
三、(项目架构的过去与现在)亿级用户行为之大数据实时分析
1. 一期工程项目技术架构

1)业务驱动
2)问题驱动
2. 二期工程项目技术架构

项目优化原则:
1)优先从架构和程序进行优化
2)考虑增加集群扩容
做任务为什么不适用kafka?
1)此业务用户量还小
2)数据量小
3)使用kafka大材小用,资源浪费
为什么同时使用db和redis
1)用户成长值需要存储在db
2)提高用户查询性能需要使用缓存redis
3)数据写入db同时还需要写入redis
为什么这个业务线使用kafka而不使用Rabbit Mq
1)kafka支持高并发
2)kafka属于大数据生态组件,提供了成熟接口,很好的支持流式计算
3)RabbitMQ对spark Storm flink支持不好
当前遗留问题/隐患:此时kafka生产者在业务系统里面,耦合度太高
3. 三期工程项目技术架构
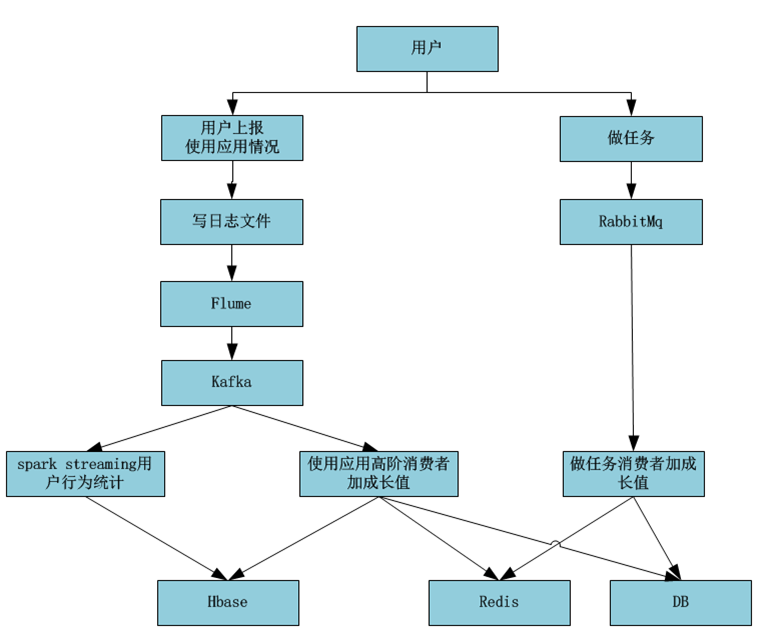
kafka中的数据为什么消费多次?
1)kafka中的数据需要使用Spark Streaming 做汇总统计
2)kafka中的数据加成长值,存入redis缓存,加快查询速度
3) kafka中的数据加成长值之后,HBase和db都保存一份
4. 项目流式计算框架
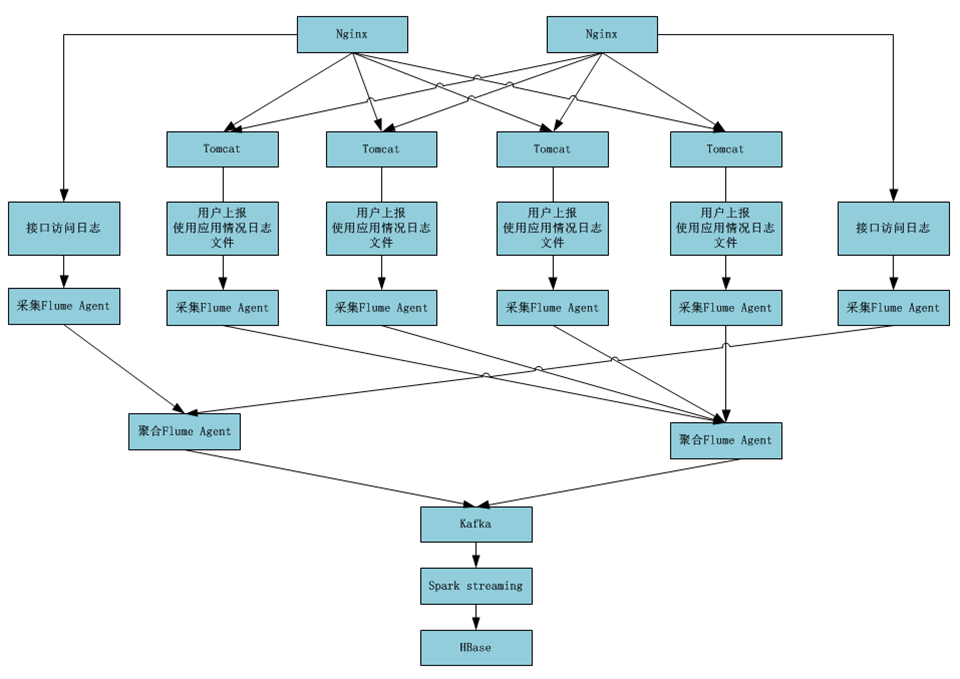
Nginx上面是一个硬件F5,F5可以实现负载均衡,用户访问请求发送过来之后,F5会按照一定的
规则轮询发送给Nginx,Nginx又按照一定的规则轮询分发给Tomcat。
无论硬件还是软件,都达到一个负载均衡的策略
F5硬件层面主备高可用,软件层面Nginx、Tomcat、Flume、kafka、Spark on yarn、HBase
都是高可用。
总结:端到端全链路都是高可用。如果整个环节/流程有一个环节不是高可用,那么整个系统
就存在风险。
哈哈

