
oracle优化-分页查询的错误认识
对于分页查询,上一篇文章总结了实现分页查询的办法。同时给出等价写法,另外在执行计划角度验证SQL的等价性https://www.cnblogs.com/handhead/p/13856505.html
分页查询的错误认识是由分页查询等价改写引申出的。下面我们先构造测试表,给出分页查询的等价写法,通过SQL的代价验证SQL的错误认识。
SQl在业务层面要求:取测试表TEST_A,status=5的记录,按sysid排序,展示3000-4000行;
1、测试表及说明


1、创建测试表 SQL>CREATE TABLE TEST_A(ID NUMBER NOT NULL,SYSID NUMBER,STATUS NUMBER,INFO VARCHAR2(2000)); SQL>INSERT INTO TEST_A SELECT ROWNUM,ROWNUM+1,TRUNC(DBMS_RANDOM.VALUE(1,9)) ,RPAD('*',2000,'*') FROM DUAL CONNECT BY ROWNUM<=100000; SQL> ALTER table test_a add primary key(id); SQL>create index ind_status_sysid on test_a(status,sysid); 说明:TEST_A中ID是主键,status字段取值[1,8]且均匀分布。 要求:取TEST_A中status=5的记录,按sysid排序,展示3000-4000行
2、分页查询的等价写法
①:两层嵌套分页查询 select * from (select row_number()over(order by sysid) rn,t.* from test_a t where status=5) where rn between 3000 and 4000; ②、三层嵌套分页查询 select * from (select rownum rn ,t.* from (select * from test_a where status=5 order by sysid )t where rownum<=4000) where rn >=3000;
3、分页查询的错误认识
*****************************************************错误认识1******************************************************************************
等价其实不等价
SQL1:select /*+gather_plan_statistics*/* from (select row_number()over(order by sysid) rn,t.* from test_a t where status=5) where rn between 3000 and 4000;
与
SQL2:select /*+gather_plan_statistics*/* from (select rownum rn,t.* from test_a t where status=5 order by sysid) where rn between 3000 and 4000;
认为SQL1与SQL2等价,其实这种认识是错误,我们从执行计划验证错误性,查看SQL1的执行计划

查看SQL2的执行计划:

从上述的执行计划我们看到同样是INDEX RANGE SCAN,SQL1实际访问了4000条记录,SQL2实际访问了12452条记录;对于逻辑读,SQL1是3608个数据块,SQL2是11065个数据块。推出SQL1与SQL2不等价。
**********************************************************错误认识2**********************************************************************************
分页查询每页的cost,buffer是一样的!这是不对的,是错误认识
SQL3:select /*+gather_plan_statistics*/* from (select row_number()over(order by sysid) rn,t.* from test_a t where status=5) where rn between 1 and 1000;
与
SQL4:select /*+gather_plan_statistics*/* from (select row_number()over(order by sysid) rn,t.* from test_a t where status=5) where rn between 3000 and 4000;
与
SQL5:select /*+gather_plan_statistics*/* from (select row_number()over(order by sysid) rn,t.* from test_a t where status=5) where rn between 10000 and 11000;

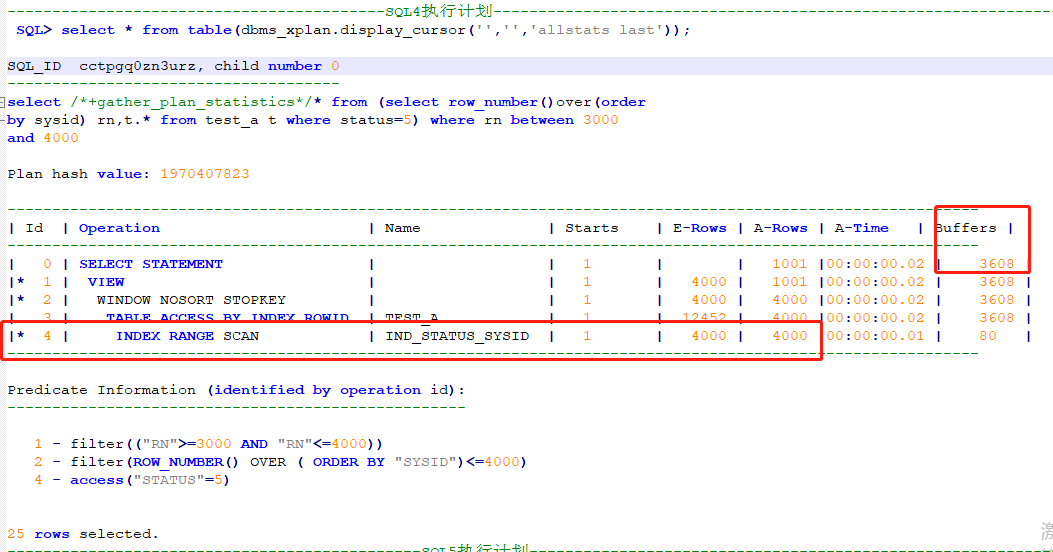

对于分页查询我们发现查询1-1000行,3000-4000行,10000-11000行,IND_STATUS_SYSID实际返回数量是不同的。会造成耗时时间不同,buffers不同,cost是由于物理读决定的,实际返回数量不同物理读肯定也大不相同。最终推出SQL3,SQL4,SQL5是不同的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号