

spark实验(一)--spark安装(1)
一、实验目的
(1)掌握 Linux 虚拟机的安装方法。Spark 和 Hadoop 等大数据软件在 Linux 操作系统 上运行可以发挥最佳性能,因此,本教程中,Spark 都是在 Linux 系统中进行相关操作,同 时,下一章的 Scala 语言也会在 Linux 系统中安装和操作。鉴于目前很多读者正在使用 Windows 操作系统,因此,为了顺利完成本教程的后续实验,这里有必要通过本实验,让读 者掌握在 Windows 操作系统上搭建 Linux 虚拟机的方法。当然,安装 Linux 虚拟机只是安 装 Linux 系统的其中一种方式,实际上,读者也可以不用虚拟机,而是采用双系统的方式安 装 Linux 系统。本教程推荐使用虚拟机方式。 (2)熟悉 Linux 系统的基本使用方法。本教程全部在 Linux 环境下进行实验,因此, 需要读者提前熟悉 Linux 系统的基本用法,尤其是一些常用命令的使用方法。
二、实验过程
环境:centos6.4,jdk1.7.0,spark1.5.2
根据这篇博文https://www.cnblogs.com/Genesis2018/p/9079787.html安装spark1.5.2
首先输入
wget http://archive.apache.org/dist/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz下载spark1.5.2

等待下载完成后,将下载完的文件进行解压
输入
tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz将下载完的文件进行解压,之后输入以下命令移动到对应的/usr/local/目录中
mv spark-1.5.2-bin-hadoop2.6 /usr/local/
接着输入
gedit /etc/profile.d/spark.sh在打开的文件中添加以下的信息
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR==$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark-1.5.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin保存退出后
输入
source /etc/profile.d/spark.sh使文件生效
接着输入
cp /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh.template /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.shgedit /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh在打开的文件中输入(IP和jdk需要根据自己本身的版本进行设置)
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.221.x86_64/jre
export SCALA_HOME=/usr/local/scala-2.10.6
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_HOST=192.168.57.128
export SPARK_LOCAL_IP=192.168.57.128
接着输入
cp /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves.template /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slavesgedit /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves将localhost中的内容改为对应虚拟机ip的地址
192.168.57.128
保存退出
验证spark安装:
sbin/start-master.sh在服务器外边输入对应
http://192.168.57.128:8080/
发现正常启动
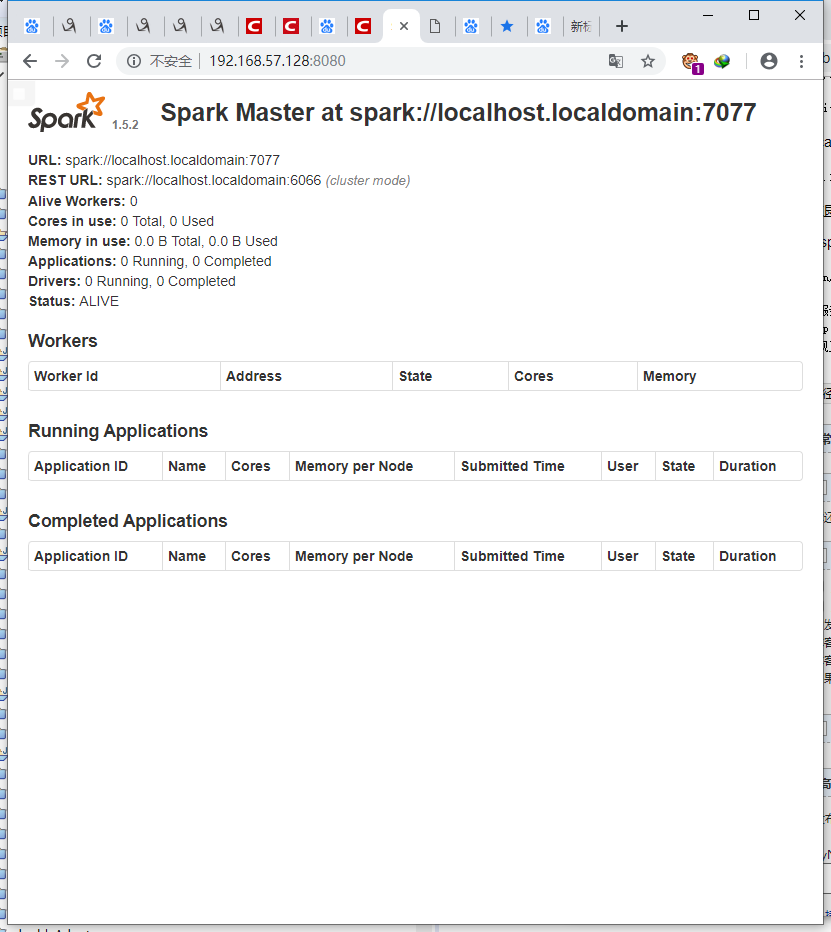
spark安装完毕

 浙公网安备 33010602011771号
浙公网安备 33010602011771号