链路追踪(二)-分布式链路追踪系统数据采集
本篇文章基于上一篇,只针对数据采集做介绍,会提供一个SDK的实现和使用,会做实现方案的介绍,具体详细介绍下面边框加粗的部分:
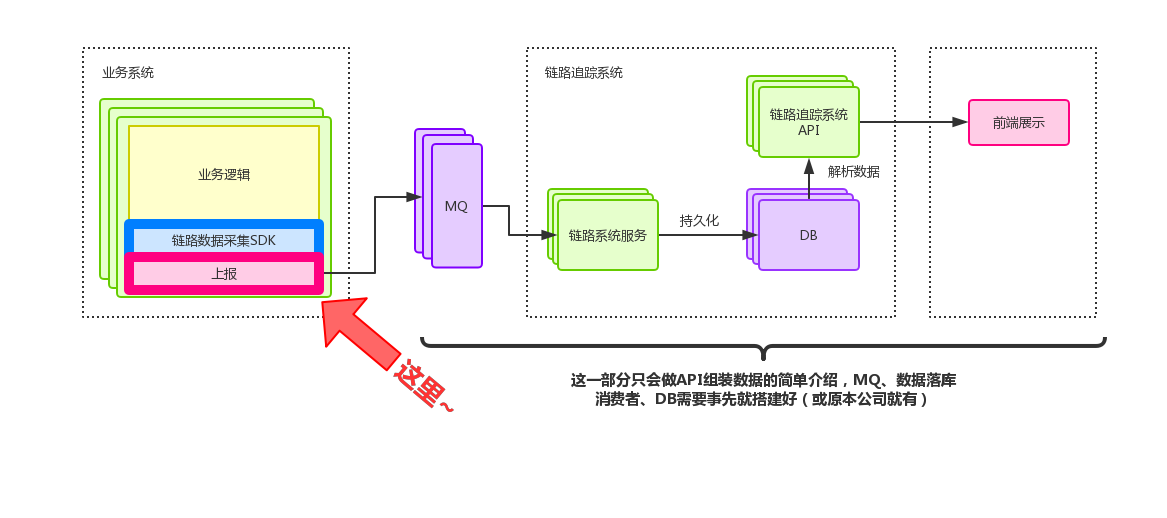
一、数据采集
接着拿上一篇里的例子来说,把例子里的图贴过来:
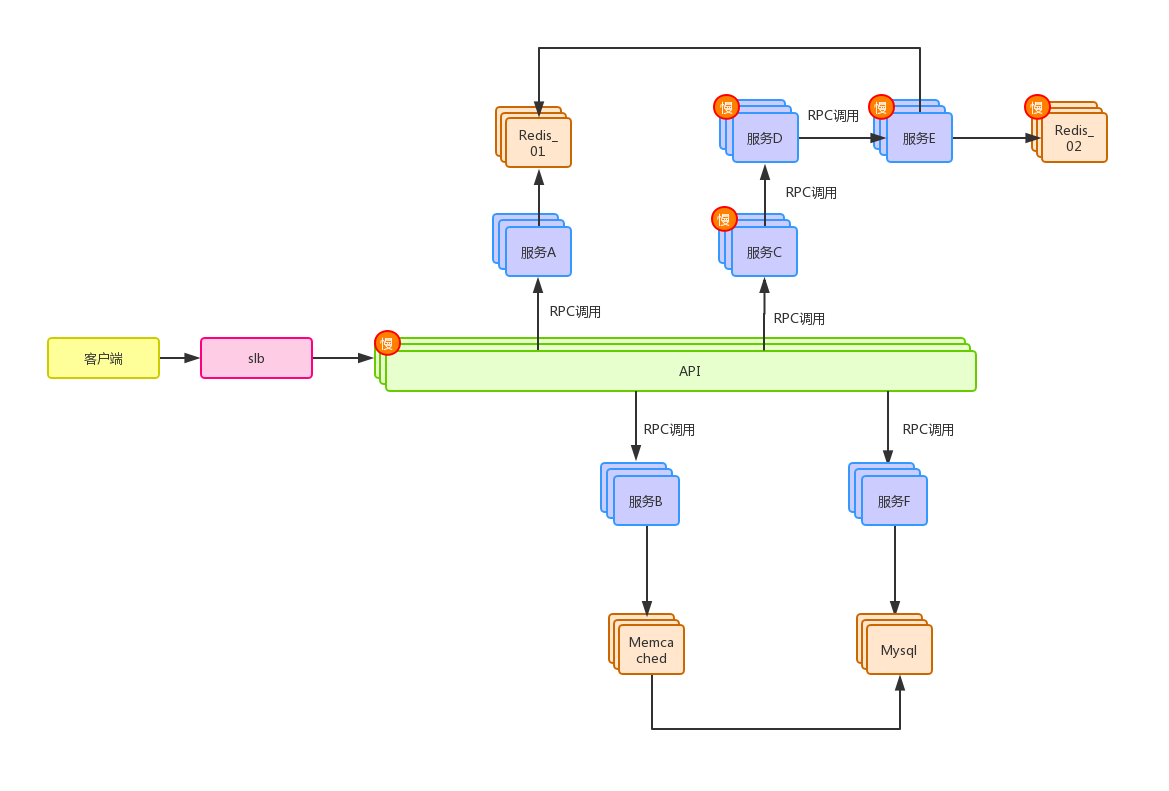
图1
简单回顾下上图,一次API调用,完成上面各个业务服务的调用,然后聚合所有服务的信息,然后Redis_02的调用发生瓶颈,继而影响到E、D、C三个服务,现在需要直观的展示这条链路上的瓶颈点,于是需要一个链路系统,展示成如下图的效果:
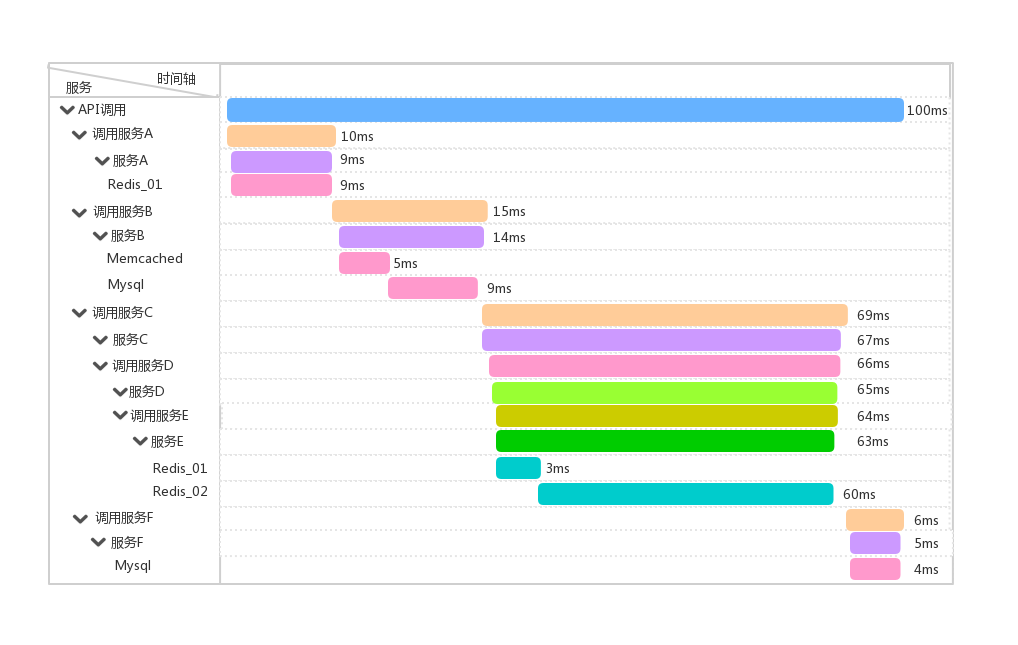
图2
要想展示成上图中的效果,则必须要进行数据的采集和上报,那么这就牵扯到两个概念,Span和Tracer,抽象成数据库的设计层面,可以理解成Tracer对Span等于一对多的关系,而一个Span可能包含多个子Span,一个Tracer表示一次调用所经过的整个系统链路,里面包含N多Span,每个Span表示一次事件的触发(也就是调用),那么就用图2来解释下这种关系:
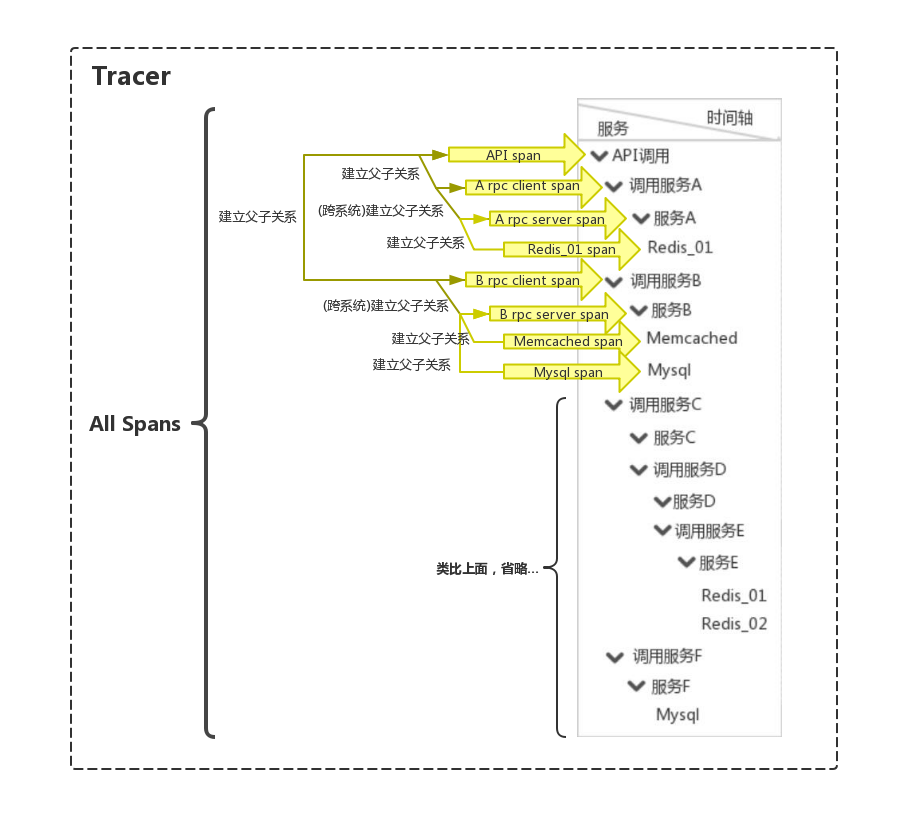
图3
所以上报数据最关键的地方就是要做到如下几点:
①在调用之处(比如例子中API调用开始的地方),创建Tracer,生成唯一Trace ID;
②在需要追踪的地方(比如例子中发生服务调用的地方),创建Span,指定Trace ID,并生成唯一Span ID,然后按需建立父子关系,追踪结束时(比如例子中调用完成时)释放Span(即置为finished,此时计时已完成);
③跨系统追踪时做好协议约定,每次跨系统调用时可以在协议头传输发起调用系统的TraceID,以便链路可以做到跨系统顺利传输。
④最终主链路执行完毕(例子中就是指API调用结束)时,推送此链路产生的所有Span到链路系统,链路系统负责落库、数据分析和展示。
以上便是链路追踪业务SDK需要参与做到的事情。
Tracer是个虚拟概念,负责聚合Span使用,实际上报的数据全是Span,下面来看下Span的结构定义(JSON):
{
"spanId": 123456,
"traceId": 1234,
"parentId": 123455,
"title": "getSomeThing",
"project": "project.tree.group.project_name",
"startTime": 1555731560000,
"endTime": 1555731570000,
"tags": {
"component": "rpc",
"span.kind": "client"
}
}
这是一个span的基本结构定义,startTime和endTime可以推算出本次Span耗时(交给链路系统前端时可以用来展示时间轴的长短),title表示的是Span本身的描述,一般是一个method的名字,project是当前所处项目的全称,项目的全称可以交给链路系统前端用来搜索出该项目的所有链路信息。spanId、traceId、parentId结合上面的图理解即可,tags表示的是一些描述信息,这里有一些标准化的东西:标准的Span tag 和 log field
二、数据采集基于Java语言的实现
一般基于io.opentracing标准实现上报SDK,下面来逐步实现一个最简单的数据收集器,首先在项目中引入io.opentracing的jar包,然后追加两个基本类SimpleTracer和SimpleSpan,这里只贴出关键代码。
SimpleTracer定义:
// 追踪器,实现Tracer接口
public class SimpleTracer implements Tracer {
private final List finishedSpans = new ArrayList<>(); //存放链路中已执行完成的span(finished span)
private String project; //项目名称
private Boolean sampled; //是否上报(由采样率算法生成该值)
public SimpleTracer(boolean sampled, String project) {
this.project = project;
this.sampled = sampled;
}
public SimpleTracer(String uri, String project) {
this.project = project;
this.sampled = PushUtils.sampled(uri); //本次追踪是否上报
}
@Override
public SpanBuilder buildSpan(String operationName) {
return new SpanBuilder(operationName); //创建span一般交给Tracer去做,这里由其内部类SpanBuilder触发创建
}
//上报span,这个方法一般在一次链路完成时调用,负责将finishedSpans里的数据上报给追踪系统
public synchronized void pushSpans() {
if (sampled != null && sampled) {
List finished = this.finishedSpans;
if (finished.size() > 0) {
finished.stream().filter(SimpleSpan::sampled).forEach(span -> PushHandler.getHandler().pushSpan(span)); //实际负责推送的方法
this.reset(); //每发生一次推送,则清理一次已完成span集合
}
}
}
// Tracer对象内部类SpanBuilder,实现了标准里的Tracer.SpanBuilder接口,用来负责创建span
public final class SpanBuilder implements Tracer.SpanBuilder {
private final String title; //操作名,也就是span的title
private long startMicros; //初始化开始时间
private List references = new ArrayList<>(); //父子关系
private Map<String, Object> initialTags = new HashMap<>(); //tag描述信息初始化
//创建span用的title传入
SpanBuilder(String title) {
this.title = title;
}
@Override
public SpanBuilder asChildOf(SpanContext parent) { //传入父子关系
return addReference(References.CHILD_OF, parent);
}
@Override
public SpanBuilder addReference(String referenceType, SpanContext referencedContext) {
if (referencedContext != null) {
//添加父子关系,其实这里就是初始化了Span里的Reference对象,这个对象会在创建Span对象时作为参数传进去,然后具体关系的确立,是在Span对象内(具体Span类的代码段会展示)
this.references.add(new SimpleSpan.Reference((SimpleSpan.SimpleSpanContext) referencedContext, referenceType));
}
return this;
}
@Override
public SimpleSpan start() {
return startManual();
}
@Override
public SimpleSpan startManual() { //创建并开始一个span
if (this.startMicros == 0) {
this.startMicros = SimpleSpan.nowMicros(); //就是在这里初始化startTime的
}
//这里触发SimpleSpan的构造方法,之前的references会被传入,此外初始化的tag信息、title、开始时间等也会被传入参与初始化
return new SimpleSpan(SimpleTracer.this, title, startMicros, initialTags, references);
}
}
}
上面放了SimpleTracer的代码片段,关键信息已标注,这个类的作用就是帮助创建span,上面还有一个比较重要的方法,也就是sampled方法,该方法用来生成这次链路是否上报(也就是采样率,实际的追踪系统不可能每次的请求都上报,对于一些QPS较高的系统,会带来额外大量的存储数据,因此需要一个上报率),下面来简单看下上报率的实现:
public class PushUtils {
public static final Random random = new Random();
private static final Map<String, Long> requestMap = Maps.newConcurrentMap();
public static boolean sampled(String uri) {
if (Strings.isNullOrEmpty(uri)) {
return false;
}
Long start = requestMap.get(uri);
Long end = System.currentTimeMillis();
if (start == null) {
requestMap.put(uri, end);
return true;
}
if ((end - start) >= 60000) { //距离上次上报已经超过1min了
requestMap.put(uri, end);
return true;
} else { // 没超过1min,则按照1/1000的概率上报
if (random.nextInt(999) == 0) {
requestMap.put(uri, end);
return true;
}
}
return false;
}
}
这种是比较适中的做法,如果1min内没有上报一次,则必定上报,如果1min内连续上报多次,则按照千分之一的概率上报,这样既保证了低QPS的系统可以有相对较多的链路数据,也可以保证高QPS的系统可以有相对较少的链路数据。
下面来看下SimpleSpan的关键代码段:
// 链路Span,实现标准里的Span接口
public class SimpleSpan implements Span {
private final SimpleTracer simpleTracer; //链路追踪对象(一次追踪建议生成一个链路对象,尽量不要用单例,会有同步锁影响并发效率)
private final long parentId; // 父span该值为0
private final long startTime; // 计时开始开始时间戳
private final Map<String, Object> tags; //一些扩展信息
private final List references; // 关系,外部传入
private final List errors = new ArrayList<>();
private SimpleSpanContext context; // spanContext,内部包含traceId、span自身id
private boolean finished; // 当前span是否结束标识
private long endTime; // 计时结束时间戳
private boolean sampled; // 是否为抽样数据,取决于父节点,依次嫡传下来给其子节点
private String project; // 追踪目标的项目名
private String title; //方法名
SimpleSpan(SimpleTracer tracer, String title, long startTime, Map<String, Object> initialTags, List refs) {
this.simpleTracer = tracer; // 这里传入的tracer是针对本次跟踪过程唯一对象,负责收集已完成的span
this.title = title;
this.startTime = startTime;
this.project = tracer.getProject();
this.sampled = tracer.isSampled(); //是否上报,该字段根据具体的采样率方法生成
if (initialTags == null) {
this.tags = new HashMap<>();
} else {
this.tags = new HashMap<>(initialTags);
}
if (refs == null) { //span对象由tracer对象创建,创建时会把父子关系传入
this.references = Collections.emptyList();
} else {
this.references = new ArrayList<>(refs);
}
SimpleSpanContext parent = findPreferredParentRef(this.references); //查看是否存在父span
if (parent == null) { //通常父span为空的情况,都是链路开始的地方,这里会生成traceId
// 当前链路还不存在父span,则本次span就置为父span,下面会生成traceId和当前父span的spanId
this.context = new SimpleSpanContext(nextId(), nextId(), new HashMap<>());
this.parentId = 0; //父span的parentId是0
} else {
// 当前链路已经存在父span了,那么子span的parentId置为当前父span的id,表示当前span是属于这个父span的子span,同时traceId也延用父span的(表示属于同一链路)
this.context = new SimpleSpanContext(parent.traceId, nextId(), mergeBaggages(this.references));
this.parentId = parent.spanId;
}
}
@Nullable
private static SimpleSpanContext findPreferredParentRef(List references) {
if (references.isEmpty()) {
return null;
}
for (Reference reference : references) {
if (References.CHILD_OF.equals(reference.getReferenceType())) { //现有的reference中存在父子关系(简单理解,这个关系就是BuildSpan的时候传入的)
return reference.getContext(); //返回父span的context信息(包含traceId和它的spanId)
}
}
return references.get(0).getContext();
}
@Override
public synchronized void finish(long endTime) {
finishedCheck("当前span处于完成态");
this.endTime = endTime;
this.simpleTracer.appendFinishedSpan(this); //span完成时放进链路对象的finishedSpans集合里
this.finished = true;
}
// SimpleSpan的内部类SimpleSpanContext,存放当前Span的id、链路id,实现了标准里的SpanContext接口
public static final class SimpleSpanContext implements SpanContext {
private final long traceId; //链路id
private final Map<String, String> baggage;
private final long spanId; //spanId
public SimpleSpanContext(long traceId, long spanId, Map<String, String> baggage) {
this.baggage = baggage;
this.traceId = traceId;
this.spanId = spanId;
}
}
public static final class Reference { //用于建立Span间关系的内部类
private final SimpleSpanContext context; //存放了某一个Span的context(用于跟当前span建立关系时使用)
private final String referenceType; //关系类型,目前有两种:child_of和follows_from,第一种代表当前span是上面context里span的子span,第二个则表示同级顺序关系
public Reference(SimpleSpanContext context, String referenceType) {
this.context = context;
this.referenceType = referenceType;
}
}
}
上面就是SimpleSpan的关键实现,关键点已标注,下面来看下数据上报这里的实现:
public class PushHandler {
private static final PushHandler handler = new PushHandler();
private BlockingQueue queue;
private PushHandler() {
this.queue = new LinkedBlockingQueue<>(); //数据管道
new Thread(this::pushTask).start();
}
public static PushHandler getHandler() {
return handler;
}
public void pushSpan(SimpleSpan span) {
queue.offer(span);
}
private void pushTask() {
if (queue != null) {
SimpleSpan span;
while (true) {
try {
span = queue.take();
//为了测试,这里只打印了基本信息,实际环境中这里需要做数据推送(kafka、UnixSocket等)
StringBuilder sb = new StringBuilder()
.append("tracerId=")
.append(span.context().traceId())
.append(", parentId=")
.append(span.parentId())
.append(", spanId=")
.append(span.context().spanId())
.append(", title=")
.append(span.title())
.append(", 耗时=")
.append((span.endTime() / 1000000) - (span.startTime() / 1000000))
.append("ms, tags=")
.append(span.tags().toString());
System.out.println(sb.toString());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
只是做了简单的测试,所以处理逻辑只是简单的做了打印,实际当中这里要上报链路数据(spans)。这里使用了一个阻塞队列做数据接收的缓冲区。
这套实现是非常简单的,只进行简单的计时、推送,并没有涉及active方式的用法,一切创建、建立父子关系均交由开发人员自己把控,清晰度也更高些。
代码完整地址:simple-trace
三、simple-trace的使用
看了上面的实现,这里利用simple-trace来进行程序追踪,看一个简单的例子:
public class SimpleTest {
private SimpleTracer tracer = null;
private SimpleSpan parent = null;
//假设这里是链路开始的地方
@Test
public void test1() {
//创建链路
tracer = new SimpleTracer("test1", "projectName");
parent = tracer.buildSpan("test1")
.withTag(SpanTags.COMPONENT, "http")
.withTag(SpanTags.SPAN_KIND, "server")
.start(); //span开始
//--------------------------------------------------
String result1 = getResult1(); //假设getResult1需要链路追踪
System.out.println("r1 = " + result1);
String result2 = getResult2(); //假设getResult2需要链路追踪
System.out.println("r2 = " + result2);
//--------------------------------------------------
//下面标记着一次链路追踪的结束
parent.finish(); //主span结束
tracer.pushSpans(); //触发span数据推送
}
public String getResult1() {
//前戏,建立getResult1自己的追踪span
SimpleSpan currentSpan = null;
if (tracer != null && parent != null) {
//当前链路视为test1方法的子链路,建立父子关系
SimpleSpan.SimpleSpanContext context = new SimpleSpan.SimpleSpanContext(parent.context().traceId(),
parent.context().spanId(), new HashMap<>()); //建立父子关系,traceId和父spanId被指定
currentSpan = tracer.buildSpan("getResult1")
.addReference(References.CHILD_OF, context)
.withTag(SpanTags.COMPONENT, "redis")
.withTag(SpanTags.SPAN_KIND, "client").start(); //启动自己的追踪span
}
try {
Thread.sleep(1000L);
return "result1";
} catch (InterruptedException e) {
e.printStackTrace();
return "";
} finally {
if (currentSpan != null) {
currentSpan.finish(); //最后完成本次链路追踪
}
}
}
public String getResult2() {
//前戏,建立getResult2自己的追踪span
SimpleSpan currentSpan = null;
if (tracer != null && parent != null) {
//当前链路视为test2方法的子链路,建立父子关系
SimpleSpan.SimpleSpanContext context = new SimpleSpan.SimpleSpanContext(parent.context().traceId(),
parent.context().spanId(), new HashMap<>()); //建立父子关系,traceId和父spanId被指定
currentSpan = tracer.buildSpan("getResult2")
.addReference(References.CHILD_OF, context)
.withTag(SpanTags.COMPONENT, "redis")
.withTag(SpanTags.SPAN_KIND, "client").start(); //启动自己的追踪span
}
try {
Thread.sleep(2000L);
return "result2";
} catch (InterruptedException e) {
e.printStackTrace();
return "";
} finally {
if (currentSpan != null) {
currentSpan.finish(); //最后完成本次链路追踪
}
}
}
}
运行结果:
r1 = result1
r2 = result2
tracerId=1507767477962777317, parentId=2107142446015091038, spanId=5095502823334701185, title=getResult1, 耗时=1555839336570 - 1555839335569 = 1001ms, tags={span.kind=client, component=redis}
tracerId=1507767477962777317, parentId=2107142446015091038, spanId=9071431876337611242, title=getResult2, 耗时=1555839338572 - 1555839336571 = 2001ms, tags={span.kind=client, component=redis}
tracerId=1507767477962777317, parentId=0, spanId=2107142446015091038, title=test1, 耗时=1555839338572 - 1555839334687 = 3885ms, tags={span.kind=server, component=http}
通过该实例,关于simple-trace的基本用法已经展示出来了(创建tracer、span、建立关系、tags、finish等),看下打印结果(打印结果就是simple-trace推送数据时直接打印的,耗时是根据startTime和endTime推算出来的),父子关系建立完成,假如说这些数据已经落库完成,那么通过链路系统的API解析和前端渲染,会变成下面这样(绘图和上面测试结果不是同一次,所以图里耗时跟上面打印的耗时不一致😭):

图4
本篇不讨论图如何生成,可以说下后端可以给前端提供的接口结构以及组装方式:首先可以根据traceId查出来所有相关span,然后根据parentId进行封装层级,比如图4的API结构大致上如下:
{
"spanId": 2107142446015091038,
"traceId": 1507767477962777317,
"parentId": 0,
"title": "test1",
"project": "projectName",
"startTime": 1555839334687,
"endTime": 1555839338572,
"tags": {
"span.kind": "server",
"component": "http"
},
"children": [{
"spanId": 5095502823334701185,
"traceId": 1507767477962777317,
"parentId": 2107142446015091038,
"title": "getResult1",
"project": "projectName",
"startTime": 1555839335569,
"endTime": 1555839336570,
"tags": {
"span.kind": "client",
"component": "redis"
},
"children": []
},
{
"spanId": 9071431876337611242,
"traceId": 1507767477962777317,
"parentId": 2107142446015091038,
"title": "getResult2",
"project": "projectName",
"startTime": 1555839336571,
"endTime": 1555839338572,
"tags": {
"span.kind": "client",
"component": "redis"
},
"children": []
}
]
}
包装成上面的结构,前端根据层级关系、startTime、endTime进行调用树和时间轴的渲染即可,在实际生产中,这个层级树可能更加庞大,比如图2。
基本使用很简单,那么基于简单的例子再进行一层抽象,如果在生实际项目中,就不能单单像上面那样使用了,需要封装、解耦,那么实际项目中一般会通过怎样的方式来使用呢?跨系统的时候如何建立层级关系呢?下面针对图2中的例子,进行简单的方案设计(图2过于复杂,这里只说服务A的调用链路,其余按照服务A类推即可),下面将会采用伪代码的方式进行说明问题的解决方案,实际当中需要自己按照实现思路自行封装。
现在引入两个概念,拦截器和Context(上下文),它们属于正常业务中常用的概念,Context是指一次调用产生的上下文信息,上下文信息可以在单次程序调用中的任意位置取到,一般上下文都是利用ThreadLocal(简称TL)实现的,线程本地变量,单纯理解就是只要本次调用的信息都处于同一个线程,那么任意地方都可以通过TL对象拿到上下文对象信息,但是由于系统的复杂度越来越高,一些地方会采用线程池来进行优化业务代码,比如一次调用可能会利用CompletableFuture来进行异步任务调度来优化当前代码执行效率,这个时候单纯使用TL就办不成事儿了,而使用InheritableThreadLocal(简称ITL)又解决不了线程池传递问题,于是就有了阿里推出的TransmittableThreadLocal(简称TTL),这个可以完美解决跨线程传递上下文信息(不管是new Thread还是线程池,都可以准确传递),当然,你也可以仿照TTL的实现,简单代理线程池对象,仍然使用TL实现跨线程传递,也是可以的,TL系列文章传送门:ThreadLocal、InheritableThreadLocal、TransmittableThreadLocal
下面是关于系统上下文的简单定义:
//自定上下文类
public class Context {
private SimpleTracer simpleTracer; //当前链路对象
private SimpleSpan parent; //当前链路全局父span
//也可以放很多别的上下文内容,这里省略...
public SimpleTracer getSimpleTracer() {
return simpleTracer;
}
public void setSimpleTracer(SimpleTracer simpleTracer) {
this.simpleTracer = simpleTracer;
}
public SimpleSpan getParent() {
return parent;
}
public void setParent(SimpleSpan parent) {
this.parent = parent;
}
}
public class ContextHolder {
//这里仅用TL简单实现,如果项目里使用了线程池,那么这里的实现要变成TTL,并让TTL代理全局的线程池对象,也可以不用TTL,自己代理线程池对象,这里不再详述
private static ThreadLocal contextThreadLocal = new ThreadLocal<>();
private ContextHolder() {
}
public static void removeContext() {
contextThreadLocal.remove();
}
public static Context getContext() {
return contextThreadLocal.get();
}
public static void setContext(Context context) {
if (context == null) {
removeContext();
}
contextThreadLocal.set(context);
}
}
我们把链路对象和链路第一次产生的父span放到上下文,意味着我们可以在这次调用的任意位置通过ContextHolder获取到当前链路对象(伪代码会出现该类),下面来结合图2的A服务链路,结合aop思想,写一次从图2API调用开始到Redis01调用结束的代码。
按照流程,API属于一次Http调用,也是链路入口,那么利用这一点,和Http服务的拦截器功能(大部分系统都会用到一个http调用的拦截器,一般上下文也是这里产生的),伪代码如下:
public class ApiInterceptor {
//开始Http处理请求之前要做的,一般这里产生上下文,并交给TL传递上下文对象,这里也是链路初始化的地方
public void beforeHandle(Request request) {
Context context = new Context(); //上下文对象
SimpleTracer tracer = null;
SimpleSpan parent = null;
//这里是为跨系统调用做的协议头传递,因为我们这个API也可能是公司内别的业务方内部调用,那么这个时候就需要约定协议头,一旦协议头中带有约定好的链路字段,那么就认为我们这个API本次调用相对于别的系统是个子链路
String traceId = request.headers.get("x1-trace-id"); //拿到协议头的父链路id,子链路继承之
String parentId = request.headers.get("x1-span-id"); //拿到协议头的父span信息
String sampled = request.headers.get.get("x1-sampled"); //是否上报
if (traceId != null && parentId != null && sampled == true) {
tracer = new SimpleTracer(request.getUri, "所属项目名"); //这里用url当成是初始化span的title
// 符合这种情况的,我们这里的parent其实只是一个相对于别的系统的child
SimpleSpan.SimpleSpanContext simpleSpanContext = new SimpleSpan.SimpleSpanContext(traceId, parentId, new HashMap<>());
parent = tracer.buildSpan(request.getUri)
.addReference(References.CHILD_OF, simpleSpanContext) //建立父子关系,如果是别的业务方调用我们这个http服务,那么这里这一步,也就建立了跟调用方的父子关系,traceId等是继承的调用方的,意味着本次调用也属于调用方的一环,这也就实现了跨系统的链路追踪
.withTag(SpanTags.COMPONENT, "http")
.withTag(SpanTags.SPAN_KIND, "server").start(); //启动span
} else { //执行else,说明该http调用是一次自己完整的调用,不属于任何父链路,那么就无需建立关系,直接初始化tracer即可
tracer = new SimpleTracer(request.getUri, "所属项目名");
parent = tracer.buildSpan(request.getUri)
.withTag(SpanTags.COMPONENT, "http")
.withTag(SpanTags.SPAN_KIND, "server")
.start(); //启动span
}
//将封装好的tracer和parentSpan设置到上下文对象里去
context.setSimpleTracer(tracer);
context.setParent(parent);
ContextHolder.setContext(context); //将本次请求生成的上下文对象放进ContextHolder(也就是TL里),方便在任意位置取出使用
}
//业务逻辑处理中
public void hadle() {
//本次API请求实际走的业务逻辑,也就是A服务调用、B服务调用等这些实际的业务逻辑处理
doing();
}
//Http业务处理完成后的触发
public void afterHandler() {
//Http调用结束的时候,取出当前链路信息,完成数据的上报
SimpleTracer tracer = ContextHolder.getContext().getTracer();
SimpleSpan parent = ContextHolder.getContext().getParent();
if (tracer != null && parent != null) {
parent.finish(); //结束掉parent Span
tracer.pushSpans(); //上报这次产生的链路数据(spans)
}
}
}
通过这个外部的API链路包装,可以知道的事情是上下文在这里面充当的角色,API调用是一个系统的入口,这种入口有很多,一次系统调用都会有一个类似的入口,比如RPC调用,跨系统后的rpcServer端也是一个入口,这种入口级的拦截器,before里面做的通常都是建立Tracer,但是代码里不是简单的创建一个Tracer对象就完事儿了,还有协议头的分析,链路系统如何实现跨系统的传输呢?这就牵扯到协议约定,比如Http请求,可以在协议头里约定几个特殊字符串来存放来源系统的tracerId等,结合上面的例子,假如我们这个API是公司内别的系统API01发起的http调用,API01本身也会有链路追踪,API01系统内发起对我们API的http请求,这就属于跨系统调用,我们这次API调用相对于API01是一个子链路,需要建立父子关系,结合上面的例子简单画下这次调用图:

图5
包括API的其他跨系统的调用,比如A服务的调用,也是使用同样的原理进行链路跨系统传输的(很多RPC框架上层协议也是支持扩展协议头的,比如grpc的上层协议就是http2),那么接下来看下图中(截自图2)标红模块对应的伪代码吧:
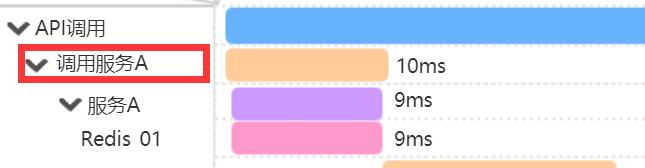
图6
这块是指当前系统通过rpc client发起对A服务的调用,从发起调用到A服务响应,这个过程仍然属于API这次调用的子span(没有出系统),但是到了A服务的触发,就牵扯到跨系统,A服务的链路相对于rpc client(图6标红的操作)的span,是一个子span,通过上面对跨系统的处理,这里rpc client里一定会把自身的spanId作为A服务的parentId传过去,包括traceId等,来看下伪代码:
public class RpcClient {
//等待服务端响应方法
public void requestRpc(RpcRequest request) {
//调用前执行
SimpleSpan span = null;
SimpleSpan parent = ContextHolder.getContext().getParent();
SimpleTracer tracer = ContextHolder.getContext().getTracer();
if (tracer != null && parent != null) {//↓这个title就设置成rpc调用的那个方法名即可
span = tracer.buildSpan(request.getRpcMethod).asChildOf(parent) //建立父子关系,因为rpc client调用属于API调用的子链路
.withTag(SpanTags.COMPONENT, "grpc")
.withTag(SpanTags.PEER_SERVICE, request.getRpcMethod)
.withTag(SpanTags.SPAN_KIND, "client")
.start(); //启动这个span
//设置协议头,因为被调用的RPC服务相对于我们来说是个子链路
request.setHeader("x1-rpc-span-id", span.context().spanId());
request.setHeader("x1-rpc-trace-id", span.context().traceId());
request.setHeader("x1-rpc-sampled", span.sampled());
}
rpcServerRequest(request); //实际调用rpc服务
//调用后执行
if(span != null){
span.finish(); //完成本次追踪
}
}
}
这样就完成了图6中红线部分的span,然后来看下被调用的服务A内部是怎么处理的(其实很像上面http入口的处理方式):
public class RpcServerInterceptor {
//服务的入口,Rpc服务处理请求之前要做的,一般这里产生上下文,并交给TL传递上下文对象,这里也是链路初始化的地方
public void beforeHandle(RpcRequest request) {
Context context = new Context(); //上下文对象
SimpleTracer tracer = null;
SimpleSpan parent = null;
//解析协议头
String traceId = request.headers.get("x1-rpc-trace-id"); //拿到协议头的父链路id,子链路继承之
String parentId = request.headers.get("x1-rpc-span-id"); //拿到协议头的父span信息
String sampled = request.headers.get.get("x1-rpc-sampled"); //是否上报
if (traceId != null && parentId != null && sampled == true) {
tracer = new SimpleTracer(request.getMethod, "所属项目名");
// 符合这种情况的,我们这里的parent其实只是一个相对于别的系统的child
SimpleSpan.SimpleSpanContext simpleSpanContext = new SimpleSpan.SimpleSpanContext(traceId, parentId, new HashMap<>());
parent = tracer.buildSpan(request.getMethod)
.addReference(References.CHILD_OF, simpleSpanContext) //建立父子关系,如果是别的业务方调用我们这个服务,那么这里这一步,也就建立了跟调用方的父子关系,traceId等是继承的调用方的,意味着本次调用也属于调用方的一环,这也就实现了跨系统的链路追踪
.withTag(SpanTags.COMPONENT, "rpc")
.withTag(SpanTags.SPAN_KIND, "server").start(); //启动span
} else { //执行else,说明该rpc调用是一次自己完整的调用,不属于任何父链路,那么就无需建立关系,直接初始化tracer即可
tracer = new SimpleTracer(request.getMethod, "所属项目名");
parent = tracer.buildSpan(request.getMethod)
.withTag(SpanTags.COMPONENT, "rpc")
.withTag(SpanTags.SPAN_KIND, "server")
.start(); //启动span
}
//将封装好的tracer和parentSpan设置到上下文对象里去
context.setSimpleTracer(tracer);
context.setParent(parent);
ContextHolder.setContext(context); //将本次请求生成的上下文对象放进ContextHolder(也就是TL里),方便在任意位置取出使用
}
//业务逻辑处理中
public void rpcServerHadle() {
doing();
}
//Rpc业务处理完成后的触发
public void afterHandler() {
//Rpc Server调用结束的时候,取出当前链路信息,完成数据的上报
SimpleTracer tracer = ContextHolder.getContext().getTracer();
SimpleSpan parent = ContextHolder.getContext().getParent();
if (tracer != null && parent != null) {
parent.finish(); //结束掉parent Span
tracer.pushSpans(); //上报这次产生的链路数据(spans)
}
}
}
可以看到,client发起调用时传递的协议字段,在服务端这里被解析了,建立好父子关系后,A服务再去处理自己的逻辑和链路。
没有牵扯到跨系统的链路追踪,如对redis、memcached、mysql等DB的调用,可以简单在调用元方法上搞个aop代理,然后通过通过上下文对象里的Tracer和parent建立父子关系,结束时finish即可,而pushSpans这个动作通常发生在一次系统调用执行完毕的时候发生,比如API的调用结束时、A服务调用结束时,都是pushSpans的触发点。
到这里基本上关于链路追踪的介绍算结束了,因为系统级的实现方式想要完整的展现在一篇文章里不太现实,所以在使用simple-trace sdk的时候使用了伪代码,便于说明问题,文章没有针对整个链路系统作说明,主要是针对数据采集、数据跨系统追踪做了描述,因为数据采集这一环算是比较重要的一环,也是跟业务开发人员息息相关的一环,如果想要完整搞一个链路追踪系统,可以参考之前的架构搭建一套,以完成采集、上报、落库、解析、展示整个流程。

