linux性能监控命令,磁盘,网络,cpu,内存
一,CPU
cpu负载是逻辑的判断与处理(类似人的大脑),
CPU 主要是运行程序的速度,影响速度的主要是主频(越高越快,但不是线性关系)、外频(基准频率、外频决定整个主板运行速度,超频就是超外频,超频会导致不稳定)、缓存容量(缓存的大小对cpu速度影响很大,缓存大,命中率高,速度就快,L1缓存与处理器同频运行,二级缓存内部和主频相同,外部是主频的一半,但比内存快得多)、逻辑结构
查看指令:
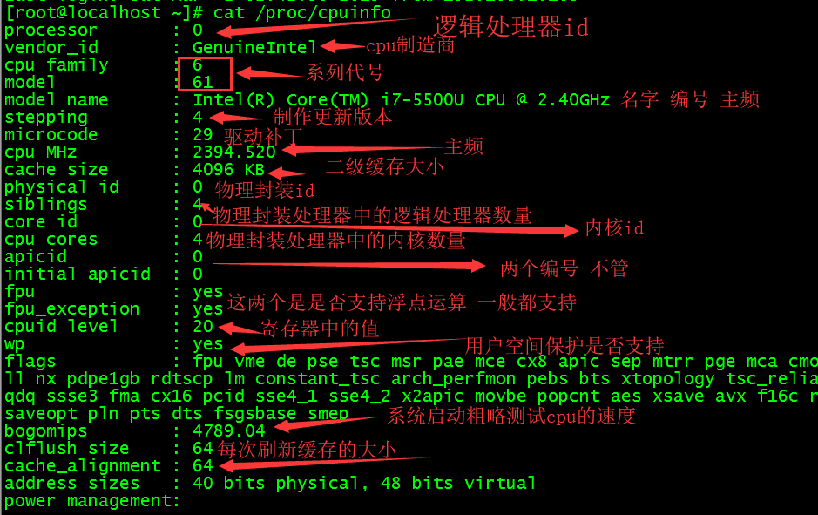
1,cat /proc/cpuinfo
2,top
使用格式: top [-] [d] [p] [q] [c] [C] [S] [s] [n] 参数说明: d:指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s:交互命令来改变之。 p:通过指定监控进程ID来仅仅监控某个进程的状态。 i:使top不显示任何闲置或者僵死进程。 c:显示整个命令行而不只是显示命令名
top 运行中内部命令如下:
s – 改变画面更新频率
l – 关闭或开启第一部分第一行 top 信息
t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息
m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息
N – 以 PID 的大小的顺序排列表示进程列表
P – 以 CPU 占用率大小的顺序排列进程列表
M – 以内存占用率大小的顺序排列进程列表
T – 按消耗cpu时间排序
h – 显示帮助
n – 设置在进程列表所显示进程的数量
q – 退出 top
= - 移除所有任务显示限制
H - 切换线程和进程模式
U - 指定用户相关进程
r - 重新设定进程的nice值
W - 存储当前设定
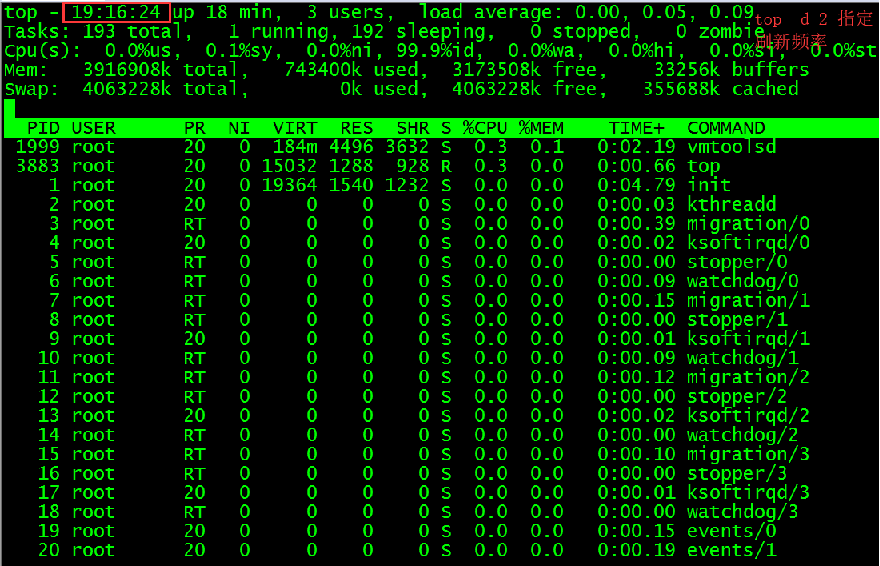
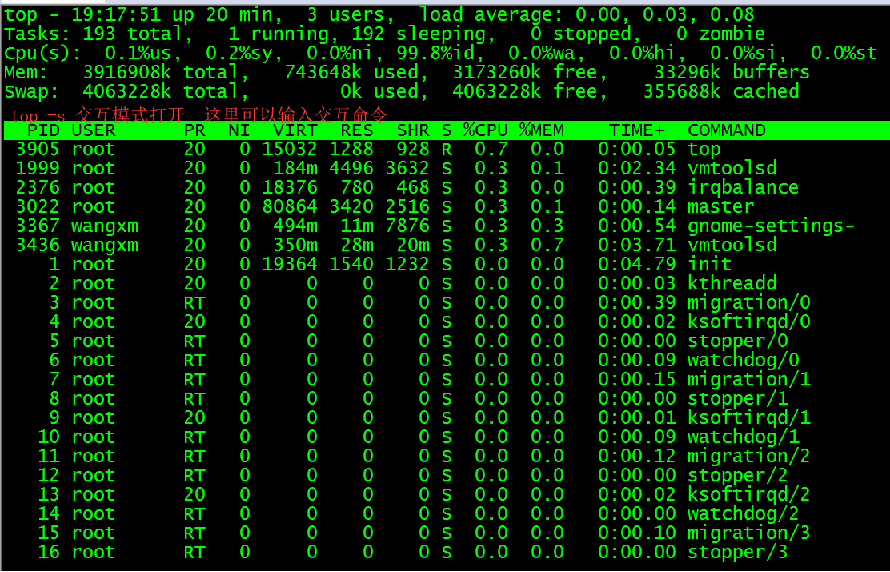
top 信息详解:

当前系统时间 启动时间长度 3个用户 最近5、10、15分钟平均负载----cpu+io等待

进程 总共192个进程 1个运行 191个休眠 0个停止 0个僵尸(进程的一种状态)

%us 用户进程的cpu时间 %sy系统内核进程的cpu时间 %ni niced:运行已调整优先级的用户进程的CPU时间 %wa IO wait: 用于等待IO完成的CPU时间 %hi hi:处理硬件中断的CPU时间 %si: 处理软件中断的CPU时间 %st:强制上下文切换消耗的cpu时间

Mem 总物理内存 used 使用内存 free剩余内存 buffers 缓冲区 存放将要写入磁盘的数据

Swap 虚拟内存 一小部分内存和一大部分磁盘一起虚拟出来的空间 total 总虚拟内存 Free 空闲虚拟内存 持续减少一点是内存有瓶颈了(物理内存不够用) Cached 缓存区,是高速缓存,cpu频繁读的数据放入缓存区 , 从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。

PID:进程ID,进程的唯一标识符
USER:进程所有者的实际用户名。
PR:进程的调度优先级。这个字段的一些值是'rt'。这意味这这些进程运行在实时态。
NI:进程的nice值(优先级)。越小的值意味着越高的优先级。负值表示高优先级,正值表示低优先级,默认20
VIRT:进程使用的虚拟内存。进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES RES:驻留内存大小。驻留内存是任务使用的非交换物理内存大小。进程使用的、未被换出的物理内存大小,单位kb。
RES=CODE+DATA
SHR:SHR是进程使用的共享内存。共享内存大小,单位kb
S:这个是进程的状态。它有以下不同的值: D - 不可中断的睡眠态。 R – 运行态 S – 睡眠态 T – 被跟踪或已停止 Z – 僵尸态
%CPU:自从上一次更新时到现在任务所使用的CPU时间百分比。 %MEM:进程使用的可用物理内存百分比。
TIME+:任务启动后到现在所使用的全部CPU时间,精确到百分之一秒。
COMMAND:运行进程所使用的命令。进程名称(命令名/命令行)
VIRT:virtual memory usage 虚拟内存
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,不是实际使用量
RES:resident memory usage 常驻内存
1、进程当前使用的内存大小,但不包括swap out,包含其他进程的共享
2、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
3、关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
DATA:
1、数据占用的内存。如果top没有显示,按s键可以显示出来。
2、真正的该程序要求的数据空间,是真正在运行中要使用的。
top的交互命令:
h 切换到交互命令窗口
1 显示多核的cpu占用情况
f 进入新试图 排基本试图的显示字段 如 s 显示data
U 输入用户名选项查看对应用户的进程
K 输入进程号和信号 终止进程 15普通终止 9 强制终止
b 打开和关闭行高亮
x 打开和关闭排序列高亮
------------------------------------------------------------
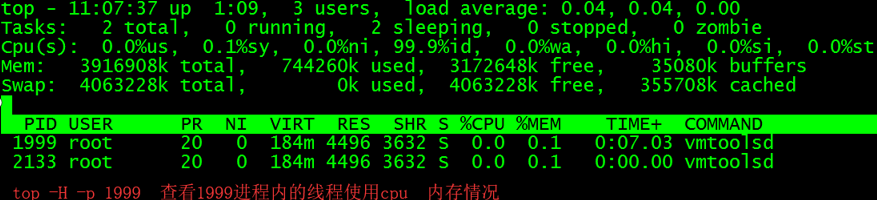
cpu高的定位方法:
1、查看那个进程占用CPU高 执行Top
2、查看进程下的那个线程占用CPU高 Top –H –p 进程号
3、按CPU排序-输入P 定位到那个线程CPU占用高 再查询此线程执行的方法
------------------------------------------------------------
vmstat的使用方法:
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量(linux下创建进程调用fork方法)
-m:显示slabinfo(内核创建的一些小对象的信息展示)
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息
vmstat 2 5 :每2秒采集一次,共计采集5次
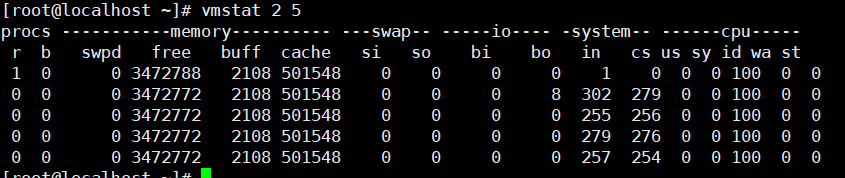
Procs 进程
r cpu正在运行的进程数,如果超过cpu核数,cpu有瓶颈
b 等待资源的进程数,比如等待io或者cpu运行的进程数,大于0说明cpu有瓶颈
Memory内存
Swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了
Free 空闲的物理内存大小,默认KB
Buff 已经使用的buff大小
Cache 已使用的cache大小
Swap虚拟内存
Si 每秒从虚拟内存写入内存的大小(KB/s),如果长期大于0,说明内存不足
So 每秒从内存写到虚拟内存的大小(KB/s),如果长期大于0,说明内存不足
io 磁盘io
Bi 表示由每秒读入的块 Bo 表示写的块 单位block 硬盘读写的最小单位是扇区,一个扇区是512 bytes,一次读写的数据量就称为1个block,基本可以按乘512来根据block计算出读写的实际数据量
System
In 表示每秒产生的中断次数
Cs 每秒产生的上下文切换次数,in和cs越大,表示内存消耗的cpu越多
Cpu
Us 用户消耗的cpu百分比,如果大于50%需要关注了
Sy 内核消耗的cpu百分比,如果us+sy大于80%需要关注
Id cpu处于空闲时间的百分比
Wa 等待所占的cpu百分比,wa值高,说明io等待严重,磁盘有瓶颈,不超20%
St 被动上下文切换消耗cpu时间,如果in、cs和st高的话,可以通过pidstat -wt -u 1 命令查看是主动切换(cswch)还是被动切换(nswch),进一步分析,如果是被动切换比较高,说明是磁盘io有问题
------------------------------sar------------------------------------------
sar(System ActivityReporter系统活动情况报告)是目前Linux上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等,sar命令由sysstat安装包安装
用法: sar [ 选项 ] [ <时间间隔> [ <次数> ] ] 选项: [ -A ] [ -B ] [ -b ] [ -C ] [ -d ] [ -H ] [ -h ] [ -p ] [ -q ] [ -R ] [ -r ] [ -S ] [ -t ] [ -u [ ALL ] ] [ -V ] [ -v ] [ -W ] [ -w ] [ -y ] [ -I { <中断> [,...] | SUM | ALL | XALL } ] [ -P { <cpu> [,...] | ALL } ] [ -m { <关键词>
Sar 使用语法:
-A:所有报告的总和
-b:显示I/O和传递速率的统计信息(缓冲区使用情况)
-B:显示换页状态
-d:输出每一块磁盘的使用信息
-e:设置显示报告的结束时间
-q:显示运行的队列大小,它与系统当时的平均负载相同
-i:设置状态信息刷新的间隔时间
-P:报告每个CPU的状态
-r:显示内存状态
–u:输出cpu使用情况和统计信息
–v:显示进程、索引节点、文件和其他内核表的状态
-W:显示交换分区的状态
-n:显示网络使用情况

这个命令主要是监控cpu的,每2秒收集一次,总共收集3次。等同于sar -p 2 3
%usr 用户进程消耗的cpu时间百分比
%nice 改变过优先级的进程的占用CPU时间的百分比
%system 系统进程消耗的cpu时间百分比
%iowait I/O等待所占cpu时间百分比
%steal (Steal time)是当hypervisor服务另一个虚拟处理器的时候,虚拟CPU等待实际CPU的时间的百分比;高steal值可能意味着主机供应商在服务器上过量地出售虚拟机。steal值还是不降的话,你应该寻找另一家服务供应商。
%idle cpu空闲状态的时间占比
需要注意的指标:%iowait和%idle,%wio过高表示磁盘I/O瓶颈;%idle值高表示cpu空闲,%idle值持续低于10%,表示cpu存在性能瓶颈
Sar –q 信息详解-查看cpu性能问题:

Runq-sz 运行队列的长度(等待运行的进程数,每核的CP不能超过3个)
plist-sz 进程列表中的进程(processes)和线程数(threads)的数量
ldavg-1 最后1分钟的CPU平均负载,即将多核CPU过去一分钟的负载相加再除以核心数得出的平均值
ldavg-5 最后5分钟的CPU平均负载
ldavg-15 最后15分钟的CPU平均负载
Sar –r 信息详解—查看内存使用情况:

Kbmemfree 空闲的物理内存大小
Kbmemused 使用的物理内存
%memused 物理内存使用率(占比)
Kbbuffers 内核中作为缓冲区使用的物理内存大小,kbbuffers和kbcached:这两个值就是free命令中的buffer和cache以核心数得出的平均值
Kbcached 缓存的文件大小
Kbcommit 保证当前系统正常运行所需要的最小内存,即为了确保内存不溢出而需要的最少内存(物理内存+Swap分区)
%commit 这个值是kbcommit与内存总量(物理内存+swap分区)的一个百分比的值
Sar –B 信息详解:

Pgpgin/s 表示每秒从磁盘或SWAP置换到内存的字节数(KB)
Pgpgout/s 表示每秒从内存置换到磁盘或SWAP的字节数(KB)
Fault/s 每秒钟系统产生的缺页数,即主缺页与次缺页之和
Majflt/s 每秒钟产生的主缺页数
Pgfree/s 每秒被放入空闲队列中的页个数
Pgscank/s 每秒被kswapd扫描的页个数
Pgscand/s 每秒直接被扫描的页个数
Pgsteal/s 每秒钟从cache中被清除来满足内存需要的页个数
%vmeff 每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比
Sar –v 信息详解:

Dentunusd 在缓冲目录条目中没有使用的条目数量
File-nr 被系统使用的文件句柄数量
Inode-nr 已经使用的索引数量
Pty –nr 使用的pty数量 这里面的索引和文件句是sysctl.conf里面定义的和内核相关的值, max-file表示系统级别的能够打开的文件句柄的数量, 可以sysctl -a | grep file查看,具体含义如下: file-max中指定了系统范围内所有进程可打开的文件句柄的数量限,当收到"Too many open files in system"这样的错误消息时, 就应该曾加这个值了。
-------------------------IO-------------------------------

Tps 磁盘每秒钟的IO总数,等于iostat中的tps
Rtps 每秒钟从磁盘读取的IO总数
Wtps 每秒钟从写入到磁盘的IO总数
Bread/s 每秒钟从磁盘读取的块总数
Bwrtn/s 每秒钟此写入到磁盘的块总数
一次I/O 当进程发起系统调用时,系统调用就进入内核模式, 然后开始I/O操作 I/O操作分为俩个步骤:
1) 磁盘把数据装载进内核的内存空间
2) 内核的内存空间的数据copy到用户的内存空间中(此过程才是真正I/O发生的地方)
一次io的详细处理过程分析:
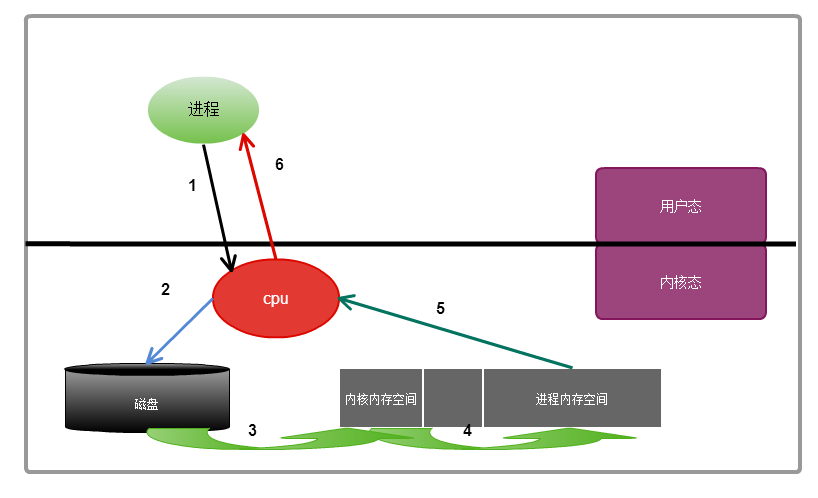
进程需要对磁盘中的数据进行操作,则会向内核发起一个系统调用,然后此进程,将会被切换出去;此进程会被挂起或者进入睡眠状态,也叫不可中 断的睡眠,因为数据还没有得到,只有等到系统调用的结果完成后,则进程会被唤醒,继续接下来的操作,从系统调用的开始到系统调用结束经过的步骤:
1,进程向内核发起一个系统调用,
2,内核接到系统调用,知道是对文件的请求,于是告诉磁盘,把文件读取出来
3,磁盘接收到来着内核的命令后,把文件载入到内核的内存空间里面
4,内核的内存空间接收到数据之后,把数据copy到用户进程的内存空间(此过程是I/O发生的地方)
5,进程内存空间得到数据后,给内核发送通知
6,内核把接收到的通知回复给进程,此过程为唤醒进程,然后进程得到数据,进行下一步操作
Sar –d 信息详解—查看磁盘是否有瓶颈:
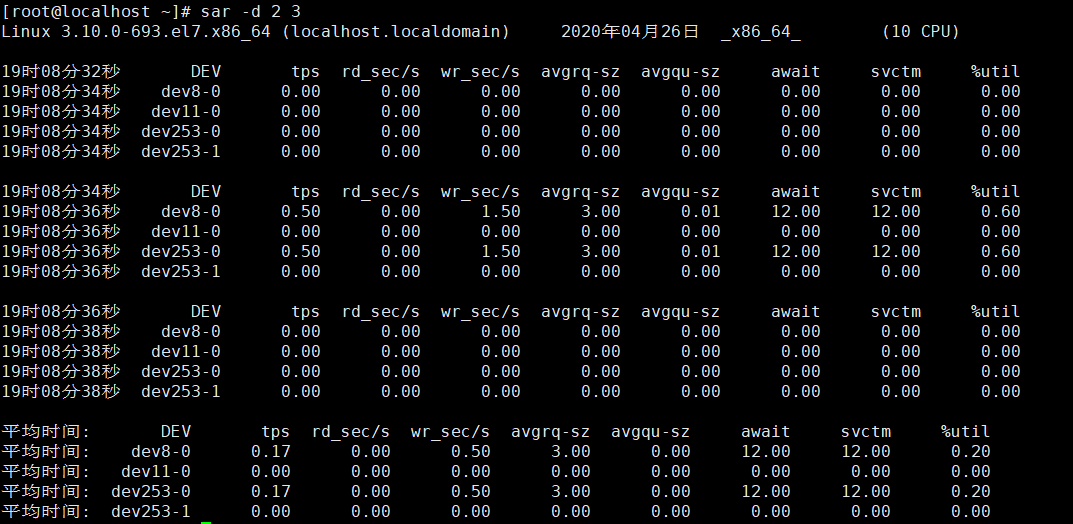
Dentunusd 在缓冲目录条目中没有使用的条目数量
Tps 每秒I/O的次数
Rd_sec/s 每秒读扇区的大小
Wr_sec/s 每秒写扇区的大小
Avgrq-sz 每次操作的I/o大小
Avgqu-sz 磁盘队列的长度,反映磁盘的繁忙程度
Await 操作磁盘的平均处理时间,等于寻道时间+队列时间+服务时间(毫秒)
Svctm 每次磁盘处理消耗的时间,不包含队列时间,不大于0.5,体现磁盘性能
%util I/O请求占用的CPU百分比,值越高,说明I/O越慢
Sar –w 信息详解-查看内存是否有瓶颈:

Pswpin/s 每秒换入的交换页面(swap page)数量
Pswpout/s 每秒换出的交换页面(swap page)数量
----------------------------网络-----------------------------------------
sar -n DEV 信息详解-查看网络瓶颈:
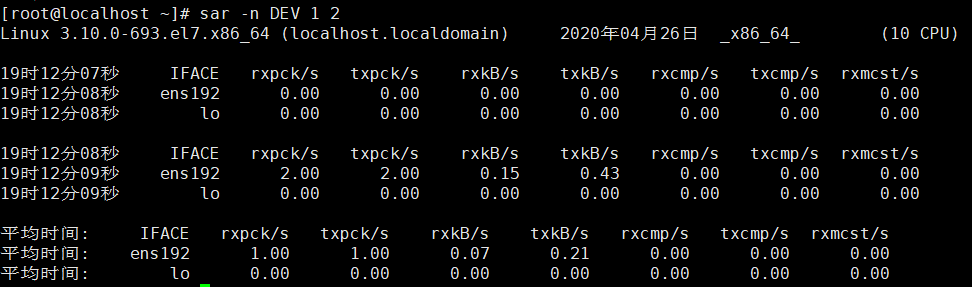
Iface 网卡名称
Rxpck/s 每秒接收的数据包
Txpck/s 每秒发送的数据包
rxkB/s 每秒接收的字节数,单位kb(重点看)
txkB/S 每秒发送的字节数,单位kb(重点看)
Rxcmp/S 每秒钟接受的压缩数据包
Txcmp/S 每秒钟发送的压缩包
Rxmcst/S 每秒钟接收的多播数据包
场景:如果我监控的数据是120000kb,负载机和被压测的服务器之间的带宽是1GB(调研所得),压测结果监控网卡的数据为120000kb,120000KB*8=960000KB,960000KB/1024=937.5Mb,非常接近带宽
1KB=8kb
1MB=1024KB
1GB=1024MB
sar -n SOCK 信息详解查看连接数:

Totsck 当前被使用的socket总数
Tcpsck 当前正在被使用的TCP的socket总数
Udpsck 当前正在被使用的UDP的socket总数
Rawsck 当前正在被使用于RAW的skcket总数
Ip-frag 当前的IP分片的数目
Tcp-tw TCP套接字中处于TIME-WAIT状态的连接数量
--------------------iostat-----------------
Iostat 使用语法:
用法:iostat [ 选项 ] [ <时间间隔> [ <次数> ]] 常用选项说明:
-c:只显示系统CPU统计信息,即单独输出avg-cpu结果,不包括device结果
-d:单独输出Device结果,不包括cpu结果
-k/-m:输出结果以kB/mB为单位,而不是以扇区数为单位
-x:输出更详细的io设备统计信息
interval/count:每次输出间隔时间,count表示输出次数,不带count表示循环输出
Iostat –x信息详解:

%user 用户进程消耗CPU时间的百分比
%nice 改变过优先级的进程的占用CPU时间的百分比
%system 系统进程消耗的CPU时间的百分比
%iowait I/O等待所占cpu时间百分比
%steal (Steal time)是当hypervisor服务另一个虚拟处理器的时候,虚拟CPU等待实际CPU的时间的百分比,如果高说明虚拟机虚的cpu太多了;
%idle cpu空闲状态的时间占比
%rrqm/s 每秒进行合并的读操作次数
%wrqm 每秒进行合并的写操作次数
%r/s 每秒完成读的I/O设备的次数
%w/s 每秒完成写的I/O设备的次数
%rsec/s 每秒读的扇区
%wsec/s 每秒写的扇区
Avgrq-sz 每个请求平均大小,单位是扇区数
Avgqu-sz 平均等待处理的io请求队列长度
Await 每次I/O操作磁盘的平均时间,等待时间+磁盘处理时间,单位毫秒,一般低于5毫秒,大于10毫秒就比较大了
Svctm 平均每次磁盘处理时间,真正的磁盘操作耗时,不包含等待,单位毫秒
%util 一秒钟用于I/O操作的时间占比,超过80%认为I/O繁忙
Iostat –c 信息详解:
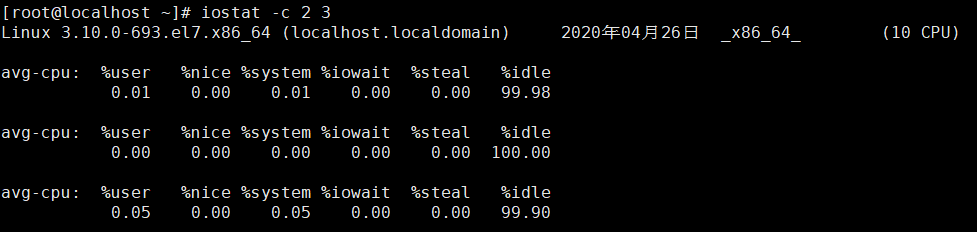
%user 用户进程消耗CPU时间的百分比
%nice 改变过优先级的进程的占用CPU时间的百分比
%system 系统进程消耗的CPU时间的百分比
%iowait I/O等待所占cpu时间百分比
%steal (Steal time)是当hypervisor服务另一个虚拟处理器的时候,虚拟CPU等待实际CPU的时间的百分比,如果高说明虚拟机虚的cpu太多了;
%idle cpu空闲状态的时间占比
Iostat –d 信息详解:
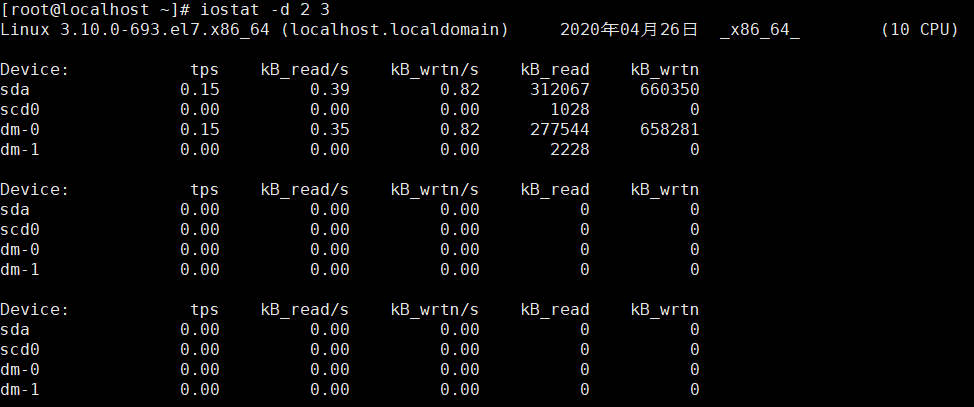
ps 磁盘每秒钟的IO总数
Blk_read/s 每秒读取的数据块数
Blk_wrtn/s 每秒写入的数据块数
Blk_read 读取的数据块总数
Blk_wrtn 写入的数据块总数
块是个虚拟出来的概念,操作系统与磁盘打交道的最小单位是磁盘块。一般是4k大小必须是扇区(512k)的整数倍。操作系统操作磁盘,也需要通过磁盘驱动器进行。所以离不开扇区的;fdisk –l 查看扇区信息
----------------free--------------------
free 命令语法:
参 数:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
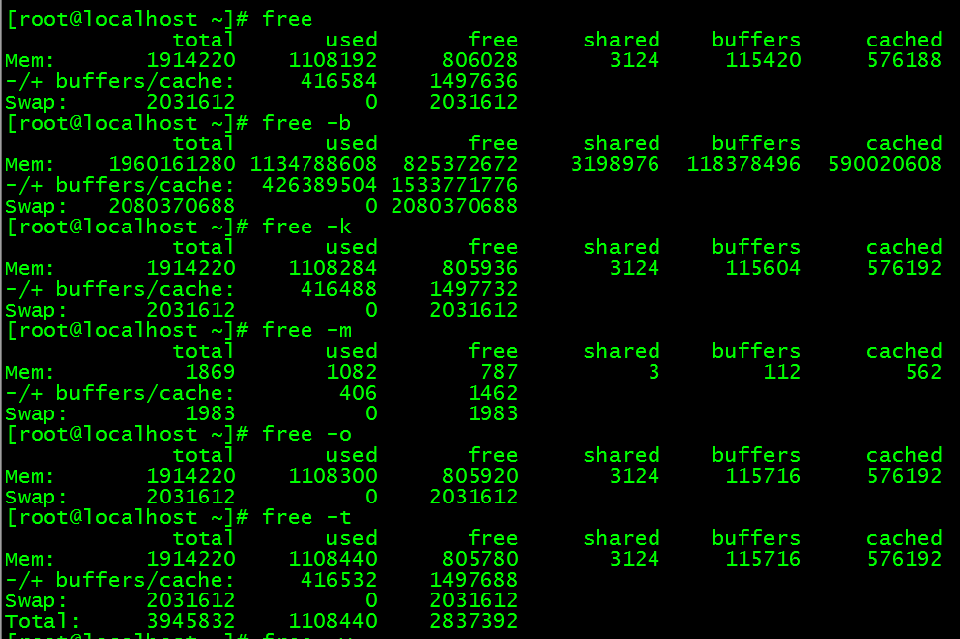

total:表示物理内存总量(total = used + free)
used:表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用
free:未被分配的内存
shared:多个进程的共享内存总和
buffers:系统分配但未被使用的buffers 数量
cached:系统分配但未被使用的cache 数量
-------------------------netstat-------------------
Netstat 使用语法:
语法
netstat [-acCeFghilMnNoprstuvVwx][-A<网络类型>][--ip]
参数说明:
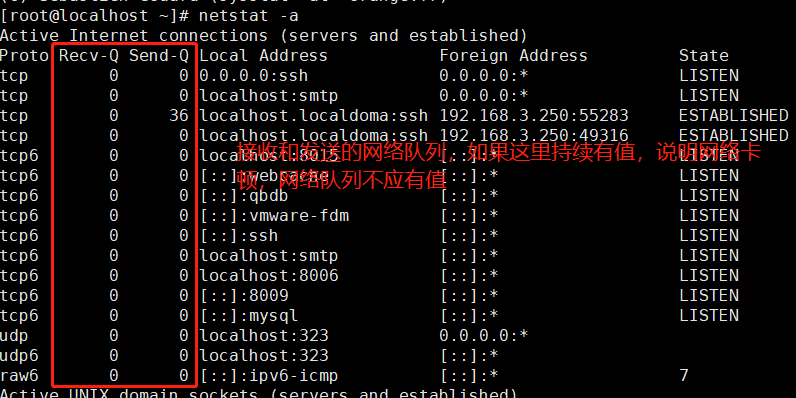
-a或--all 显示所有连线中的Socket
-c或--continuous 持续列出网络状态
-e或--extend 显示网络其他相关信息
-i或--interfaces 仅列出有在listen(监听)的服务状态
-n或--numeric 直接使用IP地址,而不通过域名服务器。
-p或--programs 显示正在使用Socket的程序识别码和程序名称。
-r或--route 显示R路由信息和当前有效连接
-s或--statistice 显示网络工作信息统计表,按协议统计
-t或--tcp 显示TCP传输协议的连线状况
-u或--udp 显示UDP传输协议的连线状况
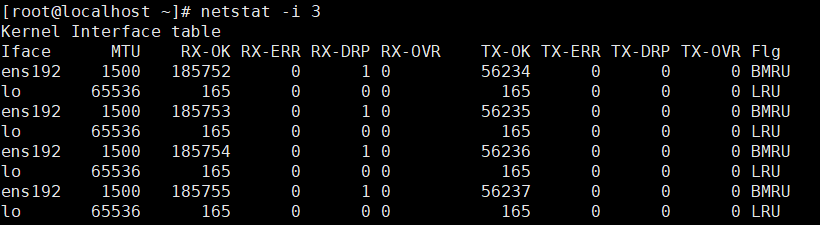
MTU 表示最大传输单元,单位字节
RX-OK/TX-OK 表示已准确地接收/发送了多少数据包(重点)
RX-ERR/ TX-ERR 表示接收/发送数据包时产生了多少错误(重点,不能有值,有值就说明有错误)
RX-DRP/TX –DRP 表示接收/发送数据包时丢弃了多少数据包(重点,不能有值,有值就说明有错误)
RX-OVR/TX-OVR 表示由于误差而丢失了多少数据包(重点,不能有值,有值就说明有错误)
FLG 表示接口标记,其中:
B 已经设置了一个广播地址
L 该接口是一个回送设备
M 接收所有数据包(混乱模式)
N 避免跟踪 O 在该接口上,禁止ARP
P 这是一个点到点链接
R 接口正在云
U 接口处于“活动”状态
RX-ERR/ TX-ERR,RX-DRP/TX –DRP,RX-OVR/TX-OVR 应该为0或者接近0,如果持续很大,网络质量肯定有问题
Netstat 常用命令:
netstat -an | awk '/^tcp/ {++S[$NF]} END {for (a in S) print a,S[a]} '

netstat -ap | grep ssh ----->找出程序运行的端口

netstat -pt ---->输出中显示 TCP连接信息

----------------------------uptime------------------------------------

19:31:50 当前时间
up 9 days, 6:55 运行了多久
1 user 运行了1个用户
Load average 在特定时间间隔内运行队列中进程数
当单cpu单核时,load averages>1则系统繁忙且面临崩溃
当单cpu多核时,load averages=1则运行正常,通常我们先看15分钟load,如果load很高,再看1分钟和5分钟负载,查看是否有下降趋势,1分钟负载值 > 1,那么我们不用担心,但是如果15分钟负载都超过1,我们要赶紧看看发生了什么事情。所以我们要根据实际情况查看这三个值
ps 监测当前进程的情况:
参数:
-A 所有的进程均显示出来,与 -e 具有同样的效用
-a 显示现行终端机下的所有进程,包括其他用户的进程
-u 以用户为主的进程状态 -x 通常与 a 这个参数一起使用,可列出较完整信息
-e 命令之后显示环境
输出格式规划:
l 较长、较详细的将该PID 的的信息列出
j 工作的格式 (jobs format)
-f :做一个更为完整的输出
ps –aux|more信息详解:

User 运行进程的用户
Pid 运行的进程id,kill进程就是k这个id
%CPU 进程占用CPU的百分比
% MEM 进程占用内存的百分比
VSZ 占用的虚拟记忆体大小
RSS 占用的记忆体大小
TTY 终端的次要装置号码 (minor device number of tty)
STAT 该行程的状态 START 进程启动时间
TIME 进程执行的时间
COMMAND 所执行的指令

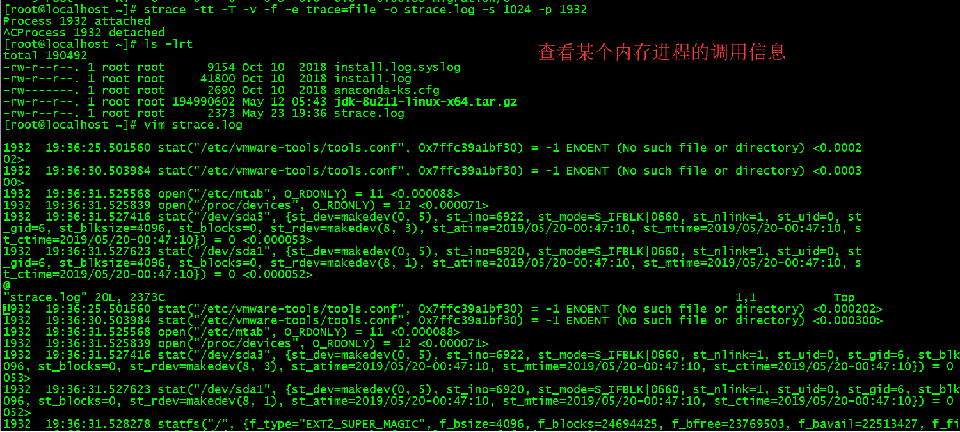
-----------------------strace---------------------------------
Strace 命令:
常用来跟踪进程执行的系统调用和接收的信号,linux下,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗时间
常用选项:
-tt 在每行输出的前面,显示毫秒级别的时间
-T 显示每次系统调用所花费的时间
-v 对于某些相关调用,把完整的环境变量,文件stat结构等打出来。
-f 跟踪目标进程,以及目标进程创建的所有子进程
-e 控制要跟踪的事件和跟踪行为,比如指定要跟踪的系统调用名称
-o 把strace的输出单独写到指定的文件
-s 当系统调用的某个参数是字符串时,最多输出指定长度的内容,默认是32个字节
-p 指定要跟踪的进程pid, 要同时跟踪多个pid, 重复多次-p选项即可。