linux内核参数注释与优化
Linux性能优化之CPU优化(一)
前言
何为性能优化?个人认为,性能优化是为了提高应用程序或系统能力为目的。那么如何才能实现对应用程序的性能调优呢?这里很设计到很多的内容,包括Linux内核、CPU架构以及Linux内核对资源的分配以及管理,了解进程的创建过程等。这方面由于篇幅较多,所以我的文章就不过多介绍。接下来的几篇文章中,都是讲解如何发现应用程序故障根源为目标讲解,这也是每一个系统工程师应该具备的能力。废话不多说,我直接进入主题。
常用术语
延时:延时是描述操作之后用来等待返回结果的时间。在某些情况下,它可以指的是整个操作时间,等同于响应时间。
IOPS:每秒发生的输入/输出操作的次数,是数据传输的一个度量方法。对于磁盘的读写,IOPS指的是每秒读写的次数。
响应时间:一般操作完成的时间。包括用于等待和服务的时间,也包括用来返回结果的时间。
使用率:对于服务所请求的资源,使用率描述在所给定时间区间内资源的繁忙程度。对于春初资源来说,使用率指的就是所消耗的存储容量。
饱和度:指的就是某一资源无法满足服务的排队工作量。
吞吐量:评价工作秩序的速率,尤其是在数据传输方面,这个属于用于数据传输速度(字节/秒和比特/秒)。在某些情况下,吞吐量指的是操作的速度。
Linux内核功能
CPU调度级别:各种先进的CPU调度算法,非一直存储访问架构(NUMA);
I/O调度界别:I/O调度算法,包括deadline/anticipatory和完全公平队列(CFQ);
TCP网络阻塞:TCP拥堵算法,允许按需选择;
常见问题
进程、线程和任务之间的区别是什么?
进程通常定义为程序的执行。用以执行用户级别程序的环境。它包括内存地址空间、文件描述符、线程栈和寄存器。
线程是某一进程中单独运行的程序。也就是说线程在进程之中。
任务是程序完成的某一活动,可以使一个进程,也可以是一个线程。
参考连接:http://blog.chinaunix.net/uid-25100840-id-271078.html
什么是上下文切换?
执行一段程序代码,实现一个功能的过程介绍,当得到CPU的时候,相关的资源必须也已经就位,就是显卡、内存、GPS等,然后CPU开始执行。这里除了CPU以外所有的就构成了这个程序的执行环境,也就是我们所定义的程序上下文。当这个程序执行完或者分配给他的CPU执行时间用完了,那它就要被切换出去,等待下一次CPU的临幸。在被切换出去的最后一步工作就是保存程序上下文,因为这个是下次他被CPU临幸的运行环境,必须保存。
I/O密集型和CPU密集型工作负载之间的区别?
I/O密集型指的是系统的CPU耗能相对硬盘/内存的耗能能要好很多,此时,系统运作,大部分的状况是 CPU 在等 I/O(硬盘/内存)的读/写,此时CPU负载不高。CPU密集型指的是系统的硬盘/内存耗能相对CPU的耗能要好很多,此时,系统运作,大部分的状况是 CPU负载 100%,CPU 要读/写 I/O (硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU负载很高。一般而言CPU占用率相当高,大部份时间用来做计算、逻辑判断等CPU动作的程序。
应用程序性能技术
1.选择I/O尺寸
执行I/O的开销包括初始化缓冲区、系统调用、上下文切换、分配内核元数据、检查进程权限和限制、映射地址到设备、执行内核和驱动代码来执行I/O,以及在最后释放元数据和缓冲区。增加I/O尺寸是应用程序提高吞吐量的常用策略。
2.缓存
操作系统用缓存提高文件系统的读性能和内存的分配性能,应用程序使用缓存也处于类似的原因。将经常执行的操作结果保存在本地缓存中以备后用,而非总是执行开销较高的操作。
3.缓冲区
为了提高写操作性能,数据在送入下一层级之前会合并并放在缓冲区中。这样会增加写延时,因为第一次写入缓冲区后,在发送之前,还要等待后续的写入。
4. 并发和并行
并行:装在和开始执行多个可运行程序的能力(比如,同时接电话和吃饭)。为了利用多核处理器系统的优势,应用程序需要在同一时间运行在多颗CPU上,这种方式称为并行。应用程序通过多进程或多线程实现。
并发:有处理多个任务的能力,不一定要同时。比如,接完电话在去吃饭,存在资源抢占;
同步原语:同步原语监管内存的访问,当不允许访问时,就会引起等待时间(延时)。常见三种类型:
mutex锁:只有锁持有者才能操作,其他线程会阻塞并等待CPU;
自旋锁:自旋锁允许锁持有者操作,其他的需要自旋锁的线程会在CPU上循环自选,检查锁是否被释放。虽然这样可以提供低延时的访问,被阻塞的线程不会离开CPU,时刻准备着运行知道锁可用,但是线程自旋、等待也是对CPU资源的浪费。
读写锁:读/写锁通过允许多个读者或者只允许一个写者而没有读者,来保证数据的完整性。
自适应自旋锁:低延迟的访问而不浪费CPU资源,是mutex锁和自旋锁的混合。
5.绑定CPU
关于CPU性能分析
uptime:
系统负载,通过汇总正在运行的线程数和正在排队等待运行的线程数计算得出。分别反映1/5/15分钟以内的负载。现在的平均负载不仅用来表示CPU余量或者饱和度,也不能单从这个值推断出CPU或者磁盘负载。
vmstat:
虚拟内存统计信息命令。最后几列打印系统全局范围内的CPU使用状态,在第一列显示可运行进程数。如下所示:
|
1
2
3
4
|
[root@zbredis-30104 ~]# vmstatprocs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st0 0 0 14834208 158384 936512 0 0 0 0 1 3 0 0 100 0 0 |
提示:
r: 运行队列长度和正在运行的线程数;
b: 表示阻塞的进程数;
swpd: 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器;
si: 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so: 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上;
bi: 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒;
bo: 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整;
in: 每秒CPU的中断次数,包括时间中断;
cs: 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
st: cpu在虚拟化环境上在其他租户上的开销;
mpstat:
多处理器统计信息工具,能够报告每个CPU的统计信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
[root@zbredis-30104 ~]# mpstat -P ALL 1Linux 2.6.32-573.el6.x86_64 (zbredis-30104) 09/14/2017 _x86_64_ (12 CPU)03:14:03 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle03:14:04 PM all 0.00 0.00 0.08 0.00 0.00 0.00 0.00 0.00 99.9203:14:04 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 6 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 7 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 8 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 9 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:14:04 PM 11 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 |
提示:
irq: 硬件中断CPU用量;
sofr: 软件中断CPU用量;
steal: 耗费在服务其他租户的时间;
guest: 花在访客虚拟机的时间;
重要关注列有%user/%sys/%idle。显示了每个CPU的用量以及用户态和内核态的时间比例。可以根据这些值查看那些跑到100%使用率(%user + %sys)的CPU,而其他CPU并未跑满可能是由单线程应用程序的负载或者设备中断映射造成。
sar:
系统活动报告器。用来观察当前的活动,以及配置用以归档和报告历史统计信息。基本上所有资源使用的信息,它都能够查看到。具体的参数说明如下所示:
-A: 所有报告的总和,类似"-bBdqrRSuvwWy -I SUM -I XALL -n ALL -u ALL -P ALL"参数一起使用;
-b: 显示I/O和传输速率的统计信息;
-B:显示分页状态;
-d:硬盘使用报告;
-r:内存和交换空间的使用统计;
-g:串口I/O的情况;
-b:缓冲区使用情况;
-a:文件读写情况;
-c:系统调用情况;
-n: 统计网络信息;
-q:报告队列长度和系统平均负载;
-R:进程的活动情况;
-y:终端设备活动情况;
-w:系统交换活动;
-x { pid | SELF | ALL }:报告指定进程ID的统计信息,SELF关键字是sar进程本身的统计,ALL关键字是所有系统进程的统计;
常用参数组合:
查看CPU:
整体CPU统计— sar -u 3 2,表示采样时间为3秒,采样次数为2次;
各个CPU统计— sar -P ALL 1 1,表示采样时间为1秒,次数为1次;
1. 若 %iowait 的值过高,表示硬盘存在I/O瓶颈;
2. 若 %idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量;
3. 若 %idle 的值持续低于1,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU;
查看内存:
查看内存使用情况 - sar -r 1 2
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap);
%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比;
pidstat:主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。
cpu使用情况统计
执行 "pidstat -u" 与单独执行 "pidstat"
内存使用情况统计
pidstat -r -p PID 1
minflt/s: 每秒次缺页错误次数(minor page faults),次缺页错误次数意即虚拟内存地址映射成物理内存地址产生的page fault次数;
majflt/s: 每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page fault,一般在内存使用紧张时产生;
IO情况统计
pidstat -d 1 2
关于CPU方面的优化
1.编译器优化
2.调度优先级和调度类(设置nice值)
例如,nice -n 19 command
renice 更改已经运行进程的优先级;
chrt 命令显示并直接修改优先级和调度策略;
3.进程绑定(一个进程可以绑定在一个或者多个CPU上)
例如,taskset -pc 0-3 10790
4.独占CPU
5.BIOS调优
前言
不知道大家看完前面一章关于CPU优化,是否受到相应的启发呢?如果遇到任何问题,可以留言和一起探讨这方面的问题。接下来我们介绍一些关于内存方面的知识。内存管理软件包括虚拟内存系统、地址转换、交换、换页和分配。与性能密切相关的内容包括:内存释放、空闲链表、页扫描、交换、进程地址空间和内存分配器。在Linux中,空闲链表通常由分配器消耗,如内核的slab分配器和SLUB,以及用户级分配器(glibc,linux系统)libmalloc、libumem和mtmalloc。
- slab: 内核slab分配器管理特定大小的对象缓存,使他们能够被快速的回收利用,并且避免页分配的开销。适用于处理固定大小结构的内核内存分配。
- slub: 基于slab分配器。它主要是解决slab分配器带来的问题,其中包括移除对象队列,以及每个CPU缓存,把NUMA优化留给页分配器。
- glibc: 结合多种非配器策略的高效分配器,它基于分配请求的长度进行分配。较小的分配来自内存集合,包括用伙伴关系算法合并长度相近的单位。较大的分配用树高效地搜索空间。对于非常大的分配,会转到mmap()。
回收大多是从内核的slab分配器缓存释放内存。这些缓存包含slab大小的未使用内存块,以供充裕。内核页面换出守护进程管理利用换页释放内存。当主存中可用的空闲链表低于阈值时,页面换出守护进程会开始页扫描。页面换出守护进程被称作kswapd(),它扫描非活动和活动内存的LRU页列表以释放页面。它的激活基于空闲内存核两个提供滞后的阈值。一旦空闲内存达到最低阈值,kswapd运行于同步模式,按需求释放内存页。该最低阈值是可调的(vm.min_free_kbytes),并且其他阈值基于它按比例放大。
相关概念
- 主存:物理内存,描述了计算机的告诉数据存储区域,通常是动态随机访问内存;
- 虚拟内存: 抽象的主从概念,它几乎是无限的和非竞争性的;
- 常驻内存:当前处于主存中的内存;
- 匿名内存:无文件系统位置或者路径名的内存。它包括进程地址空间的工作数据,称作堆;
- 地址空间:内存上下文。每个进程和内核都有对应的虚拟地址空间;
- 页:操作系统和CPU使用的内存单位。它一直以来是4KB和8KB。现代的处理器允许多种页大小以支持更大的页面尺寸,以及更大的透明大页;
- 缺页:无效的内存访问;
- 换页:在主存与存储设备间交换页;
- 交换:指页面从主从转移到交换设备(迁移交换页);
- 交换(空间):存放换页的匿名数据和交换进程的磁盘空间;
进程地址空间是一段范围的虚拟页,由硬件和软件同事管理,按需映射到物理页。这些地址被划分为段以存放线程栈、进程可执行、库和堆。应用程序可执行段包括分离的文本和数据段。库也由分离的可执行文本和数据段组成。分别如下:
- 可执行文本:包括可执行的进程CPU指令。由文件系统中的二进制应用程序文本映射而来。它是只读的并带有执行的权限。
- 可执行数据:包括已初始化的变量,由二进制应用程序的数据段映射而来。有读写权限,因此这些变量在应用程序的运行过程中可以被修改。
- 堆:应用程序的临时工作内存并且是匿名内存。它按需增长并且用mollac()分配。
- 栈:运行中的线程栈,映射为读写。
对于内存而言,经常关注的信息如下:
- 页扫描:寻找连续的页扫描(超过10秒),它是内存压力的预兆。可以使用sar -B并查看pgscan列。
- 换页:换页是系统内存低的进一步征兆。可以使用vmstat 并查看si(换入) 和 so(换出)列。
- 可用内存:查看和关注buffer和cache值;
- OOM终结者:在系统日志/var/log/messages或者dmesg中查看,直接搜索"Out of memory";
- top/prstat:查看那些进程和用户是常驻物理内存和虚拟内存的最大使用者;
- stap/perf:内存分配的栈跟踪,确认内存使用的原因;
如何快速定位内存故障?
1. 首先应该检查饱和度(作为释放内存压力的衡量,页扫描、换页、交换和Linux OOM终结者牺牲进度的使用程度),因为持续饱和状态是内存问题的征兆。这些指标可以通过vmstat、sar、dmesg等操作系统工具轻易获得。对于配置了独立磁盘交换设备的系统,任何交换设备活动都是内存压力的征兆。
2. 使用率(使用内存和可用内存,物理内存和虚拟内存都应该关注)通常较难读取和解读。比如一个系统可能会报告只有几十兆内存可用,但事实上它有10GB的文件系统缓存在,需要时立刻被应用程序回收利用。虚拟内存使用,这应该也是我们关注的一个点。
3. 内存错误(Out of memory)一般都是由应用程序报告。
关于内存性能排查命令
vmstat
|
1
2
3
4
|
[root@zbredis-30104 ~]# vmstatprocs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st0 0 0 14834208 158384 936512 0 0 0 0 1 3 0 0 100 0 0 |
提示:
swpd:交换处的内存量;
free:空闲的可用内存;
buff: 用户缓冲缓存的内存;
cache: 用于页缓存的内存;
si: 换入的内存(换页);
so:换出的内存(换页);
如果si 和 so列一直非0,那么系统正存在内存压力并换页到交换设备或文件。经常使用参数为"vmstat 1 -Sm"和"vmstat -a 1";
sar
-B: 换页统计信息;
-H: 大页面统计信息
-r: 内存使用率
-R:内存统计信息
-S:交换空间统计信息
-W:交换统计信息
slabtop
通过slab分配器实时输出内核slab缓存使用情况;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[root@localhost ~]# slabtop -scActive / Total Objects (% used) : 297064 / 300262 (98.9%)Active / Total Slabs (% used) : 6638 / 6638 (100.0%)Active / Total Caches (% used) : 66 / 96 (68.8%)Active / Total Size (% used) : 80612.41K / 81749.09K (98.6%)Minimum / Average / Maximum Object : 0.01K / 0.27K / 8.00KOBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME 7648 7528 98% 2.00K 478 16 15296K kmalloc-204865142 65142 100% 0.19K 1551 42 12408K dentry17985 17985 100% 0.58K 327 55 10464K inode_cache7110 7110 100% 1.06K 237 30 7584K xfs_inode10880 10160 93% 0.50K 170 64 5440K kmalloc-51230564 30564 100% 0.11K 849 36 3396K sysfs_dir_cache |
输出包括顶部的汇总和slab列表。其中包括对象数量(OBJS)、多少是活动的(ACTIVE)、使用百分比(USE)、对象大小(OBJ SIZE,字节)和缓存大小(CACHE SIZE,字节)。
ps
可以列出包括内存使用统计信息在内的所有进程细节;
%MEM: 主存使用(物理内存、RSS)占总内存的百分比;
RSS:常驻集合大小;
VSZ: 虚拟内存大小;
提示:RSS显示主存使用,它也包括如系统库在内的映射共享段,可能会被几十个进程共享。如果你把RSS列求和,会发现她超过系统内存总和,这是由于重复计算了这部分共享内存。
pmap
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@localhost ~]# pmap -x 10961096: /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --log-error=/var/log/mysqld.log --pid-file=/var/run/mysqld/mysqld.pid --socket=/var/lib/mysql/mysql.sockAddress Kbytes RSS Dirty Mode Mapping0000000000400000 11960 3468 0 r-x-- mysqld00000000011ae000 668 240 172 r---- mysqld0000000001255000 1028 364 208 rw--- mysqld0000000001356000 340 312 312 rw--- [ anon ]0000000001887000 7508 7344 7344 rw--- [ anon ]...省略部分...00007ffc659e9000 132 72 72 rw--- [ stack ]00007ffc65ba1000 8 4 0 r-x-- [ anon ]ffffffffff600000 4 0 0 r-x-- [ anon ]---------------- ------- ------- -------total kB 961172 121756 116468 |
内存优化
首先关于内核优化的相关参数
vm.dirty_background_bytes:默认值为0, 触发pdflush后台回写的脏存储器量;
vm.dirty_background_ratio:默认值10, 触发pdflush后台回写脏系统存储器百分比;
vm.dirty_bytes:默认值为0,触发一个写入进程开始回写的脏存储器量;
vm.dirty_ratio:默认值为20,触发一个写入进程开始回写的脏系统存储器比例;
vm.dirty_expire_centisecs:默认值为3000,使用pdflush的脏存储器最小时间;
vm.dirty_writeback_centisecs:默认值为500,pdflush活跃时间间隔(0为停用);
vm.min_free_kbytes:默认值为 dynamic,设置期望的空闲存储器量(一些内核自动分配器能消耗它);
vm.overconmmit_memory:默认值为0,0表示利用探索法允许合理的国度分配;1表示一直国度分配;3表示禁止国度分配;
vm.swappiness:默认值为60,相对于页面高速缓存回收更倾向用交换释放存储器的程度;
vm.vfs_cache_pressure:默认值为100,表示回收高速缓存的目录和inode对象的程度。较低的值会保留更多;0意味着从不回收,容器导致存储器耗尽的情况;
提示:
vm.dirty_background_bytes和vm.dirty_background_ratio是互斥的,dirty_bytes 和 dirty_ratio 也是如此,仅能设置一个。vm.swappiness参数对性能会产生显著的影响,建议设置为0;因为应用程序内存能尽可能就地驻留。
最后说明,在现在内核发展过程之中,linux内存页面已经支持大页面和超大页面以及透明大页面等,可以根据自身环境进行适当的调整。红帽企业版 Linux 6 采用第二种方法,即使用超大页面。简单说,超大页面是 2MB 和 1GB 大小的内存块。2MB 使用的页表可管理多 GB 内存,而 1GB 页是 TB 内存的最佳选择。
Linux性能优化之磁盘优化(三)
前言
关于本章内容,设计的东西比较多。这里会有关于文件系统、磁盘、CPU等方面的知识,以及涉及到关于这方面的性能排查等。
术语
文件系统通过缓存和缓冲以及异步I/O等手段来缓和磁盘的延时对应用程序的影响。为了更详细的了解文件系统,以下就简单介绍一些相关术语:
- 文件系统:一种把数据组织成文件和目录的存储方式,提供了基于文件的存取接口,并通过文件权限控制访问。另外,一些表示设备、套接字和管道的特殊文件类型,以及包含文件访问时间戳的元数据。
- 文件系统缓存:主存(通常是DRAM) 的一块区域,用来缓存文件系统的内容,可能包含各种数据和元数据。
- 操作:文件系统的操作是对文件系统的请求,包括读、写、打开、关闭、创建以及其他操作。
- I/O:输入/输出。文件系统I/O有多种定义,这里仅指直接读写(执行I/O)的操作,包括读、写、状态统计、创建。I/O不包括打开文件和关闭文件。
- 逻辑I/O:由应用程序发给文件系统的I/O。
- 物理I/O:由文件系统直接发给磁盘的I/O。
- 吞吐量:当前应用程序和文件系统之间的数据传输率,单位是B/S。
- inode:一个索引节点时一种含有文件系统对象元数据的数据结构,其中有访问权限、时间戳以及数据指针。
- VFS:虚拟文件系统,一个为了抽象与支持不同文件系统类型的内核接口。
磁盘相关术语:
- 存储设备的模拟。在系统看来,这是一块物理磁盘,但是,它可能由多块磁盘组成。
- 传输总线:用来通信的物理总线,包括数据传输以及其他磁盘命令。
- 扇区:磁盘上的一个存储块,通常是512B的大小。
- I/O:对于磁盘,严格地说仅仅指读、写,而不包括其他磁盘命令。I/O至少由方向(读或写)、磁盘地址(位置)和大小(字节数)组成。
- 磁盘命令:除了读写之外,磁盘还会被指派执行其他非数据传输的命令(例如缓存写回)。
- 带宽:存储传输或者控制器能够达到的最大数据传输速率。
- I/O延时:一个I/O操作的执行时间,这个词在操作系统领域广泛使用,早已超出了设备层。
相关概念
文件系统延时
文件系统延时是文件系统性能一项主要的指标,指的是一个文件系统逻辑请求从开始到结束的时间。它包括消耗在文件系统、内核磁盘I/O子系统以及等待磁盘设备——物理I/O的时间。应用程序的线程通常在请求时阻塞,等地文件系统请求的结束。这种情况下,文件系统的延时与应用程序的性能直接和成正比关系。在某些情况下,应用程序并不受文件系统的直接影响,例如非阻塞I/O或者I/O由一个异步线程发起。
缓存
文件系统启动之后会使用主存(RAM)当缓存以提供性能。缓存大小随时间增长而操作系统的空余内存不断减小,当应用程序需要更多内存时,内核应该迅速从文件系统缓存中释放一些内存空间。文件系统用缓存(caching)提高读性能,而用缓冲(buffering)提高写性能。文件系统和块设备子系统一般使用多种类型的缓存。
随机I/O与顺序I/O
一连串的文件系统逻辑I/O,按照每个I/O的文件偏移量,可以分为随机I/O与顺序I/O。顺序I/O里每个I/O都开始于上一个I/O结束的地址。随机I/O则找不出I/O之间的关系,偏移量随机变化。随机的文件系统负载也包括存取随机的文件。由于存储设备的某些性能特征的缘故,文件系统一直以来在磁盘上顺序和连续的存放文件数据,以努力减小随机I/O的数目。当文件系统未能达到这个目标时,文件的摆放变得杂乱无章,顺序的逻辑I/O被分解成随机的物理I/O,这种情况被称为碎片化。
提示:关于文件系统更多内容,还请自行查阅相关理论。比如你还需要了解文件系统的预读、预取、写回缓存、同步写、裸I/O、直接I/O、内存映射文件、元数据等相关知识。
性能分析
具备背景知识是分析性能问题时需要了解的。比如硬件 cache;再比如操作系统内核。应用程序的行为细节往往是和这些东西互相牵扯的,这些底层的东西会以意想不到的方式影响应用程序的性能,比如某些程序无法充分利用 cache,从而导致性能下降。比如不必要地调用过多的系统调用,造成频繁的内核 / 用户切换等。如果想深入了解Linux系统,建议购买相关书籍进行系统的学习。下面我们介绍如何分析磁盘性能工具(其实准确来说,不只是磁盘):
iostat
汇总了单个磁盘的统计信息,为磁盘负载、使用率和饱和度提供了指标。默认显示一行系统总结信息,包括内核版本、主机名、日志、架构和CPU数量等,每个磁盘设备都占一行。
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@localhost ~]# iostatLinux 3.10.0-514.el7.x86_64 (localhost.localdomain) 2017年09月18日 _x86_64_ (1 CPU)avg-cpu: %user %nice %system %iowait %steal %idle 0.74 0.00 1.24 1.35 0.00 96.67Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtnsda 14.43 456.85 60.82 218580 29098scd0 0.02 0.09 0.00 44 0dm-0 13.65 404.58 56.50 193571 27030dm-1 0.27 2.23 0.00 1068 0 |
参数说明
- tps: 每秒事物数(IOPS)。
- kB_read/s、kB_wrtn/s: 每秒读取KB数和每秒写入KB数。
- kB_read、kB_wrtn: 总共读取和写入的KB数。
如下想输出更详细的内容,可以试试下面这个命令组合:
|
1
2
3
4
5
6
7
8
|
[root@localhost ~]# iostat -xkdz 1Linux 3.10.0-514.el7.x86_64 (localhost.localdomain) 2017年09月18日 _x86_64_ (1 CPU)Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %utilsda 0.01 2.43 13.81 2.32 510.51 67.96 71.74 0.22 13.94 8.72 44.95 2.37 3.82scd0 0.00 0.00 0.03 0.00 0.10 0.00 8.00 0.00 0.27 0.27 0.00 0.27 0.00dm-0 0.00 0.00 10.52 4.73 452.10 63.13 67.56 0.44 28.56 10.41 68.93 2.47 3.76dm-1 0.00 0.00 0.30 0.00 2.49 0.00 16.69 0.00 1.50 1.50 0.00 1.38 0.04 |
参数说明
- rrqm/s:每秒合并放入驱动请求队列的读请求数(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge)。
- wrqm/s:每秒合并放入驱动请求队列的写请求数。
- rsec/s:每秒发给磁盘设备的读请求数。
- wsec/:每秒发给磁盘设备的写请求数。
- rKB/s:每秒从磁盘设备读取的KB数。
- wKB/s:每秒向磁盘设备写入的KB数。
- avgrq-sz 平均每次请求大小,单位为扇区(512B)。
- avgqu-sz 在驱动请求队列和在设备中活跃的平均请求数。
- await: 平均I/O响应时间,包括在驱动请求队列里等待和设备的I/O响应时间(ms)。一般地系统I/O响应时间应该低于5ms,如果大于10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
- svctm:磁盘设备的I/O平均响应时间(ms)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长系统上运行的应用程序将变慢。
- %util: 设备忙处理I/O请求的百分比(使用率)。在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
既然avgrq-sz是合并之后的数字,小尺寸(16个扇区或者更小)可以视为无法合并的实际I/O负载的迹象。大尺寸有可能是大I/O,或者是合并的连续负载。输出性能里最重要的指标是await。如果应用程序和文件系统使用了降低写延时的方法,w_await可能不那么重要,而更应该关注r_await。
对于资源使用和容量规划,%util仍然很重要,不过记住这只是繁忙度的一个度量(非空闲时间),对于后面有多块磁盘支持的虚拟设备意义不大。可以通过施加负载更好地了解这些设备:IOPS(r/s + w/s)以及吞吐量(rkB/s + wkB/s)。
iotop
包含磁盘I/O的top工具。
批量模式(-b)可以提供滚动输出。下面的演示仅仅显示I/O进程(-o),每5秒输出一次(-d5):
|
1
|
[root@localhost ~]# iotop -bod5 |
|
1
2
3
4
5
6
7
8
|
Total DISK READ : 0.00 B/s | Total DISK WRITE : 8.76 K/sActual DISK READ: 0.00 B/s | Actual DISK WRITE: 24.49 K/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO COMMAND21203 be/3 root 0.00 B/s 815.58 B/s 0.00 % 0.01 % [jbd2/dm-2-8]22069 be/3 root 0.00 B/s 0.00 B/s 0.00 % 0.01 % [jbd2/dm-1-8] 1531 be/0 root 0.00 B/s 6.37 K/s 0.00 % 0.01 % [loop0] 3142 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.01 % [kworker/7:0]21246 be/4 root 0.00 B/s 1631.15 B/s 0.00 % 0.00 % java -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize=2048 -Djava.endorsed.dirs=/usr/local/tomcat/endorsed -classpath /usr/local/tomcat/bin/bootstrap.jar:/usr/local/tomcat/bin/tomcat-juli.jar -Dcatalina.base=/usr/local/tomcat -Dcatalina.home=/usr/local/tomcat -Djava.io.tmpdir=/usr/local/tomcat/temp org.apache.catalina.startup.Bootstrap start |
提示:
输出显示java进程正在以大约1631.15 B/s的速率施加磁盘写负载。其他有用的选项有-a,可以输出累计I/O而不是一段时间内的平均值,选项-o,只打印那些正在执行的磁盘I/O的进程。
当然显示磁盘的命令还有例如sar、iosnoop、perf、blktrace等命令,这里只列举常用命令即可。
性能调优
文件系统优化
关于文件系统优化,并没有太多的内容需要说明。就目前的情况,Redhat Enterprise 7系列默认更换为性能更好的XFS,这也是由于XFS在性能表现确实很好的原因。在我们使用的过程中,建议对XFS做一些简单的优化即可,比如执行格式化时指定额外的一些参数,挂载该分区时指定一些额外的挂载参数,这些都能够提高文件系统的相关性能。
格式化时的参数:
|
1
|
mkfs.xfs -d agcount=256 -l size=128m,lazy-count=1,version=2 /dev/diska1 |
mount时的参数:
|
1
|
defaults,noatime,nodiratime,nobarrier,discard,allocsize=256m,logbufs=8,attr2,logbsize=256k |
磁盘相关优化
- 操作系统可调参数
包括ionice、资源控制和内核可调参数。
ionice
Linux中的ionice命令可以设置一个进程I/O调度级别和优先级。调度级别为整数,0表示无,不指定级别,内核会挑选一个默认值,优先级根据进程nice值选定;1表示实时,对磁盘的最高级别访问,如果误用会导致其他进程饿死;2表示尽力,默认调度级别,包括优先级 0~7,0为最高级;3表示空闲,在一段磁盘空闲的期限过后才允许进行I/O。如下:
|
1
|
ionice -c 3 -p 65552 |
cgroup
通过cgroup为进程或进程组提供存储设备资源控制机制。一般很少用到,不用考虑。
可调参数
/sys/block/sda/queue/scheduler:选择I/O调度器策略,是空操作、最后期限、an还是cfq;
- 磁盘设备可调参数
Linux上的hdparm(磁盘测试工具)工具可以设置多种磁盘设备的可调参数。
总结
总结
总结
系统平均负载
简介
系统平均负载:是处于可运行或不可中断状态的平均进程数。
可运行进程:使用 CPU 或等待使用 CPU 的进程
不可中断状态进程:正在等待某些 IO 访问,一般是和硬件交互,不可被打断(不可被打断的原因是为了保护系统数据一致,防止数据读取错误)
查看系统平均负载
首先top命令查看进程运行状态,如下:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10760 user 20 0 3061604 84832 5956 S 82.4 0.6 126:47.61 Process
29424 user 20 0 54060 2668 1360 R 17.6 0.0 0:00.03 **top**
程序状态Status进程可运行状态为R,不可中断运行为D(后续讲解 top 时会详细说明)
top查看系统平均负载:
top - 13:09:42 up 888 days, 21:32, 8 users, load average: 19.95, 14.71, 14.01
Tasks: 642 total, 2 running, 640 sleeping, 0 stopped, 0 zombie
%Cpu0 : 37.5 us, 27.6 sy, 0.0 ni, 30.9 id, 0.0 wa, 0.0 hi, 3.6 si, 0.3 st
%Cpu1 : 34.1 us, 31.5 sy, 0.0 ni, 34.1 id, 0.0 wa, 0.0 hi, 0.4 si, 0.0 st
...
KiB Mem : 14108016 total, 2919496 free, 6220236 used, 4968284 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 6654506 avail Mem
这里的load average就表示系统最近 1 分钟、5 分钟、15 分钟的系统瓶颈负载。
uptime查看系统瓶颈负载
[root /home/user]# uptime
13:11:01 up 888 days, 21:33, 8 users, load average: 17.20, 14.85, 14.10
查看 CPU 核信息
系统平均负载和 CPU 核数密切相关,我们可以通过以下命令查看当前机器 CPU 信息:
lscpu查看 CPU 信息:
[root@Tencent-SNG /home/user_00]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
...
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
NUMA node0 CPU(s): 0-7 // NUMA架构信息
cat /proc/cpuinfo查看每个 CPU 核的信息:
processor : 7 // 核编号7
vendor_id : GenuineIntel
cpu family : 6
model : 6
...
系统平均负载升高的原因
一般来说,系统平均负载升高意味着 CPU 使用率上升。但是他们没有必然联系,CPU 密集型计算任务较多一般系统平均负载会上升,但是如果 IO 密集型任务较多也会导致系统平均负载升高但是此时的 CPU 使用率不一定高,可能很低因为很多进程都处于不可中断状态,等待 CPU 调度也会升高系统平均负载。
所以假如我们系统平均负载很高,但是 CPU 使用率不是很高,则需要考虑是否系统遇到了 IO 瓶颈,应该优化 IO 读写速度。
所以系统是否遇到 CPU 瓶颈需要结合 CPU 使用率,系统瓶颈负载一起查看(当然还有其他指标需要对比查看,下面继续讲解)
案例问题排查
stress是一个施加系统压力和压力测试系统的工具,我们可以使用stress工具压测试 CPU,以便方便我们定位和排查 CPU 问题。
yum install stress // 安装stress工具
stress 命令使用
// --cpu 8:8个进程不停的执行sqrt()计算操作
// --io 4:4个进程不同的执行sync()io操作(刷盘)
// --vm 2:2个进程不停的执行malloc()内存申请操作
// --vm-bytes 128M:限制1个执行malloc的进程申请内存大小
stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10s
我们这里主要验证 CPU、IO、进程数过多的问题
CPU 问题排查
使用stress -c 1模拟 CPU 高负载情况,然后使用如下命令观察负载变化情况:
uptime:使用uptime查看此时系统负载:
# -d 参数表示高亮显示变化的区域
$ watch -d uptime
... load average: 1.00, 0.75, 0.39
mpstat:使用mpstat -P ALL 1则可以查看每一秒的 CPU 每一核变化信息,整体和top类似,好处是可以把每一秒(自定义)的数据输出方便观察数据的变化,最终输出平均数据:
13:14:53 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:14:58 all 12.89 0.00 0.18 0.00 0.00 0.03 0.00 0.00 0.00 86.91
13:14:58 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
13:14:58 1 0.40 0.00 0.20 0.00 0.00 0.20 0.00 0.00 0.00 99.20
由以上输出可以得出结论,当前系统负载升高,并且其中 1 个核跑满主要在执行用户态任务,此时大多数属于业务工作。所以此时需要查哪个进程导致单核 CPU 跑满:
pidstat:使用pidstat -u 1则是每隔 1 秒输出当前系统进程、CPU 数据:
13:18:00 UID PID %usr %system %guest %CPU CPU Command
13:18:01 0 1 1.00 0.00 0.00 1.00 4 systemd
13:18:01 0 3150617 100.00 0.00 0.00 100.00 0 stress
...
top:当然最方便的还是使用top命令查看负载情况:
top - 13:19:06 up 125 days, 20:01, 3 users, load average: 0.99, 0.63, 0.42
Tasks: 223 total, 2 running, 221 sleeping, 0 stopped, 0 zombie
%Cpu(s): 14.5 us, 0.3 sy, 0.0 ni, 85.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16166056 total, 3118532 free, 9550108 used, 3497416 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 6447640 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3150617 root 20 0 10384 120 0 R 100.0 0.0 4:36.89 stress
此时可以看到是stress占用了很高的 CPU。
IO 问题排查
我们使用stress -i 1来模拟 IO 瓶颈问题,即死循环执行 sync 刷盘操作: uptime:使用uptime查看此时系统负载:
$ watch -d uptime
..., load average: 1.06, 0.58, 0.37
mpstat:查看此时 IO 消耗,但是实际上我们发现这里 CPU 基本都消耗在了 sys 即系统消耗上。
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 0.33 0.00 12.64 0.13 0.00 0.00 0.00 0.00 0.00 86.90
Average: 0 0.00 0.00 99.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 1 0.00 0.00 0.33 0.00 0.00 0.00 0.00 0.00 0.00 99.67
IO 无法升高的问题:
iowait 无法升高的问题,是因为案例中 stress 使用的是 sync()系统调用,它的作用是刷新缓冲区内存到磁盘中。对于新安装的虚拟机,缓冲区可能比较小,无法产生大的 IO 压力,这样大部分就都是系统调用的消耗了。所以,你会看到只有系统 CPU 使用率升高。解决方法是使用 stress 的下一代 stress-ng,它支持更丰富的选项,比如stress-ng -i 1 --hdd 1 --timeout 600(--hdd 表示读写临时文件)。
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 0.25 0.00 0.44 26.22 0.00 0.00 0.00 0.00 0.00 73.09
Average: 0 0.00 0.00 1.02 98.98 0.00 0.00 0.00 0.00 0.00 0.00
pidstat:同上(略)
可以看出 CPU 的 IO 升高导致系统平均负载升高。我们使用pidstat查找具体是哪个进程导致 IO 升高的。
top:这里使用 top 依旧是最方面的查看综合参数,可以得出stress是导致 IO 升高的元凶。
pidstat 没有 iowait 选项:可能是 CentOS 默认的sysstat太老导致,需要升级到 11.5.5 之后的版本才可用。
进程数过多问题排查
进程数过多这个问题比较特殊,如果系统运行了很多进程超出了 CPU 运行能,就会出现等待 CPU 的进程。 使用stress -c 24来模拟执行 24 个进程(我的 CPU 是 8 核) uptime:使用uptime查看此时系统负载:
$ watch -d uptime
..., load average: 18.50, 7.13, 2.84
mpstat:同上(略)
pidstat:同上(略)
可以观察到此时的系统处理严重过载的状态,平均负载高达 18.50。
top:我们还可以使用top命令查看此时Running状态的进程数,这个数量很多就表示系统正在运行、等待运行的进程过多。
总结
通过以上问题现象及解决思路可以总结出:
- 平均负载高有可能是 CPU 密集型进程导致的
- 平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了
- 当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源
总结工具:mpstat、pidstat、top和uptime
CPU 上下文切换
CPU 上下文:CPU 执行每个任务都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)包括 CPU 寄存器在内都被称为 CPU 上下文。
CPU 上下文切换:CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
CPU 上下文切换:分为进程上下文切换、线程上下文切换以及中断上下文切换。
进程上下文切换
从用户态切换到内核态需要通过系统调用来完成,这里就会发生进程上下文切换(特权模式切换),当切换回用户态同样发生上下文切换。
一般每次上下文切换都需要几十纳秒到数微秒的 CPU 时间,如果切换较多还是很容易导致 CPU 时间的浪费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,这里同样会导致系统平均负载升高。
Linux 为每个 CPU 维护一个就绪队列,将 R 状态进程按照优先级和等待 CPU 时间排序,选择最需要的 CPU 进程执行。这里运行进程就涉及了进程上下文切换的时机:
- 进程时间片耗尽、。
- 进程在系统资源不足(内存不足)。
- 进程主动
sleep。 - 有优先级更高的进程执行。
- 硬中断发生。
线程上下文切换
线程和进程:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
所以线程上下文切换包括了 2 种情况:
- 不同进程的线程,这种情况等同于进程切换。
- 通进程的线程切换,只需要切换线程私有数据、寄存器等不共享数据。
中断上下文切换
中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
查看系统上下文切换
vmstat:工具可以查看系统的内存、CPU 上下文切换以及中断次数:
// 每隔1秒输出
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 0 157256 3241604 5144444 0 0 20 0 26503 33960 18 7 75 0 0
17 0 0 159984 3241708 5144452 0 0 12 0 29560 37696 15 10 75 0 0
6 0 0 162044 3241816 5144456 0 0 8 120 30683 38861 17 10 73 0 0
cs:则为每秒的上下文切换次数。
in:则为每秒的中断次数。
r:就绪队列长度,正在运行或等待 CPU 的进程。
b:不可中断睡眠状态的进程数,例如正在和硬件交互。
pidstat:使用pidstat -w选项查看具体进程的上下文切换次数:
$ pidstat -w -p 3217281 1
10:19:13 UID PID cswch/s nvcswch/s Command
10:19:14 0 3217281 0.00 18.00 stress
10:19:15 0 3217281 0.00 18.00 stress
10:19:16 0 3217281 0.00 28.71 stress
其中cswch/s和nvcswch/s表示自愿上下文切换和非自愿上下文切换。
自愿上下文切换:是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
非自愿上下文切换:则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换
案例问题排查
这里我们使用sysbench工具模拟上下文切换问题。
先使用vmstat 1查看当前上下文切换信息:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 514540 3364828 5323356 0 0 10 16 0 0 4 1 95 0 0
1 0 0 514316 3364932 5323408 0 0 8 0 27900 34809 17 10 73 0 0
1 0 0 507036 3365008 5323500 0 0 8 0 23750 30058 19 9 72 0 0
然后使用sysbench --threads=64 --max-time=300 threads run模拟 64 个线程执行任务,此时我们再次vmstat 1查看上下文切换信息:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 318792 3385728 5474272 0 0 10 16 0 0 4 1 95 0 0
1 0 0 307492 3385756 5474316 0 0 8 0 15710 20569 20 8 72 0 0
1 0 0 330032 3385824 5474376 0 0 8 16 21573 26844 19 9 72 0 0
2 0 0 321264 3385876 5474396 0 0 12 0 21218 26100 20 7 73 0 0
6 0 0 320172 3385932 5474440 0 0 12 0 19363 23969 19 8 73 0 0
14 0 0 323488 3385980 5474828 0 0 64 788 111647 3745536 24 61 15 0 0
14 0 0 323576 3386028 5474856 0 0 8 0 118383 4317546 25 64 11 0 0
16 0 0 315560 3386100 5475056 0 0 8 16 115253 4553099 22 68 9 0 0
我们可以明显的观察到:
- 当前 cs、in 此时剧增。
- sy+us 的 CPU 占用超过 90%。
- r 就绪队列长度达到 16 个超过了 CPU 核心数 8 个。
分析 cs 上下文切换问题
我们使用pidstat查看当前 CPU 信息和具体的进程上下文切换信息:
// -w表示查看进程切换信息,-u查看CPU信息,-t查看线程切换信息
$ pidstat -w -u -t 1
10:35:01 UID PID %usr %system %guest %CPU CPU Command
10:35:02 0 3383478 67.33 100.00 0.00 100.00 1 sysbench
10:35:01 UID PID cswch/s nvcswch/s Command
10:45:39 0 3509357 - 1.00 0.00 kworker/2:2
10:45:39 0 - 3509357 1.00 0.00 |__kworker/2:2
10:45:39 0 - 3509702 38478.00 45587.00 |__sysbench
10:45:39 0 - 3509703 39913.00 41565.00 |__sysbench
所以我们可以看到大量的sysbench线程存在很多的上下文切换。
分析 in 中断问题
我们可以查看系统的watch -d cat /proc/softirqs以及watch -d cat /proc/interrupts来查看系统的软中断和硬中断(内核中断)。我们这里主要观察/proc/interrupts即可。
$ watch -d cat /proc/interrupts
RES: 900997016 912023527 904378994 902594579 899800739 897500263 895024925 895452133 Rescheduling interrupts
这里明显看出重调度中断(RES)增多,这个中断表示唤醒空闲状态 CPU 来调度新任务执行,
总结
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题。
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈。
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看
/proc/interrupts文件来分析具体的中断类型。
CPU 使用率
除了系统负载、上下文切换信息,最直观的 CPU 问题指标就是 CPU 使用率信息。Linux 通过/proc虚拟文件系统向用户控件提供系统内部状态信息,其中/proc/stat则是 CPU 和任务信息统计。
$ cat /proc/stat | grep cpu
cpu 6392076667 1160 3371352191 52468445328 3266914 37086 36028236 20721765 0 0
cpu0 889532957 175 493755012 6424323330 2180394 37079 17095455 3852990 0 0
...
这里每一列的含义如下:
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
这里我们可以使用top、ps、pidstat等工具方便的查询这些数据,可以很方便的看到 CPU 使用率很高的进程,这里我们可以通过这些工具初步定为,但是具体的问题原因还需要其他方法继续查找。
这里我们可以使用perf top方便查看热点数据,也可以使用perf record可以将当前数据保存起来方便后续使用perf report查看。
CPU 使用率问题排查
这里总结一下 CPU 使用率问题及排查思路:
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
CPU 问题排查套路
CPU 使用率
CPU 使用率主要包含以下几个方面:
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
- 除在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
平均负载
反应了系统的整体负载情况,可以查看过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。
上下文切换
上下文切换主要关注 2 项指标:
- 无法获取资源而导致的自愿上下文切换。
- 被系统强制调度导致的非自愿上下文切换。
CPU 缓存命中率
CPU 的访问速度远大于内存访问,这样在 CPU 访问内存时不可避免的要等待内存响应。为了协调 2 者的速度差距出现了 CPU 缓存(多级缓存)。 如果 CPU 缓存命中率越高则性能会更好,我们可以使用以下工具查看 CPU 缓存命中率,工具地址、项目地址 perf-tools
# ./cachestat -t
Counting cache functions... Output every 1 seconds.
TIME HITS MISSES DIRTIES RATIO BUFFERS_MB CACHE_MB
08:28:57 415 0 0 100.0% 1 191
08:28:58 411 0 0 100.0% 1 191
08:28:59 362 97 0 78.9% 0 8
08:29:00 411 0 0 100.0% 0 9
08:29:01 775 20489 0 3.6% 0 89
08:29:02 411 0 0 100.0% 0 89
08:29:03 6069 0 0 100.0% 0 89
08:29:04 15249 0 0 100.0% 0 89
08:29:05 411 0 0 100.0% 0 89
08:29:06 411 0 0 100.0% 0 89
08:29:07 411 0 3 100.0% 0 89
[...]
总结
通过性能指标查工具(CPU 相关)
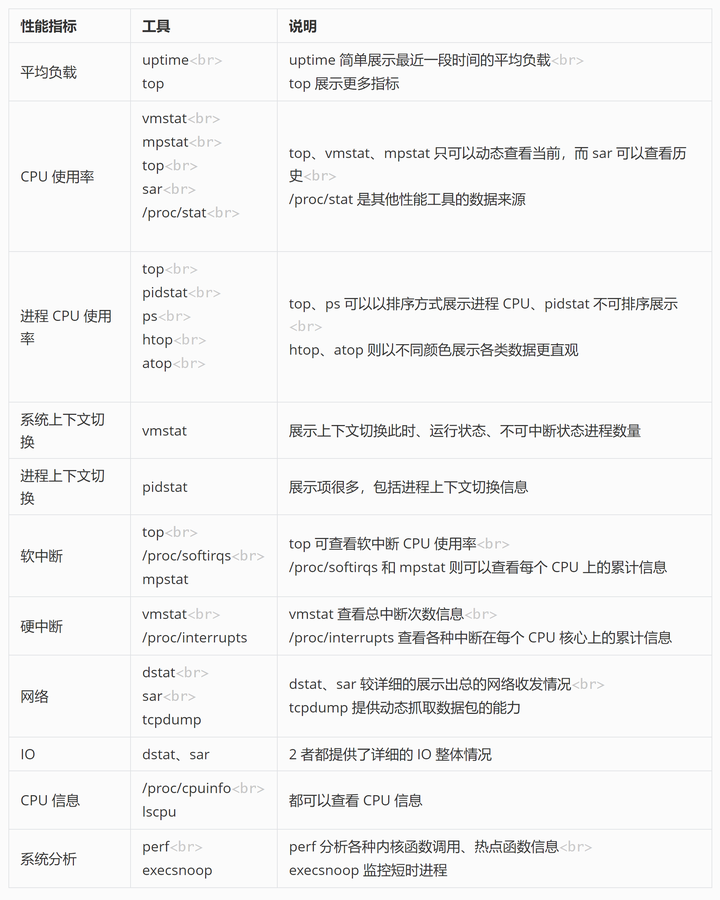
性能指标工具说明平均负载uptime
topuptime 简单展示最近一段时间的平均负载
top 展示更多指标CPU 使用率vmstat
mpstat
top
sar
/proc/stat
top、vmstat、mpstat 只可以动态查看当前,而 sar 可以查看历史
/proc/stat 是其他性能工具的数据来源进程 CPU 使用率top
pidstat
ps
htop
atop
top、ps 可以以排序方式展示进程 CPU、pidstat 不可排序展示
htop、atop 则以不同颜色展示各类数据更直观系统上下文切换vmstat展示上下文切换此时、运行状态、不可中断状态进程数量进程上下文切换pidstat展示项很多,包括进程上下文切换信息软中断top
/proc/softirqs
mpstattop 可查看软中断 CPU 使用率
/proc/softirqs 和 mpstat 则可以查看每个 CPU 上的累计信息硬中断vmstat
/proc/interruptsvmstat 查看总中断次数信息
/proc/interrupts 查看各种中断在每个 CPU 核心上的累计信息网络dstat
sar
tcpdumpdstat、sar 较详细的展示出总的网络收发情况
tcpdump 提供动态抓取数据包的能力IOdstat、sar2 者都提供了详细的 IO 整体情况CPU 信息/proc/cpuinfo
lscpu都可以查看 CPU 信息系统分析perf
execsnoopperf 分析各种内核函数调用、热点函数信息
execsnoop 监控短时进程
根据工具查性能指标(CPU 相关)
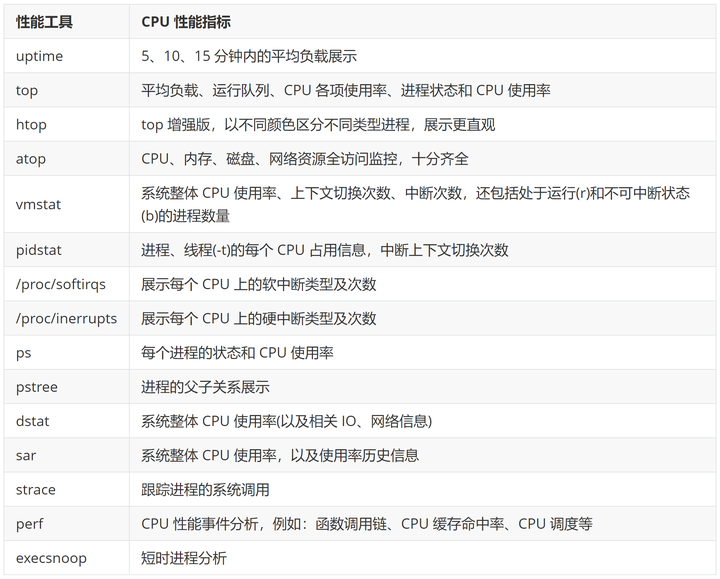
性能工具CPU 性能指标uptime5、10、15 分钟内的平均负载展示top平均负载、运行队列、CPU 各项使用率、进程状态和 CPU 使用率htoptop 增强版,以不同颜色区分不同类型进程,展示更直观atopCPU、内存、磁盘、网络资源全访问监控,十分齐全vmstat系统整体 CPU 使用率、上下文切换次数、中断次数,还包括处于运行(r)和不可中断状态(b)的进程数量pidstat进程、线程(-t)的每个 CPU 占用信息,中断上下文切换次数/proc/softirqs展示每个 CPU 上的软中断类型及次数/proc/inerrupts展示每个 CPU 上的硬中断类型及次数ps每个进程的状态和 CPU 使用率pstree进程的父子关系展示dstat系统整体 CPU 使用率(以及相关 IO、网络信息)sar系统整体 CPU 使用率,以及使用率历史信息strace跟踪进程的系统调用perfCPU 性能事件分析,例如:函数调用链、CPU 缓存命中率、CPU 调度等execsnoop短时进程分析
CPU 问题排查方向
有了以上性能工具,在实际遇到问题时我们并不可能全部性能工具跑一遍,这样效率也太低了,所以这里可以先运行几个常用的工具 top、vmstat、pidstat 分析系统大概的运行情况然后在具体定位原因。
top 系统CPU => vmstat 上下文切换次数 => pidstat 非自愿上下文切换次数 => 各类进程分析工具(perf strace ps execsnoop pstack)
top 用户CPU => pidstat 用户CPU => 一般是CPU计算型任务
top 僵尸进程 => 各类进程分析工具(perf strace ps execsnoop pstack)
top 平均负载 => vmstat 运行状态进程数 => pidstat 用户CPU => 各类进程分析工具(perf strace ps execsnoop pstack)
top 等待IO CPU => vmstat 不可中断状态进程数 => IO分析工具(dstat、sar -d)
top 硬中断 => vmstat 中断次数 => 查看具体中断类型(/proc/interrupts)
top 软中断 => 查看具体中断类型(/proc/softirqs) => 网络分析工具(sar -n、tcpdump) 或者 SCHED(pidstat 非自愿上下文切换)
CPU 问题优化方向
性能优化往往是多方面的,CPU、内存、网络等都是有关联的,这里暂且给出 CPU 优化的思路,以供参考。
程序优化
- 基本优化:程序逻辑的优化比如减少循环次数、减少内存分配,减少递归等等。
- 编译器优化:开启编译器优化选项例如
gcc -O2对程序代码优化。 - 算法优化:降低苏研发复杂度,例如使用
nlogn的排序算法,使用logn的查找算法等。 - 异步处理:例如把轮询改为通知方式
- 多线程代替多进程:某些场景下多线程可以代替多进程,因为上下文切换成本较低
- 缓存:包括多级缓存的使用(略)加快数据访问
系统优化
- CPU 绑定:绑定到一个或多个 CPU 上,可以提高 CPU 缓存命中率,减少跨 CPU 调度带来的上下文切换问题
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。
- 优先级调整:使用 nice 调整进程的优先级,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
- NUMA 优化:支持 NUMA 的处理器会被划分为多个 Node,每个 Node 有本地的内存空间,这样 CPU 可以直接访问本地空间内存。
- 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号