从零开始编写一个 Python 异步 ASGI WEB 框架
从零开始编写一个 Python 异步 ASGI WEB 框架
前言
本着 「路漫漫其修远兮,吾将上下而求索」 的精神,这次要和朋友们分享的内容是《从零开始编写一个 Python 异步 ASGI WEB 框架》。
近来,我被 Python 的异步编程深深吸引,花了两个多月的时间研究了大量资料并阅读了一些开源框架的源代码,受益匪浅。
在工作中,我常常忘记特定框架提供的方法,也不愿意频繁查看官方文档,因此我决定尝试自己编写一个简单的异步 WEB 框架,以满足我这懒惰的心态和对并不复杂的业务需求。
在我准备开始编写异步 WEB 框架之际,我曾对 aiohttp 抱有近乎崇拜的情感。
本着 "膜拜, 学习, 借鉴" 的精神,我克隆了 aiohttp 的源代码。然而,让我感到惊讶的是,aiohttp 并不是基于 ASGI 实现的 WEB 服务器。
这意味着在学习 aiohttp 构建自己的 WEB 框架时,我必须从 asyncio 提供的底层 TCP 套接字一步一步地实现 HTTP 协议。
对我当时而言,这显得有点繁琐。因此,在深思熟虑后,我决定基于 ASGI 协议编写我的首个 WEB 框架。
这篇文章大致总结了我从零开始到目前已经完成的工作,对于那些对 Python WEB 或异步编程有兴趣或希望更深入了解的朋友们来说,应该会有所帮助。
该文章可分为两大部分:前置知识和框架编写实践。
在前置知识部分,我将介绍一些基本概念,如 WSGI、ASGI 等,以帮助初学者更好地理解这些概念。
在框架编写实践部分,我将着重介绍代码编写过程中的思考,而不过多涉及具体的实现细节。
如果您感兴趣,可以在 GitHub 上克隆我的框架源代码,结合本文阅读,相信您将获益良多。
前置知识
认识 WSGI
如果您曾学习过像 Django、Flask 这样在 Python 中非常著名的 WEB 框架,那么您一定听说过 WSGI。
实际上,WSGI 是一种规范,它使得 Python 中的 WEB 服务器和应用程序解耦,让我们在编写应用程序时更加方便、高效,也更具通用的可移植性。
例如,下面是一个快速使用 Python 内置模块 wsgiref 处理 HTTP 请求的示例:
def simple_wsgi_app(environ, start_response):
# 设置响应状态和头部
status = '200 OK'
headers = [('Content-type', 'text/plain')]
start_response(status, headers)
# 返回响应内容
return [b'Hello, World!']
if __name__ == '__main__':
from wsgiref.simple_server import make_server
# 创建WSGI服务器
with make_server('', 8000, simple_wsgi_app) as httpd:
print("Serving on port 8000...")
httpd.serve_forever()
在这里,我们使用 wsgiref 提供的 make_server 创建了一个简单的 WEB 服务器,并传入一个应用程序 simple_wsgi_app (这是一个函数)。
在运行代码时,WSGI 服务器会监听 8000 端口。一旦有请求到达,它将自动执行 simple_wsgi_app 函数,该函数只是简单地返回响应内容。
尽管这段代码相对简单,但对于初学者可能仍有一些疑惑。
例如,应用程序在哪里?
实际上,WSGI 协议规定:一个应用程序接口只是一个 Python 可调用对象,它接受两个参数,分别是包含 HTTP 请求信息的字典(通常称为 environ)和用于发送 HTTP 响应的回调函数(通常称为 start_response)。
因此,在使用 WSGI 协议编写代码时,我们只需要关注如何处理业务层面的信息(即如何处理请求和返回响应),而无需过多关心底层细节。
认识 ASGI
随着 Python 异步技术的兴起,WSGI 慢慢失去了原有的光彩。这主要由以下两个不足之处导致:
- WSGI 是同步的,当一个请求到达时,WSGI 应用程序会阻塞处理该请求,直到完成并返回响应,然后才能处理下一个请求。
- WSGI 只支持 HTTP 协议,只能处理 HTTP 请求和响应,不支持 WebSocket 等协议。
因此,Django 开发团队提出并推动了 ASGI 的构想和发展。相对于 WSGI,ASGI 的优势在于:
- 纯异步支持,这意味着基于 ASGI 的应用程序具有无与伦比的性能。
- 长连接支持,ASGI 原生支持 WebSocket 协议,无需额外实现独立于协议的功能。
ASGI 的目标是最终取代 WSGI,但目前 Python 的异步生态并不够成熟,因此这是一个充满希望但漫长的过程。
鉴于目前 Python 的内置模块中没有提供 ASGI 协议的服务器实现。因此,我们可以选择一些第三方模块,如:
- uvicorn: FastApi 选择的 ASGI 服务器实现
- hypercorn: Quart 选择的 ASGI 服务器实现
- granian: 一款使用 Rust 的 Python ASGI 服务器实现
实际上,对于这些繁多的 ASGI 服务器实现选择并不需要太过纠结,因为对于编写应用程序的我们来说,它们的用法都是相似的。
以下是一个基于 uvicorn 的 ASGI 应用程序的最小可运行示例代码:
async def app(scope, receive, send):
if scope['type'] == 'http':
# 设置响应状态和头部
await send({
'type': 'http.response.start',
'status': 200,
'headers': [
[b'content-type', b'text/plain'],
],
})
# 返回响应内容
await send({
'type': 'http.response.body',
'body': b'Hello, world!',
})
if __name__ == '__main__':
from uvicorn import run
run(app="setup:app")
可以看到,ASGI 应用程序的编写方式与 WSGI 应用程序非常相似,它们的目的是相同的,即让我们编写应用程序更加方便。
ASGI 应用程序是一个异步可调用对象,接受三个参数:
- scope: 链接范围字典,至少包含一个 type 表明协议类型
- receive: 一个可等待的可调用对象,用于读取数据
- send: 一个可等待的可调用对象,用于发送数据
要使用 ASGI 协议编写应用程序,最关键的是要理解这一协议的具体规范。
因此,强烈建议对此感兴趣的朋友先阅读官方文档中的介绍。
在这里,我简要提取了一些重要信息。
首先,scope 非常重要,它包含一个 type 字段,目前常见的值有 3 个,分别是 http、websocket、lifespan 等。
lifespan 基础介绍
在 Application 运行后,lifespan 会率先执行。它是 ASGI 提供的生命周期 hooks,可用于在 Application 启动和关闭时执行一些操作。
以下是一个简单的示例:
async def startup():
# 回调函数,在服务启动时
print("Startup ...")
async def shutdown():
# 回调函数,在服务关闭时
print("Shutdown ...")
async def app(scope, receive, send):
if scope["type"] == "http":
pass
elif scope["type"] == "websocket":
pass
elif scope["type"] == "lifespan":
# 每次 Application 被动运行,都会启动一个新的 asyncio task,因此无需担心阻塞主协程
while True:
message = await receive()
# 应用程序启动了
if message["type"] == "lifespan.startup":
try:
await startup()
# 反馈启动完成
await send({"type": "lifespan.startup.complete"})
except Exception as exc:
# 反馈启动失败
await send({"type": "lifespan.startup.failed", "message": str(exc)})
# 应用程序关闭了
elif message["type"] == "lifespan.shutdown":
try:
await shutdown()
# 反馈关闭完成
await send({"type": "lifespan.shutdown.complete"})
except Exception as exc:
# 反馈关闭失败
await send({"type": "lifespan.shutdown.failed", "message": str(exc)})
finally:
break
if __name__ == "__main__":
from uvicorn import run
run("setup:app", lifespan=True)
Lifespan 的应用非常广泛,通常我们会在 shutdown 阶段关闭一些资源,比如 aiohttp 的 session、数据库的连接池等等。
恰当地使用 lifespan 可以让您的 WEB 框架更加灵活和具有更大的扩展性。
http 的 scope
当一个 HTTP 请求到来时,其 scope 是什么样的呢?让我们来看一下下面的代码块,或者您也可以查阅 官方文档 HTTP 的 scope 部分:
{
'type': 'http',
'asgi': { # ASGI 协议版本
'version': '3.0',
'spec_version': '2.3'
},
'http_version': '1.1', # HTTP 协议版本
'server': ('127.0.0.1', 5000), # 服务器的主机和端口
'client': ('127.0.0.1', 51604), # 本次请求的客户端的主机和端口
'scheme': 'http', # URL 的 scheme 部分,可以是 http 或 https,但肯定不为空
'method': 'GET', # 请求方法
'root_path': '', # 类似于 WSGI 的 SCRIPT_NAME
'path': '/index/', # 请求路径
'raw_path': b'/index/', # 原始请求路径
'query_string': b'k1=v1&k2=v2', # 请求字符串
'headers': [ # 请求头
(b'host', b'127.0.0.1:5000'),
(b'user-agent', b'Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/117.0'),
(b'accept', b'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8'),
(b'accept-language', b'en-US,en;q=0.5'),
(b'accept-encoding', b'gzip, deflate, br'),
(b'connection', b'keep-alive'),
(b'upgrade-insecure-requests', b'1'),
(b'sec-fetch-dest', b'document'),
(b'sec-fetch-mode', b'navigate'),
(b'sec-fetch-site', b'cross-site')
],
'state': {}
}
很显然,ASGI 服务器已经对请求信息进行了初步过滤,这使得我们可以在 Application 中灵活地利用这些信息。
开始编写框架
编写框架前的思考
在着手编写框架之前,良好的前期设计将省去许多麻烦。在编写这个框架时,我首先思考了一个请求的生命周期是什么样的?
这导致了下面这张图的产生:
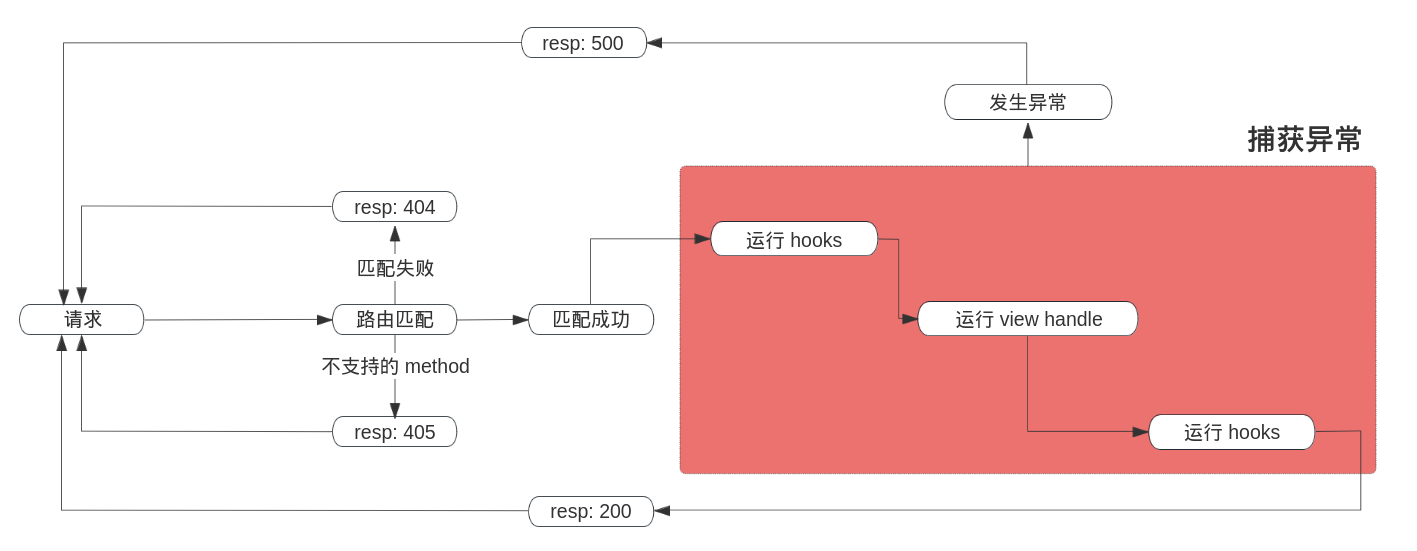
由于 ASGI 协议仅提供了相对基本的功能,因此在这之上还需要考虑很多事情,如:
- 路由器如何实现?
- 如何读取表单数据?
- 请求对象应该如何实现?
- 钩子函数应该如何设计?
- 是否需要支持 ORM?
- 是否需要支持模板引擎?
- 是否需要支持基于类的视图?
- 是否需要支持信号处理?
关于第一点,路由功能,我选择使用第三方模块 http-router,它是一个非常简单但实用的模块,提供了子路由、动态参数、正则匹配、标签转换、严格模式等常见功能。
它满足了我大部分需求,至少在目前阶段我很满意。如果后续有不满意之处,我可能会基于该模块进行扩展或自己实现一些功能(例如添加路由别名功能)。
关于第二点,表单数据如何读取,实际上,不仅是表单数据,包括上传文件的读取,本身都是一项繁琐且枯燥的工作。因此,我选择使用 python-multipart 模块来快速实现这个功能。
唯一的小遗憾是,该模块只支持同步语法,但这并不是大问题。由于 Python 异步生态目前并不成熟,故很多异步框架中也使用了同步的第三方模块或其他同步解决方案。所以只要设计得当,同步语法对性能的影响并不会像我们想象的那么大。
关于第三点,请求对象如何实现,我非常欣赏 Flask 中的 request 对象采用的上下文方式。相对于传统的将 request 实例传递给视图处理函数,上下文方式更加灵活且优雅。不过,实现上下文方式会有一定的难度,框架内部如何实现和使用上下文将是一个有挑战性的问题。
关于第四点,钩子函数的设计,我参考了 Flask、FastAPI 和 Django 中的钩子函数设计。我认为钩子函数越简单越好,因此目前除了 ASGI 的生命周期钩子外,我只想实现 exception、after_request 和 before_request 这三个钩子函数。
关于第五点,是否需要支持 ORM,我认为一个出色的 WEB 框架应该具备良好的可扩展性。目前,Python 异步生态中有许多异步 ORM 的选择,它们应该以插件的形式嵌入到 WEB 框架中,而不是 WEB 框架应提供的必备功能之一。
关于第六点,是否需要支持模板引擎,我的观点与第五点类似。特别是在现代的前后端分离方案中,模板引擎是一项锦上添花的功能,不一定是必需的。另一方面是我工作的原因,我已经有很多年没有编写过模板代码了,综合考虑来看对于这一点的结果我是持否定意见的。
关于第七点,是否需要支持基于类的视图,我认为这是必须的。这应该是一款出色的 WEB 框架必须提供的选项之一,无论是后期需要实现 RESTful API 还是其他需求,它都应该是必需的。
关于第八点,是否需要支持信号处理,我仍然认为这是必需的。但这是一个后期的实现点,当有业务需求不得不使用信号处理进行回调时(例如保证双写一致性时),信号回调是高效且有用的方法,它非常方便。
让我们开始编写 Application
Application 应当尽量保持简单,因此它本身只需要实现非插件提供的 3 个主要功能:
- 提供一个初始化方法,用于保存第三方插件或一些用户的设置信息等。
- 将不同的 ASGI scope type 分发到不同的 HandleClass 中。
- 提供一个 run 函数用以启动服务。
如下所示:
...
from uvicorn import run as run_server
...
class Application:
def __init__(self, name, trim_last_slash=False):
# trim_last_slash 是否严格匹配路由,这是插件带来的功能,这里透传一下
self.name = name
# 忽略、事件管理器的实现
self.event_manager = EventManager()
# 忽略、Router 的实现
self.router = Router(trim_last_slash)
self.debug = False
async def __call__(self, scope: AsgiScope, receive: AsgiReceive, send: AsgiSend):
# 这里主要是对不同的 scope type 做出处理
# 为什么是 __call__ 方法中编写呢?因为一个 instance object 对象加括号调用就会
# 自动执行其 __call__ 方法
if scope["type"] == "http":
asgi_handler = AsgiHttpHandle(self)
elif scope["type"] == "websocket":
asgi_handler = AsgiWebsocketHandle(self)
elif scope["type"] == "lifespan":
asgi_handler = AsgiLifespanHandle(self)
else:
raise RuntimeError("ASGI Scope type is unknown")
# 调用 Handle 的 __call__ 方法
await asgi_handler(scope, receive, send)
def run(
self,
app: Optional[str | Type["Application"]] = None,
host: str = "127.0.0.1",
port: int = 5200,
debug: bool = False,
use_reloader: bool = True,
ssl_ca_certs: Optional[str] = None,
ssl_certfile: Optional[str] = None,
ssl_keyfile: Optional[str] = None,
log_config: Optional[Union[Dict[str, Any], str]] = LOGGING_CONFIG,
**kwargs: Any
):
# 该方法主要是对 uvicorn 的 run_server 做了一层高级封装
# 打印一些信息、做出一些合理设置等等
# 让用户能更快速的启动整个框架
self.debug = debug
app = app or self
# 打印一些启动或者欢迎语句,看起来更酷一点
terminal_width, _ = shutil.get_terminal_size()
stars = "-" * (terminal_width // 4)
scheme = "https" if ssl_certfile is not None and ssl_keyfile is not None else "http"
print(f"* Serving Razor app '{self.name}'")
print(f"* Please use an ASGI server (e.g. Uvicorn) directly in production")
print(f"* Debug mode: {self.debug or False}")
print(f"* Running on \033[1m{scheme}://{host}:{port}\033[0m (CTRL + C to quit)")
# uvicorn 中若启用热重载功能,则 app 必须是一个 str 类型
# 如果是在非 debug 模式下,我会自动关闭掉热重载功能
if not isinstance(app, str) and (use_reloader or kwargs.get("workers", 1) > 1):
if not self.debug:
print("* Not in debug mode. Automatic reloading is disabled.")
else:
print("* You must pass the application as an import string to enable 'reload' or " "'workers'.")
use_reloader = False
print(stars)
# 启动 uvicorn 的 WEB Server 当有请求到来时会自动执行 __call__ 方法
# 因为我们传入的 Application 是当前的实例对象 self,
run_server(
app,
host=host,
port=port,
reload=use_reloader,
ssl_certfile=ssl_certfile,
ssl_keyfile=ssl_keyfile,
ssl_ca_certs=ssl_ca_certs,
log_config=log_config,
**kwargs
)
此外,还有一些第三方插件的二次封装方法:
class Application:
...
def route(self, *paths, methods=None, **opts):
"""
Normal mode routing
Simple route:
- @app.route('/index')
Dynamic route:
- @app.route('/users/{username}')
Converter route:
- @app.route('/orders/{order_id:int}')
Converter regex route:
- @app.route('/orders/{order_id:\\d{3}}')
Multiple path route:
- @app.route('/doc', '/help')
Class-Based View it will be processed automatically:
- @app.route('/example')
class Example:
...
"""
# 这个方法主要是透传到 self.router 中,不对数据源做任何处理
return self.router.route(*paths, methods=methods, **opts)
def re_route(self, *paths, methods=None, **opts):
"""
Regex mode routing
@app.re_route('/regexp/\\w{3}-\\d{2}/?')
"""
# 同上
return self.route(
*(re.compile(path) for path in paths),
methods=methods,
**opts
)
def add_routes(self, *routes):
"""
Add routing relationship mappings in
事件管理器的实现
事件管理器的实现较为简单,但十分有效。大道至简,不必花里胡哨:
from .exceptions import RegisterEventException
# 支持的被注册事件
EVENT_TYPE = (
# lifespan event
"startup",
"shutdown",
# http event
"after_request",
"before_request",
# exception event
"exception"
)
class EventManager:
def __init__(self):
self._events = {}
def register(self, event: str, callback):
# 如果尝试注册的事件不在支持的事件列表中,直接抛出异常
if event not in EVENT_TYPE:
raise RegisterEventException(f"Failed to register event `{event}`; event is not recognized.")
# 同一事件不允许重复注册
if event in self._events:
raise RegisterEventException(f"Failed to register event `{event}`; callback is already registered.")
self._events[event] = callback
async def run_callback(self, event, *args, **kwargs):
# 若事件已注册,运行事件的回调函数并返回调用结果
# 这个函数被设计得更像一个通用、泛型的接口函数,能够运行各种类型的回调
# 这样的设计对于类型提示可能稍显复杂
callback = self._events.get(event)
if callback:
return await callback(*args, **kwargs)
这个简洁而强大的事件管理器为框架提供了可扩展性和可自定义性,允许该框架使用者轻松注册和执行各种事件的回调函数。
不同 type 对应的 HandleClass
在 Application 的 __call__ 方法中,我会对不同的 scope type 进行不同的处理。结合上文的生命周期流程图来看会更加清晰:
import functools
from typing import TYPE_CHECKING
from .logs import logger
from .response import Response, ErrorResponse, HTTPStatus
from .types import AsgiScope, AsgiReceive, AsgiSend, AsgiMessage
from .exceptions import NotFoundException, InvalidMethodException
if TYPE_CHECKING:
from .application import Application
class AsgiLifespanHandle:
def __init__(self, app: "Application"):
self.app = app
async def __call__(self, scope: AsgiScope, receive: AsgiReceive, send: AsgiSend):
# 1. 对于生命周期处理,如应用程序启动和关闭
while True:
message = await receive()
if message["type"] == "lifespan.startup":
asgi_message = await this._callback_fn_("startup")
await send(asgi_message)
elif message["type"] == "lifespan.shutdown":
asgi_message = await this._callback_fn_("shutdown")
await send(asgi_message)
break
async def _callback_fn_(self, event: str) -> AsgiMessage:
# 2. 直接调用事件管理器的 run_callback 运行回调函数
try:
await this.app.event_manager.run_callback(event)
except Exception as exc:
return {"type": f"lifespan.{event}.failed", "message": str(exc)}
return {"type": f"lifespan.{event}.complete"}
class AsgiHttpHandle:
def __init__(self, app: "Application"):
self.app = app
def _make_context(self, scope: AsgiScope, receive: AsgiReceive, send: AsgiSend):
# 2. 封装上下文,类似于 Flask 封装 request 和当前应用程序
# 这使得以后可以直接从 razor.server 导入 request 进行调用
from .context import ContextManager
return ContextManager(this.app, scope, receive, send)
async def _run_handler(self, handle):
# 4. 运行 before_request 的事件回调函数
await this.app.event_manager.run_callback("before_request")
# 5. 运行视图处理程序
handle_response = await handle()
# 6. 如果视图处理程序的返回结果是 Response,则运行 after_request 的事件回调函数
if isinstance(handle_response, Response):
callback_response = await this.app.event_manager.run_callback("after_request", handle_response)
# 7. 如果 after_request 的回调函数返回结果是 Response,则直接返回响应
if isinstance(callback_response, Response):
return callback_response
# 8. 否则返回视图处理程序的返回结果
return handle_response
# 9. 如果视图处理程序的返回结果不是 Response,则返回一个 500 错误的响应对象
logger.error(
f"Invalid response type, expecting `{Response.__name__}` but getting `{type(handle_response).__name__}`")
return ErrorResponse(status_code=HTTPStatus.INTERNAL_SERVER_ERROR)
async def __call__(self, scope: AsgiScope, receive: AsgiReceive, send: AsgiSend):
# 1. 处理 HTTP 请求
ctx = this._make_context(scope, receive, send)
ctx.push()
path, method = scope["path"], scope["method"]
try:
# 3. 匹配路由
match = this.app.router(path, method)
match.target.path_params = match.params or {}
# 可能的结果:
# - 视图处理程序的响应
# - after_request 回调的响应
# - 500 错误的 ErrorResponse
response = await this._run_handler(functools.partial(match.target, **match.target.path_params))
except NotFoundException as exc:
# 路由未匹配到
response = ErrorResponse(HTTPStatus.NOT_FOUND)
except InvalidMethodException as exc:
# 不支持的 HTTP 方法
response = ErrorResponse(status_code=HTTPStatus.METHOD_NOT_ALLOWED)
except Exception as exc:
# 抛出异常后运行异常的事件回调函数
logger.exception(exc)
response = await this.app.event_manager.run_callback("exception", exc)
# 如果异常事件回调函数的结果类型不是 Response,则返回一个 500 错误的 ErrorResponse
if not isinstance(response, Response):
response = ErrorResponse(status_code=HTTPStatus.INTERNAL_SERVER_ERROR)
finally:
# 这是进行响应
await response(scope, receive, send)
# 清理上下文
ctx.pop()
class AsgiWebsocketHandle:
def __init__(self, app: "Application"):
self.app = app
async def __call__(self, scope: AsgiScope, receive: AsgiReceive, send: AsgiSend):
pass
这些处理程序类为不同类型的 ASGI scope 提供了处理请求的方法,从应用程序生命周期事件管理到 HTTP 请求处理和 WebSocket 处理。
它们与事件管理器一起构成了一个完整的框架,为应用程序的核心功能提供了基本的支持。
关于 context 的处理
在这个我实现的框架中,对于 HTTP 请求的处理流程里,第一步是封装上下文。
具体的上下文封装实现与 Flask 中封装请求的过程非常相似,但更加简洁。
import contextvars
from typing import Any, List, Type, TYPE_CHECKING
from .request import Request
from .types import AsgiScope, AsgiReceive, AsgiSend
from .globals import _cv_request, _cv_application
if TYPE_CHECKING:
from .application import Application
class Context:
def __init__(self, ctx_var: contextvars.ContextVar, var: Any) -> None:
"""
初始化上下文对象
Args:
ctx_var (contextvars.ContextVar): 上下文变量
var (Any): 存储在上下文中的对象
"""
self._var = var
self._ctx_var = ctx_var
self._cv_tokens: List[contextvars.Token] = []
def push(self) -> None:
"""
推入上下文对象到上下文栈
"""
self._cv_tokens.append(
self._ctx_var.set(self._var)
)
def pop(self) -> None:
"""
从上下文栈中弹出上下文对象
"""
if len(self._cv_tokens) == 1:
token = self._cv_tokens.pop()
self._ctx_var.reset(token)
class ApplicationContext(Context):
def __init__(self, app):
"""
初始化应用程序上下文对象
Args:
app: 应用程序实例
"""
self._app = app
super().__init__(
ctx_var=_cv_application,
var=self._app
)
class RequestContext(Context):
def __init__(self, scope: AsgiScope, receive: AsgiReceive, send: AsgiSend):
"""
初始化请求上下文对象
Args:
scope (AsgiScope): ASGI作用域
receive (AsgiReceive): 接收函数
send (AsgiSend): 发送函数
"""
self._request = Request(scope, receive, send)
super().__init__(
ctx_var=_cv_request,
var=self._request
)
class ContextManager:
def __init__(self, app: "Application", scope: AsgiReceive, receive: AsgiReceive, send: AsgiSend) -> None:
"""
初始化上下文管理器
Args:
app (Application): 应用程序实例
scope (AsgiReceive): ASGI作用域
receive (AsgiReceive): 接收函数
send (AsgiSend): 发送函数
"""
self._ctxs_: List[Type[Context]] = [
ApplicationContext(app),
RequestContext(scope, receive, send),
]
def push(self) -> None:
"""
将上下文对象推入上下文栈
"""
for _ctx in self._ctxs_:
_ctx.push()
def pop(self) -> None:
"""
从上下文栈中弹出上下文对象
"""
for _ctx in self._ctxs_:
_ctx.pop()
接下来是 globals 模块中的代码实现:
from contextvars import ContextVar
from .proxy import LocalProxy
from .request import Request
from .application import Application
# 上下文变量, 用于保存当前的请求和应用实例对象
_cv_request: ContextVar = ContextVar("razor.request_context")
_cv_application: ContextVar = ContextVar("razor.application_context")
# 代理变量,用于被 import 导入
request: Request = LocalProxy(_cv_request, Request)
current_application: Application = LocalProxy(_cv_application, Application)
核心的 proxy 代码实现基本和 Flask 一样:
import operator
from functools import partial
from contextvars import ContextVar
class _ProxyLookup:
def __init__(self, f):
# `f`是`getattr`函数
def bind_f(instance: "LocalProxy", obj):
return partial(f, obj)
self.bind_f = bind_f
def __get__(self, instance: "LocalProxy", owner: Type | None = None):
# `instance`是`LocalProxy`,调用其下的`_get_current_object`方法
# 会得到上下文变量中存的具体对象,如`Request`实例对象,或者
# `Application`实例对象
# 然后会返回`bind_f`
obj = instance._get_current_object()
return self.bind_f(instance, obj)
def __call__(self, instance: "LocalProxy", *args, **kwargs):
# `bind_f`中由于给`getattr`绑定了偏函数, 所以
# `getattr`的第一个参数始终是具体的上下文变量里存的对象
# 而`*args`中包含本次需要 . 访问的方法名称
# 这样就完成了代理的全步骤了
return self.__get__(instance, type(instance))(*args, **kwargs)
class LocalProxy:
def __init__(self, local, proxy):
# `local`就是上下文变量`_cv_request`和`_cv_application`
self.local = local
# 这里是代理的具体的类
self.proxy = proxy
def _get_current_object(self):
if isinstance(self.local, ContextVar):
return self.local.get()
raise RuntimeError(f"不支持的上下文类型: {type(self.local)}")
def __repr__(self) -> str:
return f"<{self.__class__.__name__} {self.proxy.__module__}.{self.proxy.__name__}>"
# 以后每次尝试使用 . 方法访问代理变量时,都将触发
# `_ProxyLookup`的`__call__`方法
__getattr__ = _ProxyLookup(getattr)
__getitem__ = _ProxyLookup(operator.__getitem__)
在这一部分,我们重点关注了上下文的处理。我的这个框架通过类似于 Flask 的方式,优雅而高效地封装了请求和应用程序上下文。
通过 Context 类的创建和管理,我们能够轻松地推入和弹出上下文,使请求和应用程序对象的访问变得更加直观和简单。这种设计允许我们在不同部分的应用程序中轻松地获取请求和应用程序对象,提高了代码的可读性和可维护性。
而通过代理机制,我们创建了 LocalProxy 类,使得在整个应用程序中访问上下文变量变得无缝和高效。这让我们的代码更加模块化,有助于减少冗余和提高代码质量。
总之,上下文的处理和代理机制的引入为框架的 HTTP 请求处理提供了强大而简洁的基础。
这将有助于提高框架的性能和可维护性,使开发者更容易创建出高质量的 Web 应用程序。
request 对象的封装
request 在 RequestContext 中会首次实例化,关于其实现过程也较为简单:
import json
from http.cookies import _unquote
from typing import Any, Union, Optional
# MultiDict 是一个特殊的字典
# 在 HTTP 请求中,会有一个 key 对应多个 value 的存在
# MultiDict 提供了 getall() 方法来获取该 key 对应的所有 value
# PS: 这是 1 个第三方库
from multidict import MultiDict
# DEFAULT_CODING 是 utf-8
# DEFAULT_CHARSET 是 latin-1
from .constants import DEFAULT_CODING, DEFAULT_CHARSET
from .forms import parse_form_data, SpooledTemporaryFile
from .types import AsgiScope, AsgiReceive, AsgiSend, AsgiMessage, JsonMapping
class Request:
# Request 对象的属性名使用 __slots__,以提高性能和节省内存
__slots__ = (
"scope",
"receive",
"send",
"_headers",
"_cookies",
"_query",
"_content",
"_body",
"_text",
"_forms",
"_files",
"_json"
)
def __init__(self, scope: AsgiScope, receive: AsgiReceive, send: AsgiSend):
# Request 主要使用 scope 中的数据和 receive 异步函数来读取请求体
self.scope = scope
self.receive = receive
self.send = send
# 懒加载属性
self._content: Optional[MultiDict[str]] = None
self._headers: Optional[MultiDict[str]] = None
self._cookies: Optional[MultiDict[str]] = None
self._query: Optional[MultiDict[str]] = None
self._body: Optional[bytes] = None
self._text: Optional[str] = None
self._json: Optional[JsonMapping] = None
self._forms: Optional[MultiDict[str]] = None
self._files: Optional[MultiDict[SpooledTemporaryFile]] = None
def __getitem__(self, key: str) -> Any:
# 使用 [] 语法可以直接获取 scope 中的资源
return self.scope[key]
def __getattr__(self, key) -> Any:
# 使用 . 语法可以直接获取 scope 中的资源
return self.scope[key]
@property
def content(self) -> MultiDict:
# 解析 content
# 其实 form 表单上传的内容等等都在 content-type 请求头里
# 所以我们这里要在 content-type 请求头中解析出
# content-type charset 以及 boundary( 保存 form 表单数据)
if not self._content:
self._content = MultiDict()
content_type, *parameters = self.headers.get("content-type", "").split(";", 1)
for parameter in parameters:
key, value = parameter.strip().split("=", 1)
self._content.add(key, value)
self._content.add("content-type", content_type)
# 如果请求没有携带 charset,则设置为默认的 CODING
self._content.setdefault("charset", DEFAULT_CODING)
return self._content
@property
def headers(self) -> MultiDict:
# 解析请求头, 将请求头添加到 MultiDict 中
if not self._headers:
self._headers = MultiDict()
for key, val in self.scope["headers"]:
self._headers.add(key.decode(DEFAULT_CHARSET), val.decode(DEFAULT_CHARSET))
self._headers["remote-addr"] = (self.scope.get("client") or ["<local>"])[0]
return self._headers
@property
def cookies(self) -> MultiDict:
# 解析 cookie
if not self._cookies:
self._cookies = MultiDict()
for chunk in self.headers.get("cookie").split(";"):
key, _, val = chunk.partition("=")
if key and val:
# 这里对于 val 必须做一次处理,使用了内置库 http.cookie 中的 _unquote 函数
self._cookies[key.strip()] = _unquote(val.strip())
return self._cookies
@property
def query(self) -> MultiDict:
# 解析查询参数
if not self._query:
self._query = MultiDict()
for chunk in self.scope["query_string"].decode(DEFAULT_CHARSET).split("&"):
key, _, val = chunk.partition("=")
if key and val:
self._query.add(key.strip(), val.strip())
return self._query
async def body(self) -> bytes:
# 读取请求体
if not self._body:
self._body: bytes = b""
while True:
message: AsgiMessage = await self.receive()
self._body += message.get("body", b"")
# 这里可以看具体的 ASGI 协议中关于 HTTP 的部分
# 当 recv 的 message 中, more_body 如果为 False 则代表请求体读取完毕了
if not message.get("more_body"):
break
return self._body
async def text(self) -> str:
# 尝试使用请求的 charset 来解码请求体
if not self._text:
body = await self.body()
self._text = body.decode(self.content["charset"])
return self._text
async def form(self) -> MultiDict:
# 读取 form 表单中的数据
if not self._forms:
self._forms, self._files = await parse_form_data(self)
return self._forms
async def files(self) -> MultiDict[SpooledTemporaryFile]:
# 读取上传的文件数据
if not self._files:
self._forms, self._files = await parse_form_data(self)
return self._files
async def json(self) -> JsonMapping:
# 尝试反序列化出请求体
if not self._json:
text = await self.text()
self._json = json.loads(text) if text else {}
return self._json
async def data(self) -> Union[MultiDict, JsonMapping, str]:
# 通过 content-type 来快速获取请求的内容
content_type = self.content["content-type"]
if content_type == "application/json":
return await self.json()
if content_type == "multipart/form-data":
return await self.form()
if content_type == "application/x-www-form-urlencoded":
return await self.form()
return self.text()
这一节我们深入研究了在框架中如何封装请求对象。Request 对象在 RequestContext 中首次实例化,它提供了简单而有效的方法来访问HTTP请求的各个部分。
首先,Request 对象提供了属性和方法,可以方便地访问请求的内容,包括请求头、cookie、查询参数、请求体、文本、表单数据、文件数据以及 JSON 数据。这些访问方法都是懒加载的,只有在首次访问时才会解析相应的内容,从而提高了性能和效率。
Request 对象的实现通过解析 HTTP 请求的各个部分,将它们以多值字典的形式保存起来,使开发者可以轻松地获取所需的信息。这种封装使得处理 HTTP 请求变得更加直观和方便,降低了编写应用程序的复杂性。
总的来说,Request 对象的封装提供了强大的功能和简洁的接口,使开发者能够轻松地处理各种类型的 HTTP 请求,无需深入处理 HTTP 协议的细节。这为构建高性能和高效的 Web 应用程序提供了坚实的基础。
关于 form 表单的解析
form 表单的解析比较麻烦,主要依赖于第三方库 python-multipart 实现,在此代码中主要是如何调用 Parser 对象,以及其作用是什么。
这里不进行详细讲解,感兴趣的朋友直接查看该库的文档即可,值得注意的地方已经在注释中进行了标记:
import re
from io import BytesIO
from urllib.parse import unquote_to_bytes
from typing import Dict, Tuple, TYPE_CHECKING
if TYPE_CHECKING:
from .request import Request
from multidict import MultiDict
from multipart.multipart import BaseParser, QuerystringParser, MultipartParser
# 需要注意,这里的临时文件并非标准库中的
from .datastructures import SpooledTemporaryFile
def unquote_plus(value: bytearray) -> bytes:
value = value.replace(b"+", b" ")
return unquote_to_bytes(bytes(value))
class FormDataReader:
"""
用于读取除 multipart/form-data 之外的编码格式的数据
比如 application/x-www-form-urlencoded 和其他编码格式
"""
__slots__ = ("forms", "curkey", "curval", "charset", "files")
def __init__(self, charset: str):
self.forms = MultiDict()
self.files = MultiDict()
self.curkey = bytearray()
self.curval = bytearray()
self.charset = charset
def on_field_name(self, data: bytes, start: int, end: int):
# curkey 实际上是最终的字段名
self.curkey += data[start:end]
def on_field_data(self, data: bytes, start: int, end: int):
# curval 实际上是最终的字段值
self.curval += data[start:end]
def on_field_end(self, *_):
# 将 bytearray 转换为 str 并添加到 self.froms 中
self.forms.add(
unquote_plus(self.curkey).decode(self.charset),
unquote_plus(self.curval).decode(self.charset),
)
self.curval.clear()
self.curkey.clear()
def get_parser(self, _: "Request") -> BaseParser:
# 通过 multipart 模块提供的 QuerystringParser 对数据进行解析
return QuerystringParser(
{
"on_field_name": self.on_field_name,
"on_field_data": self.on_field_data,
"on_field_end": self.on_field_end,
},
)
class MultipartReader:
"""
用于读取 multipart/form-data 编码格式的数据
可能包含上传文件等信息
"""
__slots__ = ("forms", "curkey", "curval", "charset", "filed_name", "headers", "filed_data", "files")
def __init__(self, charset: str):
self.forms = MultiDict()
self.files = MultiDict()
self.curkey = bytearray()
self.curval = bytearray()
self.charset = charset
self.headers: Dict[bytes, bytes] = {}
self.filed_name = ""
self.filed_data = BytesIO()
def get_parser(self, request: "Request") -> BaseParser:
# 对于 multipart/form-data 类型的数据,我们需要从内容中获取边界信息
boundary = request.content.get("boundary", "")
if not boundary:
raise ValueError("Missing boundary")
# 通过 multipart 模块提供的 MultipartParser 对数据进行解析
return MultipartParser(
boundary,
{
"on_header_field": self.on_header_field,
"on_header_value": self.on_header_value,
"on_header_end": self.on_header_end,
"on_headers_finished": self.on_headers_finished,
"on_part_data": self.on_part_data,
"on_part_end": self.on_part_end,
}
)
def on_header_field(self, data: bytes, start: int, end: int):
# curkey 不是最终的字段名
self.curkey += data[start:end]
def on_header_value(self, data: bytes, start: int, end: int):
# curval 不是最终的字段值
self.curval += data[start:end]
def on_header_end(self, *_):
# 将 curkey 和 curval 添加到 self.headers 中
self.headers[bytes(self.curkey.lower())] = bytes(self.curval)
self.curkey.clear()
self.curval.clear()
def on_headers_finished(self, *_):
_, options = parse_options_header(
self.headers[b"content-disposition"].decode(self.charset),
)
self.filed_name = options["name"]
# 如果能解析出 filename,则代表本次上传的是文件
if "filename" in options:
# 创建一个 SpooledTemporaryFile 以将文件数据写入内存
self.filed_data = SpooledTemporaryFile()
self.filed_data._file.name = options["filename"]
self.filed_data.content_type = self.headers[b"content-type"].decode(self.charset)
def on_part_data(self, data: bytes, start: int, end: int):
# 将数据写入 filed_data
self.filed_data.write(data[start:end])
def on_part_end(self, *_):
field_data = self.filed_data
# 如果是非文件类型的数据,则将 field_name 和 field_value 添加到 self.forms 中
if isinstance(field_data, BytesIO):
self.forms.add(self.filed_name, field_data.getvalue().decode(self.charset))
else:
# 否则,将文件类型的数据添加到 self.files 中
field_data.seek(0)
self.files.add(self.filed_name, self.filed_data)
self.filed_data = BytesIO()
self.headers = {}
OPTION_HEADER_PIECE_RE = re.compile(
r"""
\s*,?\s* # 换行符被替换为逗号
(?P<key>
"[^"\\]*(?:\\.[^"\\]*)*" # 带引号的字符串
|
[^\s;,=*]+ # 令牌
)
(?:\*(?P<count>\d+))? # *1,可选的连续索引
\s*
(?: # 可能后跟 =value
(?: # 等号,可能带编码
\*\s*=\s* # *表示扩展符号
(?: # 可选的编码
(?P<encoding>[^\s]+?)
'(?P<language>[^\s]*?)'
)?
|
=\s* # 基本符号
)
(?P<value>
"[^"\\]*(?:\\.[^"\\]*)*" # 带引号的字符串
|
[^;,]+ # 令牌
)?
)?
\s*;?
""",
flags=re.VERBOSE,
)
def parse_options_header(value: str) -> Tuple[str, Dict[str, str]]:
"""解析给定的内容描述头。"""
options: Dict[str, str] = {}
if not value:
return "", options
if ";" not in value:
return value, options
ctype, rest = value.split(";", 1)
while rest:
match = OPTION_HEADER_PIECE_RE.match(rest)
if not match:
break
option, count, encoding, _, value = match.groups()
if value is not None:
if encoding is not None:
value = unquote_to_bytes(value).decode(encoding)
if count:
value = options.get(option, "") + value
options[option] = value.strip('" ').replace("\\\\", "\\").replace('\\"', '"')
rest = rest[match.end():]
return ctype, options
async def parse_form_data(request: "Request") -> Tuple[MultiDict, MultiDict]:
"""
由外部提供的函数,用于解析表单数据
获取 froms 表单数据以及文件列表
"""
charset = request.content["charset"]
content_type = request.content["content-type"]
# 1. 根据不同的 content-type 来确定使用哪个 Reader
if content_type == "multipart/form-data":
reader = MultipartReader(charset)
else:
reader = FormDataReader(charset)
# 2. 获取相应的解析器
parser = reader.get_parser(request)
# 3. 将数据写入解析器
parser.write(await request.body())
parser.finalize()
# 4. 返回 froms 和 files
return reader.forms, reader.files
关于文件的处理
在处理 form 表单时使用的 SpooledTemporaryFile 类实际上是经过了封装的,并非直接由 Python 内置模块 tempfile 所提供。
封装的 SpooledTemporaryFile 类位于 datastructures 文件中,代码如下:
import os
from typing import Optional
from tempfile import SpooledTemporaryFile as BaseSpooledTemporaryFile
from aiofiles import open as async_open
class SpooledTemporaryFile(BaseSpooledTemporaryFile):
async def save(self, destination: Optional[os.PathLike] = None):
destination = destination or f"./{self.name}"
dirname = os.path.dirname(destination)
if not os.path.exists(dirname):
os.makedirs(dirname, exist_ok=True)
async with async_open(destination, mode="wb") as f:
for line in self.readlines():
await f.write(line)
如果读者足够细心,那么也应该注意到了该框架在处理文件时有一些不足之处。
它首先将用户上传的文件全部写入内存,然后在后端调用 file.save 方法时,才使用 aiofiles 模块异步的将文件写入磁盘。
更好的方法应该是按需读取文件内容,只有在后端调用 file.save 方法时才将内容直接写入磁盘。然而,由于 python-multipart 是同步库,要实现这一点需要对原模块代码进行一些修改。
如果您对此感兴趣,可以尝试自行实现。
Router 的二次封装
在完成 ctx 的构建后,路由匹配工作就开始了。通过 http-router 模块的强大功能,这一切变得非常简单。不过,我对该模块提供的功能进行了二次封装,以使使用更加便捷。
在此之前,读者可以查看该库的 README 以了解该库的基本用法:
import inspect
from typing import Optional, ClassVar, Type, Tuple, Callable, TYPE_CHECKING
from http_router import Router as HttpRouter
from .exceptions import RouterException, NotFoundException, InvalidMethodException
from .views import View
if TYPE_CHECKING:
from http_router.types import TVObj, TPath, TMethodsArg
class Router(HttpRouter):
# 首先,我们采用自定义的异常类来覆盖内置异常,以便更加方便地导入
RouterError: ClassVar[Type[Exception]] = RouterException
NotFoundError: ClassVar[Type[Exception]] = NotFoundException
InvalidMethodError: ClassVar[Type[Exception]] = InvalidMethodException
def route(
self,
*paths: "TPath",
methods: Optional["TMethodsArg"] = None,
**opts,
) -> Callable[["TVObj"], "TVObj"]:
def wrapper(target: "TVObj") -> "TVObj":
nonlocal methods
# 如果 view handle 是一个类并且是 View 的子类,则
# 调用 View 的 as_view() 方法,这一点和 Django 内部保持一致
if inspect.isclass(target) and issubclass(target, View):
target = target.as_view()
# 否则,表示采用了 FBV 模式,默认 http-router 会添加所有的请求方法
# 但在这里,我希望只默认添加 GET 请求,因此进行了一些修改
else:
methods = methods or ["GET"]
# 添加 OPTIONS 请求主要是为了处理 CORS 的情况
if "OPTIONS" not in methods:
methods.append("OPTIONS")
if hasattr(target, "__route__"):
target.__route__(self, *paths, methods=methods, **opts)
return target
if not self.validator(target):
raise self.RouterError("Invalid target: %r" % target)
target = self.converter(target)
self.bind(target, *paths, methods=methods, **opts)
return target
return wrapper
def add_routes(self, *routes):
# 提供类似于 Django 的 urlpatterns 的功能
# 但在这里,对于 FBV 的处理方式是调用了 super().route() 而非 self.route()
# 即默认允许所有的请求方法
# 同时,这也意味着对于 CBV 必须手动调用 cls.as_view()
for route_rule in routes:
*paths, handle = route_rule
super().route(*paths)(handle)
总结一下,通过对 http-router 模块的二次封装,我实现了更便捷的路由匹配方法。
这个封装还提供了更友好的异常处理,并支持 FBV 和 CBV 模式的统一处理。
response 对象的封装
下面是有关 Response 对象的封装,实现 Response 时,我曾考虑是否按照 FastAPI 的风格来设计。
例如,直接返回一个字典将自动转换为 JSON 格式。
然而,我最终决定不这样做。尽管这可能会增加编写代码时的效率,但同样也会增加维护代码时的可读性和复杂度。
因此,我决定必须显式地调用某个 Response,否则本次请求将返回 500 响应码。
import json
from http import HTTPStatus
from http.cookies import SimpleCookie
from typing import Optional
from urllib.parse import quote_plus
from multidict import MultiDict
from markupsafe import escape # markupsafe 是一个第三方库,用于防止跨站脚本攻击(XSS)
from .types import AsgiScope, AsgiReceive, AsgiSend
from .constants import DEFAULT_CODING, DEFAULT_CHARSET
class Response:
status_code: int = HTTPStatus.OK.value # 默认响应码为 200
content_type: Optional[str] = None
def __init__(self, content, *, status_code=200, content_type=None, headers=None, cookies=None) -> None:
self.status_code = status_code
self.cookies = SimpleCookie(cookies)
self.headers = MultiDict(headers or {})
self.content = self.handle_content(content)
# 处理响应的 content-type 和 charset
content_type = content_type or self.content_type
if content_type:
if content_type.startswith("text/"):
content_type = "{}; charset={}".format(content_type, DEFAULT_CODING)
self.headers.setdefault("content-type", content_type)
def handle_content(self, content):
# 处理响应体的内容,进行编码操作
if not isinstance(content, bytes):
return str(content).encode(DEFAULT_CODING)
return content
async def __call__(self, scope: AsgiScope, receive: AsgiReceive, send: AsgiSend) -> None:
# 这里在不同类型的 HandleClass 中会对 response 实例对象进行 await 操作,
# 实际上也是会调用此 __call__ 方法
# 处理响应头
self.headers.setdefault("content-length", str(len(self.content))
headers = [
(key.encode(DEFAULT_CHARSET), str(val).encode(DEFAULT_CHARSET))
for key, val in self.headers.items()
]
for cookie in self.cookies.values():
headers = [
*headers,
(b"set-cookie", cookie.output(header="").strip().encode(DEFAULT_CHARSET)),
]
# 发送响应头和响应状态
await send({
"type": "http.response.start",
"status": self.status_code,
"headers": headers,
})
# 发送响应体
await send({"type": "http.response.body", "body": self.content})
class TextResponse(Response):
content_type = "text/plain"
class HtmlResponse(Response):
content_type = "text/html"
class JsonResponse(Response):
content_type = "application/json"
# 重写 handle_content 以进行序列化和编码操作
def handle_content(self, content):
return json.dumps(content, ensure_ascii=False).encode("utf-8")
class RedirectResponse(Response):
status_code: int = HTTPStatus.TEMPORARY_REDIRECT.value # 重定向默认是 307 的响应码
def __init__(self, url, status_code: Optional[int] = None, **kwargs) -> None:
self.status_code = status_code or self.status_code
super().__init(
content=b"",
status_code=self.status_code,
**kwargs
)
assert 300 <= self.status_code < 400, f"无效的重定向状态码: {self.status_code}"
self.headers["location"] = quote_plus(url, safe=":/%#?&=@[]!$&'()*+,;")
class ErrorResponse(Response):
content_type = "text/html"
def __init__(self, status_code: int, content=None, **kwargs):
if status_code < 400:
raise ValueError("响应码 < 400")
_o = HTTPStatus(status_code)
# 如果传入了 content,则使用传递进来的 content 作为响应体
# 否则使用内置库 HTTPStatus 的状态码描述信息等返回一个默认的错误页面
content = content or self.get_err_page(_o.value, _o.phrase, _o.description)
super().__init(
content=content,
status_code=status_code,
**kwargs
)
def get_err_page(self, code, name, descript):
# 受到 Werkzeug 模块的启发
# 这里需要使用 markupsafe 中的 escape 进行防止跨站脚本攻击(XSS)的操作,最后返回响应的页面
return (
"<!doctype html>\n"
"<html lang=en>\n"
f"<title>{code} {escape(name)}</title>\n"
f"<h1>{escape(name)}</h1>\n"
f"<p>{escape(descript)}</p>\n"
)
通过对 Response 对象的封装,该框架提供了更加灵活和可控的方式来构建和处理响应。这允许开发者明确地定义响应的状态码、内容类型、头部信息、Cookies 等。
Class-Base-View 的实现
最后一节涉及到了 Class-Base-View 的实现,其实现方式非常简单,参考了 Django 中对 Class-Base-View 的处理方式。
class View:
def __init__(self, **kwargs):
for key, value in kwargs.items():
setattr(self, key, value)
@classmethod
def as_view(cls, **initkwargs):
# 1. 由 as_view 来实例化对象, 并且通过 dispatch 方法找到和本次请求方式一致的方法名称
async def view(*args, **kwargs):
self = cls(**initkwargs)
self.setup(*args, **kwargs)
return await self.dispatch(*args, **kwargs)
view.view_class = cls
view.view_initkwargs = initkwargs
view.__doc__ = cls.__doc__
view.__module__ = cls.__module__
view.__annotations__ = cls.dispatch.__annotations__
view.__dict__.update(cls.dispatch.__dict__)
return view
async def dispatch(self, *args, **kwargs):
from .globals import request
from .response import ErrorResponse, HTTPStatus
if hasattr(self, request.method.lower()):
handler = getattr(self, request.method.lower())
return await handler(*args, **kwargs)
# 2. 若派生类没有实现所请求的方法,则直接返回 code 为 405 的 ErrorResponse
return ErrorResponse(HTTPStatus.METHOD_NOT_ALLOWED)
def setup(self, *args, **kwargs):
if hasattr(self, "get") and not hasattr(self, "head"):
self.head = self.get
通过 Class-Base-View 的实现,开发者可以更轻松地构建基于类的视图,与请求方法一一对应,并实现相应的处理方法。
这种模式可以帮助开发者更好地组织和管理视图逻辑。
结语
这篇文章在此也应当告一段落了,通过这次从零编写一个基于 ASGI 的 WEB 框架,让我感到非常的满足和开心,其一是对于获得新知识的喜悦之情,其二是对于自我成就的满足之感。
但这仅仅是一个开始而已,无论如何我们应当保持充足的热情迎接各种新的事物。
这份自我实现的 WEB 框架我并未上架 pypi,它只是我学习过程中的一个半成品(尽管它可以满足了一些基础业务的需求),并未真正优秀到我会推荐给别人使用。
此外它目前也不支持 WebSocket,若后续有时间和想法对 WebSocket 的 Handle-Class 部分进行了实现,再与诸君一同分享。
最后贴一个该项目 GitHub 地址,希望能对阅读这篇文章的你带来一些正向的影响。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】凌霞软件回馈社区,携手博客园推出1Panel与Halo联合会员
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 工良出品 | 长文讲解 MCP 和案例实战
· 多年后再做Web开发,AI帮大忙
· 国产的 Java Solon v3.2.0 发布(央企信创的优选)
· centos停服,迁移centos7.3系统到新搭建的openEuler
· 记一次 .NET某旅行社酒店管理系统 卡死分析