
spark几种读文件的方式
spark.read.textFile和sc.textFile的区别
val rdd1 = spark.read.textFile("hdfs://han02:9000/words.txt") //读取到的是一个RDD对象
val rdd2 = sc.textFile("hdfs://han02:9000/words.txt") //读取到的是一个Dataset的数据集

分别进行单词统计的方法:
rdd1.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false)
rdd2.flatMap(x=>x.split(" ")).groupByKey(x=>x).count()
前者返回Array[(String,Int)],后者返回Array[(String,Long)]

![]()
TextFile(url,num)///num为设置分区个数文件超过(128)
1.从当前目录读取一个文件:
val path = "Current.txt" //Current fold file val rdd1 = sc.textFile(path,2)
2.从当前目录读取一个文件:
val path = "Current1.txt,Current2.txt," //Current fold file val rdd1 = sc.textFile(path,2)
3.从本地读取一个文件:
val path = "file:///usr/local/spark/spark-1.6.0-bin-hadoop2.6/README.md" //local file val rdd1 = sc.textFile(path,2)
4.从本地读取一个文件夹中的内容:
val path = "file:///usr/local/spark/spark-1.6.0-bin-hadoop2.6/licenses/" //local file val rdd1 = sc.textFile(path,2)
5.从本地读取一个多个文件:
val path = "file:///usr/local/spark/spark-1.6.0-bin-hadoop2.6/licenses/LICENSE-scala.txt,file:///usr/local/spark/spark-1.6.0-bin-hadoop2.6/licenses/LICENSE-spire.txt" //local file val rdd1 = sc.textFile(path,2)
6.从本地读取多个文件夹中的内容:
val path = "/usr/local/spark/spark-1.6.0-bin-hadoop2.6/data/*/*" //local file
val rdd1 = sc.textFile(path,2)
val path = "/usr/local/spark/spark-1.6.0-bin-hadoop2.6/data/*/*.txt" //local file,指定后缀名文件
val rdd1 = sc.textFile(path,2)
7.采用通配符读取相似的文件中的内容:
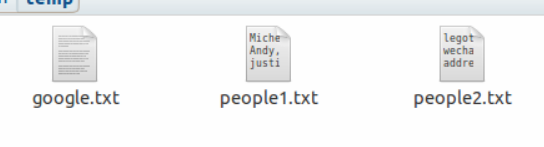
for (i <- 1 to 2){ val rdd1 = sc.textFile(s"/root/application/temp/people$i*",2) }
eg:google中的文件读取不了
本文来自博客园踩坑狭,作者:韩若明瞳,转载请注明原文链接:https://www.cnblogs.com/han-guang-xue/p/10034153.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?