zookeeper启动时的选举机制
本文是基于在b站上所学zk的课程所作出的总结
zk的选举机制
首先介绍几个概念:
- Sid:服务器id,用于在集群中唯一的标识一台zk的机器,集群中不能够重复,和myid是一致的。
- ZXID:事务id,用来表示一次服务器状态的变更;在某一时刻,集群中的每台机器的ZXID值是不一定完全一致,这和zk对于客户端的变更请求的处理逻辑有关。
- Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟是相同的,每次投完票这个值就会增加。
第一次启动
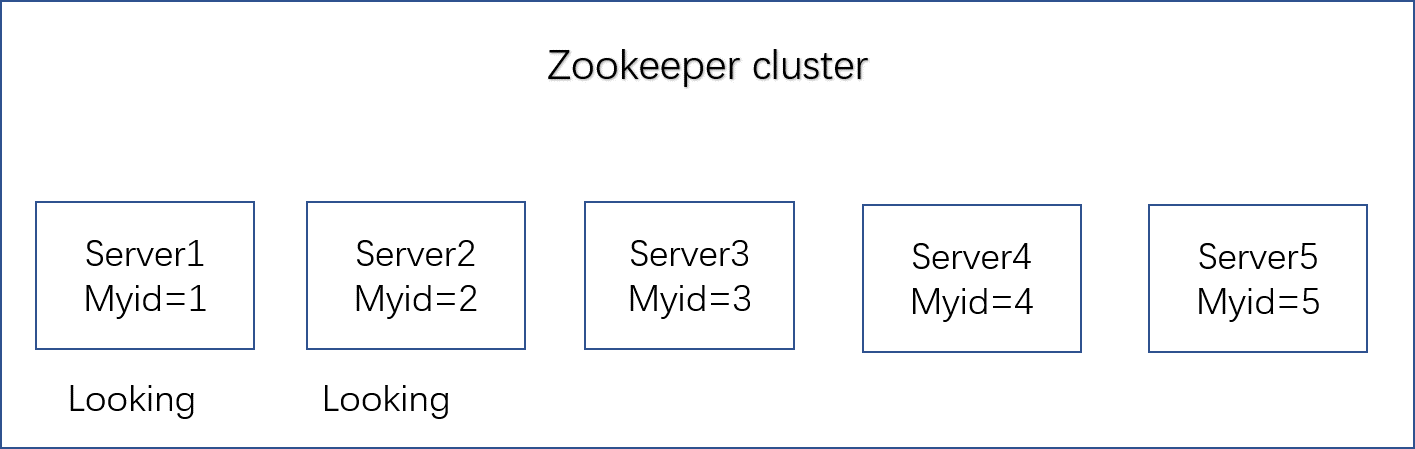
- 服务器1启动时发起一次选举,服务器1投给自己一票,此时服务器1的票数为1,不够半数3,因此服务器1保持Looking状态;
- 服务器2启动时也发起一次选举,服务器1和服务器2分别投给自己一票并交换选票信息;此时服务器1发现服务器2的myid比自己推举的服务器(服务器1)要大,因此更改选票推举服务器2;此时服务器1的选票为0,服务器2的选票为2,也没有超过半数,因此服务器1和服务器2都保持Looking状态。
- 服务器3启动发起一次选举,此时服务器1和服务器2都将选票改选为服务器3,此次投票的结果为服务器1为0票,服务器2为0票,服务器3为3票超过半数,服务器3当选为leader;服务器1和2更改状态为Following,服务器更改状态为Leading。
- 服务器4启动时,发起一次选举,此时服务器的状态不是Looking状态,不会更改选票信息。交换选票结果:服务器3为3票,服务器4为1票,此时服务器服从多数,更改选票为服务器3,并更改状态为Following.
- 服务器5启动,同服务器4的方式一样。
非第一次启动
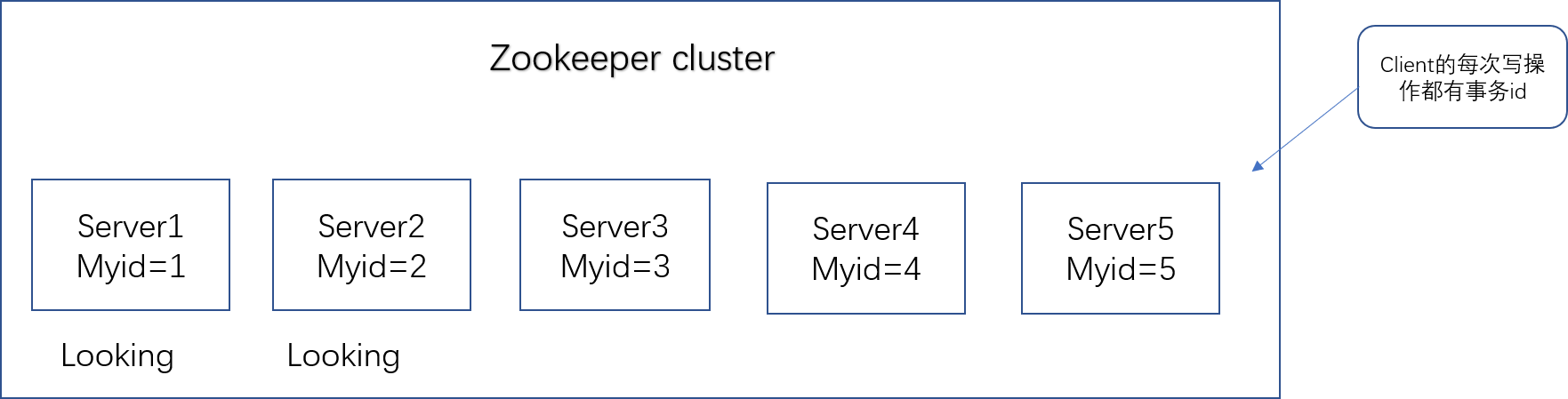
1.当zookeeper集群中出现如下两种情况之一就会进行leader的选举:
- 服务器初始化(及第一次选举)
- 服务器运行期间无法与Leader保持联系
比如说集群运行期间,server5无法与leader进行联系,此时server5认为整个leader服务器宕机,server5就会发起leader的选举
2.当一台服务器进入leader选举流程中,当前集群可能存在两种情况 - 集群中本来已经存在leader
当机器试图去选举leader时,需要进行投票并交换信息,会被告知当前集群已经存在leader节点,对于该机器来说只需要与leader进行连接并同步状态即可。 - 集群中不存在leader
假设zk集群由5台服务器组成,SID分别为1、2、3、4、5,ZXID为8、8、8、7、7,并且此时SID为3的机器为leader,某一时刻server3与server5都宕机,此时开始Leader的选举;
此时的选举规则为,a.先比较epoch的值大的直接胜出;b.再比较zxid,谁大谁胜出;c.最后比较sid的值谁大谁胜出;
举例:server1,server2,server4的epoch、zxid、sid分别为(1,8,1)、(1,8,2)、(1,7,4),则最终的选举结果为server2当选leader。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号