第一次个人编程作业
| 课程 | 软件工程 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/InformationSecurity1912-Softwareengineering/homework/12146 |
| 目标 | 学习使用PSP表格;查重算法设计;Git管理 |
GitHub地址
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 300 | 330 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 15 |
| · Design Spec | · 生成设计文档 | 30 | 10 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 90 | 100 |
| · Design | · 具体设计 | 120 | 150 |
| · Coding | · 具体编码 | 300 | 350 |
| · Code Review | · 代码复审 | 120 | 100 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 90 | 60 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1215 | 1300 |
二、实现过程(python3)
- 利用jieba库分词、去停用词
导入jieba库代码
import jieba.posseg as pseg
import codecs
from gensim import corpora, models, similarities
中文停词表:下载:https://github.com/bainingchao/DataProcess/tree/master/dataSet/StopWord
然后对文章进行分词、去停用词
- 利用词袋模型向量化文本
参考简书
例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典如下:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
- TF-IDF模型向量化文本
- LSI模型向量化文本
- 计算相似度
![]()

三、性能分析
Name显示被调用的模块或者函数;Call Count显示被调用的次数;Time(ms)显示运行时间和时间百分比,时间单位为毫秒(ms)
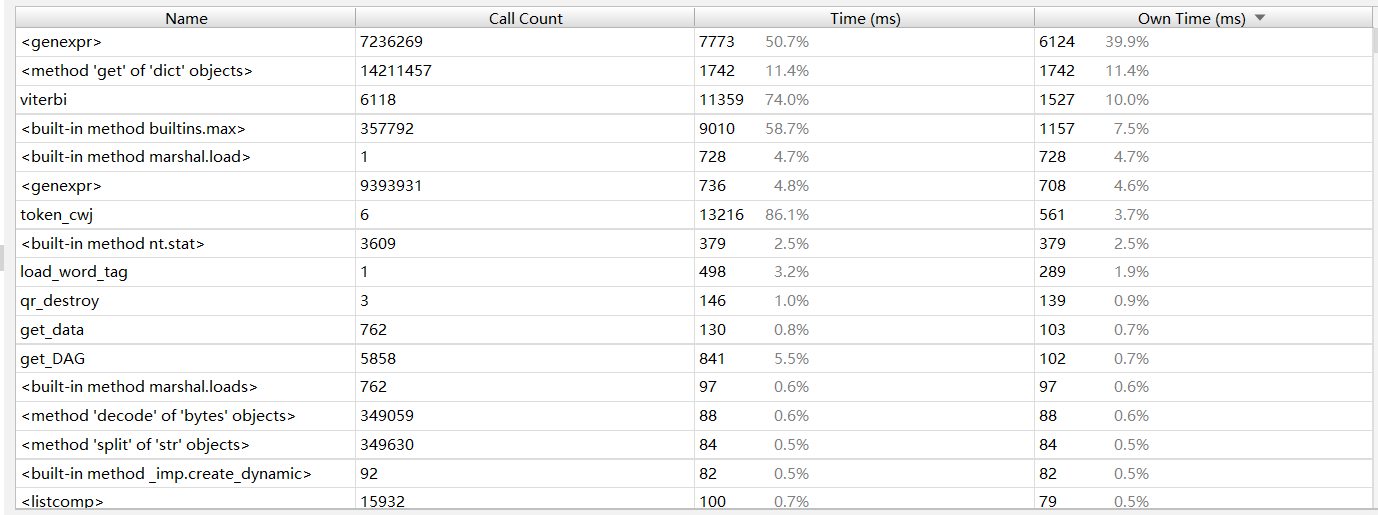
Call Graph(调用关系图):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号