
requests库的基础知识
1.安装。
cmd----------->> pip install requests.
2. 七种操作方法。
# GET 全部信息 # HEADER 仅头部信息 # Put 全部重置
# Patch 局部更新 ## 更改操作用户
# POST 后面添加新内容 ## 搜索使用 # DELETE 删除全部 import requests ''' r = requests.get("http://www.baidu.com") # 获得全部文本信息 uRL对应的页面内容 print(r.headers) # 头部信息 print(r.text) # seem is also all information ''' # requests.head ''' r2 = requests.head("http://www.baidu.com") # just head information print(r.headers) # head information print(r2.text) # no ! because just get the head information ''' # payload = {"key1":"value1","key2":"value2"} r3 = requests.post("http://www.baidu.com",data=payload) print(r3.text)


2.Response对象的属性。
import requests r = requests.get("http://www.baidu.com") print(r.status_code) # HTTP请求的返回状态,200表示连接成功。404表示失败 print(r.text) # HTTP响应内容的字符串形式,即,uRL对应的页面内容。 print(r.encoding) # 从HTTP header中猜测的响应内容编码方式 print(r.apparent_encoding) # 内容中分析出的响应内容编码方式 print(r.content) # 响应内容的二进制形式 (处理图片,视频等使用) r.encoding = r.apparent_encoding # 转化编码 r.apparent_encoding 根据它的结果转码 print(r.text)
小结:通过 r.status_code 返回的状态码,判断是否连接成功。
3.通用代码框架。
def getHTMLText(url): try: r = requests.get(url,timeout = 30) r.raise_for_status() # 如果状态是200,引发异常 r.encoding = r.apparent_encoding return r.text except: return "404" if __name__ == "__main__": # 没搞懂这个是什么鬼 url = "http://www.baidu.com" print(getHTMLText(url))
4.ROBOTS.txt协议。

实战练习。
1.京东页面的提取。
1 ''' 2 import requests 3 r = requests.get('https://item.jd.com/13115733485.html') 4 print(r.status_code) 5 print(r.encoding) 6 print(r.text) 7 ''' 8 9 ''' 10 import requests 11 url = 'https://item.jd.com/13115733485.html' 12 try: 13 r = requests.get(url, timeout=30) 14 r.raise_for_status() 15 r.encoding = r.apparent_encoding 16 print(r.text[:1000]) 17 except: 18 print("404") 19 ''' 20 21 import requests 22 def getHTMLText(url): 23 try: 24 r = requests.get(url,timeout = 30) 25 r.raise_for_status() # 如果状态是200,引发异常 26 r.encoding = r.apparent_encoding 27 return r.text 28 except: 29 return "404" 30 31 if __name__ == "__main__": 32 url = "https://item.jd.com/13115733485.html" 33 print(getHTMLText(url)[:1000])
2.亚马逊。
''' import requests r = requests.get("https://www.amazon.cn/gp/product/B00PG0MMLO/ref=s9_acsd_al_bw_c_x_5_w?pf_rd_m=A1AJ19PSB66TGU&pf_rd_s=merchandised-search-5&pf_rd_r=N8WFJMBB60D92VPHAREM&pf_rd_r=N8WFJMBB60D92VPHAREM&pf_rd_t=101&pf_rd_p=26451395-7952-4f3c-b948-09e79ff542f8&pf_rd_p=26451395-7952-4f3c-b948-09e79ff542f8&pf_rd_i=1885051071") print(r.status_code) # 503 连接出错,不是404 print(r.encoding) # ISO-8859-1 r.encoding = r.apparent_encoding # 转码 print(r.text) # 有反应,说明受限 # 报歉,由于程序执行时,遇到意外错误,您刚刚操作没有执行成功,请稍后重试。或将此错误报告给我们的客服中心 print(r.request.headers) # 获取请求头部信息 # {'User-Agent': 'python-requests/2.14.2', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} ''' ''' import requests kv = {'User-Agent':"Mazilla/5.0"} url = "https://www.amazon.cn/gp/product/B00PG0MMLO/ref=s9_acsd_al_bw_c_x_5_w?pf_rd_m=A1AJ19PSB66TGU&pf_rd_s=merchandised-search-5&pf_rd_r=N8WFJMBB60D92VPHAREM&pf_rd_r=N8WFJMBB60D92VPHAREM&pf_rd_t=101&pf_rd_p=26451395-7952-4f3c-b948-09e79ff542f8&pf_rd_p=26451395-7952-4f3c-b948-09e79ff542f8&pf_rd_i=1885051071" r = requests.get(url,headers= kv) # 更改头部信息 print(r.status_code) # 200 print(r.request.headers) # {'User-Agent': 'Mazilla/5.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} print(r.text[:1000]) '''
import requests
def getHTMLText(url): try: kv = {'User-Agent': "Mazilla/5.0"} r = requests.get(url,headers= kv,timeout = 30) # headers= r.raise_for_status() # 如果状态是200,引发异常 r.encoding = r.apparent_encoding return r.text except: return "404" if __name__ == "__main__": url = "https://www.amazon.cn/gp/product/B00PG0MMLO/ref=s9_acsd_al_bw_c_x_5_w?pf_rd_m=A1AJ19PSB66TGU&pf_rd_s=merchandised-search-5&pf_rd_r=N8WFJMBB60D92VPHAREM&pf_rd_r=N8WFJMBB60D92VPHAREM&pf_rd_t=101&pf_rd_p=26451395-7952-4f3c-b948-09e79ff542f8&pf_rd_p=26451395-7952-4f3c-b948-09e79ff542f8&pf_rd_i=1885051071" print(getHTMLText(url)[:1000])
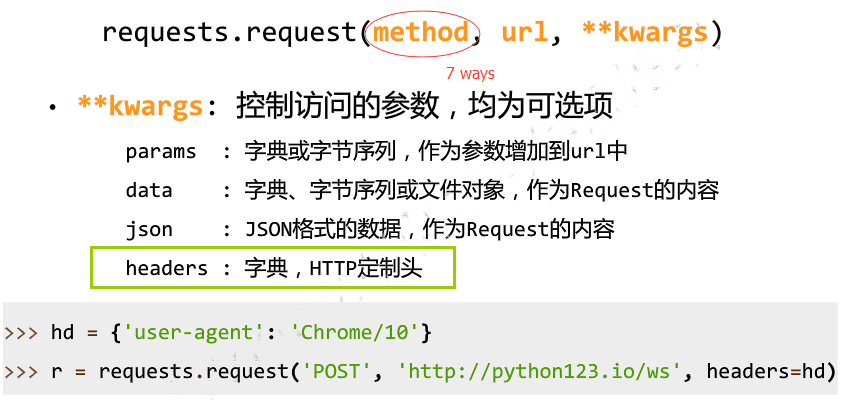
3.百度搜索
''' import requests kv = {"wd":"Python"} r = requests.get("http://www.baidu.com/s",params=kv) print(r.status_code) # 200 print(r.request.url) # http://www.baidu.com/s?wd=Python print(len(r.text)) # 196429 ''' import requests keyword = "Python" def getHTMLText(url): try: kv = {'wd':keyword} # 如何添加的???? r = requests.get(url,params=kv,timeout = 30) # params r.raise_for_status() # 如果状态是200,引发异常 r.encoding = r.apparent_encoding return r.text except: return "404" if __name__ == "__main__": url = "http://www.baidu.com" print(getHTMLText(url)[:1000])

其他控制参数的使用方法:


实例 查询IP
import requests url = "http://www.ip138.com/ips138.asp?ip=" r = requests.get(url+"202.204.80.112") # 对URL内容进行修改 print(r.status_code) print(r.encoding) # r.encoding = "utf-8" print(r.text[:-500])
下载图片:
''' import requests path = "F:/abc.jpg" url = "http://image.nationalgeographic.com.cn/2017/0721/20170721020325584.jpg" r = requests.get(url) print(r.status_code) with open(path,"wb") as f: # 文件存储 f.write(r.content) # 文件写入 # r.content 响应内容的二进制形式 # 这个句子是什么意思来着?? ''' import requests import os url = "http://image.nationalgeographic.com.cn/2017/0721/20170721020325584.jpg" root = 'F://pics//' path = root + url.split('/')[-1] if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): r = requests.get(url) with open(path, 'wb') as f: f.write(r.content) f.close() print('文件保存成功!') else: print('文件已存在。')
遇到问题很多,需要多多练习呀!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号