
linux 驱动简单案例
工具速记
- /include/uapi/asm-generic/errno-base.h #驱动返回设备状态
- fuser /dev/xxx #查看对应驱动被那些用户程序引用
- 关于
ioctl中cmd参数的使用, https://blog.csdn.net/hzn407487204/article/details/7995041
驱动练习笔记
驱动练习笔记文档: https://gitee.com/han_gx/drivers_arm_linux
一、 linux驱动简单案例
环境
[root@hgx driver_test]# cat /etc/redhat-release CentOS Linux release 8.2.2004 (Core) [root@hgx driver_test]# uname -r 4.18.0-305.3.1.el8.x86_64
驱动环境搭建
内核源码下载 https://vault.centos.org
cat /etc/redhat-release #查看Centos版本
uname -r #查看内核版本
基本命令
lsmod #现实已经安装的驱动 rmmod #卸载驱动 insmod #安装驱动。insmod xxx.ko dmesg #显示开机信息,内核加载的信息
实现一个简单驱动程序代码
示例程序
- driver_hello.c
- Makefile
其中KDIR =/usr/src/kernels/$(shell uname -r)KDIR 是驱动程序的内核目录, 这是centos的内核头文件目录。
最简单的例子
driver_hello.c
#include <linux/init.h> #include <linux/module.h> #include <linux/fs.h> #include <asm/uaccess.h> static int my_init(void) { return 0; } static void my_exit(void) { return; } module_init(my_init); module_exit(my_exit); // MODULE_xxx这种宏作用是用来添加模块描述信息 // 描述模块的许可证 MODULE_LICENSE("GPL"); // 描述模块的作者 MODULE_AUTHOR("aston"); // 描述模块的介绍信息 MODULE_DESCRIPTION("module test"); // 描述模块的别名信息 MODULE_ALIAS("alias xxx");
Makefile
CONFIG_MODULE_SIG=n obj-m += driver_hello.o KDIR =/usr/src/kernels/$(shell uname -r) all: $(MAKE) -C $(KDIR) \ SUBDIRS=$(PWD) \ modules clean: rm -rf *.o *.ko *.mod.* *.symvers *.order rm -rf .tmp_versions .driver_hello.*
加载驱动
Make编译,编译之后会生成.order,.ko,.o等文件,使用 insmod xxx.ko 加载驱动
同样使用 rmmod xxx 卸载驱动
驱动加载的原理是?
initcall 机制: https://zhuanlan.zhihu.com/p/456085454
- 生成 vmlinux 的链接阶段为 initcall 创建特定 section
- 开发者创建相关initcall函数, 并使用 xxx_initcall 声明不同类型
- 每一类initcall对应一组section
- 遍历执行 initcall section 中的 initcalls
- 在调用 module_init 的时候, 系统会将 对应的程序添加到对应 section 区中
#else #define ___define_initcall(fn, id, __sec) \ static initcall_t __initcall_##fn##id __used \ __attribute__((__section__(#__sec ".init"))) = fn; #endif #define device_initcall(fn) __define_initcall(fn, 6) #define __initcall(fn) device_initcall(fn) #define module_init(x) __initcall(x);
用户态如何调用驱动程序
修改driver_hello.c代码
实现open, write函数,实现一个简单的内核态到用户态的数据拷贝
driver_hello.c
#include <linux/init.h> #include <linux/module.h> #include <linux/fs.h> // copy_to_user, copy_from_user 所在的函数库 #include <linux/uaccess.h> // printk 日志是写在内核日志里面的,使用 dmesg 查看 static int driver_hello_open(struct inode *inode, struct file *file) { printk(KERN_INFO "driver_hello_open \n"); return 0; } static int driver_hello_release(struct inode *inode, struct file *file) { printk(KERN_INFO "driver_hello_release \n"); return 0; } char kbuf[100]; static ssize_t driver_hello_write(struct file *file, const char __user *ubuf, size_t count, loff_t *ppos) { // 使用该函数将应用层传过来的ubuf中的内容拷贝到驱动空间中的一个buf中 // memcpy(kbuf, ubuf);不行,因为2个buf不在一个地址空间中 int ret = copy_from_user(kbuf, ubuf, count); if (ret) { printk(KERN_ERR "copy_from_user fail\n"); return -EINVAL; } printk(KERN_INFO "copy_from_user success..\n"); return count; } ssize_t driver_hello_read(struct file *file, char __user *ubuf, size_t count, loff_t *ppos) { int ret = copy_to_user(ubuf, kbuf, count); if(ret) { printk(KERN_ERR "copy_from_user fail\n"); return -EINVAL; } printk(KERN_INFO "copy_to_user success..\n"); return count; } // file_operations 函数讲解。https://www.cnblogs.com/chen-farsight/p/6181341.html static const struct file_operations driver_hello_ops = { .owner = THIS_MODULE, .open = driver_hello_open, .release = driver_hello_release, .write = driver_hello_write, .read = driver_hello_read, }; #define MYNAME "driver_hello" static int mymajor; // __init关键字告诉链接器将代码放在内核对象文件中的专用部分中。 //本节事先对内核所知,并在模块加载和init函数完成后释放。这仅适用于内置驱动程序,不适用于可加载模块。内核将在启动序列期间首次运行驱动程序的init函数。 static int __init my_init(void) { mymajor = register_chrdev(0, MYNAME, &driver_hello_ops); if (mymajor < 0) { printk(KERN_ERR "register_chrdev fail\n"); return -EINVAL; } printk(KERN_INFO "register_chrdev success... mymajor = %d.\n", mymajor); return 0; } static void __exit my_exit(void) { printk(KERN_INFO "chrdev_exit helloworld exit\n"); // 在module_exit宏调用的函数中去注销字符设备驱动 unregister_chrdev(mymajor, MYNAME); return; } module_init(my_init); module_exit(my_exit); // MODULE_xxx这种宏作用是用来添加模块描述信息 // 描述模块的许可证 MODULE_LICENSE("GPL"); // 描述模块的作者 // MODULE_AUTHOR("aston"); // 描述模块的介绍信息 // MODULE_DESCRIPTION("module test"); // 描述模块的别名信息 // MODULE_ALIAS("alias xxx");
编译,创建驱动设备的文件节点
make #会根据 Makefile 文件编译驱动文件 dmesg #查看驱动设备是否加载正确 cat /proc/devices | grep driver_hello #查看注册的设备编号 mknod /dev/driver_hello c 243 0 #给驱动设备driver_hello编号234创建文件设备 fuser /dev/driver_hello #查找使用该设备的进程id #mknod的设备文件可以使用rm -rf 删除 rm -rf /dev/driver_hello
用户态调用
测试代码 driver_hello_test.c
#include <stdio.h> #include <string.h> #include <sys/types.h> #include <sys/stat.h> #include <unistd.h> #include <fcntl.h> #include <stdlib.h> int main(int argc, char const *argv[]) { int fd = open("/dev/driver_hello", O_RDWR); printf("file fd: %d \n", fd); if(fd < 0) { printf("error to open file \n"); } char *buff = "This is my frist driver for linux \n"; int count = write(fd, buff, strlen(buff) + 1); printf("write count: %d \n", count); char rbuf[50]; count = read(fd, &rbuf, sizeof(rbuf)); printf("read count: %d \n", count); printf("read rbuf: %s \n", rbuf); return 0; }
适用 gcc编译运行即可
内核API文档
中文文档:https://www.kernel.org/doc/html/latest/translations/zh_CN/core-api/kernel-api.html
英文文档:https://www.kernel.org/doc/html/latest/search.html?q=malloc&check_keywords=yes&area=default
问题记录
module verification failed: signature and/or required key missing - tainting kernel
该错误为内核没有签名造成的,linux内核从3.7 开始加入模块签名检查机制, 校验签名是否与已编译的内核公钥匹配。目前只支持RSA X.509验证, 模块签名验证并非强制使用, 可在编译内核时配置是否开启
事实上, linux 的kernel module 加载过程中存在诸多检查, 模块签名验证只是第一步, 后面还会有 vermagic 和 CRC验证
二、并发编程-锁在驱动程序中的应用
相关文档:
开源linux源码: /Documentation/atomic_t.txt
对中断上下文和进程理解
- 睡眠”与“运行”是针对进程而言的,代表进程的task_struct结构记录着进程的状态。内核中的“调度器”通过task_struct对进程进行调度。
但是,中断上下文却不是一个进程,它并不存在task_struct,所以它是不可调度的。 - 中断的产生是很频繁的,比如时钟节拍就是使用中断,可以精确到毫秒,并且中断处理过程会很快。如果为中断上下文维护一个对应的task_struct结构,那么这个结构频繁地分配、回收、并且影响调度器的管理,这样会对整个系统的吞吐量有所影响。部分操作系统为了追求实时性会将中断放在CPU调度当中,但是这样子会导致代码吞吐量降低
- 对于linux 而言,为了增加整体系统性能,对于时钟频率可以通过制作镜像的时候更改
原子操作
作用 可以让驱动程序只能被一个应用程序加载
主要对于临界区的值来说, 比如一个int类型的数据
typedef struct { int counter; } atomic_t; //32位机器原子变量操作 typedef struct { long long counter; } atomic64_t; //64位机器原子操作 atomic_t b = ATOMIC_INIT(0); //原子变量初始化 int atomic_read(atomic_t *v); //读v值 void atomic_set(atomic_t *v, int i); //写v值为i void atomic_add(int i, atomic_t *v); //给v值加上i void atomic_sub(int i, atomic_t *v); //给v值减i void atomic_inc(atomic_t *v); //v++ void atomic_dec(atomic_t *v); //v-- int atomic_dec_return(atomic_t *v); //从 v 减 1,并且返回 v 的值。 ...
原子位操作, 直接作用于内存
void set_bit(int nr, void *p); //将 p 地址的第 nr 位置 1。 void clear_bit(int nr,void *p); // 将 p 地址的第 nr 位清零。 void change_bit(int nr, void *p); // 将 p 地址的第 nr 位进行翻转。 int test_bit(int nr, void *p); // 获取 p 地址的第 nr 位的值。 int test_and_set_bit(int nr, void *p); //将 p 地址的第 nr 位置 1,并且返回 nr 位原来的值。 int test_and_clear_bit(int nr, void *p); //将 p 地址的第 nr 位清零,并且返回 nr 位原来的值。 int test_and_change_bit(int nr, void *p); // 将 p 地址的第 nr 位翻转,并且返回 nr 位原来的值。
自旋锁 spinlock_t
作用于比较复杂的变量, 比如结构体
死锁: 比如在单核模式下采用自选模式抢占CPU资源: 线程 A 和 线程 B, A 在持有锁的时候, 进入休眠状况, 休眠状况会放弃CPU使用权, 然后线程B占有CPU资源, 开始获取锁, 这个时候出现A抢占不上CPU资源, B获取不到资源持有锁, 然后陷入死锁状态
Linux 内核使用结构体 spinlock_t 表示自旋锁
include/linux/spinlock_types.h:64:
typedef struct spinlock { union { struct raw_spinlock rlock; #ifdef CONFIG_DEBUG_LOCK_ALLOC #define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map)) struct { u8 __padding[LOCK_PADSIZE]; struct lockdep_map dep_map; }; #endif }; } spinlock_t;
操作接口
DEFINE_SPINLOCK(spinlock_t lock); //定义并初始化一个自选变量。 int spin_lock_init(spinlock_t *lock); // 初始化自旋锁。 void spin_lock(spinlock_t *lock); //获取指定的自旋锁,也叫做加锁。 void spin_unlock(spinlock_t *lock); //释放指定的自旋锁。 int spin_trylock(spinlock_t *lock); //尝试获取指定的自旋锁,如果没有获取到就返回 0 int spin_is_locked(spinlock_t *lock) //检查指定的自旋锁是否被获取,如果没有被获取就返回非 0,否则返回 0。
自旋锁 API 函数适用于 SMP 或支持抢占的单 CPU 下线程之间的并发访问,
也就是用于线程与线程之间,被自旋锁保护的临界区一定不能调用任何能够引起睡眠和阻塞的
API 函数,否则的话会可能会导致死锁现象的发生
对于自旋锁, 影响最大的就是中断, 当线程A获取锁还没有释放,这个时候中断让线程A释放CPU使用权,导致死锁的产生
以下是关于自旋锁和中断的操作
void spin_lock_irq(spinlock_t *lock); //禁止本地中断,并获取自旋锁。 void spin_unlock_irq(spinlock_t *lock); //激活本地中断,并释放自旋锁。 void spin_lock_irqsave(spinlock_t *lock, unsigned long flags); //保存中断状态,禁止本地中断,并获取自旋锁。 void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags); // 将中断状态恢复到以前的状态,并且激活本地中断,释放自旋锁。
一般的很难确定某个时刻的中断状态,因此不推
荐使用 spin_lock_irq/spin_unlock_irq . 建议使用 spin_lock_irqsave/
spin_unlock_irqrestore,因为这一组函数会保存中断状态,在释放锁的时候会恢复中断状态。
一 般 在 线 程 中 使 用 spin_lock_irqsave/ spin_unlock_irqrestore , 在 中 断 中 使 用
spin_lock/spin_unlock
示例代码
DEFINE_SPINLOCK(lock); /* 定义并初始化一个自旋锁 */ /* 线程 A */ void functionA (){ unsigned long flags; /* 中断状态 */ spin_lock_irqsave(&lock, flags); /* 获取锁 */ /* 临界区 */ spin_unlock_irqrestore(&lock, flags); /* 释放锁 */ } /* 中断服务函数 */ void irq() { spin_lock(&lock); /* 获取锁 */ /* 临界区 */ spin_unlock(&lock); /* 释放锁 */ }
读写自旋锁锁 rwlock_t
Linux 内核使用 rwlock_t 结构体表示读写锁
使用场景:
1. 读和写不能同时进行 2. 可以并发读数据
顺序锁 seqlock_t
顺序锁在读写锁的基础上衍生而来的, Linux 内核使用 seqlock_t 结构体表示顺序锁
使用场景:
1. 可同时读写 2. 不允许同时并发读写
如果在读的过程中发生了写操作,可以把值重新回读一遍
顺序锁保护的资源不能是指针, 如果在写数据的时候可能会导致指针无效, 然后读指针会出现内存泄露
总结
自旋锁使用场景:
1. 因为在等待自旋锁的时候处于“自旋”状态,因此锁的持有时间不能太长,一定要短, 否则的话会降低系统性能。如果临界区比较大,运行时间比较长的话要选择其他的并发处理方 式,比如稍后要讲的信号量和互斥体。 2. 自旋锁保护的临界区内不能调用任何可能导致线程休眠的 API 函数,否则的话可能导 致死锁。 3. 不能递归申请自旋锁,因为一旦通过递归的方式申请一个你正在持有的锁,那么你就 必须“自旋”,等待锁被释放,然而你正处于“自旋”状态,根本没法释放锁。结果就是自己 把自己锁死了! 4. 在编写驱动程序的时候我们必须考虑到驱动的可移植性,因此不管你用的是单核的还 是多核的 SOC,都将其当做多核 SOC 来编写驱动程序。
信号量 semaphore
Linux 内核使用 semaphore 结构体表示信号量
struct semaphore { raw_spinlock_t lock; unsigned int count; struct list_head wait_list; };
使用场景:
1. 因为信号量可以使等待资源线程进入休眠状态,因此适用于那些占用资源比较久的场 合 2. 因此信号量不能用于中断中,因为信号量会引起休眠,中断不能休眠。 3. 如果共享资源的持有时间比较短,那就不适合使用信号量了,因为频繁的休眠、切换 线程引起的开销要远大于信号量带来的那点优势。 4. 临界区可以使用阻塞函数
接口API:
//定义一个信号量,并且设置信号量的值为 1。 DEFINE_SEAMPHORE(name); //初始化信号量 sem,设置信号量值为val。 void sema_init(struct semaphore *sem, int val); //获取信号量,因为会导致休眠,因此不能在中断中使用。 void down(struct semaphore *sem); //尝试获取信号量,如果能获取到信号量就获取,并且返回 0。如果不能就返回非 0,并且不会进入休眠。 int down_trylock(struct semaphore *sem); // 获取信号量,和 down 类似,只是使用down进入休眠状态的线程不能被信号打断。而使用此函数进入休眠以后是可以被信号打断的。 int down_interruptible(struct semaphore *sem); //释放信号量 void up(struct semaphore *sem);
代码示例
struct semaphore sem; /* 定义信号量 */ sema_init(&sem, 1); /* 初始化信号量 */ down(&sem); /* 申请信号量 */ /* 临界区 */ up(&sem); /* 释放信号量 */
互斥体-互斥锁 mutex
Linux 内核使用 semaphore 结构体表示信号量
将信号量的值设置为 1 就可以使用信号量进行互斥访问了, Linux 驱动的时候遇到需要互斥访问的地方建议使用 mutex
struct mutex { /* 1: unlocked, 0: locked, negative: locked, possible waiters */ atomic_t count; spinlock_t wait_lock; };
应用场景:
- mutex 可以导致休眠,因此根据需求用对应可以保留中断号的接口(因为中断不参与进程调度,如果一旦在中断服务函数执行过程中休眠了,休眠了则意味着交出了CPU 的使用权,CPU 使用权则跑到了其它线程了,那么就不能再回到中断断点处了)。
- 和信号量一样,mutex 保护的临界区可以调用引起阻塞的 API 函数。
- 因为一次只有一个线程可以持有 mutex,因此,必须由 mutex 的持有者释放 mutex。并且 mutex 不能递归上锁和解锁。
相关接口
DEFINE_MUTEX(name) //定义并初始化一个 mutex 变量。 void mutex_init(mutex *lock); //初始化 mutex。 void mutex_lock(struct mutex*lock); //获取 mutex,也就是给 mutex 上锁。如果获取不到就进休眠。 void mutex_unlock(struct mutex*lock); //释放 mutex,也就给 mutex 解锁。 int mutex_trylock(struct mutex*lock); //尝试获取 mutex,如果成功就返回1,如果失败就返回 0。 int mutex_is_locked(struct mutex *lock); //判断 mutex 是否被获取,如果是的话就返回 1,否则返回 0 int mutex_lock_interruptible(struct mutex *lock); /* 使用此函数互斥锁获取失败进入休眠之后, 可以被中断信号打断 */
示例代码
struct mutex lock; /* 定义一个互斥体 */ mutex_init(&lock); /* 初始化互斥体 */ mutex_lock(&lock); /* 上锁 */ /* 临界区 */ mutex_unlock(&lock); /* 解锁 */
总结
- 互斥锁和信号量, 会让程序进入休眠状态, 因此不能使用中断, 如果要想中断能够打断,必须调用相关指定函数,比如
mutex_lock_interruptible - 不能使用递归申请锁
- 自旋锁可以使用中断, 因为程序不会休眠
- 互斥锁和信号量侧重点在于: 互斥锁是锁机制, 而信号量是同步机制
- 若是能确定被锁住的代码执行时间很短,就不应该使用互斥锁,而应该选择自旋锁。
用户态下的互斥锁在发生的时候, 系统会陷入内核态, 由内核态对用户线程进行切换,上下切换的耗时大概在几十纳秒到几微秒之间,如果锁住的代码执行时间比较短,可能上下文切换的时间比锁住的代码执行时间还要长。
三、定时器、延时、超时、中断、阻塞、异步在驱动中的应用
定时器
Linux 内核使用 timer_list 结构体表示内核定时器
void init_timer(struct timer_list *timer); //初始化 timer_list 类型变量,必须初始化 void add_timer(struct timer_list *timer); //向内核注册定时器以后,定时器就会开始运行 //删除一个定时器,不管定时器有没有被激活,都可以使用此函数删除。在多处理器系统上,定时器可能会在其他的处理器上运行,因此在调用 del_timer 函数删除定时器之前要先等待其他处理器的定时处理器函数退出 int del_timer(struct timer_list * timer); int del_timer_sync(struct timer_list *timer); //会等待其他处理器使用完定时器再删除,del_timer_sync 不能使用在中断上下文中 int mod_timer(struct timer_list *timer, unsigned long expires); //用于修改定时值,如果定时器还没有激活的话,mod_timer 函数会激活定时器! //对应结构体 struct timer_list { struct hlist_node entry; unsigned long expires; void (*function)(unsigned long); //到时触发事件 unsigned long data; u32 flags; #ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map; #endif };
延时
/* 纳秒、微秒和毫秒延时函数。占用cpu资源,导致其他功能此时也无法使用cpu资源 */ void ndelay(unsigned long nsecs); void udelay(unsigned long usecs); void mdelay(unsigned long mseces);
超时
jiffies: Linux 内核使用全局变量 jiffies 来记录系统从启动以来的系统节拍数,系统启动的时候
会将 jiffies 初始化为 0,jiffies 定义在文件 include/linux/jiffies.h 中
extern u64 __jiffy_data jiffies_64; extern unsigned long volatile __jiffy_data jiffies;
对应接口:
绕回
32 位的 jiffies 只需要 49.7 天就发生了绕回,对于 64 为的 jiffies 来说大概需要 5.8 亿年才能绕回
在32位中需要对绕回做处理:
// 如果unkown 超过(或等于) known, 返回为真,否则返回假 time_after(unkown, known); time_before(unkown, known); time_after_eq(unkown, known); time_before_eq(unkown, known); //函数原型 #define time_after(a,b) \ (typecheck(unsigned long, a) && \ typecheck(unsigned long, b) && \ ((long)((b) - (a)) < 0)) #define time_before(a,b) time_after(b,a) #define time_after_eq(a,b) \ (typecheck(unsigned long, a) && \ typecheck(unsigned long, b) && \ ((long)((a) - (b)) >= 0)) #define time_before_eq(a,b) time_after_eq(b,a)
判断一个程序执行是否超时, 可以使用如下示例
unsigned long timeout; timeout = jiffies + (2 * HZ); /* 超时的时间点 */ /************************************* 具体的代码 ************************************/ if(time_after(jiffies, timeout)) { //没有超时 } else { //超时处理 }
jiffies和毫秒微妙纳秒之间的转换
//将 jiffies 类型的参数 j 分别转换为对应的毫秒、微秒、纳秒。 int jiffies_to_msecs(const unsigned long j); int jiffies_to_usecs(const unsigned long j); u64 jiffies_to_nsecs(const unsigned long j); // 将毫秒、微秒、纳秒转换为 jiffies 类型。 long msecs_to_jiffies(const unsigned int m); long usecs_to_jiffies(const unsigned int u); unsigned long nsecs_to_jiffies(u64 n);
中断
申请和释放
static inline int __must_check request_irq(unsigned int irq, \ irq_handler_t handler, \ unsigned long flags, \ const char *name, \ void *dev);
- irq: 要申请的中断号
- handler:中断处理函数
- flags:中断标记
IRQF_SHARED: 多个设备共享一个中断线,共享的所有中断都必须指定此标志。如果使用共享中断的话,dev 参数就是唯一区分他们的标志。
IRQF_ONESHOT: 单次中断
IRQF_TRIGGER_NONE: 无触发
IRQF_TRIGGER_RISING:上升沿触发
IRQF_TRIGGER_FALLING:下降沿触发
IRQF_TRIGGER_HIGH:高电平触发
IRQF_TRIGGER_LOW:低电平触发
上述可以通过 |组合使用, 还有其他的中断类型,在 include/linux/interrupt.h 中有介绍
- name: /proc/interrupts 中会有显示,可以查看
- dev:flags 设置为 IRQF_SHARED 的话,dev 用来区分不同的中断, 一般的该值将被设置为设备的结构体,dev 会传递给中断处理函数 irq_handler_t 的第二个参数
void free_irq(unsigned int irq, void *dev); //释放中断,dev 必须要和request_irq的dev一致,否则会导致系统崩溃
中断响应函数写法
irqreturn_t (*irq_handler_t) (int, void *);
参数一是要中断处理函数要相应的中断号。
参数二是一个指向 void 的指针,需要与 request_irq 函数的 dev 参数保持一致
返回值 可以是irqreturn_t类型,
/** * enum irqreturn * @IRQ_NONE 中断不是来自此设备或者未处理 * @IRQ_HANDLED 中断已经处理 * @IRQ_WAKE_THREAD 唤醒处理程序线程的处理程序请求 */ enum irqreturn { IRQ_NONE = (0 << 0), IRQ_HANDLED = (1 << 0), IRQ_WAKE_THREAD = (1 << 1), }; typedef enum irqreturn irqreturn_t; #define IRQ_RETVAL(x) ((x) ? IRQ_HANDLED : IRQ_NONE)
返回的时候使用格式 return IRQ_RETVAL(IRQ_HANDLED)
中断的使能和禁止
void enable_irq(unsigned int irq); //irq 指定中断号 void disable_irq(unsigned int irq); //要等到当前正在执行的中断处理函数执行完才返回 void disable_irq_nosync(unsigned int irq); //使用后立即返回结果 #define local_irq_enable() do { raw_local_irq_enable(); } while (0) //使能全局中断 local_irq_disable(); //禁用全局中断 /* 多任务中, 如下, 如果A需要禁用10s的中断, 然后在禁用2s之后,B开始禁用需要维持3s的中断,5s之后中断就被打开了,此时B会打断A的任务状态 A: local_irq_disable(); //todo 大概10s ... local_irq_enable(); B: local_irq_disable(); //todo 大概3s ... local_irq_enable(); 使用一下方式,可以将当前中断状态保存和恢复 */ //保存当前中断状态,并全局禁用 #define spin_lock_irqsave(lock, flags) do { raw_spin_lock_irqsave(spinlock_check(lock), flags); } while (0) //恢复全局中断状态 #define local_irq_restore(flags) do { raw_local_irq_restore(flags); } while (0)
local_irq_save和local_irq_restore在锁中使用很频繁,其中自旋锁,互斥锁,信号量等中提供的对于中断处理的接口基本都是使用该方式实现,可以通过linux内核源码中查看到
上半部与下半部
如何定义区分
在request_irq的时候,所谓注册的函数,就是上半部, 因为中断触发之后,注册的函数一定会执行,理想状态下, 注册的函数必须是要处理快, 不然会影响CPU的调度。
但是实际场景中经常会碰见比较耗时的中断处理,这种需要耗时的部分会采取另外一种措施, 俗称下半部,把处理快的部分放在注册函数中,俗称上半部。
如何选择:将那些代码归为上半部和下半部,需要视情况而定,一般的
①、如果要处理的内容不希望被其他中断打断,那么可以放到上半部。
②、如果要处理的任务对时间敏感,可以放到上半部。
③、如果要处理的任务与硬件有关,可以放到上半部
④、除了上述三点以外的其他任务,优先考虑放到下半部。
下半部机制
1. 软中断
Linux 内核提供了“bottom half”机制来实现下半部,简称“BH”。后面引入了软中断和 tasklet 来替代“BH”机制
Linux 内核使用结构体 softirq_action 表示软中断, include/linux/interrupt.h
struct softirq_action { void (*action)(struct softirq_action *); }; enum { HI_SOFTIRQ=0, TIMER_SOFTIRQ, NET_TX_SOFTIRQ, NET_RX_SOFTIRQ, BLOCK_SOFTIRQ, IRQ_POLL_SOFTIRQ, TASKLET_SOFTIRQ, SCHED_SOFTIRQ, HRTIMER_SOFTIRQ, /* Unused, but kept as tools rely on the numbering. Sigh! */ RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */ NR_SOFTIRQS }; static struct softirq_action softirq_vec[NR_SOFTIRQS]; // 在`kernel/softirq.c`一共定义了十种中断
对于软中断使用
void open_softirq(int nr, void (*action)(struct softirq_action *)); //打开中断,nr,软中断类型,action 回调函数 void raise_softirq(unsigned int nr); //回调函数原型
软中断必须在编译的时候静态注册!Linux 内核使用 softirq_init 函数初始化软中断,
softirq_init 函数定义在 kernel/softirq.c 文件里面,函数内容如下:
void __init softirq_init(void) { int cpu; for_each_possible_cpu(cpu) { per_cpu(tasklet_vec, cpu).tail = &per_cpu(tasklet_vec, cpu).head; per_cpu(tasklet_hi_vec, cpu).tail = &per_cpu(tasklet_hi_vec, cpu).head; } open_softirq(TASKLET_SOFTIRQ, tasklet_action); open_softirq(HI_SOFTIRQ, tasklet_hi_action); }
额外知识补充
- 软中断是系统比较底层的中断, 对应的类型就那时钟类型, 有网络, RCU,NET, TIMER等,在驱动程序中使用相对少
- 软中断是频繁触发是特别耗CPU的调度性能,尤其在服务器开发中,碰见高并发的这种现象,其中网络数据包特别多, 会触发网络收发的软中断, 导致CPU调度性能降低
- 软中断耗费CPU调度性能导致卡顿是常见的现象之一,通过查看软中断命中次数
cat /proc/softirqs、watch -d cat /proc/softirqs或者 查看线程ksoftirqd(每个CPU对应一个线程,专门用来处理软中断)等方式,排查定位出发生软中断最多程序, 并优化,比如smp irq affinity和RPS/RFS技术
另外: 软中断该怎么静态注册 ???
2.tasklet
tasklet 是利用软中断来实现的另外一种下半部机制
struct tasklet_struct { struct tasklet_struct *next; unsigned long state; atomic_t count; void (*func)(unsigned long); unsigned long data; }; void tasklet_init(struct tasklet_struct *t, void (*func)(unsigned long), unsigned long data); //t 要初始化的参数, func 回调函数,data 传递给func的函数参数
3.工作队列
工作 使用结构体 struct work_struct 表示, 添加自己需要处理的函数, 在文件 include/linux/workqueue.h中
工作队列 使用 struct workqueue_struct 结构体表示,包含了 work_struct
工作者线程 使用 struct worker 表示,管理 工作队列中的 工作
接口函数
#define INIT_WORK(_work, _func) //初始化工作, _work 表示要初始化的工作,_func 是工作对应的处理函数 #define DECLARE_WORK(n, f) //一次性完成工作的创建和初始化,n 表示定义的工作(work_struct),f 表示工作对应的处理函数。 bool schedule_work(struct work_struct *work) //工作的调度才能运行,
实力代码
/* 定义工作(work) */ struct work_struct testwork; /* work 处理函数 */ void testwork_func_t(struct work_struct *work); { /* work 具体处理内容 */ } /* 中断处理函数 */ irqreturn_t test_handler(int irq, void *dev_id) { ...... /* 调度 work */ schedule_work(&testwork); ...... } /* 驱动入口函数 */ static int __init xxxx_init(void) { ...... /* 初始化 work */ INIT_WORK(&testwork, testwork_func_t); /* 注册中断处理函数 */ request_irq(xxx_irq, test_handler, 0, "xxx", &xxx_dev); ...... }
补充信息
-
workqueue由工作者线程(内核线程)、工作队列、工作项组成。在CPU中线程名如下:
kworker/n:x—— 普通的每CPU工作者线程,n表示CPU编号,x表示线程编号。
kworker/n:xH —— 高优先级的每CPU工作者线程,n表示CPU编号,x表示线程编号。
kworker/u:x—— 非绑定的全局工作者线程,u表示非绑定,x表示线程编号。 -
关于内核 kworker线程CPU占用过高的思路排查,创建CPU
回溯可以观察占用过高的worker线程中的调用情况
设备树中的中断配置
Linux 内核通过读取设备树中的中断属性信息来配置中断。
设备树是为驱动文件提供的,所以是有对应驱动文件来执行中断控制的
intc: interrupt-controller@f8f01000 { compatible = "arm,cortex-a9-gic"; #interrupt-cells = <3>; interrupt-controller; reg = <0xF8F01000 0x1000>, <0xF8F00100 0x100>; };
如下:设备树增加对引脚12,key按键作为中断,设备树如下 test-node:
test-node { compatible = "test-node"; reg = <0x1e>; interrupt-parent = <&gpio0>; interrupts = <12 2>; };
驱动中获取设备树中断
unsigned int irq_of_parse_and_map(struct device_node *dev, int index); // 从 interupts 属性中提取到对应的设备号 // dev:设备节点。 // index:索引号,interrupts 属性可能包含多条中断信息,通过 index 指定要获取的信息。 // 返回值:中断号。 int gpio_to_irq(unsigned int gpio); // gpio_to_irq 函数来获取 gpio 对应的中断号 // gpio:要获取的 GPIO 编号。 // 返回值:GPIO 对应的中断号。 int irq_get_trigger_type(unsigned int gpio); //获取指定中断触发
线程状态,阻塞和非阻塞概念
说明
-
这里说的阻塞和非常阻塞都是基于线程状态和中断实现控制的, 非阻塞并不是说直接while循环一直读取
- 如果直接用while读取, CPU占用如图:
CPU: 8.1% usr 41.9% sys 0.0% nic 49.8% idle # usr: 用户态占用 # sys: 内核占用 # nic: (niced)程序占用率,nice表示程序的优先级,也就是修改过优先级的程序占用率 # idle: CPU空闲时间占比 - pthread_create创建出来的任务优先级120,相当于nice=0,
nice可以看成普通任务的优先级。nice的范围是-20~19,nice值越小代表任务的优先级越高,nice值越大代码优先级越低,默认情况下一个普通任务的nice=0 - 使用指令
renice -n 10 -p 7636修改某个占用率比较高的用户态程序, 然后top查看时, nic的值就会变了
如果直接用阻塞的方式读取,CPU占用如下
CPU: 0.0% usr 0.1% sys 0.0% nic 99.8% idle -
阻塞: 未获取则挂起线程, 获取则唤醒线程
int fd; int data = 0; fd = open("/dev/xxx_dev", O_RDWR); /* 阻塞方式打开 */ ret = read(fd, &data, sizeof(data)); /* 读取数据 */
- 非阻塞: 当未获则立马返回状态
int fd; int data = 0; fd = open("/dev/xxx_dev", O_RDWR | O_NONBLOCK); /* 非阻塞方式打开 */ ret = read(fd, &data, sizeof(data)); /* 读取数据 */
进程的状态
阻塞是基于线程的状态, 线程的状态如下
头文件 include/linux/sched.h
TASK_RUNNING: 可运行,但是CPU可能并没有执行它,也就是处于等待调度中TASK_INTERRUPTIBL: 针对等待某事件或其他资源而睡眠的进程设置的,内核发送信号给该进程时表明等待的事件已经发生或资源已经可用,进程状态变为 TASK_RUNNINGTASK_UNINTERRUPTIBLE: 处于此状态,不能由外部信号唤醒,只能由内核亲自唤醒。TASK_STOPPED: 表示进程特意停止运行。比如在调试程序时,进程被调试器暂停下来TASK_TRACED: 表示进程被 debugger 等进程监视,进程执行被调试程序所停止。
阻塞IO的实现
- 当设备文件不可操作的时候, 系统会将线程挂起,让出CPU资源
- 当设备文件可用,然后唤醒, 一般在中断中唤醒线程
- linux 内核提供了等待队列来唤醒阻塞的队列线程
等待对列头
在linux中使用等待队列,则必须创建并初始化一个等待队列头
struct wait_queue_head { spinlock_t lock; struct list_head head; }; typedef struct wait_queue_head wait_queue_head_t; //定义 等待队列头 #define init_waitqueue_head(wq_head) { xxxx }; //用来初始化 `wait_queue_head_t` //也可以直接使用以下方式一次性完成创建和初始化 #define DECLARE_WAIT_QUEUE_HEAD(name) \ struct wait_queue_head name = __WAIT_QUEUE_HEAD_INITIALIZER(name)
等待队列项
- 等待队列头就是一个等待队列的头部,每个访问设备的进程都是一个
队列项,当设备不可用 的 时 候 就 要 将 这 些 进 程 对 应 的 等 待 队 列 项 添 加 到 等 待 队 列 里 面 - 结构体
wait_queue_entry_t表示等待队列项
typedef struct wait_queue_entry wait_queue_entry_t; struct wait_queue_entry { unsigned int flags; void *private; wait_queue_func_t func; struct list_head entry; }; #define DECLARE_WAITQUEUE(name, tsk) \ struct wait_queue_entry name = __WAITQUEUE_INITIALIZER(name, tsk) //name 就是等待队列项的名字,tsk 表示这个等待队列项属于哪个任务(进程),一般设置为 //current,在 Linux 内核中 current 相当于一个全局变量,表示当前进程。因此宏 //DECLARE_WAITQUEUE 就是给当前正在运行的进程创建并初始化了一个等待队列项。
队列项 添加/移除 队列头
- 当设备不可用时, 只有添将线程添加到等待队列头中以后, 进程才能进入休眠态
- 当设备可以访问以后, 再将进程对应的等待队列项从等待队列头中移除即可
void add_wait_queue(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry); //将队列项`wq_entry`添加到等待队列头中`wq_head` void remove_wait_queue(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry); //移除
唤醒
- 当设备可以使用的时候就要唤醒进入休眠态的进程
唤醒对应的等待队列头
void wake_up(wait_queue_head_t *q); void wake_up_interruptible(wait_queue_head_t *q);
- 这两个函数会将这个等待队列头中的所有进程都唤醒。
wake_up函数可以唤醒处于TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE状态的进程wake_up_interruptible函数只能唤醒处于TASK_INTERRUPTIBLE状态的进程
等待事件
- 除了主动唤醒以外,也可以设置等待队列等待某个事件,当这个事件满足以后就自动唤醒等待队列中的进程
-
wait_event(wq, condition);- 该方法将线程设置为
TASK_UNINTERRUPTIBLE, 当condition为真时, 则唤醒等待队列头wq
- 该方法将线程设置为
-
wait_event_timeout(wq, condition, timeout);- 在 1 的基础上添加了超时时间, 超时时间以
jiffies为单位,此函数有返回值 - 如果返回 0 的话表示超时时间到,而且 condition 为假。
- 为 1 的话表示 condition 为真
- 在 1 的基础上添加了超时时间, 超时时间以
-
wait_event_interruptible(wq, condition);- 和 1 区别就是 该函数将线程状态设置为
TASK_INTERRUPTIBLE, 外部信号可以唤醒
- 和 1 区别就是 该函数将线程状态设置为
-
wait_event_interruptible_timeout(wq, condition, timeout)- 和 3 区别加了超时时间
轮询(非阻塞)
- 这为什么不直接用while呢, 因为内核提供的设备是能够被多个进程访问的。直接while是不可行的
- 用户应用程序以非阻塞的方式访问设备,内核就应该提供给应用程序非阻塞的处理方式。
- 应用程序通过
select、epoll或poll函数来查询设备是否可以操作 - 程序调用 select、epoll 或 poll 函数的时候设备驱动程序中的 poll 函数就会执行,需要在设备中实现 poll 函数
select
void FD_ZERO(fd_set *set); //将fd_set所有位清零 void FD_SET(int fd, fd_set *set); //向fd_set添加文件描述符 fd void FD_CLR(int fd, fd_set *set); //将fd从fd_set中删除 int FD_ISSET(int fd, fd_set *set); //判断某个fd是否可以操作 int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
- nfds: 要操作的文件描述符个数
- readfds: 监视文件的读变化,可以NULL, 集合里面有一个文件可以读取那么 seclect 就会返回一个大于 0,否则就会根据超时时间判断
- writefds: 监视文件的写变化
- exceptfds:监视文件的异常
- timeout: 超时时间
示例方法
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> #include <sys/mman.h> #include <poll.h> #include <sys/select.h> void main(void) { int ret, fd; /* 要监视的文件描述符 */ fd_set readfds; /* 读操作文件描述符集 */ struct timeval timeout; /* 超时结构体 */ fd = open("dev_xxx", O_RDWR | O_NONBLOCK); /* 非阻塞式访问 */ FD_ZERO(&readfds); /* 清除 readfds */ FD_SET(fd, &readfds); /* 将 fd 添加到 readfds 里面 */ /* 构造超时时间 */ timeout.tv_sec = 0; timeout.tv_usec = 500000; /* 500ms */ ret = select(fd + 1, &readfds, NULL, NULL, &timeout); switch (ret) { case 0: /* 超时 */ printf("timeout!\r\n"); break; case -1: /* 错误 */ printf("error!\r\n"); break; default: /* 可以读取数据 */ if(FD_ISSET(fd, &readfds)) { /* 判断是否为 fd 文件描述符 */ /* 使用 read 函数读取数据 */ } break; } }
poll
- 单线程中, select 函数能够监视的文件描述符数量有最大的限制, 1024个,可以通过修改内核参数将该值放大
- poll 相比于 select, 监听的数量没有变化, 其它本质上区别不大
- poll和select都是通过list存储文件描述符,所以当文件描述符越多的时候,性能越低
int poll(struct pollfd *fds, nfds_t nfds, int timeout); //函数原型 1. fds: 要监视的文件描述符集合 2. nfds:poll 函数要监视的文件描述符数量。 3. timeout:超时时间。单位ms //结构体说明 struct pollfd { int fd; /* 文件描述符 */ short events; /* 请求的事件 */ short revents; /* 返回的事件 */ }; 1. events 可以表示的属性值 POLLIN 有数据可以读取。 POLLPRI 有紧急的数据需要读取。 POLLOUT 可以写数据。 POLLERR 指定的文件描述符发生错误。 POLLHUP 指定的文件描述符挂起。 POLLNVAL 无效的请求。 POLLRDNORM 等同于 POLLIN 2. revents 是返回参数,也就是返回的事件 0,超时; -1,发生错误,并且设置 errno 为错误类型; >0, 则表示 pollfd不为0的结构体个数
示例代码
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> #include <sys/mman.h> #include <poll.h> #include <sys/select.h> void main(void) { int ret; int fd; /* 要监视的文件描述符 */ struct pollfd fds; fd = open(filename, O_RDWR | O_NONBLOCK); /* 非阻塞式访问 */ /* 构造结构体 */ fds.fd = fd; fds.events = POLLIN; /* 监视数据是否可以读取 */ ret = poll(&fds, 1, 500); /* 轮询文件是否可操作,超时 500ms */ if (ret) { /* 数据有效 */ //...... /* 读取数据 */ //...... } else if (ret == 0) { /* 超时 */ //...... } else if (ret < 0) { /* 错误 */ //...... } }
epoll
- epoll 就是为处理大并发而准备的,一般常常在网络编程中使用 epoll 函数
- 减少了用户态和内核态的文件句柄拷贝
- 减少了对可读可写文件句柄的遍历
- mmap 加速了内核与用户空间的信息传递,epoll是通过内核与用户mmap同一块内存,避免了无谓的内存拷贝
- IO性能不会随着监听的文件描述的数量增长而下降
- 使用红黑树存储fd,以及对应的回调函数,其插入,查找,删除的性能不错,相比于hash,不必预先分配很多的空间
int epoll_create(int size); //创建一个 epoll 句柄 1. size 从 Linux2.6.8 开始此参数已经没有意义了,随便填写一个大于 0 的值就可以。 2. 返回值: epoll 句柄,如果为-1 的话表示创建失败 3. 该函数会在内核中创建 "红黑树" int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); 1. epfd:要操作的 epoll 句柄,也就是使用 epoll_create 函数创建的 epoll 句柄 2. op:表示要对 epfd(epoll 句柄)进行的操作,可以设置为 EPOLL_CTL_ADD 向 epfd 添加文件参数 fd 表示的描述符。 EPOLL_CTL_MOD 修改参数 fd 的 event 事件。 EPOLL_CTL_DEL 从 epfd 中删除 fd 描述符。 3. fd:要监视的文件描述符。 4. event:要监视的事件类型,为 epoll_event 结构体类型指针 struct epoll_event { uint32_t events; /* epoll 事件 */ epoll_data_t data; /* 用户数据 */ }; > event: EPOLLIN 有数据可以读取。 EPOLLOUT 可以写数据。 EPOLLPRI 有紧急的数据需要读取。 EPOLLERR 指定的文件描述符发生错误。 EPOLLHUP 指定的文件描述符挂起。 EPOLLET 设置 epoll 为边沿触发,默认触发模式为水平触发。 EPOLLONESHOT 一次性的监视,当监视完成以后还需要再次监视某个 fd,那么就需要将 fd 重新添加到 epoll 里面。 5. 返回值:0,成功;-1,失败,并且设置 errno 的值为相应的错误码。 //一切设置好之后,就可以调用epoll_wait等待时间的发生 int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); 1. epfd:要等待的 epoll。 2. events:指向 epoll_event 结构体的数组,当有事件发生的时候 Linux 内核会填写 events,调用者可以根据 events 判断发生了哪些事件。 3. maxevents:events 数组大小,必须大于 0。 4. timeout:超时时间,单位为 ms。 5. 返回值:0,超时;-1,错误;其他值,准备就绪的文件描述符数量。
实例代码
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sys/epoll.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #define MAX_EVENTS 10 #define MAX_BUFFER_SIZE 1024 int main() { int server_socket, client_socket; struct sockaddr_in server_address, client_address; socklen_t client_address_length; int epoll_fd, event_count, i; struct epoll_event event, events[MAX_EVENTS]; char buffer[MAX_BUFFER_SIZE]; // 创建一个socket对象 server_socket = socket(AF_INET, SOCK_STREAM, 0); if (server_socket == -1) { perror("Failed to create socket"); exit(EXIT_FAILURE); } // 设置服务器地址和端口号 server_address.sin_family = AF_INET; server_address.sin_addr.s_addr = INADDR_ANY; server_address.sin_port = htons(8080); // 绑定服务器地址和端口号 if (bind(server_socket, (struct sockaddr *)&server_address, sizeof(server_address)) == -1) { perror("Failed to bind"); exit(EXIT_FAILURE); } // 监听连接 if (listen(server_socket, 5) == -1) { perror("Failed to listen"); exit(EXIT_FAILURE); } // 创建一个epoll对象 epoll_fd = epoll_create1(0); if (epoll_fd == -1) { perror("Failed to create epoll"); exit(EXIT_FAILURE); } // 将服务器socket对象添加到epoll中 event.events = EPOLLIN; event.data.fd = server_socket; if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, server_socket, &event) == -1) { perror("Failed to add server socket to epoll"); exit(EXIT_FAILURE); } while (1) { // 等待事件发生 event_count = epoll_wait(epoll_fd, events, MAX_EVENTS, -1); if (event_count == -1) { perror("Failed to wait for events"); exit(EXIT_FAILURE); } // 处理所有事件 for (i = 0; i < event_count; i++) { // 如果是服务器socket对象有新的连接请求 if (events[i].data.fd == server_socket) { client_address_length = sizeof(client_address); client_socket = accept(server_socket, (struct sockaddr *)&client_address, &client_address_length); if (client_socket == -1) { perror("Failed to accept client connection"); exit(EXIT_FAILURE); } // 将客户端socket对象添加到epoll中 event.events = EPOLLIN; event.data.fd = client_socket; if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, client_socket, &event) == -1) { perror("Failed to add client socket to epoll"); exit(EXIT_FAILURE); } printf("New client connected: %s\n", inet_ntoa(client_address.sin_addr)); } // 如果是客户端socket对象有数据到达 else { client_socket = events[i].data.fd; // 接收数据 ssize_t bytes_received = recv(client_socket, buffer, sizeof(buffer), 0); if (bytes_received == -1) { perror("Failed to receive data"); exit(EXIT_FAILURE); } else if (bytes_received == 0) { // 客户端断开连接 epoll_ctl(epoll_fd, EPOLL_CTL_DEL, client_socket, NULL); close(client_socket); printf("Client disconnected\n"); } else { printf("Received data: %s\n", buffer); // 在这里可以对接收到的数据进行处理 // 将数据发送回客户端 ssize_t bytes_sent = send(client_socket, buffer, bytes_received, 0); if (bytes_sent == -1) { perror("Failed to send data"); exit(EXIT_FAILURE); } } } } } close(server_socket); return 0; }
linux下对select和poll的使用
- linux下对设备执行select和poll时候,会调用file_operations中的poll函数,所以驱动程序当中需要实现该函数
unsigned int (*poll) (struct file *filp, struct poll_table_struct *wait); 1. filp:要打开的设备文件(文件描述符)。 2. wait:结构体 poll_table_struct 类型指针,由应用程序传递进来的。一般将此参数传递给 poll_wait 函数 3. 返回值:向应用程序返回设备或者资源状态,可以返回的资源状态如下: POLLIN 有数据可以读取。 POLLPRI 有紧急的数据需要读取。 POLLOUT 可以写数据。 POLLERR 指定的文件描述符发生错误。 POLLHUP 指定的文件描述符挂起。 POLLNVAL 无效的请求。 POLLRDNORM 等同于 POLLIN,普通数据可读 //需要在驱动程序的 poll 函数中调用 poll_wait 函数,将应用程序添加到 poll_table中,poll_wait 函数不会引起阻塞, void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p); 1. wait_address 是要添加到 poll_table 中的等待队列头 2. 参数 p 就是 poll_table,就是 file_operations 中 poll 函数的 wait 参数
异步
- 在非阻塞
poll实验当中, 用户态还是需要通过不断轮询的方式获取内核的状态 - 异步就是驱动程序能够主动向应用程序发出通知, 报告自己可以访问
- "信号" 类似于中断机制, 属于纯软件层面的, 异步就是基于 "信号" 实现的
- 整体流程就是应用程序给定内核一个信号, 然后等待响应信号
- 阻塞, 非阻塞, 异步通知, 这三种是针对不同的应用场景下提出的, 没有优劣之分
信号量
信号量包含如下, 这个在操作系统中应用非常广泛, 比如 kill -9 PID, 就是向指定线程发送 SIGKILL 的信号
#define SIGHUP 1 /* 终端挂起或控制进程终止 */ #define SIGINT 2 /* 终端中断(Ctrl+C 组合键) */ #define SIGQUIT 3 /* 终端退出(Ctrl+\组合键) */ #define SIGILL 4 /* 非法指令 */ #define SIGTRAP 5 /* debug 使用,有断点指令产生 */ #define SIGABRT 6 /* 由 abort(3)发出的退出指令 */ #define SIGIOT 6 /* IOT 指令 */ #define SIGBUS 7 /* 总线错误 */ #define SIGFPE 8 /* 浮点运算错误 */ #define SIGKILL 9 /* 杀死、终止进程 */ #define SIGUSR1 10 /* 用户自定义信号 1 */ #define SIGSEGV 11 /* 段违例(无效的内存段) */ #define SIGUSR2 12 /* 用户自定义信号 2 */ #define SIGPIPE 13 /* 向非读管道写入数据 */ #define SIGALRM 14 /* 闹钟 */ #define SIGTERM 15 /* 软件终止 */ #define SIGSTKFLT 16 /* 栈异常 */ #define SIGCHLD 17 /* 子进程结束 */ #define SIGCONT 18 /* 进程继续 */ #define SIGSTOP 19 /* 停止进程的执行,只是暂停 */ #define SIGTSTP 20 /* 停止进程的运行(Ctrl+Z 组合键) */ #define SIGTTIN 21 /* 后台进程需要从终端读取数据 */ #define SIGTTOU 22 /* 后台进程需要向终端写数据 */ #define SIGURG 23 /* 有"紧急"数据 */ #define SIGXCPU 24 /* 超过 CPU 资源限制 */ #define SIGXFSZ 25 /* 文件大小超额 */ #define SIGVTALRM 26 /* 虚拟时钟信号 */ #define SIGPROF 27 /* 时钟信号描述 */ #define SIGWINCH 28 /* 窗口大小改变 */ #define SIGIO 29 /* 可以进行输入/输出操作 */ #define SIGPWR 30 /* 断点重启 */ #define SIGSYS 31 /* 非法的系统调用 */ #define SIGUNUSED 31 /* 未使用信号 */
接口处理函数
用户态
sighandler_t signal(int signum, sighandler_t handler); //signal 函数来设置指定信号的处理函数 1. signum: 要设置处理函数的信号 2. handler: 信号的处理函数 返回值: 设置成功的话返回信号的前一个处理函数, 设置失败的话返回 SIG_ERR typedef void(*sighandler_t)(int); 1. 信号处理函数的信号
内核态
- 需要定义一个
fasync_struct的结构体
头文件: include/linux/fs.h
struct fasync_struct { spinlock_t fa_lock; int magic; int fa_fd; struct fasync_struct *fa_next; /* singly linked list */ struct file *fa_file; struct rcu_head fa_rcu; };
- fasync 函数
int (*fasync) (int fd, struct file *filp, int on); 1. 一般调用 'fasync_helper' 函数来初始化定义的 'fasync_struct' int fasync_helper(int fd, struct file *filp, int on, struct fasync_struct **fapp); 1. 函数前三个参数就是 'fasync' 函数的三个参数, 第四个就是要初始化的 `fasync_struct` 结构体指针变量 2. 当应用程序通过 'fcntl(fd, F_SETFL, flags | FASYNC)'改变 'fasync'标记的时候, 驱动程序 'file_operations' 操作集中的 'fasync' 函数就会执行
示例接口
struct xxx_dev { ...... struct fasync_struct *async_queue; /* 异步相关结构体 */ }; static int xxx_fasync(int fd, struct file *filp, int on) { struct xxx_dev *dev = (xxx_dev)filp->private_data; if(fasync_helper(fd, filp, on, &dev->async_queue) < 0) return -EIO; return 0; } static struct file_operations xxx_ops = { ...... .fasync = xxx_fasync, .release = xxx_release, ...... }; static int xxx_release(struct inode *inode, struct file *filp) { return xxx_fasync(-1, filp, 0); /* 删除异步通知 */ }
- kill_fasync 函数
- 当设备可以访问的时候, 驱动程序要向应用程序发出信号, 相当于产生 "中断".
kill_fasync函数负责发送指定信号
void kill_fasync(struct fasync_struct **fp, int sig, int band) 1. fp: 要操作的 `fasybc_struct` 2. sig: 要发送的信号 3. band:可读时设置为 POLL_IN,可写时设置为 POLL_OUT。 4. 返回值 无
内核态和用户态交互
- 使用
fcntl(fd, F_SETOWN, getpid())将本应用程序的进程号高速给内核 - 开启异步通知, 当通过 fcntl 函数设置进程状态为 FASYNC, 经过这一步, 驱动程序中的 fasync 函数就会执行
flags = fcntl(fd, F_GETFL); /* 获取当前的进程状态 */ fcntl(fd, F_SETFL, flags | FASYNC); /* 开启当前进程异步通知功能 */
总结
- 在对一些硬件数据传输带宽很高的应用场景, 使用
while(1)独占CPU的性能是最高的,而且使用其它的方式相对于独占CPU而言,性能差的不是一点两点, 起码有十几倍甚至几百倍的性能损耗。
比如之前做卷积算法的时候, i7处理器, 使用线程唤醒的方式, 执行200次, 1024*1024矩阵, 卷积核为9的情况下, 单核独占CPU需要 1s, 而唤醒和信号量的方式需要 10来秒.
基于总线框架下的驱动程序
platform 架构
意义和作用
- 虚拟总线: i2c, SPI, PCI都是基于实际总线实现的, 虚拟总线就是为了解决类似uart, gpio之类的分层问题
- 分层,不同层做不同层的事情
- linux内核驱动程序占用大部分,将一些通用性的分层出来封装成接口,可以大大减少linux内核源码
- 在 SOC 中有些外设是没有总线这个概念的,但是又要使用总线,为了解决此问题,Linux 提出了 platform 这个虚拟总线,相应的就有 platform_driver 和 platform_device
platform 总线
include/linux/device.h, 头文件
struct bus_type { const char *name; // 总线名字 const char *dev_name; struct device *dev_root; const struct attribute_group **bus_groups; //总线属性 const struct attribute_group **dev_groups; //该总线下的设备对应的属性 const struct attribute_group **drv_groups; //该总线下的驱动对应的属性 int (*match)(struct device *dev, struct device_driver *drv); //设备和驱动之间的匹配 int (*uevent)(struct device *dev, struct kobj_uevent_env *env); // int (*probe)(struct device *dev); // 和设备匹配之上才会执行该函数 int (*remove)(struct device *dev); void (*shutdown)(struct device *dev); int (*online)(struct device *dev); int (*offline)(struct device *dev); int (*suspend)(struct device *dev, pm_message_t state); int (*resume)(struct device *dev); int (*num_vf)(struct device *dev); const struct dev_pm_ops *pm; const struct iommu_ops *iommu_ops; struct subsys_private *p; struct lock_class_key lock_key; };
drivers/base/platform.c 总线定义
struct bus_type platform_bus_type = { .name = "platform", .dev_groups = platform_dev_groups, .match = platform_match, .uevent = platform_uevent, .pm = &platform_dev_pm_ops, }; EXPORT_SYMBOL_GPL(platform_bus_type);
platform_bus_type 就是 platform 平台总线,其中 platform_match 就是匹配函数
匹配方式
static int platform_match(struct device *dev, struct device_driver *drv) { struct platform_device *pdev = to_platform_device(dev); struct platform_driver *pdrv = to_platform_driver(drv); /* When driver_override is set, only bind to the matching driver */ if (pdev->driver_override) return !strcmp(pdev->driver_override, drv->name); /* Attempt an OF style match first */ if (of_driver_match_device(dev, drv)) //设备树匹配模式 return 1; /* Then try ACPI style match */ if (acpi_driver_match_device(dev, drv)) // return 1; /* Then try to match against the id table */ if (pdrv->id_table) return platform_match_id(pdrv->id_table, pdev) != NULL; /* fall-back to driver name match */ return (strcmp(pdev->name, drv->name) == 0); }
能够看出来设备树总共有四种匹配方式
设备树匹配
OF 类型的匹配,也就是设备树采用的匹配方式,of_driver_match_device 函数定义在文件 include/linux/of_device.h 中。device_driver结构体(表示设备驱动)中有个名为 of_match_table 的成员变量,此成员变量保存着驱动的 compatible 匹配表,设备树中的每个设备节点的 compatible 属性会和 of_match_table 表中的所有成员比较,查看是否有相同的条目,如果有的话就表示设备和此驱动匹配,设备和驱动, 匹配成功以后 probe 函数就会执行
ACPI 匹配
acpi 表用于 x86 架构。ACPI 表是位于闪存芯片上的 UEFI 固件的一部分。在 x86 上,内核从固件提供的 ACPI 表中获取所有平台信息(对于 x86,这通常称为 BIOS)。开发人员无法修改,只能由主板供应商修改BIOS固件.
id_table 匹配
每个 platform_driver 结构体有一个 id_table 成员变量,顾名思义,保存了很多 id 信息。这些 id 信息存放着这个 platformd 驱动所支持的驱动类型。
name 字段匹配
直接比较驱动和设备的 name 字段,看看是不是相等,如果相等的话就匹配成功。
platform 驱动
include/linux/platform_device.h, platform_device 所在头文件
struct platform_driver { int (*probe)(struct platform_device *); int (*remove)(struct platform_device *); void (*shutdown)(struct platform_device *); int (*suspend)(struct platform_device *, pm_message_t state); int (*resume)(struct platform_device *); struct device_driver driver; const struct platform_device_id *id_table; bool prevent_deferred_probe; };
- probe函数, 当驱动与设备匹配成功以后 probe函数就会执行, 如果自己要编写一个全新的驱动, 那么probe需要自行实现
- 其中
device_driver为driver成员, 该结构体相当于面向对象中的基类(父类), 然后在此基础上,又添加了一些特有的成员变量
include/linux/device.h, 头文件包含了bus和device_driver
struct device_driver { const char *name; struct bus_type *bus; struct module *owner; const char *mod_name; /* used for built-in modules */ bool suppress_bind_attrs; /* disables bind/unbind via sysfs */ enum probe_type probe_type; const struct of_device_id *of_match_table; const struct acpi_device_id *acpi_match_table; int (*probe) (struct device *dev); int (*remove) (struct device *dev); void (*shutdown) (struct device *dev); int (*suspend) (struct device *dev, pm_message_t state); int (*resume) (struct device *dev); const struct attribute_group **groups; const struct dev_pm_ops *pm; struct driver_private *p; };
其中 of_match_table 就是采用设备树匹配, 同样为数组, 定义在 include/linux/mod_devicetable.h中
/* * Struct used for matching a device */ struct of_device_id { char name[32]; char type[32]; char compatible[128]; const void *data; };
其中 compatible 非常重要, 对于设备树而言, 就是通过设备节点的 compatible 属性值和 of_match_table 中的每个项目成员变量进行比较
platform_device_id既id_table, 也就是两者之间匹配的时候用到的第三种方法, 其结构体如下:
struct platform_device_id { char name[PLATFORM_NAME_SIZE]; kernel_ulong_t driver_data; };
platform 设备
文件: include/linux/platform_device.h
struct platform_device { const char *name; int id; bool id_auto; struct device dev; u32 num_resources; struct resource *resource; const struct platform_device_id *id_entry; char *driver_override; /* Driver name to force a match */ /* MFD cell pointer */ struct mfd_cell *mfd_cell; /* arch specific additions */ struct pdev_archdata archdata; };
- 其中 device 在
include/linux/device.h中, 包含了设备的一些详细的信息 - name 表示设备名字,要和所使用的 platform 驱动的 name 字段相同
num_resources表示资源数量, 一般为resource资源大小resource表示资源, 设备信息, 外设寄存器等, 结构体如下
struct resource { resource_size_t start; resource_size_t end; const char *name; unsigned long flags; unsigned long desc; struct resource *parent, *sibling, *child; };
start 和 end 表示资源的起始和终止信息, 对于内存资源,表示内存起始和终止地址
name表示资源名字
flags 表示资源类型, 资源类型定义在了 include/linux/ioport.h
#define IORESOURCE_TYPE_BITS 0x00001f00 /* Resource type */ #define IORESOURCE_IO 0x00000100 /* PCI/ISA I/O ports */ #define IORESOURCE_MEM 0x00000200 #define IORESOURCE_REG 0x00000300 /* Register offsets */ #define IORESOURCE_IRQ 0x00000400 #define IORESOURCE_DMA 0x00000800
接口函数定义
platform_device 和 platform_driver, 的驱动注册接口
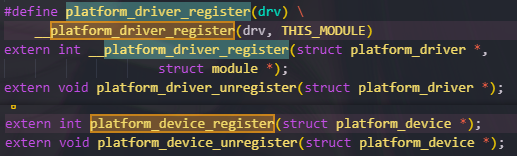
platform_driver
/* 设备结构体 */ struct xxx_dev{ struct cdev cdev; /* 设备结构体其他具体内容 */ }; struct xxx_dev xxxdev; /* 定义个设备结构体变量 */ static int xxx_open(struct inode *inode, struct file *filp) { /* 函数具体内容 */ return 0; } static ssize_t xxx_write(struct file *filp, const char __user *buf, size_t cnt, loff_t *offt) { /* 函数具体内容 */ return 0; } /* * 字符设备驱动操作集 */ static struct file_operations xxx_fops = { .owner = THIS_MODULE, .open = xxx_open, .write = xxx_write, }; /* * platform 驱动的 probe 函数 * 驱动与设备匹配成功以后此函数就会执行 */ static int xxx_probe(struct platform_device *dev) { //...... cdev_init(&xxxdev.cdev, &xxx_fops); /* 注册字符设备驱动 */ /* 函数具体内容 */ return 0; } static int xxx_remove(struct platform_device *dev) { //...... cdev_del(&xxxdev.cdev); /* 删除 cdev */ /* 函数具体内容 */ return 0; } /* 匹配列表 */ static const struct of_device_id xxx_of_match[] = { { .compatible = "xxx-gpio" }, { /* Sentinel */ } }; /* * platform 平台驱动结构体 */ static struct platform_driver xxx_driver = { .driver = { .name = "xxx", .of_match_table = xxx_of_match, }, .probe = xxx_probe, .remove = xxx_remove, }; /* 驱动模块加载 */ static int __init xxxdriver_init(void) { return platform_driver_register(&xxx_driver); } static void __exit xxxdriver_exit(void) { platform_driver_unregister(&xxx_driver); } module_init(xxxdriver_init); module_exit(xxxdriver_exit); MODULE_LICENSE("GPL"); MODULE_AUTHOR("zuozhongkai");
platform_device
/* 寄存器地址定义*/ #define PERIPH1_REGISTER_BASE (0X20000000) /* 外设 1 寄存器首地址 */ #define PERIPH2_REGISTER_BASE (0X020E0068) /* 外设 2 寄存器首地址 */ #define REGISTER_LENGTH 4 5 /* 资源 */ static struct resource xxx_resources[] = { [0] = { .start = PERIPH1_REGISTER_BASE, .end = (PERIPH1_REGISTER_BASE + REGISTER_LENGTH - 1), .flags = IORESOURCE_MEM, }, [1] = { .start = PERIPH2_REGISTER_BASE, .end = (PERIPH2_REGISTER_BASE + REGISTER_LENGTH - 1), .flags = IORESOURCE_MEM, }, }; /* platform 设备结构体 */ static struct platform_device xxxdevice = { .name = "xxx-gpio", .id = -1, .num_resources = ARRAY_SIZE(xxx_resources), .resource = xxx_resources, }; /* 设备模块加载 */ static int __init xxxdevice_init(void) { return platform_device_register(&xxxdevice); } /* 设备模块注销 */ static void __exit xxx_resourcesdevice_exit(void) { platform_device_unregister(&xxxdevice); } module_init(xxxdevice_init); module_exit(xxxdevice_exit); MODULE_LICENSE("GPL"); MODULE_AUTHOR("zuozhongkai");
Linux 设备驱动框架
what is 设备驱动框架
点击查看代码
static int device_probe(struct platform_device *dev) { u32 val; int ret; printk(KERN_INFO"driver probe \r\n"); /** 通过设备树匹配资源 */ ret = led_init(dev->dev.of_node); if(ret) return ret; // 第一种方式: 设备号申请 */ if(pridev.major) { pridev.devid = MKDEV(pridev.major, 0); /*大部分驱动次设备号都选择0*/ printk("register devid \n"); if(0 < register_chrdev_region(pridev.devid, DEVICE_NUM, DEVICE_NAME)) { printk("#ERR: error to register chrdev region \n"); } } else { printk("alloc devid \n"); /*申请设备号*/ if(0 < alloc_chrdev_region(&pridev.devid, 0, DEVICE_NUM, DEVICE_NAME)) { printk("#ERR: error to alloc chrdev region \n"); goto out1; } pridev.major = MAJOR(pridev.devid); pridev.minor = MINOR(pridev.devid); } printk("devid: %0x, major: %0x, minor: %0x \n", pridev.devid, pridev.major, pridev.minor); /* 初始化cdev结构体变量 */ pridev.cdev.owner = THIS_MODULE; cdev_init(&pridev.cdev, &driver_fops); /* 初始化cdev结构体变量*/ ret = cdev_add(&pridev.cdev, pridev.devid, 1); /* 添加字符设备*/ if(ret) goto out2; /* 自动创建设备节点 */ // 创建class pridev.class = class_create(THIS_MODULE, DEVICE_NAME); if(IS_ERR(pridev.class)) { //根据返回NULL指针判断返回状态是否有错 ret = PTR_ERR(pridev.class); //获取错误状态 goto out3; } // 创建设备 pridev.device = device_create(pridev.class, NULL, pridev.devid, NULL, DEVICE_NAME); if(IS_ERR(pridev.device)) { //根据返回NULL指针判断返回状态是否有错 ret = PTR_ERR(pridev.device); //获取错误状态 goto out4; } return 0; out4: class_destroy(pridev.class); out3: cdev_del(&pridev.cdev); out2: unregister_chrdev_region(pridev.devid, 1); out1: gpio_free(pridev.led_gpio); }
之前驱动开始初始化的流程简化如下:
- 1 申请设备号: 调用 alloc_chrdev_region 动态申请一个字符设备设备号
- 2 初始化 cdev: 调用 cdev_init 函数初始化一个cdev字符设备, 将LED设备操作函数集绑定到该设备
- 3 注册/添加 cdev: 调用cdev_add 函数向内核注册cdev 字符设备
- 4 创建类: 调用class_create 函数创建一个自定义设备类
- 5 创建设备: 调用 device_create 函数创建设备
上述的这些接口都是linux驱动最原始的API接口, 如果驱动开发的比较多的话, 形不成一种体系,会比较乱, 所以才有了设备驱动框架
设备驱动框架的概念: linux针对每个种类的驱动设计了一套成熟的、标准的、典型的驱动实现, 然后不同厂家的同一类的硬件驱动中的相同部分抽出来自己实现就好
比如LED灯, 不管LED是什么颜色,大小,能发出多少种光,但是它终究是LED,能点亮熄灭就是他们共同的特性, 如果将LED标准化处理, 就由 LED驱动框架来实现
学习驱动开发就是学习 linux 下的各种不同种类的设备驱动框架,这句话其实也没错,尤其是复杂的设备,它们的驱动框架也比较难,每种设备驱动框架都有其自己的实现思想和组织架构,我们只有理解了该类设备的驱动框架使用方法才能编写出自己的设备驱动程序。
LED 设备驱动框架
注册 LED 设备
LED驱动框架提供了 led_classdev_register 宏用于注册 LED 设备, 该宏定义在内核源 include/linux/leds.h
extern int of_led_classdev_register(struct device *parent, struct device_node *np, struct led_classdev *led_cdev); #define led_classdev_register(parent, led_cdev) \ of_led_classdev_register(parent, NULL, led_cdev) 1. "parent": LED 设备的父设备, "struct led_classdev" 类型指针变量 2. "led_cdev": 需要注册的LED设备结构体, LED驱动中用一个 "led_classdev" 结构体来描述一个LED设备 3. 成功返回0, 失败则返回一个负数 struct led_classdev { const char *name; //设备名字 enum led_brightness brightness; //LED默认亮度 enum led_brightness max_brightness; //LED的最大亮度 int flags; /* set_brightness_work / blink_timer flags, atomic, private. */ unsigned long work_flags; void (*brightness_set)(struct led_classdev *led_cdev, enum led_brightness brightness); //用于设置LED亮度的函数指针,不可休眠 int (*brightness_set_blocking)(struct led_classdev *led_cdev, enum led_brightness brightness); //用于设置LED亮度的函数指针,可以休眠 /* Get LED brightness level */ enum led_brightness (*brightness_get)(struct led_classdev *led_cdev); //获取LED亮度 ... int (*blink_set)(struct led_classdev *led_cdev, unsigned long *delay_on, unsigned long *delay_off); struct device *dev; const struct attribute_group **groups; struct list_head node; /* LED Device list */ const char *default_trigger; /* Trigger to use */ unsigned long blink_delay_on, blink_delay_off; struct timer_list blink_timer; int blink_brightness; int new_blink_brightness; void (*flash_resume)(struct led_classdev *led_cdev); struct work_struct set_brightness_work; int delayed_set_value; #ifdef CONFIG_LEDS_TRIGGERS /* Protects the trigger data below */ struct rw_semaphore trigger_lock; struct led_trigger *trigger; struct list_head trig_list; void *trigger_data; /* true if activated - deactivate routine uses it to do cleanup */ bool activated; #endif #ifdef CONFIG_LEDS_BRIGHTNESS_HW_CHANGED int brightness_hw_changed; struct kernfs_node *brightness_hw_changed_kn; #endif /* Ensures consistent access to the LED Flash Class device */ struct mutex led_access; };
- LED 亮度是可以调的, 通过
PWM调试
用户态下线程对CPU核的绑定
GUN 提供的API, 绑定核
代码如下
#define _GNU_SOURCE /* See feature_test_macros(7) */ #include <stdio.h> #include <sys/types.h> #include <unistd.h> #include <sched.h> #include <pthread.h> void thread_test() { cpu_set_t mask; printf("pid=%d\n", getpid()); CPU_ZERO(&mask); CPU_SET(3, &mask); //将cpu3绑定, 第4个CPU核 sched_setaffinity(0, sizeof(cpu_set_t), &mask); //此处0,可以直接设置成 pid, 或者是在主线程设置当前线程也可以 CPU_ZERO(&cpuset); if(0 != sched_getaffinity(0, sizeof(cpu_set_t), &cpuset)) { //查询是cpu_set_t printf("sched_getaffinity err \n"); } if(!CPU_ISSET(cur_cpu, &cpuset)) { //看是否绑定的正确 printf("CPU_ISSET err \n"); } while (1) { } } int main(int argc, char const *argv[]) { pthread_t tid1; //创建线程1 if (pthread_create(&tid1, NULL, (void *)thread_test, NULL) != 0) { fprintf(stderr, "thread create failed\n"); return -1; } while(1) { // usleep(100*1000); } return 0; }
使用 gcc编译运行,每次运行结果如下:
gcc test.c -pthread
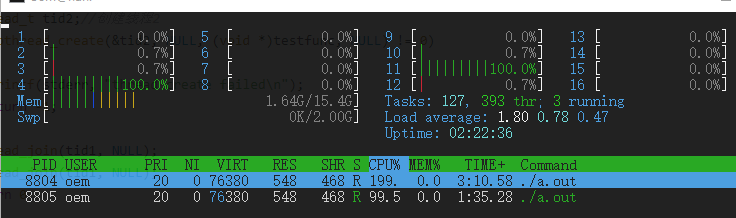
- 子线程每次启动都是运行在第四个 CPU 核上, 然后主线程会每次调度到其它核上面
指令绑定CPU核
本文来自博客园踩坑狭,作者:韩若明瞳,转载请注明原文链接:https://www.cnblogs.com/han-guang-xue/p/15769229.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人