linux 指令入门学习(持续更新)
有些话要讲
ps:这个是本人初次学习运维记录的学习文档,本文档是一篇帮助型文档,只记录一些常用的指令和操作,想要系统的学习运维还是推荐进入这个网址学习对初学者特别友好的菜鸟教程
如果你想要快速查找指令推荐进入这个网址Linux指令快速查找本人也是菜鸟,欢迎各位在评论区友好交流或者提一些建议
本文档也在随着我学习的深度越来越完善(越来越细),希望可以对你有所帮助,加油奥里给!
本文档所涉及的参数指令用法并不全,真正学习时建议多用man,help等帮助指令
本文档中存在一些重复的知识,温故而知新,要好好复习前面的指令,我来帮你巩固,不用谢我
练习指令推荐网址webminal,个人感觉非常强大,还有奥一定要多多利用
ctrl + f在本文档查找奥本人是看的极客时间的专栏(付费)和阿里云的免费课程学习的
基础设置
快捷键
终端快捷键
Ctrl + a/Home
切换到命令行开始
Ctrl + e/End
切换到命令行末尾
Ctrl + l
清除屏幕内容,效果等同于clear
Ctrl + u
清除剪切光标之前的内容
Ctrl + k
剪切清除光标之后的内容
Ctrl + y
粘贴刚才所删除的字符
Ctrl + r
在历史命令中查找 (这个非常好用,输入关键字就调出以前的命令了)
Ctrl + c
终止命令
ctrl + o
重复执行命令
Ctrl + d
退出shell,logout
Ctrl + z
转入后台运行,但在当前用户退出后就会终止
Ctrl + t
颠倒光标所在处及其之前的字符位置,并将光标移动到下一个字符
Alt + t
交换当前与以前单词的位置
Alt + d
剪切光标之后的词
Ctrl + w
剪切光标所在处之前的一个词(以空格、标点等为分隔符)
Ctrl +(x u)
按住Ctrl的同时再先后按x和u,撤销刚才的操作
Ctrl + s
锁住终端
Ctrl + q
解锁终端
!!
重复执行最后一条命令
history
显示你所有执行过的编号+历史命令。这个可以配合!编辑来执行某某命令
向上键
翻查上面的命令
Ctrl + Shift + C / V
进行复制粘贴。
ctrl + alt + F1~f6
切换窗口终端机
shift + 6
^以什么为开头
!$
显示系统最近的一条参数
最后这个比较有用,比如我先用cat /etc/sysconfig/network-scripts/ifconfig-eth0,然后我想用vim编辑。一般的做法是先用↑ 显示最后一条命令,然后用Home移动到命令最前,删除cat,然后再输入vim命令。其实完全可以用vim !$来代替。
常见目录介绍
/ 根目录
root root用户的家目录
/home/username 普通用户的家目录
/etc 配置文件目录
/bin 命令目录
/sbin 管理命令目录
/usr/bin 系统预装的其他指令
/usr/sbin 系统预装的其他指令
指令
init 3
进入字符界面
exit
退出当前用户
ls /
列出文件夹
init 0
关机
passwd
用户密码设置
type
辨别命令类型
touch
创建空文件
echo
显示一些信息到屏幕上
cat
显示整个文件内容
head
只显示文件开头10行
tail
只显示文件后10行
stat
统计文件信息
du
显示当前目录的磁盘使用情况
md5sum
验证其文件完整性
cut
切割文本文件
paste
粘贴
sort
排序
diff
比较两个文件差异
hostname
显示主机名
shutdown
关机
reboot
重启
halt
先执行shutdown命令,然后再执行其他特定的关闭操作
poweroff
将系统关机,并同时切断电源。与shutdown命令相比,poweroff命令更加彻底地关闭系统。
我们将消息重定向到一个新文件而不是屏幕。
echo "hello" > hello.txt
要追加数据必须使用>>而不是>
echo "linux" >> hello.txt
head -2 hello.txt(只查看开头两行)
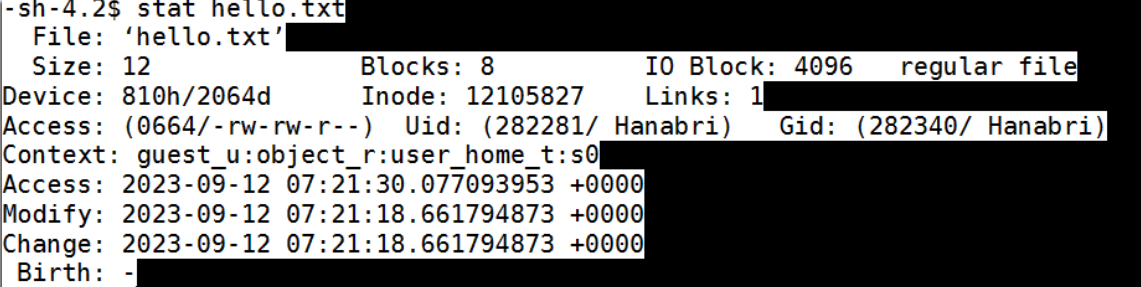
stat hello.txt
仔细检查输出中的几个重要字段。
第一行显示文件名。
第二行说它是一个大小为18的普通文件。
第三行显示了Inode编号和no。指向该inode的链接。
第四个,表示具有读写权限但其他人具有读权限的所有者(Uid)、组(Gid)。
最后三行显示访问、修改和更改时间。他们的意思是:
□Access:文件最后一次访问/读取的时间。
□Modified:内容最后一次出现的时间
书面修改。
□Change:表示对文件元数据的更改
比如改变用户权限。
du显示当前目录的磁盘使用情况。(请注意当前的du输出总量包括文件)。使用h开关以人类可读的格式输出(带k),使用x开关排除其他文件系统,而~表示您的目录。
du -xh ~
Du可能需要很长时间,所以你可以指定最大值。使用"--max-depth"选项设置目录深度。
du --max-depth 3 ~
md5sum和cp经常一起使用
8c7b96861ca8d6367ee0ae1fdbb2a9ce是计算出来的文件校验和。这有助于检测意外或故意的文件损坏,
当将文件从一台机器传输到另一台机器或从互联网下载文件时,为了验证文件的完整性,比较源机器和目标机器上的md5sum。

cut
cut -f1 -d' ' new.txt
-f1:指定切割的字段(列),这里表示选择第1列。-d' ':指定分隔符,这里使用空格作为分隔符。注意,这里的空格要用单引号括起来
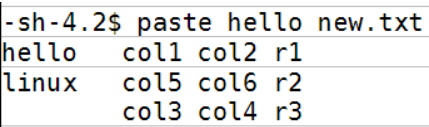
paste
paste hello new.txt
Paste合并文件行
每次粘贴一个文件
paste -s hello new.txt

sort
sort new.txt
对文件内容进行排序。
diff
比较两个文件
diff hello linux.txt
还可以比较三个
diff3 hello new.txt linux.txt
帮助命令
man
help
info
man帮助
- man 是 manual 的缩写
- man 帮助用法演示
- # man ls
- man也是一条指令,分为9章,可以使用man命令获得man的帮助
- # man 7 man
- # man -a ls (不知道是什么类型只知道名字时使用)
help帮助
-
shell(命令解释器)自带的命令称为内部指令,其他的是外部指令
-
内部指令使用help帮助
# help cd
-
外部指令使用hlep帮助
# ls --help
info帮助
- info帮助help更详细,作为help的补充
- # info ls
文件管理
一切皆文件
常用指令
ls(英文全拼:list files): 列出目录及文件名
cd(英文全拼:change directory):切换目录
pwd(英文全拼:print work directory):显示目前的目录
mkdir(英文全拼:make directory):创建一个新的目录
rmdir(英文全拼:remove directory):删除一个空的目录
cp(英文全拼:copy file): 复制文件或目录
rm(英文全拼:remove): 删除文件或目录
mv(英文全拼:move file): 移动文件与目录,或修改文件与目录的名称
文件查看
**ls ** 查看当前目录下的文件
常用参数(参数是区分大小写的)
-l
长格式显示文件
-a
显示隐藏文件
-r
逆序显示
-t
按照时间顺序显示
-R
递归显示 (显示文件夹下边的子文件夹以及子文件夹所有的文件信息)
-d
仅列出目录本身,而不是列出目录内的文件数据
-b
以可打印字符形式显示非打印字符,通常用于保留文件或目录名中的特殊字符的可识别性,例如空格、换行符等。
-C
以多列的形式输出文件列表,即每行显示多个文件或目录,默认情况下会从左至右逐行显示;
-i
可以查看到每一个文件对应的i节点
dir 是等于ls -C -b默认情况下文件按列列出,垂直排序,特殊字符用反斜杠转义序列表示。
参数是可以组合起来简写的
instance: ls -lartR /root
单独查看一个文件test ls -ld /test
file
file指令用于确定文件的类型
file linux.txt
-s
指定一个特定的文件来进行文件类型检测
file -s /dev/sda2
检测设备文件/dev/sda2的文件类型。
在任意目录下搜索文件linux.txt
find ~ -name "linux.txt"
要查找常规文件并在结果上调用file命令,请运行
find . -type f -exec file '{}' \;
find:用于在文件系统中查找文件和目录。.:表示当前目录。-type f:指定只查找文件,不包括目录。-exec:用于对每个找到的文件执行后续的命令。file '{}' \;:对每个找到的文件执行file命令进行文件类型分析,其中{}代表找到的文件名。
要使用ls命令查找常规文件并显示其属性,请运行
find . -type f -exec ls -l '{}' ;
要查找大小超过20字节的文件并列出它们,请运行
find ~ -type f -size +20c -exec ls -hl {} ;
whereis ls
查找可执行文件、源代码以及文档等相关文件所在位置我们经常需要找到某个文件的位置
-b:只查找可执行文件的位置。-m:只查找相关的文件描述信息文件的位置。-s:只查找源代码文件的位置。-u:只查找帮助文档文件的位置。
which
用于查找可执行文件路径的命令。
更改当前的操作目录
cd 更改当前的操作目录
cd /path/to/..... 绝对路径
cd ./path/to/..... (.代表当前目录) 相对路径
cd ../path/to/..... 相对路径
~表示当前目录的主目录(cd ~)
cd ..
回到上一级目录
cd -
移动到前一个工作目录
cd
将移动到你的主目录
touch
创建文件
touch命令将创建一个新文件或更改现有文件的时间戳。
创建和删除目录
mkdir
建立目录
常用参数
-p
建立多级目录
-v
显示执行过程的全部信息
-m
配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的脸色
mkdir -m 711 test2
**rmdir **
删除空目录
-p
从该目录起,一次删除多级空目录
rm
-r
递归删除目录及其内全部子文件
-r -f
(慎用)不进行任何提示删除非空目录
-i
互动模式,在删除前会询问使用者是否动作
rm -rf junk/*
复制和移动文件
cp
复制文件(默认不复制目录)
cp[选项] 文件路径
cp[选项] 文件...路径
常用参数
-r
复制目录
-p
保留用户,权限,时间等文件数性
-d
若来源档为链接档的属性(link file),则复制链接档属性而非文件本身
-a
等同于 -dpr
-f
为强制(force)的意思,若目标文件已经存在且无法开启,则移除后再尝试一次
-i
若目标档(destination)已经存在时,在覆盖时会先询问动作的进行(常用)
-l
进行硬式链接(hard link)的链接档创建,而非复制文件本身
-s
复制成为符号链接档 (symbolic link),亦即『捷径』文件
-u
若 destination 比 source 旧才升级 destination !
-v
显示执行过程详细信息
cp -v hello.txt dir2
cp -v hello.txt dir2/file2.txt
这将同时将hello.txt复制到dir2中,并将其重命名为"file2.txt"
会自动创建"file2.txt"
**mv **
移动文件
mv[选项] 源文件 目标文件
mv[选项] 源文件 目录
参数
-f
force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖
-i
若目标文件 (destination) 已经存在时,就会询问是否覆盖!
-u
若目标文件已经存在,且 source 比较新,才会升级 (update)
当您使用cp时,存在两个文件副本(类似于复制-粘贴“ctrl-c”和“ctrl-v”),而mv只有一个副本(其剪切-粘贴ctrl-x和ctrl-v)。与(cp,rm)其他命令不同,mv不需要对目录使用“-r”。
mv dir5.txt dir50.txt 将dir5.txt重命名为dir50.txt
使用mv命令,我们将hello.txt移到dir4下,而不是每次都以dir2/dir3/dir4/hi.txt的方式访问它们,我们可以创建一个链接,之后,您可以简单地访问或编辑dir2/dir3/dir4/hi.txt文件
ln
ln dir2/dir3/dir4/hi.txt hello

有两种类型的链接,硬链接。同一个索引节点有两个不同的名字和软链接,它们更像快捷键。默认创建硬链接。
Ln -s dir2/dir3/dir4/hi.txt softlink
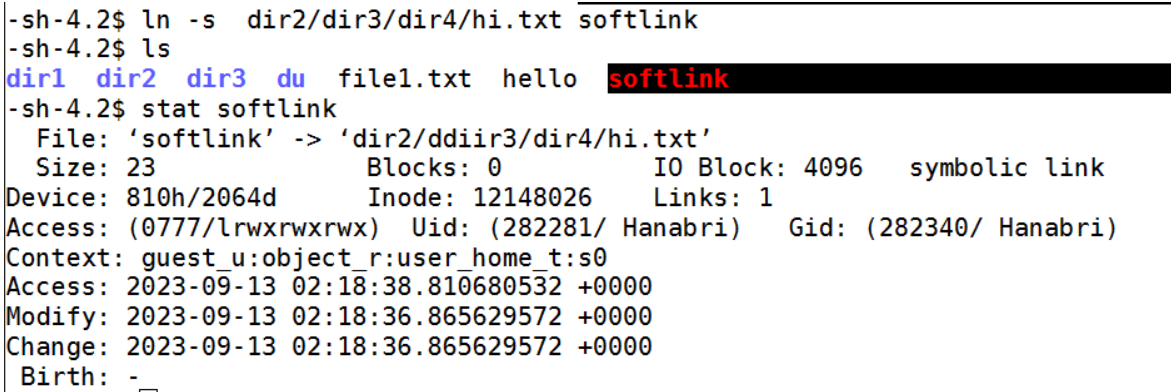
这个新的符号链接“softlink”创建了新的inode,但链接数保持为1。
通配符
定义:shell 内建的符号
用途:操作多个相似(有简单规律)的文件
常用通配符
* 匹配任何字符串
? 匹配一个字符串
[xyz] 匹配xyz任意一个字符
[a-z] 匹配一个范围
[!xyz]或[^xyz] 不匹配
文本查看指令
**cat ** 文本内容显示到终端(从第一行开始)
参数
-A
相当於 -vET 的整合选项,可列出一些特殊字符而不是空白而已;
-b
列出行号,仅针对非空白行做行号显示,空白行不标行号!
-E
将结尾的断行字节 $ 显示出来;
-n
列印出行号,连同空白行也会有行号,与 -b 的选项不同;
-T
将 [tab] 按键以 ^I 显示出来;
-v
列出一些看不出来的特殊字符
head
查看文件开头
想查看开头/结尾五行 head/tail -5
-n :后面接数字,代表显示几行的意思
tail
查看文件结尾
常用参数-f 文件内容更新后,显示信息同步更新
wc
统计文件内容信息(确定文件长度)
统计字,行和字符
第一个字段是行。第二个字段是词,第三个字段表示字节数。

tac
从最后一行开始显示,可以看出 tac 是 cat 的倒着写!
nl
显示的时候,顺道输出行号!
more
一页一页的显示文件内容
空白键 (space):代表向下翻一页;
Enter :代表向下翻『一行』;
/字串 :代表在这个显示的内容当中,向下搜寻『字串』这个关键字;
:f :立刻显示出档名以及目前显示的行数;
q :代表立刻离开 more ,不再显示该文件内容。
b 或 [ctrl]-b :代表往回翻页,不过这动作只对文件有用,对管线无用。
less
与 more 类似,但是比 more 更好的是,他可以往前翻页!
空白键 :向下翻动一页;
[pagedown]:向下翻动一页;
[pageup] :向上翻动一页;
/字串 :向下搜寻『字串』的功能;
?字串 :向上搜寻『字串』的功能;
n :重复前一个搜寻 (与 / 或 ? 有关!)
N :反向的重复前一个搜寻 (与 / 或 ? 有关!)
q :离开 less 这个程序;
grep
在文件上搜索匹配的单词或行。要搜索整个文件目录,请输入目录名
grep "linux" hello

-r
表示递归地在所有子目录中搜索。
grep -r 'Hello'
- Hello可以是一个单词、一个短语或一个正则表达式。默认情况下,grep是区分大小写的(a与A不一样),但您可以通过使用i开关忽略大小写
grep -i 'lINUX' hello

-n
显示行号
grep -n 'linux' hello
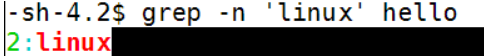
-v
显示不匹配的行
grep -v 'world' hello 这个命令会在名为 hello 的文件中搜索不包含 'world' 的内容,并显示匹配的行。
dirname
提取给定路径的目录部分
dirname dir2/dir3/dir4/hi.txt

basename
从路径名中剥离目录和后缀,并给出最后一个条目
basename dir2 / dir3 dir4 / hi.txt

打包压缩和解压缩
tar
打包命令
常用参数
c
打包
x
解包
f
指定操作类型为文件
VI文本编辑器
多模式文本编辑器
四种模式
正常模式
插入模式
命令行模式(末行模式)
可视模式
先给上一个图
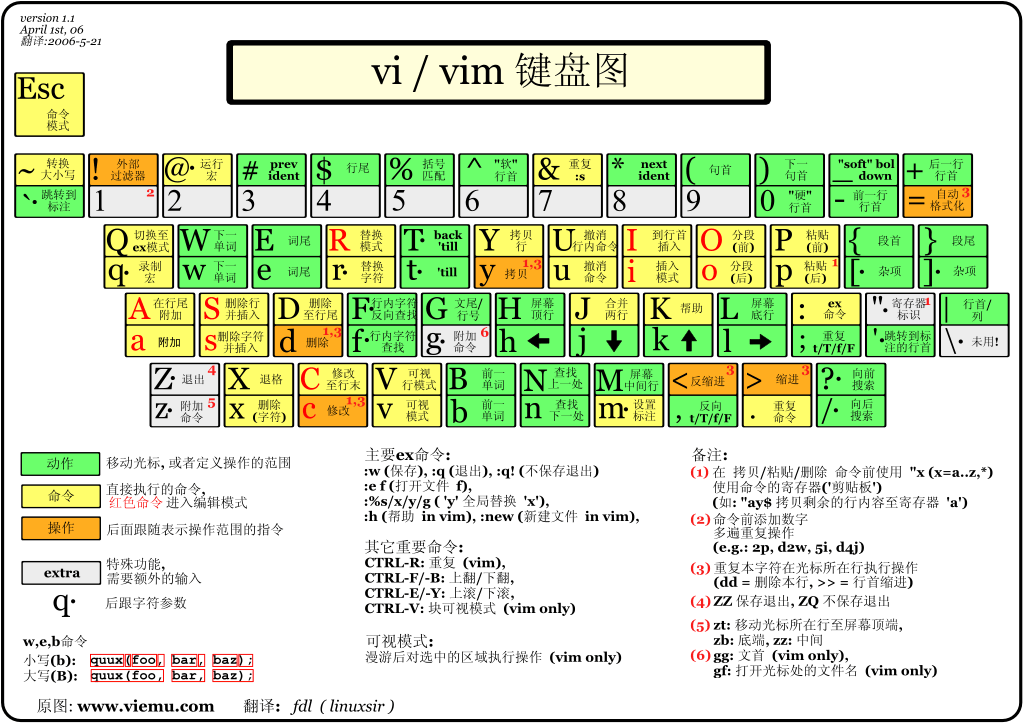
正常模式(命令模式)
用户刚刚启动 vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被 Vim 识别为命令,而非输入字符,比如我们此时按下 i,并不会输入一个字符,i 被当作了一个命令。
以下是普通模式常用的几个命令:
i -- 切换到输入模式,在光标当前位置开始输入文本。
x -- 删除当前光标所在处的字符。
: -- 切换到底线命令模式,以在最底一行输入命令。
a -- 进入插入模式,在光标下一个位置开始输入文本。
o:在当前行的下方插入一个新行,并进入插入模式。
O -- 在当前行的上方插入一个新行,并进入插入模式。
dd -- 删除当前行。
yy -- 复制当前行。
p -- 粘贴剪贴板内容到光标下方。
P -- 粘贴剪贴板内容到光标上方。
u -- 撤销上一次操作。
Ctrl + r -- 重做上一次撤销的操作。
:w -- 保存文件。
:q -- 退出 Vim 编辑器。
:q! -- 强制退出Vim 编辑器,不保存修改。
插入模式(输入模式)
在命令模式下按下 i 就进入了输入模式,使用 Esc 键可以返回到普通模式。
在输入模式中,可以使用以下按键:
字符按键以及Shift组合 -- 输入字符
ENTER -- 回车键,换行
BACK SPACE -- 退格键,删除光标前一个字符
DEL -- 删除键,删除光标后一个字符
方向键 -- 在文本中移动光标
HOME/END -- 移动光标到行首/行尾
Page Up/Page Down -- 上/下翻页
Insert --切换光标为输入/替换模式,光标将变成竖线/下划线
ESC -- 退出输入模式,切换到命令模式
命令行模式
在命令模式下按下 :(英文冒号)就进入了底线命令模式。
底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
w 保存文件。
q 退出 Vim 编辑器。
wq 保存文件并退出 Vim 编辑器。
q! 强制退出Vim编辑器,不保存修改。
按 ESC 键可随时退出底线命令模式。
更多命令可以看菜鸟教程连接点我
用户和用户管理
linux里面并不是靠用户的名称来识别用户的,而是靠用户的uid来识别的,只要uid是0,就是root身份,与用户名称无关
如果更改uid用户就会变成其他用户
系统和用户的详细信息
uptime
uptime提供当前时间、系统运行的时间、当前登录的用户数量以及过去1分钟、5分钟和15分钟的系统平均负载。

- "03:31:54"是当前的时间戳。
- "up 480 days"表示系统已经运行了480天。
- "22:42"是系统的运行时间,表示系统在最后一次重启后已经运行了22小时42分钟。
- "0 users"表示当前没有用户登录到系统中。
- "load average: 0.52, 0.86, 0.52"是系统的平均负载,分别表示过去1分钟、5分钟和15分钟的系统负载情况。在这个例子中,系统的负载相对较低,表示系统的资源使用情况较轻。
date
当前的日期和时间
who
显示当前登录到系统的用户信息。它可以显示用户的登录名、终端设备、登录时间和登录来源等信息。
-a
who -a
显示更详细的用户信息,包括登录的用户名称、终端设备、登录时间、IP地址
w
w指令提供了uptime指令提供的所有功能,还提供了当前登录用户的详细信息,包括登录用户数量和登录终端信息,适用于查看当前系统的用户情况。
mount
显示挂载的文件系统列表
mount -t ext4
-t参数用于指定文件系统类型,ext4是一个常见的Linux文件系统类型。
df
显示磁盘空间的使用情况。查看文件系统使用情况的命令
df - h
-h以人类可读的方式(以GB、MB等单位)
free
free -m
free -m命令用于显示系统的内存使用情况,以MB为单位
显示系统中空闲和已用物理内存和交换内存的总量,以及内核使用的缓冲区。
用户管理常用指令
useradd 新建用户
userdel 删除用户
passwd 修改用户密码
usermod 修改用户属性
chage 修改用户属性
用户组管理命令
groupadd 新建用户组
groupdel 删除用户组
用户切换
su 切换用户
su - USERNAME 使用login shell 方式切换用户
sudo 以其他用户身份执行命令
visudo 设置需要使用sudo的用户(组)
用户和用户组的配置文件
vim /etc/passwd
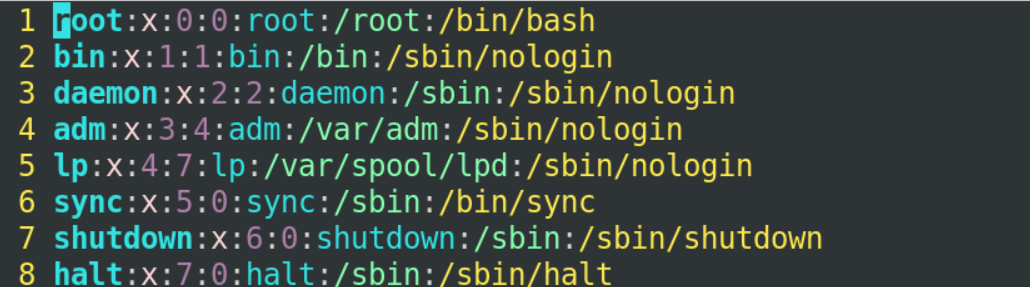
用户配置文件分为七个字段分别为
第一个字段表示用户名称
第二个字段表示是否需要密码
第三个字段表示用户的uid
第四个字段表示用户的gid
第五个字段表示注释
第六个字段表示用户的家目录在哪个位置
第七个字段表示用户登录的命令解释器(也就是用户登录成功之后我希望用哪一个命令解释器来解释你所输入的命令,现在通用的命令解释器都叫做bash)
最后一个字段还有一个另外的设置就是/sbin/nologin 就是当你把他的shell设置成nologin的时候,这个用户是不能登录终端的.
vim /etc/shadow //保存用户和用户密码相关信息

第一个字段表示用户名称
第二个字段表示用户加密过的密码
加密过的密码一般是以$6$开头后面跟着一长串的字符
这样做是为了保证用户即使有相同的密码在etc/shadow当中看到的显示结果也是不同的防止别人破解你的简单密码
vim /etc/group //用户组相关的配置文件

第一个字段表示组的名称
第二个字段表示组是否需要密码验证
第三个字段表示组的gid
第四个字段表示其他组设置(如果希望一个用户属于多个组就可以有一个其他组设置)
需要在该组的第四个字段写入用户名
文件与目录权限的表示方法
查看文件权限
ls -l命令可以查看文件的名称,各种各样的属性

不同的文件类型 它的权限的位置表示不同的功能
权限的前三个字符表示 当前标记在这的所属用户对这个文件有什么权限
中间三个字符表示 这个用户当时所属的用户组 对这个文件有什么权限
最后三个字符表示 除了当前的用户和用户组之外 其他人对文件有什么权限
如果一个文件同时所属多个用户,需要通过文件系统里边的facl功能来解决
简单解释文件权限和目录权限的区别
文件权限的读其实是读取我们文件里的内容,这个内容在datablock里边,对于目录来说,目录如果只有一个读,是读我们目录下面的文件的名称
文件类型
- 普通文件
d 目录文件
b 块特殊文件 //设备(移动硬盘)linux会把设备当作块特殊文件来去对待
c 字特殊文件 //类似终端
l 符号链接 //类似windows的快捷方式
f 命名管道 //用来做通信相关的功能
s 套接字文件 //同上
linu不是以扩展名区分的,他是以文件类型做区分的
创建之后文件的类型就被确定下来,是不可以人为的进行更改的
对不同类型他的权限表示不同功能
bin目录下文件权限如下
https://www.runoob.com/linux/linux-file-attr-permission.html
文件权限的表示方法
字符权限表示方法
(对普通文件)
r 读
w 写
x 执行
数字权限表示方法(二进制)111
r = 4
w = 2
x = 1
vim的写并不是把真正的内容写到文件,底层实际上是把内容放在隐藏文件当中(.开头的文件)当你进行保存并退出的时候,隐藏文件会再替换你原有的文件名,所以他并不是直接往文件里面去写的
创建新文件默认有权限,根据umask值计算,属主和属组根据当前进程用户决定(默认权限666-umask(022)变成了644)
目录权限的表示方法
x 进入目录
rx 显示目录内的文件名
wx 修改目录内的文件名
文件权限的修改
修改权限命令
权限限制只能限制非root用户
chmod 修改文件,目录权限(修改用户的权限)
-v 确切地看到文件或目录权限变更前后的情况。
chmod a-rw 1.txt 执行后除了root用户以外任何用户都无法对1.txt进行读写操作
权限管理命令特定的操作,例如创建、修改和删除用户、修改文件和目录的权限等,通常只有root用户或者拥有sudo权限的用户才能执行。一般用户只能使用部分权限管理命令,例如修改自己的密码、查看自己的信息等。
要更改多个文件权限请使用 -R参数
chmod u+x /tmp/testfile(增加属主执行权限)
chmod g+r /tmp/tesfile(减少属组读权限)
chmod o=w /tmp/tesfile(设置其他用户写权限)
chmod a=rwx /tmp/tesfile(设置读写执行权限给所有用户)
chmod 446 /tmp/testfile(用数字来表示 属主是4(读)属组是4(读)其他用户是4+2(读和写权限))
chown 更改属主,属组(修改所属用户与组)
chown user1 /test 更改属主
chown :group1 /test 更改属组
可以同时修改属主和属组 chown user1:group1 afile
使用-R开关更改所有文件和子目录的权限。
root:staff -R ~/dir2
将目录
dir2及其子目录中所有文件的所有者改为root,同时将文件的组改为staff。-R选项表示递归地修改文件的所有者和组。chown --from=webminal:webminal root:staff -R ~/dir2
在这个命令中,我们将 "webminal" 用户和 "webminal" 组更改为 "root" 用户和 "staff" 组,同时递归地作用于 "dir2" 文件夹下的所有文件和子文件夹。
chgrp 可以单独更改属组,不常用
当属组和属主权限冲突时如下图(属主无权限,属组有写权限),我们以属主的权限为准,即属主仍然无权限
- -R:递归更改文件属组,就是在更改某个目录文件的属组时,如果加上-R的参数,那么该目录下的所有文件的属组都会更改。

chgrp -hR root dir2命令是用于将dir2目录以及其子目录和文件的所有者改为root用户。其中,-h选项表示处理符号链接所指的文件而非链接本身,-R选项表示递归处理子目录和文件。对于不同类型的文件(目录类型和文件类型)虽然都赋予了r权限,但表达的含义完全不同
特殊权限
SUID 用于二进制可执行文件,执行命令时取得文件属主权限
如 /usr/bin/passwd
SGID 用于目录,在该目录下创建新的文件和目录,权限自动更改为该目录的属组(一般在文件共享的时候会用到)
SBIT 用于目录,该目录下新建的文件和目录,仅root和自己可以删除
(为了保证自己的文件不被其他用户删除时使用)
如 /tmp

rws 的s 就是SUID(setuid) 普通用户也可以改自己的密码
**SUID ** chmod 4xxx /test/bfile
SBIT chmod 1xxx /test/bfile
只对目录有效,使目录下的文件,只有文件拥有者才能删除
特殊权限不建议自己指定,建议保持系统的默认权限就可以了
接下来就要学习怎样去管理Linux了
网络管理
网络状态查看工具
net-tools VS iproute
1.net -tools(早期的linu版本常用)
ifconfig
route
netstat
2.iproute(centos7以后常用)
ip
ss
ifconfig
eth0 第一块网卡(网络接口)
你的第一个网络接口可能叫做下面的名字
eno1 板载网卡
ens33 PCI-E网卡
enp0s3 无法获取物理信息的PCI-E网卡
centos7 使用了一致性网络命名,以上都不匹配则使用eth0
网络接口命名修改
网卡命名规则受biosdevname和net.ifnames两个参数影响
编辑/etc/default/grub文件,增加biosdevname=0 net.ifnames=0
更新grub
#grub2-mkconfig -o /boot/grub2/grub.cfg
重启
#reboot
| biosdevname | net.ifnames | 网卡名 | |
|---|---|---|---|
| 默认 | 0 | 1 | ens33 |
| 组合1 | 1 | 0 | em1 |
| 组合2 | 0 | 0 | em0 |
网络状态查看
ifconfig
管理员可以直接使用ifconfig来查看网卡的状态
如果你的网卡过多的话也可以接单独的某一个网卡
ifconfig eth0
普通用户想要查看网卡状态需要使用 /sbin/ifconfig(需要使用命令的完整路径)

我第一块网卡叫enp0s3,一般需要把他转化成eth0,不然操作起来很麻烦
怎么转化呢,在上面其实有讲,编辑配置文件
vim /etc/default/grub
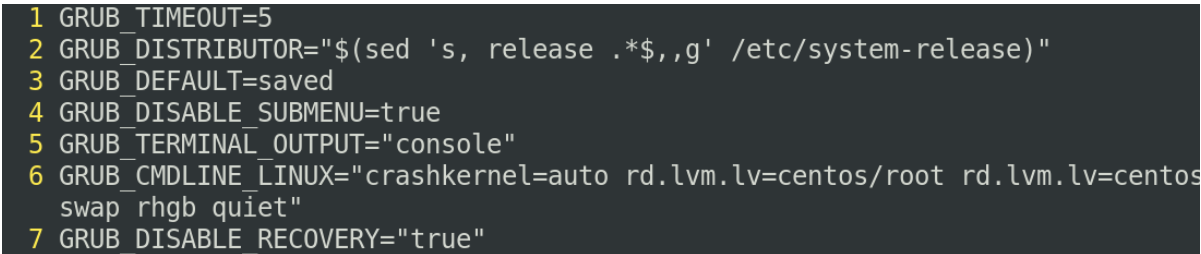
找到他的第六行,有一些grub的一些命令行的参数,grub是系统刚开始启动的时候,他要引导内核要有一个工具(类似于启动菜单一样),这个启动菜单我们可以设置一些参数,让他传递到我们的内核

添加时把biosdevname和net.ifname都指定为0,中间要有空格(他会认为这是两个参数)
biosdevname和net.ifname都与Linux系统中网络设备命名相关。
biosdevname是一个工具,用于在Linux系统上根据BIOS信息为网络设备自动命名。它可以避免系统重新启动后网络设备名称的变化,以及多个网络设备名称之间的冲突。net.ifname是一种网络设备命名规则,用于定义Linux系统中网络接口的命名方式。以前,Linux系统默认使用eth0、eth1等命名模式。然而,随着硬件和驱动的发展,接口名称可能变得复杂和难以管理。net.ifname允许用户根据设备属性(如设备类型、连接的总线类型等)来自定义命名规则。通过这种方式,可以创建更有意义的接口名称,提高系统管理的可读性和可靠性。
总结起来,biosdevname是一个工具,而net.ifname是一种规则,它们都是为了更好地管理和标识Linux系统中的网络设备。
指定好之后他不会马上生效,因为这个文件并不会被我们的启动设置所读取到,他是用来给我们用户来去看的,真正被系统启动时读取到的是 /boot/grub2/grub.cfg,所以我们编辑好文件后要把他转化为真正可读取到的文件
grub2-mkconfig -o /boot/grub2/grub.cfg
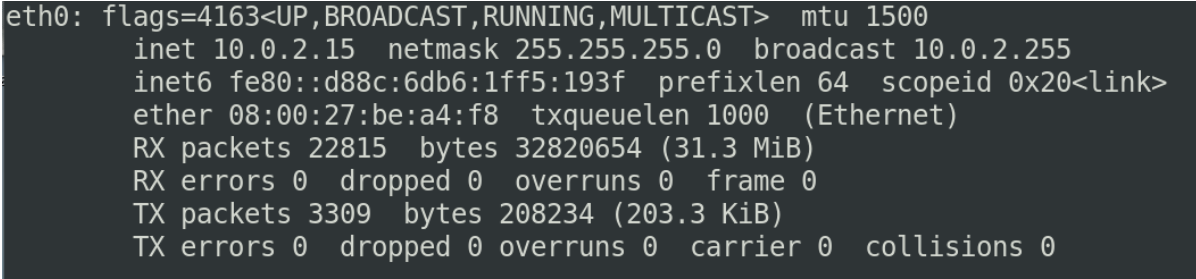
现在已经更改成了eth0
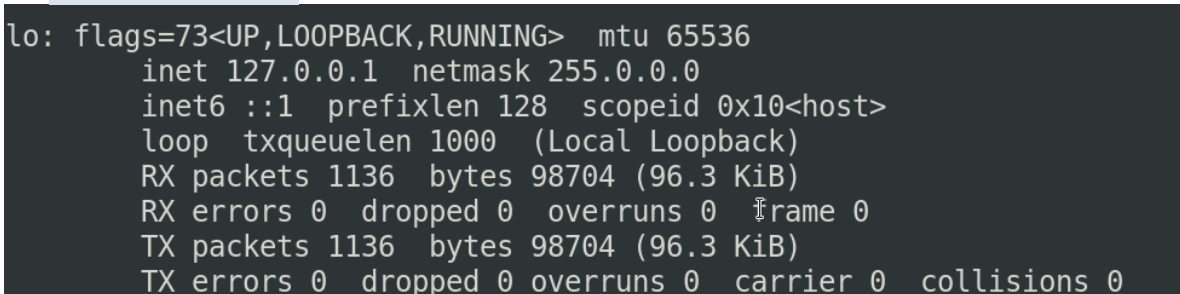
lo叫做本地的环回 他的inet(ip地址)永远都是127.0.0.1
这个ip在我们自己搭建服务的时候,希望通过网络能够访问给我们用户提供最终访问之前,最好进行一些测试,测试的时候我们一般都用127.0.0.1来去访问自己的主机上的某一个端口,这是用来测试的时候使用的
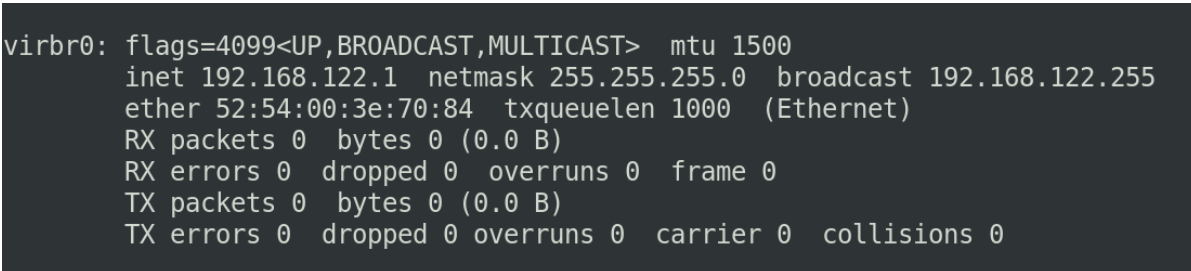
这个网卡一般是linux来进行虚拟化虚拟出来的一些网关这样的一些设备
查看网络物理连接情况
mii-tool eth0 (可以查看你的网卡的网线的连接状态)
如果我们使用虚拟机练习的时候可能会弹出错误提示,如果使用的是服务器或者云主机去查看的时候是没有问题的.
查看网关
route -n (当你网络通信的时候,需要连接其他的网络地址范围的时候,就需要配置一个网关[路由])
route命令默认使用的时候他的每一个ip都会反解成你的域名,这个显示的速度其实是很慢的,所以建议使用-n参数不解析主机名
修改网络配置
网络配置命令
ifconfig<接口> <ip地址> [netmask 子网掩码]
ifconfig eth0 10.211.55.4 netmask 255.255.255.0
设置网卡的ip地址
如果使用的是云主机的话,这样去修改是立即生效的,连接云主机就会连接断开,需要远程控制台把他改回来
ifup<接口>
启动网卡
ifdown<接口>
关闭网卡
网关配置命令
添加网关
如果想要修改默认的网关的时候,要先把他删除再添加
route add/del default gw <网关ip>
route del default gw 10.211.55.1
添加/删除默认网关
route add -host <指定ip> gw<网关ip>
route add -host 10.0.0.1 gw 10.211.55.1
如果你访问的主机是10.0.0.1的话,我就把数据包发给10.211.55.1这个网关上面
添加明细路由(当你访问A主机的时候,我要走一条新的路由,访问B主机的时候,我要走另外的一条路)
route add -net<指定网段> netmask<子网掩码> gw<网关ip>
route add -net 192.168.0.0 netmask 255.255.255.0 gw10.211.55.3
网络命令集合:ip命令
ip addr ls
ifconfig
ip link set dev eth0 up
ifup eth0
ip addr add 10.0.0.1/24 dev eth1
ifconfig eth1 10.0.0.1 netmask 255.255.255.0
ip route add 10.0.0/24 via 192.168.0.1
route add -net 10.0.0.0 netmask 255.255.255.0 gw 192.168.0.1
本人暂时还没有使用
网络故障的排除
网络故障排除命令
ping 检测你的当前主机和目标主机是否畅通
ping www.baidu.com

当前的网络状态其实是不太好的(5%的丢包率)
traceroute 检测当前主机到目标主机的网络的状况
traceroute -w 1 www.baidu.com
我们使用traceroute时,一般会加一个-w参数(表示wait)
我们traceroute的时候有可能到某一个ip长时间的超时
我们不想等他所以我们 -w 1 如果目标主机超时的话,
我只等待最多一秒钟
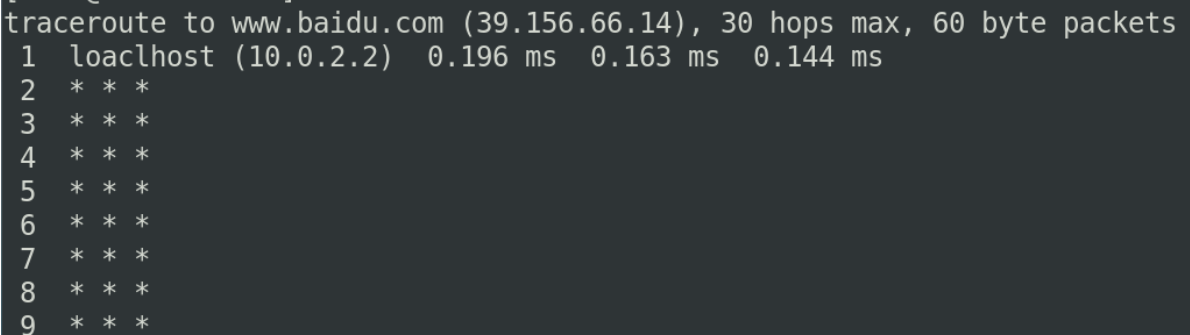
如果中间的主机不支持traceroute去追踪的话,会以***的方式来显示,如果你的主机在服务器上,***这里会显示中间经过的路由,以及中间的路由他对应的ip地址他的延时是什么情况
如果你是在服务端的话,我们控制服务器的时候,不止要连接畅通,可能要解决我们的数据包丢失到底是在哪里去丢失的,那我们可以使用traceroute来跟踪一下我们当前主机到目标主机的网络状态
如果ping检测到目标主机是畅通的,访问还是出现异常,那可能是中间的网络质量出现了问题,可以通过traceroute(追踪路由)追踪服务器的每一跳他的服务的质量
mtr 同上(一般辅助ping来使用)
检查到目标主机之间是否有数据包被丢失了
如果你想知道更详细的信息的话,我们使用mtr这个命令
建议大家用的时候使用mtr这个指令

因为现在没有主机和我进行通信,所以只显示loachost
nslookup 查看域名对应的ip
nslookup www.baidu.com
有的时候,我们去测试的时候,我的指令只支持ip地址,不支持域名,对方只给我一个域名,我们需要把域名解析成ip地址
trlnet
telnet www.baidu.com 80
检测一些我当前的主机到对方主机的80端口是否畅通
如果主机能连接但服务仍然访问不了,可以通过trlnet来检查一下端口的连接状态
tcpdump
tcpdump -i any -n port 80
端口如果也通了,仍然发现他的问题的话,我们可以更细致的分析这个数据包
netstat
netstat -ntpl
如果这些也都没有问题,可能是我们提供的监听范围不对,(比如我们只对127.0.0.1提供了服务)这时候其他的ip肯定是访问不到我们的服务的 所以我们提供了netstat 和 ss 两条命令
ss
ss -ntpl
上面讲的命令实际上是对网络临时的控制,这些参数会随着你的系统的重启,网络服务的重启,以及你的网卡重启,你的这些配置就丢失了.
网络管理和配置文件
网络服务管理
网络服务管理程序分为两种,分别为SysV和systemd
-
service network start|stop|restart
-
chkconfig -list-unit-files NetworkManager.service
-
systemctl list-unit-files NetworkManager.service
-
systemctl start|stop|restart NetworkManager
-
systemctl enable|disable NetworkManager(启用/禁用NetworkManager)
工作当中不要 两套管理工具一起用(network和NetworkManager要禁用一个)
如果要使用NetwotkManager的话,使用chconfig --list network命令查看
使用chkconfig --level 2345 network off
把2345关掉
把他还原回来chkconfig --level 2345 network on


NetworkManager一般应用在我们个人的电脑上,比如插入网线之后,它可以识别我们的网卡的激活状态,自动进行一些网络的激活(比如说我们连接到我们无线网络当中,他会自动激活我们无线的链接)
但在服务器的领域当中,我们会发现NetworkManager这个功能有点鸡肋,所以我们在服务器的配置当中经常还会沿用像network这样的脚本
网络配置文件
-
ifcfg-eth0(网卡配置文件的名称会随着你真实网卡的配置名称而变化)
-
/etc/hosts
通过这两个文件来控制网络的常用参数
网络配置文件
网卡的配置文件一般会放在 cd /etc/sysconfig/network-scripts/
里面有ifcfg开头的很多文件

这些文件当中,每一个文件默认对应我们的一个网络接口
有的时候我们可能会去做网络接口的绑定,可能会出现一个网卡的配置文件对应多个设备这样的情况
打开 vim ifcfg-enp0s3
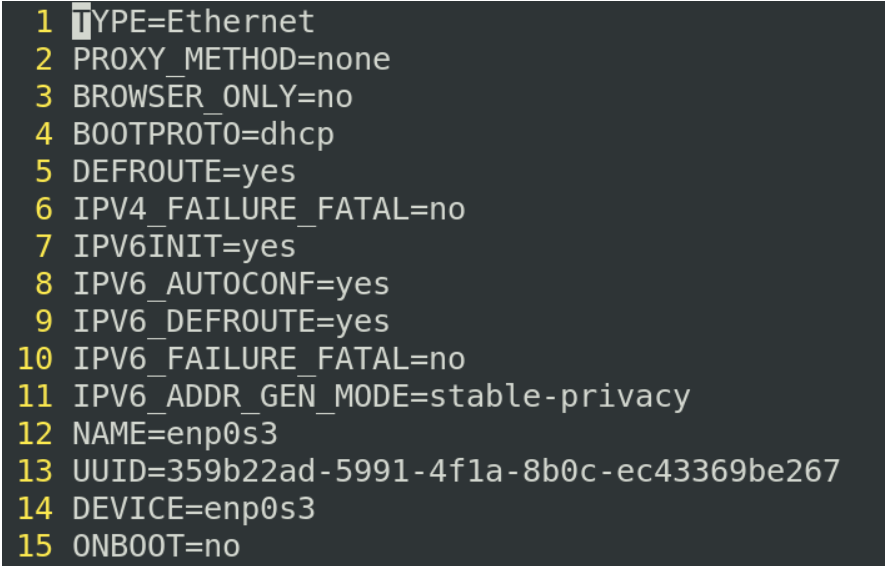
这个网卡里面的配置项其实还是很多的,基本设置格式是前面是他的设置项等号后面是他的设置值,这些设置项当中有些是比较关键的设置,有些是ipv6的初始化设置,我们关注的内容只有四行

如果BOOTPROTO他是dhcp表示自己的ip地址是动态进行分配的
这里还可以把他配置成static也就是静态分配的ip地址

这两行表示网络的设置

ONBOOT表示我们开机的时候,这块网卡是否会被启用
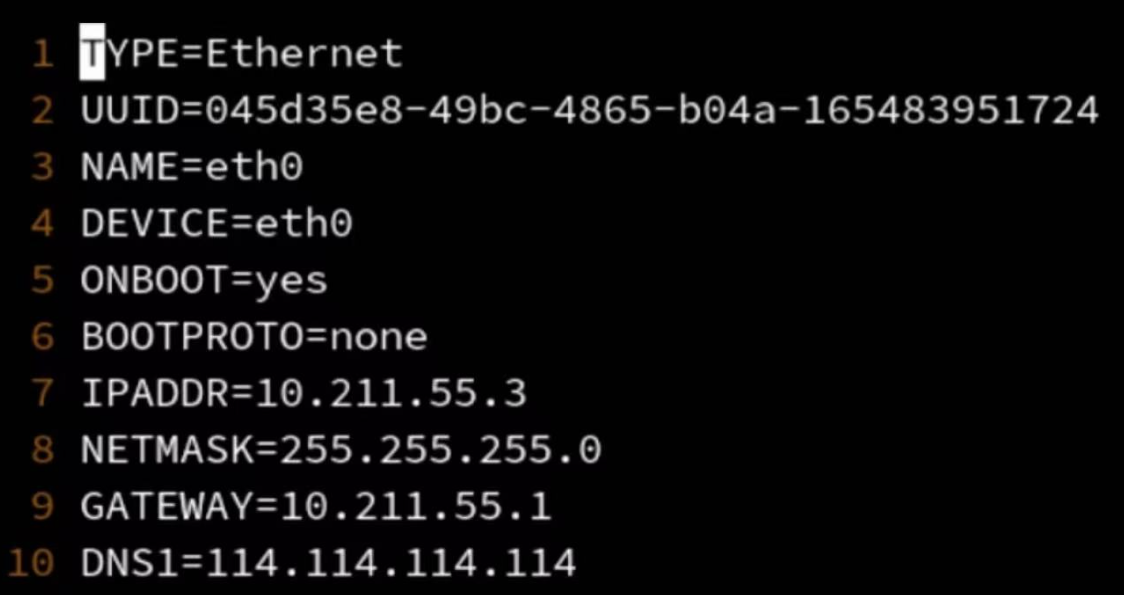
静态ip的配置
首先第6行BOOTPROTO设置为none
ip地址我们使用的是IPADDR设置项(需要记住的)
子网掩码用的是NETMASK
网关GATEWAY以及DNS
设置完如果想让他生效,可以使用service network restart
也可以systemctl restart NetworkManager.service
还有主机名我们一般使用hostname来进行查看
主机名也是可以修改的
临时修改hostname c7.test11 改完后,当前是可以立即生效的
如果想让它永久生效 可以使用hostnamectl set-hostname c7.test11
如果你需要重启的话我们可以用reboot重启和验证
但是要注意一点,你的主机名如果更改的话,很多服务器是要依赖于主机名进行工作的,我们必须在另外一个配置文件当中 vim /etc/hosts 我们要把新的主机名写在127.0.0.1的对应关系当中
如果不写的话系统启动时可能会在某一个服务上卡住,你要等待他的超时
如果大家想要向下进行兼容的话,推荐大家启用network把NetworkManager进行禁用
软件安装
在我们的linux中其实是有不同的软件的包管理器的
软件包的管理器
包管理器是方便软件安装,卸载,解决软件依赖关系的重要工具
centOS,RedHat使用yum包管理器,软件安装包格式为rpm
Debian,Ubuntu使用apt包管理器,软件安装包格式为deb
服务器对软件的版本有要求,这导致linux的包管理器发展的非常成熟
rpm包
- rpm包格式

我们比较关注的是软件的版本,因为在安装软件包的时候,软件包之间是有一个依赖关系的,版本主要是用来解决=他的依赖关系的
rpm命令
- -q查询软件包
- -i安装软件包
- -e卸载软件包
在linux里面有一个目录叫做dev
ls /dev -l

第一个位置如果是c的话我们把它称作是字符设备,如果是b的话我们把它称作是块设备
对于块设备如果想要操作他的话,只能通过挂载命令挂载到一个空白的目录,这个目录不要使用我们系统已经使用的空白的目录
linux给我们推荐使用/mnt进行挂在,我们挂载的时候可以使用参数-t来指定挂载的类型,如果没有指定它的类型就叫auto自动识别
rpm -qa(查询我们系统中已经安装的所有的软件包)
rpm -qa | more(如果查询这边显示的过多,我想让他分屏显示,我们要加上一个管道符|加上more)
rpm -q vim-common(软件包的名字)
查询某一个单独的软件包是否安装
rpm -i vim-enhanced-7.4.160-5.el7.x86_64.rpm(软件包的完整名字)
如果想要安装更新的软件包的时候 -i
rpm -e vim-enhanced(软件包的名字)
yum包管理器
rpm包的问题
- 需要自己解决依赖关系
- 软件包来源不可靠
CentOS yum 源
国内镜像
yum配置文件
- /etc/yum.repos.d/CentOS-Base.repo

- wget -O /etc/yum.repos.d/CentOS-Base.repo
http://mirrors.aliyun.com/repo/Centos-7.repo
更新的过程中不要让他中断
yum命令常用选项
install 安装软件包
remove 卸载软件包
list|grouplist 查看软件包
update 升级软件包
当你使用linux放在他的工作环境以及生产环境当中的时候,我们软件在多多少少的情况下都会有BUG,或者出现一些安全漏洞,所以建议大家定期的来给软件进行一定的升级
yum命令和我们比较原始的rpm命令比起来呢,它的好处就可以自动解决依赖关系,而且可以用来检测你的来源,软件包是否被恶意篡改
其他方式安装
-
二进制安装
-
源代码编译安装
- wget https://openresty.org/download/openresty-1.15.8.1.tar.gz
- tar -zxf openresty-VERSION.tar.gz
解压缩的时候用-zxf这样的参数进行解压缩
- cd openresty-VERSION/
进入到源代码的目录里面
源代码编译一般有以下三个通用步骤
- ./configure --prefix=/usr/local/openresty
./configure 的意思是当前的系统环境其实已经预先设置在我们的这个源代码当中了,但是呢他没有和我们真正的系统环境进行匹配,所以configure就是说让他自动去配置一下(比如说我们内核的版本啊,我们编译的时候需要用一个GCC编译器,那你的编译器在哪一个目录啊,那这个GCC是哪一个版本啊,就是进行一个匹配)除了去匹配我们的系统之外prefix这个参数还指定了你程序的一个安装位置
如果你不指定的话呢,他可能会安装到user下边,他可能就会分散到user下边(bin来目录啊,etc啊)你想要在删除这个软件的时候,就要在各个目录当中去找这个软件,就会非常的麻烦
- make -j2
make就是真正的编译了,-j2表示我要用两个逻辑的cpu来进行编译,一定程度上加快编译的速度
- make install
把编译好的应用程序安装到指定目录(prefix指定的目录)
![image-20231025145947139]()
当你没有gcc的时候
yum install gcc gcc-c++
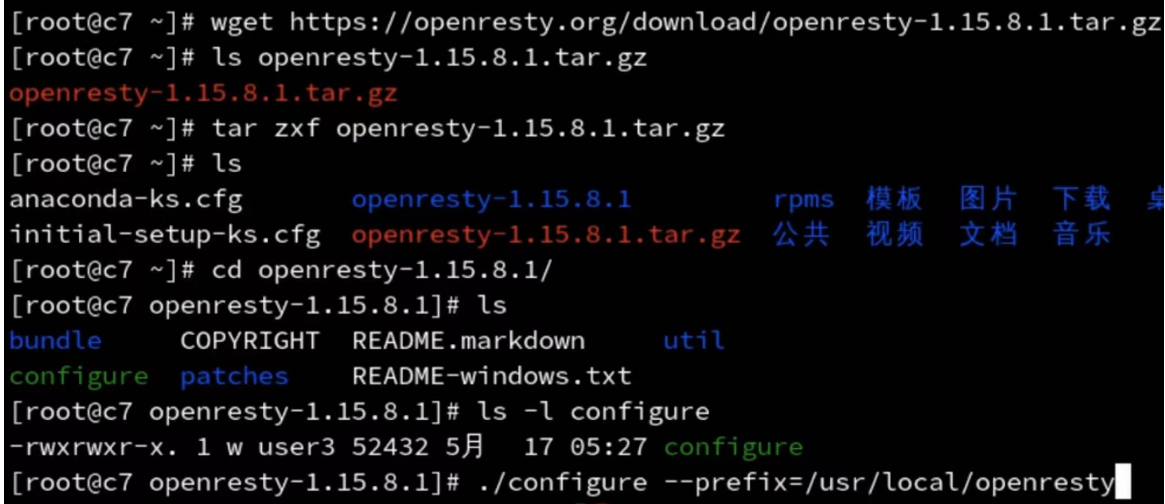
在去安装的时候,我们需要通过对源代码进行编译,编译成我们的一个可执行程序,可执行程序再拷贝到指定的工作目录来去使用
在我们用yum安装的时候你会发现他没有这么新的版本,而当你又想用最新的特性的时候,我们就必须要采用这种源代码编译的方式安装
内核升级
rpm格式内核
查看内核版本
uname -r
拓展centos软件仓库
yum install epel-release -y
升级内核版本
yum install kernel-3.10.0
升级已安装的其他软件包何补丁
yum update
内核的版本分为主版本,次版本和末版本,次版本为偶数的话是稳定版,比如2.3.14就是不稳定版本,但是在2.6版本以后就不以次版本号区分稳定和不稳定版本了,后面有[EOL]的版本以后不会再进行更新了
源代码编译安装内核比较麻烦,需要解决依赖关系,在这里就先不赘述了



grub配置文件
grub是启动系统时的引导软件
grub配置文件
在grub1当中所有的配置文件我们要手动去编辑,而且要记住每一个设置项是什么样的功能
/etc/default/grub
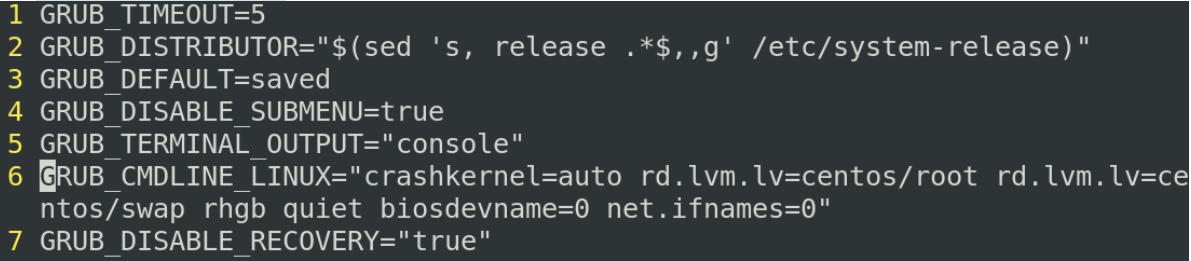
这文件中我们主要关注两个设置项,
第一个设置项是第三行的GRUB_DEFAULT,saved不是指具体要修改哪一个设置项,而是指你在引导的时候默认他引导到哪一个内核,比如我要他默认引导到5.几的内核,,这时我们可以通过一个命令grub2-editenv list,通过list我们可以看到当前我们默认引导的是哪一个内核
我们想要把3.10改成5.几时,先使用grep ^menu /boot/grub2/grub.cfg,(在文件
/boot/grub2/grub.cfg中搜索以"menu"开头的行,并将这些行输出。) 找到对应的内核从0开始排序,再使用grub2-set-defualt 指令完成设置第二个设置是第6行的GRUB_CMDLINE_LINUX,这一行用来确认引导的时候,我们对linux的内核去增加什么样的参数

/etc/grub.d/
在grub2中给我们提供了很多方便的工具,可以直接用命令进行修改
/boot/grub2/grub.cfg
grub2-mkconfig -o (可以产生新的grub配置文件) /boot/grub2/grub.cfg
进程管理
- 进程的概念与进程查看
- 进程的控制命令
- 进程的通信方式 -- 信号
- 守护进程和系统日志
- 服务管理工具systemctl
- SELinux简介
进程的概念

进程只不过是驻留在RAM中的文件内容。
在计算机中,进程是计算机程序的一个实例
一个计算机程序的实例意味着它驻留在RAM中,被执行意味着内核遵循它的指令。
进程的查看命令
ps
当前终端中能查看的到的进程状态
ls将显示磁盘上的文件,ps将显示RAM上的文件
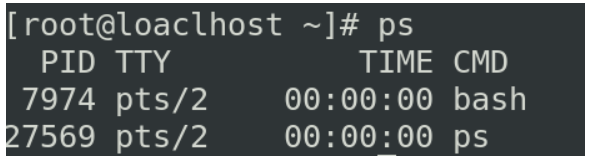
PID是进程在当前系统中的唯一标识,进程的名称是可以重复的(有多个用户登陆到Linux系统上,每个人都可以执行ps命令)
TTY是当前执行ps的终端
TIME 它指的是CPU执行该进程指令所花费的时间,以[dd-]hh:mm:ss格式表示
参数
-e
显示所有进程linux通配符,包括没有控制终端的进程。
ps -e | more
分页显示
-ef

UID有效用户ID,进程可以将自己的用户身份改为其他人,启动的用户身份不一定等于他标识的用户身份
ps -ef | grep tail
过滤

PPID父进程
一定有一些进程已经在RAM中,等待您键入字符并按下“Enter”键。对吧?所以这个家伙的唯一工作就是观察任何输入(在TTY上),分析并告诉内核,内核是否需要对输入请求采取任何行动。
在Linux系统中,第一个启动的进程是
init进程。它是所有其他进程的父进程。它的进程ID(PID)为1。init进程负责启动和管理系统中的其他进程,它是Linux系统启动和运行的基础。在现代的Linux系统中,init进程通常是由systemd或SysV Init等初始化系统来管理的。
-o
指定需要显示的特定进程信息
ps -o ppid 31400
获取31400进程的父进程。
-eLf

LWP轻量级进程(线程),我们程序有时候为了处理并发的任务,可能会启动一个进程把一个进程分成不同的线程来去处理
有的时候我们计算机计算计算资源不充足的时候,我们可以查一下是不是线程过多或者进程过多
pstree
查看你的进程树
pstree - p
显示一个进程树,要显示pid,使用-p选项。
top

默认是每3秒更新一次,如果你要加快你的更新的话,你可以按s进行修改
39min的意思是我们当前的系统从最近一次开机到现在,过了多长时间
5users是当前系统有两个用户正在登录
load average是平均负载,是用来衡量我们系统的繁忙程度,如果繁忙程度是1的话,代表他是满负载运行,0.00,0.03,0.05代表一分钟平均负载是0.00,五分钟平均负载是0.03,十五分钟平均负载是0.05
Tanks,有215个进程在运行
%CPU(s),CPU的使用比例,如果有多个cpu的话会显示平均值,如果想看每一个cpu的话我们按数字1,会把你的每个逻辑cpu的使用情况列出来
us有0.0%的cpu是被用于我们用户拿来进行计算,
sy0.3%是用来我们进程之间的状态的交互,
id99.7%是空闲状态,
wa0.0%当你的磁盘速度过慢的时候,我们cpu会等待你的io磁盘操作
KIB Mem 内存,total一共有1882084的内存,free有173304内存没有被使用,used有1133320内存在使用,buff/cache有575360内存在进行读写的缓存
KIB SWAP 交换分区(虚拟内存),当你的实际的物理内存不够,又想把空闲的内存交换出来的时候,我们就需要占用我们的swap,目前used交换分区使用的是106752,
参数
-p
top -p 29189 我只查29189进程
kill
kill 12345 杀死进程号为12345的进程
有时进程不会通过简单的kill命令死亡,在这种情况下,尖叫die!die!die!在执行kill命令时(呵呵…)开玩笑的:)你必须使用“-9”选项。
kill -9 12345
killall sleep
kellall按进程名终止进程,终止名为sleep的所有进程
无论它们是在前台还是后台运行。这会立即终止运行中的
sleep命令,而不会等待它们完成。
killall -u user
这会杀死用户user拥有的进程
kill -w -find
-w选项表示等待进程终止后才继续执行命令.等待所有发现进程死亡。Killall每秒检查一次,如果被杀死的进程仍然存在,只有在没有进程时才返回。注意,如果信号被忽略,kill可能会永远等待,没有效果。要查找可以使用的进程的进程id (pid),
pidof bash
提供正在运行的程序bash的进程ID
pidof -s bash
只返回一个进程id,而不是所有进程作为bash运行,您可以通过启动一个进程来调整您的进程的优先级
结论:进程也是树形结构
进程和权限有着密不可分的关系
进程的控制
进程的优先级调整
我们想要控制进程,如果他过多的占用资源的话,把他的资源释放出来一些,占用资源过少的话我们希望他能占用更多的资源
nice
范围从-20到19,值越小优先级越高,抢占资源就越多,nice无法对正在运行的进程进行调整

PR值可以理解为系统的优先级,NI表示进程的Nice值
PR代表的是进程的优先级。默认情况下,进程的优先级为20.优先级是一个整数值,决定了进程获得CPU时间片的顺序,值越小表示优先级越高。优先级的范围通常是从 -20 到 19,其中-20 是最高优先级,19 是最低优先级。
Nice值是用来调整进程优先级的参数,范围从-20到+19,越小的值表示进程优先级越高。默认情况下,大多数进程的Nice值为0,表示普通优先级。通过调整Nice值,可以影响进程对CPU资源的调度优先级。 较高的Nice值会降低进程的优先级,使其在竞争CPU资源时更容易被其他进程抢占。较低的Nice值则会增加进程的优先级,使其具有更高的CPU调度权。在top命令的输出中,PR和NI可以一起用来评估进程的优先级和资源调度情况。只有root可以增加优先级,例如将进程nice设置为-20,其他进程可以降低它们拥有的进程的优先级不能增加优先级。
nice -n 15 ./a.sh

PR会跟随NI值进行调整,PR值有一部分是内核控制的,只有之一部分是我们手动控制的
renice
重新设置优先级
renice 命令可以用于在运行时调整进程的 Nice 值
只有root可以增加优先级,例如将process nice设置为-20。其他人可以降低他们拥有的进程的优先级。
注意,使用renice命令,非超级用户不能增加他们自己进程的调度优先级,只能调低优先级。
renice +1 -u user
要调整用户"user"拥有的所有进程的优先级,
time ls -l
Time给出了它运行的程序的统计数据。
Real -调用和终止之间经过的实时时间。
user—用户CPU时间。
sys—系统CPU时间。

进程的作业控制
所以我们知道有一个名为init的第一个进程,它带有pid。这是系统中所有进程的父进程。一个名为“bash”的进程代表用户请求或命令与内核交互。
每次登录时,都会创建新的父bash。
我们的bash创建子进程的方式是阻塞调用。简单来说,阻塞调用方式意味着父进程会暂停执行,等待子进程完成执行后再继续执行。这可以确保父进程对子进程的操作和结果可以进行适当的处理。
我们觉得这个进程它占用的资源确实是太多了,我们希望他能临时的停一下,但是你的程序不要结束
&
./a.sh &(后台运行a.sh)

jobs
显示当前终端会话中正在运行的作业列表
fg 1

程序就会调回前台
按ctrl + z 会把前台程序调回后台并且是停止的状态(挂起状态)
我们在服务器上进行前台的备份,我们发现前台的备份太消耗我们的磁盘io了,我们可以把他调入到后台做一个临时的停止

状态保持在T,我们的程序就保存在内存当中,我们所有的作业也都是暂停的状态
如果想让他再次运行
fg 1
如果想让他后台运行
bg 1
进程状态
我们来讨论一下过程状态。man ps显示进程可以是以下任何一种状态
D 不可中断睡眠(通常为IO)
R 正在运行或可运行(在运行队列上)
S 可中断睡眠(等待事件完成)
T 由作业控制信号停止
X 死亡(不应该被看到)
Z 失效(“僵尸”)进程,终止但未被父进程获取。
我们试着重现上面的一些状态,以便更好地理解它。我们将首先通过命令列出现有进程及其状态:
ps -S

正如你所看到的,stats代表可中断睡眠。
进程 7473 是一个 bash 进程,状态为 S,表示它处于睡眠状态。
进程 20161 是一个 sleep 进程,状态也为 S。
进程 22076 是一个 ps 进程,状态为 R+,表示它正在运行。
进程 26049 是一个 -sh 进程,状态为 Ss,表示它处于睡眠状态。
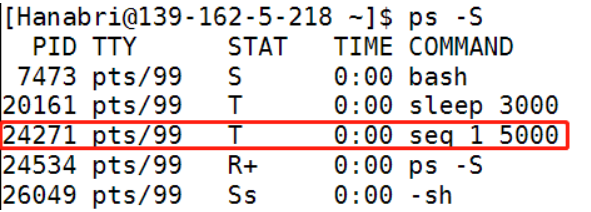
状态为T可以通过fg 来继续运行
僵尸进程是一个终止的进程,但没有被它的父进程获取。当我们说未被父节点收获时,我们的意思是“父节点尚未从子节点收集退出状态”。子进程完成了它的执行,并准备好退出状态,等待父进程请求它。

26454没有来得及被回收,如果启动这个bash shell,它将从26454收集退出状态,并获取它的子进程。因此,僵尸进程将消失。
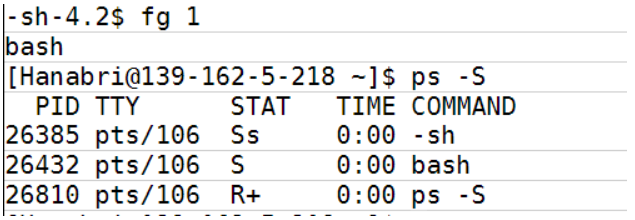
孤立的进程
孤儿进程是指没有父进程的运行进程。父节点在没有获取子节点的情况下死亡(从子节点获取退出状态)。这些没有父进程的子进程被称为孤儿进程。这些进程被pid为1的init所采用。
进程间的通信
进程间的通信是为了让进程间可以互相控制
信号是进程间通信方式之一,典型用法是:终端用户输入中断命令,通过信号机制停止一个程序的运行
-
使用信号的常用快捷键和命令
-
kill -l (查看所有信号)
- SIGINT通知前台进程组终止进程ctrl + c - SIGKILL 立即结束程序,不能被阻塞和处理 kill -9(信号编号) 22817(进程编号)
守护进程
使用nohup启动进程
nohup:运行这个程序的时候,我们希望即使关掉终端,我们的程序也能正常运行
他会忽略输入并把输出追加到"nohup.out"

我们希望有一个进程随着我们系统的开机直接启动.(不需要终端就可以直接启动)
deamon进程会把输出放在日志文件,关于 deamon 进程,它是在后台运行的一种无需用户交互和终端界面的进程。deamon 进程通常用来提供一些系统服务,例如网络服务、打印服务等。Linux 系统中的 deamon 进程通常通过在终端中运行对应的启动脚本或使用服务管理命令(如 systemctl)来启动和管理。
特殊目录
cd /proc/ proc里面所有的内容在硬盘中默认是不存在的,他是我们操作系统去读取内存的一些信息,把内存信息以文件的方式进行呈现,大多数的操作都支持查看,他里面有一个和你进程号同名的目录,目录里面的文件和目录就是你进程的属性了
我们远程连接到服务器之后,我们执行一些命令,但是因为网络的断开或异常,导致命令中断或连接中断了,我们执行到一半的数据很难进行处理.
我们进行终端操作的时候,先进入到screen的环境当中,这样即使我们网络断开了screen也可以继续运行我们的程序.
我们可以用ctrl + c结束,用exit退出screen
服务管理工具systemctl
服务(提供常见功能的守护进程)集中管理工具
service(centos6或以前的版本)
systemctl
常见操作
systemctl start|stop|restart(重启,需要停止服务,用于加载配置文件)|reload(服务不停也能重新加载)|enable(随着开机同时启动)|disable(随着开机不运行) 服务名称
软件包安装的服务单元 /usr/lib/systemd/system/
SELinux 简介
MAC(强制访问控制)与DAC(自主访问控制)
以前的linux需要用用户的权限进行访问控制,这种控制呢,如果用户自己权限配置不大,就会导致我们linux出现一些安全的风险,这种控制我们一般把它叫做自主访问控制
还有一种叫做强制访问控制,他会给我们用户,进程和文件每一个部分都打上一个标签,只要你的进程,用户和文件三个标签能够对的上,而且是一个类型的话,我下面就允许你访问这个系统,允许你来控制这个文件
SELinux虽然非常的安全,但是会降低你服务器的性能,我们处理普通权限的时候还要处理SELinux的权限,所以现在大部分生产环境的服务器SELinux其实还是关闭状态.
vim /etc/selinux/config

enforcing(强制访问控制)必须标签保持一致
permissive(只进行安全警告)
disabled(彻底把selinux关掉)
-
查看SELinux的命令
- getenforce
查看selinux当前的运行状态
- /usr/sbin/sestatus
- ps -Z and ls -Z and id -Z
-
关闭SELinux
- sentenforce 0
- /etc/selinux/sysconfig
内存与磁盘管理
进程可能会从我们的磁盘里去进行文件的读写,我们大量的数据会存入到磁盘
内存查看命令
内存使用率查看
-
常用命令介绍
-
free
free -m,free -g(人性化的显示)
![image-20231025154719911]()
total内存总的大小
used内存使用了多少
buff/cache运行程序时缓存,他会占用一部分没有使用的内存
available如果我们把buff/cache全部释放掉,我们认为还可以用多少内存,我们去看内存的时候一定要去看available
linux使用内存的原则是,如果有空闲内存,我尽可能的多的去占用
Swap是交换分区,当你的内存真的不够用的时候(比如说available接近于0了)我们的linux系统程序就会自动的把一部分暂时不需要的内存给移动到Swap上边,交换分区所占用的空间实际上是在磁盘上的(在windows中叫做虚拟内存),内存和磁盘的读写速度差10倍左右(硬盘很慢),如果你不用swap,当你内存真的耗满的时候,linux内核就有一种机制,会随机杀掉占用内存最大的几个进程(一般都是我们核心的应用)这其实是一件非常恐怖的事情,所以我们还是保留一部分swap会更安全
-
top
和free命令显示的结果基本上是一致的,只不过top是动态查看的
-

磁盘使用率查看
-
查看命令
- fdisk
这条命令即可以查看磁盘,也可以对磁盘进行分区,练习这条命令时,建议用测试机进行测试
fidsk -l
查看磁盘
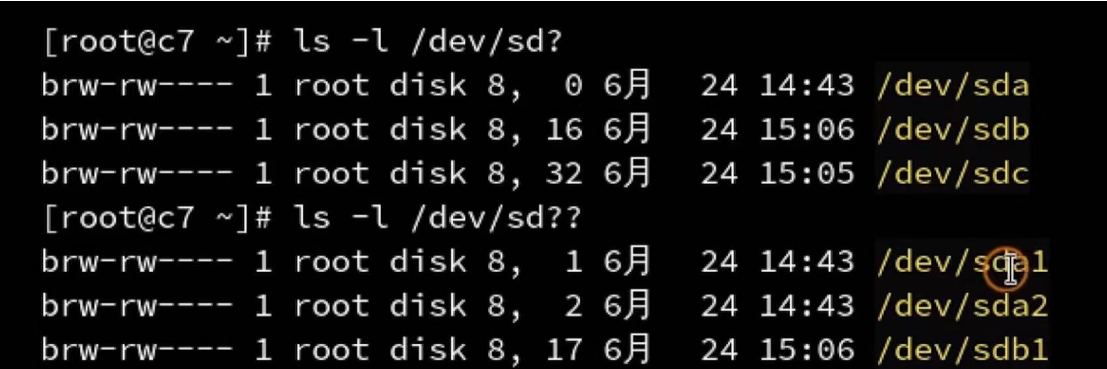
linux里面他会把所有的磁盘当作文件来对待,磁盘文件会放在 /dev/sda(可插拔)
要注意块设备的权限不要随便更改,因为他的权限是系统要去操作
![image-20231025154730251]()
8表示磁盘设备的主设备号,0表示从设备号,主设备号就是用来表示我们这个磁盘使用什么驱动程序,从设备号就是用来确定我们访问什么样的一个地址,sda1,sda2是sda的分区
查看分区其实还有一个命令叫做parted
parted -l
显示的信息和fdisk基本是一致的,只是说显示的格式略有区别,parted的功能比fdisk更为完善
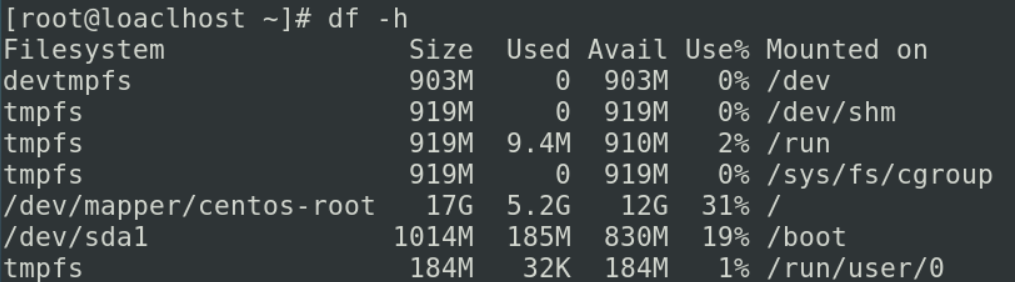
- df
df -h
可以看成是fdisk的补充
![image-20231025154743736]()
我们既可以看到我们对应的分区.又可以看到sda1挂载到的目录是/boot,我们经常用df命令来看我们的磁盘是不是满了
- du
查看实际占用的空间
ls -l 认为我们的文件如果有空洞的话,我们认为这个文件比较大
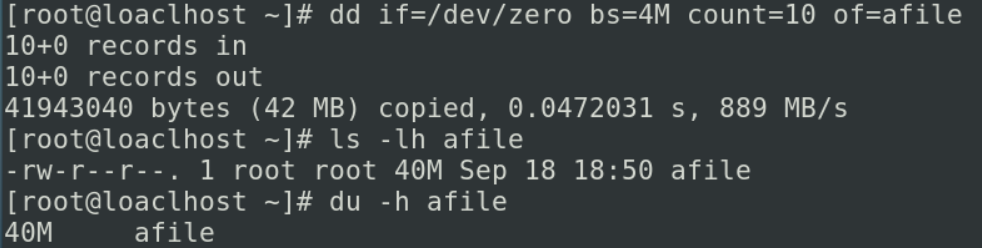
dd if=afile bs=4M count=10 of=bfile
dd会按字节的把a文件里的内容拷贝出来写入到b文件里,输入的时候可以写一些参数bs=4M,也就是我按照4M大小当作一个块来进行读写(从a文件里面读出4M,往b文件里写一次),count=10就是我想写10次的意思,当a文件足够大的时候,b文件会创建一个40M大小的文件,而且b文件和a比较的时候你会发现从开头一直到40M呢是完全相同的
如果我们想要去创建空洞文件的话我们不能指定afile,我们这边指定一个非常大的一个文件,让你足够去创建这么大的一个空间
dd if=/dev/zero(这个设备我读出来就是无穷多个零) bs=4M count=10 of=afile
![image-20231025154752587]()
ls和du读出来都是40M说明这个文件是没有空洞的,要创建一个空洞文件怎么做呢
dd if=/dev/zero bs=4M count=10 seek=20 of=bfile(创建文件的开头,我们让他seek(跳过)20块,也就是我们先创建一个叫bfile的文件名,然后跳过20*4M=80M,这80M就是一个空洞文件,最后我们再写4*10M=40M的内容,我们虽然跳过这么多,但是我们要在文件长度的记录上要记录全部也就是30块,实际上有数据的只有10块)
![image-20231025154800402]()
ls他所查看的长度是我们用来去记录到文件的开始到文件的结尾,一共写了多少字节,而du是真正去统计你的文件的长度
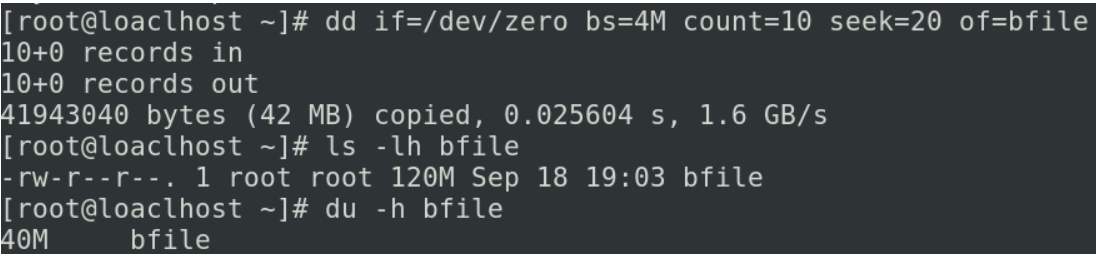
文件系统管理
linux支持多种文件系统,常见的有
我们linux中插入新的硬盘是不能直接使用的,我们必须要经过文件系统对你当前的硬盘进行一定的管理,你在进行文件的读写的时候才能在文件系统这个层面之上进行这种读写.
目前比较流行的有ext4,xfs
-
ext4
ext4文件系统基本结构比较复杂
-
超级块
超级快在我们ext4系统最开头的部分,超级块里面就记录着,你的整个的文件系统当中或者你的整个分区当中里边包含了多少个文件,所有的文件的这个总数是多少
我们使用df命令的时候很快就统计出来了这个分区里面有多少个文件,占用了多少空间,为什么这么快呢,因为他是事先统计好的,当你去创建新的文件写入数据的时候,这个超级块就会自动进行更新,所以df查到的信息其实都是超级块信息
-
超级块副本
上面这么重要的一个部分我们能没有备份嘛?所以这边就有一个超级块副本,超级块副本也不止一份,为了保证我们超级块一旦出现数据丢失的时候,可以通过副本对超级块进行还原,我们一般硬盘出现损坏或者被误格式化了,我们想恢复这些数据,其实都是恢复这个超级块的
-
i节点(inode)
i节点是记录我们每个文件的,文件的名称,大小和编号以及文件的权限在我们i节点里面都有体现,但是文件的文件名并没有和文件的编号记录到同一个i节点,那文件名记录在哪儿呢?文件名记录在自己文件的父目录的i节点里面
-
数据块(datablock)
记录我们的数据,i节点就类似于像火车头一样,我们如果写入的数据是一个数据块可以装下的话,那i节点后面就会挂一个数据块,如果装不下的话,我们系统会创建更多的数据块把他挂在我们前面的数据块之后,这种结构我们一般把它叫做链接式的结构,我们只要找到i节点就能找到有多少个数据块,根据数据块的多少我就可以统计文件的大小,ls统计的是i节点的文件大小信息du统计的是数据块的信息
-
-
xfs
centos7默认使用
-
NTFS(需安装额外软件)
NTFS这个操作系统是有版权的,如果我们需要让linux可以读写我们的NTFS文件系统的话,你需要给他装一个叫做ntfs-3g这样的一个软件包
i节点和数据块操作
touch afile
ls -li afile

如果他的大小是0的话,就意味着只有i节点,里面是没有block的

如果我们想往afile里面写入一些数据的时候,我们使用echo 123 > afile(为什么不使用vim之后会讲)
写入的数据之后再查一遍,他的大小就是4个字节

如果用du -h afile来去查看呢

大小就是4k
为什么是4k呢,在我们的xfs或ext4文件系统当中,默认创建的一个数据块他的大小就是4k
所以我们创建的文件即使他只有一个字符,他的大小也是4k
当我们在linux中去存储很多的小文件的时候,他真正的使用的开销也会很大,我们也会发明很多专门存储小文件的这样的一些网络文件系统
cp afile afile2

我们发现两个文件的i节点不同,意味着我们使用cp的时候我们创建了两个不同的文件,我们的datablock也是不同的,我们对第一个文件进行修改的时候,第二个文件不会发生变化,这两个文件名就记录到了/root目录的i节点上面
mv如果在当前目录进行移动的话
比如mv afile2 afile3
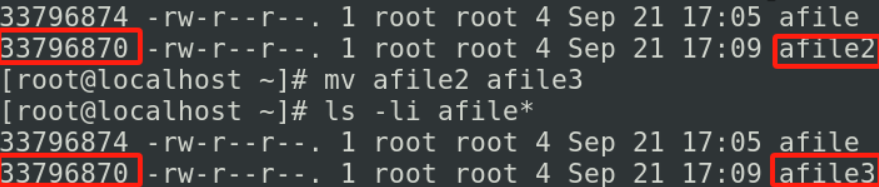
虽然他的文件名称发生变化,但是他的i节点没有变,我们执行的mv如果只是改名的话,那他呢就是改了/root目录他所记录的文件名,对文件本身是没有任何变化的,如果你的文件是非常大的(几百g)我们对他改名的时候也是一瞬间就完成了,因为他对i节点和block没有任何的影响,他只是改了目录里面去记录的i节点和文件名的对应关系
如果我们把它移动到其他位置并进行改名的话呢,那你的i节点.block和文件名一起发生变化,时间就会很长,但是其他位置也是有一定划分的,你如果把他移动的时候离开我们当前的分区,这种情况下他的时间会比较长,如果在当前分区之内进行移动的话,他也是瞬间完成的,因为i节点和block是由你的整个文件系统进行管理的,所以你在当前的文件系统里面,对这个文件来去作移动的时候他的速度还是非常快的,其实就是改了指定目录的文件名称的一个链接
vim去修改文件的时候要注意,i节点是会发生变化的

这就是为什么之前要用echo >的方式去写入,因为这样写入只会对文件的datablock发生改变,而vim会对文件的i节点也会发生改变(在centos6和centos7当中都是这样的)
如果i节点发生变化,这个文件就已经不是原有的文件了,当我们修改afile4的时候,会出现一个.afile4.swp这样一个文件,我们vim默认打开的界面就是这个swp,这样做的好处是当我们的原始的文件被其他人读取的时候,他还是一个原始的状态,被我们编辑到一半的文件,即使出现意外的宕机,你这个编辑到一半的文件还是会存在的,这就是vim对文件一致性的一个考虑

rm是删除文件的一个操作(专业点叫做把文件名和i节点的链接断开)
rm比如说要删掉一个文件,表面上看是文件消失了,实际上是做把文件名和i节点的链接断开了,这样做的好处是你删除文件无论是多大,删除的时间都是一致的,也给我们想办法找回这个文件提供了一个依据,比如说我们的文件误删了,或者文件丢失了,我们应该立即想办法让他断电,然后拿着硬盘找到我们专业维修的工具,这个工具就会扫描到我们系统所有的i节点,i节点后面像火车一样链接了一个又一个的数据块,这样我们就可以把i节点和数据块都找到,我们的文件就可以恢复了
link可以让我们更多的文件名去指向这个i节点,去解决我们所谓的误删的问题
ln afile bfile

我们发现链接数从1变成了2,这两个文件名都指向了同一个i节点,你无论从a还是从b做改变,你的文件的内容都会同时发生变化,我们删除掉任意的一个都不会影响到你现有的文件的丢失

我们删除了bfile,我们查的时候只有afile了,链接就剩一个了,你再删掉afile他的链接就会变成0,变成0的话我们目录当中已经没有文件名和这个i节点的链接了,这个i节点和它链接的datablock就可以被你的系统进行释放了.那ln会不会让你的系统占用更多的磁盘空间呢,其实在你了解他的底层原理之后你就会知道,文件名只是存在于他的父目录里面,不会占用更多的空间,但是要知道ln是不能跨越分区(文件系统)的.
我们要想跨越分区还想要这种链接形式的话呢,可以退而求其次的给他做一个软连接,
ls -li afile
ln -s afile aafile

这边的i节点就不一样了,i节点不一样的话证明他们并不是同一个文件,软连接(符号链接)就记录了目标文件的路径,而且符号链接他的类型前面会有一个l,而且他的权限是777权限,也就是说对我们的链接进行权限设置其实是无效的,你对链接做的所有的权限都会传递给链接文件指向的afile原始文件,创建符号链接的好处是我们可以跨文件系统(不同的分区),符号链接使用的时候相比硬链接会多出一个文件(非文件名)
如果你的系统很复杂,我希望user1用户可以读,user2用户可以写,user3用户可以执行,那你用原始的文件权限就没有办法可以控制了,所以呢efx和ext4文件系统支持了一个叫做文件访问控制列表facl的这样一个功能
查看这个文件的访问控制列表可以使用
getfacl afile
我们想给user1赋予读权限
setfacl -m u:user1:r afile
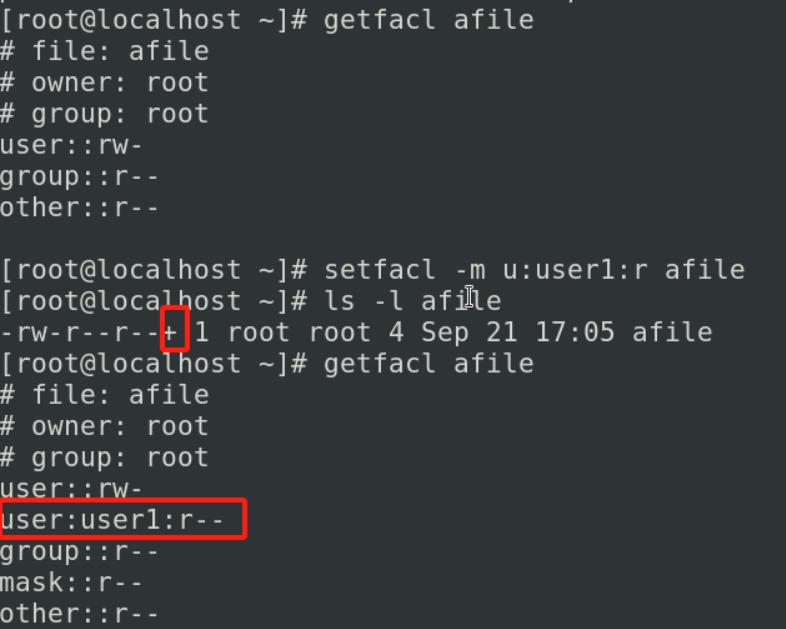
+表示除了你的标准权限之外,我们又设置了文件访问控制列表facl的权限,你必须使用getfacl来去查看
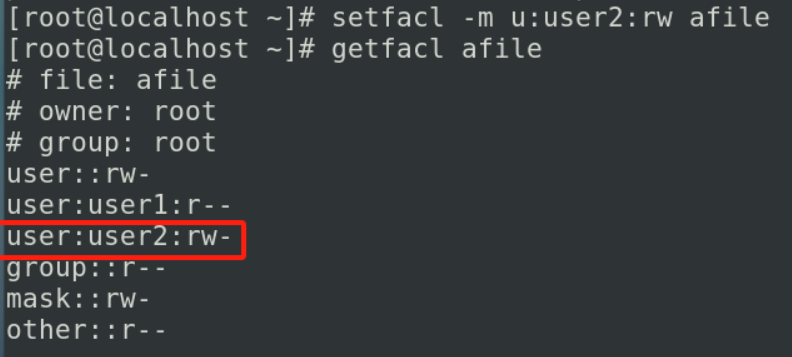
如果想要对组进行赋予权限
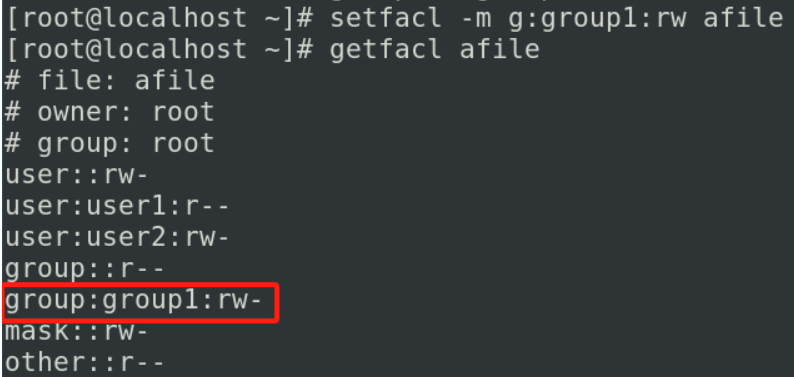
如果想要收回权限
setfacl -x g:group1 afile
分区和挂载
我们工作当中可能需要我们去使用新的硬盘,我们需要对硬盘进行分区,进行格式化,甚至我们工作当中有一台新的服务器上架了之后,我们需要对他进行重装系统,
磁盘分区和挂载
常用命令
fdisk
mkfs
parted(你的分区大于2T的时候使用)
mount(挂载)
我们这些命令执行之后,有一些设置是保存在我们内存当中的(重启之后,这些设置会消失)
常见配置文件
/etc/fstab
通过这些配置文件,可以把我们这些参数固化下来
我们使用
fdisk /dev/sdb(磁盘分区)
分区之前一定要确保我们硬盘里是没有数据的,因为一会要对硬盘进行格式化,如果我们分区或格式化调整错误的话,你这里面的数据就会丢失
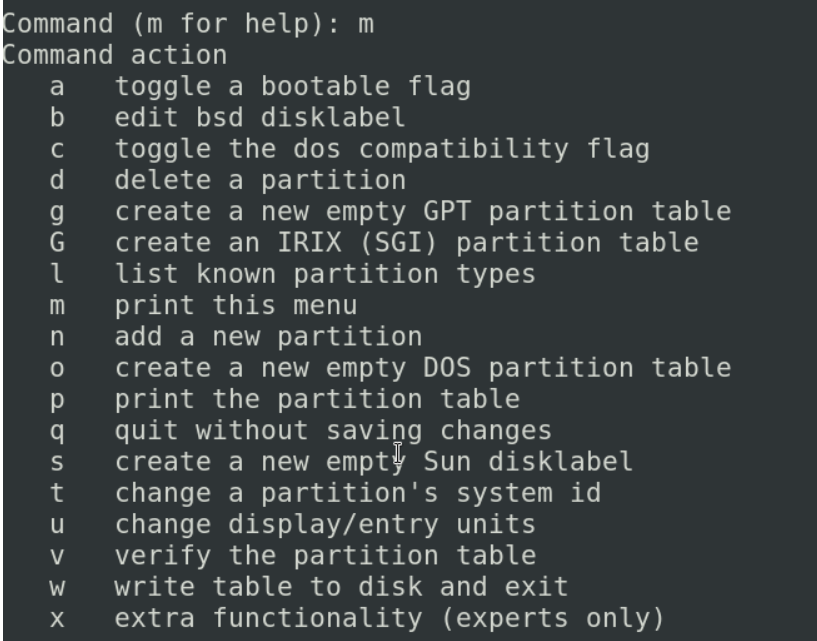
这边是对你的分区进行的一系列操作的命令
如果想要新建一个分区,输入n

我们这里分主分区和扩展分区,主分区我们这里有要求,只能建立四个,扩展分区呢我们可以在扩展分区里,再建立过多的逻辑分区
我们在建立磁盘分区的时候,如果你规划他是少于四个分区的,你就可以用主分区方式,如果是多于四个分区的,就可以把他建立成一个扩展分区
我们一般在服务器当中都是把一块硬盘划分成一个主分区的,下面的+10G也可以不输入,默认是分配全部的磁盘空间
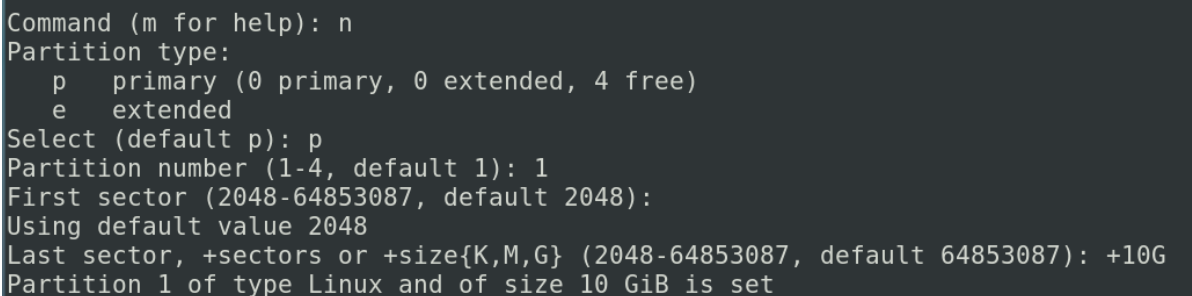
就像刚才说的,你想要创建扩展分区或者逻辑分区的时候,你只能创建三个主分区,最后一个主分区呢,把他的类型改为扩展,在扩展内部在创建逻辑分区
如果我们要查看我当前的分区我们输入p
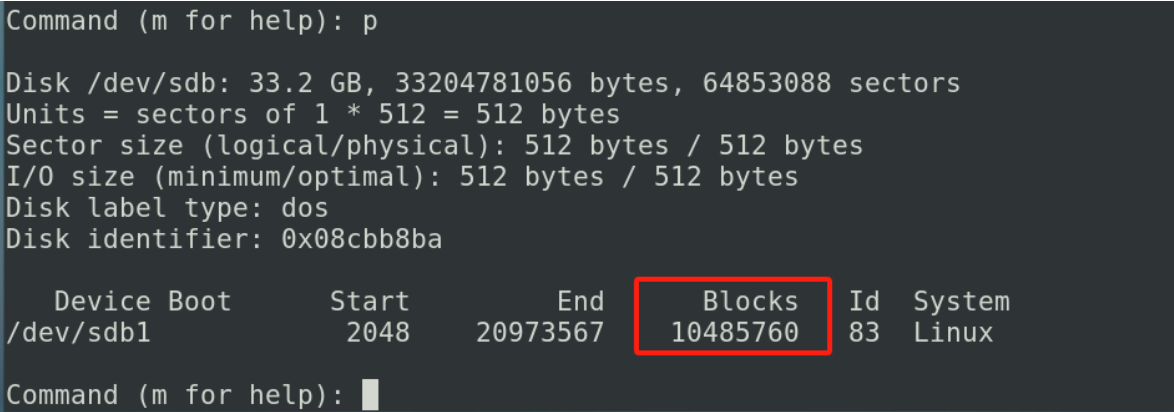
如果你觉得当前创建的分区不符合你的要求的时候 我们输入q 直接退出(不保存退出)你当前的分区表不会发生变化 如果我们想让当前的配置生效 我们可以输入w 这个分区不满足我们的要求 输入d删除 (如果你有多个分区,输入d的时候会提示你分区的个数)
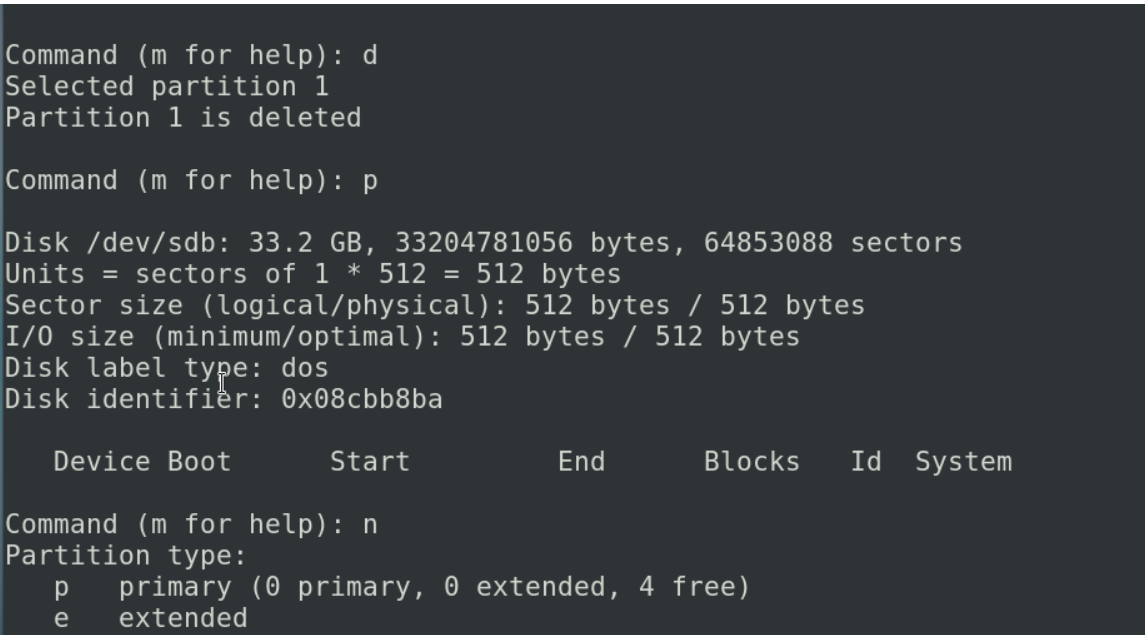
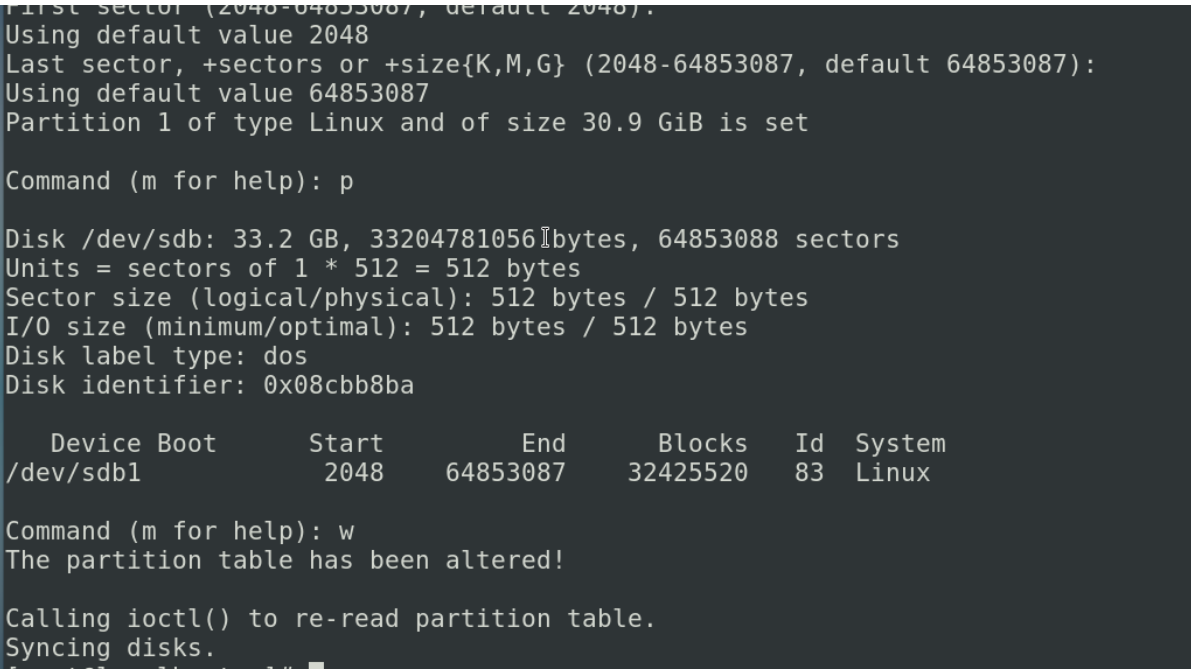
保存完成我们发现 /dev/sdb 下有一个分区 /dev/sdc1
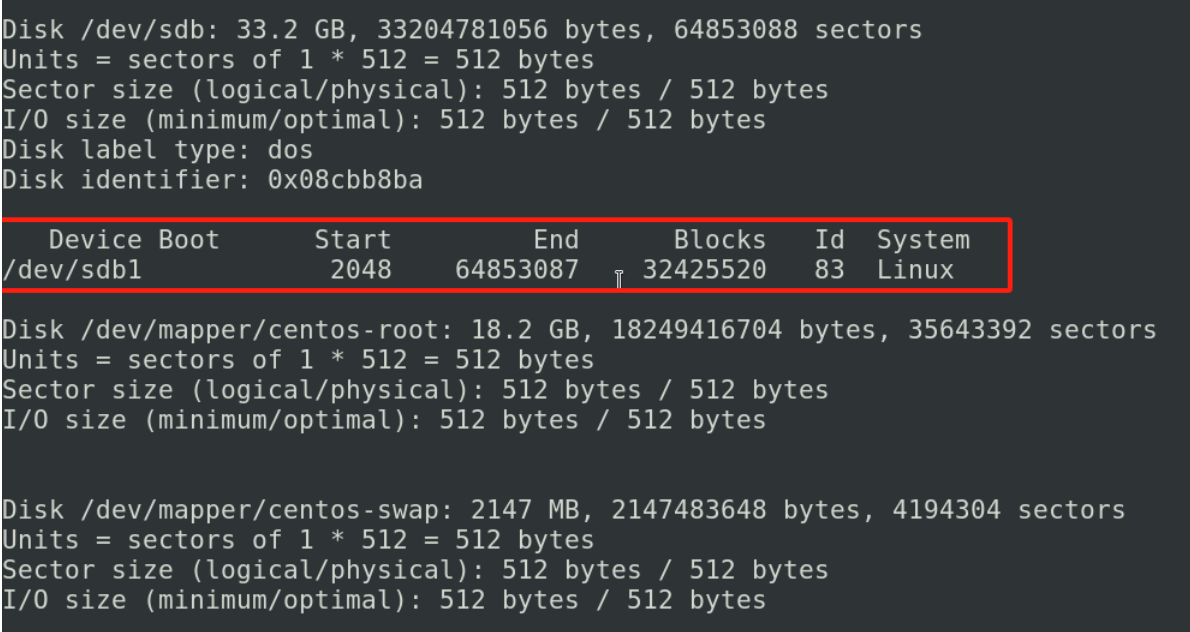
创建好分区之后接下来我们要把这个分区进行使用,我们使用mkfs. 这个命令其实后面跟着很多不同的文件系统
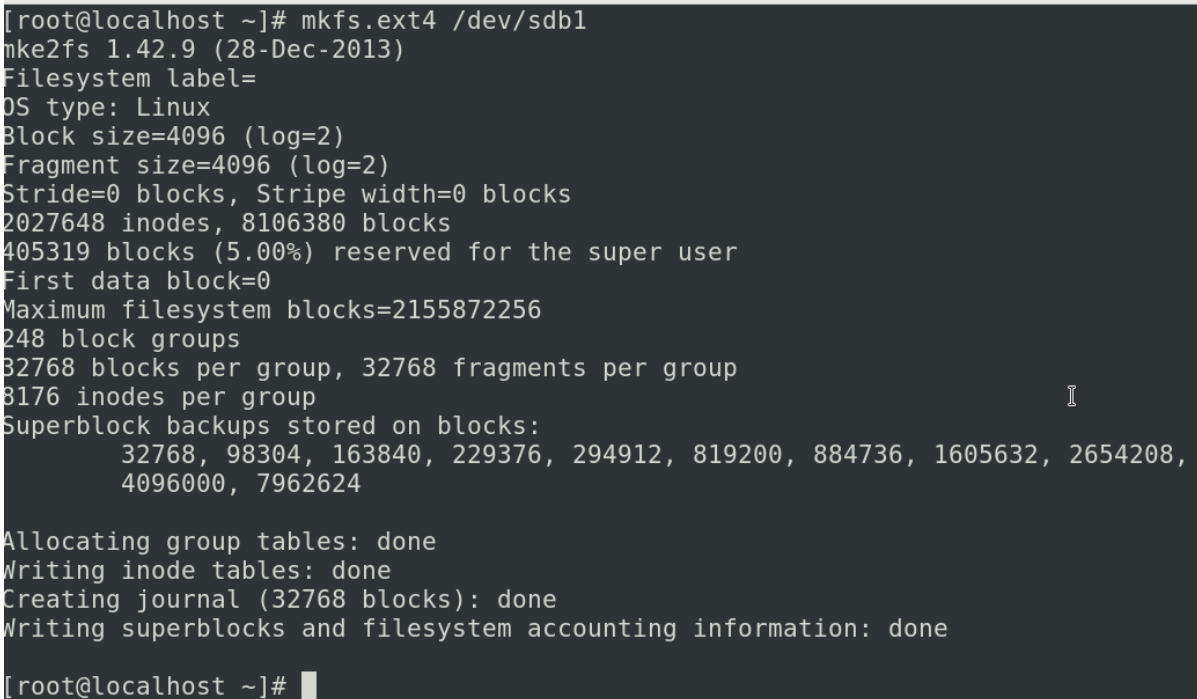
不要操作错误我们的盘符,会导致数据丢失
我们对/dev/sdc1 进行格式化(ext4文件系统)
这里的信息包括有多少个i节点,多少个block,多少个块组以及超级块的备份块,如果发生数据丢失的时候,我们可以通过备份块去得到原有的超级块信息,分区好之后我们对他进行使用,使用的时候我们说了,我们一般的操作叫文件级别的操作,文件级别的操作要在你的文件系统更上一层,所以我们没有办法直接对/dev/sdb1这样的设备文件进行操作,我们必须把他挂载到一个目录上,然后对目录进行操作,这个怎么做呢
我们可以新建一个目录 mkdir /mnt/sdb1
mount -t ext4 /dev/stb1 /mnt/sdb1
也可以用 mount auto(自动识别文件系统) mount什么都不加和加auto是一样的
我们使用mount去查的时候

这个设备已经挂载到了这个目录上,你对这个目录进行读写的话,他的所有的数据就会落入到/dev/sdb1这样一个设备上
回顾一遍流程
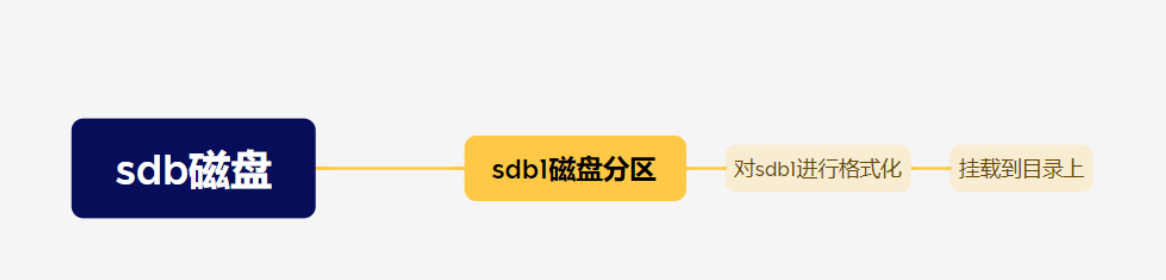
最开始是一个叫sdb这样的一整个磁盘,我们对磁盘做一个分区,分区之后我们对他进行格式化,格式化之后我们要对他进行挂载,挂载之后我们对指定的目录就可以进行操作了
如果你的硬盘大于2T的话就不能使用fdisk进行分区了,我们要用parted区分去
parted /dev/sdd
mount挂载的东西是放在内存里的面临时保存的这样一个配置,如果你进行重启之后这一条就消失了,我想让他参数进行固化,就要修改一个 vim /etc/fstab
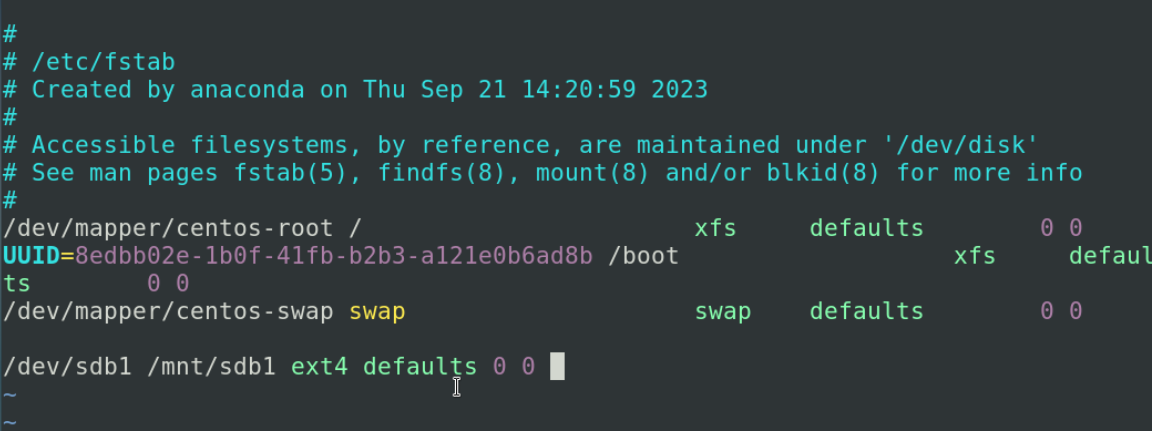
我们第一个字段表示的是要挂载的设备 /dev/sdb1 除了这种表示方法还有一种表示方法是UUID的形式,
第二个字段指定挂载的目录/mnt/sdb1
第三个字段指定你挂载的时候是一个什么样的文件系统 ext4
第四个字段是对文件系统挂载的时候使用的是什么样的权限 默认权限是读写权限 defaults
后面两个字段讲磁盘配额的时候会涉及到现在默认以0 0 写入就可以了
下次关机的时候我们文件系统就可以自动进行挂载了
用户磁盘配额
如果你的系统是多用户的话,每个用户其实都希望占用更多的资源(cpu资源,内存资源,磁盘资源,网络资源),我们的文件系统就自带了一个限制用户使用多少磁盘的功能叫做用户的磁盘配额他可以限制用户和用户组
xfs操作系统的操作比ext4要更简单

我们通过用户磁盘配额来去限制一个用户他的i节点文件的创建数量,如果想用更现代的方法你需要加入我们的虚拟化,利用虚拟化技术来去限制用户使用的发进程数量,使用的内存大小,使用的cpu的多少以及使用我们磁盘空间的多少
交换分区swap的查看和创建
swap其实是在我们硬盘当中开辟的一块区域,这块区域来去扩充你的临时内存并且作为交换作用来去使用的这样一块空间,在我们的硬盘当中我们也讲了怎么来去创建空间对这个磁盘进行挂载和格式化
我们要讲两种方式,一种是像我们创建一个新的分区一样,用一个分区来去作为新的swap空间,把他扩充到现有的系统当中
另一种就是使用文件,来去制作我们的swap分区,然后把这个文件加载到我们内存当中扩充我们的swap
交换分区
swap我们可以用 free -m 来去查一下

swap呢默认我们这里是两个G,假设我们发现你的swap已经被使用了,这种情况下你要去扩充你的内存,这种物理内存在还没有进行扩充之前建议大家去增大你的swap,避免你的swap也写满了导致你的系统杀掉你的进程
-
增加交换分区的大小
- mkswap
mkswap /dev/sdb1(类似格式化,给这个分区设置了一个swap的标记)
- swapon
swapon /dev/sdb1
- swapoff /dev/sdb1(关掉swap)
-
使用文件制作交换分区
-
dd if=/dev/zero bs=4M count=1024 of=/swapfile
(把他放到根目录下叫做swapfile,blocksize=4M(4M一个块)1024个块)
-
文件方式扩充swap时,比如你要扩充10G大小的swap,你要准备10G大小的文件,也可以创建一个空洞文件,随着swap的使用,逐渐扩大
chmod 600 /swapfile (要先把权限改为600,否则可能不安全)
mkswap /swapfile
swapon /swapfile
free -m

我们可能还有一个问题,我们这个swap其实设置的是临时的,想让他永久生效需要把他写入到 vim /etc/fstab

后面两个为0的字段,第一个0是指我们的硬盘的备份的时候要不要去备份这块硬盘(分区),现在我们都用tar来备份所以默认设置为0即可
第二个0是指你在开机的时候,我要进行一个磁盘的自检的时候一般会有一个检查的顺序的问题,现在我们的系统已经不需要这个步骤了,如果他发现我们的写入是不完整的,自动会对你的哪一个分区进行检查
如果你去写入的时候发现我们已经写错了,但是重启启动不了了,我们通过grub可以进入单用户方式,通过这个方式来修复/etc/fstab
RAID与软件RAID技术
RAID其实最开始是应用于我们的硬件的,RAID(磁盘阵列)我们以前用的都是单块磁盘,当你使用磁盘阵列呢,我们就可以把多块硬盘进行一个组合,把他组合起来进行使用,就比你单块硬盘会有更多的玩法
-
RAID的常见级别及含义
- RAID 0 striping条带方式,提高单盘吞吐率
把你的一个数据拆成两份,分别写入到两块磁盘里,如果你要组成RAID0的话最少得要有两块磁盘,我们每块磁盘存储我们数据的50%是不是就提高了单盘的吞吐率和单盘的性能,RAID 0这个级别可以加快你的数据的读写的效率
- RAID 1 mirroring镜像方式,提高可靠性
镜像模式就是你感觉你的数据是写入到一个磁盘了,这边我们的硬件或者是软件,就把你的数据又去自动做了一个备份,这样我们组成RAID 1最少也是要有两块硬盘,他的好处是如果你有一块硬盘损坏了,另外的硬盘就可以拿来用,但是他的使用率只有原来的一半,因为你的两个硬盘存储的都是一样的数据
- RAID 5 有奇偶校验
把RAID 0和RAID 1做了一个组合并简化了,至少要有三个硬盘,先往前两个硬盘里写数据,再往第三个硬盘里面写前两个硬盘的奇偶校验,当我们的某一块硬盘损坏了,比如我们前两块数据硬盘有一个损坏了,我们的校验值可以通过另外一块有数据的硬盘来去还原我们的数据,校验数据又是通过两块硬盘不同数据去生成出的校验数据,校验数据如果损坏了呢,我们也可以重新生成,RAID 5他是轮流去写的,比如我们前两块写数据的时候第三块写校验,第二块第三块写数据呢我们第一块写校验,RIAD 5如果坏掉两块磁盘及以上的话,我们数据还是会丢失
- RAID 10 是RAID 1 与 RAID 0 的结合
RAID 10 级别最少要准备4块硬盘,那我们的两块硬盘做RAID 1,另外两块也做RAID 1,然后那两个做了RAID 1的硬盘再去做一个RAID 0,只要不是同一侧的硬盘损坏,我们就可以让这个硬盘只坏两块,这边会更加安全的保障我们的数据
实现RAID的话光靠我们硬盘其实是办不到的,在我们的服务器上有一个RAID控制器,或者简称为RAID卡,这个硬件设备呢通过我们的读写,它可以自动的计算校验值,自动去计算我们把数据放到哪一个硬盘上的,甚至RAID卡上面还会带有缓存功能来加速你硬盘的访问
其实用软件可能实现RAID功能,但是有一个前提条件,就是你的系统CPU的开销并不是很高,你会发现当你去实现软件RAID有大量读写的时候,你就会发现你的CPU运行起来是非常非常高的,软件RAID只用来演示,工作当中我们多数使用RAID控制器这样的硬件设备
- 软件RAID的使用

到这里软件的RAID就已经创建完了,如果你要往/dev/md0去写数据的话,level是1也就是RAID 1级别,你的数据就会分别写在sdb1和sdc1上,如果你对sdb1和sdc1进行分区和挂载的话你的RAID其实就是一个失效的,可以把两块硬盘看作是一个底层结构,md0看做是一个上层结构,写入数据时要从他的上层往下面去进行写入,才是一个RAID的结构
我们可以使用mdadm -D /dev/md0来去查看
可以对sdb1进行破坏 dd if=/dev/zero of=/dev/sdb bs=4M count=1 (我们可以通过md0这块设备去挂载存入性文件,然后破坏这块硬盘,再去看你的文件是否存在,也可以通过mdadm来去更换我们的硬盘)
如果我们工作中真的想用软件RAID,接下来我们就可以对他去做一些配置文件上的设置,
echo DEVICE /dev/sd[b,c]1 >> /etc/mdadm.conf
这样的话你下次开机的时候RAID才会被自动加载
mdadm -Evs >> /etc/mdadm.conf
mkfs.xfs /dev/md0
格式化之后我们的md0就可以挂载到某个目录上了
逻辑卷LVM的用途与创建
逻辑卷和文件系统的关系
其实卷也是我们人为给磁盘下的定义,他认为我们的物理设备,其实就是所谓的物理卷,逻辑卷使用起来会更加灵活,比如说我们现在使用的文件系统的分区,我分好40G之后如果我想对他扩容或者减少容量的时候,你需要把里面的数据拷走,重新再对他进行分区,但是在我们工作当中,服务器上面的数据一般都是放在这不动的,如果你要拷走可能这个数据会达到几百T,这么大的数据量我们想移动其实是非常困难的,所以呢一般我们在服务器上都是对你的磁盘空间只增不减,只增不减的话我们用传统的硬盘和文件系统其实也有问题,我们的文件系统没有办法去跨我们的硬盘来去使用,所以呢就发明了逻辑卷这样的一个概念,这个逻辑卷就相当于在我们传统硬盘的底层上呢再叠一层,上面叠的这层呢也当作硬盘来对待,这个硬盘叫虚拟的硬盘.其实md0也是所谓的逻辑卷,在linux当中,大家默认使用的根目录就是使用逻辑卷去管理的.
为linux创建逻辑卷
我们新建一个逻辑卷的话呢,我们要经过下面几个步骤(如果没有遇到异常的话),
1.添加我们的硬盘(比如添加三个硬盘,sdb,sdc,sdd)(使用逻辑卷的时候没有必要要求每一个硬盘大小都相等)
2.lvm他的做法是,把我们三个物理磁盘当作三个物理卷,物理卷上层我们再搭一层虚拟的设备,这层我们把他叫做卷组,也就是说把三个大小不同的硬盘给拼接在一起,我们上层的应用再去看这块硬盘的时候就会认为他是一个完整的,大的硬盘,我们也可以继续扩容,比如说在来一块新的硬盘进来,我们可以再组成大块硬盘,组成大块硬盘的这个我们把他进行切割,切割出来的卷我们把它叫做逻辑卷
pvcreate /dev/sd[b,c,d]
如果是正常执行的话,所有的分区都会显示成功,如果你的软件RAID没有停掉可能会失败
停掉他的命令是 madam --stop /dev/md0
因为你这两个分区已经用作软件RAID了,光停掉也不行,我们需要去破坏他的超级块
dd if=/dev/zero of=/dev/sd[b,c] bs=1M count=1
然后我们回到刚才的
pvcreate /dev/sd[b,c,d]
这回三个物理卷就创建成功了
我们可以用pvs来去查看,他的类型就是lvm(linux的逻辑卷管理器)
接下来建立卷组vgcreate vg1 /dev/sd[b,c],一个pv是不能加入到两个不同的卷组的,所以划分前你要规划好你自己分区的结构
我们可以去用vgs来去进行查看
我们想给vg1创建逻辑卷怎么做呢,我们要使用lvcreate -L 100M -n lv1 vg1
我们使用lvs就可以查看到你刚才的逻辑卷,接下来就是使用逻辑卷了,依然是把他格式化然后进行挂载
mkdir /mnt/test
mkfs.xfs /dev/vg1/lv1
mount -t xfs /dev/vg1/lv1 /mnt/test
整个的过程是这样的:

这样复杂的一个过程其实就是由你的pv,vg,lv实现了动态扩展的功能,xfs实现了我们操作的时候可以以文件方式进行操作的功能,mount呢就是用来进行一个内存的管理和一个映射的,这里面有很多步骤其实是可以省略掉的,如果你不需要他进行扩展的话,直接在你的sd设备上去使用文件系统就行,如果你需要更复杂的功能,可以在这些分层上,在加上一个RAID(要在md0上去创建物理卷pv,卷组vg,逻辑卷lv),我们的硬盘文件系统的划分其实是一个分层的结构.
动态扩容逻辑卷
我们使用的时候可能会觉得root分区太小了或者根分区太小了,或者是我们在编译系统的时候我们扩展usr/src这个分区,在这里面我们可以用LVM来去扩展你现有的分区
我们用lvs以及mount可以看到,我们的根分区是挂载到我们的centos这个vg(卷组)下面的root这个lv(逻辑卷)上的


我们不管是扩展我们root用户的家目录也好还是扩展你的其他目录,他都放在了统一的逻辑卷当中,所以我们就扩展这个逻辑卷,你整个的文件系统就都可以进行扩大了
其实我们去划分根目录以及不同目录空间的时候呢我们有两种不同的派系,一种派系就是我们把所有的目录都放在根上边,然后根呢,我们都挂载在同一个分区上,当他用的时候如果发现不够用,我们把lv进行扩展就好了
还有另外的一个派系就是建议我们把root目录(root用户的家目录)还有home目录(普通用户的家目录)以及呢我们源代码编译的经常放的usr目录以及根还有boot建议把这些目录全都分开,分开之后我们可以对每一个目录进行分别的管理,哪一个不够加哪一个
这两个派系其实是不同的观点,这两个观点大家无论是赞同哪一种都可以,它体现的两种不同的系统管理思想
在这呢,我们去扩充我们根目录的lvm,首先我们要给vg扩充空间,因为如果用vgs查一下我们会发现,vgs基本已经用光了

我们用vgextend centos /dev/sdd1进行扩充,我们看到了sdd1这个pv被放在了centos这个卷组当中,centos这个卷组当中他的这个大小和free空闲的空间也有了一个增加,我们的lv其实是没有发生任何变化的,根据这个分层我们要再往上一层去扩充我们的lv,扩充前一定要保证我们的卷组vg空间一定是充足的
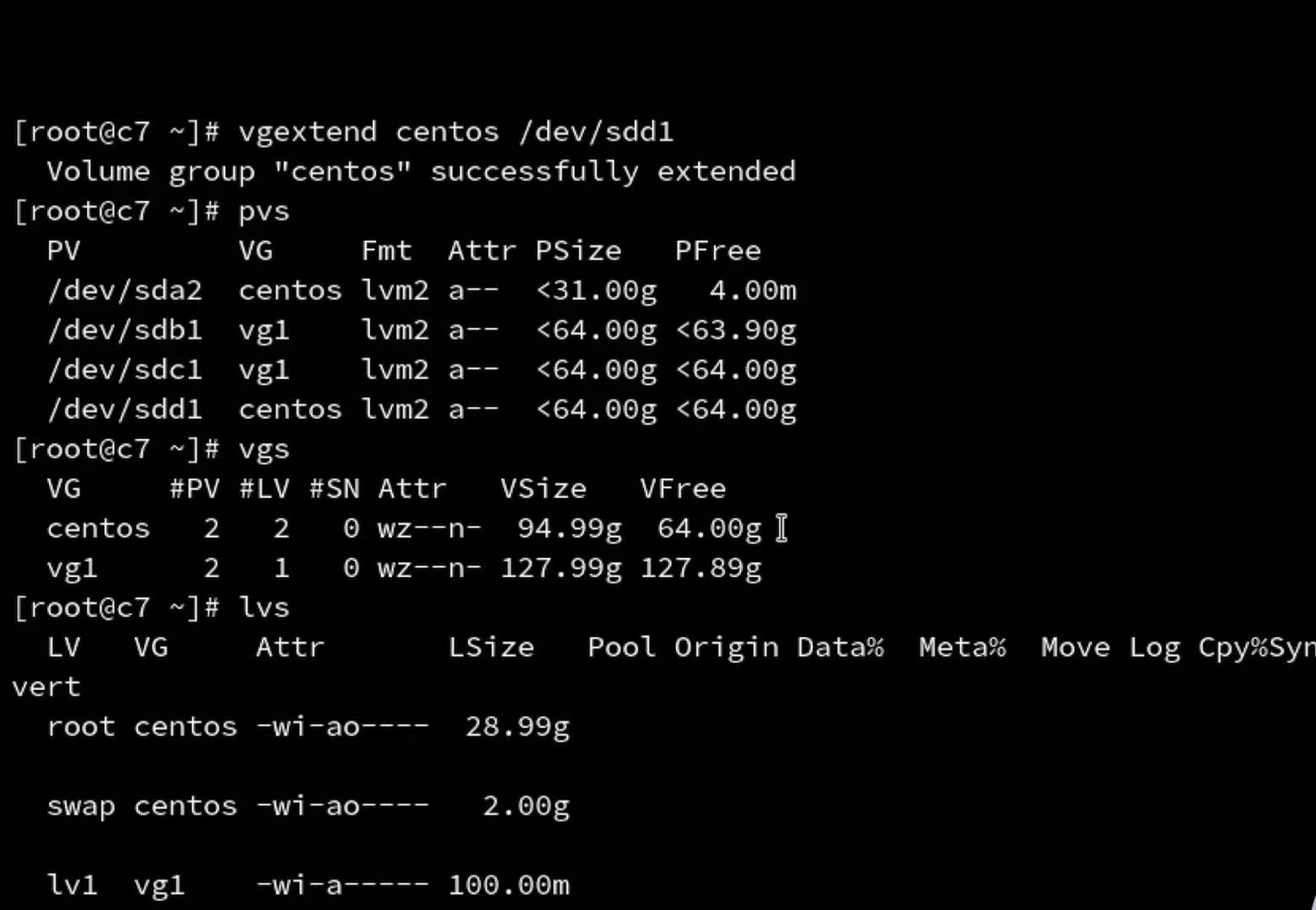
lvextend -L +50G /dev/centos/root

我们要使用df -h,发现了一个奇怪的事情,我们的分区并没有扩大,其实我们逻辑卷上一层还有个文件系统,文件系统他认为自己还没有那么大,
xfs_growfs /dev/centos/root 扩容就完成了
其实缩容在lv上面也可以实现,但是你的文件系统实现的时候可能有些危险,大家可以在网上找一些资料,可以在你的测试机上运行
系统综合状态查询
- 使用sar命令查看系统综合状态
这边只是把最常用的列举出来
sar -u 1 10
-u代表对cpu进行查看,1代表时间的间隔(每隔1s进行一次采样),10(采样10次),这个其实和我们的top显示的结果是一摸一样的
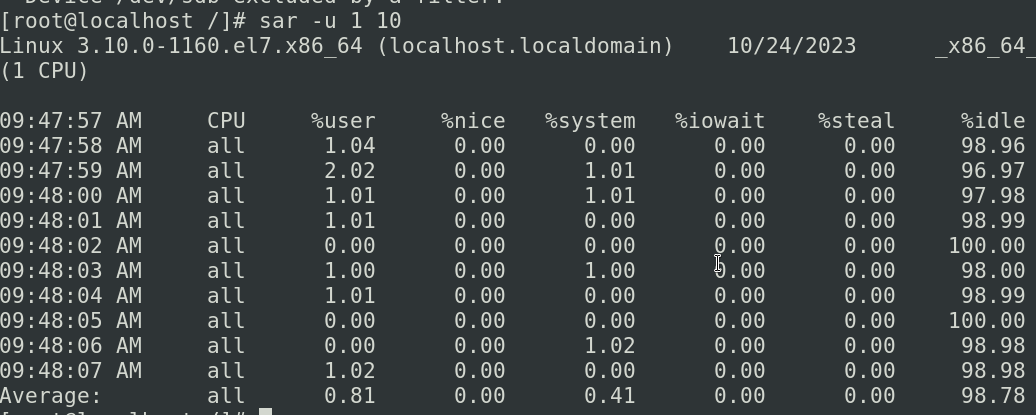
sar -r 1 10
查看关于内存读写的情况
sar -b 1 10
查看磁盘的读写io是不是有问题
sar -d 1 10
查看每一块磁盘的读写
sar -q 1 10
查看进程的使用
-
使用第三方命令查看网络流量
- yum install epel-release
- yum install iftop
- iftop -p
观察我们的网络情况(默认他是只监听我们的eth0这样的接口)
Shell篇
认识shell
什么是shell
- shell是命令解释器,用于解释用户对操作系统的操作
shell会把用户所执行的命令翻译给我们的内核,内核呢根据我们命令执行的一个结果,再把结果呢反馈给用户
比如ls这个命令底层的执行过程就是,当你去输入ls回车的时候,首先由我们的shell接受到用户执行的这条命令,接受完成之后呢他去对命令的选项和参数进行分析,分析完之后我们知道ls是查看文件的,那第一步他会交给我们的文件系统,文件系统在我们内核这个层面,我们内核就可以接收到这个命令,根据文件系统呢,我们会把ls要查看的文件和目录再翻译成我们对应的硬盘的某一个扇区,当然ssd硬盘呢,那是另外一种结构,那这边翻译到硬件,硬件会把我们翻译到的结果再交给内核,内核再返回给shell最终返回给我们的用户
- shell有很多
- cat /etc/shells
- Centos 7默认使用的shell是bash
linux的启动过程
系统自带的shell脚本有两大用处,第一个用处是用于我们linux系统的启动过程,启动过程当中呢很多功能是可以通过shell去实现的,我们很多的linux命令也是由shell编写出来的
linux启动过程在这里简单分为6个步骤
- BIOS-MBR-BootLoader(grub)-kernel-systemd-系统初始化-shell
BIOS引导:BIOS(基本输入输出系统,这个功能是在我们的主板上面的,通过BIOS呢来去选择我们要引导的一个介质,引导的介质一般有两种,一种是我们的硬盘,另一种一般就是光盘)
我们正常的启动过程当中,经过我们的BIOS之后呢.就来到了我们的硬盘,那这个硬盘是不是可引导的呢,那就要看硬盘的主引导记录部分MBR
如果硬盘是可以引导的,接下来就进入linux的过程了,linux过程当中我们第一个引导的东西不是内核,而是叫grub的软件,我们一般把他称作BootLoader,主要是用来启动和引导内核的一个主要的工具,甚至我们可以通过BootLoader来去引导我们的windows系统,如果只是linux的话我们可以把他简单的理解为grub是用来选择哪一个内核,选择指定的版本的
确定了内核的版本后,我们的内核就可以启动了,内核启动之后他会把我们的系统做一个初始化,我们通过驱动程序去加载各种各样的硬件,再之后的话就是我们所说的我们shell脚本就可以来去工作了,如果你使用centos7这个操作系统呢,我们第一个程序就是systemd,你看到你的一号进程就是systemd,如果是centos6这个版本去引导的话,我们这边的一号进程就是init,如果我们使用的是centos6这样的一个操作系统的话,那从init之后所有的引导的过程全都是shell脚本来去完成的,包括我们怎样来去加载我们的内核的需要的模块,我们怎样来去启动网络,而在contos7当中,我们有一部分已经改变成了systemd的一种配置文件方式,也就是用我们的应用程序引导,应用程序引导之后,我们的系统初始化过程仍然是我们的shell脚本
接下来我们来看看这些文件到底都在哪里
这边BIOS我就不进行演示了,大家可以在启动的时候按F2进入到BIOS的界面选择不同的引导介质
如果你选择引导介质选择了硬盘,那硬盘就会有一个可引导的部分叫做MBR,我们可以吧硬盘也当成文件去读取(一切皆文件)
dd if=/dev/sda of=mbr.bin bs=446 count=1
我们导出来的mbr.bin由于是没有文件系统的,所以我们没有办法通过cat去查看里面的内容
所以查的时候我们可以使用叫做(十六进制的方式去查,-C显示字符)hexdump -C mbr.bin
如果存储的时候把他再扩大一点,这样的话你的MBR信息就包括了磁盘的分区表
dd if=/dev/sda of=mbr2.bin bs=512 count=1
hexdump -C mbr2.bin | more
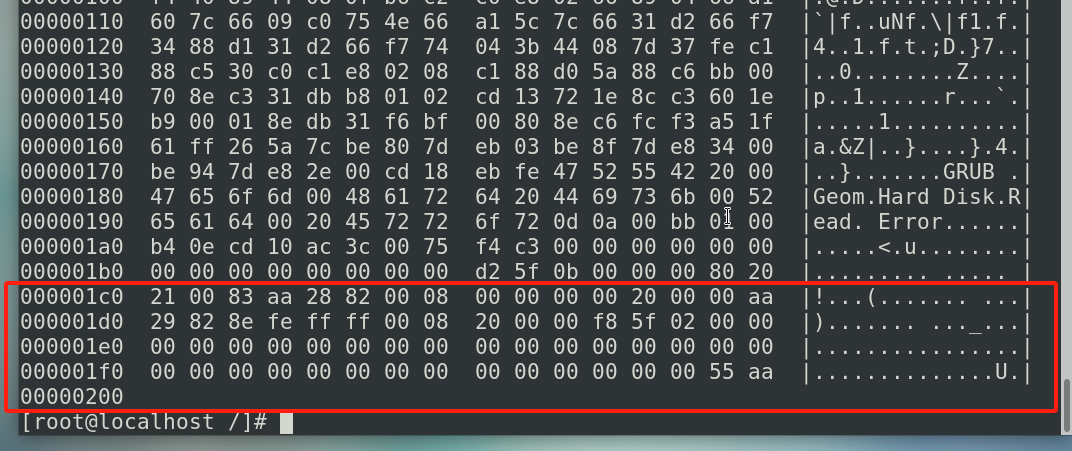
这边大概是1d0这个位置,这个范围就是我们后面的64字节,这64字节就是我们的分区表,后面还有个标记叫做55aa,55aa是用来证明我们的引导分区是正确的,在这边你的磁盘就可以进行一个引导,那么BIOS去检测我们刚才的446字节,那如果446字节认为里面写入的是正确的,而我们完整的512字节后面的是55aa这样的一个标记的话,那我们这个硬盘就是可引导的,可引导的话接下来我们BIOS就把引导的权限交给我们的grub(BootLoader程序),在linux当中使用的grub是grub2.0,他的位置是在/boot/grub2
cd /boot/grub2

在这里可以看到有grub的配置文件,,接下来的话就是根据grub的配置文件我们选择内核,当然在linux当中是由默认的内核的,
通过grub2-editenv list这个命令就可以知道默认引导的内核是什么版本
也可以通过uname -r来查看当前所使用的内核

接下来我们的grub选择了内核之后,就会把我们整个权限交给我们的内核,接下来我们的内核会去驱动我们的硬件,然后开始去初始化我们的系统的环境,如果是centos6的话使用的就是/usr/sbin/init
在centos7当中我们使用的是systemd,top -p 1,在这呢他们引导的过程就有了一个极大的区别,在contos6当中我们引导的是init,如果是systemd的话呢,他会来到我们的cd /etc/systemd/system/ ,在这呢就是之前介绍的默认的启动级别,根据我们的启动级别就会来到cd /usr/lib/systemd/system 会来到下面这样一个目录
在这个目录当中去读取我们各种各样的service,systemd的引导过程当中就不再是shell脚本了,就会变成各种各样的配置文件了
除了我们启动过程中在大量应用shell脚本,我们linux的命令也有很多在用,例如呢我们大量的grub的这些命令,比如说我们找一个
ls /sbin/grub2-mkconfig

这个命令我们执行的时候直接拿过来使用,如果呢你用vim把它打开的时候他就是一个shell脚本
Shell脚本的格式
如果我们想要自己去编写自己想要的功能,想要把这些命令组合到一起,我们还可以去实现自定义的shell脚本
现在看一下编写shell脚本的一些前置的知识
- UNIX的哲学:一条命令只做一件事
shell脚本和python这类的脚本是不一样的,像python这类的脚本你需要去掌握他特定的函数,而shell脚本它里面组成的函数是我们linux的命令,我们的脚本其实就是把我们要做的每一件事情给他组合在一起,把我们的每一个命令给他拼接和组合,当我们把这个脚本拼接完成之后如果你需要进行多次执行,或者说你这个脚本希望交给别人也能够运行的话,那我们一般把这个脚本存入到一个文件当中,也就是称作脚本文件
- 为了组合命令和多次执行,使用脚本文件来保存需要执行的命令
假如我们需要经常去执行某个功能,比如cd /var; ls(顺序执行cd /var和ls),我们把文件存入到一个文件,存入到文件之后如果想让他执行就用之前学过的chmod为他赋予一个权限,如果是二进制可执行文件的话给他一个x就可以了,如果是脚本文件的话记得要给这个文件加上一个可读和可执行权限
- 赋予该文件执行权限(chmod u+rx filename)
如果你的命令非常非常长的话除了使用;隔开以外,我们把他存入到文件的时候可以一行存放一条命令,那就变成下面这种形式
标准的shell脚本要包含哪些要素
-
Sha-Bang
!的一个声明,
-
命令
-
"#"号开头的注释
-
chmod u+rx filename可执行权限
-
执行命令
- bash ./filename.sh.
- ./filename.sh
- source ./filename.sh
- . filename.sh
建立脚本文件如果是bash脚本的话推荐大家使用.sh的扩展名结尾


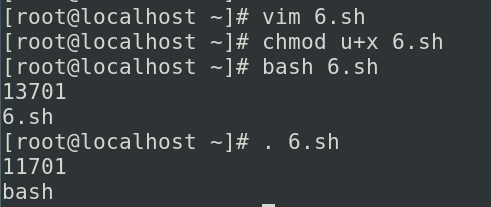
执行的话其实也有很多方式,最简单的方式就是用bash 1.sh来直接执行,这里我们还要考虑其他问题,如果你要把你的脚本传给其他人,或者是在其他文件系统环境下运行的时候可能会有一些问题,如果他的默认的shell不是bash那么他去执行1.sh的时候,可能会失败,因为可能会有一些bash特有的一些特性在脚本里面,所以呢我们在编写bash脚本的时候一般会给他在前面加一个类似声明的东西,他的书写方式是这样的,在我们文件地第一行写上#!/bin/bash这样写有什么的好处呢,如果我们使用的是bash 1.sh,就变成第一行是用bash解释出来的一行,而这一行的话如果是#开头的话在bash里面它会被认为是注释,去执行shell脚本的时候还有另外的执行方法./1.sh,这个方式他会用系统自带的方式去解释,比如说你当前是什么shell,他就用什么shell解释,这个时候我们的1.sh里的#!就变成了告诉我们的系统,你现在要用/bin/bash来进行,这是非注释的一种形式,这个方式其实是非常优雅的.
我们推荐把注释写在命令的前面
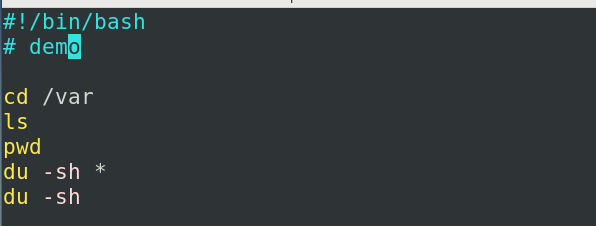
这个就是脚本的基本格式
脚本不同执行命令的方式
- bash ./filename.sh.
直接在你当前的终端下边产生一个叫做bash的子进程,子进程下面再去运行我们的脚本,和他很相似的就是./的方式,
你会发现你即使不为脚本赋予可执行权限,bash 也可以去运行他,我们发现在脚本的运行当中我们进入了/tmp目录


进入到tmp目录之后,脚本结束了我们又回到了当前的目录,我们再看其他的三种执行方式有什么区别
- ./filename.sh
这个方式也是产生一个子进程再去运行,这个运行就是使用Sha-Bang(#!)来去进行解释你的脚本的

可以看到权限不够,如果想用./方式要求他必须有可执行权限

我们脚本内部依然进入到/tmp,离开脚本之后我们就回到了/var目录(和上面bash 方式一样)
所以无论是bash 还是./方式都会产生一个新的进程,我们cd其实是一个内部命令,在执行的时候,对当前的环境是不会进行影响的
- source ./filename.sh
他执行的时候是在你当前的进程去执行的
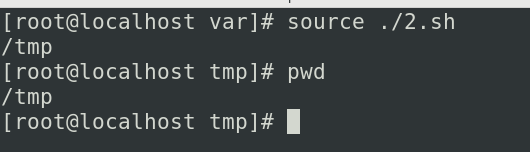
我们发现当前的目录也改成了/tmp
- . ./filename.sh

和上面source 是同一个命令
无论使用哪种法师都可以运行我们的shell脚本,但是要注意./方式需要有可执行权限,如果里面有cd命令的话,bash和./两种方式对你当前的运行环境是没有影响的,source 和. 是有影响的,为什么会有这样的区别呢,因为我们的bash 和./ 方式运行的时候,会让你的shell脚本再山剩一个新的子进程,也就是说脚本执行的时候是你的子进程切换到了新的目录,脚本结束之后回到了你的父进程,你的环境就不会变化
内建命令和外部命令的区别
- 内建命令不需要创建子进程
- 内建命令对当前shell生效
管道与重定向
管道实际上是进程通信的一个主要的通讯工具,把他拿到shell脚本编程里面,主要是为了方便我们脚本编程语言里的两条命令互相之间可以进行通信,而重定向呢我们可以让我们的程序输出到标准输出上的信息,输出到一个文件里面,还可以把文件代替我们的键盘进行一个输入,
-
管道与管道符
- 管道和信号一样,也是进程通信的方式之一
信号是做什么的呢,比如我们进程发一个kill -9,那这边实际上是让你的程序去处于某一种运行的状态,让这个程序去结束
管道通信的时候是实现另外的一些功能,他主要是把我们两个应用程序连接在一起,把第一个应用程序的输出作为第二个应用程序的输入,如果有第三个程序呢,管道符还可以把第二个和第三个程序连在一起,把第二个程序的输出,传递给第三个程序的输入,由于我们使用的管道符,他是一个符号,那这个管道呢其实是没有名字的,所以我们把这种管道符也称作是匿名管道
比如more anaconda-ks.cfg 和cat anaconda-ks.cfg | more是一样的,相当于把cat anaconda-ks.cfg 作为more的输入
![image-20231026173542667]()
- 匿名管道(管道符)是shell编程经常用的通信工具
- 管道符"|",将前一个命令执行的结果传递给后面的命令
- ps | cat
- echo 123 | ps
![image-20231027112620527]()
可以看到管道符除了把我们第一条命令的输出作为第二条命令的输入以外,管道符还会给两边的进程创建了一个相应的子进程,ps是外部命令,所以管道符加ps就产生了10504这样的进程,那cat其实也是外部命令所以呢cat这边呢他会产生一个10503这样一个进程,我们可以看到通过管道符,我们可以把管道符左边和右边(如果是外部命令的话)建立两个子进程,再把两个子进程第一个的输出和第二个的输入建立了一个链接
在这的话我们再打开一个终端
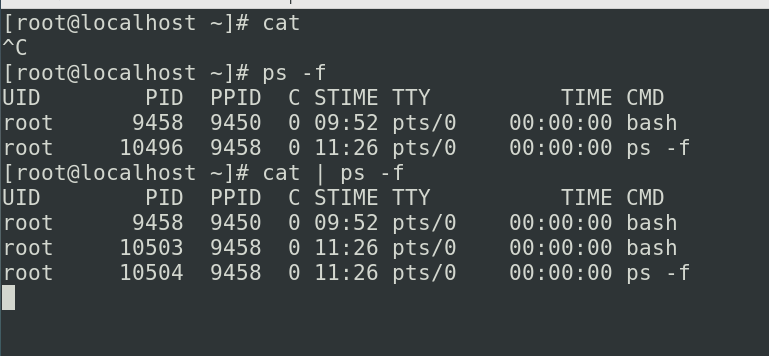

在这呢是我们进程的所有的状态,,我们看一下他的文件描述符中,这个0就表示我们的标准输入,标准输入是什么呢,/dev/pts/0就是咱们的图形界面的终端了,如果咱们运行的是字符终端呢,就应该是/dev/pty,这个1叫做标准的输出他指向了一个pipe也就是我们的管道,这边就是指向我们匿名的管道(管道符),
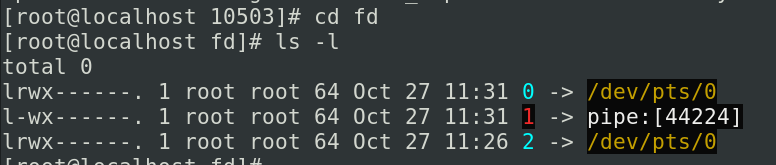
另外的呢我们的ps命令他的pid是10504,我们可以看到由于ps这个命令他执行完之后已经立即消失了,cat正在等待输入,所以我们10504的fd是没有进程何相应文件描述符的,如果两条命令都是长期可以执行的,我们可以看到第二条命令他的0(他的输入的位置)也是指向同一个管道的,也应该显示为44224,也就是把第一个的输出和第二个的输入做了一个连接

- 子进程与子shell
管道符可以创建相应的子进程,子进程如果是个shell脚本的话,这个shell脚本呢我们一般把他称作子shell,我们还要注意一点,由于我们的管道符是通过子进程方式去有运行的,所以你如果用了cd,pwd等等内部命令,那执行之后你的父进程是得不到相应的结果的,所以大家要注意如果你管道符里面需要使用内部命令的话,那把这个内部命令放到我们封装好的shell脚本里面,他的作用范围只是在这个脚本之内,离开脚本这个命令就没有作用了,如果没有必要的话建议大家避免在管道符当中使用到我们这些内部命令,我们能不能把多条命令串到一起呢?其实是可以的
- 重定向符号
重定向符号有什么作用呢,我们知道一个进程在运行的时候默认会打开标准输入,标准输出以及错误输出,这样的三个文件描述符,也就是0,1,2,管道就是把第一个命令的输出和第二个命令的输入这两个的文件描述符做了一个连接,中间用了一个匿名的管道,输入和输出是相对与执行来讲

重定向符号其实是把我们的输入和输出,去和我们的文件建立连接,我们标准输入一般是从我们的键盘,终端进行一个输入,我们的标准输出和你产生错误的输出默认也是输入到我们的终端,输入重定向其实就是利用我们的文件来去代替你的键盘进行输入,输出的话利用我们的文件代替我们的终端进行一个输入
输出重定向:如果使用>的方式呢,会把我们文件里的内容全部清空,清空之后再把我们的内容输入进去,>>表示对我们当前的内容保持不变,把我们新的内容在下一行进行追加,2>其实是对文件描述符2进行的一个操作,也叫做错误重定向,如果当前的命令执行产生了一个错误,会把错误输出到我们指定的文件当中,&>的功能是无论输出的是正确的还是错误的,这些信息全部都输出到我们指定的文件当中
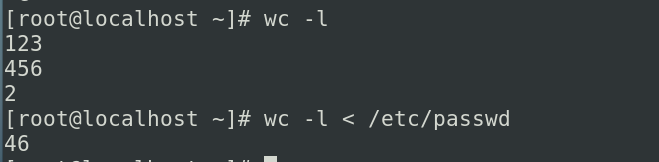
wc -l可以统计当前输入的行数(按ctrl+d结束输入),这边就是用文件/etc/passwd 代替我们的用户输入,输入到wc -l,后面会讲到变量,变量也是通过人为进行输入的,例如呢我们使用read命令来去读入一些信息,把读到的信息存入到var这样的变量里,查看变量的话使用echo $变量名称
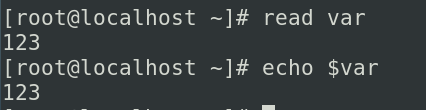
这里我们也可以使用输入重定向代替我们手动进行输入
vim a.txt
read var2 < a.txt
所以呢我们的<在我们的shell里面就是我们的输入重定向,他的右侧跟的一定是一个文件,左侧就是我们要输入的命令,我们可以用文件代替我们的键盘进行一个输入.
我们希望把echo $var2的结果输出到一个文件里,我们就可以用echo $var2 > b.txt,我们的终端就不显示信息了,特别注意>会把原有的内容清空掉如果你去输出的时候指向的是我们的系统的配置文件的话,系统配置文件的内容就会被删除
输出重定向其实还有一个追加模式>>,新的内容就会在下一行追加进行显示,除了这些信息之外我们经常还会有这样的一些操作,在你的shell脚本或者是批量执行的程序当中,可能会产生一些错误,我们希望把这些错误收集起来,放入到一个文件,其实没有nocmd这个指令,你执行他就会报错(默认显示在终端上)我们使用nocmd 2> c.txt
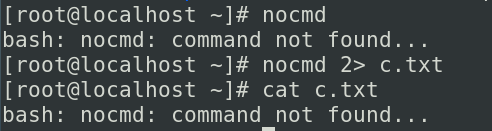
可以看到虽然这条命令执行出错了,但是他的错误没有显示在终端上,他的错误信息呢,就会被存储到我们的文件当中
有的时候我们执行这个脚本的时候我不知道我程序会产生正确的结果还是错误的结果我都想把他收集,我们就可以用&>这个就是全部重定向到我们指定的文件当中
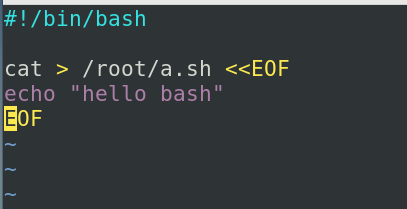
我们也可以把输入和输出重定向组合在一起使用,这种用法呢一般是在我们的shell脚本当中生成一个配置文件来去使用的,例如我们编写一个vim 3.sh,我们希望通过3.sh去生成一个配置文件a.sh

输入重定向无论是覆盖模式还是追加模式尽量不要应用于我们的系统配置文件,在应用之前建议大家对系统配置文件进行备份
变量
在我们执行各种脚本的时候,我们的脚本或者命令会有一些输出,这些输出的信息我们希望进行临时的存储,供给我们下一条命令或者是下一个脚本来去使用,用来存储这些临时的信息的这些东西呢我们就可以用变量这样的功能来进行储存
变量的定义
-
变量的命令规则
- 字母,数字,下划线
- 不以数字开头
建议大家使用有意义的单词,不建议大家使用a呀b呀单独的一个字母或者v1,v2,v3这样按顺序排下来,因为写好的程序是给我们shell来去执行的,但是我们的shell脚本实际上是要给人看的
-
为变量赋值的过程,称为变量转换
我们如果给变量进行初始化的时候,大家可能学过编译型的语言,这种语言他要求你要指定变量的类型(int,string),但是在shell脚本当中你的变量是不区分类型的(弱类型的变量)
-
变量名=变量值
- a=123
我们在赋值的
=的左侧和右侧不允许出现空格,如果出现空格的话,他会出现一个报错,如果出现空格的话,我们shell脚本会认为=前面不是变量名而是一条命令除了这样去赋值之外呢我们还可以用其他的命令来去赋值,例如之前的read命令,使用read赋值的话,我们还要通过键盘去进行输入,我们这边直接为变量进行赋值的话,我们直接去把赋的值写入到脚本里面,这两种方式分别称为交互方式和非交互方式,我们写脚本一般是希望他能够自动执行而且是批量运行的,所以我们在写脚本的时候尽量规避掉这样交互式的编程
交互式就是他弹出一条信息你做一次输入,他再弹出一条信息你再做一条输入我们希望一次性把他输入好,让脚本可以直接去运行 -
使用let为变量赋值
- let a=10+20
使用let我们可以让变量后边的整数进行一个计算,但是呢我们在使用shell脚本的时候尽量不要涉及到计算,因为他的这个计算的性能其实是所有的脚本当中性能最低的,因为他是一种解释型的语言
-
将命令赋值给变量
- l=ls
我们可以把命令以及命令带的参数赋给我们的变量,命令赋给变量其实用处不大,我们经常会命令的值赋给我们的变量
-
将命令结果赋值给变量,使用$()或者``
- lstc=$(ls -l /etc)
我们希望把ls -l/etc命令执行的结果进行一个保存,赋给我们的变量,如果这条命令要在脚本中执行几十次甚至上百次,每一次执行都会对我们系统的cpu造成一定的开销,我们执行一次并且把他赋值给我们变量的话,我们可以直接得到命令执行的结果,我们就可以对变量进行多次操作不需要让你的命令多次执行,为你的系统节省更多的资源
-
变量值有空格等特殊字符可以包含在""或''中
- "hello "bash""这样的形式他会认为前面的两个双引号匹配在一起,后面的两个匹配在一起,bash就没有被匹配进去,这种情况下就可以把双引号改为单引号'hell "bash"'相应的如果字符串里面包含单引号,"hell 'bash'"也是可以的
-
变量引用及作用范围
我们定义好了变量,接下来要如何进行输出呢,输出的方式其实就是刚才的echo这样的方式
-
变量的引用
- ${变量名} 称作对变量的引用
- echo ${变量名} 查看变量的值
![image-20231101161633090]()
- ${变量名} 在部分情况下可以省略为 $变量名
我们用echo命令其实就可以查看变量的取值,之前我们也介绍了,你在使用内部命令和外部命令的时候,他对父子进程之间也会有一些影响
-
变量的作用范围
- 变量的默认作用范围
我们定义好的变量默认是只针对我们当前的终端,或者称作当前的shell来去生效,如果在当前的shell下面再去产生新的子shell,或者说是和我们当前shell的一个平行shell甚至我们shell的父进程都是不生效的
![image-20231101162450172]()
![image-20231101162743620]()
![image-20231101162926254]()
说明我们使用bash和./方式是采用子进程的方式运行他们的
能不能把他再去扩展一下,让我们的子进程去获得父进程的变量呢
-
变量的导出
- export
export demo_var1
![image-20231101165842105]()
我们子进程可以获得父进程变量的取值了
我们可以在定义这个变量以及为变量进行赋值的时候可以在前面直接加上export
-
变量的删除
- unset
当你不需要这个变量的时候可以使用unset进行删除
unset demo_var1
主要用于我们某一个变量名称,可能在脚本当中反复去使用的时候,我们通过unset取消变量的赋值
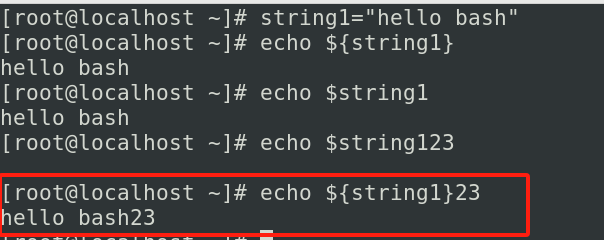
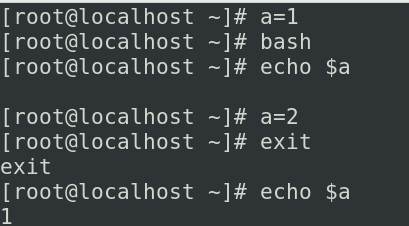
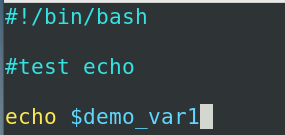
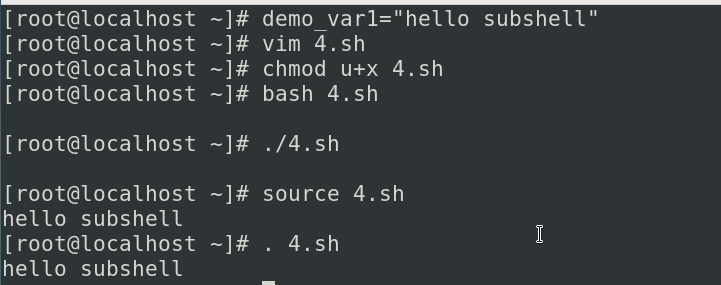

环境变量,预定义变量与位置变量
我们接下来就是要把变量保存到我们系统当中,成为一个环境变量.
-
环境变量:每一个shell打开都可以获得的变量
怎么让你的每一个进程都能读取到变量的值呢,我们有一些默认的配置文件,把他填入到配置文件就可以了
-
set和env命令
使用env可以查看环境变量,
env | more,默认的环境变量都是大写字母表示,查看单独的环境变量和查看变量一样,echo $USER我们的set命令可以查看更多的变量
set | more,除了环境变量还有其他变量,预定义变量,未知变量 -
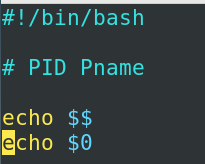
$? $$ $0
我们经常会遇到
$?,$$,$0,这三个预定义变量,echo $?是指你上一条命令是否正确执行,如果返回0就是正确,返回非0的值就是错误echo $$可以显示你当前进程的pid,一般用在我们进行脚本的监测,或者脚本的运行状态查看的时候.ehco $0表示你当前进程的名称,使用不同的执行方式,$0会有区别,比如咱们写一个脚本![image-20231102103917779]()
![image-20231102104033821]()
- $PATH
表示当前目录的搜索路径,大家去敲ls或者cd等等这一类的命令的时候,命令前面是没有带着任何的路径的,(我们说过这些命令有的是shell脚本有的是二进制可执行文件)都没有在我们的当前目录,linux是怎么找到这些命令的呢,他就是通过$PATH这样的命令搜索路径这样的功能来去找到的
例如我们的某一个命令,这个命令在/tmp下面,我们发现tmp不在PATH(命令搜索路径)当中,那你这条命令就没有办法直接去运行,就要去输入命令的完整路径
![image-20231102100546512]()
如何把/root添加到\(PATH里面呢,`PATH=\)PATH:/root`,就添加完成了,而且我们这个命令的搜索路径是对我们当前shell的所有位置都生效的,我们当前定义的变量只对当前终端生效,对子shell也能生效,这是为什么呢,因为我们用export进行过一个导出,所有的环境变量其实都是经过了export的导出,所以他对当前终端以及子shell都是会生效的,环境变量的作用域是在一个进程中.
- $PS1
$PS1是指我们当前提示的终端,我们经常会去修改我们当前提示的一个终端,让他显示的更友好,大家可以在网上找一下,例如给我们的终端加上时间,加上ip等等,这些都可以通过替换我们的PS1来去实现 -
-
位置变量
-
$1 $2 ... \(n(当n>9时,格式为`\){n}`)
当你用到第十个位置参数的时候
${10}大括号就不能进行省略了,当你去执行shell脚本的时候,我们可以为shell脚本带更多的参数,参数我们可以读取到shell脚本当中,并且对参数进行处理
-

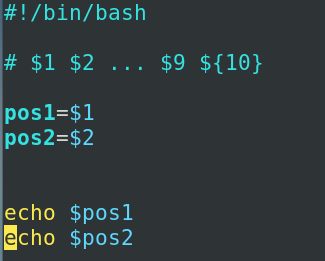

./7.sh -a -l执行完之后我们的-a 和-l 就会传递给我们的脚本,这个脚本中$1就得到了-a参数,$2就得到了-l参数,也可以不用变量,直接echo $1
这里如果我们只传入一个参数,你的$2可能是空值,我们可以在\(2后面加一个_也就是`\){2}_`也就是说$2如果是空的,我们这边读入的就是_,我们就可以规避掉我们读入的值是空值,这种情况就没法用省略的形式了,虽然解决了空值问题,但是如果以及赋值了的话就会多出一个下划线

我们还有另外一个小技巧来去处理,这个技巧叫做参数替换,它使用的方式是${2-_}这个形式就是如果你的$2变量取值为空值的话我们就用_来去为变量赋值,如果$2是有内容的,我们就用$2赋值给位置2
环境变量配置文件
- 配置文件
我们的配置文件主要都保存在一下这四个文件以及一个目录当中,为什么要做这么多的划分呢,要注意凡是保存在/etc/下的这些配置文件呢是我们所有的用户通用的一个配置,有一些环型变量不管你是root还是普通用户都需要事先声明的.~/下的配置文件一般是保存用户特有的一些配置(~/是用户的家目录)例如有些环境只能用root来去使用,就可以放在/root/.bash_profile和/root/.bashrc里面,我们发现配置文件分成了两类,一类叫profile文件另一类叫bashrc文件,因为我们在登陆的时候也分为两种,一种叫做login shell一种叫做nologin shell,我们使用这个命令一般是使用su -用户名和su 用户名,当使用su - 用户名的时候我们这四个配置文件加上/etc/profile.d/这个目录都会被执行,当使用su 用户名的时候,那我们的~/.bashrc和/etc/bashrc会被执行
- /etc/profile
这个文件主要是保存我们系统启动以及终端启动的时候的,他的一些系统的环境,当你使用su -用户名的时候这个文件就会被第一个加载,我们在这里可以加入一个显示的功能,我们再去切换用户,切换用户的时候呢,我们就可以知道哪一个文件是北加载了,被加载的时候他的一个加载顺序是什么样的 echo /etc/profile

- /etc/profile.d/
除了四个文件还有一个目录,这个目录下呢是基于不同的shell的版本,或者是不同shell的类型,我们去执行不同的脚本的,对于这个目录我们可以暂时忽略掉他,等我们讲完循环之后,我们再来去介绍
- ~/.bash_profile
同样的也加一行echo ~/.bash_profile
- ~/.bashrc
同样的也加一行echo ~/.bashrc

如果你想让他不进行提示rm可以增加-f,像cp跟mv增加-f是没有办法去掉交互式的,你可以说使用命令的绝对路径,这样的话我们的别名就不生效了
- /etc/bashrc
同样的也加一行echo etc/bashrc
接下来我们来切换su - root
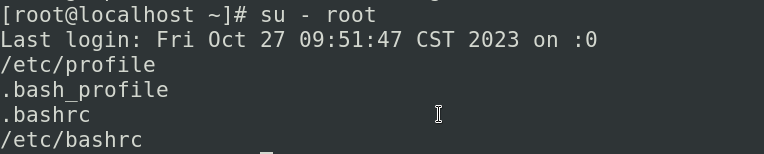
我们四个脚本都会被执行,顺序如上,如果你是login shell我们会加载.bashrc这个文件,让后由.bashrc再去加载/etc/bashrc,为什么要了解顺序呢,如果你再去定义变量的时候,如果变量名称有重复,那在这边我们后边执行的脚本,会把前面执行的脚本的变量给覆盖掉,那这边我们定义的PATH可以定义在任意的脚本当中,定义的时候记得要把原来的PATH的值加进去PATH=\(PATH:/new/path(新的路径),我们去执行的时候还要注意,定义好的环境变量一定是自己的进程和子进程都可以用export PATH=\)PATH:/new/path把这样的一行写入到我们上面的任意配置文件,你就可以给命令的搜索路径增加一个新的路径,而且这个增加是你当前系统中的所有终端全都可以增加的
还有几个注意事项需要大家去了解的,我们在登录的时候,如果我们使用
su 用户名(nologin shell)的话,我们是加载不完全的我们运行的环境和我们正常登陆的环境其实是不同的,所以不建议大家用
su 用户名的方式来去登录还有一个问题就是我们的配置文件在你打开终端的时候或者打开shell的时候,才会去运行的,如果你在配置文件当中去新添加的一个环境变量,那这边他是不会立即生效的,添加完之后怎么让它生效呢,第一种方法就是我们去关掉终端重新打开,第二种方法就是使用source加上配置文件
例如我们这边在/etc/bashrc当中去增加了我们的新的环境变量,我们可以使用
source /etc/bashrc使用这样的方式来去运行就可以了

数组
-
定义数组
- IPTS=( 10.0.0.1 10.0.0.2 10.0.0.3 )
我们定义的时候是可以加空格的,数组中的每一个元素也是有空格来去隔开的
如果你要像普通的变量来去使用他,echo $ipts他只会显示我们的第一个元素
- 显示数组的所有元素
- echo $
- 显示数组元素个数
- echo $
- 显示数组的第一个元素
- echo $
我们可以把所有的ip地址都定义到数组元素当中,取得元素内容的时候我们只需要知道一个变量名称就可以了,也可以通过循环依次的取得数组元素
转义和引用
特殊字符
-
特殊字符:一个字符不仅有字面意义,还有元意(meta-meaning)
我们的字符不但有表面的意义,还有他的本意
-
注释
可以把脚本的用法注释在开头,如果脚本出现错误,可以注释掉这一行,看一下我们脚本的运行状态是否有一些变化.
- ;分号
用来连接我们的两条命令,或者是两个脚本,如果你的命令或脚本比较短的时候我们经常把他们写为一行
- \转义符号
- 单个字符前的转义符号
\n\r\t单个字母的转义\$\"\\单个非字母的转义
- 单个字符前的转义符号
转义符号分为两类,一类是把我们的字母转义成特殊的功能,我们可以用echo的方式把他显示出来,echo /n,我们输出的时候就可以进行转义,转义字符还有一个非常大的用途,如果是非字母的符号,我们经常使用
$来引用变量,如果我就想要输出$这个符号,就可以\$用这种方式转义成一个普通的符号![image-20231120111222575]()
-

引用
- 常用的引用符号
- "双引号
在变量中,双引号也叫不完全引用,如果是"$a"这样引用显示的就是a的值
- '单引号
在变量中,双引号也叫完全引用,'$a',''里面是什么样的内容我就显示什么内容
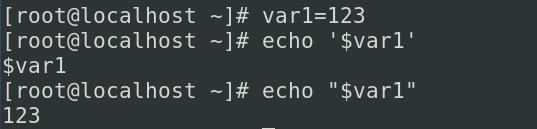
- `反引号
反引号在将括号内的命令处理完毕之后,会将返回的信息传给bash,再次执行
echo `cat test.txt`
文件test.txt的内容为:
/etc/passwd
/etc/shadow
bash会首先解析反引号里的内容,也就是cat test.txt。
/etc/shadow
/etc/passwd
在命令执行完毕后,会将返回内容作为输入重新传递到bash中。
bash获取到返回内容,将它们作为echo的参数继续执行。
echo /etc/passwd /etc/shadow
运算符
赋值运算符
- =赋值运算符,用于算数赋值和字符串赋值
shell当中变量是弱类型的,不区分他是什么类型,弱类型的好处是我们可以方便的跟踪我们变量的变化,不用担心它使用多少内存,也不用担心我们再去赋值的时候,因为类型不一致导致的赋值错误
-
基本运算符
+(加)-(减)*(乘)/(除)**(乘方)%(取余数)
-
使用expr进行运算
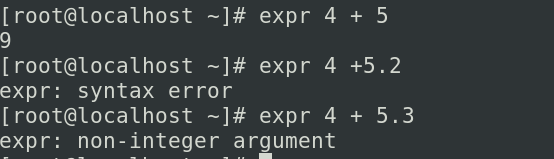
- expr 4 + 5
使用expr命令运算之后把运算的结果交给我们的变量,使用expr时要注意他后面只能支持整数,不能支持浮点数,要注意使用expr是符号(+)和数字之间要有空格,可以看出我们的shell脚本对整数的支持要比浮点数的支持要好很多
![image-20231120160400275]()
![image-20231120160604584]()

数字常量
- 数字常量的使用方法
- let "变量名=变量值"
- 变量值使用0开头为八进制
- 变量值使用0x开头为十六进制
- 双圆括号
- 双圆括号是let命令的简化
- ((a=10))
- ((a++))
- echo $((10+20))
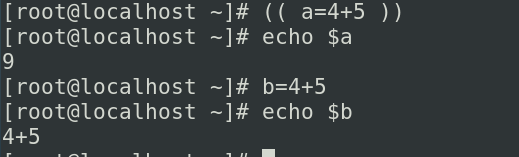
正常使用变量赋值的时候b=4+5等号后面会被当做字符串
-
使用unset取消为变量的赋值
-
=除了作为赋值运算符还可以作为测试操作符
特殊字符大全
引号
' 完全引用
" 不完全引用(会解释变量)
` 执行命令
括号
-
()(())$()圆括号- 单独使用圆括号会产生一个子shell(xyz=123)
我们子shell在为变量赋值的时候,我们父shell是看不到这个值的
![image-20231120164101505]()
- 数组初始化 IPS=(ip1 ip2 ip3)
![image-20231120164454575]()


()可以用来表示数组
(())是用来算数运算的,我们let命令的简写方式就是(())
$()我们在里面执行命令,把命令的执行结果赋给变量
-
[][[]]方括号- 单独使用方括号是测试(test)或数组元素功能
我们是主要用来做测试,test命令的简写方式就是
[],test可以用来测试两个字符串,判断我们的文件类型,可以对数字的大小进行比较![image-20231120165104440]()
- 两个方括号表示测试表达式
使用
[[]]就可以使用>或者<了,![image-20231120165303126]()
0表示结果正确,1表示错误
-
<>尖括号 重定向符号

一种用法就是刚才的比较
另外一种就是输入和输出的重定向
ls > a.txt
把ls输出的结果重定向到a.txt这个文件,可以方便我们储存某一条命令的执行结果
-
{}花括号-
输出范围
echo {0..9}
注意我们中间的数字和{}之间不要出现空格,主要是给我们的for循环使用的
![image-20231120165906327]()
-
文件复制
cp /etc/passwd{,.bak}效果等同于cp -v /etc/passwd /etc/passwd.bak
-

运算符号和逻辑符号
-
+-*/% -
><=
可以用在(()) 也可以用在[[]]
&&||!
可以看到返回的是0,两个判断都为真

当他有一个条件不成立的时候,它会返回非0的值

只要有一个成立,返回就为真

返回一个相反的判断结果

转义符号
\转义某字符- \n 普通字符转移之后有不同功能
- \`特殊字符转义之后,当作普通字符来使用
其他符号
#注释符;命令分隔符- case语句的分隔符要转义;;
:空指令
这条指令什么都不做
.[空格]和source命令相同~家目录,分割目录(上面有例子)*通配符?条件测试 或 通配符$取值符号|管道符&后台消息_空格
测试和判断
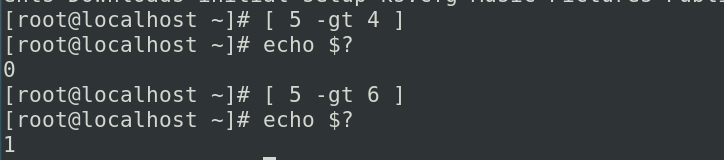
讲一下关于shell脚本的测试和判断。我们知道在运行shell脚本的时候,我们的这个脚本不一定每一次运行都是从开头到结尾把每个命令都执行到的,甚至我们的工作当中也不是说我们的这个脚本就一定是从开头直接运行到结尾的。因为在我们的这个工作中,可能会要用到脚本判断各种各样的突发的情况,以及我们来去判断各种各样的事情。所以,我们的这个shell脚本在运行的时候,中间一定会有各种各样的这种分支结构,例如根据我们的文件类型,那这边如果是文件,那我们可能要文件里面去写入内容。那如果是目录的话,那我们可能要在目录里面去新建文件再去写入内容。所以我们去写程序的时候,这边会有各种各样的一种分支结构,我们的测试和判断其实就是用来去完成我们的分支结构。所以在本节当中,我们将会大家去先介绍一下我们的test这个测试命令。
test比较
好,那我们说这个测试命令它是怎么去工作的呢?它的工作原理其实就利用我们的程序是否正常执行,然后根据程序的一个退出状态进行一个判断。好,我们之前学过一个变量,这个变量叫做$?。$?可以判断你当前的这个终端上边上一条程序的一个执行结果。那我们这边就可以利用这样的一个功能来去判断。例如我们的这个测试是成功的,或者说我们的命令是执行成功的,那这样的话我们的脚本就往其中的一个方向去发展。如果我们的这个程序是执行失败的,或者说测试是失败的,那这样我们可以让这个脚本往另外的一个分支来去发展,那这样的话我们就可以让程序利用它自己的一个退出状态,让我们的程序再往后运行的时候产生一个分支。
退出与退出状态
- 退出程序命令
- exit
- exit10 返回10给shell,返回值非0位不正常退出
- $? 判断当前shell前一个进程是否正常退出
那程序退出状态的话。我们可以知道,比如说我们去执行某一条命令,那命令执行成功和命令执行失败,它自己有自己的判断。而我们知道这个命令的话,那执行正确返回零,错误返回非零,那咱们就可以通过命令的这个返回值,直接用$?去判断。
那么shell脚本怎么办呢?shell脚本其实也有办法判断,那这边它其实默认就包含一个叫做exit,我们的这个退出的命令。如果给我们之前写的脚本当中加了这样的一个指令。那这个指令就会读取这条指令的上一条命令。如果上一条是成功了,那这个exit就自动返回成0,如果不成功就返回非零。那这个exit你也可以给它自己去指定一个返回值,是吧?比如说我们这边exit 10,那你就可以把10这个值返回给我们的shell终端。那在这儿我们可以来去写一个脚本,带着这个exit来给大家来去看。
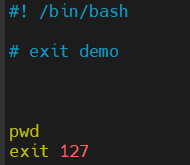
好,在这儿我们去新建一个脚本,那我们就叫做8.sh,然后这个脚本是关于我们的如何进行退出的,所以是关于一个exit的一个演示。那这边的话我可以去给它一个随意的一个命令,比如说叫做pwd,
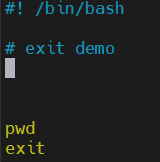
那这条命令一定会执行成功的,那在这儿我们再给他一个exit。好,这边咱们可以用bash 8.sh来去让它运行。
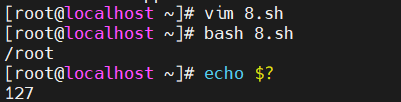
运行完之后的话,这边我会发现不带这个exit和带它其实没有什么区别是吧,因为脚本执行完成之后默认就会退出,所以我们默认去写的这个exit其实没有任何的作用。
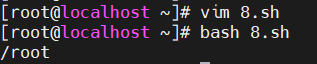
好,那在这里边的话我们给这个pwd改一下,给它改成一个错误的指令,那这边把它叫做ppwd,其实是没有这样的一条命令的。
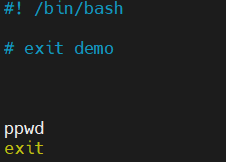
好,那这边我们再来运行8.sh,那echo $?返回的值就是非0了。所以这样的话就是我之前所提到的,exit上面的命令如果出错的话,那么exit会返回上面的这个出错的一个编码来去给到我们的终端。
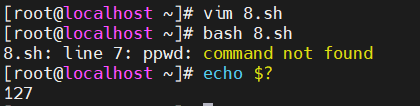
好,这里我们还可以去自定义这exit的返回的值,比如说我们这个脚本当中,无论如何我都返回exit 127,那这边我们就可以这样来去写,我们同样来去运行。即使我们的程序是执行正确的,那我们用echo $?也是返回的127。也就是说我们使用shell脚本的时候,可以自定义这个错误返回值。
这个是我们怎么来去自己编写脚本,来去进行一个错误的返回。好,那这边我们还有什么呢?
还有一些常用的命令。比如说我们去测试这个文件,它的一个类型到底是文件还是目录,那这边我们的这个文件是可读可写呀,等等这些。那我这边可能还会做一些什么测试,比如说整数的大小去比较,那还有我们的这个字符串,是不是非零的这个字符串,那这些测试其实在shell脚本里非常常用,所以这些我们就不用去编写独立的一个shell脚本了。因为系统已经给我们去编写好了相应的测试功能。那这个测试功能,其实就是一个叫做test这样的一个命令,帮我们去进行测试。
使用test的时候,我们还可以为了编写程序的美观,把它转化成一种叫方括号的一个写法,有时候我们中间是这个测试的语句,然后我们拿坊括号把它括起来,这样更符合我们的一个查看的一个习惯。那这边这个方括号是还可以扩充成两个方括号,那这边可以支持我们的大于小于符号以及我们的一些逻辑运算符号。
测试命令test
- test命令用于检查文件或者比较值
- test可以做一下测试
- 文件测试
- 整数比较测试
- 字符串测试
- test测试语句可以简化为[]符号
[]符号还有扩展写法[[]]支持&&,||,<,>
具体的用法可以使用man test来查看
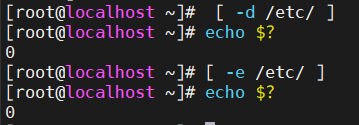
那么test我们可以去判断文件。第一种用法就是test,然后加上-f,那这边我们的/etc/passwd,我们知道它一定是文件并且是存在的。好,如果我们的这个判断是正确的,那这边通过$?就可以获取到我们的判断结果。
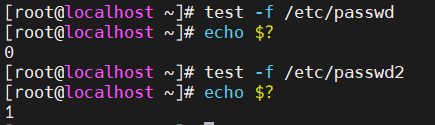
这里边的话需要去纠正大家的一个习惯。因为在我们的这个数学当中,可能说是1,这个值是真值是吧?这个0是假值。当然在我们的这个shell脚本当中,一定要注意,那么凡是为0的表示的是真值,然后凡是为1的表示的是假值。那这边甚至大家可以这样去记,零是真值,非零的一般为假值。
那这边就是根据我们的-f来去判断文件,那这边我们可以继续来去用-d,这个我换一种写法,那边如果是目录并且目录存在的话,那这边我们就可以用-d来去判断。还有的时候我们想判断什么呢?这边我们通过-e可以判断,无论是文件还是目录,还是符号链接,只要存在这样的文件名,它就是真值。
好,这些是关于我们的文件判断,那还可以对我们的这个数字进行判断。好,数字判断的话需要注意,我们这边一定是整数的数字,那这边我们的gt表示的是大于。因为如果5大于4的话,那么返回的就是真值。可以看到它的返回值是0。如果在这儿你要想使用这个大于号的话,那我们这边就要用两个方括号。因为用一个方括号的话,这个值是不准确的。这边我们看到了返回的是1。

这边我们还有一种用法叫做字符串比较是吧?字符串比较其实是这样的,那么我们可以用一个方括号,第一个字符串和第二个字符串是否相等,如果相等的话,那我们就认为这个比较的值是真值。
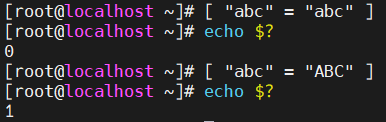
那这边是不是能够区分大小写呢?我们来看一下小写的abc和大写的ABC。然后比较的时候我们发现它是一个假值,所以在里面大家还要注意我们的test,它的一个比较是可以区分大小写的
通过以上的讲解,大家知道了无论是我们的test还是我们的这个shell脚本。那我们想要进行这个分支判断的时候,一定是利用我们的程序运行的返回值进行判断的。也就是使用我们的echo $?的方式。那这边我们常用的整数判断,我们的文件判断,以及我们的字符串判断,不用我们自己去编写shell脚本,那么已经有了一个test帮助我们去判断。在接下来当中,我将会去为大家去介绍我们的if条件语句如何来去使用。
if判断的使用
在掌握了如何判断命令的返回值,以及掌握了如何使用我们的test这样一条命令之后,我们就可以开始正式去学习我们的if判断语句了。因为我们的if判断语句,它的这个基本用法就是利用我们的test的测试和返回值来去判断的。那这边它是怎么判断呢?是这样的,我们可以用if加上我们的条件判断语句。如果我们的这个判断的结果成立,或者是命令的返回值为零,那只要是这两种当中的任何一种条件是成立的,那么这边我们的then后边的命令就可以运行。到我们的这个fi,可以去结束我们的这个if的一个语句。
使用if-then 语句
-
if-then语句的基本用法
if [ 测试条件成立 ] 或 命令返回值是否为0
then 执行相应命令
fi 结束
那在这儿我们来去演示一下,给大家看一下if该去如何使用。这边我们之前掌握了这个test,那在这儿我们可以做一个判断,怎么判断呢?例如我想判断一下当前的用户是谁,那这边有两种方法?一种是判断我们的用户的UID,如果是root的话,那它的UID一定是0是吧?那这边你就可以判断一下UID是不是等于0。

还有一种判断方法什么呢?那这边我们的这个\(USER变量是表示你当前的用户名称,所以我们经常会在这个系统脚本当中就看到,有人判断的是\)UID,有人判断的是$USER。那两种其实是一种用法。
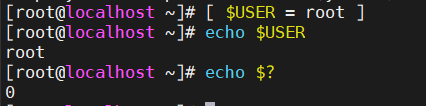
那么在if里面怎么写呢?那我们写法就是if加上我们的这个上面的测试。例如我们当前是root用户吧,那就是if [ $UID = 0 ]。然后那如果我们的用户是root的话,那么这边就挨个去显示一些信息是吧?显示什么呢?root user.
结束我们的if的话,我们可以用一个fi来去结束。那当前确实是root用户是吧?所以我们的这个判断它的返回结果就是root user。那如果是非root的话,那我会怎么样显示呢?咱们在这可以去切换一个用户,例如我们切换到user1,切换完成之后,我们同样去执行刚才的这样一个脚本。
我写同样的程序,但是这回我们的UID是不等于零的。所以在里边的话它没有执行这个echo " root user "这样的一句话,那这个就是我们使用if,然后后边加上这个test判断。

好,那这边我们说了if,后边我们还可以去增加命令是吧?那这个怎么写呢?我们这边可以用一个大家比较熟悉的叫pwd命令。那这个为什么用它呢?因为这条命令它是一定会执行成功的吧?这边我们的pwd命令执行了,然后这条命令是执行成功的,所以下面会显示pwd running。

在这儿我们去找一条不存在的任意的命令,比如说我们叫做abc这样的命令。在这儿我们看到这个if命令是可以写成一行的,是吧?那边我们的if abc,我们是没有这样的一条命令的,所以这条命令会执行失败。那在这儿then后边的echo也不会进行显示。
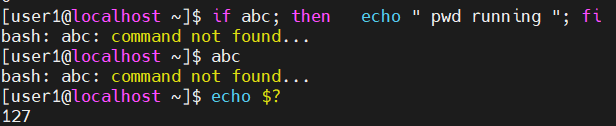
正如我们所猜想到的这样,那abc会报一个错误,没找到这条命令。由于命令执行失败,返回的结果是非零的。所以我们的if后边跟着的这条指令就没有被运行。
一些小知识
关于开机
BIOS(基本输入/输出系统)是一种位于计算机主板上的固件程序,它负责初始化硬件设备,并提供基本的输入和输出功能。BIOS启动时会进行自检(Power-On Self-Test, POST),也称为开机自检,用于检测主板、处理器、内存和其他硬件设备是否正常工作。开机自检会显示一系列的信息和错误代码,以帮助诊断计算机硬件问题,并确保系统在正常运行之前进行必要的配置和初始化。
关于安全关机
sync 将数据由内存同步到硬盘中。
shutdown 关机指令,你可以man shutdown 来看一下帮助文档。例如你可以运行如下命令关机:
shutdown –h 10 ‘This server will shutdown after 10 mins’ 这个命令告诉大家,计算机将在10分钟后关机,并且会显示在登陆用户的当前屏幕中。
shutdown –h now 立马关机
shutdown –h 20:25 系统会在今天20:25关机
shutdown –h +10 十分钟后关机
shutdown –r now 系统立马重启
shutdown –r +10 系统十分钟后重启
reboot 就是重启,等同于 shutdown –r now
halt 关闭系统,等同于shutdown –h now 和 poweroff
不管是重启系统还是关闭系统,首先要运行 sync 命令,把内存中的数据写到磁盘中。
忘记root密码了怎么办
请看下面
https://www.runoob.com/linux/linux-forget-password.html
一些疑问
硬链接和软连接的区别
- 软链接是指向另一个文件或目录的快捷方式,可以跨越文件系统边界,删除软链接不会影响目标文件或目录。
- 硬链接是同一文件的多个别名,所以修改一个链接文件会影响原始文件,硬链接只能在同一文件系统中创建,删除任一链接文件不会影响其他链接和原始文件。
为什么linux内核不能从CMD本身知道谁是什么进程?
Linux内核通过进程标识符(PID)来唯一标识每个进程。每当启动一个新进程时,内核都会为其分配一个唯一的PID。因此,内核可以通过PID来识别和操作不同的进程。
但是,内核本身并不会知道具体进程的名称或其他详细信息,因为进程的名称和其他属性是由用户空间的进程管理工具(如shell)设置和管理的,而不是由内核直接控制。内核主要负责管理进程的调度、资源分配等核心任务,而不负责处理用户态的进程属性。
用户态的进程管理工具可以使用特定的系统调用(如
ps命令)来查询内核,获取有关进程的详细信息,包括名称、资源使用情况、状态等。这些工具通过与内核进行通信,收集并显示有关进程的信息。因此,内核通过PID提供了一种标识和管理进程的机制,但具体的进程属性由用户态工具进行管理和展示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号