【笔记】【THM】Malware Analysis(恶意软件分析)(还在学)
 小朋友们你们好啊,我是贝利亚
我要来破坏地球了,奥特曼们都被我打败了,你们敢不敢来阻止我
现在快点学习,不然我就带领怪物大军占领地球
胆小的都划走了,勇敢的小朋友逆流而上
小朋友们你们好啊,我是贝利亚
我要来破坏地球了,奥特曼们都被我打败了,你们敢不敢来阻止我
现在快点学习,不然我就带领怪物大军占领地球
胆小的都划走了,勇敢的小朋友逆流而上
【笔记】【THM】Malware Analysis(恶意软件分析)
探索恶意软件的世界,分析恶意软件如何感染系统并造成破坏。
恶意软件分析就像猫捉老鼠的游戏。恶意软件的作者一直在设计新的技术来躲避恶意软件分析师的眼睛,而恶意软件分析师也一直在寻找识别和抵消这些技术的方法。在这个模块中,我们将开始学习恶意软件分析的旅程,从基础知识到理解恶意软件作者使用的常见技术。最后,我们将学习一些工具,这些工具使恶意软件分析师能够在识别恶意软件作者的意图并击败他们方面获得立足点。

x86体系结构概述
本文相关的TryHackMe实验房间链接:TryHackMe | x86 Architecture Overview
本文相关内容:x86架构的速成课程,使我们能够进行恶意软件逆向工程。

介绍

恶意软件通常通过滥用系统的设计方式来工作。因此,为了理解恶意软件的工作原理,我们必须知道它们运行的系统的架构。在这个房间里,我们将从恶意软件分析的角度对x86架构进行简要概述。请注意,我们可能会跳过很多关于x86架构的细节,但这是因为它们与恶意软件分析无关。
(补充:X86架构(The X86 architecture)是微处理器执行的计算机语言指令集,指一个intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合。)
学习目标
总而言之,我们将在这个房间里讨论以下主题。
- CPU体系结构及其组成概述
- 不同类型的CPU寄存器及其使用
- 程序查看的内存布局
- 栈布局和栈寄存器
现在,让我们深入讨论并了解上述主题。
CPU架构概述
目前使用最广泛的CPU体系结构来源于冯·诺依曼体系结构。下图展示了该架构的简要概述。

这个图显示了中央处理器(CPU)由三个组成部分:算术逻辑单元(ALU),控制单元(CU)和寄存器。CPU与CPU外部的内存和I/O设备交互。
让我们了解一下上图中提到的每个组件。
控制单元(Control Unit):
控制单元从主内存中获取指令,如图所示,主内存在CPU外部。要执行的下一条指令的地址存储在一个称为指令指针或IP的寄存器中。在32位系统中,这个寄存器称为EIP,而在64位系统中,它称为RIP。
算术逻辑单元(Arithmetic Logic Unit):
算术逻辑单元执行从存储器中取出的指令。然后,执行指令的结果存储在寄存器或内存中。
寄存器(Registers):
寄存器是CPU的存储器。寄存器通常比位于CPU外部的主内存小得多,通过直接访问CPU来放置重要数据,有助于节省执行指令的时间。
内存(Memory):
内存,也称为主存或随机存取存储器(RAM),包含程序运行所需的所有代码和数据。当用户执行一个程序时,它的代码和数据被加载到内存中,CPU从内存中一次访问一条指令。
I / O设备(Input/Output devices):
I/O设备或输入/输出设备是与计算机交互的所有其他设备。这些设备包括键盘、鼠标、显示器、打印机、大容量存储设备(如硬盘和usb)等。
简而言之,当一个程序必须被执行时,它被加载到内存中。从那里,控制单元每次使用指令指针寄存器获取一条指令,算术逻辑单元执行它。结果存储在寄存器或内存中。
问题
1.程序运行所需的代码和数据存储在计算机体系结构的哪一部分?
2.CPU的哪一部分存储少量数据?
3.算术运算在哪个单元中执行?
WP
1.程序运行所需的代码和数据存储在内存中
2.CPU的寄存器存储少量数据
3.算术运算在算术逻辑单元中执行
寄存器概述
寄存器是CPU的存储介质。CPU可以比任何其他存储介质更快地从寄存器访问数据;然而,它有限的大小意味着必须有效地使用它。为此,寄存器分为下列不同类型。
- Instruction Pointer 指令指针
- General Purpose Registers通用寄存器
- Status Flag Registers 状态标志寄存器
- Segment Registers 段寄存器
让我们在下面逐一查看这些寄存器:
指令指针:
指令指针是一个寄存器,包含了CPU要执行的下一条指令的地址。它也称为程序计数器。它最初是Intel 8086处理器(术语x86源于此)中的一个16位寄存器,缩写为IP。在32位处理器中,指令指针变成32位寄存器,称为EIP或扩展指令指针。在64位系统中,这个寄存器成为称为RIP(这里的R代表寄存器)的64位寄存器。
通用寄存器
x86系统中的通用寄存器都是32位寄存器。顾名思义,它们在CPU执行指令期间使用。在64位系统中,这些寄存器被扩展为64位寄存器。它们包含下列寄存器。

EAX或RAX:
这是累加器寄存器。算术运算的结果通常存储在这个寄存器中。在32位系统中,存在32位EAX寄存器,而在64位系统中存在64位RAX寄存器。这个寄存器的最后16位可以通过寻址AX来访问。类似地,它也可以在8位中寻址,通过使用AL为低8位,AH为高8位。
EBX或RBX:
该寄存器也称为基址寄存器,通常用于存储基址以引用偏移量。与EAX/RAX类似,它可以被寻址为64位RBX、32位EBX、16位BX、8位BH和BL寄存器。
ECX或RCX:
该寄存器也称为计数器寄存器,常用于循环等计数操作。与上述两个寄存器类似,它可以被寻址为64位RCX、32位ECX、16位CX和8位CH和CL寄存器。
EDX或RDX:
该寄存器也称为数据寄存器。它经常用于乘法/除法运算。与上述寄存器类似,它可以被寻址为64位RDX、32位EDX、16位DX和8位DH和DL寄存器。
ESP或RSP:
这个寄存器称为栈指针(Stack Pointer)。它指向栈的顶部,与栈段寄存器联合使用。它是一个32位寄存器,在32位系统中称为ESP,在64位系统中称为RSP。它不能用较小的寄存器寻址。
EBP或RBP:
这个寄存器称为基指针(Base Pointer)。它用于访问栈传递的参数。它也与栈段寄存器联合使用。它是一个32位寄存器,在32位系统中称为EBP,在64位系统中称为RBP。
ESI 或 RSI:
这个寄存器称为源索引寄存器。它用于字符串操作。它与数据段(DS)寄存器一起用作偏移量。它是一个32位寄存器,在32位系统中称为ESI,在64位系统中称为RSI。
EDI 或 RDI
该寄存器称为目标索引寄存器。它也用于字符串操作。它与额外的Segment (ES)寄存器一起用作偏移量。它是一个32位寄存器,在32位系统中称为EDI,在64位系统中称为RDI。
R8-R15:
这些64位通用寄存器在32位系统中不存在。它们被引入64位系统。它们还可以以32位、16位和8位模式寻址。例如,对于R8寄存器,我们可以使用R8D进行低32位寻址,使用R8W进行低16位寻址,使用R8B进行低8位寻址。在这里,后缀D代表Double-word, W代表Word, B代表Byte。
问题
1.哪个寄存器保存要执行的下一条指令的地址?
2.32位系统中的哪个寄存器也称为计数器寄存器?
3.上面讨论的寄存器中,哪些不存在于32位系统中?
WP
1.指令指针保存要执行的下一条指令的地址
2.32位系统中的ECX寄存器也称为计数器寄存器
3.上面讨论的寄存器中,R8-R5不存在于32位系统中
寄存器-续
状态标志寄存器:
执行命令时,有时需要一些关于执行状态的指示。这就是状态标志的作用。用于32位系统的一个32位状态标志寄存器,称为“EFLAGS”;它在64位系统中扩展为64位,在64位系统中称为“RFLAGS”。状态标志寄存器由单个位标志组成,可以是1或0。下面讨论一些必要的标志。
Zero Flag零标志:
缩写由ZF表示,表示最后执行的指令的结果是0。例如,如果执行一条从自身减去一个RAX的指令,结果将是0。在这种情况下,ZF将被设置为1。
Carry Flag进位标志:
缩写由CF表示,表示最后执行的指令导致的数字对目标来说太大或太小。例如,如果我们将0xFFFFFFFF和0x00000001相加,并将结果存储在一个32位寄存器中,那么结果对寄存器来说就太大了。在这种情况下,CF将被设置为1。
Sign Flag符号标志:
缩写由SF表示,表示操作的结果是否为负数或最高有效位是否设置为1。如果满足这些条件,SF设置为1;否则,将其设置为0。
Trap Flag陷阱标志:
缩写由TF表示,表示处理器是否处于调试模式。设置TF时,CPU将出于调试目的一次执行一条指令。这可以被恶意软件用来识别它们是否在调试器中运行。
| 通用寄存器 | 段寄存器 | 状态寄存器 | 指令指针 |
|---|---|---|---|
| RAX, EAX, AX, AH, AL | CS | EFLAG | EIP,RIP |
| RBX, EBX, BX, BH, BL | SS | ||
| RCX, ECX, CX, CH, CL | DS | ||
| RDX,EDX,DX,DH,DL | ES | ||
| RBP, EBP, BP | FS | ||
| RSP, ESP, SP | GS | ||
| RSI、ESI、SI | |||
| RDI, EDI, DI | |||
| R8-R15 |
段寄存器:
段寄存器是16位寄存器,它将平面内存空间转换为不同的段,以便于寻址。有6个段寄存器,解释如下:
- 代码段(Code Segment, CS):代码段寄存器指向内存中的代码段。
- 数据段:数据段(Data Sgment, DS)寄存器指向内存中程序的数据段。
- 栈段(Stack Segment, SS):栈段寄存器指向程序在内存中的栈。
- 额外段(ES、FS和GS):这些额外的段寄存器指向不同的数据段。这些和DS寄存器将程序的内存划分为四个不同的数据段。
问题
1.程序使用哪个标志来标识它是否在调试器中运行?
2.当操作中的最高位设置为1时,将设置哪个标志?
3.哪个段寄存器包含了指向内存中代码段的指针?
WP
1.程序使用陷阱标志来标识它是否在调试器中运行
2.当操作中的最高位设置为1时,将设置符号标志
3.代码段寄存器包含了指向内存中代码段的指针
内存概述
当一个程序被加载到Windows操作系统的内存中时,它看到的是内存的一个抽象视图。这意味着程序不能访问整个内存;相反,它只能访问自己的内存。对于这个程序来说,这就是它所需要的所有内存。为简洁起见,我们不会深入操作系统如何执行抽象的细节。我们将从程序的角度来看待内存,因为这与我们进行恶意软件的逆向工程更相关。
这里的图表是一个程序的典型内存布局的概述。可以看到,内存分为不同的部分,即栈、堆、代码和数据。虽然我们已经以特定的顺序展示了这四个部分,但这可能与它们在任何时候的顺序不同,例如,代码部分可以位于数据部分之下。
我们可以在下面找到这四个部分的简要概述。
Code代码:
代码部分,顾名思义,包含程序的代码。具体来说,本节指的是可移植可执行文件中的text部分,其中包括CPU执行的指令。这部分内存具有执行权限,这意味着CPU可以执行程序内存中的这部分数据。
Data数据:
Data部分包含了已初始化的数据,这些数据不是变量,而是常量。它指的是可移植可执行文件中的data部分。它通常包含全局变量和其他在程序执行期间不应该改变的数据。
Heap堆:
堆,也称为动态内存,包含了程序执行过程中创建和销毁的变量和数据。创建变量时,会在运行时为该变量分配内存。当该变量被删除时,内存被释放。因此命名为动态内存。
Stack栈:
从恶意软件分析的角度来看,栈是内存的重要组成部分之一。这部分内存包含局部变量、传递给程序的参数,以及调用该程序的父进程的返回地址。由于返回地址与CPU指令的控制流相关,栈经常成为恶意软件劫持控制流的目标。您可以查看缓冲区溢出空间来了解这是如何发生的。我们将在下一个任务中介绍有关栈的更多细节。
问题
1.当程序加载到内存中时,它是否有系统内存的完整视图?
2.内存中的哪一部分包含代码?
3.哪个内存部分包含与程序控制流相关的信息?
WP
1.当程序加载到内存中时,它没有系统内存的完整视图
2.内存中的Code部分包含代码
3.内存Stack部分包含与程序控制流相关的信息
堆栈的布局
栈是程序内存的一部分,其中包含传递给程序的参数、局部变量和程序的控制流。这使得该栈在恶意软件分析和逆向工程方面非常重要。恶意软件经常利用栈劫持程序的控制流。因此,理解栈、它的布局及其工作方式非常重要。
栈是后进先出(LIFO)内存。这意味着最后压入栈的元素是第一个弹出的元素。例如,如果我们将A、B和C压入栈中,当我们弹出这些元素时,第一个弹出的将是C,然后才是B和A。CPU使用两个寄存器来跟踪堆栈。一个是栈指针(ESP或RSP),另一个是基指针(EBP或RBP)。

The Stack Pointer栈指针:
栈指针指向栈的顶部。当有新元素被压入栈时,栈指针的位置会改变,以考虑刚被压入栈的新元素。类似地,当一个元素从栈弹出时,栈指针会调整自己以反映这一变化。
The Base Pointer基指针:
任何程序的基指针都是不变的。这是当前程序栈跟踪其局部变量和参数的引用地址。
Old Base Pointer and Return Address旧基指针和返回地址:
基指针下面是调用程序(调用当前程序的程序)的旧基指针。在旧基指针下面是返回地址,即当前程序执行结束后,指令指针将返回的地址。
劫持控制流的一种常见技术是溢出栈上的局部变量(Local Var),从而用恶意软件作者选择的地址覆盖返回地址。这种技术称为栈缓冲区溢出(Stack Buffer Overflow)。
Arguments参数:
传递给函数的参数在函数开始执行之前被压入栈。这些参数就在栈上的返回地址下面。
函数序言和尾声:
当函数被调用时,栈已经为函数的执行做好了准备。这意味着参数在函数开始执行之前被压入栈。之后,返回地址和旧基指针被压入栈。一旦这些元素被压入,基指针的地址就会改变到栈的顶部(此时将是调用函数的栈指针)。在函数执行时,栈指针会根据函数的需求移动。这部分代码将参数、返回地址和基指针压入栈中,并重新排列栈和基指针,这部分代码称为函数序言。
类似地,当函数退出时,旧的基指针从栈弹出到基指针上。返回地址弹出到指令指针,栈指针重新排列,指向栈顶。执行该操作的代码部分称为函数尾声(Function Epilogue)。
点击任务顶部的View Site按钮,在分屏视图中启动静态站点。现在,跳到附加的静态站点并通过正确地排列堆栈找到标志。
问题
按照附接的静态站点中的说明找到flag
WP
打开网址启动静态站点
按照顺序排列即可得到flag
x86汇编速成课
本文相关的TryHackMe实验房间链接:TryHackMe | x86 Assembly Crash Course
本文相关内容:x86汇编的速成课程,让我们能够进行恶意软件的逆向工程。
介绍
汇编语言是人类可读语言的最低级别。它也是二进制文件可以被可靠地反编译成的最高级别语言。在学习恶意软件逆向工程时,了解汇编语言的基础知识是必不可少的。这是因为当我们得到一个恶意软件样本进行分析时,它很可能是一个编译过的二进制文件。我们无法查看该二进制文件的C/C或其他语言代码,因为这对我们来说是不可用的。
然而,我们能做的是使用反编译器或反汇编器反编译代码。反编译的问题在于,编写的代码在编译成二进制文件时删除了很多信息;因此,我们不会像编写代码时那样看到变量名、函数名等。因此,对于编译好的二进制文件来说,最可靠的代码是它的汇编代码。在这个房间,我们将学习汇编的基础知识,我们可以在恶意软件分析的学习中使用,以了解二进制文件在做什么,同时查看其汇编代码。
学习目标
我们将涵盖以下主题:
- 操作码和操作数
- 一般的指令说明
- 算术和逻辑指令
- 条件
- 分支指令
先决条件
在开始这个房间之前,强烈建议您先完成x86体系结构概述的学习
操作码和操作数
程序的代码是二进制格式,写入磁盘并被CPU理解。这意味着实际的代码是由1和0组成的序列。为了便于理解,我们经常将一组8位(称为字节)组合成一个十六进制的单个数字。因此,计算机正在执行的指令对人类来说只是一串十六进制的随机数。这些随机数包括操作码(opcodes)和操作数(operand)。操作码表示实际操作的十六进制,操作数是执行操作的寄存器或内存位置。

Opcodes操作码
操作码(Opcodes)是与CPU执行的指令相对应的数字。当我们使用反汇编程序(我们将在即将到来的房间中了解反汇编程序)来反汇编程序时,它读取操作码。它将它们翻译成汇编指令,使其可读。例如,将0x5F移动到eax寄存器的指令是:
mov eax, 0x5f
当在反汇编程序中查看它时,我们将看到:
040000: b8 5f 00 00 00 mov eax, 0x5f
040000: 对应于指令所在的地址。
b8 指指令 mov eax
5F 00 00 00 表示另一个操作数 0x5f 。
请注意,由于字节序的关系,操作数0x5f被写成 5f 00 00 00 ,实际上是 00 00 00 5f ,但使用的是小端字节序表示法。类似地,汇编语言中的每条指令都有一个操作码。还有将操作码转换为汇编指令的参考资料。尽管如此,除非我们正在编写反汇编程序,否则我们将不需要它们,因为反汇编程序可以很好地运行。然而,理解底层发生了什么有助于更好地了解整体情况。
我们看到,在上面的操作中,我们有三个部分,一个指令 mov ,两个操作数 eax 和 0x5f 。在本指令中, 0x5f 被移动到 eax ;然而,在汇编语言中也可以有其他类型的操作数。
Types of Operands操作数的类型
一般来说,汇编语言有三种操作数。
- 立即数(Immediate Operands )也可以被视为常量。这些都是固定值,就像上面示例中的
0x5f一样 。 - 寄存器(Registers)也可以是操作数。上面的示例将
eax显示为存储直接操作数的寄存器。 - 内存操作数(Memory operands)由方括号表示,它们引用内存位置。例如,如果我们看到
[eax]是一个操作数,这意味着eax中的值是必须执行操作的内存位置。
现在我们已经学习了操作数和操作码,我们将在下一个任务中学习常见的汇编指令。
问题
1.表示汇编操作的十六进制代码是什么?
2.哪种类型的操作数用方括号表示?
WP
1.表示汇编操作的十六进制代码是操作码
2.内存操作数用方括号表示
一般的指令说明
指令告诉CPU要执行什么操作。指令通常使用来自寄存器、内存或直接操作数的操作数来执行操作,然后将结果存储在寄存器或内存中。在这个任务中,我们将学习在对恶意软件进行逆向工程时可能遇到的最常见的指令。
这些指令执行简单的操作,例如将值从一种存储类型移动到另一种存储类型。

MOV指令
mov指令将值从一个位置移动到另一个位置。其语法如下:
mov destination, source
mov指令可以将一个固定的值移动到一个寄存器,将一个寄存器移动到另一个寄存器,并将内存位置中的值移动到一个寄存器。下面的例子将有助于解释。
下面的指令将一个固定值复制到寄存器。在这条指令中,0x5f被移动到了eax:
mov eax, 0x5f
在这个例子中,存储在eax中的值被移动到ebx:
mov ebx, eax
下面的指令将存储在内存位置中的值复制到寄存器:
mov eax, [0x5fc53e]
如上所述,我们在引用内存位置时使用方括号。类似地,假设我们在方括号中看到一个寄存器。在这种情况下,这将意味着该寄存器中的值将被视为内存位置,该内存位置中的值将被移动到目标位置。这意味着 mov eax, [0x5fc3e] 和下面的示例将得到相同的结果。
mov ebx, 0x5fc53e
mov eax, [ebx]
在引用内存地址时,我们可以使用mov指令执行算术计算。例如,下面的指令计算ebp+4(向内存位置增加4字节的偏移量),并将结果内存地址中的值移动到eax:
mov eax, [ebp+4]
LEA指令
lea指令代表“加载有效地址”(load effective address)。有效地址通常是由一个或多个寄存器或内存地址组成的复杂表达式的结果。LEA 指令计算这个表达式的值,并将结果(即有效地址)存储到目标寄存器中,而不会去访问或修改该地址处的内存内容。此指令的格式如下:
lea destination, source
mov指令将源内存地址的数据移动到目标,而lea指令将源地址移动到目标。在下面的示例中,ebp值将增加4并移动到eax。但是,如果我们在这里使用mov指令而不是lea,它将移动内存位置为ebp+4中的值。
lea eax, [ebp+4]
在这里,我们可以注意到,我们使用一条指令对一个寄存器执行了算术运算,并将结果保存在另一个寄存器中。 lea 指令通常用于编译器,不是用于引用内存位置,而是用于在一个寄存器上执行算术运算,并用一条指令将运算保存到另一个寄存器上。
这是真实的,特别是在算术运算更复杂的情况下,比如用一条指令完成加法和乘法。我们将会看到,在这个操作中使用算术运算需要几个指令。
NOP指令
nop指令表示无操作。该指令与自身交换eax中的值,导致没有任何有意义的操作。因此,执行转移到下一条指令而不改变任何东西。nop指令用于在等待操作或其他类似目的时消耗CPU周期。它的语法如下:
nop
恶意软件的作者会使用nop指令来重定向执行到他们的shellcode。执行重定向的确切位置通常是未知的,因此恶意软件作者会使用一堆nop指令来确保shellcode不会从中间开始执行。这种nop指令的填充称为“空操作雪橇”
Shift Instructions移位指令
CPU使用移位指令将每个寄存器位移位到相邻的位。有两个shift指令可用于右移或左移。移位指令的语法如下:
shr destination, count
shl destination, count
这里shr指令用于右移操作,shl指令用于左移操作。该指令对目标操作数中的位进行移位。计数操作数决定要移位的位数。被移出的位被填满了零。所以,如果我们把00000010放在eax里然后向左平移,它就变成了00000100。
进位标志(CF)用于增加目标,因为它由溢出目标的最后一位填充。例如,如果我们在eax中有00000101,并将其右移1位,结果将在eax中得到00000010
移位指令被用来代替乘法和除以2或2的幂(2n,其中n是移位指令中的计数)。这节省了执行时间,因为在执行乘法或除法之前不必操作寄存器中的值。例如,如果eax有00000010,我们向右移动1位,我们得到00000001,这与eax除以2的结果相同。类似地,如果eax是00000001,我们左移1位,结果是00000010,与eax乘以2相同。
Rotate Instructions旋转指令
rotate指令类似于shift指令。唯一的区别是,这些位被旋转回寄存器的另一端,而不是将溢出位移动到进位标志中,或者加0而不是移出位。rotate指令的语法如下:
ror destination, count
rol destination, count
这里, ror 指令将目标旋转到右边, rol 将目标旋转到左边。其余的语法保持不变。举个例子,如果al中有10101010,我们将其右旋转1位,结果将是01010101。类似地,将结果向左旋转1位,结果仍然是10101010。
问题
1.在mov eax, ebx指令中,哪个寄存器是目标操作数?
2.什么指令不执行任何操作?
WP
1.在mov eax, ebx指令中,eax寄存器是目标操作数,ebx是源操作数
2.nop指令不执行任何操作
标志

在x86汇编语言中,CPU有几个标志来指示某些操作或条件的结果。这些标志是一个特殊寄存器中的位,称为标志寄存器或EFLAGS寄存器。每个标志表示最近一次算术或逻辑操作的特定条件或结果。下面是x86汇编中最常见的标志及其解释:
| 标志 | 缩写 | 解释 |
|---|---|---|
| Carry进/借位标志 | CF | 运算结果的最高有效位向更高位进位或运算结果的最高有效位从更高位借位时设置。也用于逐位移位操作。 |
| Parity奇偶标志 | PF | 如果结果的所有二进制位中1的个数为偶数,则设置。 |
| Auxiliary辅助进位 | AF | 在进行算术运算的时候,如果低字节中低4位产生进位或者借位的时候,则设置 |
| Zero零标志 | ZF | 如果运算结果为零,设置。 |
| Sign符号标志 | SF | 如果操作结果为负(即,最高有效位为1),则设置。 |
| Overflow溢出标志 | OF | 设置是否存在有符号算术溢出(例如,将两个正数相加并得到负结果,反之亦然)。 |
| Direction方向标志 | DF | 确定字符串处理指令的方向。如果DF=0,则向前处理字符串;如果DF=1,则向后处理字符串。 |
| Interrupt Enable中断允许标志 | IF | 如果设置为(1),则启用可屏蔽的硬件中断。如果清除(0),中断被禁用。 |
标志可用于条件跳转,对于在汇编代码中实现条件分支至关重要。例如,如果设置或清除了某个标志,则可能只跳转到特定的地址。
问题
1.如果操作的结果为零,将设置哪个标志?(答案为缩写)
2.如果操作结果为负数,将设置哪个标志?(答案为缩写)
WP
1.如果操作的结果为零,将设置ZF标志?
2.如果操作结果为负数,将设置SF标志?
算术和逻辑指令
算术运算
算术运算由CPU使用算术指令执行。
加法和减法指令
加法指令的语法如下。该值被添加到目标,结果存储在目标中。
add destination, value
减法指令遵循类似的语法。在下面的语法中,从目标中减去该值,并将结果存储在目标中。
sub destination, value
乘法和除法指令
乘法和除法操作使用eax和edx寄存器。因此,我们必须查看为每个乘法和除法操作这些寄存器的最后一条指令。
乘法指令的格式如下。它将该值与eax相乘,并将结果作为64位值存储在edx:eax中。这里需要两个寄存器,因为两个32位值相乘的结果通常大于32位。结果的低32位存储在eax寄存器中,高32位存储在edx寄存器中。
mul value
该值可以是另一个寄存器,也可以是作为即时操作数的常量。
对于除法的指令来说,情况正好相反。它将edx:eax中的64位值相除,并将结果保存在eax中,其余的部分保存在edx中。
div value
递增和递减指令
顾名思义,递增和递减指令将操作数寄存器加1或减1。将eax加1的语法如下:
inc eax
类似地,使用decrement指令使eax减1的语法如下:
dec eax
逻辑指令
逻辑指令用于执行逻辑操作。让我们看一下CPU执行的一些常见逻辑操作。

AND和指令
AND指令对操作数执行按位与操作。当两个输入都为1时,AND操作返回1;否则,返回0。示例说明如下:
and al, 0x7c
在这个例子中,0x7c转换为二进制为01111100。假设al的值是0xfc,即11111100。在这种情况下,上述指令的输出将是01111100。但是,如果al的二进制值是0x8c, 二进制转换为10001100,那么上述指令的结果将是00001100或0xc。
OR或指令
OR指令执行按位或操作。如果至少有一个操作数为1,OR操作返回1。如果所有操作数都不为1,则返回0。示例说明如下:
or al, 0x7c
在这个例子中,如果al的二进制值是0xfc或11111100,那么上述指令的输出将是11111100。类似地,如果al的二进制值是0x8c或10001100,结果仍然是二进制值11111100或0xfc。
NOT非指令
NOT指令接收一个操作数。它只是反转操作数,将1替换为0,反之亦然。在下例中,如果al的值为11110000,则结果为00001111。
not al
XOR异或指令
如果两个输入都相反,XOR操作返回1。当两个输入相同时,它返回0。该操作由汇编语言中的XOR指令执行,该指令对操作数进行按位XOR操作。它的语法如下。
xor al, 0x7c
如果al的值是0xfc,即11111100,那么这条指令的结果将是10000000或0x80。类似地,如果al的值为0x8c,即10001100,则此指令的结果将是11110000或0xf0。如果al的值为0x7c,则结果为0x00。这表明寄存器与自身异或的结果是0。因此,XOR指令通常用于寄存器归零,这比MOV指令更优化。
问题
1.在减法操作中,如果目标小于减法值,则设置哪个标志
2.哪条指令用于增加寄存器的值?
3.下面的指令是否有相同的结果?
xor eax, eax
mov eax, 0
WP
1.在减法操作中,如果目标小于减法值,则设置借位标志
为什么不设置符号标志?
进位标志与符号标志的区别
- 在减法操作中,如果被减数小于减数,就会产生借位(需要从更高位借位),因此设置进位标志(CF),它专门用于表示无符号运算的溢出或借位情况。
- 符号标志(SF)主要用于有符号数的计算,表明结果的符号。在减法操作中,符号标志的设置与结果本身的符号直接相关,而不是与是否发生了借位相关。
例子
假设在一个 8 位的无符号整数减法中,尝试执行 5 - 10:
- 结果是 -5(在二进制中表示为补码
11111011),这里借位标志(CF)会被设置,因为 5 小于 10。 - 同时,结果为负,因此符号标志(SF)也会被设置为 1。
然而,这两个标志反映的是不同的条件:CF 反映借位的发生,而 SF 反映结果的符号。这就是为什么在需要标识被减数是否小于减数时,优先使用进位标志(CF)而非符号标志(SF)。
2.递增指令用于增加寄存器的值
3.eax中的值与自身进行异或必定为0,相当于给eax赋值为0
条件语句和分支语句
条件语句
CPU经常必须判断两个值是相等、大于还是小于对方。为了执行这些操作,CPU使用了一些条件指令。本节将讨论x86汇编语言中的条件指令。
TEST指令
TEST指令执行位与(AND)操作,而不是像与(AND)指令那样将结果存储在目标操作数中,如果结果为0,它将设置零标志(ZF)。该指令通常用于检查操作数是否为NULL值,例如,通过对操作数自身进行测试。这样做是因为使用测试指令所需的字节比与0相比要少。测试指令的语法如下:
test destination, source
CMP指令
根据结果,CMP指令比较两个操作数,并设置零标志(ZF)或进位标志(CF)。它的语法如下:
cmp destination, source
compare指令的工作原理类似于subtract(减法)指令。唯一的区别是没有修改操作数。如果两个操作数相等,则设置标志ZF (Zero)。如果源操作数大于目标操作数,则设置进位标志(CF)。如果目的操作数大于源操作数,则清除ZF和CF。
分支语句
当没有分支时,指令指针会按照指令在内存中的顺序从一个指令跳转到另一个指令。除非有分支操作,否则控制流保持在一条直线上。分支操作会改变指令指针的值,并将程序的控制流从线性改为分支。

JMP指令
JMP指令使控制流跳转到指定位置。它的语法如下:
jmp location
在这里,位置操作数将移动到指令指针,使其成为获取下一条指令执行的地址。
条件跳转
通常,如果满足特定的条件,代码就需要移动。在高级语言中,有 if 条件帮助满足这个要求。但是,汇编语言中没有if语句。这个要求可以通过条件跳转来实现。条件跳转根据标志寄存器的值决定是否跳转。它们的语法类似于跳转指令。下表显示了一些常见的条件跳转。
| 指令 | 解释 |
|---|---|
| jz | 如果设置了ZF (ZF=1),则跳转。 |
| jnz | 如果ZF未设置(ZF=0),则跳转。 |
| je | 如果相等则跳转。常用于CMP指令之后。 |
| jne | 如果不相等则跳转。常用于CMP指令之后。 |
| jg | 如果目标操作数大于源操作数,则跳转。执行有符号比较,通常在CMP指令之后使用。 |
| jl | 如果目标操作数小于源操作数,则跳转。执行有符号比较,通常在CMP指令之后使用。 |
| jge | 如果大于或等于,则跳转。如果目标操作数大于或等于源操作数,则跳转。类似于上面的指令。 |
| jle | 如果小于或等于,则跳转。如果目标操作数小于或等于源操作数,则跳转。类似于上面的指令。 |
| ja | 如果在上面就跳转。类似于jg,但执行无符号比较。 |
| jb | 如果在下面就跳转。类似于jl,但执行无符号比较。 |
| jae | 如果大于或等于,则跳转。类似于上面的指令。 |
| jbe | 如果低于或等于,则跳转。类似于上面的指令。 |
问题
1.当测试指令为0时,哪个标志被设置?
2.下面哪个操作使用减法来测试两个值?1还是2?
1. cmp eax, ebx
2. test eax, ebx
3.哪个标志用于标识在jz或jnz指令之后是否进行跳转?
WP
1.当测试指令为0时,零标志被设置
2.1使用减法来对比两个值的大小,2将两个操作数进行按位AND比较且运算结果在设置过相关标记位后会被丢弃。
3.零标志用于标识在jz或jnz指令之后是否进行跳转
栈和函数调用
堆栈
在上一篇文章,我们了解了栈及其重要性。我们还了解了一些用于引用栈在内存中的位置的寄存器。栈是后进先出(LIFO)内存。这意味着最后一个压入栈的变量是第一个弹出的。这些push和pop操作是按照汇编语言中的指令执行的。

PUSH指令
push指令的语法如下:
push source
如前所述,push指令会将源操作数压入栈中。操作数的值存储在栈指针(stack pointer, ESP)指向的内存位置,实际上成为了新的栈顶。然后调整栈指针(减1),以反映更新后的栈顶位置。下面的指令也会将所有通用寄存器压入栈。
pusha (push all words):将所有16位通用寄存器推入堆栈,即AX、BX、CX、DX、SI、DI、SP、BP pushad (push all double words):将所有32位通用寄存器推入堆栈,即EAX、EBX、ECX、EDX、ESI、EDI、ESP、EBP
当我们遇到这些指令时,通常是有人手动注入汇编指令来保存寄存器的状态,就像shellcode的情况一样。
POP指令
pop指令的语法如下:
pop destination
pop指令从栈顶取出值,并将其存储在目标操作数中。因此,栈指针(ESP)会加1,以反映弹出值后所做的调整。下面的指令也会从栈中弹出所有通用寄存器。
popa(pop all words):按以下顺序将值从堆栈顶部依次弹出到通用寄存器:DI, SI, BP, BX, DX, CX, AX。调整SP或ESP以反映新的堆栈顶部位置。
popad(pop all double words):按以下顺序将值从堆栈顶部依次弹出到通用寄存器:EDI, ESI, EBP, EBX, EDX, ECX, EAX。调整SP或ESP以反映新的堆栈顶部位置。
The CALL Instruction调用指令
在汇编语言中,调用指令用于执行特定任务的函数调用操作。它的语法如下:
call location
根据调用约定,参数被放置在函数调用的栈上或寄存器中。函数序言通过调整EBP和ESP并将返回地址压入栈来准备栈。类似地,当函数返回时,尾声将恢复调用函数的堆栈。我们将在后续中了解更多关于调用约定、序言和尾声的内容。
问题
1.哪条指令用于执行函数调用?
2.哪条指令用于将所有寄存器压入栈?
WP
1.CALL指令用于执行函数调用?
2.pusha指令用于将所有寄存器压入栈
练习时间
点击这个任务右上角的“查看站点”按钮。它将在分屏中打开一个实验室。为了更方便使用全屏,你可以点击这里在一个新的选项卡中打开它。请跟随提示学习。之后,跟踪并运行指令来观察堆栈、内存、寄存器和标志。(这一部分最好到原实验房间中的站点进行学习)
顶部栏上的选项可以用于:
- 运行程序
- 执行下一条指令
- 停止执行
- 重新启动程序
汇编代码
该实验室包含以下汇编代码指令。运行这些指令并观察这些指令如何影响寄存器、标志、内存和堆栈。
算术编码
下列指令演示了不同的算术指令是如何工作的:
mov eax,20h
mov ebx,30h
add eax,ebx
nop
nop
sub eax,ebx
inc ebx
dec ebx
mul eax
MOV指令
下列指令演示了如何移动数据:
- 到寄存器
- 从寄存器到寄存器
- 从内存到寄存器
- 从寄存器到存储器
从模拟器的下拉菜单中选择Mov指令代码,运行每条指令,并观察寄存器和内存。
mov eax,10h
mov ebx,32h
mov ecx,eax
mov [eax],40h ; Observe the memory location [10]
add [eax],30h ; This will add 30 to the value placed at the memory location [eax]
; Is moving data from the memory location directly to the memory location allowed?
; Run the following instruction to find out.
mov [ebx],[eax]
堆栈
下面的指令演示了两条指令, push 和 pop 用于将数据压入堆栈并弹出数据。从模拟器的下拉菜单中选择栈代码并观察结果。
mov eax,10h
mov ebx, 15h
mov ecx, 20h
mov edx, 25h
; stack works from the higher memory location to the lower. Observe the stack on the right side.
push eax
push ebx
push ecx
push edx
; stack works in LIFO mode. Observe how the top of the stack is pulled out in the following instructions.
pop eax
pop ebx
pop ecx
pop edx
CMP和TEST指令
在前面的任务中,我们探索了两条条件指令:
test 和 cmp ,用于比较两个值,并根据结果设置标志。让我们可视化一下如何根据结果更改标志。
在比较两个值时,只有三种可能的结果;每个结果对关键标志(如ZF和CF)有不同的影响。标志的值决定了程序的流程。因此,有必要了解每个比较条件会影响哪些标志。
| 条件 | 例子 | 受cmp指令影响的标志 | 受测试指令影响的标志 |
|---|---|---|---|
| 当两个值相等时 | EAX = EBX | Parity Flag, Zero Flag奇偶标志,零标志 | 不影响标志 |
| 当eax大于ebx时 | EAX > EBX | 不影响标志 | Parity Flag, Zero Flag奇偶标志,零标志 |
| 当eax小于ebx时 | EAX < EBX | Carry Flag, Sign Flag进/借位标志,符号标记 | Parity Flag, Zero Flag奇偶标志,零标志 |
从模拟器的下拉菜单中选择Cmp和测试指令代码,并验证上表中提到的信息。
; Examine the flags for the test and cmp instructions when both values are the same
mov eax,10h
mov ebx,10h
cmp eax,ebx
test eax,ebx
; Examine the flags for the test and cmp instructions when eax > ebx
mov eax,20h
mov ebx,10h
cmp eax,ebx
test eax,ebx
; Examine the flags for the test and cmp instructions when eax < ebx
mov eax,20h
mov ebx,40h
cmp eax,ebx
test eax,ebx
LEA指令
从模拟器的下拉菜单中选择Lea指令代码,并观察数据的移动。
mov eax,20h
mov ebx,30h
add eax,ebx
nop
mov [eax],ebx
add ebx,15h
mov ecx,6
mov [ebx+ecx],eax
lea eax,[ebx+ecx]
push eax
push ebx
pop ecx
理解汇编指令是成为一名深入的恶意软件分析师的关键部分。练习组合这些指令,熟悉这些指令。
注意:第一条指令位于指令块的索引0处。
问题
1.运行MOV指令时,运行第4条指令后[eax]的值是多少?(十六进制)
2.在运行MOV指令部分的第6条指令后,会显示什么错误?
3.运行stack部分中的指令。第9条指令后eax的值是多少?(十六进制)
4.运行stack部分中的指令。在第12条指令之后,edx的值是多少?(十六进制)
5.运行stack部分中的指令。在POP ecx之后,栈顶的剩余值是什么?(十六进制)
6.运行cmp和测试指令。在第三个指令之后触发哪些标志?
7.运行测试和cmp指令。在第11条指令之后触发哪些标志?
8.运行lea部分中的指令。运行第9条指令后,eax的值是多少?(十六进制)
9.运行lea部分中的指令。在ECX寄存器中找到的最终值是什么?(十六进制)
WP
1.运行MOV指令时,运行第4条指令后[eax]的值是

可以发现[eax]的值为0x00000040
2.不允许内存到内存的数据移动。
3.运行stack部分中的指令。第9条指令后eax的值是push出的栈顶edx的值
可以发现eax的值为0x00000025
4.运行stack部分中的指令。第12条指令后edx的值是push出的栈顶eax的值
可以发现edx的值为0x00000010
5..运行stack部分中的指令。在POP ecx之后,栈顶的剩余值是最先PUSH进的eax的值

可以发现栈顶的剩余值为0x00000010
6.运行cmp和测试指令。在第三个指令对比了eax和ebx的值,对比方式即将eax减去ebx的值再判断是否为零,EAX = EBX受cmp指令影响的标志为PF和ZF
7.运行测试和cmp指令。在第11条指令对比了eax和ebx的值,对比方式即将eax减去ebx的值再判断是否为零,EAX < EBX受cmp指令影响的标志为CF和SF
8.运行lea部分中的指令。第9条指令将 ebx 和 ecx 寄存器的值相加,并将计算出的结果(作为地址值)存储在 eax中

9.运行lea部分中的指令。在ECX寄存器中找到的最终值是后入栈的栈顶值为ebx的值
Windows内部构建
本文相关的TryHackMe实验房间链接:TryHackMe | Windows Internals
本文相关内容:x86架构的速成课程,使我们能够进行恶意软件逆向工程。

介绍
操作系统背后的技术和架构比我们最初看到的要多得多。在这个房间里,我们将观察Windows操作系统和常见的内部组件。

学习目标
- 理解Windows进程及其底层技术,并与之交互。
- 了解核心文件格式以及如何使用它们。
- 与Windows内部交互,了解Windows内核如何运行。
由于Windows机器构成了企业基础设施的大部分,红队需要了解Windows的内部以及它们是如何做到的。红队可以使用Windows来帮助规避和利用,当制作攻击性工具或漏洞利用。
在开始本课程之前,请先熟悉Windows的基本用法和功能。C和PowerShell的基本编程知识也是推荐的,但不是必需的。
进程

进程维护并表示程序的执行;一个应用程序可以包含一个或多个进程。一个进程有许多组件,它被分解为存储和交互的组件。
微软文档对这些其他组件进行了分解,“每个进程提供执行程序所需的资源。进程具有虚拟地址空间、可执行代码、系统对象的打开句柄、安全上下文、唯一进程标识符、环境变量、优先级类、最小和最大工作集大小以及至少一个执行线程。”这些信息可能看起来有点吓人,但这个房间的目的是让这个概念不那么复杂。
如前所述,进程是从应用程序的执行创建的。进程是Windows功能的核心,Windows的大多数功能可以被包含为一个应用程序,并具有相应的进程。下面是启动进程的默认应用程序的几个例子。
- MsMpEng(Microsoft Defender微软卫士)
- Wininit(keyboard and mouse键盘和鼠标)
- Lsass(credential storage凭据存储)
攻击者可以针对进程来逃避检测,并将恶意软件隐藏为合法进程。下面是攻击者可能用于攻击进程的潜在攻击向量的一小部分列表。
- 进程注入(T1055)
- 进程空心化问题(T1055.012)
- 进程伪装(T1055.013)
进程有很多组成部分;它们可以分为几个关键特征,我们可以用这些特征在更高的层次上描述过程。下表描述了进程的每个关键组成部分及其用途。
| 进程组成部分 | 目的 |
|---|---|
| Private Virtual Address Space私有虚拟地址空间 | 进程分配的虚拟内存地址。 |
| Executable Program可执行程序 | 定义存储在虚拟地址空间中的代码和数据。 |
| Open Handles开放的句柄 | 定义进程可访问的系统资源句柄。 |
| Security Context安全上下文 | 访问令牌定义用户、安全组、特权和其他安全信息。 |
| Process ID进程ID | 进程的唯一数字标识符。 |
| Threads线程 | 计划执行的进程的一部分。 |
我们也可以在更低的层次上解释进程,因为它位于虚拟地址空间中。下面的表和图描述了进程在内存中的样子。
| 组成部分 | 目的 |
|---|---|
| Code代码 | 进程要执行的代码。 |
| Global Variables全局变量 | 存储变量。 |
| Process Heap进程堆 | 定义存储数据的堆。 |
| Process Resources进程的资源 | 进一步定义进程的资源。 |
| Environment Block环境块 | 定义进程信息的数据结构。 |

当我们深入开发和使用底层技术时,这些信息非常有用,但它们仍然非常抽象。我们可以在Windows任务管理器中观察它们,使进程变得有形。任务管理器可以报告有关进程的许多组件和信息。下面是一个简要列出基本进程细节的表。
| 值/组成部分 | 目的 | 例子 |
|---|---|---|
| Name名字 | 定义进程的名称,通常从应用程序继承 | conhost.exe |
| PID进程ID | 唯一的数值来识别过程 | 7408 |
| Status状态 | 确定进程如何运行(运行、挂起等)。 | Running运行 |
| User name用户名 | 启动进程的用户。可以表示过程的特权吗 | SYSTEM系统 |
这些是你作为终端用户和攻击者交互最多的内容。
有多种实用工具可以使观察进程更容易;包括Process Hacker 2、Process Explorer和Procmon。
进程是大多数Windows内部组件的核心。下面的任务将扩展有关进程以及如何在Windows中使用它们的信息。
问题
打开提供的文件:“Logfile. PML”。并回答以下问题。
1.“notepad.exe”的进程ID是什么?
2.前一个进程的父进程ID是什么?
3.进程的完整性级别是什么?
WP
PML文件在此即“ProcMon Log File”,我们使用Procmon打开可以观察进程
1.我们使用筛选工具可以筛选出notepad.exe
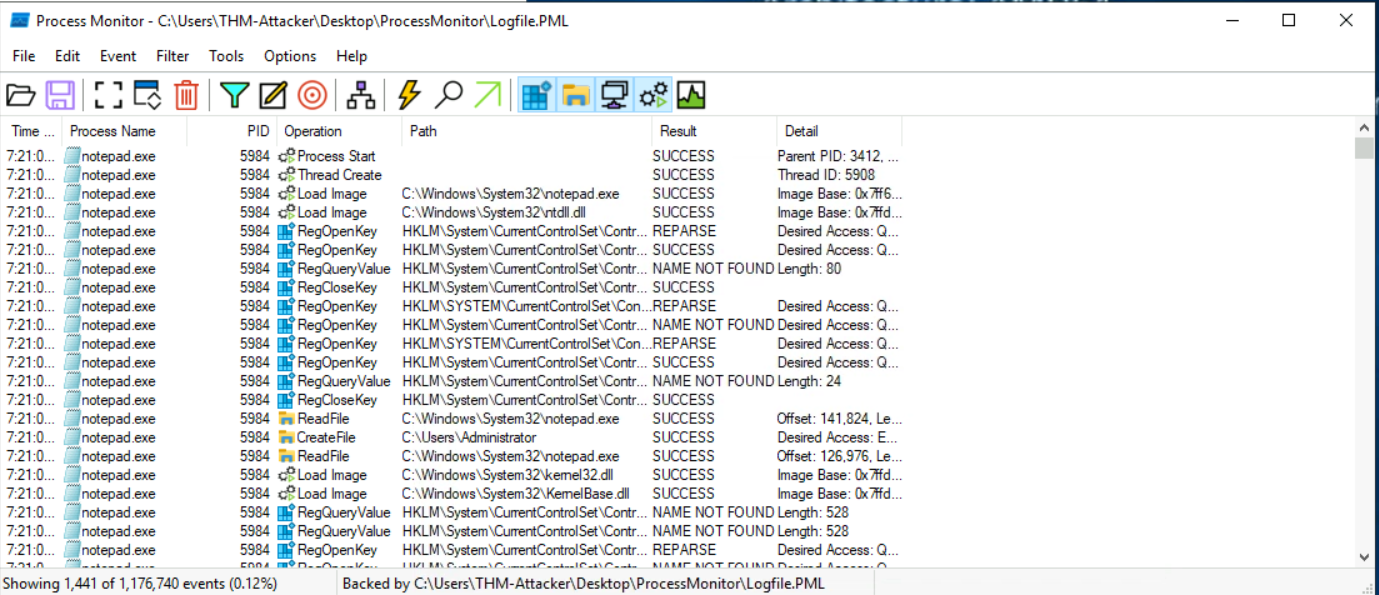
发现了notepad.exe的进程ID是5984
2、3在进程属性中可以看到notepad.exe的父进程ID和进程的完整性级别
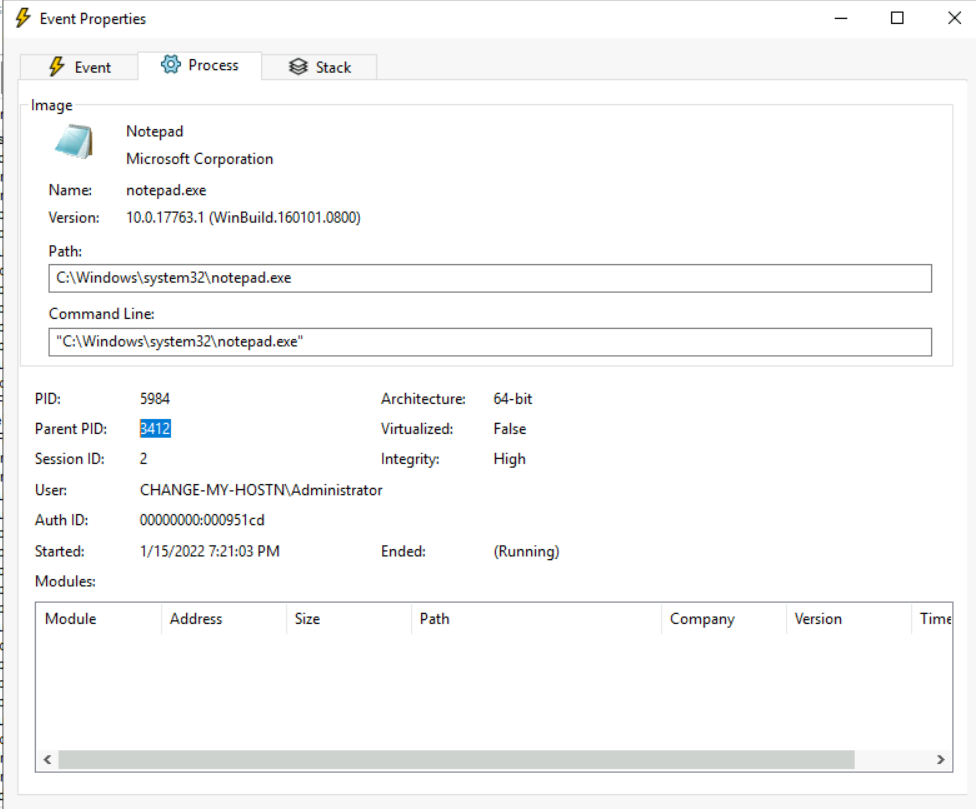
发现了notepad.exe的父进程ID是3412,进程的完整性级别为“High”
线程

线程是进程使用的可执行单元,根据设备因素进行调度。
设备因素可以根据CPU和内存规格、优先级和逻辑因素,以及其他因素而变化。
我们可以简化线程的定义:“控制进程的执行”。
由于线程控制执行,因此这是一个常见的目标组件。线程的使用可以单独用于帮助代码执行,或者作为其他技术的一部分,它更广泛地用于与其他API调用链接。
线程与它们的父进程共享相同的细节和资源,例如代码、全局变量等。线程也有其唯一的值和数据,如下表所示。
| 组件 | 目的 |
|---|---|
| Stack堆栈 | 与线程相关和特定的所有数据(异常、过程调用等) |
| Thread Local Storage线程本地存储 | 用于向唯一数据环境分配存储空间的指针 |
| Stack Argument堆栈的论点 | 分配给每个线程的唯一值 |
| Context Structure上下文结构 | 保存由内核维护的机器寄存器值 |
线程看起来像是简单的组件,但它们的功能对进程至关重要。
问题
打开提供的文件:“Logfile. PML”。并回答以下问题。
1.notepad.exe创建的第一个线程的线程ID是什么?
2.前一个线程的stack参数是什么?
WP
1.我们在Procmon中添加“TID”列查看线程ID:
发现notepad.exe创建的第一个线程的线程ID是5908
2.我们添加过滤规则查看notepad.exe创建的线程
查看属性我们可以发现notepad.exe创建的第一个线程的stack参数为6584
虚拟内存
虚拟内存是Windows内部工作和相互作用的关键组成部分。虚拟内存允许其他内部组件与内存进行交互,就像它是物理内存一样,而没有应用程序之间冲突的风险。
虚拟内存为每个进程提供了一个私有的虚拟地址空间。内存管理器用于将虚拟地址转换为物理地址。通过拥有一个私有的虚拟地址空间,而不直接写入物理内存,进程造成破坏的风险更小。
内存管理器还将使用页面或传输来处理内存。应用程序使用的虚拟内存可能比分配的物理内存更多;内存管理器将传输或分页虚拟内存到磁盘来解决这个问题。您可以在下面的图表中可视化此概念。


在32位x86系统上,理论上最大的虚拟地址空间是4 GB。
该地址空间分为两部分,下半部分(0x00000000 - 0x7FFFFFFF)分配给前文提到的进程。上半部分(0x80000000 - 0xFFFFFFFF)被分配给操作系统内存利用率。管理员可以通过设置(increeuserva)或AWE(地址窗口扩展)更改需要更大地址空间的应用程序的分配布局。
在64位现代系统上,理论上最大的虚拟地址空间是256 TB。
32位系统的精确地址布局比例被分配到64位系统。
大多数需要设置或敬畏的问题都通过增加理论最大值来解决。
您可以在上侧可视化这两种地址空间分配布局。
虽然这个概念不能直接转换为Windows内部或概念,但理解它是至关重要的。如果理解正确,它可以帮助使用Windows内部机制。
问题
1.32位x86系统理论上最大的虚拟地址空间是多少?
2.可以使用什么默认设置标志重新分配用户进程地址空间?
打开提供的文件:“Logfile. PML”。并回答以下问题。
3.“notepad.exe”的基址是什么?
WP
1.32位x86系统理论上最大的虚拟地址空间是4 GB
2..可以使用默认设置increaseUserVA标志重新分配用户进程地址空间
3.我们添加过滤规则查看notepad.exe的加载调试文件操作,查看属性可以发现调试文件的基地址为0x7ff652ec0000
动态链接库

微软官方文档将DLL描述为“一个包含代码和数据的库,可以同时被多个程序使用”。
dll是Windows应用程序执行的核心功能之一。在Windows文档中写道:“使用dll有助于促进代码的模块化、代码重用、高效使用内存和减少磁盘空间。因此,操作系统和程序的加载速度更快,运行速度更快,占用的磁盘空间更少。”
当DLL作为程序中的函数加载时,DLL被指定为依赖项。由于程序依赖于DLL,攻击者可以针对DLL而不是应用程序来控制程序执行或功能的某些方面。
- DLL劫持(T1574.001)
- DLL侧加载(T1574.002)
- DLL注入(T1055.001)
dll的创建与任何其他项目/应用程序没有什么不同;它们只需要稍微修改一下语法就可以工作。下面是一个来自Visual C Win32动态链接库项目的DLL示例。
#include "stdafx.h"
#define EXPORTING_DLL
#include "sampleDLL.h"
BOOL APIENTRY DllMain( HANDLE hModule, DWORD ul_reason_for_call, LPVOID lpReserved
)
{
return TRUE;
}
void HelloWorld()
{
MessageBox( NULL, TEXT("Hello World"), TEXT("In a DLL"), MB_OK);
}
下面是DLL的头文件;它将定义导入和导出哪些函数。我们将在本任务的下一节讨论头文件的重要性(或缺少头文件的严重性)。
#ifndef INDLL_H
#define INDLL_H
#ifdef EXPORTING_DLL
extern __declspec(dllexport) void HelloWorld();
#else
extern __declspec(dllimport) void HelloWorld();
#endif
#endif
DLL已经创建,但仍然存在一个问题,即如何在应用程序中使用它们?
可以使用加载时动态链接或运行时动态链接将dll加载到程序中。
当使用加载时动态链接加载时,应用程序对DLL函数进行显式调用。只能通过提供头文件(.h)和导入库文件(.lib)来实现这种类型的链接。下面是一个从应用程序调用导出的DLL函数的示例。
#include "stdafx.h"
#include "sampleDLL.h"
int APIENTRY WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
HelloWorld();
return 0;
}
当使用运行时动态链接加载时,一个单独的函数( LoadLibrary 或 LoadLibraryEx )用于在运行时加载DLL。加载后,需要使用 GetProcAddress 来确定要调用的导出的DLL函数。下面是在应用程序中加载和导入DLL函数的示例。
...
typedef VOID (*DLLPROC) (LPTSTR);
...
HINSTANCE hinstDLL;
DLLPROC HelloWorld;
BOOL fFreeDLL;
hinstDLL = LoadLibrary("sampleDLL.dll");
if (hinstDLL != NULL)
{
HelloWorld = (DLLPROC) GetProcAddress(hinstDLL, "HelloWorld");
if (HelloWorld != NULL)
(HelloWorld);
fFreeDLL = FreeLibrary(hinstDLL);
}
...
在恶意代码中,威胁行为者通常会更多地使用运行时动态链接而不是加载时动态链接。这是因为恶意程序可能需要在内存区域之间传输文件,而传输单个DLL比使用其他文件需求导入文件更容易管理。
问题
打开提供的文件:“Logfile. PML”。并回答以下问题。
1.从"notepad.exe"加载的"ntdll.dll"的基地址是什么?
2.从“notepad.exe”加载的“ntdll.dll”的大小是多少?
3.“notepad.exe”加载了多少dll
WP
1、2.我们添加过滤规则查看notepad.exe的加载调试文件操作、加载路径包含“ntdll.dll”的操作,查看属性可以发现ntdll.dll的基地址为0x7ffd0be20000,大小为0x1ec000
3..我们添加过滤规则查看notepad.exe的加载调试文件操作、加载路径包含“.dll”的操作,即可看出“notepad.exe”加载了51个dll
可执行文件格式

可执行文件和应用程序是Windows内部在更高层次上运行的很大一部分。PE (Portable Executable)格式定义了关于可执行文件和存储数据的信息。PE格式还定义了数据组件如何存储的结构。
PE (Portable Executable)格式是可执行文件和目标文件的总体结构。PE (Portable Executable)和COFF (Common Object File Format)文件组成了PE格式。
PE数据最常出现在可执行文件的十六进制转储中。下面我们将把十六进制的calc.exe文件分解为PE数据段。
PE数据的结构被分解为七个部分:
The DOS Header(DOS头)文件定义了文件的类型
MZ DOS头文件将文件格式定义为 .exe 。DOS头可以在下面的十六进制转储部分中看到。
Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
00000000 4D 5A 90 00 03 00 00 00 04 00 00 00 FF FF 00 00 MZ..........ÿÿ..
00000010 B8 00 00 00 00 00 00 00 40 00 00 00 00 00 00 00 ¸.......@.......
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000030 00 00 00 00 00 00 00 00 00 00 00 00 E8 00 00 00 ............è...
00000040 0E 1F BA 0E 00 B4 09 CD 21 B8 01 4C CD 21 54 68 ..º..´.Í!¸.LÍ!Th
The DOS Stub(DOS存根)是一个默认运行在文件开头的程序,它打印出兼容性信息。
对于大多数用户来说,这不会影响文件的任何功能。
DOS存根打印消息 This program cannot be run in DOS mode 。DOS存根可以在下面的十六进制转储部分中看到。
00000040 0E 1F BA 0E 00 B4 09 CD 21 B8 01 4C CD 21 54 68 ..º..´.Í!¸.LÍ!Th
00000050 69 73 20 70 72 6F 67 72 61 6D 20 63 61 6E 6E 6F is program canno
00000060 74 20 62 65 20 72 75 6E 20 69 6E 20 44 4F 53 20 t be run in DOS
00000070 6D 6F 64 65 2E 0D 0D 0A 24 00 00 00 00 00 00 00 mode....$.......
The PE File Header(PE文件头)提供二进制文件的PE头信息。
定义文件格式,包含签名和图像文件头,以及其他信息头。
PE文件头是人类可读输出最少的部分。您可以在下面的十六进制转储部分中看到从PE存根识别PE文件头的开始。
000000E0 00 00 00 00 00 00 00 00 50 45 00 00 64 86 06 00 ........PE..d†..
000000F0 10 C4 40 03 00 00 00 00 00 00 00 00 F0 00 22 00 .Ä@.........ð.".
00000100 0B 02 0E 14 00 0C 00 00 00 62 00 00 00 00 00 00 .........b......
00000110 70 18 00 00 00 10 00 00 00 00 00 40 01 00 00 00 p..........@....
00000120 00 10 00 00 00 02 00 00 0A 00 00 00 0A 00 00 00 ................
00000130 0A 00 00 00 00 00 00 00 00 B0 00 00 00 04 00 00 .........°......
00000140 63 41 01 00 02 00 60 C1 00 00 08 00 00 00 00 00 cA....`Á........
00000150 00 20 00 00 00 00 00 00 00 00 10 00 00 00 00 00 . ..............
00000160 00 10 00 00 00 00 00 00 00 00 00 00 10 00 00 00 ................
00000170 00 00 00 00 00 00 00 00 94 27 00 00 A0 00 00 00 ........”'.. ...
00000180 00 50 00 00 10 47 00 00 00 40 00 00 F0 00 00 00 .P...G...@..ð...
00000190 00 00 00 00 00 00 00 00 00 A0 00 00 2C 00 00 00 ......... ..,...
000001A0 20 23 00 00 54 00 00 00 00 00 00 00 00 00 00 00 #..T...........
000001B0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
000001C0 10 20 00 00 18 01 00 00 00 00 00 00 00 00 00 00 . ..............
000001D0 28 21 00 00 40 01 00 00 00 00 00 00 00 00 00 00 (!..@...........
000001E0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
The Image Optional Header(可选/扩展PE头)有一个误导性的名字,是PE文件头的重要组成部分
The Data Dictionaries(数据字典)是Image Optional Header的一部分。它们指向映像数据目录结构。
Section Table(Section表)将定义映像中可用的Section(节)和信息。
如前所述,节存储文件的内容,如代码、导入和数据。您可以从下面十六进制转储部分的表中识别每个节的定义。
000001F0 2E 74 65 78 74 00 00 00 D0 0B 00 00 00 10 00 00 .text...Ð.......
00000200 00 0C 00 00 00 04 00 00 00 00 00 00 00 00 00 00 ................
00000210 00 00 00 00 20 00 00 60 2E 72 64 61 74 61 00 00 .... ..`.rdata..
00000220 76 0C 00 00 00 20 00 00 00 0E 00 00 00 10 00 00 v.... ..........
00000230 00 00 00 00 00 00 00 00 00 00 00 00 40 00 00 40 ............@..@
00000240 2E 64 61 74 61 00 00 00 B8 06 00 00 00 30 00 00 .data...¸....0..
00000250 00 02 00 00 00 1E 00 00 00 00 00 00 00 00 00 00 ................
00000260 00 00 00 00 40 00 00 C0 2E 70 64 61 74 61 00 00 ....@..À.pdata..
00000270 F0 00 00 00 00 40 00 00 00 02 00 00 00 20 00 00 ð....@....... ..
00000280 00 00 00 00 00 00 00 00 00 00 00 00 40 00 00 40 ............@..@
00000290 2E 72 73 72 63 00 00 00 10 47 00 00 00 50 00 00 .rsrc....G...P..
000002A0 00 48 00 00 00 22 00 00 00 00 00 00 00 00 00 00 .H..."..........
000002B0 00 00 00 00 40 00 00 40 2E 72 65 6C 6F 63 00 00 ....@..@.reloc..
000002C0 2C 00 00 00 00 A0 00 00 00 02 00 00 00 6A 00 00 ,.... .......j..
000002D0 00 00 00 00 00 00 00 00 00 00 00 00 40 00 00 42 ............@..B
既然头文件已经定义了文件的格式和功能,节就可以定义文件的内容和数据。
| 部分 | 目的 |
|---|---|
| .text | 包含可执行代码和entry point(入口点) |
| .data | 包含已初始化的数据(字符串、变量等)。 |
| .rdata 或 .idata | 包含导入的文件(Windows API)和dll。 |
| .reloc | 包含重定位信息。 |
| .rsrc | 包含应用程序资源(映像等) |
| .debug | 包含调试信息 |
问题
阅读上面的内容并回答下面的问题
1.什么PE组件打印消息"This program cannot be run in DOS mode"?
在“Detect It Easy”中打开“notepad.exe”并回答下面的问题。
2.DiE报告的入口点是什么?
3."Sections"的值是多少?
4.".data"的虚拟地址是什么?
5.什么字符串位于偏移量“0001f99c”处?
WP
1.The DOS Stub(DOS存根)打印兼容性消息"This program cannot be run in DOS mode"
2、3.我们使用Detect It Easy打开notepad.exe即可发现:
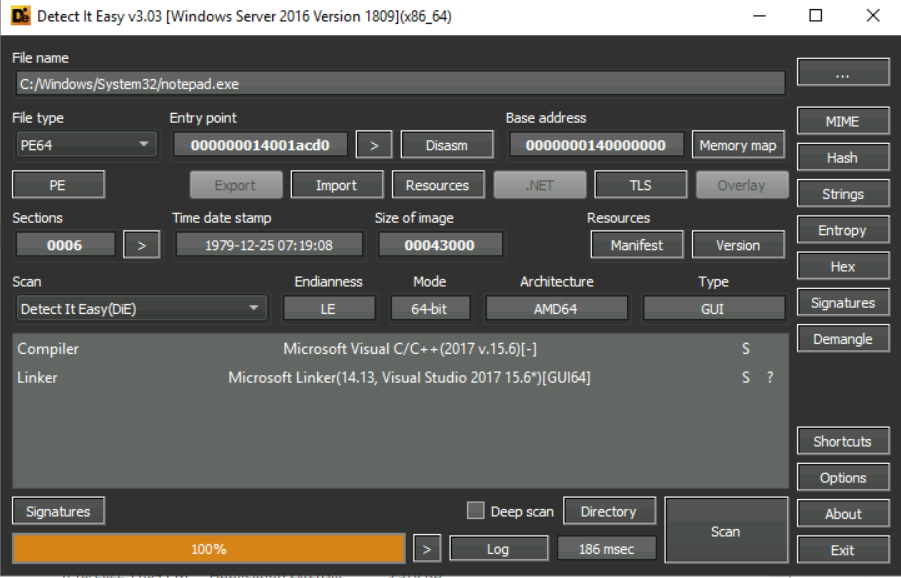
入口点Entry point为000000014001acd0
sections的值为0006,说明该可执行文件包含6个节
4.打开Sections的页面查看
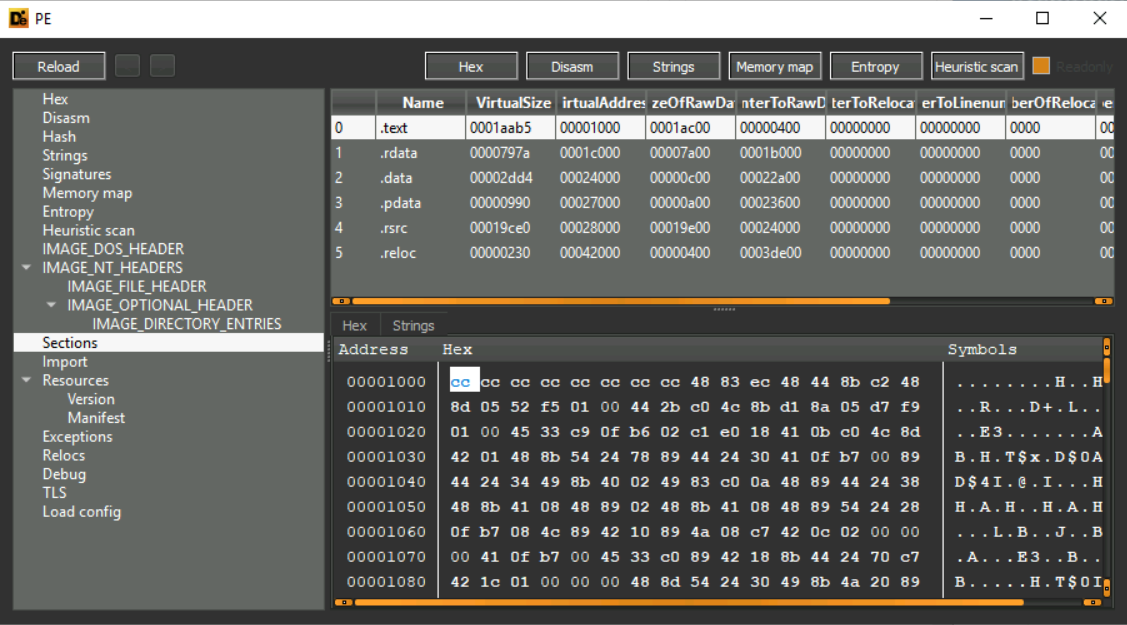
可以发现.data的虚拟地址为00024000
5.为了查看字符串,我们进入Strings的页面
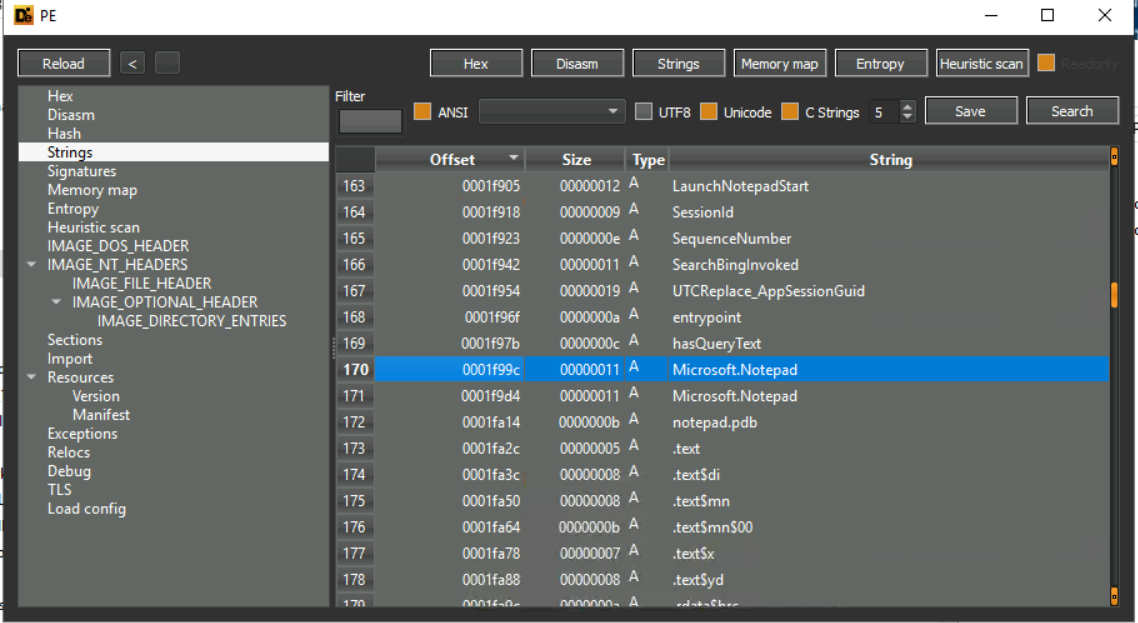
可以发现偏移量“0001f99c”处的字符串为“Microsoft.Notepad”
与Windows内部交互
与Windows内部的交互似乎令人生畏,但它已经被极大地简化了。与Windows内部交互的最容易访问和研究的选项是通过Windows API调用进行接口。Windows API提供了与Windows操作系统交互的原生功能。该API包含Win32 API,以及不太常见的Win64 API。
在这个房间里,我们将只提供与Windows内部相关的几个特定API调用的简要概述。查看Windows API空间以获取有关Windows API的更多信息。
大多数Windows内部组件需要与物理硬件和内存交互。
Windows内核将控制所有的程序和进程,并连接所有的软件和硬件交互。这一点尤其重要,因为许多Windows内部都需要以某种形式与内存进行交互。
默认情况下,应用程序通常不能与内核交互或修改物理硬件,并且需要接口。这个问题可以通过使用处理器模式和访问级别来解决。
Windows处理器有用户态和核心态。处理器将根据访问模式和请求模式在这些模式之间切换。
在用户态和核心态之间的切换,通常通过系统和API调用来实现。在文档中,这个点有时被称为“切换点”。
| 用户模式 | 内核模式 |
|---|---|
| 没有直接的硬件访问 | 直接硬件存取 |
| 在专用虚拟地址空间中创建进程 | 在一个共享的虚拟地址空间中运行 |
| 访问“拥有的内存位置” | 对整个物理内存的访问 |

在“user mode”/“userland”启动的应用程序将保持该模式,直到发出系统调用或通过API进行接口。当进行系统调用时,应用程序将切换模式。右图是描述这个过程的流程图。
当观察语言如何与Win32 API交互时,这个过程可能会进一步扭曲;应用程序将在通过API之前先通过语言运行库。最常见的例子是c#在与Win32 API交互和进行系统调用之前通过CLR执行。
我们将在本地进程中注入一个消息框,以演示与内存交互的概念验证。
将消息框写入内存的步骤概述如下。
- 为消息框分配本地进程内存。
- 将消息框写入/复制到已分配的内存中。
- 从本地进程内存执行消息框。
在第一步,我们可以使用 OpenProcess 来获得指定进程的句柄。
HANDLE hProcess = OpenProcess(
PROCESS_ALL_ACCESS, // Defines access rights
FALSE, // Target handle will not be inhereted
DWORD(atoi(argv[1])) // Local process supplied by command-line arguments
);
在第二步,我们可以使用 VirtualAllocEx 与有效载荷缓冲区分配一个内存区域。
remoteBuffer = VirtualAllocEx(
hProcess, // Opened target process
NULL,
sizeof payload, // Region size of memory allocation
(MEM_RESERVE | MEM_COMMIT), // Reserves and commits pages
PAGE_EXECUTE_READWRITE // Enables execution and read/write access to the commited pages
);
在第三步,我们可以使用 WriteProcessMemory 将有效载荷写入分配的内存区域。
WriteProcessMemory(
hProcess, // Opened target process
remoteBuffer, // Allocated memory region
payload, // Data to write
sizeof payload, // byte size of data
NULL
);
在第四步,我们可以使用 CreateRemoteThread 从内存执行有效载荷。
remoteThread = CreateRemoteThread(
hProcess, // Opened target process
NULL,
0, // Default size of the stack
(LPTHREAD_START_ROUTINE)remoteBuffer, // Pointer to the starting address of the thread
NULL,
0, // Ran immediately after creation
NULL
);
问题
打开一个命令提示符并执行提供的文件:“inject-poc.exe”并回答以下问题。
输入从下面的可执行文件中获得的flag
WP
运行程序即可获得flag
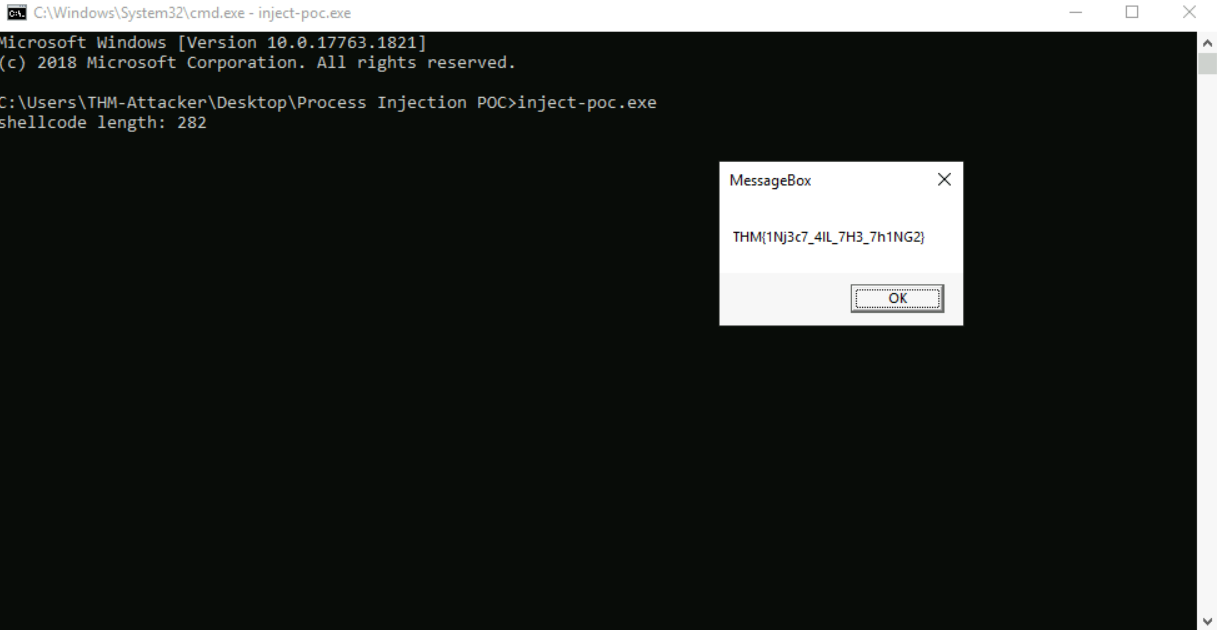
我们也可以查看一下程序的源码:
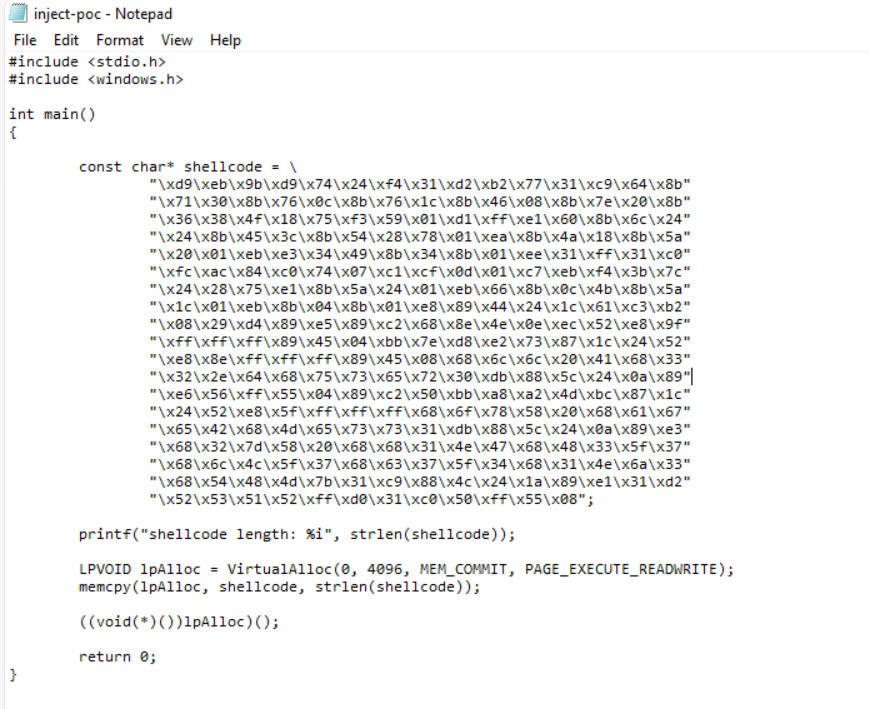
const char* shellcode 定义了一段shellcode,这段代码由十六进制字符组成。
printf("shellcode length: %i", strlen(shellcode)); 这行代码输出shellcode的长度
strlen(shellcode) 计算shellcode字符串的长度,以字节为单位。
LPVOID lpAlloc = VirtualAlloc(0, 4096, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
LPVOID 是一个 Windows API 数据类型,代表一个指向任意类型的指针。
VirtualAlloc 是一个Windows API函数,用于分配内存。这里分配了4096字节的内存,标记为可执行和可读写(PAGE_EXECUTE_READWRITE)。这种内存权限使得shellcode能够被复制到内存并执行。
memcpy(lpAlloc, shellcode, strlen(shellcode));
memcpy 将shellcode复制到分配的内存中,lpAlloc指向分配的内存位置。
((void(*)())lpAlloc)();
这段代码通过将lpAlloc(内存地址)转换为函数指针,并调用它,直接执行了shellcode。
这种方式可以在程序执行时立即运行内存中的shellcode(我们可以使用Cutter工具进行反汇编、反编译来看shellcode中的内容,由于端序排列直接解密会出现乱码):