centos7安装kubernetes k8s v1.16.0 国内环境
(kubernetes部署成功,但Dashboard(界面管理)的时候总不成功,建议安装行, 的1.16.3)
一. 为什么是k8s v1.16.0?
最新版的v1.16.2试过了,一直无法安装完成,安装到kubeadm init那一步执行后,报了很多错,如:node xxx not found等。centos7都重装了几次,还是无法解决。用了一天都没安装完,差点放弃。后来在网上搜到的安装教程基本都是v1.16.0的,我不太相信是v1.16.2的坑所以先前没打算降级到v1.16.0。没办法了就试着安装v1.16.0版本,竟然成功了。记录在此,避免后来者踩坑。
本篇文章,安装大步骤如下:
- 安装docker-ce 18.09.9(所有机器)
- 设置k8s环境前置条件(所有机器)
- 安装k8s v1.16.0 master管理节点
- 安装k8s v1.16.0 node工作节点
- 安装flannel(master)
这里有重要的一步,请记住自己master和node之间通信的ip,如我的master的ip为192.168.237.143,node的ip为:192.168.237.144 请确保使用这两个ip在master和node上能互相ping通,这个master的ip 192.168.237.143接下来配置k8s的时候需要用到。
我的环境:
- 操作系统:win10
- 虚拟机:virtual box
- linux发行版:CentOS7
- linux内核(使用uname -r查看):3.10.0-957.el7.x86_64
- master和node节点通信的ip(master):192.168.99.104
- 修改host 主 hostnamectl --static set-hostname k8s-master
- 修改host 节点 hostnamectl --static set-hostname k8s-node1
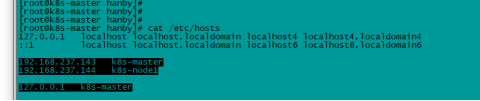
- vi /etc/hosts
- 添加
- 192.168.237.143 k8s-master
- 192.168.237.144 k8s-node1
- 127.0.0.1 k8s-master
二. 安装docker-ce 18.09.9(所有机器)
所有安装k8s的机器都需要安装docker,命令如下:
# 安装docker所需的工具
yum install -y yum-utils device-mapper-persistent-data lvm2
# 配置阿里云的docker源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 指定安装这个版本的docker-ce
yum install -y docker-ce-18.09.9-3.el7
# 启动docker
systemctl enable docker && systemctl start docker
三. 设置k8s环境准备条件(所有机器)
安装k8s的机器需要2个CPU和2g内存以上,这个简单,在虚拟机里面配置一下就可以了。然后执行以下脚本做一些准备操作。所有安装k8s的机器都需要这一步操作。
# 关闭防火墙
systemctl disable firewalld
systemctl stop firewalld
# 关闭selinux
# 临时禁用selinux
setenforce 0
# 永久关闭 修改/etc/sysconfig/selinux文件设置
sed -i 's/SELINUX=permissive/SELINUX=disabled/' /etc/sysconfig/selinux
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
# 禁用交换分区
swapoff -a
# 永久禁用,打开/etc/fstab注释掉swap那一行。
sed -i 's/.*swap.*/#&/' /etc/fstab
# 修改内核参数
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
四. 安装k8s v1.16.0 master管理节点
如果还没安装docker,请参照本文步骤二安装docker-ce 18.09.9(所有机器)安装。
如果没设置k8s环境准备条件,请参照本文步骤三设置k8s环境准备条件(所有机器)执行。
以上两个步骤检查完毕之后,继续以下步骤。
1. 安装kubeadm、kubelet、kubectl
kubeadm —— 启动 k8s 集群的命令工具
kubelet —— 集群容器内的命令工具
kubectl —— 操作集群的命令工具
由于官方k8s源在google,国内无法访问,这里使用阿里云yum源
# 执行配置k8s阿里云源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 安装kubeadm、kubectl、kubelet
yum install -y kubectl-1.16.0-0 kubeadm-1.16.0-0 kubelet-1.16.0-0
# 启动kubelet服务
systemctl enable kubelet && systemctl start kubelet
2. 初始化k8s
以下这个命令开始安装k8s需要用到的docker镜像,因为无法访问到国外网站,所以这条命令使用的是国内的阿里云的源(registry.aliyuncs.com/google_containers)。另一个非常重要的是:这里的--apiserver-advertise-address使用的是master和node间能互相ping通的ip,我这里是192.168.99.104,刚开始在这里被坑了一个晚上,你请自己修改下ip执行。 这条命令执行时会卡在[preflight] You can also perform this action in beforehand using ''kubeadm config images pull,大概需要2分钟,请耐心等待。
# 下载管理节点中用到的6个docker镜像,你可以使用docker images查看到
# 这里需要大概两分钟等待,会卡在[preflight] You can also perform this action in beforehand using ''kubeadm config images pull
kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.16.0 --apiserver-advertise-address 192.168.237.143 --pod-network-cidr=10.244.0.0/16 --token-ttl 0
上面安装完后,会提示你输入如下命令,复制粘贴过来,执行即可。
# 上面安装完成后,k8s会提示你输入如下命令,执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
3. 记住node加入集群的命令
上面kubeadm init执行成功后会返回给你node节点加入集群的命令,等会要在node节点上执行,需要保存下来,如果忘记了,可以使用如下命令获取。
kubeadm token create --print-join-command
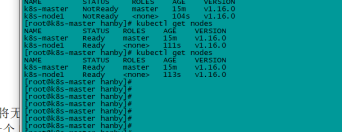
以上,安装master节点完毕。可以使用kubectl get nodes查看一下,此时master处于NotReady状态,暂时不用管。

五. 安装k8s v1.16.0 node工作节点
如果还没安装docker,请参照本文步骤二安装docker-ce 18.09.9(所有机器)安装。
如果没设置k8s环境准备条件,请参照本文步骤三设置k8s环境准备条件(所有机器)执行。
以上两个步骤检查完毕之后,继续以下步骤。
1. 安装kubeadm、kubelet
# 执行配置k8s阿里云源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 安装kubeadm、kubectl、kubelet
yum install -y kubeadm-1.16.0-0 kubelet-1.16.0-0
# 启动kubelet服务
systemctl enable kubelet && systemctl start kubelet
2. 加入集群
这里加入集群的命令每个人都不一样,可以登录master节点,使用kubeadm token create --print-join-command 来获取。获取后执行如下。
# 加入集群,如果这里不知道加入集群的命令,可以登录master节点,使用kubeadm token create --print-join-command 来获取
kubeadm join 192.168.99.104:6443 --token ncfrid.7ap0xiseuf97gikl \
--discovery-token-ca-cert-hash sha256:47783e9851a1a517647f1986225f104e81dbfd8fb256ae55ef6d68ce9334c6a2
加入成功后,可以在master节点上使用kubectl get nodes命令查看到加入的节点。
- 删除节点
首先释放 bogon 节点资源
kubectl drain bogon --delete-local-data --force --ignore-daemonsets
删除 bogon 节点
kubectl delete node bogon
查看节点
kubectl get nodes
No resources found.
六. 安装flannel(master机器)
以上步骤安装完后,机器搭建起来了,但状态还是NotReady状态,如下图,master机器需要安装flanneld。

1. 下载官方fannel配置文件
使用wget命令,地址为:(https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml),这个地址国内访问不了,所以我把内容复制下来,为了避免前面文章过长,我把它粘贴到文章末尾第八个步骤附录了。这个yml配置文件中配置了一个国内无法访问的地址(quay.io),我已经将其改为国内可以访问的地址(quay-mirror.qiniu.com)。我们新建一个kube-flannel.yml文件,复制粘贴该内容即可。
2. 安装fannel
kubectl apply -f kube-flannel.yml
七. 大功告成
至此,k8s集群搭建完成,如下图节点已为Ready状态,大功告成,完结撒花。
八. 附录
这是kube-flannel.yml文件的内容,已经将无法访问的地址(quay.io)全部改为国内可以访问的地址(quay-mirror.qiniu.com)。我们新建一个kube-flannel.yml文件,复制粘贴该内容即可。
---apiVersion: policy/v1beta1kind: PodSecurityPolicymetadata:
name: psp.flannel.unprivileged
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default
seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default
apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default
apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/defaultspec:
privileged: false
volumes:
- configMap
- secret
- emptyDir
- hostPath
allowedHostPaths:
- pathPrefix: "/etc/cni/net.d"
- pathPrefix: "/etc/kube-flannel"
- pathPrefix: "/run/flannel"
readOnlyRootFilesystem: false
# Users and groups
runAsUser:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
fsGroup:
rule: RunAsAny
# Privilege Escalation
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
# Capabilities
allowedCapabilities: ['NET_ADMIN']
defaultAddCapabilities: []
requiredDropCapabilities: []
# Host namespaces
hostPID: false
hostIPC: false
hostNetwork: true
hostPorts:
- min: 0
max: 65535
# SELinux
seLinux:
# SELinux is unused in CaaSP
rule: 'RunAsAny'---kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1beta1metadata:
name: flannelrules:
- apiGroups: ['extensions']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames: ['psp.flannel.unprivileged']
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch---kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1beta1metadata:
name: flannelroleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannelsubjects:- kind: ServiceAccount
name: flannel
namespace: kube-system---apiVersion: v1kind: ServiceAccountmetadata:
name: flannel
namespace: kube-system---kind: ConfigMapapiVersion: v1metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flanneldata:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}---apiVersion: apps/v1kind: DaemonSetmetadata:
name: kube-flannel-ds-amd64
namespace: kube-system
labels:
tier: node
app: flannelspec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/os
operator: In
values:
- linux
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
hostNetwork: true
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-amd64
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg---apiVersion: apps/v1kind: DaemonSetmetadata:
name: kube-flannel-ds-arm64
namespace: kube-system
labels:
tier: node
app: flannelspec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/os
operator: In
values:
- linux
- key: beta.kubernetes.io/arch
operator: In
values:
- arm64
hostNetwork: true
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-arm64
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-arm64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg---apiVersion: apps/v1kind: DaemonSetmetadata:
name: kube-flannel-ds-arm
namespace: kube-system
labels:
tier: node
app: flannelspec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/os
operator: In
values:
- linux
- key: beta.kubernetes.io/arch
operator: In
values:
- arm
hostNetwork: true
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-arm
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-arm
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg---apiVersion: apps/v1kind: DaemonSetmetadata:
name: kube-flannel-ds-ppc64le
namespace: kube-system
labels:
tier: node
app: flannelspec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/os
operator: In
values:
- linux
- key: beta.kubernetes.io/arch
operator: In
values:
- ppc64le
hostNetwork: true
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-ppc64le
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-ppc64le
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg---apiVersion: apps/v1kind: DaemonSetmetadata:
name: kube-flannel-ds-s390x
namespace: kube-system
labels:
tier: node
app: flannelspec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/os
operator: In
values:
- linux
- key: beta.kubernetes.io/arch
operator: In
values:
- s390x
hostNetwork: true
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-s390x
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay-mirror.qiniu.com/coreos/flannel:v0.11.0-s390x
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
九. k8s 集群部署问题整理
对kubernetes感兴趣的可以加群885763297,一起玩转kubernetes
1、hostname “master” could not be reached
在host中没有加解析
2、curl -sSL http://localhost:10248/healthz
curl: (7) Failed connect to localhost:10248; 拒绝连接 在host中没有localhost的解析
3、Error starting daemon: SELinux is not supported with the overlay2 graph driver on this kernel. Either boot into a newer kernel or…abled=false)
vim /etc/ssconfig/docker --selinux-enabled=False
4、bridge-nf-call-iptables 固化的问题:
#下面的是关于bridge的配置: net.bridge.bridge-nf-call-ip6tables = 0 net.bridge.bridge-nf-call-iptables = 1 #意味着二层的网络在转发包的时候会被iptables的forward规则过滤 net.bridge.bridge-nf-call-arptables = 0
5、The connection to the server localhost:8080 was refused - did you specify the right host or port?
unable to recognize "kube-flannel.yml": Get http://localhost:8080/api?timeout=32s: dial tcp [::1]:8080: connect: connection refused 下面如果在root用户下执行的,就不会报错 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
###6、error: unable to recognize “mycronjob.yml”: no matches for kind “CronJob” in version “batch/v2alpha1”
去kube-apiserver.yaml文件中添加: - --runtime-config=batch/v2alpha1=true,然后重启kubelet服务,就可以了
7、Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized Unable to update cni config: No networks found in /etc/cni/net.d Failed to get system container stats for “/system.slice/kubelet.service”: failed to get cgroup stats for “/system.slice/kubelet.service”: failed to get container info for “/system.slice/kubelet.service”: unknown container “/system.slice/kubelet.service”
docker pull quay.io/coreos/flannel:v0.10.0-amd64
mkdir -p /etc/cni/net.d/
cat <<EOF> /etc/cni/net.d/10-flannel.conf
{"name":"cbr0","type":"flannel","delegate": {"isDefaultGateway": true}}
EOF
mkdir /usr/share/oci-umount/oci-umount.d -p
mkdir /run/flannel/
cat <<EOF> /run/flannel/subnet.env
FLANNEL_NETWORK=172.100.0.0/16
FLANNEL_SUBNET=172.100.1.0/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.1/Documentation/kube-flannel.yml
8、Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of “crypto/rsa: verification error” while trying to verify candidate authority certificate “kubernetes”)
export KUBECONFIG=/etc/kubernetes/kubelet.conf
9、Failed to get system container stats for “/system.slice/docker.service”: failed to get cgroup stats for “/system.slice/docker.service”: failed to get container info for “/system.slice/docker.service”: unknown container “/system.slice/docker.service”
vim /etc/sysconfig/kubelet --runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice systemctl restart kubelet
大概意思是Flag --cgroup-driver --kubelet-cgroups 驱动已经被禁用,这个参数应该通过kubelet 的配置指定配置文件来配置
10、The HTTP call equal to ‘curl -sSL http://localhost:10255/healthz’ failed with error: Get http://localhost:10255/healthz: dial tcp 127.0.0.1:10255: getsockopt: connection refused.
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --fail-swap-on=false"
11、failed to run Kubelet: failed to create kubelet: miscon figuration: kubelet cgroup driver: “systemd” is different from docker cgroup driver: “cgroupfs”
kubelet: Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd" docker: vi /lib/systemd/system/docker.service -exec-opt native.cgroupdriver=systemd
12、[ERROR CRI]: unable to check if the container runtime at “/var/run/dockershim.sock” is running: exit status 1
rm -f /usr/bin/crictl
13、 Warning FailedScheduling 2s (x7 over 33s) default-scheduler 0/4 nodes are available: 4 node(s) didn’t match node selector.
如果指定的label在所有node上都无法匹配,则创建Pod失败,会提示无法调度:
14、kubeadm 生成的token过期后,集群增加节点
kubeadm token create
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null |
openssl dgst -sha256 -hex | sed 's/^.* //'
kubeadm join --token aa78f6.8b4cafc8ed26c34f --discovery-token-ca-cert-hash sha256:0fd95a9bc67a7bf0ef42da968a0d55d92e52898ec37c971bd77ee501d845b538 172.16.6.79:6443 --skip-preflight-checks
15、### systemctl status kubelet告警
cni.go:171] Unable to update cni config: No networks found in /etc/cni/net.d
May 29 06:30:28 fnode kubelet[4136]: E0529 06:30:28.935309 4136 kubelet.go:2130] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
删除 /etc/systemd/system/kubelet.service.d/10-kubeadm.conf 的 KUBELET_NETWORK_ARGS,然后重启kubelet服务 临时解决。没啥用
根本原因是缺少: k8s.gcr.io/pause-amd64:3.1
16 删除flannel网络:
ifconfig cni0 down
ifconfig flannel.1 down
ifconfig del flannel.1
ifconfig del cni0
ip link del flannel.1
ip link del cni0
yum install bridge-utils
brctl delbr flannel.1
brctl delbr cni0
rm -rf /var/lib/cni/flannel/* && rm -rf /var/lib/cni/networks/cbr0/* && ip link delete cni0 && rm -rf /var/lib/cni/network/cni0/*
17、E0906 15:10:55.415662 1 leaderelection.go:234] error retrieving resource lock default/ceph.com-rbd: endpoints “ceph.com-rbd” is forbidden: User “system:serviceaccount:default:rbd-provisioner” cannot get endpoints in the namespace “default”
`在 添加下面的这一段 (会重新申请资源) kubectl apply -f ceph/rbd/deploy/rbac/clusterrole.yaml
apiGroups: [""]
resources: [“endpoints”]
verbs: [“get”, “list”, “watch”, “create”, “update”, “patch”]`
18、flannel指定网卡设备:
- --iface=eth0
21、 Failed create pod sandbox: rpc error: code = Unknown desc = [failed to set up sandbox container “957541888b8a0e5b9ad65da932f688eb02cc182808e10d1a89a6e8db2132c253” network for pod “coredns-7655b945bc-6hgj9”: NetworkPlugin cni failed to set up pod “coredns-7655b945bc-6hgj9_kube-system” network: failed to find plugin “loopback” in path [/opt/cni/bin], failed to clean up sandbox container “957541888b8a0e5b9ad65da932f688eb02cc182808e10d1a89a6e8db2132c253” network for pod “coredns-7655b945bc-6hgj9”: NetworkPlugin cni failed to teardown pod “coredns-7655b945bc-6hgj9_kube-system” network: failed to find plugin “portmap” in path [/opt/cni/bin]]
https://kubernetes.io/docs/setup/independent/troubleshooting-kubeadm/#coredns-pods-have-crashloopbackoff-or-error-state
如果您的网络提供商不支持portmap CNI插件,您可能需要使用服务的NodePort功能或使用HostNetwork=true。
22、问题:kubelet设置了system-reserved(800m)、kube-reserved(500m)、eviction-hard(800),其实集群实际可用的内存是总内存-800m-800m-500m ,但是发现还 是会触发系统级别kill进程,
排查:使用top查看前几名的内存使用情况,发现etcd服务使用了内存达到500M以上,kubelet使用内存200m,ceph使用内存总和是200多m,加起来就已经900m了,这些都是k8s之外的系统开销,已经完全超出了系统预留内存,因此可能会触发系统级别的kill,
23、如何访问api-server?
使用kubectl proxy功能
24、使用svc的endpoint代理集群外部服务,经常出现endpoint丢失的问题
解决:去掉service.spec.selecter 标签就好了。
25、集群雪崩的一次问题处理,node节点偶尔出现noreading状态,
排查:此node节点上cpu使用率过高。
1、没有触发node节点上的cpuPressure的状态,判断出来不是k8s所管理的cpu占用过高的问题,应该是system、kube组件预留的cpu高导致的。
2、查看cpu和mem的cgroup分组,发现kubelet,都在system.sliec下面,因此判断kube预留资源没有生效导致的。
3、
--enforce-node-allocatable=pods,kube-reserved,system-reserved #采用硬限制,超出限制就oom
--system-reserved-cgroup=/system.slice #指定系统reserved-cgroup对那些cgroup限制。
--kube-reserved-cgroup=/system.slice/kubelet.service #指定kube-reserved-cgroup对那些服务的cgroup进行限制
--system-reserved=memory=1Gi,cpu=500m
--kube-reserved=memory=500Mi,cpu=500m,ephemeral-storage=10Gi
26、[etcd] Checking Etcd cluster health
etcd cluster is not healthy: context deadline exceeded
————————————————
十. k8s 部署问题解决
从snap安装导致的初始化问题
由于一开始我安装的时候没有配置好镜像源,所以导致了apt下载 k8s 三件套时出现了找不到对应包的问题,再加上 ubuntu 又提示了一下 try sudo snap isntall kubelet ... 所以我就用snap安装了三件套,使用的安装命令如下:
snap install kubelet --classic
snap install kubeadm --classic
snap install kubectl --classic
虽然我在网上也找到了不少用snap成功部署的例子,但是迫于技术不精,最终实在是无法解决出现的问题,换用了apt安装之后就一帆风顺的安装完成了。下面记录一下用snap安装时出现的问题:
kubelet isn't running or healthy
使用kubeadm init初始化时出现了下述错误,重复四次之后就超时退出了:
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.[kubelet-check] It seems like the kubelet isn't running or healthy.
官方给出的解决方案是使用systemctl status kubelet查看一下kubelet的状态。但是我运行之后显示未找到kubelet.service,然后用如下命令查看启动失败的服务:
systemctl list-units --failed
结果发现一个名为snap.kubelet.daemon.service的服务无法启动了,尝试了各种方法都没有让它复活,无奈只好放弃用snap安装了。如果有大佬知道该怎么解决请告诉我,不胜感激。下面就说一下遇到的其他问题。
初始化时的警告
在使用kubeadm init命令初始化节点刚开始时,会有如下的perflight阶段,该阶段会进行检查,如果其中出现了如下WARNING并且初始化失败了。就要回来具体查看一下问题了。下面会对下述两个警告进行解决:
# kubeadm init ...[init] Using Kubernetes version: v1.15.0[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING FileExisting-socat]: socat not found in system path
WARNING IsDockerSystemdCheck
修改或创建/etc/docker/daemon.json,加入下述内容:
{
"exec-opts": ["native.cgroupdriver=systemd"]}
重启docker:
systemctl restart docker
查看修改后的状态:
docker info | grep Cgroup
WARNING FileExisting-socat
socat是一个网络工具, k8s 使用它来进行 pod 的数据交互,出现这个问题直接安装socat即可:
apt-get install socat
节点状态为 NotReady
使用kubectl get nodes查看已加入的节点时,出现了Status为NotReady的情况。
root@master1:~# kubectl get nodesNAME STATUS ROLES AGE VERSION
master1 NotReady master 152m v1.15.0
worker1 NotReady <none> 94m v1.15.0
这种情况是因为有某些关键的 pod 没有运行起来,首先使用如下命令来看一下kube-system的 pod 状态:
kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-bccdc95cf-792px 1/1 Pending 0 3h11m
coredns-bccdc95cf-bc76j 1/1 Pending 0 3h11m
etcd-master1 1/1 Running 2 3h10m
kube-apiserver-master1 1/1 Running 2 3h11m
kube-controller-manager-master1 1/1 Running 2 3h10m
kube-flannel-ds-amd64-9trbq 0/1 ImagePullBackoff 0 133m
kube-flannel-ds-amd64-btt74 0/1 ImagePullBackoff 0 174m
kube-proxy-27zfk 1/1 Pending 2 3h11m
kube-proxy-lx4gk 1/1 Pending 0 133m
kube-scheduler-master1 1/1 Running 2 3h11m
如下,可以看到 pod kube-flannel 的状态是ImagePullBackoff,意思是镜像拉取失败了,所以我们需要手动去拉取这个镜像。这里可以看到某些 pod 运行了两个副本是因为我有两个节点存在了。
你也可以通过kubectl describe pod -n kube-system <服务名>来查看某个服务的详细情况,如果 pod 存在问题的话,你在使用该命令后在输出内容的最下面看到一个[Event]条目,如下:
root@master1:~# kubectl describe pod kube-flannel-ds-amd64-9trbq -n kube-system
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Killing 29m kubelet, worker1 Stopping container kube-flannel
Warning FailedCreatePodSandBox 27m (x12 over 29m) kubelet, worker1 Failed create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "kube-flannel-ds-amd64-9trbq": Error response from daemon: cgroup-parent for systemd cgroup should be a valid slice named as "xxx.slice"
Normal SandboxChanged 19m (x48 over 29m) kubelet, worker1 Pod sandbox changed, it will be killed and re-created.
Normal Pulling 42s kubelet, worker1 Pulling image "quay.io/coreos/flannel:v0.11.0-amd64"
手动拉取镜像
flannel的镜像可以使用如下命令拉到,如果你是其他镜像没拉到的话,百度一下就可以找到国内的镜像源地址了,这里记得把最后面的版本号修改成你自己的版本,具体的版本号可以用上面说的kubectl describe命令看到:
docker pull quay-mirror.qiniu.com/coreos/flannel:v0.11.0-amd64
等镜像拉取完了之后需要把镜像名改一下,改成 k8s 没有拉到的那个镜像名称,我这里贴的镜像名和版本和你的不一定一样,注意修改:
docker tag quay-mirror.qiniu.com/coreos/flannel:v0.11.0-amd64 quay.io/coreos/flannel:v0.11.0-amd64
修改完了之后过几分钟 k8s 会自动重试,等一下就可以发现不仅flannel正常了,其他的 pod 状态也都变成了Running,这时再看 node 状态就可以发现问题解决了:
root@master1:~# kubectl get nodesNAME STATUS ROLES AGE VERSION
master1 Ready master 3h27m v1.15.0
worker1 Ready <none> 149m v1.15.0
工作节点加入失败
在子节点执行kubeadm join命令后返回超时错误,如下:
root@worker2:~# kubeadm join 192.168.56.11:6443 --token wbryr0.am1n476fgjsno6wa --discovery-token-ca-cert-hash sha256:7640582747efefe7c2d537655e428faa6275dbaff631de37822eb8fd4c054807[preflight] Running pre-flight checks
error execution phase preflight: couldn't validate the identity of the API Server: abort connecting to API servers after timeout of 5m0s
在master节点上执行kubeadm token create --print-join-command重新生成加入命令,并使用输出的新命令在工作节点上重新执行即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号