
四、(项目架构的过去与现在)亿级用户行为之大数据实时分析
一、数据采集设计与要求
1、 数据采集设计与要求
1)彻底跟业务系统解耦:服务端数据落盘,然后通过flume采集,最后发送到kafka
2)采集架构采用两层,第一层采集层,第二层聚合层
3)采集需要有负载均衡的功能。充分利用资源
4)第一层agent挂掉后,重启采集不能丢失数据
5)第二层某个agent挂掉之后,系统要求仍然可以继续运行,不丢失数据,不能影响结果
6)同一个用户上报的数据,需要进入同一个kafka分区
2、 数据采集为什么要分层?
1)根本原因:日志服务器跟大数据平台不在同一个机房,有防火墙,无法直接通信
2)第一层专注于数据采集(采集速度快),第二层可以做ETL(简单ETL,过滤清洗,分区优化)
3)数据中间需要缓冲,聚合,减少IO
二、日志采集拓扑结构-数据高峰处理
1. 用户行为日志采集拓扑
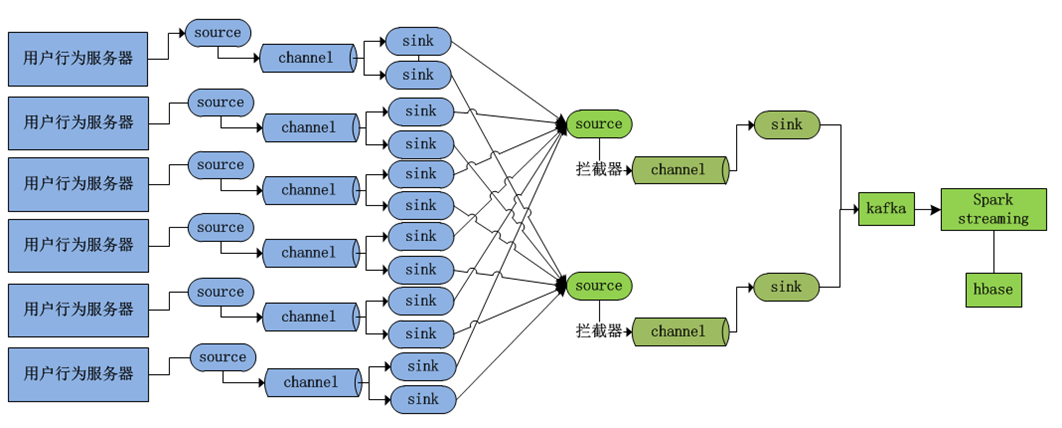
1)高可用如何保证?
第一层flume部署采集数据,如果挂掉了,可以通过脚本重新启动,重新采集数据,数据不会丢失,
因为日志服务器日志会先落盘。第一个层会有很多个日志服务器和flume刺激,整体看起来仍然在运行。
第二层flume聚合层有多个聚合节点,第一层每个flume节点采集的数据都可以负载均衡到聚合层的
每个节点。当其中一个聚合节点挂掉之后,采集层的数据可以发送到其他聚合节点,而且数据
不会丢失。
2)数据流向如何?出现数据积压如何处理?
手机客户端产生数据===》服务端,数据落盘===》flume采集(source,Channel缓存数据,
sink拉取channel数据发送给聚合节点)===》flume聚合(source,channel,sink发送给kafka)
===》kafka集群===》SparkStreaming===》HBase===》web服务器,数据落盘,===》flume采集
3)出现积压可能的原因:kafka下线升级
flume采集层和聚合层仍然可以采集数据,数据现在聚合层channel积压,当塞满之后,数据又会在
采集层channel积压,当数据塞满之后,整个采集就会停止,日志服务器产生数据直接落盘。
当kafka上线之后,解压情况会快速消失。
2.Nginx日志采集拓扑
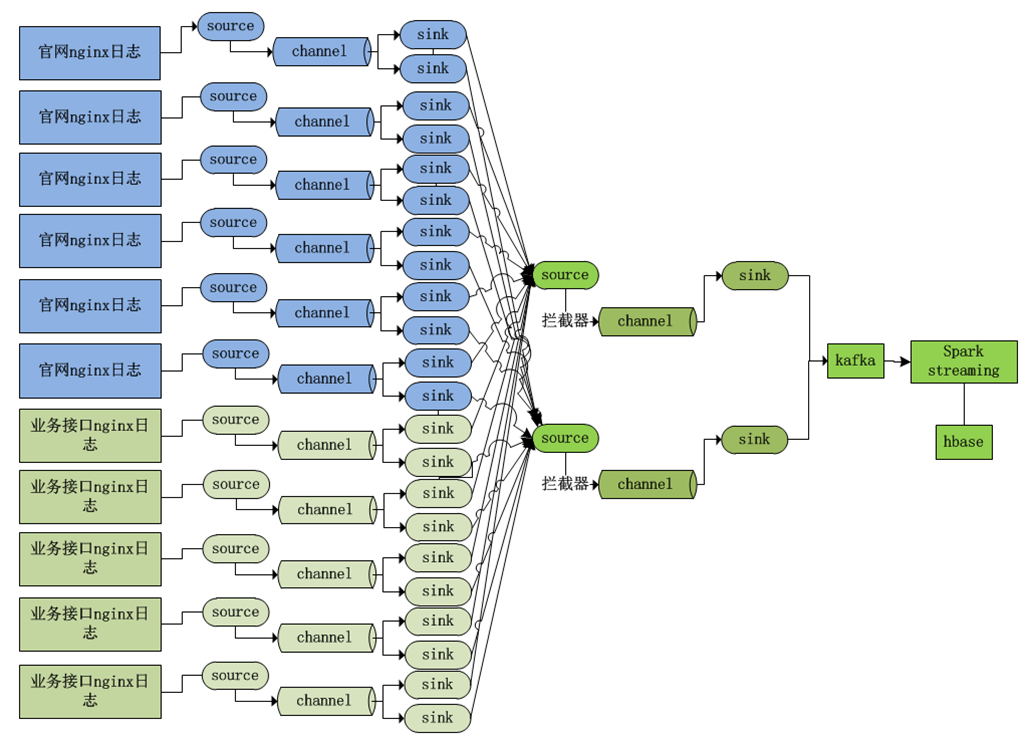
1)如何应对高峰数据请求(二八)?
一般情况下,我们的数据产生有一个二八原则:80%数据产生在20%的时间内
低峰时期有固定的Nginx服务器,高峰时期动态增加Nginx服务器。
既可以应对数据高峰时期,又减少服务器资源的浪费
2)如何低侵入动态增加采集节点?
逐个的上下线flume采集节点
新增聚合节点之后:
之前的采集配置不动,新增的采集配置增加,新增的flume聚合配置。
支队新增的采集和聚合配置做改动,对之前的采集架构不影响。
三、集群资源规划部署
1. 软件版本选择
apache+cdh+hdp
1)Zookeeper3.4.6
2)Hadoop2.6x 2.7x 2.8x 2.9x
3)HBase 1.x
4)flume 1.8
5)kafka1.0
6)Spark2.3x
7)Tomcat7/8
8)JDK1.8
9)scala2.11.8
2.线上集群规划
1)Hadoop 150节点左右:实时计算队列和离线计算队列
2)kafka 18台
3)Spark 跳板机/客户端 on yarn
4)HBase 与HDFS共用节点
5)flume多层级如何部署:flume采集节点与日志服务器节点共用
6)每个节点内存:64G、128G、256G ,4T磁盘;当前存储不要超过总磁盘70%
7)Zookeeper 单独搭建:5、7
3.实验环境集群规划
1)3个节点
2)内存16G
3)1T
项目开发流程:
数据从手机客户端到服务端
flume数据采集
kafka消息队列
hbase数据库
spark streaming实时业务开发
项目测试运行
用户行为接口开发
四、数据从手机客户端到服务器
1. 数据格式
{ "userId": 1000, "day": "2020-09-05", "begintime": 1546654200000, "endtime": 1546654800000, "data": [ { "package": "com.browser1", "activetime": 60000 }, { "package": "com.browser3", "activetime": 120000 } ] }
2. 模拟手机客户端产生数据
见项目代码
3. 服务端web项目打包部署
好吧,我绝望了,这块真的不懂,tomcat起来了,但是始终404
下一小节
五、flume数据采集
1. Flume TailDirSource断点续传
1.1 断点续传原理
TailDir Source可实时监控一批文件,并记录每个文件最新消费位置,agent进程重启后不会
有重复消费的问题
遗留问题:文件回滚会造成数据重复采集
2. Flume TailDirSource重复采集bug修复
修改ReliableTaildirEventReader中的源码,进行bug修改
3. flume高可用分布式集群构建
4. flume集群采集上报数据
六、kafka集群可用性测试
1. kafka集群常用命令使用
2. flume与kafka整合
kafkasink
3. flume与kafka实现分区优化
1)正常情况flume发送数据到kafka集群,数据随机发送到kafka每个分区(3)
uid=1001
p0 1
p1 1
p2 1
同一id数据进入到不同分区,
使用拦截器
好

