
hadoop原理
原理讲解:: https://www.cnblogs.com/mmzs/p/8031137.html#_label0_0
Hadoop项目主要包括以下四个模块
◆ Hadoop Common:
为其他Hadoop模块提供基础设施
◆ Hadoop HDFS:
一个高可靠、高吞吐量的分布式文件系统
◆ Hadoop MapReduce:
一个分布式的离线并行计算框架
◆ Hadoop YARN:
一个新的MapReduce框架,任务调度与资源管理
Apache Hadoop起源
◆Apache Lucene
开源的高性能全文检索工具包
◆Apache Nutch
开源的Web搜索引擎
◆Google三大论文
MapReduce/GFS/BigTable
◆Apache Hadoop
大规模数据处理
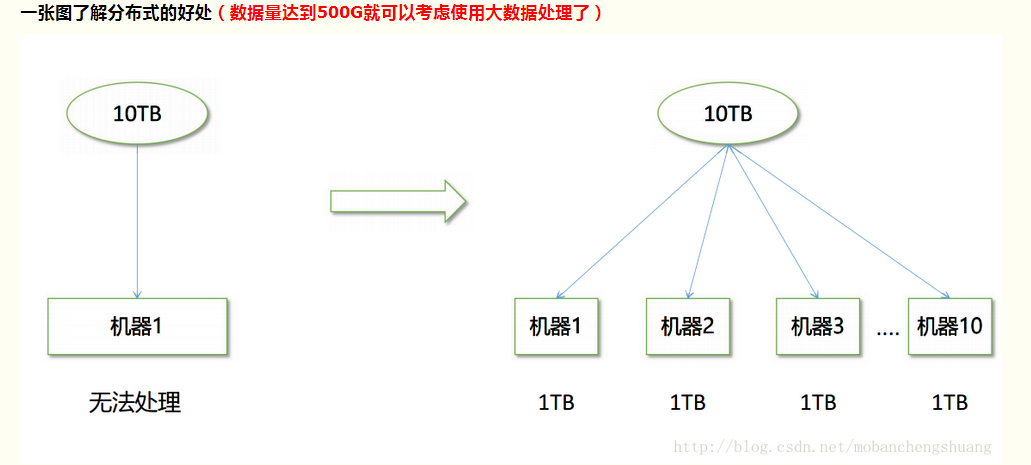
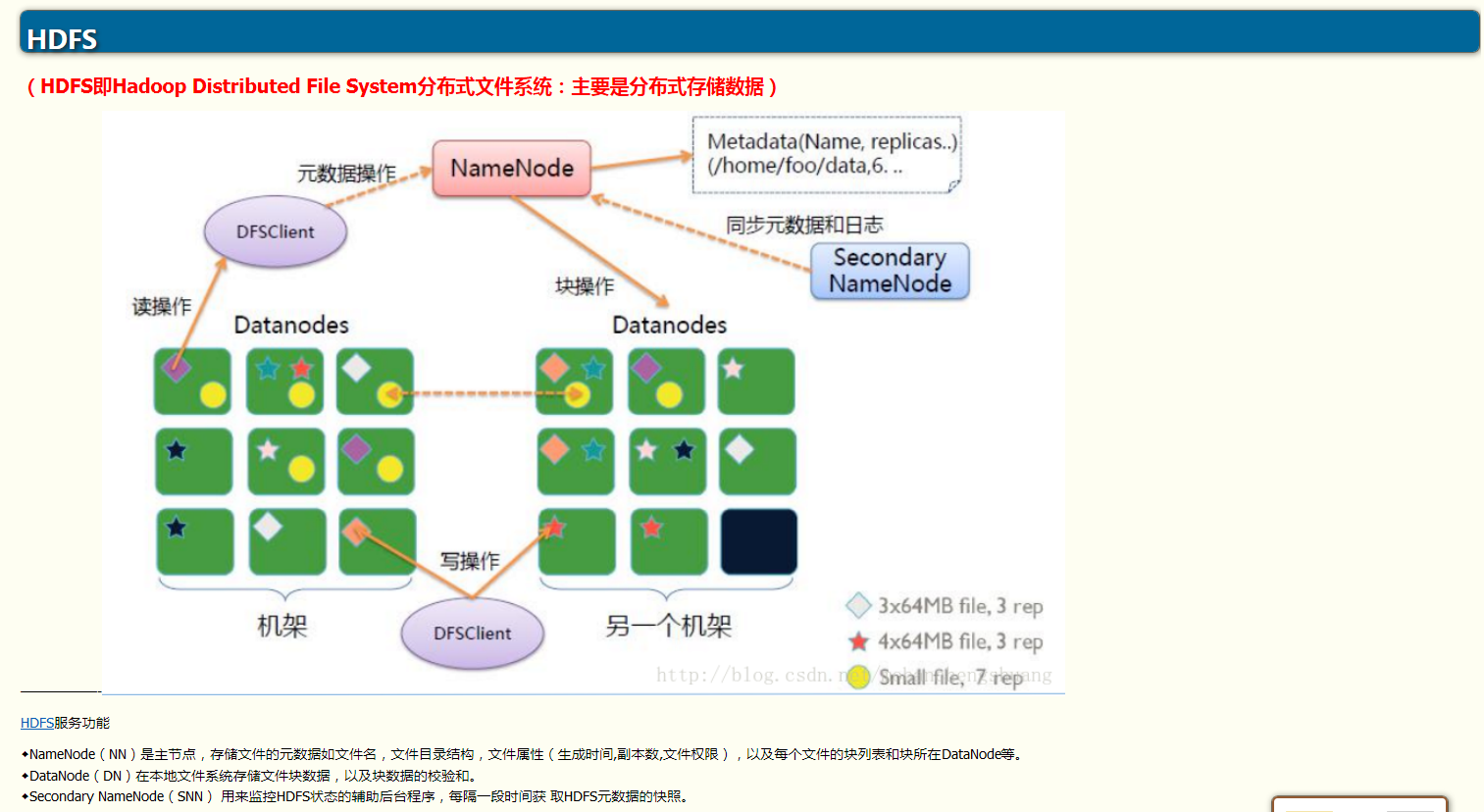
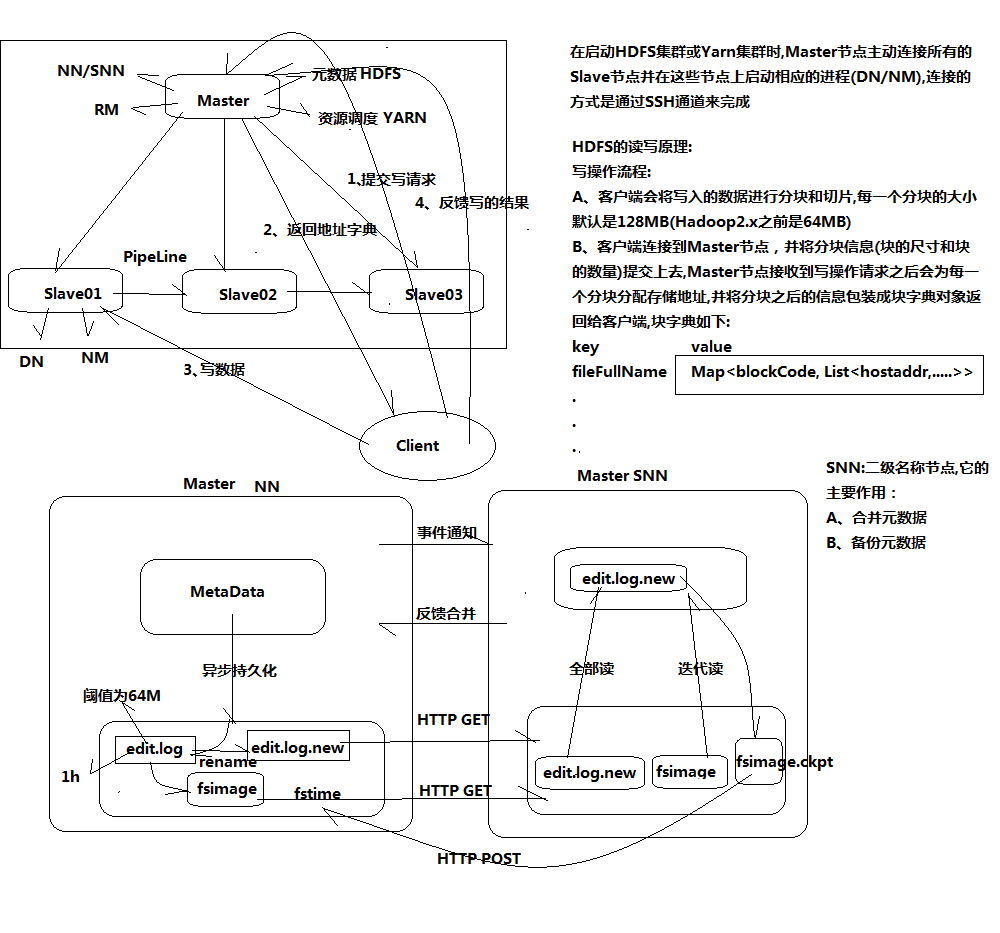


(基于磁盘IO进行迭代,开销较大)
◆将计算过程分为两个阶段:Map和Reduce
Map阶段并行处理输入数据 ;
Reduce阶段对Map结果进行汇总 ;
◆ Shuffle链接Map和Reduce两个阶段(Shuffle通俗的理解就是重新洗牌,打乱原有顺序)
Map Task将数据写到本地磁盘 ;
Reduce Task从每个Map Task上读取一份数据 ;
◆ 仅适合离线批处理
具有很好的容错性和扩展性 ;
适合简单的批处理任务 ;
◆ 缺点明显:
启动开销大,过多使用磁盘导致效率低下等;
map tasks的个数只要是看splitSize,一个文件根据splitSize分成多少份就有多少个map tasks。
该slave节点上有多少个MapTask运行,取决于该slave节点分配到了多少块(一般默认128M);
slave的cpu是几核的会影响MapTask是单线程还是多线程,及其运行效率;
如果它出现问题,挂掉,会将没运行完的块交给其它slave节点重新运算;
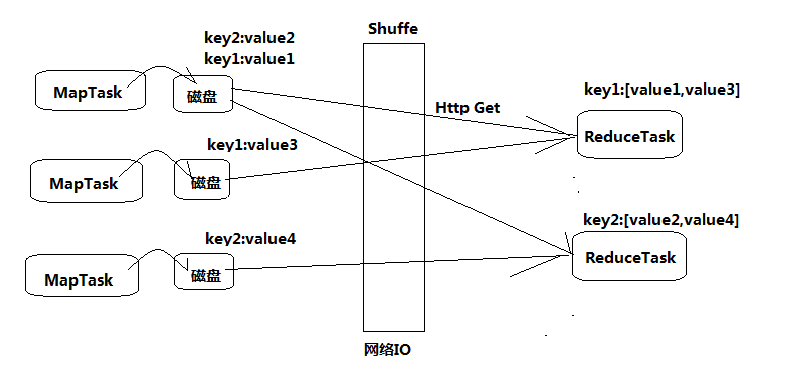
【测试中如果遇到没有输出结果,只有输出目录的情况;那么很可能是犯了小错误;比如:Mapper中的输入键值必须是LongWriteable和Text;outKey和outValue的类型不对,或者没有初始化;Driver类中Job任务没提交;
还有就是读取的文件中的数据在map中字段没有正确对应;数据中有的字段是脏数据,需要处理;导致匹配不成功,从而输出失败。
本文来自博客园踩坑狭,作者:韩若明瞳,转载请注明原文链接:https://www.cnblogs.com/han-guang-xue/p/9886171.html

