
cpython大致数据结构实现笔记
1.在Python中所有的对象都是一个结构体, 所有对象的父类的结构体是
1 #define PyObject_HEAD \ 2 int ob_refcount; \ 3 struct ob_type *ob_ref; 4 typdef struct { 5 PyObject_HEAD // 在每一个其他的结构体中都定义一个PyObject_HEAD, 为将来的多态打下基础 6 } PyObject; 7 //int 8 typedef struct { 9 PyObject_HEAD 10 long int_val; 11 } PyInt_Object; 12 //seq 13 #define PyObject_VARHEAD \ 14 PyObject\_HEAD \ 15 long size; 16 17 typedef struct { 18 PyObject_VARHEAD 19 } PyStrObject;
创建一个对象时, 先创建一个类型对象(类型对象自始至终都是只要一个的, 在C源码中, 就是定义了一个全局的变量), 保存要创建对象的类型信息, 接着再在该类型对象的方法中创建指定的对象, 并将类型对象传递进入最为该对象的属性, 如创建一个int对象, 先PyInt_Type对象创建封装了信息之后再创建PyIntObject对象
Python中的整型对象
在python中为了提高运行效率,cpython的具体地对象构建采取采取了很多优化措施,我就以这个为主线讲一下cpython涉及到的对象体系以及优化措施
对于整数对象,刚学python可能只是用它来构建变量,或是作为其他数据结构地一部分,稍有经验后可能知道了py地小整数池机制,而cpython对其的构建也是由整数池来实现的,构建了小整数池和通用整数池
小整数池的范围通过宏来定义的, 默认是-5-257, 我们可以通过修改此处的宏来调整小整数池的大小, 但是需要对python进行重新编译
小整数池是一个静态的数组, 在此数组的基础上又建立了链表
static PyIntObject *small_ints[262]
由此上面的代码可知, 在这个数组中存放是PyIntObject类型的指针, 我们已经知道了在一个PyObject结构体中都有一个PyTypeObject类型的指针,
注意: 在python程序启动时此整数对象池还没有初始化, 但是一旦初始化了其中一个对象, 则那个对象就会一个存在, 知道程序结束
node:在数组上建立的链表是通过一个PyIntBlock结构体和一个PyIntObject *类型的free_list创建的, 我们在创建通用整数池时再讲
通用整数池
通用整数池的实现核心是:
1 typedef _intblock { 2 struct _intblock *next; 3 PyIntObject objects[max_contain]; 4 } PyBlockObject; 5 6 PyBlockObject *block_list = NULL; // 代表着一个块 7 PyIntObject *free_list = NULL; // 总是指向在block中维护的数组的下 8 一个需要被分配空间的位置, 有该free_list调用fill_free_list 9 函数创建出一个PyBlockObject
为了避免空间的浪费, 在删除那个 对象时, 调用了int_dealloc方法, 有意思的是该方法并不会将空间释放归还给操作系统, 而是继续过该objects数组所有, 在该方法中有一个这样的操作: 因为objects数组也是一个链表, 随意我们可是使用指针进行索引, 在删除一个对象时, 将当期的free_list指针指向该对象所在的空间, 接着让我们删除的对象的ob_type指针指向刚才free_list指向的位置, 总而言之,int_dealloc是一个伪释放函数,而接下来的其他数据类型对象几乎都有这种机制来避免内存占用过多
小整数池的创建
前面已经提到过了, 我们在static修饰的数组中存放整数, 在创建一个PyIntObject对象时, 也是通过block和freelist机制实现的, 首先通过free_list构建出一个可变的链表, 接着该链表中存放的就是 我们需要的PyIntObject结构体, 在数组中存放其引用并指向他即可
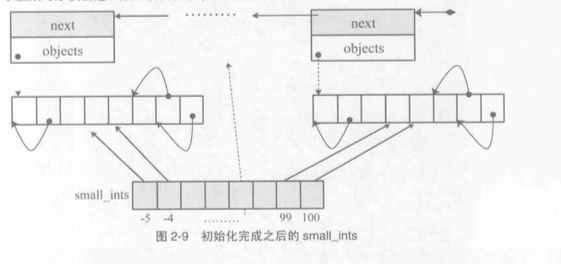
通过上图可知, 在static数组中的指针所执行的结构体分布在在几个个block维护的objects数组中 当一个block中的objects满时再创建next
Python中的字符串对象和序列对象类型都拥有的结构体
接下来就是字符串,字符串的不可变性是指引用的内存块中的字符数组不可变,在具体的python语境中,不可变对象不管是tuple,str如果切片:返回的是对象本身,重复的创建字符串对象在cpython较早的版本就已经优化过,他们都指向同一对象,也就是a=‘abcdefg’,b=‘abcdefg’,这种创建操作在字符串中反而不是博客中常总结的--可变对象做操作总是原地操作,不可变地对象总是创建新对象 起码对于创建字符串,ab也好你再出现cd也罢 都会通过interned机制指向同一个字符串对象也就是下面要讲的PyStringObject,结构体里面的字符数组已经被hash过了
typedef struct { PyObject_VARHEAD int ob_sstate; // 记录该字符串对象是否纳入了interned(实质上就是一个dict)机制 long ob_shash; // 保存字符串对象的hash值, 默认为-1, 用来缓存一个PyStringObject的hash值 char ob_sval[1]; // 用于存储一个字符, 如果是一个字符串则在该位置多申请空间 } PyStringObject;
每次新创建字符串对象a, 先判断字符长度, 如果为1, 则在字符串中的256个字节的缓冲区中找 - 如果大于1, 先标记为temp, 默认是进行interned机制,等到利用interned字典查不到key时,这个temp内存区域才算成功,否则丢弃对temp的引用,a改为指向interned对应key的value的引用,而且值得注意的是gc不仅在回收无用temp中起作用,对引用计数的小设计也使得gc能够很好的运作,例如interned字典中的引用不应该记作引用次数,否则这些字符串永远无法消失,又比如cpython中大量的引用数量的改变到底减1 2 还是3,c++程序员头疼的内存管理细节不太需要我们关心,我们只需要调用gc的一部分函数就能满足一般需求
Python中的列表对象
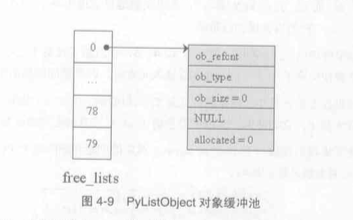
typedef struct { PyObject_VARHEAD PyObject *item; // 存储PyObject*的数组指针 int size; // 元素数量 int allocted; // 最大容量 } PyListObject;
-
对列表进行插入, 删除的操作对应的C语言函数为SetItem, GetItem
-
为了加快程序运行的速率, Python对List对象使用了缓冲,销毁的列表会被free回收, 有一个free_lists数组, 用来存放已经被删除的List对象, 其中的item, size, allocted为NULL, 0, 0, 有num_free_lists整数型变量用来记录在free_list中空闲的List个数, 每一次创建List对象时都会先判断num_free_lists的值是否为0, 如果为0, 则向内存申请空间创建一个PyListObject, 否则则直接获取在free_lists中的空间的PyListObject对象!
-
![img]()
Python中的字典对象
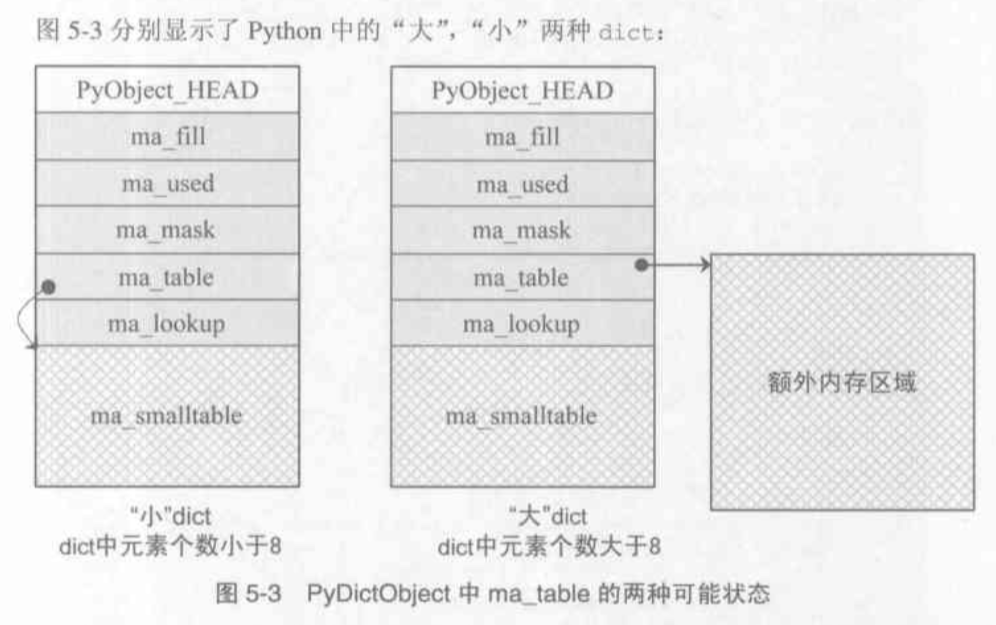
typedef struct { PyObject_HEAD int fill; int used; int mask; PyDictEntry *table; // 在PyDictObject中存放的元素较多时使用 PyDictEntry *(*lookup)(PyDictObject *self, PyObject *key, long hash) // 冲突链上的搜索函数 PyDictEntry *small_table[8]; // 一个存放PyDictEntry的数组, 在PyDictObject中存放的元素较少时使用 } PyDictObject; typedef struct { long hash; // 缓存对象的hash值 PyObject *key; PyObject *value; } PyDictEntry; // 在Python中不是对象
注意: 在PyDictObject中存放是Entry, entry中存放的是键值对 3. Java中的dict使用的是"数组 + 链表", 而在Python中使用的是"开放地址法", 如果发生了冲突则在调用PyDictObject的lookup方法寻找下一个符合条件的位置, 返回一个可用的Entry, 对其进行赋值 4. Dict也采用了类似List的对象缓冲池, 此池在一开始时什么也没有, 只有在一个Dict对象销毁时才会有一个元素, 使用num_free_dict, free_dicts数组
Python中的类型对象
Python中的虚拟机对象
PyCodeObject PyCodeObject是通过Scanner, Parser编译生成的, 存在于内存中的对象, 在Python脚本中一个名字空间对应一个PyCodeObject对象, 他是最重要的一部分, 存放的源代码的信息, 存放着让python虚拟机运行的执行集合
PyFramObject是一个执行环境, 每调用一个函数就会创建一个PyFrameObject对象, 其中包含了PyCodeObject,python代码的执行就是在这个PyFrameObject中执行的, pythonVM通过PyFrameObject对象中保存的PyCodeObject来执行Python字节码,他是一个类似os函数压栈的过程,记录了执行位置和应该跳转的位置,通过一个for(;;)循环中套着一个巨大的switch case语句, 可以说这就是一个python虚拟机了, 就是这么一个函数而已
并且命名空间也与PyFrameObject有关, 其有locals, globals, builtins字典(查找次序是local, global, builtin, 对于module来说, local与global是一样的), 用于保存对应的域的名字, local就是当前的frame中的变量, global就是当前模块中在函数之外定义的变量
Python中解释器通过堆栈展开和递归调用pyframeobj实现处理异常不会跳出,处理完异常会回到frame正在执行的流程中继续执行,否则堆栈展开冒泡异常
Python虚拟机的类机制
在执行声明class的指令时, PVM会根据继承的对象, 实现MRO机制 简单的来说就是类似java中的重载方法,本类找不到就到父类找,魔法方法的重写就是这个原理,py2.2之前是不允许这种继承int,list的操作的,2.2之后cpython加入了tp_dict提供了mro加载函数指针的机制才允许这样,不过对于tp系列的属性和函数牵扯到的就太多了,
命名空间和包导入
1. Python虚拟机初始化的时候会创建许多的内置模块, 首先创建的就是__builtin__ module, 其实我们当前的文件就是一个module, 在Python内置对象中有一个进程对象, 里面维护了一个modules的map,
它是由来存储所有模块的名字和模块对象键值对的, 因为每一个module又会有一些函数, 属性等等, 所以在每一个模块对象中又会有一个map, 用来存储module中的键值对
注意: 内置的add, len函数, 在Python源码中时PyMethodDef, 反正只要是内置的东西, 他就和我们使用python编写的函数或者对象本质上就是不一样的,也就是我们上面说的重写 比如一个"abc"的字符串对象, 我们查看"abc".__add__, 显示的是<method-wrapper '__add__' of str object at 0x106cc7308>, 而我们定义一个class A对象, 里面添加一个__add__函数, 而A.__add__显示的是<function __main__.A.__add__(self)>, 虽然我们定义的class A对象遵守了"+"的协议, 定义a = A(), b = A(), a + b 时会自动调用__add__, 但是这时的__add__已经和内置的不一样了
注意: sys.modules是全局名字空间, 这里的全局是指一个Python进程, 并且全局名字空间不会受import ... as ... 语句中重命名的影响, 其实sys.modules叫做modules pool
2. Python除了会加载__builtin__ module, 还有加载一个非常重要的module, 就是我们常用的sys module
一开始我们会以为python只是加载了__builtin__到内存中, 其实并不是这样的, python在初始化的时候就已经加载了大量的内置module到内存中, 只是没有显示出来而已, 也就是没有在命名空间中,所有当我们需要一个模块import时,只是在内存中找到他并在命名空间加入对他的引用,这也是python防止重复导入的原理
3. import加载一个package(一个文件夹)时, import pacname.some, 我们只是想要加载some文件, 但是python会一同将pacname也加载进来, 是想一个下, 我们是怎么访问some, 是通过pacname.some,由此可见我们使用该some时是需要pacname, 所以加载包对python来说是必须的, 这是的some不在local名字空间中, 而是在pacname的属性中
4. 如果我们需要只加载我们需要的, 则使用from ... import , 但是实质上还是同第3点是一样的, 还是会加载pacname, 但是some也会被放在locals名字空间中, 并将其映射为pacname.some, 通过from我们
可以做到精准加载,并且会融入local命名域,也就是调用时不用写前缀了
5. 使用del语句删除一个module, 其实只是删除了其符号在当前名字空间的位置位置, 在全局的module pool中还是存在的, 所有就算删除了, 我们还是可以在module pool中找到该对象
6. 使用reload(module)函数可以对一个模块进行动态加载(或者说是更新), 如果在一个模块中添加了 a = 10, 则调用了reload时, 就是在该module维护的dict中添加一个键值对, 而不是
重新创建一个module对象,


 浙公网安备 33010602011771号
浙公网安备 33010602011771号