scrapy原理
scarpy据说是目前最强大的爬虫框架,没有之一。就是这么自信。
官网都是这么说的。

An open source and collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way.
一个开源的,协作的框架从网络收集你需要的数据,是简单,快速以及可扩展的。
那么学习之前,首先要学习一个原理。
Scarpy有几个模块
1.engine 引擎,框架已经实现,不需要我们写,它是scrapy能够进行的重要部件。好比车的发动机。
2.spiders 爬虫文件
3.schedule 调度器 对于发起的请求入队列
4.downloader下载器 从互联网中下载网页源代码
5,Itempipline 管道文件 ,用于可持续化存储数据,可以存储在MySQL,MongoDB,Redis,也可以保存于文件。
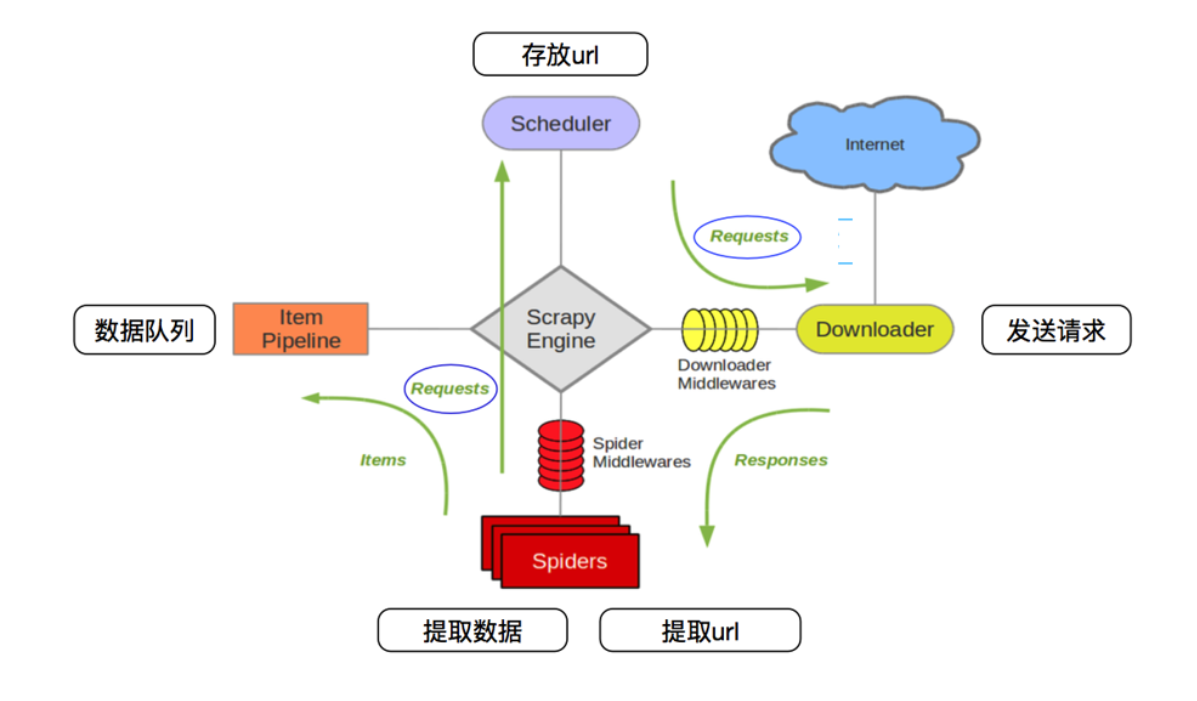
通过这个图可以看出scrapy工作的原理。
1,spiders 将发送的请求request(url)发送给 scrapy engine 引擎。然后引擎发送给调度器(scheduler),调度器对发送来的请求进行排序,入队列
2. scheduler调度器将请求request(url) ,发给scrapy engine引擎,然后引擎(Engine)将请求request 通过Downloader Middleware(下载器中间建)发送给Downloader下载器。
3,下载器Downloader 向互联网发送请求(request),下载网页源代码。得到response 响应,响应response通过 SpiderMiddleWares,发送给Spiders爬虫文件。
4.爬虫spiders对数据进行提取,然后发送数据交给Itempipeline 管道,管道将数据进行持久化操作或者保存。
spiders对下载器下载的网页源码进行数据机器,scrapy提供了css选择器。可以方便提取相关的数据。
通过这些步骤可以看出来,scrapy engine是占据很重要的位置。它负责联系各种组件之间的信号signals传递。
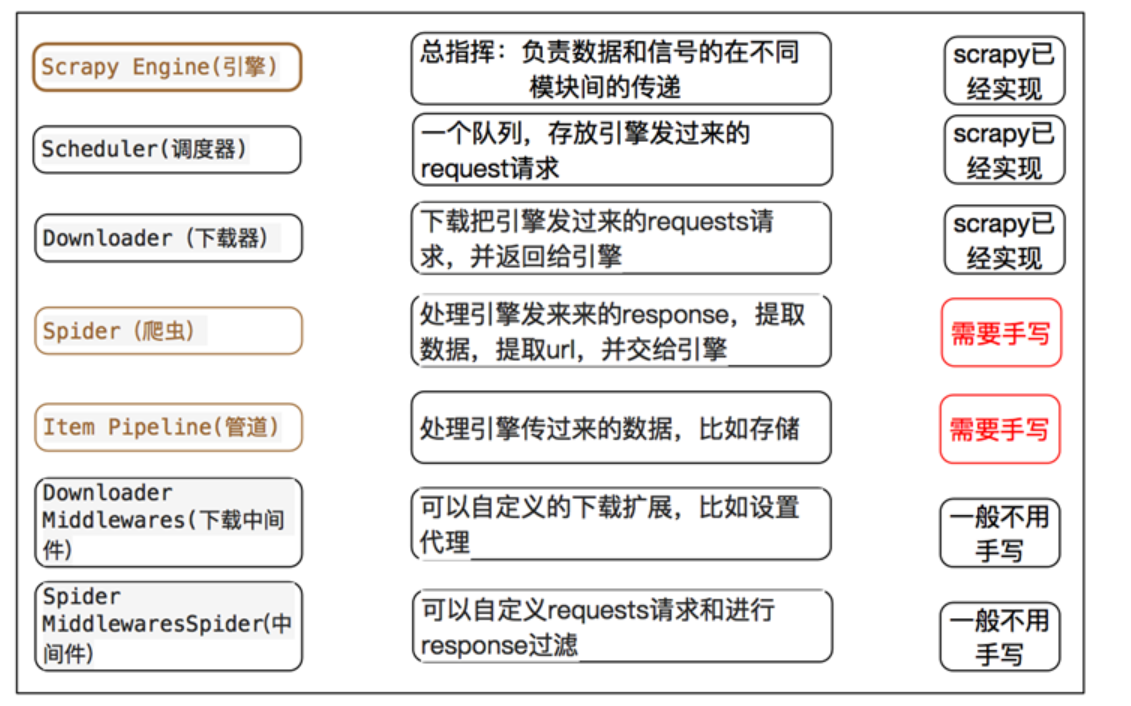
通过以下图,可以看出来,Scrapy需要我们书写的仅仅是spider,ItemPipeline,提取数据和持久化数据操作。其余的都已经替我们实现了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号