
Nginx实战-后端应用健康检查
严格来说,nginx是没有针对负载均衡后端节点的健康检查的,但是可以通过proxy_next_upstream来间接实现,但这个还是会把请求转发给故障服务器的,然后再转发给别的服务器,这样就浪费了一次转发。
nginx_upstream_check_module为淘宝技术团队开发的nginx模快,用来检测后方server的健康状态,如果后端服务器不可用,则所以的请求不转发到这台服务器。
1. 安装nginx_upstream_check_module
- 地址:https://github.com/yaoweibin/nginx_upstream_check_module, 下载完毕后解压
-
进入nginx源码目录,进行打该模块的补丁(这一步千万不能遗漏)
patch -p1 < ../nginx_upstream_check_module-master/check_1.5.12+.patch -
然后通过./configure --add-module来增加模块
./configure –add-module=../ nginx_upstream_check_module-master/ 注意:如果之前安装过nginx,需要将之前的configure参数保留 -
make
-
make之后的操作需要注意
如果nginx第一次安装,直接执行make install即可
make install如果单纯添加模块,不需要install,而是执行以下操作,将打过补丁的nginx二进制文件覆盖/usr/local/nginx/sbin/目录中的文件即可
cp /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.bak cp /nginx源码目录/objs/nginx /usr/local/nginx/sbin/
2. 配置nginx upstream参数
-
增加建议配置,后端有8181两个节点
location /{ proxy_pass http://cluster; } upstream cluster { server 127.0.0.1:8181; server 127.0.0.1:8182; #http健康检查相关配置 check interval=3000 rise=2 fall=3 timeout=3000 type=http; #/health/status为后端健康检查接口 check_http_send "HEAD /health/status HTTP/1.0\r\n\r\n"; check_http_expect_alive http_2xx http_3xx; }interval: 向后端发送的健康检查包的间隔,单位为毫秒
rsie: 如果连续成功次数达到rise_count,服务器就被认为是up
fall: 如果连续失败次数达到fall_count,服务器就被认为是down
timeout: 后端健康请求的超时时间,单位为毫秒
type: 健康检查包的类型,支持tcp、ssl_hello、http、mysql、ajp -
如果想查看后端服务器实时的健康状态,可以在对应server中增加以下location配置
location /nstatus { check_status; access_log off; #allow SOME.IP.ADD.RESS; #deny all; }
3. 查看健康检查状态
-
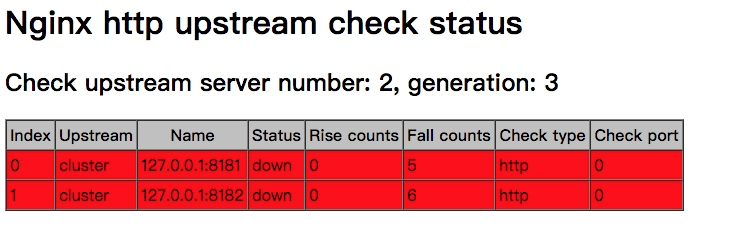
通过http://localhost:8080/nstatus 查看,如下图所示,刚开始后端两个节点都处于停止状态,status为down
![]() 
![]()
server number为后端服务器数量,generation为nginx reload的次数
-
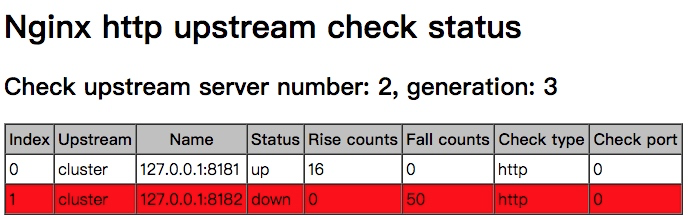
此时,启动其中一台8181,查看nginx的error.log日志,出现如下日志,说明8181这台应用已经处于可检查状态
2018/09/07 14:07:48 [error] 85860#0: enable check peer: 127.0.0.1:8181 -
刷新nstatus页面,如下图所示,发现8181这台状态变为了up,表示已连接成功
![]() 
![]()
-
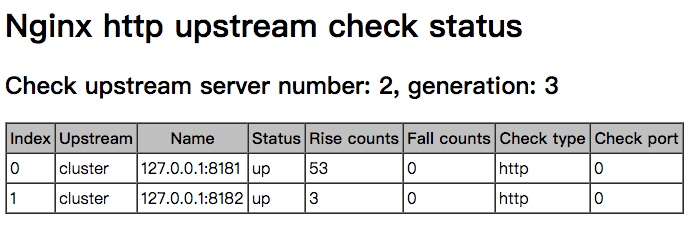
启动8182,与8181过程相同,最终页面状态变为如下,此时两台状态均为up:
![]() 
![]()
 
 
 

 浙公网安备 33010602011771号
浙公网安备 33010602011771号