
(四)HBase
续接(三)
3 habse(1.2)集成hive(1.2.1)===》不兼容集成,需要自己编译!!!
hive1.x与hbase0.98版本兼容
hive2.x与hbase1.x版本以上兼容
hive0.x与hbase0.98以下兼容
Hive提供了与HBase的集成,使得能够在HBase表上使用hive sql 语句进行查询 插入操作以及进行Join和Union等复杂查询、同时也可以将hive表中的数据映射到Hbase中。
3.1 整合配置
1、修改hive-site.xml文件,添加配置属性
<property> <name>hbase.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property>
2、修改hive-env.sh 文件,添加hbase的依赖包到hive的classpath中
export HIVE_CLASSPATH=$HIVE_CLASSPATH:/opt/bigdata/hbase/lib/*
3、使用编译好的hive-hbase-handler-1.2.1.jar替换hive之前的lib目录下的该jar包
hive-hbase-handler-1.2.1.jar 包见下发的资料
3.2 案例演示
3.2.1 将hbase表映射到hive表中
1、在hbase中创建一张表
create 'hbase_test','f1','f2','f3'
2、加载数据到hbase_test表中
put 'hbase_test','r1','f1:name','zhangsan'
put 'hbase_test','r1','f2:age','20'
put 'hbase_test','r1','f3:sex','male'
put 'hbase_test','r2','f1:name','lisi'
put 'hbase_test','r2','f2:age','30'
put 'hbase_test','r2','f3:sex','female'
put 'hbase_test','r3','f1:name','wangwu'
put 'hbase_test','r3','f2:age','40'
put 'hbase_test','r3','f3:sex','male'
3、创建基于hbase的hive表
create external table hiveFromHbase( rowkey string, f1 map<STRING,STRING>, f2 map<STRING,STRING>, f3 map<STRING,STRING> ) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:,f2:,f3:") TBLPROPERTIES ("hbase.table.name" = "hbase_test"); --这里使用外部表映射到HBase中的表,这样,在Hive中删除表,并不会删除HBase中的表,否则,就会删除。另外,除了rowkey,其他三个字段使用Map结构来保存HBase中的每一个列族。 --hbase.columns.mapping Hive表和HBase表的字段映射关系,分别为:Hive表中第一个字段映射:key(rowkey),第二个字段映射列族f1,第三个字段映射列族f2,第四个字段映射列族f3 --hbase.table.name HBase中表的名字
4、查看hive表的数据
0: jdbc:hive2://node1:10000> select * from hivefromhbase; +-----------------------+----------------------+-------------------+-------------------+--+ | hivefromhbase.rowkey | hivefromhbase.f1 | hivefromhbase.f2 | hivefromhbase.f3 | +-----------------------+----------------------+-------------------+-------------------+--+ | r1 | {"name":"zhangsan"} | {"age":"20"} | {"sex":"male"} | | r2 | {"name":"lisi"} | {"age":"30"} | {"sex":"female"} | | r3 | {"name":"wangwu"} | {"age":"40"} | {"sex":"male"} | +-----------------------+----------------------+-------------------+-------------------+--+
3.2.2 将hive表映射到hbase表中
1、创建一张映射hbase的表
create table hive_test( id string, name string, age int, address string )STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:name,f2:age,f3:address") TBLPROPERTIES ("hbase.table.name" = "hbaseFromhive");
2、查看hbase映射表是否产生
这里由于hive表是刚刚构建,目前是没有数据,同样这张hbase表也没有数据
3、向hive表加载数据
数据来源于另一张表,比如hive_source 表
--hive_source表中的测试数据 0: jdbc:hive2://node1:10000> select * from hive_source; +-----------------+-------------------+------------------+----------------------+--+ | hive_source.id | hive_source.name | hive_source.age | hive_source.address | +-----------------+-------------------+------------------+----------------------+--+ | 1 | zhangsan | 20 | hubei | | 2 | lisi | 30 | hunan | | 3 | wangwu | 40 | beijing | | 4 | xiaoming | 50 | shanghai | +-----------------+-------------------+------------------+----------------------+--+ --加载数据到hive_test表中 insert into table hive_test select * from hive_source;
4、查看hbase表hbaseFromhive是否有数据
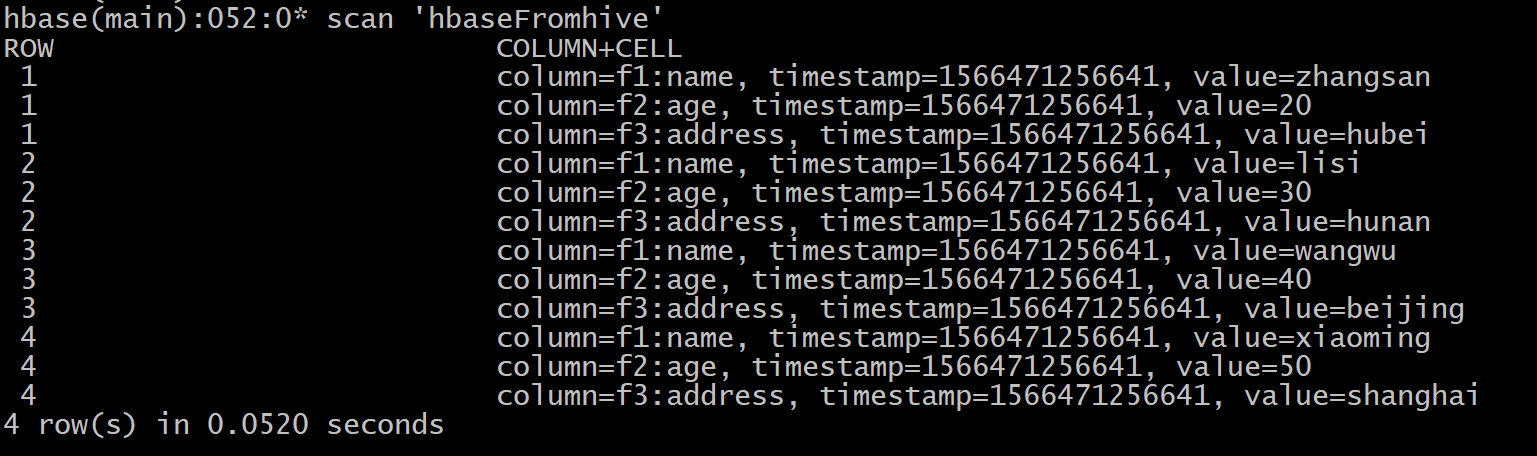
4 hbase表的rowkey设计
4.1 rowkey长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。
- 建议越短越好,不要超过16个字节
- 设计过长会降低memstore内存的利用率和HFile存储数据的效率。
4.2 rowkey散列原则
建议将rowkey的高位作为散列字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息。
所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
4.3 rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,
因此,设计rowkey的时候,要充分利用这个排序的特点,可以将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
5 hbase表的热点
5.1 什么是热点
检索habse的记录首先要通过row key来定位数据行。当大量的client访问hbase集群的一个或少数几个节点,造成少数region server的读/写请求过多、负载过大,而其他region server负载却很小,就造成了“热点”现象。
5.2 热点的解决方案
1、预分区
预分区的目的让表的数据可以均衡的分散在集群中,而不是默认只有一个region分布在集群的一个节点上。
2、加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。
3、哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
4、反转
反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
6 hbase的数据备份
6.1 基于hbase提供的类对hbase中某张表进行备份
使用hbase提供的类把hbase中某张表的数据导出hdfs,之后再导出到测试hbase表中。
(1) ==从hbase表导出==
HBase数据导出到HDFS hbase org.apache.hadoop.hbase.mapreduce.Export test /hbase_data/test_bak HBase数据导出到本地文件 hbase org.apache.hadoop.hbase.mapreduce.Export test file:///home/hadoop/test_bak
(2) ==文件导入hbase表==
将hdfs上的数据导入到备份目标表中 hbase org.apache.hadoop.hbase.mapreduce.Driver import test_bak /hbase_data/test_bak/* 将本地文件上的数据导入到备份目标表中 hbase org.apache.hadoop.hbase.mapreduce.Driver import test_bak file:///home/hadoop/test_bak/*
补充说明
以上都是对数据进行了全量备份,后期也可以实现表的增量数据备份,增量备份跟全量备份操作差不多,只不过要在后面加上时间戳。 例如: HBase数据导出到HDFS hbase org.apache.hadoop.hbase.mapreduce.Export test /hbase_data/test_bak_increment 开始时间戳 结束时间戳
6.2 基于snapshot的方式实现对hbase中某张表进行备份
- 通过snapshot快照的方式实现HBase数据的迁移和拷贝。这种方式比较常用,效率高,也是最为推荐的数据迁移方式。
- HBase的snapshot其实就是一组==metadata==信息的集合(文件列表),通过这些metadata信息的集合,就能将表的数据回滚到snapshot那个时刻的数据。
首先我们要了解一下所谓的HBase的LSM类型的系统结构,我们知道在HBase中,数据是先写入到Memstore中,当Memstore中的数据达到一定条件,
就会flush到HDFS中,形成HFile,后面就不允许原地修改或者删除了。
如果要更新或者删除的话,只能追加写入新文件。既然数据写入以后就不会在发生原地修改或者删除,这就是snapshot做文章的地方。
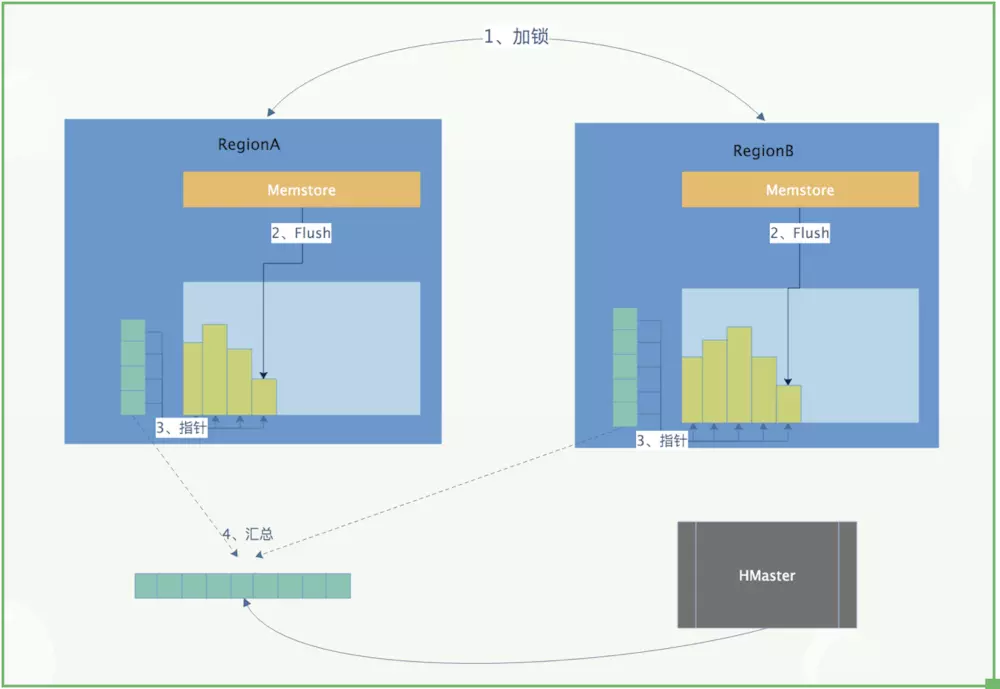
做snapshot的时候,只需要给快照表对应的所有文件创建好指针(元数据集合),恢复的时候只需要根据这些指针找到对应的文件进行恢复就Ok。
这是原理的最简单的描述,下图是描述快照时候的简单流程:
1、创建表的snapshot
snapshot 'tableName', 'snapshotName'
2、查看snapshot
list_snapshots 查找以test开头的snapshot list_snapshots 'test.*'
3、恢复snapshot
restore_snapshot 'snapshotName' ps:这里需要对表进行disable操作,先把表置为不可用状态,然后在进行进行restore_snapshot的操作 例如: disable 'tableName' restore_snapshot 'snapshotName' enable 'tableName'
4、删除snapshot
delete_snapshot 'snapshotName'
5、迁移 snapshot
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \ -snapshot snapshotName \ -copy-from hdfs://src-hbase-root-dir/hbase \ -copy-to hdfs://dst-hbase-root-dir/hbase \ -mappers 1 \ -bandwidth 1024 例如: hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \ -snapshot test \ -copy-from hdfs://node1:9000/hbase \ -copy-to hdfs://node1:9000/hbase1 \ -mappers 1 \ -bandwidth 1024 这种方式用于将快照表迁移到另外一个集群的时候使用,使用MR进行数据的拷贝,速度很快,使用的时候记得设置好bandwidth参数,以免由于网络打满导致的线上业务故障。
6、将snapshot使用bulkload的方式导入
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles \ hdfs://dst-hbase-root-dir/hbase/archive/datapath/tablename/filename \ tablename 例如: 创建一个新表 create 'newTest','f1','f2' hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles hdfs://node1:9000/hbase1/archive/data/default/test/6325fabb429bf45c5dcbbe672225f1fb newTest
五、拓展
7 hbase的二级索引
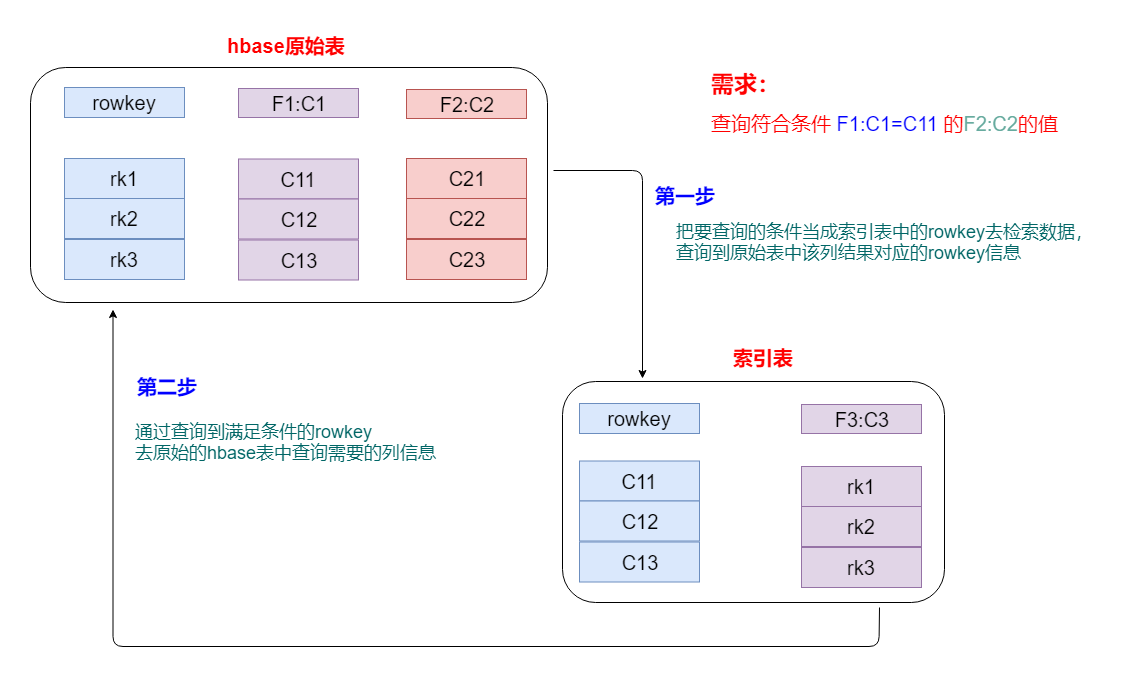
hbase表后期按照rowkey查询性能是最高的。rowkey就相当于hbase表的一级索引,
但是在实际的工作中,我们做的查询基本上都是按照一定的条件进行查找,无法事先知道满足这些条件的rowkey是什么,
正常是可以通过hbase过滤器去实现。但是效率非常低,这是由于查询的过程中需要在底层进行大量的文件扫描。
hbase的二级索引
bloomFilter:布隆过滤器BLOOMFILTER=>'Row'
就是一个算法,它会 作用在每一个HFile上,可以帮我们客户端快速进行一个反馈,
跳过不包含指定rowkey的HFile文件,可以快速定位包含指定rowkey的HFile文件
算法是有误差:如果它说包含不一定真包含,如果它说不包含是一定不包含。
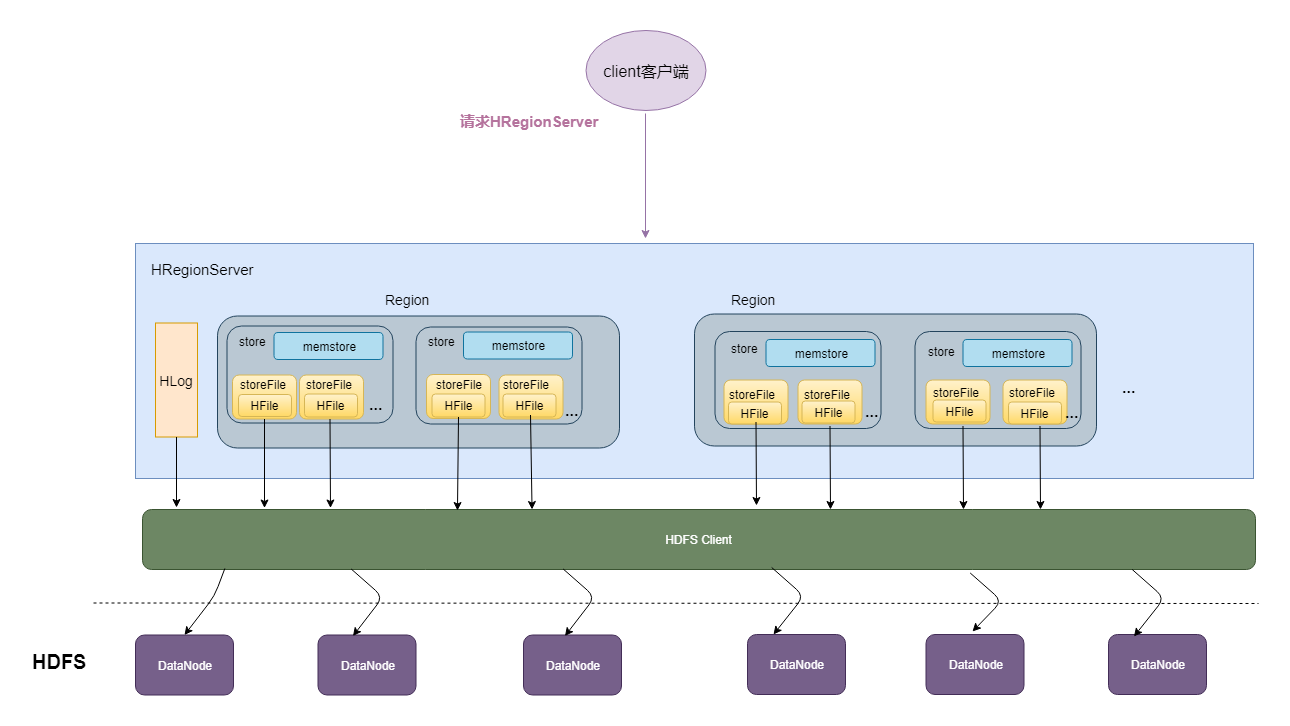
HFile格式的文件:它包含了大量的一些信息
有文件的元数据信息
有数据信息
有数据的索引信息
元数据的索引信息
等等。。。
为了HBase的数据查询更高效、适应更多的场景,诸如使用非rowkey字段检索也能做到秒级响应,
或者支持各个字段进行模糊查询和多字段组合查询等, 因此需要在HBase上面构建二级索引,
以满足现实中更复杂多样的业务需求。
hbase的二级索引其本质就是建立hbase表中列与行键之间的映射关系。
构建hbase二级索引方案
-
-
Hbase Coprocessor(协处理器)方案
-
Solr+hbase方案
-
ES+hbase方案
-
Phoenix+hbase方案
|------------------------------------------------------------------| | _| _| _|_|_| _| _| | | _| _| _| _| _| | | _| _| _|_|_|_| | | _| _| _| _| | | _| _|_|_| _| _| 多少度的酒,配得上这突如其来 2020-06-27 17:13:14 | |------------------------------------------------------------------|
Phoenix 构建二级索引
索引性能优化

