Java IO
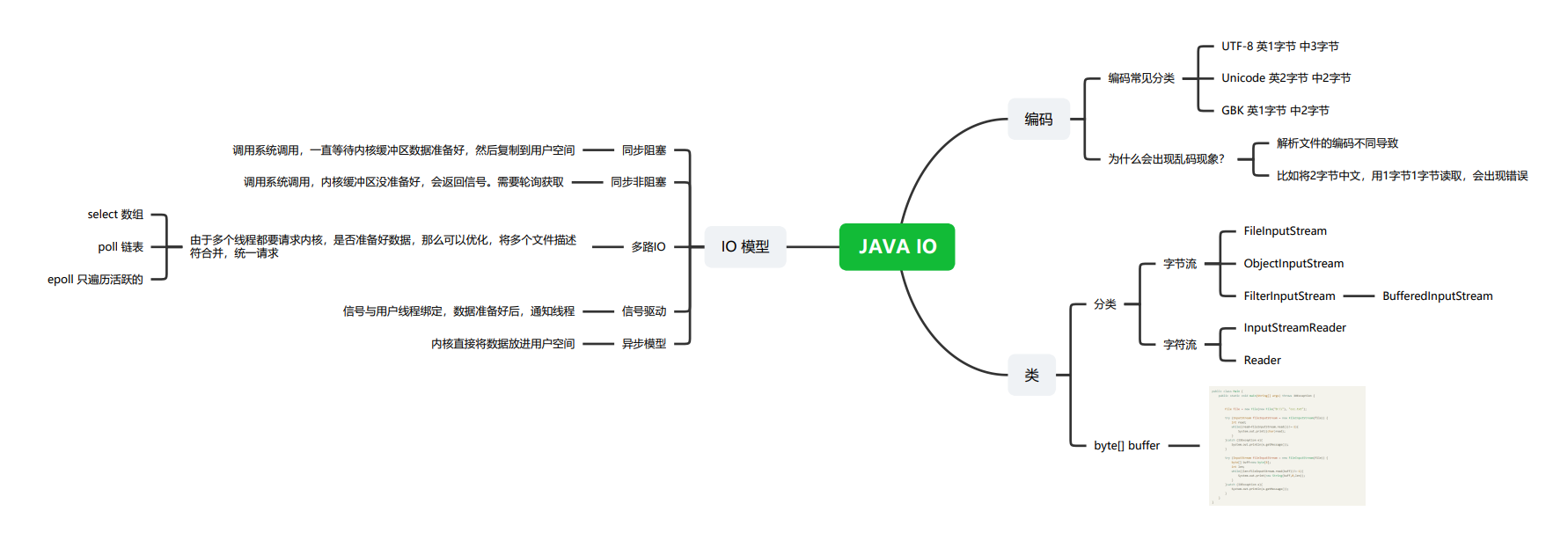
编码说明
编码占用字节
utf8: 英文1字节,中文3字节
unicode: 任何字符占2字节
gkp: 英文1字节,中文2字节
编码就像在字典里查找值并翻译:utf8、unicode 就是一本字典,解码就是查字典。
以上三种编码都能表示中文字符,那我们该如何选择编码方式呢?这就要权衡效率与空间的利弊。
为什么使用 FileInputStream 处理中文会乱码?
FileInputStream 读中文乱码是因为一个中文对应三个字节存储,也就是说,读取对应中文应该是三个字节,而英文对应一个字节存储。FileInputStream 每次读取一个数组长度的字节时,可能只读到中文的一半字节,所以就会出现乱码。
举个栗子:下图是 a.txt 文件,我们对它进行操作
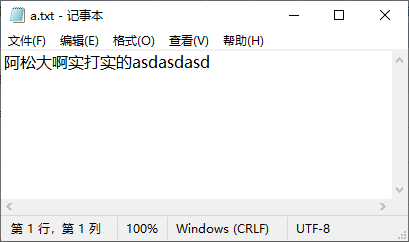
如果单独使用 read(),每次会读出一个字节,那么中文必然会导致乱码。
inputStream=new FileInputStream("D:\\a.txt");
int read;
while((read = inputStream.read())!=-1){
System.out.print((char) read);
}
// result:é¿æ¾å¤§åå®æå®çasdasdasd
如果是一次读出来,中文没有截断,那就没有问题。
inputStream=new FileInputStream("D:\\a.txt");
byte[] bytes = inputStream.readAllBytes();
System.out.println(new String(bytes));
// result:阿松大啊实打实的asdasdasd
注意要保证 System.out 的编码与文件编码一致,才能正确输出屏幕。就好比你拿英文字典查中文,那一定错误的呀。
public class IOTest {
public static void main(String[] args) throws IOException {
byte[] gbks = "你好".getBytes("gbk");
System.out.println(new String(gbks)); //result:���
byte[] utf8 = "你好".getBytes("utf-8");
System.out.println(new String(utf8)); //result:你好
}
}
JavaIO相关
Java IO
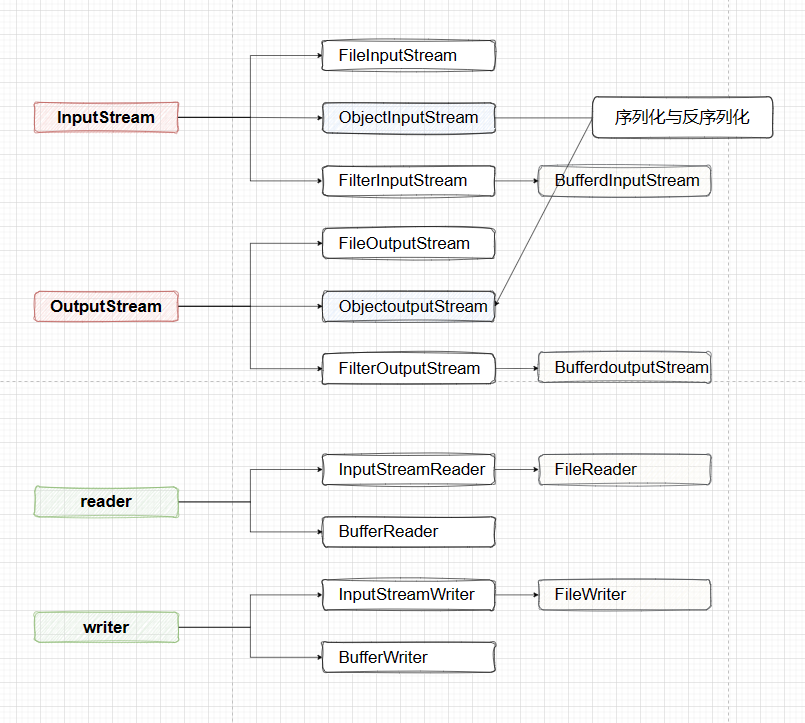
IO流介绍
输入/输出:从计算机内容到硬盘为输出,从硬盘读取数据到计算机称为输入。
IO流分类
InputStream/Reader: 输入流(字节)/(字符)OutputStream/Writer: 输出流(字节)/(字符)
一字节等于8bit
File
创建文件的三种方式:
// File file = new File("D:\\", "aaa.txt");
// File file = new File("D:\\bbb.txt");
// File file = new File(new File("D:\\"), "ccc.txt");
FileInputStream
public class Main {
public static void main(String[] args) throws IOException {
File file = new File(new File("D:\\"), "ccc.txt");
try (InputStream fileInputStream = new FileInputStream(file)) {
int read;
while((read=fileInputStream.read())!=-1){
System.out.print((char)read);
}
}catch (IOException e){
System.out.println(e.getMessage());
}
try (InputStream fileInputStream = new FileInputStream(file)) {
byte[] buff=new byte[8];
int len;
while((len=fileInputStream.read(buff))!=-1){
System.out.print(new String(buff,0,len));
}
}catch (IOException e){
System.out.println(e.getMessage());
}
}
}
String sourceFile = "D:\\ccc.txt";
String targetFile = "D:\\ddd.txt";
FileInputStream fileInputStream = null;
FileOutputStream fileOutputStream = null;
try {
fileInputStream = new FileInputStream(sourceFile);
fileOutputStream = new FileOutputStream(targetFile);
byte[] buff = new byte[1024];
int readLine = 0;
while ((readLine = fileInputStream.read(buff)) != -1) {
fileOutputStream.write(buff, 0, readLine);
}
} catch (IOException e) {
System.out.println(e.getMessage());
} finally {
if (fileInputStream != null) {
fileInputStream.close();
}
if (fileOutputStream != null) {
fileOutputStream.close();
}
}
FileReader
try (FileReader reader = new FileReader("D:\\ccc.txt")) {
char[] context=new char[1024];
int len=0;
while((len= reader.read(context))!=-1){
System.out.println(new String(context,0,len));
}
} catch (IOException e) {
throw new RuntimeException(e);
}
IO 模型
用户态与内核态:用户态运行的用户程序,内核区运行的是系统程序。用户程序不能直接访问内核内存,每次数据要先放在内核缓冲区,然后系统调用复制到用户空间,用户程序才能使用。
阻塞 IO
在应用调用recvfrom读取数据时,如果用户空间中数据没复制完成,一直等待。在这时候,线程是一直阻塞的,但是cpu不会阻塞。
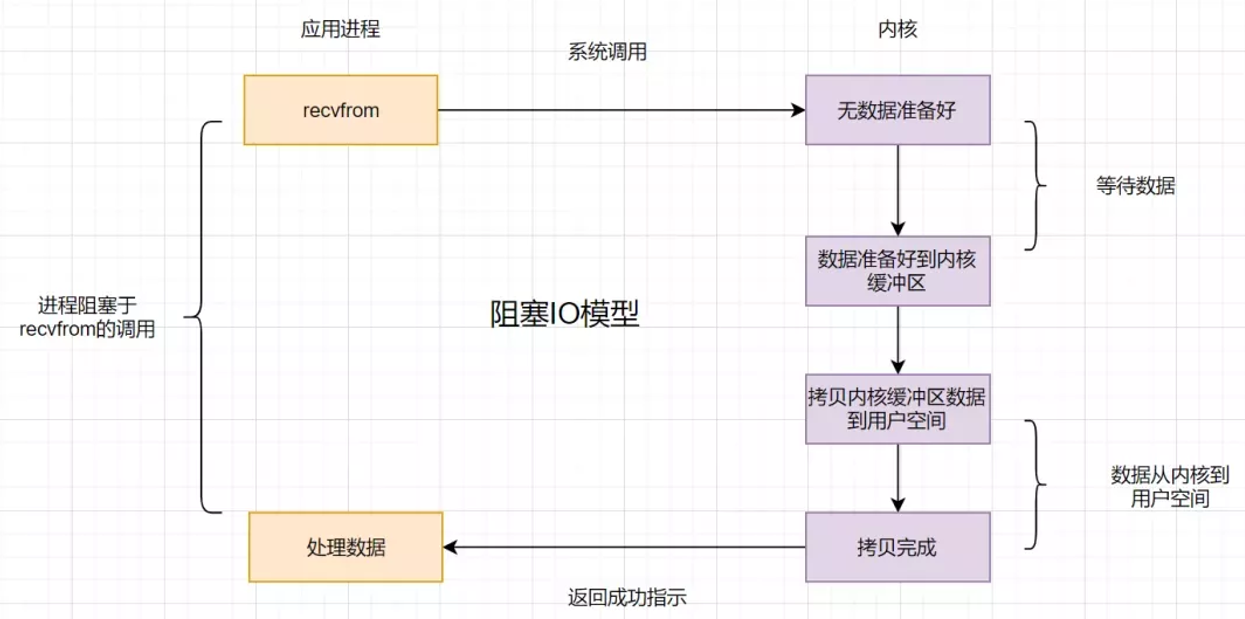
为什么大型系统不使用阻塞 IO 呢?
大型系统中,请求会很多,使用阻塞IO导致线程数会大量累积,然后线程切换也会导致性能下降。
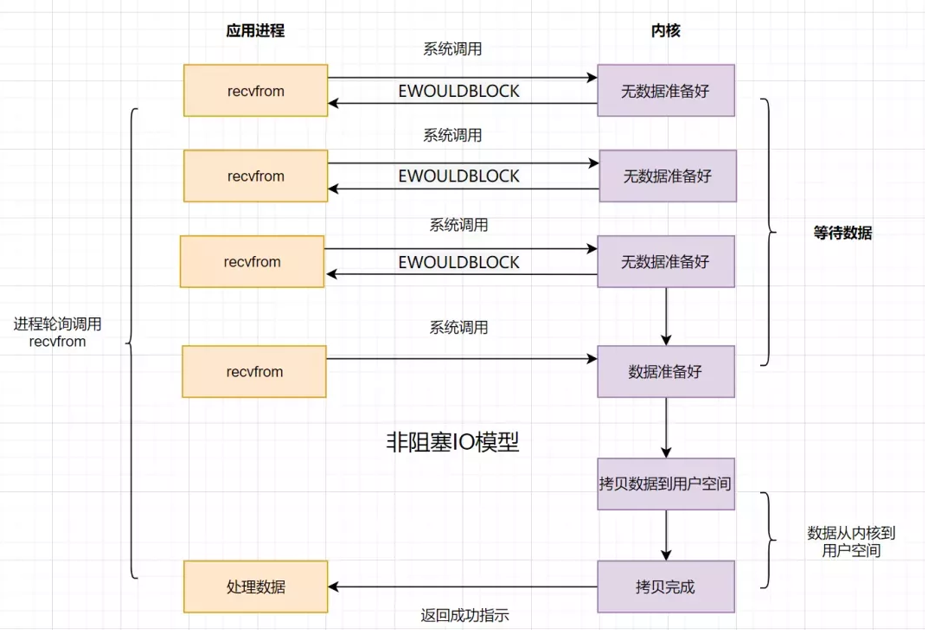
非阻塞 IO
在应用调用recvfrom读取数据时,如果内核缓冲区的数据没复制完成,会返回一个错误码,不需要一直阻塞,但是需要不断调用请求 recvfrom,会加剧消耗CPU 。
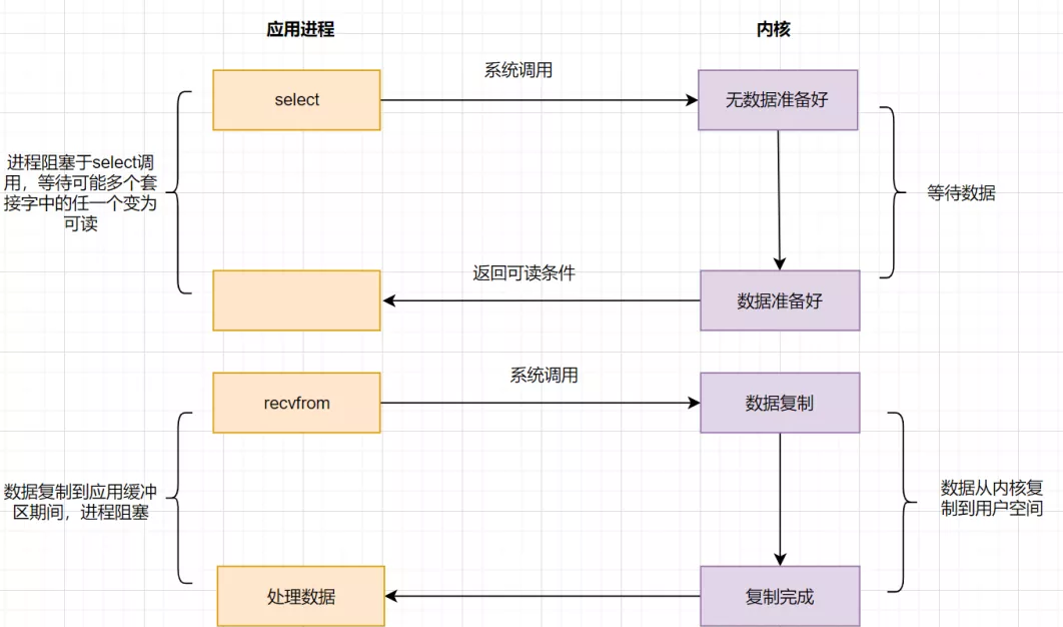
IO 多路复用
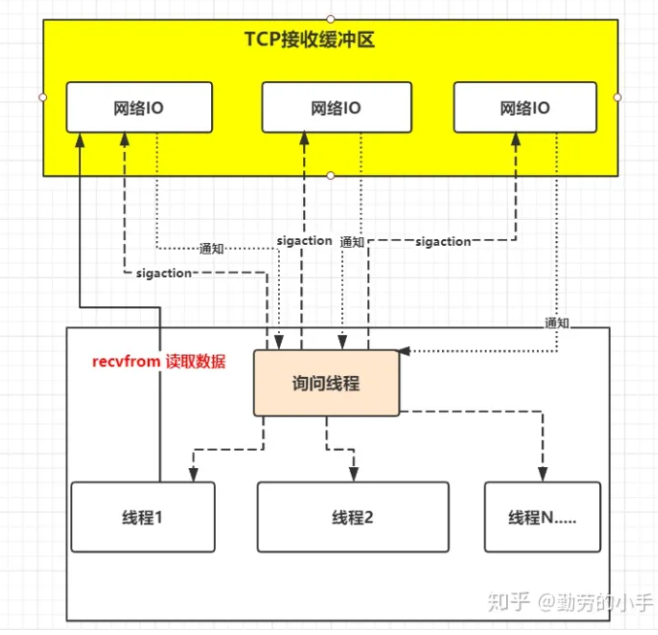
当在并发的情况下,每个线程都会自己调用 recvfrom 去读取数据。
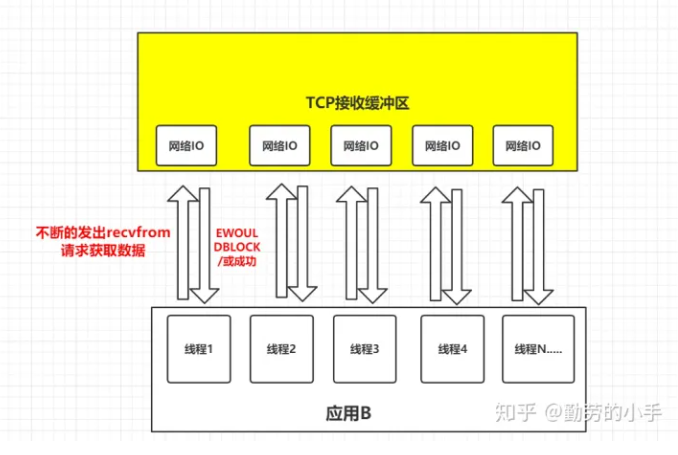
如上图一样,并发情况下服务器很可能一瞬间会收到几十上百万的请求,这种情况下应用B就需要创建几十上百万的线程去读取数据,同时又因为应用线程是不知道什么时候会有数据读取,为了保证消息能及时读取到,那么这些线程自己必须不断的向内核发送recvfrom 请求来读取数据;
那么问题来了,这么多的线程不断调用recvfrom请求数据,先不说服务器能不能扛得住这么多线程,就算扛得住那么很明显这种方式是不是太浪费资源了,线程是我们操作系统的宝贵资源,大量的线程用来去读取数据了,那么就意味着能做其它事情的线程就会少。——知乎-勤劳的小手
我们将每个线程自己调用 recvfrom 请求数据,转变为合并数据统一去查询,举个例子:
现在系统有俩接口:
User getUserInfo(String uid);
List<User> getUserInfoBatch(List<String> uids);
现在需求是查询 10 个User的信息(只需要展示,不需要做其他的),是使用for循环遍历查询,还是直接批量查询?
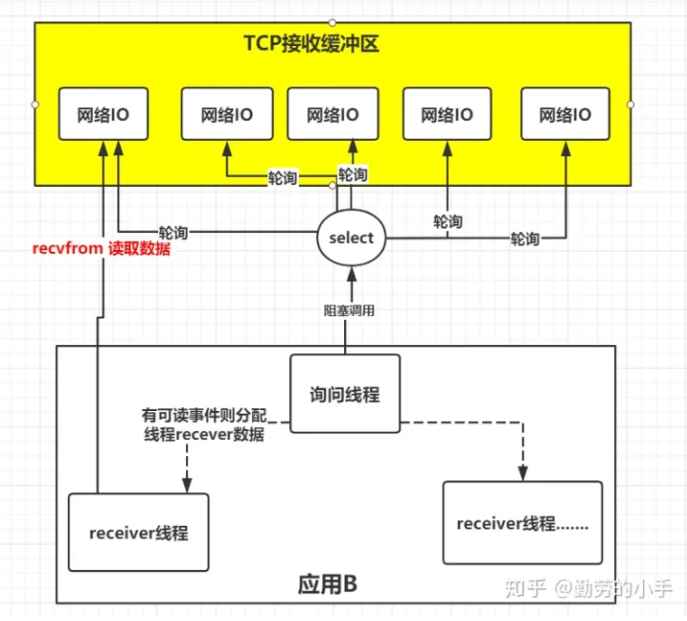
正如上图,IO复用模型的思路就是系统提供了一种函数可以同时监控多个fd的操作,这个函数就是我们常说到的select、poll、epoll函数,有了这个函数后,应用线程通过调用select函数就可以同时监控多个fd,select函数监控的fd中只要有任何一个数据状态准备就绪了,select函数就会返回可读状态,这时询问线程再去通知处理数据的线程,对应线程此时再发起recvfrom请求去读取数据。——知乎-勤劳的小手
文件描述符:

- 用户线程调用select,将fd_set从用户空间拷贝到内核空间
- 内核在内核空间对fd_set遍历一遍,检查是否有就绪的socket描述符,如果没有的话,就会进入休眠,直到有就绪的socket描述符
- 内核返回select的结果给用户线程,即就绪的文件描述符数量
- 用户拿到就绪文件描述符数量后,再次对fd_set进行遍历,找出就绪的文件描述符
- 用户线程对就绪的文件描述符进行读写操作
select:底层bitmap,最大保存1024个文件描述符,需要O(n)遍历判断哪一个文件描述符是就绪的。
poll:优化select中文件描述符限制,使用了链表的数据结构,但是还需要遍历链表,判断哪个是就绪的。
epoll:优化epoll只需要判断活跃的文件描述符。
信号驱动模型
IO 多路复用已经做出了较多的优化,但是select、poll、epoll都需要轮询,那么我们该多久轮询一圈?联想到推拉结合方案,为什么不让系统主动通知你哪个文件描述符已经准备好了呢?
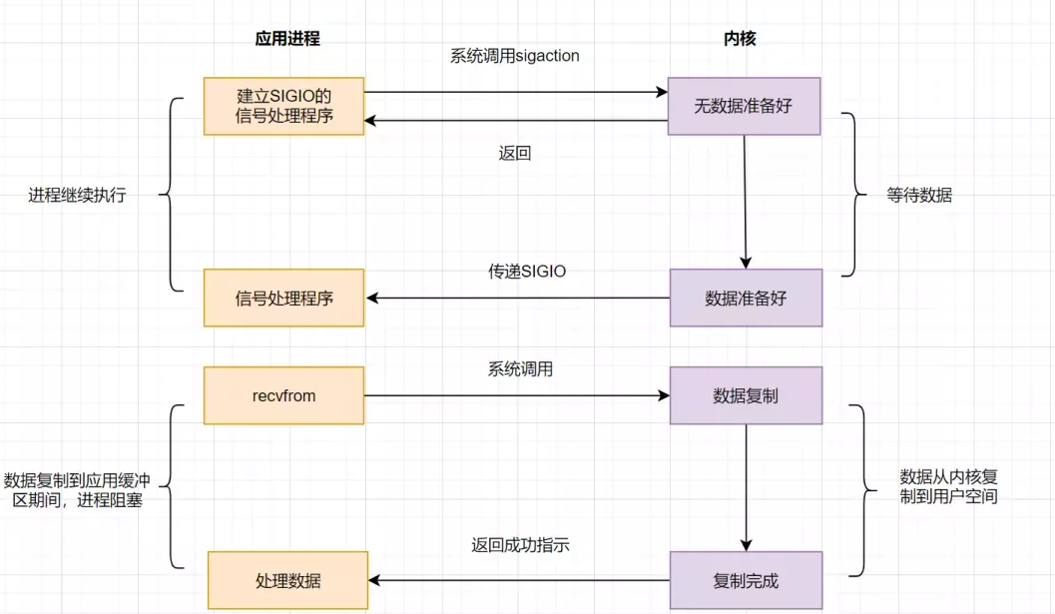
首先开启套接口信号驱动IO功能,并通过系统调用sigaction执行一个信号处理函数,此时请求即刻返回,当数据准备就绪时,就生成对应进程的SIGIO信号,通过信号回调通知应用线程调用recvfrom来读取数据。——知乎-勤劳的小手
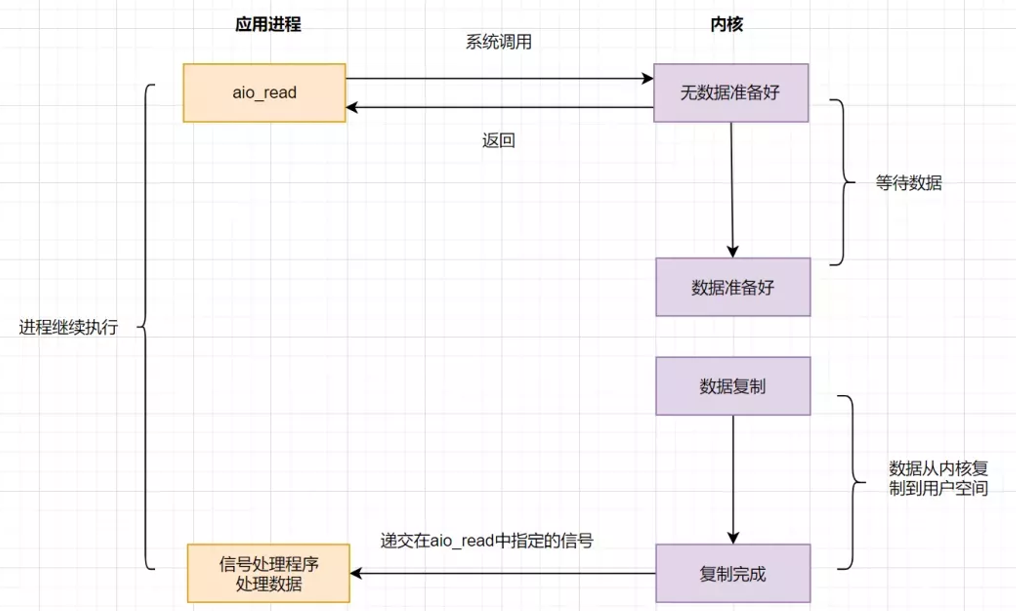
异步 IO
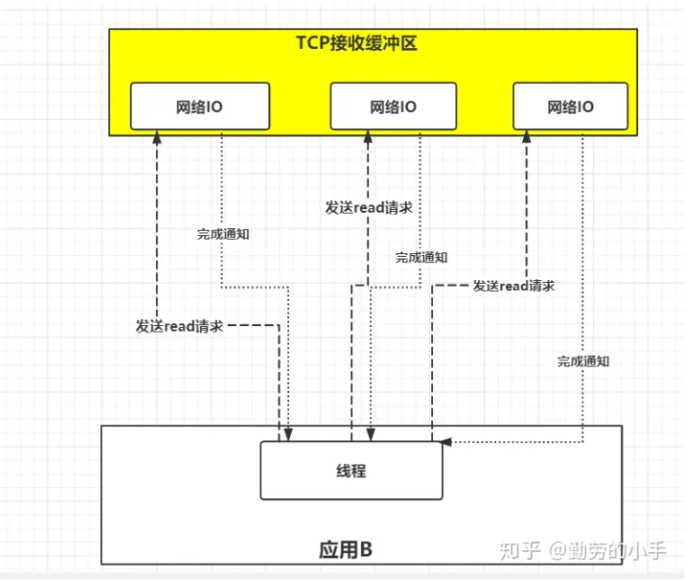
上面的方案,都需要两阶段读取,首先询问数据是否准备好,然后调用 recvfrom读取,有没有一种方案,程序说我要读数据,然后系统将数据准备好,并把数据复制到用户空间,然后告诉你数据准备完成,你直接使用就可以。
参考内容:
Java几种常见的编码方式
100%弄明白5种IO模型(文中部分内容来源于此,总结很棒)
I/O 多路复用底层原理前篇 - 五种IO模型
本文来自博客园,作者:帅气的涛啊,转载请注明原文链接:https://www.cnblogs.com/handsometaoa/p/17379850.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)