
linux 内存管理
linux 内存管理
https://zhuanlan.zhihu.com/p/468829050
内存分区
主要分为权限和分区管理, 分区管理分以下几个区域
分区管理: 主要减少内存碎片, 提升内存的利用率
权限管理: 系统安全
page
文件: include/linux/mm_types.h, struct page
物理页帧: pfn-page frame number, 就是将内存分成固定大小区域称为page
物理页帧和结构体page一一对应
PAGE_SHIFT: 12
PAGE_SIZE:也就是 2^12 = 4096B = 4KB, page大小,可设置
zone
文件: include/linux/mmzone.h, struct zone
node
node: 内存模型, 一个node既一个CPU
UMA: 一致性存储结构, 所有处理机对所有存储字具有相同的存取时间
NUMA: 非一致性存储结构, 访问本节点内的存储器所需要的时间,比访问某些远程节点内的存储器所花的时间要少得多
内存管理
通过对分区和page的管理方式
伙伴系统
概念模型
思想概念: 是一个结合了2的方幂个分配器和空闲缓冲区合并计技术的内存分配方案, 能够很好的减少内存碎片,但是无法消除
伙伴系统: 是基于分区实现的, 在每个zone中都有一个伙伴管理的模型
优点: 能够快速检测出相邻两个空闲内存并合并
free_area[MAX_ORDER] 为伙伴系统的结构体使用 cat /proc/buddyinfo 查看内存使用情况
使用 cat /proc/pagetypeinfo 查看更具体的内存使用
以下是对内存 page 管理的结构模型
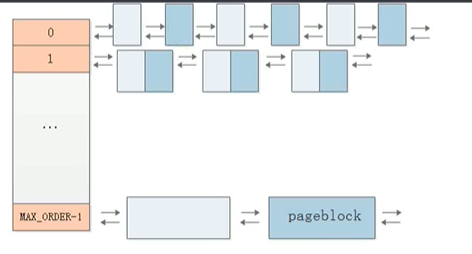
可移动页面的迁移
对伙伴系统的优化
当程序申请大块内存的时候不够用的话,系统整理内存碎片, 迁移使用过的内存到其它未使用的内存, 然后余出大内存给内存使用
以下两种情况会出现 可移动页面迁移的操作
- 当申请内存的时候, 内存不够
- 当内存碎片
compact_memory触发一个阈值
Per-CPU 页帧缓存
- 对伙伴系统的完善
struct zone中的per_cpu_pageset _percpu *pageset_percpu关键字, 是内核降低对锁的开销, 被_percpu修饰属性, 会在CPU中单独拷贝一份- 多核CPU 会将刚开始申请到的页帧数据缓存到对应的各自
pageset指针中, 如果下次当前CPU需要申请会优先选择到pageset中申请内存, 当pageset不够的时候, 到全局的伙伴系统中申请内存, 伙伴系统是全局的, 而缓存是针对CPU自己的, 这样就减少了锁, 全局访问, 然后提升了性能 - 当
pageset中的可用内存达到一定的阈值(水位控制器)的时候, 系统会将部分释放返回给伙伴系统中
水位控制器理论模型
cat /proc/zoneinfo | grep -E "Node|min|low|high "
- 通过以上指令可以查看每个内存区域当中水位相关参数
- 达到相应的阈值, 会触发相关动作, 比如内存异步回收
HugeTLB 巨页
- 初衷是为了对一些进程经常需要使用到很大内存, 能够提升其性能, 这个需要配置linux内核, 在嵌入式领域当中很少用到
页分配器
alloc_page 和 free_page 是页的分配器
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
1. "gfp_mask": 指定哪些内存分区查找分配, 头文件 "gfp.h"
2. "order": 需要申请的page大小为: "2^order"
alloc_pages 在申请页帧的时候, 会先存CPU缓存中获取, 在从get_page_from_freelist 伙伴系统空闲页中获取
__alloc_pages_slowpath 如果伙伴系统中碎片过多,申请不到, 则会对内存碎片整理,然后再次分配
CMA 连续内存分配器
- 伙伴系统最大能申请页的个数: 2^12, 一个页大小为 4KB
- 所以伙伴系统申请到的最大内存为: 4MB, 如果一些外设DMA超过这个,则需要使用CMA分配器
- CMA 再不使用的时候, 会被伙伴系统使用, 内存属性是movable
cma_release和cma_alloc分配器
slab缓存机制
-
对伙伴系统的改进和优化
-
一个page为4K, 在page基础上, 对page再次划分为小块,然后提供给系统调用,满足小内存的申请
-
三种机制, 可以配置
- slab: 最早的机制
- slob: 轻量级, 嵌入式
- slub: 5.10 内核 使用的是 slub
-
头文件 linux/slab.h
-
结构体
- slab_caches: 链表头
- kmem_cache: 链表块, 双链表
- keme_cache_cpu: __percpu修饰, 每个CPU本地会有个缓存
- kmem_cache_node: 全局的slab缓存
-
/proc/slabinfo 查看slab分配信息
-
函数接口
- kmem_cache_create: 创建一个 keme_cache
- kmem_cache_destroy: 销毁 keme_cache
- kmem_cache_usercopy: 需要拷贝到用户空间使用的
- kmem_cache_alloc: 从keme_cache中对应的slab中分配一个 object
- kmem_cache_free: 释放原来的 slab 中分配的一个 object
kmalloc 分配器
- 对 slab 接口进一步封装
- 头文件 linux/slab.h
- 接口
void *kmalloc(size_t size, gfp_t flags);void kfree(const void *);
- 基于slab缓存和基于伙伴系统申请内存
- 申请最大内存 pageblock, 4MB内存
- 返回地址对齐方式
虚拟地址和MMU
虚拟地址概念
- 线性地址, 逻辑地址: 嵌入式下不考虑
- 虚拟地址:编译和链接
- 物理地址: 对不同层面的环境, 编译出应用的虚拟环境, 以及对权限的管理
MMU
MMU是CPU的一部分, 每个处理器core都有一个MMU, 包含了 TLB 和 Table Walk Unit
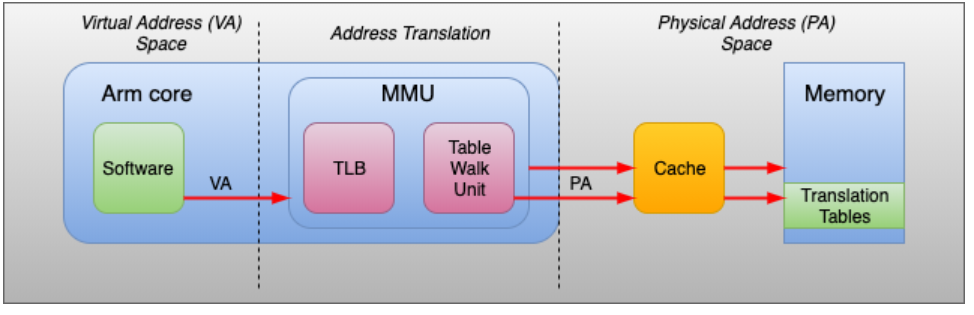
- TLB: 页表的高速缓存, 存储着最近转换的一些目录表
- Table Walk Unit: 负责从页表中读取虚拟地址对应的物理地址
- 对于每次转换,MMU首先在TLB中检查现有的缓存。如果没有命中,根据CR3寄存器,Table Walk Unit将从内存中的页表查询
- MMU: 以page为单元转换, 需要芯片级别的支持
- 用 Table walk Unit 读取 Memory 中的 Translation tables
- MMU作用, 具体看芯片手册
• 检查虚拟地址和ASID(地址空间标识符)
• 检查域访问权限
• 检查内存属性
• 虚拟到物理地址转换
• 支持四页(区域)大小
• 对缓存或外部存储器的访问映射
• 主TLB中的四个表项是可锁定的
一级页表

- 可以理解为虚拟地址到物理地址转换的一个目录表
- 一个虚拟地址对应一个物理地址的方式
- MMU负责根据虚拟地址从页表中找出对应的物理地址
- 虚拟地址: 高20位为页表索引, 低12位为偏移地址, 比如 0x1234, 页表索引: 0x00001, 偏移地址: 0x234, 然后page大小2^12, 也就是占最后三地址
- 缺点, 比较耗费内存, 内存:4GB, page:4KB, 页表占用 1MB 页表, 一个页表占4个字节, 所以一个页表需要占用4MB大小
- 每个进程都会存储一个页表, 所以一个进程占用空间为: 进程大小 + 4MB
task_struct->mm_struct用来保存当前进程的页表, 进程切换的时候,会将页表信息写入CR3控制寄存器中, CR3(32/64位): 存放页表物理内存的基地址
二级页表
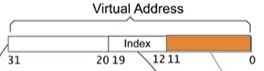
- 二级页表将 一级页表中的高20位分成两个部分
- 前12位用来存储一级页表目录, 后8位用来存储一级页表的索引, 最后12个地址用来偏移具体位置
- 相当于用二维数组去存储索引, 然后根据虚拟地址指向具体的索引, 其实页表的概念有点类似于hash表的思想
- 只存储需要被转换的页表, PGD页表和部分PTE页表
- 页表的级数越多, 可以能节省更多内存
本文来自博客园踩坑狭,作者:韩若明瞳,转载请注明原文链接:https://www.cnblogs.com/han-guang-xue/p/16518656.html
