

mapreduce课上测试
今天上课的时候进行了一个mapreduce的实验,但是由于课下对于mapreduce还有hive的理解不够透彻,因此导致了课上没能完成这次实验。
关于本次课堂上的实验的内容大致为:
1.对一个70k的文本进行简单地清洗,这个部分实验过程中,主要花费的实验的时间在于解决java和hive之间的连接问题,主要原因还是在于课下在linux上仅仅只安装了hive之后没有在windows上进行连接上的测试。不过经过了不断的尝试最终还是能连接上。
2.对这个70k的文件进行3部分简单的数据处理之后,把得到的结果存入hive数据库中。
在进行数据处理的这部分实验过程中,遇到的最大的问题其实是对mapreduce的过程不是太清晰导致的没有将其中的数据整理出来,而且,在mapreduce的过程中对数据的存储处理过程没有完全用到mapreduce的实现进行处理,还运用了一部分的外部静态变量来存储其中的数据,这个过程我想并不符合分布式的处理的思想。最终虽然能够勉强实现其中的功能,但其中实现的过程并不太完美。因此还有许多需要学习的地方,在hive数据库中的数据存储部分也不太了解,在实验之前并没有接触过类似hive的存储,仅仅只是安装了个linux可以运行的hive。因此实验在进行到了想传入数据进入hive中的时候,不知道该如何进行下去,还有对于文本里面内容的要求都是模糊的,没有。
对于3部分简单的数据处理的过程中的排序,因为对题意,还有对于基础知识的不理解,实现从大到小还有数据的清洗显得有点吃力。
最终调用了大二时候构建的通用数据库处理类中的函数成功将数据导进hive数据库中。
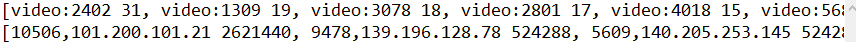
部分数据如上
经过了此次课堂上对mapreduce的实验,让我知道了自己对于大数据这款的掌握明显不足。之前总是觉得mapreduce是一个简单的过程,今天觉得,人应该得活到老,学到老。
多积累自己的代码仓库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号