【CTF入门】BUUCTF Misc刷题(持续更新)
 走进CTF,成为Misc杂项王的男人
走进CTF,成为Misc杂项王的男人
【CTF入门】BUUCTF Misc刷题
签到(简单)
点开发现签到题直接把flag交出来了,直接复制提交即可

考点:了解CTF中flag的格式一般为flag{}
第一题(新工具)
下载文件,发现里面是一张gif图片,我们查看一下发现总有东西一闪而过
这里我们介绍第一个在Misc图像隐写中非常常用的工具——StegSolve
StegSolve功能一——逐帧查看gif文件
隐写图片解析神器,下载地址:http://www.caesum.com/handbook/Stegsolve.jar
它的用途有很多,之后我们会一步一步进行讲解,首先我们打开StegSolve(打不开的,参考这篇文章:详细教程:Stegsolve的下载,jdk的下载、安装以及环境的配置_stegsolve下载-CSDN博客)
打开发现只有一个非常小的窗口,点击File->open导入gif图片

Analyse->Frame Browser使用帧浏览器功能分解gif的帧
用下面的左右箭头查看各个帧的图像,我们发现了隐藏的flag:flag{he11ohongke}



考点:利用工具逐帧查看gif文件图像
你竟然赶我走(新工具)
下载文件,发现里面是一张jpg图片,我们查看一下貌似什么也没有

图片隐写没有具体的思路,我个人一般按照以下步骤做(来源于图书《CTF那些事儿》):
图片隐写思路:
1. 查看图片的属性是否藏了东西,一定要使用能够查看exif信息的工具,PNG格式的话使用TweakPNG等工具判断是否存在PNG宽高隐写
2. 使用010 Editor、strings等工具发现插入隐藏信息
3. 使用StegSolve、zsteg等工具发现隐写隐藏信息
4. 使用binwalk、foremost等工具提取隐藏信息
5. 使用steghide、盲水印提取等工具提取特定工具隐藏信息,如果有提示最好,没有提示只能一个个尝试了,注意jpeg和png等不同格式的图片文件使用的工具也不一样
jpeg:steghide——outguess——
png:zsteg——cloacked-pixel——BlindWaterMark-master——kindred-adds/BlindWaterMarkplus
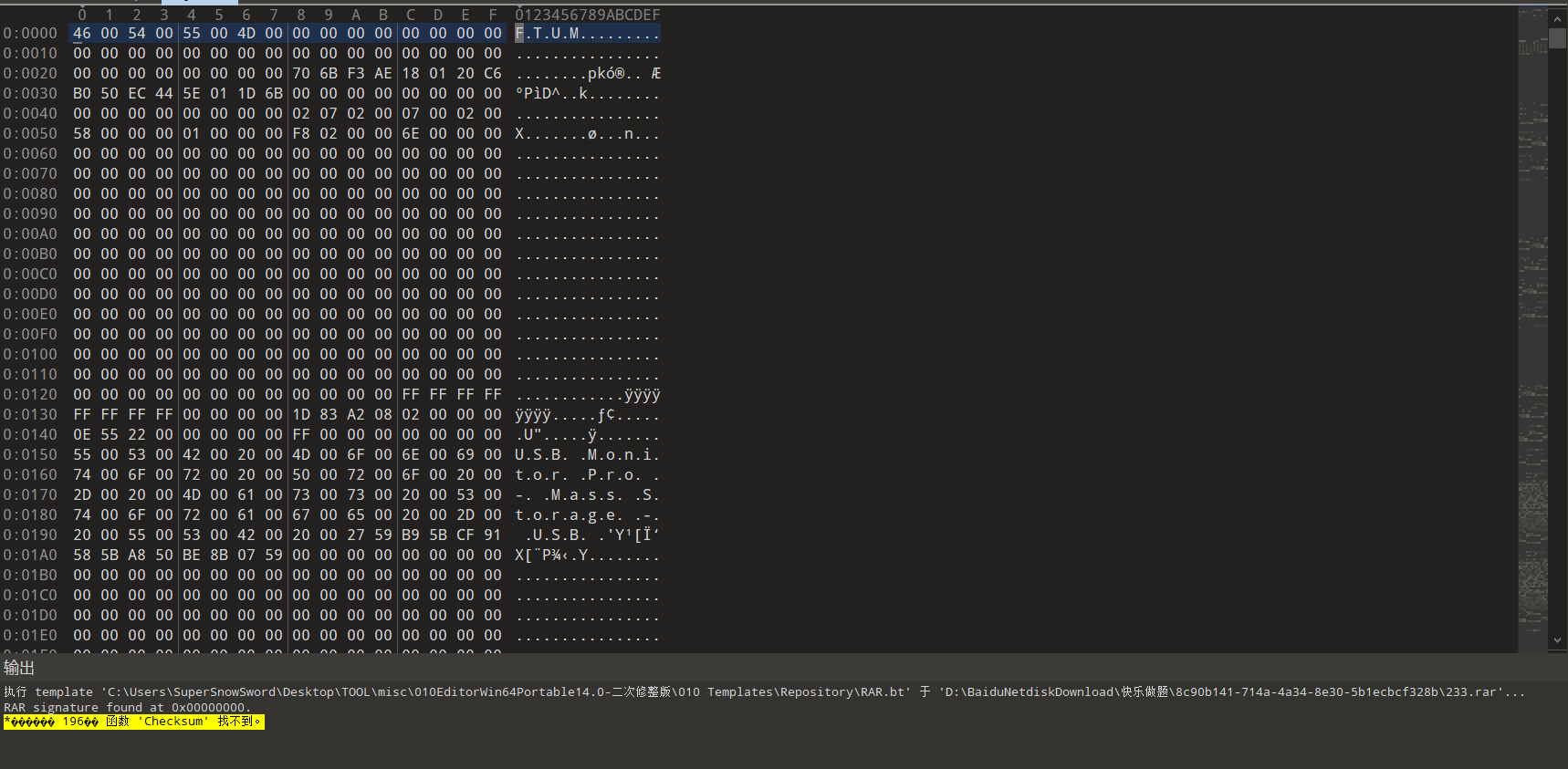
010 Editor:十六进制编辑器
它可以把文件以十六进制的格式打开、查看、修改,下载地址:http://www.caesum.com/handbook/Stegsolve.jar(虽然还有winhex等编辑器,但个人认为010 Editor更好用一些)
首先我们打开010 Editor,导入文件

我们看到花花绿绿一大片的东西,啥啊这是?
JPG文件格式介绍
JPG格式没有直接保存图像的像素值信息,而是将其转换为YUV色彩空间(Y表示像素的亮度,U和V一起表示色调与饱和度)保存到图像信息中,保存时既可以选择无损压缩也可以选择有损压缩。
JPG文件按照“段”的格式来组织存储,一个文件由多个段组成,每个段代表不同的信息。同时,每个段也有自己唯一的标识符。标识符由两个字节组成,格式形如0x FF XX,其中FF代表不同的类型。
例如,SOI(Start Of Image)表示图像的开始,其段的标识符为0X FF D8。更加详细请查看这篇文章:

整个JPG图片的组织便是由这些不同类型的段和经过JPG压缩后的数据组成的。(原文来自《CTF那些事儿》)
010 Editor的模板功能
010 Editor的模板功能可以自动为我们带来文件解析后的结果(亮色标记),我们就可以更加直观地看出JPG文件的各个段的位置,我们可以通过模板存储库来检查和添加文件的模板(一般没有模板会在你导入文件的时候提醒你自动下载)

回到题目,我们发现从头到尾文件好像都没什么问题

我们可以ctrl+f进入字符串搜索,因为是CTF题目所以直接搜索flag,查看是否有直接插入的flag信息,果然,我们发现了:

flag插入在文件结尾段的后边,被模板识别为“unknowPadding”段,我们直接可以复制flag提交了
考点:利用十六进制编辑器找到隐藏的信息
补充:StegSolve功能二——查看图片的具体信息
这道题我们导入StegSolve,使用查看图片的具体信息功能也可以解开


我们用这个功能可以查看图片的具体信息,其中包括了结尾插入的隐藏Ascii(字符串)
二维码(新工具)
下载文件,发现里面是一张png格式的二维码图片,我们用二维码识别软件QR Research扫一扫,发现隐藏信息——secret is here,并没有flag

按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

(PNG模板出了点问题,没有很明显的颜色,但不影响分析)
PNG文件格式简介
PNG是一种位图文件存储格式,既可以存储灰度图像(只有黑白灰,没有彩色),也可以存储彩色图像。PNG使用从LZ77派生的无损算法压缩图像信息,能获得较高的压缩比,并利用特殊的编码方法标记重复出现的数据,因而对图像的颜色没有影响,也不可能产生颜色的损失,这样就可以重复保存而不降低图像质量。
PNG图像格式文件由文件头和数据块(Chunk)组成。PNG图像整体格式如下:
文件头(89 50 4E 47 0D 0A 1A 0A)+数据块+数据块+数据块+......
回到题目,我们可以发现chunk[3]是PNG文件的文件尾,后面的chunk[4]块大小为0h也就是之后的内容无法被PNG模板解析了。
根据常见的文件头(记一些常用的就好)的记录我们可以发现50 4B 03 04是ZIP格式文件的文件头,也就是说这张图片后边插入了ZIP压缩包,我们应该如何把这压缩包从这张图片文件中分离出来呢?
文件分离
-
淳朴的复制粘贴手工艺:使用十六进制编辑器,我们把ZIP文件从文件头到文件尾的内容复制一遍,然后新建十六进制文件粘贴上去,保存后上“.zip”的后缀就有了。



-
利用Binwalk工具自动提取:Binwalk是一个自动提取文件系统,该工具可以自动完成指定文件的扫描,发现潜藏在文件中中所有可疑的文件类型以及文件系统。使用命令:
binwalk QR_code.png -e-e 提取隐藏文件
即可自动提取出其中的隐藏文件

-
利用foremost工具自动提取:foremost通过分析不同类型的头、尾和内部数据结构,同镜像文件的数据进行比对,来还原文件。支持19中类型文件的恢复。用户还可以通过配置文件扩展支持其他文件类型。使用命令:
foremost QR_code.png -o yincang-o 输出文件名


总而言之,我们分离出了zip文件,我们尝试打开,发现里面存在一个名为“4number.txt”的文件。我们尝试解压却发现压缩包含有密码。
遇到含有密码的压缩包思路
1. 仔细注意题目是否给出压缩包解压密码的相关线索或是压缩包中有注释/备注,有的话就填或者是利用工具爆破(一般是纯数字密码)
2. 使用010 editor观察zip文件是否存在伪加密的情况
3. 需要CRC32爆破的特殊情况
根据文件名“4number”,我们可以猜测解压密码是四个数字,我们使用ARCHPR工具开始进行爆破。
ARCHPR爆破压缩包密码
爆破压缩包密码的工具,含有多种爆破模式。因为正版需要购买所以给出吾爱破解论坛大佬的破解版下载贴:Advanced Archive Password Recovery 4.54-压缩包破解工具 - 『精品软件区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
我们打开ARCHPR,导入zip文件,攻击类型选择暴力(按照顺序一个个尝试密码),暴力范围选项选择数字,在长度那一栏最小口令和最大口令都填入4:


然后我们就可以开始爆破了,很快成功的消息就弹出来了:

我们可以知道解压密码为:7639
解压文件,在“4number.txt”中得到了flag

考点:文件分离、压缩包密码爆破
大白(新)
下载文件,发现里面是一张png格式的图片:

按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们根据题目提示,优先查看PNG图片是否进行了宽高隐写
PNG宽高隐写
原理:更改了PNG图片的宽度和高度,隐藏了被截取部分图片的信息
做法:根据图片的CRC校验值更改图片的长度和宽度(CRC校验值计算原理:https://www.bilibili.com/video/BV1V4411Z7VA?vd_source=69c558b0c7be97607c79afbd75bd1f7c,理解有这个东西就行)

因此我们首先根据图片的CRC校验值计算PNG图片正确的长度和宽度:
import binascii
import struct
crcbp = open("dabai.png", "rb").read() #打开图片
crc32frombp = int(crcbp[29:33].hex(),16) #读取图片中的CRC校验值
print(crc32frombp)
for i in range(4000): #宽度1-4000进行枚举
for j in range(4000): #高度1-4000进行枚举
data = crcbp[12:16] + \ #创建一个数据段,内容为从文件内容的字节12到16(包含第12字节,不包含第16字节),这部分通常是固定的。
struct.pack('>i', i)+struct.pack('>i', j)+crcbp[24:29] #将宽度变量'i'和高度变量'j'转换成大端格式的四字节(大端格式:字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中)
crc32 = binascii.crc32(data) & 0xffffffff #计算data数据段的CRC校验值,'& 0xffffffff'确保CRC校验值为32位
print(crc32)
if(crc32 == crc32frombp): #计算当图片大小为i:j时的CRC校验值,与图片中的CRC比较,当相同,则图片大小已经确定
print(i, j)
print('hex:', hex(i), hex(j))
exit(0)
struck.pack(format,v1,v2,...):返回一个字节对象,该对象包含根据格式字符串格式打包的值v1、v2,…。参数必须与格式要求的值完全匹配。
binascii. crc32 (data) :计算data的 32 位校验和——CRC-32
运行脚本,可以得到:

正确的宽高应该为679x479,16进制后的值应该为00 00 02 A7和00 00 01 DF,使用010editor更改PNG图片如下:
保存文件,发现图片的高度恢复出现了新的内容,得到flag:

考点:PNG宽高隐写、理解爆破PNG宽高原理
乌镇峰会种图(知识巩固题)
下载文件,发现里面是一张jpg格式的图片:

按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

又一次,我们在文件尾后面发现了插入的flag:

考点:利用十六进制编辑器找到隐藏的信息
wireshark(新工具)
下载文件,发现里面是一个pcap格式的文件。这是什么东西?
网络流量分析
网络分析工具对指定网卡进行数据包捕获,方便工作人员监测网络流量情况。
而pcap格式就是网络分析工具保存的网络数据包,是捕获的从网卡发送或者接收的每一个数据包的离线网络流量。
我们想要踏入这一部分的内容,首先我们应该熟悉网络协议的基础知识和OSI七层网络参考模型:https://www.bilibili.com/video/BV1EU4y1v7ju?vd_source=69c558b0c7be97607c79afbd75bd1f7c
我希望能够从题目入手,带大家对这方面的内容进行深入理解
回到题目,我们知道了pcap格式是网络分析工具保存的文件,那么我们应该拥有网络分析的工具。我们将重点介绍wireshark,这不仅是题目名,更是非常重要的网络分析工具。
wireshark
WireShark是非常流行的网络封包分析工具,可以截取各种网络数据包,并显示数据包详细信息。常用于开发测试过程中各种问题定位。官网下载地址:Wireshark · Download
首先我们用wireshark打开pacp文件:

花花绿绿的一大片数据包,我们应该从何处入手?
数据包分析思路
1. 观察分组数(wireshark右下角),如果分组数量较大我们就进行协议分级进行分析,数量较小就逐个人工查看(数量小协议分级效果不明显,但还是可以优先协议分级减小工作量)
2. 根据协议分级的结果,我们优先分析数量多占比高的协议流量,分析过程根据题目不同思路也有所不同
3. 如果协议分级中有文件传输协议或是有传输媒体文件内容优先进行导出,一定要使用foremost工具进行辅助
4. 如果没有思路就搜索“flag”“ctf”等关键词
5. 涉及到攻击的流量就只能逐个追踪TCP流查看了
wireshark功能一:协议分级
对数据包按TCP/IP协议栈从底层向高层逐层进行统计,显示每个协议的数据包数、字节数以及各协议所占的百分比。


我们可以发现应用层HTTP协议占比最高,应该优先分析。
wireshark功能二:显示过滤器
决定哪些数据包被显示,在显示过滤器中输入表达式,使过滤规则生效。
在前面我们已经找到了需要显示过滤来分析的HTTP协议,因此我们在协议分级窗口中选中HTTP协议作为过滤器应用:


这样我们就显示过滤了HTTP协议相关的数据包,可以看见左上方的应用显示过滤器的输入框内容也添加了”http“,现在只有29个数据包了,我们即将开始逐个分析。
HTTP协议数据包分析
HTTP协议介绍:https://www.bilibili.com/video/BV1zb4y127JU?vd_source=69c558b0c7be97607c79afbd75bd1f7c
HTTP数据包分析:HTTP数据包详解 - dream_fly_info - 博客园 (cnblogs.com)
wireshark功能三:数据包分析
在左下角的TCP/IP协议栈解析窗口我们可以以更清晰的格式分析协议的消息结构,我们逐个分析,发现第三个POST请求包的URL加密信息里面找到了“password”字段:

题目说管理员的密码即是答案,因此使用flag{}包起提交即可
考点:网络流量分析、理解HTTP协议数据包结构
补充:CTF流量分析解题钻空
我们明白要分析HTTP协议后,直接在显示过滤器中查找包含”flag“字段的数据包有时候能直接找到我们想要的东西:

N种方法解决(新工具)
下载文件,发现里面是一个exe格式的文件,我们运行也运行不起:

这又不是逆向题,给我们exe文件干嘛!所以我们优先使用010 editor分析文件:

发现它的内容纯纯的就是一普通的文本文件,根据左上方开头的提示我们发现这些数据是源内容经历了base64编码的jpg格式的图片,因此我们使用cyberchef来进行解码:

解码后的内容虽然是乱码,但看文件头含有“PNG”字段应该就是我们的PNG格式文件了!cyberchef有个很方便的魔法解密功能,可以直接分析出下一步应该如何解密,点击Output栏的魔法棒图标即可自动解密:

可以发现它自动将PNG图片16进制的乱码转为了图片,出现了二维码,直接扫描解密出二维码隐藏的内容:

考点:会使用工具解码base64、会将PNG图片的16进制的乱码转换为PNG图片
补充:
我们也可以将输出内容复制粘贴到010 editor里面创建新的16进制文件,保存为.png格式也是可以发现二维码图片的。
基础破解(知识巩固题)
下载文件,发现里面是一个rar的压缩包,根据题目提示,它是四位数字加密的。按照遇到含有密码的压缩包思路,我们直接使用工具爆破:

解出压缩包密码为:2563,打开获得经过base64编码的flag,解码即可:

考点:压缩包密码爆破
文件中的秘密(知识巩固题)
下载文件,发现里面是一张jpeg图片,我们查看一下貌似什么也没有

按照图片隐写思路首先查看图片属性的详细信息,在图片的备注中发现了flag:

考点:会查看图片属性。
LSB(新)
下载文件,发现里面是一张png图片,我们查看一下貌似什么也没有

虽然题目已经明示了这是一道LSB隐写的图片,但我们还是会按照图片隐写思路做。第一步无果,我们优先打开010 editor打开图片查看:

貌似没有插入信息,我们再用string查看:
strings flag11.png
strings 查询一个二进制文件中所含有的字符信息并将其输出来

跑出一堆没用的乱码,我们可以开始第三步了。
StegSolve功能三——调整图片通道
LSB隐写原理:隐写术鉴赏2:11分到3:57分处
我们使用StegSolve打开图片时,下面有两个箭头,我们点击可以选择调整图片通道来观察是否有隐藏的信息。(视频中有解说,每张图片每个像素点都拥有红绿蓝三种颜色还有透明度的通道)



我们可以发现,当我们关闭红色通道(red plane 0)、绿色通道或是蓝色通道时,图片的上方出现了黑白的印记,很显然是二进制的信息,我们继续使用StegSolve进行分析。
StegSolve功能四——数据提取
主要用于提取比特并排列组合

由我们之前得到的信息可知,应该如下图般配置,配置完成后点击preview查看隐藏信息:

Alpha 之前发现透明度通道没有什么隐藏信息,故不选
Red plane 0含有隐藏信息
Green plane 0含有隐藏信息
Blue plane 0含有隐藏信息
Extract By 我们发现图片上方在关闭通道出现黑白的印记是横向的,因此按row(行)提取像素而不是column(列)
Bit Order 我们知道像素值是按最低位的修改进行隐写的,因此选LSB(像素值最低位作为第一位)
Bit Plane Order 设置RGB通道的顺序,默认RGB
我们发现隐藏信息是一张png图片文件,我们点击Save Bin,将图片保存为.png格式的文件,发现是张二维码图片:

扫一扫即可得到flag

考点:理解LSB隐写原理、学会利用工具
zip伪加密(新)
下载文件,发现里面是一个rar的压缩包,根据题目提示,它是伪加密的。
ZIP压缩包格式
一个ZIP压缩文件由如下三部分组成:压缩源文件数据区、压缩源文件目录区和压缩源文件目录结束标志。具体而言,一个ZIP文件可以按如下方式分解:
[本地文件头+文件数据+数据描述符]{1,n}+目录区+目录结束标识
[本地文件头+文件数据+数据描述符] 构成压缩源文件数据区
{1,n} 表示这部分数据最少出现1次,也可以出现n次,n的数量和压缩前的文件数量一致
目录区 会保存压缩前文件和文件夹的目录信息,这部分数据一般均为明文显示
目录结束标识 存在于整个压缩包的结尾,用于标记压缩的目录数据的结束
(源于《CTF那些事儿》)
更多详细内容可以参考文章:一个zip文件由这样三个部分组成_zip 文件结构-CSDN博客
zip伪加密
原理:通过修改zip压缩包特定的字节(全局方式位标记),使得在打开文件时压缩包被识别为使用了密码加密,但实际上并没有真正加密的技术。
回到题目,我们使用010 editor打开zip文件:

我们可以在压缩源文件数据区中可以找到全局方式位标记,它的值为09 00:

当全局方式位标记的第二个数字(即09 00中的第二个数字9)为奇数时,ZIP文件被识别为加密;而当这个数字为偶数时,文件被视为未加密。因此,我们将09 00改为00 00,保存后就可以直接打开压缩文件了:


考点:理解zip伪加密原理
被嗅探的流量(新)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

可以发现HTTP协议占比最高,并且看HTTP协议内容像是在上传媒体文件:

flag可能就隐藏在这上传的文件里面,我们应该如何提取这其中的文件呢?
wireshark功能四:导出文件对象
方法一:导出对象法。这种方法依赖于wireshark自带的解析功能,wireshark可以根据不同的协议自动导出文件,这题主要导出使用http协议传输的文件:


点击全部保存即可,我们依次分析发现upload(3).php中包含一张jpg图片,并且结尾处插入了flag:

当离线流量太大或者传输文件头受损时,这种方法会失效;而且导出对象法支持的协议过少,应用范围有限。
方法二:导出分组字节流法。我们在找到的传输文件的HTTP包的内容进行导出分组字节流:

保存类型默认为.bin文件,但我们可以改成.jpg,并使用010 editor进行分析:

我们也可以在结尾处发现插入的flag。
这是一种完全由人工操作的提取方法(再不济直接把16进制文本复制下来修复),具有广泛的适用性。
方法三:binwalk提取法。利用binwalk对离线流量文件进行检测和提取:
binwalk -e 被嗅探的流量.pcapng

我们发现这道题分解不出来,所以我们使用以下命令指定输出文件:
binwalk -D=jpeg 被嗅探的流量.pcapng
发现图片文件貌似受损,但使用010 editor还是能发现其中隐藏的flag:

binwalk检测的原理是根据文件头特征,如果流量中文件的文件头损坏binwalk也无法提取成功,这时仍需手工提取。
考点:网络流量分析、理解HTTP协议数据包结构、学会提取流量包中的文件
rar(知识巩固题)
下载文件,发现里面是rar格式的压缩包,根据题目提示,这是我们遇到的第三个需要爆破密码的压缩包了,我们直接爆破得到密码:

解开rar文件,获得flag
考点:压缩包密码爆破
qr(简单)
下载文件,发现里面是一张png格式的二维码图片,我们用二维码识别软件QR Research扫一扫,发现flag:

这题应该是一道签到题,能够保证大部分同学做出来
考点:会扫二维码。
镜子里面的世界(知识巩固题)
下载文件,发现里面是一张png图片,我们查看一下貌似什么也没有

按照文件名提示我们应该使用Stegsolve来查看,在此跳过图片隐写思路前两步直接使用Stegsolve打开,调整通道查看图片发现:



我们可以发现,当我们关闭红色通道(red plane 0)、绿色通道或是蓝色通道时,图片的上方出现了黑白的印记,很显然是隐藏的二进制的信息,我们继续使用StegSolve进行分析:

我们可以以文本形式保存,获得flag。相当于我们再次复习了LSB隐写的题目。
考点:理解LSB隐写原理、学会利用工具
ningen(知识巩固题)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们可以发现EOIMaker是jpg文件的文件尾,后面的unknownPadding[204]块大小为9721h也就是之后的内容无法被PNG模板解析,看文件头是zip压缩文件
根据前文我们进行文件分离,获得加密的ZIP文件:

按照题目提示,密码是四位数字,爆破密码成功:

使用密码解压,获得flag
考点:文件分离、压缩包密码爆破
爱因斯坦(新知识巩固题)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,查看文件属性发现备注:

我们再优先打开010 editor打开图片查看:

发现文件尾部含有插入的zip文件:

提取zip文件,发现加了密,我们使用之前在属性里面看到的字符串尝试,成功提取flag
考点:文件分离、压缩包密码猜测
小明的保险箱(知识巩固题)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,查看文件属性发现备注:

我们再优先打开010 editor打开图片查看,发现文件尾部含有插入的rar文件:

提取zip文件,发现加了密,按照题目提示我们进行密码爆破:

提取出flag
考点:文件分离、压缩包密码爆破
easycap(新)
首先我们用wireshark打开pcap文件:

按照数据包分析思路,我们先进行协议分级:

非常容易,我们可以看见TCP协议传输Data数据内容,我们直接过滤观察数据包:

发现上传了38个Data数据包,每个包包含一个字节,查看前几个包内容可以发现发送的字符串为“FLAG”
也就是说我们将这些Data数据包的内容组合起来就能得到flag
wireshark功能五:数据追踪流
我们的一个完整的数据流一般都是由很多个包组成的,我们在这里跟踪TCP协议数据流可以将Data数据组合:

追踪TCP流可以得到flag
考点:网络流量分析、学会追踪协议流量
隐藏的钥匙(知识巩固题)
下载文件,发现里面是一张jpg图片,我们查看一下貌似什么也没有
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

模板解析不好,我们直接搜索是否存在”flag“字符串,发现隐藏的flag:

按照提示经过base64解码,得到了flag

考点:寻找插入隐藏flag、理解base64编码
另外一个世界(知识巩固题)
下载文件,发现里面是一张jpg图片,我们查看一下貌似什么也没有
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

“flag”查询未果,但发现文件结尾插入了规律的二进制字符串:

我们进行二进制转码,得到了隐藏的flag:

考点:寻找发现插入隐藏信息、理解二进制转码
神秘龙卷风(新编码)
下载文件,发现里面是rar格式的压缩包,根据题目提示,这是我们遇到的不知道多少个需要爆破密码的压缩包了,我们直接爆破得到密码:

打开之后,发现了奇怪的内容:

txt文件内容由“+“”.“”>“三种字符组成,这是非常著名的Brainfuck编码,我们只能使用相关代码解码(这里我使用了brainfuck解码工具,在线的工具好像失效了):

得到flag
考点:压缩包密码爆破、理解brainfuck编码
数据包中的线索(知识巩固题)
首先我们用wireshark打开pcapng文件:

按照数据包分析思路,我们先进行协议分级:

发现HTTP协议发送的Line-base text data占比最多,我们优先过滤查看:

追踪HTTP流,发现发送的数据经过了base64编码:

解码,发现是张图片,获得隐藏在图片中的flag:

考点:网络流量分析、学会追踪协议流量、base64解码图片文件
FLAG(知识巩固题)
下载文件,发现里面是一张png格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

没有宽高错误,也没有隐藏的插入信息,我们使用StegSolver进入第二步:



我们可以发现,当Red plane 0、Green plane 0、Blue plane 0时,图片顶部出现规律的黑白组合,我们进一步分析LSB隐写:

可以发现内部隐藏了一个ZIP文件,提取会报错但我们硬提取,文件提取出来发现发现是elf文件:

我们用linux系统运行看看:

发现了flag
考点:理解LSB隐写原理、学会利用工具、理解ELF文件
假如给我三天光明(新工具)
下载文件,发现里面是一张jpg格式的图片和一个压缩包
图片中下面有信息,按照提示应该是盲文,我们使用在线解密:在线盲文翻译器 (lddgo.net)
(盲文输入器也在网站下方)

输出文本出现乱码,我们盲文类型:

猜测这是zip压缩包的解压密码,于是我们解压文件,发现了一个音频文件
音频隐写思路:
1. 听一下,再查看音频的属性是否藏了东西
2. 使用Audacity观察音频是否藏有信息
3. 使用010 Editor、strings等其他工具发现插入隐藏信息,并使用binwalk和foremost尝试自动提取
4. 使用steghide、SilentEye、mp3stego等其他特殊工具提取隐写信息
回到题目,我们听到了熟悉的摩斯电码,因此推测与摩斯电码有关
音频的属性没有什么信息,我们接下来使用Audacity打开音频
Audacity
可以查看音频的波形图,有些信息可能就藏在波形图里面:

我们可以发现音频的波形图按照类似于摩斯电码的“-“和”.“组成,我们进行解码:

解出flag
(按照buuctf的格式应去掉”CTF“并小写,写为flag{wpei08732?23dz})
考点:盲文解密、摩斯电码音频
后门查杀(新工具)
下载文件,发现里面是一个网站目录的文件夹
(如果你打开了杀毒软件,那么很快有问题的文件就会被发现并且删除)
我们首先打开文件夹,发现小白搭网站的目录结构:

一般来说,我们应该逐个查询各个文件寻找是否存在木马文件,但我们有自动化的工具可以帮我们实现这一点
D盾查杀工具
D盾是目前最为流行和好用的web查杀工具,同时使用也简单方便,在web应急处置的过程中经常会用到。D盾的功能比较强大, 最常见使用方式包括如下功能:
1、查杀webshell,隔离可疑文件;
2、端口进程查看、base64解码以及克隆账号检测等辅助工具;
3、文件监控。
下载地址:D盾防火墙 (d99net.net)
我们将网站根目录文件放入D盾查杀工具扫描,发现了可疑文件:

我们优先重点观察第三个风险级别为5的文件:


找到了webshell,套上flag{}提交
什么是webshell可以查看这篇文章(待补充)
考点:使用工具扫描寻找可疑后门文件
webshell后门(知识巩固题)
下载文件,发现里面是一个网站目录的文件夹
我们首先打开文件夹,发现朋友搭网站的目录结构:

我们将网站根目录文件放入D盾查杀工具扫描,发现了可疑文件:

我们查看第一个文件,找到了webshell,套上flag{}提交(与上一题的flag一模一样……)

来首歌吧(知识巩固题)
下载文件,发现里面是一个wav格式的音频文件
播放音乐,发现是《NyanCat》的循环播放
按照音频隐写思路,音频的属性没有什么信息,我们接下来使用Audacity打开音频:

我们可以发现这首歌有两个音频轨道,右声道轨道放歌,左声道轨道隐藏着信息
我们将右声道静音,听听左声道的信息,发现是摩斯电码,我们按照波形图进行解密:

解出flag
考点:音频双音轨隐藏信息、摩斯电码音频
面具下的flag(较难)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们可以在结尾发现插入隐藏的ZIP文件,我们进行文件分离:

手工提取失败,我们尝试利用binwalk工具自动提取:
binwalk mianju.jpg -e

文件分离出一个压缩包文件,我们尝试解压,发现压缩包被加密
按照遇到含有密码的压缩包思路,题目没有给出密码的相关线索,因此我们使用010editor观察zip文件是否存在伪加密的情况:


可以发现这个ZIP文件的目录区存在伪加密的情况,我们进行修改并打开文件:

我们提取出一个vmdk文件
vmdk文件
VMDK 是 VMware Virtual Machine Disk(虚拟机磁盘)的缩写,它是 VMware 虚拟化软件使用的虚拟磁盘映像文件格式之一。VMDK 文件存储了虚拟机的硬盘数据,类似于实际计算机系统中的物理硬盘。
VMDK 文件是一种二进制文件,用于模拟和存储虚拟机的硬盘。它包含了虚拟机操作系统和应用程序所需的文件和数据,包括操作系统文件、应用程序、配置文件和用户数据等。在运行虚拟机时,VMware 虚拟机管理器会读取和操作 VMDK 文件,提供虚拟机所需的存储和访问功能。
(来源于vmdk是什么文件?-CSDN博客)
我们可以使用7z来提取vmdk虚拟磁盘文件中的内容:

我们得到两个文件夹:

我们在key_part_one中发现了_NUL文件,我们查看其内容:

按照前面的经验,我们可以知道这个是brainfuck编码的内容,我们进行解码
(这里找到了在线解码网站:https://www.splitbrain.org/services/ook)

我们得到了flag的碎片1
我们在key_part_two中发现了where_is_flag_part_two.txt文件,我们查看其内容:

里面没有内容,我们查看文件的属性也没发现什么有用的信息:

我们使用7z打开vmdk文件查看详情:


我们可以发现where_is_flag_part_two.txt文件存在1交替数据流
交替数据流
NTFS(一种文件系统,用于明确磁盘或分区上的文件的方法和数据结构)交换数据流(ADS)简介
在NTFS文件系统中存在着NTFS交换数据流(Alternate Data Streams,简称ADS),这是NTFS磁盘格式的特性之一。每一个文件,都有着主文件流和非主文件流,主文件流能够直接看到;而非主文件流寄宿于主文件流中,无法直接读取,这个非主文件流就是NTFS交换数据流。
ADS的作用在于,它允许一个文件携带着附加的信息。例如,IE浏览器下载文件时,会向文件添加一个数据流,标记该文件来源于外部,即带有风险,那么,在用户打开文件时,就会弹出文件警告提示。再如,在网址收藏中,也会附加一个favicon数据流以存放网站图标。
要使用7z查看这个文件的隐藏文件,我们使用7z的交替数据流的功能:


这是OOK编码,我们同样可以使用上面的网站进行解码:

我们得到了flag碎片2,拼凑出了完整的flag
考点:文件分离、使用工具分析vmdk文件、理解brainfuck编码、理解交替数据流隐藏文件、理解ook编码
荷兰宽带数据泄露(较难新工具)
下载文件,发现里面是一个.bin格式的配置文件(文件名为config的一般为配置文件)
bin文件
bin是binary的缩写,译为“二进制”。binary file二进制文件是一个非text file文本文件的计算机文件。binary file是一种计算机文件格式,它以二进制编码表示文件的内容。这些文件通常包含计算机程序或数据,例如软件/固件、操作系统、文档、图像、音频和视频等。
在嵌入式软件开发中,binary file通常是软件固件或操作系统的映像文件,binary file通常用于将代码和数据加载到嵌入式系统的nonvolatile memory非易失性存储器(如flash memory)或其他存储器中。此外,binary file还可以用于将数据从一个嵌入式系统传输到另一个嵌入式系统。
在操作系统中,可执行文件和库文件通常以二进制格式存储。
在网络通信中,binary file可以被用作数据传输的格式,如HTTP请求和响应、SMTP邮件等。
(来源自文章【嵌入式烧录/刷写文件】-3.1-详解二进制Bin格式文件_bin文件结构-CSDN博客)
一般来说我们可以使用十六进制编辑器查看.bin文件的内容,但我们使用010editor打开发现是一片乱码:

由题目提示可以猜测,”宽带数据泄露“可以猜测题目的config.bin文件为一路由器的配置文件,我们可以使用RoutePassView工具查看配置文件具体内容
RoutePassView功能:从路由器配置文件中恢复密码
此应用程序允许我们从路由器创建的配置文件中恢复密码或其他数据,包括 ISP 的登录用户/密码、路由器的登录密码和无线密钥,如果我们忘记了这些密码但我们有路由器配置的备份文件,我们可以从路由器配置文件中恢复密码。下载地址:RouterPassView - Recover lost password from router backup file on Windows (nirsoft.net)(官网下载)
我们打开软件,导入配置文件可以查看相关信息:

题目的提示并不充分,我们应用这个软件是为了寻找路由器配置的用户名、密码等信息的,因此flag很有可能就是路由器配置的用户名、密码等信息
我们寻找相关配置字段:

将其包裹上flag{},即可过关
考点:理解.bin文件作用、使用工具分析路由配置文件
九连环(知识巩固题新工具)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

按照模板解析除了很多层的东西,看上去很有可能插入了隐藏文件
手动提取其中的隐藏文件看上去有点困难,我们使用binwalk自动提取:
binwalk 123456cry.jpg -e

文件分离出两个加密的压缩文件,我们尝试以图片文件的文件名“123456cry”作为密码输入,失败了
因此我们逐个分析压缩包的伪加密情况,发现了这个压缩包的一个deFlags为“2049”而其他的deFlags为“2048”,判断存在伪加密:

我们进行修改,解压文件:

又是一张图片,我们继续按照图片隐写的思路进行分析
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

并没有发现什么东西,使用了StegSolve也没有看出任何隐藏信息,因此我们开始使用特定工具分析图片包含的隐藏信息。此类特定工具很多,我们将按顺序一一尝试
Steghide——最优先的特定图片隐写工具
Steghide 是一个可用于隐写术的工具。它允许您在音频和图像文件中嵌入秘密信息,包括 JPEG、BMP、WAV 和 AU 文件
我们在kali中使用命令:
steghide extract -sf good-已合并.jpg
-sf 指定文件

Enter passphrase 输入密码,没有密码就直接回车
我们可以发现我们的图片中提取除了ko.txt的隐藏文件:

我们对压缩包进行解压,得到flag
考点:文件分离、理解zip伪加密原理、使用了特定工具进行的图片文件隐写
被劫持的神秘礼物(知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

我们可以发现应用层HTTP协议占比最高,应该优先分析:

我们可以发现一些HTTP请求报文,在编号为4的数据包可以发现主机向服务器使用POST方式请求上传了“name”和“word”参数,我们可以猜测这是账号和密码,按照题目需求,我们进行MD5加密,得到了flag:

考点:网络流量分析、理解HTTP协议数据包结构
[BJDCTF2020]认真你就输了(新)
下载文件,发现里面是一个xls格式的表格文件,我们点击查看:

里面全是乱码,但我们可以看出存在ZIP格式文件头字符“PK”,我们将文件后缀改为.zip后打开查看:

我们可以看见有很多文件夹,因为如今的office办公软件的输出文件其实都是一个压缩包,包含着文件的xml文件、图片、视频等所有素材。
经过一番搜寻,我们最终找到了flag:

考点:理解office文件是一堆文件的压缩文件
被偷走的文件(知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

我们可以发现UDP协议占比最高,但存在基于TCP协议的FTP文件传输协议,我们优先查看传输的文件:

可以发现编号为49的ftp数据包传输了名为“flag.rar”的文件,我们导出对象:

我们没有任何其他的密码提示,rar格式不存在伪加密的情况,因此我们开始一边进行密码爆破一边继续分析
密码爆破成功,我们解压文件得到了flag:

考点:网络流量分析、理解FTP协议数据包结构、学会提取流量包中的文件、压缩包密码爆破
[BJDCTF2020]藏藏藏(知识巩固题)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们可以在结尾发现插入隐藏的ZIP文件,我们进行文件分离,得到的压缩包中含有一个docx文档,我们打开查看:

是一个二维码,我们进行扫描得到了flag:

考点:文件分离
[GXYCTF2019]佛系青年(新编码知识巩固题)
下载文件,发现是一个加密的压缩包:

题目没有提示,我们优先查看zip的伪加密情况:

可以发现一处deFlags的值为“9”,与其余的deFlags值“0”不同,在此修改后成功解压文件:

我们优先查看txt文本文件,打开发现:

底下是互联网著名的佛曰加密,我们在进行解密得到了flag:

(现在网上在线的佛曰解密多是新版佛曰,因此这里使用了解密工具“[随波逐流]CTF编码工具 V5.4 20140328”)
考点:理解zip伪加密原理、理解佛曰加解密
[BJDCTF2020]你猜我是个啥(知识巩固题)
下载文件,发现是一个损坏的压缩包:

我们优先使用010 editor进行分析,发现它应该是一个png格式的图片:

我们直接将后缀名修改为.png,得到图片:

扫描二维码,被骗了:

按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看,在结尾处发现了插入隐藏的flag:

考点:分析十六进制文件头
刷新过的图片(新工具)
下载文件,发现里面是一张jpg格式的图片
按照题目提示,这道题是使用特殊的隐写工具隐藏信息的,因此我们需要找到使用的是什么工具
根据“刷新”可以猜测出是使用了F5-steganography工具进行的隐写,因为网页的”刷新“与“F5”相关联
F5-steganography
jpeg/jpg文件,是一种使用DCT频域来描述的一个图像的文件格式
而F5隐写算法,就是针对jpeg/jpg格式文件在频域的隐写术
工具下载地址:GitHub - matthewgao/F5-steganography: F5 steganography
此工具使用的是java语言,我们输入命令:
java -mx40M Extract Misc.jpg
-mx40M 不清楚做什么用的,按照官方文档说使用这样的命令进行解密

生成了隐写信息的输出output.txt:

我们可以发现zip文件的文件头字符“PK”,因此我们修改后缀,解压文件发现需要密码:

我们使用010 editor进行分析,发现是伪加密:

修改后即可解压获得flag
考点:使用了特定工具进行的图片文件隐写、理解zip伪加密原理
秘密文件(知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

我们可以发现TCP协议占比最高,但存在基于TCP协议的FTP文件传输协议,我们优先查看传输的文件:

可以发现编号为95的ftp数据包传输了名为“6b0341642a8ddcbeb7eca927dae6d541.rar”的文件,我们导出对象:

导不出来,因此我们使用foremost工具进行导出:
foremost 305df1f78bef4ccfd2a3bd0fe4a6c0d7.pcapng

压缩包被加密了,我们没有任何其他的密码提示,rar格式不存在伪加密的情况,因此我们开始一边进行密码爆破一边继续分析
密码爆破成功,我们解压文件得到了flag:

考点:网络流量分析、理解FTP协议数据包结构、学会提取流量包中的文件、压缩包密码爆破
snake(脑洞)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

发现文件尾部有插入隐藏zip文件,我们进行文件分离并解压得到密文和密钥:

cipher文件是乱码,key文件是base64编码后的密文,我们进行解码:

key的内容是“Nicki Minaj最喜欢的关于蛇的歌是什么?”
我们之间上网搜索,明白了Nicki Minaj是一位歌手,她唱过一首名为《Anaconda》(蟒蛇)的歌

那么我们可以猜测key的值为“Anaconda”
我们还是不知道cipher是如何加密的,于是我们上网搜索相关的加密方式(由于只有一个key作为密钥,因此我们可以猜测这是对称加密的方式):

我们找到了名为“Serpent”(蛇)的加密方式,我们使用在线解密工具(Serpent Encryption – Easily encrypt or decrypt strings or files (online-domain-tools.com)不知道为什么其他的网址都不太好使所以用了这个)进行解密:

key的值不为“Anaconda”,那我们可以尝试一下“anaconda”

得到了正确的flag
考点:文件分离、学会用搜索引擎去搜索相关加密方式
[BJDCTF2020]鸡你太美(新知识巩固题)
下载文件,发现里面是两张gif格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:


GIF文件格式简介
参考文章:https://blog.csdn.net/Swallow_he/article/details/76165202
回到题目,我们可以发现“篮球副本.gif”文件文件头损失,我们进行修复:
我们以文本格式进行编辑,在文件头的部分添加4字节数据(由“篮球.gif”和“篮球副本.gif”两个文件对比可发现损坏的文件头缺少四字节的内容)


返回到十六进制的编辑方式,我们将添加的4字节数据更改为文件头:

再次运行模板发现成功识别出gif文件了,我们可以直接打开图片查看内容:

得到了flag
考点:文件头修复
[BJDCTF2020]just_a_rar(知识巩固题)
下载文件,发现里面是一个rar格式的压缩文件
按照文件名提示的“四位数”,不用说直接上爆破:

解压后得到了一张JPG格式的图片,我们按照图片隐写思路查看文件属性找到flag:

考点:压缩包密码爆破
菜刀666(较难知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

我们可以发现应用层HTTP协议占比最高,应该优先分析:

可以发现http协议大部分是在与上传的文件“/upload/1.php”进行交互,可以推测这是上传的webshell,菜刀工具可以通过这个webshell对服务器做出许多操作。我们可以逐一追踪流查看菜刀流量所做的操作:

根据响应包返回的内容我们可以推测tcp流1在探测服务器的主机信息

根据响应包返回的内容我们可以推测tcp流2在探测服务器的目录

根据响应包返回的内容我们可以推测tcp流3攻击机在向服务器请求“xxd_8.0.1257-2_amd64.deb”这个文件


根据响应包返回的内容我们可以推测tcp流4、5在探测服务器的目录,我们可以发现flag.txt的身影

根据响应包返回的内容我们可以推测tcp流6攻击机在向服务器请求“vim-common_8.0.1257-2_all.deb”这个文件

根据请求包发送的内容我们可以推测tcp流7在上传一个文件,再请求回显当前目录我们可以发现多了一个6666.jpg的文件,我们可以推测这就是上传的文件,我们复制下来进行解码查看(注意上传图片文件的参数是“z2”):


我们可以发现上传的是一张图片文件,尝试了之后图片的内容并不是flag,我们继续分析:

根据响应包返回的内容我们可以推测tcp流8攻击机在向服务器请求“less_487-0.1_amd64.deb”这个文件

根据响应包返回的内容我们可以推测tcp流9创造了一个“hello.zip”文件,并且向服务器请求了这个文件,我们可以将返回包的zip文件内容复制进行手动文件提取,或者使用foremost工具自动提取:

解压发现需要密码,我们尝试将前面的图片文件的内容进行尝试成功,得到flag
考点:网络流量分析、理解webshell的利用方式
[BJDCTF2020]一叶障目(知识巩固题)
下载文件,发现里面是一张png格式的图片
按照图片隐写思路,第一步使用TweakPNG工具发现图片的crc校验出现错误,因此可能存在PNG宽高隐写

我们使用之前写的PNG宽高爆破脚本,可以得到正确的图片宽高,我们进行修改即可:


打开图片,发现了隐藏的flag

考点:PNG宽高隐写、理解爆破PNG宽高原理
[SWPU2019]神奇的二维码(较难知识巩固题)
下载文件,发现里面是一张png格式的二维码图片,我们用二维码识别软件QR Research扫一扫,发现并没有flag

按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

发现了插入隐藏的rar文件,我们进行手动文件分离得到了:

鉴定为base64编码,我们进行解码,提交发现这并不是flag

这说明这张图片还有其他隐藏的信息,我们再使用binwalk自动提取工具进行提取查看:
binwalk BitcoinPay.png -e

藏的东西可真多啊……
我们逐一查看分析:
716A.rar 包含的内容就是“flag.jpg”与“看看flag在不在里面_.rar”两个文件,压缩文件显然加密了
我们尝试使用”encode.txt“的解码内容,成功解压:

根据文件名这么讨嫌的说法已经可以猜测flag不在里面了……我们先继续分析其他的文件
7104.rar 就是前文发现的“encode.txt”
17012.rar 包含了“flag.doc”

一大串乱码鉴定为base64编码,我们进行解码,发现密文貌似没什么变化,这可能是进行了多次base64编码,我们也进行多次base64解码:

总共进行了20次base64编码,得到了一字符串,尝试提交发现也不是flag
18394.rar 加密的压缩文件
使用之前得到的字符串作为密码成功解压,得到了“good.mp3”,一听鉴定为摩斯电码,我们使用Audacity观察其声波输入摩斯电码进行解密:


(按照buuctf的格式应小写,写为flag{morseisveryveryeasy})
考点:文件分离、压缩文件密码猜测、理解base64多次编码、摩斯电码音频
[BJDCTF2020]纳尼(知识巩固题)
下载文件,发现里面是一张gif格式的图片与提示文件

按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

可以发现和坤坤那题一样,GIF文件头缺失,我们进行修复即可:

我们查看一下发现flag都是一段一段的出现又一闪而过,我们可以使用StegSolver进行逐帧分析:




将字符串拼接起来并进行base64解码,得到flag
考点:文件头修复、利用工具逐帧查看gif文件图像
[HBNIS2018]excel破解(知识巩固题)
下载文件,发现里面是一个xls格式的表格文件,我们点击查看发现加密了:

我们优先使用010 editor查看文件内容,搜索“flag”,最终找到相关字段:

考点:学会使用010 editor查看打不开的文件
[HBNIS2018]来题中等的吧(知识巩固题)
下载文件,发现里面是一张png格式的图片,按照条形码只有两种“短”和“长”的形态可以猜测这是摩斯电码:

我们进行解密,得到了flag

考点:理解摩斯电码
梅花香之苦寒来(较难新工具)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步可以发现详细信息中隐藏着提示:

我们再优先打开010 editor打开图片查看:

我们可以在结尾发现插入隐藏的信息,我们可以分析出这是十六进制编码的内容,我们进行解码:

我们得到了一大堆的坐标格式的内容,我们保存输出结果。根据图片属性中给出的提示,我们可以推测这是使用画图工具绘出图像。在此我们可以使用gnuplot工具(当然也可以使用python具有绘图功能的库如matplotlib)
gnuplot——一个命令行驱动的科学绘图工具
gnuplot可将数学函数或数值资料以平面图或立体图的形式画在不同种类终端机或绘图输出装置上。它是由Colin Kelley 和 Thomas Williams于1986年开发的绘图程序发展而来的,可以在多个平台下使用。gnuplot既支持命令行交互模式,也支持脚本。
官网下载地址:gnuplot homepage
在使用gnuplot之前,我们应该把输出的坐标更改为gnuplot可以识别的模式,我们可以使用记事本的编辑功能或者自己写脚本:
with open('download.txt', 'r') as res: # 坐标格式文件比如(7,7)
re = res.read()
res.close()
with open('gnuplottxt.txt', 'w') as gnup: # 将转换后的坐标写入gnuplotTxt.txt
re = re.split()
tem = ''
for i in range(0, len(re)):
tem = re[i]
tem = tem.lstrip('(')
tem = tem.rstrip(')')
for j in range(0, len(tem)):
if tem[j] == ',':
tem = tem[:j] + ' ' + tem[j+1:]
gnup.write(tem + '\n')
gnup.close()

我们打开gnuplot.exe,使用以下命令:
load (gnuplottxt.txt的文件路径,如果直接把txt文件放到gnuplot的文件路径下可以略过这一步)
plot "gnuplottxt.txt"
即可绘出一副二维码,我们进行扫描获得flag

考点:利用十六进制编辑器找到隐藏的信息、学会使用数学坐标绘图工具
[ACTF新生赛2020]outguess(新工具)
下载文件,发现里面是一张jpg格式的图片和flag.txt文件的提示(其他文件名带“._”的文件可以忽略,他们并不是题目的一部分)

根据flag.txt和题目名的提示我们可以明白这题目使用了特殊的隐写工具——outguess
outguess
outguess是一款开源的隐写工具,可以隐藏信息在图像和声音文件中。它使用了一种基于数据的方法,而不是基于修改的方法来隐藏信息,这使得它更加难以被检测到。
使用outguess隐写信息需要加密信息的密码key,也就是说我们需要找到key来找出jpg图片中隐写的信息。
按照图片隐写思路,第一步我们在图片属性中的详细信息中发现了内容:

这是一个很有意思的编码方式,叫做“社会主义核心价值观编码”,我们可以使用在线或者本地工具进行解码:

解码出“abc”,我们可以推断出这就是我们需要的key,现在我们可以使用以下命令使用outguess进行解密了:
outguess -k 'abc' -r mmm.jpg flag.txt
-k 指定key
-r 指定输入文件和输出文件

成功解出flag
考点:理解特殊编码方式、使用了特定工具进行的图片文件隐写
谁赢了比赛?(较难知识巩固题)
下载文件,发现里面是一张png格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们可以在结尾发现插入隐藏的rar文件,我们进行文件分离,得到的压缩包中含有一张gif图片和flag.txt文件,我们尝试打开gif图片却发现压缩文件被加密了,因为没有找到其他提示所以我们优先进行爆破:


解压文件,发现这个gif真的有够长的,我们先使用stegsolve来逐帧查看,在第310帧发现了奇怪的图片:

尝试上交发现并不是flag,我们先将这一帧图片进行保存再继续分析:

最后我们发现在关闭红色通道(red plane 0)时会出现一张二维码,我们进行扫码即可获得flag

考点:LSB隐写
穿越时空的思念(知识巩固题)
下载文件,发现里面是一个mp3格式的音频文件
按照音频隐写思路,我们听出音频中含有摩斯电码的声音,音频的属性没有什么信息,我们接下来使用Audacity打开音频:

发现右声道存在摩斯电码,我们进行解码:

得到flag(这里出现了两段摩斯电码,第二段是第一段摩斯电码前半部分的重复内容,按照题目提示flag为小写的32位字符,我们不用管就行)
考点:音频双音轨隐藏信息、摩斯电码音频
[WUSTCTF2020]find_me(知识巩固题)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步我们在图片的备注中发现了盲文:

我们可以发现盲文的末尾含有等号,这说明这并不是真正的盲文内容,应该时经盲文加密后的内容(盲文翻译和盲文加密是两个东西)
我们使用相关在线网站解密得到flag:

考点:会查看图片属性、理解盲文加密与盲文翻译的区别
[SWPU2019]我有一只马里奥(知识巩固题)
下载文件,发现里面是一个exe格式的可执行文件
我们先直接运行,它会生成一个1.txt:

根据提示我们可以知道这是NTFS文件隐写,在前文交替数据流的内容中已经简介了这种隐写方式了,文件偷偷携带着附加的信息。
我们可以使用7z打开这个文件来探索它的隐藏内容,发现了flag:

考点:理解NTFS文件隐写
[GUET-CTF2019]KO(知识巩固题)
下载文件,发现里面是一份txt格式的文本:

鉴定为brainfuck编码,我们进行解码:

得到了flag
考点:理解brainfuck编码
[ACTF新生赛2020]base64隐写(新)
下载文件,发现里面是一份txt格式的文本(还有公众号的二维码图片,扫码获得提示):

我们可以看到一串串的base64编码内容,再根据题目名的提示我们可以判断这里存在base64隐写。
base64隐写原理(引用自文章:Base64隐写 | Lazzaro (lazzzaro.github.io))
原理
Base64的编码过程就是将文本字符对应成二进制后,再六个一组对应成索引,转为编码字符。如果字符串长度不是3的 倍数,则对应的二进制位数不是6的倍数,需要在末尾用0填充。若剩1个字符则在编码结果后加2个‘=’;若剩2个字符则 加1个‘=’。
Base64的解码过程,即先丢弃编码后面的‘=’,然后将每个base64字符对应索引转为6bit的二进制数,再8个一组转为ASCII码字符完成解码,最后若剩下不足8位的,则全部丢弃。
所以某些bit位在解码时会被丢弃,换句话说,这些bit值不会对解码结果产生影响。一个简单直观的例子就是QUJDRA和QUJDRC解码后都是ABCD。由此我们便可以将隐藏信息插入这些bit位中实现隐写。
这里再给个例子:
Terra这一字符串的长度为5,非3的倍数,在转为6位二进制字串时添加了两个0(红色加粗部分)。编码后的结果为VGVycmE=:

倘若添加的二进制值不全为0,虽然会改变“=”号前最后一个字符的值,使编码后的字符串变为VGVycmH=。但该字符串进行Base64解码的结果依然是Terra:

末尾有两个“=”字符的编码字符串同样如此,Lucy字符串正常编码应为THVjeQ==

修改后为THVjeV==,同上,进行base64解码结果依然是Lucy

若像这样对多个base64编码字符串结尾进行修改,即可隐藏更多的信息,这就是base64隐写。
(原文章:[MISC]Base64隐写-CSDN博客)
一串Base64的编码最多也只有4bit的隐写空间,所以实现隐写往往需要大量编码串。隐写时把明文的每个字符用8位二进制数表示,由此将整个明文串转为bit串,按顺序填入Base64编码串的可隐写位中即可实现隐写。
加密
# -*- coding: utf-8 -*-
import base64
flag = 'flag{Base64isF4n}' #flag
bin_str = ''.join([bin(ord(c)).replace('0b', '').zfill(8) for c in flag])
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('0.txt', 'rb') as f0, open('1.txt', 'wb') as f1: #'0.txt'是明文, '1.txt'用于存放隐写后的 base64
for line in f0.readlines():
rowstr = base64.b64encode(line.replace('\n', ''))
equalnum = rowstr.count('=')
if equalnum and len(bin_str):
offset = int('0b'+bin_str[:equalnum * 2], 2)
char = rowstr[len(rowstr) - equalnum - 1]
rowstr = rowstr.replace(char, base64chars[base64chars.index(char) + offset])
bin_str = bin_str[equalnum*2:]
f1.write(rowstr + '\n')
解密
d='''str
'''
e=d.splitlines()
binstr=""
base64="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
for i in e :
if i.find("==")>0:
temp=bin((base64.find(i[-3])&15))[2:]
#取倒数第3个字符,在base64找到对应的索引数(就是编码数),取低4位,再转换为二进制字符
binstr=binstr + "0"*(4-len(temp))+temp #二进制字符补高位0后,连接字符到binstr
elif i.find("=")>0:
temp=bin((base64.find(i[-2])&3))[2:] #取倒数第2个字符,在base64找到对应的索引数(就是编码数),取低2位,再转换为二进制字符
binstr=binstr + "0"*(2-len(temp))+temp #二进制字符补高位0后,连接字符到binstr
str=""
for i in range(0,len(binstr),8):
str=str+chr(int(binstr[i:i+8],2)) #从左到右,每取8位转换为ascii字符,连接字符到字符串
print(str)
我们可以使用上面的脚本进行解密,或者使用另一个非常实用的自动化工具:puzzlesolver
它可以自动帮我们进行base64隐写的解密,直接获得flag:

考点:理解base64隐写
[GXYCTF2019]gakki(新)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们可以在结尾发现插入隐藏的rar文件,我们进行文件分离,压缩文件被加密了,因为没有找到其他提示所以我们优先进行爆破:

解压出的flag.txt中包含一大堆乱序的字符:

这种乱序的文本在杂项题目里面我们优先进行字频统计并观察结果继续分析,在此我们可以使用网上有的脚本:(原文章[BUUCTF:GXYCTF2019]gakki_[gxyctf 2019]gakki-CSDN博客):
# -*- coding:utf-8 -*-
#Author: mochu7
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890!@#$%^&*()_+- =\\{\\}[]"
strings = open('./flag.txt').read()
result = {}
for i in alphabet:
counts = strings.count(i)
i = '{0}'.format(i)
result[i] = counts
res = sorted(result.items(),key=lambda item:item[1],reverse=True)
for data in res:
print(data)
for i in res:
flag = str(i[0])
print(flag[0],end="")
puzzlesolver也拥有字频统计的功能:

或者使用在线工具https://uutool.cn/str-statistics/:

我们可以发现字频统计的结果中排列在前18的字符包含了flag
考点:文件分离、字频统计
[MRCTF2020]ezmisc(知识巩固题)
下载文件,发现里面是一张png格式的图片
按照图片隐写思路,第一步使用TweakPNG工具发现图片的crc校验出现错误,因此可能存在PNG宽高隐写

我们使用之前写的PNG宽高爆破脚本,可以得到正确的图片宽高,我们进行修改即可:


打开图片,发现了隐藏的flag

考点:PNG宽高隐写、理解爆破PNG宽高原理
[HBNIS2018]caesar(知识巩固题)
下载文件,发现里面是一份txt格式的文本:

根据密文特征与题目提示,我们可以确定加密方式为类凯撒密码的替换式密码加密,我们直接进行解密得到flag:

考点:理解类凯撒密码替换式密码加密
[HBNIS2018]低个头(脑洞)
下载文件,发现里面是一份txt格式的文本:

根据密文特征与题目提示,我们可以确定加密方式为键盘加密,你真的低个头直接进行解密得到flag:

考点:打开脑洞理解键盘加密
[SUCTF2018]single dog(新编码知识巩固题)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们可以在结尾发现插入隐藏的rar文件,我们进行文件分离,解压出的1.txt中包含一大堆颜文字:

因为是没见过的加密方式,所以我们启用万能的互联网:


解密出flag
考点:文件分离、学会用搜索引擎去搜索相关加密方式
黑客帝国(知识巩固题)
下载文件,发现里面是一份txt格式的文本:

可以发现是数字和字母混合的字符串,里面的字母最大不超过“f”,说明是16进制的编码,我们进行解码:

发现是rar文件,我们保存为.rar的格式文件,又加密了,我们进行密码爆破:

解压后得到一张png格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们可以发现文件内容含有“JFIF”字符串,应该是属于jpg图片格式的特征,而文件头却是png图片格式的,文件头格式错误我们进行修复(可以挪用正常的jpg图片的文件头):

修复好的图片直接为我们展示了flag:

考点:文件头修复
[SWPU2019]伟大的侦探(新密码知识巩固题)
下载文件,发现是一个加密了的zip压缩文件,而里面的“密码.txt”可以解压出来进行分析:

我们可以使用010 editor中自带的一些编码方式尝试解码:

最后我们发现使用EBCDIC编码方式时出现了压缩包的密码:

解压文件,发现了一堆jpg格式的图片:

我们上网搜索就能搜索出相关的加密方式:

这样我们就可以对照相关的密码表进行解密得到flag了:

考点:理解使用不同编码方式恢复乱码、学会用搜索引擎去搜索相关加密方式、耐心
[MRCTF2020]你能看懂音符吗(新密码知识巩固题)
下载文件,发现里面是一个rar的压缩包,尝试解压失败我们使用010 editor查看:

文集那头除了问题,我们进行修复:

提取出一个docx文件:

里面是一堆音符,音符串结尾有等号我们猜测这不是正常的音乐而是一种加密方式,我们搜索相关加密方式:

发现了相关的加解密工具,进行解密即可得到flag:

考点:文件头修复、学会用搜索引擎去搜索相关加密方式
我吃三明治(新编码知识巩固题)
下载文件,发现里面是一张jpg格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

发现文件尾部含有插入的疑似jpg图片的文件并且文件头含有隐藏信息
我们先对隐藏信息进行分析,字符串全部由大写字母与数字组成,数字出现的仅有2-5组成
Base32
Base32 是一种数据编码机制,使用 32 个可打印字符(字母 A-Z 和数字 2-7)对任意字节数据进行编码的方案,编码后的字符串不用区分大小写并排除了容易混淆的字符,可以方便地由人类使用并由计算机处理。
可以猜测并发现是base32编码内容,解码即可得到flag:

考点:利用十六进制编辑器找到隐藏的信息、理解base32编码特征
[SWPU2019]你有没有好好看网课?(较难新编码新工具)
下载文件,发现里面是两个加密的zip的压缩包:

flag2.zip没有任何密码提示,也没有伪加密的情况,我们先对flag3.zip继续分析
flag3.zip的注释中提示了密码,我们进行爆破:


解压出内容:

我们打开flag.docx查看:

没有隐藏的内容,我们推测这里的内容5.20和7.11会是一种提示,图片可能含有隐藏信息我们之后再进行分析
MP4文件的分析思路
1. 如果视频内容较短,优先使用Kinovea等工具逐帧查看所有内容寻找隐藏内容
2. 使用010editor分析插入隐藏信息
3. 使用了特定工具的MP4隐写
按照思路加上前面的提示内容,我们优先逐帧查看(尤其是5秒和7秒左右)“影流之主.mp4”查看是否含有隐藏信息:


发现画面中的灯上隐藏了信息:
..... ../... ./... ./... ../
dXBfdXBfdXA=
第一段我们可以判断为敲击码(在线解密工具:Tap code – Encode and decode online - cryptii),第二段是base64编码,我们进行解密:


组合起来的内容并不是flag,我们推测是flag2.zip的解压密码,解压成功
发现里面是一张jpg格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

发现了插入隐藏的flag
考点:压缩包密码爆破、MP4文件的分析、理解敲击码、利用十六进制编辑器找到隐藏的信息
[ACTF新生赛2020]NTFS数据流(知识巩固题)
下载文件,发现里面是一个rar的压缩包,解压后爆了一大堆txt文件,内容都是一样的:

按照题目提示,“NTFS数据流”说明flag.rar压缩包含有NTFS交换数据流隐藏数据,我们使用7z工具进行按照交替数据流方式排列查看:

可以发现293.txt文件携带着附加的信息就是flag
考点:理解交替数据流隐藏文件
sqltest(较难知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

发现HTTP协议发送的Line-base text data占比最多,我们优先过滤查看:

HTTP数据包还是有很多,我们导出HTTP对象看看:

可以发现攻击机一直在向index.php进行请求,看得出来是在使用GET请求修改URL来进行SQL注入
我们只好进行逐行分析,首先使用tshark进行导出更方便分析:
tshark -r sqltest.pcapng -Y "http.request" -T fields -e http.request.full_uri > data.txt
-r 读取文件
-Y 过滤语句
-T pdml|ps|text|fields|psml,设置解码结果输出的格式
-e 输出特定字段
http.request.full_uri http请求的uri部分
我们打开文件进行SQL注入过程的分析(为了方便分析,在此将所有%20替换为了空格):
(1~9行)获取information_schema.SCHEMATA中数据行数的长度,从中可以知道长度是1

(10~18行)获取information_schema.SCHEMATA中数据行数chr(53) = '5',
即infomation_schema.SCHEMATA有5行数据
information_schema.SCHEMATA中保存了所有数据库,所以总共爆出5个数据库

(1961行+6566行)获取每一个数据库的长度,这一部分是并发执行的


可以发现第一个数据库长度为18
第二个数据库长度为3
第三个数据库长度为7
第四个数据库长度为4
第五个数据库长度为5
(6264行+67417行)获取每一个数据库库名,并发执行
(418~426行)已经获取到了想要探测的库名“db_flag”,获取数据库information_schema.tables中数据行数的长度,从中可以知道长度是1

(427~435行)获取information_schema.tables中数据行数chr(49) = '1',即infomation_schema.tables有1行数据
information_schema.tables中保存了所有数据表,所以在“db_flag”中总共爆出1个数据表

(436~444行)获取数据表的长度,可以发现数据表的长度为7

(445-510行)获取数据表表名
(511~519)已经获取到了想要探测的表名“tb_flag”,获取数据库information_schema.COLUMNS中数据行数的长度,从中可以知道长度是1

(520~527行)获取information_schema.COLUMNS中数据行数chr(50) = '2',
即infomation_schema.COLUMNS有1行数据
information_schema.COLUMNS中保存了所有字段,所以在“db_flag”中总共爆出2个字段

(528~545行)获取每一个字段的长度,这一部分是并发执行的

可以发现第一个字段长度为2
第二个字段长度为4
(546~601行)获取每一个字段名,并发执行
(602~610行)已经获取到了想要探测的字段,获取db_flag.tb_flag中数据行数的长度,从中可以知道长度是1

(611~619行)获取db_flag.tb_flag中数据行数chr(49) = '1',
即db_flag.tb_flag有1行数据
db_flag.tb_flag中保存了所有数据,所以在“db_flag”中总共爆出1个数据

(620~627行)获取数据的长度,可以发现数据的长度为38

(628-972行)获取数据值
这一步就是我们要找的flag了,我们可以逐一手动提取,也可以写一个脚本提取一下。
(以下脚本来源于:BUU 流量分析 sqltest - 云千 - 博客园 (cnblogs.com))
我们知道注入语句为
id=1 and ascii(substr(((select concat_ws(char(94), flag) from db_flag.tb_flag limit 0,1)), {第i个字符}, 1))>{字符的ascii值}
我们把第i个字符和ascii值提取出来,取i变化时的值,脚本为:
import urllib.parse #导入 urllib.parse 模块,用于解码 URL 编码的字符串
f = open("data.txt","r").readlines() #打开 data.txt 文件并读取其中的所有行。f 是一个列表,每一行数据作为一个元素存储在列表中。
s = [] #初始化一个空列表 s,用于存储解析后的数据。
for i in range(627,972):
data = urllib.parse.unquote(f[i]).strip() #对从文件读取的一行数据进行 URL 解码,strip()用于去除两端的空白字符。
payload = data.split("and")[1] #通过 split("and") 方法获取 "and" 后面的部分。
positions = payload.find("from db_flag.tb_flag limit 0,1)), ") #寻找特定字符串 "from db_flag.tb_flag limit 0,1)), " 在 payload 中的位置。
data1 = payload[positions+35:].split(",")[0] #从 positions+35 位置开始提取数据,并在第一个逗号前截断,提取出一个表示数据位置或长度的值。
data2 = payload[positions+35:].split(">")[1] #从 positions+35 位置开始提取数据,并在 > 符号后截断,提取出一个 ASCII 码值。
s.append([data1,data2]) #将 data1 和 data2 作为一个列表,追加到 s 列表中。
for i in range(1,len(s)):
if s[i][0]!=s[i-1][0]:
print(chr(int(s[i-1][1])),end="")
print(chr(int(s[-1][1])))
#循环输出还原消息
输出得到flag
考点:SQL注入流量分析
john-in-the-middle(较难知识巩固题)
下载文件,发现里面是一个pcap格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

发现HTTP协议发送的Media Type占比最多,媒体文件我们尝试导出对象查看:

我们优先分析图片,使用010editor逐一查看没有发现不对劲的,我们开始使用stegsolve,发现了scanlines.png图片文件在很多通道中会显示一条线:

但在logo.png的一个通道中显示出了flag:

补充:StegSolve功能六——图像拼接
上网查了其他人的wp,发现在此应该使用Stegsolve的图像组合

发现logo.png有一条很可疑的直线,我们将它与scanlines.png进行图像拼接:


考点:提取流量包中的文件、LSB隐写(?)
[ACTF新生赛2020]swp(知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

发现HTTP协议占比最多,看了下好像是有在文件传输,我们尝试导出对象查看:

值得注意的有secret.zip和hint.html(提示)文件,zip文件加密了我们先打开提示看看:

已经是明示zip存在伪加密了,我们进行修改解压即可在flag.swp文件中找到flag:
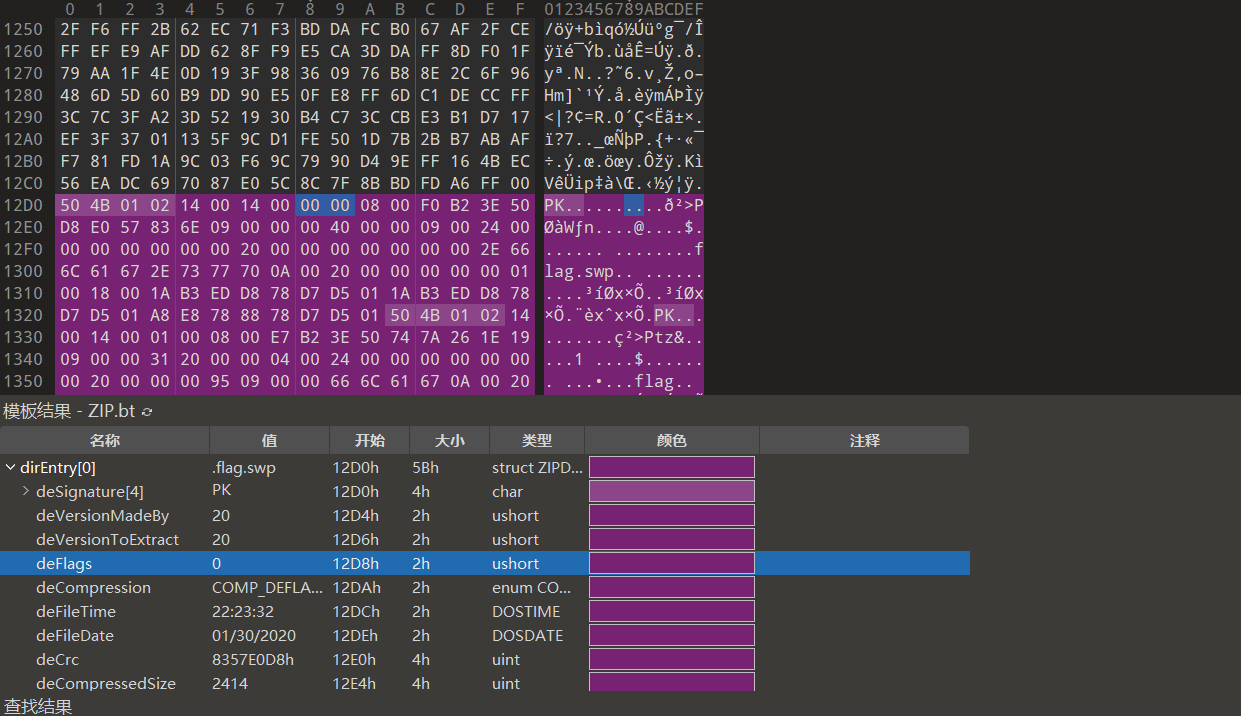
考点:提取流量包中的文件、寻找导出对象重点文件、理解zip伪加密原理
[UTCTF2020]docx(知识巩固题)
下载文件,发现里面是一个docx格式的表格文件,我们点击查看:
没发现藏着什么东西,因为如今的office办公软件的输出文件其实都是一个压缩包,包含着文件的xml文件、图片、视频等所有素材,我们将文件后缀改为.zip后打开查看找到了flag:
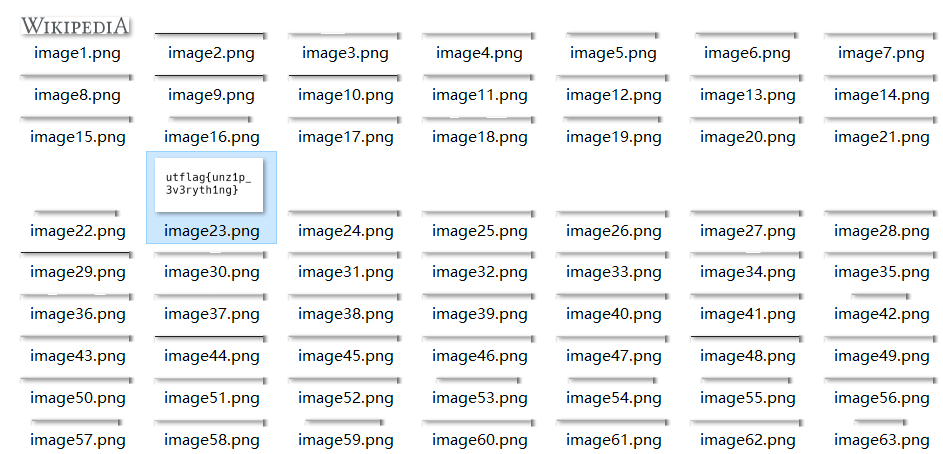
考点:理解office文件是一堆文件的压缩文件
[GXYCTF2019]SXMgdGhpcyBiYXNlPw==(知识巩固题)
下载文件,发现里面是一份txt格式的文本:

我们可以看到一串串的base64编码内容,我们可以判断这里存在base64隐写
在此我使用puzzlesolver自动进行base64隐写的解密:
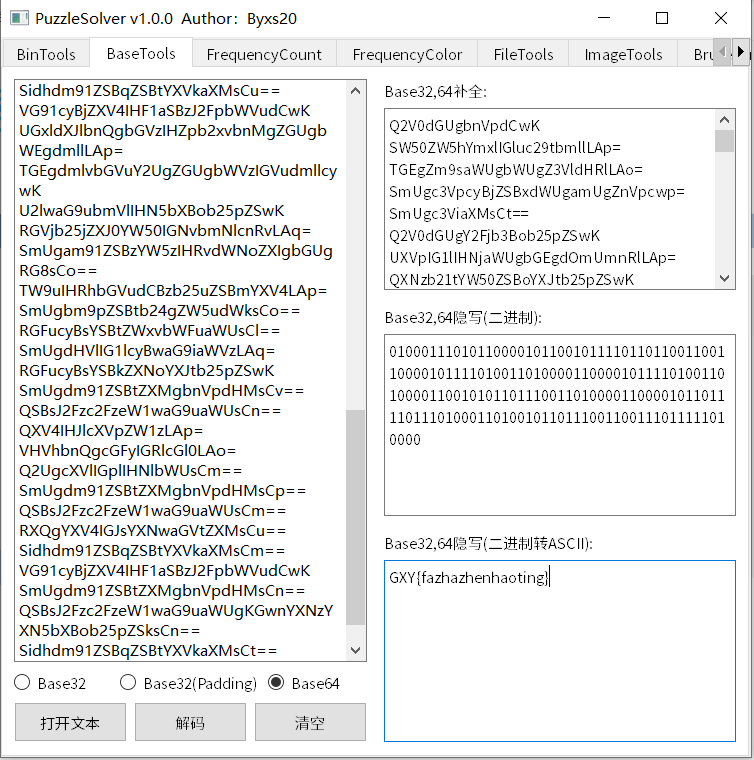
考点:理解base64隐写
间谍启示录(新)
下载文件,发现里面是一个iso格式的文件:
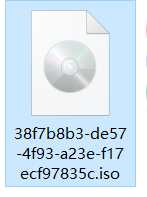
ISO文件格式简介
带有 .iso 扩展名的文件是未压缩的存档磁盘映像文件,它代表光盘(如 CD 或 DVD)上的全部数据内容。基于 ISO-9660标准,ISO 映像文件格式包含光盘数据以及存储在其中的文件系统信息。 ISO 文件包含内容的精确副本的能力使其成为创建 CD/DVD 副本的完美文件类型,并且主要用于存储可引导数据以进行安装。大多数时候,ISO 文件被刻录到 USB/CD/DVD 作为可引导内容,用于引导机器进行安装。 ISO 文件的 MIME 类型为 application/x-iso9660-image。
映像文件中的内容各种各样,我们需要分情况分析,但首先我们用7z工具查看其中的内容:

我们进行解压,大部分是空文件,还有一个类似提示的说明:

我们尝试运行exe文件:

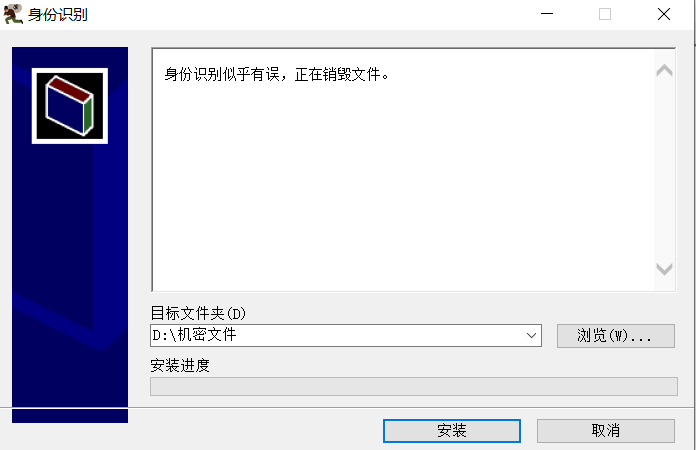
我们可以发现它是一个自解压程序,貌似我们尝试获取机密时身份识别立刻生效将文件销毁了。
自解压程序简介
一个 SFX (SelF-eXtracting)自解压文件是压缩文件的一种,因为它可以不用借助任何压缩工具,而只需双击该文件就可以自动执行解压缩,因此叫做自解压文件。同压缩文件相比,自解压的压缩文件体积要大于普通的压缩文件(因为它内置了自解压程序),但它的优点就是可以在没有安装压缩软件的情况下打开压缩文件(文件类型为·exe格式)。
参考文章(https://blog.csdn.net/d_chunyu/article/details/103270353)
我们将该exe文件使用7z当做压缩包打开观察里面包含的内容:

我们可以推测我们尝试获取机密时运行的是“flag.exe”文件,但很快接着运行了“文件已被销毁.exe”文件,我们将“systemzx.exe”进行解压并运行“flag.txt”即可得到flag机密文件:
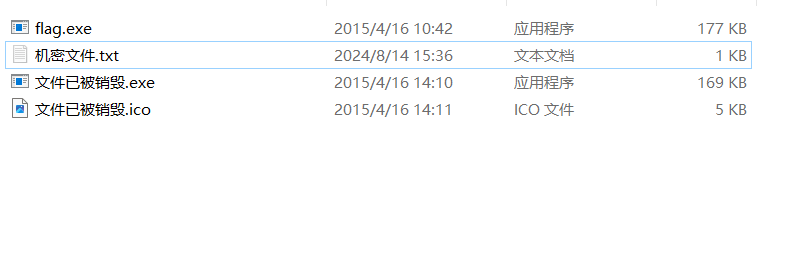
注意:这机密文件还是隐藏的,我们需要开启查看隐藏文件的选项才能看到:

补充:另一种思路
看到了不认识的后缀文件,我们使用010 editor打开,被模板解析后没有发现插入隐藏的文件,我们直接搜索文本“flag”:
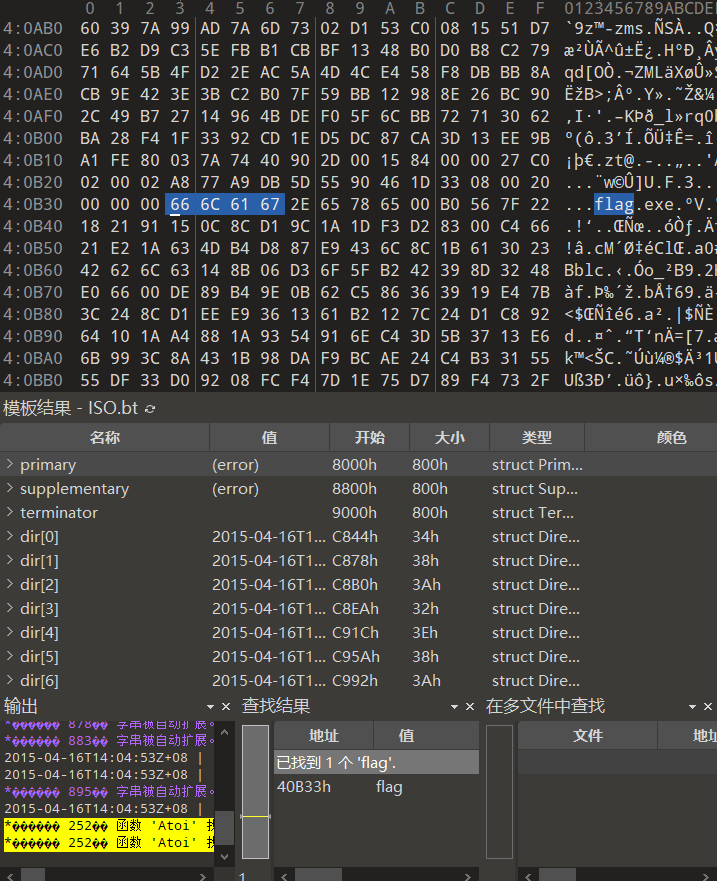
发现了其中藏着的“flag.exe”,手动提取看似非常困难,我们使用工具自动提取:
binwalk -e 38f7b8b3-de57-4f93-a23e-f17ecf97835c.iso
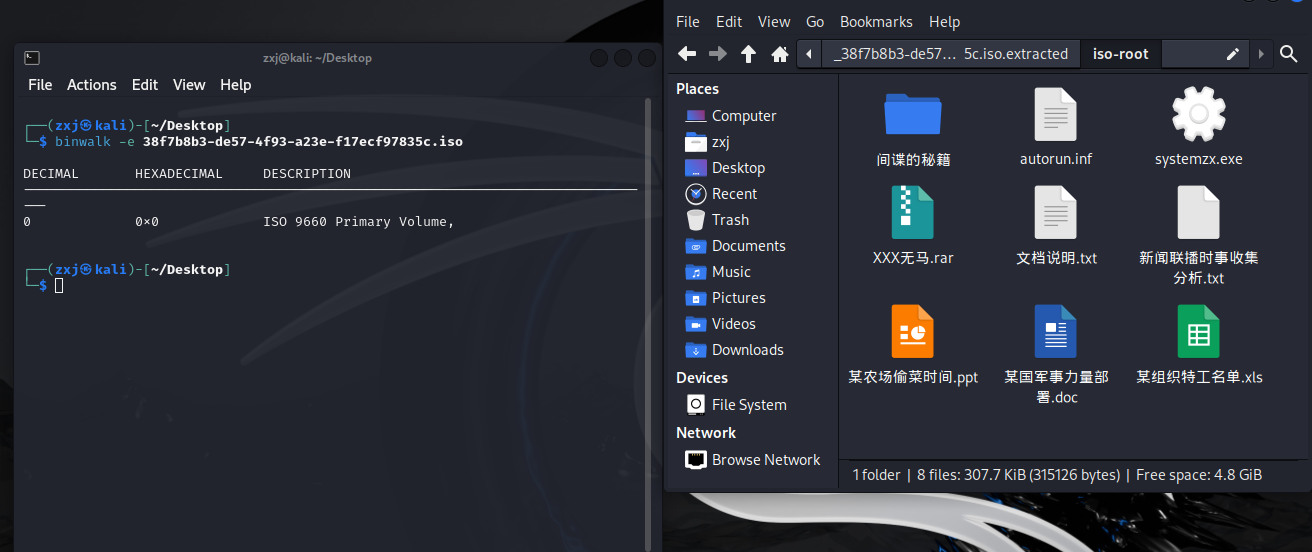
貌似无法分解,我们尝试使用foremost:
foremost 38f7b8b3-de57-4f93-a23e-f17ecf97835c.iso
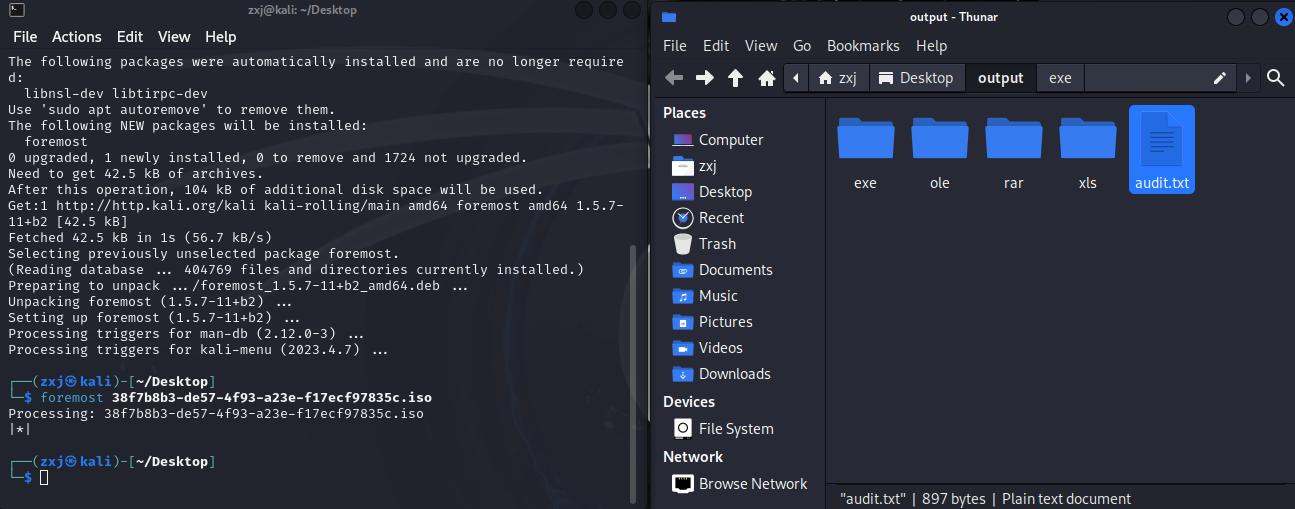
我们发现foremost按照文件格式分解出了很多文件,我们一个个分析:
exe文件夹中自解压程序强行提取被损坏了

ole文件是看不懂的格式,先跳过
rar文件包含了“flag.exe”,运行即可得到flag
考点:理解iso文件格式、理解自解压程序
喵喵喵(较难知识巩固题)
下载文件,发现里面是一张png格式的图片
按照图片隐写思路,第一步无果,第二步也无果,我们优先使用stegsolve打开图片查看:


我们可以发现,当我们关闭红色通道(red plane 0)、绿色通道或是蓝色通道时,图片的上方出现了黑白的印记,很显然是二进制的信息,我们继续使用StegSolve进行分析:

Red plane 0含有隐藏信息
Green plane 0含有隐藏信息
Blue plane 0含有隐藏信息
Extract By 我们发现图片上方在关闭通道出现黑白的印记是横向的,因此按row(行)提取像素而不是column(列)
Bit Order 我们知道像素值是按最低位的修改进行隐写的,因此选LSB(像素值最低位作为第一位)
Bit Plane Order 设置RGB通道的顺序,默认RGB,多次尝试发现正确的排列顺序是BGR才会出现正确的隐藏信息
我们发现隐藏信息是一张png图片文件,我们点击Save Bin,将图片保存为.png格式的文件,发现打不开:

这里不知道为什么010 editor不能打开进行分析了(软件抽风),所以这里介绍另一种方法
我们点击Save Text保存保存输出,用Notepad++打开:

我们发现输出很奇怪,但没关系,我们按住alt键进行按列复制:

复制的内容放到cyberchef去掉换行符并进行十六进制编码:

我们将输出保存为png格式的图片发现010 editor还是打不开,那我们直接将十六进制格式的输出复制到010 editor里面(shift+ctrl+v):


修复文件头后即可打开图片:

可以发现是半张二维码,可以猜测这里存在PNG宽高隐写,我们使用脚本进行爆破:

修改宽高值,扫描二维码即可得到flag.rar的网盘下载地址,我们进行下载:

txt文件隐藏的信息思路
1.观察txt文件的属性说不定会有线索
2.txt文件里面是一堆空行可能存在snow隐写
3.存在NTFS隐写
观察文件属性也没有备注消息,我们猜测这里存在NTFS文件隐写,我们使用7z打开flag.rar却没发现交替数据流的信息,这里我们要使用专业的软件来查看NTFS文件隐写的软件:NtfsStreamsEditor
NTFS流隐写得用WinRAR解压(这里我也不清楚原理),解压后观察flag.txt的NTFS隐写流

发现了隐藏了flag.pyc文件,pyc 文件是 Python 编译后的字节码文件,可以提高运行速度,但也有一定的限制。在此我们应该先把pyc文件反编译回python源码,这里可以利用在线工具网站python反编译 - 在线工具 (tool.lu)进行反编译:

#!/usr/bin/env python
# visit https://tool.lu/pyc/ for more information
# Version: Python 2.7
import base64
def encode():
flag = '*************'
ciphertext = []
for i in range(len(flag)):
s = chr(i ^ ord(flag[i]))
if i % 2 == 0:
s = ord(s) + 10
else:
s = ord(s) - 10
ciphertext.append(str(s))
return ciphertext[::-1]
ciphertext = [
'96',
'65',
'93',
'123',
'91',
'97',
'22',
'93',
'70',
'102',
'94',
'132',
'46',
'112',
'64',
'97',
'88',
'80',
'82',
'137',
'90',
'109',
'99',
'112']
我们分析源码,发现flag的内容经过了加密,但给我们输出了密文
def encode():
flag = '*************'
ciphertext = []
for i in range(len(flag)):
s = chr(i ^ ord(flag[i]))
if i % 2 == 0:
s = ord(s) + 10
else:
s = ord(s) - 10
ciphertext.append(str(s))
return ciphertext[::-1]
遍历字符串
for i in range(len(flag)):
s = chr(i ^ ord(flag[i]))
这个循环遍历了字符串 flag 的每一个字符。对于每个字符,首先将字符的ASCII值(使用ord()函数)与当前位置的索引值 i 进行按位异或操作,然后将结果转换为一个字符(使用chr()函数)。
根据索引的奇偶性调整ASCII值
if i % 2 == 0:
s = ord(s) + 10
else:
s = ord(s) - 10
如果索引 i 是偶数,调整后的字符的ASCII值增加10;如果是奇数,ASCII值减少10。
生成密文
ciphertext.append(str(s))
将转换后的字符的ASCII值(转换为字符串形式)添加到ciphertext列表中。
列表反转
return ciphertext[::-1]
在返回最终的密文列表之前,列表被反转。
在此我们得编码写出解密脚本:
def decode(ciphertext):
# 反转密文列表
ciphertext = ciphertext[::-1]
flag = []
for i in range(len(ciphertext)):
s = int(ciphertext[i])
# 根据索引的奇偶性进行逆操作
if i % 2 == 0:
s -= 10
else:
s += 10
# 进行逆向的按位异或操作
original_char = chr(i ^ s)
flag.append(original_char)
# 将列表中的字符拼接成字符串
return ''.join(flag)
ciphertext = [
'96', '65', '93', '123', '91', '97', '22', '93', '70', '102',
'94', '132', '46', '112', '64', '97', '88', '80', '82', '137',
'90', '109', '99', '112'
]
# 解密得到的flag
flag = decode(ciphertext)
print("解密后的flag是:", flag)
得到flag

考点:理解LSB隐写原理、学会利用工具、文件头修复、PNG宽高隐写、理解爆破PNG宽高原理、理解NTFS流隐写隐藏文件、pyc文件反编译、逆向解密脚本编写
小易的U盘(新)
下载文件,发现里面是一个iso格式的文件。首先我们用7z工具查看其中的内容:

我们找到了flag.txt,打开查看:

这里提示flag还没生成,我们按照提示应该注意可以生成flag的程序,就是上方一堆autoflag.exe的副本
最下方还有个autorun.inf文件,我们查看其中内容:

inf文件格式简介
inf 文件是 Windows 系统中非常重要的配置文件,主要用于驱动程序安装和设备配置。它们以结构化的方式包含了安装过程的所有指令,使得操作系统能够正确安装和配置硬件设备。
[AutoRun] 这个节通常用于指定在某个特定条件下自动运行的命令或程序
Open 这一行指示系统在特定情况下自动运行指定的程序或命令
我们可以推测autoflag - 副本 (32)是正确生成flag的程序我们尝试运行:

要分析exe文件我们要使用反编译软件——IDA
IDA简介
IDA是一个反编译器,同时具备调试器的功能。功能非常强大,几乎所有的逆向题目都需要用到它。
我们使用IDA进行分析:

看不懂?没事,这是misc方向的题目而不是reserve方向的题目,因此我们直接搜索字符串
按下shift+F12可以查看exe中的字符串,找到了flag

我们也可以按下F5进行反编译查看源码,可以推测报错的原因是找不到flag.txt文件:

考点:理解iso文件格式、会使用IDA打开文件查找字符串
[RoarCTF2019]黄金6年
下载文件,发现里面是一个mp4格式的视频。
按照思路,我们优先逐帧查看视频是否含有隐藏信息,发现了一闪而过的二维码:


有key2,那就有key1,我们仔细寻找:






我们尝试将key作为flag上交,发现不是。
按照思路,我们应该继续对mp4文件进行分析。
MP4文件格式简介
MP4文件中的所有数据都装在box(QuickTime中为atom)中,也就是说MP4文件由若干个box组成,每个box有类型和长度,可以将box理解为一个数据对象块。box中可以包含另一个box,这种box称为container box。一个MP4文件首先会有且只有一个“ftyp”类型的box,作为MP4格式的标志并包含关于文件的一些信息;之后会有且只有一个“moov”类型的box(Movie Box),它是一种container box,子box包含了媒体的metadata信息;MP4文件的媒体数据包含在“mdat”类型的box(Midia Data Box)中,该类型的box也是container box,可以有多个,也可以没有(当媒体数据全部引用其他文件时),媒体数据的结构由metadata进行描述。
参考文章:https://blog.csdn.net/qq_45186086/article/details/110499149
我们用010 editor打开:

可以发现除了上述的5中box最底下还出现了奇怪的box,我们分析发现这是base64编码后的内容,我们使用cyberchef进行解码:

发现是rar文件,我们进行保存,发现需要密码,我们推测密码就是前面解出来的key:iwantplayctf
解压即可得到flag
考点:MP4文件的分析、利用十六进制编辑器找到隐藏的信息
[WUSTCTF2020]alison_likes_jojo(新工具)
下载文件,发现里面是两张jpg格式的图片,我们先对第一张进行分析
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们可以在结尾发现插入隐藏的zip文件,我们进行文件分离,发现它加密了,并且不存在伪加密的情况,我们只好进行爆破:

我们解压文件,发现了“beisi.txt”文件,里面的内容我们可以使用cyberchef进行自动解密(我们也可以看出文件名提示我们这是base加密):

我们开始对第二张图片进行分析
按照图片隐写思路,第一步、第二步、第三步、第四步无果,我们可以推测这是使用了特殊的隐写工具进行的隐写,并且上一步得到的字符串“killerqueen”极有可能是隐写的密码
按照特殊隐写工具的使用顺序,我们先使用最广泛使用的steghide
steghide extract -sf jljy.jpg -p killerqueen

发现并没有使用steghide
我们使用下一个工具——outguess
Outguess——第二使用的jpeg特定图片隐写工具
outguess -k killerqueen -r jljy.jpg -t 1.txt
-k 指定密码
-r 指定图片文件
-t 指定输出文件
我们可以发现隐藏的flag

考点:文件分离、压缩包密码爆破、使用了特定工具进行的图片文件隐写
[安洵杯 2019]吹着贝斯扫二维码(新)
下载文件,发现里面是一堆没有后缀名的文件以及加密的flag.zip,(没有伪加密的情况)我们从flag.zip的备注中发现了信息:


对没有后缀的文件我们先用010 editor打开进行分析,发现是jpg图片文件:

同时我们可以发现文件尾的后边有插入的数字,我们可以推测这存在着一定的规律:

我们可以在当前目录下使用命令提示符给所有文件加上.jpg的后缀:
ren * *.jpg
ren 重命名文件
注意:此时flag.zip的后缀也被改为.jpg了,我们应该改回.zip后缀

我们可以发现图片都是零散的二维码碎片,我们应该用图片编辑软件进行拼图(这里我使用的是GIMP),我们可以先从二维码的左上、右上、左下、三个定位点开始,结合之前得到每个图片文件尾出现的数字,我们可以编写一个脚本,实现将所有图片最后两位字节提取出来并且作为图片的文件名方便我们拼图:
import os
from PIL import Image
#目录路径
dir_name = r"./"
#获取目录下文件名列表
dir_list = os.listdir('./')
#print(dir_list)
#从列表中依次读取文件
for file in dir_list:
if '.jpg' in file:
f=open(file ,'rb')
n1 = str(f.read())
n2 = n1[-3:]
#经过测试发现这里要读取最后3个字节,因为最后还有一个多余的字节,不知道是不是转字符串的原因导致在末尾多了一个字符
#print(file) #输出文件内容
#print(n2)
f.close() #先关闭文件才能重命名,否则会报`文件被占用`错误
os.rename(file,n2+'.jpg') #重命名文件
引用文章:https://blog.csdn.net/m0_46631007/article/details/119965593
按照顺序进行排列(使用GIMP的标尺工具):

我们扫描二维码,得到了以下内容:

我们可以推测这是压缩包中备注的编码过程,我们进行逆向解码(数字85代表base85,64代表base64,13代表ROT13,16代表HEX,这里需要大家对数字代表的编码有一定程度的敏感):

出现字符串,我们推测这是zip文件的解压密码,我们进行解压得到flag
考点:二维码图片拼接、对数字代表的编码有一定程度的敏感
补充:使用自动拼接的脚本(来源:https://www.cnblogs.com/m718/p/14132769.html)
# coding=utf-8
# python3
import os
from PIL import Image
# 图片压缩后的大小
width_i = 134
height_i = 130
# 每行每列显示图片数量
row_max = 6
line_max = 6
# 存储图片路径和对应的排序数字
all_path = []
# 文件夹路径
dir_name = r"D:\pythonlearning\pythonProject\吹着贝斯扫二维码"
# 获取文件夹下所有.jpg文件的列表
dir_list = [f for f in os.listdir(dir_name) if f.endswith('.jpg') and not f.startswith('__pycache__')]
# 从每个文件末尾提取数字并排序
for file in dir_list:
try:
with open(os.path.join(dir_name, file), 'rb') as f:
f.seek(-6, os.SEEK_END) # 移动到文件末尾的前6个字节
last_bytes = f.read(6) # 读取末尾的6个字节
# 查找FF D9标记
ff_d9_index = last_bytes.rfind(b'\xff\xd9')
if ff_d9_index != -1:
# 读取FF D9之后的字节
number_bytes = last_bytes[ff_d9_index+2:]
# 将字节转换为整数
file_num = int.from_bytes(number_bytes, byteorder='big')
all_path.append((file_num, os.path.join(dir_name, file)))
else:
print(f"File {file} does not contain 'FF D9'")
except Exception as e:
print(f"Error processing file {file}: {e}")
# 按文件末尾的数字排序
all_path.sort(key=lambda x: x[0])
# 创建新图片
toImage = Image.new('RGBA', (width_i * line_max, height_i * row_max))
# 拼接图片
for i, (_, file_path) in enumerate(all_path):
if i >= row_max * line_max:
break # 只处理需要的图片数量
pic_file_head = Image.open(file_path)
tmppic = pic_file_head.resize((width_i, height_i))
loc = (i % line_max * width_i, i // line_max * height_i)
toImage.paste(tmppic, loc)
# 保存图片
toImage.save('merged.png')
print("Merged image saved as 'merged.png'")
弱口令(较难新工具)
下载文件,发现是一个加密的压缩包
按照遇到含有密码的压缩包思路,我们首先注意观察压缩包是否有备注:

这是纯由空格和tab键组成的空白内容,这种可能是摩斯电码或者是snow隐写,我们先尝试摩斯电码,将空格转换成“.”,tab转换成“-”:

解压文件得到一张png格式的图片
这道题目密码的提示并不全面,并不是一道好题目,以下分析均来源于其他人的WP
使用密钥123456,对应题目“弱口令”。
按照png图片特殊隐写工具的使用顺序,我们先使用最广泛应用的脚本zsteg
Zsteg——第一使用的png特定图片隐写工具
zsteg 女神.png -a -v
-a 对所有信道所有可能进行全方面扫描
-v 提取出有效数据并显示出来

发现并没有使用zsteg
我们使用下一个工具——cloacked-pixel
Cloacked-pixel——第二使用的png特定图片隐写工具
下载地址
GitHub - livz/cloacked-pixel: LSB steganography and detection
python2 lsb.py extract 女神.png 1.txt 123456

得到flag
考点:注意观察压缩包是否有备注、使用了特定工具进行的图片文件隐写
从娃娃抓起(新)
下载文件发现里面是两个txt文件,一个进行了提示:

密文:

这里考察了我们对中国电子信息发展历史的了解或编码的眼界,我们按照提示可以看出第一段是中文电码,第二段是五笔输入法的输入
中文电码
中文电码,又称中文商用电码、中文电报码或中文电报明码,原本是于电报之中传送中文信息的方法。它是第一个把汉字化作电子讯号的编码表。
自摩尔斯电码在1835年发明后,一直只能用来传送英语或以拉丁字母拼写的文字。1873年,法国驻华人员威基杰(S·A·Viguer)参照《康熙字典》的部首排列方法,挑选了常用汉字6800多个,编成了第一部汉字电码本,名为《电报新书》。后由我国的郑观应将其改编成为《中国电报新编》。这是中国最早的汉字电码本。中国人最早研制的电报机华侨商人王承荣从法国回国后,与福州的王斌研制出我国第一台电报机,并呈请政府自办电报。清政府拒不采纳。
在此我们使用在线网站进行解密

五笔输入法
五笔字型输入法(简称:五笔)是王永民在1983年8月发明的一种汉字输入法。开创了汉字输入能直接用标准键盘,可以像西文一样方便快捷“盲打”输入的新纪元,避免了中国计算机产业(PC)的“畸形”。因为发明人姓王,所以也称为“王码五笔。五笔字型完全依据笔画和字形特征对汉字进行编码,是典型的形码输入法。
在此我们使用搜狗五笔输入法进行输入:

按照提示,我们使用cyberchef将“人工智能也要从娃娃抓起”这句话转为md5,得到flag

考点:理解中文编码、理解五笔输入法、理解其对中国汉字信息化的意义
Mysterious(较难)
下载文件,发现里面是一个exe格式的文件,我们运行会让我们输入密码:

我们使用IDA进行打开,IDA的系统介绍将会放在reverse专题,这里不多做介绍
按照misc方向的逆向思路,我们优先查看字符串(shift+F12):

可以发现“well done”的字符串,我们双击可以跳转到其地址:

我们可以看出包含这些字符串的函数名称,我们双击跳转:

可以发现我们跳转到了这个函数底下,显示的是该函数的汇编代码,我们按下F5进行反编译即可得到伪C代码:

int __stdcall DialogFunc_0(HWND hWnd, int a2, int a3, int a4)
{
int v4; // eax
char Source[260]; // [esp+50h] [ebp-310h] BYREF
_BYTE Text[257]; // [esp+154h] [ebp-20Ch] BYREF
__int16 v8; // [esp+255h] [ebp-10Bh]
char v9; // [esp+257h] [ebp-109h]
int Value; // [esp+258h] [ebp-108h]
CHAR String[260]; // [esp+25Ch] [ebp-104h] BYREF
memset(String, 0, sizeof(String));
Value = 0;
if ( a2 == 16 ) // 如果接收到 WM_CLOSE 消息
{
DestroyWindow(hWnd); // 销毁窗口
PostQuitMessage(0); // 结束消息循环
}
else if ( a2 == 273 ) // 如果接收到 WM_COMMAND 消息
{
if ( a3 == 1000 ) // 如果控件ID是1000(按钮或其他控件)
{
GetDlgItemTextA(hWnd, 1002, String, 260); // 从控件ID为1002的文本框获取输入字符串
strlen(String); // 计算字符串长度
if ( strlen(String) > 6 ) // 如果字符串长度大于6
ExitProcess(0); // 退出程序
v4 = atoi(String); // 将字符串转换为整数
Value = v4 + 1; // 将整数值加1
if ( v4 == 122 && String[3] == 120 && String[5] == 122 && String[4] == 121 )
{
strcpy(Text, "flag"); // 将 "flag" 复制到Text数组
memset(&Text[5], 0, 0xFCu); // 将 Text[5] 之后的内容清零
v8 = 0;
v9 = 0;
_itoa(Value, Source, 10); // 将 Value 转换为字符串并存储在 Source
strcat(Text, "{"); // 将 "{" 添加到 Text 末尾
strcat(Text, Source); // 将 Value 的字符串形式添加到 Text
strcat(Text, "_"); // 将 "_" 添加到 Text
strcat(Text, "Buff3r_0v3rf|0w"); // 将 "Buff3r_0v3rf|0w" 添加到 Text
strcat(Text, "}"); // 将 "}" 添加到 Text
MessageBoxA(0, Text, "well done", 0); // 显示消息框,内容为 Text
}
SetTimer(hWnd, 1u, 0x3E8u, TimerFunc); // 设置一个1秒的定时器
}
if ( a3 == 1001 ) // 如果控件ID是1001
KillTimer(hWnd, 1u); // 停止定时器
}
return 0;
}
我们可以看出题目对我们输入的字符串要求是“长度小于等于6”、“字符串转换为整数后为122”、“字符串的第4位转换ascii码值为120即字符串第4位为x”、“字符串的第6位转换ascii码值为122即字符串第6位为z”、“字符串的第5位转换ascii码值为122即字符串第5位为y”(字符串第1位为string[0])
那么我们可以得出当我们输入的字符串为“122xyz”时,程序会将我们输入的字符串转换为整数+1的值与“_Buff3r_0v3rf|0w”结合起来形成的flag,即“123_Buff3r_0v3rf|0w”

我们得到了flag
考点:IDA的使用、程序分析
[GUET-CTF2019]zips(新)
下载文件,发现是一个加密的压缩包
按照遇到含有密码的压缩包思路,第一步、第二步无果,我们只好进行爆破:

解压后,里面又是一个加密的压缩包
按照遇到含有密码的压缩包思路,第一步无果,第二步我们发现了伪加密的情况,我们进行修改:

解压文件,发现了加密的zip文件和.sh文件:

.sh和.bat文件
两者都属于shell脚本,用于在计算机上使用命令。
二者的区别源于使用对象不同,bat主要是运行在Windows 的shell脚本完成一系列的项目文件集合启动,集成多项依赖加载执行;sh 脚本是运行在Unix系统的shell脚本,方便部署应用。
我们使用任意文本编辑器都可以查看.sh的内容,我们查看:
#!/bin/bash
#
zip -e --password=`python -c "print(__import__('time').time())"` flag.zip flag
zip -e:
- -e 选项表示创建加密的ZIP文件。生成的ZIP文件会要求输入密码才能解压缩。
--password=:
- 这个选项用于指定ZIP文件的密码。密码通过反引号(`...`)中的命令动态生成。
反引号中的Python命令:
- python -c "print(__import__('time').time())":这是一个内联Python命令。
- python -c "..." 允许你在命令行中直接运行Python代码。
- __import__('time').time() 调用了Python的time模块,并获取当前时间的时间戳
时间戳
我们需要知道,时间是不断流逝的,简单地说时间戳在计算机里面表示时间的每一刻,是一串不断随时间流逝增长的数字,每度过一个时刻时间戳就会进行增长(一般按秒增长)
也就是说目前的计算机所能记录的极限时间戳为999999999999,即到了33658-09-27 09:46:39(北京时间)这一刻计算机的时间戳将会归零回归到1970-01-01 08:00:00(北京时间)
我们知道了zip压缩包的密码是其创建时的时间戳,我们使用查看文件属性并进行转换即可:

密码错误,可能存在相关时差,但最多也不会超过一年,因此我们以“15”开头,爆破剩下8位数字,我们可以进行纯数字掩码爆破:

还是爆破不出来,我们推测可能是按毫秒的时间戳,我们按照毫秒时间戳格式来(此时掩码应该减少几位):

还是解不出来,我们推测是python输出的时间戳与在线转换的不同,我们观察:

后边有这么多位!爆破需要60分钟左右,直接否定了这个方法
还是没有结果,我们可以推测不同版本的python的输出不同,我们使用python2输出时间戳:

可以发现后边只输出了两位数字,我们进行爆破得到了正确密码
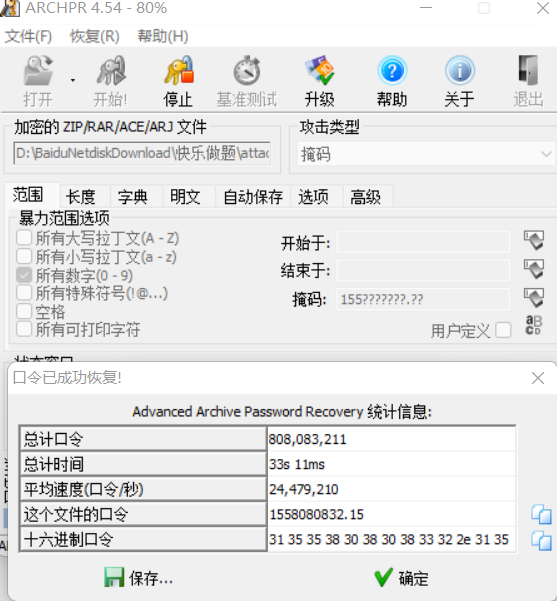
解压文件,得到flag
考点:压缩包爆破、压缩包伪加密、理解时间戳的概念、跳转思路
zip(新)
下载文件,里面是一堆加密的zip压缩文件,并且内部只有一个很小的txt文件:

每个文件大小都只有4bit,这里我们可以考虑CRC爆破的情况
CRC爆破
CRC的全称是循环冗余校验,不同长度的常数对应着不同的CRC实现算法,CRC32表示会产生一个32bit(8位十六进制)的校验值。在产生CRC32时,源数据块的每一位都参与了运算,因此即使数据块中只有一位发生改变也会得到不同的CRC32值,利用这个原理我们可以直接爆破出加密文件的内容。由于CPU能力,CRC碰撞只能用于压缩文件较小的情况。
我们使用以下python2脚本(来源于CTF解题技能之压缩包分析进阶篇 - FreeBuf网络安全行业门户):
#coding:utf-8
import zipfile
import string
import binascii
def CrackCrc(crc):
for i in dic:
for j in dic:
for p in dic:
for q in dic:
s = i + j + p + q
if crc == (binascii.crc32(s) & 0xffffffff):
# 在 Python 2.x 中,binascii.crc32 的结果是有符号整数,为了与CRC32的无符号整数比较,需要 & 0xffffffff
f.write(s)
return
def CrackZip():
for I in range(68):
file = 'out' + str(I) + '.zip'
f = zipfile.ZipFile(file, 'r')
GetCrc = f.getinfo('data.txt')
crc = GetCrc.CRC # 获取 ZIP 文件中 data.txt 文件的 CRC32 值
CrackCrc(crc)
dic = string.ascii_letters + string.digits + '+/='
# dic 包含所有可能的字符,包括大小写字母、数字以及 '+/='
f = open('out.txt', 'w')
CrackZip()
f.close()
主要功能
CrackCrc(crc):- 这是一个暴力破解函数,遍历
dic中的所有可能字符组合,尝试找到与输入的CRC32值相匹配的4字符字符串。(因为每个压缩包中的内容只有4bit大小,因此只包含4字符的循环碰撞) s = i + j + p + q:拼接4个字符,生成一个4字符字符串。binascii.crc32(s) & 0xffffffff:计算字符串的CRC32值,并与目标CRC32值(crc)比较。- 如果找到匹配的字符串,立即写入
out.txt文件,并终止函数。
- 这是一个暴力破解函数,遍历
CrackZip():- 这个函数负责遍历68个ZIP文件(因为它们名为
out0.zip到out67.zip),并从每个文件中提取data.txt文件的CRC32值。 - 然后,它调用
CrackCrc(crc)函数来尝试破解该CRC32值。
- 这个函数负责遍历68个ZIP文件(因为它们名为
dic:- 包含了所有可能的字符,用于生成4字符的排列组合。字符集包括:
- 所有大小写英文字母:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ - 数字:
0123456789 - 特殊字符:
+/=
- 所有大小写英文字母:
- 包含了所有可能的字符,用于生成4字符的排列组合。字符集包括:
- 文件操作:
out.txt文件用于存储找到的匹配字符串。
脚本输出的out.txt内容经base64编码,我们进行解码可以得到奇怪的内容:

我们保存输出后使用010 editor打开分析:

貌似是文件头确实,我们可以根据文件尾分析这是什么文件
没有经验的同学们可以将文件尾拿去搜索,看看是什么文件的文件尾:

那么可以确定是rar文件了,我们进行文件头修复即可:

解压后还是没有得到flag:

我们重新开始分析构造的rar文件,发现在他的备注里面藏着flag:

考点:CRC爆破、文件头修复、注意观察压缩包是否有备注
[UTCTF2020]file header(知识巩固题)
下载文件,是一个打不开的png格式,按照题目提示修复该文件的文件头直接得到了flag:

考点:文件头修复
[XMAN2018排位赛]通行证(知识巩固题)
一段文字,一眼base64,进行解码:

发现顺序不正确,这种调换顺序的密码让人想要尝试栅栏密码(发现解密的方式不行,那就加密出现flag的格式):

尝试上交,发现不是flag
flag的内容并不通顺,我们猜测是存在替换式密码,优先使用ROT13尝试解密,发现了正确的flag:

考点:对相关密码的敏感(可以参考https://www.cnblogs.com/handsomexuejian/p/18305321)
[WUSTCTF2020]girlfriend(新工具)
下载文件,发现里面是一个wav格式的音频文件
播放音频,发现是电话拨号音
DTMF拨号音
DTMF拨号音在拨打电话时,用于发送拨号信息。每按一个数字键,电话会发出一个特定的双音调组合,通过电话线路传送到交换机,交换机接收到这些音调后,可以识别出用户所拨的号码,并将呼叫路由到目标电话。
通过电话拨号,用户可以向远程设备发送DTMF信号,控制设备的开关、调整设置等。例如,早期的一些家用自动化系统、报警系统等可以通过电话的DTMF信号进行远程控制。
每个按键对应两个特定频率的音调组合,一个来自低频组,一个来自高频组。由于每个按键产生独特的音调组合,因此可以精确传递按键信息。
如果是拨号音,那么我们就可以使用相关工具进行分析——dtmf2num.exe
dtmf2num
一款可以将dtmf拨号音转换成数字的软件
下载后我们使用以下命令:
dtmf2num.exe girlfriend.wav

解出了数字999 666 88 2 777 33 6 999 4 444 777 555 333 777 444 33 66 3 7777
补充:网上也发现了使用python相关库识别的脚本:
import scipy.io.wavefile as wav
import scipy.fftpack as fft
# 读取音频文件
fs, data = wav.read('dtmf.wav')
# 计算帧长
frame_length = int(fs * 0.01) # 10ms
# 分帧
frames = []
for i in range(0, len(data), frame_length):
frame = data[i:i+frame_length]
frames.append(frame)
# 识别拨号音
for frame in frames:
# 计算 FFT
fft_result = fft.fft(frame)
# 计算频率分量
frequencies = fft.fftfreq(len(fft_result)) * fs
# 计算振幅分量
amplitudes = abs(fft_result)
# 找到最大振幅对应的频率
max_amplitude_index = amplitudes.argmax()
max_frequency = frequencies[max_amplitude_index]
# 根据频率判断是哪个拨号音
if max_frequency in (697, 770):
print('拨号音:1')
elif max_frequency in (697, 770, 852, 941):
print('拨号音:2')
elif max_frequency in (770, 852):
print('拨号音:3')
elif max_frequency in (770, 852, 941, 1209):
print('拨号音:4')
elif max_frequency in (770, 941):
print('拨号音:5')
elif max_frequency in (852, 941, 1209, 1336):
print('拨号音:6')
elif max_frequency in (941, 1209):
print('拨号音:7')
elif max_frequency in (697, 770,852,941,1209,1336):
print('拨号音:8')
elif max_frequency in (770, 852, 941, 1209, 1336):
print('拨号音:9')
elif max_frequency in (941):
print('拨号音:*')
elif max_frequency in (941, 1336):
print('拨号音:0')
elif max_frequency in (941, 1209, 1336):
print('拨号音:#')
这里也需要大家平时的积累或是联想能力了,这些数字与拨号按键有关,那么与拨号按键有关的就是九键输入的方式了:

以前用按键手机的时候就是按下几次数字就会出现相应数字的第几个字母,因此解密可以出来YOUREMYGIRLFRIENDS,即为flag
考点:理解DTMF拨号音、能够联想到九键输入法
[DDCTF2018](╯°□°)╯︵ ┻━┻(脑洞)
下载文件,txt的内容如下:

最底下的字符串一眼16进制编码,我们进行转码:

是乱码
这里我们需要了解一下十六进制编码是如何将字符串转换成一串十六进制数字的:
十六进制编码是如何将字符串转换成一串十六进制数字的
获取字符的ASCII值->将ASCII值转换为十六进制->组合十六进制值
如:'C' → ASCII: 67 → Hex: 43
我们现将得到的十六进制第一个十六进制值转换为十进制(ASCII值),发现远大于ASCII表中含有的128位字符:

根据做题经验(我遇到过相关的题目,我认为正常思路可能是每128位数后ASCII值就重新开始从0算起),我们将得到的十六进制字符串两两组合成十六进制值后转换成十进制,再减去128,最后将ASCII值(十进制值)转换成字符:
# 假设 data 是十六进制字符串
data = 'd4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9e1b2e2e5e2b5b4e4b8b7e6e1e1b6b9e4b5e3b8b1b1e3e5b5b6b4b1b0e4e6b2fd'
# 遍历 data,每两个字符作为一个十六进制数,转换为十进制,再转换为对应的 ASCII 字符
result = ''
for i in range(0, len(data), 2):
# 获取两个字符,组成一个十六进制数
hex_value = data[i:i+2]
# 将十六进制数转换为十进制并减去128
decimal_value = int(hex_value, 16) -128
# 将十进制数转换为对应的 ASCII 字符
result += chr(decimal_value)
# 输出转换后的字符串
print(result)

得到了flag
(不知道为什么以上的答案错误了,这里贴出[BUUCTF:[DDCTF2018](╯°□°)╯︵ ┻━┻_ddctf2018╯︵ ┻━┻-CSDN博客](https://blog.csdn.net/mochu7777777/article/details/105324802)写的正确脚本)
# -*- coding:utf-8 -*-
# author: mochu7
def hex_str(str):#对字符串进行切片操作,每两位截取
hex_str_list=[]
for i in range(0,len(str)-1,2):
hex_str=str[i:i+2]
hex_str_list.append(hex_str)
print("hex列表:%s\n"%hex_str_list)
hex_to_str(hex_str_list)
def hex_to_str(hex_str_list):
int_list=[]
dec_list=[]
flag=''
for i in range(0,len(hex_str_list)):#把16进制转化为10进制
int_str=int('0x%s'%hex_str_list[i],16)
int_list.append(int_str)
dec_list.append(int_str-128)#-128得到正确的ascii码
for i in range(0,len(dec_list)):#ascii码转化为字符串
flag += chr(dec_list[i])
print("转化为十进制int列表:%s\n"%int_list)
print("-128得到ASCII十进制dec列表:%s\n"%dec_list)
print('最终答案:%s'%flag)
if __name__=='__main__':
str='d4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9b2b2e1e2b9b9b7b4e1b4b7e3e4b3b2b2e3e6b4b3e2b5b0b6b1b0e6e1e5e1b5fd'
print("字符串长度:%s"%len(str))
hex_str(str)
考点:理解十六进制编码是如何将字符串转换成一串十六进制数字的、脑洞大开、脚本编写
[MRCTF2020]千层套路(脚本编写)
下载文件,发现是一个加密的压缩包,我们按照文件名解压发现密码正确,里面貌似是无尽的压缩包套娃(嵌套压缩包):

因此我们要编写脚本实现相关功能:自动循环解压压缩包到当前文件夹并且解压密码为压缩包的名字,直到没有压缩包为止(我用ai写的)
import os
import zipfile
def extract_zip(file_path):
# 获取压缩包的文件名(不含扩展名)作为密码
password = os.path.splitext(os.path.basename(file_path))[0].encode('utf-8')
# 创建解压目标路径
extract_path = os.path.dirname(file_path)
with zipfile.ZipFile(file_path, 'r') as zip_ref:
try:
# 解压缩文件并使用密码
zip_ref.extractall(path=extract_path, pwd=password)
print(f'Successfully extracted {file_path}')
except RuntimeError as e:
print(f'Failed to extract {file_path}. Error: {e}')
return False
return True
def recursive_extract(folder_path):
while True:
extracted = False
for root, dirs, files in os.walk(folder_path):
for filename in files:
if filename.endswith('.zip'):
file_path = os.path.join(root, filename)
if extract_zip(file_path):
# 删除已解压的压缩包
os.remove(file_path)
extracted = True
if not extracted:
break
if __name__ == "__main__":
folder_path = '.' # 当前文件夹路径
recursive_extract(folder_path)
-
extract_zip函数:
- 该函数用于解压缩单个
.zip文件,使用文件名(不含扩展名)作为密码。 - 如果解压成功,返回
True,否则返回False。
- 该函数用于解压缩单个
-
recursive_extract函数:
- 该函数递归地遍历文件夹中的所有文件和子文件夹。
- 每当发现
.zip文件时,调用extract_zip解压缩。 - 解压成功后,删除已解压的压缩包,避免重复处理。
- 如果当前遍历中没有发现压缩包,循环终止。
-
脚本主程序:
-
folder_path = '.'表示当前工作目录。 -
脚本会从当前文件夹开始递归解压。
最终我们得到了qr.txt,里面的内容如下:

包含三个数字,并且只有(255,255,255)和(0,0,0),结合文件名,这是一个二维码的RGB数据
(255,255,255)代表黑;(0,0,0)代表白
因此我们要编写脚本实现相关功能:将qr.txt中的RGB数据如(255,255,255)等内容转换成一张图片(也是用AI写的)
-
from PIL import Image
# 读取qr.txt中的RGB数据
with open('qr.txt', 'r') as file:
data = file.readlines()
# 假设每一行是一个像素,并且行数与列数一致(即图像是一个正方形)
# 计算图像的尺寸
image_size = int(len(data) ** 0.5)
# 创建一个新的图像
image = Image.new('RGB', (image_size, image_size))
# 填充图像的每个像素
for i, line in enumerate(data):
# 将RGB数据解析为整数元组
rgb = tuple(map(int, line.strip().strip('()').split(',')))
# 计算像素在图像中的位置
x = i % image_size
y = i // image_size
# 将RGB值设置到图像的相应位置
image.putpixel((x, y), rgb)
# 保存生成的图像
image.save('output.png')
print('Image saved as output.png')
-
导入库:
- 使用
PIL库中的Image模块来创建和操作图像。
- 使用
-
读取文件:
with open('qr.txt', 'r') as file:读取文件内容,并将每一行作为一个字符串存储在data列表中。
-
计算图像大小:
- 假设
qr.txt中的像素数是一个完全平方数(即图像是正方形),通过int(len(data) ** 0.5)计算图像的宽度和高度。
- 假设
-
创建图像:
- 使用
Image.new('RGB', (image_size, image_size))创建一个新的RGB图像,大小为image_size x image_size。
- 使用
-
填充图像像素:
- 循环遍历每一行数据,将字符串形式的RGB值转换为整数元组,然后通过
putpixel方法设置图像中相应位置的像素值。
- 循环遍历每一行数据,将字符串形式的RGB值转换为整数元组,然后通过
-
保存图像:
- 最后,通过
image.save('output.png')将生成的图像保存为output.png文件。
最后成功输出了二维码图片,扫描即可得到flag:

考点:嵌套压缩包、RGB数据转换成图片、脚本编写
- 最后,通过
百里挑一
下载文件,发现里面是一个pcap格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

发现HTTP协议发送的JPEG File Interchange Format占比最多,媒体文件我们尝试导出对象查看:

一堆图片,按照图片隐写思路我们要查看所有图片的属性寻找关键词,太多了!
exiftool——可交换图像文件格式编辑器
图片属性中的内容都是可交换图像文件格式(英语:Exchangeable image file format,官方简称Exif),我们可以使用这个工具输出一个图片的所有属性如:
exiftool 0.jpg

我们可以使用exiftool分析所有图片的属性,并将输出保存到一个txt文件内部进行分析:
exiftool * > 1.txt
我们在输出里面尝试输入关键词找到了半个flag:

这里我们直接搜索关键词flag也搜得到:

剩下半个flag只能自己去找了,我们只能逐一分析TCP流寻找
最终在114流找到了后半段:

考点:多张图片分析、wiresharkTCP流追踪、耐心
补充:网上有一种解法是搜索关键词“exif”,很快就能过滤出来
[SUCTF2018]followme(知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

发现HTTP协议占比最多,我们尝试导出对象查看:

可以推测攻击机在尝试登录admin的账号,那么flag应该藏在最终结果里面
我们将HTTP导出对象进行大小排列,查看哪个数据包最大,最大的应该就是登录成功的数据包:

在HTTP报文中找到了password的值为flag

考点:网络流量分析
补充:直接搜索关键词“ctf{”直接出结果
[MRCTF2020]CyberPunk(简单)
下载文件,是一个exe可执行文件,我们先运行看看:

我喜欢赛博朋克2077!他在2020.9.17发售,到了那时候我会给你flag!
并且每隔10秒检测当前月份和日期
那么我们将电脑的时间改成9月17日即可

考点:动脑子
[安洵杯 2019]Attack
下载文件,发现里面是一个pcap格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

发现HTTP协议发送的Media Type占比最多,我们过滤查看发现并不是真正的媒体文件而是一句话木马:

我们分析http导出对象,发现了一个不得了的文件——lass.dmp:

.dmp文件的重要性
.dmp 文件通常是内存转储(Memory Dump)文件的扩展名。它保存了程序在特定时间点(通常是程序崩溃或发生错误时)内存中的内容。这些文件通常用于调试目的,以帮助开发人员了解程序崩溃或错误发生的原因。
如果 .dmp 文件包含了程序内存中的敏感信息,如明文密码、加密密钥、用户数据等,黑客可能通过分析 .dmp 文件获取这些信息。
我们将.dmp文件导出,使用新工具进行分析——mimikatz
mimikatz——内网渗透神器
Mimikatz 是一个广为人知的开源工具,主要用于安全测试和渗透测试领域。它由法国安全研究员 Benjamin Delpy 开发,最初是为了展示 Windows 操作系统中存在的安全漏洞。Mimikatz 可以执行多种操作,特别是在 Windows 系统上提取敏感信息。
我们使用mimikatz分析.dmp文件:
privilege::debug
//提升 Mimikatz 的权限,使其能够访问某些受保护的进程和内存区域。
sekurlsa::minidump lsass.dmp
//告诉 Mimikatz 加载一个特定的内存转储文件
sekurlsa::logonpasswords full
//用于提取当前系统中所有用户的登录凭证信息,包括明文密码、密码哈希、Kerberos 票据等。

我们可以得到靶机用户Administrator的密码为W3lc0meToD0g3
另一边,我们导出http对象时使用foremost辅助提取出了新东西:

这个zip加密了,在备注里有密码提示:

我们将Administrator的密码作为密码解压,成功得到flag
考点:网络流量分析、分析.dmp文件、导出流量包文件对象
[UTCTF2020]basic-forensics(知识巩固题)
下载文件,是一个打不开的jpeg格式,我们使用010 editor打开:

全是电子书的内容,这种长文本我们直接搜索关键词“flag”或者是“ctf”

考点:关键词搜索
[BSidesSF2019]zippy(知识巩固题)
下载文件,发现里面是一个pcap格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

可以发现TCP协议占比最高,我们优先分析传输的Data:

第一个包看内容可以推测:攻击机监听端口4445并且传输了flag.zip文件

第二个包可以发现传输的zip文件,我们可以进行手动提取:

尝试解压发现需要密码,我们先不管,继续分析剩下的包
第三个包可以发现了解压的命令,解压密码为“supercomplexpassword”

解压文件,得到了flag
考点:网络流量分析、学会提取流量包中的文件
[SUCTF 2019]Game(较难新)
下载文件,是一张png格式的图片和html网页小游戏源码
我们优先分析图片,按照图片隐写思路,第一步、第二步无果,我们打开stegsolve打开图片查看:

我们可以发现,当我们关闭红色通道(red plane 0)、绿色通道或是蓝色通道时,图片的上方出现了一点点黑白的印记,虽然不是很明显,我们继续使用StegSolve进行分析

我们发现隐藏信息像是一串base64编码的内容,我们尝试解码:

这里出现了“Salted”的字符串,说明这是加了盐的加密
“U2FsdGVkX1”开头的密文——加了盐的加密
加盐(Salt)是在加密时使用的一个随机值,目的是防止攻击者通过预先计算的哈希表(如彩虹表)快速破解加密数据。通常,盐值会与密码结合,通过一个密钥衍生函数(如 PBKDF2)生成一个足够强的密钥。
我们有了这串加了盐的密文,那么我们明白就应该去寻找密钥了,我们接着分析html网页小游戏源码
搜索关键词flag即得到了这个:

这是一串经过base32编码的字符串(后边有三个“=”的特征,或是使用cyberchef的magic功能自动识别):

这是我们唯一能找到的字符串,因此需要猜测这就是我们需要的密钥!
我们观察我们的密钥,长度为23位或21位(去掉“{}”)或16位(去掉“{}”和“suctf”)



我们常用的对称加密有:DES(需要8位密钥)Triple DES(需要24位密钥)AES(需要16位或24位或32位密钥)、RC4等等,题目没有给出提示我们只能逐个尝试
我们优先尝试AES-128的解密方式,发现并不是:

这里再介绍以下cyberchef的这些模块(更详细的内容以后会更新在crypto方向的模块):
key 密钥
IV 初始化向量,是对称加密算法在某些模式中使用的一个额外输入参数,它保证了相同的明文和密钥在不同的加密操作中会产生不同的密文。通常,IV 应该是随机生成的并且不需要保密,但是它必须和密文一起存储或传输,因为解密时需要相同的 IV
Mode 加密模式
Input 输入格式
Output 输出格式
RC4的各种尝试也不正确,没有其他密码相关的提示,我们貌似陷入了僵局:

对称加密加解密工具的不同
有些DES加解密工具可能采用不同的处理方式,例如自动将较短的密钥扩展为合适的长度,而无需用户明确提供完整的8字节密钥。如Crypto-JS:这是一个 JavaScript 加密库,它在实现上可能更加灵活,例如自动生成 IV、填充或衍生密钥,这使得用户不必关注这些细节。而cyberchef要求用户提供8字节的密钥和一个 IV,这是严格按照标准实现的加密工具。我们可能是使用错了工具所以解不出来!
我们使用在线网址在线加密/解密,对称加密/非对称加密 (sojson.com)进行多次尝试解密发现使用的加密方式是TripleDes
得到了flag:

考点:LSB隐写、关键词搜索、理解对称加密
补充:这道题目是buuctf的简化版,原版题目只有html网页小游戏源码文件
原题我们需要在网页小游戏中找到隐藏的“secret”关键词(buuctf给的源码好像有点问题在此直接展示js源码中搜到的地方):

我们需要使用相关指令才能将该png图片下载出来:
wget http://[靶机IP]/iZwz9i9xnerwj6o7h40eauZ.png
USB(较难新)
下载文件,里面是一个藏着假flag的压缩文件和ftm未知后缀名文件:

我们优先使用010 editor分析:
很长很难分析,我们直接使用binwalk查看其中是否藏了东西:
binwalk key.ftm -e

藏了东西,主要是有一个pcap流量包,我们进行协议分级分析只有物理层的USB相关协议:

USB键盘流量包详解
usb.capdata 是 USB 数据包中的最主要的字段,用于显示捕获的 USB 数据的原始字节。这些字节通常表示设备在 USB 总线上发送的实际数据。对于 USB 键盘,usb.capdata 通常包含按键操作的编码信息。比如我们分析一下第一个数据包:

usb.capdata的值为0002000002000000
第一个字节 (00): 修饰键(Modifier Key)状态,如 Ctrl、Shift、Alt 等。值为 00 表示没有修饰键被按下。
第二个字节 (02): 保留位(Reserved)。通常没有特别意义,固定为 00。
第三到第八个字节 (00 02 00 00 00 00): 这些字节表示按键编码(Keycode)。每个字节表示一个按键,其中 00 表示没有按键被按下。按键编码 02 对应的是大键盘 1 键。
更多可以参考202106241624549419156181.pdf (willhsu.com)
总之这个流量包记录了USB连接的键盘输入数据,我们应该进行提取和分析。
在此我们也可以直接使用工具脚本:UsbKeyboardDataHacker
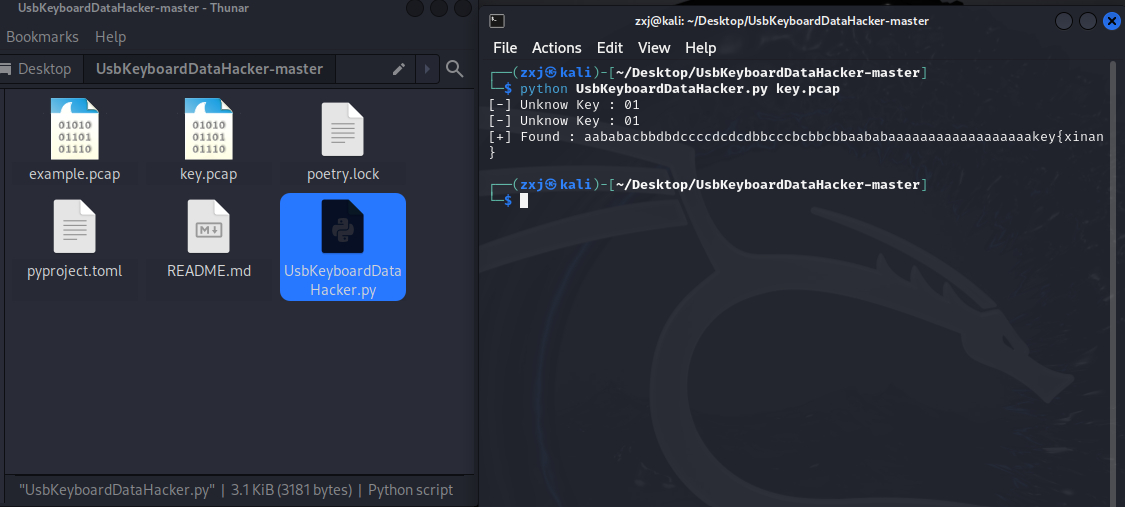
提取出了键盘输入的内容,得到了关键信息key{xinan}提交了发现并不是flag
那么我们只能继续对233.rar进行分析了,我们可以注意到当我们使用winrar打开时会报错:

我们使用RAR模板打开好像抽风了,我们只好手动分析:

RAR文件格式简介(原文:RAR文件格式学习(了解)_rar文件头-CSDN博客、CTF解题技能之压缩包分析基础篇 - FreeBuf网络安全行业门户)
RAR是有四个文件块组成的,分别是分别是标记块、压缩文件头、文件块、结束块,这些块之间没有固定地先后顺序,但要求第一个块必须是标志块并且其后紧跟一个归档头部块。每个块都包含以下内容:
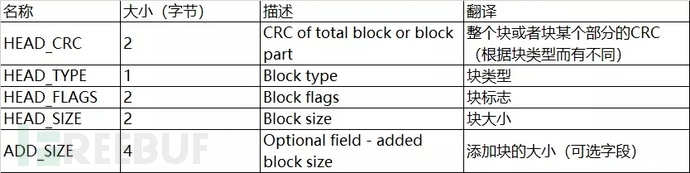
标记块(MARK_HEAD)
第一块为标记块(MARK_HEAD),其数据为:
52 61 72 21 1A 07 00
字节的说明
52 61 为头部校验和(HEAD_CRC),占两个字节,每一块均从HEAD_CRC开始,所有的RAR都以 52 61 开头
72 为 块类型(HEAD_TYPE) 占一个字节,所有文件都如此
21 1A 为 块标记(HEAD_FLAGS) 占两个字节
07 00表示块大小 ,即 52 61 72 21 1A 07 00 (标记块)共占7个字节
压缩文件头(MAIN_HEAD)
第二块为压缩文件头(MAIN_HEAD) ,和标记块一样:
CF 90 73 00 00 0D 00 00 00 00 00 00 00

CF 90 压缩文件头CRC校验值
73 头类型是0x73表示压缩文件头块
00 00 位标记,没有位被置为1 ,如果块头被加密,则位标记应该为:0x8000
0D 00 文件头大小为0x0D00,由上图可以看出这个压缩文件头块占13个字节
文件头(FILE_HEAD)
RAR文件格式及其各字段含义请参考官方文档:RAR 5.0 archive format (rarlab.com)
接下来用rar文件来讲一下文件头部分的码流分析。

16进制软件使用winhex,hex值左边是低位,右边是高位,比如52 61 实际上就是0x6152
D5 56 :HEAD_CRC,2字节,也就是文件头部分的crc校验值
74 :HEAD_TYPE,1字节,块类型,74表示块类型是文件头
20 90 :HEAD_FLAGS,2字节,位标记,这块在资料上没找到对应的数值,不知道20 90代表什么意思。
2D 00 :HEAD_SIZE,2字节,文件头的全部大小(包含文件名和注释)
10 00 00 00 :PACK_SIZE,4字节,已压缩文件大小
10 00 00 00 :UNP_SIZE,4字节,未压缩文件大小
02:HOST_OS,1字节,保存压缩文件使用的操作系统,02代表windows
C7 88 67 36:FILE_CRC,4字节,文件的CRC值
6D BB 4E 4B :FTIME,4字节,MS DOS 标准格式的日期和时间
1D:UNP_VER,1字节,解压文件所需要的最低RAR版本
30:METHOD,1字节,压缩方式,这里是存储压缩
08 00 :NAME_SIZE,2字节,表示文件名大小,这里文件名大小是8字节(flag.txt)
20 00 00 00 :ATTR,4字节,表示文件属性这里是txt文件
66 6C 61 67 2E 74 78 74:FILE_NAME(文件名) ,NAME_SIZE字节大小,这里NAME_SIZE大小为8
再往后是txt文件内容,一直到第六行 65 结束,下面是另一个文件块的开始
这个块中存在两个crc值,一个是文件头块中从块类型到文件名这38个字节的校验,后一个则是压缩包中所包含文件的crc校验,解压时,会计算解压后生成文件的crc值,如果等于这里的crc,则解压完成,如果不同,则报错中断。
结尾块
这个结尾块和标记块字节大小和分析方法是一样的。

C4 3D :HEAD_CRC,2字节,从HEAD_TYPE到HEAD_SIZE的crc校验值
7B :HEAD_TYPE,1字节,表示该块是结尾块
00 40 HEAD_FALGS ,2字节,位标记
07 00 :HEAD_SIZE,2字节,块大小
与标记块类似的是,结尾块也是一个固定字节串的块,依次是 C4 3D 7B 00 40 07 00
有了上面的RAR文件格式的分析,结合报错信息我们可以发现RAR文件的“233.png”文件头的HEAD_TYPE应为“74”却被改成了“7A”,我们修改回来,压缩包中藏着的233.png总算是出来了:

(补充:更新了010 editor版本后就没有抽风了,我们看看正常模板解析的情况下的回显。可以发现233.png的HeadType错误,应该为FILE)


我们开始分析233.png文件
按照图片隐写思路,第一步、第二步无果,我们打开stegsolve打开图片查看,发现关闭蓝色通道会出现二维码,我们扫描出现了如下信息:
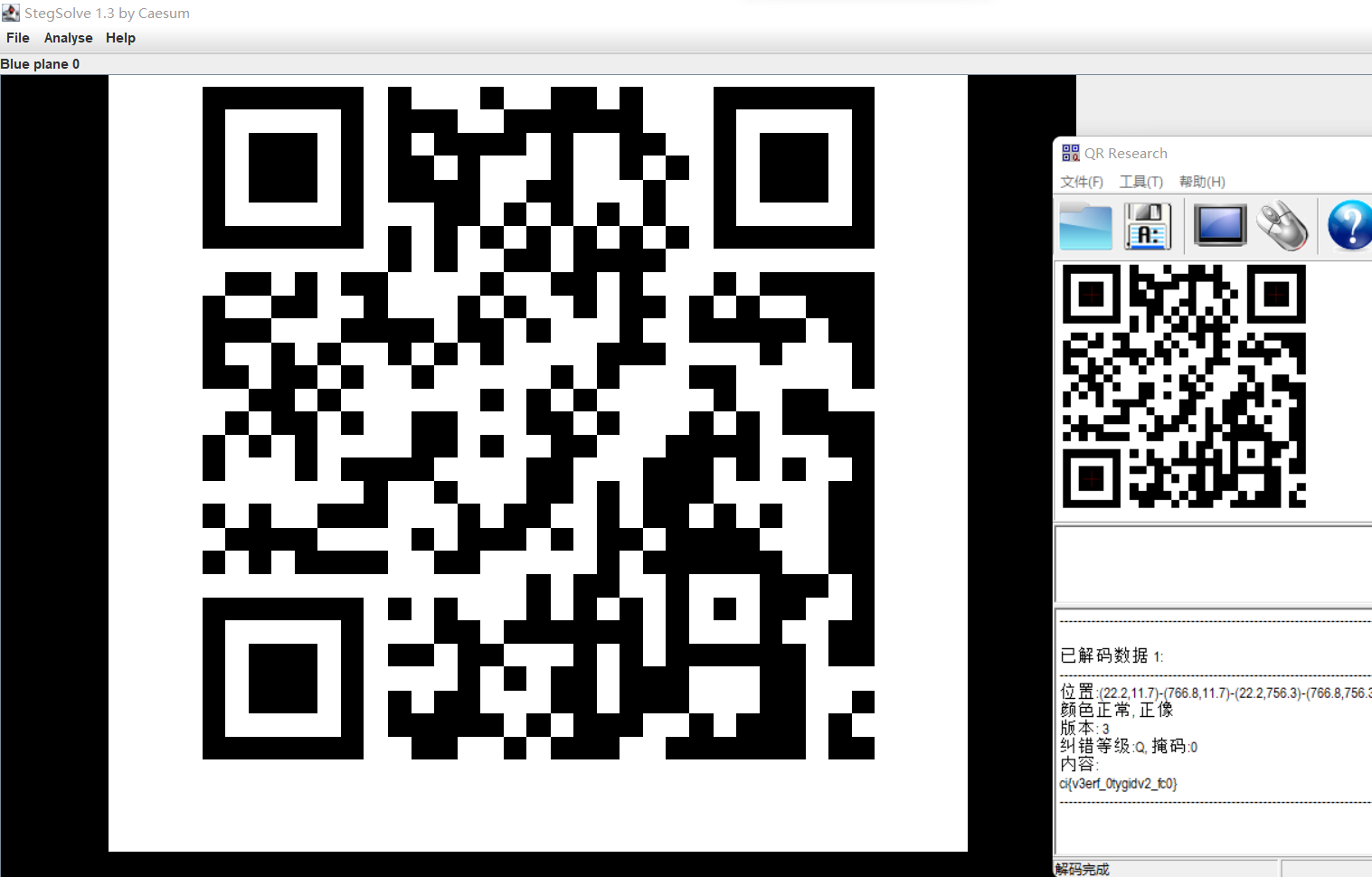
然而,这个也不是flag,按照之前得到的值,我们可以知道这串字符串一定是使用了密钥“xinan”加密的内容。
按照思路,我们需要将所有需要密钥的密码都尝试一遍,并得出最有可能的结果
需要密钥的加密方式思路顺序从古典到现代并且大众所知
维吉尼亚密码->Playfair密码->数据加密标准 (DES)->三重DES (Triple DES)->AES->RC4->Rabbit等等……(越到后边越需要复杂的条件)
我们按顺序来,发现是维吉尼亚密码加密(看上去比较合理):


我们可以看出维吉尼亚密码解密后明文以“f”开头,这种调换顺序的密码让人想要尝试栅栏密码,成功得到flag:

考点:理解USB流量分析并且会使用工具脚本、能够发现RAR文件中的文件头的HEAD_TYPE被修改了、LSB隐写、拥有需要密钥的加密方式的解密思路
[GUET-CTF2019]虚假的压缩包(较难新)
下载文件,里面是两个压缩包,“虚假的压缩包”和“真实的压缩包”,二者都进行了加密
我们逐一进行分析,第一步无果发现了“虚假的压缩包”存在伪加密:

我们得到了key:

看到熟悉的参数n和e,我们立刻能够联想到RSA加密的方法(详细会更新在crypto模块中)
在此我们直接解密:
n = 3 * 11 则p = 3 , q = 11
φ(n) = (p-1) * (q-1) = 20
gcd(e , φ(n)) = 1 (要满足e与φ(n)的公因数为1,3和20的公因数确实是1)
(d * e) mod φ(n) = 1 则解密私钥d = 7
c = m^e mod n 若明文m为解26,c为密文,得出答案是c = 20
m = c^d mod n 若密文c为解26,m为明文,得出答案是m = 5
离谱的是解压密码为“密码是5”(需要脑洞打开,能用的字符都要考虑到)
解压文件,里面是一张jpg图片和一个名为“亦真亦假”的无后缀文件
我们优先分析图片,按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

看这文件头,这应该是PNG格式的文件,我们进行修改再按照图片隐写思路,png图片第一步使用TweakPNG工具发现图片的crc校验出现错误,因此可能存在PNG宽高隐写:

我们使用脚本爆破PNG图片的正确宽高,修改即可:


可以发现隐藏的信息:

这里的“5”与上面提到过的“me”不一样,"^"在数学式中表示的是次方,在编程语言里面表示的是异或计算
我们再使用010 editor打开“亦真亦假”文件,发现就是一文本格式的文件,内容看上去是十六进制的编码:

按照提示,这些内容应该经过“^5”(与5进行异或)的计算(5异或5值为0,这里可以看出有几段文件流)
我们可以使用010 editor的计算工具进行运算:

异或后发现并不能得出什么文件,后来发现是以文本编辑的形式异或和以十六进制编辑的形式异或会有两种计算方式:
十六进制编辑的形式异或:将“e”与“5”的ASCII值进行异或
"e" 的 ASCII 值是 101(十进制),101 的二进制表示为 01100101。
"5" 的 ASCII 值是 53(十进制),53 的二进制表示为 00110101。
01100101 (101, "e")
XOR
00110101 (53, "5")
--------
01010000 (80)
得到的“80”转为字符为“`”
十六进制编辑的形式异或:将“e”与“5”看做十六进制进行异或
"e" 是16进制,转换为二进制是 1110。
"5" 是16进制,转换为二进制是 0101。
1110 (e)
XOR
0101 (5)
----
1011 (b)
结果 1011 对应的十六进制值是 "b"。
我们以十六进制编辑的形式进行异或:

结果将每个字节的十六进制与“05”进行了异或,没有看出有什么东西,也没有达到我们想要的效果
在此只好写一个脚本,能够实现将一个文件中所有字符看做十六进制数字并且与5进行异或:
# 读取1.txt中的内容
with open("1.txt", 'r') as input_file:
content = input_file.read().strip() # 去除文件中多余的空白字符
# 打开2.txt以写入处理后的结果
with open("2.txt", 'w') as output_file:
# 遍历文件中的每个字符
for char in content:
# 将字符转换为十六进制整数
hex_value = int(char, 16)
# 与5进行异或操作
xor_result = hex_value ^ 0x5
# 将结果转换为十六进制字符并写入到2.txt
output_file.write(hex(xor_result)[2:])

以复制十六进制编辑:

能够发现是以“PK”开头的zip压缩文件,总算成功了!
我们查看里面的文件,发现是doc文件

我们修改后缀后打开:

我们搜索关键词“flag”,发现藏在最后,字体颜色为白色。得到了flag:

考点:压缩包伪加密、PNG宽高隐写、理解RSA算法、理解异或计算、理解office文件是一堆文件的压缩文件
[RCTF2019]draw(新工具)
下载文件,是个txt文本,打开查看:

一头雾水,拿去问AI:

我们明白了这是Logo编程语言的代码,我们应该如何让这些代码跑起来呢?

在此使用了Logo解释器 (calormen.com)我们可以得出flag:

考点:不会就搜索就问、理解logo编程语言
[ACTF新生赛2020]明文攻击
下载文件,里面是一个加密的压缩包和一张图片:

我们优先对图片进行分析
第一步无果,我们优先打开010 editor打开图片查看:

发现有插入隐藏的zip文件,而且缺少文件头“PK”我们尝试修复后进行文件分离:

我们解压查看:

我们尝试了,这不是解压密码,那这是什么呢?
我们查看加密压缩包的内容,它的里面也有flag.txt文件,并且二者的CRC校验值是一样的!说明二者是相同的文件。

按照题目提示,这里可以使用ZIP明文攻击。
ZIP已知明文攻击
ZIP文件通常使用对称加密算法(如PKZIP的经典加密方式),并使用一个相对简单的流密码算法(CRC-32校验值和三个32位寄存器)来加密数据。这种方法依赖于一个用户提供的密码生成密钥流,对文件内容进行加密。
前提:在已知明文攻击中,攻击者已经获得了一部分加密文件的对应明文(未加密内容),并且能够访问对应的加密数据(密文)。
步骤1:获取已知明文和对应密文:攻击者知道ZIP文件中某些已加密文件的部分内容。例如,ZIP文件中可能包含一个常见文件如README.txt,攻击者可能已经知道其中的一些文本内容(明文),同时可以访问该文件的加密版本(密文)。
步骤2:推导密钥流:攻击者利用已知的明文和对应的密文来反推出生成密文的密钥流。由于ZIP使用的加密算法基于流密码,明文与密钥流的XOR(异或)操作生成密文。因此,如果知道明文和密文,攻击者可以通过简单的异或操作推导出密钥流的一部分。
步骤3:恢复密钥:利用推导出的密钥流,攻击者可以逐步逆推出用于加密的内部状态和密钥,进而推算出完整的加密密钥。
步骤4:解密整个文件:一旦掌握了密钥,攻击者可以使用该密钥解密ZIP文件中其他的内容,甚至解密整个ZIP文件。
可以参考视频https://www.bilibili.com/video/BV1qW4y1L7tN?vd_source=69c558b0c7be97607c79afbd75bd1f7c
1分50秒至3分41秒
使用ARCHPR对压缩包进行已知明文攻击

如图所示,明文攻击所需时间比较久,我们只有耐心等待,最终得到加密密钥,我们可以保存已解密的压缩包,得到flag

考点:利用十六进制编辑器找到隐藏的信息、文件头修复、理解压缩包明文攻击
[DDCTF2018]流量分析(新)
下载文件,是一个pcap格式的流量包和提示:

按照数据包分析思路,我们先进行协议分级:

我们发现TCP协议占比最高,并且使用了TLS协议加密(Transport Layer security);协议中使用了FTP协议并且占比非常高,优先查看FTP协议发了些什么文件,过滤FTP Data并且尝试导出对象:

尝试解压都加密了……
那么我们只能退而求其次,开始过滤分析TCP协议的内容,追踪TCP流从0开始看起,发现前面的数据包都是空的:

前面的TCP流量全是空的因为前面都是握手包:Wireshark的捕获设置可能限制了捕获的数据包数量或大小。如果某个TCP流的数据包在捕获开始或结束之前已经传输完毕,或者超过了捕获的窗口大小,你可能只会看到TCP连接建立(SYN、ACK等)或终止(FIN、RST等)的包,而没有数据包。那么我们直接跳过握手包,跳到有内容的数据包并追踪流:

追踪TCP流2002,这段TCP流量数据包描述了一次FTP会话的过程,其中包含了用户登录、文件传输和错误处理的相关信息。

1. FTP服务器连接:
220 (vsFTPd 3.0.2):客户端连接到FTP服务器,服务器响应表示欢迎,并告知使用的FTP服务版本是vsFTPd 3.0.2。
2. 用户登录:
USER zhangsan:客户端尝试以用户名“zhangsan”登录。
331 Please specify the password.:服务器请求用户提供密码。
PASS zhangsan:客户端提供密码(明文显示,实际传输中不建议明文传输密码)。
230 Login successful.:服务器确认登录成功。
3. 系统信息查询:
SYST:客户端请求服务器的系统类型。
215 UNIX Type: L8:服务器响应,表示它运行在UNIX系统上,类型为L8。
4. 进入被动模式:
PASV:客户端请求服务器进入被动模式(PASV模式),以便进行数据传输。
227 Entering Passive Mode (172,17,0,2,229,182).:服务器响应进入被动模式,并提供了数据连接的IP地址和端口号(组合起来为端口58726,229*256+182=58726)。
5. 目录列表传输:
LIST:客户端请求列出当前目录的内容。
150 Here comes the directory listing.:服务器开始传输目录列表。
226 Directory send OK.:服务器确认目录列表传输完成。
6. 文件传输 (Fl-g.zip):
TYPE I:客户端请求切换到二进制传输模式。
200 Switching to Binary mode.:服务器确认切换到二进制模式。
PASV:客户端再次进入被动模式。
227 Entering Passive Mode (172,17,0,2,116,151).:服务器提供新的数据连接端口(组合为29847)。
RETR Fl-g.zip:客户端请求下载文件“Fl-g.zip”。
150 Opening BINARY mode data connection for Fl-g.zip (24732680 bytes).:服务器开始传输文件,文件大小为24,732,680字节。
226 Transfer complete.:服务器确认文件传输完成。
7. 文件传输 (sqlmap.zip):
与上一步类似的过程,只不过文件名称为“sqlmap.zip”,大小为15,288,181字节。
8. 再次列出目录:
TYPE A:客户端切换到ASCII传输模式。
200 Switching to ASCII mode.:服务器确认切换到ASCII模式。
PASV:客户端进入被动模式。
227 Entering Passive Mode (172,17,0,2,223,125).:服务器提供新的数据连接端口(组合为57149)。
LIST:客户端请求再次列出当前目录的内容。
150 Here comes the directory listing.:服务器开始传输目录列表。
226 Directory send OK.:服务器确认目录列表传输完成。
9. 尝试上传文件:
TYPE I:客户端再次切换到二进制传输模式。
200 Switching to Binary mode.:服务器确认切换到二进制模式。
PASV:客户端进入被动模式。
227 Entering Passive Mode (172,17,0,2,184,236).:服务器提供新的数据连接端口(组合为47300)。
STOR /etc/profile:客户端尝试上传文件到服务器的“/etc/profile”路径。
553 Could not create file.:服务器拒绝了上传请求,可能是由于权限不足或路径问题。
10. 退出会话:
QUIT:客户端请求断开连接。
221 Goodbye.:服务器确认断开连接。
追踪TCP流2003,这段数据是从FTP服务器返回的目录列表中的一部分,列出了两个文件的详细信息

追踪TCP流2004和2005,传输了两个个zip文件


追踪TCP流2006,这段数据是从FTP服务器返回的目录列表中的一部分,列出了两个文件的详细信息

追踪TCP流2007,这段TCP流量数据包描述了一次与邮件服务器(MX服务器)的交互过程,显示了客户端尝试发送邮件时所经历的各个阶段。

1. 连接建立:
220 mx1.aliyun-inc.com MX AliMail Server(10.147.2.124):
这是邮件服务器向客户端发送的欢迎消息,表示连接成功。服务器的域名为mx1.aliyun-inc.com,IP地址为10.147.2.124。
2. EHLO 命令:
EHLO 7e040dcc799e.didi-ctf.com:
客户端向服务器发送EHLO命令(Extended HELO),以开始SMTP会话,并告知服务器客户端的标识(7e040dcc799e.didi-ctf.com)。
服务器响应:
250-mx1.aliyun-inc.com:服务器确认接受了EHLO,并列出支持的SMTP扩展功能。
250-STARTTLS:服务器支持STARTTLS命令,可以升级到加密连接。
250-8BITMIME:支持8位MIME传输。
250-AUTH=PLAIN LOGIN XALIOAUTH 和 250-AUTH PLAIN LOGIN XALIOAUTH:支持的身份验证方式包括PLAIN、LOGIN和XALIOAUTH。
250-PIPELINING:服务器支持指令流水线操作。
250 DSN:支持传递状态通知(Delivery Status Notification)。
3. 发送邮件地址:
MAIL FROM:<support@ttlsa.com>:
客户端发送MAIL FROM命令,指定发件人地址为support@ttlsa.com。
服务器响应:
250 Mail Ok:服务器确认接收发件人地址。
4. 指定收件人地址:
RCPT TO:<dengyun@ttlsa.com> ORCPT=rfc822;dengyun@ttlsa.com:
客户端发送RCPT TO命令,指定收件人地址为dengyun@ttlsa.com,并通过ORCPT参数指定原始收件人地址(适用于某些邮件转发场景)。
服务器响应:
554 Reject by behaviour spam at Rcpt State(Connection IP address:111.202.154.85)ANTISPAM_BAT[01201311R136a, e02c03309]: spf check failed CONTINUE:
服务器拒绝了收件人地址。拒绝的原因可能是因为发件人的IP地址111.202.154.85被认为是垃圾邮件来源,且SPF(Sender Policy Framework)检查失败。
5. 数据传输尝试:
DATA:
客户端尝试发送DATA命令,准备传输邮件内容。
服务器响应:
503 bad sequence of commands:服务器返回503错误,表示命令序列错误。因为前面的RCPT TO命令已经被拒绝,所以继续发送DATA命令是不符合协议的。
6. 连接重置和断开:
RSET:
客户端发送RSET命令,重置会话状态,清除所有已发送但未完成的命令。
QUIT:
客户端发送QUIT命令,请求断开连接。
服务器响应:
服务器断开连接,完成会话。
追踪TCP流2008,这段TCP流量描述了一次邮件传输的过程,其中出现了一个邮件退回(bounce)通知。这是邮件系统自动生成的,用于告知发件人邮件未能成功递送。

1. 连接建立
220 mx1.aliyun-inc.com MX AliMail Server(10.147.10.221):服务器发送的欢迎消息,表示已成功建立连接。
2. EHLO 命令
EHLO 7e040dcc799e.didi-ctf.com:客户端向服务器发送EHLO命令,声明客户端的标识。
服务器响应:
250-STARTTLS:服务器支持STARTTLS命令,可以升级到加密连接。
250-8BITMIME:服务器支持8位MIME传输。
250-AUTH PLAIN LOGIN XALIOAUTH:服务器支持的身份验证方式。
250-PIPELINING:服务器支持流水线操作。
250 DSN:服务器支持传递状态通知(Delivery Status Notification)。
3. 邮件发送
MAIL FROM:<>:发送者地址为空,表示这是一个邮件系统自动生成的邮件(例如退信通知)。
RCPT TO:<support@ttlsa.com>:指定收件人地址为support@ttlsa.com。
4. 数据传输
DATA:客户端准备发送邮件内容。
服务器响应:
250 Mail Ok和250 Rcpt Ok:服务器确认了邮件发送和收件人地址。
354 End data with <CR><LF>.<CR><LF>:服务器指示客户端可以开始传输邮件内容,结束符为.。
5. 邮件传输结束
.:客户端发送了数据结束标记。
250 Data Ok: queued as freedom:服务器确认邮件数据已成功接收并放入队列处理。
QUIT和221 Bye:会话结束,连接断开。
邮件内容是一个退信通知,说明邮件无法递送,包含以下关键信息:
退回的原因:<dengyun@ttlsa.com>: host mxn.mxhichina.com[42.120.219.27] said: 554 Reject by behaviour spam at Rcpt State(Connection IP address:111.202.154.85)ANTISPAM_BAT[01201311R136a, e02c03309]: spf check failed CONTINUE。这表明邮件被目标邮件服务器拒绝,原因是发件人的IP地址111.202.154.85被识别为垃圾邮件来源,并且SPF(Sender Policy Framework)检查失败。
诊断代码:554 表示邮件在传输过程中的永久性错误,导致邮件无法投递。
追踪TCP流2009,TCP握手包没有特殊内容

接下来的几个数据包都是发送的邮件
值得注意的是追踪TCP流2016我们发现邮件里插入了一段经base64编码的图片:

我们进行解码:

得到了一张图片,我们识别再解码:

发现是乱码,因此我们可以猜测这是我们寻找的TLS协议加密的密钥,我们按照提示给密钥进行套皮:
-----BEGIN RSA PRIVATE KEY-----
MIICXAIBAAKBgQDCm6vZmclJrVH1AAyGuCuSSZ8O+mIQiOUQCvN0HYbj8153JfSQ
LsJIhbRYS7+zZ1oXvPemWQDv/u/tzegt58q4ciNmcVnq1uKiygc6QOtvT7oiSTyO
vMX/q5iE2iClYUIHZEKX3BjjNDxrYvLQzPyGD1EY2DZIO6T45FNKYC2VDwIDAQAB
AoGAbtWUKUkx37lLfRq7B5sqjZVKdpBZe4tL0jg6cX5Djd3Uhk1inR9UXVNw4/y4
QGfzYqOn8+Cq7QSoBysHOeXSiPztW2cL09ktPgSlfTQyN6ELNGuiUOYnaTWYZpp/
QbRcZ/eHBulVQLlk5M6RVs9BLI9X08RAl7EcwumiRfWas6kCQQDvqC0dxl2wIjwN
czILcoWLig2c2u71Nev9DrWjWHU8eHDuzCJWvOUAHIrkexddWEK2VHd+F13GBCOQ
ZCM4prBjAkEAz+ENahsEjBE4+7H1HdIaw0+goe/45d6A2ewO/lYH6dDZTAzTW9z9
kzV8uz+Mmo5163/JtvwYQcKF39DJGGtqZQJBAKa18XR16fQ9TFL64EQwTQ+tYBzN
+04eTWQCmH3haeQ/0Cd9XyHBUveJ42Be8/jeDcIx7dGLxZKajHbEAfBFnAsCQGq1
AnbJ4Z6opJCGu+UP2c8SC8m0bhZJDelPRC8IKE28eB6SotgP61ZqaVmQ+HLJ1/wH
/5pfc3AmEyRdfyx6zwUCQCAH4SLJv/kprRz1a1gx8FR5tj4NeHEFFNEgq1gmiwmH
2STT5qZWzQFz8NRe+/otNOHBR2Xk4e8IS+ehIJ3TvyE=
-----END RSA PRIVATE KEY-----
将上述私钥保存为.key格式的文件

wireshark功能六:导入密钥
SSL/TLS是一种密码通信框架,TLS协议位于传输层和应用层中间,其功能是一个加密通道,和上层应用协议无关。由于HTTP采用明文传输,很容易被攻击者窃听或者篡改内容,通过引用TLS对HTTP的内容进行加密等操作,可以有效防止窃听、篡改和劫持等。
参考视频https://www.bilibili.com/video/BV1uY4y1D7Ng?vd_source=69c558b0c7be97607c79afbd75bd1f7c
我们需要导入我们获得的私钥文件进行解密:


导入私钥成功后我们就可以查看http协议中加密的内容了:

发现http数据包中藏有flag
考点:理解FTP协议、理解SMTP协议、在流量数据中寻找私钥、理解SSL/TLS密码通信框架、学会使用wireshark导入私钥文件
[SWPU2019]Network(新脑洞)
下载文件,是一个txt文件,看上去像是ascii值但是最大的超过了127所以我们排除这方向的思路:

按照题目提示Network,这里必定是存在与网络相关的加密方式
我们先分析密文,密文仅有“63”、“127”、“191”、“255”四个数字,因此我们可以猜测这与两位二进制相关加密有关(两位二进制仅有”00“、”01“、”10“、”11“四个数字)
在此提出新的加密方式——TTL隐写
TTL隐写
TTL隐写(TTL Steganography)是一种利用网络数据包的生存时间(Time To Live, TTL)字段进行数据隐写的技术。TTL字段是IPv4协议头中的一个8位字段,用来限制数据包在网络中的存活时间,每经过一个路由器或网络设备,这个值就会减一,当TTL值为0时,数据包会被丢弃。
TTL隐写的基本原理是通过控制数据包的TTL值来传输隐秘信息。具体而言,攻击者或隐写者可以在发送数据包时,将TTL字段设置为特定的值以表示某种信息。接收方只需要解析数据包中的TTL字段并恢复原始信息即可。
我们分析密文:
63(二进制后)=00111111
127(二进制后)=01111111
191(二进制后)=10111111
255(二进制后)=11111111
发现仅有最前面的两位数字不同,因此我们可以猜测明文由密文二进制后前两位组合而成
那么我们可以编写一个脚本,将63转换成00、将127转换成01、将191转换成10、将255转换成11后将所有内容组合起来(或者说是将密文转换成二进制后提取前两位,但前者应该更加高效)
# 定义一个映射表,将数值映射到二进制字符串
mapping = {
'63': '00',
'127': '01',
'191': '10',
'255': '11'
}
# 读取attachment.txt文件内容
with open('attachment.txt', 'r') as file:
content = file.read()
# 将内容根据映射表进行替换
result = ''
for value in content.split():
if value in mapping:
result += mapping[value]
else:
print(f"Value {value} not found in mapping table.")
# 输出组合后的二进制字符串
print(result)
# 将结果保存到一个新的文件中
with open('output.txt', 'w') as outfile:
outfile.write(result)
def hex_to_binary(hex_str):
# 将十六进制字符串转换为二进制字符串,并去掉前缀 '0b'
binary_str = bin(int(hex_str, 16))[2:]
# 保证二进制字符串长度是8的倍数,前面补充0
binary_str = binary_str.zfill(8)
return binary_str
def dec_to_binary(dec_str):
# 将十进制字符串转换为二进制字符串,并去掉前缀 '0b'
binary_str = bin(int(dec_str))[2:]
# 保证二进制字符串长度是8的倍数,前面补充0
binary_str = binary_str.zfill(8)
return binary_str
# 配置开关,选择十六进制或十进制
is_hex = False # 设置为True表示十六进制,False表示十进制
# 读取attachment.txt文件内容
with open('attachment.txt', 'r') as file:
lines = file.readlines()
# 初始化结果字符串
result = ''
# 遍历每一行,将每一行的数值转换成二进制并提取前两位
for line in lines:
line = line.strip() # 去掉行末的换行符
if is_hex:
binary_representation = hex_to_binary(line)
else:
binary_representation = dec_to_binary(line)
# 提取前两位
result += binary_representation[:2]
# 输出组合后的二进制字符串
print(result)
# 将结果保存到一个新的文件中
with open('output.txt', 'w') as outfile:
outfile.write(result)
不知道是不是以上脚本都非常低效,跑了我好久(也可能是密文文件太大了)
总之得到了二进制的文本,我们进行转换:


看文件头是zip压缩文件,保存输出后解压发现加密了,发现是伪加密,我们进行修改即可解压(多处deFlags):

打开flag.txt发现内容被base64编码了数次,我们进行解码即可得到flag:

考点:理解TTL隐写、压缩包伪加密
[GKCTF 2021]签到(知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看

我们先进行协议分级:

发现HTTP协议发送的Line-base text data占比最多,我们优先过滤查看:

我们可以发现服务器给的返回包中包含的数据是十六进制的字符串,我们进行进制转换:

可以发现转换出了一个文件名,但文件名好像倒序了,我们加上倒序发现:

我们可以追踪http流查看具体是做了什么请求:

发现是通过向一个tmpshell.php发送请求查看当前目录文件得到的回显,我们一路分析流,发现了请求“f14g”的内容,我们解码发现没有东西:


接着往下看,发现了经base64编码的“f14g”,我们提取并且解码:

我们发现当前解码的内容是经过了每一行的倒序的(根据结尾“==”的位置判断),这里我们可以手动一行行的进行倒序,也可以写脚本:
# 读取1.txt文件内容
with open('1.txt', 'r') as file:
lines = file.readlines()
# 初始化倒序结果列表
reversed_lines = []
# 遍历每一行,进行倒序处理
for line in lines:
line = line.strip() # 去掉行末的换行符
reversed_line = line[::-1] # 将字符串倒序
reversed_lines.append(reversed_line)
# 将倒序后的结果写入一个新的文件,或者输出到控制台
with open('output.txt', 'w') as outfile:
for reversed_line in reversed_lines:
outfile.write(reversed_line + '\n')
# 可选:输出到控制台
for reversed_line in reversed_lines:
print(reversed_line)

我们进行解码得到:

可以发现flag的输出都输出了两遍,我们进行修改即可得到flag
考点:网络流量分析、观察解密
[MRCTF2020]Hello_ misc(知识巩固题脑洞)
下载文件,里面是一个加密的rar压缩包和一张图片
我们优先对图片进行分析,第一步无果,我们优先使用010 editor分析,发现了插入隐藏的压缩包:

我们提取出来发现这个压缩包也进行了加密,我们根据图片可以推测这张图片还藏了东西,我们进入第三步继续分析图片:


发现在红色通道和蓝色通道存在这种隐藏的数据,我们进行排列组合LSB解密终于得到了一张PNG图片:


得到了zip文件的密码,我们进行解压得到output.txt:

又是ttl隐写,我们进行解密得到rar文件密码:

解压得到了fffflag.zip文件,我们打开发现了word文件夹,可以推测这是一个doc文件,我们修改后缀打开:

推测flag内容为白色字体,我们修改字体颜色发现隐藏内容:

进行解码发现是乱码:

我们只能返回上一步,我们推测这并不是二进制的内容:

那么我们只能分析其中不对劲的地方,我们可以发现base64的编码内容是有换行符的,我们一行一行的进行解密再组合:
110110111111110011110111111111111111111111111111101110000001111111111001101
110110110001101011110111111111111111111111111111111101111111111111110110011
110000101110111011110111111100011111111111001001101110000011111000011111111
110110100001111011110111111011101111111110110110101111111100110111111111111
110110101111111011110111101011101111111110110110101101111100110111111111111
110110100001100000110000001100011100000110110110101110000001111000011111111
此时输出的内容若隐若现,我们脑洞大开将所有数字1改为空格:

是的,得到了flag
He1Lo_mi5c~
考点:图片插入隐写、lsb隐写、ttl隐写、脑洞大开
[UTCTF2020]zero(新)
下载文件,查看内容:

发现有很多不可打印字符,我们尝试使用010 editor进行解析发现这些字符也都是乱码:

零宽字符隐写原理
零宽字符隐写的基本原理是将要隐藏的信息编码为零宽字符序列,并将其插入到文本中的某些特定位置。因为这些字符在普通文本显示时不可见,所以文本看起来与原始文本没有区别。
字符包括:
零宽度空格(\u200b)
零宽度非连接符(\u200c)
零宽度连接符(\u200d)
从左至右书写标记(\u200e)
从右至左书写标记(\u200f)
将要隐藏的信息(通常是二进制数据或文本)编码成零宽字符的序列。例如,可以将二进制“0”编码为零宽度空格\u200B,将二进制“1”编码为零宽度不连字\u200C,嵌入普通文本中就不会被发现
我们可以使用在线网站(Unicode Steganography with Zero-Width Characters (330k.github.io))进行解密得到flag:

考点:理解零宽字符隐写原理
[WUSTCTF2020]spaceclub(知识巩固题)
下载文件,貌似是一个空文件,但我们发现ctrl+a选中全文发现隐藏着空格:

空格的排列只有短和长两种形态,但是没有分隔符,不能猜测是摩斯电码,那猜测是二进制,我们进行替换解出flag:

考点:对相关密码的敏感
CFI-CTF 2018]webLogon capture(知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看:

只有九个数据包,我们可以逐一分析,直接追踪http流:

可以发现攻击机一直在向服务器发送请求,请求内容含有的参数是email和password,但服务器一直回显“Incorrect username or password”,我们将密码进行url解码直接得到flag了。。。
考点:网络流量分析
[ACTF新生赛2020]music(新)
下载文件,是一个.m4a格式的音频文件,但是已损坏打不开,我们使用010 editor打开进行分析:

我们可以发现文件中含有很多“A1”字符,不禁让我想起了网易云VIP音乐破解的方法(缓存音乐异或解密_音乐解密的解密设定-CSDN博客,原理即将音频文件全部与“A3”——也就是网易云的“163”进行异或运算的加密),我们在此将全部内容与“A1”进行异或:

保存后播放音频听到flag内容
考点:理解音频的异或加密方式
[MRCTF2020]Unravel!!(新工具)
下载文件,里面是一张png图片、wav音频和一个加密的压缩包,我们优先对图片进行分析
按照图片隐写思路,第一步无果,我们优先使用010 editor进行分析,发现了插入隐藏的png图片:

我们进行文件分离,得到了png图片:

这并不是加密压缩包的密码,我们继续分析
我们分析分离的png图片,发现了插入隐藏的zip文件:

分离zip文件,发现还是分离的png图片,但文件名给出提示“aes.png”

看似没有别的线索了,我们再对音频进行分析
第一步无果,我们优先使用010 editor进行分析,发现了插入隐藏的信息:

根据之前的提示,我们推测这是aes加密的内容(U2FsdGVkX1的开头)
我们进行解密:

这是zip文件的密码,我们解压得到了新的wav音频文件,我们进行分析
按照音频隐写思路,第一步、第二步、第三步无果,我们开始使用特殊工具进行解密,steghide无果,我们继续搞
SilentEye——音频隐写的巨头
SilentEye 是一种基于图像和音频的隐写工具,主要用于将信息隐藏在图片和音频文件中。它提供了一种简单而有效的方式来嵌入和提取隐秘数据,而不会对文件的外观或音质造成明显影响。
我们使用SilentEye进行解密,得到了隐藏的flag:

考点:
[GKCTF 2021]excel 骚操作(脑洞大开)
下载文件,是一个excel文件
我们打开,发现以下内容:

什么都没有吗?我们随便点点,发现还是有些格子有内容的:

为什么有内容却没有显示呢?原因是单元格格式被设置为自定义格式,且自定义格式使用了不可见字符,文本可能不会显示出来。
我们选中大部分表格内容,修改单元格格式:


我们可以发现数字1貌似在有规律的排列,我们对这些表格进行填充看看是什么图形:



再修改下表格的宽高就能得到更好的图片:

这并不是我们常用的二维码,这个叫汉信码
汉信码
汉信码是中国物品编码中心研发的一种二维码码制,现已成为国际二维码标准之一。
我们使用在线网站(在线汉信码识别,汉信码解码 - 兔子二维码 (tuzim.net))进行识别得到flag:

考点:理解excel文件隐藏信息的方式、知道汉信码
[MRCTF2020]pyFlag(知识巩固题)
下载文件,发现里面是三张jpg图片,我们一个个进行分析
按照图片隐写思路,第一步无果,我们优先使用010 editor进行分析:

可以发现三张图片都含有插入隐藏的文件,并且将文件拆成了三部分,我们手动分离并且拼接,得到了个加密的压缩包:

我们发现里面的内容也没有经过伪加密,我们只好进行爆破,得到了解压密码:


得到了经过编码后的flag,如果只是编码而不是加密的话我们可以使用cyberchef的magic功能直接自动识别得到flag:

考点:图片插入隐藏信息提取、压缩包密码爆破、多重编码内容解码
[UTCTF2020]File Carving(知识巩固题)
下载文件,是一张png图片
按照图片隐写思路,第一步无果,我们优先使用010 editor进行分析,得到插入隐藏的zip文件:

提取解压得到了名为“hidden_binary”的没有后缀名的文件,我们使用010 editor打开进行分析:

原来是ELF可执行文件,我们使用linux系统直接执行即可得到flag
考点:图片插入隐藏信息提取、理解ELF文件
[watevrCTF 2019]Evil Cuteness
下载文件,是一张jpg图片
按照图片隐写思路,第一步无果,我们优先使用010 editor进行分析,得到插入隐藏的zip文件:

提取解压得到了名为“abc”的没有后缀名的文件,我们使用010 editor打开进行分析直接得到了flag
考点:图片插入隐藏信息提取
二维码(耐心)
下载图片,一看就是要我们手动拼接二维码……

这就是个耗力气的活,原理咱都懂,那就只好拿出图片修改工具了:

扫出flag
考点:耐心
[QCTF2018]X-man-A face(简单)
下载文件,是一张图片,又是一题二维码修复

我们把二维码的定位符填上,即可得到一串密文:
KFBVIRT3KBZGK5DUPFPVG2LTORSXEX2XNBXV6QTVPFZV6TLFL5GG6YTTORSXE7I=
使用cyberchef直接解码出flag
考点:二维码修复
派大星的烦恼(脑洞大开)
下载文件,是一张bmp格式的图片
按照图片隐写思路第一步无果,我们优先使用010 editor进行分析:

BMP文件格式简介
BMP格式的文件从头到尾依次是如下信息:
- bmp文件头(bmp file header):共14字节;
- 位图信息头(bitmap information):共40字节;
- 调色板(color palette):可选;
- 位图数据;
详情参考文章:BMP格式详解_bmp头部信息-CSDN博客
我们根据提示0xf0是派大星的赘肉(调色板的粉色像素内容),在中间发现了派大星的疤痕(0x22、0x44):

(很容易往摩斯电码方向去思考,一定要按照题目提示做题)
我们将疤痕的数据提取出来:
"DD"DD""""D"DD""""""DD"""DD"DD""D""DDD""D"D"DD""""""DD""D""""DD"D"D"DD""""D"DD""D"""DD"""""DDD""""D"DD"""D"""DD"""D""DD"D"D"DD"""DD""DD"D"D""DD""DD"DD"""D"""DD""DD"DD""D"D""DD"D"D"DD"""D"""DD"""D"DD""DD"""DD"D"D""DD"""D"DD""DD""DD"""""DDD""DD""DD"""D""DD""
伤痕仅由两种字符组成,我们就应该向只有两种字符组成的加密方式进行思考
二进制编码
我们将"和D转换成1和0后进行转码结果是乱码:


摩斯电码
没有分割符所以暂时不考虑
培根密码


这时候我们应该想到:题目名“派大星的屁股“,那么密文是反着来的,我们应该逆序再试试看!

成功得到32位的字符串!提交了还不是flag,怎么回事?
我们看看疤痕组成的二进制,确实有32位字符
01101100 00101100 00001100 01101100 10011100 10101100 00001100 10000110 10101100 00101100 10001100 00011100 00101100 01000110 00100110 10101100 01100110 10100110 01101100 01000110 01101100 10100110 10101100 01000110 00101100 11000110 10100110 00101100 11001100 00011100 11001100 01001100
那么我们可以这样逆序:将每一个字符的二进制段进行逆序
00110110 00110100 00110000 00110110 00111001 00110101 00110000 01100001 00110101 00110100 00110001 00111000 00110100 01100010 01100100 00110101 01100110 01100101 00110110 01100010 00110110 01100101 00110101 01100010 00110100 01100011 01100101 00110100 00110011 00111000 00110011 00110010
我们可以使用以下脚本实现这个功能
a = "0110110000101100000011000110110010011100101011000000110010000110101011000010110010001100000111000010110001000110001001101010110001100110101001100110110001000110011011001010011010101100010001100010110011000110101001100010110011001100000111001100110001001100"
b = ''
# 将字符串按每8位进行分组并进行倒序
for i in range(0, len(a), 8):
segment = a[i:i+8] # 提取每8位的分组
reversed_bin = segment[::-1] # 将这8位倒序
b += reversed_bin # 将倒序后的结果添加到输出字符串中
print(b)

得到正确的flag
考点:理解bmp图片文件格式、两种字符组成的加密方式、脑洞大开
(吐槽:到了最后我也没发现是谁打了派大星啊?)
[INSHack2017]sanity
下载文件,md格式的文本,打开就给flag
考点:会打开md格式的文件
key不在这里
下载文件,是一张二维码,我们优先扫描:

弹出了一个网页链接,是使用bing引擎搜索“key不在这里”的链接

https://cn.bing.com/search?q=key不在这里
&m=10210897103375566531005253102975053545155505050521025256555254995410298561015151985150375568
&qs=n
&form=QBRE
&sp=-1
&sc=0-38
&sk=
&cvid=2CE15329C18147CBA4C1CA97C8E1BB8C
q 这是最重要的参数,用于传递搜索查询的关键词。这里q的值是 key不在这里,这就是你输入的搜索词。
qs 代表 "Query Suggestion",用于控制搜索建议的行为。n 表示禁用建议。
form 这是一个标识符,用于指示搜索请求的来源。QBRE 表示标准的搜索请求表单。
sp 表示搜索阶段或流程控制。-1 表示禁用自动完成功能。
sc 这个参数可能与搜索结果的精确性和建议有关,0-38 表示39个字符的查询词,可能有8个相关的建议。
sk 这是一个控制参数,通常与用户输入相关联。在这个URL中,它为空,表示未使用。
cvid 表示 "Client Version ID",是用于标识当前会话的唯一ID,可以帮助Bing跟踪和优化用户的搜索体验。
其实我们也一眼就能看出来m参数不对劲,分析一下其中的密文特征:纯数字并且没有分段,有经验的同学看开头“102 108 97 103”就能看出来是“flag”的ascii码了
我们提取出来放到cyberchef进行解密得到flag:

这里也提供脚本:
def decode_ascii(number_string):
decoded_string = ""
i = 0
while i < len(number_string):
# 尝试读取2位和3位的可能性
if i + 2 <= len(number_string):
two_digit = int(number_string[i:i+2])
if 32 <= two_digit <= 126: # 有效ASCII范围
decoded_string += chr(two_digit)
i += 2
continue
if i + 3 <= len(number_string):
three_digit = int(number_string[i:i+3])
if 32 <= three_digit <= 126: # 有效ASCII范围
decoded_string += chr(three_digit)
i += 3
continue
# 如果没有有效字符,则跳过该位(错误处理)
i += 1
return decoded_string
number_string = "10210897103375566531005253102975053545155505050521025256555254995410298561015151985150375568"
decoded_message = decode_ascii(number_string)
print(decoded_message)
考点:对相关密码的敏感
粽子的来历(脑洞大开)
下载文件,是四个doc文件并且都打不开
我们使用010editor进行分析,发现了奇怪的字符串:

可能就是在OleHeader(文件头)中出现这些导致了文件损坏,我们进行修复即可(都改成FF)
我们打开ABCD四个文件,发现都是一样的内容,但行距好像有些区别:


我们仔细查看,这些诗句之间的行距有的为1,有的为1.5


我们对全诗进行统计,统计出所有诗句之间的行距
这里给出AI帮我写的脚本:
import os
from docx import Document
import pythoncom
from win32com import client as win32
# 将 .doc 文件转换为 .docx 格式
def convert_doc_to_docx(doc_path):
doc_path = os.path.abspath(doc_path)
if not os.path.exists(doc_path):
raise FileNotFoundError(f"文件 {doc_path} 不存在。")
pythoncom.CoInitialize()
word = win32.Dispatch("Word.Application")
doc = word.Documents.Open(doc_path)
docx_path = doc_path.replace(".doc", ".docx")
doc.SaveAs(docx_path, FileFormat=16)
doc.Close()
word.Quit()
return docx_path
# 从 .docx 文件中提取每段的行距信息
def extract_line_spacing(docx_path):
document = Document(docx_path)
line_spacing_info = []
for para in document.paragraphs:
# 仅在段落有内容时提取行距信息
if para.text.strip():
if para.paragraph_format.line_spacing:
line_spacing = para.paragraph_format.line_spacing
line_spacing_info.append(f"文件: {os.path.basename(docx_path)} - 行距: {line_spacing}")
else:
line_spacing_info.append(f"文件: {os.path.basename(docx_path)} - 行距: 默认")
return line_spacing_info
# 将提取的行距信息写入到指定的文本文件中
def write_to_file(output_file, line_spacing_info):
with open(output_file, 'a') as file:
for line in line_spacing_info:
file.write(line + '\n')
if __name__ == "__main__":
input_files = ["我是A.doc", "我是B.doc", "我是C.doc", "我是D.doc"] # 需要处理的 .doc 文件列表
output_file = "1.txt" # 输出行距信息的文本文件名
try:
all_line_spacing_info = []
for input_file in input_files:
docx_file = convert_doc_to_docx(input_file)
line_spacing_info = extract_line_spacing(docx_file)
all_line_spacing_info.extend(line_spacing_info)
os.remove(docx_file) # 清理:删除临时生成的 .docx 文件
write_to_file(output_file, all_line_spacing_info)
print(f"所有文件的行距信息已成功写入 {output_file}")
except Exception as e:
print(f"发生错误: {e}")

这貌似又是某种规律,由两种字符组成的密码
二进制
无论是将“1.5”设为1、“默认”设为0还是将“1.5”设为0、“默认”设为1,都是乱码
摩斯电码
没有分隔符不考虑
培根密码
也都是乱码
后来看了其他人的write up,发现是题目提示不够明显:
正确的方法是逐一尝试,将得到的每个文件的10组合进行MD5加密,“我是C.doc”文件得出的10组合的MD5值就是flag
考点:脑洞大开
[MRCTF2020]不眠之夜(新工具)
下载文件,一大堆jpg图片,图片宽度和高度相等,一眼就看出来是拼图题,这里我们就是用montage和gaps工具进行自动拼图吧
montage
Montage 是一个在 Unix/Linux 系统上广泛使用的命令行工具,它是 ImageMagick 工具套件的一部分,用于处理图像。Montage 主要用于将多张图像拼接成一张大图,通过指定的布局和设置将这些图像排列在一起。
我们进入含有所有图片的路径下,输入命令:
montage *jpg -tile 10x12 -geometry +0+0 flag.jpg
-tile 设置拼接后的图像布局方式,10x12表示10行12列(我们先尝试拼接得出行和列)
-geometry 用于指定图像的大小和位置,+0+0指定每个图像之间的间距,即图像相对位置的偏移量,第一个+0表示水平方向上图像之间的间距为 0 像素,第二个+0表示垂直方向上图像之间的间距为 0 像素

接下来我们使用gaps工具进行自动拼接
gaps工具
详情可以查看nemanja-m/gaps: A Genetic Algorithm-Based Solver for Jigsaw Puzzles 🌀 (github.com)里面有工具介绍和安装方式
安装好后,我们将输出的flag.jpg放到gaps目录中,使用以下命令:
gaps run flag.jpg tureflag.jpg --generations=40 --population=120 --size=200
--image 指定输入拼图图片
--generationgs 遗传算法的代的数量,最好等于原始图片的数量
--population 个体数量
--size 拼图块的像素尺寸,gaps识别的拼图都是正方形的,我们原图的拼图是长方形的,论尺寸刚好可以分成两个正方形,则gaps识别的拼图size=200/2=100(看文件属性宽度为200)

得到了flag
考点:学会使用montage和gaps工具进行拼图
大流量分析(一)(新)
下载文件,是一堆pacp流量包
仔细读题,这道题目是一个问答题:黑客的攻击ip是多少?那么这次我们需要做的就不是协议分级了
wireshark功能七——会话统计和端点统计
我们先打开第一个流量包,进入会话统计,查看根据ipv4协议的会话,按照packet A->B排序查看哪个IP发送的数据包最多:


可以看到前几名ip发送了超过一万条的数据包,我们先不要下定论,再看看端点统计的内容。按照Tx packets排序查看哪个发送方发出的数据包最多:


可以发现183.129.152.140这个ip再一次出现,因此我们可以推测黑客的ip就是183.129.152.140,即为flag
考点:会话统计和端点统计
hashcat(较难新工具)
下载文件,是一个打不开的没后缀文件,我们使用010 editor进行分析:

其中发现了office 2006的字符串,推测这是office办公软件文件,我们尝试给它加上.doc后缀:

打开发现文件被加密了(之前010 editor中看到的字符串也含有加密的一些信息),按照题目提示我们应该使用hashcat工具进行解密,什么是hashcat?
hashcat
Hashcat 是一款功能强大且高效的密码破解工具,专门用于破解散列值(hashes),是一个广泛用于密码审计和恢复的工具,但它在处理速度和支持的散列算法种类上有着明显的优势。
既然我们要用hashcat来破解出doc文件的密码,那么我们首先就需要得到doc文件的hash值,我们可以使用john工具来获取doc文件的hash值
john the ripper
也是一个广泛使用的密码破解工具,主要用于检测密码强度和恢复遗忘的密码。它可以通过多种方法进行密码破解,包括字典攻击、暴力攻击和基于规则的攻击。
一般下载了john就会自动拥有john工具包(将文件转换成john能够识别的hash值)比如我们在此可以使用这个命令输出doc文件的hash值:
office2john What\ kind\ of\ document\ is\ this_.doc

$office$*2010*100000*128*16*265c4784621f00ddb85cc3a7227dade7*f0cc4179b2fcc2a2c5fa417566806249*b5ad5b66c0b84ba6e5d01f27ad8cffbdb409a4eddc4a87cd4dfbc46ad60160c9
我们保存doc的hash值至1.txt中然后打开example_hashes hashcat wiki这个网站查找相关文件的哈希算法

那么对应的哈希算法编号就是9500
再准备一个密码字典我们就可以直接开始了(这里用的是纯数字密码字典,从0~999999六位纯数字密码,因为CTF题目一般爆破密码都是纯数字密码)
# 打开或创建 number.txt 文件,模式为写入模式
with open("number.txt", "w") as f:
# 使用循环生成 0 到 999999 的所有数字
for i in range(1000000):
# 将数字写入文件,每个数字一行
f.write(f"{i}\n")
那么我们可以使用以下命令:
hashcat -m 9500 -a 0 -o cracked.txt 1.txt number.txt
-m 指定哈希算法
-a 指定攻击方式,0表示使用字典攻击
-o 表示将破解结果保存到这个文件中
稍等片刻,从输出的文件中得到了密码9919:

尝试打开doc文件发现出错,可能它并不是doc文件,我们修改成xls、ppt,最后发现它是ppt文件
我们打开文件,找到了隐藏的白色flag(更改字体颜色)

考点:会使用hashcat和john工具包
[UTCTF2020]sstv(新工具)
下载文件,是一个wav的文件,听上去全是电磁的杂音
这其实是一个非常有趣的图像传输方式sstv,可以看看这个视频的科普: https://www.bilibili.com/video/BV1Vb421779F/?share_source=copy_web&vd_source=69c558b0c7be97607c79afbd75bd1f7c
SSTV
SSTV(Slow Scan Television,慢扫描电视)是一种用于在业余无线电频段内传输静态图像的通信方式。与传统电视信号的高速扫描方式不同,SSTV 以较低的速率逐行传输图像,因此得名“慢扫描电视”。
发送端: 在发送端,静态图像被逐行扫描并转换为音频信号。这些音频信号通过无线电发射机发送出去。
接收端: 在接收端,接收的音频信号通过解码软件或硬件解码器转换回图像。最终,接收者能够看到发送的图片。
为了识别这种声音信号,我们使用软件MMSSTV
MMSSTV
MMSSTV 是一种用于接收和发送慢扫描电视(SSTV)信号的计算机软件。它专门设计用于在业余无线电操作中处理 SSTV 图像。MMSSTV 是一个流行的 SSTV 软件,广泛应用于无线电爱好者社区。
下载软件,打开后直接播放音频即可得到flag:

考点:理解SSTV
voip
下载文件,发现里面是一个pcap格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

这一回最多的是基于UDP协议的RTP协议,这是什么协议?
UDP协议
UDP(User Datagram Protocol,用户数据报协议)是一个无连接的通信协议,属于互联网协议套件中的传输层协议。与 TCP(Transmission Control Protocol,传输控制协议)相比,UDP 是一种更加轻量级的协议,主要用于需要快速传输但对可靠性要求不高的场景(如视频通话)。
RTP协议
RTP 是一种网络传输协议,用于在实时通信中传输音频和视频数据。RTP 通常与 SIP 配合使用,负责实际的媒体数据传输。
那么我们可以推测这个流量包包含了实时通信的数据,按照题目名voip我们可以知道这些协议都在给voip技术提供服务
voip技术
VoIP(Voice over Internet Protocol)是指通过互联网协议(IP)进行语音通信的技术。简单来说,VoIP使得语音信号可以通过互联网或其他基于IP的网络进行传输,而不是通过传统的电话线路(PSTN)。
wireshark功能八——电话voip通话解析
我们可以使用wireshark提取通话中的音频流:


直接播放音频,考验听力,把flag输出来就好了
考点:理解UDP协议、理解voip技术、会使用wireshark的电话功能
[SCTF2019]电单车(较难新)
下载文件,是一个wav格式的音频文件,我们听一下,只有一秒并且只有“滋”的一声
按照音频隐写思路我们优先使用Audacity观察音频是否藏有信息:

我们尝试一下,发现并不是摩斯电码,我们转换成二进制
0 0111010010101010011000100 011101001010101001100010
尝试转换也不是二进制,但我们发现了一个规律,那就是它隐藏的信息应该是发送了两次的
0 011101001010101001100010
根据题目名电单车,我们可以推测这信号与无线射频信号有关系,并且与电单车的防盗或遥控功能有关。
1. PT2262/2272 系列
- 信号格式:PT2262编码器生成的信号是一个串行的脉冲序列,通常包含12位或24位地址码和4位或8位数据码。
- 编码格式
- 每一位由3个脉冲组成,表示逻辑"1"、"0"或"浮动"状态。
- 地址码用于识别发射器和接收器的配对,数据码则传输按键的状态(如锁车、解锁)。
- 脉冲宽度:信号通过宽度调制(PWM)进行传输,不同的脉冲宽度代表不同的逻辑状态。
2. HT12E/HT12D 系列
- 信号格式:HT12E编码器发出的信号包括12位地址码和4位数据码,共16位数据。
- 编码格式
- 每位信号通过脉冲的宽度和时间间隔来表示逻辑“1”和“0”。
- 地址码与数据码依次发送,形成一个完整的数据包。
- 脉冲宽度:同样是PWM调制,不同的脉冲宽度表示不同的逻辑位。
3. 滚动码(Rolling Code)技术
- 信号格式:滚动码系统(如HCS301)采用动态的编码技术,每次信号传输的码值都会改变。
- 编码格式
- 通常包括加密后的序列号、功能码、计数器值以及唯一的密钥。
- 传输的数据包由固定的前导码、滚动码、功能码组成。
- 安全特性:由于信号每次变化,这种技术能有效防止信号重放攻击。
4. ASK/OOK(Amplitude Shift Keying / On-Off Keying)
- 信号格式
- ASK:通过调制载波信号的振幅来表示二进制数据“1”和“0”。
- OOK:是ASK的特例,当振幅完全关闭时表示“0”,打开时表示“1”。
- 调制方式:信号的振幅改变用于传输数据,振幅越高表示“1”,越低表示“0”。
- 应用:多用于简单的无线通信,如遥控器。
5. FSK(Frequency Shift Keying)
- 信号格式:FSK通过改变载波信号的频率来表示二进制数据。
- 编码格式
- 不同的频率代表不同的逻辑状态,通常高频代表“1”,低频代表“0”。
- 调制方式:频率的切换速度可以根据通信要求进行调整,适用于需要较高抗干扰能力的通信系统。
6. 红外信号
- 信号格式:红外遥控器信号通常以脉冲编码形式传输。
- 编码格式
- 常见的是NEC编码,包含前导码、地址码、命令码和校验码。
- 每一位通过不同长度的高低电平脉冲表示“0”或“1”。
- 脉冲宽度:通常在38 kHz载波频率下工作,脉冲宽度决定编码信息。
7. 蓝牙低功耗(BLE)
- 信号格式:BLE使用的信号格式基于GFSK(Gaussian Frequency Shift Keying)调制技术。
- 编码格式
- 数据通过频率的高斯调制表示,BLE的信号格式包括访问地址、PDU(Protocol Data Unit)和CRC校验。
- 传输速率:BLE通常在2.4 GHz频段工作,传输速率可以达到1 Mbps。
8. NFC(近场通信)
- 信号格式:NFC使用的信号格式基于ASK调制技术。
- 编码格式
- NFC标签的信号包含前导码、UID(唯一标识符)、命令和数据帧。
- 数据通过振幅的变化进行传输。
- 工作频率:通常在13.56 MHz频段工作,传输速率较低,适合近距离通信。
9. RFID(射频识别)
- 信号格式:RFID信号格式因标签类型不同而有所变化,常见的有ISO 14443和ISO 15693标准。
- 编码格式
- 数据通常通过ASK或PSK(Phase Shift Keying)调制传输,包含UID、数据和校验位。
- 工作频率:常见的工作频率为125 kHz、13.56 MHz或900 MHz,适合不同的应用场景。
10. Zigbee
- 信号格式:Zigbee使用的信号格式基于DSSS(Direct Sequence Spread Spectrum)和O-QPSK(Offset Quadrature Phase Shift Keying)调制技术。
- 编码格式
- 数据包通常包含前导码、地址、帧控制、数据负载和CRC校验码。
- 传输速率:通常工作在2.4 GHz频段,传输速率在20 kbps到250 kbps之间,适用于低速率低功耗的无线通信。
我们可以发现信号由三种脉冲组成,“0”、“1”和“浮动”三种状态,符合PT2242信号格式,开始分析:
[同步码] -> [地址码] -> [数据码] -> [结束码(可选)]
同步码:同步码通常是一个长时间的高电平脉冲,后跟一个低电平脉冲。这个长脉冲用于引起接收器的注意,使其进入数据接收状态。4bit
地址码:PT2242发送的信号包括20位地址码
数据码:后跟4位数据码,代表按键的状态。
0 01110100101010100110 0010
同步码 地址码 数据码






参考文章:https://www.onctf.com/posts/dda8f4cb.html
参考文章:攻防世界高手区9(73-78) (demonstaralgol.github.io)发现原题应该还有一段提示:截获了一台电动车的钥匙发射出的锁车信号,3分钟之内,我要获得它地址位的全部信息
也就是说我们的flag应该是这条信号的地址码
考点:理解无线射频信号原理
[GUET-CTF2019]soul sipse(知识巩固题)
下载文件,是一个wav格式的音频文件,我们听一下,没有什么声音
按照音频隐写思路我们第二步无果,我们使用010 editor打开文件也无法看出插入隐藏,我们使用binwalk查看其中的插入隐藏信息:

binwalk提取不出来,我们使用foremost提取:

foremost也提取不出来,那么我们只能推测是使用了特殊工具了
steghide
steghide extract -sf out.wav
分离出了文件download.txt

得到了一个网址,尝试下载文件
这题目已经过期了。。。那么只能看别人的wp了:

参考文章:misc刷题记录 - carefree669 - 博客园 (cnblogs.com)
考点:音频隐写、打开脑洞猜测flag的值
[UTCTF2020]spectogram(新)
下载文件,是一个wav的文件,听上去全是电磁的杂音
按照音频隐写思路,我们优先使用Audacity进行分析,查看音频的频谱图即可得到flag:


频谱图
频谱图(Spectrogram)是一种表示信号(尤其是声音信号)随时间变化的频率成分的图像。它通过将一个信号分解成多个频率成分,并显示这些频率成分随时间的强度变化,帮助我们理解信号的频率内容和时间动态。通过观察频谱图,可以识别出音频信号中的不同频率成分,分析音乐的音高、语音的发音特征等。
考点:理解频谱图
蜘蛛侠呀(新工具)
下载文件,发现里面是一个pcap格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

我们可以发现应用层ICMP协议占比最高,应该优先分析。
ICMP协议
ICMP(Internet Control Message Protocol,互联网控制消息协议)是一种用于在网络设备之间发送控制消息的协议,通常用于诊断网络连接问题和传递错误消息。
如 Ping 工具使用 ICMP 的 "回显请求" 和 "回显应答" 消息来测试主机之间的连通性。源主机会发送 ICMP 回显请求到目标主机,目标主机会回复 ICMP 回显应答,源主机通过计算响应时间来判断网络状况。
ICMP 协议是 TCP/IP 协议栈中的一部分,主要与 IP 协议一起使用。

我们可以发现ICMP数据包中都写有Data字段,我们使用tshark进行提取:
tshark -r out.pcap -Y "icmp" -T fields -e data > data.txt

可以发现有很多重复数据,我们使用notepad++进行去重操作(使用正则表达式进行替换或者是使用插件TextFX):
^(.*?)$\s+?^(?=.*^\1$)
一眼十六进制,我们转换为字符串查看:

提取出了很多东西,我们再把前方“$$START$$”字符串删除后进行观察:

有个等号,推测经过了base64编码,放到cyberchef里面看看:

得到了个zip文件,我们提取解压得到了个gif文件:

我们看gif图片宽高非常不匹配,我们尝试修改图片的高度,但图片还是原样,因此这里不存在宽高相关的隐藏:

这里涉及到gif的一种新的隐写方式:时间轴隐写
我们可以观察gif文件以下内容:
Data->GraphicControlExtension[0]->GraphicControlSubBlock->DelayTime
数据->图形控制扩展结构->图形控制数据块->延时时间

可以看出第一张图片延时时间为20/100=0.2s,第二张图片延时时间为50/100=0.5s……而所有图片的延时时间就只有这两种情况,聪明的同学就已经能猜到这含有某种只包含两种字符的加密方式了
identify
identify 是 ImageMagick 软件包中的一个命令行工具,用于显示图像文件的各种信息和属性。ImageMagick 是一个开源软件套件,支持多种图像处理功能,如转换、编辑、组合等,广泛应用于图像处理领域。
我们使用以下命令即可提取gif文件的动画帧的延迟时间
identify -format "%T" flag.gif
-format 用于指定输出的格式,这里%T是一个格式化标记,用来提取 GIF 动画中每一帧的延迟时间

我们将输出进行替换,将20替换为0,50替换为1,二进制转码得到字符串,按照题目提示进行MD5加密后得到flag:

考点:理解ICMP协议、理解gif时间轴隐写
[安洵杯 2019]easy misc(新孬题)
下载文件,是一个包含许多txt文件的文件夹、一个加密的压缩包、一个png图片
我们优先分析png图片,按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

发现了隐藏插入的png图片,我们文件分离提取:

是两张一模一样的图片,我们对提取出的图片进行分析。
按照图片隐写思路,第一步、第二步、第三步无果,使用了zsteg、cloacked-pixel无果后,我们优先查看其中是否存在盲水印
盲水印
盲水印隐写是一种信息隐藏技术,主要用于在数字媒体(如图像、音频、视频)中嵌入不可见的水印信息。它的关键特性在于,水印信息的提取不需要原始未嵌入水印的文件作为参考,这就是所谓的“盲”水印。以下是其基本原理:
- 嵌入过程:盲水印隐写通过对载体文件(如图片、音频等)进行微小的修改,将水印信息嵌入其中。这种修改通常在载体的某些特征(如图像的频率域、空域)中进行,使得嵌入后的文件与原始文件在视觉或听觉上几乎没有差别。
- 鲁棒性:嵌入的水印应具有鲁棒性,能够在载体文件遭受一些常见操作(如压缩、裁剪、噪声干扰等)后仍然能被检测到。
- 提取过程:提取水印时,不需要原始载体的帮助。通过检测嵌入水印时所用的规则和算法,从修改后的载体中恢复出水印信息。
- 应用场景:盲水印技术常用于版权保护、文件完整性验证等场合,确保文件的合法性并防止篡改。
这种技术的核心挑战在于在不影响载体质量的前提下,确保水印信息的鲁棒性和隐蔽性。
盲水印可以使用相关工具进行信息加密和解密,并且不同的脚本使用的加密和解密方式不同(一般看题目来)
在此我们使用github开源的BlindWaterMark-master(https://github.com/chishaxie/BlindWaterMark)进行解密:(我对图片文件名进行了更改)
python2 bwm.py decode 123.png 456.png out.png
我们提取出了盲水印的内容:

看得出来是希望我们关注11.txt中的内容
我们接着分析decode.zip文件,我们发现它存在注释:

我们可以推测((√2524921X85÷5+2)÷15-1794)+NNULLULL,为decode.zip的密码提示,但前面的式子存在未知数X咱们也不知道答案,那么我们可以进行掩码爆破可以得到正确的密码(这里有坑,字符串中的“,”也包含在密码中):

解压decode.zip得到下一个提示:

貌似是解码提示,那么我们继续分析read文件夹,我们先看其中的提示hint.txt:

重点分析其中的11.txt:

我们试着提取前16个字符“HarryPotterandth”我们可以编写脚本进行对照:
# 替换映射表
mapping = {
'a': 'dIW', 'b': 'sSD', 'c': 'adE', 'd': 'jVf', 'e': 'QW8',
'f': 'SA=', 'g': 'jBt', 'h': '5RE', 'i': 'tRQ', 'j': 'SPA',
'k': '8DS', 'l': 'XiE', 'm': 'S8S', 'n': 'MkF', 'o': 'T9p',
'p': 'PS5', 'q': 'E/S', 'r': '-sd', 's': 'SQW', 't': 'obW',
'u': '/WS', 'v': 'SD9', 'w': 'cw=', 'x': 'ASD', 'y': 'FTa',
'z': 'AE7'
}
def replace_string(input_string):
result = []
for char in input_string:
# 如果字符存在于映射表中,则进行替换
if char in mapping:
result.append(mapping[char])
else:
result.append(char) # 如果字符不在映射表中,保留原字符
return ''.join(result)
# 测试
input_string = input("请输入要替换的字符串: ")
output_string = replace_string(input_string)
print("替换后的字符串:", output_string)
得到“HdIW-sd-sdFTaPT9pobWobWQW8-sddIWMkFjVfobW5RE”,提交发现不是flag
“取前16个字符”到底是什么意思?我们使用puzzlesolver逐一尝试分析前16个字符的含义:

取前16个字符:“ etaonrhisdluygw”或者“etaonrhisdluygwm”(若空格不计)
我们可以得到:“QW8obWdIWT9pMkF-sd5REtRQSQWjVfXiE/WSFTajBtcw=”或者“QW8obWdIWT9pMkF-sd5REtRQSQWjVfXiE/WSFTajBtcw=S8S”
二者都不是flag,看了下别人的WP,这道题目出错了:

若按照题目来的话,我们得到的前16位字符应该为“etaonrhsidluygw”,这里顺序出错了
考点:文件分离、理解盲水印、压缩包密码掩码爆破、字频统计
Business Planning Group(新工具知识巩固题)
下载文件,一张png格式的图片
按照图片隐写思路,第一步无果,我们优先打开010 editor打开图片查看:

我们可以发现插入隐藏的BPG图片
BPG图片
BPG(Better Portable Graphics)是一种图像格式,旨在取代JPEG,提供更好的图像质量和更高的压缩率。BPG 文件基于 HEVC (High Efficiency Video Coding) 视频编码技术,能够在相同的文件大小下提供更好的细节和颜色表现。其主要优点包括:
- 高压缩率:BPG 比 JPEG 更有效地压缩图像,同时保持较高的图像质量。
- 支持透明度:BPG 支持透明背景(alpha 通道),而标准的 JPEG 不支持。
- 广泛的色彩支持:BPG 支持更广的色彩空间(如 10 位或 12 位色深),更适合高品质图像。
由于 BPG 不是常见的图像格式,默认情况下大多数操作系统或图像查看器无法直接打开它在此我们使用工具Honeyviewer查看图片
Honeyviewer
Honeyview 是一款轻量级、快速的图片查看器,主要用于查看多种格式的图像文件。

我们可以看到其中的密文,我们敲出来进行解码:

考点:文件分离、理解BPG图片
[GKCTF 2021]你知道apng吗
下载文件,是一个APNG格式的文件
APNG
APNG(Animated Portable Network Graphics)是一种增强版的 PNG 图像格式,支持动画功能。与传统的 GIF 格式相比,APNG 能够提供更高质量的图像和更丰富的颜色深度,且同样支持透明背景(alpha 通道)。它在外观上与普通 PNG 文件相同,未被浏览器支持的情况下,会显示为静态的 PNG。
我们可以使用上一题使用的Honeyview来查看图片的内容,我们可以发现这动图有几帧藏着二维码:




我们进行修复并扫码:




得到了flag
考点:理解apng图片、利用工具逐帧查看apng文件图像
greatescape
下载文件,发现里面是一个pcap格式的文件,我们使用wireshark打开查看:

按照数据包分析思路,我们先进行协议分级:

我们发现TCP协议占比最高,并且使用了TLS协议加密(Transport Layer security)占比的内容很多;协议中使用了FTP协议,优先查看FTP协议发了些什么文件,过滤FTP Data:

发现是TLS加密的密钥,我们通过导出分组字节流保存为私钥文件(包的后边也提示了文件名为ssc.key)
这里HTTP协议的内容已被加密:

因此我们需要导入我们获得的私钥文件进行解密:


在edit里面添加私钥文件:

解密后我们直接摸鱼搜索”FLAG“字符串:

得到了flag。
考点:网络流量分析、理解SSL/TLS密码通信框架、学会使用wireshark导入私钥文件
[湖南省赛2019]Findme(较难知识巩固题)
下载文件,内容为5张png格式的图片,我们从1.png开始分析
按照图片隐写思路,第一步我们使用tweakpng发现1.png的crc校验出现错误,因此可能存在PNG宽高隐写:

并且还警告了我们十六进制从8237处出现了无效的chunk类型

我们使用之前的脚本找出了1.png的正确宽高,我们使用010editor进行修改:


我们修改完成后,图片只修复好了一半:

根据之前警告给出的错误,我们观察十六进制从8237处出现的无效的chunk类型:

16进制中,21+200C=202D,转换成十进制刚好为8237
也就是说chunk[2]即是出现无效类型的地方,我们发现chunk[2]没有type,即IDAT标识,我们进行填补:


图片还是只修复了一点点,说明还是有地方出了问题,我们再将图片导入tweakpng中分析问题:

这次警告说16441处出现了无效的chunk类型,我们在010editor中再次运行模板进行修复:

发现这次是chunk[3]出现了问题,我们进行修复即可:

图片修复完成,我们继续分析,第二步无果,我们优先使用stegsolve,发现在图像蓝色通道的第 2 位平面出现了隐藏的二维码:


得到了第一段经base64编码的flag
我们继续分析2.png,按照图片隐写思路,第一步无果,我们优先使用010editor进行分析:

发现了插入隐藏的7z压缩文件,我们进行文件分离,发现7z文件打不开,我们再进行深入分析,发现7z的文件头为82 37 03 04,正确的7z文件头应该为,而题目中的文件头反而很像ZIP的文件头:50 4B 03 04,我们将分离的文件中所有的“7z”替换为“PK”

成功打开zip压缩包,打开发现里面有很多txt文件,并且内容都是一样的:

我们对压缩包中所有的txt文件进行大小排序啊,发现了隐藏的第二段经base64编码的flag:

继续分析3.png,按照图片隐写第一步使用tweakpng后发现一堆crc数值报错:







一次性这么多crc的值出错必定是暗藏玄机,我们将IDAT中的crc值进行输出发现了隐藏的第三段经base64编码的flag:

我们继续分析4.png,第一步即在图片的exif信息中的艺术家那一栏发现了隐藏的第四段经base64编码的flag:

我们继续分析5.png,第一步无果,第二步我们优先使用010editor进行分析,发现了第五段经base64编码的flag:

我们将所有经base64编码的flag进行排列组合:
ZmxhZ3s0X3 解码为flag{4_,应放在第一个
1RVcmVfc 解不开
3RlZ30= 解不开,但结尾包含“=”,应放在最后一个
cExlX1BsY 解码为pLe_Pl
Yzcllfc0lN 解不开
有三个无法确定顺序,但经历一次次排列组合总能得到flag:

考点:利用tweakpng、010editor、exiftool对图片进行分析
[ACTF新生赛2020]剑龙(新工具)
下载文件,打开是一个没有后缀的文件(使用010editor分析出应该为pyc文件)和一个提示的hint压缩文件,解压后查看内容:

老朋友颜文字加密了,我们进行解密:

记录下这个字符串,可能是密码
我们再继续分析图片,按照图片隐写思路在图片属性中发现了密钥:

有密钥说明图片可能经过了需要密码的加密方式,我们优先使用steghide进行解密:
steghide extract -sf hh.jpg
解密成功,使用的解密密码为welcom3!
提取出secret.txt:

密钥为“@#$%^&%%$)”长度为10位,并且密文以“U2FsdGVkX1”开头,我们尝试使用DES解密成功(这里使用了离线工具enigmator):

得到了线索stegosaurus
接下来我们分析pyc文件,首先使用工具将其进行反编译:
#!/usr/bin/env python
# visit https://tool.lu/pyc/ for more information
# Version: Python 3.6
from PIL import Image
def dtob(num): #将一个十进制数转换为对应的二进制字符串。
temp = bin(num).replace('0b', '') #将数字 num 转换为二进制表示并移除前缀 0b
length = len(temp)
over = length // 8
temp = temp.zfill((over + 1) * 8) #将字符串补齐到最近的8位倍数
return temp
def getSecret(mpath): #读取指定文件(mpath)的内容,并将其逐字节转为二进制形式
secret = ''
file = open(mpath, 'rb')
content = file.read()
length = len(content)
for i in range(length):
tmp = content[i]
tmp = dtob(tmp) #调用 dtob() 函数,将每个字节转换为8位的二进制表示,最终将所有二进制数据拼接成一个字符串 secret
secret += tmp
return secret
def start(ppath, mpath, rpath):
im = Image.open(ppath) #打开图片 ppath 并加载像素数据 px
px = im.load()
message = im.size
width = message[0]
height = message[1]
print(width, height)
secret = getSecret(mpath) #通过 getSecret() 读取文本文件并转换成二进制字符串 secret
print(secret)
s_len = len(secret)
count = 0
for i in range(height):
for j in range(width):
if count == s_len:
break
pix = px[(i, j)]
r = pix[0]
g = pix[1]
b = pix[2]
r = (r - r % 2) + int(secret[count])
count += 1
if count == s_len:
im.putpixel((j, i), (r, g, b))
break
g = (g - g % 2) + int(secret[count])
count += 1
if count == s_len:
im.putpixel((j, i), (r, g, b))
break
b = (b - b % 2) + int(secret[count])
count += 1
if count == s_len:
im.putpixel((j, i), (r, g, b))
break
if count % 3 == 0:
im.putpixel((j, i), (r, g, b))
im.save(rpath)
def extrat(mpath, rpath):
result = ''
im = Image.open(mpath)
size = im.size
px = im.load()
w = size[0]
h = size[1]
length = 80
count = 0
flag = 0
for i in range(h):
for j in range(w):
pix = px[(j, i)]
r = pix[0]
g = pix[1]
b = pix[2]
r1 = r % 2
count += 1
if count == length:
result += str(r1)
flag = 1
break
g1 = g % 2
count += 1
if count == length:
result += str(r1)
result += str(g1)
flag = 1
break
b1 = b % 2
count += 1
if count == length:
result += str(r1)
result += str(g1)
result += str(b1)
flag = 1
break
result += str(r1)
result += str(g1)
result += str(b1)
if flag == 1:
break
aa = open(rpath, 'w')
while result:
tmp = result[:8]
result = result[8:]
tmp = int(tmp, 2)
re = chr(tmp)
aa.write(re)
print('wowowo!')
start('1.png', '1.txt', 'tets.png')
这段代码实现了一个基本的隐写术操作,将文本隐藏到图片中,并且可以从图片中提取出隐藏的文本
但最后我们还是没有看出其中有什么,那么根据提示的stegosaurus,我们先得理解这是什么东西
经过搜索我们明白了这是什么
stegosaurus(剑龙)
Stegosaurus 是一种隐写工具,允许在 Python 字节码(pyc 或 pyo)中隐藏文件
Release v1.0 · AngelKitty/stegosaurus (github.com)
也就是说其实题目名称在一开始就提醒我们使用这个工具了
那么我们下载工具后执行命令:
./stegosaurus -x O_O.pyc

得到flag
考点:使用steghide工具、会AES解密、使用stegosaurus工具
大流量分析(二)(新协议)
跟大流量分析(一)一样的题目,这一次问的是黑客使用了哪个邮箱给员工发送了钓鱼邮件
既然是钓鱼邮件的分析,那么我们优先分析的肯定是与邮件相关的协议:SMTP协议、POP3协议、IMAP协议(详情可以查看【笔记】【THM】Phishing(网络钓鱼)(这个模块还没学完) - Super_Snow_Sword - 博客园 (cnblogs.com)),我们过滤查看(发现只有IMAP协议报文存在):

可以看出邮件头MAIL FROM :xsser@live.cn
说明黑客使用的邮箱地址为xsser@live.cn,即为flag
考点:邮箱协议分析
[HDCTF2019]你能发现什么蛛丝马迹吗(较难新工具)
下载文件,是一个img文件
IMG文件
IMG 文件是一种磁盘映像文件格式,用于保存整个磁盘(如硬盘、CD/DVD、软盘、U盘等)的完整副本。磁盘映像文件可以包含磁盘的所有数据,包括文件、文件夹、引导扇区、分区表等。
至今我们已经遇到了三种磁盘映像文件格式,在此我做一个总结
| 文件格式 | 用途 | 内容 | 应用场景 |
|---|---|---|---|
| IMG | 磁盘映像 | 逐字节复制的磁盘内容,包括文件系统等 | 磁盘克隆、备份、嵌入式设备烧写 |
| ISO | 光盘映像 | 逐字节复制的光盘内容,包括引导信息等 | 操作系统分发、软件安装、光盘备份 |
| VMDK | 虚拟机磁盘 | 虚拟机硬盘的完整内容 | 虚拟化平台存储虚拟机数据 |
| DMP | 内存转储文件 | 系统崩溃或调试时的内存内容 | 系统故障分析、调试、取证分析 |
我们尝试使用7z打开img文件,但是失败了,并且也无法挂载,说明该IMG文件可能是内存转储。
在某些情况下,IMG 文件不是硬盘的镜像,而是计算机的物理内存(RAM)的转储。内存转储包含系统在运行时的实时数据,包括运行的进程、打开的网络连接、加密密钥、密码、以及可能的恶意软件等。
我们要进行内存取证,那么我们需要使用Volatility工具
Volatility
Volatility 是一款强大的内存取证分析工具,专门用于从内存转储中提取重要信息。使用 Volatility 可以分析内存中的活跃进程、注册表、内核模块、网络连接等信息,并帮助识别系统是否被入侵、恶意软件的活动轨迹等。
安装过程略(参考内存取证 - Hello CTF (hello-ctf.com),这里安装的是volatility2),我们使用以下命令:
python2 vol.py -f memory.img imageinfo
-f 用于指定你想要分析的内存转储文件
imageinfo 是 Volatility 的一个插件,它可以用于确定内存镜像的操作系统类型、版本、架构等信息,以及确定应该使用哪个插件进行内存分析

在此我们逐行分析:
Suggested Profile(s) : Win2003SP0x86, Win2003SP1x86, Win2003SP2x86
这是 Volatility根据内存映像中找到的特征推荐的操作系统Profile,用于后续分析。此处建议的Profile是Windows2003x86的不同版本包括SP0(Service Pack 0)、SP1(Service Pack 1) 和 SP2(Service Pack 2)
AS Layer1 : IA32PagedMemoryPae (Kernel AS)
表示这是一个IA32PAE(Physical Address Extension)内存布局,说明系统使用了32位的分页机制,并且支持PAE扩展,可以处理超过4GB的内存
AS Layer2 : FileAddressSpace (/home/zxj/Desktop/volatility/memory.img)
表示该内存映像文件位于本地文件系统中的路径
PAE type : PAE
确认了内存映像使用 PAE(Physical Address Extension),这是一个允许 32 位操作系统访问超过 4GB 内存的扩展技术
DTB : 0xe02000L
DTB 是 页目录表基地址(Directory Table Base),它指向操作系统分页机制中的页目录表,这个值是关键的内存管理数据结构之一。值为 0xe02000L
KDBG : 0x8088e3e0L
KDBG 是 Kernel Debugger Block,它是用于调试 Windows 内核的重要结构。它提供了很多关键的内核信息,并帮助 Volatility 获取内存中的结构。其地址为 0x8088e3e0L。
Number of Processors : 1
表示这是一个单处理器(CPU)系统
Image Type (Service Pack) : 1
表示内存映像属于 Windows 2003 Service Pack 1,这是更具体的操作系统版本信息
KPCR for CPU 0 : 0xffdff000L
KPCR(Kernel Processor Control Region) 是 Windows 系统中与每个处理器相关的结构。这里显示 CPU 0 的 KPCR 地址为 0xffdff000L
KUSER_SHARED_DATA : 0xffdf0000L
KUSER_SHARED_DATA 是 Windows 内存中的一个特殊区域,存储了一些用户模式和内核模式下共享的重要数据。地址为 0xffdf0000L
Image date and time : 2019-04-25 08:43:06 UTC+0000
这是内存映像捕获时系统的时间,格式为 UTC 时间
Image local date and time : 2019-04-25 16:43:06 +0800
映像的本地时间(可能是你的时区设置)
以上很多内容过于繁杂,在此我们只需在意第一行的”Suggested Profile(s)“数据
操作系统的profile
不同的操作系统版本和构建在内存中使用不同的内核数据结构和布局。这些差异使得解析内存映像的过程变得复杂。为了正确地解码内存映像中的信息,Volatility 使用 Profile 来匹配内存映像的具体结构。
根据上述内容我们可以猜测操作系统为Win2003SP0x86
接下来我们将探索img文件中的物理内存(RAM)转储中的内容,也就是我们可以查看到在映像捕获时操作系统中运行的进程
我们使用以下命令:
python2 vol.py -f memory.img --profile=Win2003SP0x86 pslist
--profile 参数用于指定内存映像所属的操作系统版本
pslist 是 Volatility 的一个插件,通过遍历 Windows 操作系统的内核数据结构(如 EPROCESS 结构)来提取内存中的进程列表
我们发现操作失败,可能是profile设定出错,那么我们猜测操作系统为Win2003SP1x86:
python2 vol.py -f memory.img --profile=Win2003SP1x86 pslist

在此给出输出字段的详细说明:
Offset(V): 进程的虚拟地址偏移量。
Name: 进程的名称(如 smss.exe)。
PID: 进程的唯一标识符。
PPID: 进程的父进程 ID。
Thds: 进程包含的线程数。
Hnds: 进程打开的句柄数。
Sess: 会话 ID,用于区分用户登录会话(特别是在多用户系统中)。
Wow64: 如果进程运行在 64 位系统的 32 位兼容模式下,则显示为 True,否则为空。
Start: 进程的启动时间。
Exit: 进程的退出时间。如果为空,表示进程当前正在运行。
我们再逐步分析这些进程:
System 这是 Windows 系统的核心进程,负责管理硬件和系统资源。没有父进程,属于系统自启动的进程。
└─smss.exe Session Manager 子系统,负责启动会话并管理用户登录。这是操作系统启动时最早的用户模式进程之一。
└─csrss.exe 客户端/服务器运行时子系统,处理图形用户界面 (GUI) 和控制台窗口等任务。
└─winlogon.exe 负责处理用户登录和注销的进程,确保系统会话的安全。
└─services.exe Windows 服务控制管理器,负责启动和管理系统服务。
└─vmacthlp.exe VMware Tools 的一部分,通常用于虚拟机环境。帮助处理与虚拟机之间的同步操作。
└─svchost.exe 这些是系统托管服务,作用是运行动态链接库 (DLL) 格式的系统服务。Windows 通过 svchost.exe 运行共享的服务进程。每个 svchost.exe 实例可能会托管多个服务。
└─wmiprvse.exe WMI 提供程序宿主,负责处理 Windows 管理规范 (WMI) 的相关任务。
└─wuauclt.exe Windows 更新自动更新客户端,负责从 Windows 更新服务器获取更新。
└─spoolsv.exe 打印后台处理程序,负责管理打印作业。
└─msdtc.exe 分布式事务协调器,处理分布式应用程序的事务管理。
└─VGAuthService.exe VMware 认证服务,进一步证明该系统在虚拟化环境中运行。
└─vmtoolsd.exe VMware Tools 的守护进程,负责与虚拟机主机的集成。
└─dllhost.exe COM+ 服务器应用程序,负责加载和管理 DLL 文件。
└─vssvc.exe 负责管理卷影复制服务 (Volume Shadow Copy Service),用于备份和还原系统快照。
└─lsass.exe 本地安全授权子系统,负责安全策略执行和登录验证。
explorer.exe Windows 资源管理器,负责桌面和文件系统的图形用户界面。
└─ctfmon.exe 控制输入语言和其他辅助功能的进程。
└─DumpIt.exe 内存转储工具,通常用于创建内存转储文件的程序。
conime.exe 控制台输入法编辑器,主要用于处理输入法和字符转换。
对于这种题目,我们应该优先查找可疑进程,但我们没看出有什么可疑的进程,都是系统服务
那么我们就优先查看在终端里执行过的命令,输入以下命令:
python2 vol.py -f memory.img --profile=Win2003SP1x86 cmdscan
cmdscan Volatility 提供的插件,用于从内存转储中扫描并提取命令行历史记录。它会查找与命令行界面 (CMD) 相关的活动或历史记录,并列出它们。

我们对输出内容进行逐行分析:
CommandProcess: csrss.exe Pid: 516
表示当前的命令行历史与 Windows 系统的 csrss.exe 进程相关。
CommandHistory: 0x398fba8
这是一个内存地址,表示这个进程的命令历史记录的存储位置。
Application: DumpIt.exe
这表示在 csrss.exe 进程的命令行历史中,提到了 DumpIt.exe 这个应用程序。
通常,这意味着这个系统内存镜像可能是通过 DumpIt.exe 工具创建的。
Flags: Allocated
Allocated表示该命令历史记录已经分配并且可以使用,表明这段内存被用于存储命令历史。
CommandCount: 0
是命令历史中的命令数量。这里显示为 0,表示没有实际的命令被记录下来,可能是因为 csrss.exe 本身不执行终端命令,或者这些历史记录已被清空。
LastAdded: -1 LastDisplayed: -1
通常情况下,LastAdded 会显示最后一个命令的编号,LastDisplayed 则会显示最后一个显示的命令编号。-1 表示没有命令可供显示或记录。
FirstCommand: 0
这表示历史中没有第一个命令(因为 CommandCount 为 0)
CommandCountMax: 50
这是历史记录可以保存的最大命令数。它表示 csrss.exe 进程的命令历史最多可以保存 50 条命令。
ProcessHandle: 0x6e4
这是进程的句柄,用于操作系统管理该进程的句柄 ID。
我们可以发现cmd命令使用记录中包含了DumpIt.exe,那就说明我们应该重点分析这个进程。对此,我们可以提取DumpIt.exe进程的内存数据。
为了能够更全面地了解进程之间的关系或行为,我们提取DumpIt.exe的父进程的内存数据:
python2 vol.py -f memory.img --profile=Win2003SP1x86 memdump -p 1992 --dump-dir=./
memdump Volatility 的一个插件,用于从内存镜像中提取某个特定进程的内存数据。该插件会将整个进程空间的内存转储下来,并将其保存为文件。
-p 指定要提取的进程的进程 ID (PID)
--dump 指定保存转储文件的目录
我们发现memdump插件将进程的内存数据以.dmp的格式导出,那么我们就可以继续对.dmp文件进行分析
我们可以使用mimikatz分析.dmp文件:
privilege::debug
//提升 Mimikatz 的权限,使其能够访问某些受保护的进程和内存区域。
sekurlsa::minidump 1992.dmp
//告诉 Mimikatz 加载一个特定的内存转储文件
sekurlsa::logonpasswords full
//用于提取当前系统中所有用户的登录凭证信息,包括明文密码、密码哈希、Kerberos 票据等。
但我们发现mimikatz并没有发现什么,这是因为Mimikatz 主要用于从内存转储(如 .dmp 文件)中提取凭据、密码哈希、Kerberos 票据等安全相关信息,而我们提取出的.dmp文件中没有包含相关的凭据
那么我们想要对其进行分析,实现从内存转储中提取文件(如图片)的功能可以使用文件分离的工具:binwalk和foremost
binwalk和foremost的区别
**Binwalk** 主要用于分析和提取嵌入在固件镜像或二进制数据中的文件和数据,特别适用于固件分析和嵌入式系统。
**Foremost** 主要用于从磁盘镜像、内存转储等数据源中恢复丢失的文件,适用于数字取证和文件恢复。
选择工具时,应该根据具体的任务和数据类型来决定使用哪种工具。如果需要分析固件或嵌入式数据,使用 Binwalk。如果需要从存储设备或内存转储中恢复文件,使用 Foremost。
我们首先使用binwalk发现提取出了一大堆7z和zip压缩文件,但都打不开,那么我们再使用foremost看看:

提取出了许多内容,我们查看发现png文件夹中含有线索:


通过扫码我们发现了一串密文,再通过图片中给出的key(密钥)和iv(向量)来看,这应该是对称密码加密,密钥长度为16,符合AES加密的密钥特征
我们尝试解密,得到flag(这里使用了工具CaptfEncoder,由于密钥长度符合16字节所以AES加密解密的填充模式为No Padding):

未解之谜:cyberchef的AES加解密是乱码

考点:使用Volatility进行内存取证、使用foremost从内存转储中恢复文件、理解AES加密方式
[INSHack2019]INSAnity(简单)
下载文件,是一个md文件,直接给出了flag,推测是一个签到题
[INSHack2019]Sanity(简单)
下载文件,又一个md文件,还是直接给出了flag
很好的色彩呃?(新)
下载文件,是一个gif图片文件
按照图片隐写思路,第一步、第二步无果,我们优先使用stegsolve进行逐帧分析,但还是没看出什么:

此时再次看看题目,已经提示了我们注意“色彩”,那么这其中肯定存在一种隐写术
颜色隐写术
图片的内容仅仅由不同颜色的黄条组成,黄条颜色的RGB值可能暗藏玄机






我们可以注意到不同黄条的HTML标记仅最后两位发生了变化,这可能是一种16进制的信息:

提交发现即为flag
考点:理解颜色隐写术
[ACTF新生赛2020]frequency(新)
下载文件,是一个doc文件,我们打开查看内容:

这一次没有跟背景颜色一样的白色字体的隐藏,我们打开doc的显示隐藏文字选项:
文件->选项->显示->打开显示隐藏文字的功能


为了能够复制隐藏的文字内容,我们再将全文的字体设置中的隐藏选项关闭:

按照题目描述,flag有两截,我们继续寻找,在文件的属性那一栏看到了隐藏的第二段flag内容:

我们分析两段flag,cyberchef解出一大堆字母,字母看上去杂乱无章,我们尝试字频统计:


虽然括号的位置貌似出错了,但我们看到了关键词“actf”,我们推测flag提交:
flag{actfplokmijnuhbygvrdxeszwq}{} 错误
flag{actfplokmijnuhbygvrdxeszwq} 错误
flag{plokmijnuhbygvrdxeszwq}{} 错误
flag{plokmijnuhbygvrdxeszwq} 正确
考点:会打开doc显示隐藏内容功能、检查doc属性、字频统计
[INSHack2018]Self Congratulation(新)
下载文件,是一张png格式的图片:

按照图片隐写思路,第一步、第二步、第三步无果,我们注意观察图片可以发现最值得注意的地方就是图片左上方不自然的黑白方块
二进制隐写术
我们仔细分析这些黑白方块,像LSB隐写一样可能存在二进制隐写的信息

00110001001
10010001100
11001101000
01101010011
01100011011
10011100000
尝试解码上交,还真是flag:

考点:理解二进制隐写术
[INSHack2017]insanity-(简单)
下载文件,又一个md文件,还是直接给出了flag
[2022红包题]虎年大吉(知识巩固题)
下载文件,是一个png格式的图片
按照图片隐写思路,第一步无果,我们优先使用010 editor进行分析,发现文件结尾插入隐藏了信息:

我们喂给cyberchef得到了flag:

考点:使用十六进制编辑器找到插入隐藏的信息
[BSidesSF2019]table-tennis(知识巩固题)
下载文件,发现里面是一个pcapng格式的文件,我们使用wireshark打开查看
按照数据包分析思路,我们先进行协议分级:

我们发现TCP协议占比最高,并且使用了TLS协议加密(Transport Layer security)占比的内容最多;但流量包中并没有传输相关的私钥,我们无法解密,我们优先分析所有TCP流看看并没有什么值得注意的信息,我们求次分析所有的UDP流也没有找到值得注意到信息,那么我们开始分析ICMP协议的内容:

ICMP协议中的Data行又藏有信息,我们使用tshark全部提取出来进行分析:
tshark -r attachment.pcapng -Y "icmp" -T fields -e data > data.txt
去重:
^(.*?)$\s+?^(?=.*^\1$)
再进行转码,得到以下内容:
<html>
<html>
<html>
<html>
<html>
<head>
<head>
<head>
<head>
<head>
<title> <title> <title> <title> <title> I <3 CorI <3 CorI <3 CorI <3 CorI <3 Corgi </titgi </titgi </titgi </titgi </title>
<sle>
<sle>
<sle>
<sle>
<script>
dcript>
dcript>
dcript>
dcript>
document.ocument.ocument.ocument.ocument.write(atwrite(atwrite(atwrite(atwrite(atob("Q1RGob("Q1RGob("Q1RGob("Q1RGob("Q1RGe0p1c3RBe0p1c3RBe0p1c3RBe0p1c3RBe0p1c3RBUzBuZ0FiUzBuZ0FiUzBuZ0FiUzBuZ0FiUzBuZ0FiMHV0UDFuMHV0UDFuMHV0UDFuMHV0UDFuMHV0UDFuZ1Awbmd9Z1Awbmd9Z1Awbmd9Z1Awbmd9Z1Awbmd9"));
<"));
<"));
<"));
<"));
</script>/script>/script>/script>/script>
</hea
</hea
</hea
</hea
</head>
<bod>
<bod>
<bod>
<bod>
<body>
<dy>
<dy>
<dy>
<dy>
<h1> Woofh1> Woofh1> Woofh1> Woofh1> Woof!! </h1>!! </h1>!! </h1>!! </h1>!! </h1>
</bod
</bod
</bod
</bod
</body>
</hty>
</hty>
</hty>
</hty>
</ht
(好像还是有很多冗余数据,但还是看得懂的)
总之重点放在其中的document.write(atob("Q1RGe0p1c3RBUzBuZ0FiMHV0UDFuZ1Awbmd9")),使用了atob()函数来解码base64编码过的数据(我们可以像下图这样处理冗余数据),我们解码得到flag:


考点:流量协议分析、理解ICMP协议、处理冗余数据
[INSHack2019]gflag(新工具)
下载文件,是一个没有后缀的gflag文件,我们使用010editor打开发现里面的内容,一头雾水:


我们明白了这是3D打印机的G代码,我们应该如何让这些代码跑起来呢?
经过一番搜寻,我们可以使用这个在线网址进行预览gcode viewer - online gcode viewer and analyzer in your browser!,我们将gflag加上.gcode的后缀并上传

我们在2D渲染选项中将干扰视图的选项取消,得到了flag:

考点:不会就搜索就问、理解G代码
[*CTF2019]otaku(较难孬知识巩固题)
下载文件,是一个加密的zip文件,发现是伪加密我们进行修改:

解压后,内容是一个doc文件和一个加密的zip文件(不是伪加密)
我们打开doc文件:

有一块很显眼的空白,我们分析发现了隐藏的信息:

“I love you”并不是zip文件的密码
我们观察zip文件中的内容,有一个last word.txt文件,这可能是存在着已知明文攻击:只要我们推测出了last word.txt中的内容,我们就可以创建一个与last word.txt文件CRC值一样的文件进行已知明文攻击

那么按照提示last words.txt,我们尝试新建各种文件,尝试构造出与last word.txt文件CRC值一样的文件
这里失败了,原因是buuctf没有把原题的关键提示给出来:
One day,you and your otaku friend went to the comic expo together and he had a car accident right beside you.Before he died,he gave you a USB hard disk which contained this zip.Please find out his last wish.
提示:The txt is GBK encoding.
提示要我们对txt进行GBK编码。。。
那么我们就使用GBK编码来构造txt文件:
# -*- coding:GBK -*-
f = open('data.txt','w')
s = "Hello everyone, I am Gilbert. Everyone thought that I was killed, but actually I survived. Now that I have no cash with me and I’m trapped in another country. I can't contact Violet now. She must be desperate to see me and I don't want her to cry for me. I need to pay 300 for the train, and 88 for the meal. Cash or battlenet point are both accepted. I don't play the Hearthstone, and I don't even know what is Rastakhan's Rumble."
f.write(s)
f.close()
以上脚本来源于文章 *CTF2019]otaku-CSDN博客
我们可以看出last word.txt中的内容应为原文中维奥莱特回想的吉尔伯特对她说的最后一句话(“i love you是干扰项”)
我们创建一个zip文件,将生成的data.txt导入,发现它的CRC值与last word.txt的一样:

我们就此进行已知明文攻击,等待后得到了解压密码:My_waifu
解压文件,得到了flag.png图片
按照图片隐写思路,第一步、第二步无果,我们优先使用stegsolve进行分析:

图片较大,关闭相关通道仔细观察图片的左上角会有小小的黑白相间的隐写信息,我们进行解密即得到了flag
考点:压缩包伪加密、压缩包已知明文攻击、LSB隐写
[MRCTF2020]小O的考研复试(知识巩固题)
下载文件,pdf中的内容是数学题:

我们可以写一个脚本来解出这道题
a = 0
for i in range(19260816):
a = 2*pow(10,i)+a
a = a%1000000007
print(a)
跑了非常非常久。。。
我们可以使用以下更加简单的脚本:
a=2
for i in range(19260816):
a = a * 10 + 2
a=a%1000000007
print(a)
得到了flag

考点:脚本编写
真的很杂(新工具)
下载文件,是一张jpg格式的图片:

我试了,假的flag
按照图片隐写思路,第一步无果,我们优先使用010editor进行分析,发现了插入隐藏的压缩包:

分离文件并打开查看,我们可以看见压缩包中的内容:

这是一个典型的 APK(Android应用程序包) 文件内容
APK文件格式简介
APK文件是Android应用程序的分发和安装格式,实际上是一个经过压缩的ZIP文件,其中包含了应用程序运行所需的所有资源、代码和元数据。
1. META-INF 文件夹
-
META-INF
文件夹主要用于存放APK签名信息,确保应用程序在安装时没有被篡改。它通常包含以下内容:
- CERT.RSA:包含应用程序开发者的公钥,APK的签名证书。
- CERT.SF:包含签名的散列文件(hash),用于校验APK文件中的内容。
- MANIFEST.MF:列出APK中所有文件的清单及其散列值,用于完整性验证。
APK文件必须经过签名才能被Android系统安装,因此这些文件对应用程序的验证和安全性至关重要。
2. res 文件夹
-
res
文件夹包含应用程序的资源文件,比如图像、布局文件、字符串资源等。资源文件根据应用的不同需求,通常分为以下几个子文件夹:
- drawable:存放各种图像资源(.png、.jpg等)。
- layout:存放布局文件(.xml格式),定义应用界面设计。
- values:存放字符串资源(如
strings.xml)、样式文件、颜色定义等。 - raw:存放未压缩的原始文件资源,如音频、视频等。
- mipmap:存放应用程序的图标。
3. AndroidManifest.xml
-
AndroidManifest.xml
是每个Android应用程序的核心配置文件,它定义了应用程序的关键属性。该文件包括:
- 应用程序的名称、图标、版本信息等。
- 应用的权限声明,比如访问网络、使用摄像头等。
- 各个组件(Activity、Service、BroadcastReceiver等)的定义和配置信息。
- 应用程序的入口点(通常是主Activity)。
- 应用的最小支持Android版本和兼容性设置。
这个文件对于Android系统来说非常重要,它告诉系统如何加载和执行应用程序。
4. classes.dex
- classes.dex 文件是Dalvik Executable文件,包含了经过转换的字节码。Android应用程序的Java代码最终会被编译成.dex文件,供Android的Dalvik虚拟机或ART(Android Runtime)运行。
- 这个文件包含了应用的所有核心逻辑代码和实现。
5. resources.arsc
- resources.arsc 文件是一个资源索引文件,存放了已编译的资源信息。这个文件将应用程序中的资源(如字符串、颜色、布局等)进行了优化并索引,便于Android系统快速查找和加载资源。
- 它包含了所有的资源映射,允许应用程序快速访问资源,而不必每次都从
res文件夹中动态加载。
因此,我们可能需要进行Android逆向。在此参考了文章Android逆向 - 简书 (jianshu.com)
Android逆向思路
1. 先试着在模拟器中运行apk文件,查看是否存在可以直接给出flag的地方并理解软件布局
2. 使用工具AXMLPrinter2.jar对资源文件xml进行破解
3. 使用工具dex2jar将dex文件转换为jar文件
4. 使用jd-gui、GDA等工具分析java源码
5. 使用apktool等工具进行反编译修改
首先我们将.zip压缩文件后缀改为了.apk,并使用安卓模拟器运行,发现直接给出了flag

但提交了发现并不是flag,我们多次点击give you flag按钮发现flag随机生成
GDA
是一款主要用于分析安卓应用(APK 文件),特别是分析和反编译 .dex 文件中的代码的工具(直接导入apk文件即可)。
在此我直接使用GDA进行源码分析(优先分析含有main字样的主函数):


这里不做仔细分析,我们也能看出个大概
MainActivity中有一段:
this.findViewById(2131034174).setOnClickListener(new MainActivity$1(this, this.findViewById(2131034173)));
为 ID 为 2131034174 的视图设置了一个点击事件,点击事件的逻辑被定义在 MainActivity$1(即 MainActivity 的一个内部类)中
MainActivity$1 用于处理点击逻辑,点击后生成flag中含有两个参数a、b随机生成,而我们可以看出MainActivity已经给出了正确的值
String True1 = "flag{25f991b27f";
String True2 = "c";
String True3 = "dc2f7a82a2b34";
String True4 = "3";
String True5 = "86e81c4}";
考点:文件分离、Android逆向
[V&N2020 公开赛]真·签到(简单)
签到题
[GKCTF 2021]FireFox Forensics(新工具)
下载文件,里面是firefox的记录文件和密钥文件

我们可以对其中的json文件使用cyberchef进行美化方便分析:

浏览器取证
在浏览器取证中,Firefox 的 logins.json 文件是非常重要的文件之一,因为它包含了用户的已保存登录凭据。
为什么 logins.json 中会有这些敏感内容?
- 用户便利性:现代浏览器(包括 Firefox)通常会提供保存登录凭据的功能,目的是让用户在访问常用网站时无需每次都输入用户名和密码。Firefox 将这些凭据保存在本地的
logins.json文件中,供以后自动填写表单使用。 - 自动填充功能:浏览器的自动填充功能依赖于这些保存的登录信息,当用户访问登录页面时,浏览器会根据保存的凭据自动填写用户名和密码。
- 加密保护:虽然这些信息是敏感的,但 Firefox 会使用主密码(如果设置了)或操作系统的存储机制来加密这些数据,以防止未经授权的访问。如果用户没有设置主密码,这些数据可能会依赖操作系统的凭据管理器进行加密和解密。
我们可以使用专门用于火狐浏览器取证的工具脚本:lclevy/firepwd: firepwd.py, an open source tool to decrypt Mozilla protected passwords (github.com)
火狐浏览器取证firepwd工具脚本工作原理:
1.读取 logins.json 文件 → 提取加密的登录信息。
2.读取 key4.db 文件 → 获取加密密钥(若需要)。
3.使用 NSS 库进行解密 → 使用解密密钥解密 Base64 编码的用户名和密码。
4.显示解密结果 → 显示明文的用户名和密码。
将logins.json和key4.db放入同路径文件夹中,使用以下命令:
python firepwd.py
即得出了登录凭据解密后的内容:

(注:这题不知道为什么不使用flag{}了,使用GKCTF{})
考点:理解浏览器取证原理
[RCTF2019]disk(较难新工具)
下载文件,是一个vmdk文件
我们尝试使用7z提取其中的内容,打开报错了:

但我们还是可以提取其中的0.fat文件,我们可以将其当做一个虚拟硬盘文件进行挂载
FAT文件系统简介
FAT(File Allocation Table,文件分配表)是一种早期广泛使用的文件系统,最初由微软开发,用于管理存储设备上的文件和目录结构。FAT 文件系统有多个版本,包括 FAT12、FAT16 和 FAT32,其中 FAT32 是最常见的一种,尤其用于较大容量的存储设备,如 USB 闪存盘、SD 卡和外部硬盘等。
| 特性 | FAT32 | exFAT | NTFS |
|---|---|---|---|
| 最大单个文件大小 | 4GB | 128PB | 16TB |
| 最大分区大小 | 2TB | 128PB | 256TB |
| 兼容性 | 极高(所有设备和系统) | 较高(多数设备和系统) | 较低(主要是 Windows) |
| 文件权限支持 | 无 | 无 | 支持 |
| 文件压缩 | 无 | 无 | 支持 |
| 文件加密 | 无 | 无 | 支持(EFS) |
| 适用场景 | 小型存储设备、便携使用 | 大文件传输、跨平台兼容 | 大容量存储、复杂环境 |
我们可以使用VeraCrypt,对fat文件进行挂载
VeraCrypt
VeraCrypt 是一个流行的开源磁盘加密工具,它可以加密整个磁盘分区或创建虚拟加密盘。结合 FAT 文件系统,VeraCrypt 可以用于创建加密的 FAT 文件系统卷,从而为用户提供存储数据的隐私和安全保障。

我们尝试挂载,发现需要密码,一般这种密码猜测与比赛名有关,rctf猜测正确!

挂载成功,出现了一个本地磁盘A,其中有一个图片文件说是useless_file,我们先不要管它,看看password.txt的内容:

隐藏卷
在 VeraCrypt 中,同一个加密卷(如 FAT 文件系统)能够通过输入不同的密码进入不同的文件系统,这种特性被称为 “隐藏卷”功能。这是 VeraCrypt 的一个高级功能,旨在提高用户数据的安全性和隐私保护。
隐藏卷 是 VeraCrypt 中的一项技术,它允许用户在同一个加密卷中创建两个文件系统:一个是外部卷,另一个是隐藏卷。这两个文件系统共享同一个物理磁盘空间,但只有在输入正确的密码时,才能访问各自的卷内容。具体来说:
1.外部卷:
- 外部卷是一个普通的加密卷,用户可以通过 VeraCrypt 创建并访问它。
- 它像是一个正常的加密容器,存储了用户的文件和数据。任何人知道这个卷的密码,输入后都可以访问该卷中的内容。
2.隐藏卷:
- 隐藏卷存在于外部卷的空闲空间中,是一个完全独立的文件系统。隐藏卷通过不同的密码访问,只有知道隐藏卷密码的人才能进入。
- 这个隐藏卷不可见,也不会显示为外部卷中的文件或数据,除非输入了正确的隐藏卷密码。
VeraCrypt 使用密码不仅仅是为了解密文件,它还用于确定加载哪个卷。外部卷和隐藏卷有各自的密码,输入正确的密码时,VeraCrypt会根据密码解密相应的数据区域并挂载相应的卷。
因此我们卸载加密卷后再次尝试挂载[0].fat文件,这次使用密码:RCTF2019
但隐藏卷一打开就提示我们要进行格式化:

这里我们使用十六进制编辑器对磁盘进行分析,但不是010editor,而是winhex
010editor和winhex的区别
| 特性 | 010 Editor | WinHex |
|---|---|---|
| 界面 | 现代、用户友好、支持可视化模板解析 | 传统、简洁,但功能丰富 |
| 文件格式解析 | 强大的模板系统,自动解析二进制文件格式 | 无模板系统,手动解析数据 |
| 数据恢复与取证 | 基本支持 | 强大支持,特别是取证功能和数据恢复 |
| 脚本与自动化 | 强大的脚本功能,C 风格脚本 | 基本脚本功能,主要用于自动化恢复和分析 |
| 硬盘与内存编辑 | 支持,但主要面向文件级别 | 强大支持,适合物理磁盘和内存编辑 |
| 适用领域 | 文件格式分析、逆向工程、自动化处理 | 数据恢复、数字取证、磁盘与内存分析 |

打开后开头都是乱码,但往下看发现了flag后半段:

flag前半段呢?经过这个启发我对vmdk文件进行了16进制编辑分析找到了flag前半段:

考点:理解FAT文件系统、使用VeraCrypt工具挂载加密卷、理解隐藏卷、使用winhex对磁盘进行分析
MRCTF2020]摇滚DJ(建议大声播放(知识巩固题)
下载文件,是一个wav格式的音频格式
我们听一下,一听就是SSTV音频,我们使用MMSSTV进行分析得到flag(图片由于环境有些吵出现了坏点):

考点:理解SSTV
[INSHack2018]INSanity(简单)
直接给出了flag,应该是签到题
[GUET-CTF2019]520的暗示(新工具孬题)
下载文件,里面是一个.dat格式的文件
DAT格式文件
DAT格式的文件 是一种通用的数据文件格式,通常被用来存储各种应用程序所生成的原始数据。DAT 文件的具体内容和结构取决于创建它的应用程序,因此 DAT 文件本身没有严格定义的格式。
DAT 文件的常见用途
- 应用程序数据:许多应用程序使用 DAT 文件来存储数据,例如游戏中的关卡数据、配置文件、日志、缓存等。
- 多媒体数据:某些视频、音频和图像应用程序也可能使用 DAT 文件来存储多媒体信息,如视频流、音频轨道等。
- 数据库文件:一些数据库软件可能使用 DAT 文件来存储结构化数据。
- 邮件客户端:例如,早期的微软 Outlook Express 会使用 DAT 文件来存储电子邮件附件的临时数据。
DAT 文件的特点
- 没有特定的格式:DAT 文件没有标准化的文件格式,它可以包含任何类型的数据。这些数据可能是文本、二进制数据或应用程序的专有格式,因此在某些情况下,直接查看或编辑 DAT 文件可能无法理解其内容。
- 与应用程序相关:如何解释或处理 DAT 文件,通常由生成它的应用程序决定。不同的应用程序可以以完全不同的方式使用和解释 DAT 文件。
如何打开和查看 DAT 文件?
打开 DAT 文件的方式取决于文件的具体内容以及生成它的应用程序。以下是一些常见的方法来查看或编辑 DAT 文件:
- 文本编辑器:如果 DAT 文件是以文本格式存储的数据(例如日志或配置文件),您可以使用任何文本编辑器(如 Notepad++、Sublime Text、VS Code 等)来打开和查看它的内容。
- 十六进制编辑器:如果 DAT 文件包含二进制数据,可以使用 十六进制编辑器(如 010 Editor、WinHex)查看文件的二进制结构。这样可以让您看到文件中的原始数据。
- 专用应用程序:有些 DAT 文件只能通过生成它的应用程序来读取或解释。例如,如果 DAT 文件是游戏生成的关卡数据,只有该游戏或它的编辑工具才能正确读取它。
- 文件格式推断工具:如果不确定 DAT 文件的来源,可以尝试使用一些文件格式推断工具(如
TrID),它可以帮助分析 DAT 文件的类型并建议合适的程序来打开它。
总之,DAT 文件 本质上是通用的数据文件,没有统一的格式标准。打开和查看 DAT 文件的方式通常取决于生成它的应用程序。
我们根据文件名“photo.dat”分析这是一个图片文件,但图片软件打不开,推测.dat 文件在存储聊天记录、图片、音频和视频等数据时,可能进行了加密和压缩处理,采取了数据加密策略,使得存储的 .dat 文件无法直接查看或使用常规工具打开。
在这里使用了大佬写的工具:[更新]微信PC版DAT文件解密工具V0.5 - 琳迪软件(LINDI.CC)
我们可以直接使用它对.dat文件进行自动解密,输出了一张图片:

我们也可以拿输出的图片与源文件.dat进行比较,发现加密的方式仅仅是对文件进行了与0x33进行异或:

那么我们继续分析这个图片的内容(这里可能是没有给出足够的提示,以后要记住这种信息的考点了)
这张图片是一个移动网络信号强度的检测界面,提供了多个关于当前 LTE 网络的信息:
网络运营商
运营商名称:CHN-UNICOM(中国联通)
MCC(移动国家代码):460(中国)
MNC(移动网络代码):01(中国联通)
服务小区信息
数据网络类型:LTE (LTE 是 4G 网络的一种实现技术)
小区类型:LTE
TAC(跟踪区码):30542
PCI(物理小区标识):150
ECI(演进小区标识):180375296(ECI 是由 eNodeB 和 CellID 组成的唯一标识)
EARFCN(下行和上行频率的频点编号):下行1650 / 上行1965
频率:1850 MHz(下行频率)/ 1755 MHz(上行频率)
BAND(频段):3(FDD-LTE)
信号强度
RSSI(接收信号强度指示):-57 dBm(通常代表信号强度的总体电平)
RSRP(参考信号接收功率):-89 dBm(专门针对 LTE 网络的信号质量指标)
RSRQ(参考信号接收质量):-9 dB(反映信号的质量,一般取值越大越好)
SINR(信号与干扰加噪声比):11.6 dB(越高越好,表示信号与噪声的比值)
邻小区
当前没有显示邻小区的信息,显示为 “NO VALUE”。
图表
信号强度随时间的变化图表,显示了过去 1 分钟内 RSRP 信号的波动。
我们能够根据以上信息进行基站地址定位移动联通电信基站位置查询 (juhe.cn)

最终的flag也是没有给出足够的提示,为基站的地址
flag{桂林电子科技大学花江校区}
考点:理解并分析.dat文件、根据LTE定位基站地址
[GWCTF2019]huyao(新工具)
下载文件,是两张一模一样的图片
按照图片隐写思路,第一步、第二步、第三步无果,使用了zsteg、cloacked-pixel无果后,我们优先查看其中是否存在盲水印(在此我们先使用github开源的BlindWaterMark-master):
python2 bwm.py decode huyao.png stillhuyao.png out.png

看来是不存在普通的盲水印,这里我们再尝试基于频域的盲水印脚本解密
基于频域的盲水印
普通盲水印通常指时域的盲水印,这种方式直接在图像、音频或视频的原始数据(如像素值或音频采样点)中嵌入水印信息。
基于频域的盲水印则将水印嵌入到图像或音频的频率域中,而不是直接嵌入到时域中的像素或采样点。
频率域
图像的频率域是指将图像从空间域转换到频率域后的表现方式,用于描述图像中像素值的变化频率。不同于空间域中通过像素的空间位置和灰度值来表示图像,频率域则描述图像中不同位置的像素强度如何变化。
这里给出脚本kindred-adds/BlindWaterMarkplus: 频域盲水印隐写脚本 (github.com)
我们进行提取:
python2 BlindWaterMarkplus.py --original huyao.png --image stillhuyao.png --result out.png
从盲水印中提取出了flag:

考点:理解基于频域的盲水印
大流量分析(三)(知识巩固题)
跟大流量分析(一)、大流量分析(二)一样的题目,这一次问的是黑客预留的后门的文件名是什么
根据这一点,我们应该优先分析http协议:

还是没有明显的交互php文件,但我们进行逆向思维,假如我们是黑客,在上传了后门文件后肯定会对其使用命令进行测试查看能否回显,常用的测试指令便是phpinfo()
我们进行搜索:

没有给出后门文件的地址,我们再分析下一个流量包,再没有就继续找:

最终我们可以得出,黑客预留的后门的文件名为“admin.bak.php”,即为flag
考点:流量分析、后门文件分析
[XMAN2018排位赛]file(较难新工具)
下载文件,是一个img文件
我们使用7z打开解压查看,可以看见其中内容:

仅仅有一堆奇怪的猫猫图片和两个文件夹组成,其中一个还是空文件夹
[SYS]文件夹
在操作系统(OS)中,[SYS] 文件夹(或系统文件夹)通常用于存储与系统相关的重要文件和配置。我们打开发现里面有一个名为“journal”的文件,在系统文件夹中,Journal 文件通常与文件系统日志有关。文件系统日志(Journal)用于记录文件系统的变化,帮助在系统崩溃或意外断电后恢复数据。(有Journal文件可以推测这里使用了ext4文件系统)
那么我们要做的可能是将lost+found文件夹中被删除的目录或文件进行恢复
我们首先查看img文件使用的文件系统:
file attachment.img

可以发现img文件使用的是ext4文件系统
(以下内容皆为需要学习和理解的内容与题目可能无关)
ext4文件系统简介
ext4 是第四代扩展文件系统,设计用于提高性能、可扩展性和数据安全性。它最初作为 ext3 文件系统的改进版本推出,具有许多新的特性。
支持最大 1 EB(exabyte,1024 PB)的大分区,并且支持最大 16 TB 的单个文件。
使用延迟分配策略来提高性能。它不会立即为写入的数据分配磁盘块,而是等待到有足够的信息可用,从而更好地组织磁盘布局,提高写入效率并减少磁盘碎片。
进一步优化了日志的效率,并提供了三种日志模式:writeback、ordered 和 journal,以便用户根据需求选择不同的平衡点。
能够一次为文件分配多个块,从而提高大文件的写入性能。
通过元数据校验和机制,增加了系统崩溃后文件系统自我修复的能力。
常见的linux文件系统
| 文件系统 | 日志功能 | 最大文件大小 | 最大分区大小 | 快照支持 | 性能特点 | 应用场景 |
|---|---|---|---|---|---|---|
ext2 |
无 | 16 TB | 32 TB | 无 | 写入性能好,无日志开销 | 只读或数据修改不频繁的场合 |
ext3 |
有 | 16 TB | 32 TB | 无 | 较好的数据恢复能力 | 普通服务器和工作站 |
ext4 |
有 | 16 TB | 1 EB | 无 | 更好的性能和日志优化 | 大多数 Linux 系统和应用场景 |
XFS |
有 | 8 EB | 8 EB | 无 | 并发性能极佳,适合大文件 | 高并发、海量数据处理,数据中心 |
Btrfs |
有 | 16 EB | 16 EB | 有 | 快照、压缩、RAID 支持 | 容器、虚拟化、需要快照的场景 |
ZFS |
有 | 16 EB | 256 ZB | 有 | 数据完整性保障强,功能丰富 | 高可靠性存储系统、备份服务器 |
F2FS |
无 | 16 TB | 16 TB | 无 | 针对闪存优化 | 嵌入式系统、闪存存储设备 |
我们要知道之前讲过的FAT32、exFAT 和 NTFS 是 Microsoft 开发的文件系统,广泛用于 Windows 操作系统和跨平台存储设备。而 ext4 是 Linux 中常用的文件系统。
返回题目,我们使用mount命令对img文件进行挂载:
sudo mount attachment.img 1 #将img文件中的内容挂载到文件夹1中
我们很有可能遇到以下情况:

这个错误提示我们设置挂载环回设备(loop device)失败,在此有必要介绍一下linux挂载img文件原理
linux挂载img文件原理
在 Linux 系统中,“挂载”是指将一个文件系统(如磁盘分区、外部设备或文件)接入到系统的目录树中,使得用户和程序能够通过路径访问它。Linux 是一个基于文件的系统,所有资源(文件、设备等)都可以通过目录路径来访问。
通常,挂载的对象是硬盘分区、光盘等实际的物理设备,但 Linux 也允许挂载其他类型的对象,比如磁盘映像文件。这就是环回设备的作用所在。
环回设备(loop device)是一种虚拟的块设备,它允许你将一个文件当作一个块设备来对待。换句话说,环回设备把一个普通的文件变成可以被 Linux 当作磁盘来使用的虚拟设备。
环回设备的核心思想是将文件系统中的普通文件(如 .img 文件)视为一个虚拟的块设备。
通过 loop 设备,Linux 能够把一个文件(例如一个磁盘镜像)作为一个块设备处理,就像处理硬盘或 USB 一样。
这使得你能够直接挂载磁盘映像文件,将其内容映射到一个目录中,而无需物理设备。
当你挂载一个 .img 文件时,Linux 实际上通过以下步骤操作:
环回设备映射:首先,Linux 将 .img 文件映射到一个环回设备上,类似于将该文件“伪装”成一个虚拟磁盘。例如,你可以使用 losetup 命令将 .img 文件绑定到环回设备 /dev/loop0:
sudo losetup /dev/loop0 image.img
现在,Linux 将 /dev/loop0 视为一个块设备,尽管它实际上只是磁盘镜像文件的一种映射。
识别文件系统:接下来,Linux 会像处理物理磁盘一样,试图识别这个环回设备上的文件系统。如果 .img 文件包含有效的文件系统(例如 ext4、FAT32),Linux 将识别它并准备挂载。
挂载到目录:最后,使用 mount 命令将这个虚拟设备挂载到某个目录。例如:
sudo mount /dev/loop0 /mnt/img_mount
这时,.img 文件的内容就可以通过 /mnt/img_mount 目录访问了。
回归题目,我们遇到了设置挂载环回设备失败的问题,在此我们首先查看以下我们空闲的设备:
sudo losetup -f
losetup 是 Linux 中用于管理和配置环回设备的命令
-f 查找并返回下一个可用的环回设备

说明loop0这个设备空闲,可以使用,我们进行挂载:
sudo losetup /dev/loop0 attachment.img
sudo mount /dev/loop0 /mnt/ #将/dev/loop0设备中的内容挂载到文件夹/mnt/中
挂载成功,我们可以在linux系统中看到我们挂载的内容了:

文件恢复的原理
在 ext3/ext4 文件系统中,删除文件并不意味着文件数据立即从磁盘上清除。
删除操作通常只会将文件的 元数据(如 inode 表中的指针)标记为“已删除”,即将文件从目录结构中移除,释放对应的 inode 和数据块,但实际存储的数据仍然存在,直到被新的数据覆盖。
简单来说,文件删除只是更新了文件系统的结构(元数据),并未立刻抹去磁盘上存储的文件内容。
(以上内容皆为需要学习和理解的内容与题目可能无关)
现在我们可以尝试恢复文件了,在此我们需要工具extundelete
extundelete
extundelete 通过读取文件系统的 inode 表 和 日志文件(Journal),找到已删除文件的相关信息。
ext 文件系统会为每个文件分配一个 inode 结构,inode 中记录了文件所在的数据块、权限、大小等信息。当文件被删除时,inode 表中的指针被清除或标记为可用,但如果数据块未被覆盖,extundelete 可以从剩余的 inode 信息中找到数据块的位置,并尝试恢复。
在 ext3/ext4 文件系统中,文件系统的日志(Journal)还会记录文件的某些元数据。extundelete 可以利用这些日志来恢复最近删除的文件或目录。
回到题目,我们使用以下命令:
extundelete attachment.img --restore-all
--restore-all 一个选项,意思是恢复.img文件中的所有已删除文件

此时目录下出现了一个“RECOVERED_FILES”文件夹,里面就是我们恢复出来的文件,我们导出查看:

在该文件的末尾找到了flag
考点:理解ext4文件系统、理解文件恢复原理、会使用extundelete进行文件恢复
寂静之城(孬题)
题目的网址已经失效,在此给出其他文章的WP(原文地址:BUUCTF-Misc-No.4_ctf 寂静之城-CSDN博客)
打开网址,能看到一篇书评:

我们能从点赞记录中找到出题人的账号:

应该是可以通过出题人豆瓣的主页找到一篇微博找到flag:

考点:社会工程学
[SCTF2019]Ready_Player_One(较难新工具)
下载文件,是一个unity编写的游戏文件:

打开游戏,是一个打飞机的游戏,可能我们达到高分即可得到flag
貌似是逆向大佬玩的题目,尝试使用Cheat Engine对游戏数据进行修改
Cheat Engine
Cheat Engine 是一个强大的开源工具,主要用于修改和调试计算机游戏的内存和数据。它可以用来改变游戏的变量、解锁游戏功能,或者修复游戏中的问题。除了游戏修改,Cheat Engine 也可以用于其他需要内存修改的应用场景,比如测试和调试软件。
(使用教程和案例可以参考文章,有兴趣的可以试试这题反正我过关了(^-^)V,要注意的是前进的方向与坐标的关系,游戏中角色向初始面对方向前进即增大坐标利用Cheat Engine与DnSpy破解Unity游戏的技术与实践 - 先知社区 (aliyun.com))
但在这题中最终我们找不到分数变量而修改失败:

这里可能是使用了Anti-Cheat Toolkit插件防止我们作弊
(参考文章Unity 保护内存变量 Anti-Cheat Toolkit 反作弊_unity anti-cheat toolkit-CSDN博客)
对于unity逆向可以参考这篇文章[Unity逆向 | Lazzaro (lazzzaro.github.io)](https://lazzzaro.github.io/2020/12/13/reverse-Unity逆向/index.html#:~:text=直接运行Il2CppDumper.exe并依次选择il2cpp的可执行文件GameAssembly.dll和global-metadata.dat(文件头 AF 1B,B1 FA)文件,然后根据提示输入相应信息。 程序运行完成后将在当前运行目录下生成输出文件。)对于我的水平来说这题可能会成为待补充的内容了
但按照网上的WP来看,这道题目的解法为:按住W冲出游戏屏幕即可得到flag

等到我的水平能够做到逆向unity编写的exe文件后再来补充其中的逻辑吧...
考点:(待补充)
我爱Linux(较难新工具)
下载文件,是一张打不开的png图片,我们丢进010editor进行分析:

以jpg模板解析发现文件尾存在插入隐藏的内容,我们提取出来:

这是什么文件呢?我们一头雾水,我们使用file命令分析也仅仅说是data数据:

ChatGPT给了我们一个完美的答案:

Python的序列化
Python 的序列化(serialization)是将 Python 对象转换为可以存储或传输的格式的过程,常用的序列化格式包括 JSON、pickle 和 XML 等。
JSON 是易读的文本格式,键值对的形式
Pickle 是二进制格式,内容不可读,保存完整的Python对象
XML 是标记化的文本格式,具有层级结构
既然我们提取出来的是Python代码进行pikle序列化后的不可读文件,在此我们使用pikle库进行反序列化
import pickle
def load_pickle_file(filename):
"""
加载并反序列化 Pickle 文件。
:param filename: Pickle 文件的路径
:return: 反序列化后的 Python 对象
"""
try:
# 以二进制模式打开 Pickle 文件
with open(filename, 'rb') as file:
# 反序列化文件内容
data = pickle.load(file)
return data
except Exception as e:
# 如果发生错误,打印错误信息
print(f"加载 Pickle 文件时出错: {e}")
return None
def write_to_file(filename, data):
"""
将数据写入文本文件。
:param filename: 文本文件的路径
:param data: 要写入的数据
"""
with open(filename, 'w') as file:
# 将数据转换为字符串,并写入文件
file.write(str(data))
if __name__ == "__main__":
# 输入文件名,替换为你的 Pickle 文件路径
input_filename = '无标题1'
# 输出文件名,数据将被写入到这个文件中
output_filename = '1.txt'
# 加载并反序列化 Pickle 文件
deserialized_data = load_pickle_file(input_filename)
# 将反序列化的数据写入到文本文件中
if deserialized_data is not None:
write_to_file(output_filename, deserialized_data)
print(f"数据已被写入到 {output_filename}")

我们可以发现反序列化的数据是列表,这些列表有什么用呢?
按照题目的提示,linux系统下的好玩的命令“sl”其实是一个系统的小彩蛋,执行后会有一个小火车开过:

ASCII字符画
也称为 ASCII 艺术,是一种使用字符和符号来绘制图像的艺术形式。它通常使用 ASCII 字符集中的字母、数字、符号来在文本环境中创建图形。符号图像画广泛应用于早期的计算机程序、电子邮件签名、聊天平台等场合,因为这些场景往往限制了使用图像的能力。
░░▄ ▀▄▄▀▄░░░░░░░░░
░█░░░░░░░░▀▄░░░░░░▄░
█░░▀░░▀░░░░░▀▄▄░░█░█
█░▄░█▀░▄░░░░░░░▀▀░░█
█░░▀▀▀▀░░░░░░░░░░░░█
█░░░░░░░░░░░░░░░░░░█
█░░░░░░░░░░░░░░░░░░█
░█░░▄▄░░▄▄▄▄░░▄▄░░█░
░█░▄▀█░▄▀░░█░▄▀█░▄▀░Fancy ASCII Text Art Gallery (textfancy.com)
那么我们可以推测我们反序列化得到的列表数据排列出来应该就是一个ASCII字符画,我们编写以下脚本进行输出:
# 定义数据列表
data = [[(3, 'm'), (4, '"'), (5, '"'), (8, '"'), (9, '"'), (10, '#'), (31, 'm'), (32, '"'), (33, '"'), (44, 'm'), (45, 'm'), (46, 'm'), (47, 'm'), (50, 'm'), (51, 'm'), (52, 'm'), (53, 'm'), (54, 'm'), (55, 'm'), (58, 'm'), (59, 'm'), (60, 'm'), (61, 'm'), (66, 'm'), (67, '"'), (68, '"'), (75, '#')],
[(1, 'm'), (2, 'm'), (3, '#'), (4, 'm'), (5, 'm'), (10, '#'), (16, 'm'), (17, 'm'), (18, 'm'), (23, 'm'), (24, 'm'), (25, 'm'), (26, 'm'), (31, '#'), (37, 'm'), (38, 'm'), (39, 'm'), (43, '"'), (47, '"'), (48, '#'), (54, '#'), (55, '"'), (57, '"'), (61, '"'), (62, '#'), (64, 'm'), (65, 'm'), (66, '#'), (67, 'm'), (68, 'm'), (72, 'm'), (73, 'm'), (74, 'm'), (75, '#')],
[(3, '#'), (10, '#'), (15, '"'), (19, '#'), (22, '#'), (23, '"'), (25, '"'), (26, '#'), (29, 'm'), (30, 'm'), (31, '"'), (36, '"'), (40, '#'), (47, 'm'), (48, '"'), (53, 'm'), (54, '"'), (59, 'm'), (60, 'm'), (61, 'm'), (62, '"'), (66, '#'), (71, '#'), (72, '"'), (74, '"'), (75, '#')],
[(3, '#'), (10, '#'), (15, 'm'), (16, '"'), (17, '"'), (18, '"'), (19, '#'), (22, '#'), (26, '#'), (31, '#'), (36, 'm'), (37, '"'), (38, '"'), (39, '"'), (40, '#'), (45, 'm'), (46, '"'), (52, 'm'), (53, '"'), (61, '"'), (62, '#'), (66, '#'), (71, '#'), (75, '#')],
[ (3, '#'), (10, '"'), (11, 'm'), (12, 'm'), (15, '"'), (16, 'm'), (17, 'm'), (18, '"'), (19, '#'), (22, '"'), (23, '#'), (24, 'm'), (25, '"'), (26, '#'), (31, '#'), (36, '"'), (37, 'm'), (38, 'm'), (39, '"'), (40, '#'), (43, 'm'), (44, '#'), (45, 'm'), (46, 'm'), (47, 'm'), (48, 'm'), (51, 'm'), (52, '"'), (57, '"'), (58, 'm'), (59, 'm'), (60, 'm'), (61, '#'), (62, '"'), (66, '#'), (71, '"'), (72, '#'), (73, 'm'), (74, '#'), (75, '#')],
[(23, 'm'), (26, '#'), (32, '"'), (33, '"')],
[(24, '"'), (25, '"')],
[],
[(12, '#'), (17, 'm'), (18, '"'), (19, '"'), (23, 'm'), (24, 'm'), (25, 'm'), (26, 'm'), (33, '#'), (36, 'm'), (37, 'm'), (38, 'm'), (39, 'm'), (40, 'm'), (41, 'm'), (46, 'm'), (47, 'm'), (52, 'm'), (53, 'm'), (54, 'm'), (65, 'm'), (66, 'm'), (67, 'm'), (68, 'm'), (71, 'm'), (72, 'm'), (73, 'm'), (74, 'm'), (75, 'm'), (76, 'm')],
[(2, 'm'), (3, 'm'), (4, 'm'), (9, 'm'), (10, 'm'), (11, 'm'), (12, '#'), (15, 'm'), (16, 'm'), (17, '#'), (18, 'm'), (19, 'm'), (22, '"'), (26, '"'), (27, '#'), (30, 'm'), (31, 'm'), (32, 'm'), (33, '#'), (40, '#'), (41, '"'), (45, 'm'), (46, '"'), (47, '#'), (50, 'm'), (51, '"'), (55, '"'), (58, 'm'), (59, 'm'), (60, 'm'), (64, '#'), (65, '"'), (68, '"'), (69, 'm'), (75, '#'), (76, '"')],
[(1, '#'), (2, '"'), (5, '#'), (8, '#'), (9, '"'), (11, '"'), (12, '#'), (17, '#'), (24, 'm'), (25, 'm'), (26, 'm'), (27, '"'), (29, '#'), (30, '"'), (32, '"'), (33, '#'), (39, 'm'), (40, '"'), (44, '#'), (45, '"'), (47, '#'), (50, '#'), (51, 'm'), (52, '"'), (53, '"'), (54, '#'), (55, 'm'), (57, '#'), (58, '"'), (61, '#'), (64, '#'), (65, 'm'), (68, 'm'), (69, '#'), (74, 'm'), (75, '"')],
[(1, '#'), (2, '"'), (3, '"'), (4, '"'), (5, '"'), (8, '#'), (12, '#'), (17, '#'), (26, '"'), (27, '#'), (29, '#'), (33, '#'), (38, 'm'), (39, '"'), (43, '#'), (44, 'm'), (45, 'm'), (46, 'm'), (47, '#'), (48, 'm'), (50, '#'), (55, '#'), (57, '#'), (58, '"'), (59, '"'), (60, '"'), (61, '"'), (65, '"'), (66, '"'), (67, '"'), (69, '#'), (73, 'm'), (74, '"')],
[(1, '"'), (2, '#'), (3, 'm'), (4, 'm'), (5, '"'), (8, '"'), (9, '#'), (10, 'm'), (11, '#'), (12, '#'), (17, '#'), (22, '"'), (23, 'm'), (24, 'm'), (25, 'm'), (26, '#'), (27, '"'), (29, '"'), (30, '#'), (31, 'm'), (32, '#'), (33, '#'), (37, 'm'), (38, '"'), (47, '#'), (51, '#'), (52, 'm'), (53, 'm'), (54, '#'), (55, '"'), (57, '"'), (58, '#'), (59, 'm'), (60, 'm'), (61, '"'), (64, '"'), (65, 'm'), (66, 'm'), (67, 'm'), (68, '"'), (72, 'm'), (73, '"')],
[],
[],
[],
[(5, '#'), (8, '#'), (16, 'm'), (17, 'm'), (18, 'm'), (19, 'm'), (23, 'm'), (24, 'm'), (25, 'm'), (26, 'm'), (30, 'm'), (31, 'm'), (32, 'm'), (33, 'm'), (38, 'm'), (39, 'm'), (40, 'm'), (50, '#'), (57, '#'), (64, '#'), (71, 'm'), (72, 'm'), (73, 'm')],
[(2, 'm'), (3, 'm'), (4, 'm'), (5, '#'), (8, '#'), (9, 'm'), (10, 'm'), (11, 'm'), (15, '#'), (16, '"'), (19, '"'), (20, 'm'), (22, 'm'), (23, '"'), (26, '"'), (27, 'm'), (29, '#'), (34, '#'), (36, 'm'), (37, '"'), (41, '"'), (44, 'm'), (45, 'm'), (46, 'm'), (50, '#'), (51, 'm'), (52, 'm'), (53, 'm'), (57, '#'), (58, 'm'), (59, 'm'), (60, 'm'), (64, '#'), (65, 'm'), (66, 'm'), (67, 'm'), (73, '#')],
[(1, '#'), (2, '"'), (4, '"'), (5, '#'), (8, '#'), (9, '"'), (11, '"'), (12, '#'), (15, '#'), (16, 'm'), (19, 'm'), (20, '#'), (22, '#'), (25, 'm'), (27, '#'), (29, '"'), (30, 'm'), (31, 'm'), (32, 'm'), (33, 'm'), (34, '"'), (36, '#'), (37, 'm'), (38, '"'), (39, '"'), (40, '#'), (41, 'm'), (43, '#'), (44, '"'), (47, '#'), (50, '#'), (51, '"'), (53, '"'), (54, '#'), (57, '#'), (58, '"'), (60, '"'), (61, '#'), (64, '#'), (65, '"'), (67, '"'), (68, '#'), (73, '#')],
[(1, '#'), (5, '#'), (8, '#'), (12, '#'), (16, '"'), (17, '"'), (18, '"'), (20, '#'), (22, '#'), (27, '#'), (29, '#'), (33, '"'), (34, '#'), (36, '#'), (41, '#'), (43, '#'), (44, '"'), (45, '"'), (46, '"'), (47, '"'), (50, '#'), (54, '#'), (57, '#'), (61, '#'), (64, '#'), (68, '#'), (73, '#')],
[(1, '"'), (2, '#'), (3, 'm'), (4, '#'), (5, '#'), (8, '#'), (9, '#'), (10, 'm'), (11, '#'), (12, '"'), (15, '"'), (16, 'm'), (17, 'm'), (18, 'm'), (19, '"'), (23, '#'), (24, 'm'), (25, 'm'), (26, '#'), (29, '"'), (30, '#'), (31, 'm'), (32, 'm'), (33, 'm'), (34, '"'), (37, '#'), (38, 'm'), (39, 'm'), (40, '#'), (41, '"'), (43, '"'), (44, '#'), (45, 'm'), (46, 'm'), (47, '"'), (50, '#'), (51, '#'), (52, 'm'), (53, '#'), (54, '"'), (57, '#'), (58, '#'), (59, 'm'), (60, '#'), (61, '"'), (64, '#'), (65, '#'), (66, 'm'), (67, '#'), (68, '"'), (71, 'm'), (72, 'm'), (73, '#'), (74, 'm'), (75, 'm')],
[],
[],
[],
[(2, 'm'), (3, 'm'), (4, 'm'), (5, 'm'), (8, 'm'), (9, 'm'), (10, 'm'), (11, 'm'), (12, 'm'), (19, '#'), (24, 'm'), (25, 'm'), (26, 'm'), (29, '"'), (30, '"'), (31, 'm')],
[(1, '#'), (2, '"'), (5, '"'), (6, 'm'), (8, '#'), (16, 'm'), (17, 'm'), (18, 'm'), (19, '#'), (22, 'm'), (23, '"'), (27, '"'), (31, '#')],
[(1, '#'), (2, 'm'), (5, 'm'), (6, '#'), (8, '"'), (9, '"'), (10, '"'), (11, '"'), (12, 'm'), (13, 'm'), (15, '#'), (16, '"'), (18, '"'), (19, '#'), (22, '#'), (23, 'm'), (24, '"'), (25, '"'), (26, '#'), (27, 'm'), (31, '"'), (32, 'm'), (33, 'm')],
[(2, '"'), (3, '"'), (4, '"'), (6, '#'), (13, '#'), (15, '#'), (19, '#'), (22, '#'), (27, '#'), (31, '#')],
[(1, '"'), (2, 'm'), (3, 'm'), (4, 'm'), (5, '"'), (8, '"'), (9, 'm'), (10, 'm'), (11, 'm'), (12, '#'), (13, '"'), (15, '"'), (16, '#'), (17, 'm'), (18, '#'), (19, '#'), (23, '#'), (24, 'm'), (25, 'm'), (26, '#'), (27, '"'), (31, '#')],
[(29, '"'), (30, '"')]]
# 确定 ASCII 艺术图的大小
width = 80
height = 30
# 初始化一个空白的网格
ascii_art = [[' ' for _ in range(width)] for _ in range(height)]
# 将数据填充到网格中
for y, row in enumerate(data):
for pos, char in row:
if pos < width:
ascii_art[y][pos] = char
# 输出 ASCII 艺术图
for row in ascii_art:
print("".join(row))

成功得到flag
考点:理解Python序列化、理解ASCII字符画如何由列表输出
补充:一条指令让你成为黑客——打开linux系统输入“hollywood”
[DDCTF2018]第四扩展FS(知识巩固题)
下载文件,是一张jpg格式的图片
按照图片隐写思路,第一步我们查看图片属性发现了如下内容,我们先记录:

我们再优先使用010editor进行分析:

我们发现插入隐藏了数据,但难以手动分离文件,我们使用binwalk:
binwalk -e FS.jpg
我们成功提取出了一个zip文件,我们尝试解压需要密码,经尝试后发现密码就是图片属性中藏着的“Pactera”
里面是一个txt文件:

拖到cyberchef中没有反应,那么我们尝试进行字频统计得到了flag:

考点:文件分离、字频统计
Beautiful_Side(新工具)
下载文件,是一个jpg格式的图片文件
按照图片隐写思路,第一步无果,我们优先使用010editor进行分析:

文件尾部插入隐藏了一张png格式的图片,我们进行提取:

只有半张二维码,这下怎么修复?
二维码分析原理
二维码内部使用了 Reed-Solomon 纠错码,它允许在一定范围内修复丢失或损坏的部分数据。根据二维码的纠错级别,丢失或损坏的数据可以通过剩余的部分被推断出来。
Reed-Solomon 纠错码的工作原理是:它为原始数据添加了冗余信息(纠错码),当部分数据丢失或损坏时,算法通过这些冗余信息来还原原始数据。
这里有一个很好的参考视频【WOE】用肉眼识别二维码,总共分几步?
在此我们可以使用工具QRazyBox进行分析
QRazyBox分析半张二维码原理
QRazyBox 的功能是利用二维码中的纠错码来修复部分损坏的二维码。它通过识别和分析二维码中完好和丢失的部分,将二维码的完整结构和内容还原。
当半张二维码被提供时,QRazyBox 通过分析剩余的部分,利用 Reed-Solomon 算法以及二维码的固定模式(例如定位图形、格式信息区域等)来推断丢失的数据。
对于受损或不完整的部分,QRazyBox 会根据编码规则填补丢失的数据,使二维码可以恢复到足够可以被扫码器识别的程度。
我们打开QRazyBox,创建新的项目,在一旁导入二维码图片按着图片内容一点一点的画图
调整图片大小后,我们通过视频可以明白二维码的 Format Info Pattern(格式信息模式) 是一个 15 位的二进制序列,包含纠错等级和掩模模式,用于帮助解码器正确读取二维码的内容,我们在此设置成和图片一样的格式:

我们尝试画满半张先(建议从右下开始画):

然后再tool工具栏中选择Extract QR Information,开始自动分析隐藏的信息:

我们可以看出解析出的数据为
0100: 这表示数据是以 字节模式(Byte Mode)进行编码的。
000010111: 这表示接下来数据长度为 23 个字节。
0100011001101100011000010110011101111011010011110101000101010111010010010100001101011111001101000100010001010011001100010100000101011111010100110011000000110011001101000101001101111101:二进制后就是flag的值
000011101100:可能代表 终止符 或 错误校正码 的一部分
得到flag
考点:理解二维码修复与分析
[INSHack2018]42.tar.xz(新)
下载文件,是一个42.tar.xz文件
.xz文件
这是一种压缩格式,使用了 LZMA2 压缩算法。它可以将数据压缩得非常小
.tar.xz 文件首先是用 .tar 将文件打包,再使用 .xz 进行压缩,既可以合并多个文件又能节省空间。
我们用7z打开42.tar.xz,发现里面是一层层的压缩包,我们可以使用鼠标连点器连点层层打开直到找到flag我们可以使用以下命令进行循环解压:
while [ "`find . -type f -name '*.tar.xz' | wc -l`" -gt 0 ]; do find -type f -name "*.tar.xz" -exec tar xf '{}' \; -exec rm -- '{}' \;; done;
这是一个 while 循环,其条件是找到 .tar.xz 文件的数量大于 0
find . -type f -name '*.tar.xz'查找当前目录及其子目录下所有扩展名为 .tar.xz 的文件
wc -l 是一个用于统计行数的命令。它会统计 find 命令输出的 .tar.xz 文件的数量
-gt 0
-gt 是 Bash 中的一个运算符,表示 "greater than"(大于)。它用于比较两个数值。
0 表示数字零。条件的意思是:如果找到的 .tar.xz 文件数量大于 0,循环继续执行;否则退出循环。
do
find -type f -name "*.tar.xz" -exec tar xf '{}' \;
再次使用 find 命令,用于在每次循环中查找当前目录及其子目录中的所有 .tar.xz 文件
-exec 是 find 命令的一个选项,它允许在找到的每个文件上执行指定的命令。
{} 是一个占位符,表示当前找到的文件名。
tar xf
x 选项表示解压缩文件。
f 选项表示指定文件名(即 {},找到的 .tar.xz 文件)
\;是 find -exec 选项的结束符,告诉 find 这是执行命令的结束。
-exec rm -- '{}' \; 再次使用 -exec 选项,在解压缩完成后执行删除操作。删除原始压缩包,可以避免重复处理。
一旦所有 .tar.xz 文件解压并删除完毕,find 命令不会再找到任何 .tar.xz 文件,此时 find . -type f -name '*.tar.xz' | wc -l 的结果为 0,while 条件不再满足,脚本停止执行。
最终我们提取出了许多flag文件:

这些flag文件大小离谱得很,我们使用文本编辑器都难以打开(这里使用了vscode):

可以看出flag文件中藏了许多没用的冗余数据,但我们直接cat flag即可得到flag(使用more flag会更加好)
考点:嵌套压缩包
[BSidesSF2019]diskimage(较难新工具)
下载文件,是一个png格式的文件
按照图片隐写的思路,第一步、第二步无果,我们打开stegsolve打开图片查看:

这次三种颜色的通道的各个平面位上方都存在规律的黑白像素点,貌似都隐藏着消息。我们一个个排列组合过于麻烦,这时就可以使用zsteg来进行自动分析:
zsteg attachment.png -a -v

我们发现了DOS引导扇区文件,可以进行提取
DOS引导扇区(DOS Boot Sector)
是存储在磁盘(如硬盘、软盘或USB驱动器)的第一个扇区,用来引导操作系统。在DOS和其他基于BIOS的操作系统中,BIOS会从引导设备加载引导扇区到内存并执行它,启动系统或加载一个操作系统(它包含一段小型的汇编代码,用于启动操作系统)。该代码会指示计算机找到并加载操作系统内核,或执行其他必要的启动任务。
引导扇区因为其标准的格式和固定的大小,常常用于隐写术。攻击者可以将数据嵌入到空闲的引导扇区中,或者伪装为引导代码中的一部分,而实际运行的是隐写数据。
BIOS(Basic Input/Output System,基本输入输出系统)
是计算机系统中最重要的固件之一,负责在计算机启动时执行初始硬件检查并引导操作系统。
BIOS 是计算机主板上存储在非易失性存储器(通常是 ROM 或 Flash 存储器)中的固件。当用户打开计算机电源时,BIOS 会启动,并执行以下关键功能:
- 硬件初始化:BIOS 会检测并初始化系统中的硬件设备,例如 CPU、内存、键盘、显示器、存储设备等。
- 启动自检 (POST, Power-On Self Test):BIOS 在计算机开机时对系统硬件进行自检。如果发现硬件问题,BIOS 会通过发出不同的蜂鸣声或在屏幕上显示错误信息来提示用户。
- 引导加载程序 (Boot Loader):一旦硬件初始化完成,BIOS 会寻找存储设备中的引导扇区(比如硬盘、光盘或 USB),并将操作系统加载到内存中开始运行。
- 基本输入输出操作:BIOS 还提供了一些底层的硬件访问接口,例如处理输入设备(键盘)和输出设备(显示器)的基本操作,供操作系统使用。
BIOS 是计算机启动和操作的基础,它为操作系统的加载提供了环境,同时为系统提供了硬件层的控制。虽然现代计算机大多使用 UEFI 替代了 BIOS,但它仍然是理解计算机引导过程和硬件初始化的重要基础知识。
UEFI
UEFI (Unified Extensible Firmware Interface) 是一种现代的计算机系统启动固件接口,它替代了传统的BIOS(Basic Input/Output System)。UEFI在设计上克服了BIOS的一些局限性,并为现代计算机硬件和操作系统提供了更灵活和强大的启动管理能力。
UEFI系统启动时会执行以下功能:
- 固件初始化:UEFI在计算机启动时初始化硬件,并执行一些自检。
- 加载UEFI驱动:UEFI固件加载并执行硬件设备的驱动程序,这样系统可以识别并使用硬件。
- 运行启动管理器:UEFI启动管理器负责查找并启动操作系统引导文件(通常是存放在EFI系统分区中的文件)。
- 操作系统加载:操作系统的引导程序被加载到内存中并执行,系统启动过程完成。
| 特点 | UEFI | BIOS |
|---|---|---|
| 引导机制 | 使用EFI文件启动,支持GPT分区表 | 使用MBR分区表引导 |
| 最大支持磁盘容量 | 超过2TB,最大支持128个分区 | 最大支持2TB磁盘,最多4个主分区 |
| 用户界面 | 支持图形化用户界面 | 文本模式界面 |
| 启动速度 | 通常比BIOS更快 | 相对较慢 |
| 安全功能 | 支持安全启动(Secure Boot) | 无内置的安全机制,易受引导区病毒攻击 |
| 多操作系统支持 | 更好地支持多操作系统启动和兼容性 | 较为简单的多操作系统启动,兼容性较差 |
| 扩展性 | 支持更多的硬件、网络引导和其他现代功能 | 限制较多,难以支持新硬件 |
我们可以发现:
.<.~mitsumi.....
...@............
......)./W~NO NA
ME FAT12 ..
.[|.".t.V.......
^..2.......This
is not a bootabl
e disk. Please
insert a bootabl
e floppy and..pr
ess any key to t
ry again ... .. 它提示这并不是一个可引导的软盘或存储设备,并且设备未正确配置为引导。这是一个常见的错误信息。如果用户尝试从一个非引导软盘启动,系统会显示这个错误信息。
回到题目,我们对DOS引导扇区进行提取:
zsteg -e "b8,rgb,lsb,xy" attachment.png > DOS

我们挂载DOS引导扇区:
sudo losetup /dev/loop0 attachment.img
sudo mount /dev/loop0 /mnt/
查看内容发现是一堆ICO图片:

没有找到flag,我们推测是被删除了,我们需要尝试恢复文件
为了能够恢复文件,我们可以使用恢复引导扇区数据的工具TestDisk
TestDisk
是一款免费且开源的数据恢复软件,主要用于恢复丢失的分区以及修复无法启动的磁盘。
恢复引导扇区数据的原理
扫描磁盘:TestDisk 首先会扫描磁盘以识别分区和引导扇区。
识别损坏的引导扇区:如果 TestDisk 检测到引导扇区受损或不可读,它会通过分析分区的结构和文件系统元数据来判断问题。
与备份引导扇区对比:TestDisk 会自动检测分区的备份引导扇区(如果存在,在某些文件系统(如FAT和NTFS)中,会存储一个备份的引导扇区。FAT32文件系统将备份引导扇区存放在卷的第6个扇区,而NTFS会在其卷的末端保存备份。),并与主引导扇区进行比较。
恢复或修复:
- 如果备份引导扇区完好无损,TestDisk 可以将其复制到主引导扇区位置,从而恢复引导扇区的正确状态。
- 如果没有备份引导扇区或备份也受损,TestDisk 可以通过分析文件系统中的现有数据结构,尝试重新生成一个有效的引导扇区。
我们进行恢复数据:
testdisk DOS

这个界面提示我们:
有些磁盘在没有以root用户身份运行时可能不会显示。
恢复过程中,磁盘容量必须被正确检测到,否则可能会影响恢复的成功率。
如果列出的磁盘大小不正确,建议检查硬盘跳线设置、BIOS检测,并安装最新的操作系统补丁和驱动程序。
我们可以选择[Proceed] 继续操作。如果需要提升权限,可以选择 [Sudo] 以管理员权限运行
这里我们选择继续操作:

提示未检测到任何分区表类型(None partition table type has been detected)
我们需要手动选择正确的分区表类型,具体选项包括:
[Intel]:适用于大多数使用 MBR 分区表的 Intel/PC 分区。
[EFI GPT]:适用于使用 GPT 分区表的现代系统(通常是 64 位的 Mac 和一些 x86_64 架构的设备)。
[Humax]:Humax 设备的分区表。
[Mac]:Apple 的旧分区表格式。
[None]:用于没有分区表的设备或媒介(例如一些软盘)。
[Sun]:用于 Sun Solaris 系统。
[XBox]:用于 Xbox 的分区表。
我们按照检测出的选择没有分区表的设备或媒介:

这个界面显示了 TestDisk 已经识别到磁盘上的一个分区,类型为 FAT12 文件系统。FAT12 通常用于早期的软盘(例如 1.44MB 的磁盘)
我们可以进行以下操作:
[Boot]: 检查或修复分区的启动扇区。如果该分区是可启动的,你可以使用这个选项恢复启动扇区。
[Undelete]: 恢复被删除的文件。
[Image Creation]: 创建磁盘或分区的映像文件,用于备份或进一步分析。
[Quit]: 退出当前操作。
我们选择恢复被删除的文件:

找出标红的被删除的文件,按照下面的提示按下C键复制文件:

按照提示再次按下C键即可恢复出文件,得到flag

我们也可以先进行boot操作后进行重建引导扇区,重新构建一键恢复:

[Rebuild BS]:重建引导扇区,如果引导扇区损坏,可以选择这个选项来重新构建。
[List]:查看分区中的文件列表,可能用于检查是否可以恢复文件。
[Dump]:转储扇区数据用于调试。
[Repair FAT]:修复文件分配表(FAT),如果 FAT 文件系统有问题可以尝试修复。

Extrapolated boot sector and current boot sector are different:这意味着推测的引导扇区和当前引导扇区存在差异。通常,这可能意味着引导扇区已损坏或者被修改了,这里是我们已经进行了重建修复了,那么我们可以转储出其中恢复的文件
[Dump]:将数据转储出来,用于进一步调试或分析。
[List]:列出分区中的文件和目录。你可以使用这个选项查看能否访问文件。
[Write]:将修复的引导扇区或其他信息写入磁盘,但这需要谨慎操作。
[Quit]:退出当前操作。
补充:磁盘精灵
一款功能强大的磁盘管理和数据恢复软件,广泛用于磁盘分区管理、数据恢复、磁盘备份与克隆等任务。它不仅适合专业用户进行复杂的磁盘操作,也适用于普通用户对磁盘进行日常管理。
在此我们也可以使用磁盘精灵(破解版)对数据进行恢复(恢复linux系统的EXT 文件系统可能会失效):


考点:LSB隐写、理解DOS引导扇区是什么、使用TestDisk恢复数据
[INSHack2017]hiding-in-plain-sight(知识巩固题)
下载文件,是一个png格式的图片和题目介绍的md文件:

你的智能餐盘有一个嵌入式摄像头,可以拍摄你的饭菜,并自动上传到你的Instagram。然而,你担心它已经被泄露并且正在悄悄地与你的所有追随者分享信息。贝洛是最后一张上网的照片。
在坏人行动之前找到泄露的信息!
第一眼以为要按照这图片进行社工打击吓死我了
按照图片隐写的思路,第一步无果,我们使用010editor打开图片进行分析:

零零散散的模板分析可能藏了东西,我们使用binwalk进行提取:
binwalk -e chall.png

发现存在jpeg文件,但是提取失败了,我们尝试使用foremost
foremost chall.png

成功提取flag
考点:文件分离
[INSHack2017]remote-multimedia-controller(知识巩固题)
下载文件,是一个pcap文件,我们使用wireshark进行分析:

流量包很小,只有54条数据包记录,并且全是使用TCP协议的报文,我们直接追踪流进行分析:


前两个TCP流像是某种交互式命令系统的命令输入和输出,VERS 显示版本,PLAY、NEXT 和 QUIT 可能是常见的控制命令

RDBD是远程调试器(Remote Debugger)的缩写,表明这是一个调试会话的输出内容
Command: 0x7ffdff7d2730是一个内存地址,表明可能在调试过程中正在执行某个命令或访问某个内存地址。
client_sd: 4这可能是客户端套接字描述符的值,用于网络通信或进程间通信的调试环境。
后边的乱码字符和十六进制格式的数据看起来像是某种内存转储数据,包括一些特殊字符序列,可能代表二进制数据或某些字符串、指令集等。
总而言之最终回显了flag.txt经编码的值,我们放进cyberchef直接进行解码即可得到flag:

考点:流量分析
[WMCTF2020]行为艺术(新知识巩固题)
下载文件,是一张png格式的图片和提示文本:

提示应该是计算出flag.zip的md5值并给了出来方便我们验证
我们从图片开始分析,第一步将图片拖入tweakpng报错:

按照报错内容crc校验值出错,说明这里存在png宽高隐写内容,我们进行宽高爆破并且进行修改:


我们继续分析图片中的内容,发现开头的50 4B 03 04是zip文件头,所以说明这张图片就是zip压缩文件的16进制内容,我们要一个一个敲吗?也不是不行
这里我们可以使用Python 的 OpenCV 和 Pytesseract 库对其中的文字进行自动识别
OpenCV
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库,用于开发实时图像处理和计算机视觉应用。它由 Intel 于 1999 年开发并发布,现由 OpenCV 社区进行维护。OpenCV 广泛应用于工业、研究、机器人、自动驾驶、图像识别等领域,支持多种编程语言(如 C++、Python、Java 等),并且能够在多个平台上运行(如 Windows、Linux、macOS 和 Android)。
Tesseract
Tesseract 是一个开源的光学字符识别(OCR)引擎,它可以将图像中的文本转换为可编辑的文本格式。它最早由惠普开发,现在由 Google 维护和改进。
下载地址:Home · UB-Mannheim/tesseract Wiki (github.com)
下载后使用以下脚本:
import cv2
import pytesseract
import numpy as np
# 如果你在Windows上,指定Tesseract的路径
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def preprocess_image(image_path):
# 读取图像
image = cv2.imread(image_path)
# 转为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊来减少噪声
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 自适应阈值进行二值化处理
binary_image = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
# 中值滤波进一步去噪
denoised_image = cv2.medianBlur(binary_image, 3)
# 形态学操作可以用来增强图像
kernel = np.ones((2, 2), np.uint8)
processed_image = cv2.morphologyEx(denoised_image, cv2.MORPH_CLOSE, kernel)
return processed_image
def recognize_text(image):
# 使用Tesseract并指定手写字符集。你可以添加更多参数来提高识别效果
custom_config = r'--oem 1 --psm 6 -c tessedit_char_whitelist=0123456789ABCDEF'
# 使用 Tesseract 识别文本
text = pytesseract.image_to_string(image, config=custom_config)
return text
def main():
image_path = 'attachment.png' # 替换为你的图片路径
# 预处理图像
processed_image = preprocess_image(image_path)
# 识别文本
text = recognize_text(processed_image)
# 打印识别结果
print("识别到的文字:")
print(text)
# 显示原图和处理后的图像
cv2.imshow("Original Image", cv2.imread(image_path))
cv2.imshow("Processed Image", processed_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
但是这里的输出并不正确,因为没有训练集就开始做手写字体的识别是相当有难度的
所以这里就一个个敲了(麻烦的要死了):
504B0304140000000800DB93C55086A3
9007D8000000DF01000008000000666C
61672E74787475504B0E823010DD9370
8771DDCCB0270D5BBD0371815A9148AC
6951C2ED9D271F89C62E2693D7F76BB7
DE9FC80D2E6E68E782A326D2E01F81CE
6D55E76972E9BA7BCCB3ACEF7B89F7B6
E90EA16A6EE2439D45179ECDD1C5CCFB
6B9AA489C1218C92B898779D765FCCBB
58CC920B6662C5F91749931132258F32
BBA7C288C5AE103133106608409DAC41
9F77241A3412907814AB7A922106B8DE
D0D25AEC8A634929025C46A33FE5A1D3
167A100323B1ABEE4A7A0708413A19E1
7718165F5D3E73D577798E36D5144B66
315AAE315078F5E51A29246AF402504B
01021F00140009000800DB93C55086A3
9007D8000000DF010000080024000000
000000002000000000000000666C6167
2E7478740A0020000000000001001800
4A0A9A64243BD601F9D8AB39243BD601
2D00CA13223BD601504B050600000000
010001005A000000FE00000000000000
我们将输出作为十六进制文件编辑,得到zip文件:

我们可以使用cyberchef校验一下发现MD5值正确:

我们尝试进行解压,发现加密了,发现是伪加密,我们修改后进行解压得到编码后的flag:


brainfuck编码老朋友了:

考点:png宽高隐写、使用机器学习库进行图像识别、理解brainfuck编码
[XMAN2018排位赛]AutoKey(新工具知识巩固题)
下载文件,是一个pcapng文件,我们使用wireshark打开:

是USB流量,我们可以看出是键盘流量,使用UsbKeyboardDataHacker脚本进行分析即可:

可以发现输出的内容为:
<CAP>mplrvffczeyoujfjkybxgzvdgqaurkxzolkolvtufblrnjesqitwahxnsijxpnmplshcjbtyhzealogviaaissplfhlfswfehjncrwhtinsmambvexo<DEL>pze<DEL>iz
我们进行处理(<DEL>操作会删除前一个输入的字符):
mplrvffczeyoujfjkybxgzvdgqaurkxzolkolvtufblrnjesqitwahxnsijxpnmplshcjbtyhzealogviaaissplfhlfswfehjncrwhtinsmambvexpziz
看上去是一串密文,我们应该进行解密,但放进cyberchef没有任何反应,按照题目提示我们应该去探索一下什么是AutoKey
AutoKey加密
AutoKey 是一种基于 Vigenère 密码 的加密方式,它属于多表代换密码。与传统的 Vigenère 密码不同,AutoKey 密码通过使用部分明文作为密钥的一部分,从而避免了重复使用短密钥带来的弱点。
这种方式比 Vigenère 密码更安全,但仍然容易受到某些现代密码分析技术(如频率分析)的攻击。
总的来说,AutoKey 是 Vigenère 密码的改进版本,但已经被现代的加密标准(如 AES)所取代。
在此给出破解AutoKey加密的工具脚本(来自Practical Cryptography,配置文件来自Practical Cryptography):

运行脚本在其中发现密钥为“FLAGHERE”的明文,得到flag:

考点:USB流量分析、理解AutoKey加密
[INSHack2018] (not) so deep(新工具知识巩固题)
下载文件,是一个wav格式的音频,听声音是非常奇怪的电磁波声
按照音频隐写的思路,我们使用Audacity分析,在频谱图中发现了一半flag:

第三步无果,我们推测剩下的一半flag使用了特殊工具进行了隐写
按照题目中的“deep”,我们推测使用了deepsound这款音频隐写的工具
DeepSound
DeepSound 是一款用于将秘密信息嵌入音频文件中的隐写工具。它可以将文本、图片或其他文件隐藏在音频文件中,而不会显著影响音频质量。
我们将wav音频导入,发现分析隐藏文件需要密码:

DeepSound 加密使用的密码哈希是可以被破解的,在此我们使用deepsound2john得到音频文件的hash值:

得到hash值后,我们在hashcat的官网上查询相关文件的哈希算法,并没有任何发现,所以这次我们不能使用hashcat进行分析了
那么我们就只能尝试使用默认字典了,我们将hash值存入2.txt中,使用命令:
john 2.txt

我们可以发现john首先是使用了/usr/share/john/password.lst这默认字典,之后通过生成所有可能的 ASCII 字符组合逐步尝试密码,直到找到匹配的密码(一般会破解超级久)
我们得到了密码azerty,导入deepsound:

得到了隐藏文件flag2.txt,点击Extract secret files进行文件分离,打开组合得到flag
考点:理解频谱图、理解工具deepsound、会使用john对hash进行破解
[QCTF2018]X-man-Keyword(新密码脑洞知识巩固孬题)
下载文件,是一张png格式的图片文件,图片中的内容揭示了keyword:lovekfc
按照图片隐写思路,第一步、第二步、第三步无果,那么就是使用了特殊工具的隐写了
我们使用zsteg进行分析:

并没有分析出什么,接下来我们使用cloacked-pixel进行分析:
python2 lsb.py extract attachment.png 1.txt lovekfc

提交发现并不是flag,使用了ROT13爆破都没有得到正确的flag

按照提示1将keyword放到了flag前面也不是flag
再按照提示2,一种把关键词提前的置换,也就是说keyword作为关键词提前并且是置换密码
那么可能是将“lovekfcabdghijmnpqrstuwxyz”作为了密钥,这可能是一种多表置换的密码
我们可以确定PVSF对应QCTF(查了发现X-man的flag格式)
P经过密钥l加密成了Q
V经过密钥o加密成了C
S经过密钥v加密成了T
F经过密钥e加密成了F
并没有从上面的加密发现相关的规律,在此再次放开了脑洞:
密钥表:lovekfcabdghijmnpqrstuwxyz P位于17 Q位于18 V位于3 C位于7
字母表:abcdefghijklmnopqrstuvwxyz P位于16 Q位于17 V位于22 C位于3
可以发现密文在密钥表中的位置对应着明文在字母表中的位置
通过上面的发现我们找出了密文的加密方式,接下来我们就可以编写脚本进行解密了:
def decrypt(ciphertext, key_table, alphabet):
# 创建密钥表到字母表的映射
key_to_alpha = {key_table[i]: alphabet[i] for i in range(len(key_table))}
# 解密密文
plaintext = ''.join(key_to_alpha.get(char, char) for char in ciphertext)
return plaintext
# 密钥表和字母表
key_table = 'lovekfcabdghijmnpqrstuwxyzLOVEKFCABDGHIJMNPQRSTUWXYZ'
alphabet = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
# 密文
ciphertext = 'PVSF{vVckHejqBOVX9C1c13GFfkHJrjIQeMwf}'
# 解密
plaintext = decrypt(ciphertext, key_table, alphabet)
print('明文:', plaintext)

得到了flag
考点:使用了特定工具进行的图片文件隐写、脑洞大开想出加密方式
[INSHack2017]10-cl0v3rf13ld-lane-signal(知识巩固题)
下载文件,是一个unk格式的文件和提示文本:

不知道unk是什么格式的文件,我们优先使用010editor进行分析:

看到文件头,原来是jpeg文件,我们修改后缀得到图片,我们继续分析,发现文件尾藏有png图片:

文件分离后得到一张摩斯电码表:

仔细观察发现左下角藏着摩斯电码内容,我们进行解码:

记录下来,说不定是什么密码
我们继续分析png图片,发现文件尾又藏了东西:

OGG格式的音频
这是一种开放容器格式,常用于存储音频数据,如 Vorbis 编码的音频。OGG 文件可以包含多种类型的数据,但最常见的是 Ogg Vorbis 音频。
听一下发现是摩斯电码的信号声,我们使用Audacity进行分析方便我们输出解码得到flag:


考点:文件分离、理解摩斯电码
[MRCTF2020]寻找xxx(知识巩固孬题)
下载文件,发现里面是一个wav格式的音频文件
播放音频,发现是电话拨号音
使用dtmf2num进行分析:
dtmf2num.exe 密码.wav

我们尝试提交,发现并不是flag
我们使用Audacity分析频谱图,发现有很多杂音可能影响了判断:

我们边听边分析,前4个1868应该没有问题,但第5个音明显与第4个音不同,因此“88”这一段可能存在误判,只含有1个8
继续分析,“222”处只出现两个相同的音,因此应该只含有2个2
最后音的数量与输出的数量不一致,应该是被杂音误判了
那么正确输出可能是
18684221609
186842216D9
186842216D0
都不是flag,上网一搜发现要发送给公众号...

考点:理解DTMF拨号音
补充:网上WP使用sonic visualier进行分析
Sonic Visualiser 是一款开源的音频分析工具,专为音乐和音频数据的可视化而设计。它允许用户对音频文件进行详细的分析,支持多种分析和可视化方式。
将音频导入,查看频谱图

配置参数方便分析:


根据左边的频率手动分析出所有DTMF信号,就比如第一个音的高频在1209附近、低频在697附近,因此第一个音分析为1,以此类推

同理我们也可使用Audacity分析频谱图,但是不够直观:

一路到底(新)
下载文件,里面一堆txt解压都解压半天:

发现了start.txt

给了我们数字20555,并且给出了下一个文件的地址,我们按照它说的继续探索:

这一次给了我们772,这些数字都是什么意思?
经过探索,我们发现这些数字经过十六进制转换后得到的内容为ZIP文件的文件头(304要补位补成0304):


这样我们就有了清晰的逻辑:从start.txt开始,提取txt中的数字并进行十六进制转换保存到变量中(十六进制转换的值要保存为4字节内容),再提取末尾提取最后 36 个字符作为下一个txt文件的名称来读取下一个txt文件再循环以上步骤
可以编写以下脚本:
import binascii
flag = ''
with open('start.txt') as f:
cont = f.read()
next = cont[-36:] # 提取下一个文件名
flag += '{:04x}'.format(int(cont[0:cont.find(':')-1])) # 提取数字并转换为十六进制
while True:
path = next
try:
with open(path) as f:
cont = f.read()
next = cont[-36:] # 提取下一个文件名
flag += '{:04x}'.format(int(cont[0:cont.find(':')-1])) # 提取数字并转换为十六进制
except :
break
# 将 flag 写入 1.txt
with open('1.txt', 'w') as f:
f.write(flag)
(有参考BUUCTF:一路到底_buuctf 一路到底-CSDN博客)

我们将输出进行十六进制编辑,得到zip文件,发现加密了
没有任何提示也不是伪加密,我们尝试进行数字密码爆破也没有结果,那么就只能尝试字母与数字组合爆破(最多6位,爆了许久才出来):

我们解压得到png图片,图片打不开,我们使用010editor进行分析发现是文件头被修改的jpg格式的图片,我们修复:

图片中得到了flag
考点:脚本编写、压缩包爆破、图片文件头修复
[羊城杯 2020]signin(较难新脑洞)
下载文件,是含有密文的txt文件:


我们推测这是一段原创的密码,我们应该如何搜索到相关的信息呢?(提示一表人才)
Cryptology ePrint Archive
eprint.iacr.org 是国际应用密码学研究所(IACR)维护的一个在线平台,专门发布密码学领域的预印本(preprints)论文。
我们进入网址,搜索与题目相关的关键词并且加上过滤条件:
toy 玩具
Buzz 巴斯
Lightyear 光年
woody 胡迪

找到了这个标题中含有关键词的文章,我们查看:

关键的是这一段替换表,我们按照替换表编写脚本:
dic = {'M':'ACEG','R':'ADEG','K':'BCEG','S':'BDEG','A':'ACEH','B':'ADEH','L':'BCEH','U':'BDEH','D':'ACEI','C':'ADEI','N':'BCEI','V':'BDEI','H':'ACFG','F':'ADFG','O':'BCFG','W':'BDFG','T':'ACFH','G':'ADFH','P':'BCFH','X':'BDFH','E':'ACFI','I':'ADFI','Q':'BCFI','Y':'BDFI'}
text = ''
with open('signin.txt','r') as f:
f = f.read()
for i in range(0,len(f),4):
block = f[i:i+4]
for j in dic:
if block == dic[j]:
text += j
print(text)

我们得到了字符串,提交发现并不是flag
按照提示二表倒立,看不懂捏,但一定是对字符串“LDVUUCMEXMLQSSFUSXKEOCCG”进行的解密操作
羊城杯的flag为“GWHT”我们再将已有信息进行分析:
密码表:MRKSABLUDCNVHFOWTGPXEIQY
密文:LDVUUCMEXMLQSSFUSXKEOCCG
L——G L位于7 G位于18——倒数第7位
D——W D位于9 W位于16——倒数第9位
V——H V位于12 H位于13——倒数第12位
U——T U位于8 T位于17——倒数第8位
可以发现倒立的意思了,那么我们再写一个替换脚本即可:
dic = {'M':'Y','R':'Q','K':'I','S':'E','A':'X','B':'P','L':'G','U':'T','D':'W','C':'O','N':'F','V':'H','H':'V','F':'N','O':'C','W':'D','T':'U','G':'L','P':'B','X':'A','E':'S','I':'K','Q':'R','Y':'M'}
text = ''
with open('1.txt','r') as f:
f = f.read()
for i in range(0,len(f),1):
block = f[i]
for j in dic:
if block == dic[j]:
text += j
print(text)

成功得到flag
考点:信息收集、脑洞大开
[DASCTF X 0psu3十一月挑战赛|越艰巨·越狂热]签到(简单)
把flag贴你脑门上了
[HDCTF2019]信号分析
下载文件,是一个wav格式的音频,我们尝试听一下好像什么声都没有
我们优先使用Audacity进行分析:

波形图不放大根本看不见,频谱图就有东西藏着
我们尝试一下,发现并不是摩斯电码,我们转换成二进制:
1010101010101000000110 0101010101010101000000110 0101010101010101000000110 0101010101010101000000110(以下省略)
可以发现都是重复的频段(第一段和最后一段首尾相接)
0101010101010101000000110
根据题目名“信号分析”,又让我想起了被电单车支配的恐惧
在此我们对信号进行分析:


我们可以发现这次的信号排列方式符合PT2262系列

我们可以注意到这次没有开始的同步码,我们分析可以得到:
FFFFFFFF0001 停止码
地址码就是flag
考点:理解无线射频信号原理
[SUCTF2018]dead_z3r0(较难新工具知识巩固题)
下载文件,是一个没有后缀的文件,我们优先使用010 editor进行分析:


我们可以发现文件的开头藏有奇怪的看上去像是base64的字符串(尝试使用cyberchef解密失败了),结尾处有一些变量名,可以推测这是pyc文件需要我们反编译
我们尝试使用binwalk和foremost提取其中的pyc文件都失败了,看来只好手动提取了
我们先查一下pyc文件的文件头,要注意pyc文件头与python版本有关(参考文章:Python逆向(二)—— pyc文件结构分析 - Blili - 博客园 (cnblogs.com),也问了chatgpt):
Python 2.7: 03 F3 0D 0A
Python 3.2: 16 0D 0D 0A
Python 3.3: 33 0D 0D 0A
Python 3.4: 42 0D 0D 0A
Python 3.5: 5A 0D 0D 0A
Python 3.6: 33 0D 0D 0A
Python 3.7: 42 0D 0D 0A
Python 3.8: 50 0D 0D 0A
Python 3.9: 51 0D 0D 0A
Python 3.10: 52 0D 0D 0A
我们在文件中找到了python3.6的文件头:

我们提取文件,并给上后缀.pyc,现在我们使用工具进行反编译:
# Visit https://www.lddgo.net/string/pyc-compile-decompile for more information
# Version : Python 3.6
def encryt(key, plain):
cipher = ''
for i in range(len(plain)):
cipher += chr(ord(key[i % len(key)]) ^ ord(plain[i]))
return cipher
def getPlainText():
plain = ''
# WARNING: Decompyle incomplete
def main():
key = 'LordCasser'
plain = getPlainText()
cipher = encryt(key, plain)
# WARNING: Decompyle incomplete
if __name__ == '__main__':
main()
有些地方解密的不是很好,在此使用uncompyle6进行反编译
uncompyle6
uncompyle6 是一个用于反编译 Python 字节码(.pyc 文件)并还原为可读 Python 源代码的工具。它支持多种版本的 Python,包括 2.x 和 3.x 系列。
uncompyle6 attachment.pyc

我们可以看出这串代码中使用了encryt方式使用key对plain进行了加密
代码中给出了加密方式:使用key的ascii值与plain的ascii值进行异或加密
题目中没有给出plain的值,我们可以联想到我们最先发现文件的开头藏有奇怪的字符串,应该就是最后经base64编码的密文。
由于异或加密是可逆的,我们直接进行解密:
import base64
key = 'LordCasser'
plain = 'KTswVQk1OgQrOgUVODAKFikZJAUuKzwPCTUxMQE1Kxc8NxYYPjcgQwY7OxMhCzFDLyYFGBYjKwkXMDALAScZEycyJgooOigHEAoSDT42IEcBLCcdDiUxBi8mBRgoLBUKPgowBR04P1QnJj0cLyYFGBYjJBs5JywFL1wjHhkbMkI8KhoWFjAWXH55'
plain = base64.b64decode(plain).decode()
cipher = ''
for i in range(len(plain)):
cipher += chr(ord(key[i % len(key)]) ^ ord(plain[i]))
print( base64.b64decode(cipher).decode())

最终我们得到了提示:
y0u 4r3 f00l3d
th15 15 n0t that y0u want
90 0n dud3
c4tch th3 st3g05auru5
明文提示我们使用Stegosaurus隐写工具:
./stegosaurus -x attachment.pyc

考点:文件分离、逆向解密、使用stegosaurus工具
[NewStarCTF 2023 公开赛道]流量!鲨鱼!(知识点巩固)
下载文件,发现里面是一个pcap格式的文件,按照数据包分析思路,我们先进行协议分级:

发现HTTP协议发送的data-text-lines占比最多,我们优先过滤查看:

大部分是长度一致的404回显,我们按返回报文的长度排序:

我们可以找到其中使用上传的webshell提取经base64编码的ffffllllllll11111144444GGGGGG文件的回显
我们进行解码即可得到flag
考点:流量分析
[羊城杯 2020]TCP_IP(新孬题)
下载文件,发现里面是一个pcap格式的文件,按照数据包分析思路,我们先进行协议分级:

发现TCP协议发送的Data占比最多,我们优先过滤查看:

可以看出发送的Data内容含有交流,我们进行追踪流分析全是英语对话没啥可在意的
按照题目名称“TCP/IP”提示,我们开始分析tcp报文结构:

1. Source Port(源端口): 1234
表示报文的发送方端口号,源端口为 1234。
2. Destination Port(目的端口): 81
表示报文的接收方端口号,目的端口为 81。
3. Sequence Number(序列号): 1
表示该段的相对序列号,序列号用于确保数据包顺序正确,该报文的序列号是 1。
Next Sequence Number(下一个序列号): 24:表示下一个期望的序列号(当前报文长度为 23 字节,序列号为 1,所以下一个期望序列号为 24)。
4. Acknowledgment Number(确认号): 0
确认号字段用于确认已收到的数据。这里为 0,意味着没有确认数据。
5. Header Length(头部长度): 20 bytes (5)
TCP 头部的长度是 20 字节,对应 5 个 32-bit 字(每个字是 4 字节)。
6. Flags(标志位): 0x008 (PSH)
PSH(Push)标志:表示接收方应立即处理该数据,而不需要等待更多数据的到达。
7. Window Size(窗口大小): 53270
表示发送方当前的接收窗口大小,值为 53270,即接收方能够接受的最大数据量。
8. Checksum(校验和): 0x14e0 (unverified)
TCP 校验和,用于验证数据的完整性。目前状态是未验证的(unverified)。
9. Urgent Pointer(紧急指针): 0
紧急指针用于指示紧急数据的位置。此字段为 0,表明没有紧急数据。
10. TCP Segment Len(TCP 段长度): 23
该 TCP 报文的数据段长度为 23 字节。
11. TCP Payload (23 bytes)
表示报文中实际承载的有效数据长度为 23 字节。
一连看了几个数据包的内容,都没有什么变化
那么我们接下来开始解析IPv4协议:

1. Version: 4
该字段表示 IP 协议的版本。0100 表示 IPv4 协议。
2. Header Length(头部长度): 20 bytes (5)
头部长度为 20 字节。这里的 5 表示头部长度字段以 32 位(4 字节)为单位,5 * 4 = 20 bytes。
3. Differentiated Services Field(区分服务字段): 0x00
该字段包含 DSCP(Differentiated Services Code Point) 和 ECN(Explicit Congestion Notification),用于流量分类和拥塞通知。
DSCP: CS0 (Class Selector 0):表示默认的服务类别。
ECN: Not-ECT:表示没有使用显式拥塞通知。
4. Total Length(总长度): 63
IP 数据包的总长度是 63 字节(包括头部和数据)。
5. Identification(标识符): 0x0040 (64)
标识符用于分片时标识各个数据包,以便在接收端重组数据包。
6. Flags(标志位): 0x0
000:这里的标志位为 0,表示该包不分片。
第一位:保留位(必须为 0)。
第二位:DF(Don't Fragment)位,表示不允许分片,但这里是 0。
第三位:MF(More Fragments)位,表示该数据包是否有后续分片,此处为 0,表示没有更多分片。
7. Fragment Offset(片偏移量): 0
数据包没有分片,因此片偏移量为 0。
8. Time to Live (TTL,生存时间): 255
TTL 值为 255,表示该数据包最多可以经过 255 个路由器节点后被丢弃。TTL 主要用于防止数据包在网络中无限循环。 #之前我们做过TTL隐写的题目要记住
9. Protocol(协议): TCP (6)
协议字段值为 6,表示该 IP 数据包承载的是 TCP 协议的数据。
10. Header Checksum(头部校验和): 0x06a3
该字段用于验证 IP 头部是否正确。此处校验和为 0x06a3,但是校验状态是“未验证”。
11. Stream Index(流索引): 0
表示该数据包属于某个特定的流,该索引为 0。
一连看了几个数据包的内容,我们可以发现标识符一直在改变(源地址ip不同导致),这其中可能蕴含了标识符隐写
标识符隐写
标识符隐写(Identifier Steganography)是一种利用网络协议的标识符字段进行信息隐藏的技术。它属于网络隐写术(Network Steganography)的一种,通过将数据嵌入到通信协议中的特定字段或部分,而不影响正常通信流程。这种技术在不被察觉的情况下隐藏信息,因此可以用于隐蔽通信、信息传输等目的。
我们使用tshark提取其中所有ipv4协议的标识符:
tshark -r attachment.pcap -T fields -e ip.id > 1.txt
提取出的字符进行ascii解码得到:

一串乱码,cyberchef解不开
试了很久,看了别人的WP发型是使用base91解码得到flag
考点:流量分析、理解标识符隐写
[watevrCTF 2019]Unspaellablle(新脑洞)
下载文件,是一串剧本一样的东西:

在文本中搜索flag或ctf未果,我们上网搜索剧本相关的内容:

我们找到了原版剧本:

我们复制文本创建一个新文件,使用notepad++的compare插件将原文与题目进行对比查看哪里有不同的地方:

可以发现除了复制文本格式上的一些不同外,还有一些单词背偷偷修改了,我们一个个查看并提取其中添加的字母:
watevr{icantspeel_tiny.cc/2qtdez}
就是flag
补充
没有这种做题经验正常的思路应该是尝试读一读一些内容,会发现一些单词错误,结合题目名“Unspaellablle”去寻找正确的内容或是使用文本纠错的工具(也许可以我没试过)
考点:文件比较、脑洞大开
[BSidesSF2019]thekey(知识巩固题)
下载文件,是一个pcapng文件,我们使用wireshark打开:

是USB流量,我们可以看出是键盘流量,使用UsbKeyboardDataHacker脚本进行分析即可:

输出的flag有些拼写错误,我们修改成{my_favoritte_editor_is_vim}提交失败
发现要转成大写提交
考点:USB流量分析
[INSHack2019]Passthru(新)
下载文件,里面有提示文件、日志文件和流量包:

你是公司安全团队的一员,管理员最近在公司过滤代理上启用了拦截。
当涉及到域名白名单时,管理员非常自信。
他给了你一次捕获让你回顾。是时候证明他错了。
我们首先协议分级分析流量包:

我们发现HTTP协议占比最高,并且使用了TLS协议加密(Transport Layer security)
没有密钥我们就无法分析HTTP协议的内容,这一次的密钥没有藏在流量包里,这一次我们该如何得到密钥?
wireshark功能九——SSL/TLS调试
在 SSL/TLS 握手过程中,密钥材料会被生成并使用。将这些密钥写入日志文件后,可以在后续的流量捕获中用来解密 TLS 流量。也就是说Wireshark 可以利用 sslkey.log 中的密钥来解密 TLS 流量包。
我们按照导入密钥的步骤来:

我们分析http协议发现了一些参数很长的包,我们重点分析:

(下面 URL 中的 tbs 参数通常是与某种会话、身份验证或数据状态相关的标识符,先不必分析)
image_url=http%3A%2F%2Frequestbin.net%2Fr%2Fzk2s2ezk%3Fid%3D01b77323-6be9-4abd-b427-9f09d992a4df%26kcahsni%3Dce28456a0fd24ac21ec6&encoded_image=&image_content=&filename=&hl=fr
请求了以下参数
image_url
id
kcahsni
encoded_image
image_content
filename
hl=fr #设置语言为法语(fr)
其中kcahsni参数是不常见的,仔细观察它就是inshack比赛名的倒序,我们应该重点分析
我们将这些参数的值提取出来:
ce28456a0fd24ac21ec6
f2a8c7e8936667dbf7fe
534e490b3295c3d06c24
62646464343732627b41
34656265373037376332
34323166636461643033
30353331373634326335
30663937353965366432
66333861303164636130
f03c0a7d653539616433
1eaf89725ab93968fc52
26cd07e1f71df3dcee9f
9ef773fe97f56554a3b4
a12e3efe4b
我们尝试进行解码:

貌似一堆乱码,但已经出现flag格式{}的雏形了,考虑到参数kcahsni是倒序的inshack,说不定我们解码也需要逆序(在此尝试了多种情况):


最后能够得到flag的情况是按照参数传入顺序倒序读取,最后再进行逆序
考点:理解wireshark的SSL/TLS调试功能、流量分析
[NPUCTF2020]碰上彩虹,吃定彩虹!(很难新工具知识巩固题)
下载文件,里面是三个文件:

从lookatme开始分析,是一串字符串,不知道是密文还是解密用的密码,先记录,并且文件底下存在空格和换行:

进行替换:

尝试摩斯电码:

提示我们这串字符使用了AUTOKEY加密,我们使用脚本进行解密:

"YOUHAVEFOUNDME", CONGRATULATIONSONFINDINGMYSECRETNOWIWILLGIVEYOUTHEPASSWORDITISIAMTHEPASSWD
我们得到了密码IAMTHEPASSWD
再继续分析maybehint.txt,发现是零宽字符隐写。我们使用在线网站解密:

出现了乱码,我们先使用vim观察一下原文:

不懂其中的原理(待补充),只好多次尝试修改设置,最后还是成功得到了提示


提示我们这里存在NTFS隐写,我们使用工具进行查看:

我们得到了隐藏的out.txt文件,里面是一堆字符
我们进行分析,字符串只由几种字符组成:
=
w
Z
l
8
W
c
n
d
j
d
G
我们进行字频统计:


提示为encrypto
encrypto
Encrypto 是一款简单易用的文件加密工具,允许用户通过拖放文件进行加密。它提供强大的加密算法(如 AES-256)来保护文件内容,并支持设置密码以确保安全性。用户可以方便地分享加密文件,接收者需要输入正确的密码才能解密。Encrypto 的界面友好,适合非技术用户,同时也支持高级用户进行自定义设置。它在保护敏感数据和文件共享方面非常实用。
我们继续分析secret文件,文件头MPE1正是经encrypto加密后的文件,后缀为.crypto


使用之前得到的密码,等了半年都解不开。。。
看了网上的WP,是secret文件里面藏了一段。使用strings命令可以看出来:
strings secret.crypto

我们使用010editor对这段进行删除,总算解密成功!得到一张png图片:

按照图片隐写思路,第一步无果,我们使用010editor进行分析发现zip压缩包:

又是加密的压缩包(不是伪加密),我们一边爆破一边继续对图片进行分析,使用stegsolve也没有什么发现,想起了之前做过的题目——很好的色彩呃?
这里可能使用了颜色隐写术:


最后得到
70 40 73 73 57 64

成功解压压缩包得到一个docx文件:

分析密文:
大部分都是小写字母epacisj
大写字母有ALPHUCK
ALPHUCK
ALPHUCK 是一种基于简单加密和隐写术的工具,旨在通过使用字符的替代、变换或排列来隐藏信息。它通常用于创建难以被识别的加密文本,以保护敏感信息。该工具的设计可以包括对字符的替换、伪装和嵌入等技术,使得隐藏的信息在表面上看似无意义,从而提高数据的安全性。
使用在线运行代码的工具得到了flag:

考点:隐藏的摩斯电码、零宽字符隐写、理解NTFS隐写、字频统计、隐藏的十六进制干扰字符、encrypto工具的使用、颜色隐写术、文件分离、理解ALPHUCK代码
[羊城杯 2020]逃离东南亚(较难新知识巩固题)
下载文件,是三个日记的压缩包:

我们从日记1开始分析,里面是一张png格式的图片和日记:

按照图片隐写思路,第一步使用TweakPNG工具发现图片的crc校验出现错误,因此可能存在PNG宽高隐写

修改宽高得到压缩包密码:

成功解压日记2的压缩包,打开发现三个文件:

我们先从test中寻找求救信号吧,使用010editor进行分析:

brainfuck老朋友了,但我们尝试解密出现了乱码:

这时我们需要知道,brainfuck编程语言中[表示开始一个循环,条件是当前内存单元的值不为 0。当内存单元的值为 0 时,循环会结束并跳到相应的 ]。而在开头brainfuck当前内存单元的初始值为0,我们一般使用++++++++进行8次加法操作,表示在当前内存单元中将值增加到8。(不信去看看前面的brainfuck题目都是++++++++开头的)
我们添上,又是得到一串字符:

丢进cyberchef得到了elf程序文件:

提取出来,运行看看:

使用IDE看看也没啥玩意,看来求救信号已经被搞走了:

那么开始从音频分析了,听一下是住手你们不要再打了啦的音频
按照音频隐写思路,第一步、第二步、第三步无果,我们使用steghide无果,那么使用silenteye发现了密码:

解压日记3成功,发现这次给的是个源码文件夹:

按照提示肯定是将求救信息隐藏在其中几个源码文件中了(上百个源码文件。。。)
提示说不能直接明文交流,不能很容易被公司审计专员看出来,那么可能又是一堆空行的内容(空格和tab键的组合),我们需要从.c源码文件中寻找到这些组合
我们可以编写脚本来寻找含有“ \t ”组合的.c文件:
import os
def find_tab_in_c_files(directory):
# 遍历给定的目录及其子目录
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith('.c'): # 只检查以 .c 结尾的文件
file_path = os.path.join(root, file)
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
if '\t' in content: # 查找是否包含制表符
print(f"Found '\t' in: {file_path}")
except (UnicodeDecodeError, IOError) as e:
print(f"Could not read file: {file_path}, due to {e}")
# 指定你要遍历的文件夹路径
directory = 'C:\Users\SuperSnowSword\Desktop\组会\attachment\日记3\source_code' # 请将此处替换为实际的文件夹路径
find_tab_in_c_files(directory)

我们从第一个文件开始分析:

我们可以发现所有隐藏的信息都在“}”后边,因此我们可以编写脚本对其进行提取和修改:
def process_c_file(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
# 遍历每一行
for line_num, line in enumerate(lines, 1):
if '}' in line:
# 查找 '}' 的位置
index = line.find('}')
# 提取 '}' 后面的内容
after_brace = line[index + 1:]
# 将空格替换为 '0',将制表符替换为 '1'
transformed = after_brace.replace(' ', '0').replace('\t', '1')
# 输出行号和转换后的结果
print(f"Line {line_num}: {transformed.strip()}")
except (UnicodeDecodeError, IOError) as e:
print(f"Could not read file: {file_path}, due to {e}")
# 指定1.c文件的路径
file_path = r'C:\Users\SuperSnowSword\Desktop\组会\attachment\日记3\source_code\elf\rtld.c' # 请将此处替换为实际的文件路径
process_c_file(file_path)
输出不是很好,但我们还是成功提取到了需要的内容


找到求救信号了!我们接下来继续输出剩下文件的内容:

考点:png宽高爆破、理解brainfuck编码、silenteye隐写、多文件分析
[NPUCTF2020]签到(孬题)
下载下来是一个mc地图:

不知道你们玩不玩我的世界,反正我玩。用HMCL启动器打开:

为了防止世界地图出现错误,下载相应版本进行游戏:

这里说要找到灯的开关,但我们先不急,反正是创造模式我们出去看看红石电路:

原理是我们拉下开关后,沙子和龙蛋不断下落,每次都会形成不同的回路:

根据实验可以发现:当红石全灭或全两时,灯泡常亮;当红石只有一边亮时,灯泡闪烁。
沙子使红石亮,龙蛋使红石暗
这样的话就像是做类似于异或操作一样,沙子作为0,龙蛋作为1,不断下落进行计算观察,相同则灯泡常亮记为1;不同则灯泡闪烁记为0
观察了下灯闪烁的结果与外边固定的组合不同(不知道是不是龙蛋和沙子下落时间不同造成了相应的误差)
以灯闪烁的结果为准,录制了视频并进行分析得到了结果:
001110010110000100111001

上网查了才知道原来是要进行md5大写后再提交
考点:玩我的世界
[BSidesSF2020]barcoder(简单)
下载文件,是一张图片和提示:

条形码被遮挡了,但又没有完全遮挡,这就需要我们去手动修复
条形码算是一种一维码,只要有了一部分的宽度就可以尽情修复:
我们先选中一部分未遮挡的内容

然后进行自由变形拉伸即可

(或者是直接用笔工具进行修复也行吧)

使用工具bctester进行扫描即可得到flag

考点:一维码修复
[GKCTF 2021]0.03(知识巩固题)
下载文件,里面是一个无效的zip和secret提示:

我们使用010editor对zip文件进行分析:

没有任何成果,按照压缩包名给出的“flag_in_the_disk”的提示,我们尝试将其作为磁盘进行挂载,由于不知道它使用的文件系统我们先从windows的VeraCrypt开始挂载:

发现需要密码,不输入密码尝试挂载失败,尝试使用secret.txt中的密码进行挂载失败,分析了很久的secret.txt中的密码没有结果,按照txt文件隐藏信息的思路再返回上一层去查看题目给的0.03rar压缩包发现了NTFS隐藏的文件:


又给出一张密码表,数字与表格矩阵形成对应关系:
311——E
223——B
313——C
313——C
112——A
122——F
312——D
312——D
313——C
311——E
成功挂载磁盘得到flag:

考点:NTFS隐写、密码解密、理解磁盘挂载
[INSHack2018]Spreadshit(新知识巩固题)
下载文件,是一个.ods表格和提示文档:

打开表格文件发现什么都没有:

我们全部选中,给字体上所有buff(加粗斜体下划线染色),找到了蹊跷(用边框的滑块找不然office会自动扩展):

找到了由空格组成的信息,我们将含有空格的表格进行填充:

修改表格长宽:

得到flag
考点:理解excel文件隐藏信息的方式
[羊城杯 2020]image_rar(知识巩固孬题)
下载文件,解压是一个mp4文件:

是雷军的经典鬼畜视频,由于时长太长了所以难以逐帧分析,在此我们使用010editor进行分析:

Box[3]后边的内容难以解析了,可能存在插入隐藏的信息,我们使用binwalk分析:
binwalk -e xiao_mi2.mp4

解析出了很多图片文件和一个压缩包:

是bad apple的MV,我们在其中发现了一个无法显示缩略图的图片,我们重点分析(而且几张图片也提示我们重点分享这个文件)

按照图片隐写思路,第一步无果,我们使用010 editor进行分析:

模板无法解析,文件头字符为ara!,没有这种文件头,但能让人联想到rar文件
我们尝试改成Rar!作为文件头,打开文件需要密码
题目没有任何有关密码的提示,我们只好开始爆破,但导入ARCHPR失败了:

我们使用file命令调查文件可以发现,题目给出的rar文件使用的是RAR5。RAR5是WinRAR 5.0及更高版本使用的一种压缩文件格式,它在安全性和压缩算法方面进行了改进,提供了更强的加密和压缩效率,所以ARCHPR难以破解。

RAR5的加密方式没有找到很好的爆破工具,这里就使用hashcat进行爆破
使用以下命令输出rar文件的hash值:
rar2john 65.rar

我们保存rar的hash值至1.txt中然后打开example_hashes hashcat wiki这个网站查找相关文件的哈希算法

编号为13000,我们开始爆破(用了先前的纯数字字典和默认字典失败了,网上说原题有提示密码是GWXXXX)
hashcat -m 13000 -a 3 -o cracked.txt 1.txt GW?a?a?a?a
-a 指定攻击方式,3表示使用掩码攻击
GW?a?a?a?a 指定掩码,?a表示所有可打印字符(大小写字母、数字、特殊字符)
跑了非常非常久猜得到最终的密码:

解压文件,得到一个没有后缀的flag文件,我们使用010editor进行分析:

发现是png图片,我们加上后缀打开即可得到flag:

考点:文件分离、压缩包爆破
[QCTF2018]picture(孬题)
下载文件,是一个没有后缀的文件我们使用010editor进行分析:

是一个png图片,我们加上后缀后继续分析

按照图片隐写思路,第一步、第二步、第三步无果,我们使用zsteg也没有东西,使用cloacked-pixel需要密码
上网查了WP发现,密码就是图片中的文字首字母wwjkwywq
原题的话会有提示:

提示我们文件名里面藏了这个密码
有了提示我们就可以进行解密了:
python2 lsb.py extract attachment.png 1.txt wwjkwywq

1.txt中留下了一大串代码:
#_*_ coding:utf-8 _*_
import re
import sys
# 定义 DES 算法中用到的置换表和 S 盒
# 初始置换表
ip= (58, 50, 42, 34, 26, 18, 10, 2,
60, 52, 44, 36, 28, 20, 12, 4,
62, 54, 46, 38, 30, 22, 14, 6,
64, 56, 48, 40, 32, 24, 16, 8,
57, 49, 41, 33, 25, 17, 9 , 1,
59, 51, 43, 35, 27, 19, 11, 3,
61, 53, 45, 37, 29, 21, 13, 5,
63, 55, 47, 39, 31, 23, 15, 7)
# 逆置换表
ip_1=(40, 8, 48, 16, 56, 24, 64, 32,
39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30,
37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28,
35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26,
33, 1, 41, 9, 49, 17, 57, 25)
# 扩展置换表
e =(32, 1, 2, 3, 4, 5, 4, 5,
6, 7, 8, 9, 8, 9, 10, 11,
12,13, 12, 13, 14, 15, 16, 17,
16,17, 18, 19, 20, 21, 20, 21,
22, 23, 24, 25,24, 25, 26, 27,
28, 29,28, 29, 30, 31, 32, 1)
# 置换表
p=(16, 7, 20, 21, 29, 12, 28, 17,
1, 15, 23, 26, 5, 18, 31, 10,
2, 8, 24, 14, 32, 27, 3, 9,
19, 13, 30, 6, 22, 11, 4, 25)
# S 盒
s=[ [[14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7],
[0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8],
[4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0],
[15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13]],
[[15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10],
[3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5],
[0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15],
[13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9]],
[[10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8],
[13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1],
[13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7],
[1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12]],
[[7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15],
[13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14,9],
[10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4],
[3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14]],
[[2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9],
[14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6],
[4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14],
[11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3]],
[[12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11],
[10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8],
[9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6],
[4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13]],
[[4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1],
[13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6],
[1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2],
[6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12]],
[[13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7],
[1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2],
[7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8],
[2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11]]]
#定义密钥的置换表
pc1=(57, 49, 41, 33, 25, 17, 9,
1, 58, 50, 42, 34, 26, 18,
10, 2, 59, 51, 43, 35, 27,
19, 11, 3, 60, 52, 44, 36,
63, 55, 47, 39, 31, 23, 15,
7, 62, 54, 46, 38, 30, 22,
14, 6, 61, 53, 45, 37, 29,
21, 13, 5, 28, 20, 12, 4);
pc2= (14, 17, 11, 24, 1, 5, 3, 28,
15, 6, 21, 10, 23, 19, 12, 4,
26, 8, 16, 7, 27, 20, 13, 2,
41, 52, 31, 37, 47, 55, 30, 40,
51, 45, 33, 48, 44, 49, 39, 56,
34, 53, 46, 42, 50, 36, 29, 32)
#定义了每轮中左移的位数
d = ( 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1)
__all__=['desencode']
class DES():
'''des 加密'''
def __init__(self):
pass
#加密
def code(self,from_code,key,code_len,key_len):
output=""
trun_len=0
#将密文和密钥转换为二进制
code_string=self._functionCharToA(from_code,code_len)
code_key=self._functionCharToA(key,key_len)
#如果密钥长度不是16的整数倍则以增加0的方式变为16的整数倍
if code_len%16!=0:
real_len=(code_len/16)*16+16
else:
real_len=code_len
if key_len%16!=0:
key_len=(key_len/16)*16+16
key_len*=4
#每个16进制占4位
trun_len=4*real_len
#对每64位进行一次加密
for i in range(0,trun_len,64):
run_code=code_string[i:i+64]
l=i%key_len
run_key=code_key[l:l+64]
#64位明文、密钥初始置换
run_code= self._codefirstchange(run_code)
run_key= self._keyfirstchange(run_key)
#16次迭代
for j in range(16):
#取出明文左右32位
code_r=run_code[32:64]
code_l=run_code[0:32]
#64左右交换
run_code=code_r
#右边32位扩展置换
code_r= self._functionE(code_r)
#获取本轮子密钥
key_l=run_key[0:28]
key_r=run_key[28:56]
key_l=key_l[d[j]:28]+key_l[0:d[j]]
key_r=key_r[d[j]:28]+key_r[0:d[j]]
run_key=key_l+key_r
key_y= self._functionKeySecondChange(run_key)
#异或
code_r= self._codeyihuo(code_r,key_y)
#S盒代替/选择
code_r= self._functionS(code_r)
#P转换
code_r= self._functionP(code_r)
#异或
code_r= self._codeyihuo(code_l,code_r)
run_code+=code_r
#32互换
code_r=run_code[32:64]
code_l=run_code[0:32]
run_code=code_r+code_l
#将二进制转换为16进制、逆初始置换
output+=self._functionCodeChange(run_code)
return output
#异或
def _codeyihuo(self,code,key):
code_len=len(key)
return_list=''
for i in range(code_len):
if code[i]==key[i]:
return_list+='0'
else:
return_list+='1'
return return_list
#密文或明文初始置换
def _codefirstchange(self,code):
changed_code=''
for i in range(64):
changed_code+=code[ip[i]-1]
return changed_code
#密钥初始置换
def _keyfirstchange (self,key):
changed_key=''
for i in range(56):
changed_key+=key[pc1[i]-1]
return changed_key
#逆初始置换
def _functionCodeChange(self, code):
lens=len(code)/4
return_list=''
for i in range(lens):
list=''
for j in range(4):
list+=code[ip_1[i*4+j]-1]
return_list+="%x" %int(list,2)
return return_list
#扩展置换
def _functionE(self,code):
return_list=''
for i in range(48):
return_list+=code[e[i]-1]
return return_list
#置换P
def _functionP(self,code):
return_list=''
for i in range(32):
return_list+=code[p[i]-1]
return return_list
#S盒代替选择置换
def _functionS(self, key):
return_list=''
for i in range(8):
row=int( str(key[i*6])+str(key[i*6+5]),2)
raw=int(str( key[i*6+1])+str(key[i*6+2])+str(key[i*6+3])+str(key[i*6+4]),2)
return_list+=self._functionTos(s[i][row][raw],4)
return return_list
#密钥置换选择2
def _functionKeySecondChange(self,key):
return_list=''
for i in range(48):
return_list+=key[pc2[i]-1]
return return_list
#将十六进制转换为二进制字符串
def _functionCharToA(self,code,lens):
return_code=''
lens=lens%16
for key in code:
code_ord=int(key,16)
return_code+=self._functionTos(code_ord,4)
if lens!=0:
return_code+='0'*(16-lens)*4
return return_code
#二进制转换
def _functionTos(self,o,lens):
return_code=''
for i in range(lens):
return_code=str(o>>i &1)+return_code
return return_code
#将unicode字符转换为16进制
def tohex(string):
return_string=''
for i in string:
return_string+="%02x"%ord(i)
return return_string
def tounicode(string):
return_string=''
string_len=len(string)
for i in range(0,string_len,2):
return_string+=chr(int(string[i:i+2],16))
return return_string
#入口函数
def desencode(from_code,key):
#转换为16进制
from_code=tohex(from_code)
key=tohex(key)
des=DES()
key_len=len(key)
string_len=len(from_code)
if string_len<1 or key_len<1:
print 'error input'
return False
key_code= des.code(from_code,key,string_len,key_len)
return key_code
if __name__ == '__main__':
if(desencode(sys.argv[1],'mtqVwD4JNRjw3bkT9sQ0RYcZaKShU4sf')=='e3fab29a43a70ca72162a132df6ab532535278834e11e6706c61a1a7cefc402c8ecaf601d00eee72'):
print 'correct.'
else:
print 'try again.'
是一串DES加密脚本,密钥为mtqVwD4JNRjw3bkT9sQ0RYcZaKShU4sf,密文为e3fab29a43a70ca72162a132df6ab532535278834e11e6706c61a1a7cefc402c8ecaf601d00eee72
我们使用在线工具解密失败,正常思路是只能根据源码进行逆向解密了(源码地址:):
#_*_ coding:utf-8 _*_
import re
import sys
# 定义 DES 算法中用到的置换表和 S 盒
# 初始置换表
ip= (58, 50, 42, 34, 26, 18, 10, 2,
60, 52, 44, 36, 28, 20, 12, 4,
62, 54, 46, 38, 30, 22, 14, 6,
64, 56, 48, 40, 32, 24, 16, 8,
57, 49, 41, 33, 25, 17, 9 , 1,
59, 51, 43, 35, 27, 19, 11, 3,
61, 53, 45, 37, 29, 21, 13, 5,
63, 55, 47, 39, 31, 23, 15, 7)
# 逆置换表
ip_1=(40, 8, 48, 16, 56, 24, 64, 32,
39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30,
37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28,
35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26,
33, 1, 41, 9, 49, 17, 57, 25)
# 扩展置换表
e =(32, 1, 2, 3, 4, 5, 4, 5,
6, 7, 8, 9, 8, 9, 10, 11,
12,13, 12, 13, 14, 15, 16, 17,
16,17, 18, 19, 20, 21, 20, 21,
22, 23, 24, 25,24, 25, 26, 27,
28, 29,28, 29, 30, 31, 32, 1)
# 置换表
p=(16, 7, 20, 21, 29, 12, 28, 17,
1, 15, 23, 26, 5, 18, 31, 10,
2, 8, 24, 14, 32, 27, 3, 9,
19, 13, 30, 6, 22, 11, 4, 25)
# S 盒
s=[ [[14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7],
[0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8],
[4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0],
[15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13]],
[[15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10],
[3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5],
[0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15],
[13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9]],
[[10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8],
[13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1],
[13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7],
[1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12]],
[[7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15],
[13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14,9],
[10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4],
[3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14]],
[[2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9],
[14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6],
[4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14],
[11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3]],
[[12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11],
[10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8],
[9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6],
[4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13]],
[[4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1],
[13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6],
[1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2],
[6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12]],
[[13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7],
[1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2],
[7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8],
[2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11]]]
#定义密钥的置换表
pc1=(57, 49, 41, 33, 25, 17, 9,
1, 58, 50, 42, 34, 26, 18,
10, 2, 59, 51, 43, 35, 27,
19, 11, 3, 60, 52, 44, 36,
63, 55, 47, 39, 31, 23, 15,
7, 62, 54, 46, 38, 30, 22,
14, 6, 61, 53, 45, 37, 29,
21, 13, 5, 28, 20, 12, 4);
pc2= (14, 17, 11, 24, 1, 5, 3, 28,
15, 6, 21, 10, 23, 19, 12, 4,
26, 8, 16, 7, 27, 20, 13, 2,
41, 52, 31, 37, 47, 55, 30, 40,
51, 45, 33, 48, 44, 49, 39, 56,
34, 53, 46, 42, 50, 36, 29, 32)
#定义了每轮中左移的位数
d = ( 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1)
__all__=['desdecode']
class DES():
'''解密函数,DES加密与解密的方法相差不大
只是在解密的时候所用的子密钥与加密的子密钥相反
'''
def __init__(self):
pass
def decode(self,string,key,key_len,string_len):
output=""
trun_len=0
num=0
#将密文转换为二进制
code_string=self._functionCharToA(string,string_len)
#获取字密钥
code_key=self._getkey(key,key_len)
#如果密钥长度不是16的整数倍则以增加0的方式变为16的整数倍
real_len=(key_len/16)+1 if key_len%16!=0 else key_len/16
trun_len=string_len*4
#对每64位进行一次加密
for i in range(0,trun_len,64):
run_code=code_string[i:i+64]
run_key=code_key[num%real_len]
#64位明文初始置换
run_code= self._codefirstchange(run_code)
#16次迭代
for j in range(16):
code_r=run_code[32:64]
code_l=run_code[0:32]
#64左右交换
run_code=code_r
#右边32位扩展置换
code_r= self._functionE(code_r)
#获取本轮子密钥
key_y=run_key[15-j]
#异或
code_r= self._codeyihuo(code_r,key_y)
#S盒代替/选择
code_r= self._functionS(code_r)
#P转换
code_r= self._functionP(code_r)
#异或
code_r= self._codeyihuo(code_l,code_r)
run_code+=code_r
num+=1
#32互换
code_r=run_code[32:64]
code_l=run_code[0:32]
run_code=code_r+code_l
#将二进制转换为16进制、逆初始置换
output+=self._functionCodeChange(run_code)
return output
#获取子密钥
def _getkey(self,key,key_len):
#将密钥转换为二进制
code_key=self._functionCharToA(key,key_len)
a=['']*16
real_len=(key_len/16)*16+16 if key_len%16!=0 else key_len
b=['']*(real_len/16)
for i in range(real_len/16):
b[i]=a[:]
num=0
trun_len=4*key_len
for i in range(0,trun_len,64):
run_key=code_key[i:i+64]
run_key= self._keyfirstchange(run_key)
for j in range(16):
key_l=run_key[0:28]
key_r=run_key[28:56]
key_l=key_l[d[j]:28]+key_l[0:d[j]]
key_r=key_r[d[j]:28]+key_r[0:d[j]]
run_key=key_l+key_r
key_y= self._functionKeySecondChange(run_key)
b[num][j]=key_y[:]
num+=1
return b
#异或
def _codeyihuo(self,code,key):
code_len=len(key)
return_list=''
for i in range(code_len):
if code[i]==key[i]:
return_list+='0'
else:
return_list+='1'
return return_list
#密文或明文初始置换
def _codefirstchange(self,code):
changed_code=''
for i in range(64):
changed_code+=code[ip[i]-1]
return changed_code
#密钥初始置换
def _keyfirstchange (self,key):
changed_key=''
for i in range(56):
changed_key+=key[pc1[i]-1]
return changed_key
#逆初始置换
def _functionCodeChange(self, code):
return_list=''
for i in range(16):
list=''
for j in range(4):
list+=code[ip_1[i*4+j]-1]
return_list+="%x" %int(list,2)
return return_list
#扩展置换
def _functionE(self,code):
return_list=''
for i in range(48):
return_list+=code[e[i]-1]
return return_list
#置换P
def _functionP(self,code):
return_list=''
for i in range(32):
return_list+=code[p[i]-1]
return return_list
#S盒代替选择置换
def _functionS(self, key):
return_list=''
for i in range(8):
row=int( str(key[i*6])+str(key[i*6+5]),2)
raw=int(str( key[i*6+1])+str(key[i*6+2])+str(key[i*6+3])+str(key[i*6+4]),2)
return_list+=self._functionTos(s[i][row][raw],4)
return return_list
#密钥置换选择2
def _functionKeySecondChange(self,key):
return_list=''
for i in range(48):
return_list+=key[pc2[i]-1]
return return_list
#将十六进制转换为二进制字符串
def _functionCharToA(self,code,lens):
return_code=''
lens=lens%16
for key in code:
code_ord=int(key,16)
return_code+=self._functionTos(code_ord,4)
if lens!=0:
return_code+='0'*(16-lens)*4
return return_code
#二进制转换
def _functionTos(self,o,lens):
return_code=''
for i in range(lens):
return_code=str(o>>i &1)+return_code
return return_code
#将unicode字符转换为16进制
def tohex(string):
return_string=''
for i in string:
return_string+="%02x"%ord(i)
return return_string
def tounicode(string):
return_string=''
string_len=len(string)
for i in range(0,string_len,2):
return_string+=chr(int(string[i:i+2],16))
return return_string
#入口函数
def desdecode(from_code,key):
key=tohex(key)
des=DES()
key_len=len(key)
string_len=len(from_code)
if string_len%16!=0:
return False
if string_len<1 or key_len<1:
return False
key_code= des.decode(from_code,key,key_len,string_len)
return tounicode(key_code)
if __name__ == '__main__':
print("DES 解密\n")
c=raw_input("请输入密文(长度不限):")
k=raw_input("请输入密钥(长度不限):")
print desdecode(c,k)
k=raw_input("按确定退出")

考点:特殊工具的隐写、理解DES加密
[XMAN2018排位赛]ppap(较难新知识巩固题)
下载文件,发现里面是一个pcap格式的文件,按照数据包分析思路,我们先进行协议分级:

发现TCP协议传输Data数据内容最多,我们直接过滤追踪流观察数据包找到了这个:

除了经base64编码的图片文件,里面还有对话的提示:
yaaaaaaaar, land ho!
Hey wesley, you got that flag?
Ayy, I got yer files right here, matey!
And here be the map to the booty!(注意,这个下面是另一个文件,之前我差点漏掉)
I don't understand, this isn't even a ma-
Yarrrr, the booty be buried by that which the map points to! (no spaces and no caps)Ayy, now I be off. But remember, the factor of scales be 1.02, and the neighborly sorts be limited to 50! Lastly, if ye sail the seven seas, you do be a pirate!
重点提示是其中的“没有空格和大写字母”,这可能是什么密码的提示


使用010editor发现图片还藏有很多东西,我们使用binwalk自动提取:
binwalk -e download.jpg

这里识别出了很多JPG图片却没有输出,用foremost成功了(在使用 binwalk 的时候,-e 选项会尝试提取嵌入的文件,但如果 binwalk 识别到的 JPG 图片没有适当的头尾信息,或者在提取时遇到文件系统的问题,可能就不会输出任何结果。而 foremost 是基于文件头信息来恢复文件的,它会检查文件中的特征并提取所有符合条件的文件类型,因此能成功恢复 JPG 图片)

jpg中有很多图片,zip中是一个加密的压缩包(这里可以直接使用这个网站进行字典查询找到压缩包密码从而得到flagZIP File Password Recovery Online | passwordrecovery.io,以下内容参考文章:BUUCTF-MISC-XMAN2018排位赛]ppap(详细解析)-CSDN博客)

但按照流程,我们应该分析一堆图片:
exiftool * > 1.txt
并没有密码相关的信息,我们只好先放弃
回到TCP报文,里面还有一个map to the booty的内容:

这段 XML 文件是 OpenCV 中的 Haar 级联分类器的配置文件,主要用于人脸检测或其他对象检测。
XML 文件中的内容提供了对象检测的模型,我们可以提取其中一个分析一下:

结构为:
<_>
<maxWeakCount>3</maxWeakCount>
<stageThreshold>-7.7261334657669067e-01</stageThreshold>
<weakClassifiers>
<_>
<internalNodes>
0 -1 24 1.3377459347248077e-01</internalNodes>
<leafValues>
-6.1252444982528687e-01 9.0941596031188965e-01</leafValues>
</_>
</weakClassifiers>
</_>
解析弱分类器
-
弱分类器的结构:
<maxWeakCount>: 该阶段的最大弱分类器数量(这里为 3)。<stageThreshold>: 该阶段的阈值,用于判断分类结果,通常为负值(-0.77)。如果计算结果低于这个值,说明该区域不符合目标(如人脸)。
-
内部节点:
-
<internalNodes>: 这是决策树的结构,包含多个参数。以“0 -1 24 1.3377459347248077e-01”为例:
0: 该节点的特征索引。-1: 表示没有子节点,通常表示叶子节点。24: 代表特征值的阈值索引。1.3377459347248077e-01: 该特征的阈值,用于判断该特征值与目标的关系。
-
-
叶子值:
<leafValues>: 包含该弱分类器的输出结果。这里有两个值:-6.1252444982528687e-01和9.0941596031188965e-01,分别表示当特征值小于阈值时的输出和大于阈值时的输出。
人脸检测的流程
- 图像预处理:
- 加载待检测图像并将其转换为灰度图(Haar 特征通常在灰度图上计算)。
- 特征提取:
- 级联分类器使用预定义的特征(如 Haar 特征)来分析图像。特征通过内部节点的索引提取。
- 弱分类器评估:
- 对每个检测窗口应用多个弱分类器,并根据阈值进行判断。每个弱分类器独立地给出是否为目标(人脸)的判断。
- 阶段处理:
- 如果某个阶段的弱分类器结果达不到阈值,则该检测窗口将被丢弃,继续处理下一个窗口。如果多个弱分类器通过,则继续到下一个阶段。
- 最终结果:
- 如果最后一个阶段通过,说明在该窗口中检测到了人脸,通常会在图像中用矩形框标记出来。
通过这种方式,级联分类器能够以较高的效率和准确度在图像中检测到人脸或其他目标。
我们使用以下Python 脚本实现对具体图片的处理和检测:
import os
import sys
import cv2 # cv2模块需要自行安装
# 获取所有的图片
imgs = os.listdir('jpg') # 'jpg'为分离出来的图片文件夹
# 加载用于检测的级联分类器
cascade = cv2.CascadeClassifier('download.xml') # 'download.xml'为保存的级联分类器文件
# 缩放因子和邻居数参数
scaling_factor = 1.02
min_neighbors = 65 # 提高这个值直到只剩下一张图片
for img_name in imgs:
# 加载图片并运行级联分类器
img = cv2.imread(os.path.join('jpg', img_name)) # 'jpg'为分离出来的图片文件夹
# print img
detect = cascade.detectMultiScale(img, scaling_factor, min_neighbors)
if len(detect) > 0:
print('ok')
for (x, y, w, h) in detect:
# 标记检测到的区域
cv2.line(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.line(img, (x, y + h), (x + w, y), (255, 0, 0), 2)
# 保存处理后的新图片
cv2.imwrite(os.path.join('123', img_name), img) # '123'为新建的空文件夹
能发现输出的图片:

于是我们知道了密码skullandcrossbones(就是海盗帽头上的那个)
解压压缩包得到了flag
考点:流量分析、文件分离、压缩包密码爆破、理解级联分类器和python的联动
[DASCTF X CBCTF 2023|无畏者先行]签到
签到题,没啥说的
[SUCTF2019]protocol(新脑洞)
下载文件,是一个pcapng文件,我们使用wireshark进行分析:

是USB协议,我们使用UsbKeyboardDataHacker脚本进行分析无果,说明不是键盘流量,我们仔细分析

可以发现假的flag
我们将数据包按照长度大小排序可以发现藏着PNG图片的数据包

我们直接使用foremost进行提取:
foremost usbtraffic.pcapng

现在我们要做的就是找规律了
排序规律
15张有字符的图片+10张无字符的图片 总共重复了六次
我们再看流量包中是否藏有什么线索:

我们可以看出所有的图片数据包的前方还有隐藏信息,前四位为0000~000e,无字符的图片的隐藏信息可以和有字符的图片的隐藏信息进行对应


我们进行对应:
suctf{My_u
可行,我们继续进行对应

suctf{My_usb_pr0toco1_s0_w3ak}@?YQE4YJB8
考点:流量分析、规律分析
[CFI-CTF 2018]Kadyrov's Cat(新孬题)
下载文件,是一个图片和pdf文件
原题是有提示的在此放出:
A man from the soviet union has sent you two strange documents. Find the identity of the man as well as his location.
Flag format is : CFI{Firstname_Lastname_of_City}
一个苏联人给你寄了两份奇怪的文件。找出该男子的身份及其所在位置
flag格式为:CFI{名字_姓氏_of_城市}
需要我们对文件进行电子取证找到文件作者身份信息,这涉及到社会工程学的知识
社会工程学思路:
1. 观察文件属性,可能隐藏着经纬度等信息,使用地图工具查询地址
谷歌地图:Google 地图
有些数码相机和智能手机在拍摄照片时自动生成经纬度的EXIF数据。这样做的好处是,用户可以轻松地追踪照片的拍摄地点,也可以用于整理和管理照片。
我们从图片入手:

我们我们先将经纬度的度分秒单位转换为度:
纬度 56°56'46.6259999999891761" 56.946285°
经度 24°6'18.2807999999931958" 24.105078°
这里使用了在线工具进行转换:在线经纬度和度分秒转换
我们使用地图工具进行经纬度查询:

我们就得到了城市所在地,Riga
我们再分析PDF,打开文件属性是看不出什么的:

我们需要打开pdf从中查看属性:

发现了作者的姓名Kotik Kadyrov
则flag为:flag{Kotik_Kadyrov_of_Riga}
考点:社会工程学
[*CTF2019]She(新工具脑洞)
下载文件,是RPG MAKER XP制作的一款游戏
在游戏里面随便逛一下发现要打败这个BOSS来拿到flag,这boss防御拉满根本打不动

这里我掏出了平时玩RPG游戏用的翻译工具(也能修改数值作弊)MTool ReleasePage
(使用作弊工具的时候字体可能会出问题,在工具首页更改字体即可)
战斗中直接点击胜利即可过关:

我们进入与蝙蝠对话有:

后面的房间有9个门,我们得找到开门的顺序,我一个个试了,开门顺序是382157(其他的门打不开,开完7号门后会出现隐藏房间的门)
每个宝箱的事件都是显示一个数字(我这边可能是字体原因显示不出来)打开迷你地图功能,查看分析宝箱事件:


按顺序得到数字串371269
进入隐藏房间,说是要将得到的数字组合起来MD5加密上交

进行MD5加密后上交错误,我们再对得到的两串数字进行分析:
开门顺序:382157
得到的宝箱数字:371269
要上交的绝对是得到的宝箱数字
开门顺序从小到大排序:123578
宝箱数字排序:213697
MD5加密后上交flag成功
(碎碎念:小时候我玩RPG MAKER制作的游戏挺多的,自己也用RPG MAKER VX尝试做过类《大雄的生化危机》的ARPG游戏,大伙有兴趣的可以玩玩)
上网搜WP都有游戏源文件(Game.rxproj)...?为什么我没有
考点:脑洞大开、RPG游戏exe文件逆向
[DASCTF 2023六月挑战赛|二进制专项]签到
签到题
[De1CTF2019]Mine Sweeping(较难新工具)
下载文件,是一个unity编写的游戏文件:

扫雷,根本不会玩
这次难以使用Cheat Engine了(没有明显的数值分析),所以在此使用DnSpy进行分析
DnSpy
dnSpy 是一个用于 .NET 应用程序的调试和反编译工具,允许用户查看、编辑和调试 .NET 程序的 IL 代码和资源。它支持对 DLL 和 EXE 文件进行反编译,并提供丰富的功能,如断点设置、单步调试和变量监控。dnSpy 还支持 C# 和 VB.NET,适合用于逆向工程、调试以及学习 .NET 编程。
unity开发的游戏使用的正好是C#语言,我们可以直接进行分析
Assembly-CSharp.dll是unity的程序集,所以我们反汇编这个文件就好了:

我们导入能看到这些东西,都是些啥?
Assembly-CSharp (0.0.0.0):
- 这是一个程序集(Assembly),名称为
Assembly-CSharp,版本号为0.0.0.0。该程序集通常是由 Unity 编译出的代码,包含游戏逻辑和用户自定义脚本。 - Unity 项目中
Assembly-CSharp.dll文件是主要用来存放用户编写的 C# 代码。
Assembly-CSharp.dll:
- 这是程序集的 DLL 文件,表示这个项目的编译结果。
- 下方有三个子项:
- PE:表示 Portable Executable(便携式可执行文件),这是一个通用的文件格式,包含编译的二进制代码、资源和元数据。该条目表示该程序集的结构符合 PE 格式。
- 类型引用:显示该程序集引用的类型,可以包括外部库或者其他程序集中的类型。
- 引用:表示该程序集引用了哪些其他程序集。
- {}:通常表示该程序集中的“全局命名空间”(Global Namespace)。在反编译工具(如 dnSpy)中,
{}通常用于表示未包含在任何命名空间中的类型或全局定义的类型、函数、或数据。
mscorlib (4.0.0.0):
mscorlib.dll是 .NET 框架中的核心库,包含最基础的类和功能,比如System.String、System.Int32等基础类型。版本号为4.0.0.0表示它是 .NET Framework 4.x 版本的程序集。
UnityEngine.CoreModule (0.0.0.0):
- 这是 Unity 的核心模块之一,
UnityEngine.CoreModule.dll包含 Unity 的基本功能和组件,涉及图形处理、物理引擎、输入系统等。版本号0.0.0.0可能是因为它是 Unity 打包时的一部分,未设置具体版本号。
我们重点分析{}中的内容:
Module:表示一个模块,通常是一个程序集(DLL 或 EXE 文件)中的代码。它包含类、方法、属性等。
Caller:通常指的是调用当前方法或函数的上下文或代码位置。可以帮助你了解代码的执行流程。
Elements:可能指的是集合或数组中的元素,通常是某种数据结构中的成员。
Grids:可能与 UI 组件有关,特别是在处理表格或网格布局时。它可以包含显示数据的行和列。
在Element中找到了这个:

可以发现其中有一段if判断语句,如果踩到地雷那么游戏结束
那么我们将if中的判断内容修改为false,那么if语句中游戏结束的内容永远不会执行,那么我们踩到地雷也不会GAME OVER!
我们进行修改:



打开游戏,我用了连点器加速了踩雷的过程。
踩完雷给出了二维码:

扫描二维码即可得到flag
考点:unity游戏exe文件逆向、代码审计
[RoarCTF2019]forensic(较难新)
下载文件,是.raw文件,010 editor难以分析,我们使用以下命令:
file mem.raw

Windows Event Trace Log
Windows Event Trace Log(ETL)的一种形式,通常用于记录系统和应用程序的事件。这个文件可能包含有关操作系统性能、错误和安全事件的详细信息,通常用于分析和取证。
一般是使用volatility进行分析,这次我使用了github.com/RemusDBD/ctftools-all-in-one项目尝试
首先确定内存镜像的操作系统类型、版本、架构等信息:

然后枚举进程:

可疑的进程目测两个notepad.exe mspaint.exe,是笔记和绘图的软件,可能会有输出的文件
所以我们再显示文件:
python2 vol.py -f mem.raw --profile=Win7SP1x86 filescan

输出的文件很多,我们重点关注png|jpg|gif|zip|rar|7z|pdf|txt|doc这些文件
python2 vol.py -f mem.raw --profile=Win7SP1x86 filescan|grep -E 'png|jpg|gif|zip|rar|7z|pdf|txt|doc'
我个人是将输出导入了txt文件然后进行搜索找到了这个:

出现了中文肯定是很重要的文件,我们进行分析
python2 vol.py -f mem.raw --profile=Win7SP1x86 dumpfiles -Q 0x000000001efb29f8 --dump-dir /home/zxj
-Q 指定要提取的文件的内存地址
在集成工具中直接指定文件虚拟地址即可:


不是flag,可能是什么文件的密钥,我们先保存下来
IYxfCQ6goYBD6Q
lYxfCQ6goYBD6Q
1YxfCQ6goYBD6Q
IYxfCQ6yoYBD6Q
lYxfCQ6yoYBD6Q
1YxfCQ6yoYBD6Q
没有进展了,接下来我们优先查看在终端里执行过的命令,输入以下命令:
python2 vol.py -f mem.raw --profile=Win7SP1x86 cmdscan
集成工具可以直接查看cmd历史命令:

我们可以发现cmd命令使用记录中包含了DumpIt.exe,那就说明我们应该重点分析这个进程。对此,我们可以提取DumpIt.exe进程的内存数据
python2 vol.py -f mem.raw --profile=Win7SP1x86_23418 memdump -p 1636 --dump-dir=./
这里用了自定义命令:

导出后使用foremost恢复了文件:

我们找到了加密的zip,使用之前图片中的内容进行解密即可得到flag
考点:使用Volatility进行内存取证、使用Volatility进行文件提取、使用foremost从内存转储中恢复文件
[*CTF2019]babyflash()
下载文件,是一个swf文件
swf文件
SWF(Small Web Format)文件是一种用于描述动画、矢量图形和声音的文件格式,最初由Macromedia开发(后被Adobe收购)。SWF文件广泛用于网页中,通常用于展示动画、游戏、广告和交互式内容。
以下是一些SWF文件的主要特点:
- 矢量图形:SWF文件支持矢量图形,这意味着图形可以在不失真的情况下缩放,非常适合网页应用。
- 动画支持:SWF文件可以包含复杂的动画效果,能够在用户的浏览器中流畅播放。
- 音频和视频:SWF文件不仅可以包含图形和动画,还可以嵌入音频和视频,允许开发者创建多媒体内容。
- 交互性:SWF文件支持ActionScript,一种用于编程的脚本语言,允许开发者为动画添加交互功能。
- 嵌入性:SWF文件可以嵌入到HTML网页中,用户只需点击链接即可查看内容。
尽管SWF曾经是网页内容的主要格式之一,但由于安全性和性能问题,许多现代浏览器和平台已经逐步停止支持SWF格式,推荐使用HTML5等更安全和高效的技术来替代。
这里我们使用JPEXS对swf文件进行逆向分析
JPEXS
JPEXS(JPEXS Free Flash Decompiler)是一个开源工具,用于反编译和编辑SWF文件。它允许用户提取SWF文件中的资源,如图像、音频和ActionScript代码。
我们将swf文件导入JPEXS:

我们先启动swf查看是什么东西(需自行配置flash playerFlashPlayer/README.md at main · JimmyJLNU/FlashPlayer)启动后发现就是一个不停在黑白闪烁并且放着奇怪音频的小动画
我们从形状和图像开始分析:


形状是以图像构造出来的,我们选择其一全部导出,黑白信号让我们想起了二进制信息
我们编写脚本进行识别与输出:
import os
from PIL import Image
# 设置图片文件夹路径
folder_path = './images'
# 获取文件夹中的所有PNG文件,并按数字顺序排序
png_files = sorted(
[f for f in os.listdir(folder_path) if f.endswith('.png')],
key=lambda x: int(os.path.splitext(x)[0]) # 依据文件名数字排序
)
# 打开输出文件
with open('1.txt', 'w') as output_file:
# 遍历所有PNG文件
for filename in png_files:
# 构造完整的文件路径
file_path = os.path.join(folder_path, filename)
# 打开图片并转换为黑白模式
with Image.open(file_path) as img:
bw_img = img.convert('1') # 转换为黑白模式
# 获取图片的像素数据
pixels = bw_img.getdata()
# 检查第一个像素值
first_pixel = next(iter(pixels))
if first_pixel == 0:
output_file.write('1\n') # 黑色
else:
output_file.write('0\n') # 白色
然后发现并不是二进制信息:


总共有882/2=441张图片,刚好能够组成21*21的图像,我们将1和0的输出改为(255,255,255)和(0,0,0)进行拼装看看:
from PIL import Image
# 读取qr.txt中的RGB数据
with open('1.txt', 'r') as file:
data = file.readlines()
# 假设每一行是一个像素,并且行数与列数一致(即图像是一个正方形)
# 计算图像的尺寸
image_size = int(len(data) ** 0.5)
# 创建一个新的图像
image = Image.new('RGB', (image_size, image_size))
# 填充图像的每个像素
for i, line in enumerate(data):
# 将RGB数据解析为整数元组
rgb = tuple(map(int, line.strip().strip('()').split(',')))
# 计算像素在图像中的位置
x = i % image_size
y = i // image_size
# 将RGB值设置到图像的相应位置
image.putpixel((x, y), rgb)
# 保存生成的图像
image.save('output.png')
print('Image saved as output.png')
用的是这个脚本https://www.cnblogs.com/handsomexuejian/p/18302560#tid-D4c8Qz

得到一张二维码,扫描得到了半个flag:

我们再导出音频进行分析:

频谱图藏着另一半flag
buuctf交不起,上网搜WP发现要把下划线删去才行flag{halfflag&&_the_rest}
考点:swf文件逆向分析
[网鼎杯 2020 青龙组]虚幻2(新较难题)
下载文件,是一个单纯的file
我们优先使用010 editor进行分析:

可以发现是一个png格式的图片,我们加上后缀后打开进行分析:

按照图片隐写思路,第一步、第二步无果,我们使用stegsolve进行分析:



好像都藏着点东西,我们使用zsteg进行分析没扫出个什么东西:

既然如此,我们只能在RGB不同的通道分出三张图片继续进行分析,我们先裁剪图片:

可以得到图片大小数据的差异:
R 31*10
G 31*11
B 31*10
我们对三者的黑白组合进行组合输出(黑为1白为0):
from PIL import Image
# 打开 PNG 图片
image_path = 'R.png' # 替换为你的图片路径
image = Image.open(image_path)
# 转换为黑白模式(1-bit pixels)
bw_image = image.convert('1')
# 获取图像的宽度和高度
width, height = bw_image.size
# 存储结果
result = []
# 遍历每个像素
for y in range(height):
row = []
for x in range(width):
pixel = bw_image.getpixel((x, y))
# 1 表示黑色,0 表示白色
row.append('1' if pixel == 0 else '0')
result.append(''.join(row))
# 将结果写入文件
with open('1.txt', 'w') as f:
for line in result:
f.write(line + '\n')
print("分析完成,结果已保存到 1.txt")

结果输出是乱码,这时我们仔细观察Green通道的图片,可以看出四个角落是框框一样的东西:

我们分析三张图片以某种顺序拼接在一起可能会出现类似于二维码的的图片,由于G通道比其他两个通道多了一行像素,我们先以GBR的顺序进行拼接(G一行,B一行,R一行,循环往复)
写出一个合并脚本:
# 文件路径
file1_path = '1.txt'
file2_path = '2.txt'
file3_path = '3.txt'
output_path = 'output.txt'
# 读取文件内容
with open(file1_path, 'r') as f1, open(file2_path, 'r') as f2, open(file3_path, 'r') as f3:
lines1 = f1.readlines()
lines2 = f2.readlines()
lines3 = f3.readlines()
# 计算最大行数
max_lines = max(len(lines1), len(lines2), len(lines3))
# 合并结果
result = []
for i in range(max_lines):
if i < len(lines1):
result.append(lines1[i].strip())
if i < len(lines2):
result.append(lines2[i].strip())
if i < len(lines3):
result.append(lines3[i].strip())
# 写入输出文件
with open(output_path, 'w') as output_file:
for line in result:
output_file.write(line + '\n')
print("合并完成,结果已保存到 output.txt")
然后将1和0的输出改为(255,255,255)和(0,0,0)进行拼装看看:

生成了个疑似汉信码的图片,颜色好像上反了我们进行反色修改:

左下角的定位符出了问题,我们将汉信码的矫正图形弄到该到的位置上(这里有一定愚蠢的设定,要镜像反转加旋转180°使得):



我们可以看出左下角的寻像图形位置不对,并且每个折线的延长线都有一个定位点,我们进行旋转和填涂:

剩下的随便填充可以使用中国编码APP矫正识别出来,识别不出来边扫边就撤回(注意要把汉信码放在白色背景下):



考点:lsb隐写、汉信码修复
[GKCTF 2021]银杏岛の奇妙冒险
下载文件,是我的世界游戏启动器+地图:

进入游戏,箱子里有宝剑和书:

使用指令tp到指定地址
tp 255 -41 71
传送到世界外面了,可能书上的坐标是按着小地图的XZY来的:

/tp 255 71 -41
出门有线索(差点错过)



我们传送击败web狗:


/tp 291 67 -95
我们传送击败谜语人:


/tp 324 79 -190
我们传送击败逆向爹:


觉得难打就开指令:
/effect @p minecraft:health_boost 10000 200
/effect @p minecraft:instant_health 1 233
/effect @p minecraft:strength 26666 233

为了回到出生点,我们自杀(misc妈妈的照骗辣眼睛就不放了)
/kill


最终得到flag(要用比赛的flag格式)
GKCTF{w3lc0me_t0_9kctf_2021_Check_1n}
考点:玩我的世界
[b01lers2020]image_adjustments(新)
下载文件,这次给我们的图不同寻常

在红黑相间的像素中仿佛隐藏着文字,我们仔细观察发现每列红色像素条长度都为11个像素点

也就是说当红色的像素条对其时,图片可能会出现新的信息
我们可以使用以下脚本进行
from PIL import Image
# 打开图像
img_path = "/mnt/data/attachment.png"
img = Image.open(img_path)
width, height = img.size
# 将图像转换为 RGBA 格式
img = img.convert("RGBA")
pixels = img.load()
# 创建一个新图像用于存放对齐后的结果
aligned_img = Image.new("RGBA", (width, height), (255, 255, 255, 0))
aligned_pixels = aligned_img.load()
# 对每一列进行处理
for x in range(width):
# 提取当前列的红色像素位置
red_pixels = [y for y in range(height) if pixels[x, y][0] > 200 and pixels[x, y][1] < 100 and pixels[x, y][2] < 100]
# 如果找到长度为11的红色像素条
if len(red_pixels) == 11:
# 计算第一个红色像素条的偏移位置
top_y = red_pixels[0]
# 计算移动量,使得第一个红色像素条对齐到顶部
shift_amount = top_y
# 对整列像素进行循环移位
for y in range(height):
# 新的y位置
new_y = (y - shift_amount) % height
aligned_pixels[x, new_y] = pixels[x, y]
# 保存对齐后的图像
aligned_img.save("/mnt/data/aligned_output.png")
aligned_img.show()

emmm虽然不是很完美但好歹是成功了
这里贴上别人写的脚本(来自2020 b01lers Misc image_adjustments 赛题详解 - ⚡Lunatic BLOG⚡)
from PIL import Image
from random import randint
f = './attachment.png'
img = Image.open(f)
print('Width: {}\n'.format(img.size[0]))
print('Height: {}\n'.format(img.size[1]))
pixels = img.load()
for r in range(img.size[0]):
backup_row = []
# 将每一列的像素都拷贝到新的列表中
for c in range(img.size[1]):
backup_row += [pixels[r, c]]
done = False
# 爆破每列的偏移量
for i in range(0, img.size[1]):
if done:
break
# 根据偏移量重新排列每列的像素
for c in range(img.size[1]):
pixels[r, (c + i) % img.size[1]] = backup_row[c]
# 判断红色像素段是否对齐
if (pixels[r, 2] == (255, 0, 0, 255) and pixels[r, 12] == (255, 0, 0, 255) and pixels[r, 1] == (255, 255, 255, 255) and pixels[r, 50] == (255, 255, 255, 255)):
done = True
print("Done: {}".format(r))
img.show()
考点:像素对齐
静静听这么好听的歌(新较难孬题)
下载文件,是一个txt文件和wav音频文件
首先打开txt文件,是mathlab的代码,我们进行分析
% 打开名为 '33.wav' 的音频文件,以二进制读取模式
fid = fopen('33.wav', 'rb');
% 读取音频文件中的所有字节,存储为无符号字符型(uchar)
a = fread(fid, inf, 'uchar');
% 计算音频数据的长度(去掉 WAV 头的 44 字节)
n = length(a) - 44;
% 关闭音频文件
fclose(fid);
% 读取名为 'kkk.bmp' 的图像文件
io = imread('kkk.bmp');
% 获取图像的行数和列数
[row, col] = size(io);
% 将图像数据展开为列向量
wi = io(:);
% 检查音频文件是否足够大以容纳水印
if row * col > n
error('文件太小'); % 如果水印长度大于音频数据长度,抛出错误
end
% 初始化水印音频数据,开始时与原音频数据相同
watermarkedaudio = a;
% 水印的长度为图像的总像素数
watermarklength = row * col;
% 循环将水印数据嵌入到音频数据中
for k = 1:row * col
% 在音频数据的第 44 + k 字节中设置最低位(LSB)为水印位wi(k)
watermarkedaudio(44 + k) = bitset(watermarkedaudio(44 + k), 1, wi(k));
end
% 绘制原音频数据和水印音频数据的波形图
figure;
subplot(2, 1, 1);
plot(a); % 绘制原音频
subplot(2, 1, 2);
plot(watermarkedaudio); % 绘制水印后的音频
% 打开一个新文件 '2.wav' 以二进制写入模式
fid = fopen('2.wav', 'wb');
% 将水印后的音频数据写入新文件
fwrite(fid, watermarkedaudio, 'uchar');
% 关闭新文件
fclose(fid);
这段代码的目的是将一个图像的二进制数据嵌入到音频文件中,具体是将水印信息添加到 WAV 格式的音频文件中
因此我们推测静静听这么好听的歌.wav就是加了水印的音频,我们现在要做的就是提取水印
要从 2.wav 文件中提取嵌入的水印图像 kkk.bmp,我们可以通过读取音频数据的最低有效位(LSB)来恢复图像数据,但我们并不知道kkk.bmp图像的宽高,不知道它需要读取多少数据
网上的WP说原题的题目得分为不寻常的388分,是一个特殊的数值可以作为宽或高,然后源音频文件名为33.wav我们首先尝试33作为宽或高,写出脚本:
import numpy as np
from PIL import Image
# 打开 WAV 文件并读取内容
def extract_watermark(wav_file, output_image):
with open(wav_file, 'rb') as wav:
content = wav.read() # 读取整个文件的字节内容
bins = [] # 初始化一个空列表,用于存储提取的水印位
for i in range(45, 45 + 388 * 33):
# 从第 45 字节开始读取 388 * 33 个字节
bins.append(255 if content[i] & 1 else 0) # 使用位运算提取最低有效位
# 创建 NumPy 数组并重塑为 388 行和 33 列
flag = np.array(bins, dtype=np.uint8).reshape(388, 33)
# 保存为 BMP 图像
img = Image.fromarray(flag)
img.save(output_image)
# 定义 WAV 文件和输出图像的路径
wav_file = '静静听这么好听的歌.wav'
output_image = 'res.bmp'
# 提取水印图像
extract_watermark(wav_file, output_image)
print(f"提取的图像已保存为 {output_image}")


比起33*388,388*33更像是存在拉伸的字符串,我们调整数值不断尝试


在388*50中已经初见端倪,最终在388*100中得到了flag
考点:代码审计、理解音频水印
[NewStarCTF 公开赛赛道]最后的流量分析(知识巩固题)
下载文件,是pcap文件,我们使用wireshark分析
按照数据包分析思路,我们先进行协议分级:

可以发现HTTP协议占比最高,HTTP协议在传送text data:

我们追踪HTTP流,可以发现攻击机正在尝试爆破出flag内容:

为了找出不同的回显,我们以长度排序报文:

找到了开始隐藏flag的地方,我们将这一部分报文提取即可得到flag
我们使用tshark提取长度大于765的报文内容:
tshark -r sqli.pcap -Y "data-text-lines and frame.len > 765" -T fields -e http.request.full_uri > data.txt
过滤处理一下得到flag:

考点:流量分析
[INSHack2018]GCorp - Stage 1(知识巩固题)
下载文件,是pcap文件,我们使用wireshark分析
按照数据包分析思路,我们先进行协议分级:

非常容易,我们可以看见TCP协议传输Data数据内容,我们直接过滤观察数据流:

在TCP流结尾藏着base64编码内容:

解码即可得到flag
考点:流量分析
[SWPU2019]Android1(新较难)
下载文件,是APK安装包,我们首先用模拟器运行一下看看:

点击登录软件直接退出
我们丢入GDA看看(重点分析MainActivity):

// MainActivity类,继承自AppCompatActivity
public class MainActivity extends AppCompatActivity // class@000764
{
// 定义一个EditText变量,用于输入密码
private EditText password;
// 静态代码块,加载本地库"native-lib"
static {
System.loadLibrary("native-lib");
}
// 构造函数
public void MainActivity(){
super(); // 调用父类的构造函数
}
// 声明一个本地方法Encrypt,用于加密
public native String Encrypt();
// 重写onCreate方法,Activity的入口
protected void onCreate(Bundle savedInstanceState){
super.onCreate(savedInstanceState); // 调用父类的onCreate方法
// 设置当前Activity的布局视图
this.setContentView(2131296284); // 2131296284是布局资源ID
// 为一个视图添加点击事件监听器
this.findViewById(2131165262).setOnClickListener(new MainActivity$1(this, this.findViewById(2131165275)));
}
}
// 这个类是一个匿名内部类,继承自Object并实现了View.OnClickListener接口
class MainActivity$1 extends Object implements View.OnClickListener // class@000763
{
// 引用外部类MainActivity的实例
final MainActivity this$0;
// 用于存储输入的密码EditText
final EditText val$password;
// 构造函数
void MainActivity$1(MainActivity this$0, EditText p1){
this.this$0 = this$0; // 将外部类实例赋值给this$0
this.val$password = p1; // 将EditText引用赋值给val$password
super(); // 调用父类构造函数
}
// 实现onClick方法,当视图被点击时调用
public void onClick(View view){
// 检查输入的密码是否与Encrypt方法返回的结果相等
if (this.val$password.getText().equals(this.this$0.Encrypt())) {
// 如果匹配,显示“登录成功”的Toast提示
Toast.makeText(this.this$0, "登录成功", Toast.LENGTH_SHORT).show();
} else {
// 如果不匹配,显示“登录失败”的Toast提示
Toast.makeText(this.this$0, "登录失败", Toast.LENGTH_SHORT).show();
}
return; // 返回
}
}
我们可以发现应用加载调用了本地库native-lib,并且无论是否登录成功它都不会有什么内容
因此我们主要分析本地库文件
APK中的lib文件夹
在APK压缩文件中,lib文件夹包含了与特定平台相关的本地库文件(即使用C或C++编写的代码)。这些库文件通常以.so(共享对象)文件的形式存在,分别针对不同的CPU架构。
- 平台特定的库:
lib文件夹下通常会有多个子文件夹,每个子文件夹对应一个CPU架构,比如:armeabi-v7a:针对32位ARM架构arm64-v8a:针对64位ARM架构x86:针对32位Intel架构x86_64:针对64位Intel架构
- 本地代码调用:这些本地库可以通过Java的
System.loadLibrary()方法被加载,并与Java代码进行交互。这种方式常用于性能要求较高的计算或需要直接访问系统底层功能的场景。 - 功能扩展:本地库常常用于实现一些复杂的算法、加密解密、图像处理等功能,或者集成第三方的C/C++库。
lib文件夹是APK的关键组成部分,允许开发者在Android应用中使用本地代码,以提升性能或访问特定的系统资源。
我们将.apk文件后缀改为.zip文件,打开lib文件夹,使用IDA分析其中的代码

看左边比较吸引人的函数名为:Aa aA aa AA我们跳转函数分析:




我们对代码进行分析(V3的值经过了字符的转换):
char *Aa(void)
{
int i; // 用于循环的计数器
char v2[3]; // 存储加密后的字符,长度为3
int v3; // 用于存储字符的整数表示
unsigned __int64 v4; // 存储从线程局部存储中读取的值
// 从线程局部存储中读取某个值(通常与线程安全相关)
v4 = __readfsqword(0x28u);
// 将字符'MWa'的整数表示倒序赋值给 v3
v3 = 'MWa'; // 实际上只使用了'M'和'W'的部分('a'会被忽略)
// 对 v3 中的每个字节进行异或操作,加密过程
for (i = 0; i < 3; ++i)
v2[i] = *((_BYTE *)&v3 + i) ^ 0x38; // 使用0x38进行异或
// 返回加密后的字符数组
return v2;
}
char *aA(void)
{
int i; // 用于循环的计数器
char v2[3]; // 存储加密后的字符,长度为3
int v3; // 用于存储字符的整数表示
unsigned __int64 v4; // 存储从线程局部存储中读取的值
// 从线程局部存储中读取某个值
v4 = __readfsqword(0x28u);
// 将字符'AVE'的整数表示倒序赋值给 v3
v3 = 'AVE'; // 实际上只使用了'A'和'V'的部分('E'会被忽略)
// 对 v3 中的每个字节进行异或操作,加密过程
for (i = 0; i < 3; ++i)
v2[i] = *((_BYTE *)&v3 + i) ^ 0x24; // 使用0x24进行异或
// 返回加密后的字符数组
return v2;
}
char *aa(void)
{
int i; // 用于循环的计数器
char v2[3]; // 存储加密后的字符,长度为3
int v3; // 用于存储字符的整数表示
unsigned __int64 v4; // 存储从线程局部存储中读取的值
// 从线程局部存储中读取某个值
v4 = __readfsqword(0x28u);
// 将字符'R_C'的整数表示倒序赋值给 v3
v3 = 'R_C'; // 实际上只使用了'R'和'_'的部分('C'会被忽略)
// 对 v3 中的每个字节进行异或操作,加密过程
for (i = 0; i < 3; ++i)
v2[i] = *((_BYTE *)&v3 + i) ^ 0x37; // 使用0x37进行异或
// 返回加密后的字符数组
return v2;
}
char *AA(void)
{
int i; // 用于循环的计数器
char v2[3]; // 存储加密后的字符,长度为3
char v3[13]; // 存储明文,长度为13
// 从线程局部存储中读取某个值
*(_QWORD *)&v3[5] = __readfsqword(0x28u);
// 将字符串 "5D$#" 复制到 v3 中
strcpy(v3, "5D$#");
// 对 v3 中的前4个字符进行异或操作,加密过程
for (i = 0; i < 4; ++i)
v2[i] = v3[i] ^ 0x77; // 使用0x77进行异或
// 返回加密后的字符数组
return v2;
}
我们尝试计算V2的所有密文字符:




组合起来即是flag{YouaretheB3ST}
考点:Android逆向、理解lib文件夹、分析lib文件函数
[RCTF2019]printer(新较难)
下载文件,是pcapng文件,我们使用wireshark分析

全是USB流量,看前面的都是键盘的数据包我直接使用了键盘流量分析的脚本:

得出了一串没有用的字符串,继续分析流量包,发现其中的端倪:

从第464个数据包开始,Info那一栏的信息就不再是单纯的URB_INTERRUPT in(可以推测是键盘USB设备输入)了,而是GET DESCRIPTOR Request CONFIGURATION了
USB协议报文信息
1. GET DESCRIPTOR Request CONFIGURATION
说明:主机向 USB 设备发送的请求,目的是获取设备的配置描述符。
- 请求内容:主机指定要获取的描述符类型为配置描述符。
2. GET DESCRIPTOR Response CONFIGURATION
说明:USB 设备对上述请求的响应。
- 响应内容:设备返回其配置描述符,包括设备的配置、接口数量、功耗等信息。
3. GET DESCRIPTOR Status
说明:表示 GET DESCRIPTOR 请求的状态。
- 状态内容:成功或失败的信息,指示主机是否成功接收到配置描述符。
4. SET CONFIGURATION Request
说明:主机向 USB 设备发送的请求,以设置设备的当前配置。
- 请求内容:主机指定要设置的配置编号。
5. SET CONFIGURATION Status
说明:USB 设备对上述请求的状态响应。
- 状态内容:指示配置是否成功设置,通常为成功或失败的标志。
6. GET DESCRIPTOR Request DEVICE
说明:主机向 USB 设备发送请求以获取设备描述符。
- 请求内容:主机指定要获取的描述符类型为设备描述符。
7. GET DESCRIPTOR Response DEVICE
说明:USB 设备对获取设备描述符请求的响应。
- 响应内容:设备返回其设备描述符,包括厂商ID、产品ID、设备版本等信息。
8. GET DESCRIPTOR Request STRING
说明:主机向 USB 设备发送请求以获取字符串描述符。
- 请求内容:主机指定要获取的字符串描述符类型,通常用于获取设备的字符串标识(如制造商、产品名称等)。
9. GET DESCRIPTOR Response STRING
说明:USB 设备对获取字符串描述符请求的响应。
- 响应内容:设备返回所请求的字符串描述符,包含设备的标识信息。
10. GET_DEVICE_ID Request
说明:主机向 USB 设备发送请求以获取设备 ID。
- 请求内容:请求设备的唯一标识符,通常用于识别设备。
11. GET_DEVICE_ID Response
说明:USB 设备对获取设备 ID 请求的响应。
- 响应内容:设备返回其唯一标识符,便于主机进行设备管理和识别。
12. URB_CONTROL Status
说明:通用请求块(URB)的控制状态。
- 状态内容:表示控制请求的处理状态,指示请求是否成功完成。
然后经过一系列的键盘输入,终于有了打印机与主机的通信了

13. URB_BULK out
说明:主机向 USB 设备发送数据的批量传输请求。
请求内容:主机向 USB 设备发送数据,以实现写入操作,通常用于传输大量数据,如文件传输、命令发送等。
我们查看报文内容可以发现
SIZE 47.5 mm, 80.1 mm
说明:定义了标签的尺寸。
解释:标签的宽度为 47.5 毫米,高度为 80.1 毫米。
GAP 3 mm, 0 mm
说明:设置标签之间的间隙。
解释:垂直方向的间隙为 3 毫米,水平方向的间隙为 0 毫米。
DIRECTION 0,0
说明:指定标签打印的方向。
解释:通常用来设置标签的旋转或对齐,0,0 表示不旋转,保持原始方向。
REFERENCE 0,0
说明:设置标签的参考点。
解释:通常用来定义标签的起始打印位置,0,0 表示参考点位于标签的左上角。
OFFSET 0 mm
说明:设置打印偏移量。
解释:0 mm 表示没有偏移,打印位置与标签的原点一致。
SET PEEL OFF
说明:设置标签撕离功能。
解释:启用撕离功能,打印后标签会自动撕离,以便于分发。
SET CUTTER OFF
说明:设置切割器状态。
解释:禁用切割器,打印后不进行标签切割,标签将连续输出。
SET PARTIAL_CUTTER OFF
说明:设置部分切割功能。
解释:禁用部分切割功能,标签将不会被部分切割,保持连续输出。
主机向打印机发送了
SET TEAR ON
说明:启用撕离功能。
解释:设置打印机在完成打印后自动撕离标签,方便分发。
CLS
说明:清除打印区域。
解释:清空当前打印缓冲区,准备开始新的打印任务。
BITMAP 138,75,26,48,1,<一堆数据>
说明:绘制位图图像。
参数:138(X坐标),75(Y坐标),26(宽度),48(高度),1(位图编号),<一堆数据>(位图的像素数据)
解释:在指定位置绘制一个位图。
BITMAP 130,579,29,32,1,<一堆数据>
BAR x, y, width, height
说明:绘制条形(线条)。
参数:x(X坐标),y(Y坐标),width(宽度),height(高度)。
解释:在指定位置绘制一条垂直或水平的线条。以下是各条线的详细信息:
BAR 348, 439, 2, 96
BAR 292, 535, 56, 2
BAR 300, 495, 48, 2
BAR 260, 447, 2, 88
BAR 204, 447, 56, 2
BAR 176, 447, 2, 96
BAR 116, 455, 2, 82
BAR 120, 479, 56, 2
BAR 44, 535, 48, 2
BAR 92, 455, 2, 80
BAR 20, 455, 72, 2
BAR 21, 455, 2, 40
BAR 21, 495, 24, 2
BAR 45, 479, 2, 16
BAR 36, 479, 16, 2
BAR 284, 391, 40, 2
BAR 324, 343, 2, 48
BAR 324, 287, 2, 32
BAR 276, 287, 48, 2
BAR 52, 311, 48, 2
BAR 284, 239, 48, 2
BAR 308, 183, 2, 56
BAR 148, 239, 48, 2
BAR 196, 191, 2, 48
BAR 148, 191, 48, 2
BAR 68, 191, 48, 2
BAR 76, 151, 40, 2
BAR 76, 119, 2, 32
BAR 76, 55, 2, 32
BAR 76, 55, 48, 2
BAR 112, 535, 64, 2
BAR 320, 343, 16, 2
BAR 320, 319, 16, 2
BAR 336, 319, 2, 24
BAR 56, 120, 24, 2
BAR 56, 87, 24, 2
BAR 56, 88, 2, 32
BAR 224, 247, 32, 2
BAR 256, 215, 2, 32
BAR 224, 215, 32, 2
BAR 224, 184, 2, 32
BAR 224, 191, 32, 2
BAR 272, 311, 2, 56
BAR 216, 367, 56, 2
BAR 216, 319, 2, 48
BAR 240, 318, 2, 49
BAR 184, 351, 2, 16
BAR 168, 351, 16, 2
BAR 168, 311, 2, 40
BAR 152, 351, 16, 2
BAR 152, 351, 2, 16
这些命令依次在指定的 (x, y) 坐标绘制条形,宽度和高度各不相同。绘制的条形可以用于构建图形或图案。
我们首先关注这些坐标,使用相关绘图库进行绘图(让聪明的AI来写):
import matplotlib.pyplot as plt # 导入绘图库,用于创建图形
import matplotlib.patches as patches # 导入用于绘制形状的模块
# 创建一个绘图窗口,设置大小为 8x6 英寸
fig, ax = plt.subplots(figsize=(8, 6))
# 清除画布,设置 x 轴和 y 轴的范围
ax.set_xlim(0, 400) # x 轴范围从 0 到 400
ax.set_ylim(0, 600) # y 轴范围从 0 到 600
ax.set_title('Bar and Bitmap Drawing') # 设置图形标题
# 绘制 BAR(条形)
# 定义条形的坐标和尺寸,列表中的每个元组表示 (x, y, width, height)
bars = [
(348, 439, 2, 96), (292, 535, 56, 2), (300, 495, 48, 2),
(260, 447, 2, 88), (204, 447, 56, 2), (176, 447, 2, 96),
(116, 455, 2, 82), (120, 479, 56, 2), (44, 535, 48, 2),
(92, 455, 2, 80), (20, 455, 72, 2), (21, 455, 2, 40),
(21, 495, 24, 2), (45, 479, 2, 16), (36, 479, 16, 2),
(284, 391, 40, 2), (324, 343, 2, 48), (324, 287, 2, 32),
(276, 287, 48, 2), (52, 311, 48, 2), (284, 239, 48, 2),
(308, 183, 2, 56), (148, 239, 48, 2), (196, 191, 2, 48),
(148, 191, 48, 2), (68, 191, 48, 2), (76, 151, 40, 2),
(76, 119, 2, 32), (76, 55, 2, 32), (76, 55, 48, 2),
(112, 535, 64, 2), (320, 343, 16, 2), (320, 319, 16, 2),
(336, 319, 2, 24), (56, 120, 24, 2), (56, 87, 24, 2),
(56, 88, 2, 32), (224, 247, 32, 2), (256, 215, 2, 32),
(224, 215, 32, 2), (224, 184, 2, 32), (224, 191, 32, 2),
(272, 311, 2, 56), (216, 367, 56, 2), (216, 319, 2, 48),
(240, 318, 2, 49), (184, 351, 2, 16), (168, 351, 16, 2),
(168, 311, 2, 40), (152, 351, 16, 2), (152, 351, 2, 16)
]
# 绘制条形
for bar in bars:
x, y, width, height = bar # 解包条形的坐标和尺寸
# 创建一个矩形对象,并设置边框颜色和填充颜色
rect = patches.Rectangle((x, y), width, height, linewidth=1, edgecolor='black', facecolor='black')
ax.add_patch(rect) # 将条形添加到绘图区域
# 设置图形的宽高比为1,使得 x 和 y 轴的单位长度相同
plt.gca().set_aspect('equal', adjustable='box')
# 显示绘制的图形
plt.show()

成功得到半个flag,我们还有BITMAP的位图数据没有分析
bitmap函数的格式我们在TSPL编程的官方文档中可以明白:16384539210f9796.pdf
要想打印出图像,我们首先要将得到的位图数据转换成二进制(使用010 editor很方便),然后以黑0白1的形式输出(源码来源于:从一道题学习打印机流量(RCTF2019-Printer)_rctf2019]printer-CSDN博客):
from PIL import Image # 导入Pillow库中的Image模块,用于图像处理
# 定义两个位图区域的参数,包含坐标和大小
bitmap_ins = [138, 75, 26, 48] # [x坐标, y坐标, 宽度, 高度]
# 设置名为data的内容,作为位图数据
data = "111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111110000000011111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111110000111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111100111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111110011111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111001111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111100111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111110011111111111111000111111111111111110000111111111111111111111111111111111111111111000000001111100000000111100011000000011111111000000011111000000011111100000000000000111111101111111111100000001111110000000011001111111111100000000011111111111100000000011111111000000011111000000001111111111111100011111111100011111000001001111100011111111000111111111000111111111111100011111111111110011111111111100111111110001111100100111111111000111111100011111111100111110000111111111000111111111100111111111111111110001111111110001111111000001111111001111111110001111111100011111111111110001111111111111001111111111111011111110001111111000011111111000111111111001111111101111111110001111111100011111111110011111111111111111100011111111000111111100001111111100011111111100111111110001111111111111000111111111111100011111111111101111110001111111110001111111100111111111100011111101111111111100011111110001111111111001111111111111111110001111111100011111110001111111111000111111110001111111000111111111111100011111111111110001111111111110111111001111111111100111111100011111111110001111100111111111110000111111000111111111100111111111111111111100011111110001111111000111111111100011111111100011111100011111111111110001111111111111000011111111111011111000111111111110011111110001111111110000111110111111111111100011111100011111111110011111111111111111110001111111000111111100011111111110001111111110001111110001111111111111000111111111111100001111111111101111100011111111111001111110000111111111100011110011111111111110001111110001111111111001111111111111111111100011111100011111110001111111111000111111111100011111000111111111111100011111111111110100011111111110111110001111111111100111111000111111111110011111011111111111111000011111000111111111100111111111111111111110001111110001111111000111111111110011111111111000111000011111111111110001111111111111010001111111111011111001111111111110011111100011111111111111111111111111111111110001111100011111111110011111111111111111111100011111000111111100011111111111001111111111100011000001111111111111000111111111111101100011111111101111100111111111111001111111000111111111111111111111111111111111000111110001111111111001111111111111111111110001111100011111110001111111111100111111111111000001000111111111111100011111111111110110001111111110111110011111111111100111111100011111111111111111111111111111111100011111000111111111100111111111111111111111000111110001111111000111111111100011111111111110001100011111111111110001111111111111011100011111111011111001111111111110011111110001111111111111111111111111111111110001111100011111111110011111111111111111111110001111000111111100011111111110001111111111111001110001111111111111000111111111111101110001111111101111100011111111111001111111100011111111111111111111111111111111000011110001111111111001111111111111111111111000111100011111110001111111111000111111111111001111000111111111111100011111111111110111100011111110111110001111111111100111111111001111111111111111111111111111111100001111000111111111100111111111111111111111110001100001111111000111111111100111111111111001111100011111111111110001111111111111011110001111111011111000111111111100011111111110001111111111111111111111111111110000111100011111111110011111111111111111111111000100000111111100011111111100011111111111001111110001111111111111000111111111111101111100011111101111110011111111110001111111111110000011111111111111111111111111000011111001111111110001111111111111111111111110000100011111110000111111100011111111111101111111000111111111111100011111111111110111110001111110111111000111111110100111111111111000011111111111111111111111111100001111100111111110100111111111111111111111111000110001111111000001111100011111111111100111111100011111111111110001111111111111011111100011111011111110001111100110011111111110001111111111111111111111111111110001111110001111100110011111111111111111111111110011000111111100010000000011111111100000000111110001111111111111000111111111111101111110001111101111111110000000111000001111110001111111111111111111111111111111000111111100000000111001111111111111111111111110011100011111110001111001111111111111111111111111000111111111111100011111111111110111111100011110111111111111001111101111111110001111111111111111111111111111111100011111111100001111100111111111111111111111111011110001111111000111111111111111111111111111111100011111111111110001111111111111011111110000111011111111111111111111111111111000111111111111111111111111111111110001111111111111111110011111111111111111111111001111000111111100011111111111111111111111111111110001111111111111000111111111111101111111100011101111111111111111111111111111100011111111111111111111111111111110000111111111111111111001111111111111111111111001111100011111110001111111111111111111111111111111000111111111111100011111111111110111111110000110111111111111111111111111111110001111111110011111011111111111111000111111111111111111100111111111111111111111101111110001111111000111111111111111111111111111111100011111111111110001111111111111011111111100011011111111111111111111111111111000111111110000111100111111111111100011111111111111111110011111111111111111111101111111000111111100011111111111111111111111111111110001111111111111000111111111111101111111110000101111111111111111111111111111100011111111100011111011111111111100011111111111111111111001111111111111111111100111111100011111110001111111111111111111111111111111000111111111111100011111111111110111111111100010111111111111111111111111111110001111111110001111100111111111110001111111111111111111100111111111111111111100111111110001111111000111111111111111111111111111111100011111111111110001111111111111011111111111000011111111111111111111111111111100111111111001111110011111111110001111111111111111111110011111111111111111100011111111000111111100011111111111111111111111111111110001111111111111000111111111111101111111111100001111111111111111111111111111110001111111100111111000111111110001111111111111111111111001111111111111111100001111111100001111110000111111111111111111111111111111000111111111111100001111111111100111111111111000111111111111111111111111111111100001111001111111100000111110001111111111111111111111100011111111111111000000001111000000001111000000111111111111111111111111111100000011111000000000000001111000000011111111100000111111111111111111111111111111100000001111111111111000000011111111111111111111111110000011111111111111111111111111111111111101111111111111111111111111111111110011111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111011111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111"
counter = 0 # 初始化计数器,用于跟踪数据读取的位置
# 创建一个新的位图,尺寸为800x800,模式为"1"(黑白图像)
bitmap = Image.new("1", (800, 800))
bitmap_pixel = bitmap.load() # 加载位图的像素数据,便于后续操作
# 从bitmap_ins中获取绘制位图的参数
x, y, width, height = bitmap_ins
# 使用嵌套循环填充位图的像素
for v in range(height): # 外层循环遍历高度
for h in range(8 * width): # 内层循环遍历宽度(每个像素占用8位)
tx = x + h # 计算当前像素的x坐标
ty = y + v # 计算当前像素的y坐标
bitmap_pixel[tx, ty] = eval(data[counter]) # 从data1中读取数据并设置像素值
counter += 1 # 增加计数器,移动到下一个数据
# 显示生成的位图
bitmap.show()

成功输出第二部分flag,组合即是正确的flag!
补充:其实以正确的宽高也能看出数据:

贴上能够按照格式排序字符串的脚本:
def format_characters(chars, width, height):
# 计算总字符数
total_chars = width * height
# 截取字符到指定长度
chars = chars[:total_chars]
# 将字符分割成多行
formatted_lines = [chars[i:i + width] for i in range(0, len(chars), width)]
# 填充空行以确保总行数
while len(formatted_lines) < height:
formatted_lines.append(' ' * width)
return formatted_lines
# 示例输入
long_string = "111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111110000000011111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111110000111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111100111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111110011111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111001111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111100111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111110011111111111111000111111111111111110000111111111111111111111111111111111111111111000000001111100000000111100011000000011111111000000011111000000011111100000000000000111111101111111111100000001111110000000011001111111111100000000011111111111100000000011111111000000011111000000001111111111111100011111111100011111000001001111100011111111000111111111000111111111111100011111111111110011111111111100111111110001111100100111111111000111111100011111111100111110000111111111000111111111100111111111111111110001111111110001111111000001111111001111111110001111111100011111111111110001111111111111001111111111111011111110001111111000011111111000111111111001111111101111111110001111111100011111111110011111111111111111100011111111000111111100001111111100011111111100111111110001111111111111000111111111111100011111111111101111110001111111110001111111100111111111100011111101111111111100011111110001111111111001111111111111111110001111111100011111110001111111111000111111110001111111000111111111111100011111111111110001111111111110111111001111111111100111111100011111111110001111100111111111110000111111000111111111100111111111111111111100011111110001111111000111111111100011111111100011111100011111111111110001111111111111000011111111111011111000111111111110011111110001111111110000111110111111111111100011111100011111111110011111111111111111110001111111000111111100011111111110001111111110001111110001111111111111000111111111111100001111111111101111100011111111111001111110000111111111100011110011111111111110001111110001111111111001111111111111111111100011111100011111110001111111111000111111111100011111000111111111111100011111111111110100011111111110111110001111111111100111111000111111111110011111011111111111111000011111000111111111100111111111111111111110001111110001111111000111111111110011111111111000111000011111111111110001111111111111010001111111111011111001111111111110011111100011111111111111111111111111111111110001111100011111111110011111111111111111111100011111000111111100011111111111001111111111100011000001111111111111000111111111111101100011111111101111100111111111111001111111000111111111111111111111111111111111000111110001111111111001111111111111111111110001111100011111110001111111111100111111111111000001000111111111111100011111111111110110001111111110111110011111111111100111111100011111111111111111111111111111111100011111000111111111100111111111111111111111000111110001111111000111111111100011111111111110001100011111111111110001111111111111011100011111111011111001111111111110011111110001111111111111111111111111111111110001111100011111111110011111111111111111111110001111000111111100011111111110001111111111111001110001111111111111000111111111111101110001111111101111100011111111111001111111100011111111111111111111111111111111000011110001111111111001111111111111111111111000111100011111110001111111111000111111111111001111000111111111111100011111111111110111100011111110111110001111111111100111111111001111111111111111111111111111111100001111000111111111100111111111111111111111110001100001111111000111111111100111111111111001111100011111111111110001111111111111011110001111111011111000111111111100011111111110001111111111111111111111111111110000111100011111111110011111111111111111111111000100000111111100011111111100011111111111001111110001111111111111000111111111111101111100011111101111110011111111110001111111111110000011111111111111111111111111000011111001111111110001111111111111111111111110000100011111110000111111100011111111111101111111000111111111111100011111111111110111110001111110111111000111111110100111111111111000011111111111111111111111111100001111100111111110100111111111111111111111111000110001111111000001111100011111111111100111111100011111111111110001111111111111011111100011111011111110001111100110011111111110001111111111111111111111111111110001111110001111100110011111111111111111111111110011000111111100010000000011111111100000000111110001111111111111000111111111111101111110001111101111111110000000111000001111110001111111111111111111111111111111000111111100000000111001111111111111111111111110011100011111110001111001111111111111111111111111000111111111111100011111111111110111111100011110111111111111001111101111111110001111111111111111111111111111111100011111111100001111100111111111111111111111111011110001111111000111111111111111111111111111111100011111111111110001111111111111011111110000111011111111111111111111111111111000111111111111111111111111111111110001111111111111111110011111111111111111111111001111000111111100011111111111111111111111111111110001111111111111000111111111111101111111100011101111111111111111111111111111100011111111111111111111111111111110000111111111111111111001111111111111111111111001111100011111110001111111111111111111111111111111000111111111111100011111111111110111111110000110111111111111111111111111111110001111111110011111011111111111111000111111111111111111100111111111111111111111101111110001111111000111111111111111111111111111111100011111111111110001111111111111011111111100011011111111111111111111111111111000111111110000111100111111111111100011111111111111111110011111111111111111111101111111000111111100011111111111111111111111111111110001111111111111000111111111111101111111110000101111111111111111111111111111100011111111100011111011111111111100011111111111111111111001111111111111111111100111111100011111110001111111111111111111111111111111000111111111111100011111111111110111111111100010111111111111111111111111111110001111111110001111100111111111110001111111111111111111100111111111111111111100111111110001111111000111111111111111111111111111111100011111111111110001111111111111011111111111000011111111111111111111111111111100111111111001111110011111111110001111111111111111111110011111111111111111100011111111000111111100011111111111111111111111111111110001111111111111000111111111111101111111111100001111111111111111111111111111110001111111100111111000111111110001111111111111111111111001111111111111111100001111111100001111110000111111111111111111111111111111000111111111111100001111111111100111111111111000111111111111111111111111111111100001111001111111100000111110001111111111111111111111100011111111111111000000001111000000001111000000111111111111111111111111111100000011111000000000000001111000000011111111100000111111111111111111111111111111100000001111111111111000000011111111111111111111111110000011111111111111111111111111111111111101111111111111111111111111111111110011111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111011111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111"
# 设置宽度和高度
width = 26*8
height = 48
# 调用函数并获取格式化后的字符行
result = format_characters(long_string, width, height)
# 输出结果
for line in result:
print(line)

考点:打印机流量分析、坐标绘图、位图数据绘图
[NewStarCTF 2023 公开赛道]隐秘的图片(新)
下载文件,是两个二维码图片:

我们先尝试扫一下第一张图片:

出现一串字符先记下
我们尝试修复第二张图片(反色+定位符),失败了
其中四个角落黑色的区域太大,我们进行重叠观察:

可以发现四个定位符都被黑色笼盖,这其中可能包含着两张图片之间的加密,key1是加密后的密文二维码,那么key2极有可能是加密用的密钥
我们尝试使用StegSolve的图像拼接功能进行解密:

可以发现key1经与key2进行异或解密即可得到正确的二维码
考点:两张图片的加密算法
[NewStarCTF 2023 公开赛道]机密图片(知识巩固题)
下载文件,是一张二维码图片,我们先扫:

既然没有什么内容那就按照图片隐写思路来了,第一步在属性中看到了内容先记录下:

第二步无果,我们使用stegsolve进行分析:

又在关闭红色通道的左上角发现了隐藏的数据,LSB隐写:

考点:LSB隐写
[NewStarCTF 2023 公开赛道]CyberChef's Secret(知识巩固题)
下载文件:

懂得都懂:

考点:会用cyberchef
[watevrCTF 2019]Polly(新)
下载文件,一大串字符:

仔细一看是数学式子,其中含有未知数x,结尾存在+199的式子:

199经ascii解码得到w,符合watevrCTF的比赛格式,因此我们可以推测,当x=0时前面的式子解得值为0,+119后得到w的开头,那当x=1时应该可以得到a的开头
我们编写脚本(精度一定要够,用分数):
from fractions import Fraction
# 读取文件中的数学表达式
with open('attachment.txt', 'r') as file:
expression = file.read().strip() # 读取表达式并去掉空白字符
# 循环计算 x 从 0 到 60 的值
for x in range(61): # 0 到 60,包括60
try:
# 使用 fractions.Fraction 计算表达式值
value = eval(expression.replace('x', f"Fraction({x})"))
# 确保将结果转换为整数进行 ASCII 解码
integer_value = int(value) # 将结果转换为整数
# ASCII 解码
if 0 <= integer_value <= 127: # 只对有效的 ASCII 范围进行解码
ascii_char = chr(integer_value)
print(f"{ascii_char}")
else:
print(f"x = {x}: {value}, ASCII: 'Out of range'")
except Exception as e:
print(f"Error evaluating expression for x = {x}: {e}")
输出得到flag
考点:计算表达式
[INSHack2019]Crunchy(新存疑)
下载文件,是一个python脚本:

我们进行分析:
def crunchy(n):
if n < 2: # 如果 n 小于 2,直接返回 n
return n # 递归调用 crunchy 函数,计算当前 n 的值
return 6 * crunchy(n - 1) + crunchy(n - 2) # 返回数学计算结果
g = 17665922529512695488143524113273224470194093921285273353477875204196603230641896039854934719468650093602325707751568
print("Your flag is: INSA{%d}" % (crunchy(g) % 100000007))
我们判断一下,crunchy(g)的回显只可能小于2,并且按照数学计算的表达式g貌似只能取为整数,那么g的返回值只可能为0 1 2
实在是看不懂这个,这里放一个网上的代码(来自CTFtime.org / INS'hAck 2019 / Crunchy / Writeup):
# 定义一个大整数 n 和一个模数 m
n = 17665922529512695488143524113273224470194093921285273353477875204196603230641896039854934719468650093602325707751568
m = 100000007
# 计算斐波那契数列的周期函数
def getSequencePeriod(m):
s = [] # 初始化空列表 s,用来存储斐波那契数列模 m 的值
s.append(0) # 斐波那契数列的第一个值是 0
s.append(1) # 斐波那契数列的第二个值是 1
# 生成斐波那契数列的模 m 的前 m*6 项,直到发现周期
for i in range(2, m*6):
# 斐波那契数列的下一项是前两项之和,取模 m
s.append((6 * s[i-1] + s[i-2]) % m)
# 如果发现序列中出现了 1 后面接 0,说明周期开始重复,提前终止
if (s[i] == 1 and s[i-1] == 0):
break
return s # 返回生成的斐波那契数列模 m 的周期
# 计算第 n 项斐波那契数在模 m 下的值
def getFibonacciRest(n, m):
s = getSequencePeriod(m) # 获取斐波那契数列的周期
period = len(s) - 2 # 斐波那契数列的周期长度(去掉最后两个值:1 和 0)
val = n % period # 计算 n 在周期内的位置
return s[val] # 返回第 n 项在模 m 下的值
# 输出第 n 项斐波那契数在模 m 下的值
print(getFibonacciRest(n, m)) # 输出:41322239
我的评价是:

考点:斐波那契数列?
Weird_List(新孬题)
下载文件,是一串串数组:

搜寻一番发现了其中的规律:
所有数组中元素的和为120
重复最多的数字为1
我们可以推测这是一个ascii艺术画,1可以输出为❤而其他数字输出为数字*空格
arrays = [
[120],
[120],
[24, 1, 87, 1, 7],
[7, 1, 15, 1, 21, 1, 16, 1, 49, 1, 7],
[2, 1, 1, 1, 2, 1, 15, 1, 4, 1, 3, 1, 1, 1, 10, 1, 16, 1, 4, 1, 1, 1, 2, 1, 1, 1, 19, 1, 7, 1, 1, 1, 2, 1, 1, 1, 3, 1, 6],
[2, 1, 1, 1, 3, 1, 14, 1, 3, 1, 1, 1, 2, 1, 1, 1, 10, 1, 16, 1, 4, 1, 1, 1, 2, 1, 1, 1, 18, 1, 8, 1, 1, 1, 2, 1, 1, 1, 4, 1, 5],
[2, 1, 1, 1, 3, 1, 14, 1, 3, 1, 1, 1, 2, 1, 1, 1, 10, 1, 16, 1, 4, 1, 1, 1, 2, 1, 1, 1, 17, 1, 1, 1, 7, 1, 1, 1, 2, 1, 1, 1, 4, 1, 5],
[2, 1, 5, 1, 14, 1, 3, 1, 1, 1, 4, 1, 10, 1, 16, 1, 7, 1, 4, 1, 16, 1, 1, 1, 7, 1, 2, 1, 4, 1, 3, 1, 5],
[2, 1, 5, 1, 14, 1, 3, 1, 2, 1, 4, 1, 9, 1, 16, 1, 7, 1, 4, 1, 16, 1, 1, 1, 10, 1, 4, 1, 3, 1, 5],
[2, 1, 5, 1, 3, 1, 1, 1, 2, 1, 5, 1, 3, 1, 2, 1, 4, 1, 1, 1, 5, 1, 1, 1, 2, 1, 9, 1, 3, 1, 2, 1, 4, 1, 4, 1, 1, 1, 1, 1, 7, 1, 1, 1, 4, 1, 3, 1, 6, 1, 4, 1, 3, 1, 5],
[2, 1, 5, 1, 3, 1, 1, 1, 2, 1, 1, 1, 3, 1, 3, 1, 2, 1, 3, 1, 2, 1, 4, 1, 1, 1, 2, 1, 1, 1, 7, 1, 1, 1, 2, 1, 1, 1, 5, 1, 4, 1, 1, 1, 1, 1, 7, 1, 1, 1, 4, 1, 3, 1, 1, 1, 4, 1, 4, 1, 3, 1, 5],
[2, 1, 5, 1, 3, 1, 1, 1, 2, 1, 1, 1, 3, 1, 3, 1, 2, 1, 3, 1, 2, 1, 4, 1, 1, 1, 2, 1, 9, 1, 4, 1, 1, 1, 5, 1, 3, 1, 2, 1, 2, 1, 6, 1, 2, 1, 3, 1, 2, 1, 2, 1, 4, 1, 4, 1, 3, 1, 5],
[2, 1, 1, 1, 3, 1, 5, 1, 2, 1, 1, 1, 3, 1, 3, 1, 2, 1, 2, 1, 8, 1, 1, 1, 2, 1, 9, 1, 4, 1, 1, 1, 4, 1, 3, 1, 6, 1, 6, 1, 2, 1, 3, 1, 2, 1, 2, 1, 4, 1, 2, 1, 5, 1, 5],
[2, 1, 1, 1, 3, 1, 6, 1, 1, 1, 1, 1, 2, 1, 4, 1, 1, 1, 3, 1, 3, 1, 4, 1, 1, 1, 2, 1, 9, 1, 4, 1, 1, 1, 4, 1, 3, 1, 6, 1, 6, 1, 2, 1, 3, 1, 2, 1, 2, 1, 3, 1, 3, 1, 5, 1, 5],
[2, 1, 5, 1, 6, 1, 1, 1, 4, 1, 4, 1, 1, 1, 3, 1, 3, 1, 4, 1, 2, 1, 1, 1, 9, 1, 4, 1, 6, 1, 3, 1, 6, 1, 6, 1, 2, 1, 3, 1, 2, 1, 2, 1, 3, 1, 3, 1, 1, 1, 4, 1, 4],
[2, 1, 5, 1, 3, 1, 1, 1, 2, 1, 4, 1, 4, 1, 1, 1, 4, 1, 2, 1, 4, 1, 2, 1, 1, 1, 9, 1, 4, 1, 6, 1, 4, 1, 3, 1, 1, 1, 6, 1, 2, 1, 3, 1, 2, 1, 2, 1, 3, 1, 5, 1, 3, 1, 5],
[2, 1, 5, 1, 3, 1, 1, 1, 2, 1, 5, 1, 3, 1, 1, 1, 5, 1, 2, 1, 3, 1, 2, 1, 2, 1, 9, 1, 3, 1, 1, 1, 3, 1, 6, 1, 1, 1, 1, 1, 7, 1, 2, 1, 3, 1, 2, 1, 2, 1, 3, 1, 5, 1, 3, 1, 5],
[2, 1, 5, 1, 3, 1, 2, 1, 1, 1, 5, 1, 4, 1, 1, 1, 4, 1, 1, 1, 4, 1, 2, 1, 2, 1, 9, 1, 3, 1, 1, 1, 3, 1, 6, 1, 1, 1, 2, 1, 6, 1, 2, 1, 3, 1, 2, 1, 2, 1, 2, 1, 6, 1, 3, 1, 5],
[2, 1, 5, 1, 3, 1, 2, 1, 1, 1, 5, 1, 6, 1, 4, 1, 6, 1, 2, 1, 3, 1, 9, 1, 2, 1, 1, 1, 3, 1, 6, 1, 1, 1, 2, 1, 6, 1, 2, 1, 3, 1, 2, 1, 2, 1, 2, 1, 6, 1, 3, 1, 5],
[2, 1, 5, 1, 3, 1, 1, 1, 2, 1, 1, 1, 3, 1, 6, 1, 4, 1, 1, 1, 4, 1, 2, 1, 4, 1, 9, 1, 1, 1, 1, 1, 3, 1, 6, 1, 1, 1, 2, 1, 6, 1, 2, 1, 3, 1, 2, 1, 2, 1, 2, 1, 6, 1, 3, 1, 5],
[2, 1, 5, 1, 3, 1, 1, 1, 2, 1, 1, 1, 3, 1, 5, 1, 5, 1, 6, 1, 1, 1, 5, 1, 9, 1, 1, 1, 1, 1, 2, 1, 7, 1, 1, 1, 2, 1, 6, 1, 2, 1, 3, 1, 2, 1, 2, 1, 1, 1, 7, 1, 3, 1, 5],
[2, 1, 5, 1, 3, 1, 1, 1, 2, 1, 1, 1, 3, 1, 5, 1, 4, 1, 2, 1, 1, 1, 2, 1, 1, 1, 17, 1, 2, 1, 1, 1, 6, 1, 2, 1, 1, 1, 7, 1, 2, 1, 3, 1, 2, 1, 2, 1, 1, 1, 4, 1, 2, 1, 3, 1, 5],
[2, 1, 5, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 3, 1, 3, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 7, 1, 1, 1, 2, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 7, 1, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 4, 1, 5],
[2, 1, 6, 1, 2, 1, 2, 1, 1, 1, 5, 1, 3, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 7, 1, 1, 1, 2, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 7, 1, 1, 1, 3, 1, 1, 1, 2, 1, 3, 1, 1, 1, 2, 1, 1, 1, 4, 1, 5],
[12, 1, 5, 1, 4, 1, 4, 1, 3, 1, 10, 1, 4, 1, 9, 1, 14, 1, 4, 1, 8, 1, 1, 1, 8, 1, 9, 1, 4, 1, 6],
[19, 1, 4, 1, 62, 1, 24, 1, 7],
[19, 1, 4, 1, 62, 1, 24, 1, 7],
[17, 1, 1, 1, 31, 1, 1, 1, 1, 1, 25, 1, 1, 1, 1, 1, 1, 1, 32],
[17, 1, 1, 1, 31, 1, 1, 1, 1, 1, 25, 1, 1, 1, 1, 1, 1, 1, 32],
[17, 1, 1, 1, 67, 1, 32],
[120],
[21, 1, 1, 1, 1, 1, 86, 1, 1, 1, 1, 1, 3],
[120],
[120]
]
for i in arrays:
for j in i:
if (j==1):
print("■",end="")
else:
print(" "*j,end="")
print("")

给输出的图像进行处理:

flag{93ids_sk23a_p1o23}
考点:数组列表ASCII艺术画
[b01lers2020]minecraft_purdue
下载文件,是我的世界地图
打开游戏,是一幅地图,根据题目我们可以知道这是普渡大学的地图

根据提示,flag藏在某栋建筑里:

开启观察者模式和夜视效果更快地寻找flag:
/gamemode spectator
/effect @p minecraft:night_vision 65535
上网进行信息收集,发现了普渡大学的CTF战队常到HAAS楼里面开会


flag就在HAAS中,我们按照地图去找那栋楼:

空空如也,但在出生点后面的另一栋MTHW楼中找到了flag:

可能有别的线索吧,像是普渡大学CTF战队的官网有训练营的时间表,但找不到2020年的了

没有离出生点太远,还是能做的
考点:玩我的世界、社会工程学
[BSidesSF2020]toast-clicker1(知识巩固题)
下载文件,是一个apk文件
我们尝试运行以下,就是个点击软件,没多少可以交互的点

拖进GDA中分析发现了这两个方法:

分析代码:
String printSecondFlag() {
// 初始化输出字符串
String output = "";
// 第一个密钥部分,硬编码的字符串
String keyPart1 = "742375c48a7";
// 从资源文件中获取第二个密钥部分
String keyPart2 = this.getString(R.string.key_part2);
// 组合密钥的各个部分
String key = keyPart1 + keyPart2 + this.keyStringFromJNI();
try {
// 创建帮助类实例,使用组合的密钥
helper h = new helper(key);
// 使用帮助类解密从 JNI 获取的加密字符串
output = h.decrypt(this.encryptedStringFromJNI());
} catch (java.lang.Exception e5) {
// 捕获异常并打印堆栈跟踪
e5.printStackTrace();
}
// 返回解密后的输出
return output;
}
String printFirstFlag() {
// 初始化输出字符串
String output = "";
// 初始化计数器
int i = 0;
// 无限循环,直到手动中断
while (true) {
// 获取输入数组
MainActivity tinput = this.input;
// 检查计数器是否小于输入数组的长度
if (i < tinput.length) {
// 计算当前字符的 ASCII 值,基于输入数组和索引
int t = tinput[i] + i;
// 将字符添加到输出字符串
output = "".append(output).append(Character.toString((char)t)).toString();
// 增加计数器
i++;
} else {
// 如果计数器超过数组长度,退出循环
break;
}
}
// 返回生成的输出字符串
return output;
}
也找到了input参数:

我们先看printFirstFlag方法,,它将input中的字符的ASCII值都进行了+i的操作
也就是说我们可以手动解码:
| input | ascii | +i | 之后ascii | output |
|---|---|---|---|---|
| C | 67 | 0 | 67 | C |
| S | 83 | 1 | 84 | T |
| D | 68 | 2 | 70 | F |
| x | 120 | 3 | 123 | { |
| > | 62 | 4 | 66 | B |
| m | 109 | 5 | 114 | r |
| _ | 95 | 6 | 101 | e |
| Z | 90 | 7 | 97 | a |
| \ | 92 | 8 | 100 | d |
| p | 112 | 9 | 121 | y |
| U | 85 | 10 | 95 | _ |
| I | 73 | 11 | 84 | T |
| c | 99 | 12 | 111 | o |
| R | 82 | 13 | 95 | _ |
| 5 | 53 | 14 | 67 | C |
| c | 99 | 15 | 114 | r |
| e | 101 | 16 | 117 | u |
| \ | 92 | 17 | 109 | m |
| P | 80 | 18 | 98 | b |
| Y | 89 | 19 | 108 | l |
| Q | 81 | 20 | 101 | e |
| h | 104 | 21 | 125 | } |
就是一种变异凯撒,可以看这一篇用脚本:https://www.cnblogs.com/handsomexuejian/p/18305321#tid-nHSxDj
也可以用随波逐流工具一键解密(包含变异凯撒):

考点:安卓逆向、代码审计、变异凯撒
[BSidesSF2019]bWF0cnlvc2hrYQ(新较难工具)
下载文件,是.eml文件
eml文件
.eml 文件是一种用于存储电子邮件消息的文件格式。它通常包含完整的邮件内容,包括邮件的主题、发件人、收件人、发送时间、正文和任何附件,是一种灵活且广泛使用的电子邮件存储格式,适合邮件的保存、共享和备份。
一般可以使用微软自带的outlook软件查看邮件并且很方便分析,但新版的outlook无法预览这个过期的邮件:

所以这里用的软件是Free EML Viewer Tool

可以发现邮件附件中有Matry_Oshka.key和hack.pgp两个文件
先翻译一下邮件内容(机翻):
Matry,
我有些东西要给你。你知道该怎么做。我将留给你们
这样的:
让我轻轻躺在绿天鹅绒的田野里
在碧蓝如丝的天空下休息
在那里我可以凝视白色的棉花云
闪烁的蜻蜓飘过
在红色缎面花瓣间混合
黄色和银色,四周都是金色
捕捉到大自然柔和的惊人之美
美化天空,点缀大地
我将留在那里,平静地奉献
呼吸着松香清新的空气
感受着阳光洒在我周围的温暖
远离所有的烦恼、心痛和烦恼
来吧,你愿意和我一起感受这一切的辉煌吗
这样的幻想就存在于你的脑海中
和我一起跳舞,一起唱歌,然后投降
你的每一个牵挂,都被我的魔咒所迷惑
参阅附件。
Valerie
没有特别重要的信息,分析附件前我们先分析以下其他信息:

这里有软件没有显示的发件人头像的内容,我们将内容提取并base64解码得到了一张二维码:

得到字符串h4ck_the_plan3t,我们先记下
我们再分析附件:
pgp文件
PGP 文件是一种用于加密和签名电子邮件及文件的文件格式,基于 PGP(Pretty Good Privacy)技术
之前我有个文章用过linux系统中的pgp程序进行过解密,这次来个简单点的方法https://www.cnblogs.com/handsomexuejian/p/18302329#tid-ep4fNG
附件中已经把私钥给出来了,我们使用软件PGPTool进行解密:

首先导入私钥,然后导入pgp加密文件,输入密码后即可解密,得到file.bin文件
使用010editor分析没啥东西,我们使用以下命令分析:
file file.bin

我们再使用binwalk看看有没有插入隐藏的信息

还真有,其中存在lzip文件,我们尝试提取出来但是提取不出来,foremost也提取不出来
我们使用010editor打开并关注第11字节处:

可以发现LZIP字样的文件头,正好在第12字节处,我们将文件头修复:

修复后使用以下命令解压:
lzip -d file.bin
-d 这是一个选项,用于指定解压缩操作
我们得到解压文件file.bin.out,使用010 editor进行分析发现是PDF文件:

打开pdf文件,只有一张图片:

使用了特殊工具(这里是从PDF文件提取图像 - 迅捷,在线,免费 - PDF24 Tools)提取了PDF中的图片
按照文件隐写思路,使用stegsolve发现了东西:

疑似存在二维码,但我们又看不出来,找不到相关解密的密钥那可能是需要到网上寻找相同的图作为密钥:


扫码得到信息:
/Td6WFoAAATm1rRGAgAhARwAAAAQz1jM4ELCAORdABhgwwZfNTLh1bKR4pwkkcJw0DSEZd2BcWATAJkrMgnKT8nBgYQaCPtrzORiOeUVq7DDoe9feCLt9PG-MT9ZCLwmtpdfvW0n17pie8v0h7RS4dO/yb7JHn7sFqYYnDWZere/6BI3AiyraCtQ6qZmYZnHemfLVXmCXHan5fN6IiJL7uJdoJBZC3Rb1hiH1MdlFQ/1uOwaoglBdswAGo99HbOhsSFS5gGqo6WQ2dzK3E7NcYP2YIQxS9BGibr4Qulc6e5CaCHAZ4pAhfLVTYoN5R7l/cWvU3mLOSPUkELK6StPUBd0AABBU17Cf970JQABgALDhQEApzo4PbHEZ/sCAAAAAARZWg==
看着像base64,但base64编码中不存在-号,我们尝试将其修改为+ 、/或 =试试:

发现7z文件头,我们进行解压:

最后一步将密码放入cyberchef进行解密即可(二进制->八进制那一段两个数字之间会出现两个空格导致十进制难以转换):

考点:eml文件分析、pgp文件解密、理解lzip文件、寻找密钥解密图片、理解base64编码规则
[NewStarCTF 2023 公开赛道]阳光开朗大男孩(知识巩固题)
下载文件一个文件是emoji,一个文件是社会主义核心价值观加密:

emoji不能直接解码,这里尝试搜索关键词:

成功解密

考点:学会用搜索引擎去搜索相关加密方式
[NewStarCTF 2023 公开赛道]新建Word文档(知识巩固题)
下载文件,doc文件中有我们熟悉的佛曰加密:

直接解密:

考点:理解佛曰加解密
[GWCTF2019]math(新)
下载文件,是一个elf可执行文件,此次还有靶机供我们开,这是类pwn形式的题目,这里给出pwn题的基本做题流程:https://www.cnblogs.com/handsomexuejian/p/18516640#tid-CmKafD
我们先使用nc连上靶机看看是怎么回事:

它会让我们迅速给出数学计算式的答案,否则自动断开连接
我们使用IDA分析文件:

我们分析一下:
srand(seed); // 用指定的 seed 初始化随机数生成器
do
{
alarm(5u); // 设置一个 5 秒的定时器,超时后程序会收到一个 SIGALRM 信号
v6 = rand() % 200; // 生成一个范围在 0 到 199 的随机数,赋值给 v6
v7 = rand() % 200; // 生成一个范围在 0 到 199 的随机数,赋值给 v7
v8 = rand() % 200; // 生成一个范围在 0 到 199 的随机数,赋值给 v8
v9 = rand() % 200; // 生成一个范围在 0 到 199 的随机数,赋值给 v9
puts("Pass 150 levels and i will give you the flag~"); // 输出提示信息
puts("===================================================="); // 输出分隔线
printf("Now level %d\n", (unsigned int)v4); // 输出当前关卡(v4)
// 输出数学题:计算 v6 * v7 - v8 + v9 的结果
printf("Math problem: %d * %d - %d + %d = ??? ", v6, v7, v8, v9);
puts("Give me your answer:"); // 提示用户输入答案
read(0, buf, 0x80uLL); // 从标准输入读取用户输入的答案,存入 buf,最大长度为 128 字节
// 将用户输入的字符串转换为长整型并与计算结果进行比较
if ((unsigned int)strtol(buf, 0LL, 10) != v7 * v6 - v8 + v9)
{
puts("Try again?"); // 如果答案错误,输出提示信息
exit(0); // 退出程序
}
puts("Right! Continue~"); // 如果答案正确,输出提示信息
++v4; // 进入下一个关卡,增加关卡计数器 v4
sleep((unsigned int)"Right! Continue~"); // 睡眠一段时间(这里的参数有误,应该是数字)
}
while (v4 <= 149); // 循环,直到通过 150 关
if (v4 != 150)
{
puts("Wrong!"); // 如果没有达到 150 关,输出提示信息
exit(0); // 退出程序
}
puts("Congratulation!"); // 当通过 150 关后,输出祝贺信息
system("/bin/sh"); // 执行 shell,可以用来获取 flag
return 0; // 返回 0,正常结束程序
也就是说我们5秒内必须回答出数学题,数学题的格式永远为a*b-c+d
我们可以使用pwntool写出脚本,对接收到的信息进行处理并发送(脚本来自BUUCTF:GWCTF2019]math - B0mbax - 博客园):
from pwn import * # 导入 pwntools 库,用于进行网络连接和交互
# 创建一个远程连接对象 p,连接到指定的 IP 地址和端口
p = remote("node5.buuoj.cn", 25259)
# 循环150次,处理150道数学题
for i in range(0, 150):
ou = p.recvuntil('problem: ') # 接收直到字符串 'problem: ' 的所有数据
print(ou) # 输出接收到的内容,便于调试
# 依次接收数学问题的各个部分
a = int(p.recvuntil('*')[:-1]) # 接收第一个数字 a,直到 '*' 字符为止,去掉末尾的空格并转换为整数
b = int(p.recvuntil('-')[:-1]) # 接收第二个数字 b,直到 '-' 字符为止,转换为整数
c = int(p.recvuntil('+')[:-1]) # 接收第三个数字 c,直到 '+' 字符为止,转换为整数
d = int(p.recvuntil('=')[:-1]) # 接收第四个数字 d,直到 '=' 字符为止,转换为整数
# 计算数学表达式的结果,并将其作为字符串发送回去
p.sendline(str(a * b - c + d))
# 切换到交互模式,允许用户与程序进行交互
p.interactive()
运行一段时间后得到flag

考点:代码审计、理解pwn
[NPUCTF2020]回收站(新工具)
原文件已经404 not found 了,只能上网看看wp
来源文章:(CTF刷题记录-MISC-NPUCTF2020]回收站 - 哔哩哔哩、[BUUOJ Misc · 西风秘典](https://codex.lemonprefect.cn/writeups/BUUOJ Misc.html))
题目会给出三个文件,后缀名分别是.E01 .E02 .E03
EnCase 镜像文件
EnCase 镜像文件(通常以 .E01 为扩展名)是由 EnCase Forensic 工具创建的专有磁盘映像格式,广泛应用于数字取证领域。它能够精确地捕捉存储介质(如硬盘、USB 驱动器、网络存储等)上的所有数据,包括已删除文件、隐藏文件、元数据等,且确保数据的完整性和不可篡改性。
| 文件格式 | 用途 | 内容 | 应用场景 |
|---|---|---|---|
| .E01 | 法医取证、数据恢复、证据保全 | 包括磁盘数据、文件系统元数据、分区信息和完整性校验 | 用于数字取证,恢复已删除文件,进行法医分析,证据链管理等 |
对此,我们需要使用X-Ways Forensics工具进行挂载
X-Ways Forensics
X-Ways Forensics 是为计算机取证分析人员提供的一个功能强大的、综合的取证、分析软件,可在 Windows XP/2003/Vista/2008/7/8/8.1/2012/10/2016/2019/11操作系统下运行,支持32 /64 位, Standard/PE/FE等版本。(Windows FE is described here, here and here.) 与其他竞争产品相比,由于它在运行时占用的资源更少,因此它在工作时更高效,运行更快速,并且能恢复已删除的文件,还能搜索到其他软件搜索不到的结果,还包含许多特有的功能,最重要的是成本更低廉。X-Ways Forensics 可随身携带,能够通过U盘在任意Windows操作系统下使用,无需安装。不像其他一些取证分析工具那样,X-ways Forensics不需要使用者设置数据库等繁琐的操作,并且超小化的安装包可以在数秒内下载并安装。它可以与WinHex hex和 disk editor 紧密结合,[提供高效率的工作流模型](https://www.x-ways.com/investigator/X-Ways Investigator (English).pps), 这样计算机取证调查员就可以与使用X-Ways Investigator 的调查员共享数据,协同工作。
看网上的WP用的都是AccessData FTK Imager,当然也是可以的,个人认为X-Ways Forensics功能更强大些
然后的步骤是在挂载的磁盘中找到flag文件
考点:磁盘分析
[NewStarCTF 2023 公开赛道]压缩包们(知识巩固题)
下载文件,没有后缀名使用010 editor进行分析:

没有文件头但是含有zip文件头和一串疑似base64编码的内容,我尝试使用foremost和binwalk进行文件分离,然后解码:

提示了我们密码是六位数,我们尝试爆破解密压缩包,但报错了:

我们使用010 editor进行分析,发现存在伪不加密:


我们进行修复,即可爆破:

解开即可得到flag
考点:文件分离、压缩包修复、压缩包爆破
[NewStarCTF 2023 公开赛道]大怨种(知识巩固题)
下载文件,是一张gif图片,我们提取帧

其中存在汉信码,扫码即可得到flag
考点:利用工具逐帧查看gif文件图像
[BSidesSF2020]mpfrag(新工具知识巩固题)
下载文件,是个.bin文件,我们首先使用010 editor分析:

难以看出有什么东西,我们使用file进行分析:

发现是ext2文件系统文件,推测是虚拟磁盘,我们进行挂载:
sudo losetup /dev/loop0 disk.bin
sudo mount /dev/loop0 /mnt/
但是报错了
mount: /mnt: wrong fs type, bad option, bad superblock on /dev/loop0, missing codepage or helper program, or other error.
dmesg(1) may have more information after failed mount system call.
这里说可能是错误的fs(filesystem)类型,但我们看之前的file命令观察的fs类型确实是挂载到linux系统中的ext2系统
也有可能是超级块的损坏
超级块
超级块(Superblock)是文件系统的一个核心数据结构,存储了文件系统的关键元数据。它包含了有关文件系统的基本信息,如文件系统类型、大小、使用情况、挂载状态、块大小、节点数等。每个文件系统在创建时都会生成一个超级块。
超级块的重要性:
- 挂载文件系统:当系统挂载文件系统时,内核首先会读取超级块来获取关于文件系统的信息。
- 文件系统修复:如果文件系统出现问题(如电源中断、硬件故障等),超级块中的信息用于修复文件系统。例如,在
ext4文件系统中,如果超级块损坏,文件系统可以通过备份的超级块进行恢复。
既然超级块损坏了,我们就可以使用工具修复
fsck
fsck(File System Consistency Check)是一个用于检查和修复文件系统错误的工具。在 Unix 和类 Unix 操作系统(如 Linux)中,fsck 被广泛使用来检查磁盘或分区的文件系统一致性,确保文件系统没有损坏,并且可以正常使用。它会扫描文件系统中的元数据(如目录结构、i-node、数据块分配等)以检测和修复潜在的错误。
fsck 的工作流程:
- 扫描文件系统:
fsck扫描文件系统的元数据(如超级块、i-node、数据块等),并检查它们是否符合文件系统的规则。 - 修复错误:如果
fsck发现文件系统错误,它会尝试根据文件系统的修复策略自动修复错误。 - 报告修复结果:修复完成后,
fsck会显示文件系统的修复结果,指出修复了哪些问题。
我们使用以下命令:
sudo fsck /dev/loop0
之后成功挂载:

成功了,我们再看看有没有删除的文件
首先是用fls列出文件系统中所有文件
fls
fls 是 Sleuth Kit 工具集中的一个命令行工具,用于显示文件系统中的目录和文件列表。
fls disk.bin

可以发现这里存在我们没有发现的cloud_key.mpeg文件,我们难以恢复(居然连foremost都提取不出来)
这里用磁盘精灵恢复了

MPEG
MPEG(Moving Picture Experts Group)是一种视频和音频压缩标准,通常用于数字视频和音频的编码。MPEG 文件通常是基于这种标准的文件格式,常见的文件扩展名包括 .mpg、.mpeg、.mp4(用于更现代的编码格式)等。MPEG 文件一般包含视频和音频流,可以用来存储电影、电视节目、视频片段等。
MPEG 标准包含多个不同的版本,常见的包括:
- MPEG-1:最早的版本,主要用于低分辨率的文件,常见于视频CD(VCD)。
- MPEG-2:用于高质量视频压缩,广泛用于DVD和广播电视。
- MPEG-4:支持更高压缩率,通常用于网络视频流媒体,且广泛用于现代视频播放和传输中,
.mp4文件格式就是基于 MPEG-4 的。
因此,MPEG 文件通常用于视频文件的存储、传输和播放。
为了打开这个恢复的文件,使用了VLC工具
VLC
VLC 是一款免费的开源跨平台多媒体播放器,可以播放大多数多媒体文件以及 DVD、音频 CD、VCD 和各种流协议
网上也有的WP都是将磁盘文件后缀改为.mp4成功的

视频中的字符串为:
SF-G0lden-Gl0w-1849
可以用于解密压缩包,得到flag(不知道为什么磁盘精灵提取出压缩包的不能解密)
考点:磁盘文件恢复、磁盘分析
[NewStarCTF 2023 公开赛道]空白格(新)
下载文件,是一个全是空格的文本文件:

我们尝试将空格转换成0,tab转换成1,没有发现
推测是snow隐写,没有密码所以解密失败
推测是空白格隐写
white_space
white_space是一种编程语言,由空格、回车、tab组成
我们进行解密whitespace在线运行,在线工具,在线编译IDE_w3cschool
[NewStarCTF 2023 公开赛道]Nmap(新)
请给出Nmap扫描得到所有的开放端口用英文逗号分隔,端口号从小到大排列。 例如flag{21,22,80,8080}
在此之前我们分析一下nmap的工作原理:【笔记】Nmap工具原理探索 - Super_Snow_Sword - 博客园
SYN扫描执行的是不完整的TCP三次握手过程,在SYN扫描中,客户端在接收到来自服务器的一个设置了SYN/ACK标志位的数据包之后,将直接发送一个设置了RST标志位的TCP数据包结束握手(这可以防止服务器端重复尝试发出TCP数据包)
也就是说我们直接过滤查看含有RST标志的数据包,查看其目的端口即可:
tcp.flags.reset == 1

我们发现还有很多含有RST标志和ACK标志的数据包,可能是nmap发送了一个无效的TCP请求包导致服务器请求断开连接
我们再添加过滤语句:
tcp.flags.reset ==1 && tcp.flags.ack == 0

我们可以发现端口41190出现次数多且发送请求的端口多,可以推测nmap运行在端口41190上
我们统计它的交互端口:

则flag为
flag{80,3306,5000,7000,8021,9000}
考点:流量分析、理解nmap工具原理
[UTCTF2020]dns-shell(新已过期)
下载文件,使用wireshark进行分析,首先进行协议分级:

TCP协议占比最高,但是内容经过了TLS协议加密,我们难以读取,我们先分析UDP流:

前两个流即客户端 192.168.232.129 对dns服务器 35.225.16.21 进行了查询 dns.google.com
之后客户端就知道了google.com的dns地址是 35.188.185.68


我们进行base64解码:


这是典型的 DNS 隧道 技术,常用于数据隐蔽通信甚至远程命令控制。
DNS隧道技术
DNS 隧道技术是一种利用 DNS 协议传输数据的隐秘通信方式。由于 DNS 通信是网络中非常常见且通常不受严格监控的协议,攻击者可以通过将数据嵌入到 DNS 查询和响应中,构建一个隐蔽的通信通道,用于绕过防火墙、传输敏感数据或进行命令控制。
1.DNS 通信结构:
- 客户端向 DNS 服务器发送查询,请求解析域名。
- DNS 服务器根据查询类型返回响应(如 IP 地址、TXT 记录等)。
- 这种查询-响应模式为隧道通信提供了传输数据的载体。
2.数据嵌入:
-
数据可以被编码后嵌入到 DNS 查询的域名部分中。
-
例如,将数据
cat /flag编码为 Base64 后,嵌入查询:
Y2F0IC9mbGFn.example.com
目标 DNS 服务器解析后执行命令,并通过响应返回执行结果。
解析与响应:
- 目标 DNS 服务器提取域名中的编码数据,并处理后返回响应。
- 响应可以是包含执行结果的 TXT 记录或其他形式的数据。
原题描述:
我的一个服务器被入侵了,但我搞不清楚。看看你能不能帮帮我吧!
看别人的WP,题目的需求应该是希望我们也去访问一下这个被攻击的DNS服务器(已经无法访问)
nslookup -type=A dns.google.com 35.225.16.21
nslookup:一个命令行工具,用于查询域名系统 (DNS) 的记录。常用于检查域名解析状态。
-type=A:指定查询记录类型为 A 记录,即返回域名的 IPv4 地址。
dns.google.com:这是目标查询的域名。我们根据流量包去查询 dns.google.com 的 A 记录。
35.225.16.21:指定的 DNS 服务器 IP 地址。
找到正确的ip地址(3.88.57.227 )后,我们尝试注入:
nslookup -type=TXT Y2F0IGZsYWcudHh0 3.88.57.227
-type=TXT:指定查询类型为 TXT 记录。TXT 记录通常包含与域名相关的文本信息,可用于多种用途,比如验证、描述性信息等。
Y2F0IGZsYWcudHh0:应该为查询的目标域名,这里的内容是 Base64 编码后的cat flag.txt,DNS服务器命令执行后 会将 cat flag.txt 命令的执行结果(即 flag.txt 中的内容)作为 TXT 记录返回给我们

直接得到了flag
参考文章:UTCTF2020 - NETWORKING]Do-Not-Stop
考点:流量分析、理解DNS隧道技术
洞拐洞拐洞洞拐(知识巩固题)
下载文件,是一张图片,看上去隐藏着信息我们首先将黑白组合的像素排列出来(黑1白0)

有两种排列方式这里给出脚本
逐行分析png中的黑白:
from PIL import Image
# 打开 PNG 图片
image_path = '' # 替换为你的图片路径
image = Image.open(image_path)
# 转换为黑白模式(1-bit pixels)
bw_image = image.convert('1')
# 获取图像的宽度和高度
width, height = bw_image.size
# 存储结果
result = []
# 遍历每个像素
for y in range(height):
row = []
for x in range(width):
pixel = bw_image.getpixel((x, y))
# 1 表示黑色,0 表示白色
row.append('1' if pixel == 0 else '0')
result.append(''.join(row))
# 将结果写入文件
with open('1.txt', 'w') as f:
for line in result:
f.write(line + '\n')
print("分析完成,结果已保存到 1.txt")
逐列分析png中的黑白:
from PIL import Image
# 打开 PNG 图片
image_path = '' # 替换为你的图片路径
image = Image.open(image_path)
# 转换为黑白模式(1-bit pixels)
bw_image = image.convert('1')
# 获取图像的宽度和高度
width, height = bw_image.size
# 存储结果
result = []
# 遍历每个像素
for x in range(height):
row = []
for y in range(width):
pixel = bw_image.getpixel((x, y))
# 1 表示黑色,0 表示白色
row.append('1' if pixel == 0 else '0')
result.append(''.join(row))
# 将结果写入文件
with open('1.txt', 'w') as f:
for line in result:
f.write(line + '\n')
print("分析完成,结果已保存到 1.txt")
逐列分析图片出现了信息:

发现是音频文件,我们保存后分析:

我们进行分析,其中波形图出现了八种不同的振幅,我们提取分析:
import wave
import numpy as np
def calculate_longest_amplitude(wav_file, output_file=None):
try:
# 打开 WAV 文件
with wave.open(wav_file, 'rb') as wf:
n_channels = wf.getnchannels() # 通道数
samp_width = wf.getsampwidth() # 每个样本的字节数
framerate = wf.getframerate() # 采样率
n_frames = wf.getnframes() # 总帧数
# 读取音频数据
audio_data = wf.readframes(n_frames)
audio_array = np.frombuffer(audio_data, dtype=np.int16)
# 如果是立体声,取平均值转换为单声道
if n_channels > 1:
audio_array = audio_array.reshape(-1, n_channels).mean(axis=1).astype(np.int16)
# 计算每秒持续时间最长的振幅
seconds = n_frames // framerate
longest_amplitude_per_second = []
for i in range(seconds):
start = i * framerate
end = (i + 1) * framerate
second_data = audio_array[start:end]
# 找到持续时间最长的振幅
unique_values, counts = np.unique(second_data, return_counts=True)
max_index = np.argmax(counts)
longest_amplitude = unique_values[max_index]
longest_amplitude_per_second.append(longest_amplitude)
# 输出结果
for i, amp in enumerate(longest_amplitude_per_second):
print(f"第 {i + 1} 秒持续时间最长的振幅: {amp}")
# 如果需要保存到文件
if output_file:
with open(output_file, 'w') as f:
for i, amp in enumerate(longest_amplitude_per_second):
f.write(f"第 {i + 1} 秒持续时间最长的振幅: {amp}\n")
print("处理完成!")
except Exception as e:
print(f"发生错误: {e}")
# 使用示例
wav_file = '' # 替换为你的音频文件路径
output_file = '1.txt' # 可选,保存输出结果
calculate_longest_amplitude(wav_file, output_file)
输出了八种数据,我们推测为8进制:
-24575 -16383 -8191 0 8191 16383 24575 32767
我们进行转换得到
115132127107103132063063107064064107107116122124110105063104105115132123107121064124121115132121115131062127103116122132107132123104103117102131110102122107115115132125115106123127111115132123107126122124121131063104107111132127111132104102117065123104113115114062120112131130125115122124107115132124107131114102120125

MZWGCZ33G44GGNRTHE3DEMZSGQ4TQMZQMY2WCNRZGZSDCOBYHBRGMMZUMFSWIMZSGVRTQY3DGIZWIZDBO5SDKML2PJYXUMRTGMZTGYLBPU
观察这串密文,最大字母为Z,最小字母为B,最大数字为5,最小数字为2
符合base32(A-Z,2-7)

考点:图片像素分析、音频振幅分析
[RoarCTF2019]davinci_cipher(新工具较难)
下载文件,有一个流量包和一个flag.txt
我们先看flag.txt:

很明显的UNICODE编码
UNICODE编码
Unicode(统一码)是一种字符编码标准,用于在不同的计算机系统、软件和设备之间表示、处理和交换文本信息。它的主要目标是为全球所有语言和符号提供唯一的编码。
我们使用这个在线网站进行转码

这里的emoji并不是base100编码,可能是emoji AES但我们没有密钥所以先放着
再来分析流量:

TCP流量有TLS协议加密,HTTP协议传输了媒体文件,还有USB流量存在,真是目不暇接,先从简单的HTTP协议开始分析:

提取出一张蒙娜丽莎,对应了题目名字“达芬奇密码”
按照图片隐写思路都试过了,没有结果也先放着
HTTP协议还存在着这些,但我尝试了都不是emoji的key:

那么就是令人怀疑的USB协议了,我们过滤进行分析:


可以发现这是数位板的数据流量,我们进行分析:

看不懂,网上WP给出了相关文档
详细说明在USB协议文档里的Figure 19:示例数码压力手写笔输入报文

表的字段定义如下:
-
字节 0: Report ID = 3
-
字节 1-2: X 坐标
-
字节 3-4: Y 坐标
-
字节 5:
状态位:
- Bit 7: "In Range" 标志
- Bit 6: Barrel Switch(例如笔按钮)
- 其余位未使用
-
字节 6: 压力值
那么我们对第一个传递的数据进行分析:
10402a46001e3c0000000000000000003f00000000000000000000
即
10 402A 4600 1E 3C 00000000000000003F0000000000000000000000
10 Report ID = 3 ,表示这是一份压力触控笔(Stylus)的输入报告
402A X 坐标:40 (低字节) = 64 2A (高字节) = 42 X = (42 << 8) | 64 = 10816
4600Y 坐标:46 (低字节) = 70 00 (高字节) = 0 Y = (0 << 8) | 70 = 70
1E 状态字节,二进制为0001 1110
- Bit 7 ("In Range") = 0(不在范围内)
- Bit 6 (Barrel Switch) = 0(未按下)
- 其余位未定义
3C 压力值 = 3C (十六进制) = 60。
数据中剩余部分为 00 或 3F,不属于此输入报告的有效字段
我们首先将相关的报文提取出来:
tshark -r 'k3y.pcapng' -T fields -e usbhid.data |sed '/^$/d' > usbdata.txt
然后用分析的脚本进行分析并给出图像(脚本来源于:数位板流量分析探索 - zysgmzb - 博客园):
import os
import matplotlib.pyplot as plt
#os.system("tshark -r 1.pcapng -T fields -e usb.capdata| sed '/^\s*$/d' > 1.txt")
data=[]
with open('1.txt',"r") as f:
for line in f.readlines():
if line[16:18] !="00":
data.append(line)
X = []
Y = []
for line in data:
x0=int(line[4:6],16)
x1=int(line[6:8],16)
x=x0+x1*256
y0=int(line[10:12],16)
y1=int(line[12:14],16)
y=y0+y1*256
X.append(x)
Y.append(-y)
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_title("result")
ax1.scatter(X, Y, c='b', marker='o')
plt.show()

得到了密钥MONA_LISA_IS_A_MAN成功对emojiAES进行解密:

考点:USB流量分析、Unicode解码、emojiAES
[HITCON2018]ev3basic(新较难)
下载文件,是没有后缀名的文件,我们先使用010 editor进行分析:

看上去里面藏了很多文件(有很多文件头),我们使用binwalk自动提取看看:

提取出了一张图片和一个流量包
对图片隐写分析无果,我们分析流量包:

可以发现这流量包传递的是蓝牙的流量
蓝牙协议
根据题目名ev3我们可以搜索出这是乐高的机器人

蓝牙核心技术概述(四):蓝牙协议规范(HCI、L2CAP、SDP、RFOCMM)_蓝牙通信帧分类-CSDN博客
LEGO Wireless Protocol 3.0.00 Doc v3.0.00 r17 documentation
你至少要知道这四个协议:HCI、L2CAP、SDP、RFCOMM。对比于英特网五层结构来说:HCI相当于与物理层打交道的协议,L2CAP协议则是链路层相关协议,SDP和RFCOMM则是运输层相关协议,当然其上也有对应的应用层相关的一些协议。SDP用来发现周围蓝牙服务,然后由L2CAP来建立信道链接,然后传输由上层RFCOMM给予的数据分组。(来源于文章HITCON2018 两道蓝牙流量分析相关题目 – 消失的夜丶)
网上难以找到其中具体的ev3数据内容分析,这里给出网上的分析协议过程
我们分析RFCCOMM协议发送的data内容:

我们主要在289和299数据包中找到了flag的数据“hi”(对应比赛名HITCON),但在下一个Sent数据包中找到的却是“}”
按照ev3_basic——HITCON CTF 2018 - B1u3Buf4 - 博客园中的说法,对不同长度的数据包进行了分类,框起来的字符分别表示了组内序号,组号,字符
那么我们可以推测ev3发送的数据需要根据这三者来进行拼接
32的:直接是组内序号

33的:组内序号前加了0x81

34的:组内序号前加了0x82,序号后加了0x00

那么我们进行分析:
| 数据包序号 | 数据包长度 | 组内序号 | 组号 | 字符 |
|---|---|---|---|---|
| 289 | 32 | 0a | 28 | h-68 |
| 299 | 32 | 14 | 28 | i-69 |
| 309 | 33 | 64 | 52 | }-7d |
| 319 | 33 | 46 | 28 | {-7b |
| 329 | 33 | 5a | 28 | 1-31 |
最后得到的排序为
h,b0017 2711 0a 28 68
i,b0017 2711 14 28 69
t,b0017 2711 1e 28 74
c,c0018 2912 28 28 63
o,c0018 2912 32 28 6f
n,c0018 2912 3c 28 6e
{,c0018 2912 46 28 7b
m,c0018 2912 50 28 6d
1,c0018 2912 5a 28 31
n,c0018 2912 64 28 6e
d,c0018 2912 6e 28 64
5,c0018 2912 78 28 35
t,d0019 2b13 82 28 74
0,d0019 2b13 8c 28 30
r,d0019 2b13 96 28 72
m,d0019 2b13 a0 28 6d
_,b0017 2711 0a 36 5f
c,b0017 2711 14 36 63
o,b0017 2711 1e 36 6f
m,c0018 2912 28 36 6d
m,c0018 2912 32 36 6d
u,c0018 2912 3c 36 75
n,c0018 2912 46 36 6e
i,c0018 2912 50 36 69
c,c0018 2912 5a 36 63
a,c0018 2912 64 36 61
t,c0018 2912 6e 36 74
i,c0018 2912 78 36 69
o,d0019 2b13 82 36 6f
n,d0019 2b13 8c 36 6e
_,d0019 2b13 96 36 5f
a,d0019 2b13 a0 36 61
n,b0017 2711 0a 44 6e
d,b0017 2711 14 44 64
_,b0017 2711 1e 44 5f
f,c0018 2912 28 44 66
i,c0018 2912 32 44 69
r,c0018 2912 3c 44 72
m,c0018 2912 46 44 6d
w,c0018 2912 50 44 77
a,c0018 2912 5a 44 61
r,c0018 2912 64 44 72
e,c0018 2912 6e 44 65
_,c0018 2912 78 44 5f
d,d0019 2b13 82 44 64
e,d0019 2b13 8c 44 65
v,d0019 2b13 96 44 76
e,d0019 2b13 a0 44 65
l,b0017 2711 0a 52 6c
o,b0017 2711 14 52 6f
p,b0017 2711 1e 52 70
e,c0018 2912 28 52 65
r,c0018 2912 32 52 72
_,c0018 2912 3c 52 5f
k,c0018 2912 46 52 6b
i,c0018 2912 50 52 69
t,c0018 2912 5a 52 74
},c0018 2912 64 52 7d
考点:分析ev3流量
[NewStarCTF 公开赛赛道]还是流量分析(新)
救赎之道,就在其中。 Flag格式:flag{WebShell-Key值_机密文件内容} 例如:flag{d8ff731bdba84bf5_sercet} P.S:请注意Key值并非密码!
下载文件,用wireshark打开流量包进行分析:

【原创】哥斯拉Godzilla加密流量分析 - FreeBuf网络安全行业门户
从中我们可以知道哥斯拉流量的特征:
- 使用密钥对请求数据进行了加密,还会在最终的请求数据前后额外再追加一些扰乱数据,然后才通过POST请求发送给服务器
- 哥斯拉传入的数据首先URL解码+倒序+base64编码

我们解码传入的流量,可以发现其中的密钥key=421eb7f1b8e4b3cf:

有了密钥我们就好分析了,这里使用了abc123info/BlueTeamTools: 蓝队分析研判工具箱,功能包括内存马反编译分析、各种代码格式化、网空资产测绘功能、溯源辅助、解密冰蝎流量、解密哥斯拉流量、解密Shiro/CAS/Log4j2的攻击payload、IP/端口连接分析、各种编码/解码功能、蓝队分析常用网址、java反序列化数据包分析、Java类名搜索、Fofa搜索、Hunter搜索等。项目中的哥斯拉流量解码的功能
因为要寻找机密文件,所以我们重点关注返回包的内容
最终我们在第35个tcp流中找到了机密文件:

考点:哥斯拉流量分析
[NewStarCTF 2023 公开赛道]永不消逝的电波(知识巩固题)
下载文件,我们听一下像是摩斯电码
使用Audacity进行音频分析:

得到
..-. .-.. .- --. - .... . -... . ... - -.-. - ..-. . .-. .. ... -.-- --- ..-

得到flag
考点:摩斯电码
[NPUCTF2020]HappyCheckInVerification(新工具已过期孬题)
下载文件,没有后缀名我们使用010 editor分析:

我们可以发现endLocator(ZIP文件尾)出现在了头部位置,我们将其弄到文件尾:

但还是打不开文件,可能是还有些比特位没有修复好,怎么办?
这里使用bandzip打开,bandzip会自动修复填充比特位并打开:

发现要密码,这可能存在伪密码的情况,但我们的010 editor难以模块化分析怎么办?
成功修复伪密码:

提取出黑人抬棺的视频和一张没有定位符的二维码,我们先修复:


多段密文,我们分别分析:
三曳所諳陀怯耶南夜缽得醯怯勝數不知喝盧瑟侄盡遠故隸怯薩不娑羯涅冥伊盧耶諳提度奢道盧冥以朋罰所即栗諳蒙集皤夷夜集諳利顛呐寫無怯依奢竟
#¥#%E68BBFE4BD9BE68B89E6A0BCE79A84E5A7BFE58ABFE59CA8E69C80E5908E32333333||
254333254242254338254342254231254338254345254432254238254643254236254145254239254441254437254234254232254131254236254245253244253244254343254438254330254341254336254435
...sadwq#asdsadasf faf$use$dasdasdafafa_$ba##se64$



最后一段不知道是什么编码或密码,只能看出use base64
接下来分析视频,黑人抬棺的视频19秒处存在电话拨号音,我们进行分析(个人将片段截取后使用格式工厂转换成wav,再用了AI提取,这里用的AI模型是团子AI - 人工智能在线工具箱,最终得到的音频比较清晰但不知道为何与答案不同)

(以下内容来自Ha1cyon_CTF write up(部分)-腾讯云开发者社区-腾讯云)
然后开头几个数字去找了出题人得到了hint,最后得到手机号码xxx18070885
那么发短信过去会提示NWPUSEC
去微信公众号关注了以后,发送了手机号码base64encode的结果,然后发送了一段音频
得知是无线电(SSTV),手机上用Robot36识别出来一张图:

flag就在这里
考点:zip伪加密、DTMF拨号音
[RoarCTF2019]TankGame(较难)
下载文件,只有单人模式太难过关了,我们上DnSpy对Assembly-CSharp.dll进行逆向:

我们找到了可疑的FlagText,我们右键对其进行分析,继续跟进

跟进找到了调用其的WinGame()函数,我们对其进行分析:
// WinGame 方法用于判断是否满足获胜条件,并在条件满足时生成并显示 Flag
public static void WinGame()
{
// 如果游戏还未胜利且摧毁的数量为 4 或 5,则继续检查
if (!MapManager.winGame && (MapManager.nDestroyNum == 4 || MapManager.nDestroyNum == 5))
{
// 初始化字符串,后续用于生成 flag 的基础内容
string text = "clearlove9";
// 循环遍历地图状态,构建一个包含 MapState 数组中所有值的字符串
for (int i = 0; i < 21; i++) // 外循环遍历 21 行
{
for (int j = 0; j < 17; j++) // 内循环遍历 17 列
{
// 将每个地图单元的状态值(MapState[i, j])转换为字符串并拼接到 text 变量中
text += MapManager.MapState[i, j].ToString();
}
}
// 对拼接后的字符串进行 Sha1 哈希计算
string a = MapManager.Sha1(text);
// 如果计算出的 Sha1 值与预期的值匹配,则表示满足条件
if (a == "3F649F708AAFA7A0A94138DC3022F6EA611E8D01")
{
// 显示 Flag,激活 FlagText 对象
FlagText._instance.gameObject.SetActive(true);
// 设置 Flag 内容,使用 Md5 对 text 字符串进行加密,并作为 flag 的一部分
FlagText.str = "RoarCTF{wm-" + MapManager.Md5(text) + "}";
// 设置游戏为获胜状态
MapManager.winGame = true;
}
}
再看看地图单元的状态值分布:

public static void Init()
{
MapManager.MapState = new int[,]
{
{
8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8
},
{
8,8,4,5,8,1,1,1,1,1,1,8,8,8,8,4,8
},
{
8,2,8,1,8,8,5,1,8,8,8,1,8,1,8,4,8
},
{
8,5,8,2,8,8,8,8,1,8,8,4,8,1,1,5,8
},
{
8,8,8,8,2,4,8,1,1,8,8,1,8,5,1,5,8
},
{
8,8,8,8,5,8,8,1,5,1,8,8,8,1,8,8,8
},
{
8,8,8,1,8,8,8,8,8,8,8,8,1,8,1,5,8
},
{
8,1,8,8,1,8,8,1,1,4,8,8,8,8,8,1,8
},
{
8,4,1,8,8,5,1,8,8,8,8,8,4,2,8,8,8
},
{
1,1,8,5,8,2,8,5,1,4,8,8,8,1,5,1,8
},
{
0,1,4,8,8,8,8,8,8,8,8,8,8,8,8,8,8
},
{
1,1,8,1,8,8,2,1,8,8,5,2,1,8,8,8,8
},
{
8,8,8,8,4,8,8,2,1,1,8,2,1,8,1,8,8
},
{
8,1,1,8,8,4,4,1,8,4,2,4,8,4,8,8,8
},
{
8,4,8,8,1,2,8,8,8,8,1,8,8,1,8,1,8
},
{
8,1,1,5,8,8,8,8,8,8,8,8,1,8,8,8,8
},
{
8,8,1,1,5,2,8,8,8,8,8,8,8,8,2,8,8
},
{
8,8,4,8,1,8,2,8,1,5,8,8,4,8,8,8,8
},
{
8,8,2,8,1,8,8,1,8,8,1,8,2,2,5,8,8
},
{
8,2,1,8,8,8,8,2,8,4,5,8,1,1,2,5,8
},
{
8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8
}
};
}

对应到游戏地图,我们可以得出:
8 黑路
1 砖块
4 水
5 草
2 白墙
0 家
为了能够得到flag,地图状态计算出的Sha1 值必须与预期的值匹配,然后输出当前地图状态的MD5值作为flag
并且能够更改的地图区块仅为1、8(砖块被摧毁后从1成为8)
# coding=utf-8
import hashlib # 引入 hashlib 模块用于进行 SHA1 和 MD5 哈希计算
# 这个二维数组代表了游戏地图的数据,数字 8、4、5、2、1、9 表示不同的状态
data = [
[8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8],
[8, 8, 4, 5, 8, 1, 1, 1, 1, 1, 1, 8, 8, 8, 8, 4, 8],
[8, 2, 8, 1, 8, 8, 5, 1, 8, 8, 8, 1, 8, 1, 8, 4, 8],
[8, 5, 8, 2, 8, 8, 8, 8, 1, 8, 8, 4, 8, 1, 1, 5, 8],
[8, 8, 8, 8, 2, 4, 8, 1, 1, 8, 8, 1, 8, 5, 1, 5, 8],
[8, 8, 8, 8, 5, 8, 8, 1, 5, 1, 8, 8, 8, 1, 8, 8, 8],
[8, 8, 8, 1, 8, 8, 8, 8, 8, 8, 8, 8, 1, 8, 1, 5, 8],
[8, 1, 8, 8, 1, 8, 8, 1, 1, 4, 8, 8, 8, 8, 8, 1, 8],
[8, 4, 1, 8, 8, 5, 1, 8, 8, 8, 8, 8, 4, 2, 8, 8, 8],
[1, 1, 8, 5, 8, 2, 8, 5, 1, 4, 8, 8, 8, 1, 5, 1, 8],
[9, 1, 4, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8],
[1, 1, 8, 1, 8, 8, 2, 1, 8, 8, 5, 2, 1, 8, 8, 8, 8],
[8, 8, 8, 8, 4, 8, 8, 2, 1, 1, 8, 2, 1, 8, 1, 8, 8],
[8, 1, 1, 8, 8, 4, 4, 1, 8, 4, 2, 4, 8, 4, 8, 8, 8],
[8, 4, 8, 8, 1, 2, 8, 8, 8, 8, 1, 8, 8, 1, 8, 1, 8],
[8, 1, 1, 5, 8, 8, 8, 8, 8, 8, 8, 8, 1, 8, 8, 8, 8],
[8, 8, 1, 1, 5, 2, 8, 8, 8, 8, 8, 8, 8, 8, 2, 8, 8],
[8, 8, 4, 8, 1, 8, 2, 8, 1, 5, 8, 8, 4, 8, 8, 8, 8],
[8, 8, 2, 8, 1, 8, 8, 1, 8, 8, 1, 8, 2, 2, 5, 8, 8],
[8, 2, 1, 8, 8, 8, 8, 2, 8, 4, 5, 8, 1, 1, 2, 5, 8],
[8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8]
]
# 将二维数组转化为一维字符串,用来进一步处理
text = ''
for i in range(21): # 遍历 21 行
for j in range(17): # 遍历每行的 17 列
text += str(data[i][j]) # 将每个元素转换为字符串并拼接到 text
# 将拼接后的字符串转化为列表
text = list(text)
# 递归处理函数,搜索不同的字符组合
def work(data, index, num):
# 如果递归调用次数达到 3
if num == 3:
# 将数据列表重新拼接为字符串
temp = ''.join(data)
# 对拼接后的字符串进行 SHA1 哈希计算,前缀是 'clearlove9'
if hashlib.sha1('clearlove9' + temp).hexdigest() == '3f649f708aafa7a0a94138dc3022f6ea611e8d01':
# 如果哈希值匹配,计算 MD5 哈希并取前 10 个字符作为 key
key = hashlib.md5('clearlove9' + temp).hexdigest().upper()[:10]
# 生成 flag 格式
flag = "RoarCTF{wm-" + key + "}"
# 打印 flag
print(flag)
return
# 如果 index 达到 21*17,递归结束
if index == 21 * 17:
return
# 如果当前字符是 '1',将其替换为 '8' 并继续递归
if data[index] == '1':
temp = list(data) # 创建当前数据的副本
temp[index] = '8' # 替换当前字符
work(temp, index + 1, num + 1) # 递归调用
# 继续递归调用不改变当前字符的情况
work(data, index + 1, num)
# 主程序入口
if __name__ == "__main__":
# 调用递归函数,从 index = 0 和 num = 0 开始
work(text, 0, 0)
脚本来源于浅谈CTF中的unity游戏逆向 |
关于算法内容可以看看带你学透回溯算法(理论篇)| 回溯法精讲!
考点:unity逆向
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步