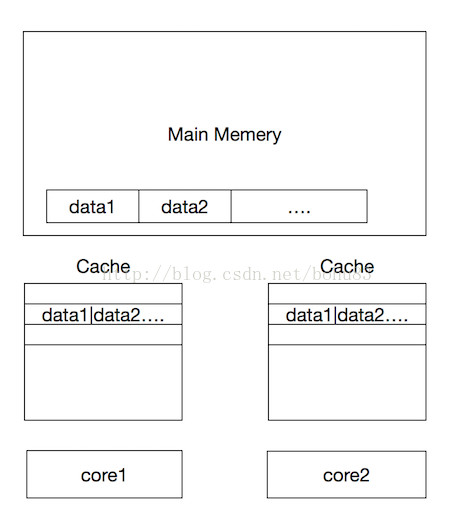
比如我们有一个类存放了两个变量的值data1,data2。当加载data1的时候,data2也被加载到缓存中,也就是存在于同一个缓存行。当core1改变data1的值的时候,core1缓存中的值和内存中的值都被改变了,这时候core2也会重新加载这个缓存行,因为data1变了,而core2只是想读取自己缓存中的data2,却任然要等从内存中重新加载这个缓存行。
这种无法充分使用缓存行特性的现象,称为伪共享。
ArrayBlockingQueue有三个成员变量:
takeIndex:需要被取走的元素下标
putIndex:可被元素插入的位置的下标
count:队列中元素的数量
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。
好了,上面是说了相关缺点,那么disruptor是怎么实现的呢?
三 disruptor
Disruptor是由LMAX公司开发的一款高效无锁内存队列。使用无锁方式实现了一个环形队列代替线性队列。相对于普通的线性队列,环形队列不需要维护头尾两个指针,只需维护一个当前位置就可以完成出入队操作。受限于环形结构,队列的大小只能初始化时指定,不能动态扩展。
如下图所示,Disruptor的实现为一个循环队列,ringbuffer拥有一个序号(Seq),这个序号指向数组中下一个可用的元素
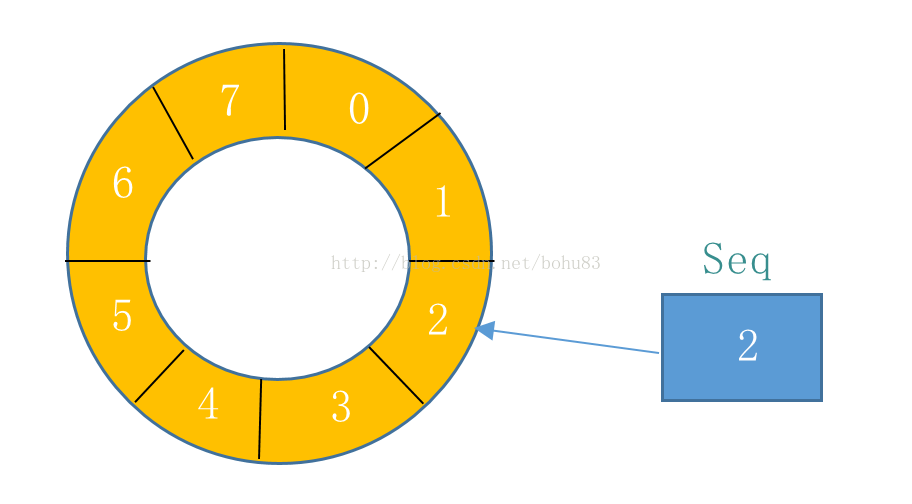
相关设计上的知识点:
1)Disruptor要求数组大小设置为2的N次方。这样可以通过Seq & (QueueSize - 1) 直接获取,其效率要比取模快得多。这是因为(Queue - 1)的二进制为全1等形式。例如,上图中QueueSize大小为8,Seq为10,则只需要计算二进制1010 & 0111 = 2,可直接得到index=2位置的元素。
2)在RingBuffer中,生产者向数组中写入数据,生产者写入数据时,使用CAS操作。消费者从中读取数据时,为防止多个消费者同时处理一个数据,也使用CAS操作进行数据保护。
3)这种固定大小的RingBuffer还有一个好处是,可以内存复用。不会有新空间需要分配或者旧的空间回收,当数组填充满后,再写入数据会将数据覆盖。
4)增加缓存行补齐, 提升cache缓存命中率
需要去看代码。
四 demo:
/**
* 事件对象:
* 只模拟放一条消息
* @author daojia
*
*/
public class MsgData {
private String msg;
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
}
/**
* 工厂类:构造缓冲区对象实例
* @author daojia
*
*/
public class MsgDataFactory implements EventFactory<MsgData> {
@Override
public MsgData newInstance() {
// TODO Auto-generated method stub
return new MsgData();
}
}
/**
* 消费者
* @author daojia
*
*/
public class MsgDataHandler implements WorkHandler<MsgData> {
@Override
public void onEvent(MsgData event) throws Exception {
// TODO Auto-generated method stub
String msg = event.getMsg();
//模拟业务调用
System.out.println(msg+"over");
Thread.sleep(10);
}
}
/**
* 生产者:
*
* @author daojia
*
*/
public class MsgDataProducer {
private final RingBuffer<MsgData> ringBuffer;
public MsgDataProducer(RingBuffer<MsgData> ringBuffer){
this.ringBuffer = ringBuffer;
}
public void pushData(String msg) {
//可以把ringBuffer看做一个事件队列,那么next就是得到下面一个事件槽
long seq = ringBuffer.next();
try {
// 获取可用位置
MsgData event = ringBuffer.get(seq);
// 填充可用位置
event.setMsg(msg);
} catch (Exception e) {
e.printStackTrace();
} finally {
//发布事件, 通知消费者
ringBuffer.publish(seq);
}
}
}
public class DisruptorMain {
public static void main(String[] args) {
// TODO Auto-generated method stub
// 工厂
MsgDataFactory factory = new MsgDataFactory();
// 线程池
ExecutorService executor = Executors.newCachedThreadPool();
int bufferSize = 1024; // 必须为2的幂指数
// 初始化Disruptor
Disruptor<MsgData> disruptor = new Disruptor<>(factory, bufferSize, executor, ProducerType.SINGLE,new YieldingWaitStrategy());
// 启动消费者
disruptor.handleEventsWithWorkerPool(new MsgDataHandler(),new MsgDataHandler(),new MsgDataHandler());
disruptor.start();
//获取ringBuffer
RingBuffer<MsgData> ringBuffer = disruptor.getRingBuffer();
long t1 =System.currentTimeMillis();
System.out.println("begin="+t1);
// 启动生产者
MsgDataProducer producer = new MsgDataProducer(ringBuffer);
for(int i=0;i<=100000;i++)
{
//模拟生成数据
producer.pushData(i+"");
}
System.out.println("over ,user="+(System.currentTimeMillis()-t1));
}
}
在单个消费者,单个生产者,设置长度都是1024的 情况下,本地测试的性能跟blockingqueue没啥区别。
不知道是不是我设置的参数不对,没体现出设计的优势。
单纯的100W数据循环放入,耗时在10s左右。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号