使用binlog+canal或binlake进行数据库的复制
前言
在进行冷热分离的时候,需要将数据实时的复制在历史数据库中,我们使用的是binlog+canal的思想,将每次数据库数据的变更转换成消息发出来,然后再操作这些消息达到数据复制的
在京东,实现同样功能的组件,叫binlake
接下来详细说下:
1.Binlog
mysql有多种日志,常见的有:
错误日志(ErrorLog)
更新日志(UpdateLog)
二进制日志(Binlog)
查询日志(QueryLog)
慢查询日志(SlowQueryLog)
Binlog可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,此外Binlog是事务安全型的。
Binlog一般作用是可以用于实时备份,与master/slave主从复制结合。
2.Canal
Canal是应阿里巴巴存在杭州和美国的双机房部署,存在跨机房同步的业务需求而提出的。
Canal作为阿里巴巴提供的开源的数据抽取项目,能够做到实时抽取,原理就是伪装成mysql从节点,读取mysql的binlog,生成消息,客户端订阅这些数据变更消息,处理并存储
github : https://github.com/alibaba/canal
3.Binlake
BinLake坚持技术和资源共享的原则,为京东商城各个业务部门提供统一的资源和技术服务,各个业务部门通过使用BinLake服务,避免的重复投入人力对同一项技术进行研究,避免了各个部门为了满足同一种业务需求而重复申请资源,进而避免的资源浪费,避免的各个业务部门重复投入人力和物力进行数据库日志采集、管理、分发、订阅系统的运维。
Binlake架构图:

1.BinLake总共包括三大服务组件:
1.1 Wave服务
Wave服务完成实际的数据库Binary Log的持续采集、管理和分发写入到下游的消息发布和订阅系统中。在BinLake集群中会存在N个Wave服务,这些Wave服务共同组成一个无状态集群。
1.2 Tower服务
Tower服务是整个BinLake的管理中心,提供BinLake接入服务的申请、完成Wave服务、数据源、接入应用的管理。当用户申请接入到BinLake中时,会登录到Tower服务提供的申请界面,填写申请接入BinLake的应用信息、数据源信息和Topic信息,Tower服务会按照用户提供的信息做如下判断,并完成用户接入申请,接入流程如下:

如果不同申请者申请相同数据源的数据采集,由Tower管理端依据其申请的采集规则(如指定表,指定库),如果规则相同,默认复用相同规则的Topic,也可强制生成新的Topic进行订阅。
1.3 Judge服务
Judge服务主要完成两个功能:Wave节点监控信息采集和loadBalance决策。
Wave节点监控信息采集:
通过在各个Wave服务节点部署agent采集各个Wave服务节点上的监控信息,包括:服务器的内存使用、系统负载、CPU负载、网络负载、JVM的堆内存使用、GC信息、每个Wave服务中的instance个数等,采集到的所有这些信息都会在后续的loadBalance中作为基础metics,参与到最终的loadBalance决策中。
loadBalance决策:
新应用接入到BinLake时,若需要采集的数据源在BinLake现有的数据源池中不存在,则需要针对于新的数据源在相应的Wave服务上创建对应的instance(数据源与instance是1对1的关系)。那么在创建instance的时候,就需要选在在哪个Wave服务上创建。这时就会请求Judge服务提供的loadBalance决策接口,若Judge服务中没有配置loadBalance plugin,则会返回一个随机的Wave服务节点的IP,那么就会在该随机的Wave服务上创建instance;若配置了loadBalance的plugin,则从Judge服务提供的loadBalance决策接口获得建议Wave服务节点,并从该节点创建新的instance。
2.BinLake依赖于两大外部服务:
2.1 ZooKeeper
BinLake使用zookeeper服务进行Wave无状态集群的管理、状态同步和消息通知等,包括:
【1】Instance的自动化创建与初始化
【2】Instance的HA
【3】数据源offset实时追踪
【4】binlog分发失败重试
【5】数据源切换自适配
【6】Tower元数据管理
【7】instance消息通知
2.2 消息发布与订阅系统
目前BinLake可以无缝集成JMQ和Kafka,从而进行消息的发布和订阅管理。instance采集到的BinLog Event会发布到JMQ或者Kafka的Topic中,实际的业务应用只需要订阅和消费对应的topic,既可以实时的获得BinLog Event,并在后续的业务逻辑中对获得的Binlog Event进行处理即可。
BinLake部署拓扑
在BinLake服务实际部署时,其拓扑结构如下:
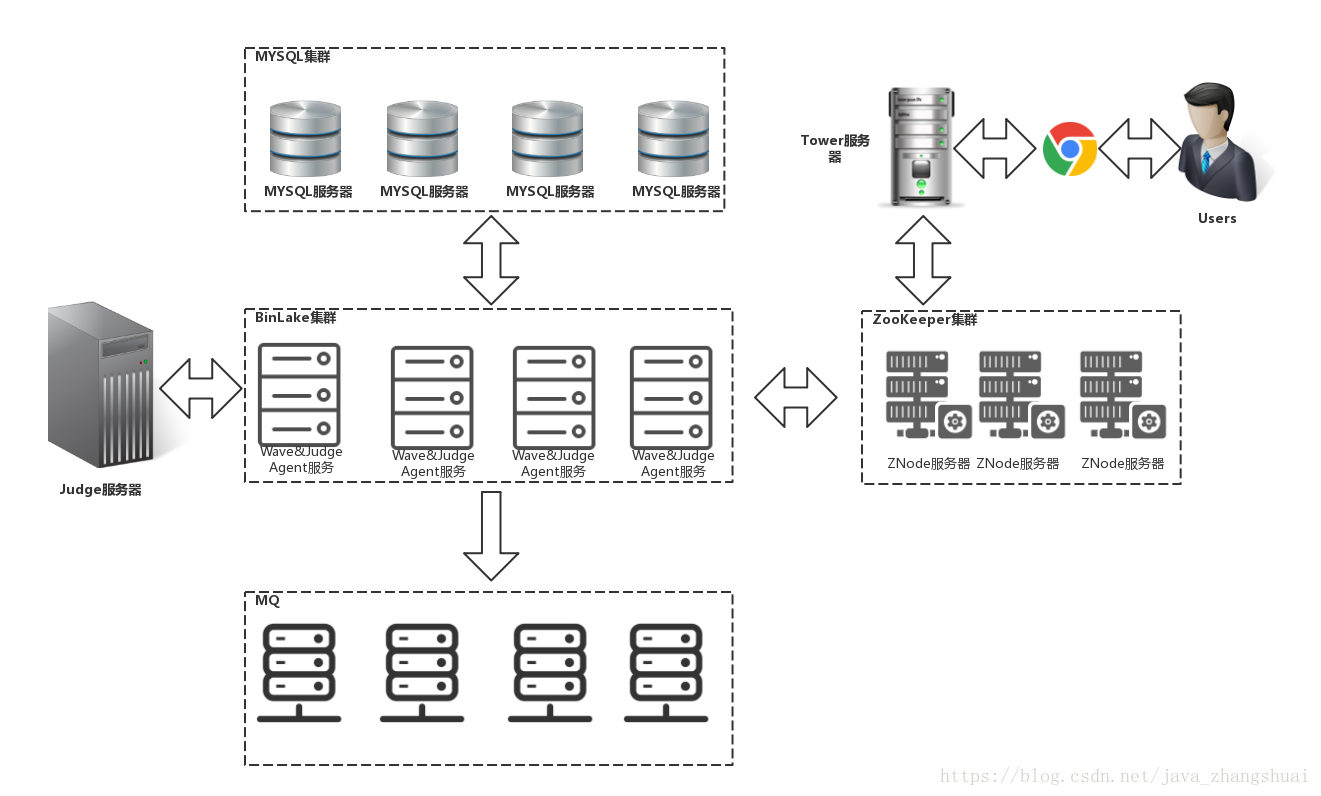
对上述部署拓扑图说明如下:
(1)一台Tower服务器:用于用户元数据、过滤规则、应用和订阅信息管理
(2)2N+1台ZooKeeper服务器:用于构建一个zookeeper集群,从而进行Wave集群管理和消息通知等
(3)一台Judge服务器:用户采集负载信息,并提供负载均衡建议决策。其中负载信息的采集是通过部署在各个Wave服务器上的Judge-Agent进程定期推送给Judge服务的
(4)N台Wave服务器:构成Wave集群。每台Wave服务器上部署两种服务:
【1】Wave服务:用于数据库binary log的采集并分发给下游MQ集群(Kafka或者JMQ)
【2】Judge-Agent服务:用于定期采集Wave服务器的系统以及Wave服务的负载和监控信息,并调用Judge服务提供的Restful接口,推送给Judge服务
(5)N台已经存在的线上MySQL服务器:不属于BinLake提供的服务器,是使用的已经存在的MySQL服务器,作为BinLake的数据源
(6)N台已经存在的MQ服务器:不属于BinLake提供的服务器,是已经存在的MQ服务器,处于Wave服务的下游,Wave服务会将采集到的Bianry Log Events分发给MQ集群中的Topic
Canal
Canal原理

原理相对比较简单:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
Canal架构

Canal集群

大致步骤:
- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
- 一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.
Canal数据流程

相关问题:
canal过滤数据的单位是数据库,可以过滤到表:
|
参数名字 |
参数说明 |
默认值 |
|
canal.instance.filter.regex (白名单) |
mysql 数据解析关注的表,Perl正则表达式. 多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
1. 所有表:.* or .*\\..* 5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔) |
.*\\..* |
|
canal.instance.filter.black.regex (黑名单) |
mysql 数据解析表的黑名单,表达式规则见白名单的规则 |
无 |
Canal单实例和多实例:instance对应于一个数据队列(1个server对应1..n个instance)(canal官方文档--简介)
Canal集群仅仅是为了可靠性:为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态。(针对同一主备)
(canal官方文档--简介)
Otter
Otter原理

原理描述:
1. 基于Canal开源产品,获取数据库增量日志数据。
2. 典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
3. 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
Otter架构

名词解释
- Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成
- Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成
- DataMediaPair:根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等
- DataMedia : 抽象的数据介质概念,可以理解为数据表/mq队列定义
- DataMediaSource : 抽象的数据介质源信息,补充描述DateMedia
- ColumnPair : 定义字段映射关系
- ColumnGroup : 定义字段映射组
- Node : 处理同步过程的工作节点,对应一个jvm
Otter分布式架构

由于单节点容易导致宕机时数据丢失,所以可以将多个Node绑定到同一Zookeeper集群,在宕机时重新选举工作节点,实现高可用。
Otter完整搭建图

Otter完整搭建需要otter数据库,zookeeper集群,Manager管理组件和Node工作组件。otter运行时数据保存在单独的otter数据库,zookeeper实现高可用,Node完成同步数据的工作。
Otter操作
安装完成后打开manager地址例如:http://172.16.0.3:8080,默认用户名密码是admin/admin

单向同步配置:
前提条件: 数据库表结构相同


 浙公网安备 33010602011771号
浙公网安备 33010602011771号