Jdk8新特性目录总结
Lambda体验
Lambda是一个匿名函数,可以理解为一段可以传递的代码。
Lambda表达式写法,代码如下:
借助Java 8的全新语法,上述 Runnable 接口的匿名内部类写法可以通过更简单的Lambda表达式达到相同的效果
* 从匿名类到Lambda表达式的转变
*/
@Test public void testLambdaHelloWorld() {
// 匿名类01
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Hello");
}
}).start();
// lambda01
new Thread(() -> System.out.println("Hello")).start();
}
这段代码和刚才的执行效果是完全一样的,可以在JDK 8或更高的编译级别下通过。从代码的语义中可以看出:我们启动了一个线程,而线程任务的内容以一种更加简洁的形式被指定。我们只需要将要执行的代码放到一个Lambda表达式中,不需要定义类,不需要创建对象。
Lambda的优点:简化匿名内部类的使用,语法更加简单。
Lambda的标准格式
Lambda省去面向对象的条条框框,Lambda的标准格式格式由3个部分组成:
(参数类型 参数名称) -> {
代码体;
}
无参数无返回值的Lambda
@Test
public void test(){
goSwimming(new Swimmable(){
@Override
public void swimming() {
System.out.println("我要游泳");
}
});
goSwimming( () -> {
System.out.println("我要游泳");
});
}
// 练习无参数无返回值的Lambda
public static void goSwimming(Swimmable s) {
s.swimming();
}
/**
* @author WGR
* @create 2020/3/23 -- 23:29
*/
public interface Swimmable {
public abstract void swimming();
}
有参数有返回值的Lambda
@Test
public void test1(){
goEatting( name ->{
System.out.println("吃"+name);
return 0 ;
});
}
public static Integer goEatting(Eatable e){
return e.eatting("饭");
}
/**
* @author WGR
* @create 2020/3/23 -- 23:29
*/
public interface Swimmable {
public abstract void swimming();
}
@Test
public void test3(){
ArrayList<Person> persons = new ArrayList<>();
persons.add(new Person("刘德华", 58, 174));
persons.add(new Person("张学友", 58, 176));
persons.add(new Person("刘德华", 54, 171));
persons.add(new Person("黎明", 53, 178));
Collections.sort(persons, (o1, o2) -> {
return o2.getAge() - o1.getAge(); // 降序
});
persons.forEach((t) -> {
System.out.println(t);

Lambda的实现原理
匿名内部类的class文件

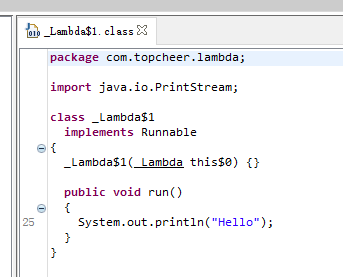
Lambda表达式的断点

关于这个方法 lambda$test$1 的命名:以lambda开头,因为是在test()函数里使用了lambda表达式,所以带有$test表示,因为是第二个,所以$01
如何调用这个方法呢?其实Lambda在运行的时候会生成一个内部类,为了验证是否生成内部类,可以在运行时加
上 -Djdk.internal.lambda.dumpProxyClasses ,加上这个参数后,运行时会将生成的内部类class码输出到一个文
件中。使用java命令如下:
java -Djdk.internal.lambda.dumpProxyClasses 要运行的包名.类名
小结 :
匿名内部类在编译的时候会一个class文件
Lambda在程序运行的时候形成一个类
1. 在类中新增一个方法,这个方法的方法体就是Lambda表达式中的代码
2. 还会形成一个匿名内部类,实现接口,重写抽象方法
3. 在接口的重写方法中会调用新生成的方法.
Lambda省略格式
/**
* lambda语法: 能省则省
*/
@SuppressWarnings("unused")
@Test public void testLambdaSyntax() {
// 语法
BinaryOperator<Integer> bo = (Integer x, Integer y) -> {
return x+y;
};
// 简化1: 由于类型推断(编译器javac根据上下文环境推断出类型), 可以省略参数的类型
bo = (x,y) -> {
return x+y;
};
// 简化2: 当Lambda体只有一条语句的时候可以省略return和大括号{}
bo = (x,y) -> x + y;
// 简化3: 当参数只有一个时, 可以省略小括号
Consumer<String> fun = args -> System.out.println(args);
// 简化4: 当参数个数为零时, 使用()即可
Runnable r1 = () -> System.out.println("Hello Lambda");
// 简化5: 方法引用(下个新特性)
Consumer<String> fun02 = System.out::println;
}
Lambda的前提条件
Lambda的语法非常简洁,但是Lambda表达式不是随便使用的,使用时有几个条件要特别注意:
1. 方法的参数或局部变量类型必须为接口才能使用Lambda
2. 接口中有且仅有一个抽象方法
/**
* @author WGR
* @create 2020/3/24 -- 0:11
*/
public class LambdaCondition {
public static void main(String[] args) {
// 方法的参数或局部变量类型必须为接口才能使用Lambda
test(() -> {
});
Flyable f = () -> {
System.out.println("我会飞啦");
};
}
public static void test(Flyable a) {
new Person() {
};
}
}
// 只有一个抽象方法的接口称为函数式接口,我们就能使用Lambda
@FunctionalInterface // 检测这个接口是不是只有一个抽象方法
interface Flyable {
// 接口中有且仅有一个抽象方法
public abstract void eat();
// public abstract void eat2();
}
JDK 8接口增强介绍
interface 接口名 {
静态常量;
抽象方法;
}
JDK 8对接口的增强,接口还可以有默认方法和静态方法
JDK 8的接口:
interface 接口名 {
静态常量;
抽象方法;
默认方法;
静态方法;
}
接口引入默认方法的背景
在JDK 8以前接口中只能有抽象方法。存在以下问题:
如果给接口新增抽象方法,所有实现类都必须重写这个抽象方法。不利于接口的扩展。
interface A {
public abstract void test1();
// 接口新增抽象方法,所有实现类都需要去重写这个方法,非常不利于接口的扩展
public abstract void test2();
}
class B implements A {
@Override
public void test1() {
System.out.println("BB test1");
}
// 接口新增抽象方法,所有实现类都需要去重写这个方法
@Override
public void test2() {
System.out.println("BB test2");
}
}
class C implements A {
@Override
public void test1() {
System.out.println("CC test1");
}
// 接口新增抽象方法,所有实现类都需要去重写这个方法
@Override
public void test2() {
System.out.println("CC test2");
}
}
以前假如一个接口有很多的抽象方法的时候,可以写一个装饰类
例如,JDK 8 时在Map接口中增加了 forEach 方法:
接口默认方法的使用
方式一:实现类直接调用接口默认方法
方式二:实现类重写接口默认方法
public class Demo02UseDefaultFunction {
public static void main(String[] args) {
BB bb = new BB();
bb.test01();
CC cc = new CC();
cc.test01();
}
}
interface AA {
public default void test01() {
System.out.println("我是接口AA默认方法");
}
}
// 默认方法使用方式一: 实现类可以直接使用
class BB implements AA {
}
// 默认方法使用方式二: 实现类可以重写接口默认方法
class CC implements AA {
@Override
public void test01() {
System.out.println("我是CC类重写的默认方法");
}
}
接口静态方法
为了方便接口扩展,JDK 8为接口新增了静态方法。
public class Demo03UseStaticFunction {
public static void main(String[] args) {
BBB bbb = new BBB();
// bbb.test01();
// 使用接口名.静态方法名();
AAA.test01();
}
}
interface AAA {
public static void test01() {
System.out.println("我是接口静态方法");
}
}
class BBB implements AAA {
// @Override
// public static void test01() {
// System.out.println("我是接口静态方法");
// }
}
接口默认方法和静态方法的区别
1. 默认方法通过实例调用,静态方法通过接口名调用。
2. 默认方法可以被继承,实现类可以直接使用接口默认方法,也可以重写接口默认方法。
3. 静态方法不能被继承,实现类不能重写接口静态方法,只能使用接口名调用。
如果方法要被继承或者重写就用默认方法,如果不需要被继承就使用静态方法
函数式接口介绍
它们主要在 java.util.function 包中。下面是最常用的几个接口。
1. Supplier接口
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
2. Consumer接口
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
}
3. Function接口
@FunctionalInterface
public interface Function<T, R> {
/**
* Applies this function to the given argument.
*
* @param t the function argument
* @return the function result
*/
R apply(T t);
}
4. Predicate接口
@FunctionalInterface
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
*
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
}
Supplier 接口
java.util.function.Supplier<T> 接口,它意味着"供给" , 对应的Lambda表达式需要“对外提供”一个符合泛型类型的对象数据。
/**
* @author WGR
* @create 2020/3/24 -- 21:46
*/
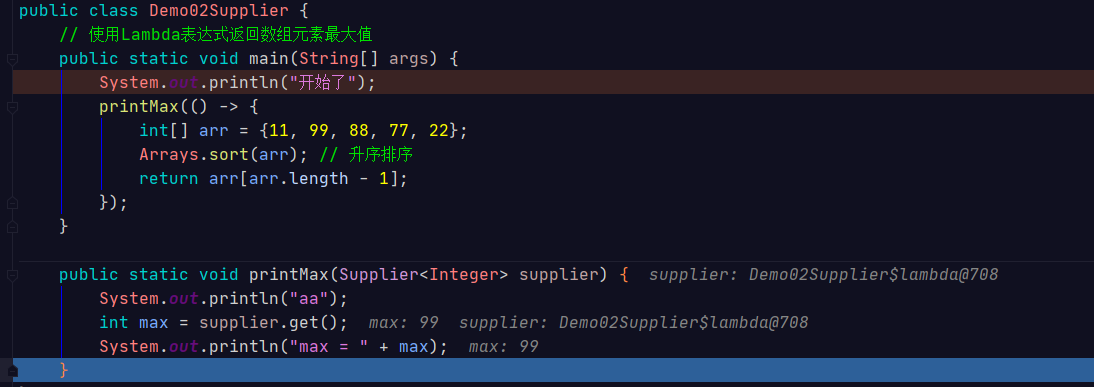
public class Demo02Supplier {
// 使用Lambda表达式返回数组元素最大值
public static void main(String[] args) {
System.out.println("开始了");
printMax(() -> {
int[] arr = {11, 99, 88, 77, 22};
Arrays.sort(arr); // 升序排序
return arr[arr.length - 1];
});
}
public static void printMax(Supplier<Integer> supplier) {
System.out.println("aa");
int max = supplier.get();
System.out.println("max = " + max);
}
}
Consumer 接口
java.util.function.Consumer<T> 接口则正好相反,它不是生产一个数据,而是消费一个数据,其数据类型由泛型参数决定。
public class Demo03Consumer {
public static void main(String[] args) {
printHello( str ->{
//HELLO JDK8
System.out.println(str.toUpperCase());
});
}
public static void printHello(Consumer<String> consumer) {
consumer.accept("hello jdk8");
}
}
public class Demo04ConsumerAndThen {
public static void main(String[] args) {
printHello( str1 ->{
System.out.println(str1.toUpperCase());
},str2 ->{
System.out.println(str2.toLowerCase());
});
}
public static void printHello(Consumer<String> c1, Consumer<String> c2) {
String str = "Hello Jdk8";
// default Consumer<T> andThen(Consumer<? super T> after) {
// Objects.requireNonNull(after);
// return (T t) -> { accept(t); after.accept(t); };
// }
c2.andThen(c1).accept(str);
}
}
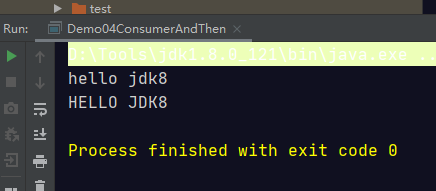
由于c2在前面,所以先操作c2再去操作c1,结果如图所示。
Function 接口
java.util.function.Function<T,R> 接口用来根据一个类型的数据得到另一个类型的数据,前者称为前置条件,后者称为后置条件。有参数有返回值。
public class Demo05Function {
public static void main(String[] args) {
getNumber( str ->{
return Integer.parseInt(str);
});
}
public static void getNumber(Function<String, Integer> function) {
String num = "20";
Integer apply = function.apply(num);
System.out.println(apply);
}
}
public class Demo06FunctionAndThen {
public static void main(String[] args) {
getNumber(str -> {
return Integer.parseInt(str);
}, num -> {
return num * 5;
});
}
public static void getNumber(Function<String, Integer> f1, Function<Integer, Integer> f2) {
String num = "20";
Integer integer = f1.andThen(f2).apply(num);
System.out.println(integer); //100
}
}
Predicate 接口
有时候我们需要对某种类型的数据进行判断,从而得到一个boolean值结果。这时可以使用java.util.function.Predicate<T> 接口。
public class Demo07Predicate {
public static void main(String[] args) {
isLongName( str -> {
return str.length() > 3;
});
}
public static void isLongName(Predicate<String> predicate) {
boolean test = predicate.test("新年快乐");
System.out.println(test);
}
}
public class Demo08Predicate_And_Or_Negate {
// 使用Lambda表达式判断一个字符串中即包含W,也包含H
// 使用Lambda表达式判断一个字符串中包含W或者包含H
// 使用Lambda表达式判断一个字符串中不包含W
public static void main(String[] args) {
test((String str) -> {
// 判断是否包含W
return str.contains("W");
}, (String str) -> {
// 判断是否包含H
return str.contains("H");
});
}
public static void test(Predicate<String> p1, Predicate<String> p2) {
String str = "Hello World";
boolean b = p1.and(p2).test(str);
if (b) {
System.out.println("即包含W,也包含H");
}
// 使用Lambda表达式判断一个字符串中包含W或者包含H
boolean b1 = p1.or(p2).test(str);
if (b1) {
System.out.println("包含W或者包含H");
}
// 使用Lambda表达式判断一个字符串中不包含W
boolean b2 = p1.negate().test("Hello W");
// negate相当于取反 !boolean
if (b2) {
System.out.println("不包含W");
}
}
}
方法引用的格式
符号表示 : ::
符号说明 : 双冒号为方法引用运算符,而它所在的表达式被称为方法引用。
应用场景 : 如果Lambda所要实现的方案 , 已经有其他方法存在相同方案,那么则可以使用方法引用。
方法引用在JDK 8中使用方式相当灵活,有以下几种形式:
1. instanceName::methodName 对象::实例方法
2. ClassName::staticMethodName 类名::静态方法
3. ClassName::methodName 类名::普通方法
4. ClassName::new 类名::new 调用的构造器
5. TypeName[]::new String[]::new 调用数组的构造器
对象名 ::实例方法
这是最常见的一种用法,与上例相同。如果一个类中已经存在了一个成员方法,则可以通过对象名引用成员方法,代码为:
// 对象::实例方法
@Test
public void test01() {
Date d = new Date();
Supplier<Long> getTime = d::getTime;
Long time = getTime.get();
System.out.println(time);
}
方法引用的注意事项
1. 被引用的方法,参数要和接口中抽象方法的参数一样
2. 当接口抽象方法有返回值时,被引用的方法也必须有返回值
类名 ::引用静态方法
由于在 java.lang.System 类中已经存在了静态方法 currentTimeMillis ,所以当我们需要通过Lambda来调用该
方法时,可以使用方法引用 , 写法是:
// 类名::静态方法
@Test
public void test02() {
//1585110320763
Supplier<Long> timeMillis = System::currentTimeMillis;
System.out.println(timeMillis.get());
}
类名 ::引用实例方法
Java面向对象中,类名只能调用静态方法,类名引用实例方法是有前提的,实际上是拿第一个参数作为方法的调用者。
// 类名::实例方法
@Test
public void test03() {
//1
Function<String, Integer> length = String::length;
System.out.println(length.apply("hello")); // 5
Function<String, Integer> length1 = s1 -> {
return s1.length();
};
//2
BiFunction<String, Integer, String> substring = String::substring;
String s = substring.apply("hello", 3); //lo
System.out.println(s);
BiFunction<String, Integer, String> substr = (String s1, Integer i1) -> {
return s1.substring(i1);
};
String hello = substr.apply("hello", 3);
System.out.println(hello);
}
类名 ::new引用构造器
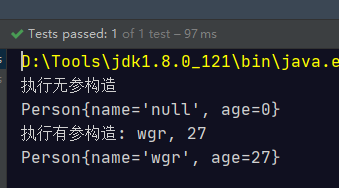
由于构造器的名称与类名完全一样。所以构造器引用使用 类名称 ::new 的格式表示。首先是一个简单的 Person 类:
// 类名::new引用类的构造器
@Test
public void test04() {
Supplier<Person> p1 = Person::new;
Person person = p1.get();
System.out.println(person);
BiFunction<String, Integer, Person> p2 = Person::new;
Person wgr = p2.apply("wgr", 27);
System.out.println(wgr);
}
数组 ::new 引用数组构造器
数组也是 Object 的子类对象,所以同样具有构造器,只是语法稍有不同。
// 类型[]::new
@Test
public void test05() {
Function<Integer, int[]> f1 = int[]::new;
int[] arr1 = f1.apply(10);
System.out.println(Arrays.toString(arr1));
}
Stream流式思想概述
注意:Stream和IO流(InputStream/OutputStream)没有任何关系,请暂时忘记对传统IO流的固有印象!
Stream流式思想类似于工厂车间的“生产流水线”,Stream流不是一种数据结构,不保存数据,而是对数据进行加工
处理。Stream可以看作是流水线上的一个工序。在流水线上,通过多个工序让一个原材料加工成一个商品。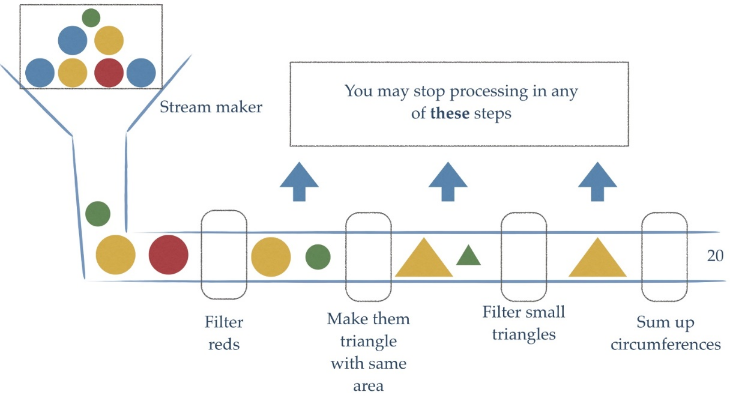

tream API 能让我们快速完成许多复杂的操作,如筛选、切片、映射、查找、去除重复,统计,匹配和归约。
小结
Stream是流式思想,相当于工厂的流水线,对集合中的数据进行加工处理
获取 Stream流的两种方式
方式1 : 根据Collection获取流
首先, java.util.Collection 接口中加入了default方法 stream 用来获取流,所以其所有实现类均可获取流。
public interface Collection {
default Stream<E> stream()
}
public class Demo04GetStream {
public static void main(String[] args) {
// 集合获取流
// Collection接口中的方法: default Stream<E> stream() 获取流
List<String> list = new ArrayList<>();
// ...
Stream<String> stream1 = list.stream();
Set<String> set = new HashSet<>();
// ...
Stream<String> stream2 = set.stream();
Vector<String> vector = new Vector<>();
// ...
Stream<String> stream3 = vector.stream();
}
}
public class Demo05GetStream {
public static void main(String[] args) {
// Map获取流
Map<String, String> map = new HashMap<>();
// ...
Stream<String> keyStream = map.keySet().stream();
Stream<String> valueStream = map.values().stream();
Stream<Map.Entry<String, String>> entryStream = map.entrySet().stream();
}
}
方式2 : Stream中的静态方法of获取流
由于数组对象不可能添加默认方法,所以 Stream 接口中提供了静态方法 of ,使用很简单:
public class Demo06GetStream {
public static void main(String[] args) {
// Stream中的静态方法: static Stream of(T... values)
Stream<String> stream6 = Stream.of("aa", "bb", "cc");
String[] arr = {"aa", "bb", "cc"};
Stream<String> stream7 = Stream.of(arr);
Integer[] arr2 = {11, 22, 33};
Stream<Integer> stream8 = Stream.of(arr2);
// 注意:基本数据类型的数组不行
int[] arr3 = {11, 22, 33};
Stream<int[]> stream9 = Stream.of(arr3);
}
}
Stream常用方法
Stream流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
终结方法 :返回值类型不再是 Stream 类型的方法,不再支持链式调用。
非终结方法 :返回值类型仍然是 Stream 类型的方法,支持链式调用。(除了终结方法外,其余方法均为非终结方法。)
Stream的3个注意事项:
1. Stream只能操作一次
2. Stream方法返回的是新的流
3. Stream不调用终结方法,中间的操作不会执行
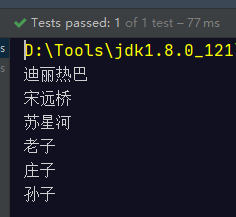
Stream 流的forEach方法
/**
* @author WGR
* @create 2020/3/26 -- 21:52
*/
public class StreamTest {
@Test
public void test(){
List<String> strings = Arrays.asList("迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");
strings.stream().forEach(System.out::print); // 对象 + 实例方法
}
}
Stream 流的count方法
Stream流提供 count 方法来统计其中的元素个数:
public class StreamTest {
@Test
public void test(){
List<String> strings = Arrays.asList("迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");
long count = strings.stream().count();
System.out.println(count); //6
}
}
Stream 流的filter方法
filter用于过滤数据,返回符合过滤条件的数据
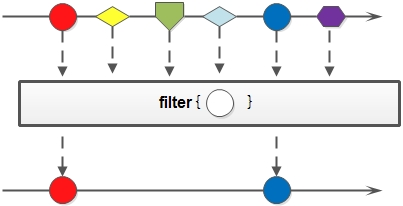
可以通过 filter 方法将一个流转换成另一个子集流。方法声明:
Stream<T> filter(Predicate<? super T> predicate);
该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
Stream流中的 filter 方法基本使用的代码如:
public class StreamTest {
@Test
public void test(){
List<String> strings = Arrays.asList("迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");
strings.stream().filter( s -> s.length() ==2 ).forEach(System.out::println);
}
}
在这里通过Lambda表达式来指定了筛选的条件:姓名长度为2个字。
Stream 流的limit方法
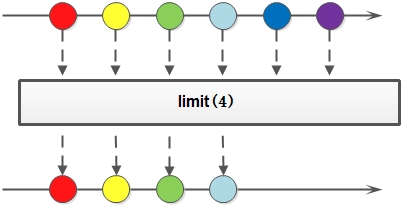
limit 方法可以对流进行截取,只取用前n个。方法签名:
Stream<T> limit(long maxSize);
参数是一个long型,如果集合当前长度大于参数则进行截取。否则不进行操作。基本使用:
public class StreamTest {
@Test
public void test(){
List<String> strings = Arrays.asList("迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");
strings.stream().limit(3).forEach(System.out::println);
}
}

Stream 流的skip方法
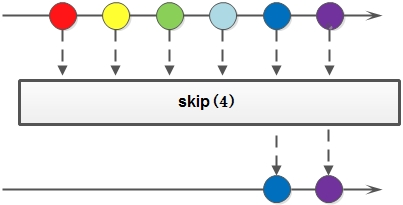
如果希望跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流:
Stream<T> skip(long n);
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:
public class StreamTest {
@Test
public void test(){
List<String> strings = Arrays.asList("迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");
strings.stream().skip(2).forEach(System.out::println);
}
}
Stream 流的map方法
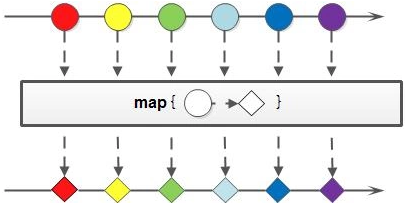
如果需要将流中的元素映射到另一个流中,可以使用 map 方法。方法签名:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
Stream流中的 map 方法基本使用的代码如:
@Test
public void test(){
Stream<String> stringStream = Stream.of("11", "22", "33");
stringStream.map(Integer::parseInt).forEach(System.out::println);
}
这段代码中, map 方法的参数通过方法引用,将字符串类型转换成为了int类型(并自动装箱为 Integer 类对象)。
Stream 流的sorted方法
如果需要将数据排序,可以使用 sorted 方法。方法签名:
Stream<T> sorted(); Stream<T> sorted(Comparator<? super T> comparator);
Stream流中的 sorted 方法基本使用的代码如:
@Test
public void test(){
Stream<String> stringStream = Stream.of( "22", "33","11");
stringStream.map(Integer::parseInt).sorted( (o1,o2) -> o1 -o2 ).forEach(System.out::println);
}
这段代码中, sorted 方法根据元素的自然顺序排序,也可以指定比较器排序。
Stream 流的distinct方法
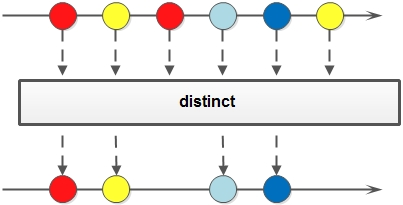
如果需要去除重复数据,可以使用 distinct 方法。方法签名:
Stream<T> distinct();
Stream流中的 distinct 方法基本使用的代码如:
@Test
public void test(){
Stream<String> stringStream = Stream.of( "11","22", "33","11");
stringStream.map(Integer::parseInt).distinct().forEach(System.out::println);
}
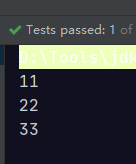
@Test
public void test(){
Stream.of(
new Person("刘德华", 58),
new Person("张学友", 56),
new Person("张学友", 56),
new Person("黎明", 52))
.distinct()
.forEach(System.out::println);
}
/**
* @author WGR
* @create 2020/3/26 -- 22:07
*/
public class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
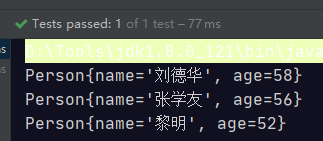
自定义类型是根据对象的hashCode和equals来去除重复元素的。
Stream 流的match方法
如果需要判断数据是否匹配指定的条件,可以使用 Match 相关方法。方法签名:
boolean allMatch(Predicate<? super T> predicate); boolean anyMatch(Predicate<? super T> predicate); boolean noneMatch(Predicate<? super T> predicate);
Stream流中的 Match 相关方法基本使用的代码如:
@Test
public void test(){
Stream<String> stringStream = Stream.of( "11","22", "33","11");
boolean b = stringStream.map(Integer::parseInt).allMatch(i -> i > 10);
System.out.println(b); //true 全部大于十
boolean b1 = stringStream.map(Integer::parseInt).anyMatch(i -> i < 10);
System.out.println(b1); // 没有比10小的 //false
boolean b3 = stringStream.map(Integer::parseInt).noneMatch(i -> i < 20);
System.out.println(b3); // 没有比20小的 //false
}
Stream 流的find方法
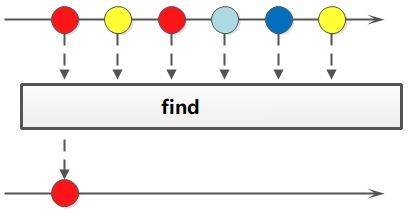
如果需要找到某些数据,可以使用 find 相关方法。方法签名:
Optional<T> findFirst(); Optional<T> findAny();
Stream流中的 find 相关方法基本使用的代码如:
@Test
public void testFind(){
Optional<Integer> first = Stream.of(5, 3, 6, 1).findFirst();
System.out.println("first = " + first.get()); //first = 5
Optional<Integer> any = Stream.of(5, 3, 6, 1).findAny();
System.out.println("any = " + any.get()); // any = 5
}
Stream 流的max和min方法
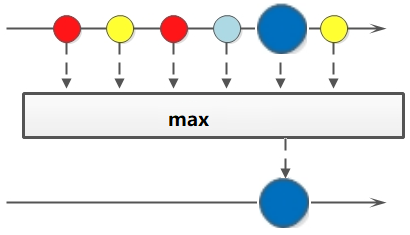
如果需要获取最大和最小值,可以使用 max 和 min 方法。方法签名:
Optional<T> max(Comparator<? super T> comparator); Optional<T> min(Comparator<? super T> comparator);
Stream流中的 max 和 min 相关方法基本使用的代码如:
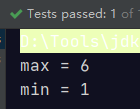
@Test
public void testFind(){
Optional<Integer> max = Stream.of(5, 3, 6, 1).max( (o1,o2) -> o1 - o2); // 取升序的最后一个
System.out.println("max = " + max.get());
Optional<Integer> min = Stream.of(5, 3, 6, 1).min( (o1,o2) -> o1 - o2); // 取升序的第一个
System.out.println("min = " + min.get());
}
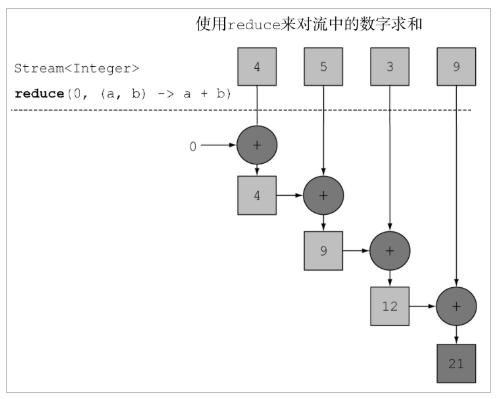
Stream 流的reduce方法

如果需要将所有数据归纳得到一个数据,可以使用 reduce 方法。方法签名:
T reduce(T identity, BinaryOperator<T> accumulator);
Stream流中的 reduce 相关方法基本使用的代码如:
@Test
public void testFind(){
Integer reduce = Stream.of(5, 3, 6, 1).reduce(0, Integer::sum);
System.out.println(reduce); //15
}
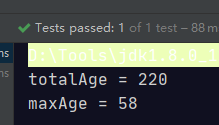
Stream 流的map和reduce组合使用
@Test
public void testFind(){
int totalAge = Stream.of(
new Person("刘德华", 58),
new Person("张学友", 56),
new Person("郭富城", 54),
new Person("黎明", 52))
.map(Person::getAge)
.reduce(0, Integer::sum);
System.out.println("totalAge = " + totalAge);
int maxAge = Stream.of(
new Person("刘德华", 58),
new Person("张学友", 56),
new Person("郭富城", 54),
new Person("黎明", 52))
.map(Person::getAge)
.reduce(0, Math::max);
System.out.println("maxAge = " + maxAge);
}
@Test
public void testFind(){
// 统计 数字2 出现的次数
int count = Stream.of(1, 2, 2, 1, 3, 2)
.map(i -> i == 2 ? 1 : 0)
.reduce(0, Integer::sum);
System.out.println("count = " + count);
}
Stream 流的mapToInt
如果需要将Stream中的Integer类型数据转成int类型,可以使用 mapToInt 方法。方法签名:
IntStream mapToInt(ToIntFunction<? super T> mapper);
@Test
public void testFind(){
// Integer占用的内存比int多,在Stream流操作中会自动装箱和拆箱
Stream<Integer> stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5});
IntStream intStream = stream.mapToInt(Integer::intValue);
int reduce = intStream
.filter(i -> i > 3)
.reduce(0, Integer::sum);
System.out.println(reduce);
}
Stream 流的concat方法
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat :
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
备注:这是一个静态方法,与 java.lang.String 当中的 concat 方法是不同的。
该方法的基本使用代码如:
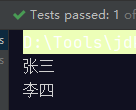
@Test
public void testFind(){
Stream<String> streamA = Stream.of("张三");
Stream<String> streamB = Stream.of("李四");
Stream<String> result = Stream.concat(streamA, streamB);
result.forEach(System.out::println);
}
Stream流中的结果到集合中
Stream流提供 collect 方法,其参数需要一个 java.util.stream.Collector<T,A, R> 接口对象来指定收集到哪
种集合中。java.util.stream.Collectors 类提供一些方法,可以作为 Collector`接口的实例:
public static <T> Collector<T, ?, List<T>> toList() :转换为 List 集合。 public static <T> Collector<T, ?, Set<T>> toSet() :转换为 Set 集合。
下面是这两个方法的基本使用代码:
// 将流中数据收集到集合中
@Test
public void testStreamToCollection() {
Stream<String> stream = Stream.of("aa", "bb", "cc");
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new));
}
Stream流中的结果到数组中
Stream提供 toArray 方法来将结果放到一个数组中,返回值类型是Object[]的:
@Test
public void testStreamToArray() {
Stream<String> stream = Stream.of("aa", "bb", "cc");
String[] strings = stream.toArray(String[]::new);
for (String str : strings) {
System.out.println(str);
}
}
对流中数据进行聚合计算
当我们使用 Stream流处理数据后,可以像数据库的聚合函数一样对某个字段进行操作。比如获取最大值,获取最小
值,求总和,平均值,统计数量。
@Test
public void test(){
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
//1. 最大值
Optional<Student> collect = studentStream.collect(Collectors.maxBy(Comparator.comparing(Student::getSocre)));
//studentStream.collect(Collectors.maxBy((o1,o2) ->( o1.getSocre() - o2.getSocre())));
System.out.println(collect.get()); //Student{name='迪丽热巴', age=56, socre=99}
}
@Test
public void test(){
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
//最小值
Optional<Student> collect = studentStream.collect(Collectors.minBy(Comparator.comparing(Student::getSocre)));
//studentStream.collect(Collectors.minBy((o1,o2) ->( o1.getSocre() - o2.getSocre())));
System.out.println(collect.get()); //Student{name='柳岩', age=52, socre=77}
}
@Test
public void test(){
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
// studentStream.map(Student::getSocre).reduce(Integer::sum);
Integer collect = studentStream.collect(Collectors.summingInt(Student::getSocre));
System.out.println(collect);
}
@Test
public void test(){
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
Double collect = studentStream.collect(Collectors.averagingDouble(Student::getSocre));
System.out.println(collect);
}
对流中数据进行分组
当我们使用Stream流处理数据后,可以根据某个属性将数据分组:
@Test
public void test(){
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
Map<Integer, List<Student>> collect = studentStream.collect(Collectors.groupingBy(Student::getAge));
collect.forEach( (k,v) -> {
System.out.println(k + "::" + v);
});
}

@Test
public void test(){
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 58),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 47));
Map<String, List<Student>> collect = studentStream.collect(Collectors.groupingBy(s -> s.getSocre() > 60 ? "及格" : "不及格"));
collect.forEach( (k,v) -> {
System.out.println(k + "::" + v);
});
}

对流中数据进行多级分组
@Test
public void test(){
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
Map<Integer, Map<String, List<Student>>> map =
studentStream.collect(Collectors.groupingBy(Student::getAge, Collectors.groupingBy(s -> {
if (s.getSocre() >= 90) {
return "优秀";
} else if (s.getSocre() >= 80 && s.getSocre() < 90) {
return "良好";
} else if (s.getSocre() >= 80 && s.getSocre() < 80) {
return "及格";
} else {
return "不及格";
}
})));
map.forEach((k, v) -> {
System.out.println(k + " == " + v);
});
}

对流中数据进行分区
Collectors.partitioningBy 会根据值是否为true,把集合分割为两个列表,一个true列表,一个false列表。
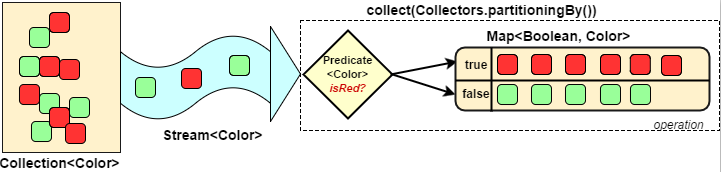
@Test
public void test(){
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
// partitioningBy会根据值是否为true,把集合分割为两个列表,一个true列表,一个false列表。
Map<Boolean, List<Student>> map = studentStream.collect(Collectors.partitioningBy(s ->
s.getSocre() > 90));
map.forEach((k, v) -> {
System.out.println(k + " == " + v);
});
}

对流中数据进行拼接
Collectors.joining 会根据指定的连接符,将所有元素连接成一个字符串。
@Test
public void test(){
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
String collect = studentStream
.map(Student::getName)
.collect(Collectors.joining(">_<", "^_^", "^v^"));
System.out.println(collect);
}
/**
* 测试flatMap
*/
@Test public void testFlatMap() {
List<String> strs = Arrays.asList("孙悟空", "猪八戒");
String collect = strs.stream()
.map(s -> {
char[] arr01 = s.toCharArray();
Character[] arr02 = new Character[arr01.length];
for (int i = 0; i < arr02.length; i++) {
arr02[i] = arr01[i];
}
return arr02;
})
.flatMap(Arrays::stream) // 扁平化
.map(String::valueOf)
.collect(Collectors.joining(","));
System.out.println(collect); // 孙,悟,空,猪,八,戒
}
/**
* SQL与Stream
*
*/
@Test public void testStreamCompSql() {
// select name, max(age) from person where name in ('孙悟空','猪八戒') and age is not null group by name order by name
LinkedHashMap<String, Optional<Integer>> map =
plist.stream()
.filter(p -> Arrays.asList("孙悟空","猪八戒").contains(p.getName())) // name in ('孙悟空','猪八戒')
.filter(p -> nonNull(p.getAge())) // age is not null
.sorted(comparing(Person::getName,nullsLast(naturalOrder()))) // order by name, 注意空值问题
//.collect(groupingBy(Person::getName) // Map<String, List<Person>>, 此处搜集到的还是人,但需要的是年龄,继续downstream搜集
.collect(groupingBy(Person::getName,LinkedHashMap::new,mapping(Person::getAge, maxBy(Integer::compare)))) // group by name
;
System.out.println(map); // {孙悟空=Optional[18], 猪八戒=Optional[28]}
// select * from person where age = (select max(age) from person) limit 1
Optional<Person> first = plist.stream().sorted((p1,p2) -> p2.getAge() - p1.getAge()).findFirst();
System.out.println(first.get()); // Person [name=沙悟净, age=48, salary=40000.0]
}
对比一下串行流和并行流的效率:
/**
* @author WGR
* @create 2020/3/31
*/
public class Demo07Parallel {
private static final int times = 500000000;
long start;
@Before
public void init() {
start = System.currentTimeMillis();
}
@After
public void destory() {
long end = System.currentTimeMillis();
System.out.println("消耗时间:" + (end - start));
}
// 并行的Stream : 消耗时间:431
@Test
public void testParallelStream() {
LongStream.rangeClosed(0, times).parallel().reduce(0, Long::sum);
}
// 串行的Stream : 消耗时间:623
@Test
public void testStream() {
// 得到5亿个数字,并求和
LongStream.rangeClosed(0, times).reduce(0, Long::sum);
}
}
我们可以看到parallelStream的效率是最高的。
Stream并行处理的过程会分而治之,也就是将一个大任务切分成多个小任务,这表示每个任务都是一个操作。
下面具体来做一下实验:
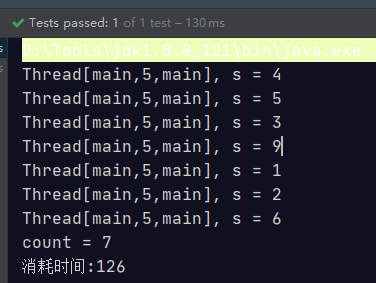
@Test
public void test0Serial() {
long count = Stream.of(4, 5, 3, 9, 1, 2, 6)
.filter(s -> {
System.out.println(Thread.currentThread() + ", s = " + s);
return true;
})
.count();
System.out.println("count = " + count);
}
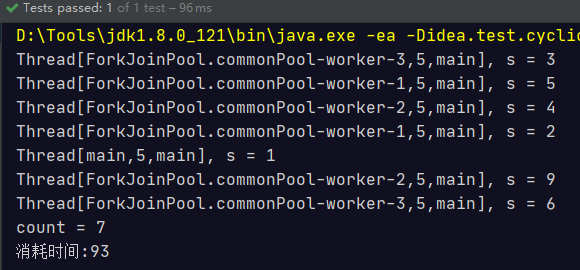
并行流:
@Test
public void test0Parallel() {
long count = Stream.of(4, 5, 3, 9, 1, 2, 6)
.parallel() // 将流转成并发流,Stream处理的时候将才去
.filter(s -> {
System.out.println(Thread.currentThread() + ", s = " + s);
return true;
})
.count();
System.out.println("count = " + count);
}
获取并行流有两种方式:
直接获取并行流: parallelStream()
将串行流转成并行流: parallel()
并行流的线程安全问题:
@Test
public void parallelStreamNotice() {
ArrayList<Integer> list = new ArrayList<>();
IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
list.add(i);
});
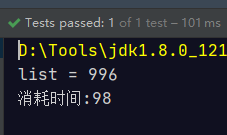
System.out.println("list = " + list.size());
}
@Test
public void parallelStreamNotice() {
ArrayList<Integer> list = new ArrayList<>();
// IntStream.rangeClosed(1, 1000)
// .parallel()
// .forEach(i -> {
// list.add(i);
// });
// System.out.println("list = " + list.size());
// 解决parallelStream线程安全问题方案一: 使用同步代码块
Object obj = new Object();
IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
synchronized (obj) {
list.add(i);
}
});
System.out.println("list = " + list.size());
}

// parallelStream线程安全问题
@Test
public void parallelStreamNotice() {
ArrayList<Integer> list = new ArrayList<>();
// IntStream.rangeClosed(1, 1000)
// .parallel()
// .forEach(i -> {
// list.add(i);
// });
// System.out.println("list = " + list.size());
// 解决parallelStream线程安全问题方案一: 使用同步代码块
// Object obj = new Object();
// IntStream.rangeClosed(1, 1000)
// .parallel()
// .forEach(i -> {
// synchronized (obj) {
// list.add(i);
// }
// });
// 解决parallelStream线程安全问题方案二: 使用线程安全的集合
Vector<Integer> v = new Vector();
List<Integer> synchronizedList = Collections.synchronizedList(list);
IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
synchronizedList.add(i);
});
System.out.println("list = " + synchronizedList.size());
}

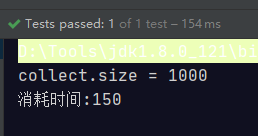
// parallelStream线程安全问题
@Test
public void parallelStreamNotice() {
List<Integer> collect = IntStream.rangeClosed(1, 1000)
.parallel()
.boxed()
.collect(Collectors.toList());
System.out.println("collect.size = " + collect.size());
}
旧版日期时间 API 存在的问题
1. 设计很差: 在java.util和java.sql的包中都有日期类,java.util.Date同时包含日期和时间,而java.sql.Date仅包含日期。此外用于格式化和解析的类在java.text包中定义。
2. 非线程安全:java.util.Date 是非线程安全的,所有的日期类都是可变的,这是Java日期类最大的问题之一。
3. 时区处理麻烦:日期类并不提供国际化,没有时区支持,因此Java引入了java.util.Calendar和java.util.TimeZone类,但他们同样存在上述所有的问题。
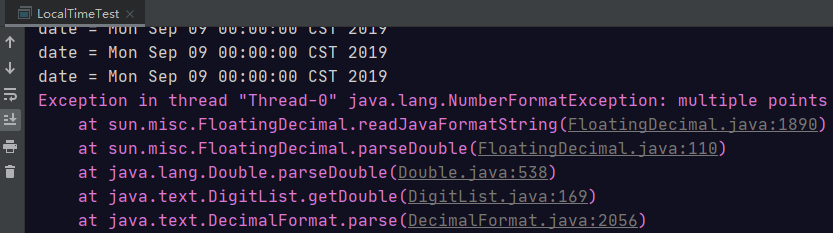
public static void main(String[] args) {
// 旧版日期时间 API 存在的问题
// 1.设计部合理
Date now = new Date(1985, 9, 23);
System.out.println(now);
// 2.时间格式化和解析是线程不安全的
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
for (int i = 0; i < 50; i++) {
new Thread(() -> {
try {
Date date = sdf.parse("2019-09-09");
System.out.println("date = " + date);
} catch (ParseException e) {
e.printStackTrace();
}
}).start();
}
}
/**
* 线程安全的 DateTimeFormatter
*/
@Test public void testDateFormatter() throws InterruptedException, ExecutionException {
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyyMMdd");
// 定义线程池, 任务, 提交100个解析任务并输出任务的执行情况
ExecutorService pool = Executors.newFixedThreadPool(10);
Callable<LocalDate> task = () -> LocalDate.parse("20190305",dtf);
List<Future<LocalDate>> results = new ArrayList<>();
IntStream.rangeClosed(0, 100).forEach(i -> results.add(pool.submit(task)));
for (Future<LocalDate> future : results) {
println(future.get());
}
}
新日期时间 API介绍
JDK 8中增加了一套全新的日期时间API,这套API设计合理,是线程安全的。新的日期及时间API位于 java.time 包
中,下面是一些关键类。
- LocalDate :表示日期,包含年月日,格式为 2019-10-16
- LocalTime :表示时间,包含时分秒,格式为 16:38:54.158549300
- LocalDateTime :表示日期时间,包含年月日,时分秒,格式为 2018-09-06T15:33:56.750
- DateTimeFormatter :日期时间格式化类。
- Instant:时间戳,表示一个特定的时间瞬间。
- Duration:用于计算2个时间(LocalTime,时分秒)的距离
- Period:用于计算2个日期(LocalDate,年月日)的距离
- ZonedDateTime :包含时区的时间
Java中使用的历法是ISO 8601日历系统,它是世界民用历法,也就是我们所说的公历。平年有365天,闰年是366天。此外Java 8还提供了4套其他历法,分别是:
- ThaiBuddhistDate :泰国佛教历
- MinguoDate :中华民国历
- JapaneseDate :日本历
- HijrahDate :伊斯兰历
JDK 8 的日期和时间类
LocalDate 、LocalTime、LocalDateTime类的实例是不可变的对象,分别表示使用 ISO -8601 日历系统的日期、时间、日期和时间。它们提供了简单的日期或时间,并不包含当前的时间信息,也不包含与时区相关的信息。
@Test
public void testLocalDate() {
// LocalDate: 表示日期,有年月日
LocalDate date = LocalDate.of(2020, 4, 1);
System.out.println("date = " + date);
LocalDate now = LocalDate.now();
System.out.println("now = " + now);
System.out.println(now.getYear());
System.out.println(now.getMonthValue());
System.out.println(now.getDayOfMonth());
}
@Test
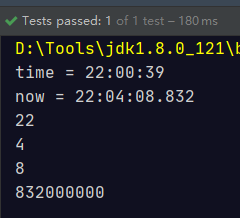
public void testLocalTime() {
// LocalTime: 表示时间,有时分秒
LocalTime time = LocalTime.of(22, 00, 39);
System.out.println("time = " + time);
LocalTime now = LocalTime.now();
System.out.println("now = " + now);
System.out.println(now.getHour());
System.out.println(now.getMinute());
System.out.println(now.getSecond());
System.out.println(now.getNano());
}
@Test
public void testLocalDateTime() {
// LocalDateTime: LocalDate + LocalTime 有年月日 时分秒
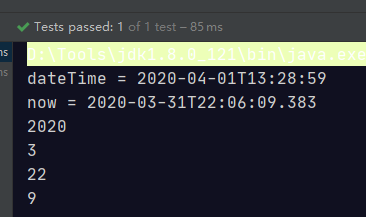
LocalDateTime dateTime = LocalDateTime.of(2020, 4, 1, 13, 28, 59);
System.out.println("dateTime = " + dateTime);
LocalDateTime now = LocalDateTime.now();
System.out.println("now = " + now);
System.out.println(now.getYear());
System.out.println(now.getMonthValue());
System.out.println(now.getHour());
System.out.println(now.getSecond());
}
对日期时间的修改,对已存在的LocalDate对象,创建它的修改版,最简单的方式是使用withAttribute方法。
withAttribute方法会创建对象的一个副本,并按照需要修改它的属性。以下所有的方法都返回了一个修改属性的对象,他们不会影响原来的对象。
// LocalDateTime 类: 对日期时间的修改
@Test
public void test05() {
LocalDateTime now = LocalDateTime.now();
System.out.println("now = " + now);
// 修改日期时间
LocalDateTime setYear = now.withYear(2078);
System.out.println("修改年份: " + setYear);
System.out.println("now == setYear: " + (now == setYear));
System.out.println("修改月份: " + now.withMonth(6));
System.out.println("修改小时: " + now.withHour(9));
System.out.println("修改分钟: " + now.withMinute(11));
System.out.println( now.withYear(2021).withMonth(1).withHour(11).withMinute(11));
// 再当前对象的基础上加上或减去指定的时间
LocalDateTime localDateTime = now.plusDays(5);
System.out.println("5天后: " + localDateTime);
System.out.println("now == localDateTime: " + (now == localDateTime));
System.out.println("10年后: " + now.plusYears(10));
System.out.println("20月后: " + now.plusMonths(20));
System.out.println("20年前: " + now.minusYears(20));
System.out.println("5月前: " + now.minusMonths(5));
System.out.println("100天前: " + now.minusDays(100));
}
now = 2020-03-31T22:10:02.710 修改年份: 2078-03-31T22:10:02.710 now == setYear: false 修改月份: 2020-06-30T22:10:02.710 修改小时: 2020-03-31T09:10:02.710 修改分钟: 2020-03-31T22:11:02.710 2021-01-31T11:11:02.710 5天后: 2020-04-05T22:10:02.710 now == localDateTime: false 10年后: 2030-03-31T22:10:02.710 20月后: 2021-11-30T22:10:02.710 20年前: 2000-03-31T22:10:02.710 5月前: 2019-10-31T22:10:02.710 100天前: 2019-12-22T22:10:02.710 Process finished with exit code 0
日期时间的比较
// 日期时间的比较
@Test
public void test06() {
// 在JDK8中,LocalDate类中使用isBefore()、isAfter()、equals()方法来比较两个日期,可直接进行比较。
LocalDate now = LocalDate.now();
LocalDate date = LocalDate.of(2020, 4, 1);
System.out.println(now.isBefore(date)); //true
System.out.println(now.isAfter(date)); // false
}
JDK 8 的时间格式化与解析
通过 java.time.format.DateTimeFormatter 类可以进行日期时间解析与格式化。
@Test
public void test04(){
LocalDateTime now = LocalDateTime.now();
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String format = now.format(dtf);
System.out.println(format); //2020-03-31 22:15:50
// 将字符串解析为日期时间
LocalDateTime parse = LocalDateTime.parse("1985-09-23 10:12:22", dtf);
System.out.println("parse = " + parse);
}
JDK 8 的 Instant 类
Instant 时间戳/时间线,内部保存了从1970年1月1日 00:00:00以来的秒和纳秒。
@Test
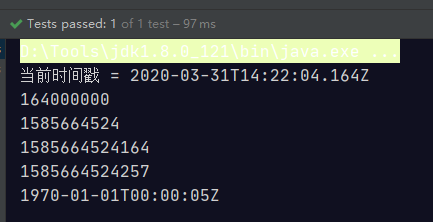
public void test07() {
Instant now = Instant.now();
System.out.println("当前时间戳 = " + now);
// 获取从1970年1月1日 00:00:00的秒
System.out.println(now.getNano());
System.out.println(now.getEpochSecond());
System.out.println(now.toEpochMilli());
System.out.println(System.currentTimeMillis());
Instant instant = Instant.ofEpochSecond(5);
System.out.println(instant);
}
JDK 8 的计算日期时间差类
Duration/Period类: 计算日期时间差。
1. Duration:用于计算2个时间(LocalTime,时分秒)的距离
2. Period:用于计算2个日期(LocalDate,年月日)的距离
// Duration/Period 类: 计算日期时间差
@Test
public void test08() {
// Duration计算时间的距离
LocalTime now = LocalTime.now();
LocalTime time = LocalTime.of(14, 15, 20);
Duration duration = Duration.between(time, now);
System.out.println("相差的天数:" + duration.toDays());
System.out.println("相差的小时数:" + duration.toHours());
System.out.println("相差的分钟数:" + duration.toMinutes());
// Period计算日期的距离
LocalDate nowDate = LocalDate.now();
LocalDate date = LocalDate.of(1998, 8, 8);
// 让后面的时间减去前面的时间
Period period = Period.between(date, nowDate);
System.out.println("相差的年:" + period.getYears());
System.out.println("相差的月:" + period.getMonths());
System.out.println("相差的天:" + period.getDays());
}
相差的天数:0 相差的小时数:8 相差的分钟数:492 相差的年:21 相差的月:7 相差的天:23
JDK 8 的时间校正器
有时我们可能需要获取例如:将日期调整到“下一个月的第一天”等操作。可以通过时间校正器来进行。
TemporalAdjuster : 时间校正器。
TemporalAdjusters : 该类通过静态方法提供了大量的常用TemporalAdjuster的实现。
/**
* TemporalAdjuster
*/
@Test public void testTemporalAdjuster() {
LocalDate ld = LocalDate.now();
println(ld.with(firstDayOfMonth())); // 2020-03-01 月初
println(ld.with(firstDayOfNextYear())); // 2021-01-01 年初
println(ld.with(lastDayOfMonth())); // 2020-03-31 月末
println(ld.with(lastDayOfYear())); // 2020-12-31 年末
println(ld.with(next(SUNDAY))); // 2020-04-05 下周日
println(ld.with(previousOrSame(MONDAY))); // 2020-03-30 前一个或相同的周一
}
private void println(Object obj) {
System.out.println(obj);
}
JDK 8 设置日期时间的时区
Java8 中加入了对时区的支持,LocalDate、LocalTime、LocalDateTime是不带时区的,带时区的日期时间类分别
为:ZonedDate、ZonedTime、ZonedDateTime。其中每个时区都对应着 ID,ID的格式为 “区域/城市” 。例如 :Asia/Shanghai 等。
ZoneId:该类中包含了所有的时区信息。
// 设置日期时间的时区
@Test
public void test10() {
// 1.获取所有的时区ID
// ZoneId.getAvailableZoneIds().forEach(System.out::println);
// 不带时间,获取计算机的当前时间
LocalDateTime now = LocalDateTime.now(); // 中国使用的东八区的时区.比标准时间早8个小时
System.out.println("now = " + now); //now = 2020-03-31T22:43:42.289
// 2.操作带时区的类
// now(Clock.systemUTC()): 创建世界标准时间
ZonedDateTime bz = ZonedDateTime.now(Clock.systemUTC());
System.out.println("bz = " + bz); //bz = 2020-03-31T14:43:42.290Z
// now(): 使用计算机的默认的时区,创建日期时间
ZonedDateTime now1 = ZonedDateTime.now();
System.out.println("now1 = " + now1); // now1 = 2020-03-31T22:43:42.290+08:00[Asia/Shanghai]
// 使用指定的时区创建日期时间
ZonedDateTime now2 = ZonedDateTime.now(ZoneId.of("America/Vancouver"));
System.out.println("now2 = " + now2); // now2 = 2020-03-31T07:43:42.293-07:00[America/Vancouver]
// 修改时区
// withZoneSameInstant: 即更改时区,也更改时间
ZonedDateTime withZoneSameInstant = now2.withZoneSameInstant(ZoneId.of("Asia/Shanghai"));
System.out.println("withZoneSameInstant = " + withZoneSameInstant); //withZoneSameInstant = 2020-03-31T22:43:42.293+08:00[Asia/Shanghai]
// withZoneSameLocal: 只更改时区,不更改时间
ZonedDateTime withZoneSameLocal = now2.withZoneSameLocal(ZoneId.of("Asia/Shanghai"));
System.out.println("withZoneSameLocal = " + withZoneSameLocal); // withZoneSameLocal = 2020-03-31T07:43:42.293+08:00[Asia/Shanghai]
}
重复注解的使用
自从Java 5中引入 注解 以来,注解开始变得非常流行,并在各个框架和项目中被广泛使用。不过注解有一个很大的限制是:在同一个地方不能多次使用同一个注解。JDK 8引入了重复注解的概念,允许在同一个地方多次使用同一个注解。在JDK 8中使用@Repeatable注解定义重复注解。
/**
* @author WGR
* @create 2020/4/1 -- 19:02
*/
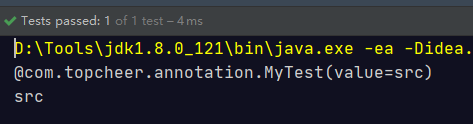
@MyTest("ta")
@MyTest("tb")
@MyTest("tc")
public class Test {
@org.junit.Test
@MyTest("ma")
@MyTest("mb")
public void test() {
}
public static void main(String[] args) throws NoSuchMethodException {
// 4.解析重复注解
// 获取类上的重复注解
// getAnnotationsByType是新增的API用户获取重复的注解
MyTest[] annotationsByType = Test.class.getAnnotationsByType(MyTest.class);
for (MyTest myTest : annotationsByType) {
System.out.println(myTest);
}
MyTests[] annotationsByType1 = Test.class.getAnnotationsByType(MyTests.class);
for ( MyTests myTests : annotationsByType1){
System.out.println(myTests);
}
System.out.println("----------");
// 获取方法上的重复注解
MyTest[] tests = Test.class.getMethod("test").getAnnotationsByType(MyTest.class);
for (MyTest test : tests) {
System.out.println(test);
}
MyTests[] test = Test.class.getMethod("test").getAnnotationsByType(MyTests.class);
for (MyTests t : test) {
System.out.println(t);
}
}
}
// 1.定义重复的注解容器注解
@Retention(RetentionPolicy.RUNTIME)
@interface MyTests { // 这是重复注解的容器
MyTest[] value();
}
// 2.定义一个可以重复的注解
@Retention(RetentionPolicy.RUNTIME)
@Repeatable(MyTests.class)
@interface MyTest {
String value();
}
@com.topcheer.annotation.MyTest(value=ta) @com.topcheer.annotation.MyTest(value=tb) @com.topcheer.annotation.MyTest(value=tc) @com.topcheer.annotation.MyTests(value=[@com.topcheer.annotation.MyTest(value=ta), @com.topcheer.annotation.MyTest(value=tb), @com.topcheer.annotation.MyTest(value=tc)]) ---------- @com.topcheer.annotation.MyTest(value=ma) @com.topcheer.annotation.MyTest(value=mb) @com.topcheer.annotation.MyTests(value=[@com.topcheer.annotation.MyTest(value=ma), @com.topcheer.annotation.MyTest(value=mb)])
类型注解的使用
JDK 8为@Target元注解新增了两种类型: TYPE_PARAMETER , TYPE_USE 。
TYPE_PARAMETER :表示该注解能写在类型参数的声明语句中。 类型参数声明如: <T> 、
TYPE_USE :表示注解可以再任何用到类型的地方使用。
@MyTest("src1")
public int show01(@MyTest("src")String src) {
@MyTest("123")int i = 10;
System.out.println(i + ": " + src);
return i;
}
/**
* 类型参数读取
*/
@org.junit.Test public void testTypeParameter() throws NoSuchMethodException, SecurityException {
Class<?> clazz = this.getClass();
Method method01 = clazz.getDeclaredMethod("show01", String.class);
AnnotatedType[] types = method01.getAnnotatedParameterTypes();
for (AnnotatedType at : types) {
MyTest anno = at.getAnnotation(MyTest.class);
System.out.println(anno);
System.out.println(anno.value());
}
}
在Java 8中,Base64编码已经成为Java类库的标准。
Java 8 内置了 Base64 编码的编码器和解码器。
Base64工具类提供了一套静态方法获取下面三种BASE64编解码器:
- 基本:输出被映射到一组字符A-Za-z0-9+/,编码不添加任何行标,输出的解码仅支持A-Za-z0-9+/。
- URL:输出映射到一组字符A-Za-z0-9+_,输出是URL和文件。
- MIME:输出隐射到MIME友好格式。输出每行不超过76字符,并且使用'\r'并跟随'\n'作为分割。编码输出最后没有行分割。
内嵌类
| 序号 | 内嵌类 & 描述 |
|---|---|
| 1 | static class Base64.Decoder
该类实现一个解码器用于,使用 Base64 编码来解码字节数据。 |
| 2 | static class Base64.Encoder
该类实现一个编码器,使用 Base64 编码来编码字节数据。 |
方法
| 序号 | 方法名 & 描述 |
|---|---|
| 1 | static Base64.Decoder getDecoder()
返回一个 Base64.Decoder ,解码使用基本型 base64 编码方案。 |
| 2 | static Base64.Encoder getEncoder()
返回一个 Base64.Encoder ,编码使用基本型 base64 编码方案。 |
| 3 | static Base64.Decoder getMimeDecoder()
返回一个 Base64.Decoder ,解码使用 MIME 型 base64 编码方案。 |
| 4 |
static Base64.Encoder getMimeEncoder() 返回一个 Base64.Encoder ,编码使用 MIME 型 base64 编码方案。 |
| 5 | static Base64.Encoder getMimeEncoder(int lineLength, byte[] lineSeparator)
返回一个 Base64.Encoder ,编码使用 MIME 型 base64 编码方案,可以通过参数指定每行的长度及行的分隔符。 |
| 6 | static Base64.Decoder getUrlDecoder()
返回一个 Base64.Decoder ,解码使用 URL 和文件名安全型 base64 编码方案。 |
| 7 | static Base64.Encoder getUrlEncoder()
返回一个 Base64.Encoder ,编码使用 URL 和文件名安全型 base64 编码方案。 |
注意:Base64 类的很多方法从 java.lang.Object 类继承。
import java.io.UnsupportedEncodingException;
import java.util.Base64;
import java.util.UUID;
/**
* @author WGR
* @create 2020/4/8 -- 20:53
*/
public class Java8Tester {
public static void main(String args[]){
try {
// 使用基本编码
String base64encodedString = Base64.getEncoder().encodeToString("runoob?java8".getBytes("utf-8"));
System.out.println("Base64 编码字符串 (基本) :" + base64encodedString);
// 解码
byte[] base64decodedBytes = Base64.getDecoder().decode(base64encodedString);
System.out.println("原始字符串: " + new String(base64decodedBytes, "utf-8"));
base64encodedString = Base64.getUrlEncoder().encodeToString("runoob?java8".getBytes("utf-8"));
System.out.println("Base64 编码字符串 (URL) :" + base64encodedString);
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < 10; ++i) {
stringBuilder.append(UUID.randomUUID().toString());
}
byte[] mimeBytes = stringBuilder.toString().getBytes("utf-8");
String mimeEncodedString = Base64.getMimeEncoder().encodeToString(mimeBytes);
System.out.println("Base64 编码字符串 (MIME) :" + mimeEncodedString);
}catch(UnsupportedEncodingException e){
System.out.println("Error :" + e.getMessage());
}
}
}
Base64 编码字符串 (基本) :cnVub29iP2phdmE4 原始字符串: runoob?java8 Base64 编码字符串 (URL) :cnVub29iP2phdmE4 Base64 编码字符串 (MIME) :NWY0ZGRjNzQtYzhlOS00MTY4LWFkNWYtNTlkZGVhMTBhNDNjYmJmNDJhY2ItOTA1Ni00MDNlLThh YTEtYTExMTFiOTU2Njg5OGQ3NWZmMDUtODBkMy00YjFhLTg3ODktN2I4N2FmMGVmZGRjNTZiZGFh YjgtMzllMS00OGQ0LTkyMWItNTEwNTVhYzNjNGQwN2IwMTFjYzktOWM0Zi00YzVjLWE4OWMtOGJk MDE3MGZlOWRkYTg2MDhmYTItOTU5Mi00Yjg4LWIxMDQtMzkxZDJmMGI3NjMwYmJkZWExYjgtOTJk ZS00OGI2LWE0MmYtNDcwNWMxZDM3MDU4ZTcyNjFkMjgtN2MwOC00ZDI4LTk3MDAtOTcxZWJlMDUx NmQ2ZjRkNzU0ZjEtMWVjMi00OGJmLTkxODYtN2ZiNzIwMjg4ZWU4MGVjZDAyNjctYzUxNi00YjNh LTgzZjYtMTViMTI2YjgwMmEw Process finished with exit code 0
Comparator提供的方法
/**
* @author WGR
* @create 2020/4/13 -- 16:12
*/
public class Person {
private String name;
private Integer age;
private Double salary;
public Person(String name, Integer age, Double salary) {
super();
this.name = name;
this.age = age;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", salary=" + salary + "]";
}
}
排序实现
/**
* @author WGR
* @create 2020/4/13 -- 16:14
*/
public class _Comparator {
List<Person> personList = new ArrayList<>();
@Before
public void before() {
personList.add(new Person("hepengju", 28, 20000.0));
personList.add(new Person("lisi", 44, 40000.0));
personList.add(new Person("wangwu", 55, 50000.0));
personList.add(new Person("zhaoliu", 66, 60000.0));
personList.add(new Person("zhangsan", 33, 33333.0));
personList.add(new Person("zhangsan", 23, 30000.0));
}
//按照名字排序
@Test
public void test() {
personList.stream().sorted(Comparator.comparing(Person::getName)).forEach(System.out::println);
// Person [name=hepengju, age=28, salary=20000.0]
// Person [name=lisi, age=44, salary=40000.0]
// Person [name=wangwu, age=55, salary=50000.0]
// Person [name=zhangsan, age=33, salary=33333.0]
// Person [name=zhangsan, age=23, salary=30000.0]
// Person [name=zhaoliu, age=66, salary=60000.0]
}
//按照名字排序降序
@Test
public void test4() {
personList.stream().sorted(Comparator.comparing(Person::getName).reversed()).forEach(System.out::println);
// Person [name=zhaoliu, age=66, salary=60000.0]
// Person [name=zhangsan, age=33, salary=33333.0]
// Person [name=zhangsan, age=23, salary=30000.0]
// Person [name=wangwu, age=55, salary=50000.0]
// Person [name=lisi, age=44, salary=40000.0]
// Person [name=hepengju, age=28, salary=20000.0]
}
// 先按照名字排序, 名字一样再按照年龄排序, 年龄一样再按照薪资排序
@Test
public void test2(){
personList.stream().sorted(Comparator.comparing(Person::getName).thenComparing(Person::getAge).thenComparing(Person::getSalary)).forEach(System.out::println);
// Person [name=hepengju, age=28, salary=20000.0]
// Person [name=lisi, age=44, salary=40000.0]
// Person [name=wangwu, age=55, salary=50000.0]
// Person [name=zhangsan, age=23, salary=30000.0]
// Person [name=zhangsan, age=33, salary=33333.0]
// Person [name=zhaoliu, age=66, salary=60000.0]
}
// 4. 处理所有空值问题(null都到最后)
@Test
public void test3(){
// personList.add(null);
personList.add(new Person(null, 33, 30000.0));
personList.add(new Person("zhangsan", null, 30000.0));
personList.add(new Person("zhangsan", 33, null));
personList.add(new Person(null, null, null));
personList.stream().sorted(Comparator.comparing(Person::getName,Comparator.nullsLast(Comparator.naturalOrder()))
.thenComparing(Person::getName,Comparator.nullsLast(Comparator.naturalOrder()))
.thenComparing(Person::getName,Comparator.nullsLast(Comparator.naturalOrder()))
).forEach(System.out::println);
// Person [name=hepengju, age=28, salary=20000.0]
// Person [name=lisi, age=44, salary=40000.0]
// Person [name=wangwu, age=55, salary=50000.0]
// Person [name=zhangsan, age=33, salary=33333.0]
// Person [name=zhangsan, age=23, salary=30000.0]
// Person [name=zhangsan, age=null, salary=30000.0]
// Person [name=zhangsan, age=33, salary=null]
// Person [name=zhaoliu, age=66, salary=60000.0]
// Person [name=null, age=33, salary=30000.0]
// Person [name=null, age=null, salary=null]
}
//jdk8 lambda排序
@Test
public void test5() {
personList.stream().sorted((p1,p2) -> p1.getName().compareTo(p2.getName()) ).forEach(System.out::println);
// Person [name=hepengju, age=28, salary=20000.0]
// Person [name=lisi, age=44, salary=40000.0]
// Person [name=wangwu, age=55, salary=50000.0]
// Person [name=zhangsan, age=33, salary=33333.0]
// Person [name=zhangsan, age=23, salary=30000.0]
// Person [name=zhaoliu, age=66, salary=60000.0]
}
@Test
public void test6() {
personList.stream().sorted((p1,p2) -> p1.getAge() - p2.getAge() ).forEach(System.out::println);
// Person [name=zhangsan, age=23, salary=30000.0]
// Person [name=hepengju, age=28, salary=20000.0]
// Person [name=zhangsan, age=33, salary=33333.0]
// Person [name=lisi, age=44, salary=40000.0]
// Person [name=wangwu, age=55, salary=50000.0]
// Person [name=zhaoliu, age=66, salary=60000.0]
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号