
MySQL 学习笔记 进阶(锁 下,InnoDB引擎 上)
锁
锁-表级锁-表锁
- 介绍
表级锁,每次操作锁住整张表。锁定粒度大,发生锁冲突的概率最高,并发度最低。应用在MyISAM,InnoDB,BDB等存储引擎中。
对于表级锁,主要分为以下三类:
- 表锁
- 元数据锁(meta data lock,MDL)
- 意向锁
- 表锁
对于表锁,分为两类:
- 表共享读锁(read lock)
- 表独占写锁(write lock)
语法:
- 加锁:lock tables 表名... read/write。
- 释放锁:unlock tables / 客户端断开连接。
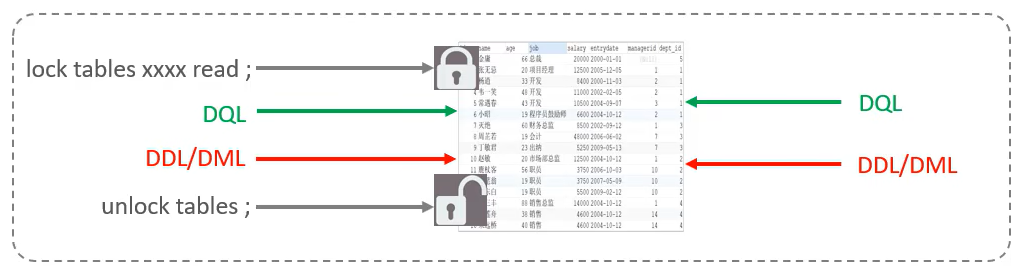
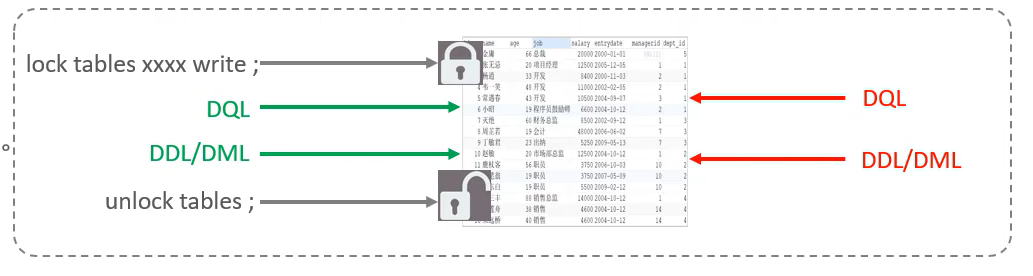
读锁不会阻塞其他客户端的读,但是会阻塞写。写锁既会阻塞其他客户端的读,又会阻塞其他客户端的写。
锁-表级锁-元数据锁
MDL加锁过程是系统自动控制,无需显式使用,在访问一张表的时候会自动加上。MDL锁主要作用是维护表元数据的数据一致性,在表上有活动事务的时候,不可以对元数据进行写入操作。为了避免DML与DDL冲突,保证读写的正确性。
在MySQL5.5中引入了MDL,当对一张表进行增删改查的时候,加MDL读锁(共享);当对表结构进行变更操作的时候,加MDL写锁(排他)。

查看元数据锁:
select object_type, object_schema, object_name, lock_type, lock_duration from performance_schema.metadata_locks;
锁-表级锁-意向锁
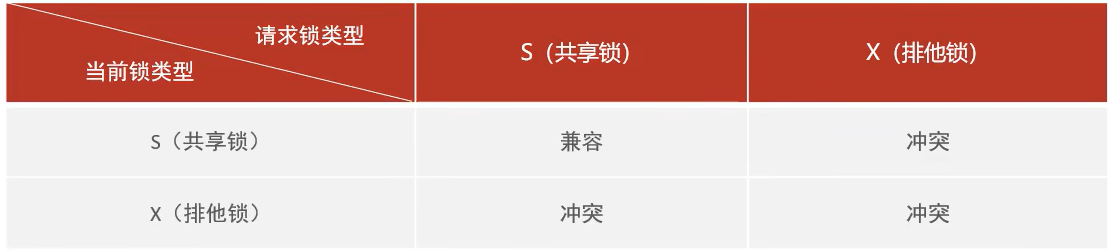
- 意向共享锁(IS):由语句select ... lock in share mode添加。与表锁共享锁(read)兼容,与表锁排他锁(write)互斥。
- 意向排他锁(IX):由insert,update,delete,select ... for update添加。与表锁共享锁(read)及排他锁(write)都互斥。意向锁之间不会互斥。
可以通过以下SQL,查看意向锁及行锁的加锁情况:
select object_schema, object_name, index_name, lock_type, lock_mode, lock_data from performance_schema.data_locks;
锁-行级锁-介绍
行级锁,每次操作锁住对应的行数据,锁定粒度最小,发生锁冲突的概率最低,并发度最高。应用在InnoDB存储引擎中。
InnoDB的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。对于行级锁,主要分为以下三类:
- 行锁(Record Lock):锁定单个行记录的锁,防止其他事务对此行进行update和delete。在RC、RR隔离级别下都支持。
- 间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持。
- 临键锁(Next-Key Lock):行锁和间隙锁组合,同时锁住数据,并锁住前面的间隙Gap。在RR隔离级别下支持。
锁-行级锁-行锁
InnoDB实现了以下两种类型的行锁:
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。

默认情况下,InnoDB在REPEATABLE READ事务隔离级别运行,InnoDB使用next-key锁进行搜索和索引扫描,以防止幻读。
- 针对唯一索引进行检索时,对已存在的记录进行等值匹配时,将会自动优化为行锁。
- InnoDB的行锁是针对于索引加的锁,不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,此时就会升级为表锁。
可以通过以下SQL,查看意向锁及行锁的加锁情况:
select object_schema, object_name, index_name, lock_type, lock_mode, lock_data from performance_schema.data_locks;
锁-行级锁-间隙锁&临键锁
默认情况下,InnoDB在REPEATABLE READ事务隔离级别运行,InnoDB使用next-key锁进行搜索和索引扫描,以防止幻读。
- 索引上的等值查询(唯一索引),给不存在的记录加锁时,优化为间隙锁。
- 索引上的等值查询(普通索引),向右遍历时最后一个值不满足查询需求时,next-key lock退化成间隙锁。
- 索引上的范围查询(唯一索引),会访问到不满足条件的第一个值为止。
注意:间隙锁唯一的目的是防止其他事务插入间隙。间隙锁可以共存,一个事务采用的间隙锁不会阻止另一个事务在同一个间隙上采用间隙锁。
InnoDB引擎
InnoDB引擎-逻辑存储结构

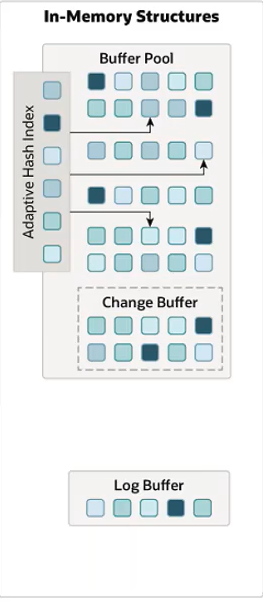
InnoDB引擎-架构-内存结构
Buffer Pool:缓冲池是主内存区中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
缓冲池以Page页为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三种类型:
- free page:空闲page,未被使用。
- clean page:被使用page,数据没有被修改过。
- dirty page:脏页,被使用page,数据被修改过,其中数据与磁盘的数据产生了不一致。
Change Buffer:更改缓冲区(针对于非唯一二级索引),在执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存在更改缓冲区Change Buffer中,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。
Change Buffer的意义是什么?
与聚集索引不同,二级索引通常是非唯一的,并且以相对随机的顺序插入二级索引。同样,删除和更新可能会影响索引树中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了Change Buffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
Adaptive Hash Index:自适应hash索引,用于优化对Buffer Pool数据的查询。InnoDB存储引擎会监控对表上各索引页的查询,如果观察到hash索引可以提升速度,则建立hash索引,称之为自适应hash索引。
自适应哈希索引,无需人工干预,是系统根据情况自动完成。
参数:adaptive_hash_index
Log Buffer:日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log,undo log),默认大小为16MB,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新,插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘I/O。
参数:
innodb_log_buffer_size:缓冲区大小
innodb_flush_log_at_trx_commit:日志刷新到磁盘时机(1:日志在每次事务提交时写入并刷新到磁盘,0:每秒将日志写入并刷新到磁盘一次,2:日志在每次事务提交后写入,并每秒刷新到磁盘一次)
InnoDB引擎-架构-磁盘结构
System Tablespace:系统表空间是更改缓冲区的存储区域。如果表是在系统表空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典,undolog等)
参数:innodb_data_file_path
File-Per-Table Tablespaces:每个表的文件表空间包含单个InnoDB表的数据和索引,并存储在文件系统上的单个数据文件中。
参数:innodb_file_per_table
General Tablespaces:通用表空间,需要通过CREATE TABLESPACE语法创建通用表空间,在创建表时,可以指定该空间。
CREATE TABLESPACE xxxx ADD DATAFILE 'file_name' ENGINE = engine_name; CREATE TABLE xxx ... TABLESPACE ts_name;
Undo Tablespaces:撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
Temporary Tablespaces:InnoDB使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
Doublewrite Buffer Files:双写缓冲区,InnoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。
Redo Log:重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲区(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中,用于在刷新脏页到磁盘时,发生错误时,进行数据恢复使用。
以循环方式写入重做日志文件,涉及两个文件:
InnoDB引擎-架构-后台线程
- Master Thread:核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新,合并插入缓存,undo页的回收。
- IO Thread:在InnoDB存储引擎中大量使用了AIO来处理IO请求,这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
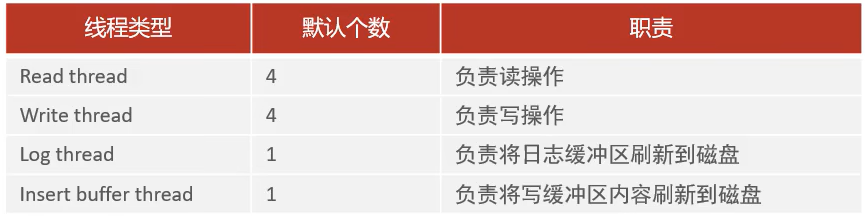
- Purge Thread:主要用于回收事务已经提交了的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
- Page Cleaner Thread:协助Master Thread刷新脏页到磁盘的线程,它可以减轻Master Thread的工作压力,减少阻塞。

