
测试工具-慢sql日志分析工具pt-query-digest
pt-query-digest分析来自慢速日志文件,常规日志文件和二进制日志文件的MySQL查询。它还可以分析来自tcpdump的查询和MySQL协议数据。
开启慢日志
set global slow_query_log=on;
set global slow_query_log_file='/data/logs/mysql/mysql_slow.log';
下载安装
yum install percona-toolkit-3.0.3-1.el7.x86_64.rpm
下载地址:https://www.percona.com/downloads/percona-toolkit/3.0.3/
推荐用法
查询保存到query_history表查看慢sql,数据结构清晰,方便分析,方便与其他系统集成。
pt-query-digest --user=root --password=epPfPHxY --history h=10.8.8.66,D=testDb,t=query_review--create-history-table mysql_slow.log --since '2020-10-01 09:30:00' --until '2020-10-21 18:30:00'

常见用法
直接分析慢查询文件
pt-query-digest slow.log > slow_report.log
分析某个用户的慢sql
pt-query-digest --filter '($event->{user} || "") =~ m/^root/i' slow.log
分析某个数据库的慢sql
pt-query-digest --filter '($event->{db} || "") =~ m/^sonar/i' slow.log
分析某段时间内的慢sql
pt-query-digest mysql_slow.log --since '2020-09-21 09:30:00' --until '2020-09-21 18:30:00'
输出结果说明
第一部分:总体统计结果
Overall:总共有多少条查询
Time range:查询执行的时间范围
unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询
total:总计 min:最小 max:最大 avg:平均
95%:把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值
median:中位数,把所有值从小到大排列,位置位于中间那个数
......
#语句执行时间
#锁占用时间
#发送到客户端的行数
#select语句扫描行数
#查询的字符数
第二部分:查询分组统计结果
Rank:所有语句的排名,默认按查询时间降序排列,通过--order-by指定
Query ID:语句的ID,(去掉多余空格和文本字符,计算hash值)
Response:总的响应时间
time:该查询在本次分析中总的时间占比
calls:执行次数,即本次分析总共有多少条这种类型的查询语句
R/Call:平均每次执行的响应时间
V/M:响应时间Variance-to-mean的比率
Item:查询对象
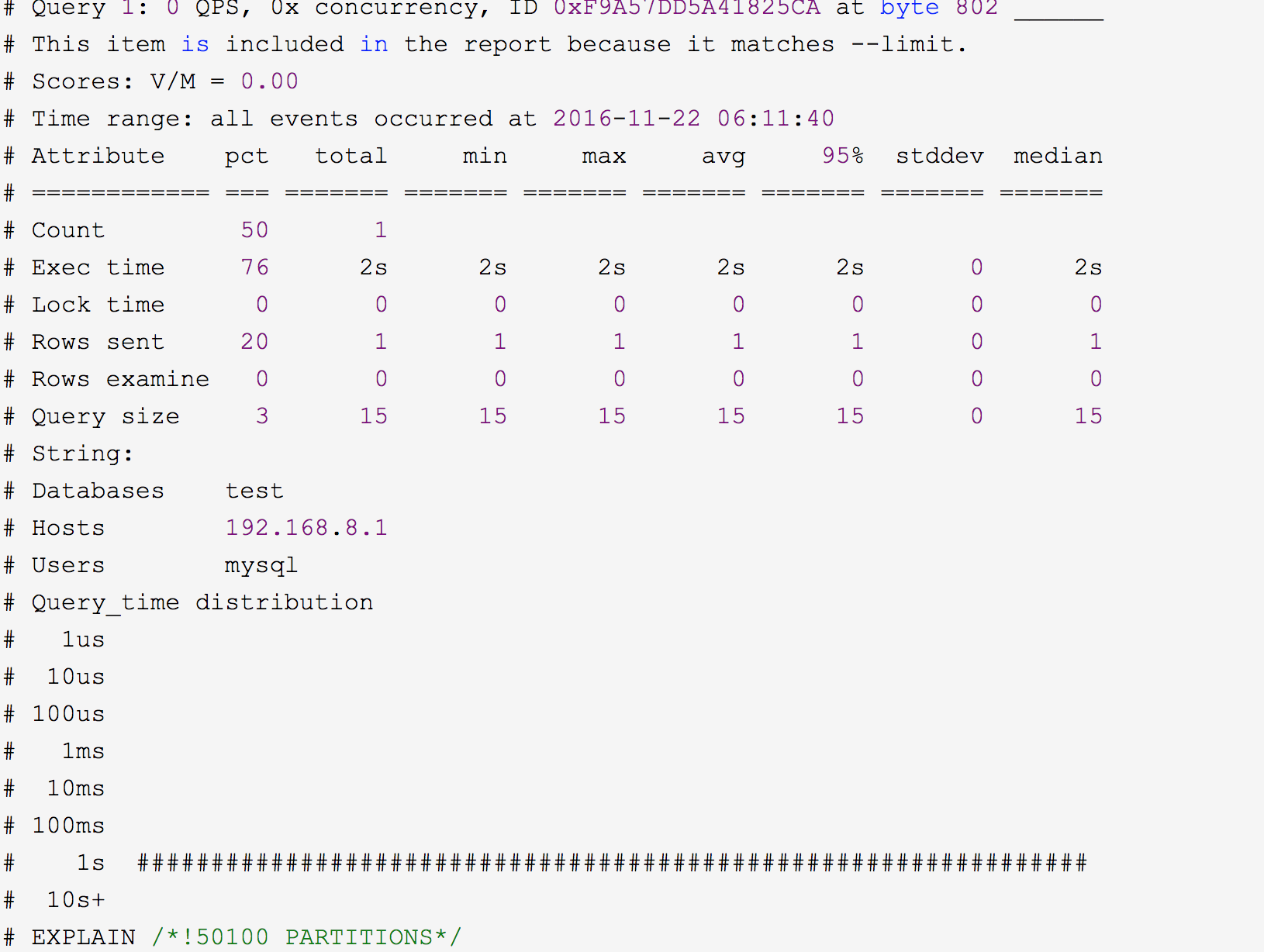
第三部分:每一种查询的详细统计结果
由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
ID:查询的ID号,和上图的Query ID对应
Databases:数据库名
Users:各个用户执行的次数(占比)
Query_time distribution :查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量是10s以上的两倍。
Tables:查询中涉及到的表
Explain:SQL语句
扫一扫,关注我

