
MySQL---索引-性能-配置参数优化
一般来说,要保证数据库的效率,要做好以下四个方面的工作:数 据库设计、sql语句优化、数据库参数配置、恰当的硬件资源和操作系统,这个顺序也表现了这四个工作对性能影响的大小。下面我们逐个阐明:
1、设计符合范式的数据库:https://blog.csdn.net/a745233700/article/details/80933854
2、选择合适的存储引擎:https://blog.csdn.net/a745233700/article/details/80793894
3、SQL表结构、字段优化:https://blog.csdn.net/a745233700/article/details/84405087
4、SQL语句优化与索引优化:https://blog.csdn.net/a745233700/article/details/84455241
5、读写分离:主数据库负责写操作,从数据库负责读操作。https://blog.csdn.net/a745233700/article/details/85263543
6、分库分表:垂直切分与水平切分。https://blog.csdn.net/a745233700/article/details/85244436
7、分区:将表的数据按照特定的规则放在不同的分区,提高磁盘的IO效率,提高数据库的性能。https://blog.csdn.net/a745233700/article/details/85250173
8、数据库参数优化:IO参数、CPU参数:https://blog.csdn.net/a745233700/article/details/114506553
9、硬件配置升级
10、数据库集群
一、数据库设计
适度的反范式,注意是适度的
我们都知道三范式,基于三范式建立的模型是最有效保存数 据的方式,也是最容易扩展的模式。我们在开发应用程序时,设计的数据库要最大程度的遵守三范式,特别是对于OLTP型的系统,三范式是必须遵守的规则。当 然,三范式最大的问题在于查询时通常需要join很多表,导致查询效率很低。所以有时候基于性能考虑,我们需要有意的违反三范式,适度的做冗余,以达到提 高查询效率的目的。注意这里的反范式是适度的,必须为这种做法提供充分的理由。下面就是一个糟糕的实例:
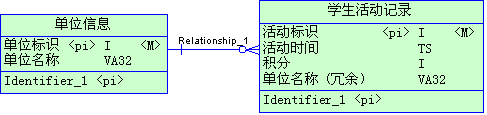
在这里,为了提高学生活动记录的检索效率,把单位名称冗余到学生活动记录表里。单位信息有500条记录,而学生活动记录在一年内大概有200万数据量。 如果学生活动记录表不冗余这个单位名称字段,只包含三个int字段和一个timestamp字段,只占用了16字节,是一个很小的表。而冗余了一个 varchar(32)的字段后则是原来的3倍,检索起来相应也多了这么多的I/O。而且记录数相差悬殊,500 VS 2000000 ,导致更新一个单位名称还要更新4000条冗余记录。由此可见,这个冗余根本就是适得其反。
下面这个冗余就很好
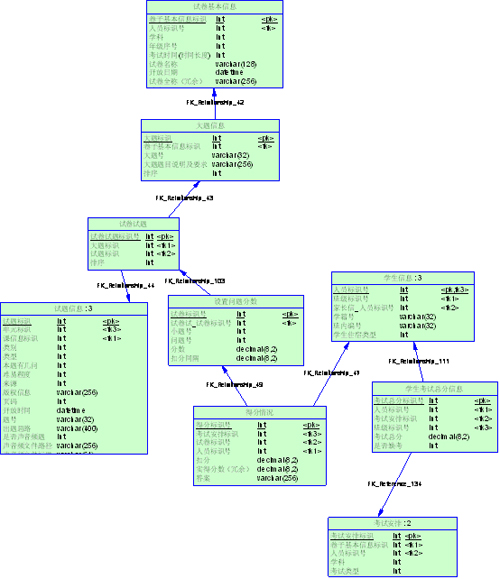
可以看到,[学生考试总分]是冗余的,这个分数完全可以通过[得分情况]汇总得到。在【学生考试总分】里,一次考试一个学生只有一条记录,而在【得分情 况】里,一个学生针对试卷里一个小题的一个小问一条记录,粗略的算一下比例大概是1:100。而且判卷子得分是不会轻易变的,更新的频率不高,所以说这个 冗余是比较好的。
适当建立索引
说起提高数据库性能,索引是最物美价廉的东西了。不用加内存,不用改程序,不用调sql,只要执行个正确的’create index’,查询速度就可能提高百倍千倍,这可真有诱惑力。可是天下没有免费的午餐,查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的I/O。由于索引的存储结构不同于表的存储,一个表的索引所占空间比数据所占空间还大的情况经常发生。这意味着我们在写数据库的时候做了很多额外的工作,而这个工作只是为了提高读的效率。因此,我们建立一个索引,必须保证这个索引不会“亏本”。一般需要遵守这样的规则:
索引的字段必须是经常作为查询条件的字段;
如果索引多个字段,第一个字段要是经常作为查询条件的。如果只有第二个字段作为查询条件,这个索引不会起到作用;
索引的字段必须有足够的区分度;
Mysql 对于长字段支持前缀索引;
对表进行水平划分
如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了。如果我拆成100个表,那么每个表只有10万条记录。当然这 需要数据在逻辑上可以划分。一个好的划分依据,有利于程序的简单实现,也可以充分利用水平分表的优势。比如系统界面上只提供按月查询的功能,那么把表按月 拆分成12个,每个查询只查询一个表就够了。如果非要按照地域来分,即使把表拆的再小,查询还是要联合所有表来查,还不如不拆了。所以一个好的拆分依据是 最重要的。
这里有个比较好的实例

每个学生做过的题都记录在这个表里,包括对题和错题。每个题会对应一个或多个知识点,我们需要根据错题来分析学生在哪个知识点上掌握的不足。这个表很容 易达到千万级,迫切需要拆分,那么根据什么来拆呢?从需求上看,无论是老师还是学生,最终会把焦点落在一个学生的身上。学生会关心自己,老师会关心自己班 的学生。而且每个学科的知识点是不同的。所以我们很容易想到,联合学科和知识点两个字段来拆分这个表。这样拆下来,每个表大概2万条数据,检索效率非常 高。
对表进行垂直划分
有些表记录数并不多,可能也就2、3万条,但是字段却很长,表占用空间很大,检索表时需要执行大量I/O,严重降低了性能。这个时候需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
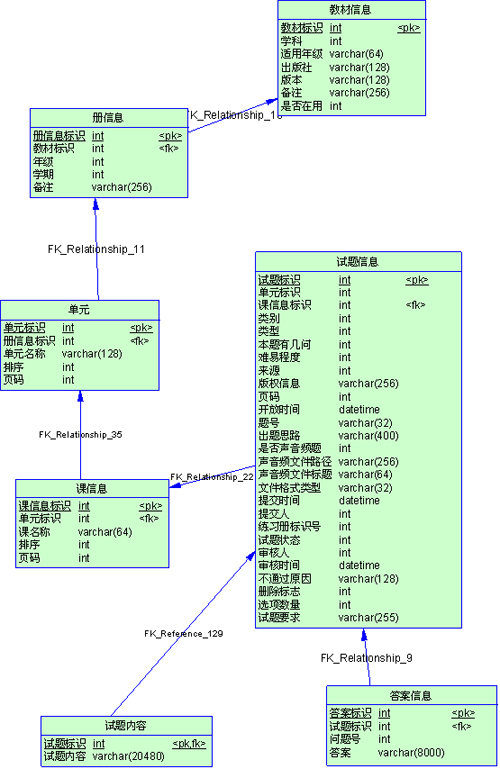
【试题内容】、【答案信息】两个表,最初是作为几个字段添加到【试题信息】里的,可以看到试题内容和答案这两个字段很长,在表里有3万记录时,表已经占 了1G的空间,在列试题列表时非常慢。经过分析,发现系统很多时候是根据【册】、【单元】、类型、类别、难易程度等查询条件,分页显示试题详细内容。而每 次检索都是这几个表做join,每次要扫描一遍1G的表,很郁闷啊。我们完全可以把内容和答案拆分成另一个表,只有显示详细内容的时候才读这个大表,由此 就产生了【试题内容】、【答案信息】两个表。
选择适当的字段类型,特别是主键
选择字段的一般原则是保小不保大,能用占用字节小的字段就不用大字段。比如主键, 我们强烈建议用自增类型,不用guid,为什么?省空间啊?空间是什么?空间就是效率!按4个字节和按32个字节定位一条记录,谁快谁慢太明显了。涉及到 几个表做join时,效果就更明显了。值得一提的是,datetime和timestamp,datetime占用8个字节,而timestamp占用4 个字节,只用了一半,而timestamp表示的范围是1970—2037,对于大多数应用,尤其是记录什么考试时间,登录时间这类信息,绰绰有余啊。
文件、图片等大文件用文件系统存储,不用数据库
不用多说,铁律!!!数据库只存储路径。
外键表示清楚,方便建立索引
我们都知道,在powerdesigner里为两个实体建立关系,生成物理模型时会自动给外键建立索引。所以我们不要怕建立关系把线拉乱,建立个ShortCut就好了。
掌握表的写入时机
在库模式相同的情况下,如何使用数据库也对性能有着重要作用。同样是写入一个表,先写和后写对后续的操作会产生很大影响。例如在上面提到的适度冗余里的例子,
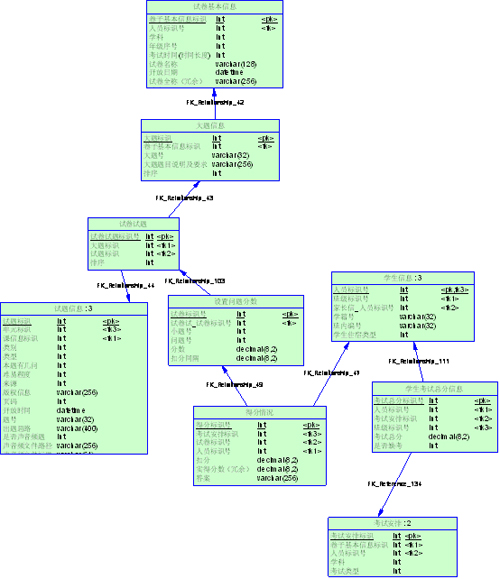
我们最初的目的是记录考生的总分,以达到提高检索效率的目的,也就是在录入成绩时写入这个表。在需求里有这样的要求:列出本次考试的所有学生成绩,没有 录入成绩的也显示该学生名称,只是总分显示为空。这个查询就需要用【学生信息】left outer join 【学生考试总分信息】,大家都知道outer join 的效率比join是要低的,为了避免这个问题,我们就在布置考试的时候写入这个表,把所有学生都插入进去,分数都是null,这样一来我们就可以用 join达到这个效果了。而且还有这样的好处:在某次考试中,安排了一个班所有学生考试,所有学生都录入了成绩。现在班里转来一个新生,那么在此时如果查 询学生成绩,就会列出这个新生,结果是未录入成绩,这显然是不对的。如果在安排的时候就写入,就可以记录下该次考试中实际的考生了,这个表的作用,也就不 知是冗余了。
宁可集中批量操作,避免频繁读写
系统里包含了积分部分,学生和老师通过系统做了操作都可以获得积分,而且积分规 则很复杂,限制每类操作获得积分不同,每人每天每类积分都有上限。比如登录,一次登录就可以获得1分,但是不管你登录多少次,一天只能累积一个登录积分。 这个还是简单的,有的积分很变态,比如老师积分中有一类是看老师判作业的情况,规则是:老师判了作业,发现学生有错的,学生改过了,老师再判,如果这时候 学生都对了,就给老师加分,如果学生还是错的,那就接着改,知道学生都改对了,老师都判完了,才能给老师加分。如果用程序来处理,很可能每个功能都会额外 的写一堆代码来处理这个鸡肋似的积分。不仅编程的同事干活找不到重点,还平白给数据库带来了很大的压力。经过和需求人员的讨论,确定积分没有必要实时累 积,于是我们采取后台脚本批量处理的方式。夜深人静的时候,让机器自己玩去吧。
这个变态的积分规则用批处理读出来是这样的:
1 select person_id, @semester_id, 301003, 0, @one_marks, assign_date, @one_marks2 from hom_assignmentinfo ha, hom_assign_class hac3 where ha.assignment_id = hac.assignment_id4 and ha.assign_date between @time_begin and @time_end5 and ha.assignment_id not in6 (7 select haa.assignment_id from hom_assignment_appraise haa, hom_check_assignment hca8 where haa.appraise_id = hca.appraise_id and haa.if_submit=19 and (10 (hca.recheck_state = 3004001 and hca.check_result in (3003002, 3003003) )11 or12 (hca.recheck_state = 3004002 and hca.recheck_result in (3003002, 3003003))13 )14 )15 and ha.assignment_id not in16 (17 select assignment_id from hom_assignment_appraise where if_submit=0 and result_type = 018 )19 and ha.assignment_id in 20 (21 select haa.assignment_id from hom_assignment_appraise haa, hom_check_assignment hca22 where haa.appraise_id = hca.appraise_id and haa.if_submit=123 and hca.check_result in (3003002, 3003003)24 ); |
这还只是个中间过程,这要是用程序实时处理,即使编程人员不罢工,数据库也会歇了。
选择合适的引擎
Mysql提供了很多种引擎,我们用的最多的是myisam,innodb,memory这三类。官方手册上说道myisqm比innodb的读速度要 快,大概是3倍。不过书不能尽信啊,《OreIlly.High.Performance.Mysql》这本书里提到了myisam和innodb的比 较,在测试中myisam的表现还不及innodb。至于memory,哈哈,还是比较好用的。在批处理种作临时表是个不错的选择(如果内存够大)。在我的一个批处理中,速度比近乎1:10。
二、SQL语句优化
Sql语句优化工具
·慢日志
如果发现系统慢了,又说不清楚是哪里慢,那么就该用这个工具了。只需要为mysql配置参数,mysql会自己记录下来慢的sql语句。配置很简单,参数文件里配置:
slow_query_log=d:/slow.txt
long_query_time = 2
就可以在d:/slow.txt里找到执行时间超过2秒的语句了,根据这个文件定位问题吧。
·mysqldumpslow.pl
慢日志文件可能会很大,让人去看是很难受的事。这时候我们可以通过mysql自带的工具来分析。这个工具可以格式化慢日志文件,对于只是参数不同的语句 会归类类并,比如有两个语句select * from a where id=1 和select * from a where id=2,经过这个工具整理后就只剩下select * from a where id=N,这样读起来就舒服多了。而且这个工具可以实现简单的排序,让我们有的放矢。Explain
现在我们已经知道是哪个语句慢了,那么它为什么慢呢?看看mysql是怎么执行的吧,用explain可以看到mysql执行计划,下面的用法来源于手册
EXPLAIN语法(获取SELECT相关信息)
EXPLAIN [EXTENDED] SELECT select_options
EXPLAIN语句可以用作DESCRIBE的一个同义词,或获得关于MySQL如何执行SELECT语句的信息:
· EXPLAIN tbl_name是DESCRIBE tbl_name或SHOW COLUMNS FROM tbl_name的一个同义词。
· 如果在SELECT语句前放上关键词EXPLAIN,MySQL将解释它如何处理SELECT,提供有关表如何联接和联接的次序。
该节解释EXPLAIN的第2个用法。
借助于EXPLAIN,可以知道什么时候必须为表加入索引以得到一个使用索引来寻找记录的更快的SELECT。
如果由于使用不正确的索引出现了问题,应运行ANALYZE TABLE更新表的统计(例如关键字集的势),这样会影响优化器进行的选择。
还可以知道优化器是否以一个最佳次序联接表。为了强制优化器让一个SELECT语句按照表命名顺序的联接次序,语句应以STRAIGHT_JOIN而不只是SELECT开头。
EXPLAIN为用于SELECT语句中的每个表返回一行信息。表以它们在处理查询过程中将被MySQL读入的顺序被列出。MySQL用一遍扫描多次联 接(single-sweep multi-join)的方式解决所有联接。这意味着MySQL从第一个表中读一行,然后找到在第二个表中的一个匹配行,然后在第3个表中等等。当所有的 表处理完后,它输出选中的列并且返回表清单直到找到一个有更多的匹配行的表。从该表读入下一行并继续处理下一个表。
当使用EXTENDED关键字时,EXPLAIN产生附加信息,可以用SHOW WARNINGS浏览。该信息显示优化器限定SELECT语句中的表和列名,重写并且执行优化规则后SELECT语句是什么样子,并且还可能包括优化过程的其它注解。
如果什么都做不了,试试全索引扫描
如果一个语句实在不能优化了,那么还有一个方法可以试试:索引覆盖。
如果一个语句可以从索引上获取全部数据,就不需要通过索引再去读表,省了很多I/O。比如这样一个表
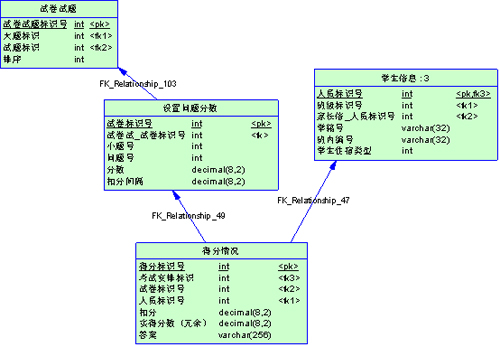
如果我要统计每个学生每道题的得分情况,我们除了要给每个表的主键外键建立索引,还要对【得分情况】的实际得分字段索引,这样,整个查询就可以从索引得到数据了。
三、数据库参数配置
最重要的参数就是内存,我们主要用的innodb引擎,所以下面两个参数调的很大
# Additional memory pool that is used by InnoDB to store metadata
# information. If InnoDB requires more memory for this purpose it will
# start to allocate it from the OS. As this is fast enough on most
# recent operating systems, you normally do not need to change this
# value. SHOW INNODB STATUS will display the current amount used.
innodb_additional_mem_pool_size = 64M
# InnoDB, unlike MyISAM, uses a buffer pool to cache both indexes and
# row data. The bigger you set this the less disk I/O is needed to
# access data in tables. On a dedicated database server you may set this
# parameter up to 80% of the machine physical memory size. Do not set it
# too large, though, because competition of the physical memory may
# cause paging in the operating system. Note that on 32bit systems you
# might be limited to 2-3.5G of user level memory per process, so do not
# set it too high.
innodb_buffer_pool_size = 5G
对于myisam,需要调整key_buffer_size
当然调整参数还是要看状态,用show status语句可以看到当前状态,以决定改调整哪些参数
Cretated_tmp_disk_tables 增加tmp_table_size
Handler_read_key 高表示索引正确 Handler_read_rnd高表示索引不正确
Key_reads/Key_read_requests 应小于0.01 计算缓存损失率,增加Key_buffer_size
Opentables/Open_tables 增加table_cache
select_full_join 没有实用索引的链接的数量。如果不为0,应该检查索引。
select_range_check 如果不为0,该检查表索引。
sort_merge_passes 排序算法已经执行的合并的数量。如果该值较大,应增加sort_buffer_size
table_locks_waited 不能立即获得的表的锁的次数,如果该值较高,应优化查询
Threads_created 创建用来处理连接的线程数。如果Threads_created较大,要增加 thread_cache_size值。
缓存访问率的计算方法Threads_created/Connections。
四、合理的硬件资源和操作系统
如果你的机器内存超过4G,那么毋庸置疑应当采用64位操作系统和64位mysql
读写分离
如果数据库压力很大,一台机器支撑不了,那么可以用mysql复制实现多台机器同步,将数据库的压力分散。
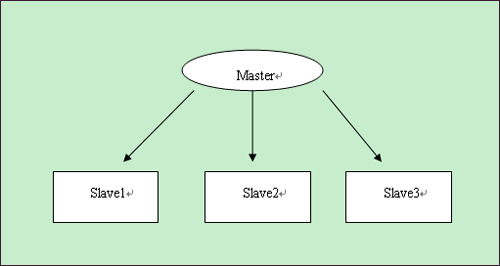
Master
Slave1
Slave2
Slave3
主库master用来写入,slave1—slave3都用来做select,每个数据库分担的压力小了很多。
要实现这种方式,需要程序特别设计,写都操作master,读都操作slave,给程序开发带来了额外负担。当然目前已经有中间件来实现这个代理,对程 序来读写哪些数据库是透明的。官方有个mysql-proxy,但是还是alpha版本的。新浪有个amobe for mysql,也可达到这个目的,结构如下
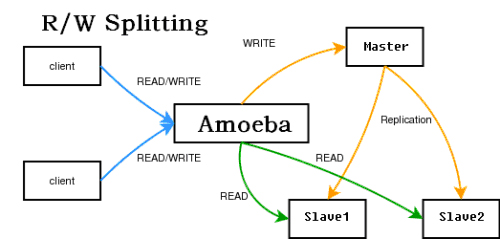
使用方法可以看amobe的手册。
--------------------------------------------------
1、索引优化全攻略
所谓索引就是为特定的mysql字段进行一些特定的算法排序,比如二叉树的算法和哈希算法,哈希算法是通过建立特征值,然后根据特征值来快速查找。而用的最多,并且是mysql默认的就是二叉树算法 BTREE,通过BTREE算法建立索引的字段,比如扫描20行就能得到未使用BTREE前扫描了2^20行的结果,具体的实现方式后续本博客会出一个算法专题里面会有具体的分析讨论;
Explain优化查询检测
EXPLAIN可以帮助开发人员分析SQL问题,explain显示了mysql如何使用索引来处理select语句以及连接表,可以帮助选择更好的索引和写出更优化的查询语句.
使用方法,在select语句前加上Explain就可以了:
Explain select * from blog where false;
mysql在执行一条查询之前,会对发出的每条SQL进行分析,决定是否使用索引或全表扫描如果发送一条select * from blog where falseMysql是不会执行查询操作的,因为经过SQL分析器的分析后MySQL已经清楚不会有任何语句符合操作;
Example
mysql> EXPLAIN SELECT `birday` FROM `user` WHERE `birthday` < "1990/2/2"; -- 结果: id: 1 select_type: SIMPLE -- 查询类型(简单查询,联合查询,子查询) table: user -- 显示这一行的数据是关于哪张表的 type: range -- 区间索引(在小于1990/2/2区间的数据),这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL,const代表一次就命中,ALL代表扫描了全表才确定结果。一般来说,得保证查询至少达到range级别,最好能达到ref。 possible_keys: birthday -- 指出MySQL能使用哪个索引在该表中找到行。如果是空的,没有相关的索引。这时要提高性能,可通过检验WHERE子句,看是否引用某些字段,或者检查字段不是适合索引。 key: birthday -- 实际使用到的索引。如果为NULL,则没有使用索引。如果为primary的话,表示使用了主键。 key_len: 4 -- 最长的索引宽度。如果键是NULL,长度就是NULL。在不损失精确性的情况下,长度越短越好 ref: const -- 显示哪个字段或常数与key一起被使用。 rows: 1 -- 这个数表示mysql要遍历多少数据才能找到,在innodb上是不准确的。 Extra: Using where; Using index -- 执行状态说明,这里可以看到的坏的例子是Using temporary和Using
select_type
- simple 简单select(不使用union或子查询)
- primary 最外面的select
- union union中的第二个或后面的select语句
- dependent union union中的第二个或后面的select语句,取决于外面的查询
- union result union的结果。
- subquery 子查询中的第一个select
- dependent subquery 子查询中的第一个select,取决于外面的查询
- derived 导出表的select(from子句的子查询)
Extra与type详细说明
- Distinct:一旦MYSQL找到了与行相联合匹配的行,就不再搜索了
- Not exists: MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了
- Range checked for each Record(index map:#):没有找到理想的索引,因此对于从前面表中来的每一个行组合,MYSQL检查使用哪个索引,并用它来从表中返回行。这是使用索引的最慢的连接之一
- Using filesort: 看到这个的时候,查询就需要优化了 。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
- Using index: 列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候
- Using temporary 看到这个的时候,查询需要优化了 。这里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
- Where used 使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index,这就会发生,或者是查询有问题不同连接类型的解释(按照效率高低的顺序排序
- system 表只有一行:system表。这是const连接类型的特殊情况
- const:表中的一个记录的最大值能够匹配这个查询(索引可以是主键或惟一索引)。因为只有一行,这个值实际就是常数,因为MYSQL先读这个值然后把它当做常数来对待
- eq_ref:在连接中,MYSQL在查询时,从前面的表中,对每一个记录的联合都从表中读取一个记录,它在查询使用了索引为主键或惟一键的全部时使用
- ref:这个连接类型只有在查询使用了不是惟一或主键的键或者是这些类型的部分(比如,利用最左边前缀)时发生。对于之前的表的每一个行联合,全部记录都将从表中读出。这个类型严重依赖于根据索引匹配的记录多少—越少越好+
- range:这个连接类型使用索引返回一个范围中的行,比如使用>或<查找东西时发生的情况+
- index: 这个连接类型对前面的表中的每一个记录联合进行完全扫描(比ALL更好,因为索引一般小于表数据)+
- ALL:这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,应该尽量避免
其中type:
- 如果是Only index,这意味着信息只用索引树中的信息检索出的,这比扫描整个表要快。
- 如果是where used,就是使用上了where限制。
- 如果是impossible where 表示用不着where,一般就是没查出来啥。
- 如果此信息显示Using filesort或者Using temporary的话会很吃力,WHERE和ORDER BY的索引经常无法兼顾,如果按照WHERE来确定索引,那么在ORDER BY时,就必然会引起Using filesort,这就要看是先过滤再排序划算,还是先排序再过滤划算。
索引
索引的类型
UNIQUE唯一索引
不可以出现相同的值,可以有NULL值
INDEX普通索引
允许出现相同的索引内容
PRIMARY KEY主键索引
不允许出现相同的值,且不能为NULL值,一个表只能有一个primary_key索引
fulltext index 全文索引
上述三种索引都是针对列的值发挥作用,但全文索引,可以针对值中的某个单词,比如一篇文章中的某个词, 然而并没有什么卵用,因为只有myisam以及英文支持,并且效率让人不敢恭维,但是可以用coreseek和xunsearch等第三方应用来完成这个需求
索引的CURD
索引的创建
ALTER TABLE
适用于表创建完毕之后再添加
ALTER TABLE 表名 ADD 索引类型 (unique,primary key,fulltext,index)[索引名](字段名)
ALTER TABLE `table_name` ADD INDEX `index_name` (`column_list`) -- 索引名,可要可不要;如果不要,当前的索引名就是该字段名; ALTER TABLE `table_name` ADD UNIQUE (`column_list`) ALTER TABLE `table_name` ADD PRIMARY KEY (`column_list`) ALTER TABLE `table_name` ADD FULLTEXT KEY (`column_list`)
CREATE INDEX
CREATE INDEX可对表增加普通索引或UNIQUE索引
--例,只能添加这两种索引; CREATE INDEX index_name ON table_name (column_list) CREATE UNIQUE INDEX index_name ON table_name (column_list)
另外,还可以在建表时添加
CREATE TABLE `test1` ( `id` smallint(5) UNSIGNED AUTO_INCREMENT NOT NULL, -- 注意,下面创建了主键索引,这里就不用创建了 `username` varchar(64) NOT NULL COMMENT '用户名', `nickname` varchar(50) NOT NULL COMMENT '昵称/姓名', `intro` text, PRIMARY KEY (`id`), UNIQUE KEY `unique1` (`username`), -- 索引名称,可要可不要,不要就是和列名一样 KEY `index1` (`nickname`), FULLTEXT KEY `intro` (`intro`) ) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='后台用户表';
索引的删除
DROP INDEX `index_name` ON `talbe_name` ALTER TABLE `table_name` DROP INDEX `index_name` -- 这两句都是等价的,都是删除掉table_name中的索引index_name; ALTER TABLE `table_name` DROP PRIMARY KEY -- 删除主键索引,注意主键索引只能用这种方式删除
索引的查看
show index from tablename \G;
索引的更改
更改个毛线,删掉重建一个既可
创建索引的技巧
1.维度高的列创建索引
数据列中 不重复值 出现的个数,这个数量越高,维度就越高
如数据表中存在8行数据a ,b ,c,d,a,b,c,d这个表的维度为4
要为维度高的列创建索引,如性别和年龄,那年龄的维度就高于性别
性别这样的列不适合创建索引,因为维度过低
2.对 where,on,group by,order by 中出现的列使用索引
3.对较小的数据列使用索引,这样会使索引文件更小,同时内存中也可以装载更多的索引键
4.为较长的字符串使用前缀索引
5.不要过多创建索引,除了增加额外的磁盘空间外,对于DML操作的速度影响很大,因为其每增删改一次就得从新建立索引
6.使用组合索引,可以减少文件索引大小,在使用时速度要优于多个单列索引
组合索引与前缀索引
注意,这两种称呼是对建立索引技巧的一种称呼,并非索引的类型;
组合索引
MySQL单列索引和组合索引究竟有何区别呢?
为了形象地对比两者,先建一个表:
CREATE TABLE `myIndex` ( `i_testID` INT NOT NULL AUTO_INCREMENT, `vc_Name` VARCHAR(50) NOT NULL, `vc_City` VARCHAR(50) NOT NULL, `i_Age` INT NOT NULL, `i_SchoolID` INT NOT NULL, PRIMARY KEY (`i_testID`) );
假设表内已有1000条数据,在这 10000 条记录里面 7 上 8 下地分布了 5 条 vc_Name=”erquan” 的记录,只不过 city,age,school 的组合各不相同。来看这条 T-SQL:
SELECT `i_testID` FROM `myIndex` WHERE `vc_Name`='erquan' AND `vc_City`='郑州' AND `i_Age`=25; -- 关联搜索;
首先考虑建MySQL单列索引:
在 vc_Name 列上建立了索引。执行 T-SQL 时,MYSQL 很快将目标锁定在了 vc_Name=erquan 的 5 条记录上,取出来放到一中间结果集。在这个结果集里,先排除掉 vc_City 不等于”郑州”的记录,再排除 i_Age 不等于 25 的记录,最后筛选出唯一的符合条件的记录。虽然在 vc_Name 上建立了索引,查询时MYSQL不用扫描整张表,效率有所提高,但离我们的要求还有一定的距离。同样的,在 vc_City 和 i_Age 分别建立的MySQL单列索引的效率相似。
为了进一步榨取 MySQL 的效率,就要考虑建立组合索引。就是将 vc_Name,vc_City,i_Age 建到一个索引里:
ALTER TABLE `myIndex` ADD INDEX `name_city_age` (vc_Name(10),vc_City,i_Age);
建表时,vc_Name 长度为 50,这里为什么用 10 呢?这就是下文要说到的前缀索引,因为一般情况下名字的长度不会超过 10,这样会加速索引查询速度,还会减少索引文件的大小,提高 INSERT 的更新速度。
执行 T-SQL 时,MySQL 无须扫描任何记录就到找到唯一的记录!!
如果分别在 vc_Name,vc_City,i_Age 上建立单列索引,让该表有 3 个单列索引,查询时和上述的组合索引效率一样吗?答案是大不一样,远远低于我们的组合索引。虽然此时有了三个索引, 但 MySQL 只能用到其中的那个它认为似乎是最有效率的单列索引,另外两个是用不到的,也就是说还是一个全表扫描的过程 。
建立这样的组合索引,其实是相当于分别建立了
- vc_Name,vc_City,i_Age
- vc_Name,vc_City
- vc_Name
这样的三个组合索引!为什么没有 vc_City,i_Age 等这样的组合索引呢?这是因为 mysql 组合索引 “最左前缀” 的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这三列的查询都会用到该组合索引,下面的几个 T-SQL 会用到:
SELECT * FROM myIndex WHREE vc_Name=”erquan” AND vc_City=”郑州” SELECT * FROM myIndex WHREE vc_Name=”erquan”
而下面几个则不会用到:
SELECT * FROM myIndex WHREE i_Age=20 AND vc_City=”郑州” SELECT * FROM myIndex WHREE vc_City=”郑州”
也就是,name_city_age(vc_Name(10),vc_City,i_Age) 从左到右进行索引,如果没有左前索引Mysql不执行索引查询
前缀索引
如果索引列长度过长,这种列索引时将会产生很大的索引文件,不便于操作,可以使用前缀索引方式进行索引前缀索引应该控制在一个合适的点,控制在0.31黄金值即可(大于这个值就可以创建)
SELECT COUNT(DISTINCT(LEFT(`title`,10)))/COUNT(*) FROM Arctic; — 这个值大于0.31就可以创建前缀索引,Distinct去重复 ALTER TABLE `user` ADD INDEX `uname`(title(10)); — 增加前缀索引SQL,将人名的索引建立在10,这样可以减少索引文件大小,加快索引查询速度
什么样的sql不走索引
要尽量避免这些不走索引的sql
SELECT `sname` FROM `stu` WHERE `age`+10=30;-- 不会使用索引,因为所有索引列参与了计算 SELECT `sname` FROM `stu` WHERE LEFT(`date`,4) <1990; -- 不会使用索引,因为使用了函数运算,原理与上面相同 SELECT * FROM `houdunwang` WHERE `uname` LIKE'后盾%' -- 走索引 SELECT * FROM `houdunwang` WHERE `uname` LIKE "%后盾%" -- 不走索引 -- 正则表达式不使用索引,这应该很好理解,所以为什么在SQL中很难看到regexp关键字的原因 -- 字符串与数字比较不使用索引; CREATE TABLE `a` (`a` char(10)); EXPLAIN SELECT * FROM `a` WHERE `a`="1" -- 走索引 EXPLAIN SELECT * FROM `a` WHERE `a`=1 -- 不走索引 select * from dept where dname='xxx' or loc='xx' or deptno=45 --如果条件中有or,即使其中有条件带索引也不会使用。换言之,就是要求使用的所有字段,都必须建立索引, 我们建议大家尽量避免使用or 关键字 -- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引
多表关联时的索引效率
- SELECT `sname` FROM `stu` WHERE LEFT(`date`,4) <1990; — 不会使用索引,因为使用了函数运算,原理与上面相同
- SELECT * FROM `houdunwang` WHERE `uname` LIKE’后盾%’ — 走索引
- SELECT * FROM `houdunwang` WHERE `uname` LIKE “%后盾%” — 不走索引
从上图可以看出,所有表的type为all,表示全表索引;也就是6 6 6,共遍历查询了216次;
除第一张表示全表索引(必须的,要以此关联其他表),其余的为range(索引区间获得),也就是6+1+1+1,共遍历查询9次即可;
所以我们建议在多表join的时候尽量少join几张表,因为一不小心就是一个笛卡尔乘积的恐怖扫描,另外,我们还建议尽量使用left join,以少关联多.因为使用join 的话,第一张表是必须的全扫描的,以少关联多就可以减少这个扫描次数.
索引的弊端
不要盲目的创建索引,只为查询操作频繁的列创建索引,创建索引会使查询操作变得更加快速,但是会降低增加、删除、更新操作的速度,因为执行这些操作的同时会对索引文件进行重新排序或更新;
但是,在互联网应用中,查询的语句远远大于DML的语句,甚至可以占到80%~90%,所以也不要太在意,只是在大数据导入时,可以先删除索引,再批量插入数据,最后再添加索引。
2、性能优化全攻略
MySQL 对于很多 Linux 从业者而言,是一个非常棘手的问题,多数情况都是因为对数据库出现问题的情况和处理思路不清晰。
在进行 MySQL 的优化之前必须要了解的就是 MySQL 的查询过程,很多的查询优化工作实际上就是遵循一些原则让 MySQL 的优化器能够按照预想的合理方式运行而已。
MySQL 查询过程
优化的哲学
注:优化有风险,修改需谨慎。
优化可能带来的问题:
-
优化不总是对一个单纯的环境进行,还很可能是一个复杂的已投产的系统。
-
优化手段本来就有很大的风险,只不过你没能力意识到和预见到。
-
任何的技术可以解决一个问题,但必然存在带来一个问题的风险。
-
对于优化来说解决问题而带来的问题,控制在可接受的范围内才是有成果。
-
保持现状或出现更差的情况都是失败。
优化的需求:
-
稳定性和业务可持续性,通常比性能更重要。
-
优化不可避免涉及到变更,变更就有风险。
-
优化使性能变好,维持和变差是等概率事件。
-
切记优化,应该是各部门协同,共同参与的工作,任何单一部门都不能对数据库进行优化。
所以优化工作,是由业务需求驱使的!
优化由谁参与?在进行数据库优化时,应由数据库管理员、业务部门代表、应用程序架构师、应用程序设计人员、应用程序开发人员、硬件及系统管理员、存储管理员等,业务相关人员共同参与。
优化思路
优化什么
在数据库优化上有两个主要方面:
-
安全:数据可持续性。
-
性能:数据的高性能访问。
优化的范围有哪些
存储、主机和操作系统方面:
-
主机架构稳定性
-
I/O 规划及配置
-
Swap 交换分区
-
OS 内核参数和网络问题
应用程序方面:
-
应用程序稳定性
-
SQL 语句性能
-
串行访问资源
-
性能欠佳会话管理
-
这个应用适不适合用 MySQL
数据库优化方面:
-
内存
-
数据库结构(物理&逻辑)
-
实例配置
说明:不管是设计系统、定位问题还是优化,都可以按照这个顺序执行。
优化维度
数据库优化维度有如下四个:
-
硬件
-
系统配置
-
数据库表结构
-
SQL 及索引
优化选择:
-
优化成本:硬件>系统配置>数据库表结构>SQL 及索引。
-
优化效果:硬件<系统配置<数据库表结构<SQL 及索引。
优化工具有啥
数据库层面
检查问题常用的 12 个工具:
-
MySQL
-
mysqladmin:MySQL 客户端,可进行管理操作
-
mysqlshow:功能强大的查看 shell 命令
-
SHOW [SESSION | GLOBAL] variables:查看数据库参数信息
-
SHOW [SESSION | GLOBAL] STATUS:查看数据库的状态信息
-
information_schema:获取元数据的方法
-
SHOW ENGINE INNODB STATUS:Innodb 引擎的所有状态
-
SHOW PROCESSLIST:查看当前所有连接的 session 状态
-
explain:获取查询语句的执行计划
-
show index:查看表的索引信息
-
slow-log:记录慢查询语句
-
mysqldumpslow:分析 slowlog 文件的工具
不常用但好用的 7 个工具:
-
Zabbix:监控主机、系统、数据库(部署 Zabbix 监控平台)
-
pt-query-digest:分析慢日志
-
MySQL slap:分析慢日志
-
sysbench:压力测试工具
-
MySQL profiling:统计数据库整体状态工具
-
Performance Schema:MySQL 性能状态统计的数据
-
workbench:管理、备份、监控、分析、优化工具(比较费资源)
关于 Zabbix 参考:http://www.cnblogs.com/clsn/p/7885990.html
数据库层面问题解决思路
一般应急调优的思路:针对突然的业务办理卡顿,无法进行正常的业务处理,需要马上解决的场景。
-
1、show processlist
-
2、explain select id ,name from stu where name='clsn'; # ALL id name age sex
-
select id,name from stu where id=2-1 函数 结果集>30;
-
show index from table;
-
3、通过执行计划判断,索引问题(有没有、合不合理)或者语句本身问题
-
4、show status like '%lock%'; # 查询锁状态
-
kill SESSION_ID; # 杀掉有问题的session
常规调优思路:针对业务周期性的卡顿,例如在每天 10-11 点业务特别慢,但是还能够使用,过了这段时间就好了。
-
1)查看slowlog,分析slowlog,分析出查询慢的语句;
-
2)按照一定优先级,一个一个排查所有慢语句;
-
3)分析top SQL,进行explain调试,查看语句执行时间;
-
4)调整索引或语句本身。
系统层面
CPU方面:vmstat、sar top、htop、nmon、mpstat。
内存:free、ps-aux。
IO 设备(磁盘、网络):iostat、ss、netstat、iptraf、iftop、lsof。
vmstat 命令说明:
-
Procs:r 显示有多少进程正在等待 CPU 时间。b 显示处于不可中断的休眠的进程数量。在等待 I/O。
-
Memory:swpd 显示被交换到磁盘的数据块的数量。未被使用的数据块,用户缓冲数据块,用于操作系统的数据块的数量。
-
Swap:操作系统每秒从磁盘上交换到内存和从内存交换到磁盘的数据块的数量。s1 和 s0 最好是 0。
-
IO:每秒从设备中读入 b1 的写入到设备 b0 的数据块的数量。反映了磁盘 I/O。
-
System:显示了每秒发生中断的数量(in)和上下文交换(cs)的数量。
-
CPU:显示用于运行用户代码,系统代码,空闲,等待 I/O 的 CPU 时间。
iostat 命令说明:
-
实例命令:iostat -dk 1 5;iostat -d -k -x 5 (查看设备使用率(%util)和响应时间(await))。
-
TPS:该设备每秒的传输次数。“一次传输”意思是“一次 I/O 请求”。多个逻辑请求可能会被合并为“一次 I/O 请求”。
-
iops :硬件出厂的时候,厂家定义的一个每秒最大的 IO 次数。
-
"一次传输"请求的大小是未知的。
-
KB_read/s:每秒从设备(drive expressed)读取的数据量。
-
KB_wrtn/s:每秒向设备(drive expressed)写入的数据量。
-
KB_read:读取的总数据量。
-
KB_wrtn:写入的总数量数据量;这些单位都为 Kilobytes。
系统层面问题解决办法
你认为到底负载高好,还是低好呢?在实际的生产中,一般认为 CPU 只要不超过 90% 都没什么问题。当然不排除下面这些特殊情况。
CPU 负载高,IO 负载低:
-
内存不够
-
磁盘性能差
-
SQL 问题:去数据库层,进一步排查 SQL 问题
-
IO 出问题了(磁盘到临界了、raid 设计不好、raid 降级、锁、在单位时间内 TPS 过高)
-
TPS 过高:大量的小数据 IO、大量的全表扫描
IO 负载高,CPU 负载低:
-
大量小的 IO 写操作
-
autocommit,产生大量小 IO;IO/PS,磁盘的一个定值,硬件出厂的时候,厂家定义的一个每秒最大的 IO 次数。
-
大量大的 IO 写操作:SQL 问题的几率比较大
IO和 CPU 负载都很高:
-
硬件不够了或 SQL 存在问题
基础优化
优化思路
定位问题点吮吸:硬件>系统>应用>数据库>架构(高可用、读写分离、分库分表)。
处理方向:明确优化目标、性能和安全的折中、防患未然。
硬件优化
①主机方面
根据数据库类型,主机 CPU 选择、内存容量选择、磁盘选择:
-
平衡内存和磁盘资源
-
随机的 I/O 和顺序的 I/O
-
主机 RAID 卡的 BBU(Battery Backup Unit)关闭
②CPU 的选择
CPU 的两个关键因素:核数、主频。根据不同的业务类型进行选择:
-
CPU 密集型:计算比较多,OLTP 主频很高的 CPU、核数还要多。
-
IO 密集型:查询比较,OLAP 核数要多,主频不一定高的。
③内存的选择
OLAP 类型数据库,需要更多内存,和数据获取量级有关。OLTP 类型数据一般内存是 CPU 核心数量的 2 倍到 4 倍,没有最佳实践。
④存储方面
根据存储数据种类的不同,选择不同的存储设备,配置合理的 RAID 级别(raid5、raid10、热备盘)。
对于操作系统来讲,不需要太特殊的选择,最好做好冗余(raid1)(ssd、sas、sata)。
主机 raid 卡选择:
-
实现操作系统磁盘的冗余(raid1)
-
平衡内存和磁盘资源
-
随机的 I/O 和顺序的 I/O
-
主机 raid 卡的 BBU(Battery Backup Unit)要关闭
⑤网络设备方面
使用流量支持更高的网络设备(交换机、路由器、网线、网卡、HBA 卡)。注意:以上这些规划应该在初始设计系统时就应该考虑好。
服务器硬件优化
服务器硬件优化关键点:
-
物理状态灯
-
自带管理设备:远程控制卡(FENCE设备:ipmi ilo idarc)、开关机、硬件监控。
-
第三方的监控软件、设备(snmp、agent)对物理设施进行监控。
-
存储设备:自带的监控平台。EMC2(HP 收购了)、 日立(HDS)、IBM 低端 OEM HDS、高端存储是自己技术,华为存储。
系统优化
CPU:基本不需要调整,在硬件选择方面下功夫即可。
内存:基本不需要调整,在硬件选择方面下功夫即可。
SWAP:MySQL 尽量避免使用 Swap。阿里云的服务器中默认 swap 为 0。
IO :raid、no lvm、ext4 或 xfs、ssd、IO 调度策略。
Swap 调整(不使用 swap 分区):
/proc/sys/vm/swappiness的内容改成0(临时),/etc/sysctl. conf上添加vm.swappiness=0(永久)
这个参数决定了 Linux 是倾向于使用 Swap,还是倾向于释放文件系统 Cache。在内存紧张的情况下,数值越低越倾向于释放文件系统 Cache。
当然,这个参数只能减少使用 Swap 的概率,并不能避免 Linux 使用 Swap。
修改 MySQL 的配置参数 innodb_flush_ method,开启 O_DIRECT 模式。
这种情况下,InnoDB 的 buffer pool 会直接绕过文件系统 Cache 来访问磁盘,但是 redo log 依旧会使用文件系统 Cache。
值得注意的是,Redo log 是覆写模式的,即使使用了文件系统的 Cache,也不会占用太多。
IO 调度策略:
#echo deadline>/sys/block/sda/queue/scheduler 临时修改为deadline
永久修改:
-
vi /boot/grub/grub.conf
-
更改到如下内容:
-
kernel /boot/vmlinuz-2.6.18-8.el5 ro root=LABEL=/ elevator=deadline rhgb quiet
系统参数调整
Linux 系统内核参数优化:
-
vim/etc/sysctl.conf
-
net.ipv4.ip_local_port_range = 1024 65535:# 用户端口范围
-
net.ipv4.tcp_max_syn_backlog = 4096
-
net.ipv4.tcp_fin_timeout = 30
-
fs.file-max=65535:# 系统最大文件句柄,控制的是能打开文件最大数量
用户限制参数(MySQL 可以不设置以下配置):
-
vim/etc/security/limits.conf
-
* soft nproc 65535
-
* hard nproc 65535
-
* soft nofile 65535
-
* hard nofile 65535
应用优化
业务应用和数据库应用独立。
防火墙:iptables、selinux 等其他无用服务(关闭):
-
chkconfig --level 23456 acpid off
-
chkconfig --level 23456 anacron off
-
chkconfig --level 23456 autofs off
-
chkconfig --level 23456 avahi-daemon off
-
chkconfig --level 23456 bluetooth off
-
chkconfig --level 23456 cups off
-
chkconfig --level 23456 firstboot off
-
chkconfig --level 23456 haldaemon off
-
chkconfig --level 23456 hplip off
-
chkconfig --level 23456 ip6tables off
-
chkconfig --level 23456 iptables off
-
chkconfig --level 23456 isdn off
-
chkconfig --level 23456 pcscd off
-
chkconfig --level 23456 sendmail off
-
chkconfig --level 23456 yum-updatesd off
安装图形界面的服务器不要启动图形界面 runlevel 3。
另外,思考将来我们的业务是否真的需要 MySQL,还是使用其他种类的数据库。用数据库的最高境界就是不用数据库。
数据库优化
SQL 优化方向:
-
执行计划
-
索引
-
SQL 改写
架构优化方向:
-
高可用架构
-
高性能架构
-
分库分表
数据库参数优化
①调整
实例整体(高级优化,扩展):
-
thread_concurrency:# 并发线程数量个数
-
sort_buffer_size:# 排序缓存
-
read_buffer_size:# 顺序读取缓存
-
read_rnd_buffer_size:# 随机读取缓存
-
key_buffer_size:# 索引缓存
-
thread_cache_size:# (1G—>8, 2G—>16, 3G—>32, >3G—>64)
②连接层(基础优化)
设置合理的连接客户和连接方式:
-
max_connections # 最大连接数,看交易笔数设置
-
max_connect_errors # 最大错误连接数,能大则大
-
connect_timeout # 连接超时
-
max_user_connections # 最大用户连接数
-
skip-name-resolve # 跳过域名解析
-
wait_timeout # 等待超时
-
back_log # 可以在堆栈中的连接数量
③SQL 层(基础优化)
query_cache_size: 查询缓存 >>> OLAP 类型数据库,需要重点加大此内存缓存,但是一般不会超过 GB。
对于经常被修改的数据,缓存会马上失效。我们可以使用内存数据库(redis、memecache),替代它的功能。
存储引擎层优化
3、配置参数优化全攻略
MySQL参数优化对于不同的网站,及其在线量,访问量,帖子数量,网络情况,以及机器硬件配置都有关系,优化不可能一次性完成,需要不断的观察以及调试,才有可能得到最佳的效果。
1、max_connections
MySQL的最大连接数,如果服务器的并发连接请求量较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,MySQL回味每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。
数值过小经常会出现ERROR 1040:Too mant connetcions错误,可以通过mysql>show status like ‘connections';通配符来查看当前状态的连接数量(试图连接到MySQL(不管是否连接成功)的连接数),以定夺该值的大小。
show variadles like ‘max_connections'最大连接数
show variables like ‘max_used_connection'相应连接数
max_used_connection/max_connections*100%(理想值约等于85%)
如果max_used_connections和max_connections相同,那么就是max_connections值设置过低或者超过服务器的负载上限了,低于10%则设置过大了。
2、back_log
MySQL能够暂存的连接数量。当主要MySQL线程在一个很短时间内得到非常多的连接请求,他就会起作用。如果MySQL的连接数据达到max_connections时,新的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈数量即back_log,如果等待连接的数量超过back_log,将不被接受连接资源。
3、wait_timeout和interative_timeout
wait_timeout:指的是MySQL再关闭一个非交互的连接之前所需要等待的秒数。
interative_timeout:指的是关闭一个交互的连接之前所需要等待的秒数。
对性能的影响
wait_timeout
(1)如果设置太小,那么连接关闭的很快,从而使一些持久的连接不起作用
(2)如果设置太大容易造成连接打开时间过长,在show processlist时,能够看到太多的sleep状态的连接,从而造成too many connections错误。
(3)一般希望wait_timeuot尽可能的低
interative_timeout的设置将对你的web application没有多大的影响
2)缓冲区变量
全局缓冲
4、key_buffer_size
key_buffer_size指定索引缓冲区的大小,他决定索引的处理速度,尤其是索引读的速度。通过检查状态值 key_read_requests和key_reads,可以知道key_buffer_size设置是否合理。比例key_reads/key_read_requests应该尽可能的低,至少是1:100,1:1000更好(上述状态值可以使用show status like ‘key_read%'获得)
未命中缓存的概率:
key_cache_miss_rate = key_reads/key_read_requests*100%
key_buffer_size只对MAISAM表起作用。
如何调整key_buffer_size的值
默认的配置数时8388608(8M),主机有4G内存可以调优值为268435456(256M)
5、query_cache_size(查询缓存简称QC)
使用查询缓存,MySQL将查询结果存放在缓冲区中,今后对同样的select语句(区分大小写),将直接从缓冲区中读取结果。
一个SQL查询如果以select开头,那么MySQL服务器将尝试对其使用查询缓存。
注:两个SQL语句,只要相差哪怕是一个字符(例如 大小写不一样:多一个空格等),那么两个SQL将使用不同的cache
通过 show ststus like ‘Qcache%' 可以知道query_cache_size的设置是否合理
Qcache_free_blocks:缓存中相邻内存块的个数。如果该值显示过大,则说明Query Cache中的内存碎片较多了。
注:当一个表被更新后,和他相关的cache block将被free。但是这个block依然可能存在队列中,除非是在队列的尾部。可以用 flush query cache语句来清空free blocks。
Qcache_free_memory:Query Cache 中目前剩余的内存大小。通过这个参数我们可以较为准确的观察当前系统中的Query Cache内存大小是否足够,是需要增多还是过多了。
Qcache_hits:表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询能缓存的效果。数字越大缓存效果越理想。
Qcache_inserts:表示多少次未命中而插入,意思是新来的SQL请求在缓存中未找到,不得不执行查询处理,执行查询处理后把结果insert带查询缓存中。这样的情况次数越多,表示查询缓存 应用到的比较少,效果也就不理想。
Qcache_lowmen_prunes:多少条Query因为内存不足而被清除出Query Cache,通过Qcache_lowmem_prunes和Qcache_free_memory 相互结合,能够更清楚的了解到我们系统中Query Cache的内存大小是否真的足够,是否非常频繁的出现因为内存不足而有Query被换出。这个数字最好是长时间来看,如果这个数字在不断增长,就表示可能碎片化非常严重,或者内存很少。
Qcache_queries_in_cache:当前Query Cache 中cache的Query数量
Qcache_total_blocks:当前Query Cache中block的数量
查询服务器关于query_cache的配置
各字段的解释:
query_cache_limit:超出此大小的查询将不被缓存
query_cache_min_res_unit:缓存块的最小大小,query_cache_min_res_unit的配置是一柄双刃剑,默认是 4KB ,设置值大对大数据查询有好处,但是如果你查询的都是小数据查询,就容易造成内存碎片和浪费。
query_cache_size:查询缓存大小(注:QC存储的单位最小是1024byte,所以如果你设定的一个不是1024的倍数的值。这个值会被四舍五入到最接近当前值的等于1024的倍数的值。)
query_cache_type:缓存类型,决定缓存什么样子的查询,注意这个值不能随便设置必须设置为数字,可选值以及说明如下:
0:OFF 相当于禁用了
1:ON 将缓存所有结果,除非你的select语句使用了SQL_NO_CACHE禁用了查询缓存
2:DENAND 则只缓存select语句中通过SQL_CACHE指定需要缓存的查询。
query_cache_wlock_invalidate:当有其他客户端正在对MyISAM表进行写操作时,如果查询在query cache中,是否返回cache结果还是等写操作完成在读表获取结果。
查询缓存碎片率:Qcache_free_block/Qcache_total_block*100%
如果查询缓存碎片率超过20%,可以用flush query cache整理缓存碎片,或者试试减小query_cache_min_res_unit,如果你的查询都是小数据量的话。
查询缓存利用率:(query_cache_size-Qcache_free_memory)/query_cache_size*100%
查询缓存利用率在25%以下的话说明query_cache_size设置过大,可以适当减小:查询缓存利用率在80%以上而且Qcache_lowmem_prunes>50
的话说明query_cache_size可能有点小,要不就是碎片太多
查询缓存命中率:Qcache_hits/(Qcache_hits+Qcache_inserts)*100%
Query Cache的限制
a)所有子查询中的外部查询SQL 不能被Cache:
b)在p'rocedure,function以及trigger中的Query不能被Cache
c)包含其他很多每次执行可能得到不一样的结果的函数的Query不能被Cache
6、max_connect_errors:
是一个MySQL中与安全有关的计数器值,他负责阻止过多尝试失败的客户端以防止暴力破解密码的情况,当超过指定次数,MySQL服务器将禁止host的连接请求,直到mysql服务器重启或通过flush hotos命令清空此host的相关信息。(与性能并无太大的关系)
7、sort_buffer_size:
每个需要排序的线程分配该大小的一个缓冲区。增加这值加速ORDER BY 或 GROUP BY操作
sort_buffer_size是一个connection级的参数,在每个connection(session)第一次需要使用这个buffer的时候,一次性分配设置的内存。
sort_buffer_size:并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统的内存资源。例如:500个连接将会消耗500*sort_buffer_size(2M)=1G
8、max_allowed_packet=32M
根据配置文件限制server接受的数据包大小。
9、join_buffer_size=2M
用于表示关联缓存的大小,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。
10、thread_cache_size=300
服务器线程缓存,这个值表示可以重新利用保存在缓存中的线程数量,当断开连接时,那么客户端的线程将被放到缓存中以响应下一个客户而不是销毁(前提时缓存数未达上限),如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,这个线程将被重新请求,那么这个线程将被重新创建,如果有很多新的线程,增加这个值可以改善系统性能,通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。
设置规则如下:1G内存配置为8,2G内存为16.服务器处理此客户的线程将会缓存起来以响应下一个客户而不是被销毁(前提是缓存数未到达上限)
Threads_cached:代表当前此时此刻线程缓存中有多少空闲线程。
Threads_connected:代表当前已建立连接的数量,因为一个连接就需要一个线程,所以也可以看成当前被使用的线程数。
Threads_created:代表最近一次服务启动,已创建线程的数量,如果发现Threads_created值过大的话,说明MySQL服务器一直在创建线程,这也比较消耗资源,可以适当增加配置文件中thread_cache_size值
Threads_running:代表当前激活的(非睡眠状态)线程数。并不是代表正在使用的线程数,有时候连接已建立,但是连接处于sleep状态。
3)配置Innodb的几个变量
11、innodb_buffer_pool_size
对于innodb表来说,innodb_buffer_pool_size的作用相当于key_buffer_size对于MyISAM表的作用一样。Innodb使用该参数指定大小的内存来缓冲数据和索引。最大可以把该值设置成物理内存的80%。
12、innodb_flush_log_at_trx_commit
主要控制了innodb将log buffer中的数据写入日志文件并flush磁盘的时间点,取值分别为0,1,2.
实际测试发现,该值对插入数据的速度影响非常大,设置为2时插入10000条记录只需要两秒,设置为0时只需要一秒,设置为1时,则需要229秒。因此,MySQL手册也建议尽量将插入操作合并成一个事务,这样可以大幅度提高速度。
13、innodb_thread_concurrency=0
此参数用来设置innodb线程的并发数,默认值为0表示不被限制,若要设置则与服务器的CPU核心数相同或是CPU的核心数的2倍。
14、innodb_log_buffer_size
此参数确定日志文件所用的内存大小,以M为单位。缓冲区更大能提高性能,对于较大的事务,可以增大缓存大小。
15、innodb_log_file_size=50M
此参数确定数据日志文件的大小,以M为单位,更大的设置可以提高性能。
16、innodb_log_files_in_group=3
为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3
17、read_buffer_size=1M
MySQL 读入缓冲区大小。对表进行顺序扫描的请求将分配到一个读入缓冲区MySQL会为他分配一段内存缓冲区
18、read_rnd_buffer_size=16M
MySQL 的随机读(查询操作)缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配到一个随机都缓冲区。进行排序查询时,MySQL会首先扫描一遍该缓冲区,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但是MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存消耗过大。
注:顺序读是根据索引的叶节点数据就能顺序的读取所需要的行数据。随机读是指一般需要根据辅助索引叶节点中的主键寻找侍其巷进行数据,而辅助索引和主键所在的数据端不同,因此访问方式是随机的。
19、bulk_insert_buffer_size=64M
批量插入数据缓存大小,可以有效的提高插入效率,默认为8M
20、binary log
binlog_cache_size=2M //为每个session分配的内存,在事务过程中用来存储二进制日志的缓存,提高记录bin-log的效率。
max_binlog_cache_size=8M //表示的是binlog能够使用的最大cache内存大小
max_binlog_size=512M //指定binlog日志文件的大小。不能将变量设置为大于1G或小于4096字节。默认值为1G.在导入大容量的sql文件时,建议关闭,sql_log_bin,否则硬盘扛不住,而且建议定期做删除。
expire_logs_days=7 //定义了mysql清除过期日志的时间
参数汇总:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
[mysqld]basedir = /usr/local/mysqldatadir = /usr/local/mysql/dataserver_id = 1socket = /usr/local/mysql/mysql.socklog-error = /usr/local/mysql/data/mysqld.errslow_query_log = 1slow_query_log_file=/usr/local/mysql/data/slow-query.loglong_query_time = 1log-queries-not-using-indexesmax_connections = 1024back_log = 128wait_timeout = 60interactive_timeout = 7200key_buffer_size = 256Mquery_cache_size = 256Mquery_cache_type = 1query_cache_limit = 50M max_connect_errors = 20sort_buffer_size = 2Mmax_allowed_packet = 32Mjoin_buffer_size = 2Mthread_cache_size = 200innodb_buffer_pool_size = 2048Minnodb_flush_log_at_trx_commit = 1innodb_log_buffer_size = 32Minnodb_log_file_size = 128Minnodb_log_files_in_group = 3log-bin=/usr/local/mysql/data/mysqlbinbinlog_cache_size = 2M max_binlog_cache_size = 8Mmax_binlog_size = 512Mexpire_logs_days = 7read_buffer_size = 1Mread_rnd_buffer_size = 16Mbulk_insert_buffer_size = 64M# Remove leading # and set to the amount of RAM for the most important data# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.# innodb_buffer_pool_size = 128M# Remove leading # to turn on a very important data integrity option: logging# changes to the binary log between backups.# log_bin# These are commonly set, remove the # and set as required.# basedir = .....# datadir = .....# port = .....# server_id = .....# socket = .....# Remove leading # to set options mainly useful for reporting servers.# The server defaults are faster for transactions and fast SELECTs.# Adjust sizes as needed, experiment to find the optimal values.# join_buffer_size = 128M# sort_buffer_size = 2M# read_rnd_buffer_size = 2M sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES |
innodb 基础优化参数:
-
default-storage-engine
-
innodb_buffer_pool_size # 没有固定大小,50%测试值,看看情况再微调。但是尽量设置不要超过物理内存70%
-
innodb_file_per_table=(1,0)
-
innodb_flush_log_at_trx_commit=(0,1,2) # 1是最安全的,0是性能最高,2折中
-
binlog_sync
-
Innodb_flush_method=(O_DIRECT, fdatasync)
-
innodb_log_buffer_size # 100M以下
-
innodb_log_file_size # 100M 以下
-
innodb_log_files_in_group # 5个成员以下,一般2-3个够用(iblogfile0-N)
-
innodb_max_dirty_pages_pct # 达到百分之75的时候刷写 内存脏页到磁盘。
-
log_bin
-
max_binlog_cache_size # 可以不设置
-
max_binlog_size # 可以不设置
-
innodb_additional_mem_pool_size #小于2G内存的机器,推荐值是20M。32G内存以上100M

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步