benthos的简单使用
项目内的大佬推荐了一种流式处理框架benthos,该工具使用go语言编写,使用起来比较方便,只需要编写yaml配置文件即可完成对数据的处理;
启动就不说了,推荐大家看下官网,讲的比较详细。
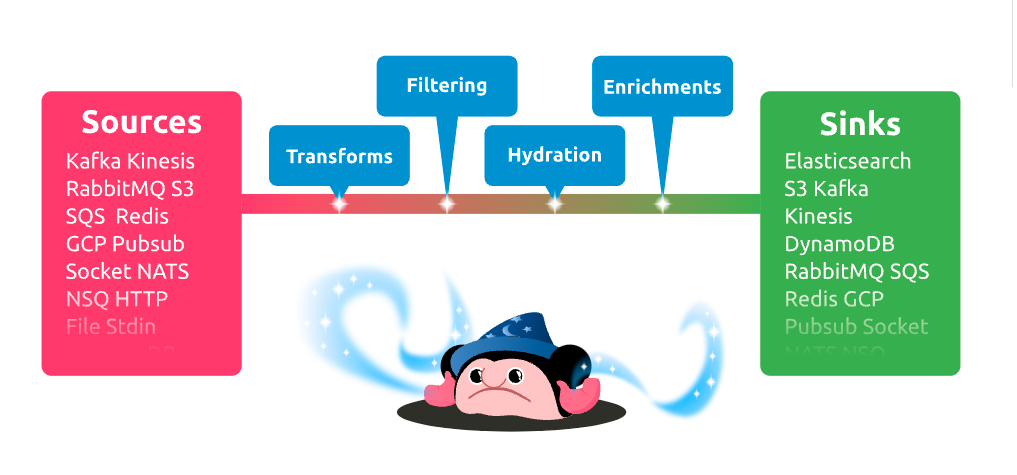
该框架有三大组件:
- input 输入
- pipeline 流水线处理
- output 输出
该框架包含多种输入源,多种输出方式,数据处理提供了一些映射方法,并提供了一种自定义的语言Bloblang,功能比较强大。
官方一个简单的例子:
input:
type: stdin
pipeline:
processors:
- bloblang: root = content().uppercase()
output:
type: stdout
上面的例子控制台输入信息,处理的方式是将输入字符变成大写,最后输出至控制台;
benthos感觉可以当一个etl工具使用。
input 组件:
每一个yaml文件都必须有的一个组件,这是程序的入口,从input 触发整个数据的流动。
我们常用的input组件有file和kafka。
# Common config fields, showing default values
input:
file:
paths: [ ./data/*.csv ]
codec: csv
delete_on_finish:false
file
Metadata元数据(-path),元数据在流转过程中是“不可见的”,但是可以获取到。file的元数据保存的是文件的路径path。
这个元数据会附加到每一条消息上。
Fields:属性
paths:表明文件的路径
codec:表明文件的格式,支持的格式有csv、line、gzip、tar等。
max_buffer:读取文件的大小,默认1000000(不记得单位了)
delete_on_finish:数据处理完成后是否删除原文件。
当目录下有文件时就会触发程序的流转。
generate
可以当一个触发器使用,没有数据源的时候,即没有输入,那么正常来说程序就如法继续进行,但是有的场景就是不需要输入的,这是可以使用generate作为input,触发程序的运行。
# Config fields, showing default values
input:
label: ""
generate:
mapping: ""
interval: 1s
count: 0
Fields 属性:
mapping 可以作为生成的数据。
interval 出发周期,可以使用 5s,1min 或者0,30 */2 * * * *的形式,注意时区,默认时UTC时区。
count 触发的次数。
其他input 还包括:hdfs、socket、http、stdin等等
processor组件
processor主要就是做数据处理的部分,benthos已经自定义了很组件例如:catch、awk、branch、compress、depress、log、sql等等,
官方提供了30多种的处理组件,刚开始做这个项目的时候感觉一切被限制的死死的,写代码(写配置文件)就必须得用官方的组件进行组合来实现我的功能,感觉代码是组合出来的,特别别扭。
一方面来源于,确实对benthos的使用比较陌生,国内用的人比较少,参考资料比较少。后来用着用着熟悉了也还好吧。另外processor中有个组件叫做bloblang,这是官方自定义的一种映射语言,
稍微让代码灵活了一点,有点写代码的赶脚了。
组件比较多,建议大家去看官方文档。
output 组件
输出的方式
直接上示例吧:
file的
# Config fields, showing default values
output:
label: ""
file:
path: "/tmp/data.txt"
codec: lines
上述的例子中,最终输出到文件中,方式是一行一行的写入。output组件中也可以使用processor,表示输出前进行一些处理。
github地址:https://github.com/Jeffail/benthos
官方网站:https://www.benthos.dev/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号