
kafka监控框架预研
本文讨论了五种实现方案:
-
jmxtrans+influxdb +grafana
-
jmx_exporter +ps + grafana
-
kafka_exporter + ps + grafana
-
cmak
-
logi_kafkamanager
JMXTrans + InfluxDB + Grafana
个人觉得是一种通用的监控框架
数据来源:
kafka提供了大量的监控指标,这些监控指标可以通过jmx获取。jmxtrans为开源工具,通过配置json文件将,采集到的数据存储至influxdb。
jconsole的监控图:
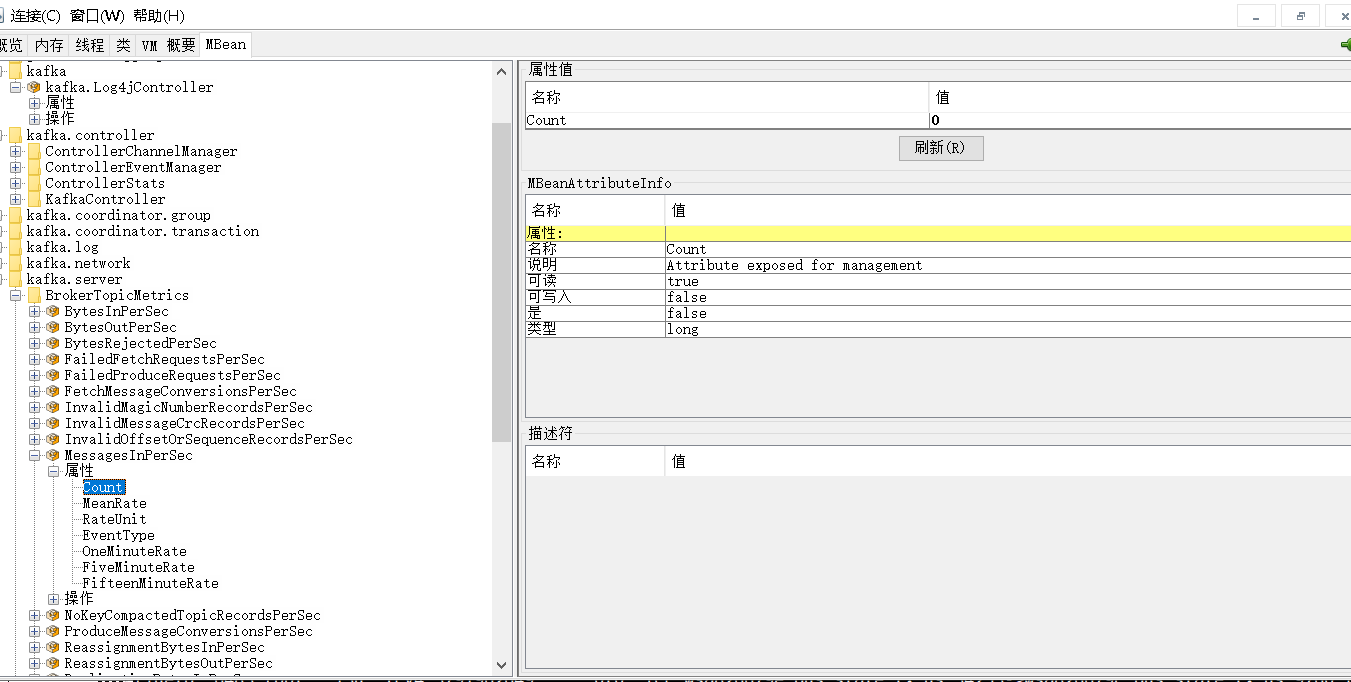
提供的监控指标包含:kafka.log 、kafka.server,kafka.log、kafka.network;具体的有:BytesInPerSec、BytesOutPerSec、MessagesInPerSec、RequestsPerSec、Threading
使用上比较简单,配置JMXTrans所需要的json文件。
需要配置jmx端口:"port" : "9760", 监控的brokerip"host" : "168.38.103.155",要监控一个集权的各个机器只需要配置多个ip即可。
{
"servers" : [ {
"port" : "9760",
"host" : "100.10.100.100",
"queries" : [ {
"obj" : "kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=access_cdn_big",
"attr" : [ "Count" ],
"resultAlias":"MessagesInPerSec",
"outputWriters" : [ {
"@class" : "com.googlecode.jmxtrans.model.output.InfluxDbWriterFactory",
"url" : "http://110.20.110.110:8086/",
"username" : "admin",
"password" : "123456",
"database" : "jmxDB",
"tags" : {"application" : "MessagesInPerSec"}
} ]
} ]
}]}
数据存储:
使用时序数据库InfluxDB,根据jmxtrans的配置自动创建表,并存储数据。

数据展示与告警:
通过grafana实现监控与告警,配置相应的查询sql语句。
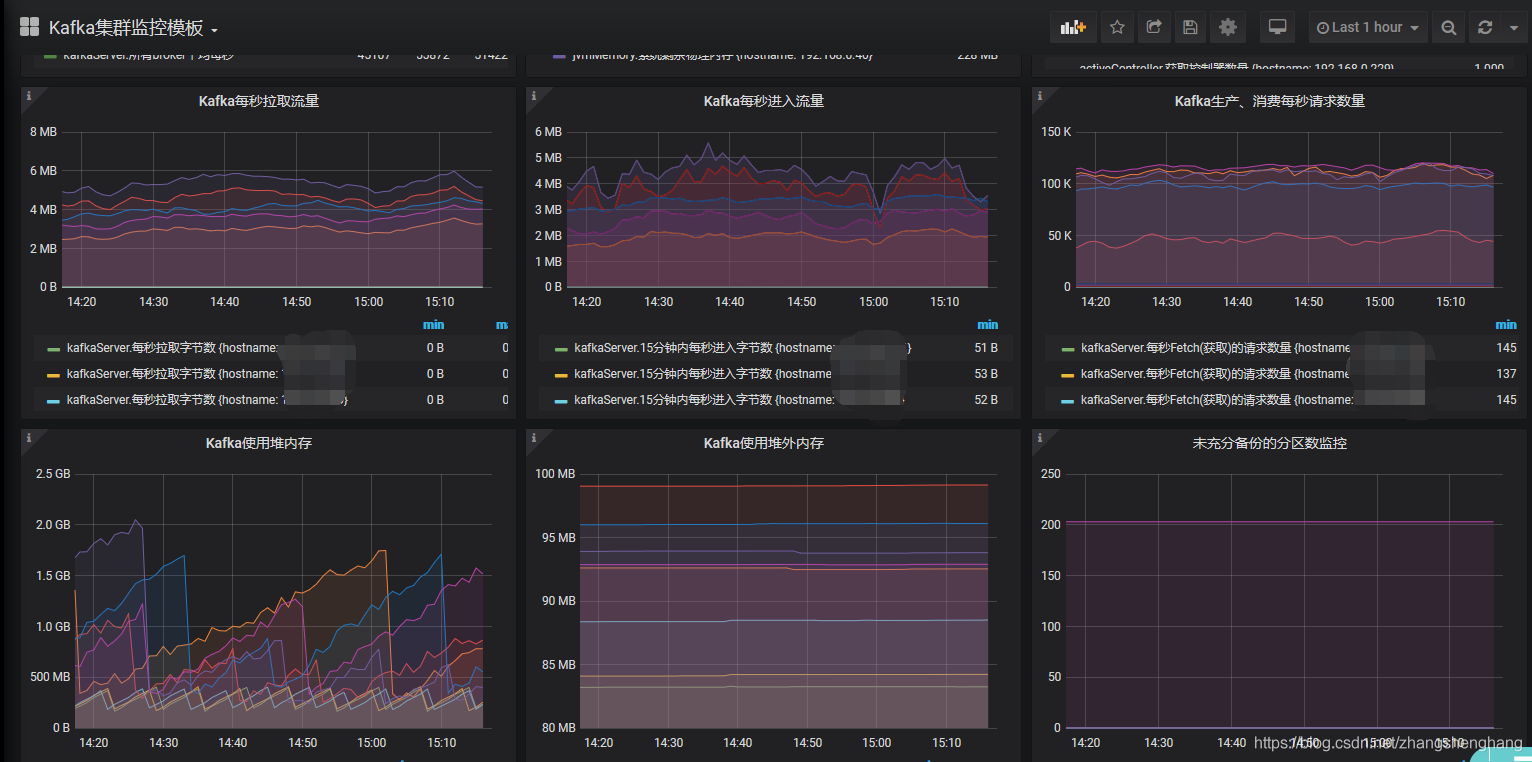
(JMX_exporter|kafka_exporter)+Prometheus+Grafana
与JMXTrans + InfluxDB + Grafana 的方式大同小异,都是通过jmx暴露的指标获取数据,写入时序数据库中,以时序数据库为数据源,通过grafana进行监控与告警。
数据采集:
-
jmx_exporter:
ps生态下的一个组件,通过jmx获取监控数据,理论上任何使用jmx暴露metric的应用都可以使用。jmx_exporter有两种启动方式,一种是以httpserver的方式启动,一种是java agent的方式与java应用一起启动。因此jmx_exporter分成两个jar包,分别是jmx_prometheus_javaagent.jar 、jmx_prometheus_httpserver.jarjmx_prometheus_javaagent.jar 可以通过java_agent获得更全面的数据,官网强烈推荐此方式,只需要维护一个进程。但是若修改配置,则需要重启kafka。
修改启动脚本:
export KAFKA_OPTS="-javaagent:/opt/kafka/kafka_2.11-1.0.0/jmx_prometheus_javaagent-0.9.jar=9997:/opt/kafka/kafka_2.11-1.0.0/kafka-agent.yaml";
jmx_prometheus_httpserver.jar 该方式可以独立部署,通过配置文件读取指定的jmx,相比于上一种需要多维护一个独立进程。
java -Dcom.sun.management.jmxremote.ssl=false
-cp /home/setup/kafka_exporter_ps_grafana/jmx_exporter/jmx_prometheus_httpserver-0.12.0-jar-with-dependencies.jar io.prometheus.jmx.WebServer 9997
/home/setup/kafka_exporter_ps_grafana/jmx_exporter/config.yaml
端口9997为jmx_exporter暴露出来的数据端口,供ps采集使用。主要工作量在jmx_exporter配置上,内容就是配置的kafka metrics。
jmx_exporter配置:
hostPort: 127.0.0.1:9999
lowercaseOutputName: true
whitelistObjectNames:
- "kafka.controller:type=KafkaController,name=OfflinePartitionsCount"
- "kafka.controller:type=KafkaController,name=ActiveControllerCount"
- "kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec"
- "kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec"
- "kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions"
- "kafka.server:type=ReplicaFetcherManager,name=MaxLag,clientId=Replica"
官方提供配置模板事例:
- kafka_exporter:
Kafka exporter for Prometheus. For other metrics from Kafka, have a look at the JMX exporter.
通过Kafka Protocol Specification 收集 Brokers, Topics 以及 Consumer Groups的相关指标,使用简单,运行高效,相比于以往通过kafka内置的脚本进行收集,由于没有了JVM的运行开销,指标收集时间从分钟级别降到秒级别,便于大规模集群的监控。kafka_exporter不需要进行配置,后台启动即可。
启动方式:kafka_exporter --kafka.server=kafka:9092 [--kafka.server=another-server ...]
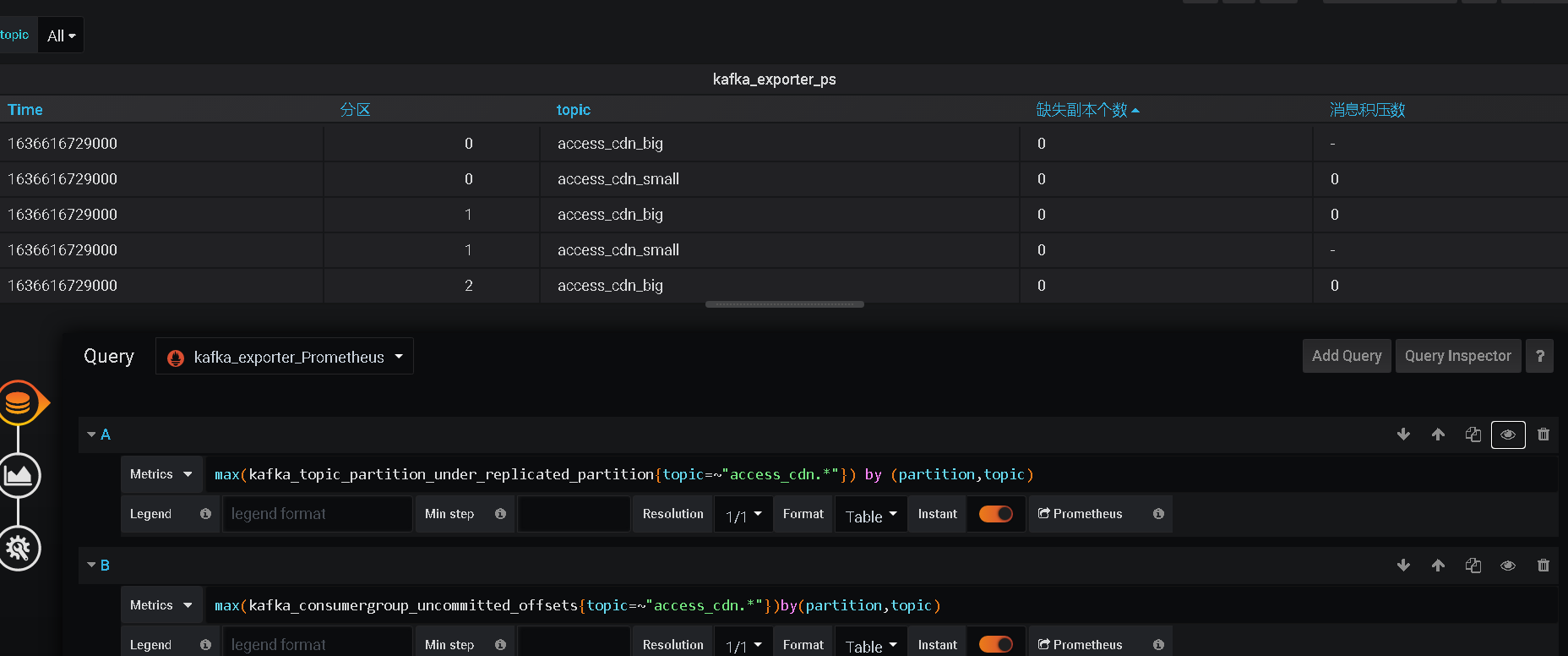
监控指标:
| 指标 | 输出 | 含义 |
|---|---|---|
| kafka_brokers | kafka_brokers3 | broker数量 |
| kafka_consumergroup_current_offset | kafka_consumergroup_current_offset{consumergroup="crsstreamingsort",partition="0",topic="access_cdn_big"} 2.726367e+06 | 每个消费者组再各个topic的各个partiton消费到的当前offset |
| kafka_consumergroup_current_offset_sum | kafka_consumergroup_current_offset_sum{consumergroup="crsstreamingsort",topic="access_cdn_big"} 5.452707e+06 | 每个消费者组再各个topic的消费到的当前offset |
| kafka_consumergroup_lag | kafka_consumergroup_lag{consumergroup="KMOffsetCache-kafka-manager-3806276532-ml44w",partition="0",topic="__consumer_offsets"} 1 | 每个consumergroup对于patrtion/topic消费滞后的值 |
| kafka_consumergroup_lag_sum | 每个consumergroup对于topic消费滞后的值 | |
| kafka_consumer_lag_millis | kafka_consumer_lag_millis{consumergroup="perf-consumer 74084",partition="0",topic="test"} 3.4457231197552e+10 | |
| kafka_consumergroup_members | kafka_consumergroup_members{consumergroup="zycdn_streamingstat"} 11 | 展示各个消费者组和每个消费者组的连接数量 |
| kafka_consumergroup_uncommitted_offsets | kafka_consumergroup_uncommitted_offsets{consumergroup="crsstreamingsort",partition="0",topic="access_cdn_big"} 0 | 每个消费者组再各个topic的各个partiton未提交的offset |
| kafka_consumergroup_uncommitted_offsets_sum | kafka_consumergroup_uncommitted_offsets_sum{consumergroup="crsstreamingsort",topic="access_cdn_big"} 0 | 每个消费者组再各个topic的还未提交的offset |
| kafka_topic_partition_current_offset | kafka_topic_partition_current_offset{partition="0",topic="hellokafka"} 600000 | 各个分区当前的offset |
| kafka_topic_partition_in_sync_replica | kafka_topic_partition_in_sync_replica{partition="0",topic="crs-kafka-topic"} 3 | 当前分区已经同步的副本 |
| kafka_topic_partition_leader | kafka_topic_partition_leader{partition="0",topic="access_cdn_big"} 10002 | 分区leader |
| kafka_topic_partition_leader_is_preferred | kafka_topic_partition_leader_is_preferred{partition="0",topic="access_cdn_small"} 1 | 是否为优选leader |
| kafka_topic_partition_oldest_offset | kafka_topic_partition_oldest_offset{partition="0",topic="access_cdn_small"} 874864 | 每个分区最老的offset |
| kafka_topic_partition_replicas | kafka_topic_partition_replicas{partition="0",topic="statuscode_details"} 3 | 每个分区的副本个数 |
| kafka_topic_partition_under_replicated_partition | kafka_topic_partition_under_replicated_partition{partition="0",topic="hellokafka"} 0 | 副本丢失数量 |
| kafka_topic_partitions | kafka_topic_partitions{topic="__consumer_offsets"} 50 | 分区数量 |
数据存储:
通过ps主动拉取数据进行存储。Prometheus采取的是pull的方式,influxdb采取的是push方式,ps只需要配置数据源即可:
static_configs:
- targets: ['localhost:9090']
- job_name: 'vpc_md_kafka'
static_configs:
- targets: ['localhost:9308']
数据展示与告警:
通过grafana接入ps的数据,进行展示;主要工作就是在进行dashbord的配置。
{
...........
"panels": [
{
"styles": [
{
"alias": "缺失副本个数",
"align": "auto",
"colorMode": null,
"colors": [
"rgba(245, 54, 54, 0.9)",
"rgba(237, 129, 40, 0.89)",
.............
}
CMAK (KAFKA-MANAGER)
测试环境:http://10...**:9001
该项目为web工程,使用scala语言编写;同时具有监控与运维的功能,没有数据数据库存储,只是实时的展示出来,没有告警功能,框架比较简洁。
数据获取方式:通过kakfa的协议获取整个集群的指标,还通过jmx获得broker和topic的指标。
运行环境: 从3.0.0.2版本起需要jdk11运行环境,zk版本也要求在3.5+以上,但是实测在看法环境上没啥问题。
cmak能够提供以下的功能:
-
多集群的管理
-
获得集群的状态:topics, consumers, offsets, brokers, replica distribution, partition distribution
-
进行副本的优选
-
创建删除topic
-
增加删除分区,分区重新分配
-
更新topic的配置
从jmx种获得broker和topic级别的监控指标
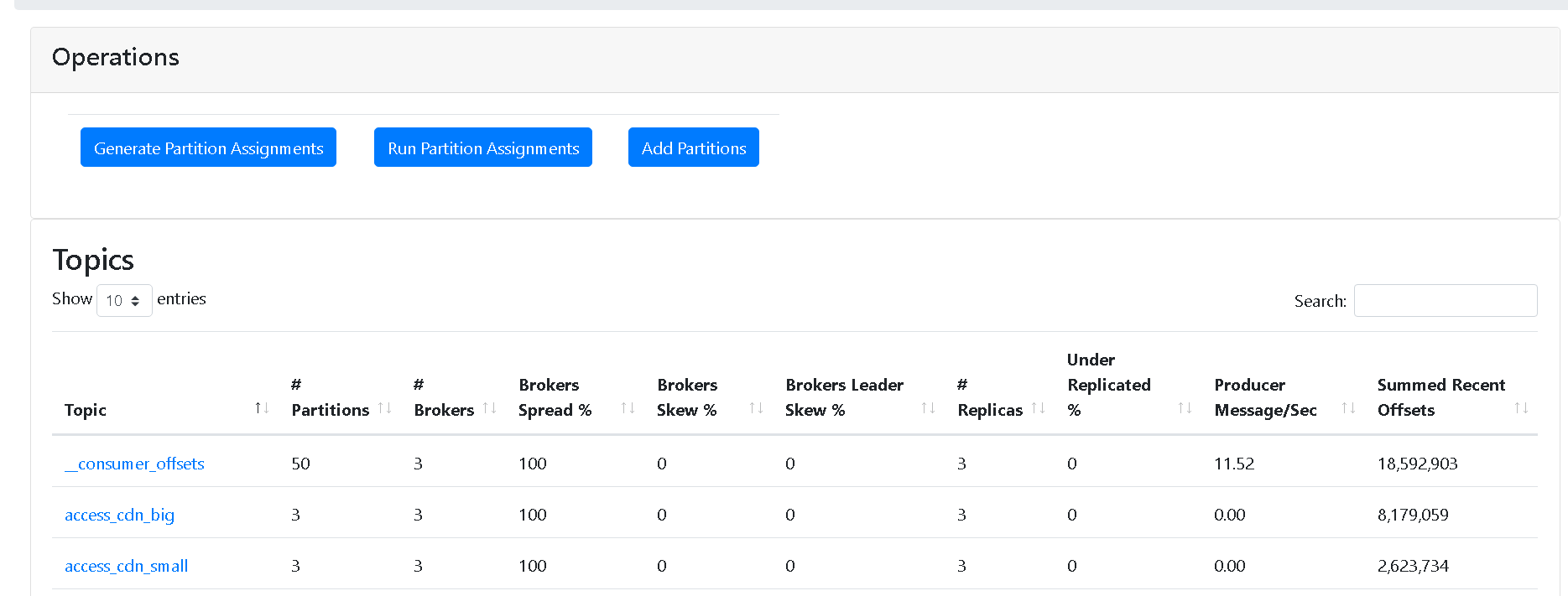
topic整体概况:
分区重置策略:
Logi-KafkaManager
滴滴开源的一站式集群指标监控与运维管控平台,定位是kafka集群全方位管控系统,它以kafka集群为主体,封装和集成了kafka对外提供给的api,以kafka集群和topic资源为运营对象,面向应用系统用户、kafka管控平台开发者、kafka管控平台运维者提供便捷的资源管理能力。体验网站:http://117.51.150.133:8080/kafka/admin。
数获取方式:jmx的监控指标、kafka开放的协议。
开发环境: 该项目为前后端分离的web架构(sprintboot+reactJS+Typescript),使用java语言编写,开发环境jdk8+,MySQL5.7+。
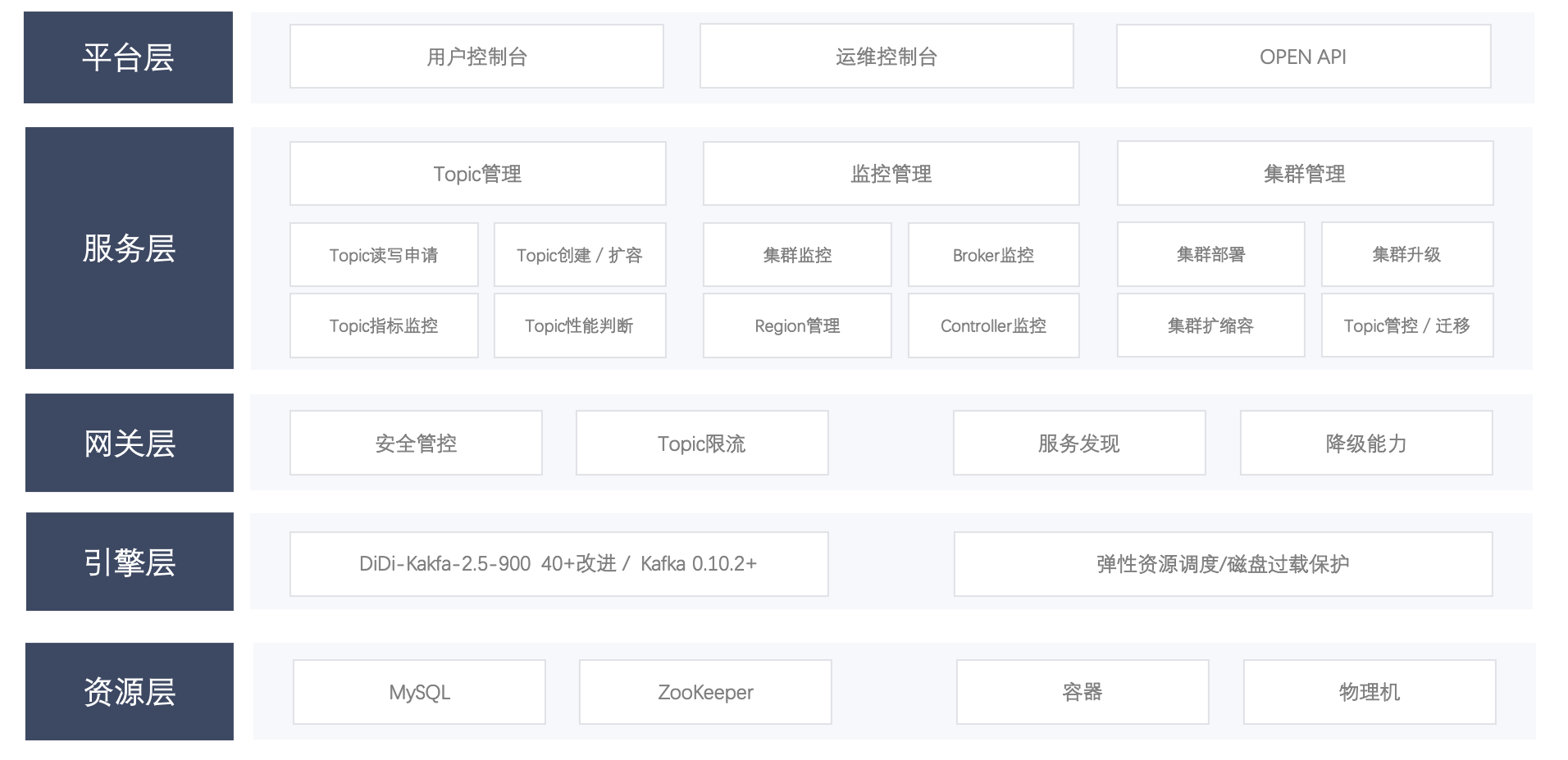
整体架构:
主要功能:
-
topic管理:
-
topic读写申请、topic创建/扩容、 topic指标监控、topic 性能指标、限流
-
集群管理:
-
集群部署、集群升级、集群扩缩容、topic管控/迁移、集群的性能指标
监控管理:
- 集群监控、broker监控、 region监控、controller监控
![]()
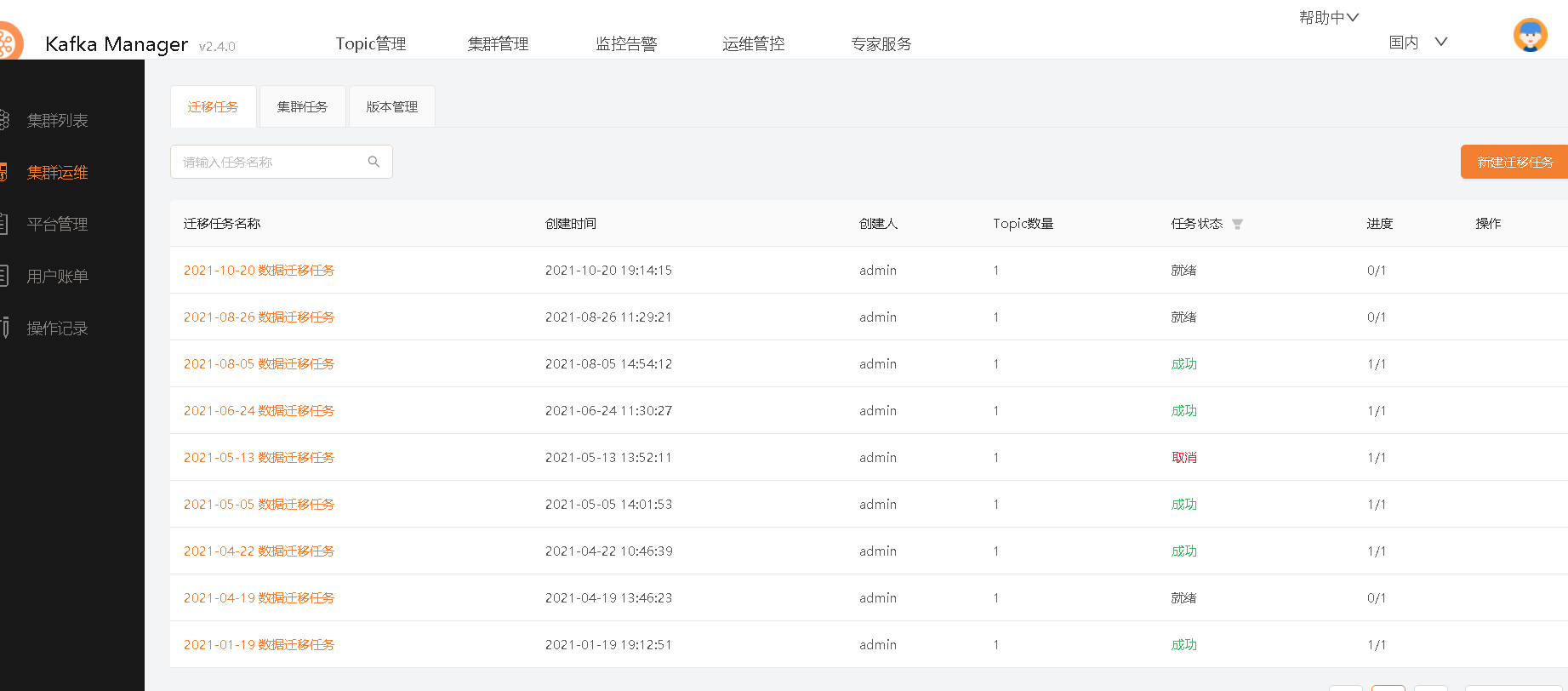
总结:
五种实现方案的对比:
| 实现方式 | 安装部署 | 监控指标采集 | 扩展性(监控指标) | 通用性(监控其他组件的能力) | 运维功能 | 改造开发 |
|---|---|---|---|---|---|---|
| jmxtrans+infludb+grafana | 省份部署一套即可,通过增加ip即可完成整个集群的监控 | 省份部署一套即可,通过增加ip即可完成整个集群的监控。 | 弱 | 强 | 无 | 无 |
| jmx_exporter+Prometheus+Grafana | jmx_exporter一次只能监控一个进程jmx的指标,每台kafka都要部署一个。(目前找到有人修改的jmx_exporter_multi,可以监控多个jvm) | 所有能获取的监控指标都进行采集。 | 弱 | 强 | 无 | 无 |
| kafka_exporter+Prometheus+Grafana | 省份部署一套即可,指定kafka端口即可监控整个集群 | 所有能获取的监控指标都进行采集 | 弱 | 弱 | 无 | 无 |
| cmak | 只需要在集团部署即可监控各个省份集群 | 自定义监控指标,代码实现 | 强 | 弱 | 有 | 需要增加数据存储与告警功能 |
| Logi-KafkaManager | 只需要在集团部署即可监控各个省份集群 | 只需要在集团部署即可监控各个省份集群 | 强 | 弱 | 有 | 需要去除一些不必要的功能 |
前三种实现方案与后两种相比,实现方便,不需要进行代码的开发,只需采集jmx指标即可,有告警功能,但是没有运维功能,可以直接接入目前的监控框架,极大地节省运维成本;后两种具有一定的运维功能,但是都需要进行改造,改造和维护的成本较高;改造便可以实现自定义的一些功能,扩展性较强。
-
JMXTrans + InfluxDB + Grafana 使用开发上比较方便,框架搭好后,只需要后续增加jxmtrans采集的json文件,同时增加grafana展示的sql语句即可;但是由于采集指标是从jmx中获取,监控指标不能自定义,取决于jmx提供的数据,官方说是500多种应该是够用了,但实际采集的也就几十种;这套方案只能作为监控系统,不能提供管理的能力。由于jmxTrans可以采集所有的jmx的消息,因此这套系统可以监控hdfs等其他java程序,可以接入易监测的grafana,通用性较强。
-
jmx_exporter+Prometheus+Grafana 同上
-
kafka_exporter+Prometheus+Grafana 部署简单,但只能监控kafka的数据,采集的指标由版本决定,当前版本只有16种监控指标,要想获取更多的指标只能等版本更新或者自己开发;不过好在他是基于ps的组件,可以联合ps的其他组件一起使用。提供了consumergroup维度的指标,这个维度对于我们来说是比较有用的。
-
cmak 由scala编写的web,没有数据存储系统和告警系统,需要进行改造,改造成本有些高。
-
Logi-KafkaManager 功能比较强大,但是很多功能用不到,监控指标可能不满足需求需要进行二次开发;整个系统比较复杂,需要去除一些不需要的功能,再开发一些监控指标;但是与现有的监控框架无法融合,单独搞一套的成本比较高。使用java,开发难度比cmak小一些。
凡是采用jmx获取数据的方式理论上也可以监控hdfs、zk等运行在jvm上的程序。
参考资料:
kakfa 度量指标: https://kafka.apache.org/documentation/#consumer_fetch_monitoring
滴滴开源地址:https://github.com/didi/LogiKM
cmak开源地址:https://github.com/yahoo/CMAK
jmx_exporter开源地址: https://github.com/prometheus/jmx_exporter
jmx_exporter_multi改编:https://github.com/gentlezuo/jmx_exporter_multi(一种抓取多个jmx的采集器)
kafka_exporter:https://github.com/danielqsj/kafka_exporter
jmx_trans:https://github.com/jmxtrans/jmxtrans
jmx_trans+influxdb+grafana环境的搭建:https://www.cnblogs.com/bluesky-yuan/p/14842518.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号