理解select,poll,epoll实现分析
资料1
- 对于select和poll来说,所有文件描述符都是在用户态被加入其文件描述符集合的,每次调用都需要将整个集合拷贝到内核态;epoll则将整个文件描述符集合维护在内核态,每次添加文件描述符的时候都需要执行一个系统调用。系统调用的开销是很大的,而且在有很多短期活跃连接的情况下,epoll可能会慢于select和poll由于这些大量的系统调用开销。
- select使用线性表描述文件描述符集合,文件描述符有上限;poll使用链表来描述;epoll底层通过红黑树来描述,并且维护一个ready list,将事件表中已经就绪的事件添加到这里,在使用epoll_wait调用时,仅观察这个list中有没有数据即可。
- select和poll的最大开销来自内核判断是否有文件描述符就绪这一过程:每次执行select或poll调用时,它们会采用遍历的方式,遍历整个文件描述符集合去判断各个文件描述符是否有活动;epoll则不需要去以这种方式检查,当有活动产生时,会自动触发epoll回调函数通知epoll文件描述符,然后内核将这些就绪的文件描述符放到之前提到的ready list中等待epoll_wait调用后被处理。
- select和poll都只能工作在相对低效的LT模式下,而epoll同时支持LT和ET模式。
- 综上,当监测的fd数量较小,且各个fd都很活跃的情况下,建议使用select和poll;当监听的fd数量较多,且单位时间仅部分fd活跃的情况下,使用epoll会明显提升性能。
资料2
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
select:
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:
1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。
一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.
2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
poll:
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
- 大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
- poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
epoll:
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无 论fd中是否还有数据可读。
所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者 遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
当没有 IO 事件的时候, epoll 也是会阻塞掉当前进程。这个是合理的,因为没有事情可做了占着 CPU 也没啥意义。epoll 本身是阻塞的,但一般会把 socket 设置成非阻塞。epoll内核源码解析:https://mp.weixin.qq.com/s/dUo-a01uSssWkSc9wQpt2A
epoll为什么要有EPOLLET触发模式?
如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边沿触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。
如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符
epoll的优点:
- 没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
- 效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
- 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
select、poll、epoll 区别总结:
1、支持一个进程所能打开的最大连接数
select
单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。
poll
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的
epoll
虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接
2、FD剧增后带来的IO效率问题
select
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
poll
同上
epoll
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
3、 消息传递方式
select
内核需要将消息传递到用户空间,都需要内核拷贝动作
poll
同上
epoll
epoll通过内核和用户空间共享一块内存来实现的。
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
今天对这三种IO多路复用进行对比,参考网上和书上面的资料,整理如下:
1、select实现
select的调用过程如下所示:
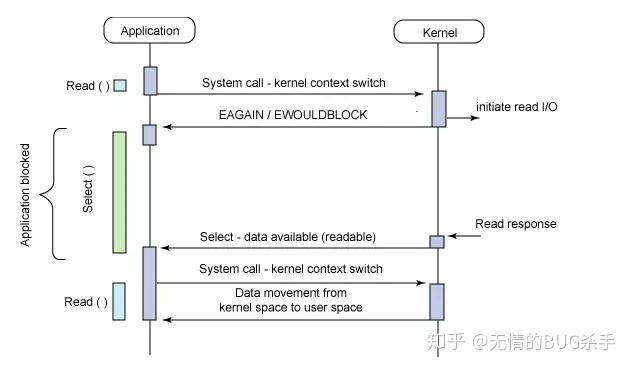
- 使用copy_from_user从用户空间拷贝fd_set到内核空间
- 注册回调函数__pollwait
- 遍历所有fd,调用其对应的poll方法(对于socket,这个poll方法是sock_poll,sock_poll根据情况会调用到tcp_poll,udp_poll或者datagram_poll) -以tcp_poll为例,其核心实现就是__pollwait,也就是上面注册的回调函数。
- __pollwait的主要工作就是把current(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,对于tcp_poll来说,其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。在设备收到一条消息(网络设备)或填写完文件数据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时current便被唤醒了。
- poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值。
- 如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是current)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。
- 把fd_set从内核空间拷贝到用户空间。
总结:
select的几大缺点:
- 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
- 同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
- select支持的文件描述符数量太小了,默认是1024
2、poll实现
poll的实现和select非常相似,只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构,其他的都差不多,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。
poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
3、epoll
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。
而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。
虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
Select 模型
下面是 select 函数接口:
int select (int n, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);select 函数监视的文件描述符分 3 类,分别是 writefds、readfds 和 exceptfds。调用后 select 函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有 except),或者超时(timeout 指定等待时间,如果立即返回设为 null 即可)。当 select 函数返回后,通过遍历fd_set,来找到就绪的描述符。
select 目前几乎在所有的平台上支持,其良好跨平台支持是它的一大优点。select 的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在 Linux 上一般为 1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。
poll 模型
int poll (struct pollfd *fds, unsigned int nfds, int timeout);不同于 select 使用三个位图来表示三个 fdset 的方式,poll 使用一个 pollfd 的指针实现。
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events to watch */
short revents; /* returned events witnessed */
};pollfd 结构包含了要监视的 event 和发生的 event,不再使用 select “参数-值”传递的方式。同时,pollfd 并没有最大数量限制(但是数量过大后性能也是会下降)。和 select 函数一样,poll 返回后,需要轮询 pollfd 来获取就绪的描述符。
从上面看,select 和 poll 都需要在返回后,通过遍历文件描述符来获取已经就绪的 socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
epoll 模型
epoll 的接口如下:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
int epoll_wait(int epfd, struct epoll_event * events,
int maxevents, int timeout);
主要是 epoll_create,epoll_ctl 和 epoll_wait 三个函数。epoll_create 函数创建 epoll 文件描述符,参数 size 并不是限制了 epoll 所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。epoll_ctl 完成对指定描述符 fd 执行 op 操作控制,event 是与 fd 关联的监听事件。op 操作有三种:添加 EPOLL_CTL_ADD,删除 EPOLL_CTL_DEL,修改 EPOLL_CTL_MOD。分别添加、删除和修改对 fd 的监听事件。epoll_wait 等待 epfd 上的 IO 事件,最多返回 maxevents 个事件。
在 select/poll 中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而 epoll 事先通过 epoll_ctl() 来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似 callback 的回调机制,迅速激活这个文件描述符,当进程调用 epoll_wait 时便得到通知。
epoll 的优点主要是一下几个方面:
- 监视的描述符数量不受限制,它所支持的 fd 上限是最大可以打开文件的数目,这个数字一般远大于 2048, 举个例子, 在 1GB 内存的机器上大约是 10 万左右,具体数目可以通过
cat /proc/sys/fs/file-max 进行查看, 一般来说这个数目和系统内存关系很大。select 的最大缺点就是进程打开的 fd 是有数量限制的。这对于连接数量比较大的服务器来说根本不能满足。虽然也可以选择多进程的解决方案( Apache 就是这样实现的),不过虽然 linux 上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案。 - IO 的效率不会随着监视 fd 的数量的增长而下降。epoll 不同于 select 和 poll 轮询的方式,而是通过每个 fd 定义的回调函数来实现的。只有就绪的 fd 才会执行回调函数。
- 支持水平触发和边沿触发两种模式:
-
水平触发模式,文件描述符状态发生变化后,如果没有采取行动,它将后面反复通知,这种情况下编程相对简单,libevent 等开源库很多都是使用的这种模式。
-
边沿触发模式,只告诉进程哪些文件描述符刚刚变为就绪状态,只说一遍,如果没有采取行动,那么它将不会再次告知。理论上边缘触发的性能要更高一些,但是代码实现相当复杂(Nginx 使用的边缘触发)。
- mmap 加速内核与用户空间的信息传递。epoll 是通过内核与用户空间 mmap 同一块内存,避免了无谓的内存拷贝。
select()/poll() 的内核实现
05 Jan 2015
同时对多个文件设备进行I/O事件监听的时候(I/O multiplexing),我们经常会用到系统调用函数select() poll(),甚至是为大规模成百上千个文件设备进行并发读写而设计的epoll()。
I/O multiplexing: When an application needs to handle multiple I/O descriptors at the same time, and I/O on any one descriptor can result in blocking. E.g. file and socket descriptors, multiple socket descriptors
一旦某些文件设备准备好了,可以读写了,或者是我们自己设置的timeout时间到了,这些函数就会返回,根据返回结果主程序继续运行。
用了这些函数有什么好处? 我们自己本来就可以实现这种I/O Multiplexing啊,比如说:
- 创建多个进程或线程来监听
- Non-blocking读写监听的轮询(polling)
- 异步I/O(Asynchronous I/O)与Unix Signal事件触发
想要和我们自己的实现手段做比较,那么首先我们就得知道这些函数在背后是怎么实现的。 本文以Linux(v3.9-rc8)源码为例,探索select() poll()的内核实现。
select()源码概述
首先看看select()函数的函数原型,具体用法请自行输入命令行$ man 2 select查阅吧 : )
int select(int nfds,
fd_set *restrict readfds,
fd_set *restrict writefds,
fd_set *restrict errorfds,
struct timeval *restrict timeout);
下文将按照这个结构来讲解select()在Linux的实现机制。
select()内核入口do_select()的循环体struct file_operations设备驱动的操作函数scull驱动实例poll_wait与设备的等待队列- 其它相关细节
- 最后
好,让我们开始吧 : )
select()内核入口
我们首先把目光放到文件fs/select.c文件上。
SYSCALL_DEFINE5(select, int, n,
fd_set __user *, inp,
fd_set __user *, outp,
fd_set __user *, exp,
struct timeval __user *, tvp)
{
// …
ret = core_sys_select(n, inp, outp, exp, to);
ret = poll_select_copy_remaining(&end_time, tvp, 1, ret);
return ret;
}
int core_sys_select(int n,
fd_set __user *inp,
fd_set __user *outp,
fd_set __user *exp,
struct timespec *end_time)
{
fd_set_bits fds;
// …
if ((ret = get_fd_set(n, inp, fds.in)) ||
(ret = get_fd_set(n, outp, fds.out)) ||
(ret = get_fd_set(n, exp, fds.ex)))
goto out;
zero_fd_set(n, fds.res_in);
zero_fd_set(n, fds.res_out);
zero_fd_set(n, fds.res_ex);
// …
ret = do_select(n, &fds, end_time);
// …
}
很好,我们找到了一个宏定义的select()函数的入口,继续深入,可以看到其中最重要的就是do_select()这个内核函数。
do_select()的循环体
do_select()实质上是一个大的循环体,对每一个主程序要求监听的设备fd(File Descriptor)做一次struct file_operations结构体里的poll操作。
int do_select(int n, fd_set_bits *fds, struct timespec *end_time)
{
// …
for (;;) {
// …
for (i = 0; i < n; ++rinp, ++routp, ++rexp) {
// …
struct fd f;
f = fdget(i);
if (f.file) {
const struct file_operations *f_op;
f_op = f.file->f_op;
mask = DEFAULT_POLLMASK;
if (f_op->poll) {
wait_key_set(wait, in, out,
bit, busy_flag);
// 对每个fd进行I/O事件检测
mask = (*f_op->poll)(f.file, wait);
}
fdput(f);
// …
}
}
// 退出循环体
if (retval || timed_out || signal_pending(current))
break;
// 进入休眠
if (!poll_schedule_timeout(&table, TASK_INTERRUPTIBLE,
to, slack))
timed_out = 1;
}
}
(*f_op->poll)会返回当前设备fd的状态(比如是否可读可写),根据这个状态,do_select()接着做出不同的动作
- 如果设备fd的状态与主程序的感兴趣的I/O事件匹配,则记录下来,
do_select()退出循环体,并把结果返回给上层主程序。 - 如果不匹配,
do_select()发现timeout已经到了或者进程有signal信号打断,也会退出循环,只是返回空的结果给上层应用。
但如果do_select()发现当前没有事件发生,又还没到timeout,更没signal打扰,内核会在这个循环体里面永远地轮询下去吗?
select()把全部fd检测一轮之后如果没有可用I/O事件,会让当前进程去休眠一段时间,等待fd设备或定时器来唤醒自己,然后再继续循环体看看哪些fd可用,以此提高效率。
int poll_schedule_timeout(struct poll_wqueues *pwq, int state,
ktime_t *expires, unsigned long slack)
{
int rc = -EINTR;
// 休眠
set_current_state(state);
if (!pwq->triggered)
rc = schedule_hrtimeout_range(expires, slack, HRTIMER_MODE_ABS);
__set_current_state(TASK_RUNNING);
/*
* Prepare for the next iteration.
*
* The following set_mb() serves two purposes. First, it's
* the counterpart rmb of the wmb in pollwake() such that data
* written before wake up is always visible after wake up.
* Second, the full barrier guarantees that triggered clearing
* doesn't pass event check of the next iteration. Note that
* this problem doesn't exist for the first iteration as
* add_wait_queue() has full barrier semantics.
*/
set_mb(pwq->triggered, 0);
return rc;
}
EXPORT_SYMBOL(poll_schedule_timeout);
struct file_operations设备驱动的操作函数
设备发现I/O事件时会唤醒主程序进程? 每个设备fd的等待队列在哪?我们什么时候把当前进程添加到它们的等待队列里去了?
mask = (*f_op->poll)(f.file, wait);
就是上面这行代码干的好事。 不过在此之前,我们得先了解一下系统内核与文件设备的驱动程序之间耦合框架的设计。
上文对每个设备的操作f_op->poll,是一个针对每个文件设备特定的内核函数,区别于我们平时用的系统调用poll()。 并且,这个操作是select() poll()epoll()背后实现的共同基础。
Support for any of these calls requires support from the device driver. This support (for all three calls,
select()poll()andepoll()) is provided through the driver’s poll method.
Linux的设计很灵活,它并不知道每个具体的文件设备是怎么操作的(怎么打开,怎么读写),但内核让每个设备拥有一个struct file_operations结构体,这个结构体里定义了各种用于操作设备的函数指针,指向操作每个文件设备的驱动程序实现的具体操作函数,即设备驱动的回调函数(callback)。
struct file {
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
// …
} __attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iterate) (struct file *, struct dir_context *);
// select()轮询设备fd的操作函数
unsigned int (*poll) (struct file *, struct poll_table_struct *);
// …
};
这个f_op->poll对文件设备做了什么事情呢? 一是调用poll_wait()函数(在include/linux/poll.h文件); 二是检测文件设备的当前状态。
unsigned int (*poll) (struct file *filp, struct poll_table_struct *pwait);
The device method is in charge of these two steps:
- Call
poll_wait()on one or more wait queues that could indicate a change in the poll status. If no file descriptors are currently available for I/O, the kernel causes the process to wait on the wait queues for all file descriptors passed to the system call.- Return a bit mask describing the operations (if any) that could be immediately performed without blocking.
或者来看另一个版本的说法:
For every file descriptor, it calls that fd’s
poll()method, which will add the caller to that fd’s wait queue, and return which events (readable, writeable, exception) currently apply to that fd.
下一节里我们会结合驱动实例程序来理解。
scull驱动实例
由于Linux设备驱动的耦合设计,对设备的操作函数都是驱动程序自定义的,我们必须要结合一个具体的实例来看看,才能知道f_op->poll里面弄得是什么鬼。
在这里我们以Linux Device Drivers, Third Edition一书中的例子——scull设备的驱动程序为例。
scull(Simple Character Utility for Loading Localities). scull is a char driver that acts on a memory area as though it were a device.
scull设备不同于硬件设备,它是模拟出来的一块内存,因此对它的读写更快速更自由,内存支持你顺着读倒着读点着读怎么读都可以。 我们以书中“管道”(pipe)式,即FIFO的读写驱动程序为例。
首先是scull_pipe的结构体,注意wait_queue_head_t这个队列类型,它就是用来记录等待设备I/O事件的进程的。
struct scull_pipe {
wait_queue_head_t inq, outq; /* read and write queues */
char *buffer, *end; /* begin of buf, end of buf */
int buffersize; /* used in pointer arithmetic */
char *rp, *wp; /* where to read, where to write */
int nreaders, nwriters; /* number of openings for r/w */
struct fasync_struct *async_queue; /* asynchronous readers */
struct mutex mutex; /* mutual exclusion semaphore */
struct cdev cdev; /* Char device structure */
};
scull设备的轮询操作函数scull_p_poll,驱动模块加载后,这个函数就被挂到(*poll)函数指针上去了。
我们可以看到它的确是返回了当前设备的I/O状态,并且调用了内核的poll_wait()函数,这里注意,它把自己的wait_queue_head_t队列也当作参数传进去了。
static unsigned int scull_p_poll(struct file *filp, poll_table *wait)
{
struct scull_pipe *dev = filp->private_data;
unsigned int mask = 0;
/*
* The buffer is circular; it is considered full
* if "wp" is right behind "rp" and empty if the
* two are equal.
*/
mutex_lock(&dev->mutex);
poll_wait(filp, &dev->inq, wait);
poll_wait(filp, &dev->outq, wait);
if (dev->rp != dev->wp)
mask |= POLLIN | POLLRDNORM; /* readable */
if (spacefree(dev))
mask |= POLLOUT | POLLWRNORM; /* writable */
mutex_unlock(&dev->mutex);
return mask;
}
当scull有数据写入时,它会把wait_queue_head_t队列里等待的进程给唤醒。
static ssize_t scull_p_write(struct file *filp, const char __user *buf, size_t count,
loff_t *f_pos)
{
// …
/* Make sure there's space to write */
// …
/* ok, space is there, accept something */
// …
/* finally, awake any reader */
wake_up_interruptible(&dev->inq); /* blocked in read() and select() */
// …
}
可是wait_queue_head_t队列里的进程是什么时候装进去的? 肯定是poll_wait搞的鬼! 我们又得回到该死的Linux内核去了。
poll_wait与设备的等待队列
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}
/*
* Do not touch the structure directly, use the access functions
* poll_does_not_wait() and poll_requested_events() instead.
*/
typedef struct poll_table_struct {
poll_queue_proc _qproc;
unsigned long _key;
} poll_table;
/*
* structures and helpers for f_op->poll implementations
*/
typedef void (*poll_queue_proc)(struct file *, wait_queue_head_t *, struct poll_table_struct *);
可以看到,poll_wait()其实就是只是直接调用了struct poll_table_struct结构里绑定的函数指针。 我们得找到struct poll_table_struct初始化的地方。
The
poll_tablestructure is just a wrapper around a function that builds the actual data structure. That structure, forpollandselect, is a linked list of memory pages containingpoll_table_entrystructures.
struct poll_table_struct里的函数指针,是在do_select()初始化的。
int do_select(int n, fd_set_bits *fds, struct timespec *end_time)
{
struct poll_wqueues table;
poll_table *wait;
poll_initwait(&table);
wait = &table.pt;
// …
}
void poll_initwait(struct poll_wqueues *pwq)
{
// 初始化poll_table里的函数指针
init_poll_funcptr(&pwq->pt, __pollwait);
pwq->polling_task = current;
pwq->triggered = 0;
pwq->error = 0;
pwq->table = NULL;
pwq->inline_index = 0;
}
EXPORT_SYMBOL(poll_initwait);
static inline void init_poll_funcptr(poll_table *pt, poll_queue_proc qproc)
{
pt->_qproc = qproc;
pt->_key = ~0UL; /* all events enabled */
}
我们现在终于知道,__pollwait()函数,就是poll_wait()幕后的真凶。
add_wait_queue()把当前进程添加到设备的等待队列wait_queue_head_t中去。
/* Add a new entry */
static void __pollwait(struct file *filp, wait_queue_head_t *wait_address,
poll_table *p)
{
struct poll_wqueues *pwq = container_of(p, struct poll_wqueues, pt);
struct poll_table_entry *entry = poll_get_entry(pwq);
if (!entry)
return;
entry->filp = get_file(filp);
entry->wait_address = wait_address;
entry->key = p->_key;
init_waitqueue_func_entry(&entry->wait, pollwake);
entry->wait.private = pwq;
// 把当前进程装到设备的等待队列
add_wait_queue(wait_address, &entry->wait);
}
void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait)
{
unsigned long flags;
wait->flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
__add_wait_queue(q, wait);
spin_unlock_irqrestore(&q->lock, flags);
}
EXPORT_SYMBOL(add_wait_queue);
static inline void __add_wait_queue(wait_queue_head_t *head, wait_queue_t *new)
{
list_add(&new->task_list, &head->task_list);
}
/**
* Insert a new element after the given list head. The new element does not
* need to be initialised as empty list.
* The list changes from:
* head → some element → ...
* to
* head → new element → older element → ...
*
* Example:
* struct foo *newfoo = malloc(...);
* list_add(&newfoo->entry, &bar->list_of_foos);
*
* @param entry The new element to prepend to the list.
* @param head The existing list.
*/
static inline void
list_add(struct list_head *entry, struct list_head *head)
{
__list_add(entry, head, head->next);
}
其它相关细节
fd_set实质上是一个unsigned long数组,里面的每一个long整值的每一位都代表一个文件,其中置为1的位表示用户要求监听的文件。 可以看到,select()能同时监听的fd好少,只有1024个。
#define __FD_SETSIZE 1024
typedef struct {
unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;
typedef __kernel_fd_set fd_set;
- 所谓的文件描述符fd (File Descriptor),大家也知道它其实只是一个表意的整数值,更深入地说,它是每个进程的file数组的下标。
struct fd {
struct file *file;
unsigned int flags;
};
select()系统调用会创建一个poll_wqueues结构体,用来记录相关I/O设备的等待队列;当select()退出循环体返回时,它要把当前进程从全部等待队列中移除——这些设备再也不用着去唤醒当前队列了。
The call to
poll_waitsometimes also adds the process to the given wait queue. The whole structure must be maintained by the kernel so that the process can be removed from all of those queues before poll or select returns.
/*
* Structures and helpers for select/poll syscall
*/
struct poll_wqueues {
poll_table pt;
struct poll_table_page *table;
struct task_struct *polling_task;
int triggered;
int error;
int inline_index;
struct poll_table_entry inline_entries[N_INLINE_POLL_ENTRIES];
};
struct poll_table_entry {
struct file *filp;
unsigned long key;
wait_queue_t wait;
wait_queue_head_t *wait_address;
};
wait_queue_head_t就是一个进程(task)的队列。
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
select()与epoll()的比较
- select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用
epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。- epoll所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以
cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
更具体的比较可以参见这篇文章。
最后
非常艰难的,我们终于来到了这里(T^T)
总结一下select()的大概流程(poll同理,只是用于存放fd的数据结构不同而已)。
- 先把全部fd扫一遍
- 如果发现有可用的fd,跳到5
- 如果没有,当前进程去睡觉xx秒
- xx秒后自己醒了,或者状态变化的fd唤醒了自己,跳到1
- 结束循环体,返回
我相信,你肯定还没懂,这代码实在是乱得一逼,被我剪辑之后再是乱得没法看了(叹气)。 所以看官请务必亲自去看Linux源码,在这里我已经给出了大致的方向,等你看完源码回来,这篇文章你肯定也就明白了。 当然别忘了下面的参考资料,它们可帮大忙了 :P

 浙公网安备 33010602011771号
浙公网安备 33010602011771号