ElasticSearch架构及详解
1. 图解es内部机制
1.1. 图解es分布式基础
1.1.1es对复杂分布式机制的透明隐藏特性
- 分布式机制:分布式数据存储及共享。
- 分片机制:数据存储到哪个分片,副本数据写入。
- 集群发现机制:cluster discovery。新启动es实例,自动加入集群。
- shard负载均衡:大量数据写入及查询,es会将数据平均分配。
- shard副本:新增副本数,分片重分配。
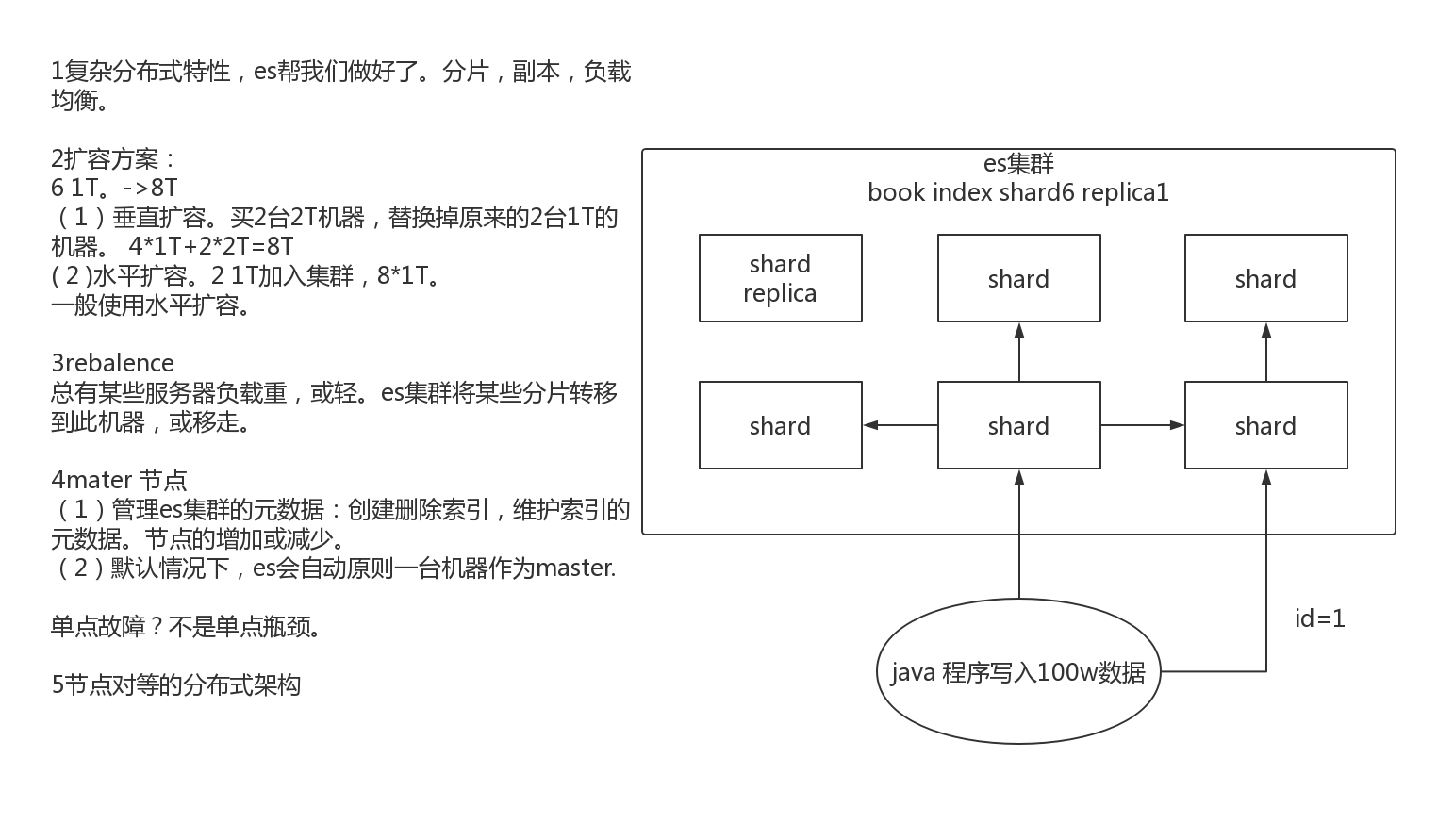
1.1.2Elasticsearch的垂直扩容与水平扩容
垂直扩容:使用更加强大的服务器替代老服务器。但单机存储及运算能力有上线。且成本直线上升。如10t服务器1万。单个10T服务器可能20万。
水平扩容:采购更多服务器,加入集群。大数据。
1.1.3增减或减少节点时的数据rebalance
新增或减少es实例时,es集群会将数据重新分配。
1.1.4master节点
功能:
- 创建删除节点
- 创建删除索引
1.1.5节点对等的分布式架构
- 节点对等,每个节点都能接收所有的请求
- 自动请求路由
- 响应收集
1.2. 图解分片shard、副本replica机制
1.2.1shard&replica机制
(1)每个index包含一个或多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是1,replica默认是1,默认共有2个shard,1个primary shard,1个replica shard
注意:es7以前primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上

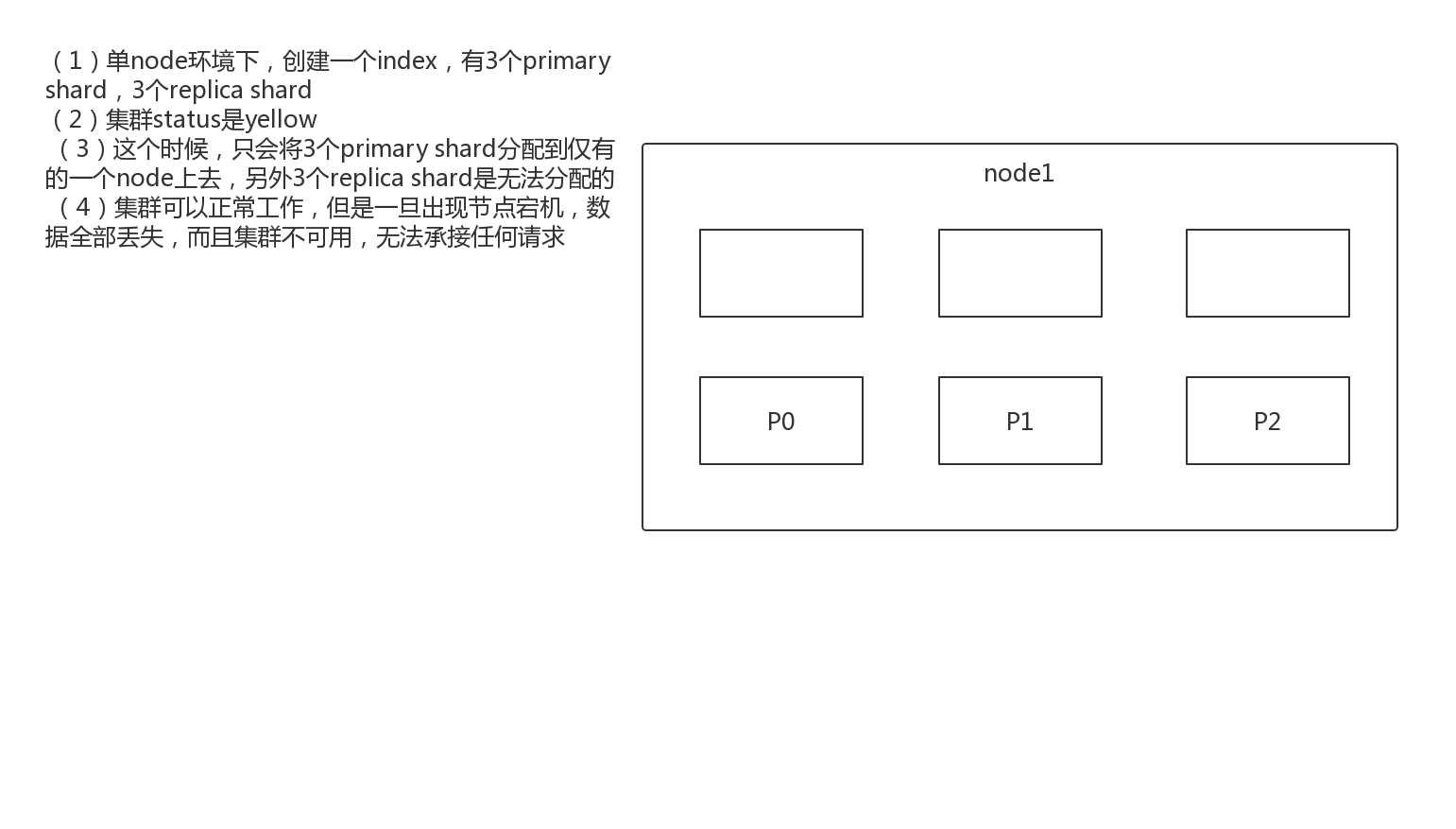
1.3图解单node环境下创建index是什么样子的
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index1
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
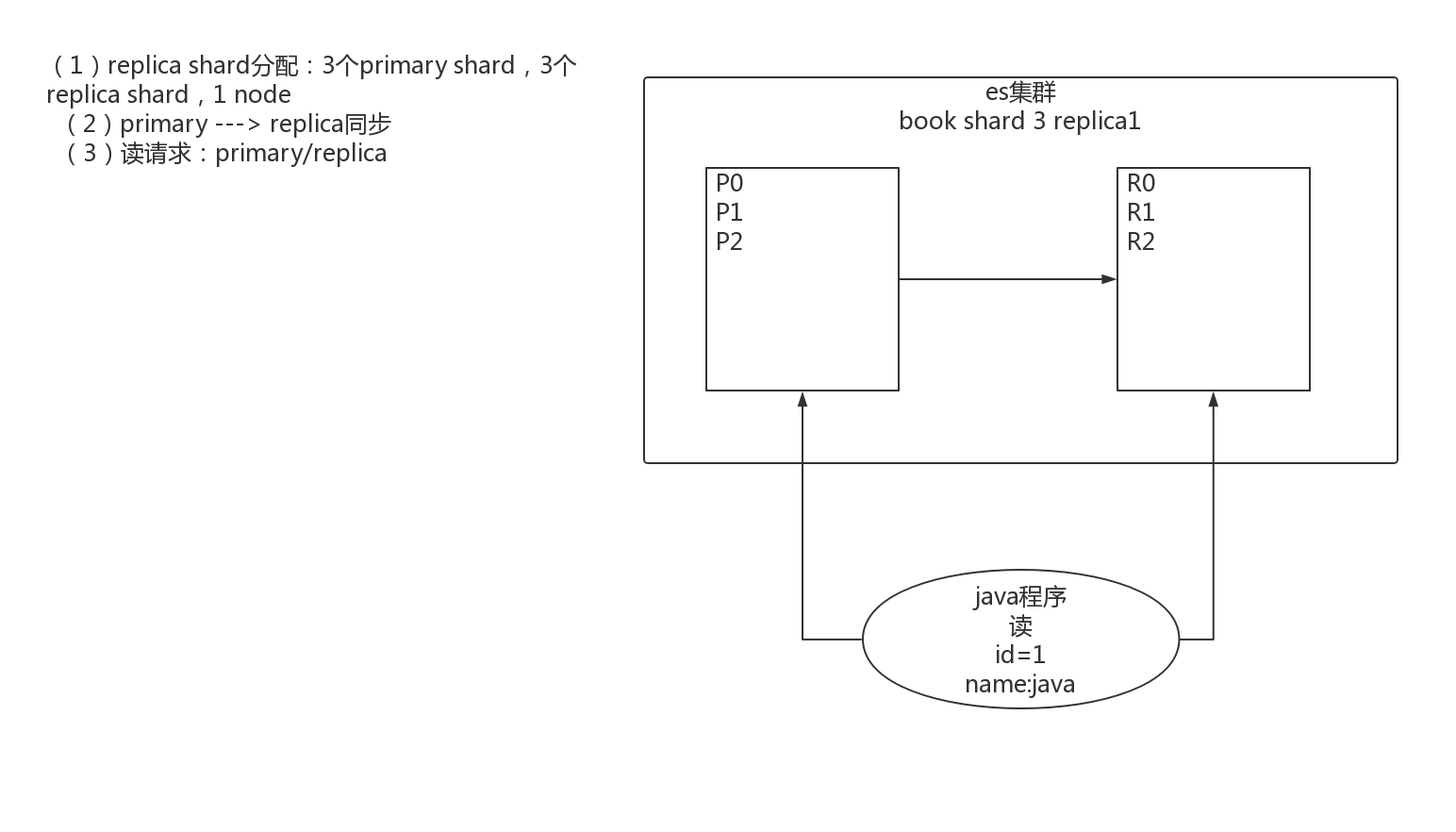
1.4图解2个node环境下replica shard是如何分配的
(1)replica shard分配:3个primary shard,3个replica shard,1 node
(2)primary ---> replica同步
(3)读请求:primary/replica
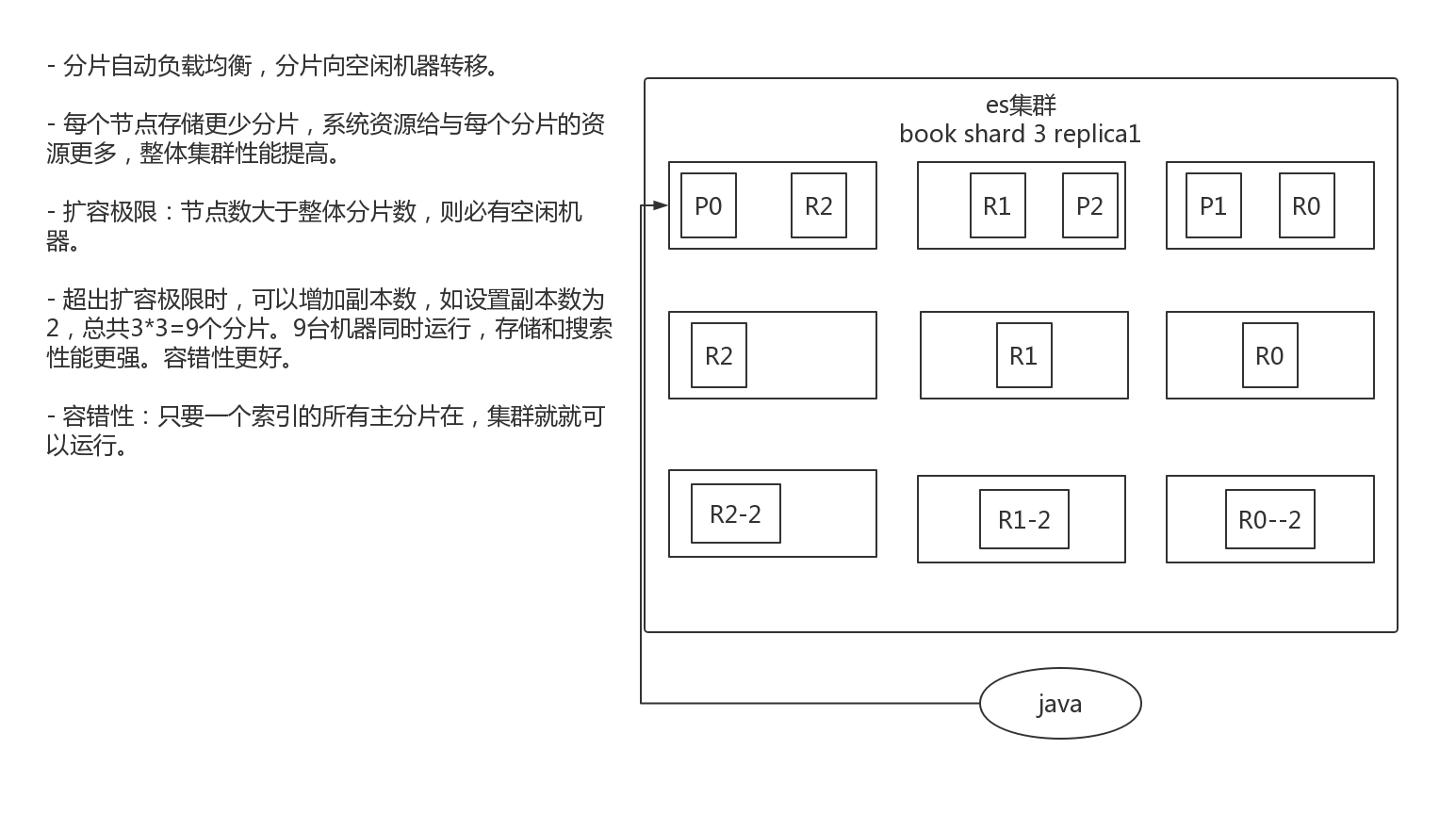
1.5图解横向扩容
- 分片自动负载均衡,分片向空闲机器转移。
- 每个节点存储更少分片,系统资源给与每个分片的资源更多,整体集群性能提高。
- 扩容极限:节点数大于整体分片数,则必有空闲机器。
- 超出扩容极限时,可以增加副本数,如设置副本数为2,总共3*3=9个分片。9台机器同时运行,存储和搜索性能更强。容错性更好。
- 容错性:只要一个索引的所有主分片在,集群就就可以运行。
1.6 图解es容错机制 master选举,replica容错,数据恢复
以3分片,2副本数,3节点为例介绍。
- master node宕机,自动master选举,集群为red
- replica容错:新master将replica提升为primary shard,yellow
- 重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,green

2. 图解文档存储机制
2.1. 数据路由
2.1.1文档存储如何路由到相应分片
一个文档,最终会落在主分片的一个分片上,到底应该在哪一个分片?这就是数据路由。
2.1.2路由算法
shard = hash(routing) % number_of_primary_shards
哈希值对主分片数取模。
举例:
对一个文档经行crud时,都会带一个路由值 routing number。默认为文档_id(可能是手动指定,也可能是自动生成)。
存储1号文档,经过哈希计算,哈希值为2,此索引有3个主分片,那么计算2%3=2,就算出此文档在P2分片上。
决定一个document在哪个shard上,最重要的一个值就是routing值,默认是_id,也可以手动指定,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的
无论hash值是几,无论是什么数字,对number_of_primary_shards求余数,结果一定是在0~number_of_primary_shards-1之间这个范围内的。0,1,2。
2.1.3手动指定 routing number
PUT /test_index/_doc/15?routing=num
{
"num": 0,
"tags": []
}
场景:在程序中,架构师可以手动指定已有数据的一个属性为路由值,好处是可以定制一类文档数据存储到一个分片中。缺点是设计不好,会造成数据倾斜。
所以,不同文档尽量放到不同的索引中。剩下的事情交给es集群自己处理。
2.1.4主分片数量不可变
涉2及到以往数据的查询搜索,所以一旦建立索引,主分片数不可变。
2.2. 图解文档的增删改内部机制
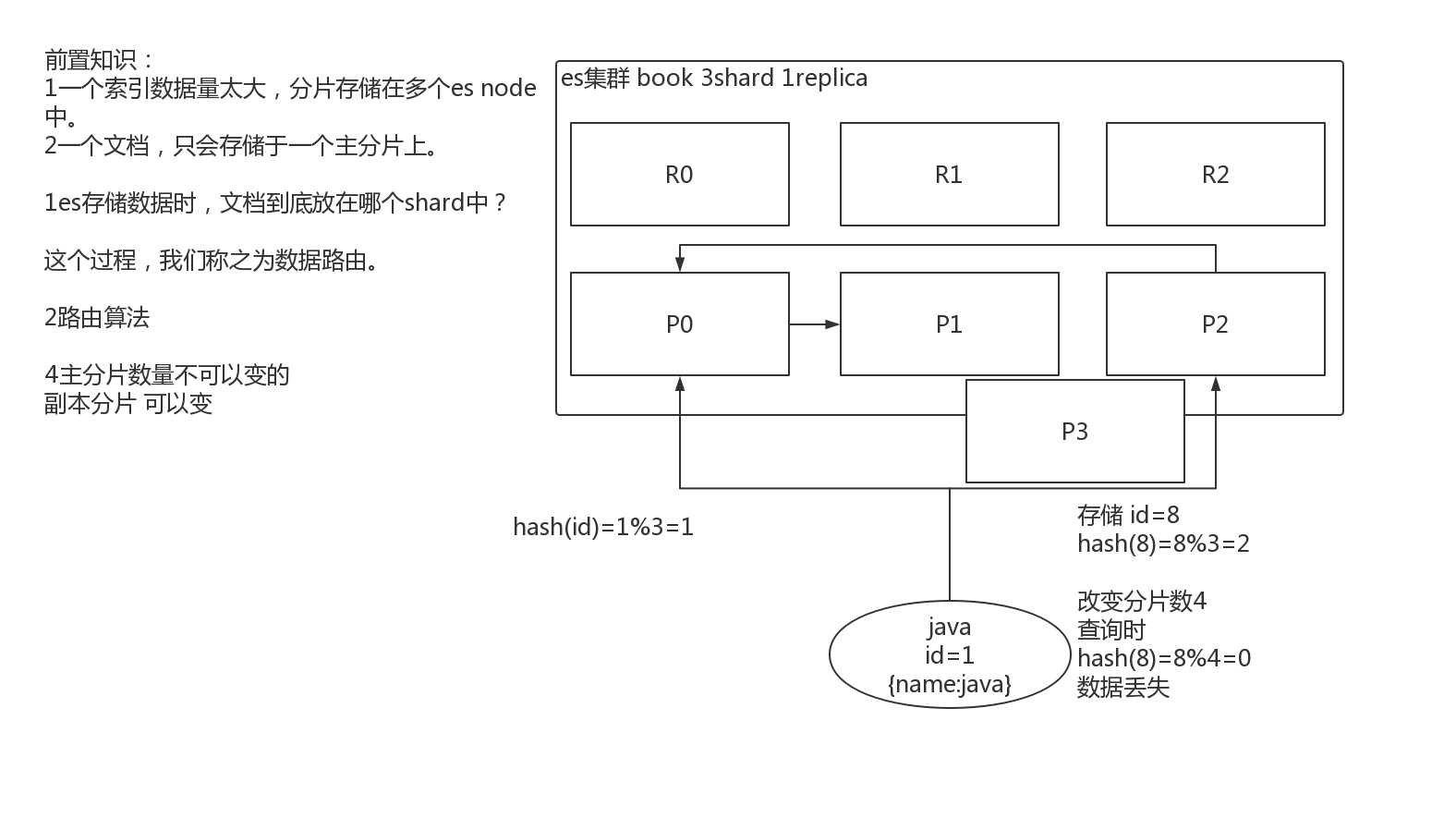
增删改可以看做update,都是对数据的改动。一个改动请求发送到es集群,经历以下四个步骤:
(1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
(2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
(3)实际的node上的primary shard处理请求,然后将数据同步到replica node。
(4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。
2.3.图解文档的查询内部机制
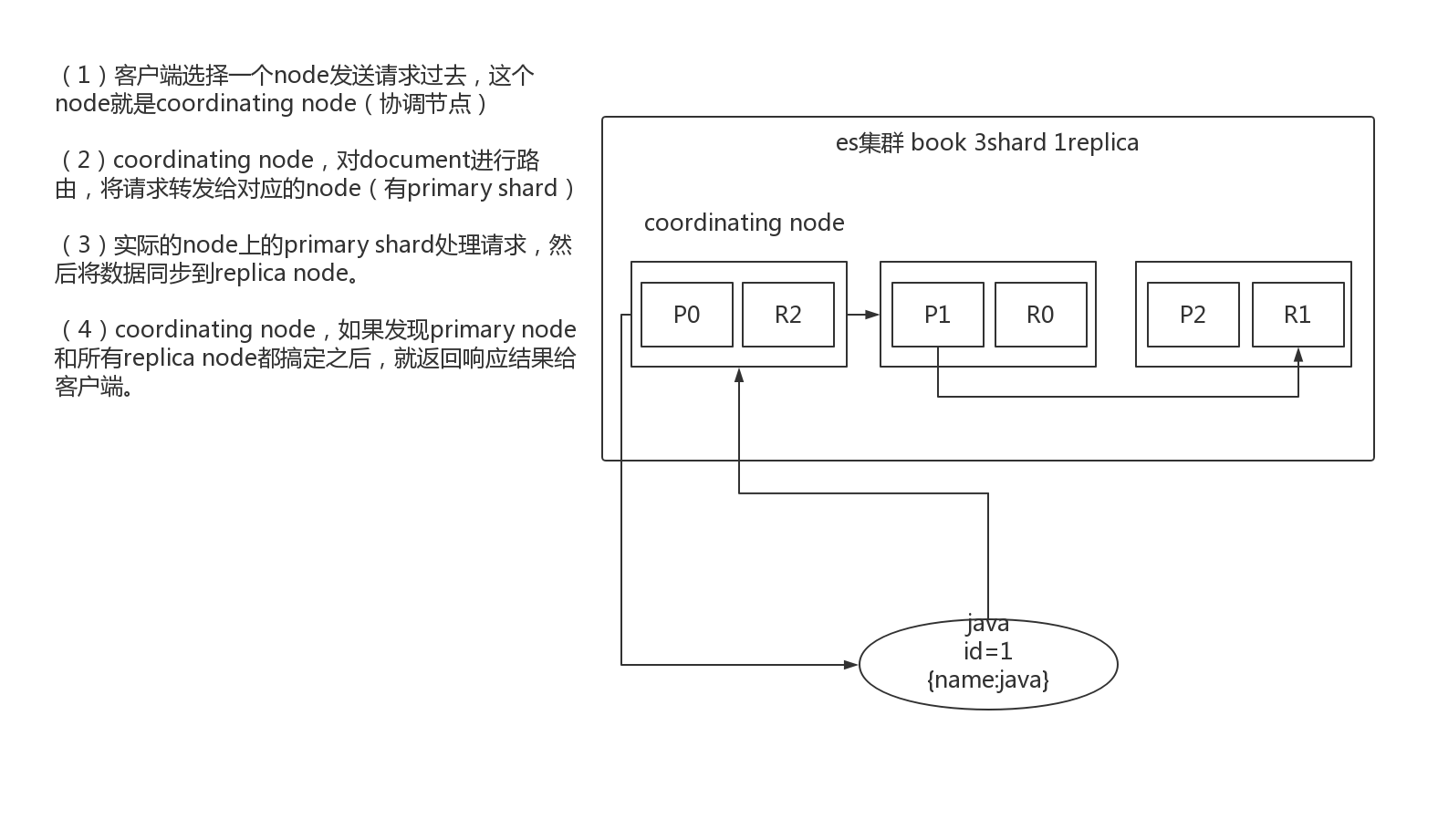
1、客户端发送请求到任意一个node,成为coordinate node
2、coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
3、接收请求的node返回document给coordinate node
4、coordinate node返回document给客户端
5、特殊情况:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了。
2.4.bulk api奇特的json格式
POST /_bulk
{"action": {"meta"}}\n
{"data"}\n
{"action": {"meta"}}\n
{"data"}\n
[
{
"action":{
"method":"create"
},
"data":{
"id":1,
"field1":"java",
"field1":"spring",
}
},
{
"action":{
"method":"create"
},
"data":{
"id":2,
"field1":"java",
"field1":"spring",
}
}
]
1、bulk中的每 node的shard去执行
2、如果采用比较良好的json数组格式
允许任意的换行,整个可读性非常棒,读起来很爽,es拿到那种标准格式的json串以后,要按照下述流程去进行处理
(1)将json数组解析为JSONArray对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是JSONArray对象
(2)解析json数组里的每个json,对每个请求中的document进行路由
(3)为路由到同一个shard上的多个请求,创建一个请求数组。100请求中有10个是到P1.
(4)将这个请求数组序列化
(5)将序列化后的请求数组发送到对应的节点上去
3、耗费更多内存,更多的jvm gc开销
我们之前提到过bulk size最佳大小的那个问题,一般建议说在几千条那样,然后大小在10MB左右,所以说,可怕的事情来了。假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB = 1GB,然后每个请求的json都copy一份为jsonarray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成jsonarray之后,还可能会多搞一些其他的数据结构,2GB+的内存占用。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降。
另外的话,占用内存更多,就会导致java虚拟机的垃圾回收次数更多,跟频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致es的java虚拟机停止工作线程的时间更多。
4、现在的奇特格式
POST /_bulk
{ "delete": { "_index": "test_index", "_id": "5" }} \n
{ "create": { "_index": "test_index", "_id": "14" }}\n
{ "test_field": "test14" }\n
{ "update": { "_index": "test_index", "_id": "2"} }\n
{ "doc" : {"test_field" : "bulk test"} }\n
(1)不用将其转换为json对象,不会出现内存中的相同数据的拷贝,直接按照换行符切割json
(2)对每两个一组的json,读取meta,进行document路由
(3)直接将对应的json发送到node上去
5、最大的优势在于,不需要将json数组解析为一个JSONArray对象,形成一份大数据的拷贝,浪费内存空间,尽可能地保证性能。
什么是裂脑?
让我们以一个带有两个节点的enlasticsearch集群的简单情况为例。集群包含一个带有一个分片和一个副本的索引。节点1在群集启动时被选为主节点,并拥有主分片(在以下架构中标记为0P),而节点2则拥有副本分片(0R)。

现在,如果由于任何原因两个节点之间的通信失败,将会发生什么?发生这种情况的原因可能是网络故障,也可能只是因为其中一个节点没有响应(例如,在世界停止垃圾回收的情况下)。

两个节点都认为另一个已失败。节点1不会执行任何操作,因为它已被选为主节点。但是节点2会自动将自己选举为主节点,因为它认为它是群集的一部分,而该群集不再具有主节点。在Elasticsearch集群中,主节点负责在节点之间平均分配分片。节点2拥有一个副本分片,但它认为主分片不再可用。因此,它将自动将副本分片提升为主数据库。

我们的集群现在处于不一致状态。为将要命中节点1的索引请求编制索引将在其主分片副本中索引数据,而发送至节点2的请求将填充该分片的第二份副本。在这种情况下,碎片的两个副本已经分开,并且如果没有完全重新索引的话,将很难(如果不是不可能)重新对齐它们。更糟糕的是,对于不了解群集的索引客户端(例如使用REST接口的客户端),此问题将完全透明-每次调用索引节点时,索引请求都将成功完成。搜索数据时,该问题仅会稍微引起注意:根据搜索请求命中的节点,结果将有所不同。
如何避免裂脑问题
elasticsearch配置具有出色的默认值。但是,elasticsearch团队无法事先知道您的特定情况的所有详细信息。因此,应更改某些配置参数以适合您的特定需求。可以在elasticsearch安装的config文件夹中的elasticsearch.yml文件中更改本文中提到的所有参数。
为了避免出现脑裂情况,我们可以查看的第一个参数是Discovery.zen.minimum_master_nodes。此参数确定要选举一个主机需要通信的节点数。默认值为1。经验法则是应将其设置为N / 2 + 1,其中N是群集中节点的数量。例如,在3节点群集的情况下,minimum_master_nodes应该设置为3/2 + 1 = 2(向下舍入为最接近的整数)。
让我们想象一下,如果我们将Discovery.zen.minimum_master_nodes设置为2(2/2 + 1),在上述情况下会发生什么。当两个节点之间的通信丢失时,节点1将失去其主控状态,而节点2将永远不会被选举为主节点。没有一个节点会接受索引或搜索请求,这使所有客户端的问题立即显而易见。此外,所有分片都不会处于不一致状态。
您可以调整的另一个参数是Discovery.zen.ping.timeout。默认值为3秒,它确定节点在假定节点发生故障之前将等待集群中其他节点响应的时间。在网络速度较慢的情况下,稍微增加默认值绝对是个好主意。此参数不仅可以满足更高的网络延迟,而且在节点由于过载而响应较慢的情况下也很有用。
两节点集群?
如果您认为在两节点集群的情况下将minimum_master_nodes参数设置为2是错误的(或至少是不直观的),则可能是正确的。在这种情况下,节点发生故障时,整个群集都会发生故障。尽管这消除了出现裂脑的可能性,但它也否定了弹性搜索的主要功能之一-通过使用副本分片内置的高可用性机制。
如果您刚开始使用Elasticsearch,建议您计划一个3节点集群。这样,您可以将minimum_master_nodes设置为2,从而限制了发生裂脑问题的机会,但仍保持了高可用性优势:如果配置了副本,则可以承受丢失节点但仍保持集群正常运行的风险。
但是,如果您已经在运行两个节点的Elasticsearch集群怎么办?您可以选择保留裂脑,同时保持高可用性,或者选择避免裂脑而失去高可用性。为了避免妥协,这种情况下最好的选择是将节点添加到群集。这听起来很激烈,但不一定如此。对于每个elasticsearch节点,您可以通过设置node.data参数来选择该节点是否保留数据。默认值为“ true”,这意味着默认情况下,每个elasticsearch节点也将是一个数据节点。
对于两节点群集,您可以向其添加一个新节点,该节点的node.data参数设置为“ false”。这意味着该节点将永远不会容纳任何分片,但可以将其选为主节点(默认行为)。由于新节点是一个无数据节点,因此可以在较便宜的硬件上启动它。现在您有了一个由三个节点组成的集群,可以安全地将minimum_master_nodes设置为2,避免出现裂脑现象,并且仍然可以在不丢失数据的情况下丢失节点。
结论
裂脑问题显然很难永久解决。在Elasticsearch的问题跟踪器中,仍然存在一个未解决的问题,描述了一个极端情况,即使使用了minimum_master_nodes参数的正确值,仍然会发生裂脑。elasticsearch小组目前正在努力更好地实现主选举算法,但是如果您已经在运行Elasticsearch集群,那么一定要意识到这一潜在问题。
尽快识别它也很重要。一种检测出问题的简单方法是为每个节点安排对/ _nodes端点响应的检查。该端点返回集群中所有节点的简短状态报告。如果两个节点报告的群集组成不同,则表明发生裂脑情况是一个明显的迹象。
ElasticSearch的Query和Filter区别
这个其实在官网也有一定的介绍:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/full-text-queries.html
相关性分数
默认情况下,Elasticsearch 按相关性分数对匹配的搜索结果进行排序,相关性分数衡量每个文档与查询的匹配程度。 相关性分数是一个正浮点数,在搜索 API 的 _score 元字段中返回。 _score 越高,文档越相关。虽然每种查询类型可以不同地计算相关性分数,但分数计算还取决于查询子句是在query 还是 filter中运行。
查询
在查询上下文中,查询子句回答“此文档与此查询子句匹配程度如何?”的问题。除了决定文档是否匹配外,查询子句还会在 _score 元字段中计算相关性分数。 只要将查询子句传递给查询参数,例如搜索 API 中的查询参数,查询上下文就会生效。
过滤
在过滤器上下文中,查询子句回答“此文档是否与此查询子句匹配?”的问题。答案是简单的 Yes 或 No —— 不计算分数。过滤上下文主要用于过滤结构化数据,例如 这个时间戳是否在 2015 年到 2016 年的范围内? 状态字段是否设置为“已发布”? Elasticsearch 会自动缓存常用的过滤器,以提高性能。 只要将查询子句传递给过滤器参数,例如 bool 查询中的 filter 或 must_not 参数、constant_score 查询中的过滤器参数或过滤器聚合,过滤器上下文就会生效。
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}
filter与query对比大解密
filter,仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响
query,会去计算每个document相对于搜索条件的相关度,并按照相关度进行排序
一般来说,如果你是在进行搜索,需要将最匹配搜索条件的数据先返回,那么用query;如果你只是要根据一些条件筛选出一部分数据,不关注其排序,那么用filter除非是你的这些搜索条件,你希望越符合这些搜索条件的document越排在前面返回,那么这些搜索条件要放在query中;如果你不希望一些搜索条件来影响你的document排序,那么就放在filter中即可
filter与query性能
- filter,不需要计算相关度分数,不需要按照相关度分数进行排序,同时还有内置的自动cache最常使用filter的数据
- query,相反,要计算相关度分数,按照分数进行排序,而且无法cache结果
filter缓存的秘密
(1)在倒排索引中查找搜索串,获取document list
举例
| word | doc1 | doc2 | doc3 |
|---|---|---|---|
| 2017-01-01 | * | ||
| 2017-02-02 | * | * | |
| 2017-03-03 | * | * | * |
如果对2017-02-02进行过滤的话,可以在倒排索引中搜到doc2,doc3
(2)为每个在倒排索引中搜索到的结果,构建一个bitset
使用找到的doc list,构建一个bitset,就是一个二进制的数组,数组每个元素都是0或1,用来标识一个doc对一个filter条件是否匹配,如果匹配就是1,不匹配就是0,以上面的例子来说,这个bitset即为[0, 1, 1]。doc1:不匹配这个filter的,doc2和do3:是匹配这个filter的,通过这个简单的数据结构去实现复杂的功能,可以节省内存空间,提升性能
(3)遍历每个过滤条件对应的bitset,优先从最稀疏的开始搜索,查找满足所有条件的document
一次性其实可以在一个search请求中,发出多个filter条件,每个filter条件都会对应一个bitset遍历每个filter条件对应的bitset,先从最稀疏的开始遍历,如下
[0, 0, 0, 1, 0, 0]:比较稀疏 ,[0, 1, 0, 1, 0, 1]比较密集。先遍历比较稀疏的bitset,就可以先过滤掉尽可能多的数据,遍历所有的bitset,找到匹配所有filter条件的doc。
请求:filter,postDate=2017-01-01,userID=1
postDate: [0, 0, 1, 1, 0, 0]
userID: [0, 1, 0, 1, 0, 1]
遍历完两个bitset之后,找到的匹配所有条件的doc,只剩下doc4了,就可以将document作为结果返回给client了
(4)caching bitset,跟踪query,在最近256个query中超过一定次数的过滤条件,缓存其bitset。对于小segment(<1000,或<3%),不缓存bitset。
-
跟踪query,在最近256个query中超过一定次数的过滤条件,缓存其bitset。对于小segment(<1000,或<3%),不缓存bitset。使用缓存,可以不用重新扫描倒排索引,不用反复生成bitset,可以大幅度提升性能。为什么小的segment不进行缓存:segment数据量很小,此时哪怕是扫描也很快;segment会在后台自动合并,小segment很快就会跟其他小segment合并成大segment,此时就缓存也没有什么意义,segment很快就消失了。
-
filter大部分情况下来说,在query之前执行,先尽量过滤掉尽可能多的数据
- query:是会计算doc对搜索条件的relevance score,还会根据这个score去排序
- filter:只是简单过滤出想要的数据,不计算relevance score,也不排序
-
以后只要是有相同的filter条件的,会直接来使用这个过滤条件对应的cached bitset
-
filter比query的好处就在于会caching,实际上并不是一个filter返回的完整的doc list数据结果。而是filter bitset缓存起来。下次不用扫描倒排索引了。
(5)filter大部分情况下来说,在query之前执行,先尽量过滤掉尽可能多的数据
- query:是会计算doc对搜索条件的relevance score,还会根据这个score去排序
- filter:只是简单过滤出想要的数据,不计算relevance score,也不排序
(6)如果document有新增或修改,那么cached bitset会被自动更新
(7)以后只要是有相同的filter条件的,会直接来使用这个过滤条件对应的cached bitset
ElasticSearch的深度分页
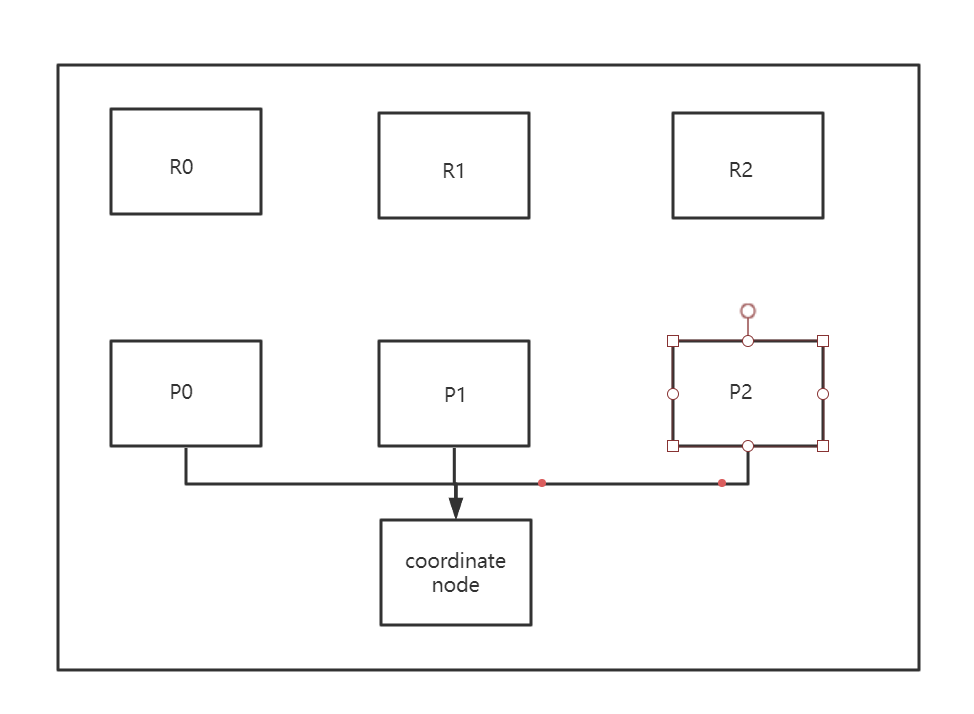
coordinate node节点
搜索和bulk等请求可能会涉及到多个节点上的不同shard里的数据,比如一个search请求,就需要两个阶段执行,首先第一个阶段就是一个coordinating node接收到这个客户端的search request。接着,coordinating node会将这个请求转发给存储相关数据的node,每个data node都会在自己本地执行这个请求操作,同时返回结果给coordinating node,接着coordinating node会将返回过来的所有的请求结果进行缩减和合并,合并为一个global结果。
每个node都是一个coordinating node。这就意味着如果一个node,将node.master,node.data,node.ingest全部设置为false,那么它就是一个纯粹的coordinating node,仅仅用于接收客户端的请求,同时进行请求的转发和合并。
分页查询的流程
以前项目中主要用的solr,当分页到几十万页的时候,就会要等2秒左右,有一定的延迟,ElasticSearch也有这样的问题。
常见深度分页方式 from+size
es 默认采用的分页方式是 from+ size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如from = 10000, size=10,首先请求可能会请求到不包含这个index的shard的node上去,这个node就是一个coordinate node,那么这个coordinate node就会将搜索请求转发到index的三个shard所在node上。 es 需要在各个分片上匹配排序并得到10010条有效数据,如果是3个shard的话,那么协调节点就会拿到30030节点,然后对这些数据进行排序,相关度分数 ,在结果集中取最后10条数据返回,这种方式类似于mongo的 skip + size。
除了效率上的问题,还有一个无法解决的问题是,es 目前支持最大的 skip 值是 max_result_window ,默认为 10000 。也就是当 from + size > max_result_window 时,es 将返回错误,我们项目中是将它设置10000000。
 但是这种数据量大的话,还是治标不治本,其实还可以通过scroll来实现
但是这种数据量大的话,还是治标不治本,其实还可以通过scroll来实现
分页方式 scroll
如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scoll滚动查询,一批一批的查,直到所有数据都查询完处理完。
使用scoll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来scoll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的。
采用基于_doc进行排序的方式,性能较高每次发送scroll请求,我们还需要指定一个scoll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了。
原理上是对某次查询生成一个游标 scroll_id , 后续的查询只需要根据这个游标去取数据,直到结果集中返回的 hits 字段为空,就表示遍历结束。scroll_id 的生成可以理解为建立了一个临时的历史快照,在此之后的增删改查等操作不会影响到这个快照的结果。
使用 curl 进行分页读取过程如下:
先获取第一个 scroll_id,url 参数包括 /index/_type/ 和 scroll,scroll 字段指定了scroll_id 的有效生存期,以分钟为单位,过期之后会被es 自动清理。如果文档不需要特定排序,可以指定按照文档创建的时间返回会使迭代更高效。
{
"query": {
"match_all": {}
},
"sort": [ "_doc" ],
"size": 3
}
返回的结果如下:
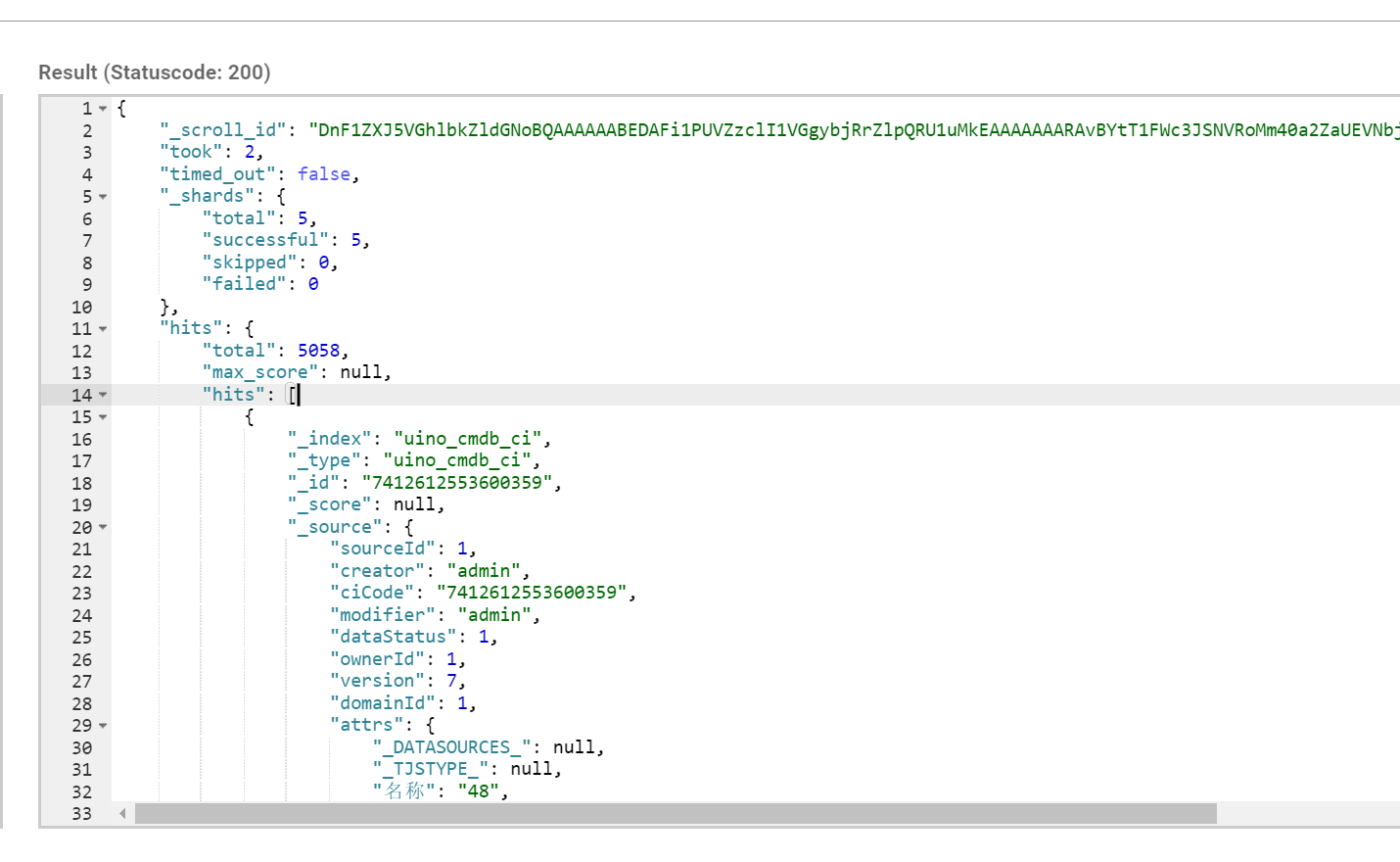
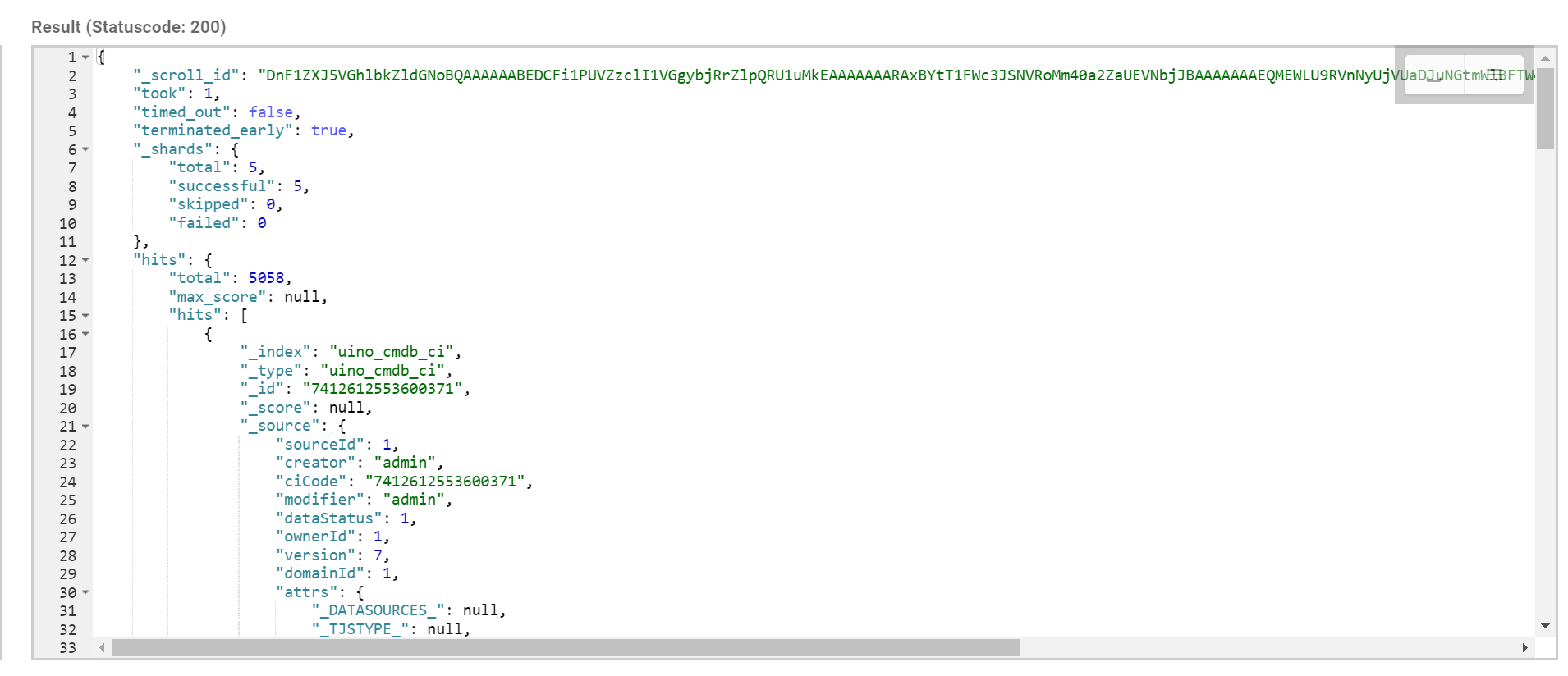
后续的文档读取上一次查询返回的scroll_id 来不断的取下一页,如果srcoll_id 的生存期很长,那么每次返回的 scroll_id 都是一样的,直到该 scroll_id 过期,才会返回一个新的 scroll_id。请求指定的 scroll_id 时就不需要 /index/_type 等信息了。每读取一页都会重新设置 scroll_id 的生存时间,所以这个时间只需要满足读取当前页就可以,不需要满足读取所有的数据的时间,1 分钟足以。
{
"scroll": "1m",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAABEDCFi1PUVZzclI1VGgybjRrZlpQRU1uMkEAAAAAAARAxBYtT1FWc3JSNVRoMm40a2ZaUEVNbjJBAAAAAAAEQMEWLU9RVnNyUjVUaDJuNGtmWlBFTW4yQQAAAAAABEDFFi1PUVZzclI1VGgybjRrZlpQRU1uMkEAAAAAAARAwxYtT1FWc3JSNVRoMm40a2ZaUEVNbjJB"
}
public List<T> getListByScroll(String scrollId) {
Scroll scroll = new Scroll(TimeValue.timeValueMinutes(3L));
SearchResponse searchResponse = null;
JSONArray rs = new JSONArray();
try {
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(scroll);
searchResponse = getClient().scroll(scrollRequest, RequestOptions.DEFAULT);
SearchHit[] searchHits = searchResponse.getHits().getHits();
for (SearchHit hit : searchHits) {
String res = hit.getSourceAsString();
JSONObject result = JSON.parseObject(res);
rs.add(result);
}
} catch (IOException e) {
log.error(e.getMessage(), e);
}
return rs.toJavaList(clazz);
}
返回结果
所有文档获取完毕之后,需要手动清理掉 scroll_id 。虽然es 会有自动清理机制,但是 srcoll_id 的存在会耗费大量的资源来保存一份当前查询结果集映像,并且会占用文件描述符。所以用完之后要及时清理。使用 es 提供的 CLEAR_API 来删除指定的 scroll_id
删掉指定的srcoll_id
删除掉所有索引上的 scroll_id

public Integer clearScroll(String scrollId) {
Integer flag = 1;
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
try {
getClient().clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
flag = 0;
}
return flag;
}
查询当前所有的scroll 状态
默认情况下ElasticSearch索引的refresh_interval为1秒,这意味着数据写1秒才就可以被搜索到。
每次索引refresh会产生一个新的 lucene 段,这会导致频繁的 segment merge 行为,对系统 CPU 和 IO 占用都比较高。
如果产品对于实时性要求不高,则可以降低刷新周期,如:index.refresh_interval: 120s。
但是这种特性对于功能测试来说比较麻烦:
- 因为实时性不能保证,所以每次插入测试数据之后,都需要sleep一段时间,才能进行测试。
- 因为实时性不能保证,及时通过sleep策略通过的case,也可能偶尔失败。
为了解决上述问题,需要提供ElasticSearch增删改数据之后数据立即刷新的策略。
源码
ElasticSearch 6.6.2
org.elasticsearch.action.support.WriteRequestBuilder#setRefreshPolicy接口如下:
default B setRefreshPolicy(RefreshPolicy refreshPolicy) {
request().setRefreshPolicy(refreshPolicy);
return (B) this;
}
枚举org.elasticsearch.action.support.WriteRequest.RefreshPolicy定义了三种策略:
NONE,
IMMEDIATE,
WAIT_UNTIL;
可知有以下三种刷新策略:
RefreshPolicy#IMMEDIATE:
请求向ElasticSearch提交了数据,立即进行数据刷新,然后再结束请求。
优点:实时性高、操作延时短。
缺点:资源消耗高。RefreshPolicy#WAIT_UNTIL:
请求向ElasticSearch提交了数据,等待数据完成刷新,然后再结束请求。
优点:实时性高、操作延时长。
缺点:资源消耗低。RefreshPolicy#NONE:
默认策略。
请求向ElasticSearch提交了数据,不关系数据是否已经完成刷新,直接结束请求。
优点:操作延时短、资源消耗低。
缺点:实时性低。
实现此接口的主要类如下:
- DeleteRequestBuilder
- IndexRequestBuilder
- UpdateRequestBuilder
- BulkRequestBuilder
ES的分词
1.什么是分析
分析是在文档被发送并加入倒排索引之前,Elasticsearch在其主体上进行的操作。一般会经历下面几个阶段。
字符过滤:使用字符串过滤器转变字符串。
文本切分为分词:将文本切分为单个或多个分词。
分词过滤:使用分词过滤器转变每个分词。
分词索引:将这些分词存储到索引中。
1、character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello --> hello),& --> and(I&you --> I and you)
2、tokenizer:分词,hello you and me --> hello, you, and, me
3、token filter:lowercase,stop word,synonymom,dogs --> dog,liked --> like,Tom --> tom,a/the/an --> 干掉,mother --> mom,small --> little
stop word 停用词: 了 的 呢。
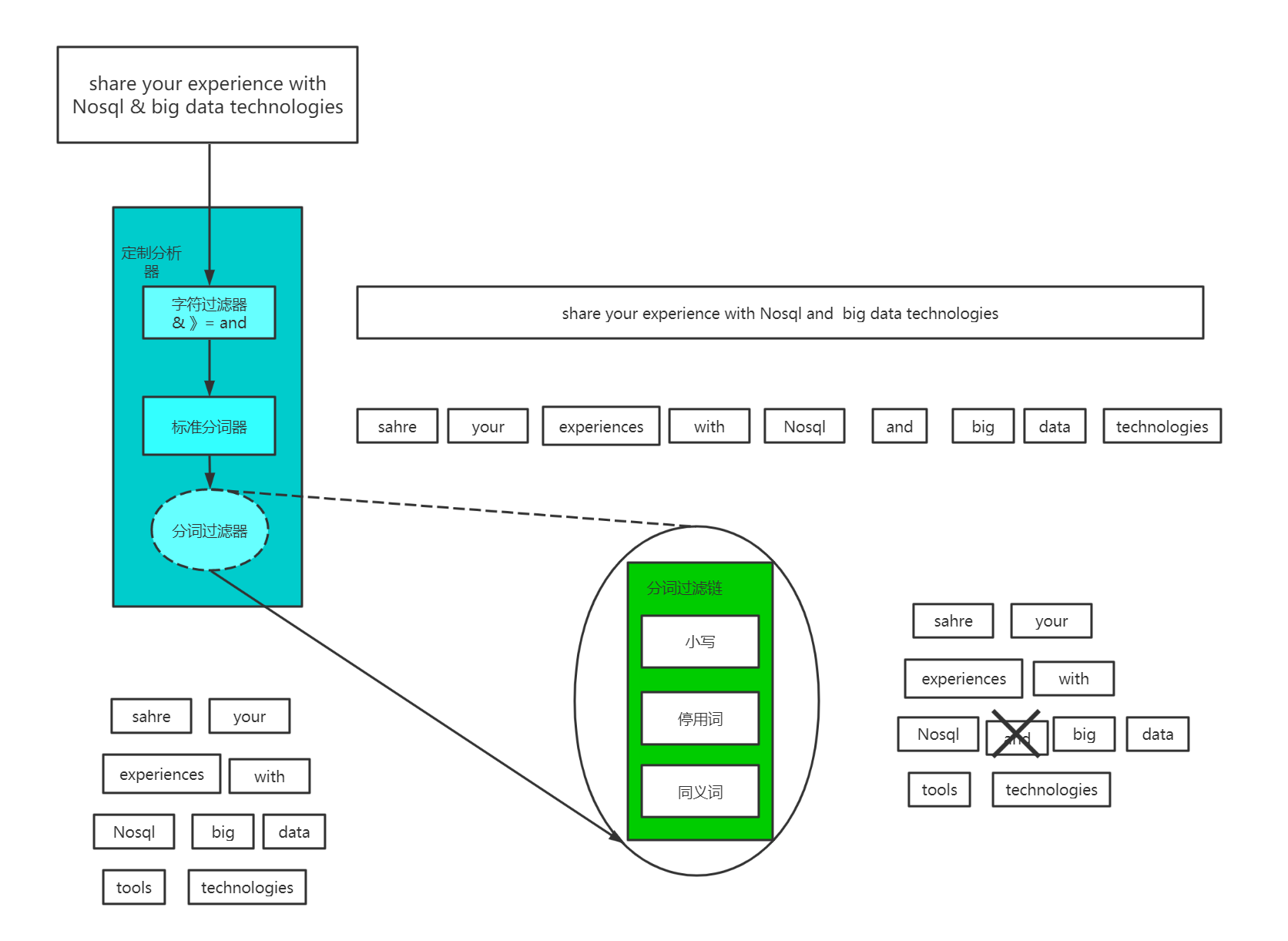
字符过滤
Elasticsearch首先运行字符过滤器。这些过滤器将特定的字符序列转变为其他的字符序列。这个可以用于将HTML从文本中剥离,或者是将任意数量的字符转化为
其他字符(也许是将“I love u 2”这种缩写的短消息纠正为“I love you too”)。
切分为分词
在应用了字符过滤器之后,文本需要被分割为可以操作的片段。Lucene自己不会对大块的字符串数据进行操作。相反,它处理的是被称为分词的数据。分词是从文本片段生成的,可能会产生任意数量(甚至是0)的分词。例如,在英文中一个通用的分词是标准分词器,它根据空格,换行和破折号等其他字符,将文本切割为分词。
分词过滤器
一旦文本块被转换为分词,Elasticsearch将会对每个分词运用分词过滤器(token filter)。这些分词过滤器可以将一个分词作为输人,然后根据需要进行修改,添加或者是删除。最为有用的和常用的分司过滤器是小写分词过滤器,它将输人的分词变为小写,确保在搜索词条“nosql”的时候,可以发现关于“NoSql”的聚会。分词可以经过多于1个的分词过滤器,每个过滤器对分词进行不同的操作,将数据塑造为最佳的形式,便于之后的索引。
2. 字符过滤
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/analysis-charfilters.html
2.1 HTML Strip Char Filter
请求:
POST /_analyze
{
"tokenizer": "keyword",
"char_filter": [ "html_strip" ],
"text": "<p>I'm so <b>happy</b>!</p>"
}
响应:
{
"tokens": [
{
"token": "\nI'm so happy!\n",
"start_offset": 0,
"end_offset": 32,
"type": "word",
"position": 0
}
]
}
2.2 Mapping Char Filter
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "keyword",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
"٠ => 0",
"١ => 1",
"٢ => 2",
"٣ => 3",
"٤ => 4",
"٥ => 5",
"٦ => 6",
"٧ => 7",
"٨ => 8",
"٩ => 9"
]
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "My license plate is ٢٥٠١٥"
}
响应:
{
"tokens": [
{
"token": "My license plate is 25015",
"start_offset": 0,
"end_offset": 25,
"type": "word",
"position": 0
}
]
}
2.3 Pattern Replace Char Filter
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "My credit card is 123-456-789"
}
响应:
{
"tokens": [
{
"token": "My",
"start_offset": 0,
"end_offset": 2,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "credit",
"start_offset": 3,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "card",
"start_offset": 10,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "is",
"start_offset": 15,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "123_456_789",
"start_offset": 18,
"end_offset": 29,
"type": "<NUM>",
"position": 4
}
]
}
3.分词
3.1 Word Oriented Tokenizers
3.1.1 Standard Tokenizer
请求:
POST _analyze
{
"tokenizer": "standard",
"text": "The 2 QUICKww Brown-Foxes "
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "<NUM>",
"position": 1
},
{
"token": "QUICKww",
"start_offset": 6,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "Brown",
"start_offset": 14,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "Foxes",
"start_offset": 20,
"end_offset": 25,
"type": "<ALPHANUM>",
"position": 4
}
]
}
自定义的时候
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "standard",
"max_token_length": 5
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "The 2 QUICKww Brown-Foxes "
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "<NUM>",
"position": 1
},
{
"token": "QUICK",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "ww",
"start_offset": 11,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "Brown",
"start_offset": 14,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "Foxes",
"start_offset": 20,
"end_offset": 25,
"type": "<ALPHANUM>",
"position": 5
}
]
}
注意这里的字符串长度超过5,就被分词了
3.1.2 Letter Tokenizer
字母分词
请求:
POST _analyze
{
"tokenizer": "letter",
"text": "The 2 Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "Brown",
"start_offset": 7,
"end_offset": 12,
"type": "word",
"position": 1
},
{
"token": "Foxes",
"start_offset": 13,
"end_offset": 18,
"type": "word",
"position": 2
},
{
"token": "dog",
"start_offset": 20,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "s",
"start_offset": 24,
"end_offset": 25,
"type": "word",
"position": 4
},
{
"token": "bone",
"start_offset": 26,
"end_offset": 30,
"type": "word",
"position": 5
}
]
}
3.1.3 Lowercase Tokenizer
他是基于上面的字母分词的
请求:
POST _analyze
{
"tokenizer": "lowercase",
"text": "The 2 Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "brown",
"start_offset": 7,
"end_offset": 12,
"type": "word",
"position": 1
},
{
"token": "foxes",
"start_offset": 13,
"end_offset": 18,
"type": "word",
"position": 2
},
{
"token": "dog",
"start_offset": 20,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "s",
"start_offset": 24,
"end_offset": 25,
"type": "word",
"position": 4
},
{
"token": "bone",
"start_offset": 26,
"end_offset": 30,
"type": "word",
"position": 5
}
]
}
3.1.4 Whitespace Tokenizer
请求:
POST _analyze
{
"tokenizer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
响应:
[ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog's, bone. ]
3.1.5 UAX URL Email Tokenizer
请求:
POST _analyze
{
"tokenizer": "uax_url_email",
"text": "Email me at john.smith@global-international.com"
}
响应:
[ Email, me, at, john.smith@global-international.com ]
3.2 Partial Word Tokenizers
里面的2个有点分词,就没有进行测试。
3.3 Structured Text Tokenizers
3.3.1 Keyword Tokenizer
请求:
POST _analyze
{
"tokenizer": "keyword",
"text": "New York"
}
响应:
[ New York ]
3.3.2 Pattern Tokenizer
请求:
POST _analyze
{
"tokenizer": "pattern",
"text": "The foo_bar_size's default is 5."
响应:
[ The, foo_bar_size, s, default, is, 5 ]
自定义的匹配
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "pattern",
"pattern": ","
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "comma,separated,values"
}
响应:
[ comma, separated, values ]
3.3.3 Simple Pattern Tokenizer
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "simple_pattern",
"pattern": "[0123456789]{3}"
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "fd-786-335-514-x"
}
响应:
[ 786, 335, 514 ]
3.3.4 Char Group Tokenizer
请求:
POST _analyze
{
"tokenizer": {
"type": "char_group",
"tokenize_on_chars": [
"whitespace",
"-",
"\n"
]
},
"text": "The QUICK brown-fox"
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "QUICK",
"start_offset": 4,
"end_offset": 9,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 10,
"end_offset": 15,
"type": "word",
"position": 2
},
{
"token": "fox",
"start_offset": 16,
"end_offset": 19,
"type": "word",
"position": 3
}
]
}
3.3.5 Simple Pattern Split Tokenizer
请求:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "simple_pattern_split",
"pattern": "_"
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "an_underscored_phrase"
}
响应:
[ an, underscored, phrase ]
3.3.6 Path Hierarchy Tokenizer
请求:
POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/one/two/three"
}
响应:
{
"tokens": [
{
"token": "/one",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 0
},
{
"token": "/one/two",
"start_offset": 0,
"end_offset": 8,
"type": "word",
"position": 0
},
{
"token": "/one/two/three",
"start_offset": 0,
"end_offset": 14,
"type": "word",
"position": 0
}
]
}
自定义:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "path_hierarchy",
"delimiter": "-",
"replacement": "/",
"skip": 2
}
}
}
}
}
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "one-two-three-four-five"
}
响应:
[ /three, /three/four, /three/four/five ]
4.Token Filters
这个比较简单,具体看官网 https://www.elastic.co/guide/en/elasticsearch/reference/7.4/analysis-tokenfilters.html
5 分词
官网一共有2中推荐,第一种就是自带的,当然也可以自己在上面进行扩展,另外一种就是自己自定义,但是类型要自定成type:custom
5.1 官方自带分词
一个分词器,很重要,将一段文本进行各种处理,最后处理好的结果才会拿去建立倒排索引。
官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/analysis-analyzers.html

停顿词:
_arabic_, _armenian_, _basque_, _bengali_, _brazilian_, _bulgarian_, _catalan_, _czech_, _danish_, _dutch_, _english_, _finnish_, _french_, _galician_, _german_, _greek_, _hindi_, _hungarian_, _indonesian_, _irish_, _italian_, _latvian_, _norwegian_, _persian_, _portuguese_, _romanian_, _russian_, _sorani_, _spanish_, _swedish_, _thai_, _turkish_.
下面对几大分词进行简单的测试。
5.1.1 Standard Analyzer
请求:
{
"analyzer":"standard",
"text":"hello world"
}
响应:
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]
}
token 实际存储的term 关键字
position 在此词条在原文本中的位置
start_offset/end_offset字符在原始字符串中的位置
5.1.2 Simple Analyzer
它只使用了小写转化分词器,这意味着在非字母处进行分词,并将分词自动转化为小写。
请求:
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "dog",
"start_offset": 25,
"end_offset": 28,
"type": "word",
"position": 4
},
{
"token": "s",
"start_offset": 29,
"end_offset": 30,
"type": "word",
"position": 5
},
{
"token": "bone",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 6
}
]
}
5.1.3 Whitespace Analyzer
只是根据空白将文本切分成若干分词。
请求:
{
"analyzer": "whitespace",
"text": "The 2 QUICK Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "The",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "word",
"position": 1
},
{
"token": "QUICK",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 2
},
{
"token": "Brown-Foxes",
"start_offset": 12,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "dog's",
"start_offset": 25,
"end_offset": 30,
"type": "word",
"position": 4
},
{
"token": "bone.",
"start_offset": 31,
"end_offset": 36,
"type": "word",
"position": 5
}
]
}
5.1.4 Stop Analyzer
只是在分词流中额外地过滤了停用词
请求:
{
"analyzer": "stop",
"text": "The 2 QUICK Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "dog",
"start_offset": 25,
"end_offset": 28,
"type": "word",
"position": 4
},
{
"token": "s",
"start_offset": 29,
"end_offset": 30,
"type": "word",
"position": 5
},
{
"token": "bone",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 6
}
]
}
如果是自己自定义的话:
PUT /stop_example
{
"settings": {
"analysis": {
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
}
},
"analyzer": {
"rebuilt_stop": {
"tokenizer": "lowercase",
"filter": [
"english_stop"
]
}
}
}
}
}
POST /stop_example/_analyze
{
"analyzer": "rebuilt_stop",
"text": "The 2 QUICK Brown-Foxes dog's bone."
}
响应:
{
"tokens": [
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "dog",
"start_offset": 25,
"end_offset": 28,
"type": "word",
"position": 4
},
{
"token": "s",
"start_offset": 29,
"end_offset": 30,
"type": "word",
"position": 5
},
{
"token": "bone",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 6
}
]
}
5.1.5 Keyword Analyzer
就是把整个字段当作一个单独的分词。
请求:
{
"analyzer": "keyword",
"text": "The 2 QUICK Brown-Foxes"
}
响应:
{
"tokens": [
{
"token": "The 2 QUICK Brown-Foxes",
"start_offset": 0,
"end_offset": 23,
"type": "word",
"position": 0
}
]
}
5.1.6 Pattern Analyzer
允许指定一个分词切分的模式。
请求:
PUT /mypattern
{
"settings": {
"analysis": {
"analyzer": {
"my_email_analyzer": {
"type": "pattern",
"pattern": "\\W|_",
"lowercase": true
}
}
}
}
}
POST /mypattern/_analyze
{
"analyzer": "my_email_analyzer",
"text": "John_Smith@foo-bar.com"
}
响应:
{
"tokens": [
{
"token": "john",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 0
},
{
"token": "smith",
"start_offset": 5,
"end_offset": 10,
"type": "word",
"position": 1
},
{
"token": "foo",
"start_offset": 11,
"end_offset": 14,
"type": "word",
"position": 2
},
{
"token": "bar",
"start_offset": 15,
"end_offset": 18,
"type": "word",
"position": 3
},
{
"token": "com",
"start_offset": 19,
"end_offset": 22,
"type": "word",
"position": 4
}
]
}
5.2 自定义分词
官网说明:自定义的分词中,必须要有一个分词器,其他2个可以有,也可以没有。
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and"]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": ["the", "a"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["html_strip", "&_to_and"],
"tokenizer": "standard",
"filter": ["lowercase", "my_stopwords"]
}
}
}
}
}
响应:
{
"analyzer": "my_analyzer",
"text": "tom&jerry are a friend in the house, <a>, HAHA!!"
}
1. 评分机制详解
1.1. 评分机制 TF\IDF
1.1.1 算法介绍
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度。
Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法。TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关。

举例:搜索请求:hello world
doc1 : hello you and me,and world is very good.
doc2 : hello,how are you
Inverse document frequency:搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关.
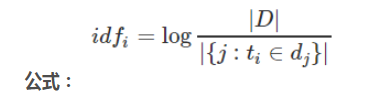

举例:搜索请求:hello world
doc1 : hello ,today is very good
doc2 : hi world ,how are you
整个index中1亿条数据。hello的document 1000个,有world的document 有100个。
doc2 更相关
Field-length norm:field长度,field越长,相关度越弱
举例:搜索请求:hello world
doc1 : {"title":"hello article","content ":"balabalabal 1万个"}
doc2 : {"title":"my article","content ":"balabalabal 1万个,world"}
1.1.2 _score是如何被计算出来的
GET /book/_search?explain=true
{
"query": {
"match": {
"description": "java程序员"
}
}
}
返回
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.137549,
"hits" : [
{
"_shard" : "[book][0]",
"_node" : "MDA45-r6SUGJ0ZyqyhTINA",
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
},
"_explanation" : {
"value" : 2.137549,
"description" : "sum of:",
"details" : [
{
"value" : 0.7936629,
"description" : "weight(description:java in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.7936629,
"description" : "score(freq=2.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.7675597,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 2.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" :