数据密集型应用-数据复制

大家(说)好才是真的好。
引入:假如公司数据全部在单个存储服务器存储,这个阶段存在什么问题呢?
一、单节点
读写数据都在同一节点

单节点模式存在的问题:
数据量太大,超过单个存储服务器存储上限。(暂时不讲,数据分区)- 并发量太小,大量读写请求打在同一个节点,处理不过来。【并发】
- 假如果节点挂了(无论什么原因),服务不可用。【可用】
- 单个服务器硬件损伤、被黑客入侵(勒索软件、病毒),那么就可能会丢失数据。【数据安全】
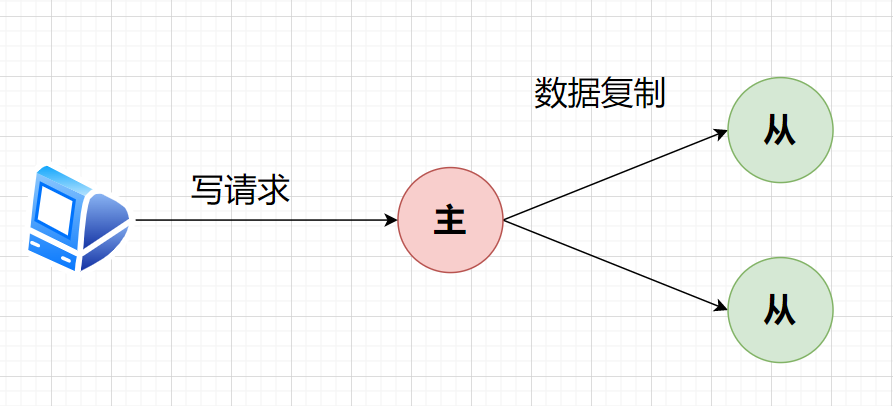
二、单主节点-主从复制
主节点可读可写,从节点只读。
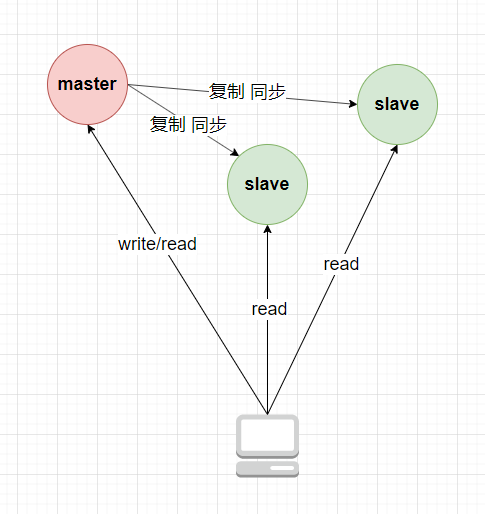
从节点通过复制日志(replication log)记录或变更流(change stream)进行复制同步主节点数据。
2.1 解决了什么问题
- 读写分离,并发能力提高。
- 主从备份,可以增加数据安全性、服务的高可用性。
2.2 产生了什么问题
- 主节点挂了,怎么办?
- 从节点挂了,怎么办?
- 怎么新增从节点?
- 从节点与主节点的数据怎么进行数据复制?
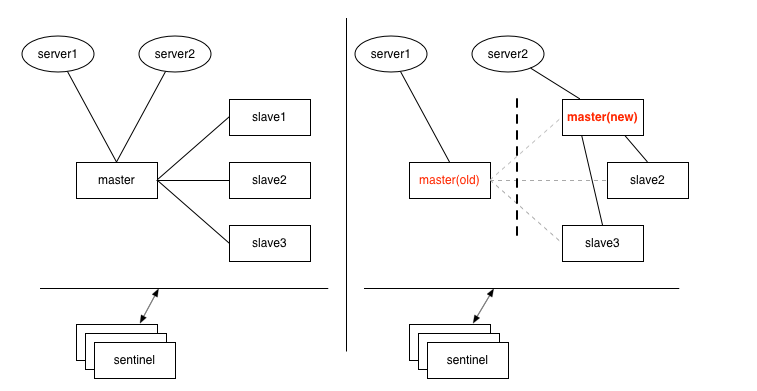
2.2.1 主节点挂了怎么办?故障切换
-
确认主节点挂了
基于超时机制,发送心跳包,30秒不回复你,那就是挂了。 -
选举新的主节点。
选取与主节点同步最完整(数据滞后最少)的从节点 -
配置使新主节点生效,原主节点降为从节点
产生问题
-
从节点不可能时时刻刻与主节点完全同步,这就导致会有数据丢失。
-
如果Redis先缓存了数据,而节点数据丢失,那么会发生缓存不一致的问题。
-
会出现脑裂的问题,同时有多个主节点。当检测到两个主库节点
同时存在时会关闭其中一个节点。(*方案怎么设计?)
-
超时时间的选择问题。比如高负载的情况。
2.2.2 从节点挂了怎么办?
待从节点恢复后,根据节点本地复制日志,查找到崩溃前一个事务,然后请求主库同步所有变更,这样从库就能追赶上主库。
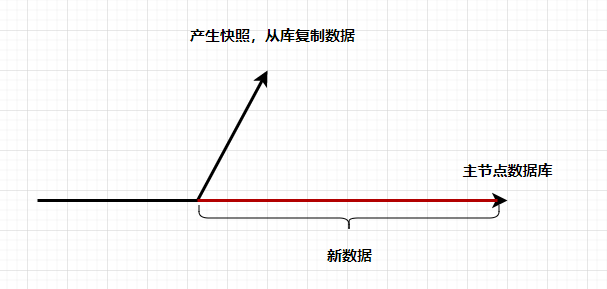
2.2.3 新增从节点怎么办?
- 不能直接复制某个节点快照,因为数据一直在发生变化。
- 不能将数据库停机复制,这将违反高可用设计目标。
解决方式:
- 主节点产生一个快照
- 从节点对快照数据进行同步
- 从节点将主节点快照以后的数据更改日志再进行同步
- 主从节点数据复制完成
Redis:RDB与AOF混合模式
2.3 复制日志的实现
2.3.1 基于语句的复制
主节点将语句(增、删、改)发送给从节点

产生问题:
- 非确定性函数语句,比如now()。将now() 替换为具体的值
- 语句使用自增列,那么要求从节点执行语句的顺序性
- 有副作用的语句,可能会在每个每个副本产生不同的副作用
2.3.2 传输预写日志(Write Ahead Log)
「修改并不直接写入到数据库文件中,而是写入到另外一个称为 WAL 的文件中;如果事务失败,WAL中的记录会被忽略,撤销修改;如果事务成功,它将在随后的某个时间被写回到数据库文件中,提交修改。」
数据将写入都存进日志,主节点发送日志给从节点。
2.3.3 逻辑日志复制(基于行)
比如关系数据库逻辑日志通常是基于行级别写请求:MySQL : binlog
- 插入 相关列的新值
- 删除 唯一标记删除的行,比如主键
- 更新 唯一标记更新的行,还有新值
2.3.4 基于触发器的复制
- 在主副本的数据表中创建相应的触发器,当数据表进行写操作并成功提交时,就会触发触发器,将当前副本的变化反映到其他从副本中,实现副本数据的同步。
主数据库发生变化时,自动执行触发器中的代码,消耗较大。
2.4 复制滞后问题
2.4.1 读自己写
在主从复制架构中,主节点与从节点的数据不可能强一致性(除非是同步写),这样就会出现一种情况:
Client A写进主节点数据,然后在从节点读数据时候消失不见。(自己写进去的,自己却读不到了)
解决方式:
- 访问可能修改的数据时直接从主节点进行读取,但是假如可能修改的数据过多,那么主从架构的优势就没显示出来
- 统计主从复制需要的时间,如果读取时间间隔超过复制时间,那么直接在从线程读,否则主线程。
- 客户端可以记住最近更新时的时间戳,并附在请求中,可以保证读服务都包含此时间戳,如果不包含则换服务器
- 副本在多数据中心,把请求路由到主节点的数据中心
如果要求多设备,比如手机与PC,要实现写后读一致性,那么我们需要将请求路由到主节点,但首先需要将请求路由到同一个数据中心。
单调读
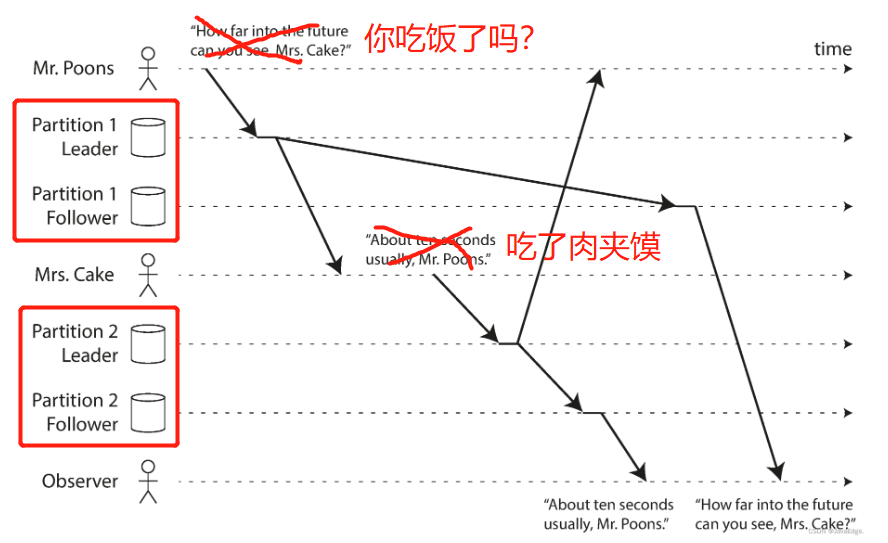
案例:请求第一次从副本A读,读到了数据。第二次从副本B读,数据由于复制滞后消失。
解决方式:确保每一个用户总是固定从一个副本读。
前缀一致读
案例:分区数据经过副本复制,出现先果后因的情况。
解决方案:
- 全写入一个分区(实现效率低下)
复制滞后的解决方案
- 事务(电商支付等)
- 最终一致性(解决为什么会滞后的问题)
三、多主节点
引入:为什么需要多主节点?那一定是但单主节点有解决不了的问题😎。
饿了么的数据中心就是异地多活:饿了么异地多活技术实现知乎 (zhihu.com)
异地多活的好处:
- 降低延迟性,访问最近的数据中心。
- 进行容灾备份,北京机房烧了,武汉机房还在。
- 其他好处。
多主节点说明图 :
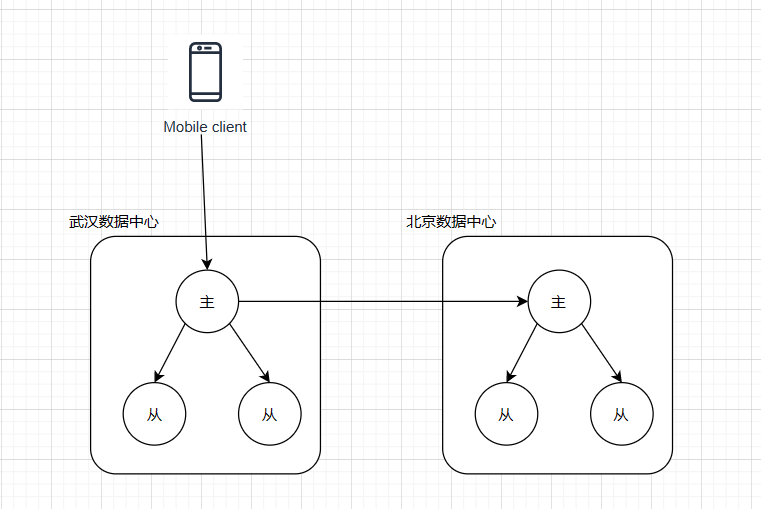
配置多个主节点,多个从节点之间数据交换,并传递给从节点。
3.1 解决了什么问题?
- 性能(延迟低)
- 容忍数据中心出错
- 容忍网络问题
3.2 产生了什么问题?
多主节点之间同步会产生并发问题。
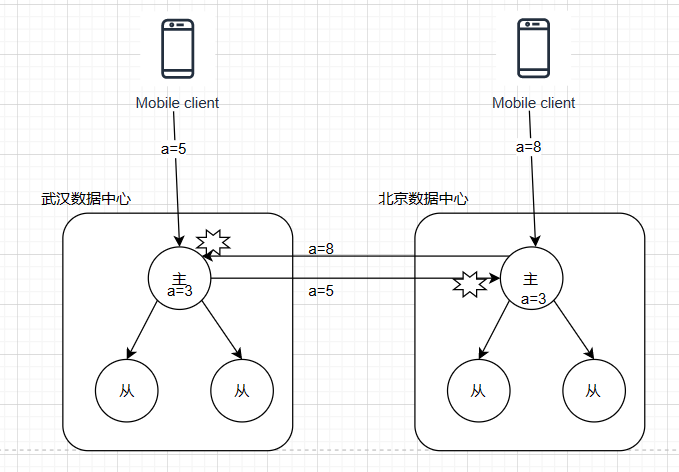
同步- 避免冲突:写请求到某一数据中心,(假如某一时刻数据中心挂了,会切换另一数据中心,要有处理冲突的可能性)
- 收敛于一致性:对每个写入分配ID,最后写入者有效
- (推荐)自定义解决冲突:
- 写入时,执行检测冲突并解决。
- 读取时,检测冲突,将所有冲突值保存,返回提示用户解决冲突。
我有证据:饿了么异地多活技术实现知乎 (zhihu.com)

四、无主节点
为什么会产生这种方案?因为.........
所有节点都是主节点,写入时将数据写入多个节点。

Quroum [ˈkwɔːrəm]机制:
N:副本数 W:写入-需要确认节点数 R:读取-至少查询r个节点
W+R>N 那么读取的节点一定包含最新值。
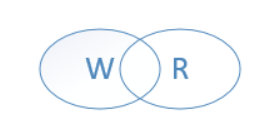
靠的是W与R之间有重叠。
休息吧,不重要,讲不完,安心睡。😁你以为是我困了,其实是我看不懂。
五、感想
单节点无备份:我用
单节点-主从复制:小公司/B端用
多节点-主从复制:大公司/C端用
多主节点:我看不懂的公司用
读完作者上面内容以后,发现没有一种神技,完美解决遇到的所有问题。
你好,没用的东西🤡。
理论来了: CAP原理:
- 一致性(所有节点访问同一份最新的数据副本)
- 可用性(非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应))
- 分区容忍性(分布式系统出现网络分区的时候,仍然能够对外提供服务)
单机情况下,P是可以保证的,我们只需要考虑保证CA,比如传统关系型数据库。
分布式环境下,我们需要保证P,A/C我们只能2选1。
遇不到分布式,学这些有什么用?我们能看着别人用。
举例:
ZooKeeper 保证的是 CP。 任何时刻对 ZooKeeper 的读请求都能得到一致性的结果,但是, ZooKeeper 不保证每次请求的可用性比如在 Leader 选举过程中或者半数以上的机器不可用的时候服务就是不可用的。
Eureka 保证的则是 AP。 Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。
Nacos 不仅支持 CP 也支持 AP。
参考内容:
本文来自博客园,作者:帅气的涛啊,转载请注明原文链接:https://www.cnblogs.com/handsometaoa/p/17167524.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)