
spark的UDF操作,RDD与DataFrame转换,RDD DataFrame DataSet的分析
1 >spark的UDF操作
理解:就是在sql中查询语句中提供了max(),avg(),min(),count()等函数操作, 同样的在spark中也有这些函数,但是用户的需求是多变的,比如:
select name,age,length(name)/name.length from user
很明显,不管是使用length(name)或是name.length都不可能实现这种效果, 于是spark提供UDF的操作可以实现这样的效果
代码如下:
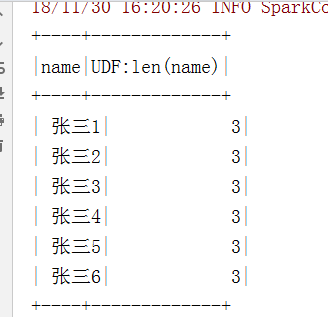
val conf = new SparkConf().setMaster("local").setAppName("json") val spark = SparkSession.builder().config(conf).getOrCreate() def fun1(): Unit ={ //得到conf val people:DataFrame = spark.read.json("E:\\user.json") //通过SQL语句操作dataFrame people.createTempView("user") import spark.sql spark.udf.register[Int,String]("len",lengthName) //注册在spark中 sql("select name,len(name) from user").show() } //该方法需要注册在spark里 def lengthName(name:String): Int ={ name.length }
执行:
2 >RDD与DataFrame 相互转化
>通过样例类转化:
/** * rdd与dataframe互操作 * 1.通过样例类进行转换 * 2.通过编程的方式进行转换 */ //1.通过样例类进行转化 case class People(name:String, age:Int) //样例类 def fun2(): Unit ={ val sc = spark.sparkContext val rdd = sc.parallelize(Array("张三 12","成吉思汗 20","李四 33","占城 45")) val rddT = rdd.map(x=>{ val p = x.split(" ") People(p(0),p(1).trim.toInt) }) import spark.implicits._ //隐式转化 val dataFrame:DataFrame = rddT.toDF //将RDD转化dataFrame dataFrame.show() println(rdd.collect().toBuffer) println(dataFrame.rdd.collect().toBuffer) //将dataFrame转化为RDD println(dataFrame.javaRDD.collect()) //同下,输出结果一样, println(dataFrame.toJavaRDD.collect()) }
通过查看源码: toJavaRDD与javaRDD都一样

输出结果:
dataFrame.show() 的输出
+----+---+ |name|age| +----+---+ | 张三| 12| |成吉思汗| 20| | 李四| 33| | 占城| 45| +----+---+
println(rdd.collect().toBuffer)
ArrayBuffer(张三 12, 成吉思汗 20, 李四 33, 占城 45)
println(dataFrame.rdd.collect().toBuffer) 的输出
ArrayBuffer([张三,12], [成吉思汗,20], [李四,33], [占城,45])
println(dataFrame.javaRDD.collect()) //同下,输出结果一样,
println(dataFrame.toJavaRDD.collect())
[[张三,12], [成吉思汗,20], [李四,33], [占城,45]]
3 >RDD DataFrame DataSet数据集的理解
参考:https://www.cnblogs.com/starwater/p/6841807.html
相同点:
1>全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
分布式弹性数据集:(spark的核心)弹性就是对于丢失的数据集,可以很快的重建
参考:https://www.cnblogs.com/han-guang-xue/p/10036225.html
2>三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算,
极端情况下,如果代码里面有创建、转换,但是后面没有在Action中使用对应的结果,在执行时会被直接跳过,如
val rdd=spark.sparkContext.parallelize(Seq(("a", 1), ("b", 1), ("a", 1))) rdd.map{line=> println("运行") //不会执行 line._1 }
3>三者都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
区别:
1> RDD一般和spark mlib同时使用 MLlib是Apache Spark的可扩展机器学习库。
2> RDD不包含源数据的信息 RDD是分布式的Java对象的集合
如,RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的,DataFrame是一种以RDD为基础的分布式数据集,也就是分布式的Row对象的集合(每个Row对象代表一行记录),提供了详细的结构信息,
也就是我们经常说的模式(schema),Spark SQL可以清楚地知道该数据集中包含哪些列、每列的名称和类型。
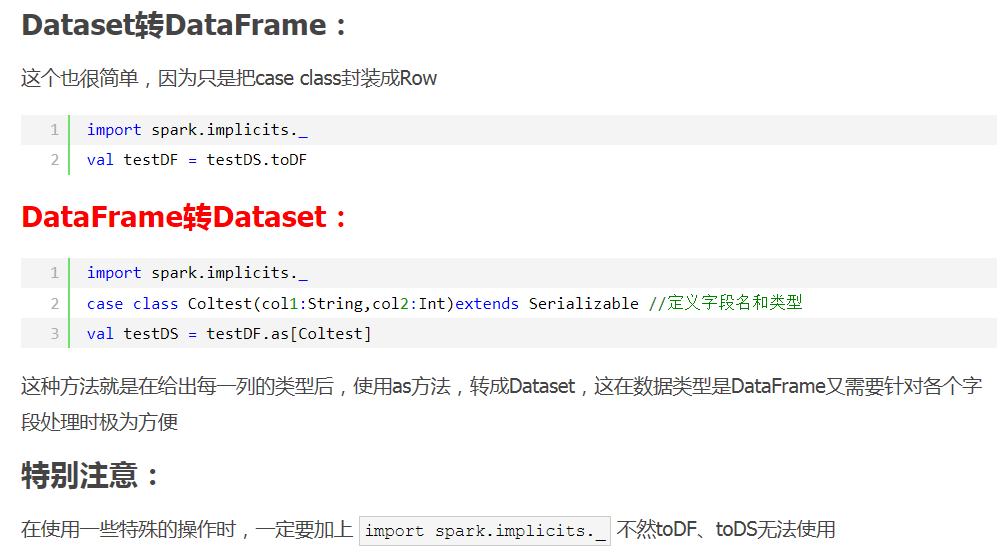
3>这里主要对比Dataset和DataFrame,因为Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同DataFrame也可以叫Dataset[Row],每一行的类型是Row,
不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段而Dataset中,每一行是什么类型是不一定的,
在自定义了case class之后可以很自由的获得每一行的信息
可以看出,Dataset在需要访问列中的某个字段时是非常方便的,然而,如果要写一些适配性很强的函数时,如果使用Dataset,行的类型又不确定,可能是各种case class,无法实现适配,这时候用DataFrame即Dataset[Row]就能比较好的解决问题
本文来自博客园踩坑狭,作者:韩若明瞳,转载请注明原文链接:https://www.cnblogs.com/han-guang-xue/p/10045413.html

