并发相关知识点-学习总结
并发
并发不提高,可用就是耍流氓
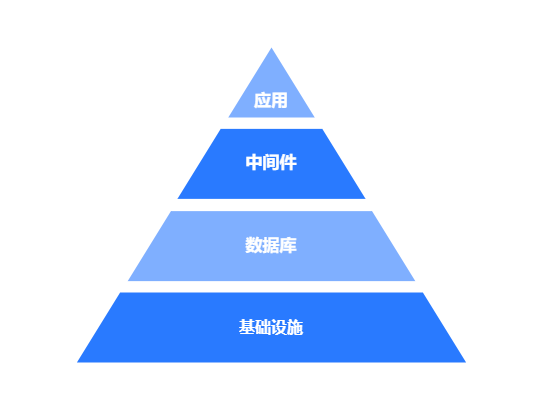
基础设施
在分层架构中,最底层就是基础设施,一般来说包含物理服务器、IDC、部署方式等等,就像一个金字塔,只有底座稳定了,上层才能稳定。基础不牢,地动山摇。
异地多活
https://zhuanlan.zhihu.com/p/32009822
为什么做异地多活?饿了么的数据量越来越大,用户越来越多,单个数据处理中心撑不住了。
为什么?要是....会怎么样?怎么做?
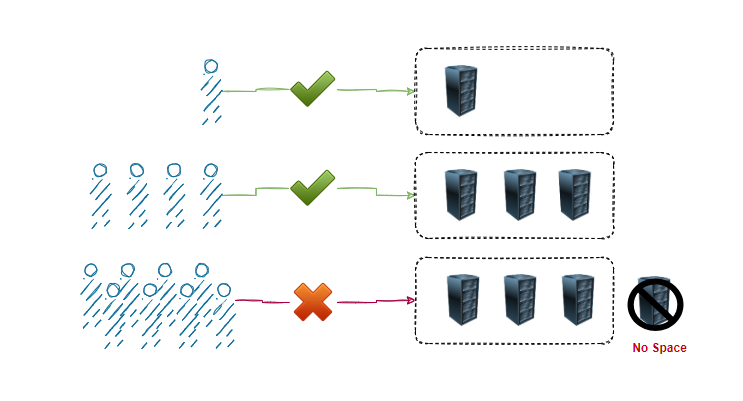
原因:1.处理数据量增多 2.没有空间增加服务器 3.单机房故障,导致服务不可用
目的:1.服务扩展多机房,多个机房共同支持服务,一处不可用,另一处接替工作。
为什么做异地多活?
业务发展驱动,经过多年的发展,饿了么单个数据中心撑不住了。
- 主要机房空间限制,业务需要扩容,双方矛盾
- 单个机房故障,要进行业务迁移保证可用
归结起来就是:
- 服务扩展到多个机房
- 能够应对机房级别故障
解决方案:异地多活
不是每个公司都需要选择异地多活的方案,技术投入与服务器故障损失之间存在一个平衡点,当超过平衡点,这时便要使用一些高可用的方案。

数据库
读写分离:
一主多从:主库承担写流量,从库承担读流量
主从延迟:
1.MYSQL默认是主从复制的,如果主库插入数据马上从库查询,可能发生查不到的情况。所以一些关键查询,可以绑定在主库查询,避免主从延迟。
2.从库数量有限,理论上从库越多,承受QPS越高,但是增加从库,主库复制IO压力会增加。
3.无法解决写操作的QPS
分库分表
只有在读写分离没办法承受流量我们才考虑分库分表。
1.分表:
垂直拆分,按业务拆分
*订单表分为:用户信息表、支付信息表
水平拆分,按容量拆分
*订单表拆分为:512张订单子表
2. 分库:把原来在一个DB中的实例分在N个DB实例中
分库分表带来的问题:
- 改造成本高:
分库分表一般需要中间件的支持,常见有客户端模式与代理模式。 - 客户端模式:
客户端模式会通过在服务上引用client包的方式来实现分库分表的逻辑,比较有代表的是开源的sharding JDBC。 - 代理模式
代理模式是指所有的服务不是直接连接MySQL,而是通过连接代理,代理再连接到MySQL的方式,代理需要实现MySQL相关的协议。
事务问题
一致性、原子性、持久性、隔离性
无法支持多维度查询
数据迁移:停机迁移/双写,新增增量数据
架构,缓存、消息队列、资源隔离
缓存
- 本地缓存:Guava Cache 、EHCache
- 分布式缓存:Redis、Mencached
- 如何保证缓存与数据库的数据一致性 https://coolshell.cn/articles/17416.html https://zhuanlan.zhihu.com/p/434421404
缓存更新的套路
更新缓存的四种设计模式
引入:先删缓存,后更新数据库,会出现什么问题?

那么请静下心来想想,程序3的数据是不是脏数据?
- Cache Aside
最常用的模式,逻辑如下:
- 缓存命中:查询缓存,返回数据。
- 缓存不命中:查询缓存->缓存不命中->查询数据库->放入缓存
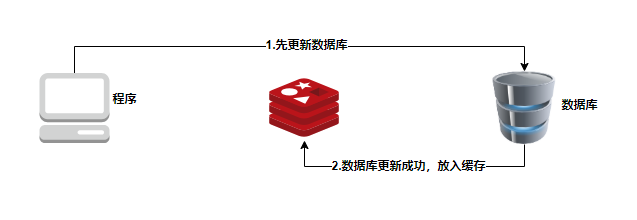
- 更新数据:先更新数据库,后更新缓存。

这个模式又分为 读模式、写模式,读模式比较简单。
读模式:先读缓存,缓存不存在读数据库,查出来数据更新缓存。
写模式:蜀道难,难于上青天,四种模式:
- 先更新DB,再更新缓存

PC1先更新的DB,理论应该缓存是PC2的数据,但是现在是PC1的数据,导致了错误。
1.1. 假如果刚开始缓存未空,P1删缓存(无缓存)P2查数据 P1更新数据库 P2更新缓存,会导致缓存失效。
热点key,先进行预热
1.2. 写操作比较频繁,导致cache频繁删除
数据库与缓存强一致性,更新db更新缓存,分布式锁保证更新缓存不会出现线程安全的问题
短暂允许数据库与缓存不一致,更新db更新缓存,再给缓存一个较短的过期时间
-
先更新缓存,再更新DB
与1一样,但是会引发更严重的并发写问题,会导致数据库的数据,与更新的先后数据不一致,导致数据库为脏数据。
1中的情况,知识缓存的暂时不一致,而2是数据库数据的不一致。 -
先删除缓存,再更新DB

-
先更新DB,再删除缓存(推荐)

与3情况相同,有并发写的问题,仍然存在数据不一致的可能。但不一致发生的前提是写请求插在读请求中间,我们知道同一条数据数据库读通常是比写要快的,缓存操作也肯定要比数据库快,所以这种不一致发生的概率很小。 -
Read Through
调用方只管查询,从哪里查调用方不需要管,由缓存服务来处理,如果缓存未命中,由缓存服务来加载。这会让代码变得简洁。

-
Write Through
Write Through 套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作) -
Write Behind Caching Pattern
在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。所以它有时会将几次的更新数据一起写回数据库,提高性能。但是带来的问题是数据丢失,及如果机器强制断电,缓存中数据便会丢失。有时候强一致、高可用、高性能是有冲突的。
以上这些都是经过考验的设计模式,根据自己的业务,选择适合自己的缓存设计模式。
1.并发很高,防止缓存击穿
热点Key失效,大量请求打在数据库,数据库承受不住压力会崩溃。
解决方法:比如热点key不过期。
2.缓存空值,需要防止缓存穿透
一个数据库中不存在的key,查询数据库时,没进行处理一定会落在数据库,这样连续多次查询一个key,一直会请求数据库,导致数据库性能下降。
解决方法:首先处理查询的key,当key不符合规范时,直接返回。当key符合规范时,数据库中不存在key对应的值,查询数据库后,将空值存进缓存。
3.设置过期时间,使用随机数避免缓存雪崩。
比如我现在设置一大批数据同样过期时间,等到过期后,全部请求都会落到数据库。
解决方法:使用随机数,将过期时间分散开,防止一时间缓存全部过期。
参考文章:
一直再说高并发,多少QPS才算高并发?
本文来自博客园,作者:帅气的涛啊,转载请注明原文链接:https://www.cnblogs.com/handsometaoa/p/17098731.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)